
A Spectral-Texture Kernel-Based Classification Method for Hyperspectral Images



Abstract
:
1. Introduction
2. Related Techniques
2.1. Entropy Rate Superpixel Segmentation
2.2. The Spectral Histogram Model
- (i)
- Ideally, optical remote sensing systems should have the same property of a Dirac delta function, which records the intensity value at a pixel location.and which is also constrained to satisfy the identity
- (ii)
- Laplacian filters are derivative filters for detecting areas of edges in images. Since derivative filters are very sensitive to noise, it is common to perform Gaussian smoothing on the image before applying the Laplacian. This two-step process is named as the LoG operation:where is the standard deviation of the Gaussian function used in the LoG filters.
- (iii)
- Gabor filters are generally used for edge detection and texture extraction. and are special classes of bandpass filters, i.e., they allow a certain ‘band’ of frequencies and reject the others. The Gabor filter is defined as follows:where is the standard deviation of the Gaussian function used in the Gabor filter, θ specifies the orientation of the normal to the parallel stripes of the Gabor function and the ratio is set to 0.5.
3. Spectral-Texture Kernel-Based Classification Method
3.1. Structure Areas Generation
3.2. Texture Features Extraction
3.3. Spectral-Texture Support Vector Machines
| Algorithm 1. STK Based Classification Algorithm |
| Input: An original hyperspectral image u, the available training samples Step 1: Initialize the number of segments nb_seg; Step 2: Obtain the first principle component of u using the PCA transform; Step 3: Perform the ERS segmentation according to Equation (1) on the first principle component map obtained from Step 2; Step 4: Convolve the first component map separately with the Dirac delta function, the LoG filter and the Gabor filter according to Equations (7)–(10); Step 5: Compute for each structure area in segmentation map obtained from Step 3 the corresponding spectral histogram according to Equations (5)–(6) using textures features extracted from Step 4; Step 6: Apply the supervised multiclass One vs. All SVM classifier with the proposed spectral-texture kernel according to Equation (12) to classify u by adopting the randomly selected training samples; Step 7: Obtain the resultant classification map. |
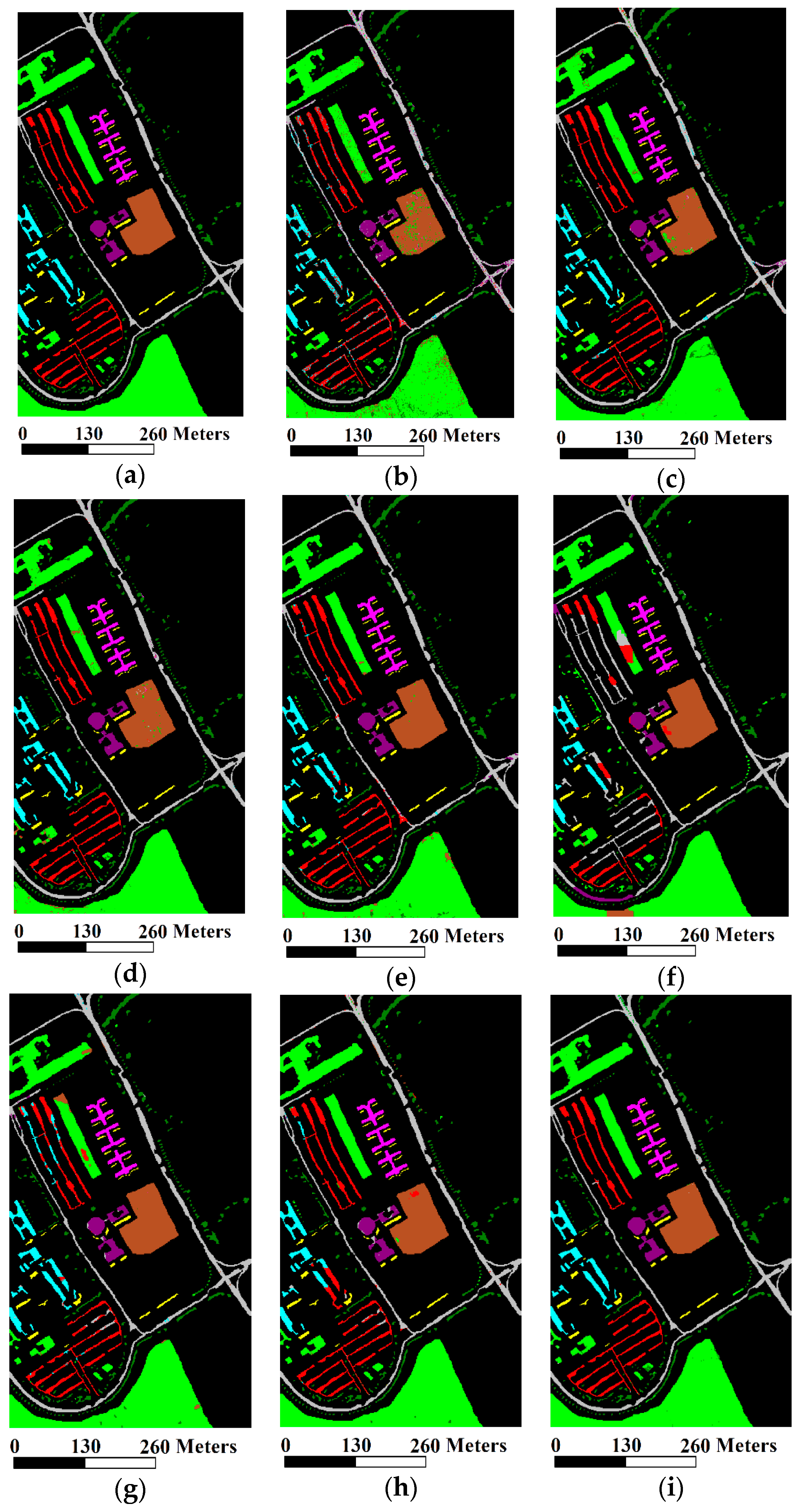
4. Results
4.1. Evaluation Measures
- (1)
- The pixel-wise SVM classifier with a Gaussian RBF kernel. The parameters of the classifier were determined for each dataset in the following experiments.
