New Residue Number System Scaler for the Three-Moduli Set {2n+1 − 1, 2n, 2n − 1}


Abstract
:1. Introduction
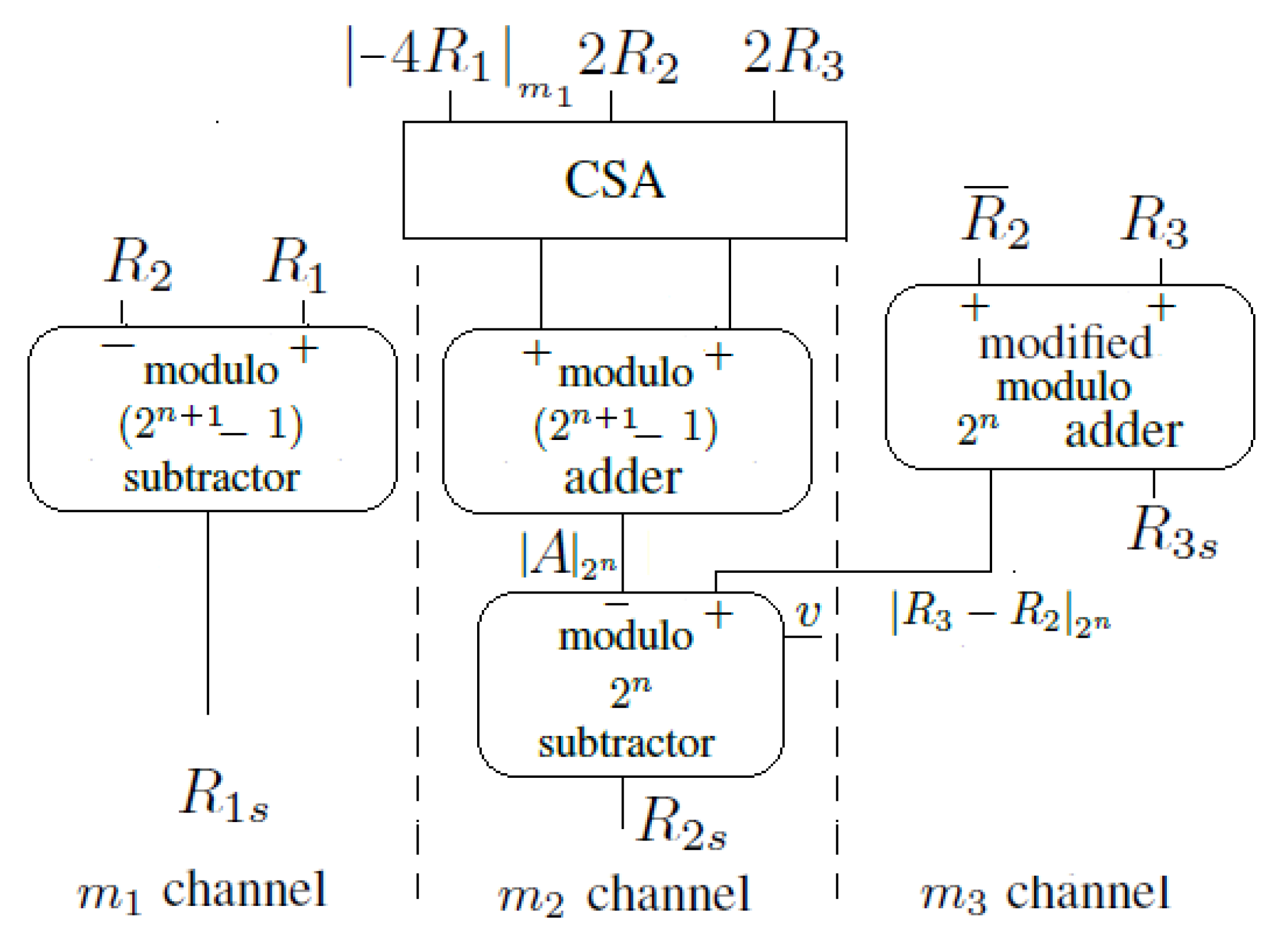
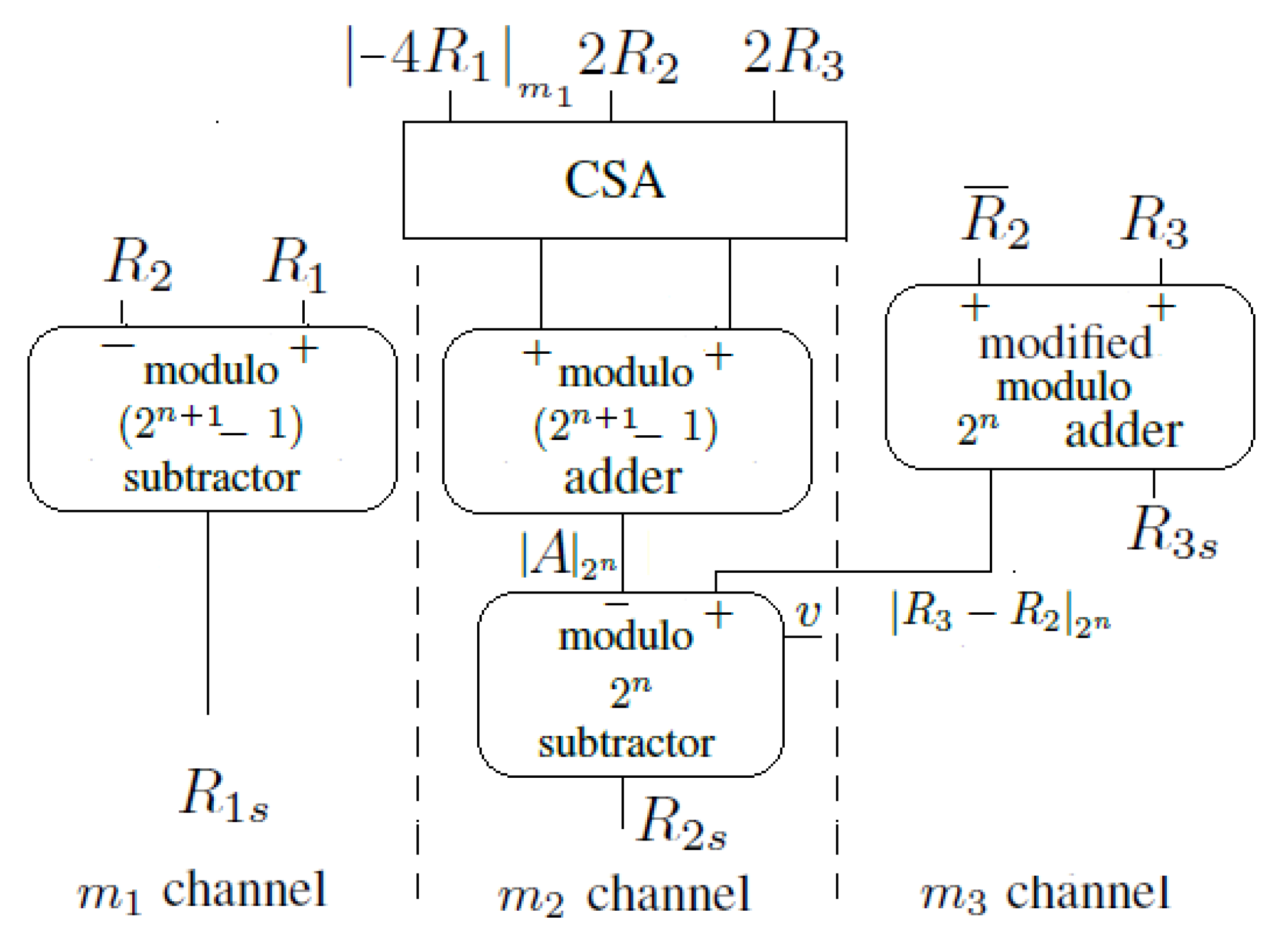
2. The Proposed Scaler
2.1. Decoding Analysis
- , , and ;
- , , and ;
- , , and ;
- M is the dynamic range given by ;
- X is an integer such that , with the binary value of X represented using bits;
- the RNS representation of X is , where , (the least non-negative remainder when dividing X by ).
