
Forecasting Urban Air Quality via a Back-Propagation Neural Network and a Selection Sample Rule

Abstract
:1. Introduction
2. Data
3. Methods
3.1. Identification of the Key Factors
- (a)
- Obtaining the representative data for the meteorological factorThe specific data include the average value of the ascending period , the average value of the descending period , the maximum value of the analysis period , the minimum value of the analysis period, and the overall average value . The represents the specific meteorological factor.
- (b)
- Numerical normalization
- (c)
- Variation analysis of the meteorological factor ()
- (d)
- Computation of the influencing weight
3.2. A Selection Sample Rule Based on the Similarity Principle
3.2.1. The Basic Description
3.2.2. Identification of wj
3.2.3. Identification of
3.3. Identification of the Variation Trend Consistency
3.3.1. Variation Trend Consistency for Wind Speed
- (1)
- Calculate the variation between the forecasting day and the day before.where is the difference between the squared values of wind speed on the day of forecasting and the day before; and are the two wind vectors on the day of forecasting; and and represent the two wind vectors before the day of forecasting.
- (2)
- Calculate the variation between the two adjacent days in the samples selected in Section 3.1,where is the difference between the squared values of wind speed on the forecasting day and the day before and are the two wind vectors on the forecasting day; and and are the two wind vectors on the day before the forecasting day.
- (3)
- Identify whether the wind speed in the forecasting data shows the same tendency of ascending or descending as that in the selected samples. If the tendency is the same, the samples are reserved; otherwise, the samples are removed.
3.3.2. The Variation Trend Consistency Identification of Rainfall
3.3.3. Similarity Identification of Background Concentration
- (1)
- The background concentration on the day of forecasting is calculated as follows:
- (2)
- The background concentration in the sample data is calculated as follows:
- (3)