- (2)
- The spectral-spatial kernel-based classifier (SSK) [43] using a morphological area filter with a size of 30, a vector median filter and a contextual spectral-spatial SVM classifier with a Gaussian RBF kernel.
- (3)
- The spectral-spatial extended EMP classifier [17]. The EMP was constructed based on the first three principal components of a hyperspectral image, a flat disk-shaped structuring element with radius from 1 to 17 with a step of 2, and the number of openings/closings is 8 for each principle component.
- (4)
- An edge-preserving filter based spectral-spatial classifier [44]. A joint bilateral filter was applied to a binary image for edge preservation and the first principal component of a hyperspectral image was employed as a guidance image. In this work, this classifier was named as EPF-B and its parameters were set as and .
- (5)
- (6)
- The spectral-spatial classifier using loopy belief propagation and active learning (LBP-AL) [45].
- (7)
- The logistic regression via splitting and augmented Lagrangian-multilevel logistic classifier with active learning (LORSAL-AL-MLL) [47].
- (1)
- Objective measures including three widely used global accuracy (GA) measures of the overall accuracy (OA), the average accuracy (AA) and the kappa coefficient (κ), and the class-specific accuracy (CA), which can be computed from a confusion matrix based on the ground truth data.
- (2)
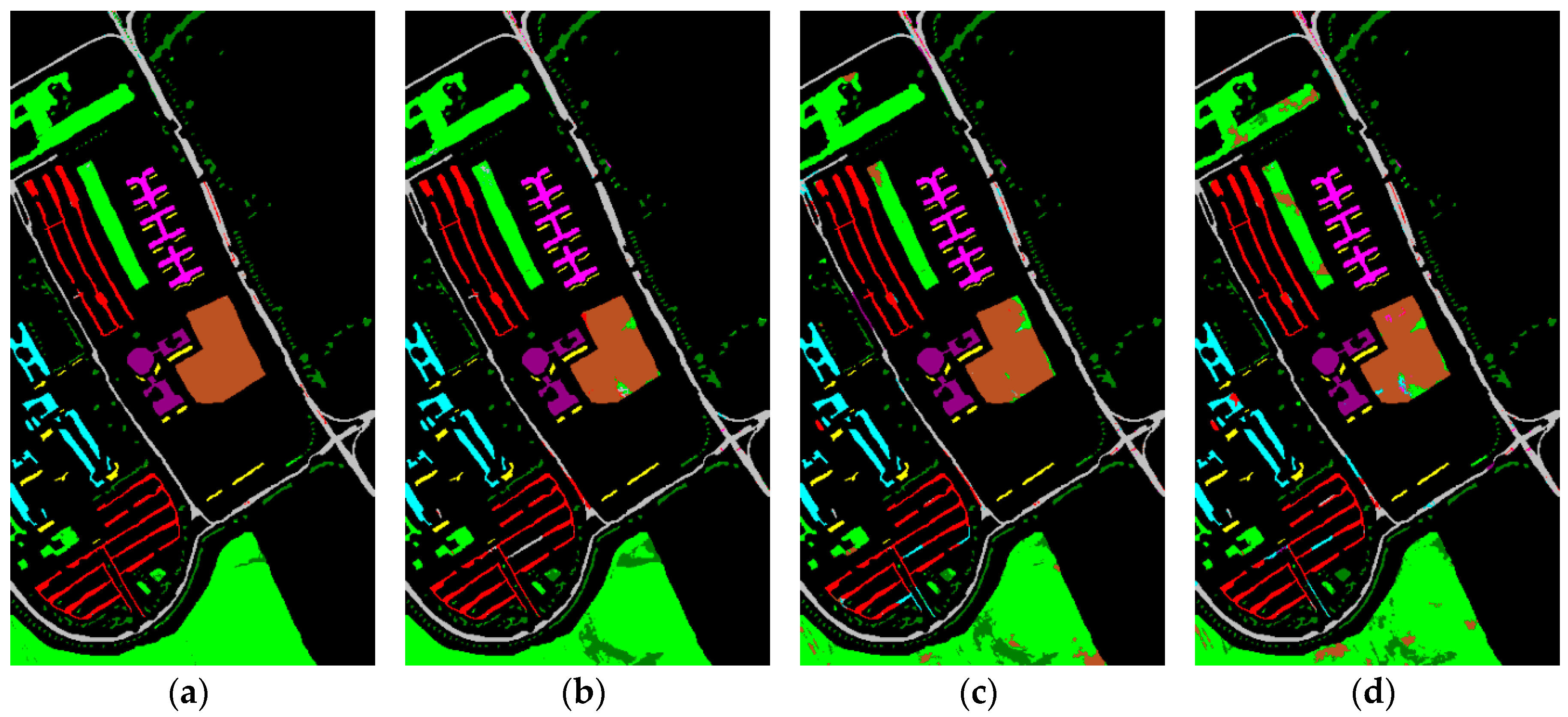
- Subjective measure: visual comparison of classification maps.
