Hierarchical Structures and Leadership Design in Mean-Field-Type Games with Polynomial Cost
by
 ,
,
Zahrate El Oula Frihi
1 ,
,
Julian Barreiro-Gomez
2,3,*,
Salah Eddine Choutri
2,3 and
Hamidou Tembine
2,3 1
Lab. of Probability and Statistics (LaPS), Department of Mathematics, Badji-Mokhtar University, B.P.12, Annaba 23000, Algeria
2
Learning & Game Theory Laboratory, Engineering Division, New York University Abu Dhabi, Saadiyat Campus, PO Box 129188, Abu Dhabi 44966, UAE
3
Research Center on Stability, Instability and Turbulence, New York University Abu Dhabi, Abu Dhabi 44966, UAE
*
Author to whom correspondence should be addressed.
Games 2020, 11(3), 30; https://doi.org/10.3390/g11030030
Submission received: 8 June 2020
/
Revised: 28 July 2020
/
Accepted: 30 July 2020
/
Published: 6 August 2020
(This article belongs to the Special Issue Mean-Field-Type Game Theory)
Abstract
:This article presents a class of hierarchical mean-field-type games with multiple layers and non-quadratic polynomial costs. The decision-makers act in sequential order with informational differences. We first examine the single-layer case where each decision-maker does not have the information about the other control strategies. We derive the Nash mean-field-type equilibrium and cost in a linear state-and-mean-field feedback form by using a partial integro-differential system. Then, we examine the Stackelberg two-layer problem with multiple leaders and multiple followers. Numerical illustrations show that, in the symmetric case, having only one leader is not necessarily optimal for the total sum cost. Having too many leaders may also be suboptimal for the total sum cost. The methodology is extended to multi-level hierarchical systems. It is shown that the order of the play plays a key role in the total performance of the system. We also identify a specific range of parameters for which the Nash equilibrium coincides with the hierarchical solution independently of the number of layers and the order of play. In the heterogeneous case, it is shown that the total cost is significantly affected by the design of the hierarchical structure of the problem.
1. Introduction
The idea of hierarchy dates back at least to 1934, when Stackelberg [1] introduced a game that models markets where some firms have a stronger influence on others. Stackelberg games consist of two players, a leader and a follower. The leader who moves first decides an optimal strategy after anticipating the best response of the follower. Then, the follower eventually chooses the anticipated best response to optimize their cost or payoff. Therefore, this game is a game with two-level hierarchy. A dynamic Linear-Quadratic (LQ) Stackelberg differential game was studied by Samaan and Cruz [2]. A stochastic LQ Stackelberg differential game was investigated by Bagchi and Başar [3]. Bensoussan et al. [4] derived a maximum principle for the leader’s Stackelberg solution under the adapted closed-loop memoryless information structure.
Having two or more players, the Stackelberg game is called a hierarchical game, and it becomes more interesting and involved due to its multi-layer structure, including various forms of information. The players act in sequential order, such that each one of them is a leader for the previous and a follower of the next player in the hierarchy. For hierarchical mean-field-free differential games, see, for example, [5,6,7,8,9].
Only a few papers have considered hierarchical structures in mean-field-related games. Open-loop Stackelberg solutions are addressed in a linear-quadratic setting in [10,11]; and in the context of large populations, mean-field Stackelberg games are investigated in [12,13,14,15,16]. Besides, the leader-follower configuration has been used in several problems and fields to illustrate and model a variety of hierarchical behaviors. For instance, in [17], a leader-follower stochastic differential game with asymmetric information is studied, motivated by applications in finance, economics, and management engineering. In [18], a large-population leader-follower stochastic multi-agent system is analyzed with coupled cost functions and by using a mean-field Linear-Quadratic-Gaussian (LQG) approach. Regarding control applications, [19] presents a tracking control design in a distributed manner in a multi-agent system configured in a leader-follower fashion, and it is shown that the setup can be used to model the power sharing problem in microgrids. In [20], a security problem in networked control systems is studied by means of a Stackelberg approach, and in [21] a hierarchical control structure or sequential predictive control is designed for a large-scale water system. In [22], leadership is studied in the context of public goods games by means of the reward and punishment effects. The works mentioned above do not consider a hierarchical mean-field-type game setting where the payoff functionals are non-linear with respect to the probability measure of the state.
mean-field-type control was first introduced by Anderson and Djehiche [23], as well as Buckdahn, Djehiche, and Li [24]. The authors solved a one-player mean-field-type game in which the state dynamics and the payoff function depend on the first moment of the state (the mean-field coupling). The stochastic mean-field-type control problem is generalized to the stochastic mean-field-type game with several players—see, for example, [25,26,27,28,29,30,31].
The hierarchical mean-field-type game theory studies a class of hierarchical games in which the payoffs and/or state dynamics depend not only on the state-action pairs, but also the distribution of them [30]. This class of games offers several features:
- A single decision-maker can have a strong impact on the mean-field terms;
- The expected payoffs are not necessarily linear with respect to the state distribution;
- The number of decision-makers is not necessarily infinite.
Games with non-linear distribution-dependent quantity-of-interest are very attractive in terms of applications, since the non-linear dependence of the payoff functions in terms of state distribution allow us to capture risk measures, which are functionals of variance, inverse quantile, and/or higher moments. In portfolio optimization, for instance, payoff functions may include the third and the fourth moments, known as the kurtosis and skewness (e.g., [32,33]). Generally, equilibrium solutions to mean-field-type games are presented as either open-loop or closed-loop solutions. The open-loop solutions are controls that do not explicitly depend on the state process at time t, that is, they are rather adapted processes that depend only on time and the initial data. The stochastic maximum principle can be used as a methodology for finding such optimal control strategies. Closed-loop solutions (i.e., feedback solutions) are deterministic functions that depend on the state of the process at time t, as well as its marginal distribution. The dual adjoint functions which are obtained from the Hamilton-Jacobi-Bellman (HJB) equations can be used for finding feedback optimal controls. We will use this approach throughout this paper. For linear quadratic stochastic differential games, Sun and Yong [34] established that the existence of open-loop optimal control strategies is equivalent to the solvability of the corresponding optimality system, which is a forward-backward Stochastic Differential Equation (SDE), and the existence of closed-loop optimal strategies is equivalent to the existence of a regular solution to the corresponding Riccati equation.
Our contribution can be summarized as follows. This work examines a class of hierarchical mean-field-type games with multiple layers, leaders, and followers. Based on infinite-dimensional partial integro-differential equations (PIDEs) on the space of measures, we provide semi-explicit solutions in closed-loop form of a class of master systems with hierarchical structure and non-quadratic cost, which are not covered in the earlier works. Recall that the non-quadratic costs allow for analysis other classes of higher risk terms, such as kurtosis [32,33]. The novelty of this paper mainly lies in the analysis of the effect of hierarchy and leadership on the solutions.
The rest of this article is structured as follows. We present the model setup in Section 2. Section 3 investigates the Nash equilibrium (no leader). Section 4 presents the Stackelberg solution. The multi-layer case is presented in Section 5. Numerical examples are presented in Section 6. Finally, concluding remarks are drawn in Section 7.
