A Novel Fault Diagnosis System on Polymer Insulation of Power Transformers Based on 3-stage GA–SA–SVM OFC Selection and ABC–SVM Classifier


Abstract
:1. Introduction
1.1. Motivation
1.2. Related Work
1.3. Contribution and Paper Orgnization
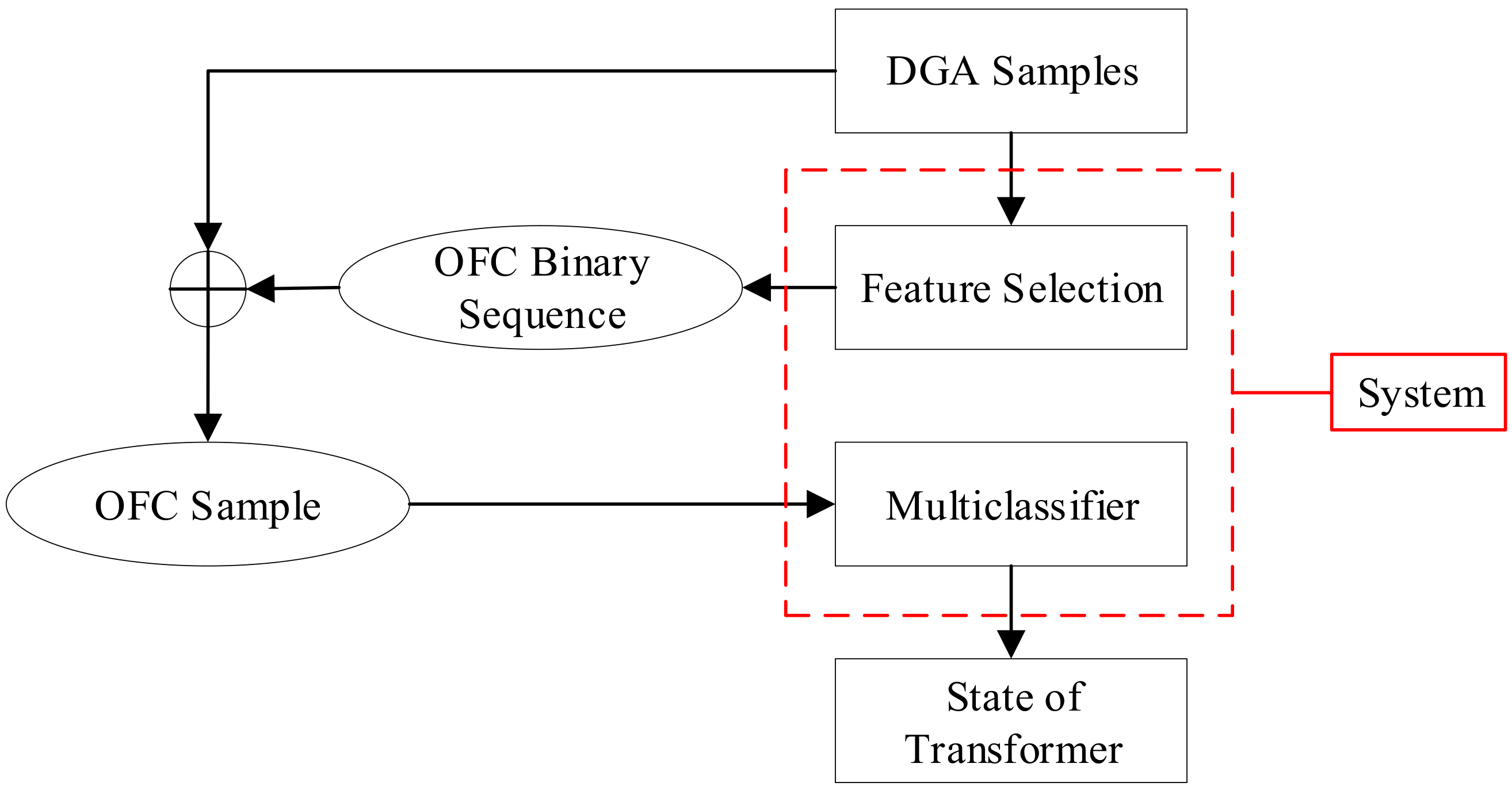
2. Optimal Feature Combination Selection
