1. Introduction
In the majority of current research on hard or firm real-time taskset scheduling in multi-core systems, an assumption is made that the taskset is known a priori [
1]. As a result, it is possible to apply in advance the traditional schedulability tests to check if a specific taskset violates its timing constraints. However, numerous contemporary real-time systems execute dynamic workloads, where tasks join and leave the system in a way not known during the design time [
2]. Dynamic tasksets are usually not consistent with relatively simple periodic or sporadic task models. However, it is rather difficult to find a schedulability analysis method for multi-core systems that is based on more sophisticated models [
3]. The tasksets that are not compatible with these basic models, for example including asynchronous tasks, are more commonly analysed in the High Performance Computing (HPC) domain, for instance in [
4]. The experience of the HPC community with such tasksets can help introduce the corresponding workload models in the real-time multi-core systems.
On HPC systems, tasks allocation and scheduling heuristics that employ feedback control have been demonstrated to be beneficial in the case of dynamic workloads as they can lead to increased platform utilisation and satisfy the timing constraints [
5]. Despite many successful applications in the HPC domain, these heuristics have been, to our best knowledge, never used in multi-core embedded platforms with hard or firm real-time constraints.
According to the IEEE Technical Committee on Real-Time Systems, three real-time types can be singled out based on the consequences of missing a deadline: hard, where any deadline violation may jeopardise the correct behavior of the entire system, firm, where it does not endanger the correct system behaviour but the task late completion is worthless, and soft, where a late task has still a reduced value for the system. Control-theory-based mechanisms are relatively often applied to soft real-time systems [
6], but this is not the case for the remaining real-time system types. For example, the Roadmap on Control of Real-Time Computing Systems [
7], created during the Network of Excellence ARTIST2 program, explicitly states that feedback scheduling is not appropriate for applications with strict timing constraints, as algorithms in feedback-based systems use prior error values to perform actions relevant for the current time instant. However, applying feedback mechanisms to tasks with even hard real-time constraints is possible and beneficial especially in the situation when there is no a priori knowledge about the system load and its service performance [
8]. For example, this approach has been applied to find a compromise between several objectives, such as the minimum slack or maximum utilisation of cores in [
9]. It can be also employed as a heuristic method for approximated schedulability analysis for hard real-time tasks [
10]. Similarly, feedback mechanisms can be used for decreasing energy dissipation. For example, in [
11], controllers are used to find a trade-off between dissipated energy and task processing speed not violating any deadline by utilising Dynamic Voltage and Frequency Scaling (DVFS), one of the most popular power-saving techniques in digital circuits.
In modern processors, e.g., Intel Xeon (Santa Clara, CA, USA), typically, a limited range of discrete voltage/frequency levels is offered, following the Advanced Configuration and Power Interface (ACPI) open standard (
http://www.uefi.org). This standard defines the operating state of a processor as C0, whereas halt, stop-clock and sleep states are referred to as C1, C2 and C3, respectively. Some chip vendors have introduced additional C-states as well, e.g., C6 in Intel Xeon named deep power conservation state [
12]. In operating state C0, the core can be in one of the predefined power-performance states referred to as P-states. The P-states with higher indices are characterised by lower performance and lower energy dissipation.
To make a right decision about voltage scaling, assorted metrics provided by monitoring infrastructure tools and services can be used, for example the infrastructure utilisation or latency between the input and output timestamps [
13]. In contemporary Multiprocessor Systems on Chips (MPSoCs), their cores can operate at various voltage and frequency levels in the same time instant, so selecting a core for a real-time task becomes a more sophisticated problem even for a homogeneous architecture [
14]. It is caused by the fact that assigning a task to a lower-voltage core can lead to a deadline violation, whereas this deadline would be met after allocation to a core with a higher frequency. Such scheduling policies considering various voltage and frequency levels are referred to as voltage scheduling.
A task can be allocated to a core in an MPSoC in a static or dynamic manner. The former is advised in case the workload is known in advance, whereas dynamic allocation, performed after the release of a task, is the only possibility for workloads not known a priori [
15]. Dynamic task mapping in MPSoCs supporting DVFS is even more challenging, as not only the target core is to be chosen, but also the range of the available voltage levels is to be considered. Important exemplifications of such allocation are the scheduling algorithms in Windows or Linux (since kernel version 2.6), which utilise dynamic frequency scaling for contemporary multicore processors from Intel (SpeedStep technology) and AMD (Santa Clara, CA, USA) (PowerNow! or Cool‘n’Quiet technology). In modern operating systems, selecting a proper P-state is done by the governor. For example, the ondemand governor in Linux selects P0 instantly in the case of a high load, whereas the conservative governor changes the current P-state gradually [
16]. The goal of these heuristics is to keep the processor utilisation close to 90% by reactive decreasing or increasing frequency with certain heuristics [
17]. However, in the case of real-time tasks, the frequency should be chosen in a way not only to maintain a certain processor utilisation, but also meet the timing constraints. Hence, custom governors need to be used. Such governor is proposed in this paper.
Custom governors can operate on a per-core or per-chip (chip-wide) basis. An interesting comparison between per-chip and per-core DVFS is given in [
18], according to which per-core DVFS lead to about 20% more energy savings than a typical chip-wide DVFS with off-chip regulators. Despite such results, per-core DVFS has not been implemented widely in hardware. For example, the active cores in contemporary Intel i7 processors have to work with the same frequency and voltage in steady states, whereas cores in AMD processors can operate with various frequencies, but still with a single voltage value, required by the core in the fastest P-state [
19].
This paper concerns a dynamic taskset mapping using a custom governor algorithm for both per-chip and per-core DVFS. The proposed algorithm performs a dynamic allocation of firm real-time tasks to resources. Two-level resource allocation is performed. Firstly, a global dispatcher fetches a task from a common task queue and selects the least utilised multi-core processor. Then, a local admission control block performs an approximate, but fast task schedulability analysis and selects an appropriate voltage and frequency level for the processing core. The processing cores are switched to lower frequency states when the current workload demands lower computational power. Consequently, a considerable amount of energy can be saved without a significant impact on the performance.
A preliminary stage of the research presented in this paper has been published in [
20]. However, in that publication, only one architecture platform has been considered, in which both voltage and frequency are scaled in a per chip manner. This paper differs in the following aspects: (i) two more platform architectures have been added and compared against the previously proposed one; (ii) a new scheduling algorithm, suitable for the newly proposed architectures, has been proposed; (iii) a detailed discussion of the experimental results comparing the newly proposed platform architecture with the previously proposed one is presented; and (iv) more realistic platform sizes are used for comparison.
This paper is organized into seven sections.
Section 2 reviews related research work. In
Section 3, the assumptions regarding the application and platform models are presented and the problem considered in this paper is formulated. In
Section 4, some preliminary information regarding the elements of control theory applied to the proposed solution is provided.
Section 5 describes the proposed algorithm for energy-efficient task admission control.
Section 6 discusses the experiments and demonstrates the obtained results.
Section 7 presents the final remarks.
2. Related Work
To map tasks to cores, techniques originated from control-theory offer soft real-time guarantees in which an infrequent deadline miss is possible. Therefore, they cannot be applied to time-critical systems [
5], as hard real-time guarantees are required. Related to the firm or hard real-time systems, relatively little work exists. In these systems, the task dispatching should ensure admission control and guaranteed resource provisions. This implies that the execution of a task can start only when (i) the system can allocate a necessary resource budget to meet its timing requirements; and (ii) guarantee that no access of a task being executed to its allocated resources is denied or blocked by any other tasks [
21]. The requirements of time critical systems, e.g., automotive and avionic systems, where meeting the timing constraints is essential [
22,
23], can be fulfilled by providing such kind of guaranteed facilitates.
For scheduling in hard or firm real-time systems, typically, the worst-case execution time (WCET) of each task in the workload should be known in advance in order to guarantee the schedulability of the whole system [
1]. However, WCET and the average execution time (ET) can differ substantially as shown by a number of experimental results [
24]. Therefore, system resources are often underutilised during execution. This provides an opportunity to use the resources differently than in the WCET scenario while executing tasks in a typical scenario.
For typical scenarios that are different from the worst case, a control mechanism to adjust the voltage level of unicore portable devices in a control-theory-based manner to conserve energy is proposed in [
8]. In [
25], proportional-integral-derivative (PID) controllers are proposed that determine voltage of systems dealing with the workload not accurately known in advance. With regards to dynamic workloads, the authors also interpreted the meaning of the discrete PID equation terms. To predict the future system load based on the workload rate of change, they proposed a heuristic that leads to significant reduction in energy consumption. The authors have also demonstrated that, with the changes in the PID controller parameters, the design space is not significantly changed. However, in this work, the controller does not use any feedback information about the processing core status. Rather, it is used to predict the future workload.
A feedback-based approach is presented in [
26], where tasks’ slack time is managed to conserve energy in real-time systems. The real execution time of a task is predicted by a PID controller and is usually lower than its WCET. For a task, each execution time slot is split into two parts, where the first part is executed with a lower voltage assuming the controller’s predicted execution time. In case the task does not finish in the first slot, the core is switched to its highest voltage to guarantee the execution completion before the deadline.
For soft real-time systems that allow a slight amount of deadline violations, energy-based feedback scheduler and a power-aware optimization algorithm is proposed in [
27]. The load of the system is adjusted by controlling the speed of the task execution with the help of a proportional (P) controller used by the dispatcher. The appropriate speed for each task and the proper voltage level is computed by employing a greedy algorithm. For dispatching the tasks, earliest deadline first (EDF) or Rate-monotonic scheduling (RMS) are used. As the controlled variable, energy saving ratio over the sampling period is used and the controller’s manipulated variable is considered as the worst-case utilisation.
In [
28], voltage scheduling for MPSoCs has been initiated. The configuration of an MPSoC platform has to be set into a pipelined multi-layer way, where feedback policies for adjusted core frequencies of processors are based on the occupancy levels of the task input queues of each processor. The authors have implemented and compared linear and nonlinear feedback strategies. However, for core configurations other than the pipelined ones, the scheme is not applicable.
A formal analytic approach for DVFS dedicated to multiple clock domain processors is proposed in [
29]. The approach benefits from the fact that the voltage and frequency level in each domain or functional block can be chosen independently. A multiple clock domain processor is modelled as a queue-domain network, where queue occupancies connecting two clock domains are considered as feedback signals. A proportional-integral (PI) controller is used to adapt the clock domain frequency to any workload changes.
In [
6], the queue occupancy also drives PI controllers. In contradiction to the previous research, the limitation of using solely single-input queues has been lessened and multiple processing stages have been allowed. However, it is still required to have a pipelined configuration. For demonstrating the superiority of feedback techniques over the local DVFS policies for soft real-time guarantees, a realistic cycle-accurate, energy-aware, multiprocessor virtual platform is used. It is assumed that a sufficient number of deadlines is met and no further analysis or simulation of deadline misses are provided as long as the queues are not empty.
Instead of PIDs, linear quadratic regulators (LQRs) are used in [
30] and demonstrated that a decreased number of feedback lines is required. However, the approach is applicable only to systems where read/write rates to queues connecting different voltage frequency islands are constant and known a priori. Therefore, it cannot deal with dynamic workloads, although some robustness to workload variations in an LQR-based approach is demonstrated in [
31]. Furthermore, the controller is synthesised for a particular application and thus it cannot be efficiently applied to a system with limited a priori knowledge about future workloads. In [
32], a controller based on a fractal model has been demonstrated to be superior to the PID and LQR-based ones due to the fractal nature of the considered workloads. Additionally, these works have been carried out under the assumption that the task mapping is static and the controller is used only for determining the voltage and frequency.