2. The Setup
There are decision-makers interacting within the time horizon The set of decision-makers is denoted by Decision-maker has a control action The state x is driven by a Drift-Jump-Diffusion process of mean-field-type, given by
where
where denotes the set of probability measures on We assume that and N are mutually independent. The performance functional of decision-maker i is
where is the probability measure of the state at time and
In addition, each decision-maker is assumed to have a computational capability, such as being able to compute an aggregative term of m from the model. Let be the set of control strategies of decision-maker i that are progressively measurable with respect to the filtration generated by the unions of events in
2.1. Games with Polynomial Cost
We investigate the mean-field-type game with the following data:
where are natural numbers, and the coefficients are time-dependent. The coefficient functions and are nonnegative functions, and
2.2. Hierarchical Leader Design and Algorithmic Approach
The hierarchical leadership design consists of finding the optimal number of hierarchical layers h and the non-empty subsets of players , partitioning the set of all players as
The performance functional for the hierarchical design is the sum cost at the chosen hierarchical solution, that is,
Here, we take into consideration three main game scenarios, described as follows. First, the game has a unique layer, that is, a situation in which all the players select their strategies simultaneously. Second, the game is played in two layers (bi-level hierarchy). The players are grouped into two sets (): leaders, which are those who decide first, as well as simultaneously; and followers, which are those who react against the decision of the leaders. Third, the game is structured to take into account as many layers as the number of players (fully hierarchical configuration with ), that is, players select strategically in sequence one-by-one in I layers. For all configurations, let denote the optimal cost of the player in the hierarchical mean-field-type game problem, and denotes the total (social) cost at the hierarchical solution. The hierarchical leadership design consists in determining the optimal leaders, followers, and/or number of layers, such that the total cost is minimized.
Notice that, for both the bi-level and fully hierarchical cases, there are multiple combinations for the players. In the bi-level scenario, the set of all possible sets of leaders is given by the power set and any set of leaders is denoted by with the corresponding set of followers, . Regarding the fully hierarchical game, there are as many possibilities in the strategic ordering as permutations of the set of players . All possible permutations of the players are considered.
For the bi-level case, the optimal set for leaders and followers is
On the other hand, for the fully hierarchical case, we have that the optimal permutation is
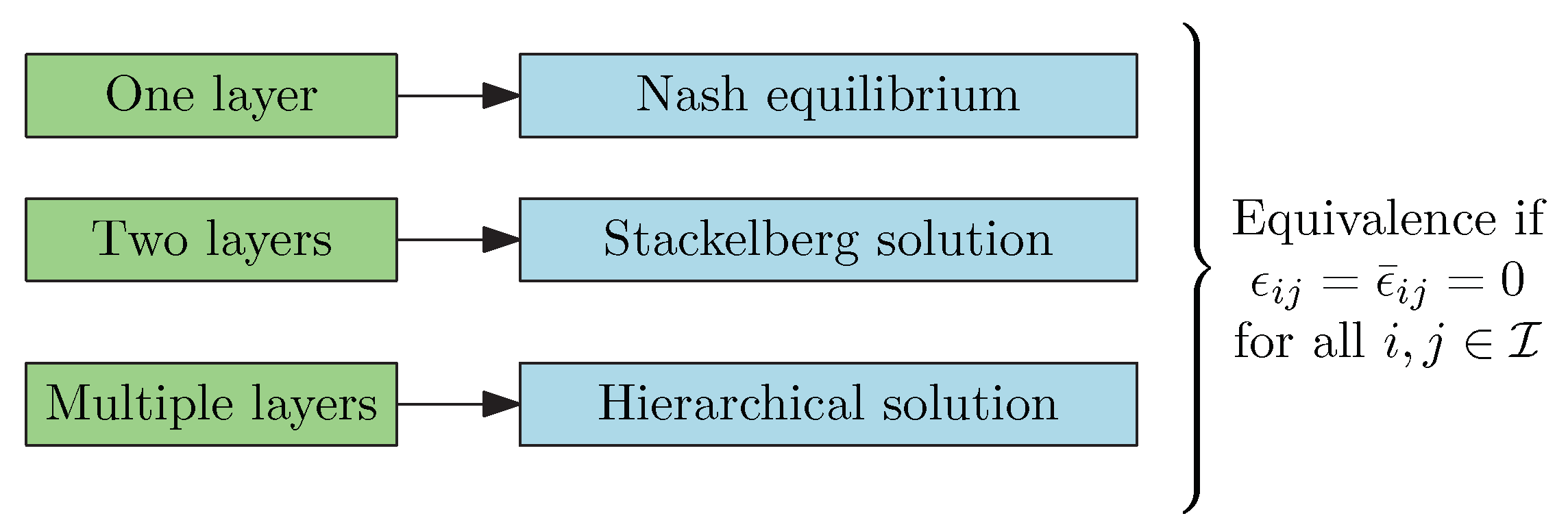
In this paper, we study the three aforementioned scenarios involving one, two, and I layers, as presented in Figure 1. We also present under which conditions all the three configurations have the same solution, that is, when the Nash solution coincides with the hierarchical solutions at different layers. Furthermore, we present numerical examples considering different levels of hierarchy. The problem addressed in this paper can be interpreted as a mechanism design that, instead of determining the appropriate cost functionals or utility functions to induce a desired output, we design the best hierarchical structure in order to reduce the overall social cost.
Remark 1
(Feasibility and Existence). The set of possible combinations for the layers/levels and players per level is non-empty and finite. Then, the optimal hierarchical leader design is feasible, and there exists an optimal solution (combination) such that the social cost is minimized.
Since the feasible set of possible combinations for the hierarchical configurations is non-empty and finite, then it is possible to find the best hierarchical structure by means of Algorithm 1. The main results evoked in the Algorithm 1, given by Propositions 1–3, are presented throughout the paper.