2.1. The Candidate DGA Feature Sets
2.2. DGA Feature Selection Model
2.2.1. Multiclass Nonlinear SVM Model
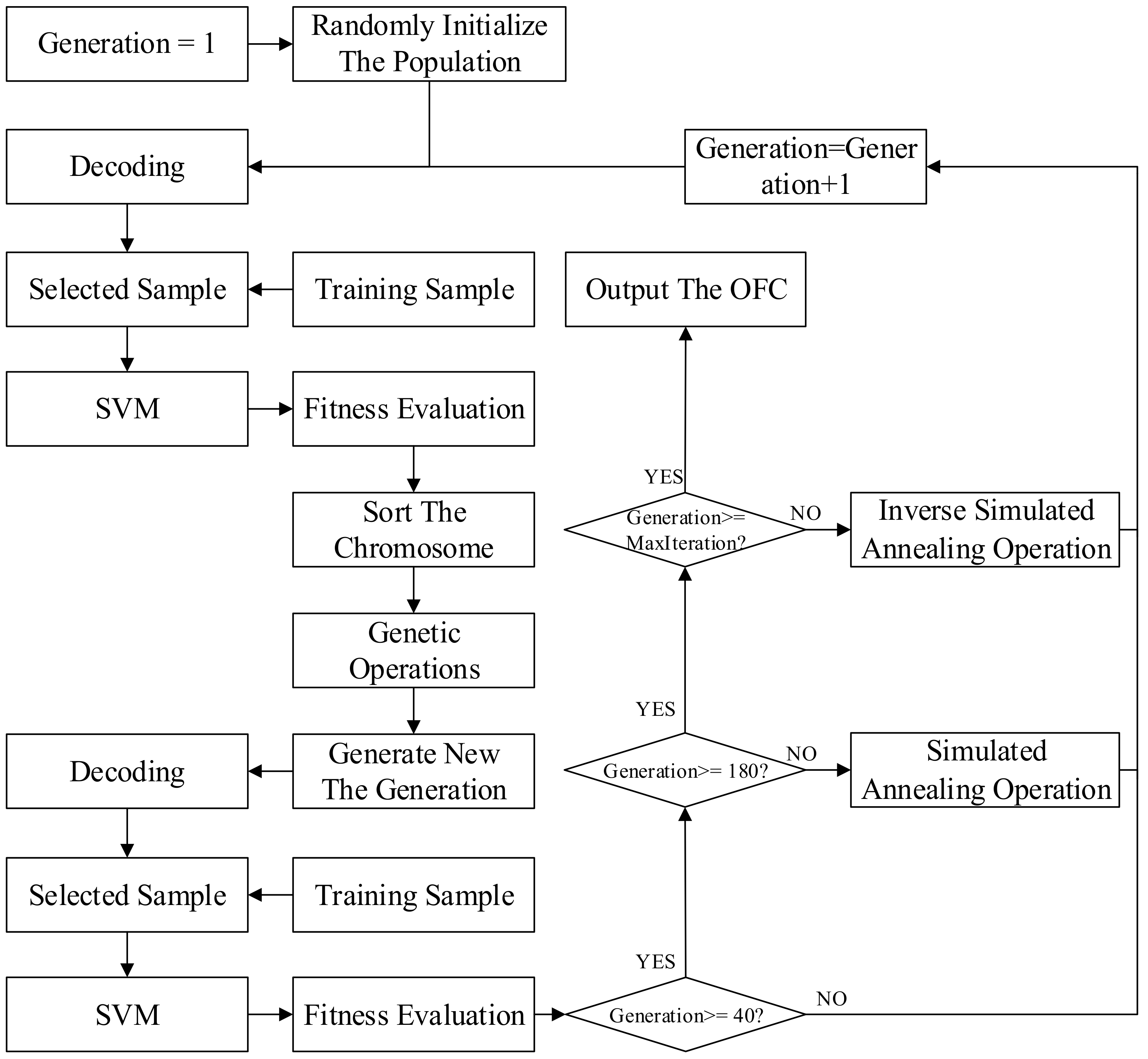
2.2.2. Application of Genetic Algorithm
- Chromosome coding
- Genetic fitness calculation
- Genetic operations
2.2.3. Combination of SA Algorithm and GA
- Simulated annealing operation
- Metropolis criterion
