Introducing Disappointment Dynamics and Comparing Behaviors in Evolutionary Games: Some Simulation Results

Abstract
:1. Introduction
2. Evolutionary Dynamics and the Notion of Disappointment
3. The Model
3.1. Theoretical Background
3.2. The ‘Short-Sightedness’ Protocol
pt+1,i(c) = 1–μ·(πt,i(ht, st-i) – πt,i(ct, st-i))/Δ,
where ht∈BRt,i, 0 < μ ≤ 1.
3.3. The ‘n-Period Memory’ Protocol
 (πτ,I(hτ, sτ-i) – πτ,i(cτ, sτ-i)) ≠ 0,
(πτ,I(hτ, sτ-i) – πτ,i(cτ, sτ-i)) ≠ 0,then pt+1,i(y) = Σ
(πτ,i(hτ, sτ-i) – πτ,i(cτ, sτ-i))/((mi – 1)nΔ),for all y ≠ c, y∈Si, pt+1,i(c) = 1 – Σ
(πτ,i(hτ, sτ-i)–πτ,i(cτ, sτ-i))/nΔ.If Π
(πτ,I(hτ, sτ-i) – πτ,i(cτ, sτ-i)) = 0, then pt+1,i(y) = 0,for all y ≠ c, y∈Si, pt+1,i(c) = 1, where hτ∈BRτ,i, and πτ,i(hτ, sτ-i) = πτ,i(cτ, sτ-i) = 0 when τ<0.
3.4. The ‘Additive Disappointment’ Protocol
 ρt-τ·(πτ,i(hτ,sτ-i) – πτ,i(cτ,sτ-I)) ≥ Ζ, then pt+1,i(y) = 1/(mi – 1),