| Algorithm 1: Finding the best hierarchical structure |
 |
According to the procedure in Algorithm 1, one of the main concerns in the leadership design problem is related to the dimensionality of the feasible set for the hierarchical structures (NP-hard problem). The total number of combinations is, given by the total number of ordered partitions from a set, where such total combinations are computed by means of the ordered Bell number —that is, for I players we have:
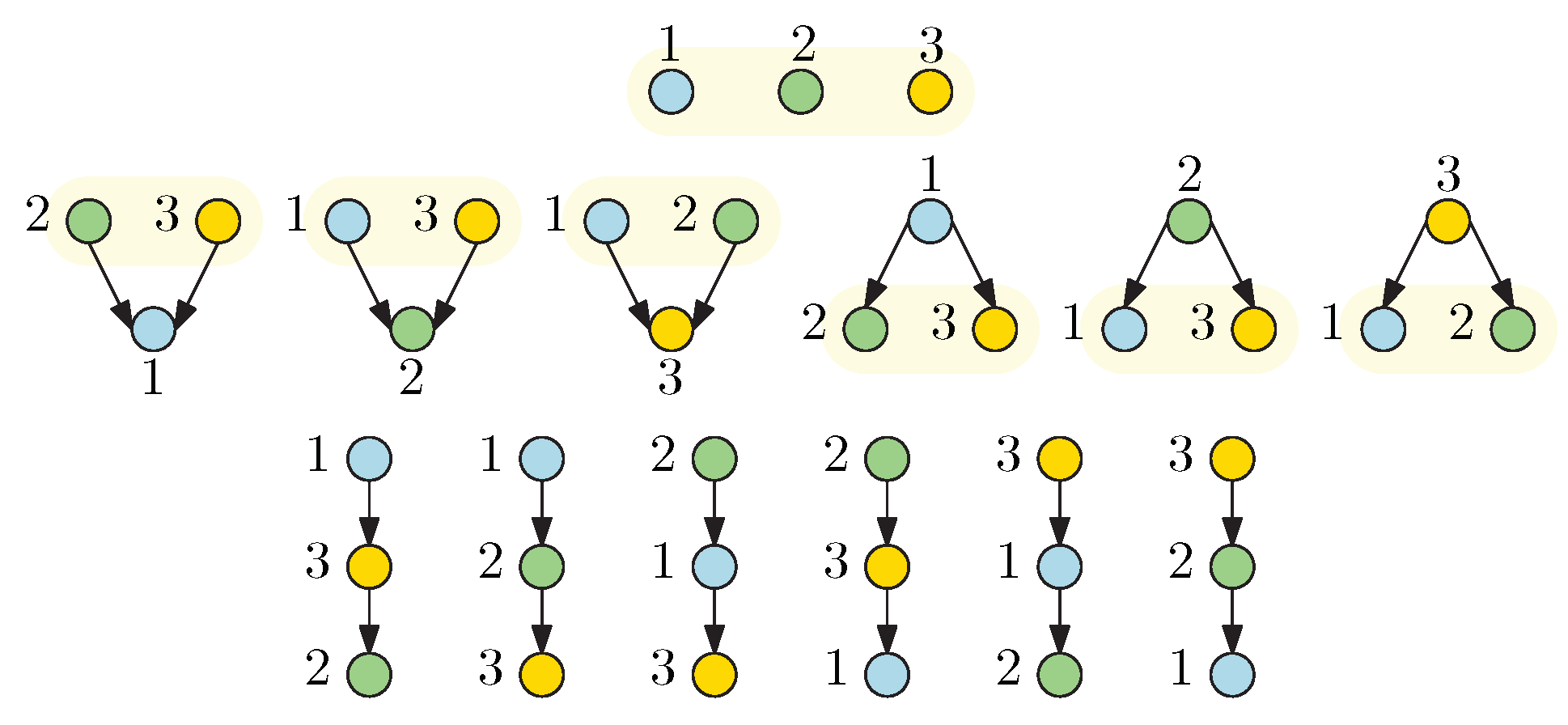
For instance, if , then there are possible leadership configurations, as shown in Figure 2; i , and then there are possible leadership structures presented in Figure 3, and , , and . Figure 4 illustrates the rapid increment of the number of combinations as the decision-makers increase. Notice that it is not possible to have more levels than players in the hierarchical game (). The following sections are devoted to the presentation of semi-explicit solutions for hierarchical mean-field-type games with different levels from one (Nash scenario) up to the number of players I (fully hierarchical scenario).
3. Nash Mean-Field-Type Equilibrium
The risk-neutral mean-field-type game is, given by
A risk-neutral Nash mean-field-type Equilibrium is a solution of the following fixed-point problem:
Let be the optimal cost-to-go from m at time given the strategies of the others, that is,
We say that is a Gâteaux derivative of , with respect to the measure m, if
If , then adding a constant to does not change the value of the integral in (2). For any scalar and one has, Thus, is also a Gâteaux-derivative of the constant function However, in our problem, the term , which is the gradient of , will be used in the Hamiltonian, and does not have the constant ambiguity. Let us denote the jump operator J as
Let us introduce the integrand Hamiltonian as
A sufficiency condition for a risk-neutral Nash equilibrium system is, given by the following PIDE system:
We refer the reader to [35] for a derivation of this equilibrium system. The system (3) is an infinite-dimensional PIDE system in m and it provides the Nash equilibrium values of the mean-field-type game. Notice that from (3), the equilibrium strategies have the best response to the integrand Hamiltonian and can be expressed as functions of
Next, we semi-explicitly provide the Nash mean-field-type equilibrium in linear state-and-mean -field feedback strategies. To do so, we use (3).
Proposition 1.
A risk-neutral Nash mean-field-type equilibrium is given in a semi-explicit way, as follows:
for all with
whenever the above coefficient system admits a solution which does not escape within .
Proof.
The proof is presented in Appendix A. □
The following Remark discusses the existence and uniqueness of the terms in Proposition 1.
Remark 2.
The uniqueness of the coefficient system (4) in η requires a strong condition, that is,
- Let I be an arbitrary integer and , the system in η becomes linear and has a unique solution if, and only if the determinant of the matrix M is non-zero, with and When the determinant is zero, the resulting control strategies become non-admissible and the costs become infinite.
- For , and the system in η becomes a binary cubic polynomial, given byFor , there is a unique solution, given byFor , we derive from the first equation thatBy substituting it to the second equation, we arrive atThe latter equation is a polynomial of odd degree “9”. It has a unique real root in if its derivative has a constant sign. Its derivative isIt has a constant sign if and have opposite signs. If and are positive, then the condition is reduced to
- and arbitrary . Thus, a sufficiency condition is that and have opposite signs. In particular if , then the condition reduces to
- The same reasoning applies to the system in , and has a unique real solution if
- For decision-makers and arbitrary , the system can be rewritten as a fixed-point equation which fulfils a contraction mapping condition if the norms of r and ϵ are sufficiently small. In this case, there is a unique solution.
In the next section, we investigate the bi-level case with multiple leaders and multiple followers.
4. Multiple Leaders and Multiple Followers
We consider the description in (1) in a bi-level hierarchical game with two and more leaders, that is, and two and more followers, that is, We restrict our attention to the admissible strategies, which are Lipschitz, in the state Given the strategies of the leaders a risk-neutral best-response strategy of follower j is a strategy that solves The set of risk-neutral best responses of j is denoted by
A mean-field-type risk-neutral Nash equilibrium among the followers given the first movers’ strategies is a strategy profile of all followers, such that for every decision-maker
The followers solve the following Nash game given the strategy of the leaders , that is,
Then, the leaders solve the following PIDE system:
A minimizer of the integrand Hamiltonian , denoted by
provides a candidate Stackelberg strategy of the leader i. A mean-field-type risk-neutral Stackelberg solution between multiple leaders and multiple followers is a strategy of all decision-makers, such that
and for every follower,
The next result presents the Stackelberg mean-field-type solution involving several leaders and followers in a semi-explicit manner.
Proposition 2.
The risk-neutral Stackelberg mean-field-type solution with multiple leaders and multiple followers is given in a semi-explicit way, as follows:
and
with
whenever the above coefficient system admits a unique solution.
Proof.
The proof is presented in Appendix A. □
Remark 3.
Clearly, the mean-field-type Nash equilibrium in (4) differs from the Stackelberg solution in (7) when the are non-zero.
