
Cost-Effective Class-Imbalance Aware CNN for Vehicle Localization and Categorization in High Resolution Aerial Images


Abstract
:
1. Introduction
2. Related Work
3. Background
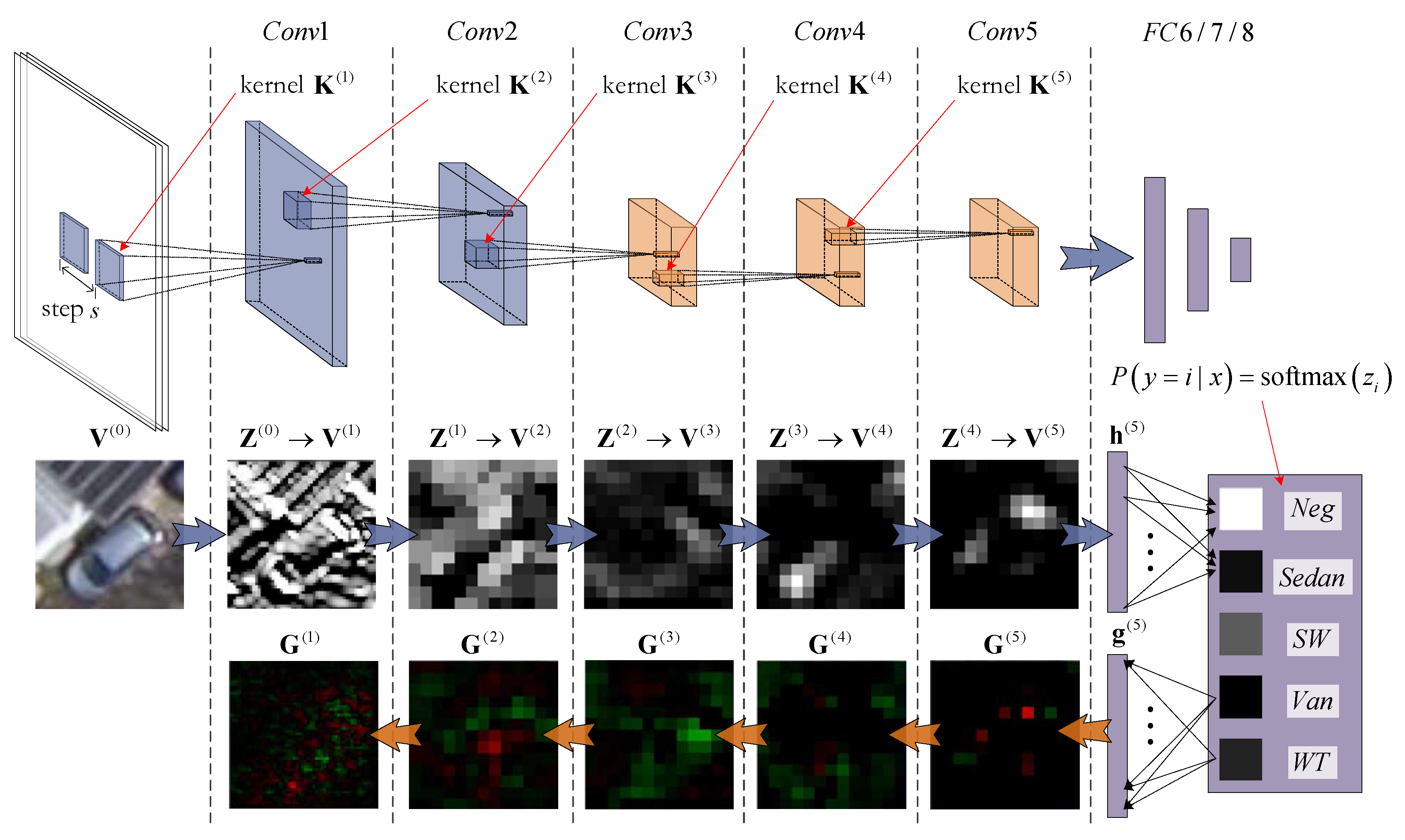
3.1. Basic Knowledge of Convolutional Neural Networks
3.2. The Semantic Texture Encoding Pattern for Convolutional Kernels
4. Methods
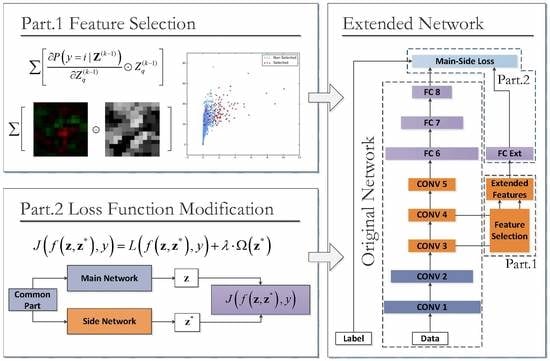
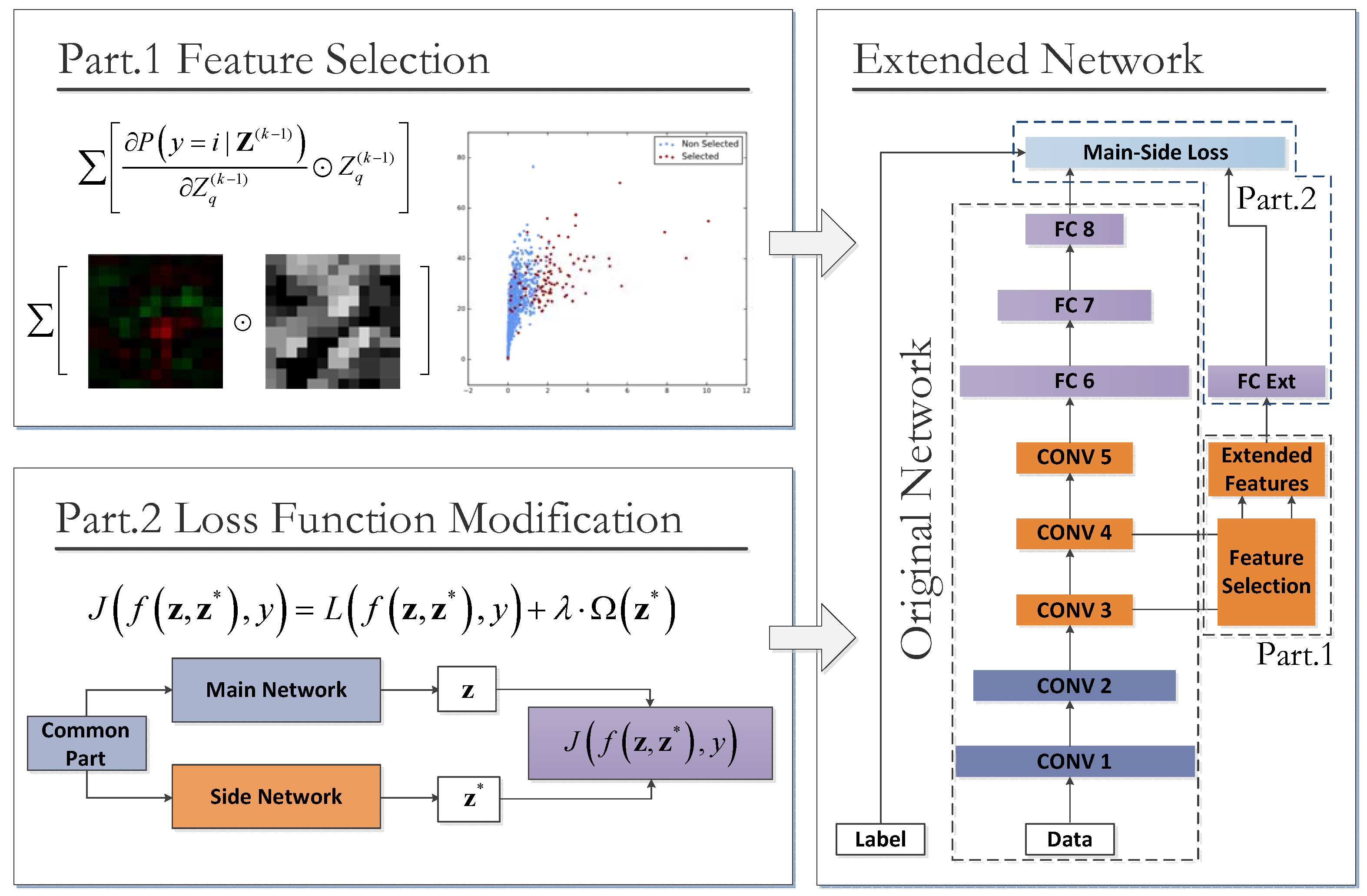
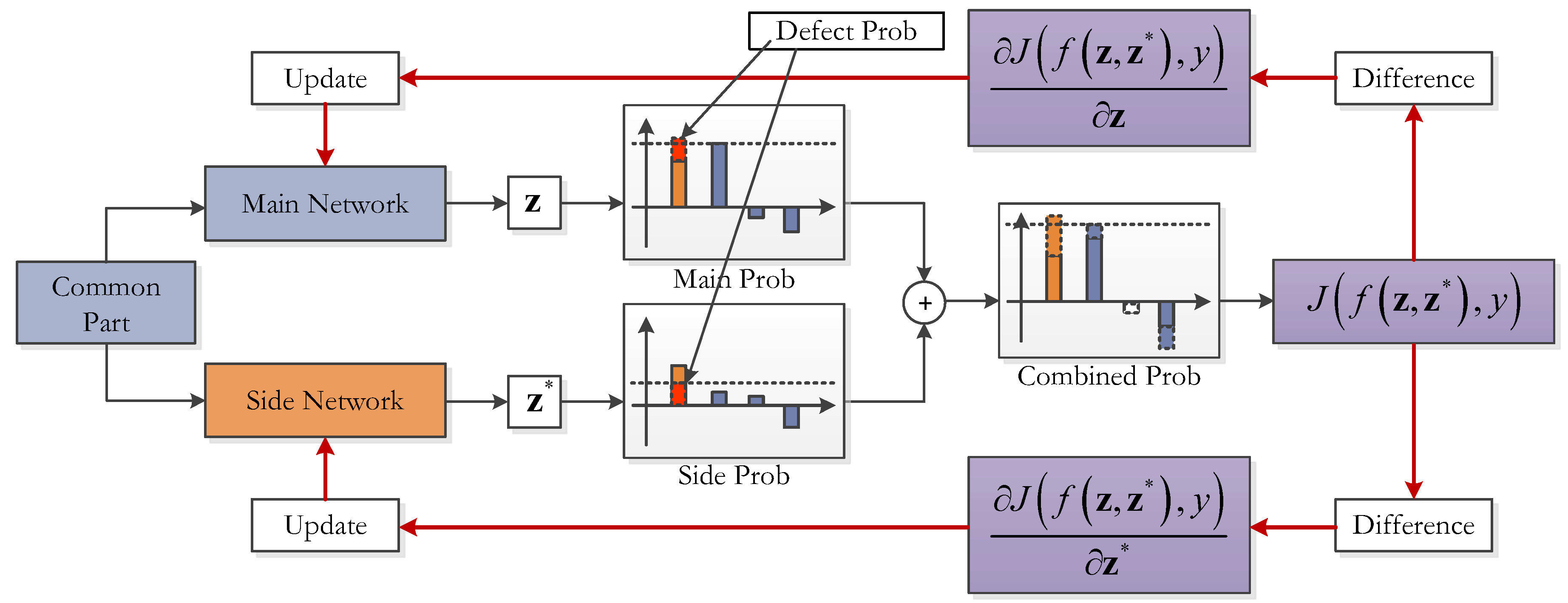
