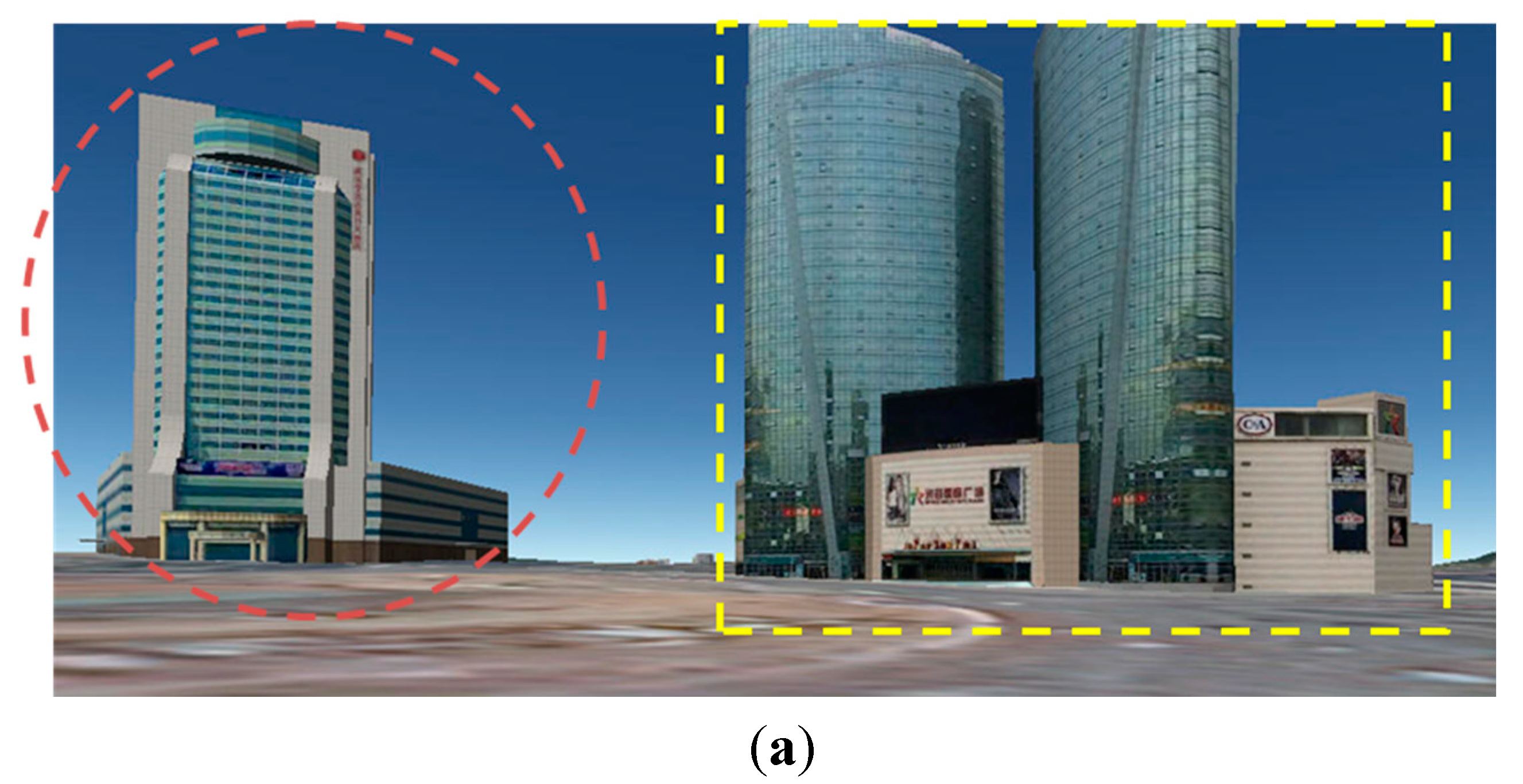
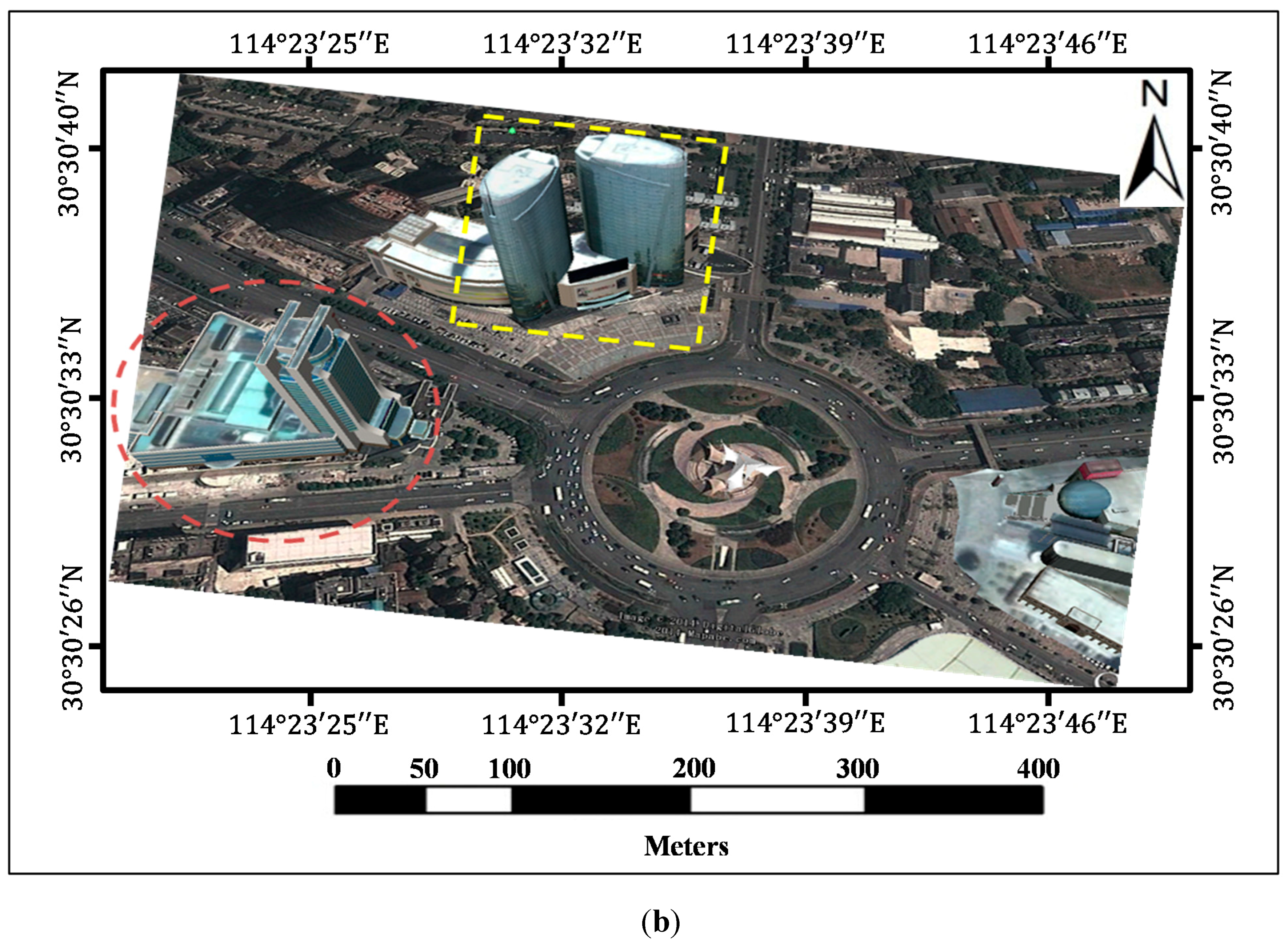