4.2. Data Descriptions
4.3. The Indian Pines Dataset
4.4. The University of Pavia Dataset
5. Discussion
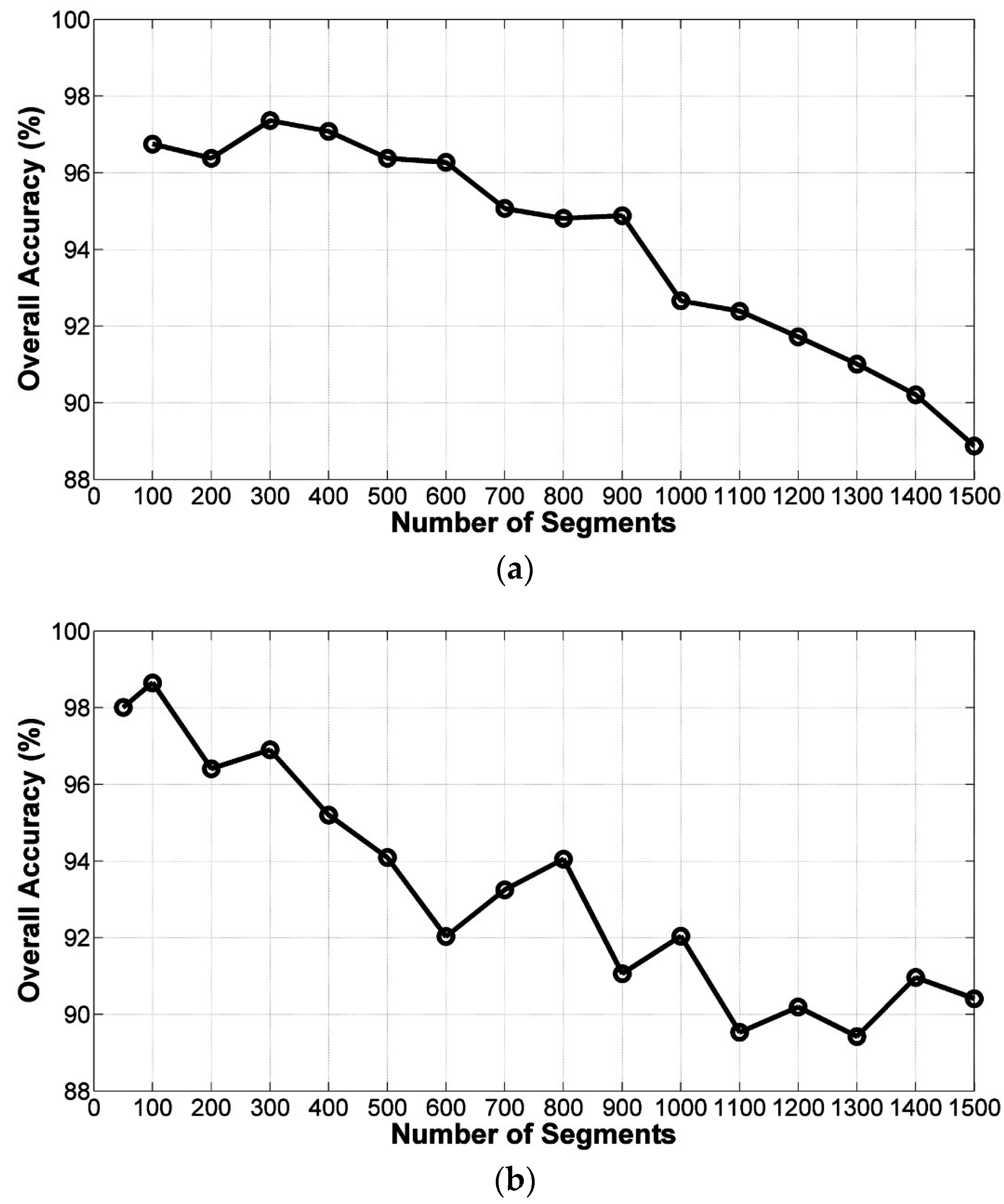
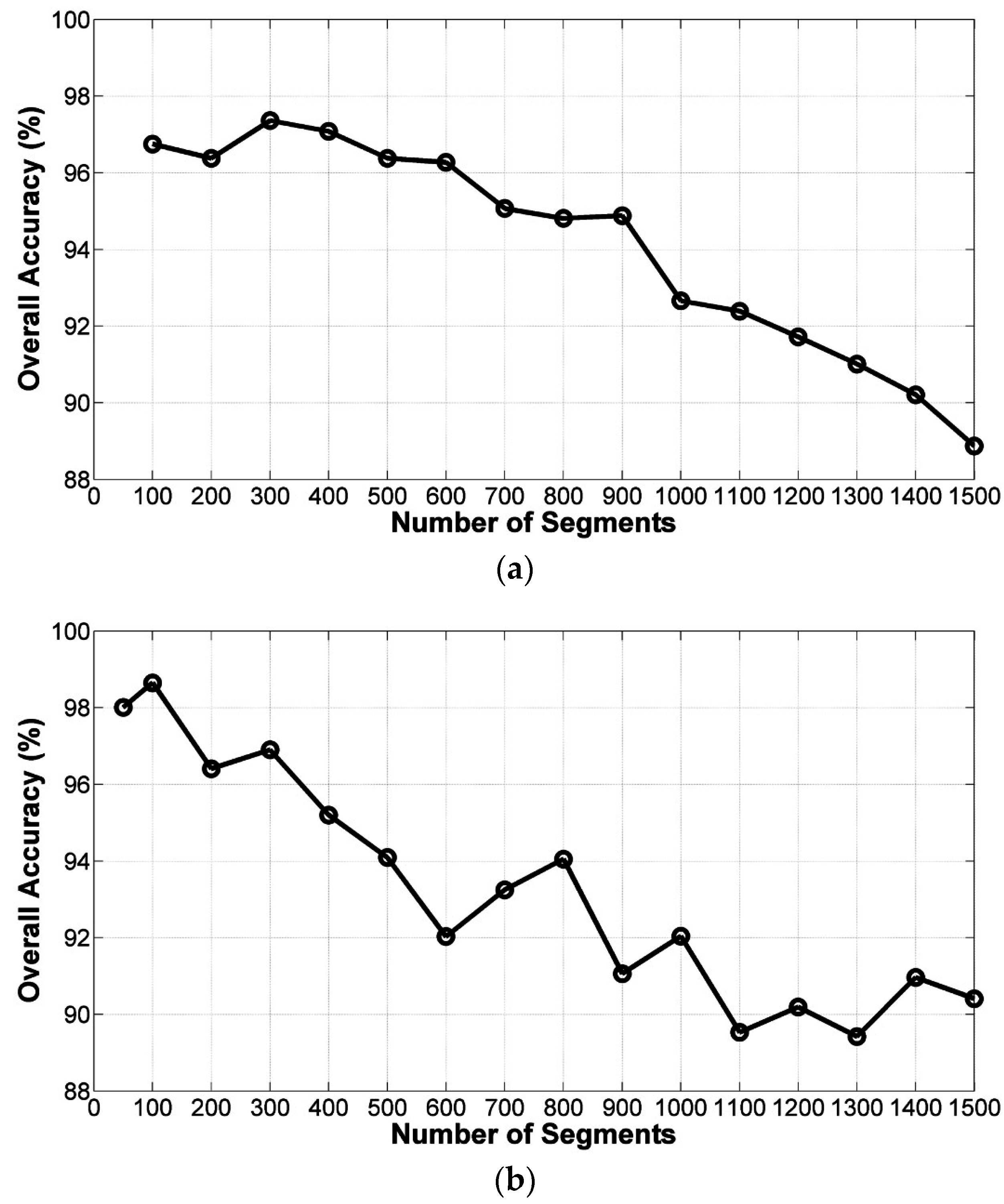
5.1. Influence of Parameters
(1) Influence of nb_seg
(2) Influence of μ
(3) Influence of M
(4) Influence of and
(5) Influence of C and
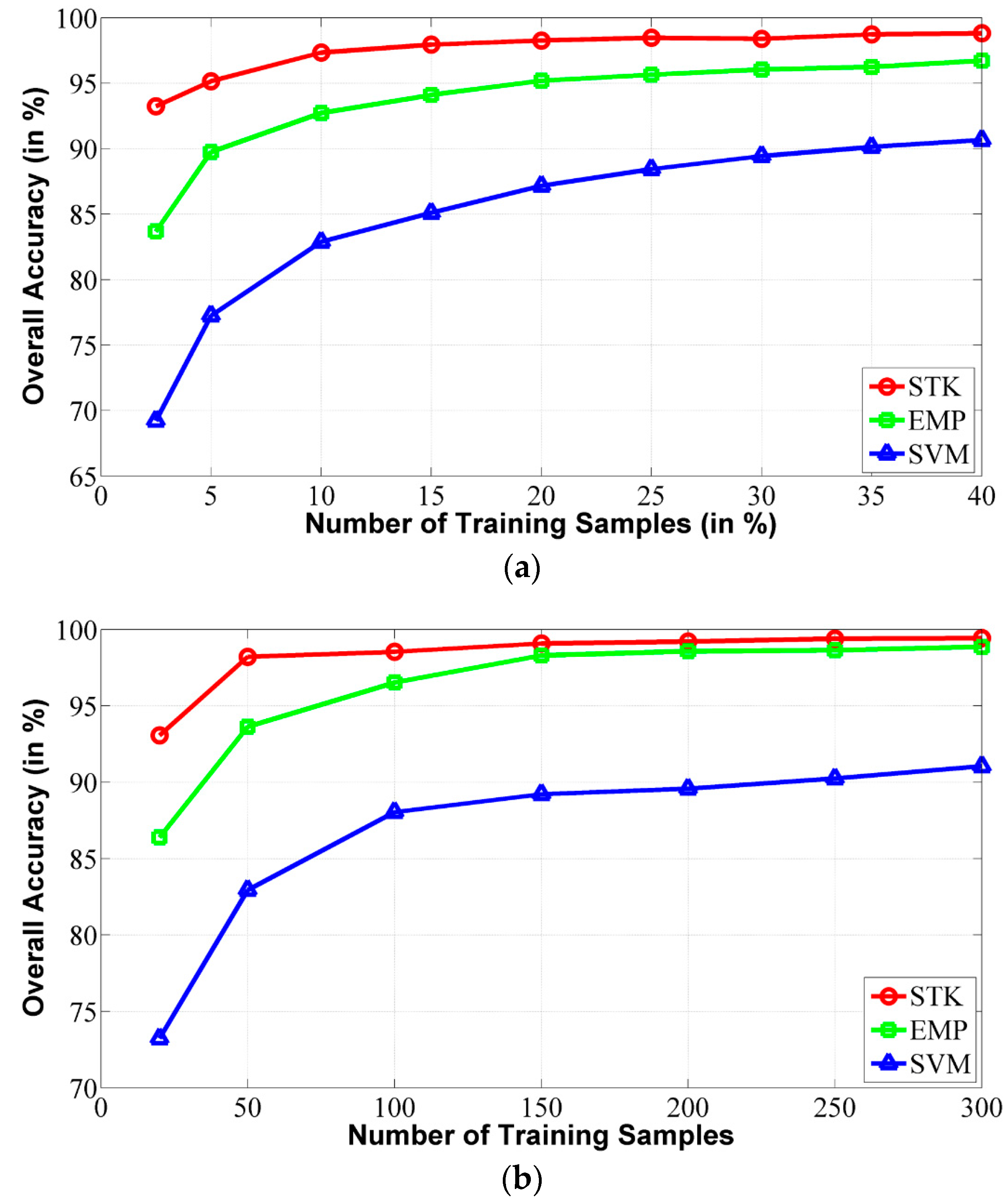
5.2. Classification Results with Different Number of Training Samples
5.3. Classification Results with Different Number of PCA Components
- (1)
- The first component (PC1) which corresponds to the highest eigenvalue and contains the most abundant data information;
- (2)
- The first two components (PC1 + PC2);
- (3)
- The first three components (PC1 + PC2 + PC3).