2.2. Hardware Implementation
3. Comparison and VLSI Realization
4. Conclusions
Funding
Conflicts of Interest
References
- Soderstrand, M.A.; Jenkins, W.; Jullien, G.; Taylor, F. (Eds.) Residue Number System Arithmetic: Modern Applications in Digital Signal Processing; IEEE Press: New York, NY, USA, 1986. [Google Scholar]
- Hiasat, A. A suggestion for a fast residue multiplier for a family of moduli of the form (2n − (2p ± 1)). Comput. J. 2004, 47, 93–102. [Google Scholar] [CrossRef]
- Hiasat, A.; Khateeb, A. Efficient digital sweep oscillator with extremely low sweep rates. IEE Proc. Circuits Devices Syst. 1998, 145, 409–414. [Google Scholar] [CrossRef]
- Esmaeildoust, M.; Schinianakis, D.; Javashi, H.; Stouraitis, T.; Navi, K. Efficient RNS implementation of elliptic curve point multiplication over GF(p). IEEE Trans. VLSI Syst. 2013, 21, 1545–1549. [Google Scholar] [CrossRef]
- Sousa, L.; Antao, S.; Martins, P. Combining residue arithmetic to design efficient cryptographic circuits and systems. IEEE Circuits Syst. Mag. 2016, 16, 6–32. [Google Scholar] [CrossRef]
- Hiasat, A. Design and implementation of an RNS division algorithm. In Proceedings of the 13th IEEE Sympsoium on Computer Arithmetic, Asilomar, CA, USA, 6–9 July 1997; pp. 240–249. [Google Scholar]
- Ye, J.; Ma, S.; Hu, J. An efficient 2n RNS scaler for moduli set (2n − 1, 2n, 2n + 1). In Proceedings of the 2008 International Symposium on Information Science and Engineering ISISE, Shanghai, China, 20–22 December 2008; pp. 511–515. [Google Scholar]
- Hiasat, A.; Sweidan, A. Residue Number System to Binary Converter for the Moduli Set (2n−1, 2n − 1, 2n + 1). J. Syst. Arch. 2003, 49, 53–58. [Google Scholar] [CrossRef]
- Chang, C.H.; Low, J.; Yung, S. Simple, fast, and exact RNS scaler for the three-moduli set (2n − 1, 2n, 2n + 1). IEEE Trans. Circuits Syst. I 2011, 58, 2686–2697. [Google Scholar] [CrossRef]
- Low, J.; Chang, C.H. A VLSI efficient programmable power-of-two scaler for (2n − 1, 2n, 2n + 1). IEEE Trans. Circuits Syst. I 2012, 59, 2911–2919. [Google Scholar] [CrossRef]
- Tay, T.; Chang, C.H.; Low, J. Efficient VLSI implementation of 2n scaling of signed integer in RNS (2n − 1, 2n, 2n + 1). IEEE Trans. Very Large Scale Integr. Syst. 2013, 21, 1936–1940. [Google Scholar] [CrossRef]
- Sousa, L. 2n RNS scalers for extended 4-moduli sets. IEEE Trans. Comput. 2015, 64, 3322–3334. [Google Scholar] [CrossRef]
- Hiasat, A. Efficient RNS scalers for the extended three-moduli set (2n − 1, 2n+p, 2n + 1). IEEE Trans. Comput. 2017, 66, 1253–1260. [Google Scholar] [CrossRef]
- Zimmermann, R. Efficient VLSI implementation of modulo (2n ± 1) addition and multiplication. In Proceedings of the 14th IEEE Symposium on Computer Arithmetic (Cat. No.99CB36336), Adelaide, Australia, 14–16 April 1999; pp. 158–167. [Google Scholar]