ρt-τ·(πτ,i(hτ,sτ-i) – πτ,i(cτ,sτ-I)) ≥ Ζ, then pt+1,i(y) = 1/(mi – 1),for all y ≠ c, y∈Si, pt+1,i(c) = 0.
If Σ
ρt-τ·(πτ,i(hτ,sτ-i) – πτ,i(cτ,sτ-I)) < Ζ, then pt+1,i(y) = 0,for all y ≠ c, y∈Si, pt+1,i(c) = 1, where hτ∈BRτ,i, 0 < ρ ≤ 1, and Ζ∈R+.
4. The Simulation
4.1 Short-Sightedness
pt+1,i(c) = 1 – (πt,i(ht, st-i) – πt,i(ct, st-i))/3Δ,
where ht∈BRt,i.
4.2 Three-Period Memory
 (πτ,i(hτ, sτ-I) – πτ,i(cτ, sτ-i)) ≠ 0,
(πτ,i(hτ, sτ-I) – πτ,i(cτ, sτ-i)) ≠ 0,then pt+1,i(y) = Σ
(πτ,i(hτ, sτ-I) – πτ,i(cτ, sτ-i))/3Δ, y ≠ c, y∈Si,pt+1,i(c) = 1 – Σ
(πτ,i(hτ, sτ-i) – πτ,i(cτ, sτ-i))/3Δ.If Π
(πτ,i(hτ, sτ-i) – πτ,i(cτ, sτ-i)) = 0 then pt+1,i(y) = 0, y ≠ c, y∈Si, pt+1,i(c) = 1,where hτ∈BRτ,i, and πτ,i(hτ, sτ-i) = πτ,i(cτ, sτ-i) = 0 when τ < 0.
4.3 Additive Disappointment
 0.9t-τ·(πτ,i(hτ, sτ-i) – πτ,i(cτ, sτ-i)) ≥ 2Δ,