In [
10], the problem of the hard real-time tasks allocation is investigated. For an approximate schedulability analysis, feedback mechanisms have been applied as heuristics. The tasks passing this early test have been then analysed with a time-consuming exact schedulability analysis. In contrast to this paper, the energy-saving mechanisms were not applied and the application model included hard real-time tasks only.
From the literature survey, it follows that there has been no previous work on mapping a real-time taskset dynamically to an MPSoC system while using DVFS together with control-theory based algorithms.
3. System Model
In this paper, we investigate a method to allocate (or schedule) a firm real-time taskset to an MPSoC platform. Therefore, we need a system model that covers the appropriate applications representing the workload as well as the platform architecture.
3.1. Application Model
A taskset is comprised of an arbitrary number of independent tasks, . Each task , is described with a tuple , where denotes its release time, is the worst-case execution time (WCET) and is its absolute deadline. The timing constraints are firm. It means that infrequent deadline misses are tolerable, but the result has no value after its deadline. The taskset is not known in advance and all tasks have the same priority.
As in a typical scenario, the execution time of task
is usually significantly lower than
[
1], a non-zero slack time for this task appears, which is defined as the temporal difference between deadline
and the actual task completion time.
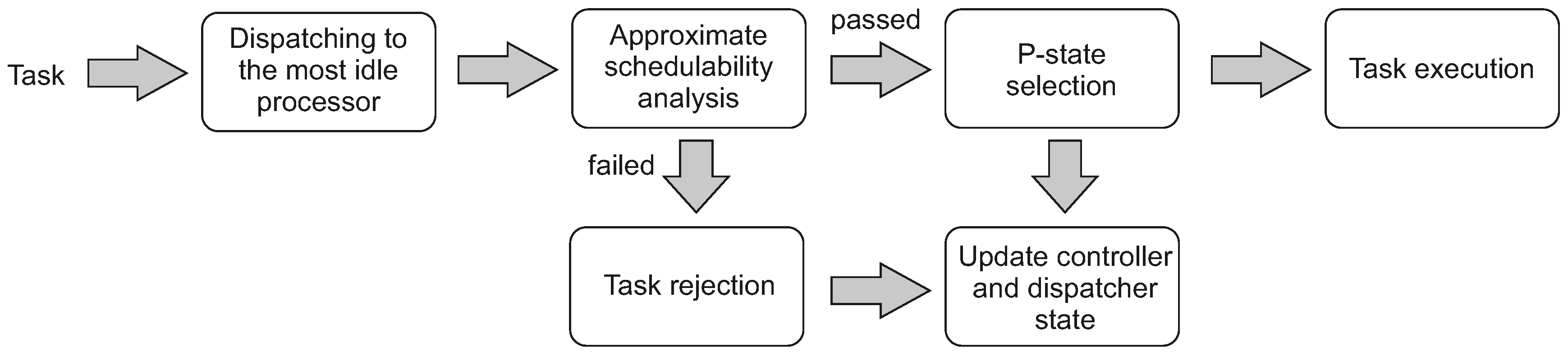
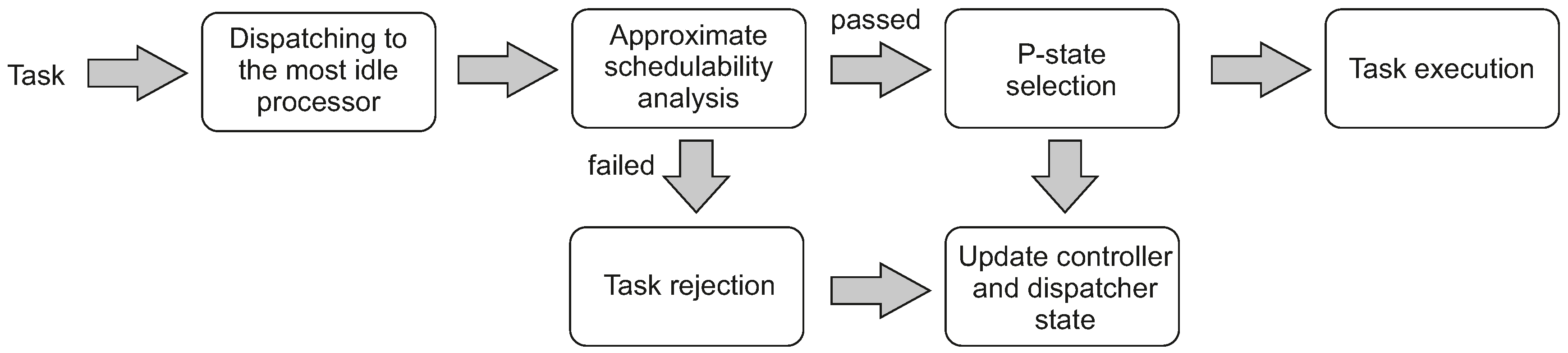
The consecutive stages of a task life-cycle are presented in
Figure 1. The task
is released at an arbitrary instant
. Then, it is dispatched to the least utilised processor at that instant. The admission control block in the selected processor performs an approximate schedulability test. If this test proves schedulability, task
is admitted and then executed by a core in this processor, after setting a new P-state if required. Then, the states of both the controller and the dispatcher are updated.
The details regarding the platform architecture are provided in the following subsection.
3.2. Platform Model
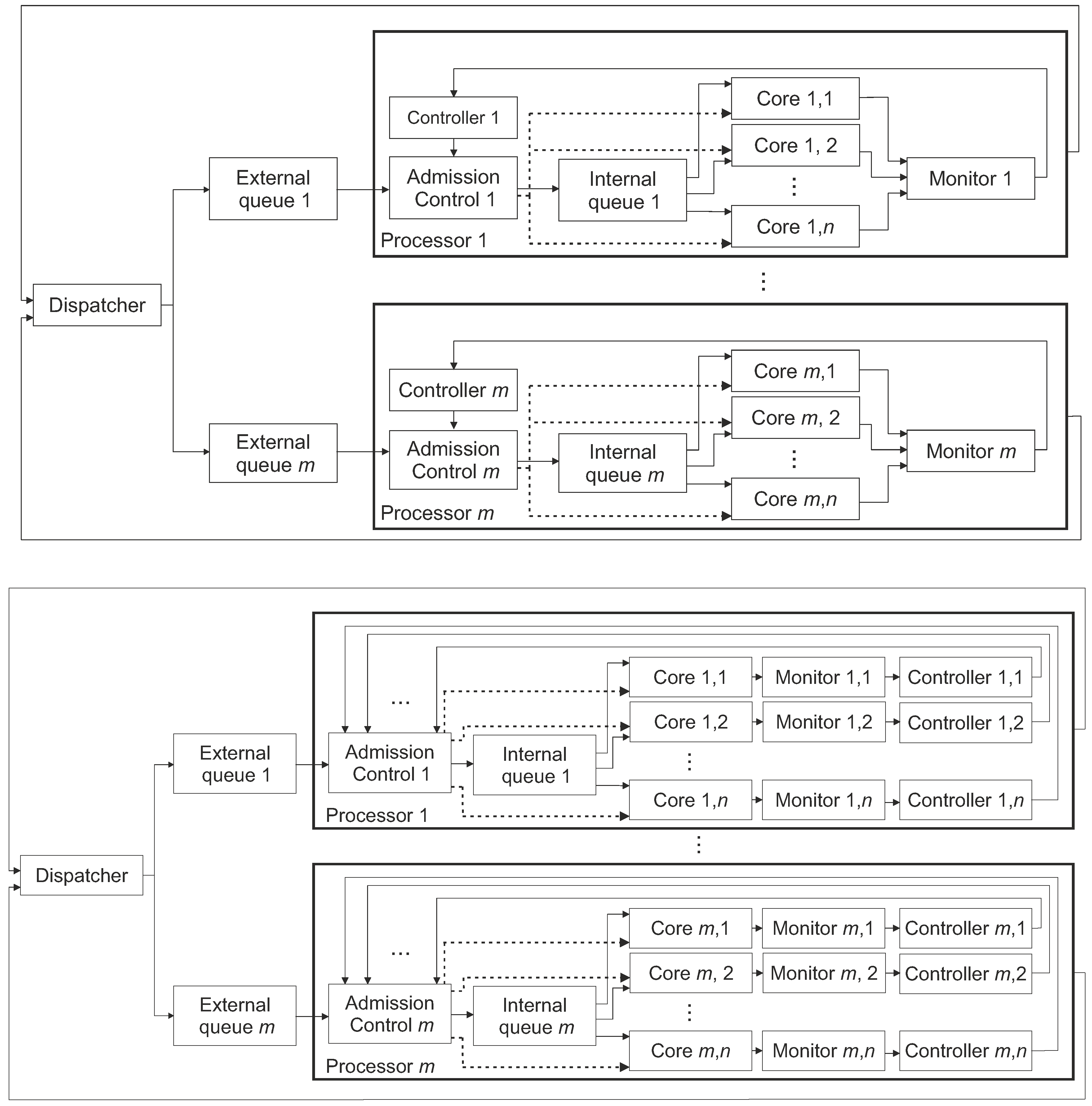
The platform is comprised of m processors, each including n cores. Each core can be configured to work in several P-states, from P0 to Pmax, which differ with respect to the computing performance and energy dissipation.
Three variants of the platforms are considered, referred to as A–C, as summarised in
Table 1. In platform A, all cores in a chip operate with the same frequency and the same voltage, similarly to the Intel i7 chips. Platform B supports different frequencies in a single chip, but still the same voltage is applied across its cores, as in the contemporary AMD chips. Finally, architecture C allows both various voltage levels and frequencies in a single chip.
