Probabilistic Hesitant Intuitionistic Linguistic Term Sets in Multi-Attribute Group Decision Making


1
Department of IT, AGI Education, Auckland 1051, New Zealand
2
Department of Information Technology, Otago Polytechnic, Auckland International Campus, Auckland 1141, New Zealand
3
Department of Mathematics, Quaid-i-Azam University, Islamabad 45320, Pakistan
4
Department of Mathematics, University of Management and Technology, Lahore 54770, Pakistan
*
Author to whom correspondence should be addressed.
Symmetry 2018, 10(9), 392; https://doi.org/10.3390/sym10090392
Submission received: 22 July 2018
/
Revised: 31 August 2018
/
Accepted: 3 September 2018
/
Published: 10 September 2018
(This article belongs to the Special Issue Fuzzy Techniques for Decision Making 2018)
Abstract
:Decision making is the key component of people’s daily life, from choosing a mobile phone to engaging in a war. To model the real world more accurately, probabilistic linguistic term sets (PLTSs) were proposed to manage a situation in which several possible linguistic terms along their corresponding probabilities are considered at the same time. Previously, in linguistic term sets, the probabilities of all linguistic term sets are considered to be equal which is unrealistic. In the process of decision making, due to the vagueness and complexity of real life, an expert usually hesitates and unable to express its opinion in a single term, thus making it difficult to reach a final agreement. To handle real life scenarios of a more complex nature, only membership linguistic decision making is unfruitful; thus, some mechanism is needed to express non-membership linguistic term set to deal with imprecise and uncertain information in more efficient manner. In this article, a novel notion called probabilistic hesitant intuitionistic linguistic term set (PHILTS) is designed, which is composed of membership PLTSs and non-membership PLTSs describing the opinions of decision makers (DMs). In the theme of PHILTS, the probabilities of membership linguistic terms and non-membership linguistic terms are considered to be independent. Then, basic operations, some governing operational laws, the aggregation operators, normalization process and comparison method are studied for PHILTSs. Thereafter, two practical decision making models: aggregation based model and the extended TOPSIS model for PHILTS are designed to classify the alternatives from the best to worst, as an application of PHILTS to multi-attribute group decision making. In the end, a practical problem of real life about the selection of the best alternative is solved to illustrate the applicability and effectiveness of our proposed set and models.
1. Introduction
The choices we make today determine our future, therefore, to choose the best alternative subject to certain attributes is an important problem. Multi-attribute group decision making (MAGDM) has established its importance by providing the optimal solution considering different attributes in many real life problems. For this purpose, many sets and models have been designed to express and comprehend the opinions of DMs. The classical set theory is too restrictive to express one’s opinion, as some real life scenarios are too complicated and the vague data are often involved, therefore the DMs are unable to form a definite opinion. Fuzzy set theory is proposed as a remedy for such kind of real life problems. Fuzzy set approaches are suitable to use when the modelling of human knowledge is necessary and when human evaluations are required. However, the usual fuzzy set theory is limited to the modelling in which the diversity of variants occurs at the same time.
To overcome such situation, different extensions of fuzzy set have been proposed to better model the real world, such as intuitionistic fuzzy set [1], hesitant fuzzy set [2], hesitant probabilistic fuzzy set [3], hesitant probabilistic multiplicative set [4], and necessary and possible hesitant fuzzy set [5]. Zadeh [6] suggested the concept of a linguistic variable that is more natural for humans to express there will in situations where data are imprecise. Thus far, linguistic environment has been extensively used to cope with the problems of decision making within [7]. Mergió et al. [8] used the Dempster–Shafer theory of evidence to construct an improved linguistic representation model for the sake of decision making process. Next, they introduced several linguistic aggregation operators. Zhu et al. [9] proposed a two-dimensional linguistic lattice implication algebra to determine implicitly and further the compilation of two-dimensional linguistic information decision in MAGDM dilemmas. Meng and Tang [10] generalized the 2-tuple linguistic aggregation operators and then used them in MAGDM dilemmas. Li and Dong [11] gave an introduction to the proportional 2-tuple linguistic form to make easy the solving of MAGDM dilemmas. Xu [12] introduced a dynamic linguistic weighted geometric operator to cumulate the linguistic information and then solved the problem of MAGDM when the judgment in different periods to change the linguistic information. Li [13] applied the concept of extended linguistic variables to construct an advanced way to cope with MAGDM dilemmas under linguistic environments. Agell et al. [14] used qualitative thinking approaches to perform and incorporate linguistic decision information and then applied it to MAGDM dilemmas.
Because of the uncertainty, vagueness and complexity of real world problems, it is troublesome for experts to grant linguistic judgment using a single linguistic term. Torra [2] managed the situation where several membership values of a fuzzy set are possible by defining hesitant fuzzy set (HFS). Experts may hesitate among several possible linguistic terms. For this purpose, Rodriguez et al. [15] introduced the concept of hesitant fuzzy linguistic term sets (HFLTS) to improve the flexibility of linguistic information within hesitant situation. Zhu and Li [16] designed hesitant fuzzy linguistic aggregation operators based on the Hamacher t-norm and t-conorm. Cui and Ye [17] proposed multiple-attribute decision-making method using similarity measures of hesitant linguistic neutrosophic numbers regarding least common multiple cardinality. Liu et al. [18] defined new kind of similarity and distance measures based on a linguistic scale function. However, in some cases, the probabilities of these possible terms are not equal. Given this reality, Peng et al. [19] proposed the more generalized concept, called probabilistic linguistic term sets (PLTSs). PLTSs allow DMs to state more than one linguistic term, as an assessment for linguistic variable. This increases the flexibility and the fruitfulness of the expression of linguistic information and it is more reasonable for DMs to state their preference in terms of PLTSs because the PLTSs can reflect different probabilities for each possible assessment of a given object. Therefore, the research on the PLTSs is necessary. Thus, they used PLTSs in multi-attribute group decision making problem and construct an extended TOPSIS method as well as an aggregation-based method for MAGDM. Recently, in 2017, Lin et al. [20] extended the PLTSs to probabilistic uncertain linguistic term set, which is designed as some possible uncertain linguistic terms coupled with the corresponding probabilities, and developed an extended approach for preference to rank the alternatives.
