1. Introduction
Image registration refers to the process of aligning two images of the same scene taken at different times, from different sensors, or at different views [
1,
2]. It is the basis of remote sensing image processing, and its result has been widely used in many areas, including image fusion [
3], environment monitoring [
4], and change detection [
5].
Existing image registration methods can be generally divided into two categories: appearance-based methods and feature-based methods. Among appearance-based methods, the most representative approaches are the cross correlation [
6] and mutual information [
7] methods. These methods directly use the grayscale distribution information of an image in the registration task; they have been extensively used in the area of medical image registration [
8]. In feature-based methods, significant features are extracted from images and then matched based on their similarities. These features, which are extracted as shape contours [
9], points [
10], lines and curves [
11], can be more stable than grayscale information. Compared with appearance-based methods, feature-based methods can achieve high-accuracy registration for images with significant differences in grayscale at a lower computation cost. In the area of remote sensing image registration, images are typically taken at different times; thus, difference in grayscale is relatively apparent. Therefore, most existing registration methods for remote sensing images are based on various features.
Among all the features used in image registration, point features are the most common. In 2004, a method called scale-invariant feature transform (SIFT) [
12] was proposed; since then, this method has become the most popular point feature descriptor. SIFT extracts local extrema in scale space to achieve scale invariance and then generates descriptors by using local gradient distribution information. To improve robustness or reduce computation cost, various point feature descriptors [
13,
14,
15,
16,
17,
18] have been proposed based on the SIFT descriptor. Bradley [
19] proposed a registration method for intensity-range images, where mutual information was combined with SIFT features. Although these SIFT-like features have been widely used in a variety of areas, they continue to exhibit limits in remote sensing images with evident background changes, which affect the location and description of interest points. Therefore, other point features have been proposed in recent years, and shape context (SC) [
20] is one of the most well-known; SC uses the points relative to a reference point to generate a descriptor called shape context. Huang and Li [
21] first applied shape context to remote sensing image registration. Subsequently, Jiang et al. [
22] improved shape context to achieve rotation and scale invariance. However, the performance of these shape context-based methods deteriorates when geometric distortion is caused by a view change between the images. Arandjelović [
23] proposed an object matching method using boundary descriptors. The the local curvature maxima along a contour were detected as boundary keypoints. Then, the local boundary descriptor was constructed using the profile of boundary normals’ directions. Finally, the set of boundary descriptors is clustered, and an object is represented. Evaluated on a large data set, this method can successfully match objects in terms of view change. Whereas, since there are abundant objects in a remote sensing image, it might be difficult to represent an object with a cluster of boundary descriptors. The incorrect shape components in remote sensing images may also influence the effectiveness of this method.
Compared with point features, line features in an image contain more geometric and structural information. Thus, registration methods based on line segments have attracted increasing attention in recent years. Existing registration methods based on line segments can be divided into two classes: descriptor-based methods and search-based methods.
In descriptor-based methods, the local appearance of a line segment must be described to match lines with maximal similarity. Bay et al. [
24] proposed a line-matching method that used a color histogram to match lines and a topological filter to remove outliers. This method is capable of working with a wide range of scenes based on line segments in color images. Wang et al. [
25] proposed a line descriptor called mean-standard deviation line descriptor (MSLD), which was constructed in a SIFT-like manner. MSLD defines the local area of a line segment as a pixel support region (PSR) and then uses the mean and standard deviation of the gradient in PSR to generate a line descriptor. An improved descriptor, called line band descriptor (LBD) [