4.1. No Control-Coupling within Classes
It follows from (7) that, for for the term is explicitly, given by
and
4.1.1. No Leader and All Followers
In this case, there is no leader. All decision-makers are followers. This case is similar to the model proposed in the Nash game above. The solution is given by (4).
4.1.2. One Leader and Multiple Followers
There is a unique leader in , and the remaining decision-makers in are followers. We assume that the leader (decision-maker ) uses a state- and mean-field-type feedback strategy and each of the followers (decision-maker ) finds a state- and mean-field-type feedback strategy given The followers solve a Nash game given the strategy of the leader
4.1.3. Multiple Leaders and One Follower
Since there is only one follower, the reaction set of the follower will be computed given the strategies of the leaders.
4.1.4. All Leaders and No Follower
In this case, there is no follower. All decision-makers are leaders. In terms of the information structure, this case is similar to the model proposed in the Nash game above. The solution is given by (4).
5. Fully Hierarchical Game
In the previous sections, we had only bi-level game problems. In this section, we make as many levels as the number of decision-makers. There are hierarchical levels. At each layer decision-maker i chooses a control strategy knowing the control strategy of the preceding decision-makers, that is, This becomes a sequential decision-making problem. We use a backward induction method to solve the hierarchical game problem. This means that the decision-making problem at the last layer I, which is the reaction of decision-maker I, can be seen as a mean-field-type control problem. This is because at the th level, the strategies are already known by decision-maker
The Proposition 1 next presents the multi-level hierarchical-structure solution in the context of mean-field-type games in a semi-explicit manner.
Proposition 1.
The risk-neutral level hierarchical mean-field-type solution is given in a semi-explicit way, as follows:
with
where the coefficient functions are, given by
whenever these equations admit a solution.
Proof.
This proof is presented in Appendix A. □
From the analysis above, the following remarks are in order:
- For the order of the play matters because of the informational difference between the decision-makers at different levels of hierarchy in (8). One open question that we leave for future investigation is: How to determine the optimal ordering among all permutations of heterogenous decision-makers?
- When all the and are zero, the Nash equilibrium coincides with the bi-level solution, which coincides with any level of hierarchical solution. The order of the play and the informational difference do not generate an extra advantage for the first mover in this particular case. Consequently, the hierarchical leader design is only performed when the parameters .
6. Numerical Investigation
In this section, we perform some numerical examples in order to analyze two main scenarios. We study the effect of the number of leaders on the total cost for both homogeneous and heterogeneous scenarios, and we investigate the effect of the hierarchical structure considering a heterogeneous scenario.
6.1. Effect of the Number of Leaders on the Total Cost
We investigate the effect of the number of leaders on the total performance of the system. The total cost at the Stackelberg solution is
For and the total cost is
6.1.1. Uniform Coupling and Homogeneous Players
When all other parameters are identical across the players except their role, can be expressed as a function It follows from (7) that
The optimal number of leaders is, given by
where depends on as well. We observe that the latter function is not necessarily monotone in This means that increasing the number of leaders in the interaction does not necessarily improve the total performance of the system.
We numerically investigate as a function of for Let us consider a symmetric six-player game problem involving the parameters presented here:
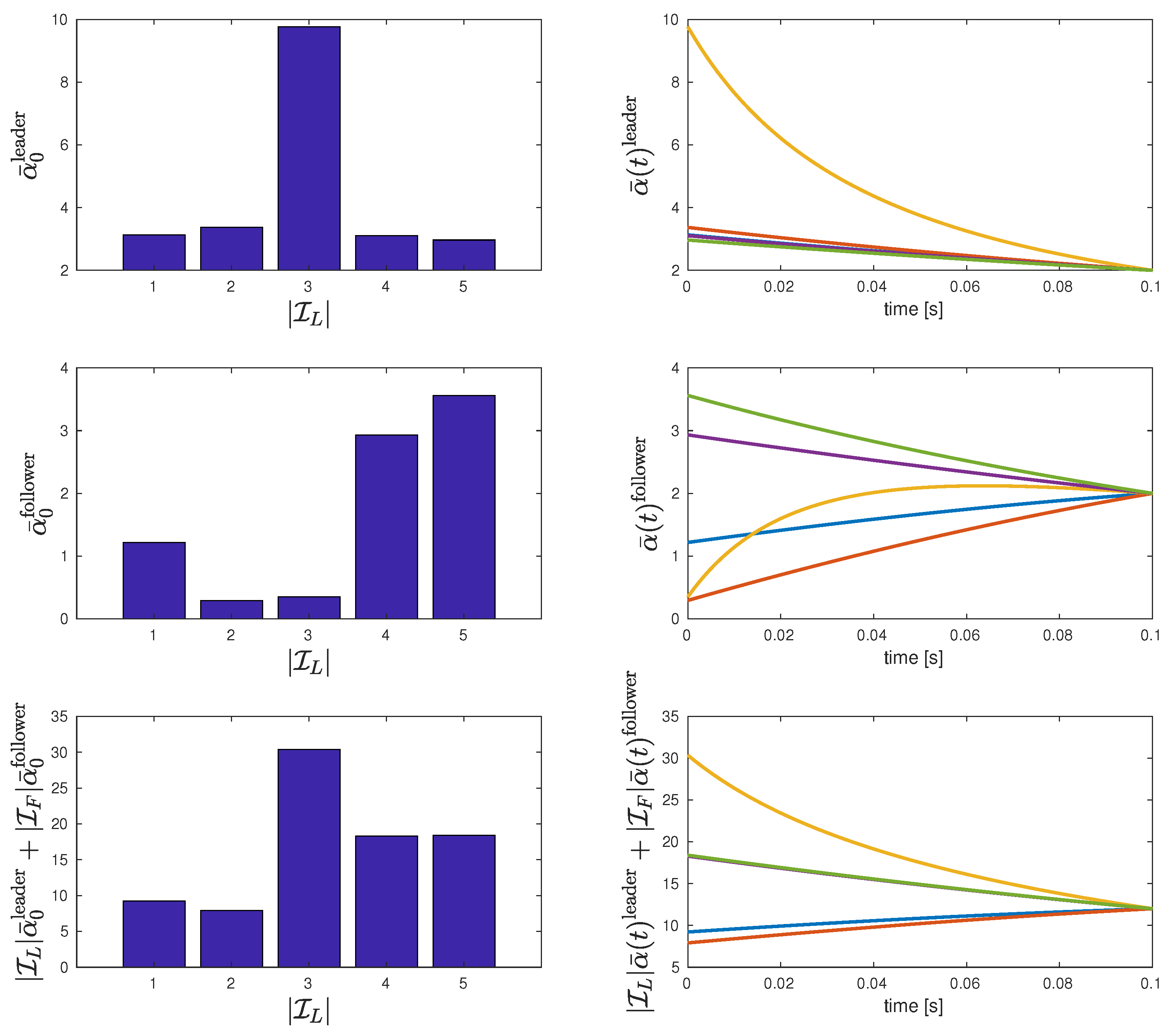
Figure 5 presents the evolution of both and for a different number of leaders . Notice that the initial values and determine the optimal cost considering that
Figure 5 and Table 1 also show that, under the considered parameters, the lowest total cost is obtained when corresponding to a cost . These results offer an insight into the game’s structural design for the sake of either individual or total costs. We observe that having only one leader is suboptimal for the total cost. Having too many leaders (where the majority of the decision-makers are leaders) is not suboptimal for the total cost. In this setting, there is a tradeoff between leaders and followers, so that the system’s cost gets balanced.