Atanassov [1,21] presented the concept of the intuitionistic fuzzy set (IFS) which has three main parts, membership function, non-membership function and hesitancy function, and is better suited to handling uncertainty than the usual fuzzy set. Many researchers have been applying IFS for multi-attribute decision making under various different fuzzy environments. Up to now, the intuitionistic fuzzy set has been applied extensively to decision making problems [22,23,24,25,26,27]. Beg and Rashid [28] generalized the concept of HFLTS by hesitant intuitionistic fuzzy linguistic term set (HIFLTS) which is characterized by a membership and non-membership function that is more applicable for dealing with uncertainty than the HFLTS. HIFLTS collects possible membership and non-membership linguistic values provided by the DMs. This approach is useful to model more complex real life scenarios.
In this article, we introduce the concept of PHILTS. The main idea is to facilitate DMs to provide their opinions about membership and non-membership linguistic terms more freely to cope with the vagueness and uncertainties of real life. To make meaningful decision making, the basic framework of PHILTS is developed. In this regard, normalization process for the purpose to equalize the length of PHILTSs, basic operations and their governing laws are presented. Furthermore, to deal with different scenarios, range of aggregation operators, i.e., probabilistic hesitant intuitionistic linguistic averaging operator, probabilistic hesitant intuitionistic linguistic weighted averaging operator, probabilistic hesitant intuitionistic linguistic geometric operator and probabilistic hesitant intuitionistic linguistic weighted geometric operator are proposed. The DM can choose the aggregation operator according to his preference. Lastly, for practical use of PHILTS in decision making, an extended TOPSIS method is derived, in which the DMs provide their opinions in PHILTSs which are further aggregated and processed according to the proposed mechanism of extended TOPSIS to find the best alternative.
This paper is organized as follows. In Section 2, we review some basic knowledge needed to understand our proposal. In Section 3, the concept of PHILTSs is firstly proposed and then some concepts concerning PHILTS, i.e., normalization process, deviation degree, score function, operations and comparison between probabilistic hesitant intuitionistic linguistic term elements (PHILTEs), are also discussed. In Section 4, aggregation operators, deviation degree between two PHILTEs and weight vector are derived. In Section 5, we propose an extended TOPSIS method and aggregation based method designed for MAGDM with probabilistic hesitant intuitionistic linguistic information. An example is provided in Section 6 to illustrate the usefulness and practicality of our methodology by ranking of alternatives. Section 7 is dedicated to highlighting the advantages of the proposed set and comparing proposed models with existing theory. Finally, some concluding remarks are given in Section 8.
2. Preliminaries
In this section, we give some concepts and operations related to HFLTSs, HIFLTSs and PLTSs that will be used in coming sections.
2.1. Hesitant Fuzzy Linguistic Term Set
The DMs may face such a problem where they hesitate with certain possible values. For this purpose, Rodriguez et al. [15] introduced the following concept of hesitant fuzzy linguistic term set (HFLTS).
Definition 1
([15]).Let be a linguistic term set; then, HFLTS, , is a finite and ordered subset of the consecutive linguistic terms of S.
Example 1.
Let be a linguistic term set. Then, two different HFLTSs may be defined as: and .
Definition 2
([15]).Let be an ordered finite set of linguistic terms and E be an ordered finite subset of the consecutive linguistic terms of S. Then, the operators “max” and “min” on E can be defined as follows:
- (i)
- ; and
- (ii)
- ; and
2.2. Hesitant Intuitionistic Fuzzy Linguistic Term Set
In 2014, Beg and Rashid [28] introduced the concept of hesitant intuitionistic fuzzy linguistic term set (HIFLTS). This concept is actually based on HFLTS and intuitionistic fuzzy set.
Definition 3
([28]).Let X be a universe of discourse, and be a linguistic term set, then HIFLTS on X are two functions h and that when applied to an element of X return finite and ordered subsets of consecutive linguistic terms of S, this can be presented mathematically as:
where and denote the possible membership and non-membership degree in terms of consecutive linguistic terms of the element to the set A such that the following conditions are satisfied:
- (i)
- +
- (ii)
- +
2.3. Probabilistic Linguistic Term Sets
Recently, in 2016, Pang et al. [19] introduced the concept of PLTSs by attaching probabilities with each linguistic term, which is basically the generalization of HFLTS, and thus they opened a new dimension of research in decision theory.
Definition 4
([19]).Let be a linguistic term set, then a PLTS can be presented as follows:
where is the ith linguistic term associated with the probability and denotes the number of linguistic terms in
Definition 5
([19]).Let , be the lower index of linguistic term , is called an ordered PLTS, if all the elements in are ranked according to the values of in descending order.
However, in a PLTS, it is possible for two or more linguistic terms with equal values of . Taking a PLTS , here
According to the above rule, these two values cannot be arranged. To handle such type of problem, Zhang et al. [29] defined the following ranking rule.
Definition 6
([29]).Let , be the lower index of linguistic term .
- (1)
- If the values of are different for all elements in PLTS, then arrange all the elements according to the values of directly.
- (2)
- If all the values of become equal for two or more elements, then
- (a)
- When the lower indices are unequal, arrange according to the values of in descending order.
- (b)
- When the lower indices are incomparable, arrange according to the values of in descending order.
Definition 7
Definition 8
([19]).Let and be two PLTSs, where and denote the number of linguistic terms in and , respectively. If , then linguistic terms will be added to so that the number of elements in and becomes equal. The added linguistic terms are the smallest one’s in and the probabilities of all the linguistic terms are zero.
Let and , then the Normalized PLTSs denoted by and can be obtained according to the following two steps:
- (1)
- If , then is calculated according to Definition 7.
- (2)
- If , then according to Definition 8, add some linguistic terms to the one with the smaller number of elements.
The deviation degree between PLTSs, which is analogous to the Euclidean distance between hesitant fuzzy sets [30] can be defined as:
Definition 9
([19]).Let and be two PLTSs, where and denote the number of linguistic terms in and , respectively, with = . Then, the deviation degree between these two PLTSs can be defined as
where and denote the lower indices of linguistic terms and , respectively.