26], was also proposed; it realized scale invariance by using a scale-space line extraction strategy. Verhagen et al. [
27] introduced a common method to add scale-invariance to a line descriptor, and scale-invariant MSLD was presented in this manner. Wang et al. [
28] clustered line segments into local groups based on their spatial relations. A group of line segments was called a line signature (LS). The similarity of LS features is determined by the length and angle information of line segments, which is sensitive to endpoint changes. Fan et al. [
29] introduced a method called line matching leveraged by point correspondences (LP). In this method, an affine invariance from one line and two coplanar points was used to improve the distinctiveness and robustness of line matching. Arandjelović [
30] proposed a frontal face recognition algorithm based on edge information. This algorithm can robustly match frontal faces under extreme illuminations; but the vertical symmetry of frontal faces which was used to remove false edges, might not be effective in other scenarios. Shi and Jiang [
31] proposed an automatic image registration method that utilized the midpoints of line segments to generate shape context and describe shape contours (named RMLSM for short). The experimental results showed that this method could be used in the registration of remote sensing images with evident background changes. Nonetheless, the location of a midpoint is sensitive to segment fragmentation, which limits the use of this method.
Unlike descriptor-based methods, search-based methods typically use an iterative strategy to register two images without describing line features. Coiras et al. [
32] proposed an iterative method for visual-infrared image registration that randomly selected three line segments at a time and used their intersections to calculate the affine matrix between two images. An improved method was presented by Li and Stevenson [
33], who adopted a selective search strategy to reduce computation cost. Zhao and Goshtasby [
34] introduced a registration method for multitemporal remote sensing images. In this method, four lines in each image are selected concurrently starting from the longest line segment to estimate the homography parameters. Then, the parameters are refined by selecting more lines. This method works efficiently when the scale difference between images is small.
In the present study, a novel registration method for optical remote sensing images is proposed. The method is called registration with line segments and their intersections (or RLI, for short). First, line segments are extracted in the image pyramid. These segments will be used to estimate and unify the scales of the reference image and the test image. The problem of segment fragmentation becomes negligible when the scales of the two images are at close levels. Second, a novel line descriptor is introduced, and the line segments are matched in image pyramids based on the distances of the descriptors. The local area near a line segment remains relatively stable; therefore, this descriptor can obtain a robust description of a line feature. Lastly, a triplet of intersections of matching lines is selected to estimate the affine parameters between images, and the registration result is refined through an iterative process. The experimental results demonstrate that the proposed RLI method can register optical remote sensing images with high accuracy.
2. Methodology
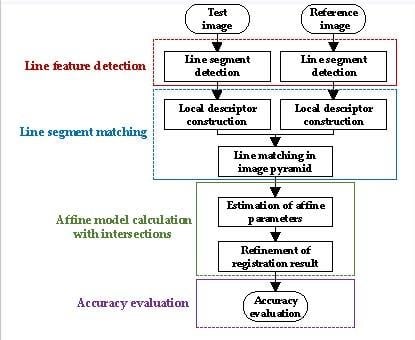
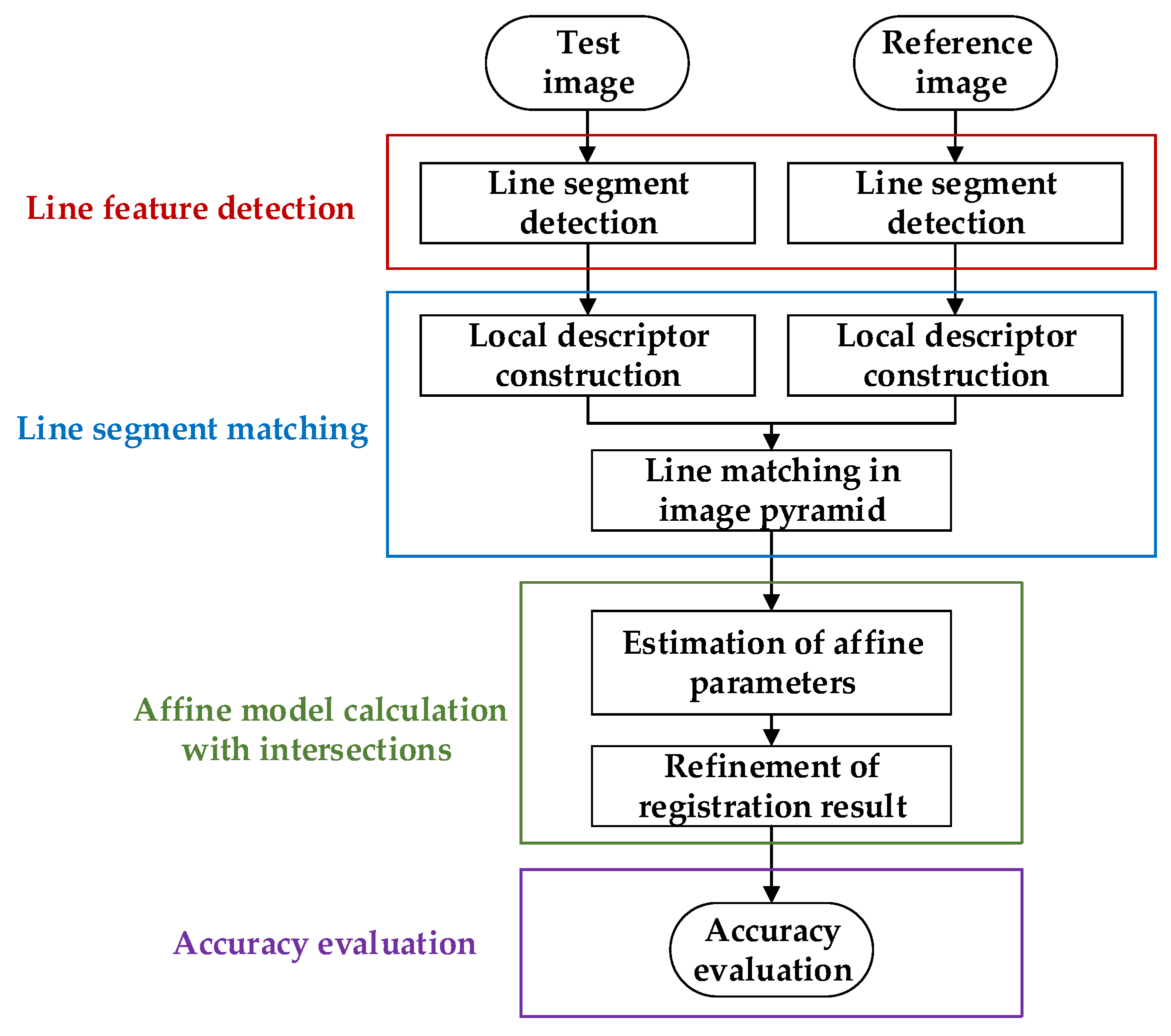
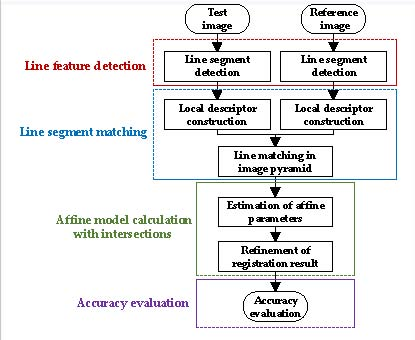
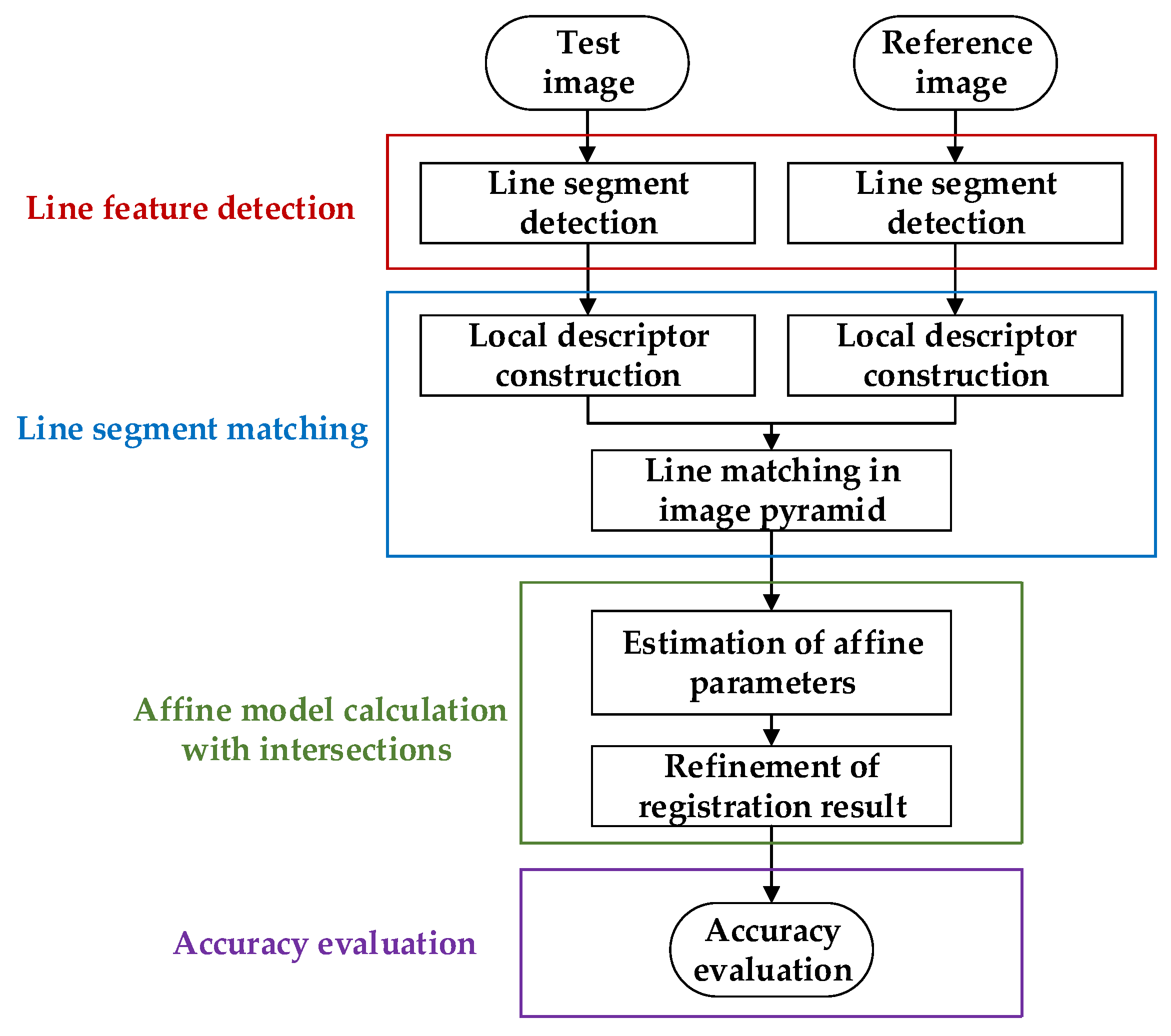
The flowchart of the proposed RLI method is presented in
Figure 1. The core steps can be divided into four aspects: line feature detection, line segment matching, affine model calculation with intersections, and accuracy evaluation. These four aspects are described in detail in the succeeding sections.
2.1. Line Segment Detection
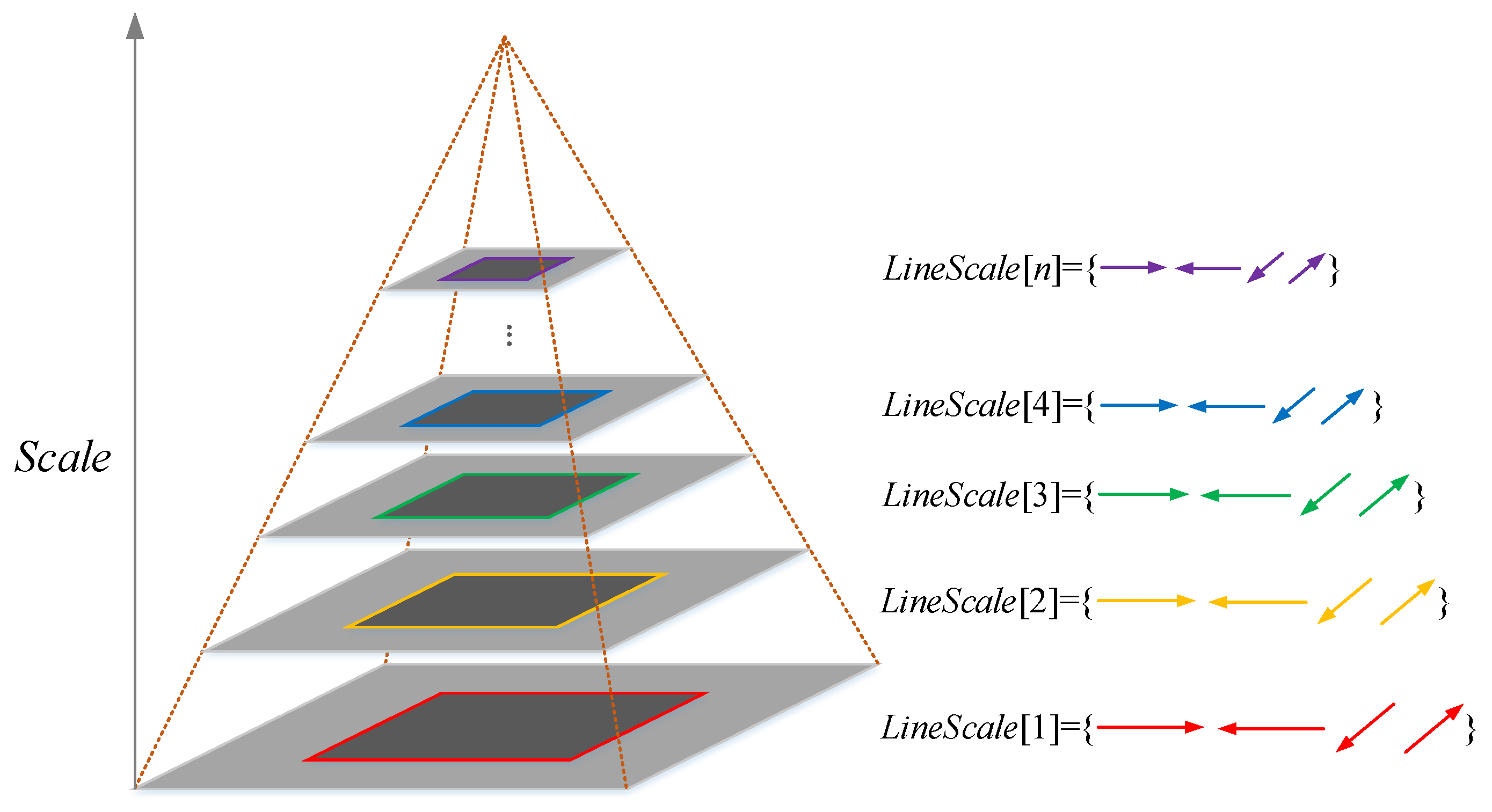
Segment fragmentation is a common problem for line detection algorithms, and it has a significant influence on the results of image registration. If the scales of the reference and test images are estimated, then we can unify the scales of these two images via downsampling to overcome the segment fragmentation problem. Thus, we propose a strategy for unifying the scales of images via an image pyramid. First, line segments are extracted from the image pyramid. Second, local descriptors for line segments from different scales are generated. Third, the scales of the two images are estimated by calculating the Euclidean distances of the descriptors. Lastly, the scales of the two images are unified into the same level, and the line segments are matched based on the distances of their descriptors. The image pyramid line segment detection method is presented in this section.