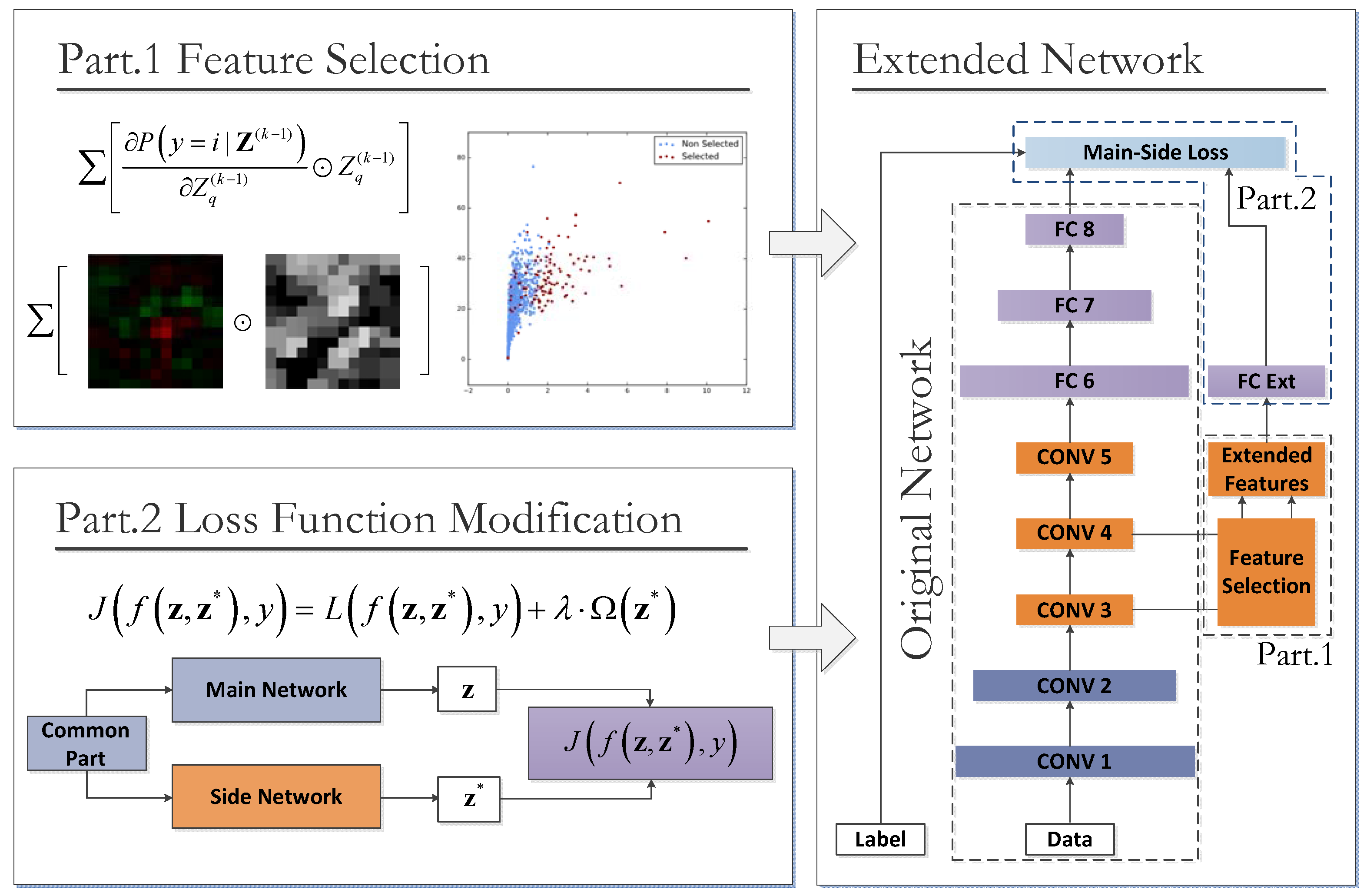
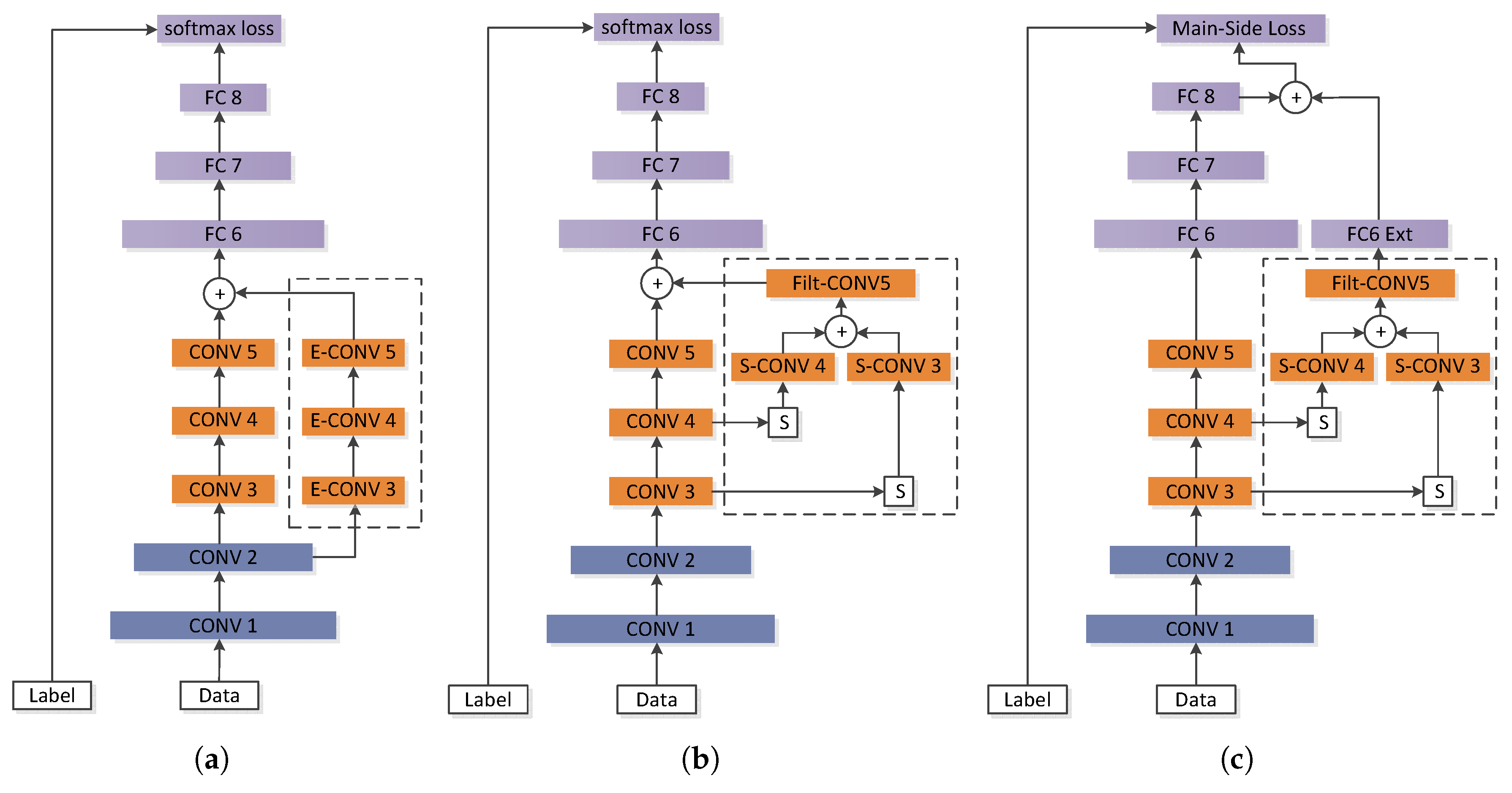
4.1. Overview of the Proposed CNN Extension Scheme
- (1)
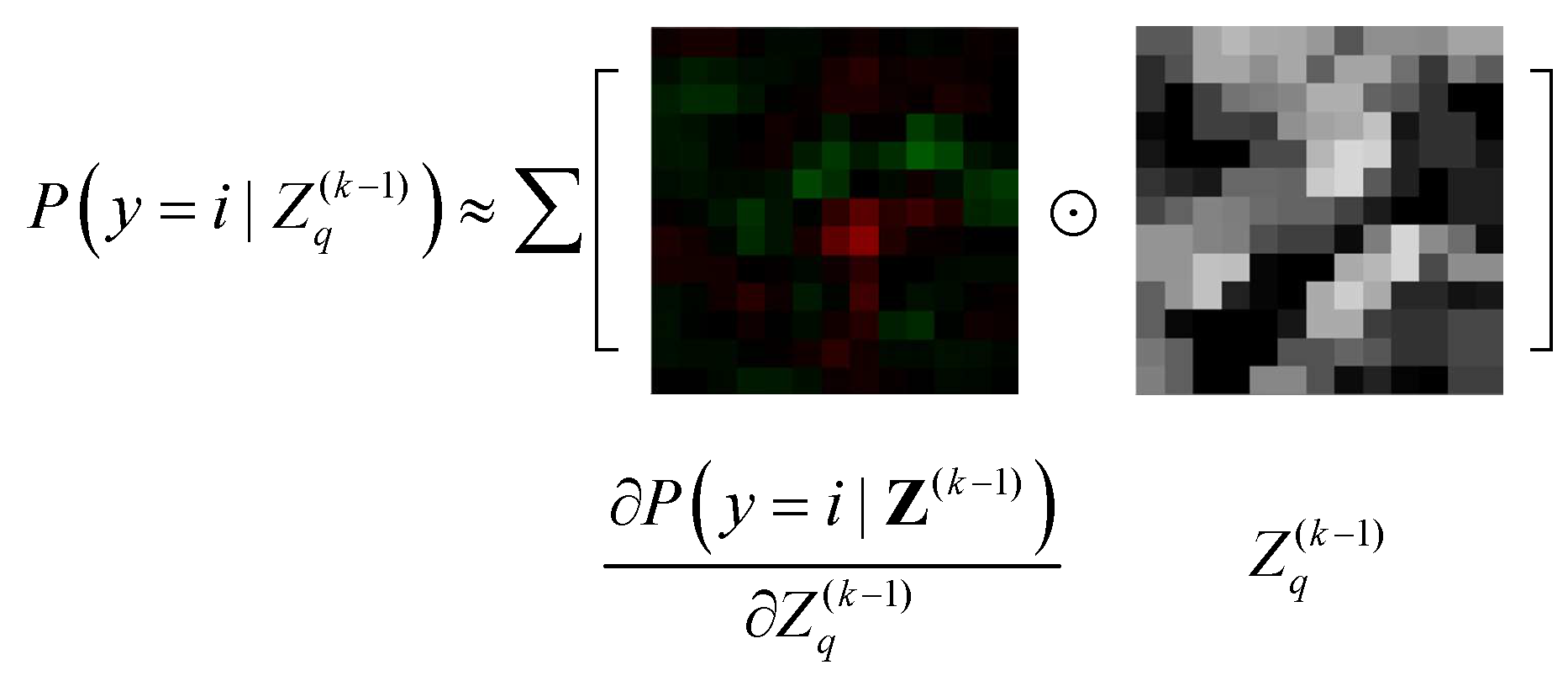
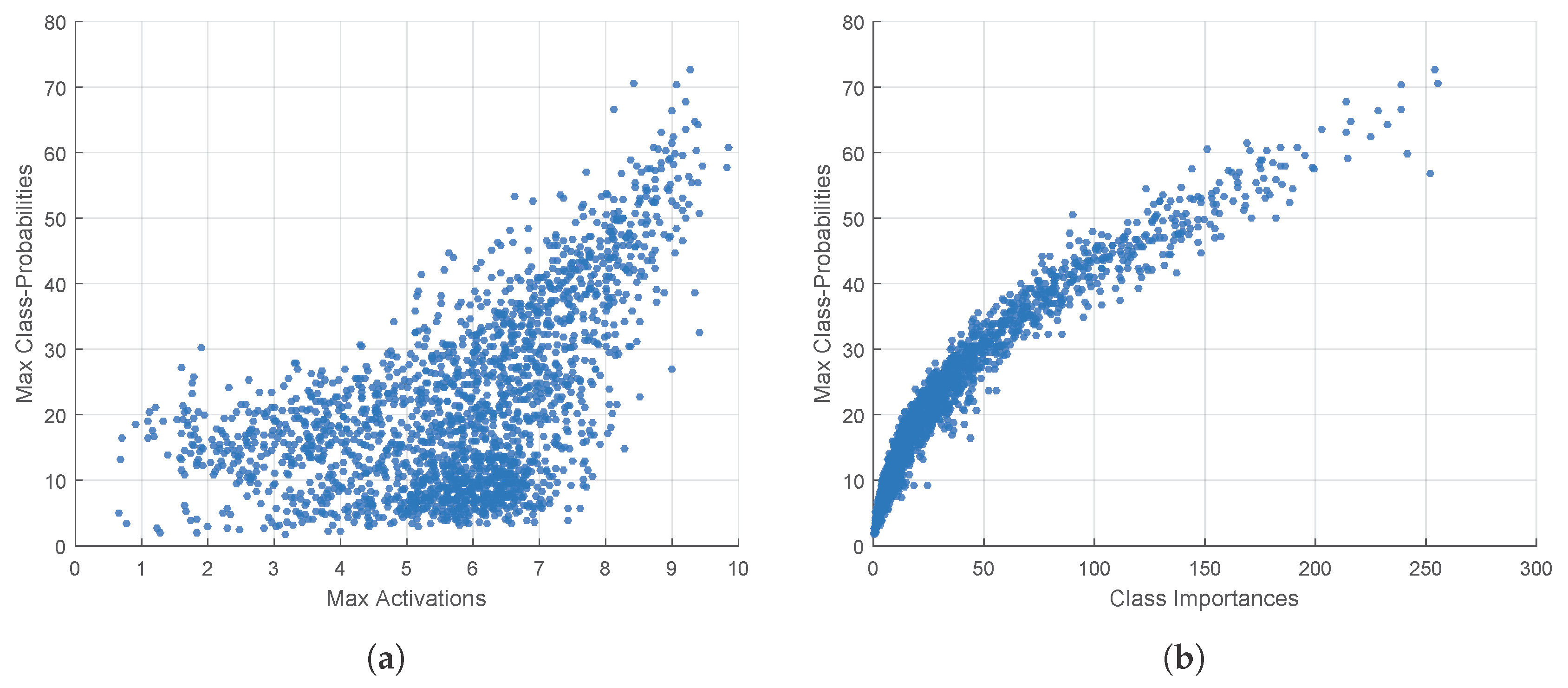
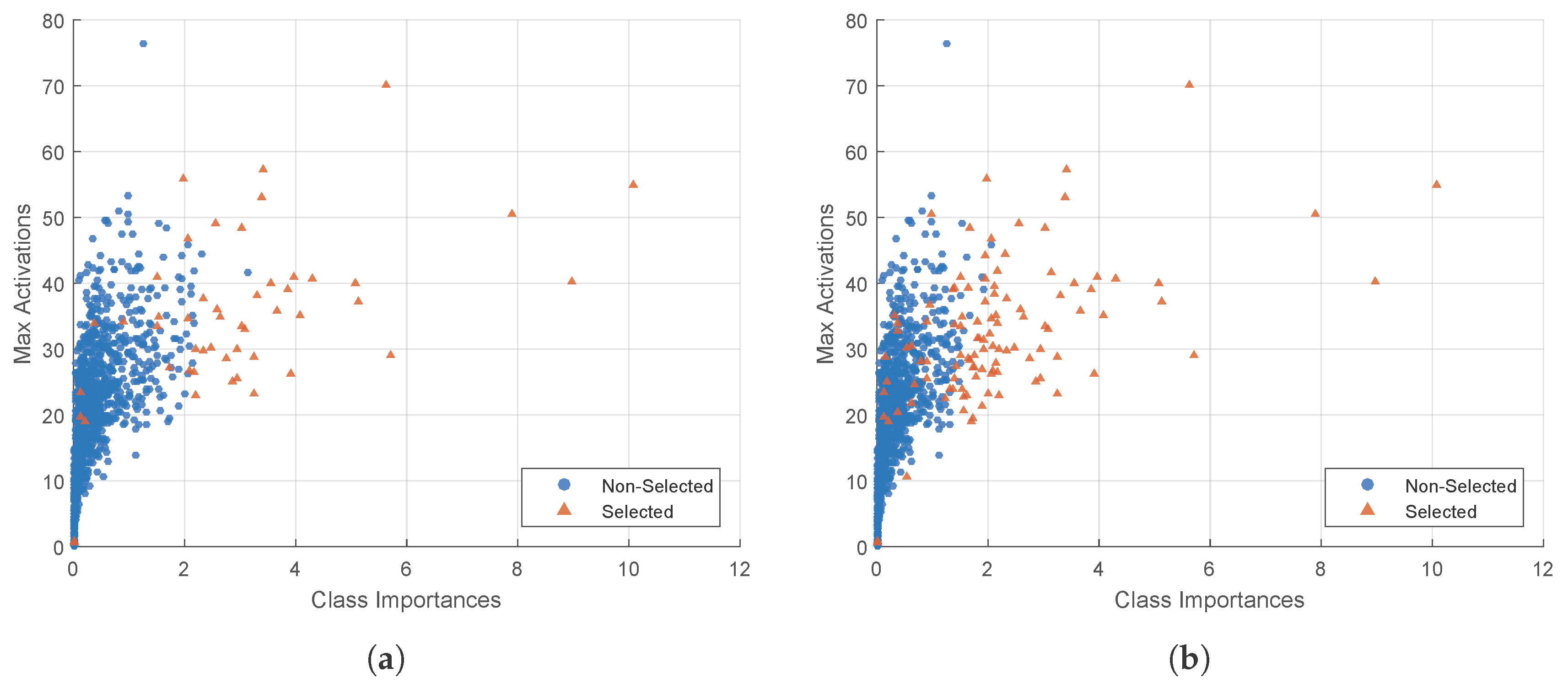
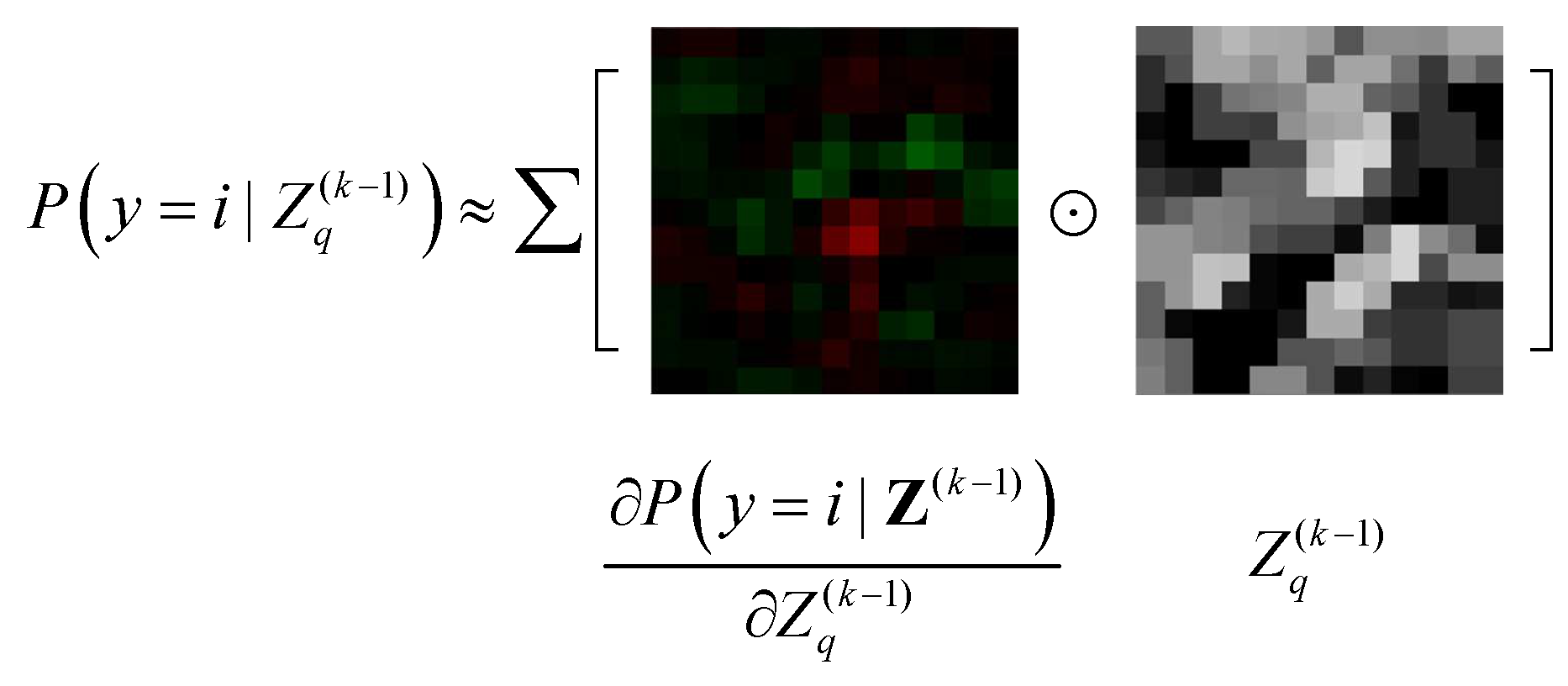
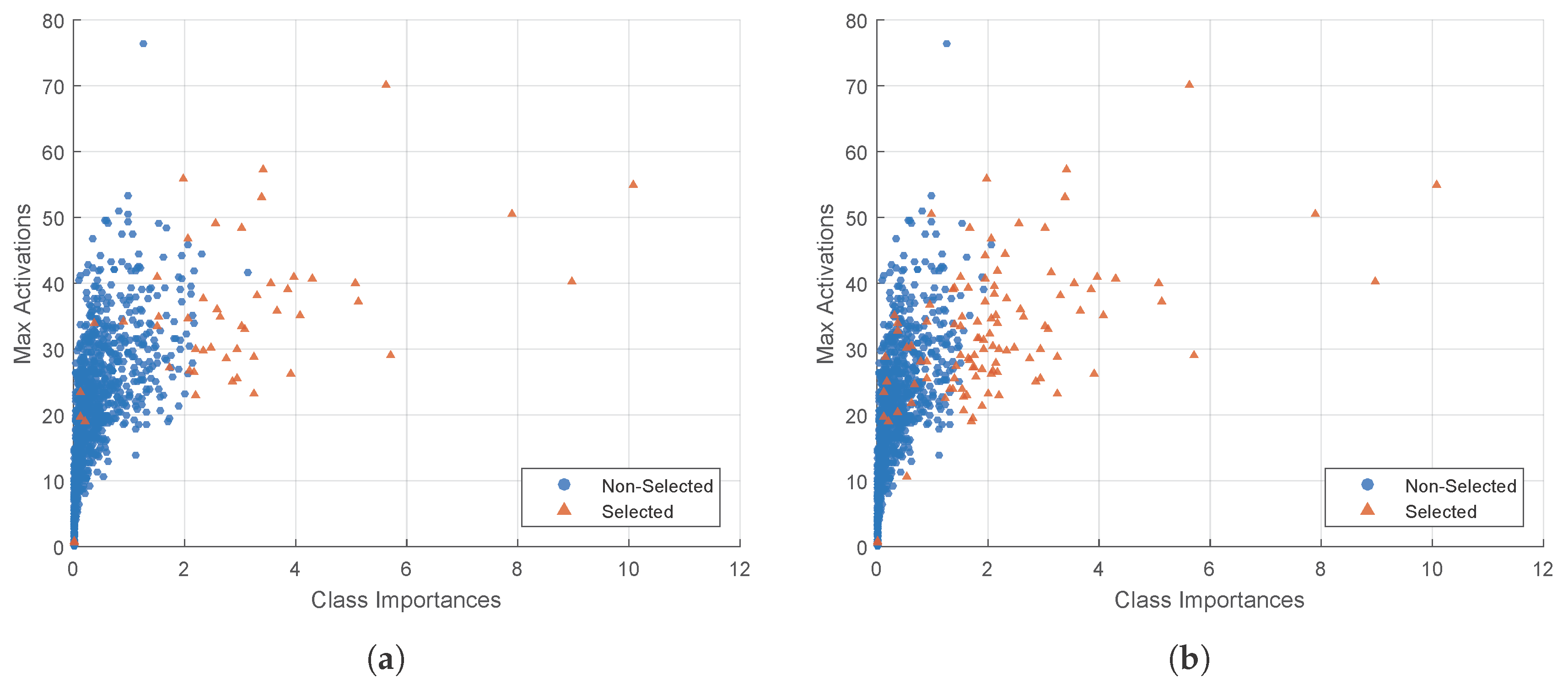
- Part 1: The selective feature map extension by class-importance measurement. This measure aims to reduce the convolution overhead by reusing feature maps selected from the preceding layers. The criteria adopted in the feature selection process—named feature map class-importance—are similar to that in [58], but are further extended for a multi-class problem with slight modification. Additionally, according to [58], these selected feature maps are further filtered by an extra convolutional layer to reduce noise before being used as the Extended Features component in Figure 3.