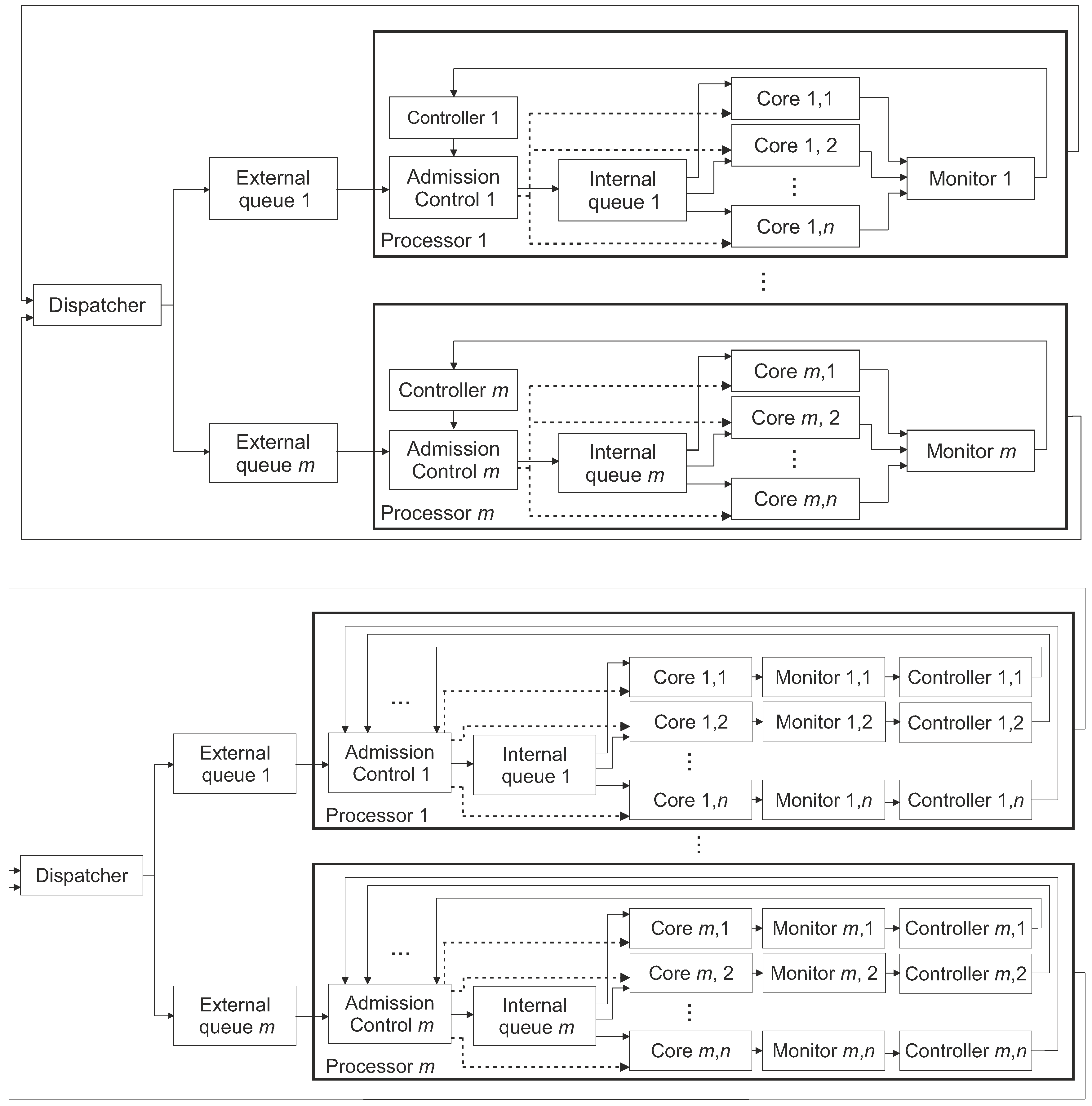
The general architecture of Platform A is sketched in
Figure 2 (top). There is one Controller block per processor, executed on a certain core, including a single discrete-time PID controller, invoked every
time. The controller uses the processor’s core utilisation,
y, as the observed value, compares it with the setpoint,
r, computes the difference between these values,
e, and outputs the so-called control function
u depending on the current and previous values of
e, as detailed in
Section 4. The Admission Control block, based on the information provided by Controller, sets an appropriate P-state of the processing Cores, one for the entire processor. In the figure, the dashed lines denote the connections used for steering P-states in the cores. Platforms B and C are outlined in
Figure 2 (bottom). These platforms operate similarly to Platform A described above except for the fact that an activity of each processing Core is observed by a single Monitor, which, in turn, is connected to a Controller. Thus, the frequency (in Platform B) or both the voltage and frequency (in Platform C) can be selected independently for each processing Core.
3.3. Problem Formulation
Given an application taskset and platform models, the problem is to execute a maximal number of firm real-time tasks before their deadlines in the highest possible (and thus the most energy-saving) P-state. As these two objectives are contradictory, some trade-off between them needs to be proposed.
4. Preliminary
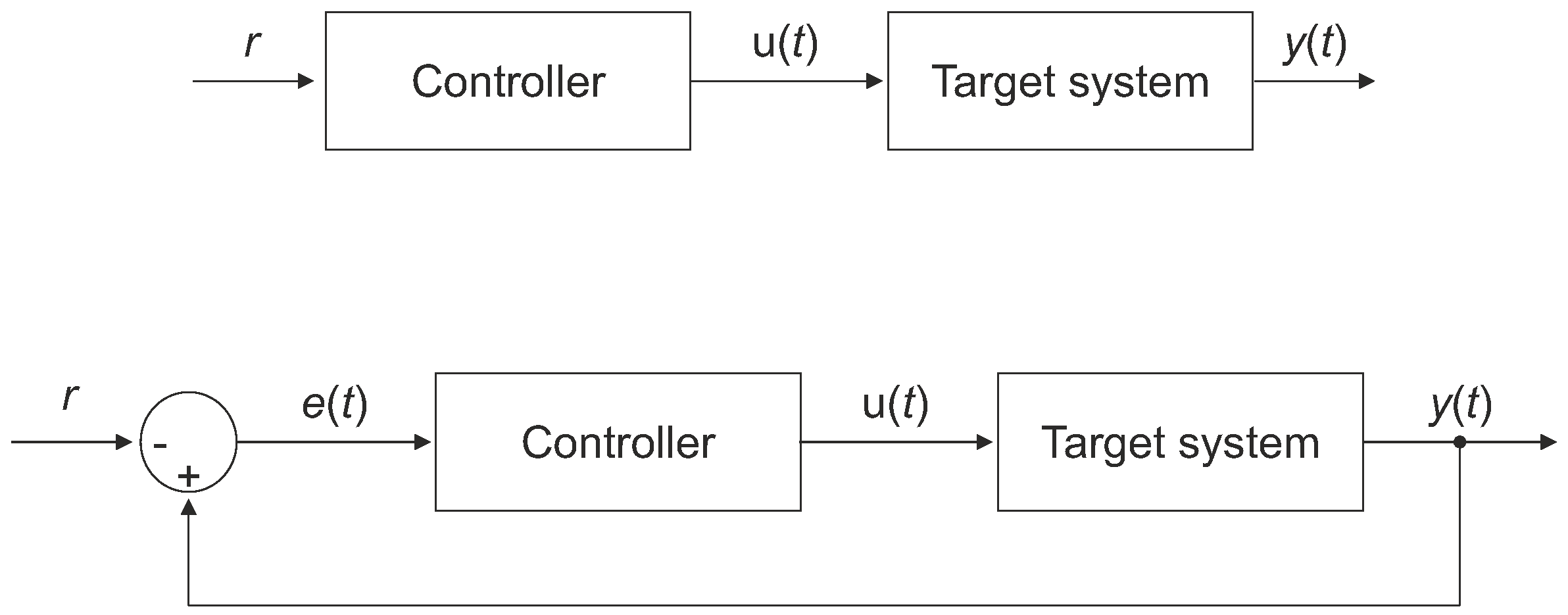
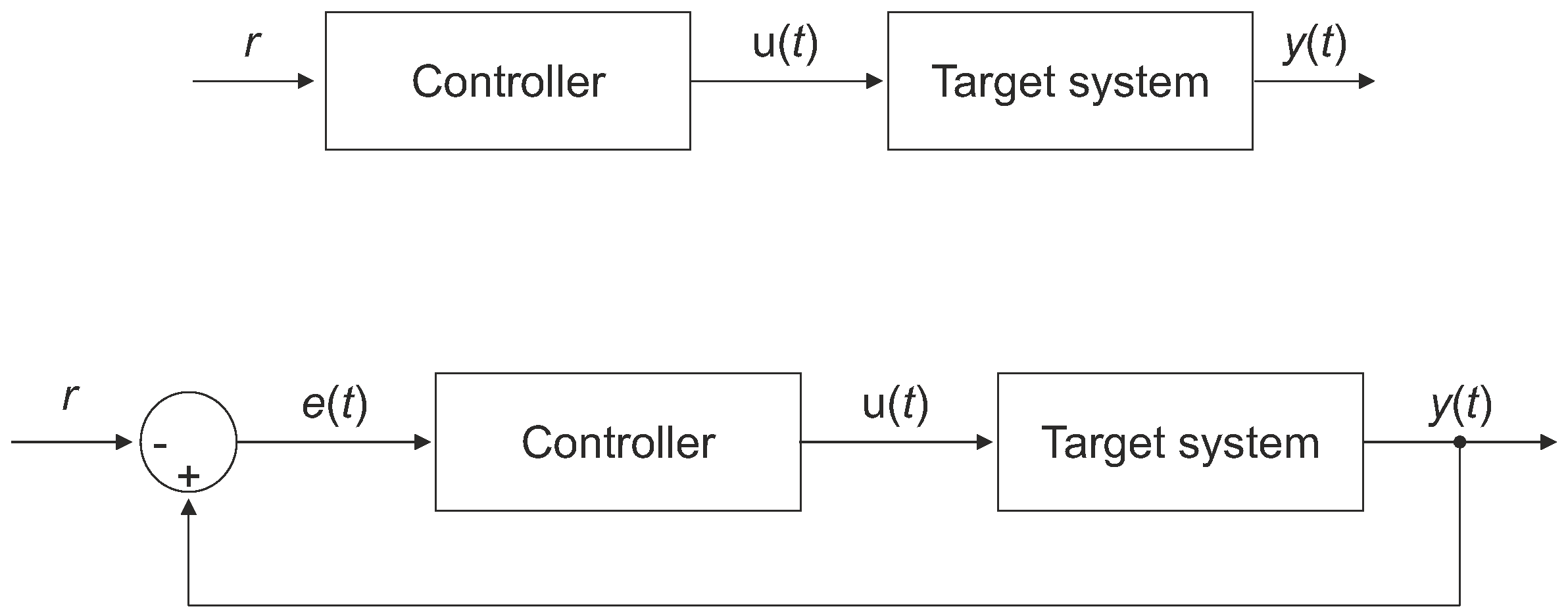
A dynamic behaviour of a system can be controlled in accordance with either an open-loop or closed-loop architecture, as illustrated in
Figure 3. The main difference between these approaches is that in a close-loop system, the control input (
) partially depends on the measured output,
, also known as controlled value of the target system, where
t denotes time. Due to this feedback mechanisms, the imperfection of the Controller adjustment to the Target system can be compensated to a certain degree. As a result, the closed-loop architecture can employ less accurate models of the target system and is usually more resistant to various unexpected disturbances than its open-loop counterpart [
33].
The role of the Controller is to steer the Target system using control input so that the measured output is close to the desired reference signal (r, also known as setpoint). The difference between and r is referred to as error and is usually denoted as .
Among various controller types, the proportional-integral-derivative (PID) controller is particularly widely applied in assorted industrial control systems, including computing systems [
34,
35]. The control input of this controller operating in the continuous time domain is computed according to the following equation:
The controller output value, , is thus a sum of three components: proportional, integral and derivative. The proportional component is equal to the current error value multiplied by a certain coefficient . The integral component is proportional to the accumulated error over time with coefficient . The derivative component is based on the current rate of error change with coefficient .
In case of computer-based systems, a discretised form of a standard PID controlled is usually employed with a sampling time
. It can be described with equation:
where the integral component is approximated with a sum of errors in so called
I-Window, which is a time window of length
. The role of coefficients
,
and
is similar to their equivalents in Equation (
1).
The optimal control function has to be individually determined for each control application by tuning coefficients
,
and
in Equation (
2). There exist numerous techniques for determining approximate values of these constants. In this paper, we use the popular AMIGO (Approximate M-constrained Integral Gain Optimisation) tuning formulas as described in [
33]. A detailed description of applying these formulas to a conceptually similar problem of real-time task allocation to high-performance computing clusters is presented in [
36].
The derivative term in Equation (
2) is highly sensitive to measurement noise, so it is often omitted in numerous practical applications [
34]. The PID controller whose derivative coefficient equals 0 is referred to as PI controller. A discrete version of a PI controller is also used in the work described in this paper.