6.1.2. Uniform Coupling and Heterogeneous Players
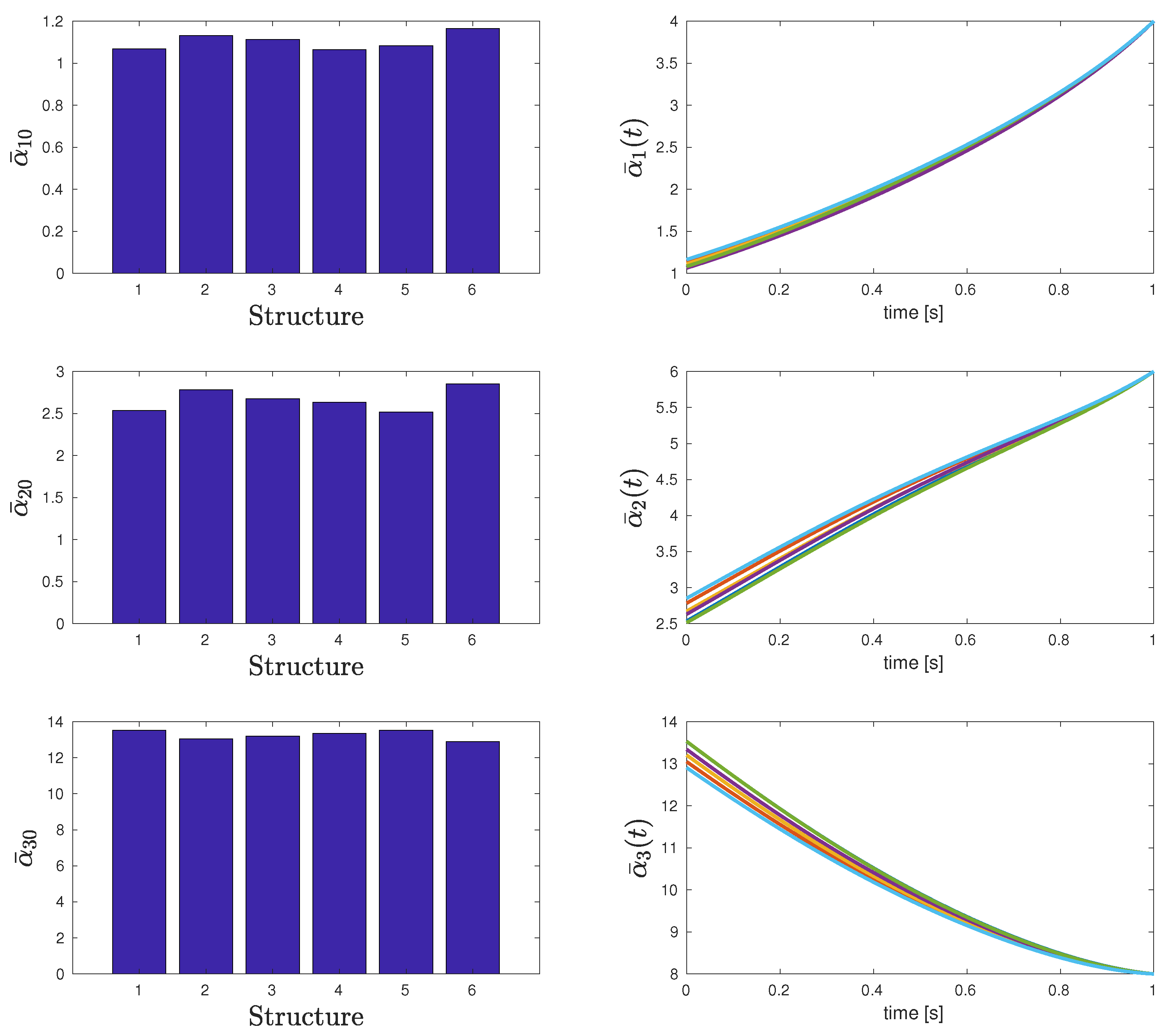
Now we investigate the two-layer case with uniform coupling, that is, , for all combinations and for the heterogeneous case with . We consider the following parameters:
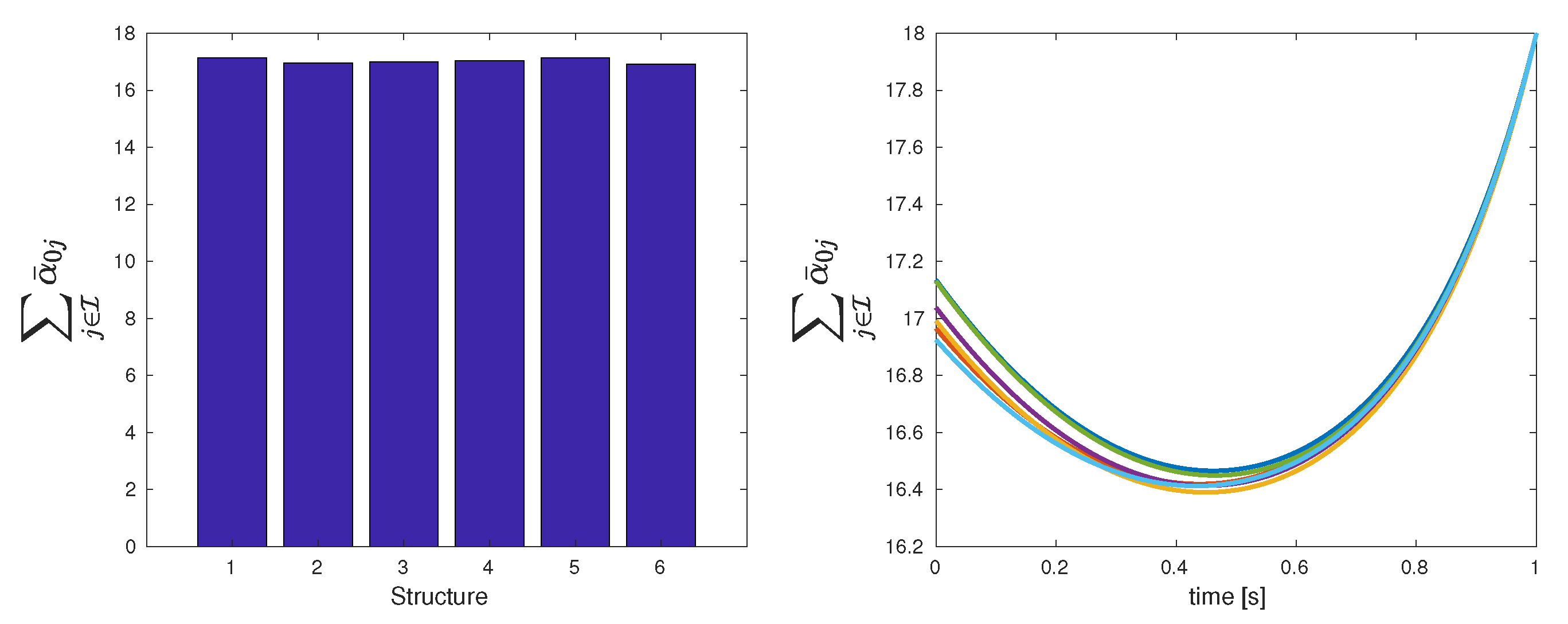
Figure 6 shows the evolution of and for the different topologies presented in Table 2. It can be seen in Figure 7 that all the structures return a close value for the total cost. However, Table 2 shows that the best topology is the last one, where the third player acts as the unique leader assuming an initial condition, such that (10) holds.