- (2)
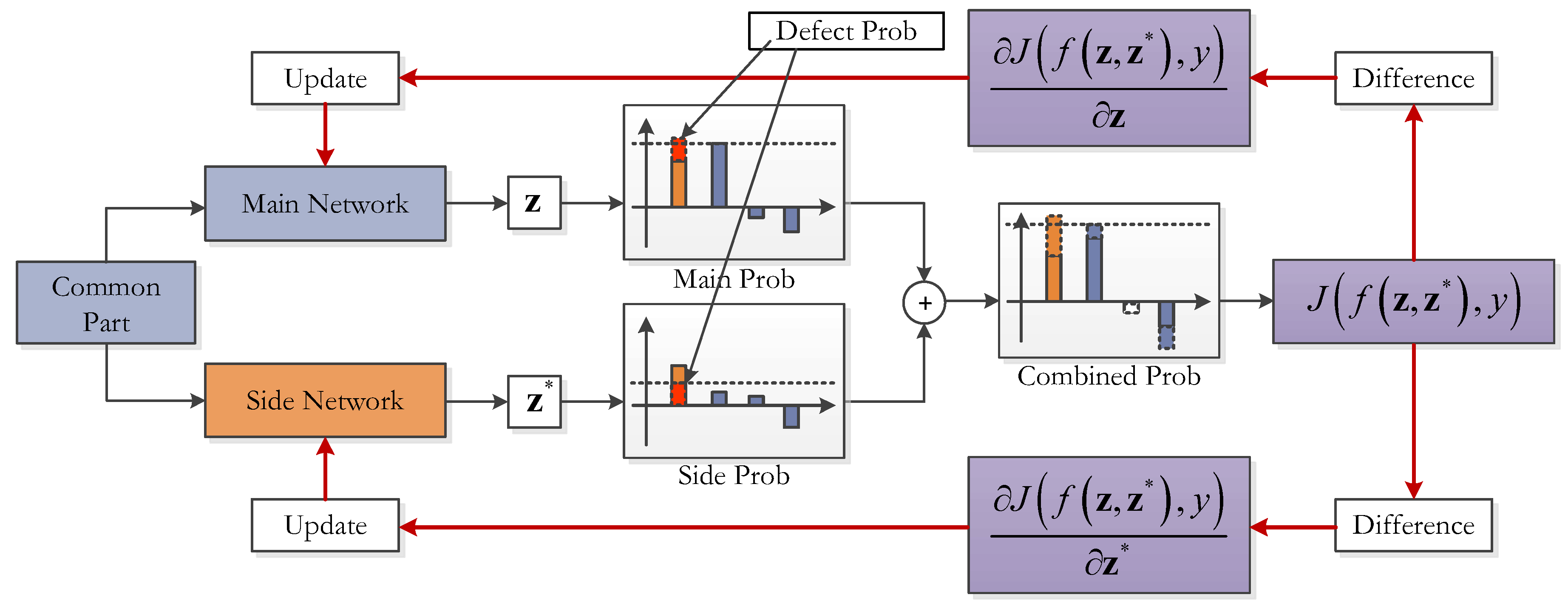
- Part 2: the class-imbalance-sensitive softmax loss function. This measure aims at reducing the connection overhead and increasing the class-imbalance awareness of the improved structure. Firstly, the extended network components holding the Extended Features are isolated from the main part of the Original Network by a single-layered fully-connected (FC) layer FC Ext. This FC layer has hidden neurons only as few as the number of output classes; thus, the additional connection quantity for the new maps is largely reduced. Secondly, as shown in the right-most text-box of Figure 3, a new loss function named main-side loss is adopted in place of the original softmax loss to raise the sensitivities of the Extended Features to the minority classes.
4.2. The Network Extension by Selected Feature Maps
| Algorithm 1 Class Imbalance-Aware Extension Feature Map Selection |
| Input: Classification accuracies , class-importance for feature maps from the CONV3 and CONV4 layers, and the total number of maps to be selected . Output: Selected feature map indexes on CONV3 and CONV4
|
4.3. Class Imbalance-Sensitive Softmax Loss Function
5. Experiments and Analysis
5.1. Data Set Description and Experiment Setup
5.1.1. DLR 3K Aerial Image Dataset
5.1.2. Training and Testing Preparation as a Classification Problem
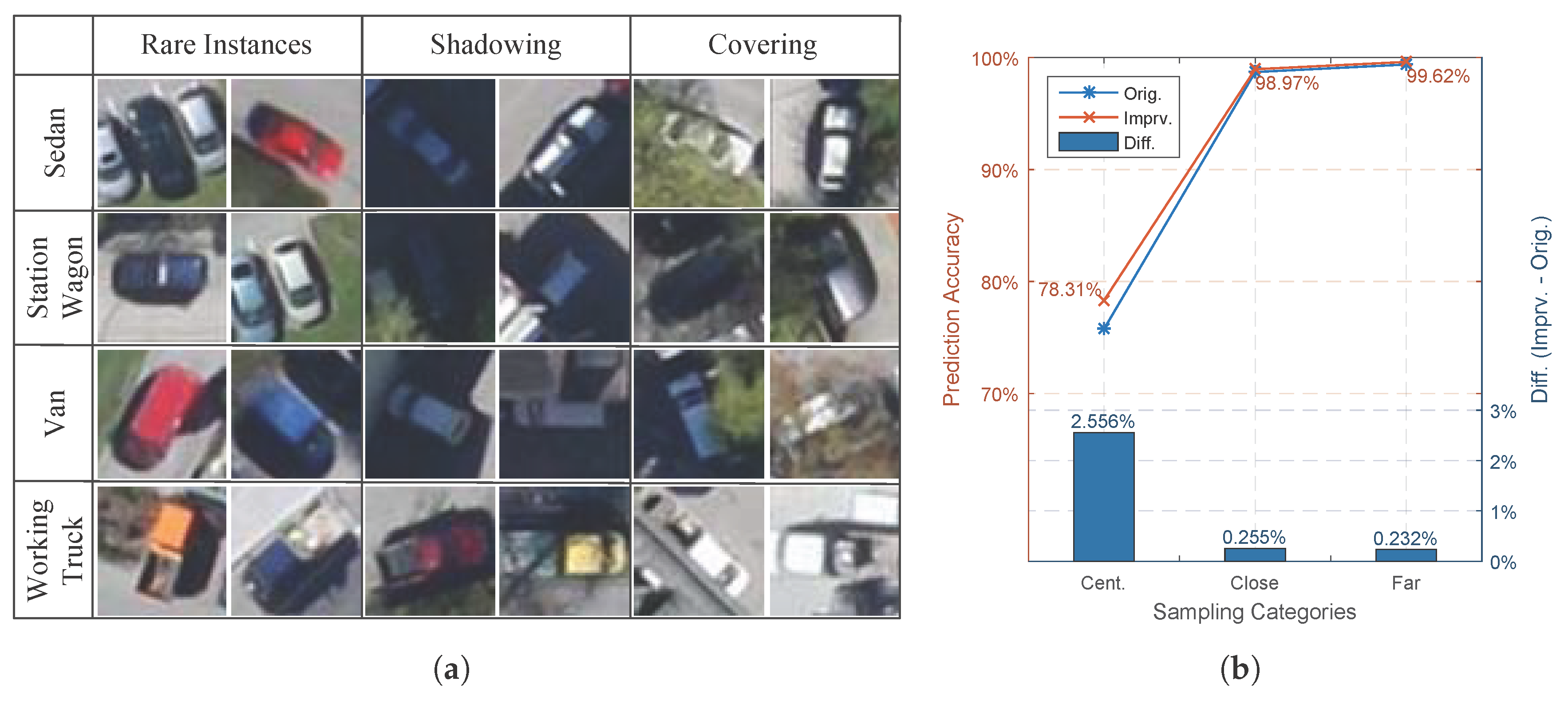
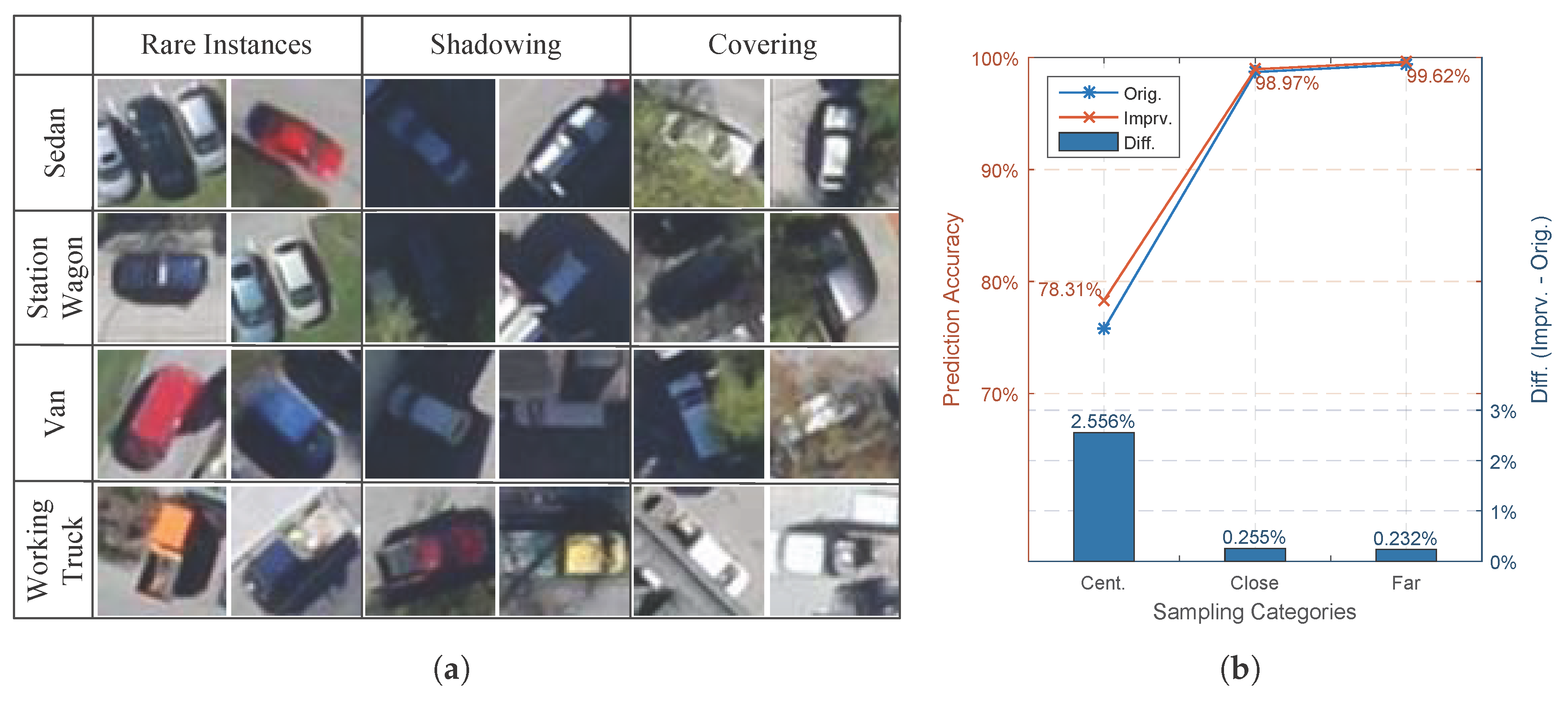
- The Centered category: position marked by yellow square in sub-figure c in Figure 10 with no more than 3 pixels;
- The Close Range category: positions marked by red squares within the blue shaded region in sub-figure c in Figure 10, whose are in range from 4 to 20 pixels;
- The Far Range category: in sub-figure c from Figure 10, positions marked by green squares outside the blue shaded region with more than 20 pixels.