- Identify whether the background concentration in the forecasting data and the absolute difference of the background concentration on the day of forecasting is in the range of the threshold value. If they are in the range, the samples are reserved; otherwise, they are removed.
3.4. Improvements in BP Neural Network

{kind=link}
{kind=link}
| Pollutants | Experiments | N Input | Mean (mg/m3) | MAE (mg/m3) | MAPE | R | TFA | Ef | Af |
|---|---|---|---|---|---|---|---|---|---|
| SO2 | Basic (Group 1) | 10 | 0.027 | 0.009 | 37.4 | 0.422 | 0500 | −0.322 | 1.513 |
| RF * (Group 2) | 10 | 0.027 | 0.009 | 36.6 | 0.510 | 0.536 | 0.010 | 1.543 | |
| WS (Group 3) | 10 | 0.027 | 0.010 | 43.2 | 0.304 | 0.464 | −0.583 | 1.693 | |
| BC (Group 4) | 10 | 0.027 | 0.009 | 40.3 | 0.345 | 0.483 | −0.937 | 1.577 | |
| RF + WS (Group 5) | 10 | 0.027 | 0.009 | 38.5 | 0.430 | 0.482 | −0.192 | 1.501 | |
| RF + BC (Group 6) | 10 | 0.027 | 0.011 | 49.7 | 0.118 | 0.464 | −1.726 | 1.575 | |
| WS + BC (Group 7) | 10 | 0.027 | 0.012 | 52.8 | 0.178 | 0.393 | −1.174 | 1.716 | |
| PM10 | basic(Group 1) | 7 | 0.105 | 0.025 | 26.6 | 0.536 | 0.492 | 0.210 | 1.297 |
| RF (Group 2) | 7 | 0.105 | 0.026 | 28.8 | 0.476 | 0.433 | 0.108 | 1.319 | |
| WS (Group 3) | 7 | 0.105 | 0.025 | 26.2 | 0.527 | 0.483 | 0.190 | 1.289 | |
| BC (Group 4) | 7 | 0.105 | 0.024 | 24.6 | 0.563 | 0.500 | 0.225 | 1.280 | |
| RF + WS (Group 5) | 7 | 0.105 | 0.025 | 27.8 | 0.479 | 0.417 | 0.159 | 1.315 | |
| RF + BC * (Group 6) | 7 | 0.105 | 0.023 | 22.7 | 0.672 | 0.550 | 0.348 | 1.269 | |
| WS + BC (Group 7) | 7 | 0.105 | 0.024 | 26.9 | 0.581 | 0.417 | 0.317 | 1.290 | |
| NO2 | Basic (Group 1) | 10 | 0.073 | 0.020 | 25.0 | 0.680 | 0.550 | 0.261 | 1.340 |
| RF (Group 2) | 10 | 0.073 | 0.020 | 24.1 | 0.660 | 0.533 | 0.199 | 1.345 | |
| WS (Group 3) | 10 | 0.073 | 0.018 | 22.7 | 0.702 | 0.533 | 0.352 | 1.291 | |
| BC (Group 4) | 10 | 0.073 | 0.019 | 23.7 | 0.715 | 0.517 | 0.337 | 1.315 | |
| RF + WS (Group 5) | 10 | 0.073 | 0.018 | 23.7 | 0.723 | 0.617 | 0.386 | 1.298 | |
| RF + BC (Group 6) | 10 | 0.073 | 0.019 | 24.3 | 0.716 | 0.483 | 0.380 | 1.306 | |
| WS + BC * (Group 7) | 10 | 0.073 | 0.018 | 22.5 | 0.688 | 0.567 | 0.397 | 1.271 |
3.5. Indices of Model Evaluation
4. Results and Discussion