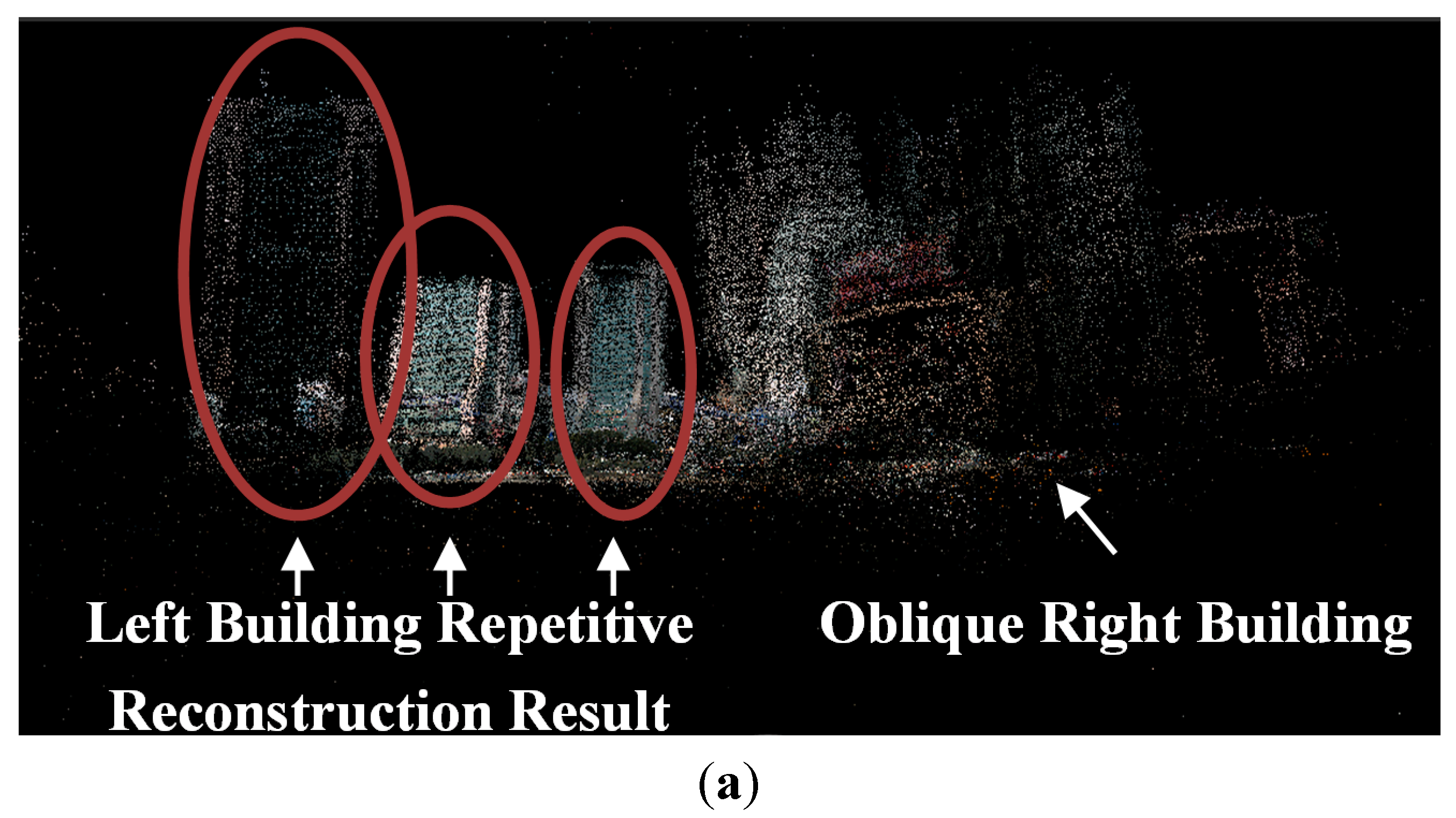