5. Proposed Approach
In case of a workload known a priori, there is a possibility of performing an exact schedulability analysis during the system design stage and then modify the platform or alter the workload itself to guarantee its timely execution even in the most adverse conditions. On the other hand, the schedulability of dynamic workloads can be analysed only during run-time. Each released task from taskset can potentially jeopardise the system timeliness. It is advisable then not to admit such task that will violate its timing constraint to the processing cores and to execute other tasks before their deadlines instead. Such strategy is particularly suitable for firm real-time tasks, when there are no benefits stemming from completion a task that missed its deadline. Early rejection of such tasks not only prevent the processors from wasting their time, but also offers a possibility of early signalling of a potential deadline violation of that task, which can be used for minimising the negative impact of such situation. For example, the task can be migrated to another platform to be executed before its deadline.
In the proposed solution, the allocation of a newly released task to multi-core processors is performed by Dispatcher. It selects processor , to execute the task in any of the processor’s cores based on the processor utilisation metric, which is defined as the percentage of busy cores in with executing tasks at the current time instant. The task is then placed in the External queue of the processor with the lowest utilisation. When utilisations of several processors are equal to the lowest value of the utilisation, the decision is made arbitrarily among these processors. After this stage, the platform behaviour varies depending on the architecture, which is explained in the following subsections.
5.1. Platform A Scheduling
The scheduling algorithm for platform A has been described in detail in [
20]. For the sake of self-consistency of this paper, it is briefly outlined below, whereas the algorithms for the two newly analysed architecture platforms, namely B and C, are detailed in the next subsection.
The path traversed by task
inside a processor is indicated with solid arrows inside a processor boundary box in
Figure 2 (top). The admittance control in each
,
, is performed in accordance with the closed-loop control system architecture depicted in
Figure 3. The
block implements both the proportional and integral components of a discrete variant of a PID controller, described with Equation (
2). The error
that is consumed by
is equal to the difference between the
current utilisation of
denoted as
and the
setpoint value of this utilisation,
r, where the utilisation of
is defined as the number of active cores in that processor at time point
t,
, divided by the number of cores in that processor,
m. Then, the controller computes value
, according to Equation (
2), and provides this value to the
Admission Control block in this processor,
. Depending on the value of
,
decides whether a task
popped from
External Queuej is going to be executed by a core in that processor or rejected. This decision can be treated as an approximate schedulability analysis, as it is performed using the controller output value and does not involve any computational intensive exact schedulability tests, for example described in [
1]. However, even if the cores’ utilisation is below the setpoint, the tasks are additionally checked whether their earliest possible completion time will not violate their deadline
based on their worst-case execution time
, namely if
If task
satisfies both condition (
3) and
, task
is pushed in the
Internal Queuej. This queue can be very short as the tasks are rejected when the cores are busy and an idle core
,
,
immediately fetches a task from the internal queue. Task
is executed non-preemptively up to its completion. The state of the core, i.e., its business or idleness, is observed continuously by
. This block computes the utilisation of entire
and sends this value to
. Then, the controller recomputes its output in the following time instant.
As indicated with dashed lines, the Admission Control block also steers the P-state of the entire processor. When the cores in
are utilised above a certain value of the
threshold,
can change P-state of this processor to increase its performance at the cost of a higher energy dissipation. Notice that, since the controller output depends not only on the current processor utilisation, but also on its previous utilisation values due to the influence of the integral component in Equation (
2), a high value of controller output
indicates that the high utilisation of the processor lasts for a prolonged interval. The influence of these historic values depends both on the length of I-Window,
, and integral coefficient
. In contrast, a low value of controller output
, in particular below threshold
, indicates a rather low utilisation of the cores in
that can signalise some possibility of decreasing the processor performance to lower its energy dissipation. In the described approach, the value of the
threshold is selected after choosing the controller parameters, such as the proportional and integral constants of the controller (
and
, respectively), and the length of I-Window used in the integral component (
). An example of determining the values of these constants is presented in
Section 6.
Depending on the physical placement of the DVFS regulator in hardware, the P-state switching time can vary from the order of tens of nanoseconds in the case of on-chip regulator model to several orders of magnitude slower when off-chip regulators are employed [
18] and the energy dissipation of the P-mode switching operation itself can be noticeable [
19]. Consequently, applying some mechanisms that would prevent too frequent P-state switching is necessary. In the described method, the P-mode switching is prohibited when the time interval between the previous P-mode switching and the current time instant is lower than certain threshold
. Hence, if the algorithm described above requires a P-state switching earlier than
time after the previous alteration, this request is ignored. As the time and energy cost of P-state switching is platform-dependent, it is advisable to select this parameter experimentally, as a trade-off between the system flexibility (lower values of
) and efficiency (higher values of
). An influence of this parameter value on the taskset execution is discussed in
Section 6.
5.2. Platforms B and C Scheduling
The proposed scheduling algorithm for platforms B and C is outlined in Algorithm 1. In principle, this algorithm is similar to its counterpart for the platform A architecture, described earlier. The primary difference is that the current P-state values are selected independently for each processing core and thus stored in an n-element vector rather than a scalar. Similarly, the latest P-state switching time can be different for each processing core and thus is stored in vector . Then, when a task is released, the processing cores in a given processor are browsed independently in a loop. In the body of this loop, variables , , refer to a particular vector element and thus are indexed with the loop iterator, k. Similarly, I-Window refers to I-Window of the k-th controller in a considered processor.
The proposed algorithm for admission control is composed of two parts that are intended to be executed in parallel, as presented in Algorithm 1. The first part of the algorithm consists of lines 1–32, in which the following steps can be singled out.
| Algorithm 1: Pseudo-code of the proposed admission controller functionality for per-core DVFS. |
![Computers 07 00026 i001]() |
- Step 1.
Invocation and initialisation (lines 1–2, 30): The block functionality is executed in an infinite loop (line 2), activated every time interval (line 30). The current P-state is set to the lowest value, P0 (i.e., the one with the highest performance—line 1), and the vector of times of the previous P-state changes, , is set to 0 (line 1).
- Step 2.
Task fetching (lines 3–4): The tasks’ external (FIFO) queue is checked if empty (line 3) and, if not, a task is fetched (line 4).
- Step 3.
Task conditional rejection (lines 6–14): The code related to this step is executed inside a loop whose iterator k ranges from 1 to n, which is the number of cores in the processor (line 5). If the output value of the k-th controller () is negative and the corresponding k-th core operates with the highest performance (its P-state is set to P0) or the k-th core operates below the highest performance and the interval between the previous P-state switching time () and the current time (t) is long enough (determined by condition ), this core is assumed to have no capacity to execute task . Consequently, if all the cores in the analysed processor have no capacity (line 12), task is rejected (line 13). Moreover, if P-state of the k-th core is different from P0 and its P-state has not been switched for at least time (line 7), P-state in the k-th core is decreased (line 8) and the k-th element of vector , storing the previous time of the P-state alteration of the k-th core, is updated (line 9). As the previous errors in the k-th controller have been observed in a different P-state, I-Window of the k-th controller is cleared (line 10). Hence, these obsolete values do not influence future admittance decisions.
- Step 4.
Task conditional admittance (lines 16–27): If the output value of the k-th controller is lower than threshold , P-state of the k-th core is different from P0 and the interval between the current time (t) and the previous switching of P-state in the k-th core is long enough (line 16), the P-state is lowered (line 17) and is updated accordingly (line 18). In case the k-th controller output value is above threshold , P-state of the k-th core is different from the highest P-state available in the processor () and the previous switching of P-state in the k-th core has been done early enough (line 20), P-state of the k-th core is increased (line 21) and is updated appropriately (line 22). Task is sent to the Internal queue (line 25).
The second part of the algorithm is located between lines 33-44 and contains two steps only, as described below.
- Step 1.
Invocation (lines 33, 43): The block functionality is executed in an infinite loop (line 33), activated every time interval (line 43).
- Step 2.
P-state conditional increase (lines 34–43): The functionality of this step is activated when no new tasks have been fetched from the External queue for interval (line 34). Under such condition, P-states of all n cores are analysed in a loop (line 35). If the core performance is not the lowest possible (P-state is different from ), the core’s P-state is increased (line 37), the appropriate I-Window is cleared (line 38) and is updated accordingly (line 39).
The effectiveness of the proposed algorithm is experimentally evaluated in the following section.
6. Experimental Results
In this section, the efficiency of the proposed feedback-based admission control and real-time task allocation is evaluated for all three platform architectures. The experiments are performed using a cycle-accurate virtual platform developed in the SystemC language. The entities identified in
Figure 2 have been implemented as custom SystemC module instances connected with the signal primitive channels, whereas both the internal and external queues are instances of the FIFO primitive channels. The SystemC module named
Core employs ACPI parameters of a Pentium family processor. As detailed below, the
Admission Control module implements the proposed per-core or per-chip DVFS admission controller functionality and the
Controller module implements the discretised form of the PI controller.
Before the actual comparison between per-core and per-chip DVFS, a configuration of the parameters of the controller and admission control block has to be performed.