- Inverse simulated annealing operation
- Multi stage of GA–SA-combination
2.2.4. K-Fold Cross-Validation
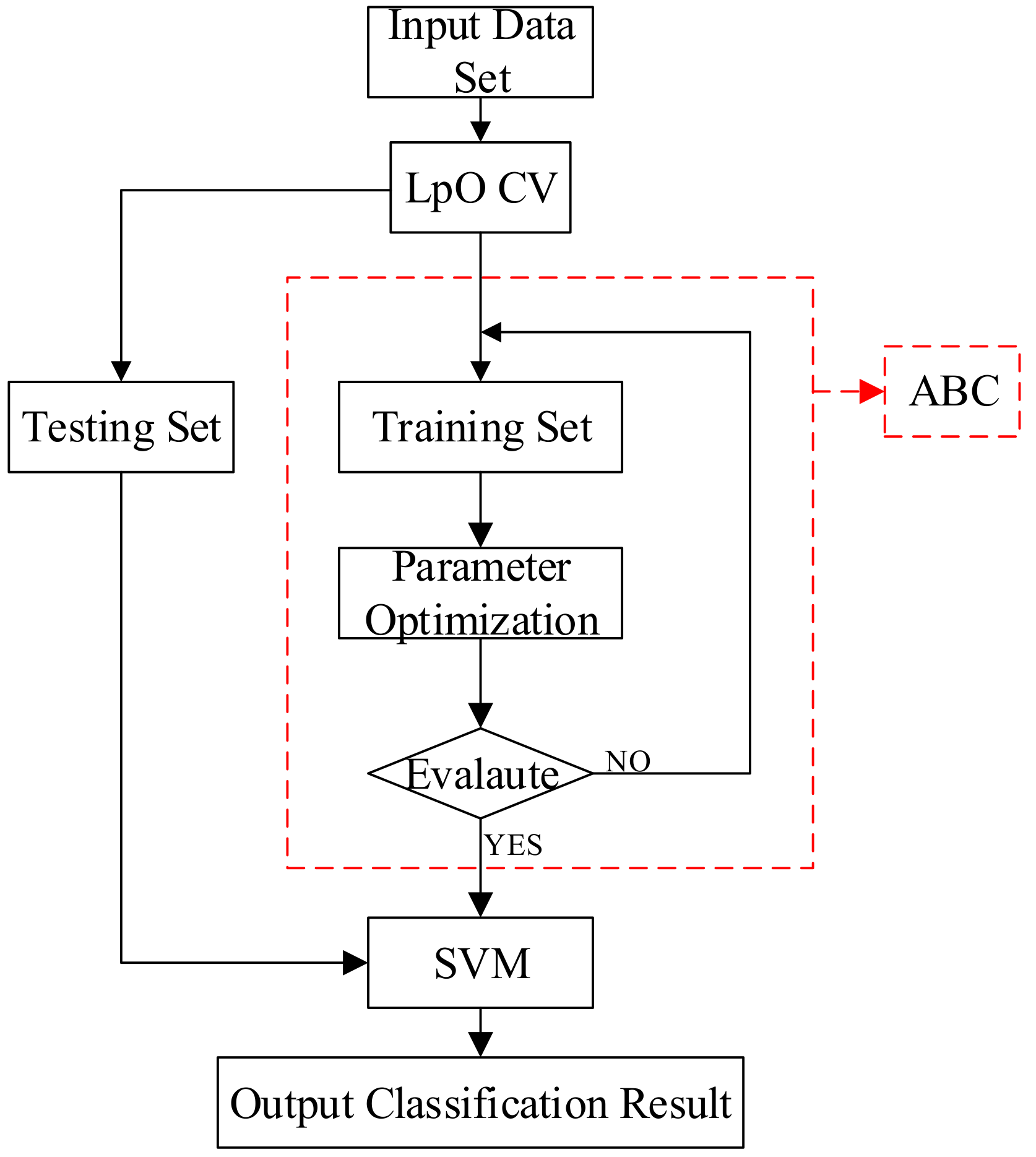
3. Fault Diagnosis Model Based on ABC–SVM
3.1. The Mechanism of ABC
3.2. ABC Optimization Model
3.3. Leave-P-Out Cross Validation
3.4. Process of Classification Based on ABC–SVM
- Step 1.