4.1. The Results of the Sensitivity Experiments in Guangzhou No. 5 Middle School (Num. 2)
4.2. Errors of the Selected Models of Num. 2 for May 2011 to April 2012
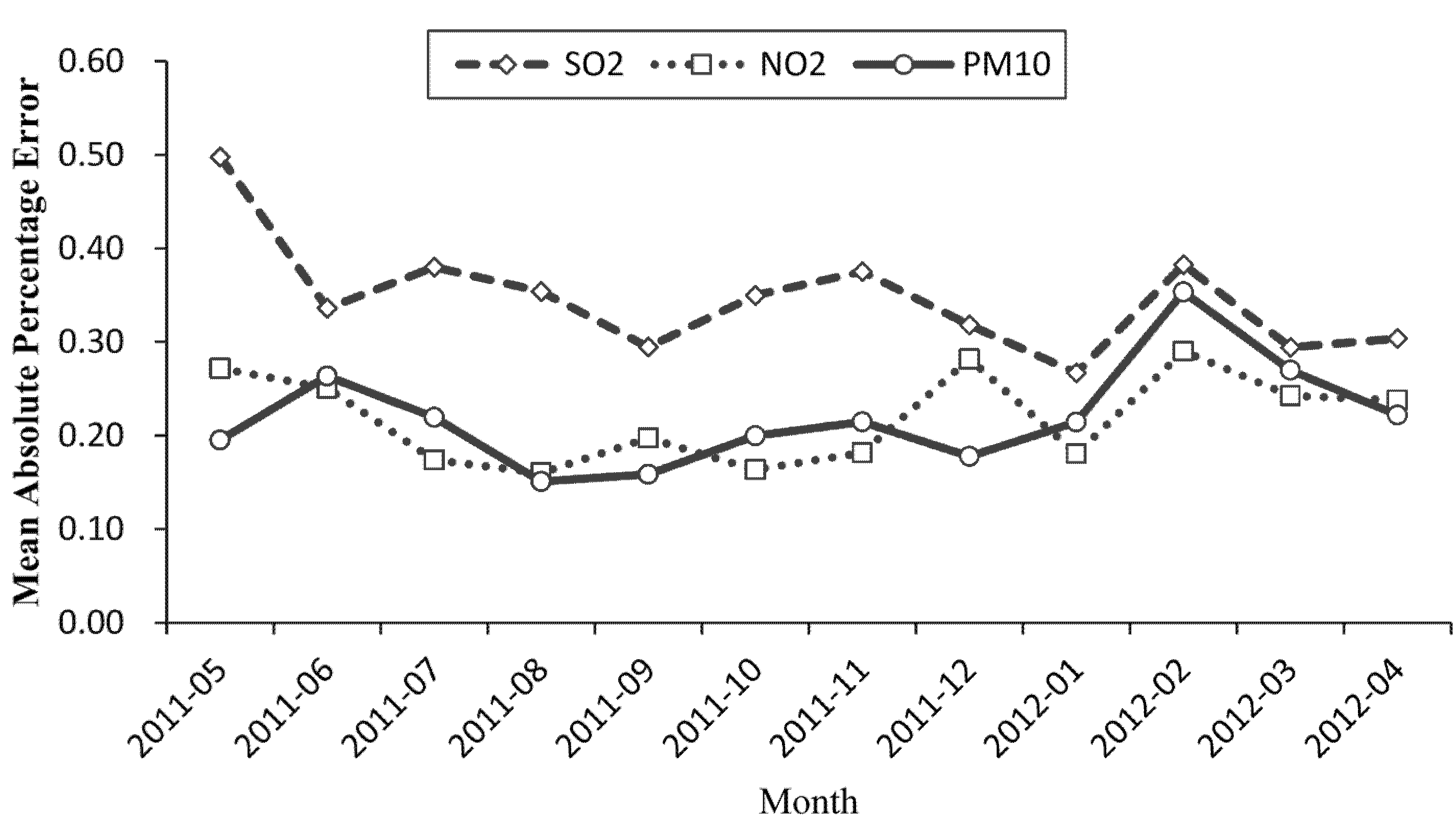
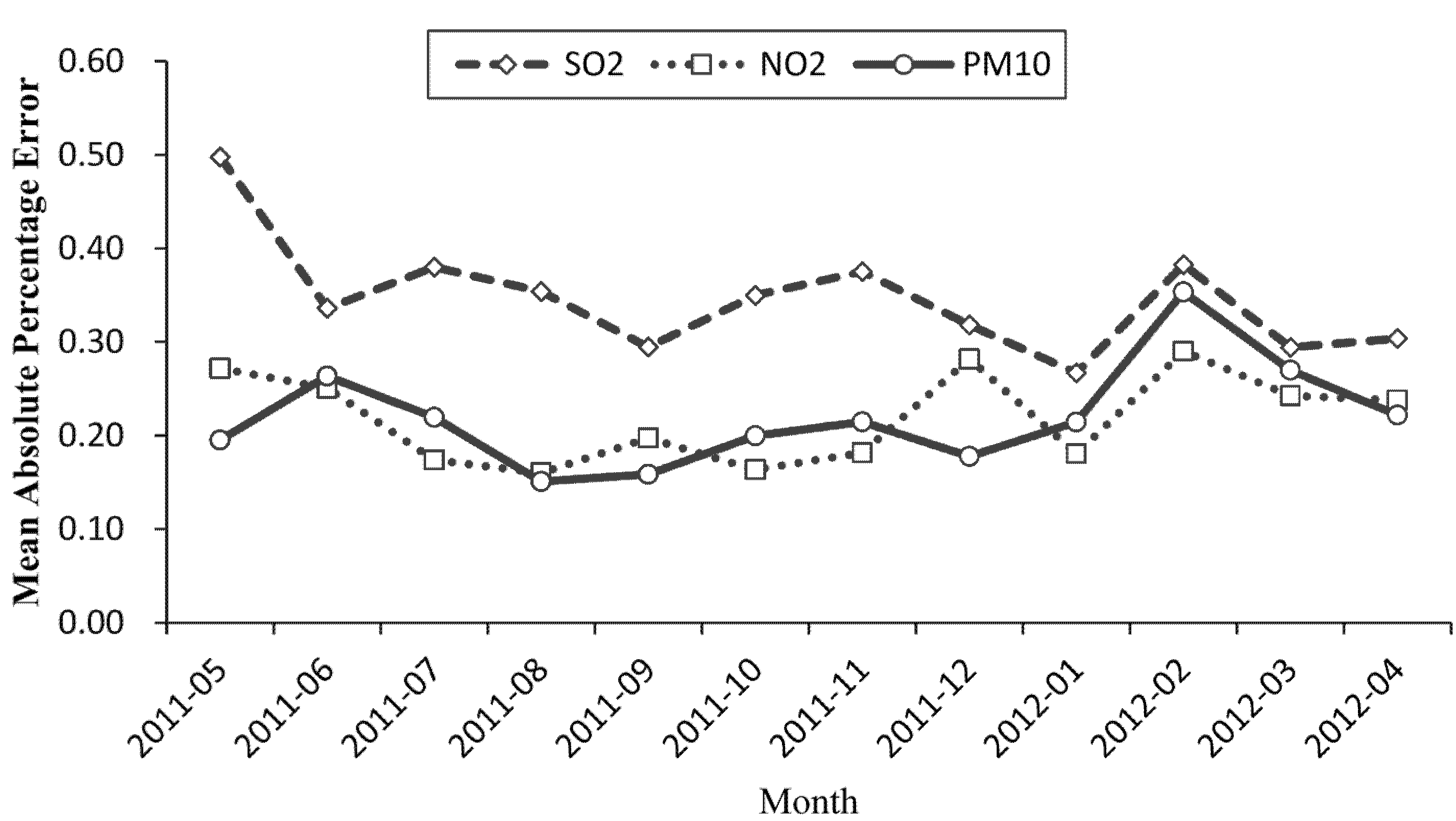
4.3. Errors in the Selected Models for Others Sites
| Pollutant | Site | Model | Mean (mg/m3) | MAE (mg/m3) | MAPE | R | TFA | Ef | Af |
|---|---|---|---|---|---|---|---|---|---|
| SO2 | Num. 1 | Basic | 0.024 | 0.008 | 36.8 | 0.525 | 0.506 | 0.159 | 1.459 |
| Selected | 0.024 | 0.008 | 34.9 | 0.614 | 0.525 | 0.237 | 1.451 | ||
| Num. 3 | Basic | 0.027 | 0.010 | 43.6 | 0.418 | 0.511 | −0.164 | 1.539 | |
| Selected | 0.027 | 0.010 | 40.4 | 0.409 | 0.475 | −0.181 | 1.548 | ||
| Num. 4 | Basic | 0.023 | 0.009 | 44.2 | 0.394 | 0.509 | −0.301 | 1.567 | |
| Selected | 0.023 | 0.009 | 41.3 | 0.456 | 0.527 | −0.332 | 1.541 | ||
| Num. 5 | basic | 0.022 | 0.007 | 35.6 | 0.441 | 0.455 | −0.019 | 1.468 | |
| Selected | 0.022 | 0.007 | 31.6 | 0.472 | 0.515 | 0.059 | 1.408 | ||
| Num. 6 | Basic | 0.027 | 0.011 | 42.8 | 0.355 | 0.466 | 0.055 | 1.587 | |
| Selected | 0.027 | 0.010 | 39.6 | 0.451 | 0.508 | 0.019 | 1.551 | ||
| Num. 7 | basic | 0.036 | 0.015 | 47.8 | 0.298 | 0.527 | −0.580 | 1.662 | |
| Selected | 0.036 | 0.013 | 41.2 | 0.422 | 0.561 | −0.239 | 1.563 | ||
| PM10 | Num. 1 | Basic | 0.083 | 0.023 | 26.2 | 0.656 | 0.438 | 0.348 | 1.328 |
| Selected | 0.083 | 0.022 | 24.9 | 0.713 | 0.509 | 0.397 | 1.335 | ||
| Num. 3 | Basic | 0.067 | 0.018 | 32.1 | 0.604 | 0.132 | 0.348 | 1.354 | |
| Selected | 0.067 | 0.018 | 26.8 | 0.694 | 0.542 | 0.459 | 1.322 | ||
| Num. 4 | basic | 0.061 | 0.017 | 31.6 | 0.680 | 0.493 | 0.454 | 1.350 | |
| Selected | 0.061 | 0.017 | 26.4 | 0.741 | 0.506 | 0.523 | 1.317 | ||
| Num. 5 | basic | 0.067 | 0.016 | 24.7 | 0.742 | 0.465 | 0.537 | 1.268 | |
| Selected | 0.067 | 0.016 | 22.7 | 0.729 | 0.531 | 0.487 | 1.267 | ||
| Num. 6 | Basic | 0.063 | 0.018 | 30.4 | 0.583 | 0.493 | 0.301 | 1.358 | |
| Selected | 0.063 | 0.019 | 29.2 | 0.589 | 0.492 | 0.247 | 1.390 | ||
| Num. 7 | basic | 0.087 | 0.022 | 25.4 | 0.682 | 0.467 | 0.408 | 1.308 | |
| Selected | 0.087 | 0.022 | 23.3 | 0.717 | 0.525 | 0.431 | 1.288 | ||