5.4. Running Time Comparison for Different Approaches
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Plaza, A.; Benediktsson, J.A.; Boardman, J.W.; Brazile, J.; Bruzzone, L.; Camps-Valls, G.; Chanussot, J.; Fauvel, M.; Gamba, P.; Gualtieri, A.; et al. Recent advances in techniques for hyperspectral image processing. Remote Sens. Environ. 2009, 113, S110–S122. [Google Scholar] [CrossRef]
- Camps-Valls, G.; Tuia, D.; Bruzzone, L.; Benediktsson, J.A. Advances in hyperspectral image classification: Earth monitoring with statistical learning methods. IEEE Signal Peocess. Mag. 2014, 31, 45–54. [Google Scholar] [CrossRef]
- Hughes, G. On the mean accuracy of statistical pattern recognizers. IEEE Trans. Inf. Theory 1968, 14, 55–63. [Google Scholar] [CrossRef]
- Landgrebe, D.A. Signal Theory Methods in Multispectral Remote Sensing; Wiley-Interscience: Hoboken, NJ, USA, 2003. [Google Scholar]
- Chen, C.H.; Peter Ho, P.-G. Statistical pattern recognition in remote sensing. Pattern Recognit. 2008, 41, 2731–2741. [Google Scholar] [CrossRef]
- Ham, J.; Chen, Y.; Crawford, M.M.; Ghosh, J. Investigation of the random forest framework for classification of hyperspectral data. IEEE Trans. Geosci. Remote Sens. 2005, 43, 492–501. [Google Scholar] [CrossRef]
- Ratle, F.; Camps-Valls, G.; Weston, J. Semisupervised neural networks for efficient hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2010, 48, 2271–2282. [Google Scholar] [CrossRef]
- Yang, H. A back-propagation neural network for mineralogical mapping from AVIRIS data. Int. J. Remote Sens. 1999, 20, 97–110. [Google Scholar] [CrossRef]
- Melgani, F.; Bruzzone, L. Classification of hyperspectral remote sensing images with support vector machines. IEEE Trans. Geosci. Remote Sens. 2004, 42, 1778–1790. [Google Scholar] [CrossRef]
- Bennett, K.P.; Demiriz, A. Semi-supervised support vector machines. In Proceedings of the 1998 Conference on Advances in Neural Information Processing Systems II; MIT Press: Denver, CO, USA, 1999; pp. 368–374. [Google Scholar]
- Moustakidis, S.; Mallinis, G.; Koutsias, N.; Theocharis, J.B.; Petridis, V. SVM-based fuzzy decision trees for classification of high spatial resolution remote sensing images. IEEE Trans. Geosci. Remote Sens. 2012, 50, 149–169. [Google Scholar] [CrossRef]
- Camps-Valls, G.; Bruzzone, L. Kernel Methods for Remote Sensing Data Analysis; Wiley: New York, NY, USA, 2009. [Google Scholar]
- Camps-Valls, G.; Marsheva, T.V.B.; Zhou, D. Semi-supervised graph-based hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2007, 45, 3044–3054. [Google Scholar] [CrossRef]
- Fauvel, M.; Tarabalka, Y.; Benediktsson, J.A.; Chanussot, J.; Tilton, J.C. Advances in spectral-spatial classification of hyperspectral images. Proc. IEEE 2013, 101, 652–675. [Google Scholar] [CrossRef]
- Zhang, Y. Optimisation of building detection in satellite images by combining multispectral classification and texture filtering. ISPRS J. Photogramm. Remote Sens. 1999, 54, 50–60. [Google Scholar] [CrossRef]
- Huang, X.; Zhang, L. A comparative study of spatial approaches for urban mapping using hyperspectral rosis images over Pavia City, northern Italy. Int. J. Remote Sens. 2009, 30, 3205–3221. [Google Scholar] [CrossRef]
- Benediktsson, J.A.; Palmason, J.A.; Sveinsson, J.R. Classification of hyperspectral data from urban areas based on extended morphological profiles. IEEE Trans. Geosci. Remote Sens. 2005, 43, 480–491. [Google Scholar] [CrossRef]
- Mura, M.D.; Villa, A.; Benediktsson, J.A.; Chanussot, J.; Bruzzone, L. Classification of hyperspectral images by using extended morphological attribute profiles and independent component analysis. IEEE Geosci. Remote Sens. Lett. 2011, 8, 542–546. [Google Scholar] [CrossRef]
- Shen, L.; Zhu, Z.; Jia, S.; Zhu, J.; Sun, Y. Discriminative Gabor feature selection for hyperspectral image classification. IEEE Geosci. Remote Sens. Lett. 2013, 10, 29–33. [Google Scholar] [CrossRef]
- Chen, C.; Li, W.; Su, H.; Liu, K. Spectral-spatial classification of hyperspectral image based on kernel extreme learning machine. Remote Sens. 2014, 6, 5795–5814. [Google Scholar] [CrossRef]
- Li, J.; Bioucas-Dias, J.M.; Plaza, A. Spectral-spatial hyperspectral image segmentation using subspace multinomial logistic regression and Markov random fields. IEEE Trans. Geosci. Remote Sens. 2012, 50, 809–823. [Google Scholar] [CrossRef]