- Utilize LpO CV to generate a training set and a testing set. The training set was sent to the ABC model.
- Step 2.
- Use training set and nonlinear multiclassification support vector machine to construct unknown parameters and to form the optimal objective function.
- Step 3.
- Apply ABC to find the best solution to determine the best parameters of SVM. The best parameters are obtained when the training accuracy meets the threshold of checking; otherwise, step 3 is replayed.
- Step 4.
- Input testing is set to SVM, then the output will be obtained.
4. Case Study and Analysis
4.1. Data Preprocessin
4.2. Result of DGA Optimal Feature Selection
4.2.1. Parameter Setting in Three Stage-GA–SA–SVM
4.2.2. Comparison with Other Methods
4.3. ABC Diagnostic Results
4.3.1. Parameter Setting in Three ABC–SVM
4.3.2. Diagnostic Result
4.3.3. Result of Comparison
- Self-comparing
- Comparison with Standard Algorithms and other Wrapper Algorithms
5. Conclusions and Future Directions
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Li, J.S.; Zhou, H.W.; Meng, J.; Yang, Q.; Chen, B. Carbon emissions and their drivers for a typical urban economy from multiple perspectives: A case analysis for Beijing city. Appl. Energy 2018, 226, 1076–1086. [Google Scholar] [CrossRef]
- Liu, J.; Zheng, H.; Zhang, Y.; Zhou, T.; Zhao, J.; Li, J.; Liu, J.; Li, J. Comparative Investigation on the Performance of Modified System Poles and Traditional System Poles Obtained from PDC Data for Diagnosing the Ageing Condition of Transformer Polymer Insulation Materials. Polymers 2018, 10, 191. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, J.; Zheng, H.; Wei, H.; Liao, R.; Sciubba, E. Study on Quantitative Correlations between the Ageing Condition of Transformer Cellulose Insulation and the Large Time Constant Obtained from the Extended Debye Model. Energies 2017, 10, 1842. [Google Scholar] [CrossRef]
- Liu, J.; Zheng, H.; Zhang, Y.; Wei, H.; Liao, R. Grey Relational Analysis for Insulation Condition Assessment of Power Transformers Based Upon Conventional Dielectric Response Measurement. Energies 2017, 10, 1526. [Google Scholar] [CrossRef]
- Borutzky, W. Bond Graph Modelling of Engineering Systems; Springer: New York, NY, USA, 2011; pp. 105–135. ISBN 978-1-4419-9367-0. [Google Scholar]
- Djeziri, M.A.; Ananou, B.; Ouladsine, M. Data driven and model based fault prognosis applied to a mechatronic system. In Proceedings of the Fourth International Conference on Power Engineering, Energy and Electrical Drives, Istanbul, Turkey, 13–17 May 2013. [Google Scholar]
- Sun, H.-C.; Huang, Y.-C.; Huang, C.-M. A Review of Dissolved Gas Analysis in Power Transformers. Energy Procedia 2012, 14, 1220–1225. [Google Scholar] [CrossRef]
- Sica, F.C.; Guimarães, F.G.; Duarte, R.d.O.; Reis, A.J.R. A cognitive system for fault prognosis in power transformers. Electr. Power Syst. Res. 2015, 127, 109–117. [Google Scholar] [CrossRef]
- Bengtsson, C. Status and trends in transformer monitoring. IEEE Trans. Power Deliv. 1996, 11, 1379–1384. [Google Scholar] [CrossRef]