| NO2 | Num. 1 | basic | 0.061 | 0.013 | 20.9 | 0.688 | 0.483 | 0.392 | 1.248 |
| Selected | 0.061 | 0.013 | 20.5 | 0.715 | 0.500 | 0.448 | 1.243 | ||
| Num. 3 | Basic | 0.068 | 0.016 | 22.2 | 0.596 | 0.463 | 0.226 | 1.272 | |
| Selected | 0.068 | 0.015 | 21.5 | 0.676 | 0.557 | 0.320 | 1.266 | ||
| Num. 4 | Basic | 0.052 | 0.010 | 21.9 | 0.685 | 0.511 | 0.456 | 1.232 | |
| Selected | 0.052 | 0.010 | 19.3 | 0.722 | 0.541 | 0.502 | 1.215 | ||
| Num. 5 | Basic | 0.038 | 0.009 | 25.8 | 0.613 | 0.454 | 0.363 | 1.285 | |
| Selected | 0.038 | 0.009 | 23.0 | 0.599 | 0.462 | 0.308 | 1.267 | ||
| Num. 6 | Basic | 0.053 | 0.014 | 26.8 | 0.757 | 0.497 | 0.405 | 1.337 | |
| Selected | 0.053 | 0.015 | 24.6 | 0.728 | 0.528 | 0.310 | 1.334 | ||
| Num. 7 | Basic | 0.041 | 0.010 | 27.4 | 0.668 | 0.476 | 0.435 | 1.305 | |
| Selected | 0.041 | 0.009 | 23.1 | 0.700 | 0.505 | 0.465 | 1.269 |
5. Conclusions
- (1)
- A meteorological similarity principle was applied in the development of the selection sample rule. Key meteorological factors influencing the daily SO2, NO2, and PM10 concentrations were determined and weight matrices and threshold matrices were generated. A basic model was then developed based on the improved BP neural network. The selection sample rule consisted of three layers.
- (2)
- In improving the basic model, identification of the variation consistency of some factors was added in the rule, and seven sets of sensitivity experiments (one in each of the seven sites) were conducted to obtain the selected model. These experiments determined that the variation consistency of the rainfall level added to the SO2 forecast model, the rainfall level variation tendency and the background concentration similarity identification added to the PM10 forecast model, while wind speed variation identification and background concentration similarity identification added to the NO2 forecast model. The improved BP neural network was also used for data-driven computation.
- (3)
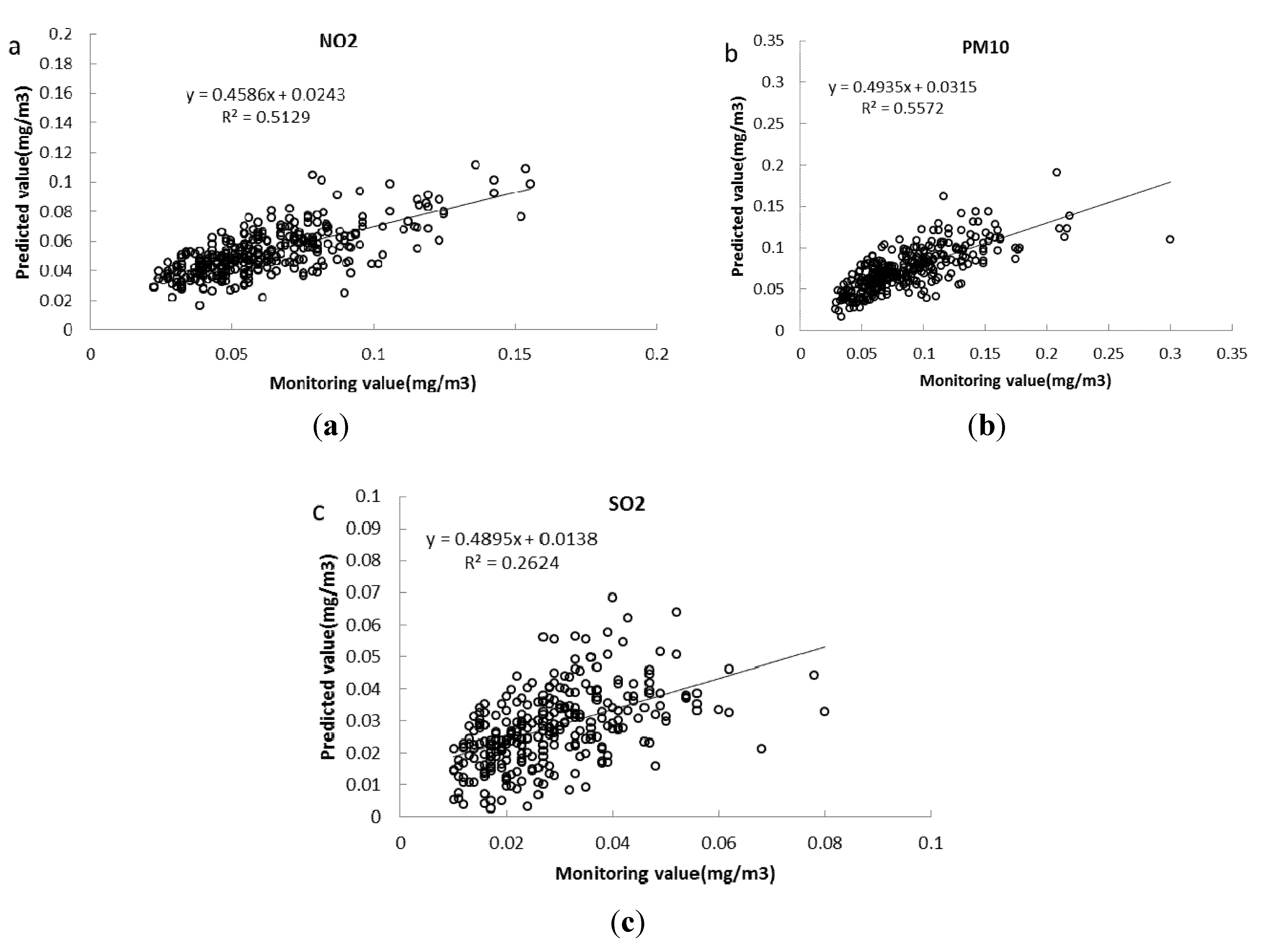