- Xia, J.; Chanussot, J.; Du, P.; He, X. Spectral-spatial classification for hyperspectral data using rotation forests with local feature extraction and Markov random fields. IEEE Trans. Geosci. Remote Sens. 2015, 53, 2532–2546. [Google Scholar] [CrossRef]
- Camps-Valls, G.; Gomez-Chova, L.; Munoz-Mari, J.; Vila-Frances, J.; Calpe-Maravilla, J. Composite kernels for hyperspectral image classification. IEEE Geosci. Remote Sens. Lett. 2006, 3, 93–97. [Google Scholar] [CrossRef]
- Mathieu, F.; Jocelyn, C.; Atli, B.J. A spatial–spectral kernel-based approach for the classification of remote-sensing images. Pattern Recognit. 2012, 45, 381–392. [Google Scholar]
- Camps-Valls, G.; Shervashidze, N.; Borgwardt, K.M. Spatio-spectral remote sensing image classification with graph kernels. IEEE Geosci. Remote Sens. Lett. 2010, 7, 741–745. [Google Scholar] [CrossRef]
- Tarabalka, Y.; Chanussot, J.; Benediktsson, J.A. Segmentation and classification of hyperspectral images using watershed transformation. Pattern Recognit. 2010, 43, 2367–2379. [Google Scholar] [CrossRef]
- Huang, X.; Zhang, L. An adaptive mean-shift analysis approach for object extraction and classification from urban hyperspectral imagery. IEEE Trans. Geosci. Remote Sens. 2008, 46, 4173–4185. [Google Scholar] [CrossRef]
- Ghamisi, P.; Couceiro, M.S.; Fauvel, M.; Benediktsson, J.A. Integration of segmentation techniques for classification of hyperspectral images. IEEE Geosci. Remote Sens. Lett. 2014, 11, 342–346. [Google Scholar] [CrossRef]
- Tarabalka, Y.; Tilton, J.C.; Benediktsson, J.A.; Chanussot, J. A marker-based approach for the automated selection of a single segmentation from a hierarchical set of image segmentations. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2012, 5, 262–272. [Google Scholar] [CrossRef]
- Song, H.; Wang, Y. A spectral-spatial hyperspectral image classification based on algebraic multigrid methods and hierarchical segmentation. Remote Sens. 2016, 8, 296. [Google Scholar] [CrossRef]
- Fang, L.; Li, S.; Kang, X.; Benediktsson, J.A. Spectral-spatial classification of hyperspectral images with a superpixel-based discriminative sparse model. IEEE Trans. Geosci. Remote Sens. 2015, 53, 4186–4201. [Google Scholar] [CrossRef]
- Kettig, R.L.; Landgrebe, D.A. Classification of multispectral image data by extraction and classification of homogeneous objects. IEEE Trans. Geosci. Electron. 1976, 14, 19–26. [Google Scholar] [CrossRef]
- Tarabalka, Y.; Chanussot, J.; Benediktsson, J.A. Segmentation and classification of hyperspectral images using minimum spanning forest grown from automatically selected markers. IEEE Trans. Syst. Man Cybern. Part B Cybern. 2010, 40, 1267–1279. [Google Scholar] [CrossRef] [PubMed]
- Tarabalka, Y.; Rana, A. Graph-cut-based model for spectral-spatial classification of hyperspectral images. In Proceedings of the IEEE Geoscience and Remote Sensing Symposium, Quebec, QC, Canada, 13–18 July 2014.
- Wang, Y.; Song, H.; Zhang, Y. Spectral-spatial classification of hyperspectral images using joint bilateral filter and graph cut based model. Remote Sens. 2016, 8, 748. [Google Scholar] [CrossRef]
- Yuan, J.; Wang, D.; Li, R. Image segmentation using local spectral histograms and linear regression. Pattern Recognit. Lett. 2012, 33, 615–622. [Google Scholar] [CrossRef]
- Liu, M.Y.; Tuzel, O.; Ramalingam, S.; Chellappa, R. Entropy rate superpixel segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Colorado Springs, CO, USA, 20–25 June 2011.
- Liu, X.; Wang, D. Image and texture segmentation using local spectral histograms. IEEE Trans. Image Process. 2006, 15, 3066–3077. [Google Scholar] [CrossRef] [PubMed]
- Yuan, J.; Wang, D.; Li, R. Remote sensing image segmentation by combining spectral and texture features. IEEE Trans. Geosci. Remote Sens. 2014, 52, 16–24. [Google Scholar] [CrossRef]
- Schölkopf, B.; Smola, A.J. Learning with Kernels. Support Vector Machines, Regularization, Optimization, and Beyond; MIT Press: Cambridge, MA, USA, 2002. [Google Scholar]
- Liu, X.; Wang, D. A spectral histogram model for texton modeling and texture discrimination. Vis. Res. 2002, 42, 2617–2634. [Google Scholar] [CrossRef]
- Camps-Valls, G.; Bruzzone, L. Kernel-based methods for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2005, 43, 1351–1362. [Google Scholar] [CrossRef]
- Fauvel, M.; Chanussot, J.; Benediktsson, J.A. A spatial-spectral kernel-based approach for the classification of remote-sensing images. Pattern Recognit. 2012, 45, 381–392. [Google Scholar] [CrossRef]