- Hiasat, A.; Abdel-Aty-Zohdy, H. Design and implementation of a fast and compact residue-based semi-custom VLSI arithmetic chip. In Proceedings of the 1994 37th Midwest Symposium on Circuits and Systems, Lafayette, LA, USA, 3–5 August 1994; pp. 428–431. [Google Scholar]
- Hiasat, A. RNS arithmetic multiplier for medium and large moduli. IEEE Trans. Circuits Syst. 2000, 47, 937–940. [Google Scholar] [CrossRef]
- Muralidharan, R.; Chang, C.-H. Area-power efficient modulo 2n − 1 and modulo 2n + 1 multipliers for (2n − 1, 2n, 2n + 1) based RNS. IEEE Trans. Circuits Syst. I 2012, 59, 2263–2274. [Google Scholar] [CrossRef]
- Sheu, M.-H.; Siao, S.M.; Hwang, Y.T.; Sun, C.C.; Lin, Y.P. New adaptable three-moduli {2n+k, 2n − 1, 2n−1 − 1} residue number system-based finite impulse response implementation. IEICE Electron. Express 2016, 13, 20160090. [Google Scholar] [CrossRef]
- Kalamboukas, L.; Efstathiou, C.; Nikoloo, D.; Vergos, H.T.; Kalamatianos, J. High-speed parallel-prefix modulo 2n − 1 adders. IEEE Trans. Comput. 2000, 49, 673–680. [Google Scholar] [CrossRef]
- Vergos, H.T.; Efstathiou, C.; Nikolos, D. Diminished-one modulo 2n + 1 adder design. IEEE Trans. Comput. 2002, 51, 1389–1399. [Google Scholar] [CrossRef]

{kind=link}
| Channel | Proposed | [12] | [13] | |||
|---|---|---|---|---|---|---|
| Area | Delay | Area | Delay | Area | Delay | |
| +3 | +7 | +5 | ||||
| Total | ||||||
| Scaler | Area | Delay | Power | |
|---|---|---|---|---|
| n | (m) | (ps) | (W) | |
| Proposed | 6 | 1769.4 | 626.3 | 61.5 |
| 12 | 3706.6 | 723.7 | 90.1 | |
| 18 | 5928.1 | 875.1 | 120.6 | |
| 24 | 7056.2 | 902.9 | 143.4 | |
| 30 | 8097.9 | 925.6 | 160.7 | |
| [12] | 6 | 2084.1 | 575.4 | 67.9 |
| 12 | 4210.6 | 662.3 | 102.5 | |
| 18 | 6747.9 | 776.5 | 140.4 | |
| 24 | 7883.4 | 797.8 | 160.7 | |
| 30 | 9419.2 | 809.3 | 183.1 | |
| [13] | 6 | 1892.1 | 555.7 | 65.2 |
| 12 | 3988.0 | 633.5 | 96.5 | |
| 18 | 6241.0 | 757.9 | 129.3 | |
| 24 | 7389.4 | 782.7 | 152.4 | |
| 30 | 8675.2 | 803.6 | 169.8 |
© 2018 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hiasat, A. New Residue Number System Scaler for the Three-Moduli Set {2n+1 − 1, 2n, 2n − 1}. Computers 2018, 7, 46. https://doi.org/10.3390/computers7030046
Hiasat A. New Residue Number System Scaler for the Three-Moduli Set {2n+1 − 1, 2n, 2n − 1}. Computers. 2018; 7(3):46. https://doi.org/10.3390/computers7030046
Chicago/Turabian StyleHiasat, Ahmad. 2018. "New Residue Number System Scaler for the Three-Moduli Set {2n+1 − 1, 2n, 2n − 1}" Computers 7, no. 3: 46. https://doi.org/10.3390/computers7030046
APA StyleHiasat, A. (2018). New Residue Number System Scaler for the Three-Moduli Set {2n+1 − 1, 2n, 2n − 1}. Computers, 7(3), 46. https://doi.org/10.3390/computers7030046