- Evaluations in the site by comparison of the basic model from May 2011 to April 2012 showed the selected model for PM10 displayed better forecasting performance, with MAPE values decreasing by 4% and R2 values increasing from 0.53 to 0.68. The selected model for NO2 had little improvements compared with the basic model, while the MAPE values of the selected model for SO2 were as high as 36.6% with R2 values of 0.51.
- (4)
- Evaluations conducted at the six other sites revealed similar performances. The MAPE values of the selected models for SO2, PM10, and NO2 were 37.7%, 25.0%, and 22.0%, respectively. Of course, the above results showed that the SO2 model may be further improved in future research, by developing a combined model or by considering the interaction of atmospheric pollutants.
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Dimitriou, K.; Kassomenos, P.A.; Paschalidou, A.K. Assessing air quality with regards to its effect on human health in the European Union through air quality indices. Ecol. Indic. 2013, 27, 108–115. [Google Scholar] [CrossRef]
- Pope, C.A., III; Burnett, R.T.; Thun, M.J.; Calle, E.E.; Krewski, D.; Ito, K.; Thurston, G.D. Lung cancer, cardiopulmonary mortality, and long-term exposure to fine particulate air pollution. JAMA 2002, 287, 1132–1141. [Google Scholar] [CrossRef] [PubMed]
- Li, G.; Sang, N. Delayed rectifier potassium channels are involved in SO2 derivative-induced hippocampal neuronal injury. Ecotoxicol. Environ. Saf. 2009, 72, 236–241. [Google Scholar] [CrossRef] [PubMed]
- Juhos, I.; Makra, L.; Tóth, B. Forecasting of traffic origin NO and NO2 concentrations by Support Vector Machines and neural networks using Principal Component Analysis. Simul. Model. Pract. Theory 2008, 16, 1488–1502. [Google Scholar] [CrossRef]
- Finardi, S.; de Maria, R.; D’Allura, A.; Cascone, C.; Calori, G.; Lollobrigida, F. A deterministic air quality forecasting system for Torino urban area, Italy. Environ. Model. Softw. 2008, 23, 344–355. [Google Scholar] [CrossRef]
- Dong, M.; Yang, D.; Kuang, Y.; He, D.; Erdal, S.; Kenski, D. PM2.5 concentration prediction using hidden semi-Markov model-based times series data mining. Expert Syst. Appl. 2009, 36, 9046–9055. [Google Scholar] [CrossRef]