- Kang, X.; Li, S.; Benediktsson, J.A. Spectral-spatial hyperspectral image classification with edge-preserving filtering. IEEE Trans. Geosci. Remote Sens. 2014, 52, 2666–2677. [Google Scholar] [CrossRef]
- Li, J.; Bioucas-Dias, J.M.; Plaza, A. Spectral-spatial classification of hyperspectral data using loopy belief propagation and active learning. IEEE Trans. Geosci. Remote Sens. 2013, 51, 844–856. [Google Scholar] [CrossRef]
- Bioucas-Dias, J.M.; Figueiredo, M. Logistic Regression via Variable Splitting and Augmented Lagrangian Tools; Instituto Superior Tecnico: Lisbon, Portugal, 2009. [Google Scholar]
- Li, J.; Bioucas-Dias, J.M.; Plaza, A. Hyperspectral image segmentation using a new Bayesian approach with active learning. IEEE Trans. Geosci. Remote Sens. 2011, 49, 3947–3960. [Google Scholar] [CrossRef]
- Chang, C.-C.; Lin, C.-J. LIBSVM: A library for support vector machines. ACM Trans. Intell. Syst. Technol. 2011, 2. [Google Scholar] [CrossRef]
- Wu, T.-F.; Lin, C.-J.; Weng, R.C. Probability estimates for multiclass classification by pairwise coupling. J. Mach. Learn. Res. 2004, 5, 975–1005. [Google Scholar]
- Tadjudin, S.; Landgrebe, D. Classification of High Dimensional Data with Limited Training Samples; Purdue University: West Lafayette, IN, USA, 1998. [Google Scholar]
- Duarte-Carvajalino, J.M.; Castillo, P.E.; Velez-Reyes, M. Comparative study of semi-implicit schemes for nonlinear diffusion in hyperspectral imagery. IEEE Trans. Image Process. 2007, 16, 1303–1314. [Google Scholar] [CrossRef] [PubMed]
- Baumgardner, M.F.; Biehl, L.L.; Landgrebe, D.A. 220 Band AVIRIS Hyperspectral Image Data Set: June 12, 1992 Indian Pine Test Site 3; Purdue University Research Repository: West Lafayette, IN, USA, 2015. [Google Scholar] [CrossRef]
- Holzwarth, S.; Müller, A.; Habermeyer, M.; Richter, R.; Hausold, A.; Thiemann, S.; Strobl, P. Hysens-DAIS/ROSIS imaging spectrometers at DLR. In Proceedings of the 3rd EARSeL Workshop on Imaging Spectroscopy, Herrsching, Germany, 13–16 May 2003.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Indiana Pines | University of Pavia | ||||
|---|---|---|---|---|---|---|
| Name | Train | Test | Name | Train | Test | |
| 1 | Alfalfa | 10 | 44 | Asphalt | 250 | 6381 |
| 2 | Corn-no till | 143 | 1291 | Meadows | 250 | 18,399 |
| 3 | Corn-min till | 83 | 751 | Gravel | 250 | 1849 |
| 4 | Corn | 23 | 211 | Trees | 250 | 2814 |
| 5 | Grass/pasture | 49 | 448 | Metal Sheets | 250 | 1095 |
| 6 | Grass/trees | 74 | 673 | Bare Soil | 250 | 4779 |
| 7 | Grass/pasture-mowed | 10 | 16 | Bitumen | 250 | 1080 |
| 8 | Hay-windrowed | 48 | 441 | Self-Blocking Bricks | 250 | 3432 |
| 9 | Oats | 10 | 10 | Shadow | 250 | 697 |
| 10 | Soybeans-no till | 96 | 872 | |||
| 11 | Soybeans-min till | 246 | 2222 | |||
| 12 | Soybeans-clean till | 61 | 553 | |||
| 13 | Wheat | 21 | 191 | |||
| 14 | Woods | 129 | 1165 | |||
| 15 | Bldg-Grass-Trees-Drives | 38 | 342 | |||
| 16 | Stone-steel towers | 10 | 85 | |||
| Total | 1051 | 9315 | 2250 | 40,526 | ||
| Class | SVM | SSK | EMP | EPF-B | MLR-LORSAL | LBP-AL | LORSAL-AL-MLL | STK |
|---|---|---|---|---|---|---|---|---|
| Alfalfa | 81.82 | 86.36 | 88.64 | 81.82 | 93.18 | 97.73 | 93.18 | 100 |
| Corn-no till | 76.61 | 91.01 | 83.35 | 88.77 | 37.80 | 79.63 | 97.06 | 95.74 |
| Corn-min till | 72.7 | 82.29 | 95.07 | 91.74 | 83.62 | 85.09 | 87.22 | 98.54 |
| Corn | 46.45 | 91.94 | 82.46 | 94.79 | 99.53 | 80.57 | 97.16 | 97.63 |
| Grass/pasture | 86.16 | 94.87 | 87.95 | 97.32 | 82.37 | 87.95 | 94.87 | 95.54 |
| Grass/trees | 89.75 | 98.07 | 96.88 | 98.66 | 97.03 | 100 | 100 | 98.07 |
| Grass/pasture-mowed | 87.5 | 100 | 100 | 100 | 100 | 93.75 | 100 | 100 |
| Hay-windrowed | 97.28 | 99.09 | 99.09 | 100 | 99.32 | 99.09 | 99.09 | 99.32 |
| Oats | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 |
| Soybeans-no till | 83.03 | 90.02 | 90.37 | 86.70 | 98.74 | 78.9 | 92.43 | 95.30 |
| Soybeans-min till | 87.62 | 93.74 | 98.02 | 98.74 | 76.42 | 89.65 | 96.04 | 98.56 |
| Soybeans-clean till | 66.55 | 93.67 | 80.11 | 99.28 | 97.65 | 72.33 | 93.13 | 95.30 |
| Wheat | 96.34 | 98.95 | 98.95 | 100 | 99.48 | 100 | 100 | 98.95 |
| Woods | 93.3 | 99.57 | 99.83 | 99.66 | 100 | 94.59 | 97.94 | 99.14 |
| Bldg-Grass-Trees-Drives | 61.4 | 98.53 | 96.78 | 72.51 | 4.09 | 97.95 | 88.89 | 98.54 |