For further detail of PLTS, one can see Ref. [19].
3. Probabilistic Hesitant Intuitionistic Linguistic Term Set
Although HIFLTS allow the DM to state his assessments by using several linguistic terms, it cannot reflect the probabilities of the assessments of DM.
To overcome this issue, in this section, the concept of probabilistic hesitant intuitionistic linguistic term set (PHILTS) which is based on the concept of HIFLTS and PLTS is proposed. Furthermore, some basic operations for PHILTS are also designed.
Definition 10.
Let X be a universe of discourse, and be a linguistic term set, then a PHILTS on X are two functions l and that when applied to an element of X return finite and ordered subsets of the consecutive linguistic terms of S along with their occurrence probabilities, which can be mathematically expressed as
where and are the PLTSs, denoting the membership and non-membership degree of the element to the set such that the following two conditions are satisfied:
- (i)
- (ii)
- .
For the sake of simplicity and convenience, we call the pair as the intuitionistic probabilistic linguistic term element (PHILTE), denoted by for short.
Remark 1.
Particularly, if the probabilities of all linguistic terms in membership part and non-membership part become equal, then PHILTE reduces to HIFLTE.
Example 2.
Let be a linguistic term set. A PHILTS is
One can easily check the conditions of PHILTS for .
To illustrate the PHILTS more straightforwardly, in the following, a practical life example is given to depict the difference between the PHILTS and HIFLTS:
Example 3.
Take the evaluation of a vehicle on the comfortable degree attribute/criteria as an example. Let S be a linguistic term set used in the above example. An expert provides an HIFLTE on the comfortable degree due to his/her hesitation for this evaluation. However, he/she is more confident in the linguistic term for the membership degree set and the linguistic term for the non-membership degree set. The HIFLTS fails to express his/her confidence. Therefore, we utilize the PHILTS to present his/her evaluations. In this case, his/her evaluations can be expressed as .
In the following, the ordered PHILTE is defined to make sure that the operational results among PHILTEs can be determined easily.
Definition 11.
A PHILTE is known to be an ordered PHILTE, if and are ordered PLTSs.
Example 4.
Consider a PHILTE used in the Example 2. Then, according to Definition 11 the ordered PHILTE is
3.1. The Normalization of PHILTEs
Ideally, the sum of the probabilities is one, but in PHILTE if either of the membership probabilities or non-membership probabilities have sum less than one than this issue is resolved as follows.
Definition 12.
Consider a PHILTE , the associated PHILTE is defined, where
and
Example 5.
Consider a PHILTE . Here, we see that also so the associated PHILTE
In decision making process, experts usually face such problems in which the length of PHILTEs is different. Let and be two PHILTEs of different lengths. Then, the following three cases are possible and . In such situation, they need to equalize their lengths by increasing the number of probabilistic linguistic terms in that PLTS in which the number of probabilistic linguistic terms are relatively small because PHILTEs of different lengths create great problems in operations, aggregation operators and finding the deviation degree between two PHILTEs.
Definition 13.
Given any two PHILTEs and if then linguistic terms should be added to to make their cardinalities identical. The added linguistic terms are the smallest one(s) in , and the probabilities of all the linguistic terms are zero.
The remaining cases are analogous to Case .
Let and be two PHILTEs. Then, the following two simple steps are involved in normalization process.
Step 2: If or , then we add some elements according to Definition 13 to the one with small number of elements.
The resultant PHILTEs are called the normalized PHILTEs which are denoted as and .
Note, for the convenience of presentation, we denote the normalized PHILTEs by and as well.
Example 6.
Let and then
Step 1: According to Equation (6)
Step 2: Since , so we add the linguistic term to so that the number of linguistic terms in and becomes equal, thus . In addition, so we add the linguistic term to , . Therefore, after normalization, we have
and
3.2. The Comparison between PHILTEs
In this section, the comparison between two PHILTEs is presented. For this purpose, the score function and the deviation degree of the PHILTE are defined.
Definition 14.
Let be a PHILTE with a linguistic term set such that and denote, respectively, the lower indices of linguistic terms and , then the score of is denoted and defined as follows:
where ; and .
It is easy to see that which means
Apparently, the score function represents the averaging linguistic term of PHILTE.
For two PHILTEs and , if , then is superior to , denoted as ; if , then is inferior to , denoted as ; and, if , then we cannot distinguish between them. Thus, in this case, we define another indicator, named as the deviation degree as follows:
Definition 15.
Let be a PHILTE such that and denote, respectively, the lower indices of linguistic terms and , then the deviation degree of is denoted and defined as follows:
The deviation degree shows the distance from the average value in the PHILTE. The greater value of implies lower consistency while the lesser value of indicates higher consistency.
Thus, and can be ranked by the following procedure:
- (1)
- if , then ;
- (2)
- if and
- (a)
- , then ;
- (b)
- , then ;
- (c)
- , then is indifferent to and is denoted as .
Example 7.
Let , and S be the linguistic term set used in Example 2 then
, ,
,
, ,
,
Since , we have to calculate the deviation degree of and
= ,
Thus, > so is inferior to .
In the following, we present a theorem which shows that the association does not affect the score and deviation degree of PHILTE.
Theorem 1.
Let be a PHILTE and be the associated PHILTE then and .
Proof.
where and . Since and , which implies that and . Since and which further implies that Hence,
Next,
Since , , , and .
It yields that . ☐
The following theorem shows that order of comparison between two PHILTEs remains unaltered after normalization.
Theorem 2.
Let and be any two PHILTEs, and be the corresponding normalized PHILTEs respectively, then
Proof.
The proof is quite clear because, according to Theorem 1, and , so order of comparison in Step of normalization process is preserved and so for Step is concerned in that step we add some elements to PHILTEs though it does not change the order as we attach zero probabilities with the corresponding added elements so this means and Hence, the result holds true. ☐
In the following definition, we summarize the fact that comparison of any two PHILTEs can be done by their corresponding normalized PHILTEs.