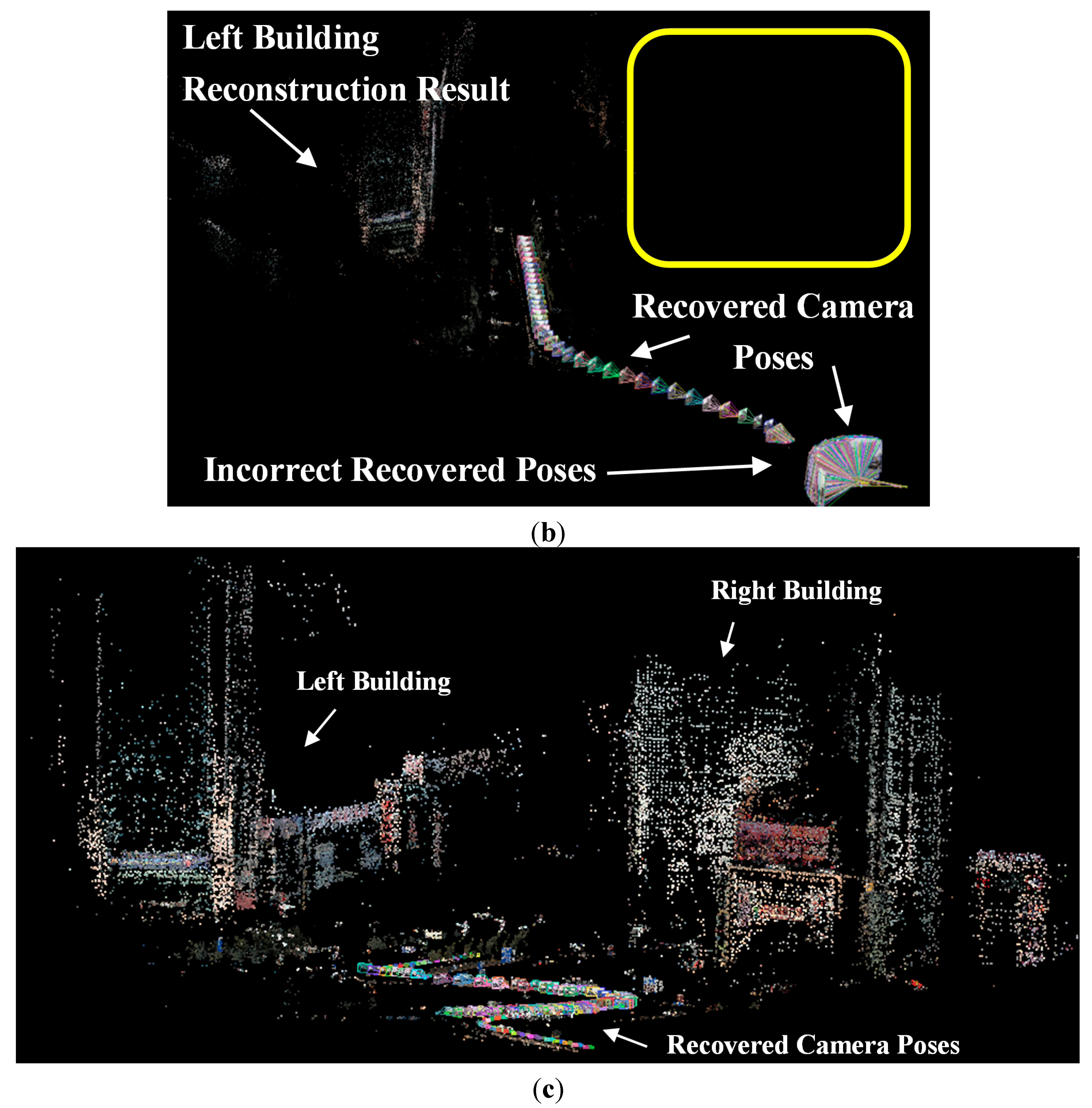
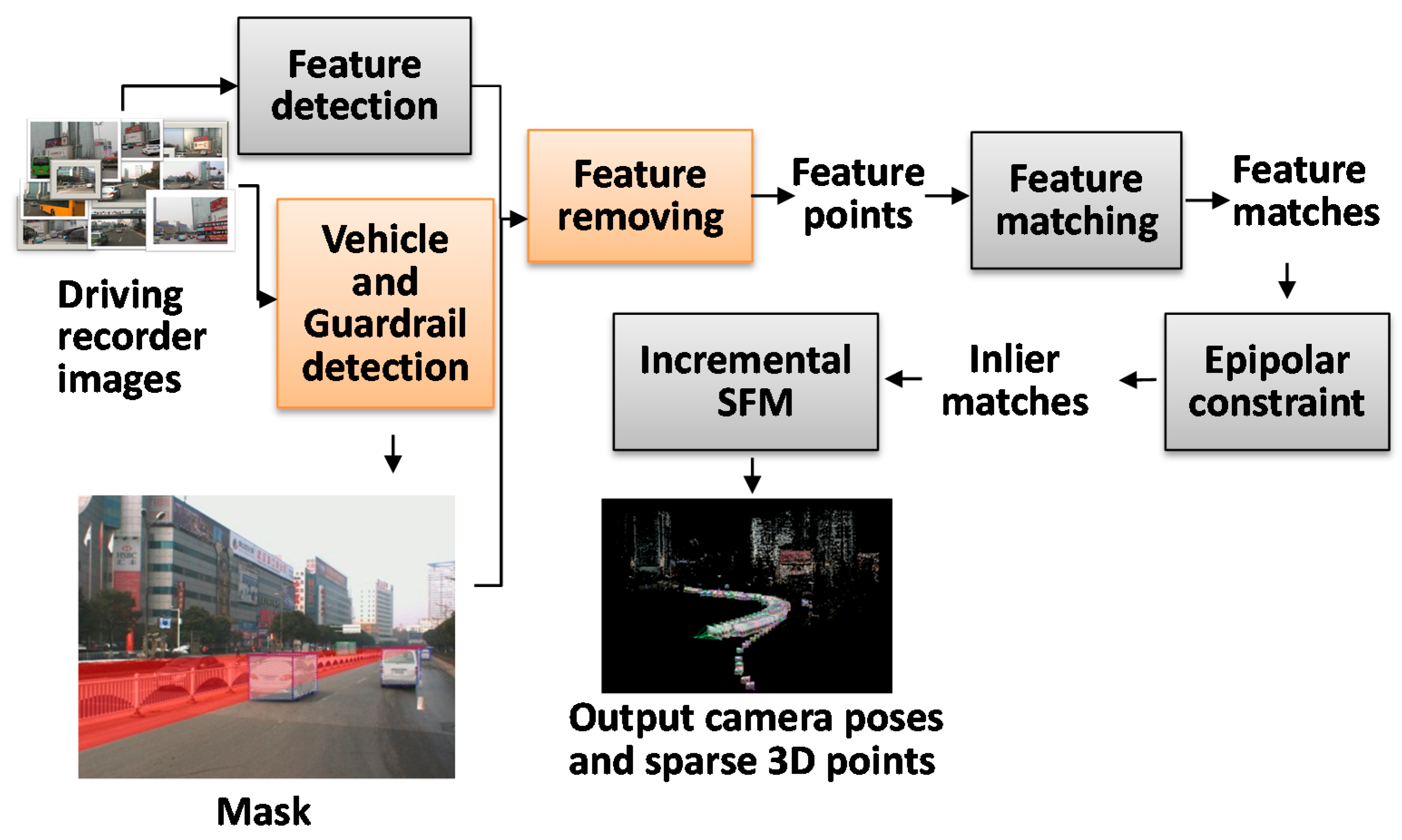