- Pai, T.Y.; Ho, C.L.; Chen, S.W.; Lo, H.M.; Sung, P.J.; Lin, S.W.; Lai, W.J.; Tseng, S.C.; Ciou, S.P.; Kuo, J.L.; Kao, J.T. Using seven types of GM (1, 1) model to forecast hourly particulate matter concentration in Banciao City of Taiwan. Water Air Soil Pollut. 2011, 217, 25–33. [Google Scholar] [CrossRef]
- Pai, T.Y.; Hanaki, K.; Chiou, R.J. Forecasting Hourly Roadside Particulate Matter in Taipei County of Taiwan Based on First-Order and One-Variable Grey Model. CLEAN Soil Air Water 2013, 41, 737–742. [Google Scholar] [CrossRef]
- Comrie, A.C. Comparing neural networks and regression models for ozone forecasting. J. Air Waste Manag. Assoc. 1997, 47, 653–663. [Google Scholar] [CrossRef]
- Schlink, U.; Dorling, S.; Pelikan, E.; Nunnari, G.; Cawley, G.; Junnine, H.; Greig, A.; Foxall, R.; Eben, K.; Chatterton, T.; et al. A rigorous inter-comparison of ground-level ozone predictions. Atmos. Environ. 2003, 37, 3237–3253. [Google Scholar] [CrossRef]
- Kukkonen, J.; Partanen, L.; Karppinen, A.; Ruuskanen, J.; Junninen, H.; Kolehmainen, M.; Niska, H.; Dorling, S.; Chatterton, T.; Foxall, R.; et al. Extensive evaluation of neural network models for the prediction of NO2 and PM10 concentrations, compared with a deterministic modelling system and measurements in central Helsinki. Atmos. Environ. 2003, 37, 4539–4550. [Google Scholar] [CrossRef]
- Diaz-Robles, L.A.; Ortega, J.C.; Fu, J.S.; Reed, G.D.; Chow, J.C.; Watson, J.G.; Moncada-Herrera, J.A. A hybrid ARIMA and artificial neural networks model to forecast particulate matter in urban areas: The case of Temuco, Chile. Atmos. Environ. 2008, 42, 8331–8340. [Google Scholar] [CrossRef]
- Yi, J.; Prybutok, V.R. A neural network model forecasting for prediction of daily maximum ozone concentration in an industrialized urban area. Environ. Pollut. 1996, 92, 349–357. [Google Scholar] [CrossRef]
- Grivas, G.; Chaloulakou, A. Artificial neural network models for prediction of PM10 hourly concentrations, in the Greater Area of Athens, Greece. Atmos. Environ. 2006, 40, 1216–1229. [Google Scholar] [CrossRef]
- Hooyberghs, J.; Mensink, C.; Dumont, G.; Fierens, F.; Brasseur, O. A neural network forecast for daily average PM10 concentrations in Belgium. Atmos. Environ. 2005, 39, 3279–3289. [Google Scholar] [CrossRef]