Definition 16.
Let and be any two PHILTEs, and be the corresponding normalized PHILTEs, respectively, then
- (I)
- If then >.
- (II)
- If then .
- (III)
- If then in this case we are unable to decide which one is superior. Thus, in this case, we do the comparison of PHILTEs on the bases of the deviation degree of normalized PHILTEs as follows.
- (1)
- If then .
- (2)
- If then .
- (3)
- If in such case we say that is indifferent to and is denoted by .
Example 8.
Let S be the linguistic term set used in Example 2, and then the corresponding normalized PHILTEs are and .
We calculate the score of these normalized PHILTEs
, ,
,
, ,
,
Since so
3.3. Basic Operations of PHILTEs
Based on the operational laws of the PLTSs [19], we develop some basic operational framework of PHILTEs and investigate their properties in preparation for applications to the practical real life problems. Hereafter, it is assumed that all PHILTEs are normalized.
Definition 17.
Let and be two normalized and ordered PHILTEs, then
Addition:
Multiplication:
Scalar multiplication:
Scalar power:
where and are the linguistic terms in and , respectively; and are the linguistic terms in and , respectively; and are the probabilities of the linguistic terms in and , respectively; and are the probabilities of the linguistic terms in and , respectively; and γ denote a nonnegative scalar.
Theorem 3.
Let be any three ordered and normalized PHILTEs, , then
- (1)
- (2)
- (3)
- (4)
- (5)
- (6)
- (7)
- (8)
Proof.
. ☐
4. Aggregation Operators and Attribute Weights
This section is dedicated to discussion on some basic aggregation operators of PHILTS. Deviation degree between two PHILTEs is also defined in this section. Finally, we calculate the attribute weights in the light of PHILTEs.
4.1. The Aggregation Operators for PHILTEs
The aggregation operators are powerful tools to deal with linguistic information. To make a better usage of PHILTEs in real world problems, in the following, aggregation operators for PHILTEs have been developed.
Definition 18.
Let be n ordered and normalized PHILTEs. Then
is called the probabilistic hesitant intuitionistic linguistic averaging (PHILA) operator.
Definition 19.
Let be n ordered and normalized PHILTEs. Then
is called the probabilistic hesitant intuitionistic linguistic weighted averaging (PHILWA) operator, where is the weight vector of , , , and .
Particularly, if we take , then the PHILWA operator reduces to the PHILA operator.
Definition 20.
Let be n ordered and normalized PHILTEs. Then,
is called the probabilistic hesitant intuitionistic linguistic geometric (PHILG) operator.
Definition 21.
Let be n ordered and normalized PHILTEs. Then
is called the probabilistic hesitant intuitionistic linguistic weighted geometric (PHILWG) operator, where is the weight vector of , , , and .
Particularly, if we take , then the PHILWG operator reduces to the PHILG operator.
4.2. Maximizing Deviation Method for Calculating the Attribute Weights
The choice of weights directly affects the performance of weighted aggregation operators. For this purpose, in this subsection, the affective maximizing deviation method is adopted to calculate weight in MAGDM when weights are unknown or partly known. Based on Definition 9, the deviation degree between two PHILTEs is defined as follows:
Definition 22.
Let and be any two PHILTEs of equal length. Then, the deviation degree D between and is given by
where
denote the lower index of the linguistic term of and denote the lower index of the linguistic term of .
Based on the above definition, in the following, we derive attribute weight vector because working on the probabilistic linguistic data to deal with the MAGDM problems, in which the weight information of attribute values is completely unknown or partly known, we must find the attribute weights in advance.
Given the set of alternatives and the set of “n” attributes , respectively, then, by using Equation (17), the deviation measure between the alternative “” and all other alternatives with respect to the attribute “” can be given as:
In accordance with the theme of the maximizing deviation method, if the deviation degree among alternatives is smaller for an attribute, then the attribute should give a smaller weight. This one shows that the alternatives are homologous to the attribute. Contrarily, it should give a larger weight. Let
show the deviation degree of one alternative and others with respect to the attribute “” and let
express the sum of the deviation degrees among all attributes.
To obtain the attribute weights vector , we build the following single objective optimization model (named as ) to drive the deviation degree as large as possible.
To solve the above model , we use the Lagrange multiplier function:
where η is the Lagrange parameter.
Then, we compute the partial derivatives of Lagrange function with respect to and η and let them be zero:
By solving Equation (24), one can obtain the optimal weight
where
Obviously, ∀j. By normalizing Equation (25), we get:
where
The above end result can be applied to the situations where the information of attribute weights is completely unknown. However, in real life decision making problems, the weight information is usually partly known. In such cases, let H be a set of the known weight information, which can be given in the following forms based on the literature [31,32,33,34].
Form 1. A weak ranking: .
Form 2. A strict ranking: .
Form 3. A ranking of differences: .
Form 4. A ranking with multiples: .
Form 5. An interval form: .
and denote the non-negative numbers.
With the set H, we can build the following model:
from which the optimal weight vector obtained.