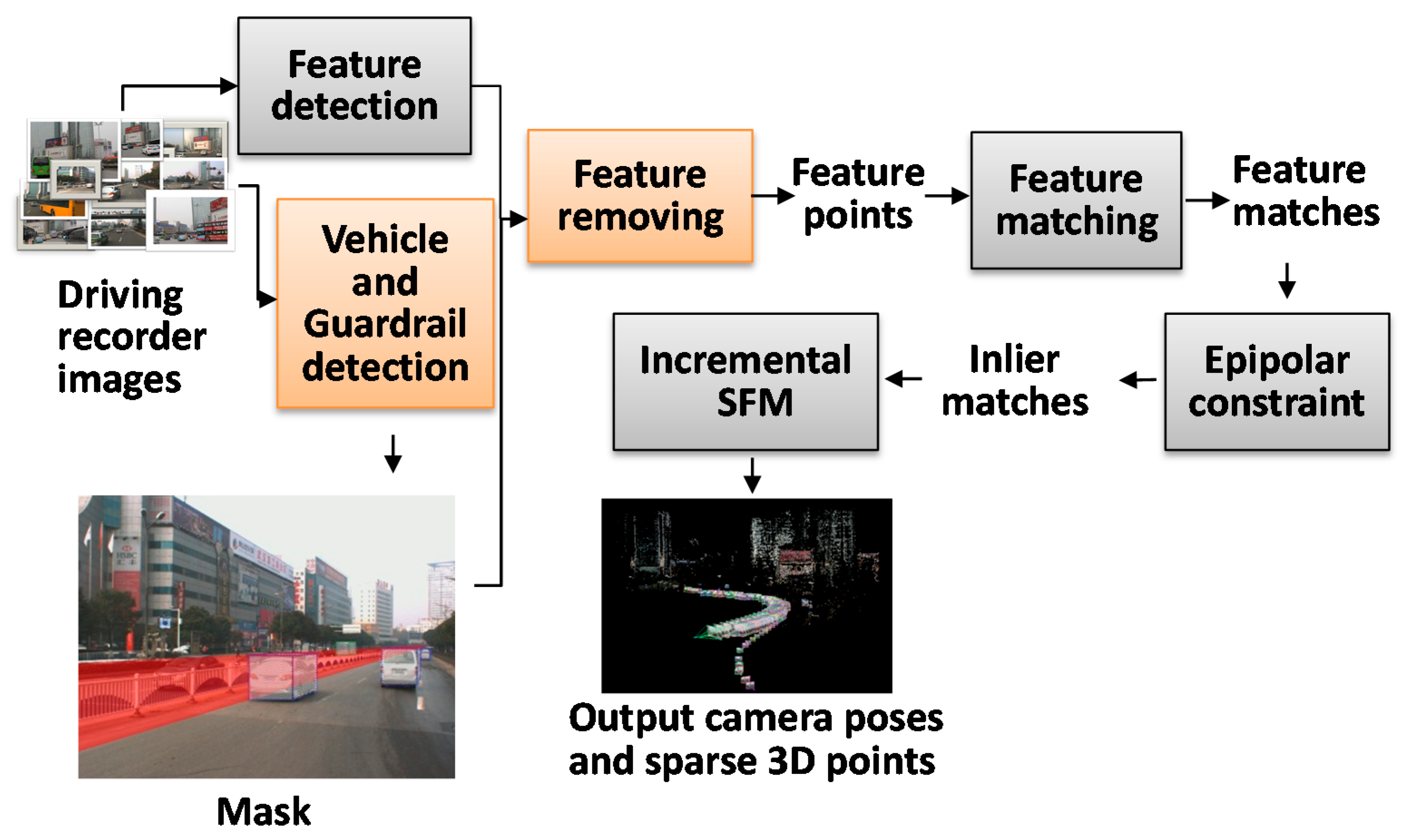
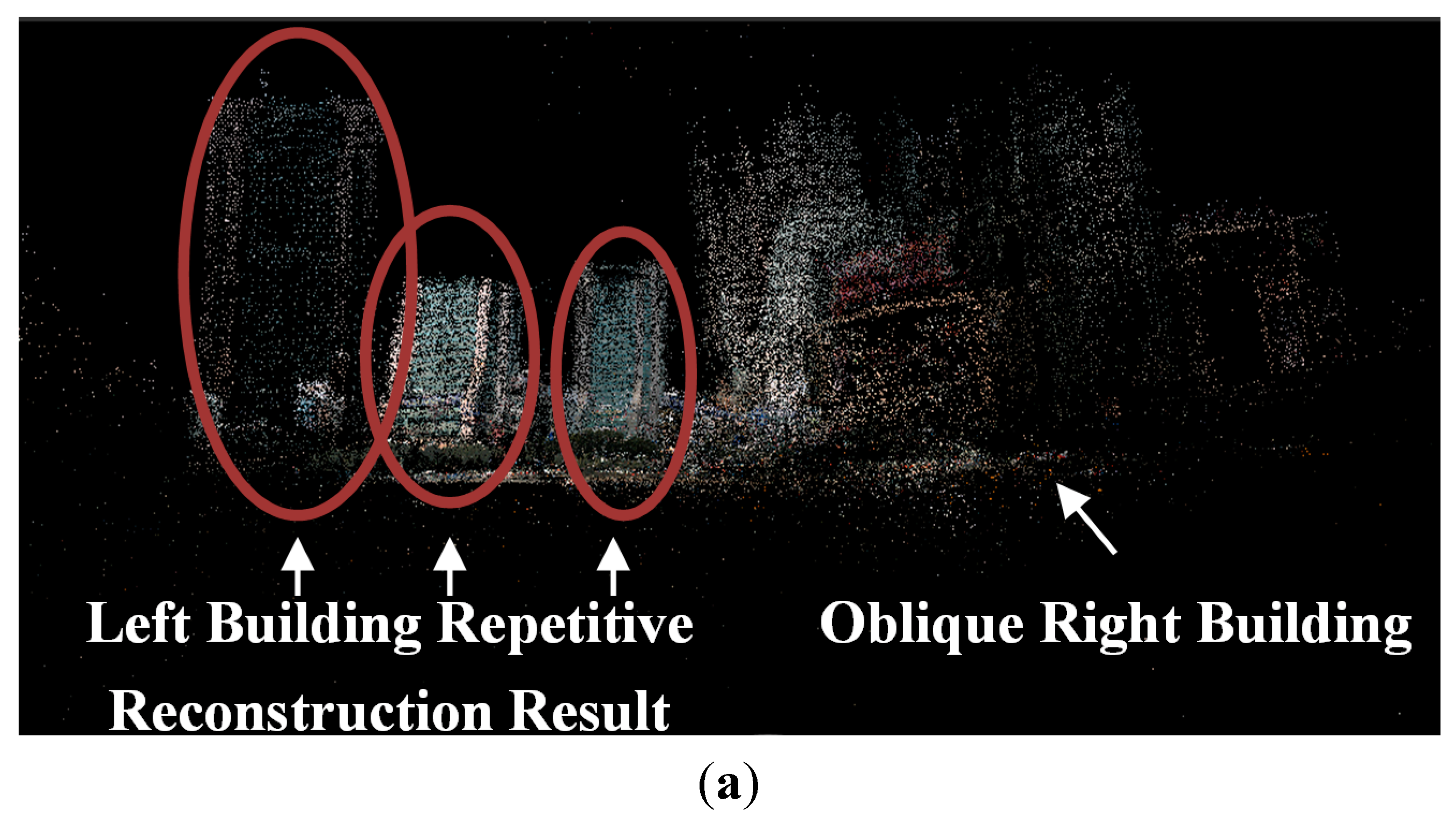