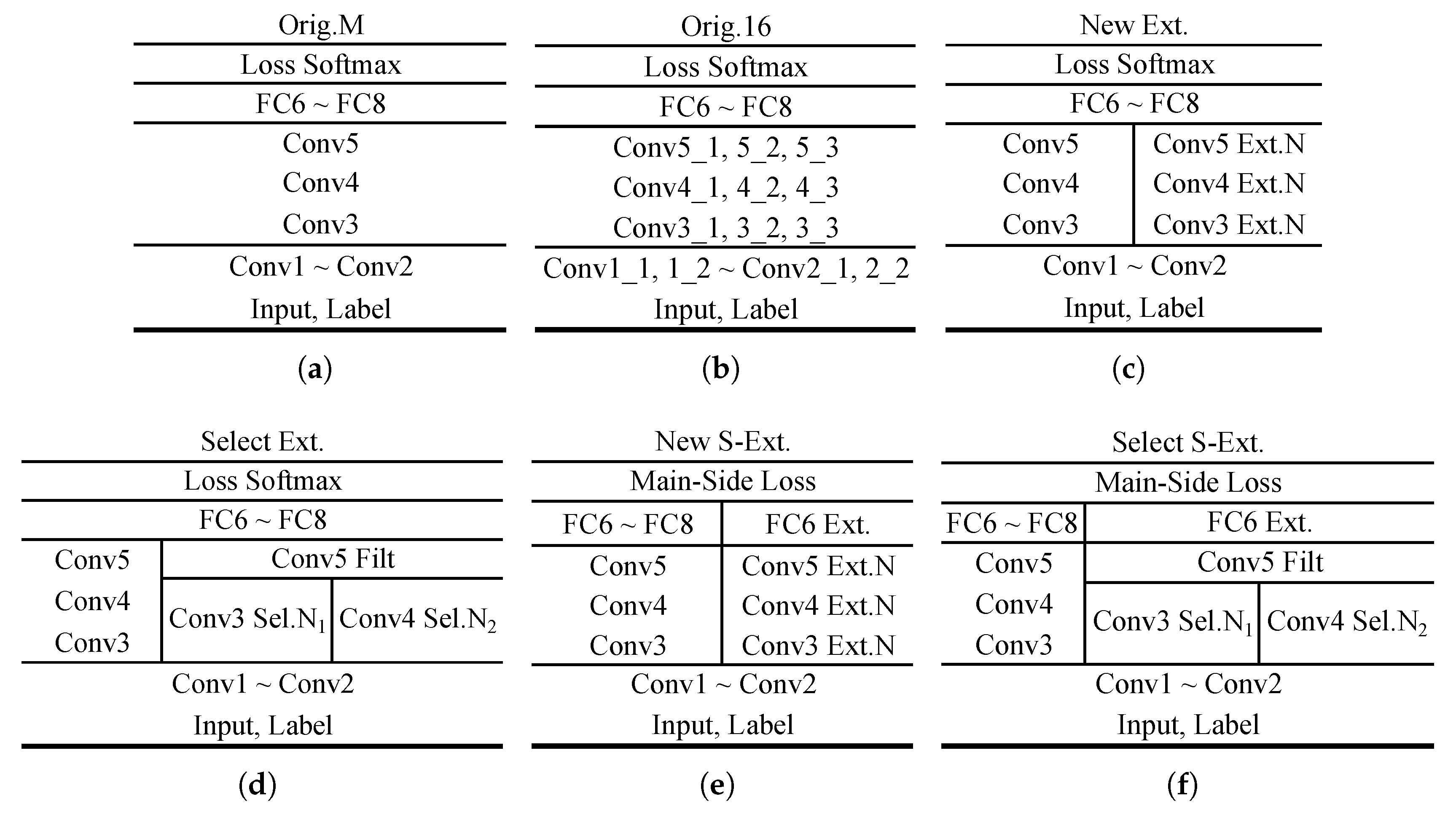
5.1.3. The Baseline Network Structure and Extension Styles for Analysis
5.2. Experimental Results
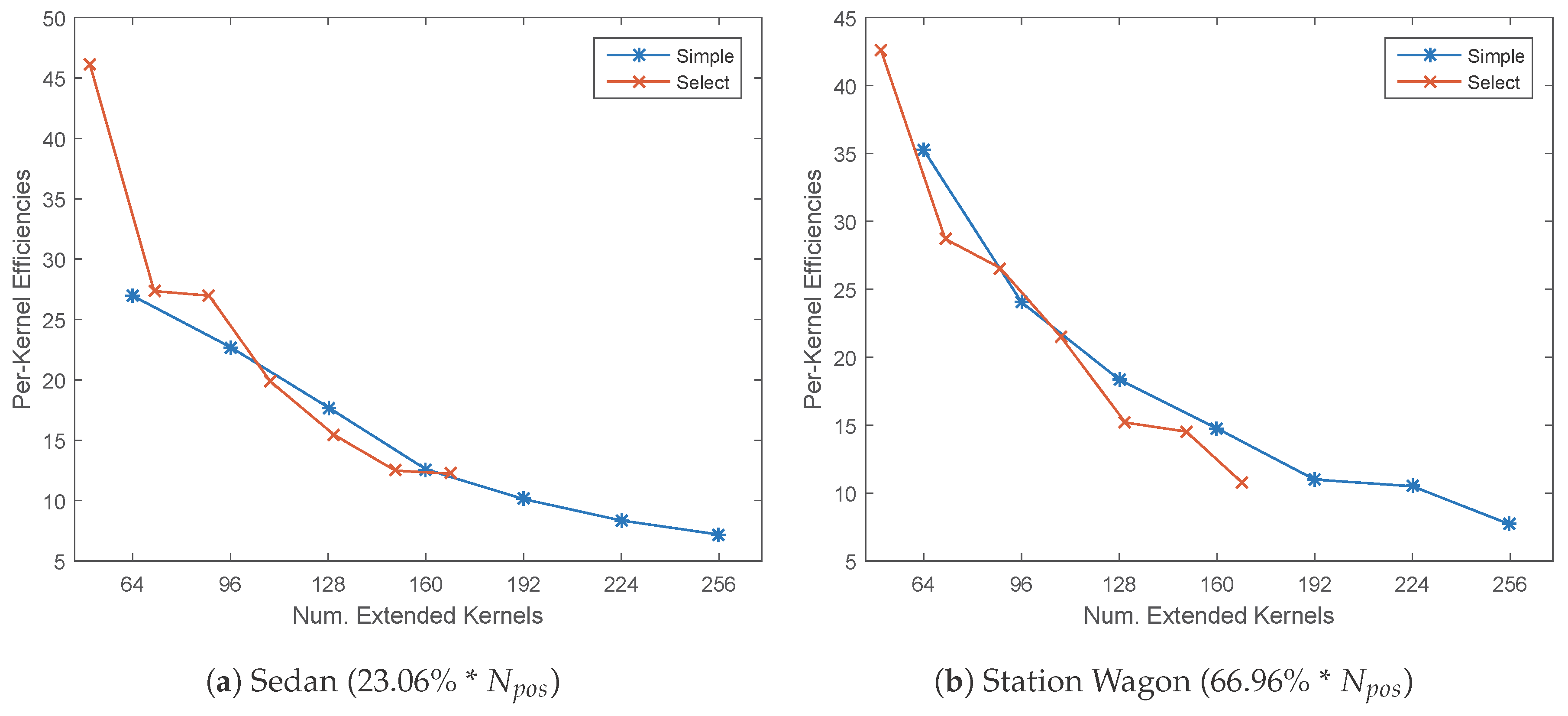
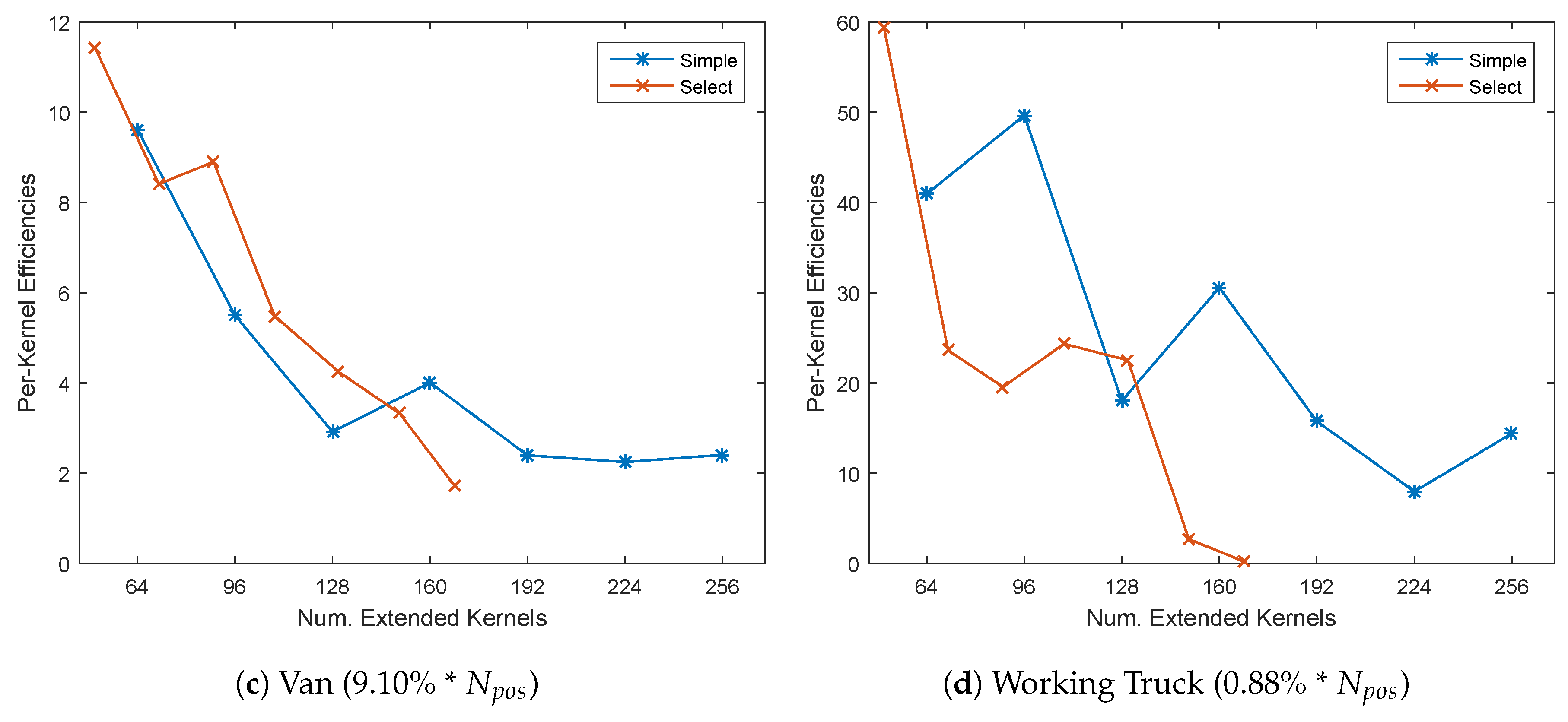
5.3. Network Extension Efficiency by Selected Feature Maps
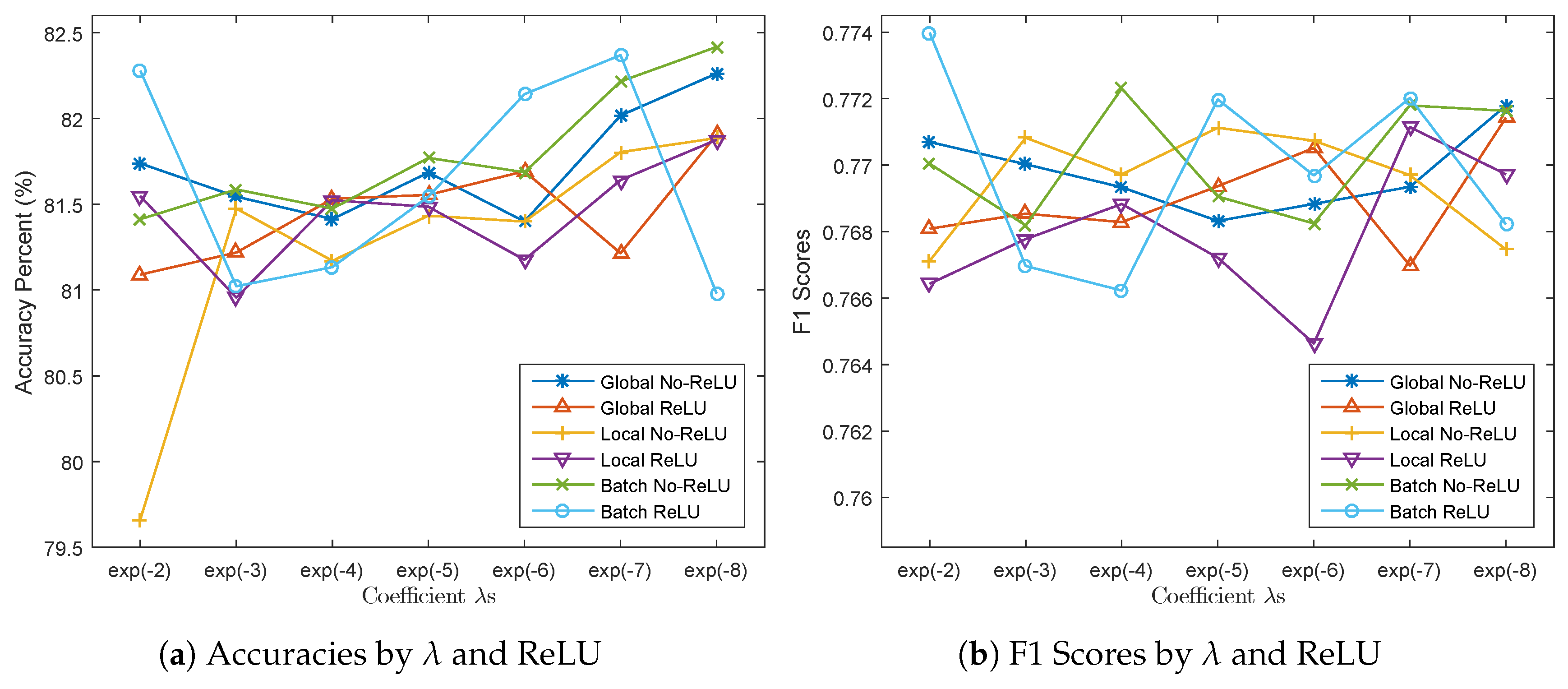
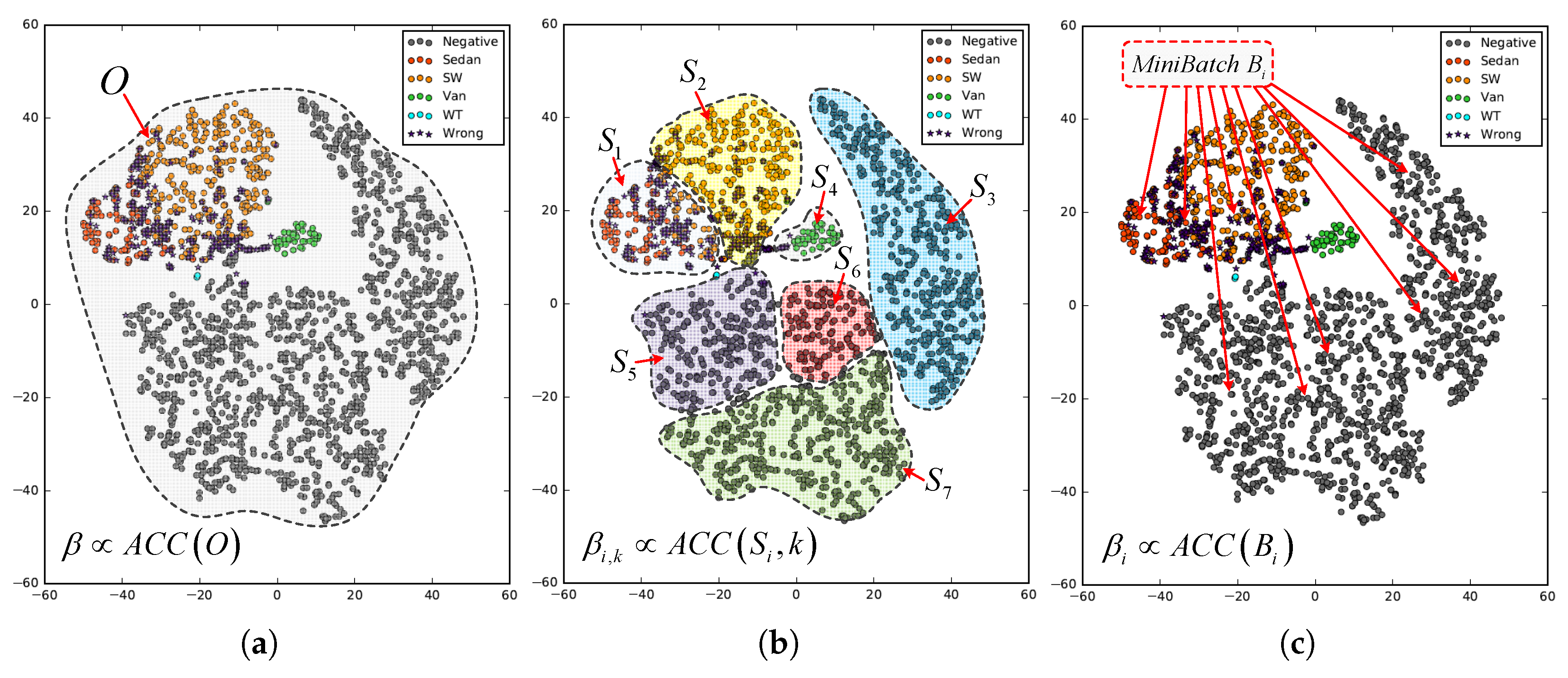
5.4. Main Factors in Main-Side Loss Function-based Fine-Tuning
6. Discussion
- (a)
- (b)
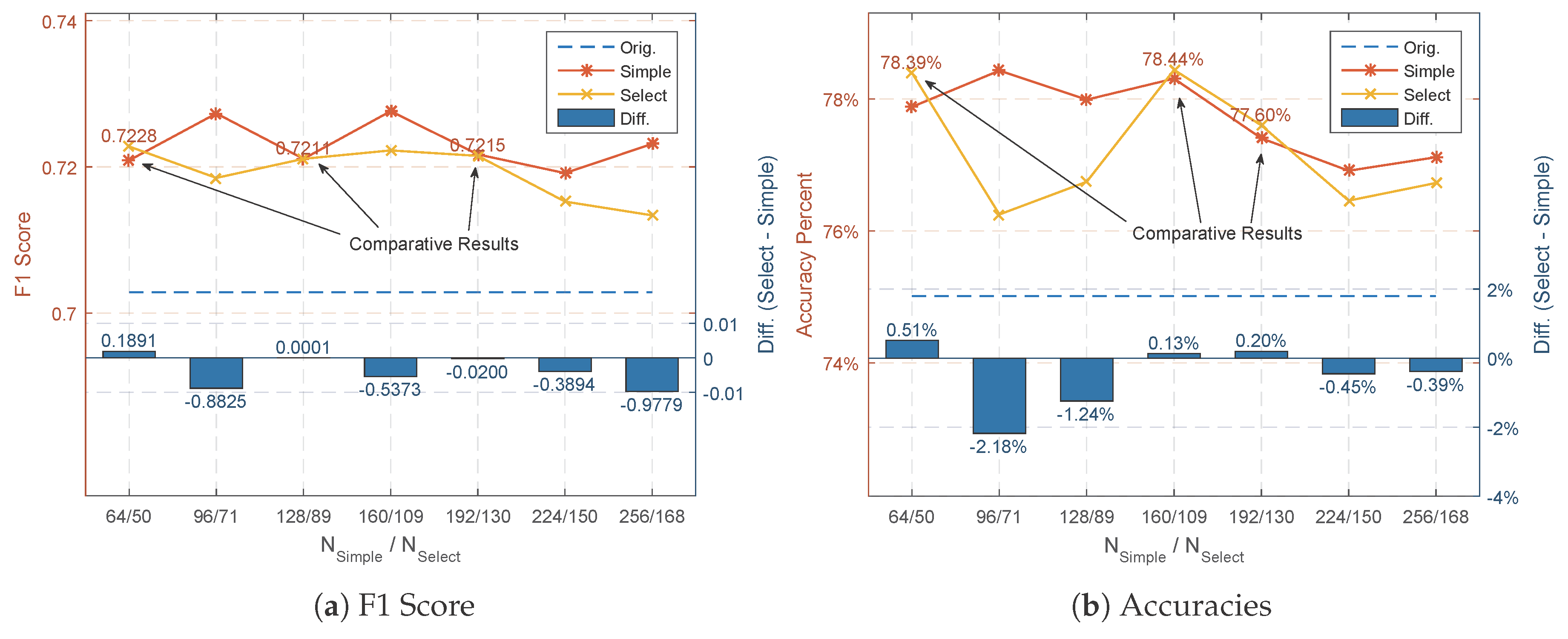
- According to Table 5, the effectiveness of the softmax loss-based plain width extension with either blank kernels or selected feature maps will decrease rapidly as the extension quantity increases. Additionally, the selected feature maps are more effective under small extension quantity, while losing their advantage in large extension, as they lack flexibility.
- (c)
- As can be seen from Table 3, Table 4 and Table 5, selected feature maps are more helpful for improving the classification accuracies, while they can barely keep up with the blank kernel-based extension in overall F1 score by Figure 15a. To maintain a reasonably high F1 score performance, the penalization mode Glb.ReLU and Bat.ReLU are preferred, as in Table 3 and Table 4.