5. MAGDM with Probabilistic Hesitant Intuitionistic Linguistic Information
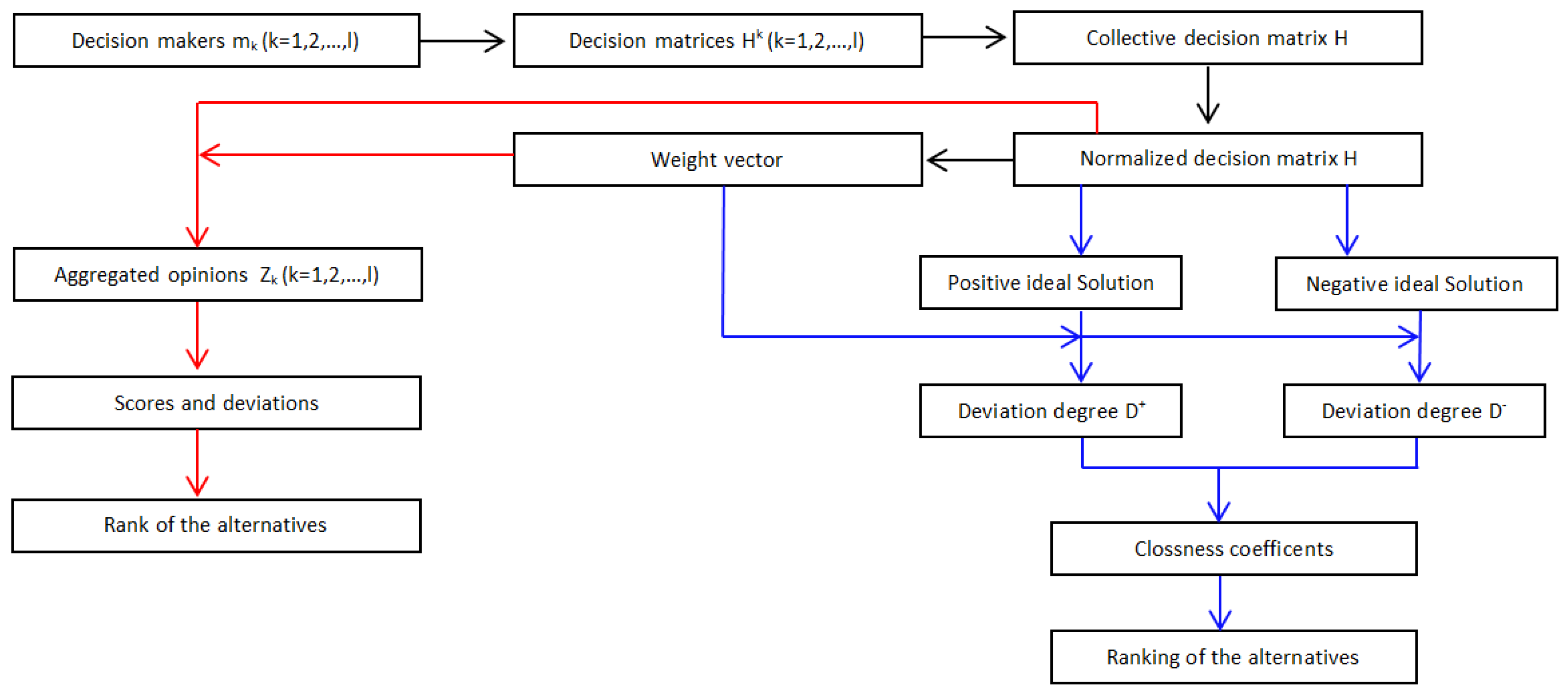
In this section, two practical methods, i.e., an extended TOPSIS method and an aggregation based method, for MAGDM problems are proposed, where the opinions of DMs take the form of PHILTSs.
5.1. Extended TOPSIS Method for MAGDM with Probabilistic Hesitant Intuitionistic Linguistic Information
Of the numerous MAGDM methods, TOPSIS (Technique for Order of Preference by Similarity to Ideal Solution) is one of the effective methods for ranking and selecting a number of possible alternatives by measuring Euclidean distances. It has been successfully applied to solve evaluation problems with a finite number of alternatives and criteria [19,24,28] because it is easy to understand and implement, and can measure the relative performance for each alternative.
In the following, we discuss the complete construction of extended TOPSIS method in PHILTS regard. This methodology involves the following steps.
Step 1: Analyze the given MAGDM problem; since the problem is group decision making, so let there be “l” decision makers or experts involved in the given problem. The set of alternatives is and the set of attributes is . The experts provide their linguistic evaluation values for membership and non-membership by using linguistic term set over the alternative with respect to the attribute .
The DM states his membership and non-membership linguistic evaluation values keeping in mind all the alternatives and attributes in the form of PHILTEs. Thus, intuitionistic probabilistic linguistic decision matrix is constructed. It should be noted that preference of alternative “” with respect to decision maker “” and attribute “” is denoted as PHILTE in a group decision making problem with “l” experts.
Step 2: Calculate the one probabilistic hesitant intuitionistic linguistic decision matrix H by aggregating the opinions of DMs where
where
,
,
,
,
Here, and are taken according to the maximum and minimum value of , respectively, where denotes the lower index of the linguistic term and is its corresponding probability.
In this aggregated matrix H, the preference of alternative with respect to attribute is denoted as .
Each term of the aggregated matrix H i.e., is also an PHILTE; for this, we have to prove that
and . Since we know that is a PHILTS for every expert, alternative and attribute, a PHILTS it must satisfy the conditions
, .
Thus, the above simple construction of , , , and guarantees that the is a PHILTE.
Step 3: Normalize the probabilistic hesitant intuitionistic linguistic decision matrix H according to the method in Section 3.1.
Step 4: Obtain the weight vector of the attributes ,
Step 5: The PHILTS positive ideal solution (PHILTS-PIS) of alternatives, denoted by , is defined as follows:
where and and is lower index of the linguistic term while and and is lower index of the linguistic term . Similarly, the PHILTS negative ideal solution (PHILTS-NIS) of alternatives, denoted by , is defined as follows:
where and and is lower index of the linguistic term while and and is lower index of the linguistic term .
Step 6: Compute the deviation degree between each alternative PHILTS-PIS as follows:
The smaller is the deviation degree , the better is alternative
Similarly, compute the deviation degree between each alternative PHILTS-NIS as follows:
The larger is the deviation degree , the better is alternative
Step 7: Determine and where
and
Step 8: Determine the closeness coefficient of each alternative to rank the alternatives.
Step 9: Pick the best alternative on the basis of the closeness coefficient , where the larger is the closeness coefficient the better is alternative . Thus, the best alternative
5.2. The Aggregation-Based Method for MAGDM with Probabilistic Hesitant Intuitionistic Linguistic Information
In this subsection, the aggregation-based method for MAGDM is presented, where the preference opinions of DMs are represented by PHILTS. In Section 4, we have developed some aggregation operators, i.e., PHILA, PHILWA, PHILG and PHILWG. In this algorithm, we use PHILWA operator to aggregate the attribute values of each alternative , into the overall attribute values. The following steps are involved in this algorithm. The first four Steps are similar to the extended TOPSIS method. Therefore, we go to Step 5.