6.1. Controller Coefficient Setup
Controller coefficients
,
and
can be tuned by analysis of the corresponding open-loop (i.e., without any feedback) system output (i.e., core utilisation,
) growth to a bursty workload. Analysis of such response is one of the most popular techniques among the control-theory-based parameter customisations [
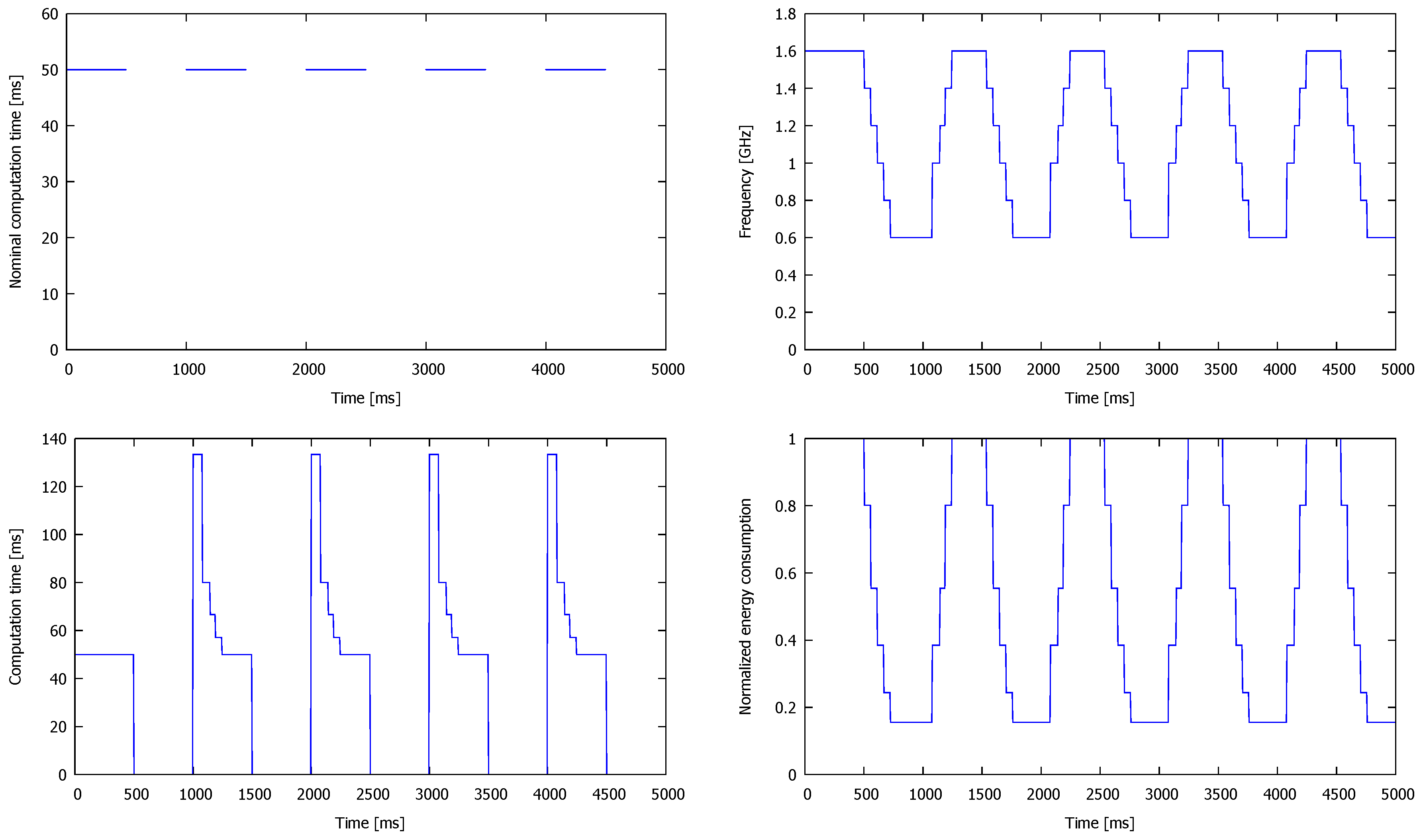
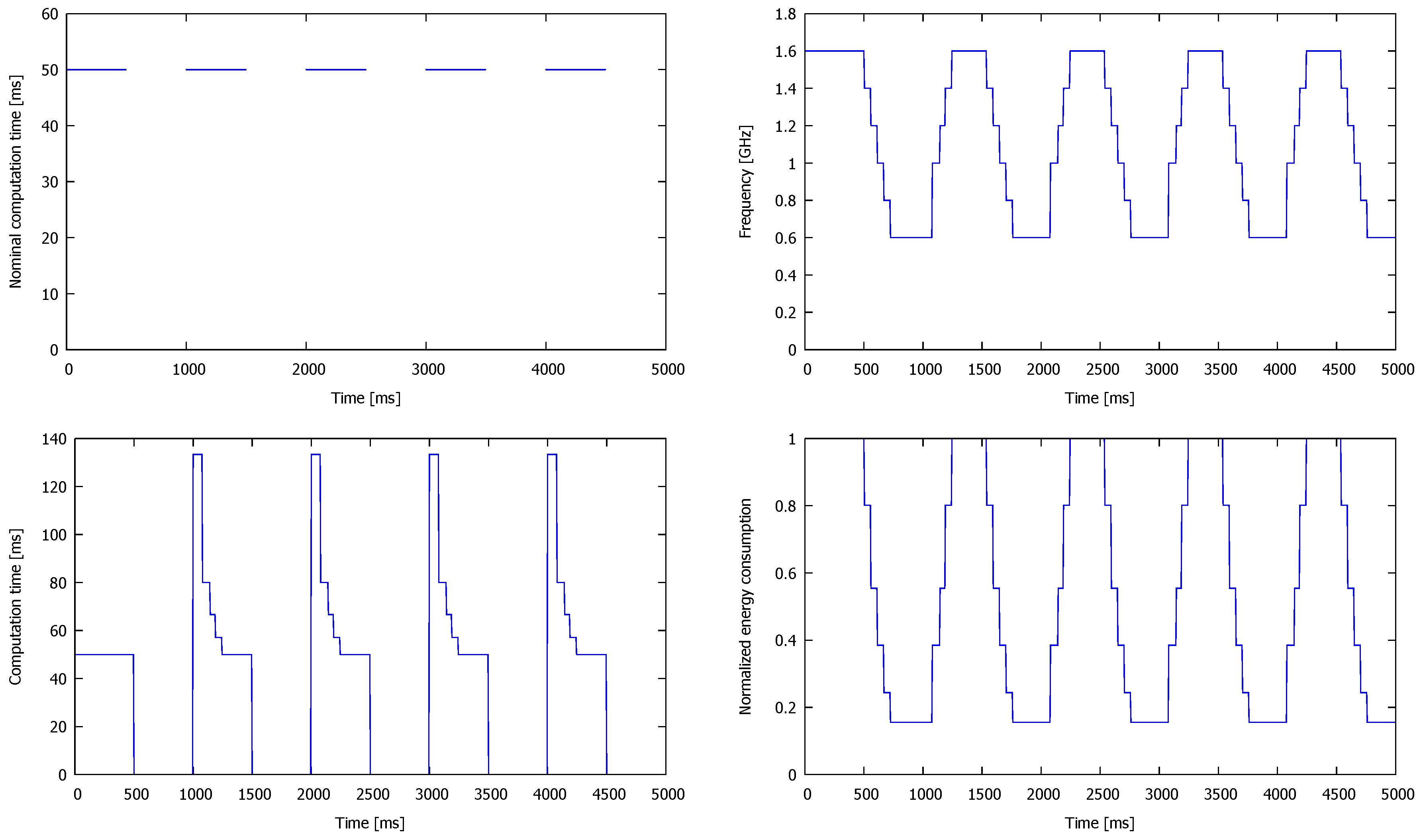
33]. The workload used as a stimuli follows the On/Off pattern in which tasks are released periodically every 5 ms during the On period lasting 500 ms, after which 500 ms-long Off period follows without any task release, as shown in
Figure 4. The rationale for choosing On/Off traffic models stems from its difficulty and popularity. Some research works even claim that it is the most commonly used source model [
37]. In the applied bursty workload, the computation time of each task equals 50 ms and its relative deadline is set to 75 ms. This difference between task’s WCET and its relative deadline enables some level of flexibility during the task scheduling. Otherwise, if WCET equals the relative deadline, all tasks would require being started exactly at their release time to meet such tight deadline.
The response of the target system confirms the accumulating (or integrating) nature of the process, i.e., the growth of the core utilisation up to the natural saturation at 100%. Due to this observed nature, the accumulating process version of Approximate M-constraint Integral Gain Optimization (AMIGO) tuning formulas can be applied to determine the PID controller coefficient values [
33], similarly as shown in [
35,
36]. Then, the closed-loop version of a control system architecture is ready to be used.
As a baseline solution, DVFS steering capabilities have been disabled by setting threshold to the highest possible value, denoted later as . Five On/Off cycles have been executed, so 500 tasks have been released in total. A system with one processor with four cores managed to execute 185 tasks before their deadlines and, thanks to the early rejection of 315 tasks by using the proposed algorithm, not a single admitted task missed its deadline.
6.2. DVFS-Related Parameter Fine-Tuning
After determining the values of the controller coefficients, a suitable value of the threshold needs to be found. Substituting a too low value for this threshold would result in too frequent P-state switching, which is not recommended due to the additional energy and delay cost stemming from each P-state alteration. Moreover, such frequent change could prevent the proposed admission control subsystem to answer appropriately to the given workload. The reason for this is that each P-state change results in clearing the I-Window in controllers. Consequently, there would be no information available about the previous workload weight for making a decision about changing to a new P-state value. Arguably, P-state should be switched in the situation when not only the current value error is high, but also similarly high values have been observed for certain time, which in turn is indicated with a high value of the integral component.
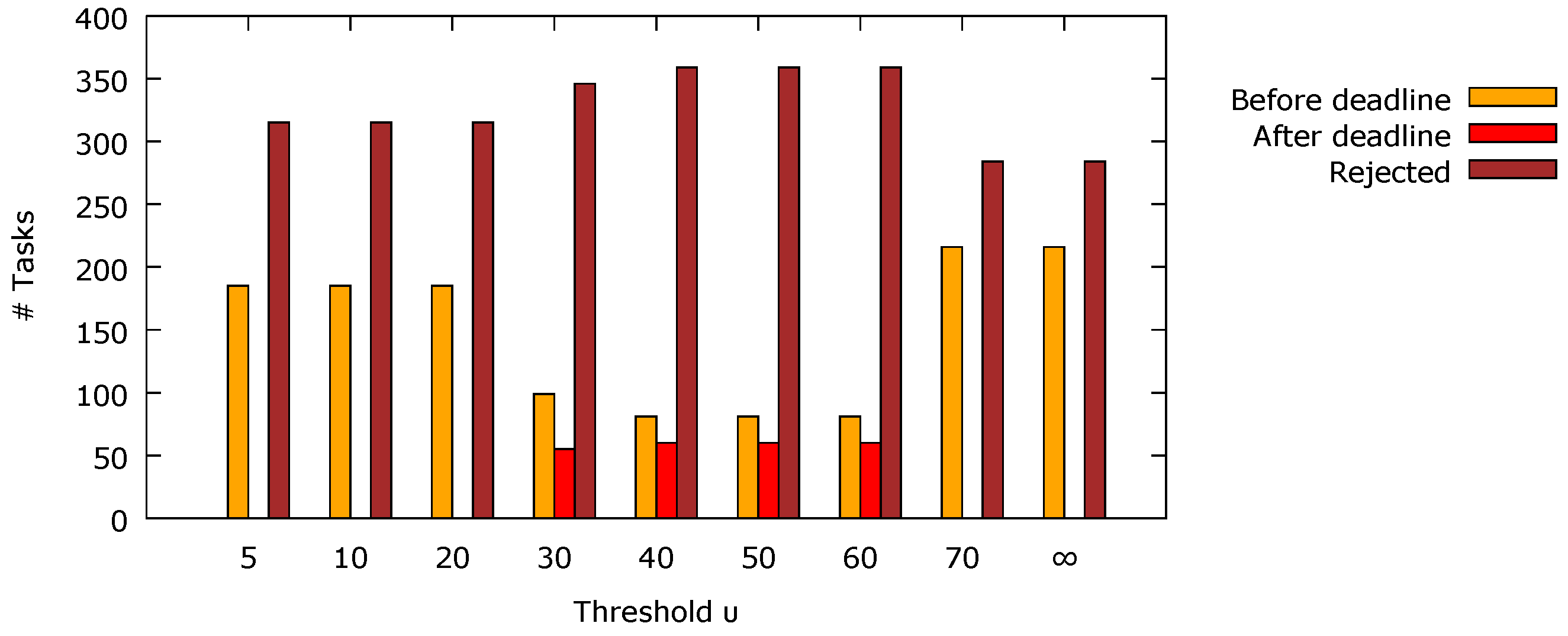
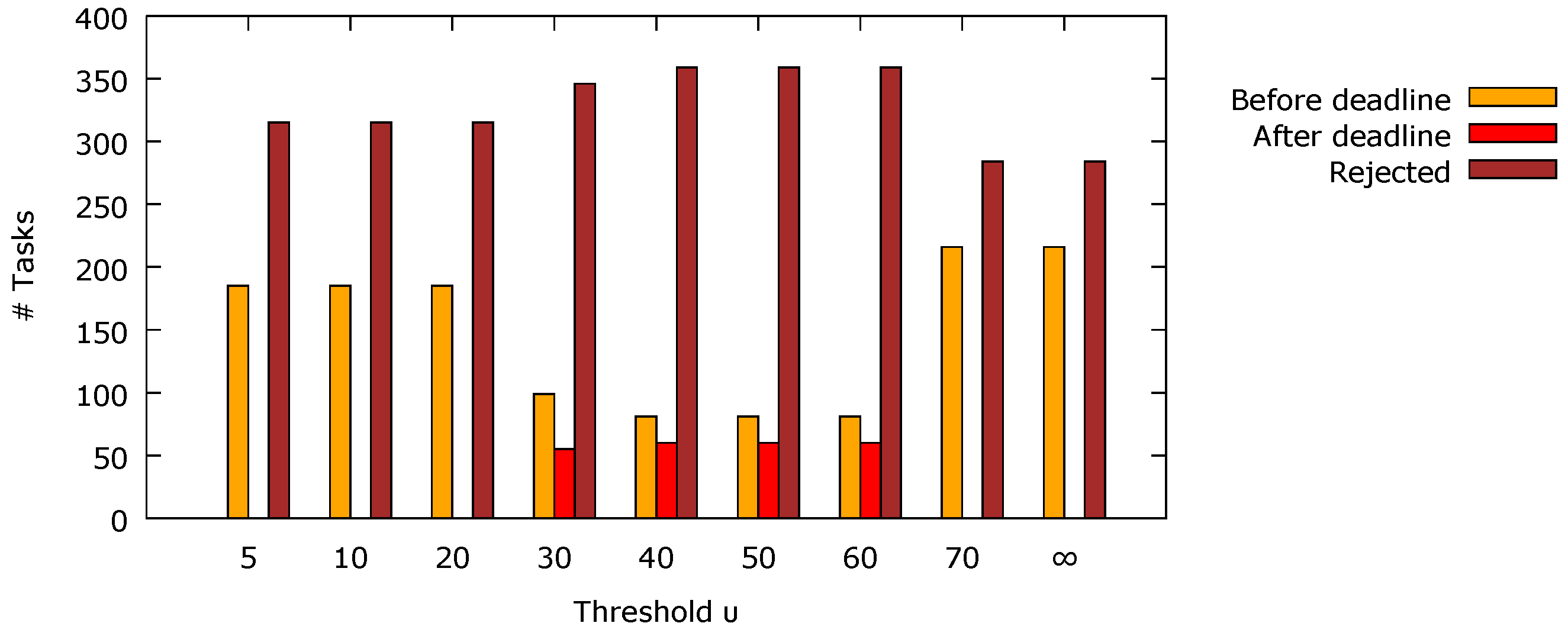
The On/Off workload pattern described previously has been applied to a platform with one processor including four cores. Several
threshold values have been evaluated, from 5 to 70, as well as the highest possible value of this parameter, denoted as ∞, practically disabling the DVFS functionality. The results of this experiment are presented in
Figure 5. It is clearly visible that setting a too high value of the
threshold leads to too big of a latency in P-state switching at the beginning of the busy periods in the On/Off workload (the integral component is lower than the threshold for too long after clearing its previous values in I-Window). As a result, the number of the tasks executed before their deadlines is rather low for