6.2. Impact of the Hierarchical Structures
Here, we analyze the impact on the order of the strategic selection, that is, the hierarchical order on the heterogeneous case with . We consider the following heterogeneous parameters:
and
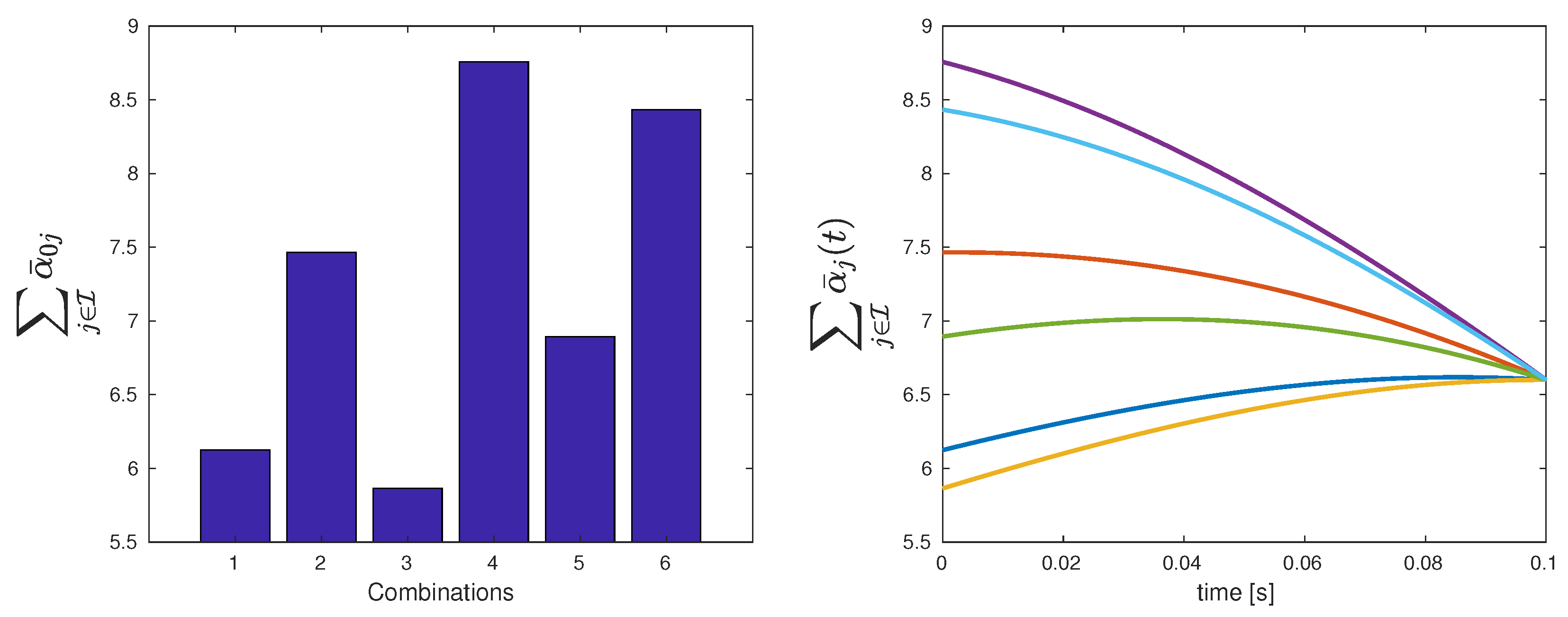
Table 3 shows the summary of the total costs for the six different possible hierarchical orders assuming an initial condition, such that (10) holds. It can be seen that the third configuration is the best to minimize the total cost. Moreover, Figure 8 presents the evolution of the equations for all the possible structures.
7. Conclusions
In this paper, we have examined multi-layer hierarchical mean-field-type games with non-quadratic polynomial costs. We derived hierarchical mean-field-type solutions in linear state- and mean-field feedback form by using a partial integro-differential system, and also established the relationship between the Nash and the hierarchical solutions. Furthermore, we studied the impact of the number of leaders on a bi-level Stackelberg problem for both symmetric and non-symmetric scenarios. In addition, we have shown that the number of layers, permutations of the decision-makers per layer, and their identity significantly affect the total cost of the system. We have also numerically shown that the ordering among all permutations of heterogenous decision-makers may reduce the cost by a significant proportion, depending on the horizon. One open question that we leave for future investigation is to find, theoretically, the optimal ordering among all permutations of heterogenous decision-makers, and to examine the benefits/costs of structure design and leadership.
Author Contributions
All authors have equally contributed. All authors have read and agreed to the published version of the manuscript.
Funding
U.S. Air Force Office of Scientific Research under grant number FA9550-17-1-0259.
Acknowledgments
We gratefully acknowledge support from U.S. Air Force Office of Scientific Research under grant number FA9550-17-1-0259.
Conflicts of Interest
There is no conflict of interest.
Appendix A
Proof of Proposition 1.
Under the assumption of perfect state observation and perfect knowledge of the model, a sufficiency condition for equilibrium is, given by the PIDE system (3). We aim to solve (3). To do so, we start with the following guess functional of decision-maker i as
where the coefficient functions and need to be determined. Notice that, for , the functional becomes a mean-variance-dependent functional, and for an arbitrary parameter , the functional may support higher order moments. We compute the key terms , ,
with The Integrand Hamiltonian is strictly convex in . The optimal control strategy is the unique minimizer of
By strictly convexity and by orthogonality between and the following condition system holds:
By solving the previously mentioned conditions, one obtains the optimal control input in a closed-loop form. The linear state- and mean-field-type feedback strategy solves the system if the coefficients satisfy
The integrand Hamiltonian of i becomes
By identification the coefficients solve the following ordinary differential equation:
The aggregate mean-field term can be derived in a semi-explicit way by taking the expected value of the state dynamics. It follows that
This completes the proof. □
Proof of Proposition 2.
For the data in (1), the integrand Hamiltonian has a unique minimizer, denoted by
which provides the reaction strategies of the follower decision-makers. Following (1) with leaders in and followers in the first order optimality condition yields
and
which provides as function of and . Following (1) with leaders in and followers in the leaders’ integrand Hamiltonian can be rewritten as follows
In view of (A7),
The optimal Stackelberg strategies of the leaders satisfy the following system:
whose solution provides the coefficients . □
Appendix A.1. I-th Hierarchical Level
Proof of Proposition 3.
We use a backward induction procedure to prove the statement.