Step 5: Determine the overall attribute values where is the weight vector of attributes, using PHILWA operator, this can be expressed as follows:
where
Step 6: Compare the overall attribute values mutually, based on their score function and deviation degree whose detail is given in Section 3.2.
Step 7: Rank the alternatives according to the order of and pick the best alternative.
The flow chart of the proposed models is presented in Figure 1.
6. A Case Study
To validate the proposed theory and decision making models, in this section, a practical example taken from [28] is solved. A group of seven peoples need to invest their savings in a most profitable way. They considered five possibilities: is real estate, is stock market, is T-bills, is national saving scheme, and is insurance company. To determine best option, the following attributes are taken into account: is the risk factor, is the growth, is quick refund, and is complicated documents requirement. Base upon their knowledge and experience, they provide their opinion in terms of following HIFLTSs.
6.1. The Extended TOPSIS Method for the Considered Case
We handle the above problem by applying the extended TOPSIS method.
Step 1: The probabilistic hesitant intuitionistic linguistic decision matrices derived from Table 1, Table 2 and Table 3 are shown in Table 4, Table 5 and Table 6, respectively.
Step 3: The normalized probabilistic hesitant intuitionistic linguistic decision matrix of the group is shown in Table 8.
Step 4: The weight vector is derived from Equation (26) as follows:
Step 5: The PHILTS-PIS “” and the PHILTS-NIS “” of each alternative are derived using Equations (27) and (28) as follows:
Step 8: Determine the closeness coefficient of each alternative by Equation (33) :
Step 9: Rank the alternatives according to the ranking of : and thus, (insurance company) is the best alternative.
6.2. The Aggregation-Based Method for the Considered Case
We can also apply the aggregation-based method to attain the ranking of alternatives for the case study.
Step 1: Construct the probabilistic hesitant intuitionistic fuzzy decision matrices of the group as listed in Table 4, Table 5 and Table 6, and then aggregated and normalized as shown in Table 7 and Table 8.
Step 2: Utilize Equation (26) to obtain the weight vector
Step 3: Derive the overall attribute value of each alternative by using Equation (35) :
Step 4: Compute the score of each attribute value by Definition 14:
, , , ,
Step 5: Compare the overall attribute values of alternatives according to the values of the score function. It is obvious, that Thus, again, we get the best alternative
7. Discussions and Comparison
For the purpose of comparison, in this subsection, the case study is again solved by applying the TOPSIS method with traditional HIFLTSs.
Step 1: The decision matrix X in Table 9 is constructed by utilizing Table 1, Table 2 and Table 3 as follows:
Step 2: Determine the HIFLTS-PIS “” and the HIFLTS-NIS “” for cost criteria cc and benefit criteria c,c as follows:
Note: One can see the detail of HIFLTS-PIS “” and the HIFLTS-NIS “” in [28].
Step 3: Calculate the positive ideal matrix and the negative ideal matrix as follows:
in which
Other entries can be found by similar calculation.
Step 4: The relative closeness of each alternative to the ideal solution can be obtained as follows:
The of other alternatives can be find by similar calculations.
, , .
Step 5: The ranking of alternatives of alternatives according to the closeness coefficient is:
- In Table 9, the disadvantages of HIFLTS are apparent because in HIFLTS the probabilities of the linguistic terms is not considered which means that all possible linguistic terms in HIFLTS have same occurrence possibility which is unrealistic, whereas the inspection of Table 7 shows that PHILTS not only contains the linguistic terms, but also considers the probabilities of linguistic terms, and, thus, PHILTS constitutes an extension of HIFLTS.
- The inspection of Table 10 reveals that the extended TOPSIS method and the aggregation-based method give the same best alternative . The TOPSIS method with the traditional HIFLTSs gives as the best alternative.
- This difference of best alternative in Table 10 is due to the effect of probabilities of membership and non-membership linguistic terms, which highlight the critical role of probabilities. Thus, our methods are more rational to get the ranking of alternatives and further to find the best alternative.
- Extended TOPSIS method and aggregation-based method for MAGDM with PLTS information explained in [19] are more promising and better than extended TOPSIS method and aggregation-based method for MAGDM with HFLTS information. However, a clear superiority of PHILTS is that it assigns to each element the degree of belongingness and also the degree of non-belongingness along with probability. PLTS only assigns to each element a belongingness degree along with probability. Using PLTSs, various frameworks have been developed by DMs [19,29] but they are still intolerant, since there is no mean of attributing reliability or confidence information to the degree of belongingness.
The comparisons and other aspects are summarized in Table 11.
8. Conclusions
Because of the blurring of human thinking, sometimes it becomes difficult for experts to accurately measure the opinions in the area of the usual fuzzy set theory, even in the HIFLTSs and PLTSs. For this purpose, in this article, a new concept called PHILTS was introduced to extend the current HIFLTS and PLTS. To facilitate the calculation of the PHILTSs, a normalization process, basic operations and aggregation operators for PHILTSs are also designed. An extended TOPSIS method and aggregation based method have been proposed to solve decision ranking problems of the group with the multiple conflict criteria in PHILTS. The proposed models are compared with existing model of TOPSIS. The PLTS and HIFLTS are special cases of PHILTS, it grants the freedom to DMs to express their opinions in more dynamic way. Furthermore, the occurrence probabilities of membership and non-membership linguistic term sets greatly affects the decision making, validating the importance of designed theory and models in this manuscript. The probability is one of the best tool to handle uncertainty of future, thus our proposed models are more suitable of decision making related to the possible future scenarios. However, its arithmetic complexity is high.
In the future, all the work which has been done thus far PLTSs and HIFLTSs can be studied for PHILTS and then applied to decision making.
Author Contributions
Conceptualization, Z.B., T.R. and J.A.; Formal analysis, Z.B., M.G.A.M., T.R. and J.A.; Investigation, Z.B. and J.A.; Methodology, M.G.A.M.; Resources, T.R.; Software, M.G.A.M.
Funding
This work is partially supported by AGI Education, Auckland, New Zealand.