- (d)
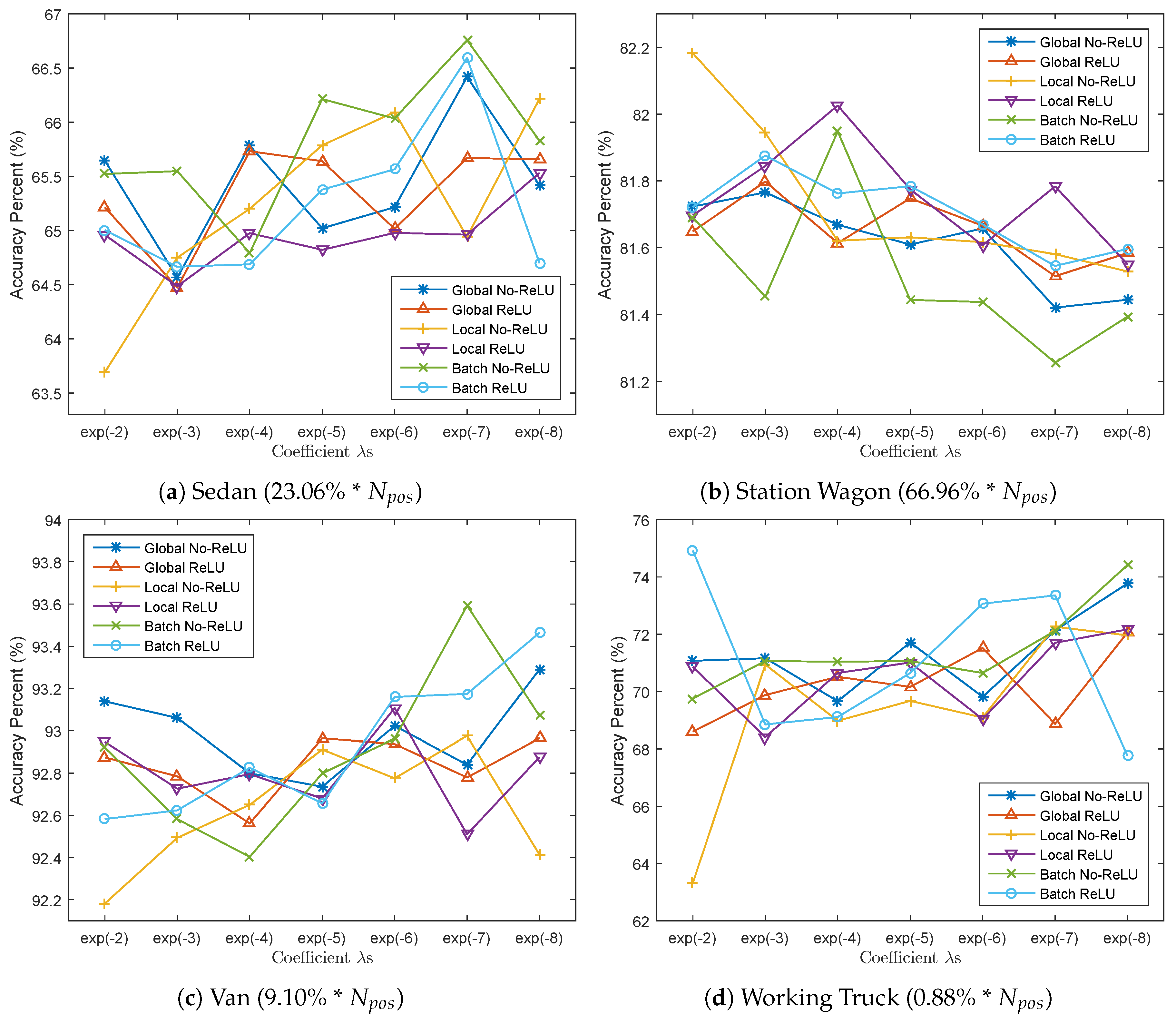
- As seen by Figure 17a, penalization modes without ReLU constraint in the Main-Side loss-related fine-tuning can produce a more significant increment in accuracies as the global penalization decreases. The existence of a ReLU layer helps to stabilize the fluctuation in F1 scores when changes, as in Figure 17b.
- (e)
- By Figure 18, the class-imbalance-sensitive penalization term helps to improve the classification accuracies for the medium-sized minority classes (Sedan and Van), but is not so ideal for classes with an absolutely trivial sample quantity (Working Truck).
- (f)
- The sizes of most effective vehicle classes for the three penalization modes are different. Shown by Table 7, the Global penalization mode is effective on medium-sized classes (Sedan and Van), the Local mode is effective for large- and medium-sized classes (Station Wagon and Sedan), while the Batch-wise mode is effective for small-sized classes (Working Truck).
7. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Abbreviations
| ADASYN | Adaptive Synthetic Sampling |
| CBO | Cluster-based Oversampling |
| CNN | Convolutional Neural Network |
| DBN | Deep Belief Network |
| FCN | Fully Convolutional Neural Network |
| HOG | Histogram of Oriented Gradients |
| GAN | Generative Adversarial Network |
| GSD | Ground Sampling Distance |
| LBP | Local Binary Pattern |
| R-CNN | Regions with Convolutional Neural Network Features |
| ROI | Region of Interest |
| SIFT | Scale Invariant Feature Transform |
| SMOTE | Synthetic Minority Over-sampling Technique |
| SVM | Support Vector Machine |
| t-SNE | t-Distributed Stochastic Neighbor Embedding |
| VGG | Visual Geometry Group |
References
- Xu, Y.; Yu, G.; Wang, Y.; Wu, X.; Ma, Y. A Hybrid Vehicle Detection Method Based on Viola-Jones and HOG + SVM from UAV Images. Sensors 2016. [Google Scholar] [CrossRef] [PubMed]
- Tuermer, S.; Kurz, F.; Reinartz, P.; Stilla, U. Airborne vehicle detection in dense urban areas using HoG features and disparity maps. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2013, 6, 2327–2337. [Google Scholar] [CrossRef]
- Hinz, S.; Schlosser, C.; Reitberger, J. Automatic car detection in high resolution urban scenes based on an adaptive 3D-model. In Proceedings of the 2nd GRSS/ISPRS Joint Workshop on Remote Sensing and Data Fusion over Urban Areas, Berlin, Germany, 22–23 May 2003; pp. 167–171. [Google Scholar]
- Qu, T.; Zhang, Q.; Sun, S. Vehicle detection from high-resolution aerial images using spatial pyramid pooling-based deep convolutional neural networks. Multimedia Tools Appl. 2016. [Google Scholar] [CrossRef]
- Chen, X.; Xiang, S.; Liu, C.L.; Pan, C.H. Vehicle detection in satellite images by hybrid deep convolutional neural networks. IEEE Geosci. Remote Sens. Lett. 2014, 11, 1797–1801. [Google Scholar] [CrossRef]
- Cao, L.; Jiang, Q.; Cheng, M.; Wang, C. Robust vehicle detection by combining deep features with exemplar classification. Neurocomputing 2016, 215, 225–231. [Google Scholar] [CrossRef]
- Zhu, H.; Chen, X.; Dai, W.; Fu, K.; Ye, Q.; Jiao, J. Orientation robust object detection in aerial images using deep convolutional neural network. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015; pp. 3735–3739. [Google Scholar]
- Qu, S.; Wang, Y.; Meng, G.; Pan, C. Vehicle Detection in Satellite Images by Incorporating Objectness and Convolutional Neural Network. J. Ind. Intell. Inf. 2016. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Los Alamitos, CA, USA, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems, Montréal, QC, Canada, 7–12 December 2015. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In European Conference on Computer Vision; Springer: New York, NY, USA, 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Stanford, CA, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. In European Conference on Computer Vision; Springer: New York, NY, USA, 2014; pp. 346–361. [Google Scholar]
- Tang, T.; Zhou, S.; Deng, Z.; Zou, H.; Lei, L. Vehicle Detection in Aerial Images Based on Region Convolutional Neural Networks and Hard Negative Example Mining. Sensors 2017. [Google Scholar] [CrossRef] [PubMed]
- Wang, Q.; Lin, J.; Yuan, Y. Salient band selection for hyperspectral image classification via manifold ranking. IEEE Trans. Neural Netw. Learn. Syst. 2016, 27, 1279–1289. [Google Scholar] [CrossRef] [PubMed]
- Zhang, F.; Du, B.; Zhang, L. Saliency-guided unsupervised feature learning for scene classification. IEEE Trans. Geosci. Remote Sens. 2015, 53, 2175–2184. [Google Scholar] [CrossRef]
- Holt, A.C.; Seto, E.Y.; Rivard, T.; Gong, P. Object-based detection and classification of vehicles from high-resolution aerial photography. Photogramm. Eng. Remote Sens. 2009, 75, 871–880. [Google Scholar] [CrossRef]
- Liu, K.; Mattyus, G. Fast multiclass vehicle detection on aerial images. IEEE Geosci. Remote Sens. Lett. 2015, 12, 1938–1942. [Google Scholar]
- Razakarivony, S.; Jurie, F. Vehicle detection in aerial imagery: A small target detection benchmark. J. Vis. Commun. Image Represent. 2016, 34, 187–203. [Google Scholar] [CrossRef]
- Bell, S.; Lawrence Zitnick, C.; Bala, K.; Girshick, R. Inside-outside net: Detecting objects in context with skip pooling and recurrent neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Stanford, CA, USA, 27–30 June 2016; pp. 2874–2883. [Google Scholar]
- Ma, Z.; Yu, L.; Chan, A.B. Small instance detection by integer programming on object density maps. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3689–3697. [Google Scholar]
- Arteta, C.; Lempitsky, V.; Noble, J.A.; Zisserman, A. Interactive object counting. In European Conference on Computer Vision; Springer: New York, NY, USA, 2014; pp. 504–518. [Google Scholar]
- Yuan, Y.; Wan, J.; Wang, Q. Congested scene classification via efficient unsupervised feature learning and density estimation. Pattern Recognit. 2016, 56, 159–169. [Google Scholar] [CrossRef]
- He, H.; Garcia, E.A. Learning from imbalanced data. IEEE Trans. Knowl. Data Eng. 2009, 21, 1263–1284. [Google Scholar]
- Branco, P.; Torgo, L.; Ribeiro, R. A survey of predictive modelling under imbalanced distributions. arXiv 2015. [Google Scholar]
- He, H.; Ma, Y. Imbalanced Learning: Foundations, Algorithms, and Applications; John Wiley & Sons: New York, NY, USA, 2013. [Google Scholar]
- Krawczyk, B. Learning from imbalanced data: Open challenges and future directions. Prog. Artif. Intell. 2016, 5, 221–232. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar]
- He, H.; Bai, Y.; Garcia, E.A.; Li, S. ADASYN: Adaptive synthetic sampling approach for imbalanced learning. In Proceedings of the IEEE International Joint Conference on Neural Networks, Hong Kong, China, 1–8 June 2008; pp. 1322–1328. [Google Scholar]
- Jo, T.; Japkowicz, N. Class imbalances versus small disjuncts. ACM Sigkdd Explor. Newsl. 2004, 6, 40–49. [Google Scholar] [CrossRef]
- Zhou, Z.H.; Liu, X.Y. On Multi-Class Cost-Sensitive Learning. Comput. Intell. 2010, 26, 232–257. [Google Scholar] [CrossRef]
- Ting, K.M. A comparative study of cost-sensitive boosting algorithms. In Proceedings of the 17th International Conference on Machine Learning, Stanford, CA, USA, 29 June–2 July 2000. [Google Scholar]
- Krawczyk, B.; Woźniak, M.; Schaefer, G. Cost-sensitive decision tree ensembles for effective imbalanced classification. Appl. Soft Comput. 2014, 14, 554–562. [Google Scholar] [CrossRef]
- Huang, C.; Li, Y.; Change Loy, C.; Tang, X. Learning deep representation for imbalanced classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Stanford, CA, USA, 27–30 June 2016; pp. 5375–5384. [Google Scholar]
- Jeatrakul, P.; Wong, K.W.; Fung, C.C. Classification of imbalanced data by combining the complementary neural network and SMOTE algorithm. In International Conference on Neural Information Processing; Springer: New York, NY, USA, 2010; pp. 152–159. [Google Scholar]
- Simpson, A.J. Over-sampling in a deep neural network. arXiv 2015. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Khan, S.H.; Bennamoun, M.; Sohel, F.; Togneri, R. Cost sensitive learning of deep feature representations from imbalanced data. arXiv 2015. [Google Scholar]
- Cheng, G.; Zhou, P.; Han, J. Rifd-cnn: Rotation-invariant and fisher discriminative convolutional neural networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Stanford, CA, USA, 27–30 June 2016; pp. 2884–2893. [Google Scholar]
- Bertasius, G.; Shi, J.; Torresani, L. Deepedge: A multi-scale bifurcated deep network for top-down contour detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4380–4389. [Google Scholar]
- Shen, W.; Wang, X.; Wang, Y.; Bai, X.; Zhang, Z. Deepcontour: A deep convolutional feature learned by positive-sharing loss for contour detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3982–3991. [Google Scholar]
- Robinson, J.P.; Shao, M.; Wu, Y.; Fu, Y. Families in the Wild (FIW): Large-Scale Kinship Image Database and Benchmarks. In Proceedings of the 2016 ACM on Multimedia Conference, Amsterdam, The Netherlands, 15–19 October 2016; pp. 242–246. [Google Scholar]
- Santos, C.N.d.; Xiang, B.; Zhou, B. Classifying relations by ranking with convolutional neural networks. arXiv 2015. [Google Scholar]
- Schroff, F.; Kalenichenko, D.; Philbin, J. Facenet: A unified embedding for face recognition and clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar]
- Oh Song, H.; Xiang, Y.; Jegelka, S.; Savarese, S. Deep metric learning via lifted structured feature embedding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Stanford, CA, USA, 27–30 June 2016; pp. 4004–4012. [Google Scholar]
- Wen, Y.; Zhang, K.; Li, Z.; Qiao, Y. A Discriminative Feature Learning Approach for Deep Face Recognition. In Computer Vision—ECCV 2016; Springer International Publishing: Cham, The Netherlands, 2016; pp. 499–515. [Google Scholar]
- Chu, J.L.; Krzyak, A. Analysis of feature maps selection in supervised learning using convolutional neural networks. In Canadian Conference on Artificial Intelligence; Springer: New York, NY, USA, 1994; pp. 59–70. [Google Scholar]
- Marcu, A.; Leordeanu, M. Dual Local-Global Contextual Pathways for Recognition in Aerial Imagery. arXiv 2016. [Google Scholar]
- Yan, Z.; Zhang, H.; Piramuthu, R.; Jagadeesh, V.; DeCoste, D.; Di, W.; Yu, Y. HD-CNN: hierarchical deep convolutional neural networks for large scale visual recognition. In Proceedings of the IEEE International Conference on Computer Vision, Los Alamitos, CA, USA, 7–13 December 2015; pp. 2740–2748. [Google Scholar]
- Jaderberg, M.; Simonyan, K.; Zisserman, A.; Kavukcuoglu, K. Spatial transformer networks. In Proceedings of the Advances in Neural Information Processing Systems, Montréal, QC, Canada, 7–12 December 2015. [Google Scholar]
- Wang, N.; Li, S.; Gupta, A.; Yeung, D.Y. Transferring rich feature hierarchies for robust visual tracking. arXiv 2015. [Google Scholar]
- Ng, W.W.; Zeng, G.; Zhang, J.; Yeung, D.S.; Pedrycz, W. Dual autoencoders features for imbalance classification problem. Pattern Recognit. 2016, 60, 875–889. [Google Scholar] [CrossRef]