When decision-maker I optimizes the preceding decision-makers have already chosen their strategy and that is known by Hence, integrand Hamiltonian of I is
It follows from strictly convex optimization above that the best response strategy can be expressed as:
where
In particular,
If the preceding decision-makers have all used linear state-and-mean-field feedback strategies then the reaction of the I-th decision-maker who is at I-th level of hierarchy can be rewritten as
□
Appendix A.2. (I − 1)-th Hierarchical Level
At the hierarchical level the preceding levels are and the succeeding level is Having the expression of the optimal control strategies of the last layer I we can move to the preceding layer, that is, Decision-maker has and the reaction of decision-maker Therefore, the integrand Hamiltonian of is, given by
In view of (A9), the terms with depend on , , …, The first-order optimality condition for yields
where we have used (A9) for .
Appendix A.3. i-th Hierarchical Level
For
By identification from the first-order optimality condition the coefficient functions satisfy the following equations
Appendix A.4. 1-st Hierarchical Level
We now examine first level of the hierarchy. The integrand Hamiltonian of decision-maker 1 is
By identification from the first-order optimality condition the coefficient functions satisfy the following equations
Putting all together we arrive at the announced statement. This completes the proof.
References
- Stackelberg, H.V. The Theory of the Market Economy; Peacock, A.J.; Hodge, W., Translators; Originally Published as Grundlagen der Theoretischen Volkswirtschaftlehre; Oxford University Press: Oxford, UK, 1948. [Google Scholar]
- Simaan, M.; Cruz, J.B. On the Stackelberg strategy in nonzero-sum games. J. Optim. Theory Appl. 1973, 11, 533–555. [Google Scholar] [CrossRef]
- Bagchi, A.; Basar, T. Stackelberg strategies in linear-quadratic stochastic differential games. J. Optim. Theory Appl. 1981, 35, 443–464. [Google Scholar] [CrossRef]
- Bensoussan, A.; Chen, S.; Sethi, S.P. The maximum principle for global solutions of stochastic Stackelberg differential games. SIAM J. Control Optim. 2015, 53, 1956–1981. [Google Scholar] [CrossRef]
- Pan, L.; Yong, J. A differential game with multi-level of hierarchy. J. Math. Anal. Appl. 1991, 161, 522–544. [Google Scholar] [CrossRef] [Green Version]
- Simaan, M.; Cruz, J. A Stackelberg solution for games with many players. IEEE Trans. Autom. Control 1973, 18, 322–324. [Google Scholar] [CrossRef]
- Cruz, J. Leader-follower strategies for multilevel systems. IEEE Trans. Autom. Control 1978, 23, 244–255. [Google Scholar] [CrossRef] [Green Version]
- Gardner, B.; Cruz, J. Feedback Stackelberg strategy for M-level hierarchical games. IEEE Trans. Autom. Control 1978, 23, 489–491. [Google Scholar] [CrossRef]
- Basar, T.; Selbuz, H. Closed-loop Stackelberg strategies with applications in the optimal control of multilevel systems. IEEE Trans. Autom. Control 1979, 24, 166–179. [Google Scholar] [CrossRef]
- Lin, Y.; Jiang, X.; Zhang, W. An Open-Loop Stackelberg Strategy for the Linear Quadratic Mean-Field Stochastic Differential Game. IEEE Trans. Autom. Control 2019, 64, 97–110. [Google Scholar] [CrossRef]
- Du, K.; Wu, Z. Linear-Quadratic Stackelberg Game for Mean-Field Backward Stochastic Differential System and Application. Math. Probl. Eng. 2019, 2019, 1798585. [Google Scholar] [CrossRef] [Green Version]
- Moon, J.; Basar, T. Linear-quadratic stochastic differential Stackelberg games with a high population of followers. In Proceedings of the 54th IEEE Conference on Decision Control, Osaka, Japan, 15–18 December 2015; pp. 2270–2275. [Google Scholar]
- Bensoussan, A.; Chau, M.H.M.; Yam, S.C.P. Mean-field Stackelberg games: Aggregation of delayed instructions. SIAM J. Control Optim. 2015, 53, 2237–2266. [Google Scholar] [CrossRef] [Green Version]
- Bensoussan, A.; Chau, M.; Lai, Y.; Yam, S. Linear-quadratic mean field Stackelberg games with state and control delays. SIAM J. Control Optim. 2017, 55, 2748–2781. [Google Scholar] [CrossRef]
- Averboukh, A.Y. Stackelberg solution for first-order mean-field game with a major player. Izv. Inst. Mat. Inform. Udmurt. 2018, 52. [Google Scholar] [CrossRef]
- Moon, J.; Basar, T. Linear quadratic mean field Stackelberg differential games. Automatica 2018, 97, 200–213. [Google Scholar] [CrossRef]
- Shi, J.; Wang, G.; Xiong, J. Leader-follower stochastic differential game with asymmetric information and applications. Automatica 2016, 63, 60–73. [Google Scholar] [CrossRef] [Green Version]
- Nourian, M.; Caines, P.; Malhamé, R.P.; Huang, M. Mean Field LQG Control in Leader-Follower Stochastic Multi-Agent Systems: Likelihood Ratio Based Adaptation. IEEE Trans. Autom. Control 2012, 57, 2801–2816. [Google Scholar] [CrossRef] [Green Version]
- Cai, H.; Hu, G. Distributed Tracking Control of an Interconnected Leader-Follower multi-agent System. IEEE Trans. Autom. Control 2017, 62, 3494–3501. [Google Scholar] [CrossRef]
- Li, Y.; Shi, D.; Chen, T. False Data Injection Attacks on Networked Control Systems: A Stackelberg Game Analysis. IEEE Trans. Autom. Control 2018, 63, 3503–3509. [Google Scholar] [CrossRef]
- Barreiro-Gomez, J.; Ocampo-Martinez, C.; Quijano, N. Partitioning for large-scale systems: A sequential distributed MPC design. In Proceedings of the 20th IFAC World Congress, Toulouse, France, 9–14 July 2017; pp. 8838–8843. [Google Scholar]
- Sutter, M.; Rivas, M.F. Leadership, Reward and Punishment in Sequential Public Goods Experiments. In Reward and Punishment in Social Dilemmas; Lange, P.A.V., Rockenbach, B., Yamagishi, T., Eds.; Oxford University Press: Oxford, UK, 2014; pp. 1–39. [Google Scholar]
- Andersson, D.; Djehiche, B. A Maximum Principle for SDEs of mean-field-type. Appl. Math. Optim. 2011, 63, 341–356. [Google Scholar] [CrossRef]
- Buckdahn, R.; Djehiche, B.; Li, J. A General Stochastic Maximum Principle for SDEs of mean-field-type. Appl. Math. Optim. 2011, 64, 197–216. [Google Scholar] [CrossRef]
- Tembine, H. Risk-sensitive mean-field-type games with Lp-norm drifts. Automatica 2015, 59, 224–237. [Google Scholar] [CrossRef]
- Tcheukam, A.; Tembine, H. mean-field-type Games for Distributed Power Networks in Presence of Prosumers. In Proceedings of the 2016 28th Chinese Control and Decision Conference (CCDC), Yinchuan, China, 28–30 May 2016; pp. 446–451. [Google Scholar]
- Djehiche, B.; Tcheukam, A.; Tembine, H. mean-field-type Games in Engineering. AIMS Electron. Electr. Eng. 2017, 1, 18. [Google Scholar] [CrossRef]
- Tembine, H. mean-field-type games. AIMS Math. 2017, 2, 706–735. [Google Scholar] [CrossRef]
- Duncan, T.; Tembine, H. Linear-Quadratic mean-field-type Games: A Direct Method. Games 2018, 9, 7. [Google Scholar] [CrossRef] [Green Version]
- Barreiro-Gomez, J.; Duncan, T.E.; Tembine, H. Linear-Quadratic mean-field-type Games: Jump-Diffusion Process with Regime Switching. IEEE Trans. Autom. Control 2019, 64, 4329–4336. [Google Scholar] [CrossRef]
- Barreiro-Gomez, J.; Duncan, T.E.; Tembine, H. Linear-Quadratic mean-field-type Games with Multiple Input Constraints. IEEE Control Syst. Lett. 2019, 3, 511–516. [Google Scholar] [CrossRef]
- Beardsley, X.W.; Field, B.; Xiao, M. Mean-variance-skewness-kurtosis portfolio optimization with return and liquidity. Commun. Math. Financ. 2012, 1, 13–49. [Google Scholar]
- Theodossiou, P.; Savva, C.S. Skewness and the Relation Between Risk and Return. Manag. Sci. 2016, 62, 1598–1609. [Google Scholar] [CrossRef] [Green Version]
- Sun, J.; Yong, J. Linear Quadratic Stochastic Differential Games: Open-Loop and Closed-Loop Saddle Points. SIAM J. Control. Optim. 2014, 52, 4082–4121. [Google Scholar] [CrossRef] [Green Version]
- Bensoussan, A.; Djehiche, B.; Tembine, H.; Yam, S.C.P. mean-field-type Games with Jump and Regime Switching. Dyn. Games Appl. 2020. [Google Scholar] [CrossRef]
Figure 1.