Acknowledgments
The authors would like to thank the editors and the anonymous reviewers, whose insightful comments and constructive suggestions helped us to significantly improve the quality of this paper. This research work is partially supported by AGI Education, Auckland, New Zealand.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Atanassov, K. Intuitionistic fuzzy sets. Fuzzy Sets Syst. 1986, 20, 87–96. [Google Scholar] [CrossRef]
- Torra, V. Hesitant fuzzy sets. Int. J. Intell. Syst. 2010, 25, 529–539. [Google Scholar] [CrossRef]
- Xu, Z.; Zhou, W. Consensus building with a group of decision makers under the hesitant probabilistic fuzzy environment. Fuzzy Optim. Decis. Mak. 2017, 16, 481–503. [Google Scholar] [CrossRef]
- Bashir, Z.; Rashid, T.; Wątróbski, J.; Sałabun, W.; Malik, A. Hesitant Probabilistic Multiplicative Preference Relations in Group Decision Making. Appl. Sci. 2018, 8, 398. [Google Scholar] [CrossRef]
- Alcantud, J.C.R.; Giarlotta, A. Necessary and possible hesitant fuzzy sets: A novel model for group decision making. Inf. Fusion 2019, 46, 63–76. [Google Scholar] [CrossRef]
- Zadeh, L.A. The concept of a linguistic variable and its applications to approximate reasoning. Inf. Sci. Part I II III 1975, 8–9, 43–80, 199–249, 301–357. [Google Scholar]
- Ju, Y.B.; Yang, S.H. Approaches for multi-attribute group decision making based on intuitionistic trapezoid fuzzy linguistic power aggregation operators. J. Intell. Fuzzy Syst. 2014, 27, 987–1000. [Google Scholar]
- Merigó, J.M.; Casanovas, M.; Martínez, L. Linguistic aggregation operators for linguistic decision making based on the Dempster–Shafer theory of evidence. Int. J. Uncertain. Fuzziness Knowl. Based Syst. 2010, 18, 287–304. [Google Scholar]
- Zhu, H.; Zhao, J.B.; Xu, Y. 2-Dimension linguistic computational model with 2-tuples for multi-attribute group decision making. Knowl. Based Syst. 2016, 103, 132–142. [Google Scholar] [CrossRef]
- Meng, F.Y.; Tang, J. Extended 2-tuple linguistic hybrid aggregation operators and their application to multi-attribute group decision making. Int. J. Comput. Intell. Syst. 2014, 7, 771–784. [Google Scholar] [CrossRef]
- Li, C.C.; Dong, Y. Multi-attribute group decision making methods with proportional 2-tuple linguistic assessments and weights. Int. J. Comput. Intell. Syst. 2014, 7, 758–770. [Google Scholar] [CrossRef] [Green Version]
- Xu, Z.S. Multi-period multi-attribute group decision-making under linguistic assessments. Int. J. Gen. Syst. 2009, 38, 823–850. [Google Scholar] [CrossRef]
- Li, D.F. Multiattribute group decision making method using extended linguistic variables. Int. J. Uncertain. Fuzziness Knowl. Based Syst. 2009, 17, 793–806. [Google Scholar] [CrossRef]
- Agell, N.; Sánchez, M.; Prats, F.; Roselló, L. Ranking multi-attribute alternatives on the basis of linguistic labels in group decisions. Inf. Sci. 2012, 209, 49–60. [Google Scholar] [CrossRef]
- Rodríguez, R.M.; Martínez, L.; Herrera, F. Hesitant fuzzy linguistic term sets for decision making. IEEE Trans. Fuzzy Syst. 2012, 20, 109–119. [Google Scholar]
- Zhu, J.; Li, Y. Hesitant Fuzzy Linguistic Aggregation Operators Based on the Hamacher t-norm and t-conorm. Symmetry 2018, 10, 189. [Google Scholar] [CrossRef]
- Cui, W.; Ye, J. Multiple-Attribute Decision-Making Method Using Similarity Measures of Hesitant Linguistic Neutrosophic Numbers Regarding Least Common Multiple Cardinality. Symmetry 2018, 10, 330. [Google Scholar] [CrossRef]
- Liu, D.; Liu, Y.; Chen, X. The New Similarity Measure and Distance Measure of a Hesitant Fuzzy Linguistic Term Set Based on a Linguistic Scale Function. Symmetry 2018, 10, 367. [Google Scholar] [CrossRef]
- Pang, Q.; Wang, H.; Xu, Z. Probabilistic linguistic term sets in multi-attribute group decision making. Inf. Sci. 2016, 369, 128–143. [Google Scholar] [CrossRef]
- Lin, M.; Xu, Z.; Zhai, Y.; Zhai, T. Multi-attribute group decision-making under probabilistic uncertain linguistic environment. J. Oper. Res. Soc. 2017. [Google Scholar] [CrossRef]
- Atanassov, K. Intuitionistic Fuzzy Sets; Springer: Heidelberg, Germany, 1999. [Google Scholar]
- Bashir, Z.; Rashid, T.; Wątróbski, J.; Sałabun, W.; Ali, J. Intuitionistic-fuzzy goals in zero-sum multi criteria matrix games. Symmetry 2017, 9, 158. [Google Scholar] [CrossRef]
- Beg, I.; Rashid, T. Group Decision making Using Intuitionistic Hesitant Fuzzy Sets. Int. J. Fuzzy Logic Intell. Syst. 2014, 14, 181–187. [Google Scholar] [CrossRef]
- Boran, F.E.; Gen, S.; Kurt, M.; Akay, D. A multi-criteria intuitionistic fuzzy group decision making for supplier selection with TOPSIS method. Expert Syst. Appl. 2009, 36, 11363–11368. [Google Scholar] [CrossRef]
- De, S.K.; Biswas, R.; Roy, A.R. An application of intuitionistic fuzzy sets in medical diagnosis. Fuzzy Sets Syst. 2001, 117, 209–213. [Google Scholar] [CrossRef]