| Stone-steel towers | 63.53 | 97.65 | 95.29 | 89.41 | 100 | 94.12 | 84.71 | 100 |
| OA | 82.51 | 93.69 | 93.24 | 94.61 | 79.51 | 87.99 | 95.31 | 97.61 |
| AA | 80.63 | 94.74 | 93.30 | 93.71 | 85.58 | 90.71 | 95.11 | 98.16 |
| κ | 79.96 | 92.81 | 92.27 | 93.84 | 76.97 | 86.23 | 94.64 | 97.27 |
| Class | SVM | SSK | EMP | EPF-B | MLR-LORSAL | LBP-AL | LORSAL-AL-MLL | STK |
|---|---|---|---|---|---|---|---|---|
| Asphalt | 85.02 | 96.01 | 95.73 | 96.11 | 91.88 | 98.67 | 98.35 | 98.72 |
| Meadows | 92.26 | 97.6 | 92.96 | 97.75 | 94.42 | 97.14 | 99.79 | 99.34 |
| Gravel | 84.32 | 96.85 | 97.59 | 95.57 | 70.87 | 96.81 | 77.48 | 100 |
| Trees | 97.58 | 94.19 | 98.90 | 98.65 | 80.49 | 98.47 | 95.16 | 95.62 |
| Metal Sheets | 99.73 | 99.92 | 100 | 99.82 | 99.92 | 99.73 | 99.84 | 100 |
| Bare Soil | 91.88 | 96.47 | 88.10 | 99.73 | 98.14 | 99.96 | 98.21 | 99.74 |
| Bitumen | 93.24 | 98.81 | 99.52 | 98.61 | 90.16 | 95.95 | 92.62 | 100 |
| Self-Blocking Bricks | 85.23 | 96.96 | 98.06 | 96.42 | 44.99 | 81.67 | 93.66 | 99.34 |
| Shadow | 100 | 99.89 | 99.54 | 100 | 100 | 99.28 | 99.89 | 100 |
| OA | 90.85 | 97.04 | 94.45 | 97.69 | 88.26 | 96.55 | 97.24 | 99.11 |
| AA | 92.14 | 97.41 | 96.71 | 98.07 | 85.65 | 96.37 | 94.99 | 99.20 |
| κ | 87.81 | 96.07 | 92.67 | 96.89 | 84.36 | 95.35 | 96.32 | 98.82 |
| Method | Integration Scale | Classification Accuracy (%) | ||
|---|---|---|---|---|
| OA | AA | κ | ||
| STK | 15 × 15 | 93.15 | 94.26 | 90.94 |
| 25 × 25 | 96.34 | 97.2 | 95.14 | |
| 35 × 35 | 97.17 | 97.8 | 96.24 | |
| 45 × 45 | 97.6 | 98.05 | 96.81 | |
| 55 × 55 | 97.67 | 98.18 | 96.91 | |
| 65 × 65 | 98.2 | 98.51 | 97.64 | |
| 75 × 75 | 98.16 | 98.49 | 97.55 | |
| 85 × 85 | 97.84 | 98.18 | 97.12 | |
| STK | 99.11 | 99.2 | 98.82 | |
| Filter(s) | Overall Accuracy (%) |
|---|---|
| Intensity | 98.5 |
| Two LoG filters | 97.14 |
| Two Gabor filters | 95.06 |
| Intensity + two LoG filters | 99.09 |
| Intensity + two Gabor filters | 99.06 |
| Two LoG filters + two Gabor filters | 96.67 |
| Intensity + two LoG filters + two Gabor filters | 99.11 |
| Parameter | Indian Pines | University of Pavia | ||
|---|---|---|---|---|
| Value | OA (%) | Value | OA (%) | |
| 0.5 | 97.61 | 0.5 | 99.11 | |
| 1 | 97.58 | 1 | 99.1 | |
| 2 | 97.56 | 2 | 99.1 | |
| 4 | 97.55 | 4 | 99.11 | |
| 8 | 97.53 | 8 | 99.1 | |
| 16 | 97.54 | 16 | 99.1 | |
| 1.5 | 97.61 | 1.5 | 99.11 | |
| 2 | 97.6 | 2 | 99.14 | |
| 2.5 | 97.63 | 2.5 | 98.99 | |
| 3 | 97.6 | 3 | 99.15 | |
| 3.5 | 97.57 | 3.5 | 99.16 | |
| 4 | 97.58 | 4 | 99.11 | |
| 4.5 | 97.54 | 4.5 | 99.09 | |
| 5 | 97.55 | 5 | 98.59 | |
| Parameter | Indian Pines | University of Pavia | ||
|---|---|---|---|---|
| Value | OA (%) | Value | OA (%) | |
| C | 50 | 97.43 | 50 | 98.01 |
| 100 | 97.53 | 100 | 98.91 | |
| 150 | 97.58 | 150 | 99.12 | |
| 200 | 97.61 | 200 | 99.11 | |
| 250 | 97.57 | 250 | 99.1 | |
| 300 | 97.57 | 300 | 99.1 | |
| 0.2 | 97.39 | 0.2 | 98.24 | |
| 0.5 | 97.61 | 0.5 | 99.11 | |
| 1 | 97.46 | 1 | 98.66 | |
| 1.5 | 97.37 | 1.5 | 98.46 | |
| 2 | 97.31 | 2 | 98.48 | |
| 2.5 | 97.25 | 2.5 | 98.44 | |
| 3 | 97.2 | 3 | 98.44 | |
| Option | Classification Accuracy | |||||
|---|---|---|---|---|---|---|
| Indian Pines | University of Pavia | |||||
| OA | AA | κ | OA | AA | κ | |
| PC1 | 97.61 | 98.16 | 97.27 | 99.11 | 99.2 | 98.82 |
| PC1 + PC2 | 97.63 | 98.19 | 97.29 | 99.13 | 99.24 | 99.84 |
| PC1 + PC2 + PC3 | 97.64 | 98.2 | 97.31 | 99.14 | 99.24 | 99.85 |
| Method | Time Used (s) | |
|---|---|---|
| Indian Pines | University of Pavia | |
| SVM | 133.24 | 26.59 |
| EMP | 38.74 | 19.76 |
| MLR-LORSAL | 5.36 | 9.42 |
| LORSAL-AL-MLL | 211.46 | 170.34 |
| STK | 2.58 | 12.10 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Zhang, Y.; Song, H. A Spectral-Texture Kernel-Based Classification Method for Hyperspectral Images. Remote Sens. 2016, 8, 919. https://doi.org/10.3390/rs8110919
Wang Y, Zhang Y, Song H. A Spectral-Texture Kernel-Based Classification Method for Hyperspectral Images. Remote Sensing. 2016; 8(11):919. https://doi.org/10.3390/rs8110919
Chicago/Turabian StyleWang, Yi, Yan Zhang, and Haiwei Song. 2016. "A Spectral-Texture Kernel-Based Classification Method for Hyperspectral Images" Remote Sensing 8, no. 11: 919. https://doi.org/10.3390/rs8110919
APA StyleWang, Y., Zhang, Y., & Song, H. (2016). A Spectral-Texture Kernel-Based Classification Method for Hyperspectral Images. Remote Sensing, 8(11), 919. https://doi.org/10.3390/rs8110919