0.9t-τ·(πτ,i(hτ, sτ-i) – πτ,i(cτ, sτ-i)) ≥ 2Δ,then pt+1,i(y) = 1, y ≠ c, y∈Si, pt+1,i(c) = 0.
If Σ
0.9t-τ·(πτ,i(hτ, sτ-i) – πτ,i(cτ, sτ-i)) < 2Δ,then pt+1,i(y) = 0, y ≠ c, y∈Si, pt+1,i(c) = 1,
where hτ∈BRτ,i.
4.4 The Games

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
 |
4.5 Simulation Results: Case without Random Perturbations
4.5.1. Prisoner’s Dilemma and Hawk-Dove
4.5.2. Coordination, Hi-Lo, and Stag Hunt
 |
| Short-Sightedness | Three-Period Memory | Additive Disappointment | |
|---|---|---|---|
| Prisoner’s Dilemma | p = 0 from any initial state | ||
| Coordination | Randomness, possible convergence to p = 0 or p = 1 | p = 1, if p > 1/2 at t = 0 p = 0, if p < 1/2 at t = 0 | p = 1, if p > 1/2 at t = 0 p = 0, if p < 1/2 at t = 0 |
| Hi-Lo | p = 1, if p > 0 at t = 0 p = 0, if p = 0 at t = 0 | p = 1, if p > 0.42 at t = 0 p = 0, if p < 0.42 at t = 0 | p = 1, if p > 0.17 at t = 0 p = 0, if p < 0.17 at t = 0 |