- Yang, M.-T.; Hu, L.-S. Intelligent fault types diagnostic system for dissolved gas analysis of oil-immersed power transformer. IEEE Trans. Dielectr. Electr. Insul. 2013, 20, 2317–2324. [Google Scholar] [CrossRef]
- Singh, S.; Bandyopadhyay, M.N. Dissolved gas analysis technique for incipient fault diagnosis in power transformers: A bibliographic survey. IEEE Electr. Insul. Mag. 2010, 26, 41–46. [Google Scholar] [CrossRef]
- Duval, M.; Pablo, A.D.; Atanasova-Hoehlein, I.; Grisaru, M. Significance and detection of very low degree of polymerization of paper in transformers. IEEE Electr. Insul. Mag. 2017, 1, 31–38. [Google Scholar] [CrossRef]
- Peischl, S.; Walker, J.P.; Ryu, D.; Kerr, Y.H. Analysis of Data Acquisition Time on Soil Moisture Retrieval from Multiangle L-Band Observations. IEEE Trans. Geosci. Remote 2017, 56, 966–971. [Google Scholar] [CrossRef]
- Unsworth, J.; Mitchell, F. Degradation of electrical insulating paper monitored with high performance liquid chromatography. IEEE Trans. Electr. Insul. 1990, 25, 737–746. [Google Scholar] [CrossRef]
- Verma, H.C.; Baral, A.; Pradhan, A.K.; Chakravorti, S. A method to estimate activation energy of power transformer insulation using time domain spectroscopy data. IEEE Trans. Dielectr. Electr. Insul. 2017, 24, 3245–3253. [Google Scholar] [CrossRef]
- Saha, T.K.; Purkait, P.; Muller, F. An attempt to correlate time & frequency domain polarisation measurements for the insulation diagnosis of power transformer. In Proceedings of the Power Engineering Soc. General Meeting, Denver, CO, USA, 6–10 June 2004. [Google Scholar]
- Bakar, N.A.; Abu-Siada, A.; Islam, S. A review of dissolved gas analysis measurement and interpretation techniques. IEEE Electr. Insul. Mag. 2014, 30, 39–49. [Google Scholar] [CrossRef]
- Gómez, N.A.; Wilhelm, H.M.; Santos, C.C.; Stocco, G.B. Dissolved gas analysis (DGA) of natural ester insulating fluids with different chemical compositions. IEEE Trans. Dielectr. Electr. Insul. 2014, 21, 1071–1078. [Google Scholar]
- Rogers, R.R. IEEE and IEC Codes to Interpret Incipient Faults in Transformers, Using Gas in Oil Analysis. IEEE Trans. Electr. Insul. 1978, El-13, 349–354. [Google Scholar] [CrossRef]
- Duval, M.; Depabla, A. Interpretation of gas-in-oil analysis using new IEC publication 60599 and IEC TC 10 databases. IEEE Electr. Insul. Mag. 2001, 31–41. [Google Scholar] [CrossRef]
- Irungu, G.K.; Akumu, A.O.; Munda, J.L. A new fault diagnostic technique in oil-filled electrical equipment; the dual of Duval triangle. IEEE Trans. Dielectr. Electr. Insul. 2016, 23, 3405–3410. [Google Scholar] [CrossRef]
- Irungu, G.K.; Akumu, A.O.; Munda, J.L. Comparison of IEC 60599 gas ratios and an integrated fuzzy-evidential reasoning approach in fault identification using dissolved gas analysis. In Proceedings of the International Universities Power Engineering Conference (UPEC), Coimbra, Portugal, 6–9 September 2016. [Google Scholar]
- Barbosa, T.M.; Ferreira, J.G.; Finocchio, M.A.F.; Endo, W. Development of an Application Based on the Duval Triangle Method. IEEE Latin Am. Trans. 2017, 15, 1439–1446. [Google Scholar] [CrossRef]