. In particular, with certain
values, some tasks are admitted but executed after their deadlines, which is shown with red bars in
Figure 5. In such situations, some computing resources are treated as wasted as there are no benefits from such firm real-time tasks with late completion time. It is also noticeable that, for
, the delay before the allowed P-state changes is too long for the considered On/Off workload and the obtained results are the same as in the case of a disabled DVFS feature. In this situation, slightly more tasks are admitted, but much more energy is dissipated. Based on these observations, the
threshold value has been set to 10 in the experiments described below as a trade-off between the flexibility of the voltage switching and the platform performance.
The next parameter to be determined is the threshold, which specifies the minimal interval elapsing between two subsequent alterations of P-states. An experiment with the same On/Off workload has been conducted with the threshold values ranged from 25 ms to 400 ms. The highest number of tasks completed before their deadlines has been observed for three values of , namely 25 ms, 50 ms and 100 ms. For ms, the obtained results have been the same as the platform without the DVFS features. In the following experiments, two values have been used: ms and ms.
To estimate the energy dissipation of a multi-core processor, ACPI data from one of the Pentium family processors (with Intel SpeedStep Technology) has been used. The analysed processor can operate in six P-states, from P0 (1.6 GHz, 1.484 V, 24.5 W) to P5 (600 MHz, 0.956 V, 6 W). However, the proposed solution is technology-agnostic as long as the chosen processor follows the ACPI standard. It can be, for example, applied to AMD processors as well (For example, the ACPI parameters of AMD Family 16h Series Processors can be found in AMD Family 16h Models 00h—0Fh Processor Power and Thermal Data Sheet, AMD, 2013).
In the analysed On/Off workload, the voltage and frequency levels during each On period should be high, but close to the minimum during each Off period. The results obtained in this experiment are presented in
Figure 4. Notice that the frequency (and voltage, as these two values change simultaneously) does not change instantly due to the selected
ms threshold. It prevents too frequent transitions and the related additional costs of switching between P-States. At the beginning of an On period, each processor is in the least energy-consuming P-State, P5, which is characterised by the lowest clock frequency. In the analysed case, the task execution time grows from 50 ms to over 133 ms. In the next P-state, P4, this time is equal to 100 ms, whereas the tasks are executed with their nominal execution time in P0. The task execution times observed in the experiment are presented in
Figure 4. Notice the difference between the execution time of the tasks in the first and the remaining On periods, caused by the cores initialisation with P0 (line 1 in Algorithm 1). If the current P-State is initialised with P5, this difference disappears. Finally, we checked a normalised energy consumption and noticed its 80% decrease during the majority of the Off periods’ duration, as presented in
Figure 4. Analysing energy dissipation during the entire experiment, its reduction has been equal to 43% in comparison with the corresponding system without DVFS. The latter is, however, able to process 17% more tasks before their deadlines.
As the selected parameter values lead to rather significant energy savings in this introductory experiment, it is worth analysing how a system with the same parameter values would behave while executing more sophisticated workloads or when including more processors and cores. Such experiments are presented in the remaining part of this section.