| Hawk-Dove | p ≈ 0.41 | p ≈ 0.46 | p ≈ 0.41 |
| Hawk-Dove #2 | p ≈ 0.33 | p ≈ 0.43 | p ≈ 0.25 |
| Stag-Hunt | Same results as ‘Coordination’ | ||
| Stag-Hunt #2 | Same results as ‘Hi-Lo’ | ||
| Stag-Hunt #3 | p = 0, if p < 1 at t = 0 p = 1, if p = 1 at t = 0 | p = 1, if p > 0.55 at t = 0 p = 0, if p < 0.55 at t = 0 | p = 1, if p > 0.74 at t = 0 p = 0, if p < 0.74 at t = 0 |
4.6 Simulation Results: Case with Random Perturbations
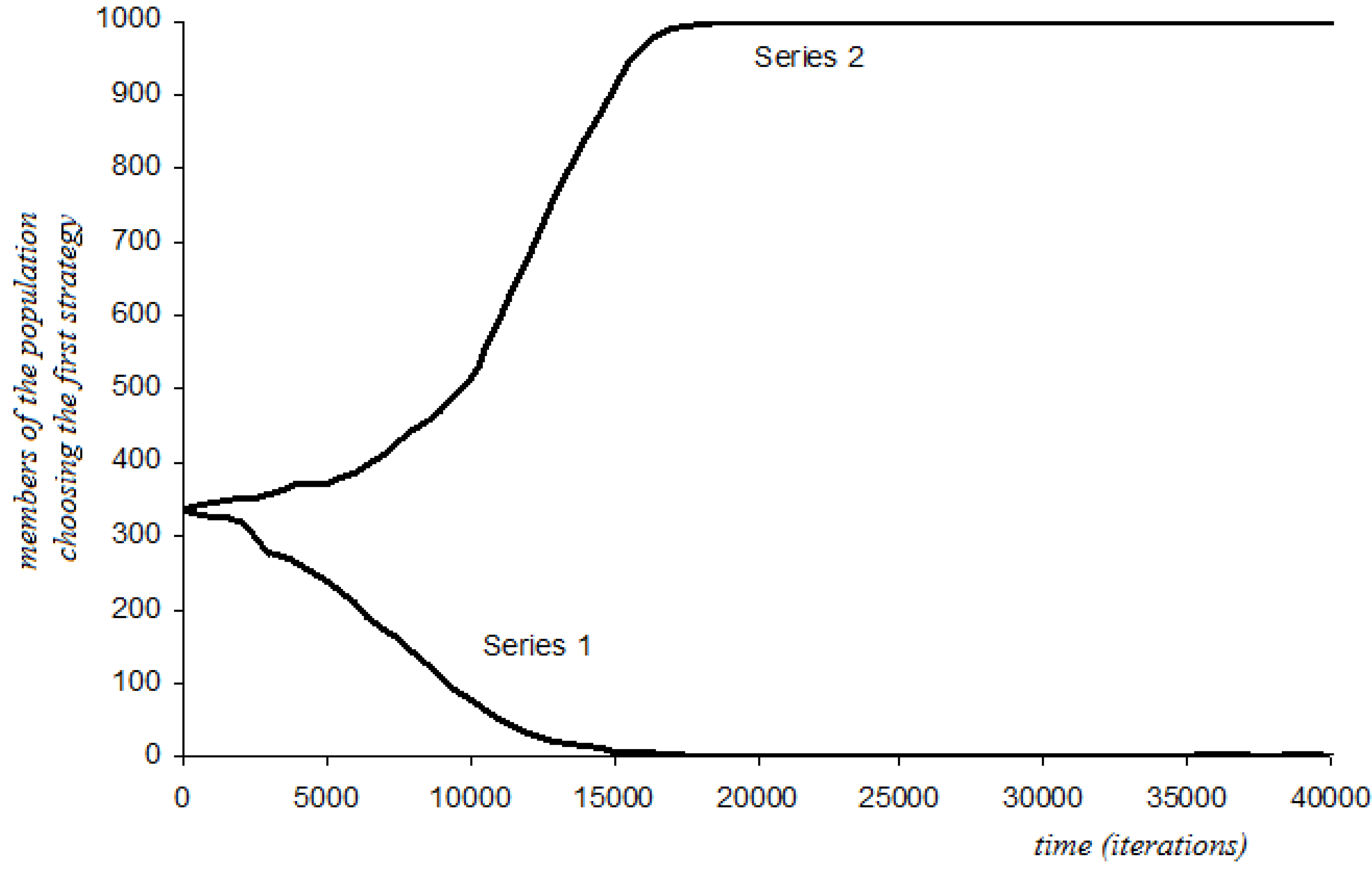
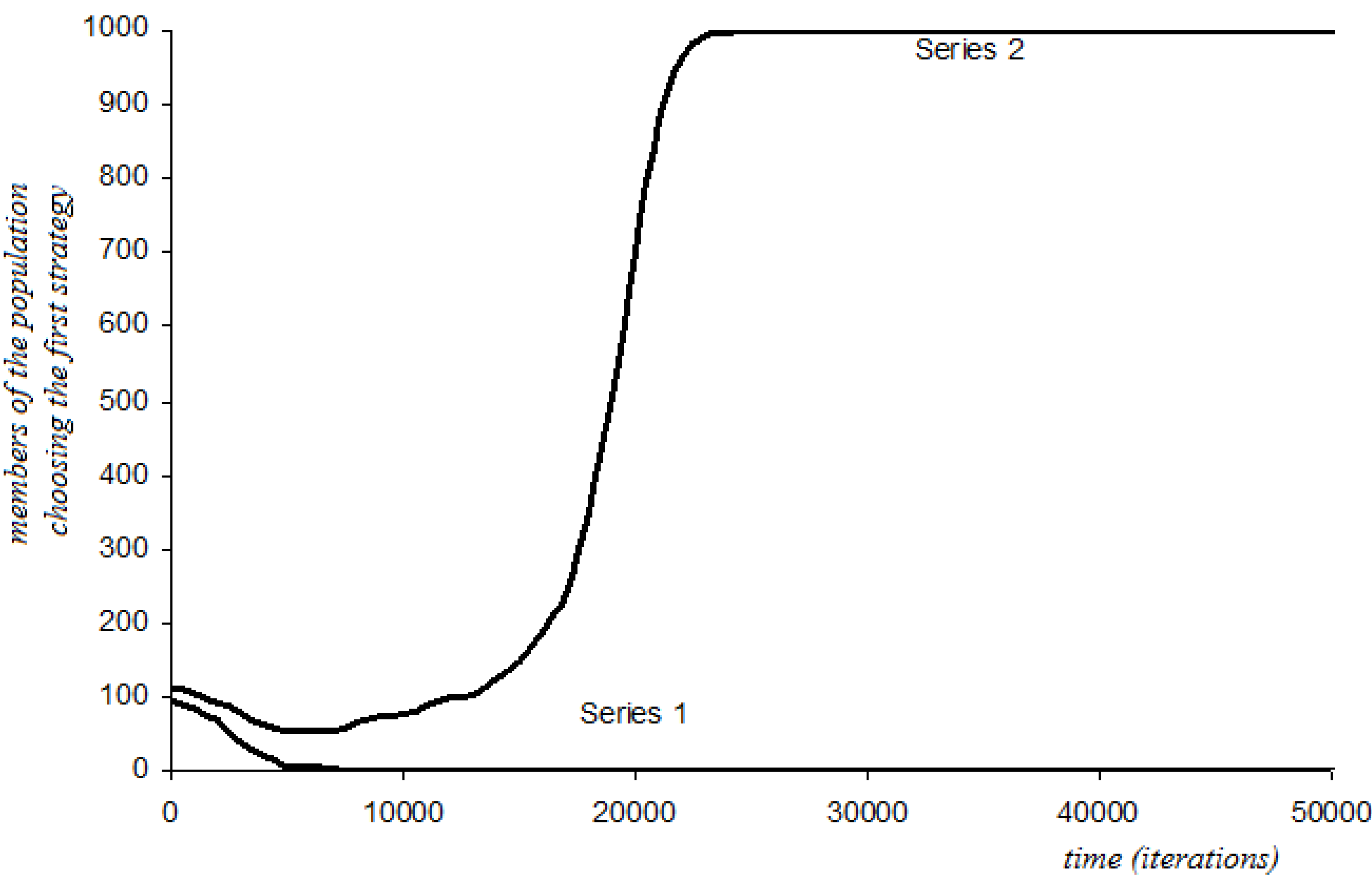
4.6.1. Short-Sightedness with Stochastic Perturbations
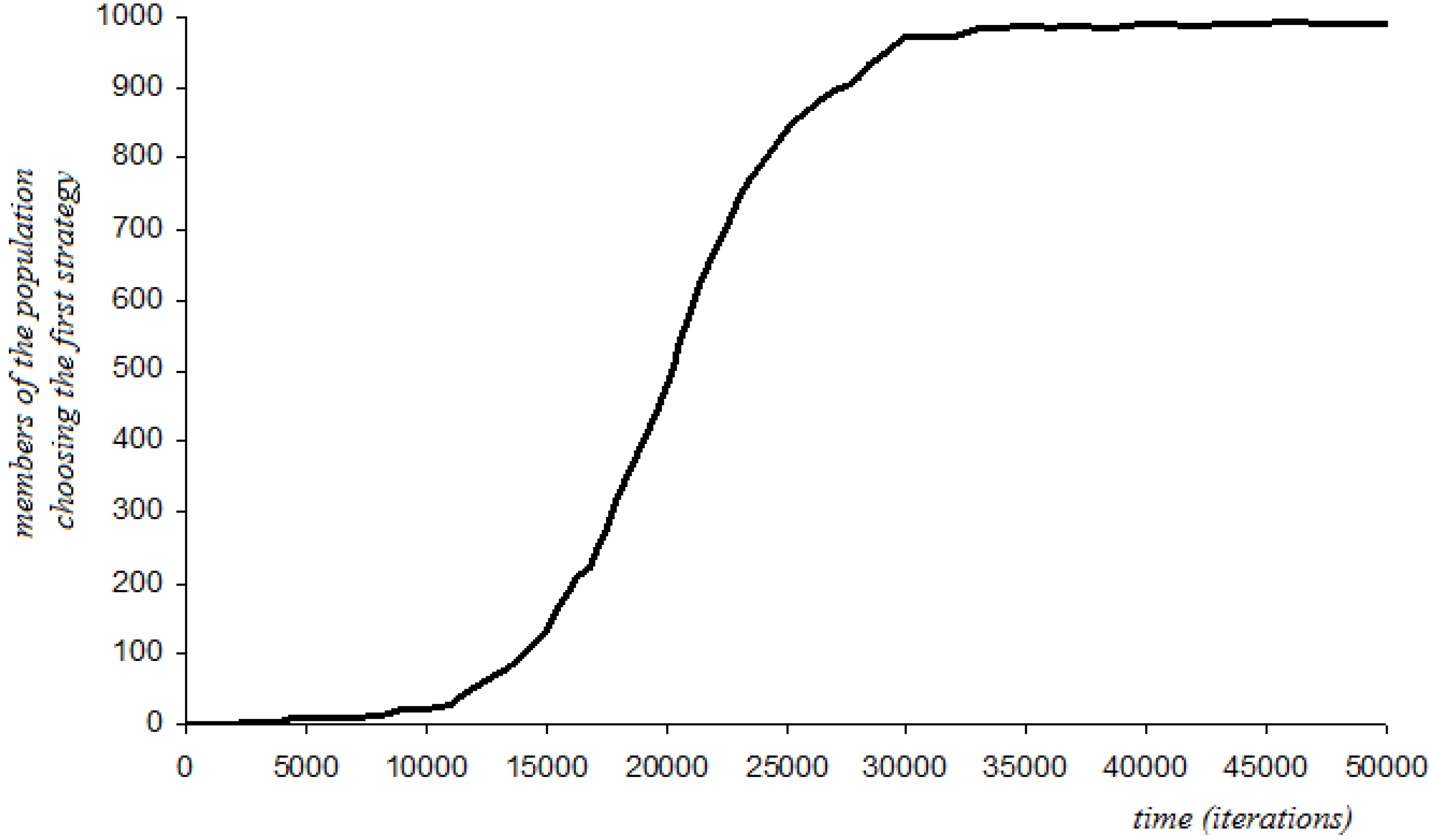
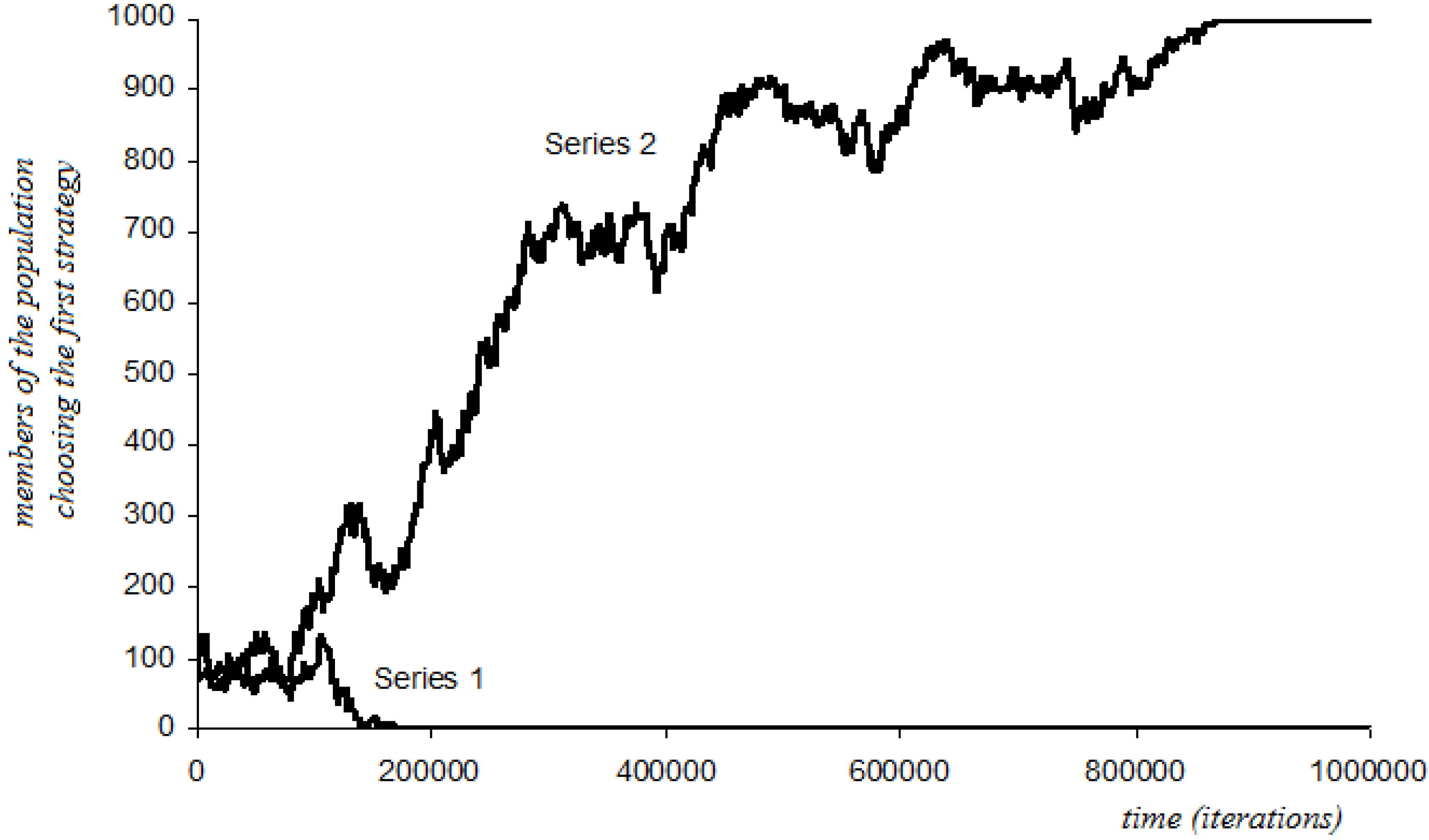
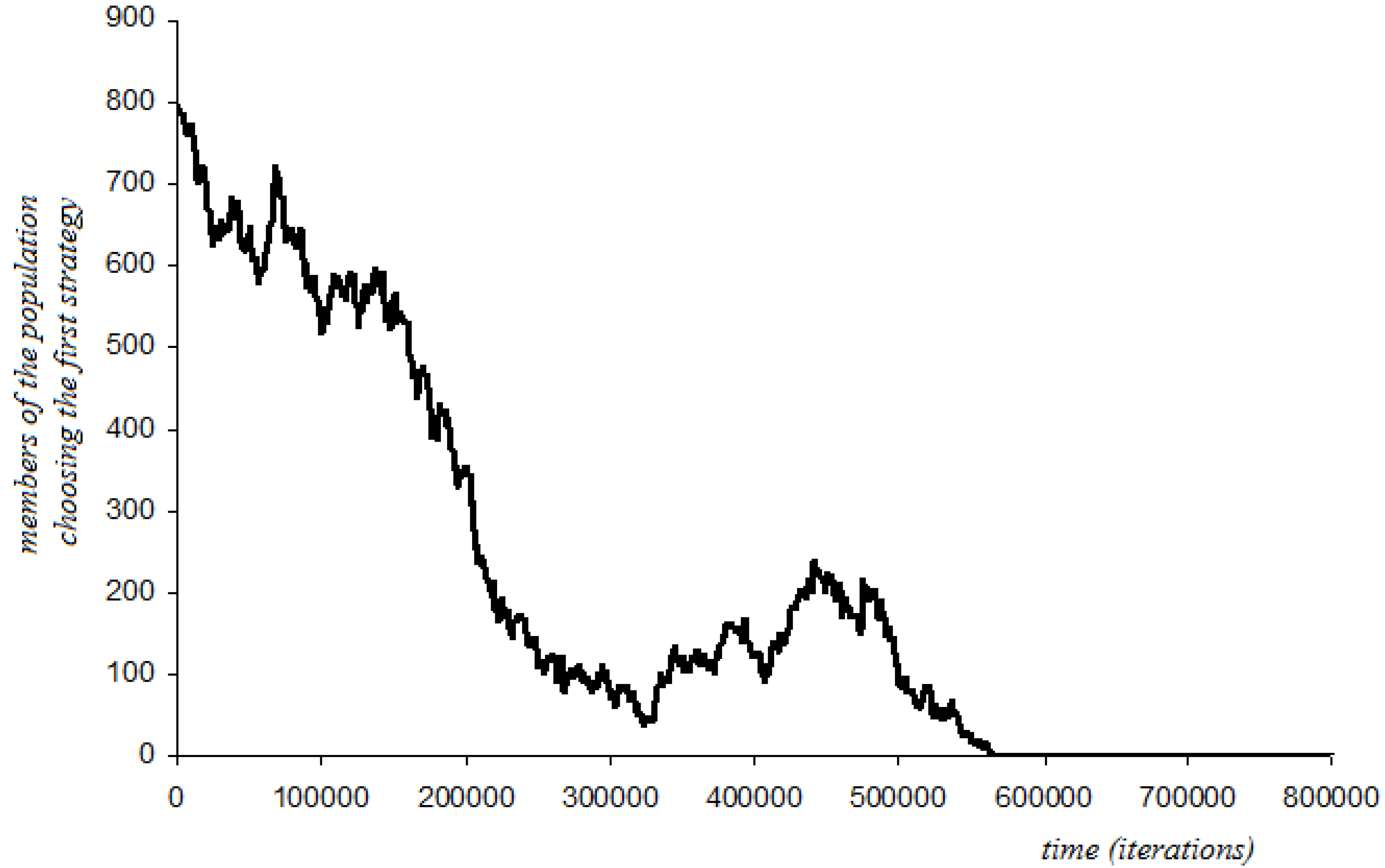

4.6.2. Three-Period Memory with Stochastic Perturbations
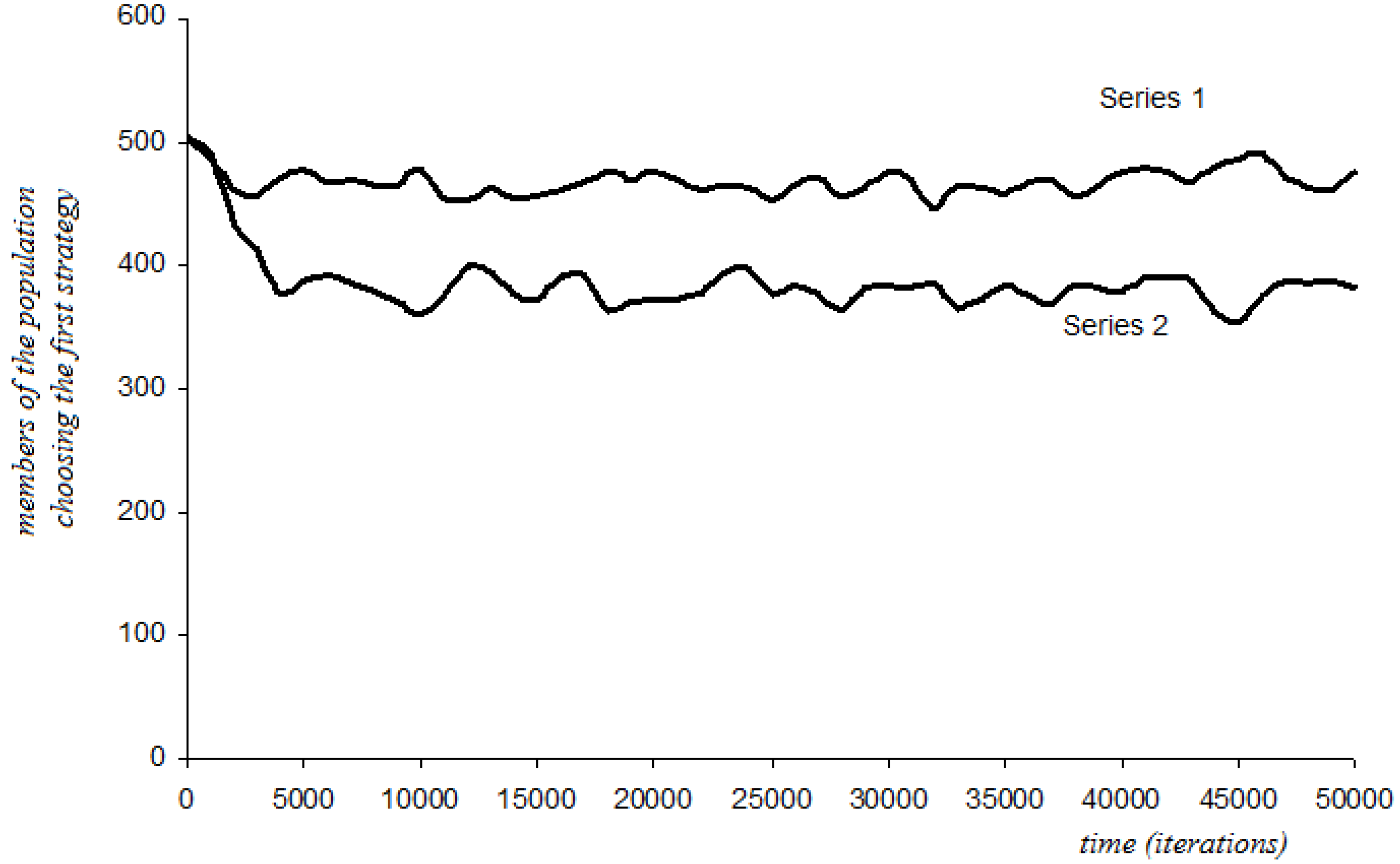