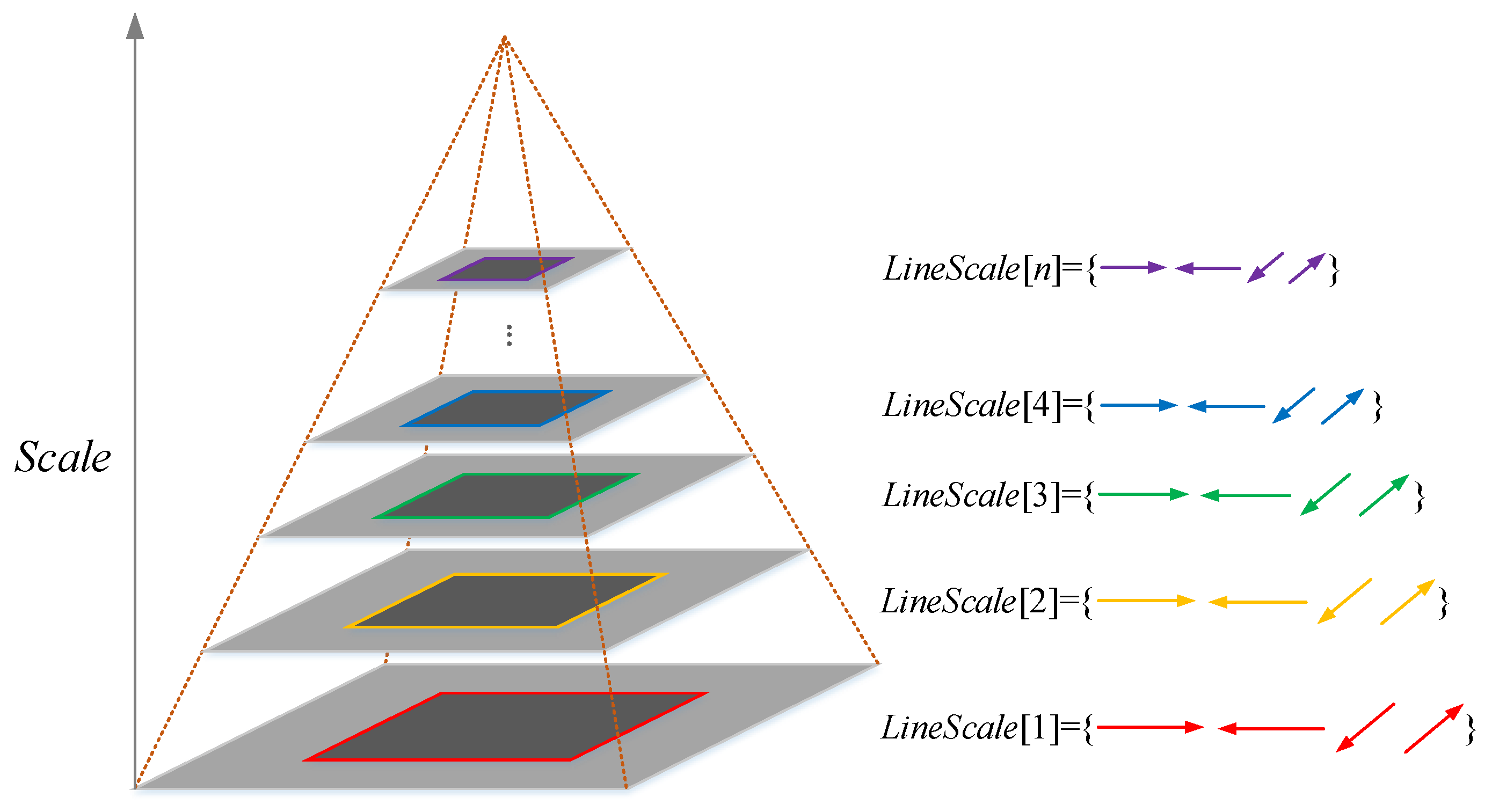
In this study, we assume that all the input images contain a considerable amount of artificial objects (e.g., roads, buildings, farmlands, and airports) that can be detected as line segments. To overcome the problem of segment fragmentation, an image pyramid that consists of n octaves is used. In this image pyramid, each octave is generated by downsampling the original input image with a series of scales, and the first octave is established as the input image. Furthermore, each octave has only one layer; such a scenario differs from the traditional Gaussian pyramid. We can obtain the multi-resolution representation of an image by using this image pyramid.
To detect line segments, EDLines [
35] algorithm is used in this paper. EDLines is an automatic line segment detection algorithm with no requirement for parameter tuning, and it is one of the state-of-the-art line detection algorithms [
36]. It can obtain meaningful and accurate segments by using a false positive control criterion named the Helmholtz principle [
37]. Thus, EDLines is suitable for extracting line segments from the main shape contours in remote sensing images. As shown in
Figure 2, EDLines algorithm is applied to each octave image in the image pyramid.
Although EDLines algorithm can obtain meaningful segments as mentioned above, there still exists segment fragmentation in practice. In this study, a line-merging procedure is performed according to the parallel relation and distance of the line segments. The underlying idea of line-merging procedure is to merge two segments that lie on one line belonging to the same shape contour. This procedure can reduce the number of segments by an average of 20%, thereby not only helping improve segment quality but also reduce computation cost. It is worth mentioning that the proposed RLI can work without this line-merging procedure. Then, all the remaining line segments from the ith octave of the pyramid are represented as LineScale[i]. The descriptor for each segment and the image pyramid line matching method are introduced in the following sections.
2.2. Line Segment Matching
In this section, a novel line descriptor based on the distribution of local gradient information is proposed. Unlike descriptors with fixed widths of sub-regions, such as MSLD [
25] and LBD [
26], the proposed descriptor divides the local area into a series of bands (sub-regions) with gradually changing widths. The center band of this descriptor has the minimal width, and the peripheral bands have the maximal widths. Thus, the widths of bands change gradually, and we called it line descriptor with gradually changing bands (LDGCB). The LDGCB descriptor is more distinctive than traditional descriptors.