- Benmahamed, Y.; Teguar, M.; Boubakeur, A. Application of SVM and KNN to Duval Pentagon 1 for transformer oil diagnosis. IEEE Trans. Dielectr. Electr. Insul. 2017, 24, 3443–3451. [Google Scholar] [CrossRef]
- Faiz, J.; Soleimani, M. Dissolved gas analysis evaluation in electric power transformers using conventional methods a review. IEEE Trans. Dielectr. Electr. Insul. 2017, 24, 1239–1248. [Google Scholar] [CrossRef]
- Islam, S.M.; Wu, T.; Ledwich, G. A novel fuzzy logic approach to transformer fault diagnosis. IEEE Trans. Dielectr. Electr. Insul. 2000, 7, 177–186. [Google Scholar] [CrossRef]
- Miranda, V.; Castro, A.R.G. Improving the IEC table for transformer failure diagnosis with knowledge extraction from neural networks. IEEE Trans. Power Deliv. 2005, 20, 2509–2516. [Google Scholar] [CrossRef]
- Zheng, H.; Zhang, Y.; Liu, J.; Wei, H.; Zhao, J.; Liao, R. A novel model based on wavelet LS-SVM integrated improved PSO algorithm for forecasting of dissolved gas contents in power transformers. Electr. Power Syst. Res. 2018, 155, 196–205. [Google Scholar] [CrossRef]
- Zhang, Y.; Wei, H.; Liao, R.; Wang, Y.; Yang, L.; Yan, C. A New Support Vector Machine Model Based on Improved Imperialist Competitive Algorithm for Fault Diagnosis of Oil-immersed Transformers. J. Electr. Eng. Technol. 2017, 12, 830–839. [Google Scholar] [CrossRef] [Green Version]
- Dai, J.; Song, H.; Sheng, G.; Jiang, X. Dissolved gas analysis of insulating oil for power transformer fault diagnosis with deep belief network. IEEE Trans. Dielectr. Electr. Insul. 2017, 24, 2828–2835. [Google Scholar] [CrossRef]
- Mirowski, P.; LeCun, Y. Statistical Machine Learning and Dissolved Gas Analysis: A Review. IEEE Trans. Power Deliv. 2012, 27, 1791–1799. [Google Scholar] [CrossRef]
- Huang, Y.C. A new data mining approach to dissolved gas analysis of oil-insulated power apparatus. IEEE Trans. Power Deliv. 2003, 18, 1257–1261. [Google Scholar] [CrossRef]
- Chen, W.; Pan, C.; Yun, Y.; Liu, Y. Wavelet Networks in Power Transformers Diagnosis Using Dissolved Gas Analysis. IEEE Trans. Power Deliv. 2008, 24, 187–194. [Google Scholar] [CrossRef]
- Zhou, J.; Yang, Y.; Ding, S.X; Zi, Y.; Wei, M. A Fault Detection and Health Monitoring Scheme for Ship Propulsion Systems Using SVM Technique. IEEE Access 2018, 6, 16207–16215. [Google Scholar] [CrossRef]
- Zhang, Y.; Zheng, H.; Liu, J.; Zhao, J.; Sun, P. An Anomaly Identification Model for Wind Turbine State Parameters. J. Clean. Prod. 2018, 195, 1214–1227. [Google Scholar] [CrossRef]
- Qin, L.; Wang, J.; Li, H.; Sun, Y.; Li, S. An Approach to Improve the Performance of Simulated Annealing Algorithm Utilizing the Variable Universe Adaptive Fuzzy Logic System. IEEE Access 2017, 5, 18155–18165. [Google Scholar] [CrossRef]
- Xin, F.; Ni, S.; Li, H.; Zhou, X. General Regression Neural Network and Artificial-Bee-Colony Based General Regression Neural Network Approaches to the Number of End-of-Life Vehicles in China. IEEE Access 2018, 6, 19278–19286. [Google Scholar] [CrossRef]