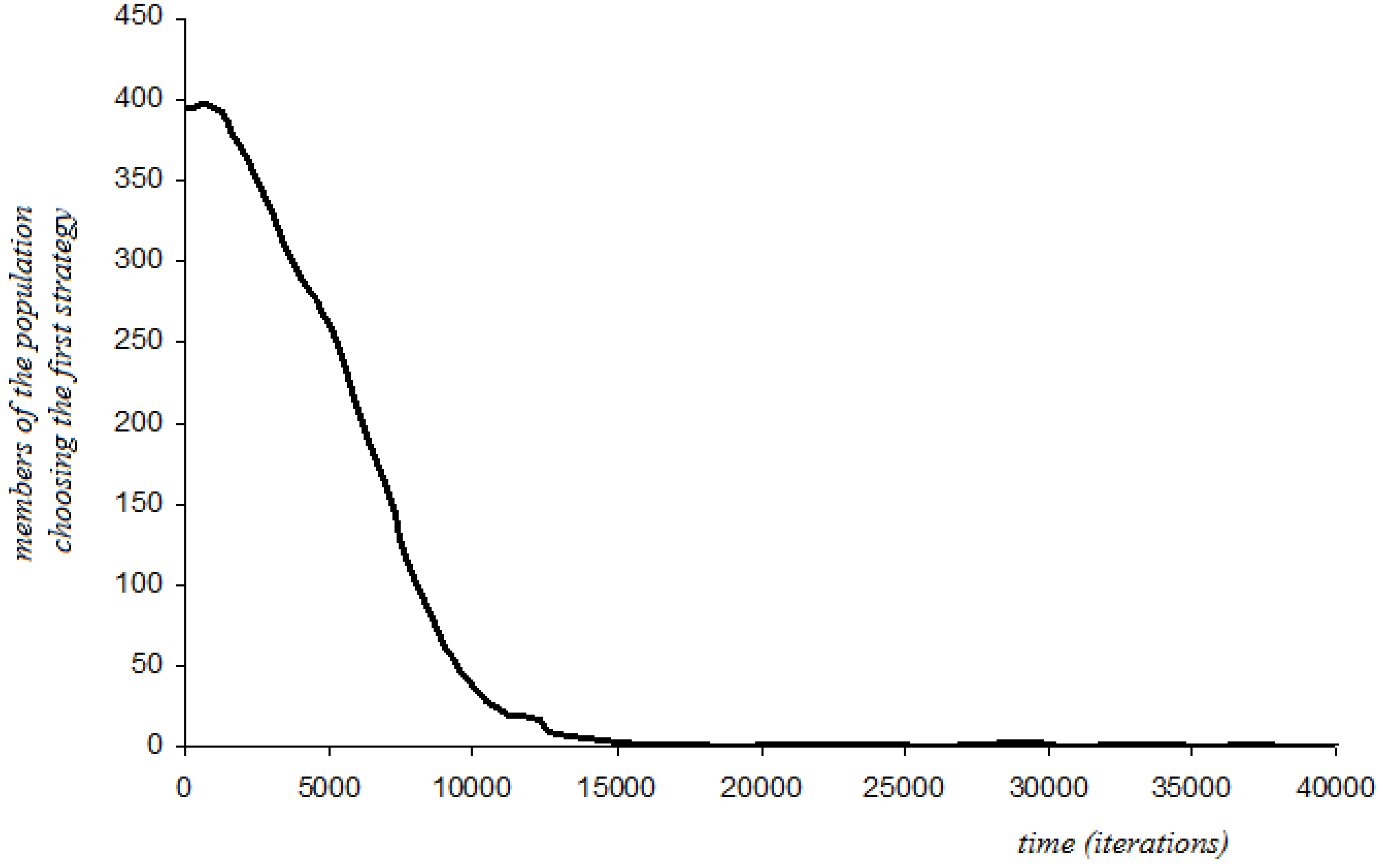

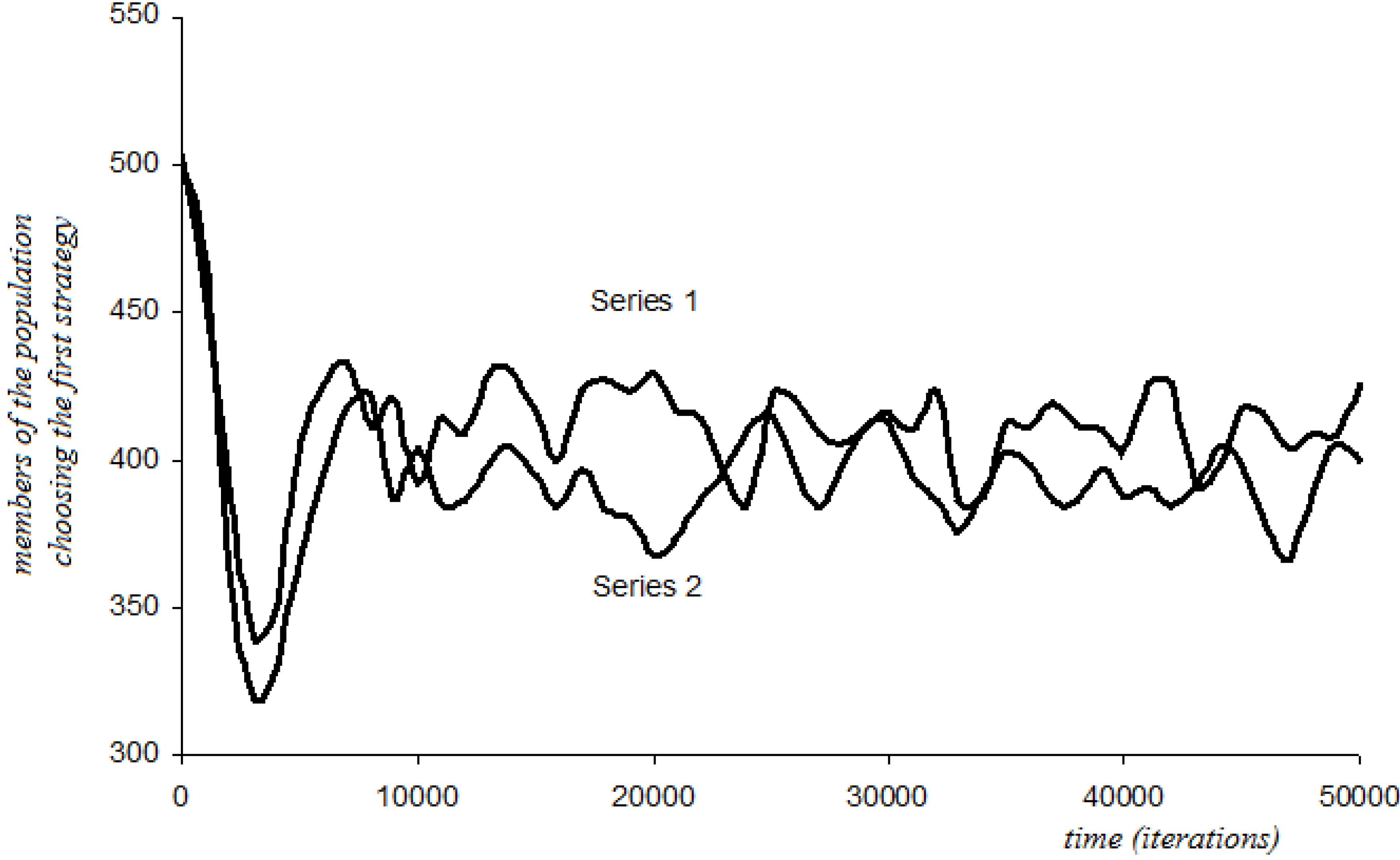
4.6.3. Additive Disappointment with Stochastic Perturbations
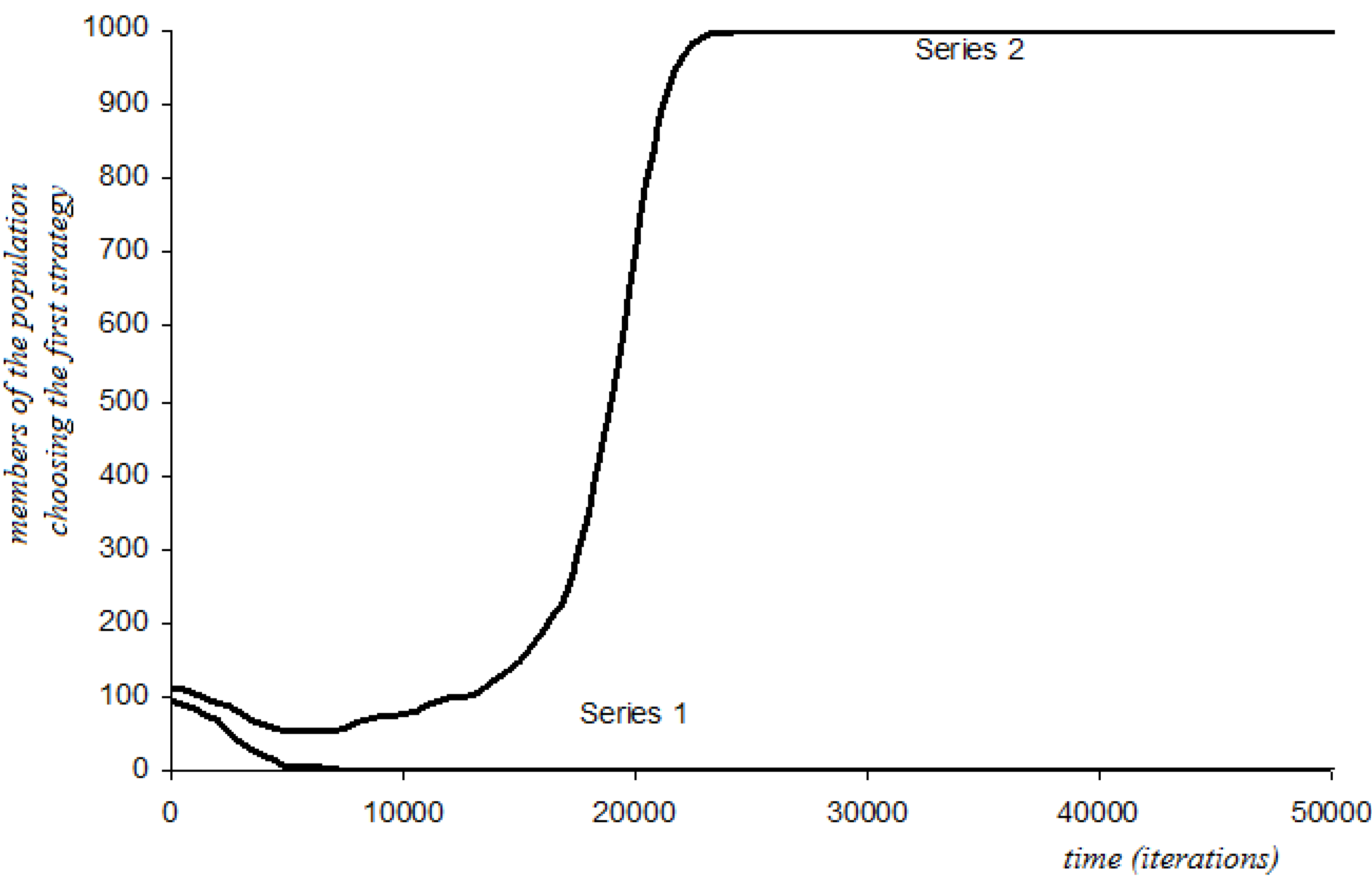


| Protocol: Short-Sightedness | |||
|---|---|---|---|
| Game | Initial Condition | Convergence | Comments |
| Stag-Hunt | p = 0.1, a = 0.01, b = 1 | p = 1 | If a = 0 (no perturbations) we have convergence at p = 0. |
| Stag-Hunt | p = 0.8, a = 0.01, b = 0 | p = 0 | If a = 0 (no perturbations) we have convergence at p = 1. |
| Stag-Hunt #3 | p = 0.5, a = 0.5, b = 1 | p = 1 | If a = 0 (no perturbations) we have convergence at p = 0. |
| Protocol: Three-Period Memory | |||
|---|---|---|---|
| Game | Initial Condition | Convergence | Comments |
| Hi-Lo | p = 0.35, a = 0.1, b = 1 | p = 0 | |
| p = 0.35, a = 0.15, b = 1 | p = 1 (6 out of 10 runs) | ||