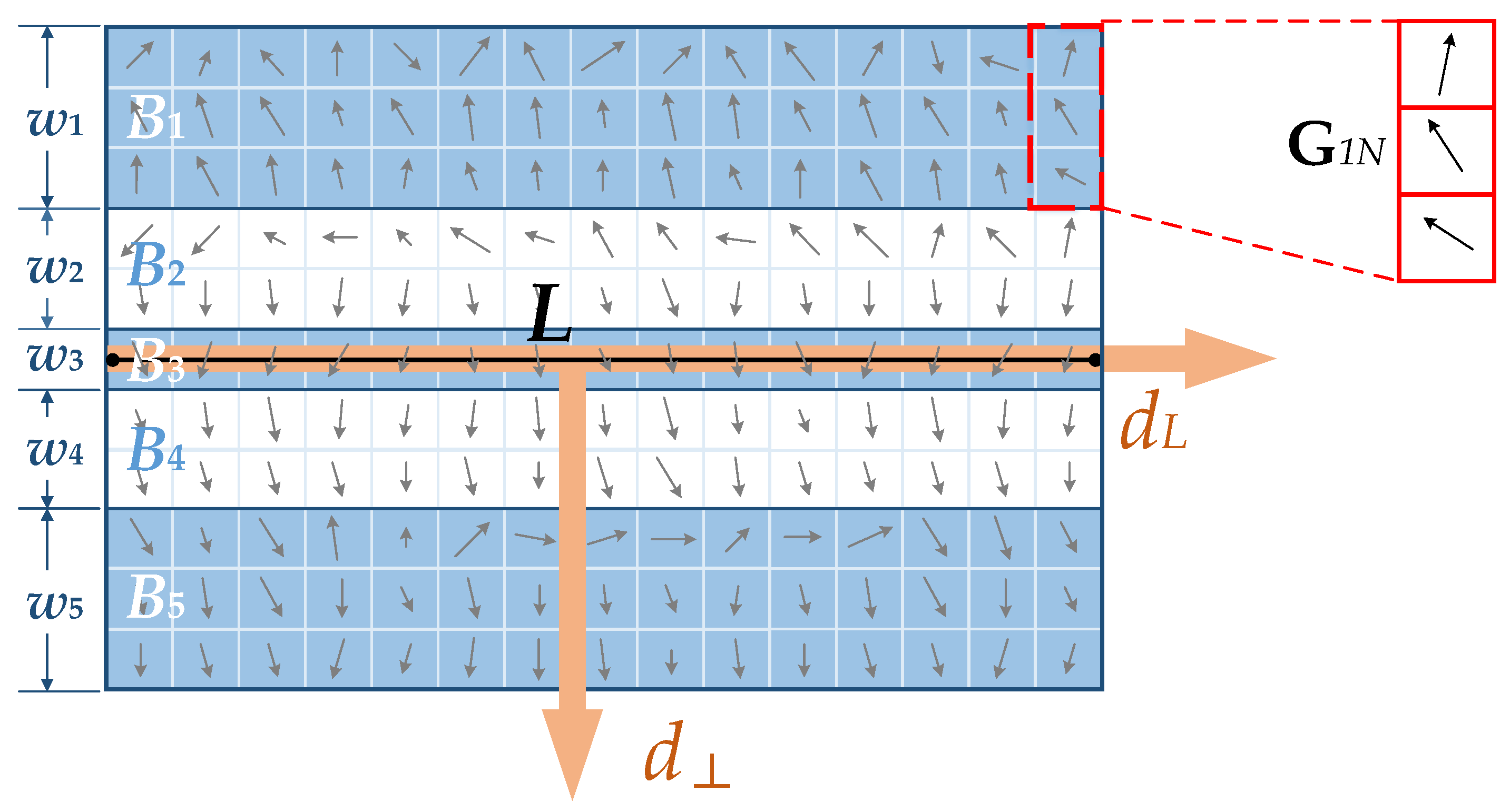
2.2.1. Construction of Local Descriptor
Let
L denote a line segment with length
N in an octave image. Centered on
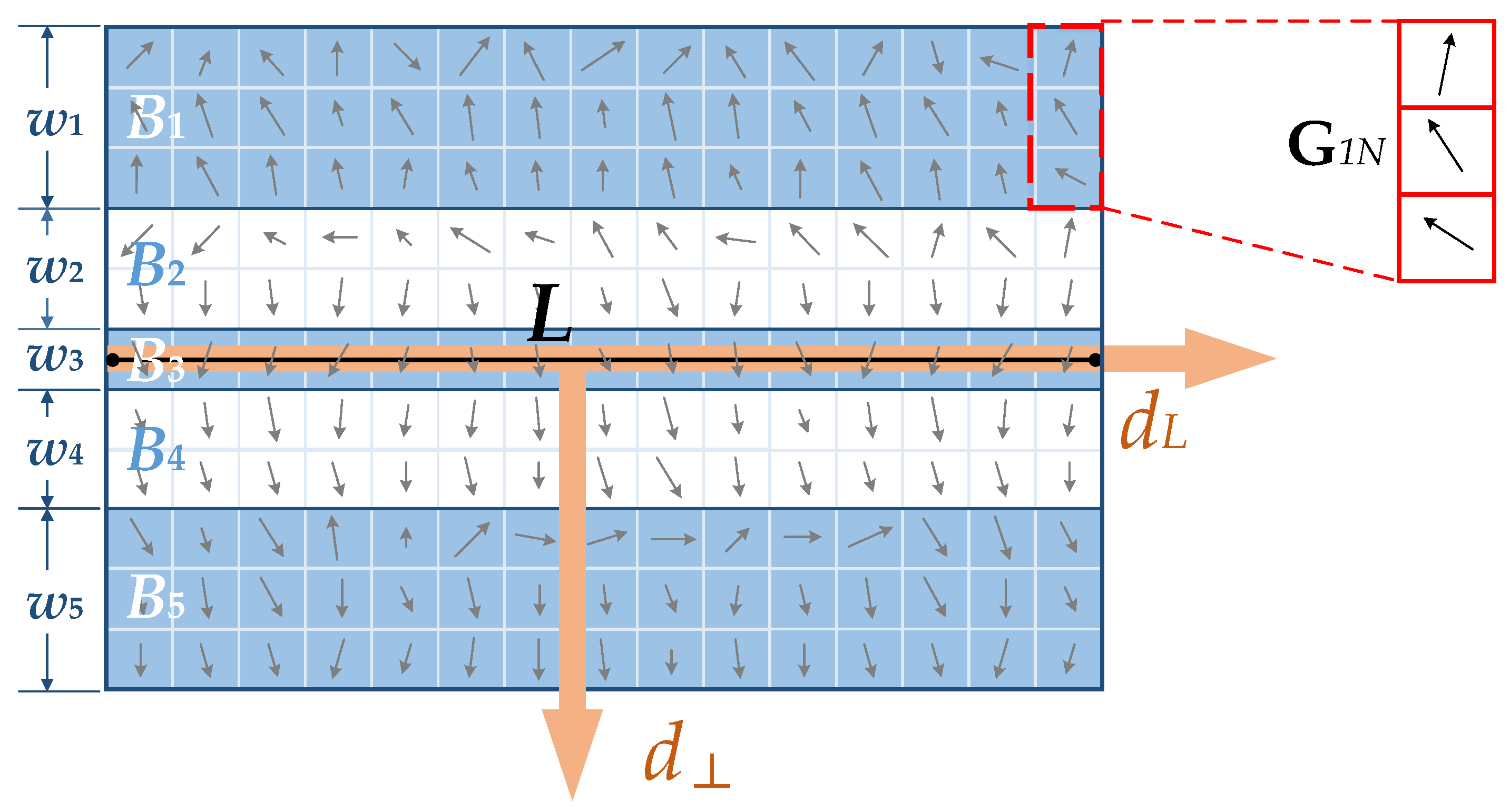
L, a rectangular region, which is also known as the support region, is chosen as the local neighborhood of line segment
L. Then, we divide this region into
m banded sub-regions
, which are parallel with
L, and the corresponding widths are
.
Figure 3 presents an example of the banded sub-regions of line segment
L, where
and
.
Motivated by MSLD, the gradient information is used to determine two critical directions of a line segment. The orthogonal direction is defined as the average gradient orientation of all the pixels on segment L, and the direction is defined as the counterclockwise orthogonal direction of . For each pixel in the rectangular support region, the corresponding gradient g is decomposed into the following two directions , thereby obtaining rotation invariance.
To emphasize the importance of center sub-regions, a Gaussian function with weighting coefficient , is applied to all the rows of the support region, where d is the distance from the row to line L, and is equal to the half width of the entire support region. location changes along direction cause boundary effects; hence, a simple method is provided to reduce these effects. A pixel with gradient g is given in sub-region . Then, g can affect the nearest two sub-regions and , with the weighting coefficients ( and ). We denote the distances from this pixel to the centers of and as and , respectively. We can then obtain the coefficients and .
Let
denote the gradient distribution of the
jth column in sub-region
. The variable
is a 4D vector, calculated by accumulating all the gradients in this column along four directions as follows:
where
A description matrix of the gradient distribution, called the band gradient matrix (BGM), is constructed by crossing all columns in sub-region
as follows:
The mean and standard deviation of each row in
are computed and denoted as two 4D vectors, i.e.,
and
, respectively. After crossing all the BGMs, we obtain a vector with 8
m dimensions as follows:
Similar to MSLD, the first half and the second half of LDGCB are normalized separately, thereby guaranteeing that both parts will have equal distinctiveness. A threshold of 0.4 is empirically applied to each element of LDGCB to improve its robustness against nonlinear illumination. Lastly, a renormalization process is performed, and a unit LDGCB descriptor is generated.
2.2.2. Line Segment Matching in Image Pyramids
Line segments and descriptors are generated as discussed in the previous sections. In this section, we present a method to unify the scales of the reference image and the test image, as well as to match line segments at a unified scale. The influence of segment fragmentation is significantly reduced using this method, thereby allowing the registration method to work with a wide range of scale changes. To achieve this goal, the scales of two input images should be first estimated by comparing the Euclidean distances of local descriptors from different octaves of the image pyramid.
Let denote the test image and denote the reference image. These two images of the same scene, are taken at different times, and the ground truth scale between and is denoted as . An image pyramid that consists of N octaves is constructed based on , and the scale between two adjacent octaves is s. The original test image is denoted as , and the ith octave is denoted as . Thus, the scale between and is equal to . The image pyramid based on is constructed in the same manner. In this study, we set and .