- Li, D.F. Multiattribute decision making models and methods using intuitionistic fuzzy sets. J. Comput. Syst. Sci. 2005, 70, 73–85. [Google Scholar] [CrossRef]
- Liu, P.; Mahmood, T.; Khan, Q. Multi-Attribute Decision-Making Based on Prioritized Aggregation Operator under Hesitant Intuitionistic Fuzzy Linguistic Environment. Symmetry 2017, 9, 270. [Google Scholar] [CrossRef]
- Beg, I.; Rashid, T. Hesitant intuitionistic fuzzy linguistic term sets. Notes Intuit. Fuzzy Sets 2014, 20, 53–64. [Google Scholar]
- Zhang, Y.; Xu, Z.; Wang, H.; Liao, H. Consistency-based risk assessment with probablistic linguistic prefrence relation. Appl. Soft Comput. 2016, 49, 817–833. [Google Scholar] [CrossRef]
- Xu, Z.S.; Xia, M.M. On distance and correlation measures of hesitant fuzzy information. Int. J. Intell. Syst. 2011, 26, 410–425. [Google Scholar] [CrossRef]
- Kim, S.H.; Ahn, B.S. Interactive group decision making procedure under incomplete information. Eur. J. Oper. Res. 1999, 116, 498–507. [Google Scholar] [CrossRef]
- Kim, S.H.; Choi, S.H.; Kim, J.K. An interactive procedure for multiple attribute group decision making with incomplete information: Range-based approach. Eur. J. Oper. Res. 1999, 118, 139–152. [Google Scholar] [CrossRef]
- Park, K.S. Mathematical programming models for characterizing dominance and potential optimality when multicriteria alternative values and weights are simultaneously incomplete. IEEE Trans. Syst. Man Cybern. 2004, 34, 601–614. [Google Scholar] [CrossRef]
- Xu, Z.S. An interactive procedure for linguistic multiple attribute decision making with incomplete weight information. Fuzzy Optim. Decis. Mak. 2007, 6, 17–27. [Google Scholar] [CrossRef]
Figure 1.
Extended TOPSIS and Aggregation-based models.

{kind=link}
Table 1.
Decision matrix provided by the DMs 1, 2, 3 .
| c | c | c | c | |
|---|---|---|---|---|
| x | ||||
| x | ||||
| x | ||||
| x | ||||
| x |
Table 2.
Decision matrix provided by the DMs 4, 5 .
| c | c | c | c | |
|---|---|---|---|---|
| x | ||||
| x | ||||
| x | ||||
| x | ||||
| x |
Table 3.
Decision matrix provided by the DMs 6, 7 .
| c | c | c | c | |
|---|---|---|---|---|
| x | ||||
| x | ||||
| x | ||||
| x | ||||
| x |
Table 4.
Probabilistic hesitant intuitionistic linguistic decision matrix with respect to DMs 1, 2, 3
Table 4.
Probabilistic hesitant intuitionistic linguistic decision matrix with respect to DMs 1, 2, 3
| c | c | |
|---|---|---|
| x | ||
| x | ||
| x | ||
| x | ||
| x | ||
| c | c | |
| x | ||
| x | ||
| x | ||
| x | ||
| x |
Table 5.
Probabilistic hesitant intuitionistic linguistic decision matrix with respect to DMs .
| c | c | |
|---|---|---|
| x | ||
| x | ||
| x | ||
| x | ||
| x | ||
| c | c | |
| x | ||
| x | ||
| x | ||
| x | ||
| x |
Table 6.
Probabilistic hesitant intuitionistic linguistic decision matrix with respect to DMs .
| c | c | |
|---|---|---|
| x | ||
| x | ||
| x | ||
| x | ||
| x | ||
| c | c | |
| x | ||
| x | ||
| x | ||
| x | ||
| x |
Table 7.
Decision matrix (H).
| c | c | |
|---|---|---|
| x | ||
| x | ||
| x | ||
| x | ||
| x | ||
| c | c | |
| x | ||
| x | ||
| x | ||
| x | ||
| x |
Table 8.
The normalized probabilistic hesitant intuitionistic linguistic decision matrix.
| c | |
|---|---|
| x | |
| x | |
| x | |
| x | |
| x | |
| c | |
| x | |
| x | |
| x | |
| x | |
| x | |
| c | |
| x | |
| x | |
| x | |
| x | |
| x | |
| c | |
| x | |
| x | |
| x | |
| x | |
| x |
Table 9.
Decision matrix (X).
| c | c | c | c | |
|---|---|---|---|---|
| x | ||||
| x | ||||
| x | ||||
| x | ||||
| x |
Table 10.
Comparison of Results.
| TOPSIS [28] | |
| Proposed extend TOPSIS | |
| Proposed aggregation model |
Table 11.
The advantages and limitations of the proposed methods.
| Advantages | Limitations |
|---|---|
| 1. PHILTS generalize the existing PLTS models | 1. It is essential to take membership as |
| since PHILTS take more information from the DMs | well as non-membership probabilistic |
| into account. | data. |
| 2. PHILTS is not affected by partial vagueness. | 2. Its computational index is |
| 3. PHILTS is more in line with people’s language, | high. |
| leading to much more fruitful decisions. | |
| 4. The attribute weights are calculated with | |
| objectivity (without favor). |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Malik, M.G.A.; Bashir, Z.; Rashid, T.; Ali, J. Probabilistic Hesitant Intuitionistic Linguistic Term Sets in Multi-Attribute Group Decision Making. Symmetry 2018, 10, 392. https://doi.org/10.3390/sym10090392
AMA Style
Malik MGA, Bashir Z, Rashid T, Ali J. Probabilistic Hesitant Intuitionistic Linguistic Term Sets in Multi-Attribute Group Decision Making. Symmetry. 2018; 10(9):392. https://doi.org/10.3390/sym10090392
Chicago/Turabian StyleMalik, M. G. Abbas, Zia Bashir, Tabasam Rashid, and Jawad Ali. 2018. "Probabilistic Hesitant Intuitionistic Linguistic Term Sets in Multi-Attribute Group Decision Making" Symmetry 10, no. 9: 392. https://doi.org/10.3390/sym10090392
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.