| Stag-Hunt | p = 0.4, a = 0.15, b = 1 | p = 0 | Convergence at p = 1 under short-sightedness. |
| Stag-Hunt #3 | p = 0.6, a = 0.1, b = 0 | p = 1 | If a = 0 convergence at p = 1 is quicker. |
| Protocol: Additive disappointment | |||
|---|---|---|---|
| Game | Initial Condition | Convergence | Comments |
| Hi-Lo | p = 0.1, a = 0.05, b = 1 | p = 1 | If a = 0 (no perturbations) we have convergence at p = 0. |
| Stag-Hunt | p = 0.1, a = 0. 1, b = 1 | p = 1 | If a = 0 (no perturbations) we have convergence at p = 0. |
| Stag-Hunt #3 | p = 0.5, a = 0.25, b = 1 | p ≈ 0.15 | |
5. Discussion and Conclusions
Acknowledgements
Conflicts of Interest
References
- Sugden, R. The evolutionary turn in game theory. J. Econ. Methodol. 2001, 1, 113–130. [Google Scholar] [CrossRef]
- Rubinstein, A. Modeling Bounded Rationality; MIT Press: Cambridge, MA, USA, 1998. [Google Scholar]
- Maynard Smith, J.; Price, G.R. The logic of animal conflict. Nature 1973, 246, 15–18. [Google Scholar] [CrossRef]
- Maynard Smith, J. The theory of games and the evolution of animal conflicts. J. Theor. Biol. 1974, 47, 209–221. [Google Scholar] [CrossRef]
- Lewontin, R.C. Evolution and the theory of games. J. Theor. Biol. 1961, 1, 382–403. [Google Scholar] [CrossRef]
- Taylor, P.; Jonker, L. Evolutionary stable strategies and game dynamics. Math. Biosci. 1978, 40, 145–156. [Google Scholar] [CrossRef]
- Mailath, G.J. Do people play Nash equilibrium? Lessons from evolutionary game theory. J. Econ. Lit. 1998, 36, 1347–1374. [Google Scholar]
- Weibull, J.W. What have we learned from evolutionary game theory so far? Research Institute of Industrial Economics IUI. 1998. Available online: http://swopec.hhs.se/iuiwop/papers/iuiwop0487.pdf (accessed on 1 November 2013).