Different hierarchical designs and their solution concepts considered in this paper.

Figure 2.
Possible combinations in the hierarchical leadership design for two decision-makers. Ordered Bell number .
Figure 2.
Possible combinations in the hierarchical leadership design for two decision-makers. Ordered Bell number .

Figure 3.
Possible combinations in the hierarchical leadership design for three decision-makers. Ordered Bell number .
Figure 3.
Possible combinations in the hierarchical leadership design for three decision-makers. Ordered Bell number .

Figure 4.
Number of possible hierarchical structures for given set of decision-makers described by the ordered Bell number .
Figure 4.
Number of possible hierarchical structures for given set of decision-makers described by the ordered Bell number .

Figure 5.
Evolution of the differential equations , and the corresponding initial values for the different number of leaders in the homogeneous scenario.
Figure 5.
Evolution of the differential equations , and the corresponding initial values for the different number of leaders in the homogeneous scenario.

Figure 6.
Evolution of the differential equations , and the corresponding initial values for the different number of leaders in the heterogeneous scenario.
Figure 6.
Evolution of the differential equations , and the corresponding initial values for the different number of leaders in the heterogeneous scenario.

Figure 7.
Evolution of the sum of differential equations and the corresponding total cost for the heterogeneous scenario.
Figure 7.
Evolution of the sum of differential equations and the corresponding total cost for the heterogeneous scenario.

Figure 8.
Evolution of the differential equations , and the corresponding initial values for different hierarchical structures in the heterogeneous scenario.
Figure 8.
Evolution of the differential equations , and the corresponding initial values for different hierarchical structures in the heterogeneous scenario.


{kind=link}
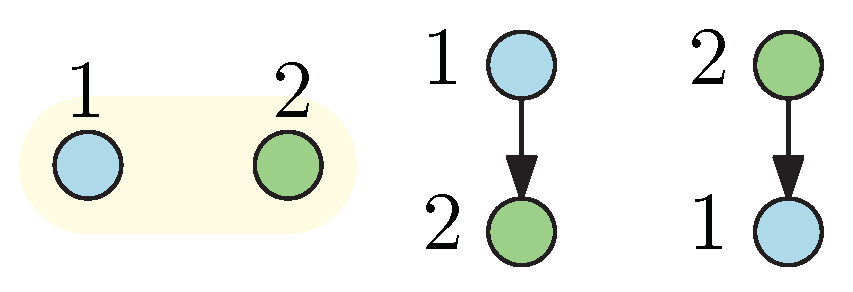{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Summary of , , and for the different number of leaders in the homogeneous scenario. bold—significant difference.
Table 1.
Summary of , , and for the different number of leaders in the homogeneous scenario. bold—significant difference.
| Leader(s)-Follower(s) Structure |  |  |  |  |  |
|---|---|---|---|---|---|
| Individual leader cost | 3.132 | 3.37 | 9.772 | 3.107 | 2.968 |
| Individual follower cost | 1.217 | 0.2931 | 0.3481 | 2.933 | 3.562 |
| Total cost | 9.219 | 7.911 | 30.36 | 18.29 | 18.4 |
Table 2.
Summary of , , and for the different number of leaders in the heterogeneous scenario. bold—significant difference.
Table 2.
Summary of , , and for the different number of leaders in the heterogeneous scenario. bold—significant difference.
| Leader(s)-Follower(s) Structure |  |  |  |  |  |  |
|---|---|---|---|---|---|---|
| Leaders | ||||||
| Followers | ||||||
| Total cost | 17.14 | 16.96 | 16.99 | 17.04 | 17.13 | 16.92 |
Table 3.
Total cost for the different hierarchical orders in a three-player case in the heterogeneous scenario. bold—significant difference.
Table 3.
Total cost for the different hierarchical orders in a three-player case in the heterogeneous scenario. bold—significant difference.
| Hierarchical Structure |  |  |  |  |  |  |
|---|---|---|---|---|---|---|
| Combination label | 1 | 2 | 3 | 4 | 5 | 6 |
| Hierarchical order | ||||||
| Total cost | 6.124 | 7.464 | 5.864 | 8.757 | 6.894 | 8.433 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
El Oula Frihi, Z.; Barreiro-Gomez, J.; Eddine Choutri, S.; Tembine, H. Hierarchical Structures and Leadership Design in Mean-Field-Type Games with Polynomial Cost. Games 2020, 11, 30. https://doi.org/10.3390/g11030030
AMA Style
El Oula Frihi Z, Barreiro-Gomez J, Eddine Choutri S, Tembine H. Hierarchical Structures and Leadership Design in Mean-Field-Type Games with Polynomial Cost. Games. 2020; 11(3):30. https://doi.org/10.3390/g11030030
Chicago/Turabian StyleEl Oula Frihi, Zahrate, Julian Barreiro-Gomez, Salah Eddine Choutri, and Hamidou Tembine. 2020. "Hierarchical Structures and Leadership Design in Mean-Field-Type Games with Polynomial Cost" Games 11, no. 3: 30. https://doi.org/10.3390/g11030030
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.