- Paschalidou, A.K.; Karakitsios, S.; Kleanthous, S.; Kassomenos, P.A. Forecasting hourly PM10 concentration in Cyprus through artificial neural networks and multiple regression models: Implications to local environmental management. Environ. Sci. Pollut. Res. 2011, 18, 316–327. [Google Scholar] [CrossRef] [PubMed]
- Zhang, G.; Eddy Patuwo, B.; Hu, Y.M. Forecasting with artificial neural networks: The state of the art. Int. J. Forecast. 1998, 14, 35–62. [Google Scholar] [CrossRef]
- Gardner, M.W.; Dorling, S.R. Artificial neural networks (the multilayer perceptron)—A review of applications in the atmospheric sciences. Atmos. Environ. 1998, 32, 2627–2636. [Google Scholar] [CrossRef]
- Kolehmainen, M.; Martikainen, H.; Ruuskanen, J. Neural networks and periodic components used in air quality forecasting. Atmos. Environ. 2001, 35, 815–825. [Google Scholar] [CrossRef]
- Lu, W.Z.; Fan, H.Y.; Lo, S.M. Application of evolutionary neural network method in predicting pollutant levels in downtown area of Hong Kong. Neurocomputing 2003, 51, 387–400. [Google Scholar] [CrossRef]
- Niska, H.; Hiltunen, T.; Karppinen, A.; Ruuskanen, J.; Kolehmainen, M. Evolving the neural network model for forecasting air pollution time series. Eng. Appl. Artif. Intell. 2004, 17, 159–167. [Google Scholar] [CrossRef]
- Sousa, S.I.V.; Martins, F.G.; Alvim-Ferraz, M.C.M.; Pereira, M.C. Multiple linear regression and artificial neural networks based on principal components to predict ozone concentrations. Environ. Model. Softw. 2007, 22, 97–103. [Google Scholar] [CrossRef]
- Al-Alawi, S.M.; Abdul-Wahab, S.A.; Bakheit, C.S. Combining principal component regression and artificial neural networks for more accurate predictions of ground-level ozone. Environ. Model. Softw. 2008, 23, 396–403. [Google Scholar] [CrossRef]
- Pires, J.C.M.; Gonçalves, B.; Azevedo, F.G.; Carneiro, A.P.; Rego, N.; Assembleia, A.J.B.; Silva, P.A.; Lima, J.F.B.; Alves, C.; Martins, F.G. Optimization of artificial neural network models through genetic algorithms for surface ozone concentration forecasting. Environ. Sci. Pollut. Res. 2012, 19, 3228–3234. [Google Scholar] [CrossRef] [PubMed]
- Guangzhou Weather Forecasts. Available online: http://www.tqyb.com.cn/ (accessed on 1 January 2013).