The concept of scale estimation originates from the fact that the distances between tentatively matched descriptors are minimal, when the scales of two images are at the same level. Thus, we can regard the scale with minimal distances as the estimated scale between two images. In this study, descriptors from any octave are tentatively matched with descriptors from the first octave of the other image pyramid. Therefore,
candidate scales, i.e.,
, are observed from the image pyramids. In each candidate scale, the top
M least Euclidean distances of the tentatively matched descriptors are accumulated. The scale with the minimal sum of Euclidean distances is denoted as
, which is the estimated value of the scale between two images. In this paper, the recommended value range of
M is 60 ∼ 120, and we use
among all experiments. The qualitative sensitivity analysis of
M is given in
Section 3.4.3.
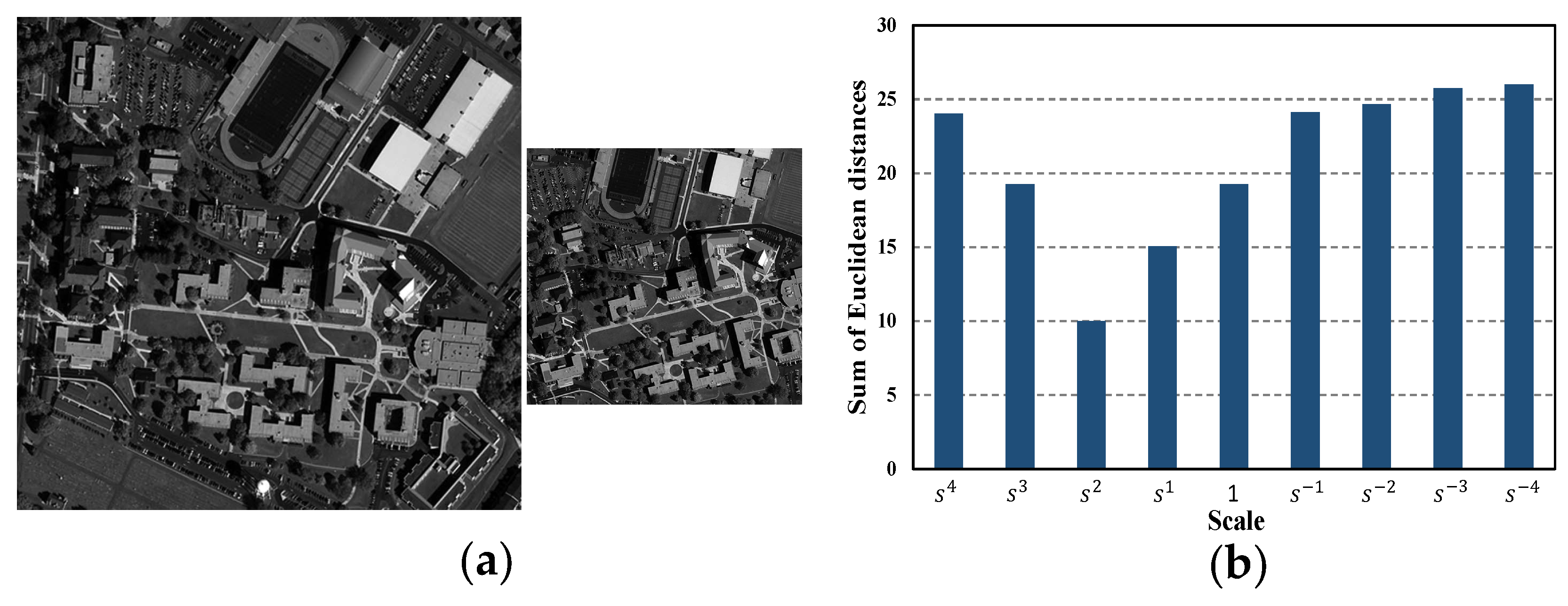
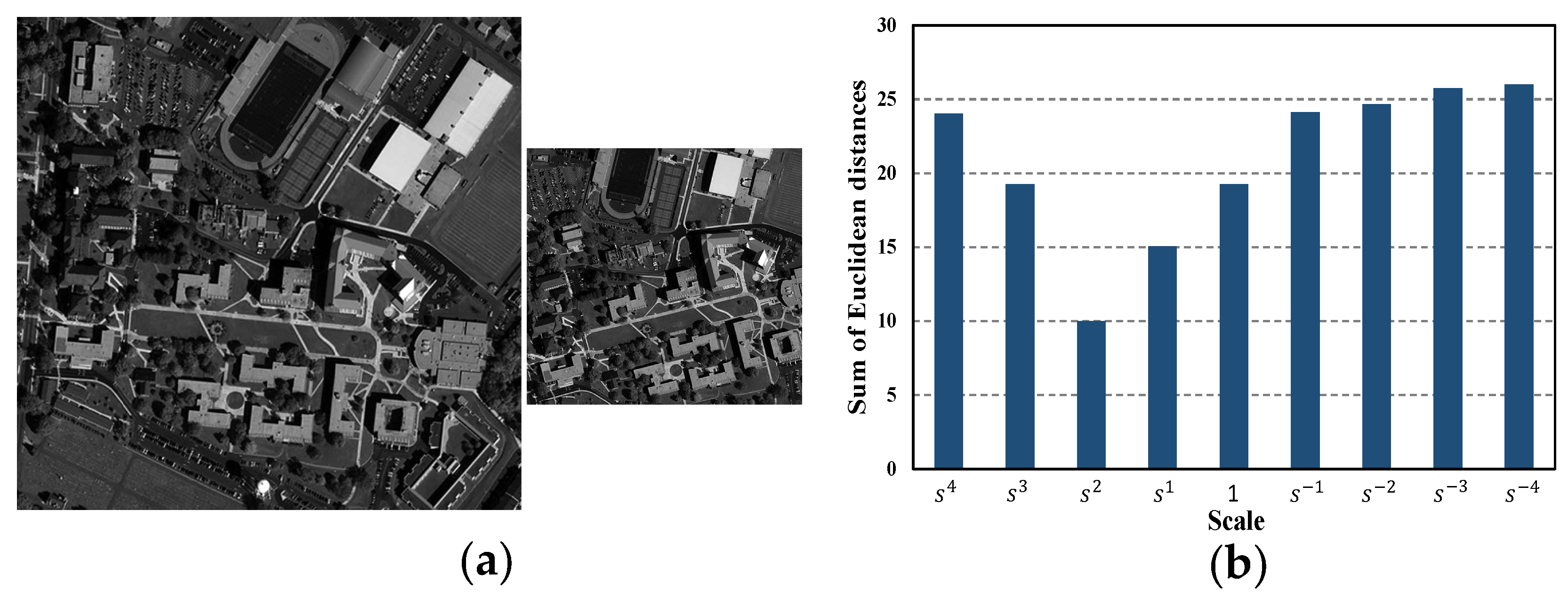
An example for scale estimation is provided in
Figure 4, where the ground-truth scale between
and
is
. Evidently, the estimated scale is
, which is the closest among the nine candidate scales. Furthermore, the sum of the top 100 least distances between tentatively matched descriptors in this estimated scale is significantly smaller than the others, as shown in
Figure 4b.
After the scale estimation process, we can unify the scales of the test and reference images by selecting the corresponding octave images. Let and denote the test and reference line segments, respectively, detected from the octave images in the aforementioned estimated scale. Then, these line segments are tentatively matched based on the LDGCB descriptor. Lastly, the candidate matching results are arranged in ascending order of the nearest neighbor distance ratio (NNDR), which is represented as . The matches with low NNDR are more likely to be correct than those with high NNDR.
Compared with close-range images, remote sensing images are sensed from a considerably larger area, and thus, the same type of objects may occur more than once in an image. An effective method to select correct matches is necessary in the area of remote sensing image registration considering the influence of repeated objects. Hence, an iterative process that aims to improve registration accuracy is introduced in the next section.
2.3. Affine Model Calculation with Intersections
Images are sensed remotely with minimal viewpoint changes; hence, the transformation model between two remote sensing images can be approximated to the affine model [
38]. The line equations of corresponding lines are generally used to calculate the affine model. However, the intersection points of matching lines have at least two advantages over line equations, namely, lower computation cost and easier outlier removal. Thus, the intersection points of matching lines are selected as tentative matching points in this study, and an iterative process is used to calculate the transformation parameters.
Let T denote the affine model between images. The calculation process for the affine model is divided into two steps: (1) the estimation of affine parameters and (2) the refinement of the registration result. In Step (1), the affine model is estimated iteratively using three intersection pairs at a time, and the final estimated model is denoted as . In Step (2), additional intersections are provided as candidate matching points, thereby refining the affine model . Before these two steps, an intuitive and effective similarity metric is addressed.
2.3.1. Similarity Metric
The number of matched pixels (NMP) is proposed as a similarity metric in [
39]; that is, it indicates the number of matched pixels between two edge images transformed via affine transformation
T. NMP is an intuitionistic reflection of the similarity between images, and a high value of NMP suggests a good estimated value of
T. Nevertheless, this similarity metric frequently fails in the field of remote sensing image registration, in which the high resolution of images typically leads to considerable difficulty in matching pixels directly.