- Tang, W.H.; Goulermas, J.Y.; Wu, Q.H.; Richardson, Z.J.; Fitch, J. A Probabilistic Classifier for Transformer Dissolved Gas Analysis with a Particle Swarm Optimizer. IEEE Trans. Power Deliv. 2008, 23, 751–759. [Google Scholar]
- Kim, S.W.; Kim, S.J.; Seo, H.D.; Jung, J.R.; Yang, H.J.; Duval, M. New methods of DGA diagnosis using IEC TC 10 and related databases Part 1: Application of gas-ratio combinations. IEEE Trans. Dielectr. Electr. Insul. 2013, 20, 685–690. [Google Scholar]
- Karaboga, D.; Akay, B. A survey: Algorithms simulating bee swarm intelligence. Artif. Intell. Rev. 2009, 31, 61. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ratios | Ratios | Ratios | Ratios | Ratios |
|---|---|---|---|---|
| H2/CO | H2/CO2 | H2/CH4 | H2/C2H2 | H2/C2H4 |
| H2/C2H6 | H2/TH | CO/CO2 | CO/CH4 | CO/C2H2 |
| CO/C2H4 | CO/C2H6 | CO/TH | CO2/CH4 | CO2/C2H2 |
| CO2/C2H4 | CO2/C2H6 | CO2/TH | CH4/C2H2 | CH4/C2H4 |
| CH4/C2H6 | CH4/TH | C2H2/C2H4 | C2H2/C2H6 | C2H4/TH |
| C2H4/C2H6 | C2H4/TH | C2H6/TH | H2/C2H2 | H2/C2H4 |
| Label | Quantity |
|---|---|
| 1 | 23 |
| 2 | 45 |
| 3 | 10 |
| 4 | 14 |
| 5 | 26 |
| Max Iteration | Population Scale | L1 | L2 | L3 |
|---|---|---|---|---|
| 200 | 20 | 22 | 22 | 28 |
| GA–SVM | GA–SA–SVM | Inverse SA–GA–SVM |
|---|---|---|
| [0, 40] | [20, 180] | [180, 200] |
| Method | CV Accuracy | Selected Combinations |
|---|---|---|
| GA–SVM | 88.17% | H2/CO, H2/CO2, H2/TH, CO/CO2, CO/C2H2, CO2/CH4, CO2/C2H4, CH4/TH, C2H4/TH, C2H4/C2H6 |
| GA–SA–SVM | 89.40% | H2/CO, H2/CO2, H2/CH4, H2/C2H2, CO/CH4, CO/C2H4, CO/TH, CO2/CH4, CO2/C2H4, CO2/TH, C2H2/C2H4, C2H2/C2H6 |
| 2-stage GA–SA–SVM | 89.45% | H2/CO, H2/C2H2, CO/CO2, CO/C2H2, CO2/CH4, CO2/C2H4, CH4/TH, C2H4/TH, C2H4/C2H6 |
| 3-stage GA–SA–SVM | 90.36% | H2/CO2, H2/C2H2, H2/C2H4, H2/TH, CO2/CH4, CO2/C2H2, CO2/C2H4, CH4/C2H6, C2H6/TH, CH4/TH, C2H2/C2H4, C2H2/C2H6 |
| Ratios |
|---|
| H2/CO2, H2/C2H2, H2/C2H4, H2/TH, CO2/CH4, CO2/C2H2, CO2/C2H4, CH4/C2H6, C2H6/TH, CH4/TH, C2H2/C2H4, C2H2/C2H6 |
| Label | Quantity |
|---|---|
| 1 | 5 |
| 2 | 10 |
| 3 | 3 |
| 4 | 3 |
| 5 | 4 |
| Number of Honey Source | Scale of The Bee Colony | Max Number of New Sources in One Generation | Max Number of Loops |
|---|---|---|---|
| 10 | 20 | 100 | 10 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, X.; Zhang, Y.; Liu, J.; Zheng, H.; Wang, K. A Novel Fault Diagnosis System on Polymer Insulation of Power Transformers Based on 3-stage GA–SA–SVM OFC Selection and ABC–SVM Classifier. Polymers 2018, 10, 1096. https://doi.org/10.3390/polym10101096
Huang X, Zhang Y, Liu J, Zheng H, Wang K. A Novel Fault Diagnosis System on Polymer Insulation of Power Transformers Based on 3-stage GA–SA–SVM OFC Selection and ABC–SVM Classifier. Polymers. 2018; 10(10):1096. https://doi.org/10.3390/polym10101096
Chicago/Turabian StyleHuang, Xiaoge, Yiyi Zhang, Jiefeng Liu, Hanbo Zheng, and Ke Wang. 2018. "A Novel Fault Diagnosis System on Polymer Insulation of Power Transformers Based on 3-stage GA–SA–SVM OFC Selection and ABC–SVM Classifier" Polymers 10, no. 10: 1096. https://doi.org/10.3390/polym10101096