- Samuelson, L. Evolution and game theory. J. Econ. Perspect. 2002, 16, 47–66. [Google Scholar] [CrossRef]
- Hofbauer, J.; Sigmund, K. Evolutionary game dynamics. B. Am. Math. Soc. 2003, 40, 479–519. [Google Scholar]
- Friedman, D. On economic applications of evolutionary game theory. J. Evol. Econ. 1998, 8, 15–43. [Google Scholar] [CrossRef]
- Schlag, K.H. Why imitate, and if so, how? A bounded rational approach to multi-armed bandits. J. Econ. Theory 1998, 78, 130–156. [Google Scholar] [CrossRef]
- Cross, J. A stochastic learning model of economic behavior. Q. J. Econ. 1973, 87, 239–266. [Google Scholar] [CrossRef]
- Borgers, T.; Sarin, R. Learning through reinforcement and replicator dynamics. J. Econ. Theory 1997, 77, 1–14. [Google Scholar] [CrossRef]
- Erev, I.; Roth, A.E. Predicting how people play games: Reinforcement learning in experimental games with unique, mixed strategy equilibria. Am. Econ. Rev. 1998, 88, 848–881. [Google Scholar]
- Fudenberg, D.; Kreps, D. Learning mixed equilibria. Game Econ. Behav. 1993, 5, 320–367. [Google Scholar] [CrossRef]
- Fudenberg, D.; Levine, D.K. The Theory of Learning in Games; MIT Press: Cambridge, MA, USA, 1998. [Google Scholar]
- Cressman, R. Evolutionary Dynamics and Extensive Form Games; MIT Press: Cambridge, MA, USA, 2003. [Google Scholar]
- Sandholm, W.H. Population Games and Evolutionary Dynamics; MIT Press: Cambridge, MA, USA, 2010. [Google Scholar]
- Foster, D.; Young, H.P. Stochastic evolutionary game dynamics. Theor. Popul. Biol. 1990, 38, 219–232. [Google Scholar]
- Kandori, M.; Mailath, G.J.; Rob, R. Learning, mutation, and long run equilibria in games. Econometrica 1993, 61, 29–56. [Google Scholar] [CrossRef]
- Young, H.P. The evolution of conventions. Econometrica 1993, 61, 57–84. [Google Scholar] [CrossRef]
- Binmore, K.; Samuelson, L.; Vaughan, R. Musical chairs: Modeling noisy evolution. Game Econ. Behav. 1995, 11, 1–35. [Google Scholar] [CrossRef]
- Young, H.P. Individual Strategy and Social Structure; Princeton University Press: Princeton, NJ, USA, 1998. [Google Scholar]
- Loomes, G.; Sugden, R. Regret theory: An alternative theory of rational choice under uncertainty. Econ. J. 1982, 92, 805–824. [Google Scholar] [CrossRef]
- Gul, F. A theory of disappointment aversion. Econometrica 1991, 59, 667–686. [Google Scholar] [CrossRef]
- Braun, M.; Muermann, A. The impact of regret on the demand of insurance. J. Risk Insur. 2004, 71, 737–767. [Google Scholar] [CrossRef]
- Irons, B.; Hepburn, C.J. Regret theory and the tyranny of choice. Econ. Rec. 2007, 83, 191–203. [Google Scholar] [CrossRef]
- Laciana, C.E.; Weber, E.U. Correcting expected utility for comparisons between alternative outcomes. Journal of Risk and Uncertainty 2008, 36, 1–17. [Google Scholar] [CrossRef]
- Grant, S.; Atsushi, K.; Polak, B. Different notions of disappointment aversion. J. Econ. Lit. 2001, 81, 203–208. [Google Scholar]
- Hart, S.; Mas-Colell, A. A simple adaptive procedure leading to correlated equilibrium. Econometrica 2000, 68, 1127–1150. [Google Scholar] [CrossRef]
- Macy, M.W.; Flache, A. Learning dynamics in social dilemmas. P. Natl. A. Sci. 2002, 99, 7229–7236. [Google Scholar] [CrossRef]
- Hogdson, G.M.; Knudsen, T. The complex evolution of a simple traffic convention: the functions and implications of habit. J. Econ. Behav. Organ. 2004, 54, 19–47. [Google Scholar] [CrossRef] [Green Version]
- Radax, W.; Wäckerle, M.; Hanappi, H. From agents to large actors and back; Formalized story-telling of emergence and exit in political economy. 2009. Available online: http://publik.tuwien.ac.at/files/PubDat_177962.pdf (accessed on 1 November 2013).
- Heinrich, T.; Schwardt, H. Institutional inertia and institutional change in an expanding normal-form game. Games 2013, 4, 398–425. [Google Scholar] [CrossRef] [Green Version]
- Weibull, J.W. Evolutionary Game Theory; MIT Press: Cambridge, MA, USA, 1995. [Google Scholar]
- 2As agent i is assumed as capable of acknowledging when they could have earned more payoffs, it would probably be more realistic to argue that, if i is to change their current strategy, then they are not going to select another strategy at random (as implied by the above distribution), but they shall choose a strategy belonging to the set of best replies to the opponents’ choice at t (i.e., the set BRt,i). In the case of 2 × 2 games (that shall be studied here), it is obvious that this issue is not a concern. Obviously, for larger games, this protocol reflects a very weak form of learning, and should probably be modified in accordance to the sophistication one would wish to endow the individuals with.
- 3The software was written by the author in Microsoft Visual Basic 6.0. Random numbers are generated by use of the language’s Rnd and Randomize functions.
- 4As this adjustment causes no ambiguity, we will simplify notation by not adding i subscripts to the time periods, as a more formal representation would require.
© 2014 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Patokos, T. Introducing Disappointment Dynamics and Comparing Behaviors in Evolutionary Games: Some Simulation Results. Games 2014, 5, 1-25. https://doi.org/10.3390/g5010001
Patokos T. Introducing Disappointment Dynamics and Comparing Behaviors in Evolutionary Games: Some Simulation Results. Games. 2014; 5(1):1-25. https://doi.org/10.3390/g5010001
Chicago/Turabian StylePatokos, Tassos. 2014. "Introducing Disappointment Dynamics and Comparing Behaviors in Evolutionary Games: Some Simulation Results" Games 5, no. 1: 1-25. https://doi.org/10.3390/g5010001