To adapt to high-resolution remote sensing images, an improvement to NMP called score of nearest pixels (SNP) is proposed. The implementation of SNP is as follows. A pixel
is given in the test edge image, and
is transformed into
by affine model
. Then, the nearest point of
is identified as
in the reference edge image, and the distance between
and
is denoted as
. The SNP of
is computed as follows:
where the maximal sensitive distance is three pixels. The final SNP is determined by crossing all the pixels in the test edge image as follows:
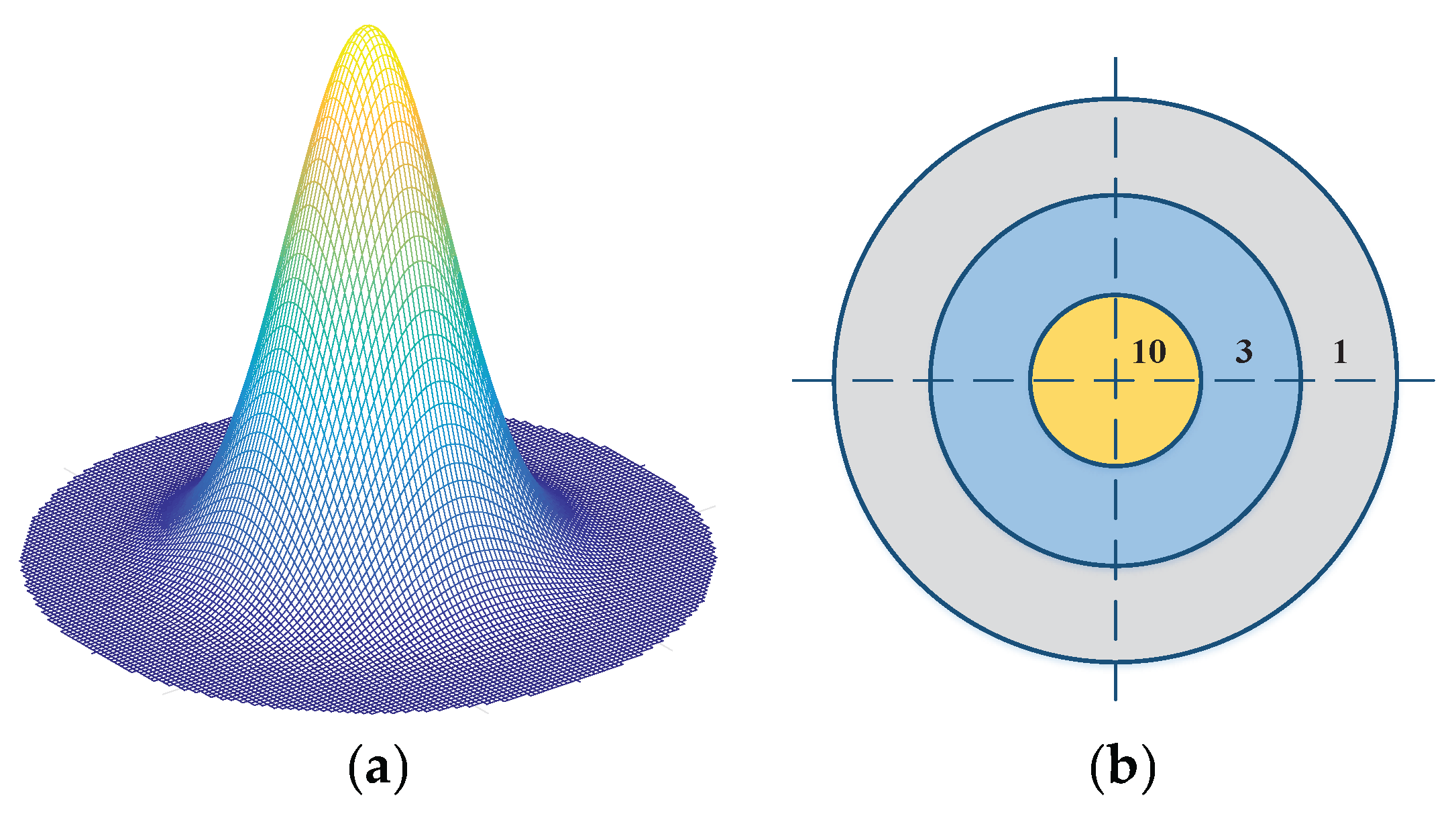
The idea of parameter settings of SNP metric comes from 2D Gaussian distribution model, as shown in
Figure 5. Given 2D Gaussian distribution
where
is equal to one pixel, about 68% of values are within one pixel; about 95% of the values are within two pixels; and about 99.7% are within 3 pixels [
40]. Then, taking the probabilities of different distances as weights, the parameters of SNP are set to integers
for calculating easily. This scoring model (as shown in
Figure 5b) not only emphasizes the importance of matched pixels (within one pixel), but also extends the sensitivity range to three pixels. Thus, the proposed SNP metric can sufficiently describe similarity in high-resolution images by scoring the nearest edge pixels based on their distance.
In order to reduce the computation cost of calculating the similarity metric, the distance transform [
41] is used. In this paper, the distance transform is applied to the reference edge image. The result is a grayscale image, in which each pixel is assigned to the distance of its nearest edge pixel. Distance transform is computed only once for each image pair to be registered, thereby reducing the computation cost efficiently.
2.3.2. Estimation of Affine Parameters
As mentioned in
Section 2.2.2, the tentatively matched lines with low NNDR are more likely to be correct than those with high NNDR. Therefore, a new set of candidate matches with NNDR less than 0.75, is empirically selected from
and denoted as
.
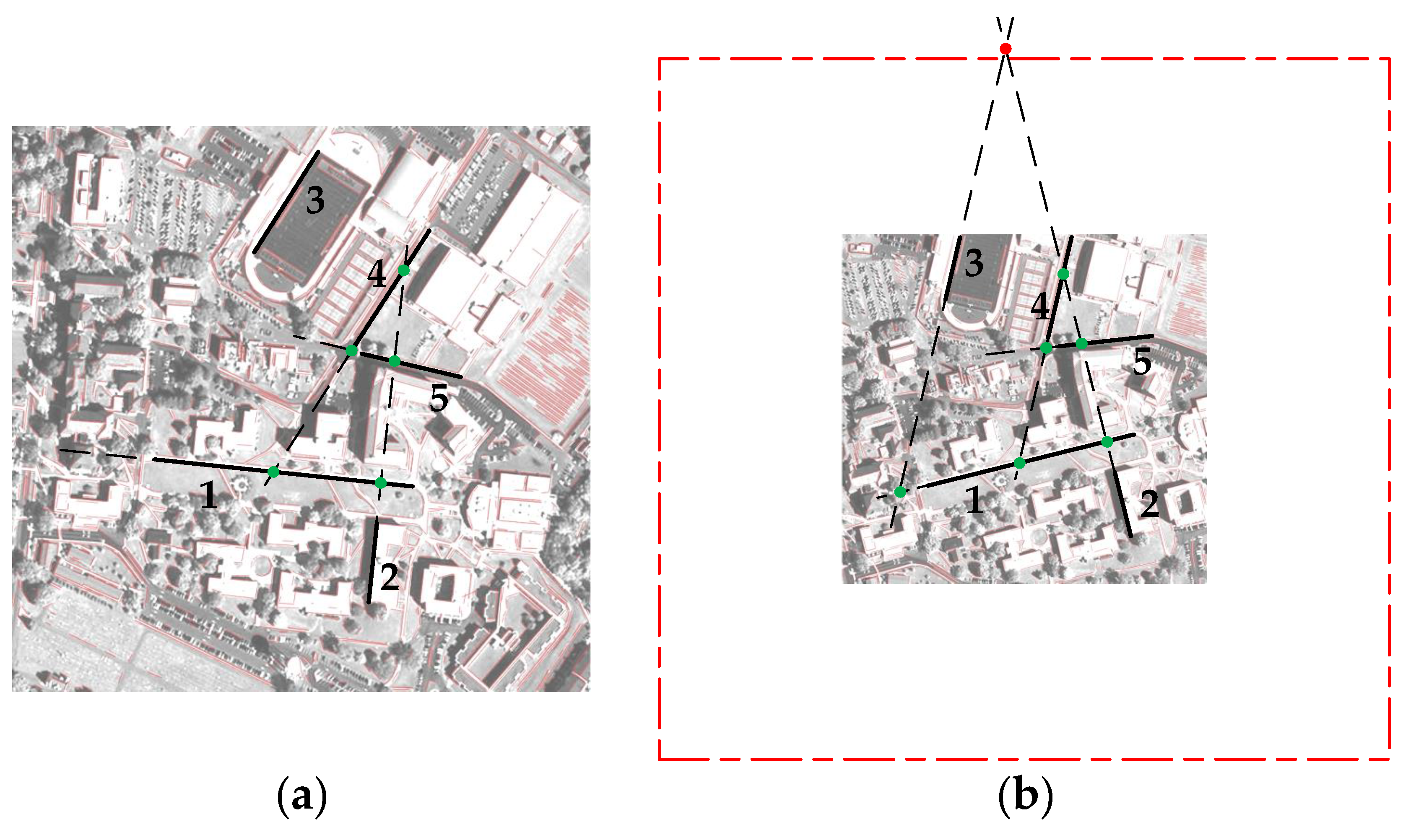
An iterative process is adopted to estimate the affine model between images. In each iteration, a triplet of matching line segments is selected from , and the affine parameters are determined based on their intersections. All the intersections must be located in a rectangular region around the image with an area that is three times larger than the image area. If this location constraint is not satisfied, then this iteration is skipped.