6.3. Scheduled Tasks and Energy Dissipation with per-Chip DVFS
After determining all the necessary system parameters using the On/Off workload, the efficiency of the proposed solution has been evaluted with 11 sets of 10 random workloads each. The probability distributions of the task release times and WCETs in these workloads have been based on a grid workload in an engineering design department of a large aircraft manufacturer presented in [
38]. Each workload includes 100 jobs with a certain number of independent tasks, ranging from 1 to 20. All tasks belonging to a particular job with index
l are released simultaneously, whereas the tasks of the subsequent job with index
are released between
and
, where
is the sum of all WCETs of tasks belonging to the
l-th job released at
, and
,
. The values of
and
are inversely proportional to the workload heaviness.
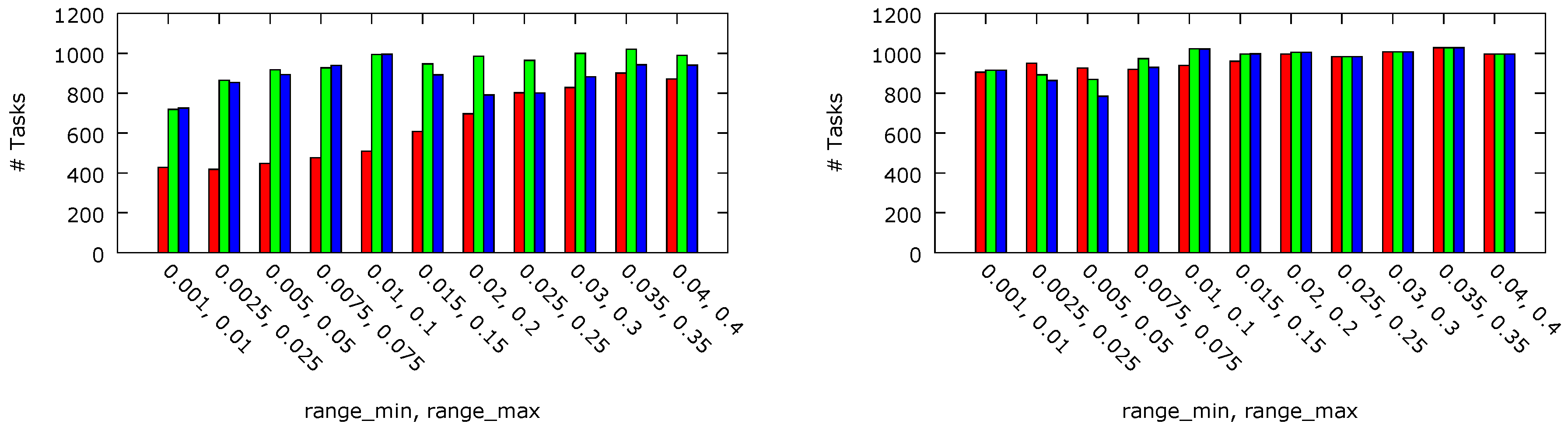
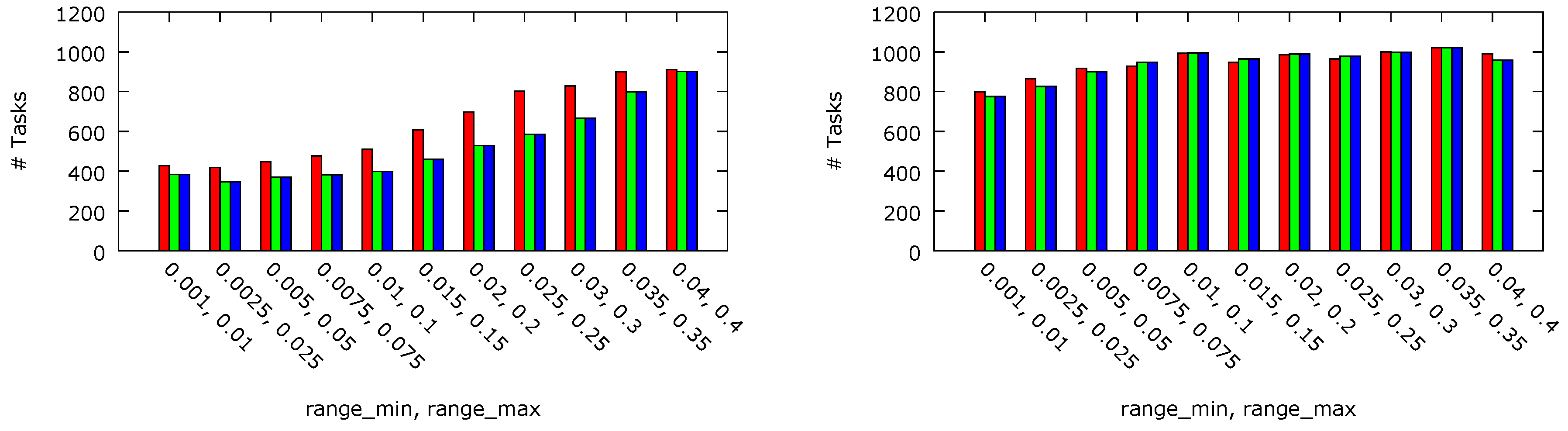
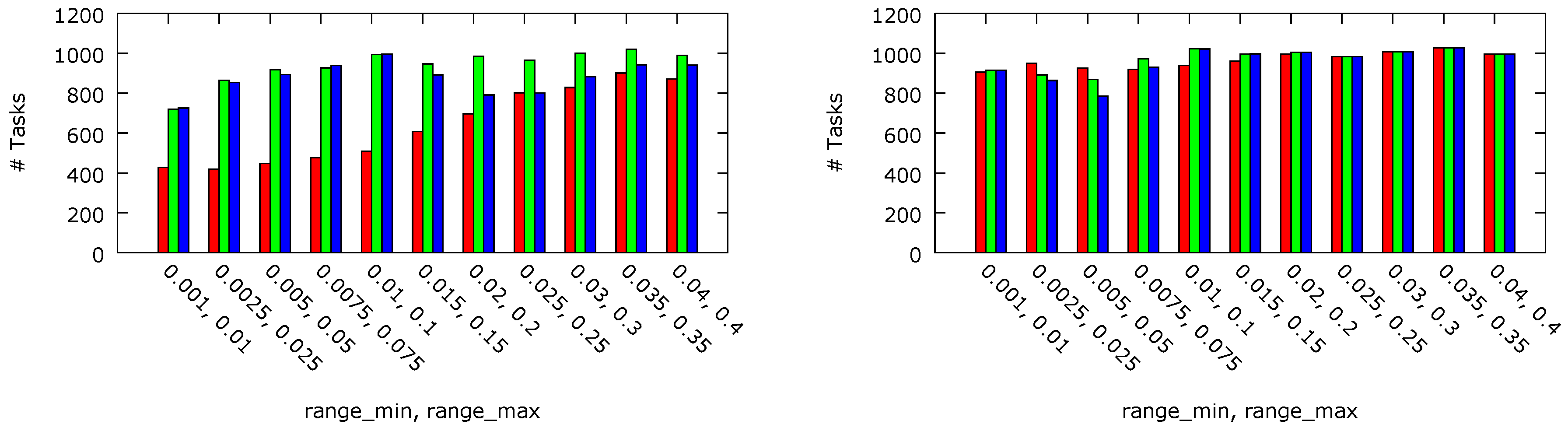
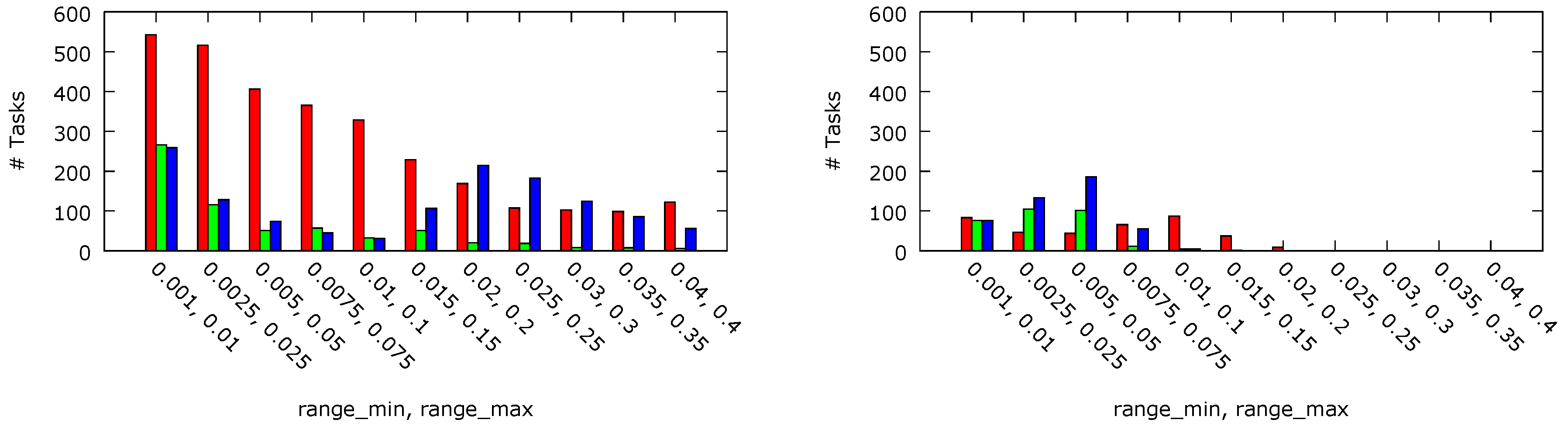
The numbers of the tasks completed before their deadlines and the numbers of the tasks rejected by the admission control block have been measured for a 2-processor platform with four cores each and a 4-processor platform with eight cores each. For both platform sizes, per-chip DVFS compliant with the platform A architecture have been compared with its counterpart without the DVFS facilities. The results are presented in
Figure 6 and
Figure 7, respectively. For the 2-processor platform, 47% more tasks have been admitted with threshold
ms in comparison with threshold
ms. This result can be explained by the fact that, with
ms, P-states are switched more often. Hence, it is more likely that a core operates at a lower frequency and voltage level when a task is fetched. As P-state switching is performed gradually (lines 8, 17, 21 and 37 in Algorithm 1), the tasks are likely to be executed with a lower core performance. This reasoning is confirmed by the observed reduction of the energy dissipation. The smaller platform with
ms dissipated about 53% energy less than with
ms and 63% less in comparison with the equivalent platform with the DVFS feature disabled (i.e., with
equal to
). It can be viewed as counter-intuitive that, for lighter workloads, the number of the tasks executed before their deadlines is higher for a platform with threshold
ms than in the equivalent platform with disabled DVFS. The observed phenomenon can be explained by a deeper analysis of Algorithm 1. In a platform with disabled DVFS, each core is always in P0. The admission controller cannot then decrease the P-state when the controller output value is below 0 (which is tested in line 6) and then to clear the corresponding I-Window in the controller and, eventually, admit the task by pushing it in the internal queue (line 25). In the case of the 4-processor platform, the number of processing cores (4 × 8) is high enough to admit similar numbers of tasks regardless of the workload weight. In particular, for lighter workloads, no task is rejected nor executed after its deadline. The total numbers of tasks executed with different
threshold values are almost equal (the observed differences are lower than 1.5%). However, the dissipated energy differs significantly and in the case of
ms it is almost 56% lower than with
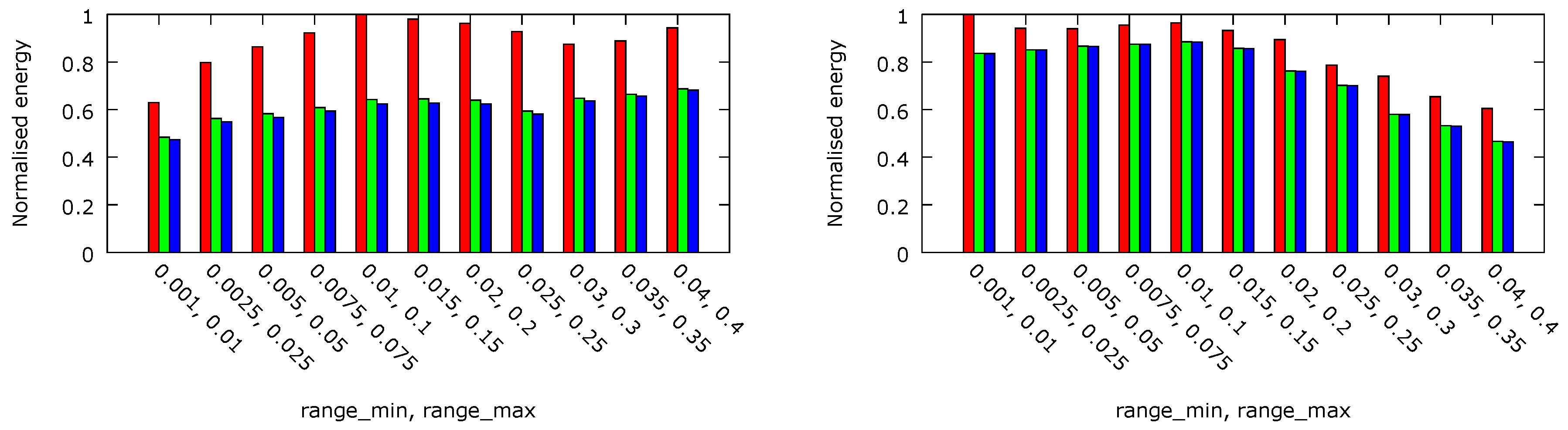
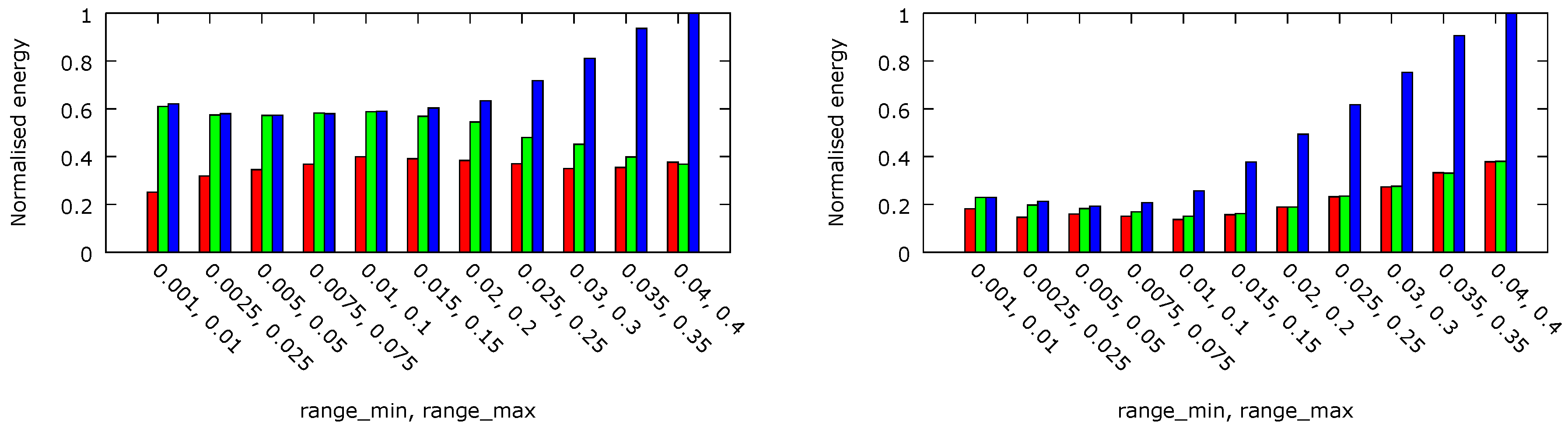
. The dynamic energy dissipation per task executed before its deadline, normalised to the maximal obtained value, is shown in
Figure 8. In case of the 2 × 4 core platform, almost 49% and 25% less energy have been dissipated thanks to the per-chip DVFS approach with
ms and
ms, respectively. For the 4 × 8 core system, the energy dissipated in the per-chip DVFS system with both values of the
parameter are similar (6% difference), but with
ms is almost 56% lower than in the case of no DVFS (
).