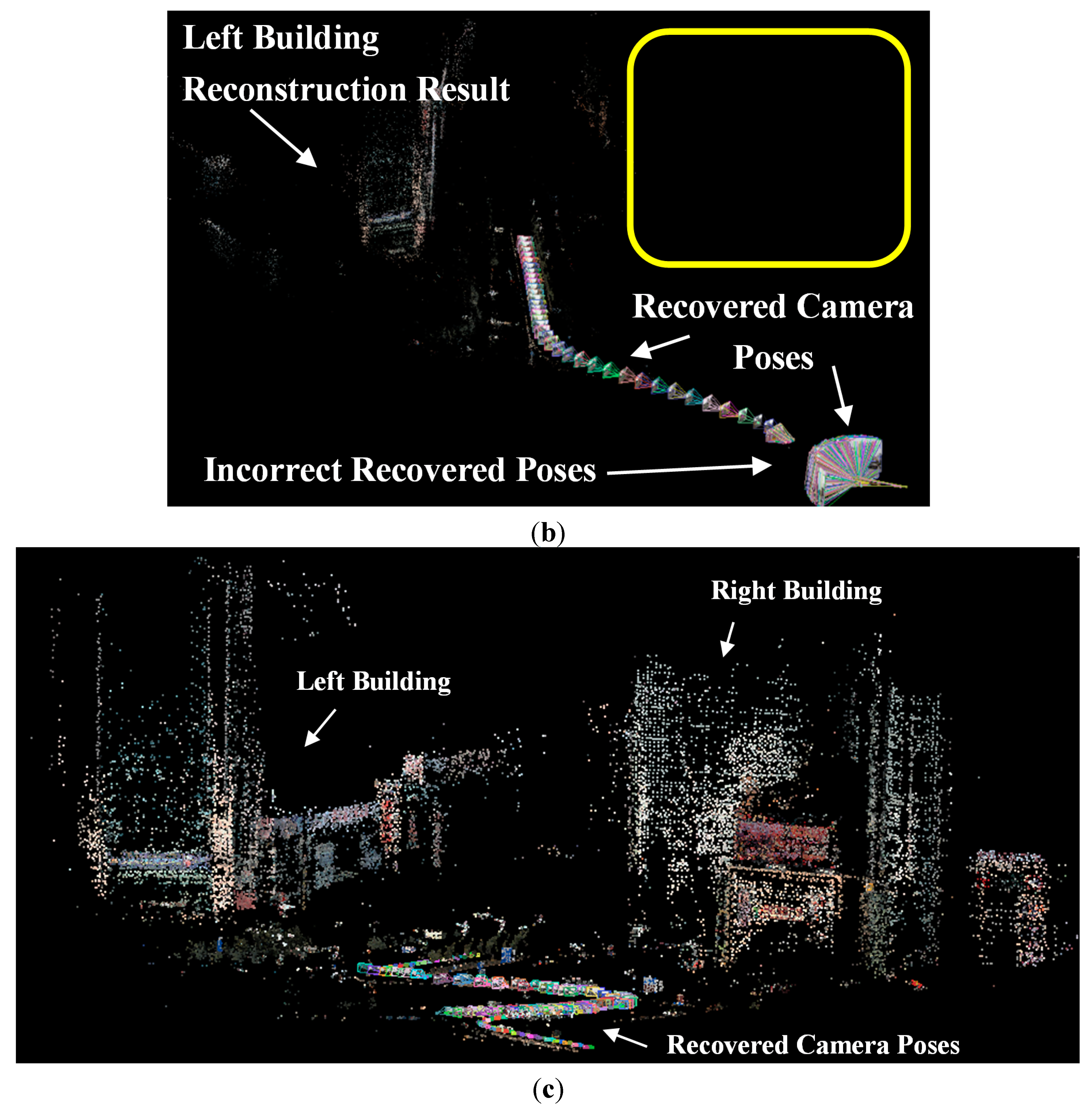