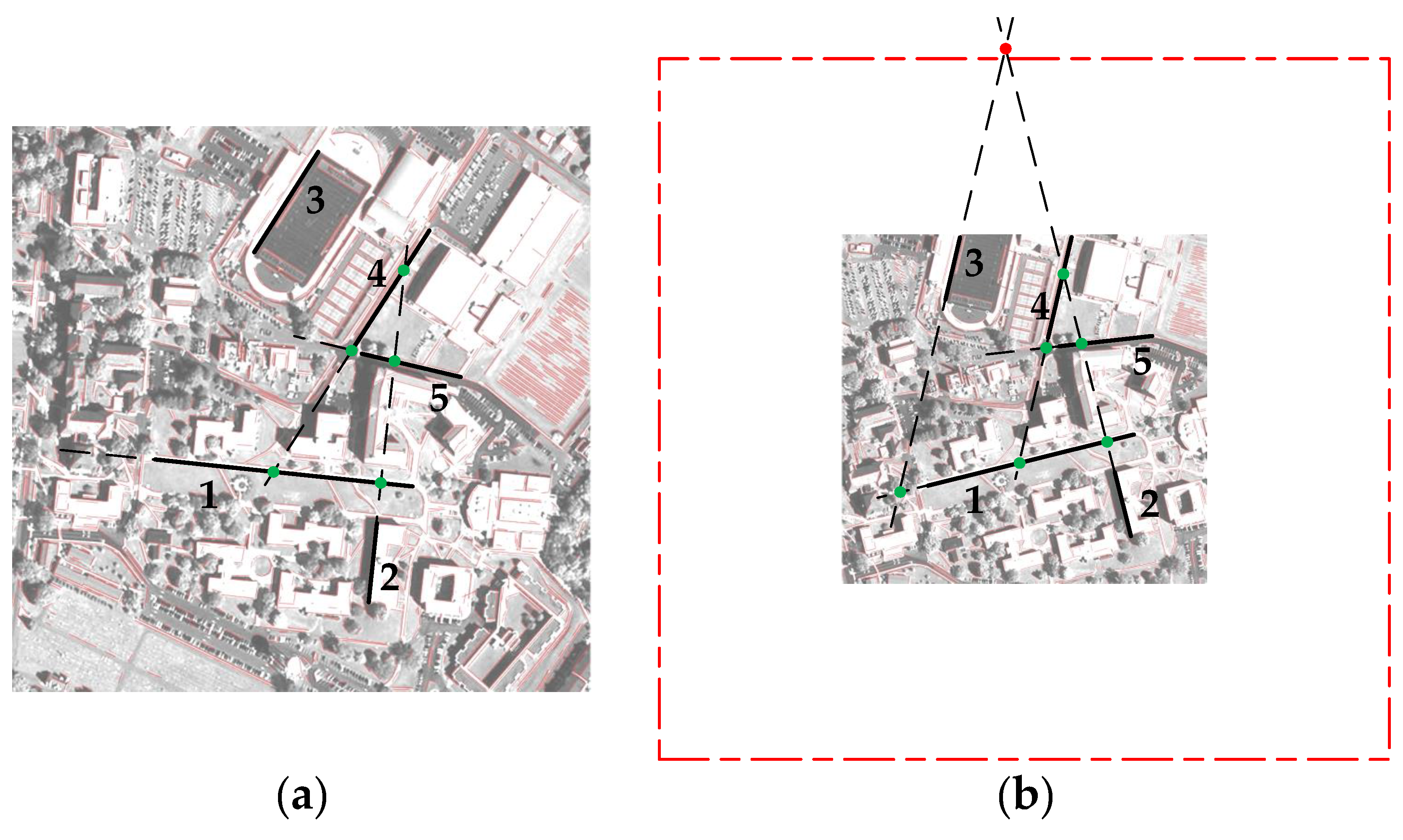
Figure 6 illustrates the process where triplets of intersections are generated from matching lines
. At first, a triplet match
is chosen to generate intersections. Since the intersection of
and
does not satisfy the location constraint (colored red in
Figure 6b), this iteration is skipped. Then,
is selected, and all the three corresponding intersections satisfy the location constraint. This triplet of intersections is used to estimate the affine parameters. Another feasible triple match is
in this example. The location constraint in this paper is effective, because intersections not satisfying the location constraint often come from low-quality line pairs with long distances (such as
and
) or close directions (such as
and
).
An updating strategy of SNP is used in the iterative process, and its implementation is described as follows. The current maximal value of SNP is denoted as MAXSNP. If SNP is greater than MAXSNP in an iteration, then we update the value of MAXSNP and the estimated affine model . After the iteration, the affine model between two images is estimated as . In the ideal situation, the estimated affine model , which is determined from a single triplet of matching line segments, can be regarded as the final affine model. In reality, however, many line segments in can be utilized to improve the accuracy of registration. Therefore, additional corresponding segments are provided to refine the affine transformation in the succeeding section.
2.3.3. Refinement of Registration Result
In this section, additional corresponding intersections are provided to the candidate matching points based on the estimated affine model . Subsequently, is refined by removing the outliers.
To determine which intersection pair can be added as a candidate match, a simple method is introduced in this study. First, each two corresponding lines of intersect at , and the projected distance of this point pair is calculated as . Second, the intersection pairs with projected distances greater than four pixels are removed. Lastly, all the remaining point pairs are arranged in ascending order of the projected distance, and the top 100 point pairs are stored as candidate matching points, i.e., , where .
The affine parameters are refined iteratively based on the SNP similarity metric, and the least squares method is used to calculate the affine model in each iteration. In each iteration, we remove the point pair (starting from the point pair with the maximum projected distance) if the similarity metric is improved without this point pair, and then update the affine parameters and SNP metric. The iteration is terminated when the similarity metric is no longer updated.
After the iteration, all the preserved point pairs are stored in a set of matching points , and the final affine model is calculated from using the least squares method.
2.4. Accuracy Evaluation
To evaluate the performance of the proposed RLI method, three types of criteria are used in this study, namely, number of correct matches, precision, and root-mean-square error (RMSE), which are expressed as follows:
The refers to the number of correct matches in the final matching results, whereas refers to the number of false matches in the final matching results. The image pairs are first registered by an expert, and then the ground truth affine models are generated. A point pair is considered a correct match when its projected distance is less than three pixels.
4. Discussion
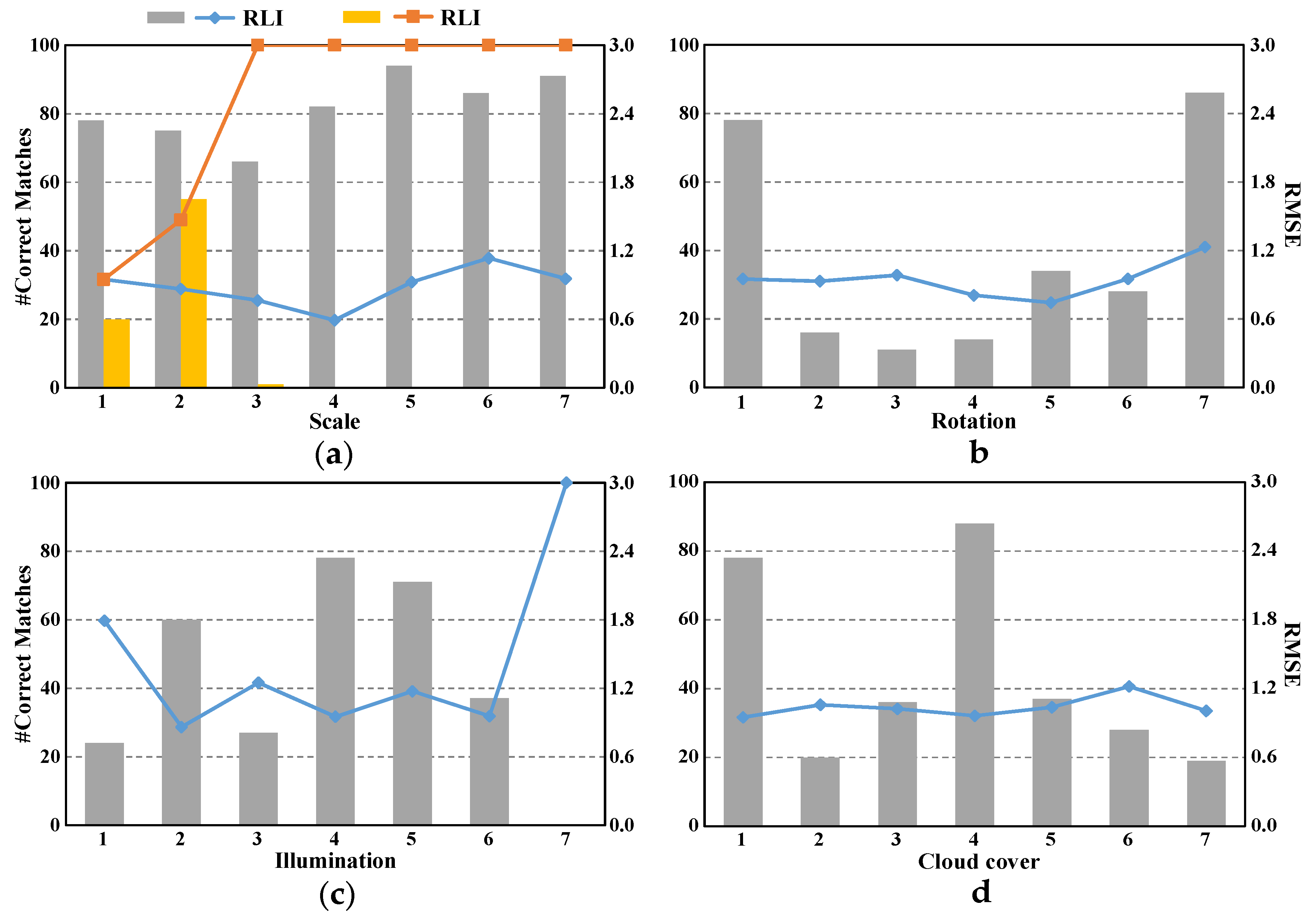
A novel registration method for multitemporal optical remote sensing images based on line segments and their intersections is proposed in this study. The performance of RLI is investigated through a variety of experiments on synthetic and real remote sensing images, and the qualitative sensitivity analysis is given in this paper.