6.4. Scheduled Tasks and Energy Dissipation in per-Core and per-Chip DVFS
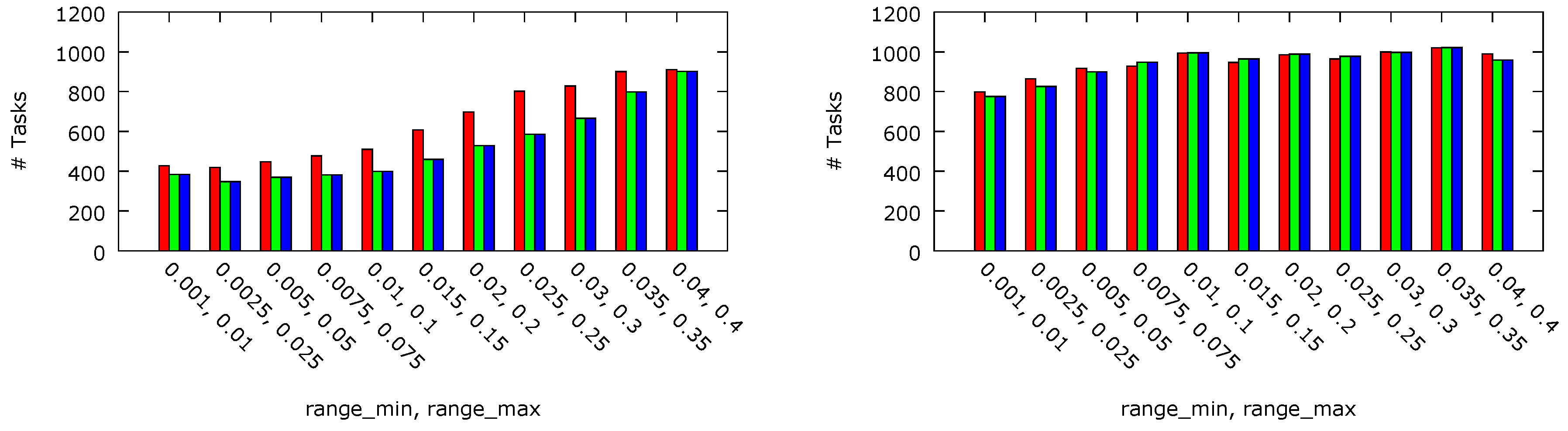
Finally, three platform architectures A-C have been compared with respect to the number of tasks timely executed and the dissipated energy.
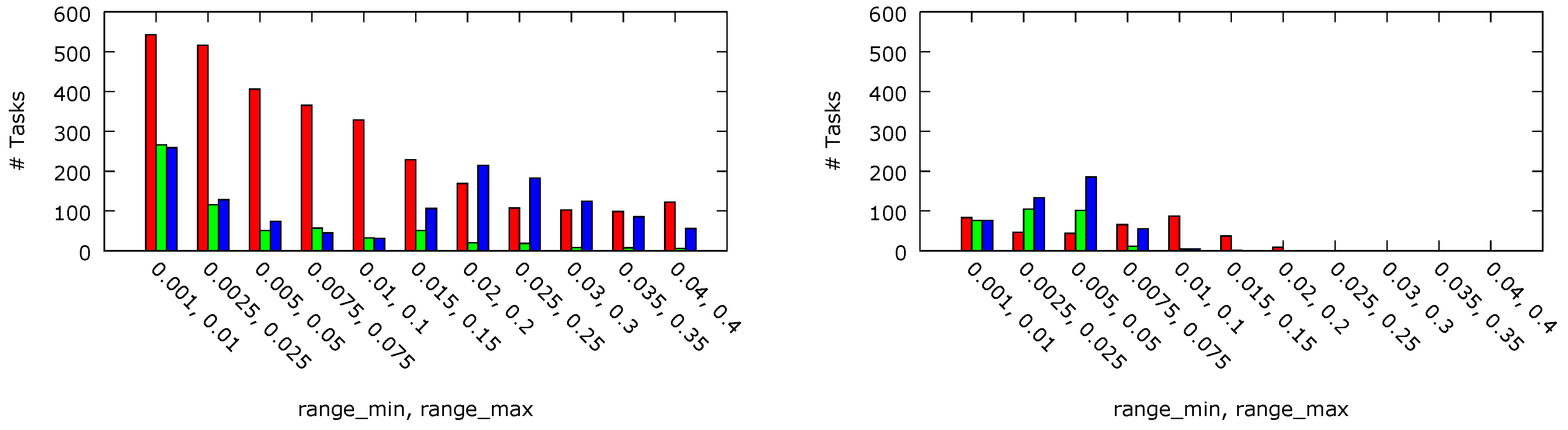
Figure 9 depicts the number of the tasks executed before their deadlines in the random workload scenarios for platform A (left bar), platform B (middle bar) and platform C (right bar) architectures with
ms (left) and
ms (right). As both the per-core DVFS types (platform B and C) use the same scheduling algorithm outlined in
Section 5.2, they execute the same number of tasks before the deadline in all cases. In case of
ms, it is noticeable that per-core DVFS (i.e., platform A) executes fewer tasks (17%) due to the higher probability that more cores are in lower P-states as the cores can be moved into slower states independently from each other. This phenomenon can be balanced by increasing the
threshold and for its value
ms, the numbers of tasks executed before their deadlines are almost equal for all the considered platform architectures.
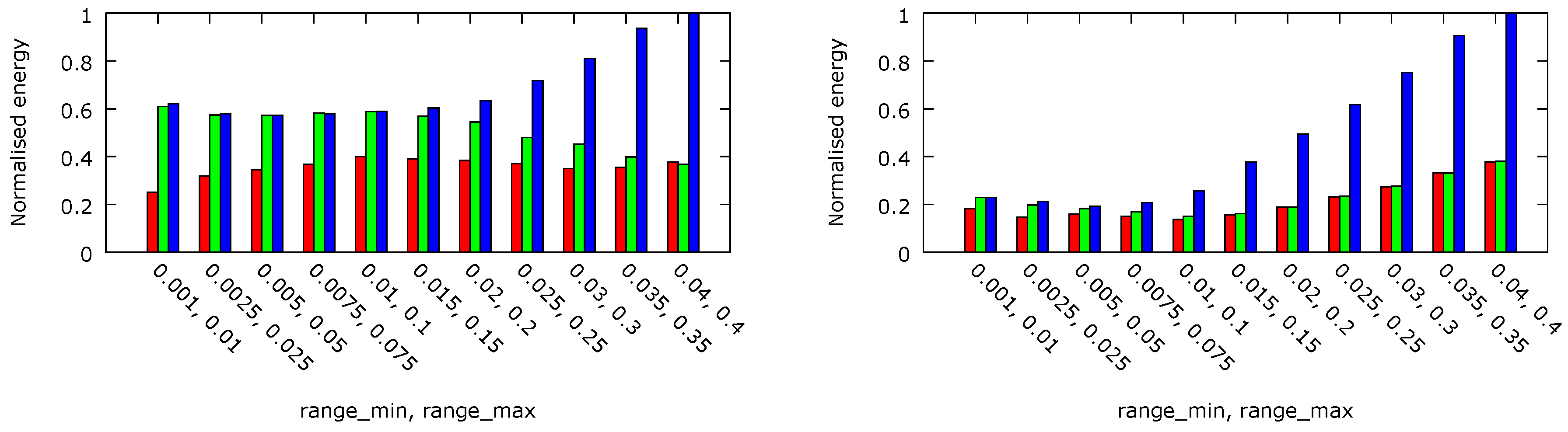
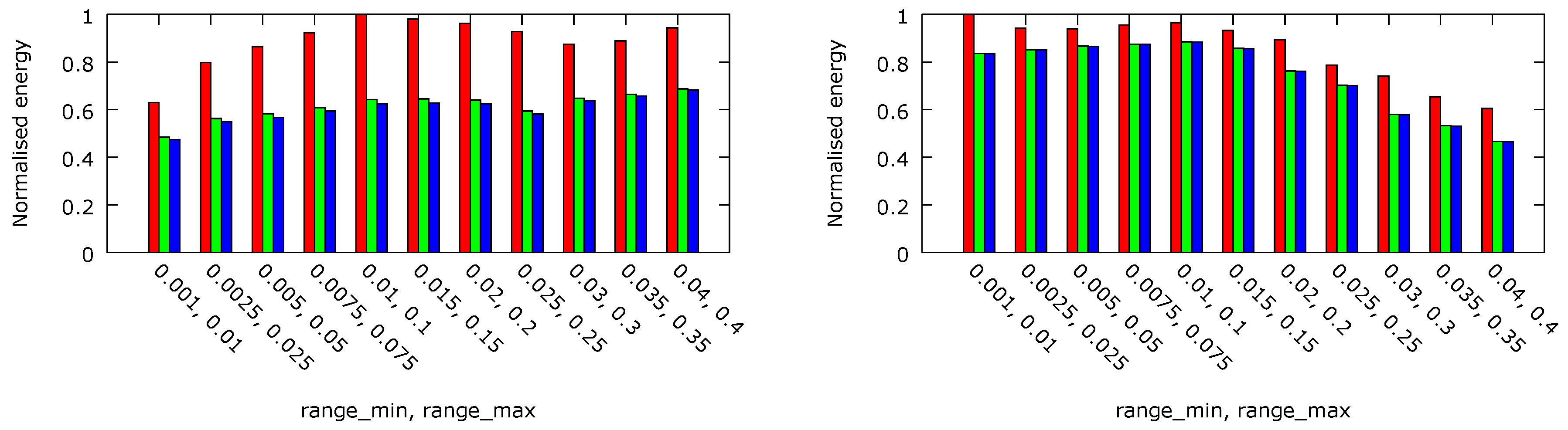
In
Figure 10, the normalised energy dissipated per task executed before its deadline is presented for the three platform architectures. In all cases, the difference between per-core frequency and voltage (platform C) and per-core frequency (platform B) is slight and equals about 1%. However, the difference between these platforms and platform A with both per-chip voltage and frequency DVFS is equal to 32% for
ms and almost 13% for
ms.
6.5. Discussion
Due to the initial assumption of the workload not known a priori, it is difficult to design a system that simultaneously executes most real-time tasks on time and also dissipates low energy. The experimental results show clearly that the benefits of the proposed scheduling scheme depend significantly on the processor utilisation, which in turns depends on both the workload heaviness and the available computational power. Due to the presence of busy and idle periods in numerous practical situations, it is important for a system to react to urgent growth and decrease of the workload heaviness. This property has been demonstrated with the On/Off period workload in the initial experiment. The platform gradually increased the performance of its processing cores to cope with the accumulating tasks. During all On periods, the energy dissipation has grown significantly, but soon decreased after entering an Off period. In total, above 40% energy has been saved, whereas only 17% more tasks have been timely executed on the platform with no energy saving facilities. This trade-off can be even more favourable if some hints regarding the future workload are available, which would lead to better adjustment of the and threshold values.
The experiment with random workloads has led to similar conclusions. If a workload is too heavy for a considered platform, then the influence of the threshold parameters is significant. By increasing the value of the threshold, significantly more tasks are admitted and executed before their deadlines, but the cost in terms of dissipated energy is significant. However, in case a workload is rather light for a considered platform, the majority of tasks are admitted and timely executed. In this situation, the energy savings can be particularly significant and can reach above 60% (as it has been demonstrated for the heaviest workloads for the 4x8 core system in the conducted experiments).
In all considered cases, per-chip DVFS has demonstrated higher energy dissipation (per task executed on time). This difference has been particularly visible for the workloads with medium heaviness executed on the smaller platform (2 × 4 cores), where it reached almost 40% in comparison with the corresponding per-core DVFS case. However, the difference between the platform in which both the voltage and frequency can be chosen independently per each core and the platform, in which only frequency can be set in the per-core manner, is rather negligible in all cases. Thus, the conducted experiments confirm the soundness of the MPSoC architecture proposed by AMD, where cores can operate at assorted frequencies, but all cores are supplied with the same voltage level, appropriate to the core operating at the fastest frequency.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}