- Guyon, I.; Gunn, S.; Nikravesh, M.; Zadeh, L.A. Feature Extraction: Foundations and Applications; Springer: New York, NY, USA, 2008. [Google Scholar]
- Bar, Y.; Diamant, I.; Wolf, L.; Lieberman, S.; Konen, E.; Greenspan, H. Chest pathology identification using deep feature selection with non-medical training. Comput. Methods Biomech. Biomed. Eng. Imaging Vis. 2016. [Google Scholar] [CrossRef]
- Matsugu, M.; Cardon, P. Unsupervised feature selection for multi-class object detection using convolutional neural networks. In Advances in Neural Networks—ISNN 2004; Springer: New York, NY, USA, 2004; pp. 864–869. [Google Scholar]
- Zou, Q.; Ni, L.; Zhang, T.; Wang, Q. Deep Learning Based Feature Selection for Remote Sensing Scene Classification. IEEE Geosci. Remote Sens. Lett. 2015, 12, 2321–2325. [Google Scholar] [CrossRef]
- Wang, L.; Ouyang, W.; Wang, X.; Lu, H. Visual tracking with fully convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Los Alamitos, CA, USA, 7–13 December 2015; pp. 3119–3127. [Google Scholar]
- Liu, D.R.; Li, H.L.; Wang, D. Feature selection and feature learning for high-dimensional batch reinforcement learning: A survey. Int. J. Autom. Comput. 2015, 12, 229–242. [Google Scholar] [CrossRef]
- Yang, B.; Yan, J.; Lei, Z.; Li, S.Z. Convolutional channel features. In Proceedings of the IEEE International Conference on Computer Vision, Los Alamitos, CA, USA, 7–13 December 2015; pp. 82–90. [Google Scholar]
- Zhong, B.; Zhang, J.; Wang, P.; Du, J.; Chen, D. Jointly Feature Learning and Selection for Robust Tracking via a Gating Mechanism. PLoS ONE 2016, 11, e0161808. [Google Scholar] [CrossRef] [PubMed]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; pp. 166–373. [Google Scholar]
- Jarrett, K.; Kavukcuoglu, K.; LeCun, Y.; Ranzato, M. What is the best multi-stage architecture for object recognition? In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 2146–2153. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the 27th International Conference on Machine Learning (ICML-10), Haifa, Israel, 21–25 June 2010; pp. 807–814. [Google Scholar]
- Yosinski, J.; Clune, J.; Nguyen, A.; Fuchs, T.; Lipson, H. Understanding neural networks through deep visualization. arXiv 2015. [Google Scholar]
- Simonyan, K.; Vedaldi, A.; Zisserman, A. Deep inside convolutional networks: Visualising image classification models and saliency maps. arXiv 2013. [Google Scholar]
- Nguyen, A.; Yosinski, J.; Clune, J. Deep neural networks are easily fooled: High confidence predictions for unrecognizable images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 427–436. [Google Scholar]
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.; Fergus, R. Intriguing properties of neural networks. arXiv 2013. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In European Conference on Computer Vision; Springer: New York, NY, USA, 2014; pp. 818–833. [Google Scholar]
- Erhan, D.; Bengio, Y.; Courville, A.; Vincent, P. Visualizing Higher-Layer Features of a Deep Network. Univ. Montr. 2009, 1341, 3. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, ND, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- LeCun, Y.; Denker, J.S.; Solla, S.A.; Howard, R.E.; Jackel, L.D. Optimal Brain Damage; NIPs: Tokyo, Japan, 1989; Volume 2, pp. 598–605. [Google Scholar]
- Maaten, L.v.d.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Chatfield, K.; Simonyan, K.; Vedaldi, A.; Zisserman, A. Return of the devil in the details: Delving deep into convolutional nets. arXiv 2014. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Stanford, CA, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Weinberger, K.Q.; van der Maaten, L. Densely connected convolutional networks. arXiv 2016. [Google Scholar]
- Targ, S.; Almeida, D.; Lyman, K. Resnet in Resnet: Generalizing residual architectures. arXiv 2016. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Samples | Training Set | Testing Set | ||||
|---|---|---|---|---|---|---|---|
| L (px) | W (px) | N | L (px) | W (px) | N | ||
| Sedan |  | 21.45 | 10.47 | 776 | 20.83 | 10.16 | 1075 |
| Station Wagon |  | 19.99 | 9.76 | 2302 | 19.14 | 9.32 | 4178 |
| Van |  | 24.65 | 12.06 | 312 | 24.14 | 11.83 | 512 |
| Working Truck |  | 27.17 | 13.31 | 29 | 26.58 | 13.02 | 34 |
| Net Struct. | Orig.M | Orig.16 | New Ext. 128 | New Ext. 256 | Sel. Ext. 128 | Sel. Ext. 256 | Sel. S-Ext. 128 | Sel. S-Ext. 256 |
|---|---|---|---|---|---|---|---|---|
| Model (Mb) | 361.7 | 537.1 | 439.6 | 519.8 | 426.1 | 460.9 | 362.2 | 362.8 |
| Model (Mb) | - | 175.4 | 77.9 | 158.1 | 64.4 | 99.2 | 0.5 | 1.1 |
| Mem (Mb) | 1820.3 | 10547.1 | 1988.4 | 2093.0 | 2018.5 | 2053.7 | 1977.4 | 2004.3 |
| Mem (Mb) | - | 8726.8 | 168.0 | 272.7 | 192.7 | 223.1 | 157.1 | 183.9 |
| Negative | Sedan | Station Wagon | Van | Working Truck | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| ACC | F1 | ACC | F1 | ACC | F1 | ACC | F1 | ACC | F1 | |
| Orig.M | 96.83% | 0.9791 | 58.40% | 0.6247 | 81.81% | 0.8010 | 90.11% | 0.8422 | 69.72% | 0.5435 |
| Orig.16 | 99.68% | 0.9624 | 57.13% | 0.6433 | 82.04% | 0.8329 | 91.64% | 0.8650 | 70.05% | 0.5914 |
| New Ext. | 97.20% | 0.9822 | 63.38% | 0.6474 | 82.13% | 0.8245 | 91.92% | 0.8459 | 74.52% | 0.5666 |
| Sel. Ext. | 96.90% | 0.9808 | 63.56% | 0.6487 | 82.25% | 0.8247 | 93.00% | 0.8501 | 68.16% | 0.5609 |
| Glb. | 97.01% | 0.9810 | 65.73% | 0.6438 | 81.51% | 0.8303 | 92.38% | 0.8471 | 71.29% | 0.5377 |
| Glb.ReLU | 97.22% | 0.9820 | 65.95% | 0.6410 | 81.27% | 0.8315 | 92.69% | 0.8477 | 71.25% | 0.5406 |
| Lcl. | 97.00% | 0.9813 | 65.45% | 0.6408 | 81.65% | 0.8310 | 92.66% | 0.8497 | 69.63% | 0.5418 |
| Lcl.ReLU | 97.27% | 0.9823 | 64.61% | 0.6404 | 81.53% | 0.8285 | 92.56% | 0.8498 | 70.70% | 0.5375 |
| Bat. | 97.12% | 0.9814 | 64.40% | 0.6417 | 81.54% | 0.8276 | 92.89% | 0.8471 | 70.38% | 0.5351 |
| Bat.ReLU | 97.30% | 0.9820 | 63.87% | 0.6407 | 81.67% | 0.8273 | 92.66% | 0.8505 | 72.78% | 0.5556 |
| Negative | Sedan | Station Wagon | Van | Working Truck | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| ACC | F1 | ACC | F1 | ACC | F1 | ACC | F1 | ACC | F1 | |
| Orig.M | 96.83% | 0.9791 | 58.40% | 0.6247 | 81.81% | 0.8010 | 90.11% | 0.8422 | 69.72% | 0.5435 |
| Orig.16 | 99.68% | 0.9624 | 57.13% | 0.6433 | 82.04% | 0.8329 | 91.64% | 0.8650 | 70.05% | 0.5914 |
| New Ext. | 97.23% | 0.9823 | 61.97% | 0.6431 | 82.26% | 0.8207 | 92.26% | 0.8484 | 71.97% | 0.5804 |
| Sel. Ext. | 96.96% | 0.9808 | 61.98% | 0.6453 | 82.39% | 0.8192 | 91.69% | 0.8451 | 70.85% | 0.5439 |
| Glb. | 97.12% | 0.9816 | 64.26% | 0.6419 | 81.47% | 0.8263 | 92.83% | 0.8453 | 70.31% | 0.5409 |
| Glb.ReLU | 97.16% | 0.9818 | 64.47% | 0.6441 | 81.80% | 0.8290 | 92.94% | 0.8505 | 73.60% | 0.5472 |
| Lcl. | 96.94% | 0.9809 | 65.91% | 0.6384 | 81.45% | 0.8306 | 92.46% | 0.8507 | 68.53% | 0.5469 |
| Lcl.ReLU | 97.11% | 0.9816 | 65.11% | 0.6439 | 81.69% | 0.8296 | 92.46% | 0.8481 | 72.05% | 0.5564 |
| Bat. | 97.01% | 0.9809 | 63.75% | 0.6413 | 81.52% | 0.8242 | 92.92% | 0.8457 | 69.94% | 0.5442 |
| Bat.ReLU | 97.31% | 0.9823 | 65.12% | 0.6420 | 81.45% | 0.8303 | 92.70% | 0.8482 | 71.70% | 0.5419 |
| Original | Sedan | Station Wagon | Van | Working Truck | ||||
|---|---|---|---|---|---|---|---|---|
| ACC 58.40% | ACC 81.81% | ACC 90.11% | ACC 69.72% | |||||
| New Ext. & Sel. Ext. | New | Select | New | Select | New | Select | New | Select |
| N64/S50 | 63.02% | 63.19% | 81.85% | 82.27% | 92.58% | 91.81% | 74.06% | 76.30% |
| N96/S71 | 63.00% | 62.78% | 82.11% | 82.35% | 92.76% | 91.90% | 75.84% | 67.97% |
| N128/S89 | 63.38% | 63.56% | 82.13% | 82.25% | 91.92% | 93.00% | 74.52% | 68.16% |
| N160/S109 | 63.23% | 63.59% | 82.07% | 81.96% | 92.62% | 92.48% | 75.30% | 75.73% |
| N192/S130 | 62.55% | 62.30% | 81.99% | 82.40% | 92.53% | 92.07% | 72.54% | 73.62% |
| N224/S150 | 63.38% | 63.10% | 81.84% | 82.05% | 92.46% | 91.95% | 69.97% | 68.73% |
| N256/S168 | 61.97% | 61.98% | 82.26% | 82.39% | 92.26% | 91.69% | 71.97% | 70.85% |
| Sedan | Station Wagon | Van | Working Truck | |||||
|---|---|---|---|---|---|---|---|---|
| ACC | F1 | ACC | F1 | ACC | F1 | ACC | F1 | |
| Global No ReLU, Fix-M | 62.12% | 0.6275 | 81.10% | 0.8212 | 91.46% | 0.8479 | 72.67% | 0.5492 |
| Global ReLU, Fix-M | 60.26% | 0.6289 | 81.48% | 0.8132 | 91.03% | 0.8463 | 72.33% | 0.5542 |
| Global No ReLU, Joint | 65.42% | 0.6435 | 81.44% | 0.8320 | 93.29% | 0.8497 | 73.77% | 0.5508 |
| Global ReLU, Joint | 65.66% | 0.6449 | 81.58% | 0.8325 | 92.96% | 0.8484 | 72.06% | 0.5490 |
| Sedan | Station Wagon | Van | Working Truck | |||||
|---|---|---|---|---|---|---|---|---|
| ACC | F1 | ACC | F1 | ACC | F1 | ACC | F1 | |
| Global No ReLU, Joint | 65.42% | 0.6435 | 81.44% | 0.8320 | 93.29% | 0.8497 | 73.77% | 0.5508 |
| Global ReLU, Joint | 65.66% | 0.6449 | 81.58% | 0.8325 | 92.96% | 0.8484 | 72.06% | 0.5490 |
| Local No ReLU, Joint | 65.79% | 0.6415 | 81.63% | 0.8335 | 92.91% | 0.8494 | 69.67% | 0.5491 |
| Local ReLU, Joint | 65.53% | 0.6441 | 81.55% | 0.8320 | 92.88% | 0.8468 | 72.17% | 0.5432 |
| Batch-wise No ReLU, Joint | 64.79% | 0.6442 | 81.95% | 0.8308 | 92.40% | 0.8498 | 71.04% | 0.5548 |
| Batch-wise ReLU, Joint | 65.00% | 0.6435 | 81.72% | 0.8307 | 92.58% | 0.8477 | 74.92% | 0.5662 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, F.; Li, S.; Zhu, C.; Lan, X.; Chang, H. Cost-Effective Class-Imbalance Aware CNN for Vehicle Localization and Categorization in High Resolution Aerial Images. Remote Sens. 2017, 9, 494. https://doi.org/10.3390/rs9050494
Li F, Li S, Zhu C, Lan X, Chang H. Cost-Effective Class-Imbalance Aware CNN for Vehicle Localization and Categorization in High Resolution Aerial Images. Remote Sensing. 2017; 9(5):494. https://doi.org/10.3390/rs9050494
Chicago/Turabian StyleLi, Feimo, Shuxiao Li, Chengfei Zhu, Xiaosong Lan, and Hongxing Chang. 2017. "Cost-Effective Class-Imbalance Aware CNN for Vehicle Localization and Categorization in High Resolution Aerial Images" Remote Sensing 9, no. 5: 494. https://doi.org/10.3390/rs9050494
APA StyleLi, F., Li, S., Zhu, C., Lan, X., & Chang, H. (2017). Cost-Effective Class-Imbalance Aware CNN for Vehicle Localization and Categorization in High Resolution Aerial Images. Remote Sensing, 9(5), 494. https://doi.org/10.3390/rs9050494