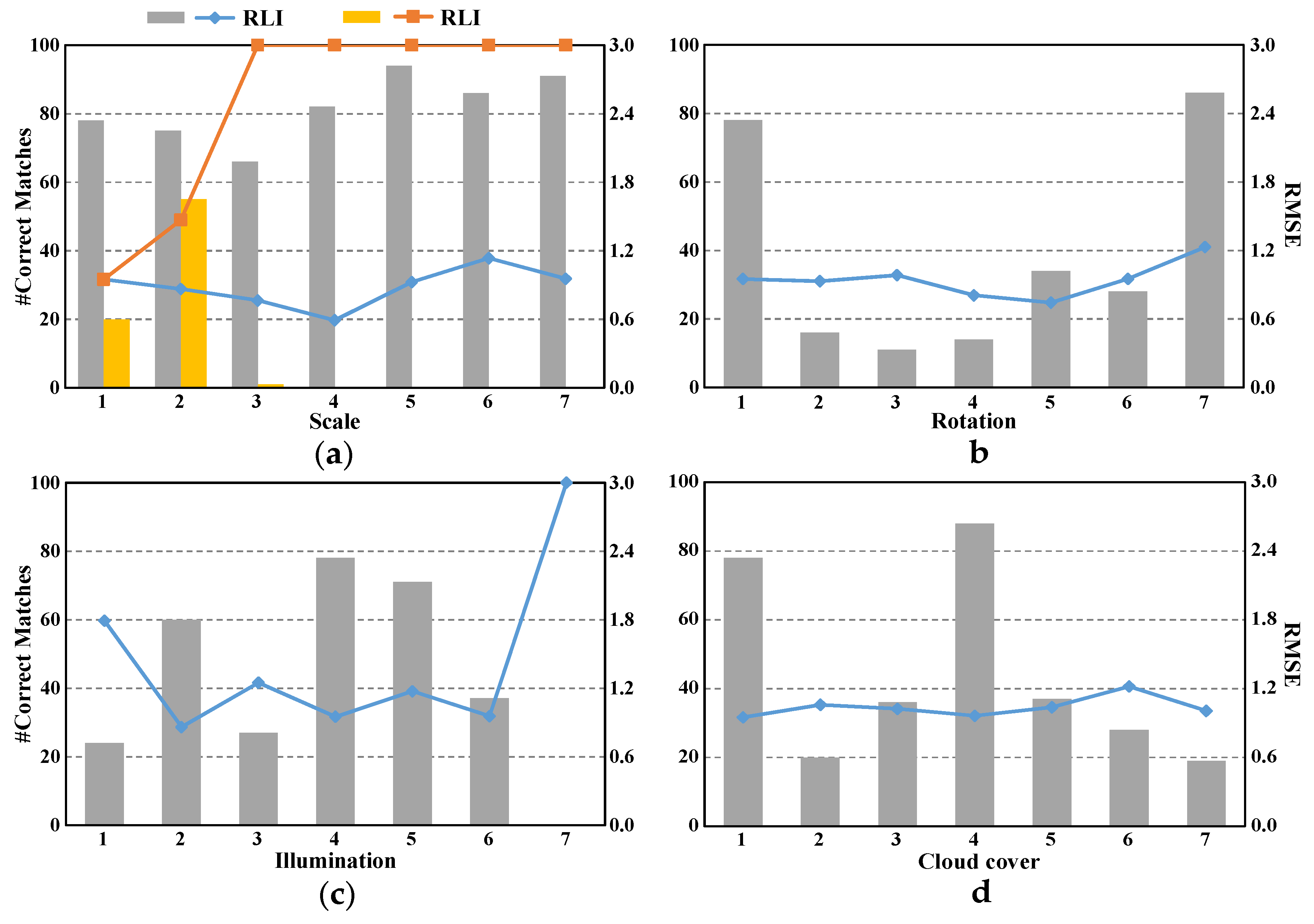
The validity of image pyramid line segment detection is proven using the first group of synthetic images. The RLI method achieves robustness against scale changes by unifying the scales of images. All the experimental results on synthetic images shows that RLI is robust to scale, rotation, illumination, and cloud cover, thereby indicating that RLI can be used to register images with evident background changes (e.g., images taken before and after a disaster).
In this study, real remote sensing image pairs present considerable challenges to a registration method, and their characteristics are as follows. The high-resolution images (with 2 m GSD) in Data set 2-1 are taken by QuickBird at different times, and the background is influenced by floods in Pakistan. The runways in the airport are preserved completely, which can be detected as line features. The images in Data set 2-2 are taken by SPOT4 before and after a tsunami, and they are medium-resolution images (with 10 m GSD). Certain objects in this image pair are damaged by the tsunami. Furthermore, excessive cloud cover is present in this data set. Data set 2-3 corresponds to the MODIS Flood Maps from Aqua satellites. This data set is composed of low-resolution images (with 231.65 m GSD) before and after the Myanmar floods. The flooded regions are shown in red, the original water regions are shown in blue, land is gray, and clouds are white. Although the background changes considerably in this data set, the main shapes of the objects remain stable. Data set 2-4 are high-resolution remote sensing images (with 0.61 m GSD) taken by QuickBird. There are significant geometric distortions and background changes in this data set. This data set is the most challenging one among all the four real data sets.
As shown in
Table 3, RLI outperforms other methods on these challenging real data sets. RMLSM performs the second best among all methods. However, influenced by the geometric distortions, its precision decreases on Data set 2-4. The average RMSE of RLI on real image pairs is 0.90, whereas those for RMLSM, MSLD, SIFT, and LP are 1.08, 1.23, 1.26 and 1.22, respectively. Furthermore, the precision of RLI remains at
on all the data sets, thereby indicating that all the output matches are correct correspondences.
The main reasons for the good performance of RLI are analyzed as follows. (1) When faced with background changes in images, the main shape contours of artificial objects are more stable than point features; these shape contours can be extracted as a group of line segments; (2) The proposed local descriptor is more distinctive and detailed than MSLD; (3) The RLI method can register images with high accuracy by using the intersection points of matching lines to estimate and refine the affine parameters through an iterative process. In practice, our method can also be used to register general images with coplanar lines under affine transformation.
In this study, the use of an iterative strategy for result refinement improves the accuracy of the registration results. However, this process leads to a rapid increase in computation cost when an image is large. Our next work will focus on improving the speed of image registration under the precondition of high accuracy.
5. Conclusions
A registration method based on line segments and their intersections has been proposed for optical remote sensing images in this study. First, the EDLines algorithm is used to detect line segments. To improve robustness against scale changes, the scales of the test image and the reference image are unified into the same level with the use of image pyramids. Then, a novel line descriptor is introduced based on the local gradient information of a line segment, and line segments are matched according to the distances of descriptors. Lastly, triplets of intersection points of matching lines are selected to estimate affine parameters, and the registration result is refined through an iterative process. The experimental results of the synthetic image pairs show that the RLI method is robust to scale, rotation, illumination, and cloud cover. Four challenging real image pairs are selected to analyze the performance of RLI, and the results indicate that RLI outperforms four other methods in terms of RMSE and precision.
In this study, the problem of line-based registration is solved by combining line segments and their intersection points. The stability of line features and the validity of calculating affine transformation via intersection points have been proven by the experimental results, even in images with significant background changes.
In the future, a more robust line segment detector, which can extract complete line segments in disaster images, should be investigated. In addition, the computation speed of the proposed registration method should be improved.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}