- Ministry of Environmental Protection of China. Ambient Air Quality Standards; China Environmental Science Press: Beijing, China, 2012.
- Guangzhou Environmental Protection. Available online: http://www.gzepb.gov.cn/comm/apidate.asp (accessed on 1 January 2013).
- Elminir, H.K. Dependence of urban air pollutants on meteorology. Sci. Total Environ. 2005, 350, 225–237. [Google Scholar] [CrossRef] [PubMed]
- Pearce, J.L.; Beringer, J.; Nicholls, N.; Hyndman, R.J.; Tapper, N.J. Quantifying the influence of local meteorology on air quality using generalized additive models. Atmos. Environ. 2011, 45, 1328–1336. [Google Scholar] [CrossRef]
- Yu, Z.Y.; Yuan, J.Y.; Yu, Y.; Zhang, W.; Wu, Z.H. Research on Relationship of Control Parameters of Cement Concrete Strength by Orthogonal Test Method. J. Huangshi Inst. Technol. 2012, 3, 38–41. [Google Scholar]
- Lin, Y.; Yang, X.G.; MA, Y.Y. An Analysis of Factors Causing Congestion with the Application of Orthogonal Experimental Design Method. Syst. Eng. 2005, 10, 39–43. [Google Scholar]
- Hornik, K.; Stinchcombe, M.; White, H. Multilayer feedforward networks are universal approximators. Neural Netw. 1989, 2, 359–366. [Google Scholar] [CrossRef]
- Li, L. Study on urban air quality forecast model based on adaptive artificial neural network. M.Sc. Thesis, Sun Yet-Sen University, Guangzhou, China, 2011. [Google Scholar]
- Zhu, Q.R. Study on combined urban air quality forecast model. M.Sc. Thesis, Sun Yet-sen University, Guangzhou, China, 2013. [Google Scholar]
- Cai, M.; Yin, Y.; Xie, M. Prediction of hourly air pollutant concentrations near urban arterials using artificial neural network approach. Transp. Res. Part D Transp. Environ. 2009, 14, 32–41. [Google Scholar] [CrossRef]
- Singh, K.P.; Gupta, S.; Kumar, A.; Shukla, S.P. Linear and nonlinear modeling approaches for urban air quality prediction. Sci. Total Environ. 2012, 426, 244–255. [Google Scholar] [CrossRef] [PubMed]
- Kurt, A.; Oktay, A.B. Forecasting air pollutant indicator levels with geographic models 3days in advance using neural networks. Expert Syst. Appl. 2010, 37, 7986–7992. [Google Scholar] [CrossRef]
© 2015 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Y.; Zhu, Q.; Yao, D.; Xu, W. Forecasting Urban Air Quality via a Back-Propagation Neural Network and a Selection Sample Rule. Atmosphere 2015, 6, 891-907. https://doi.org/10.3390/atmos6070891
Liu Y, Zhu Q, Yao D, Xu W. Forecasting Urban Air Quality via a Back-Propagation Neural Network and a Selection Sample Rule. Atmosphere. 2015; 6(7):891-907. https://doi.org/10.3390/atmos6070891
Chicago/Turabian StyleLiu, Yonghong, Qianru Zhu, Dawen Yao, and Weijia Xu. 2015. "Forecasting Urban Air Quality via a Back-Propagation Neural Network and a Selection Sample Rule" Atmosphere 6, no. 7: 891-907. https://doi.org/10.3390/atmos6070891