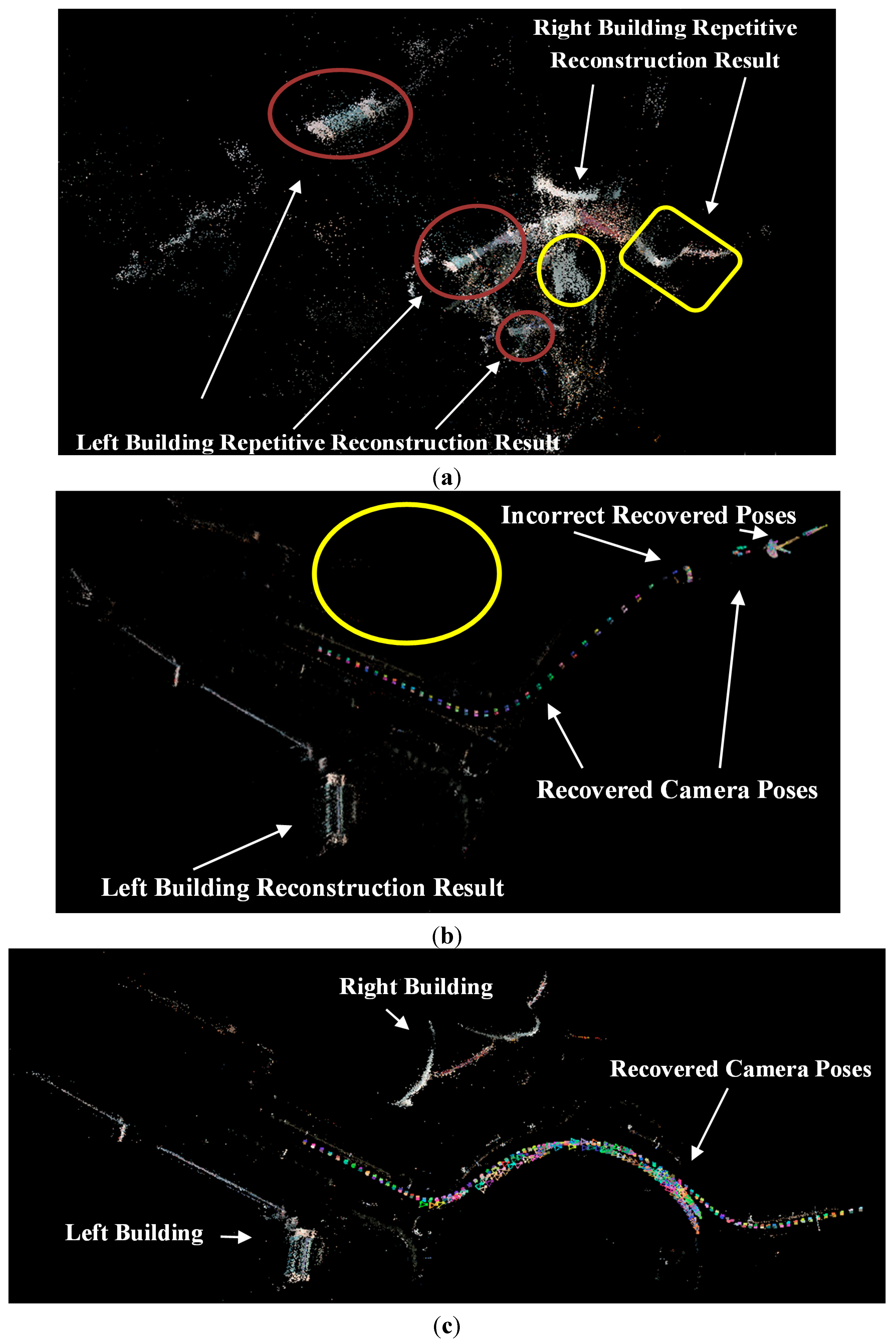
The paper proposed guardrail and vehicle region detection methods, and then masked feature points on guardrail and vehicle regions to improve the reconstruction result. We propose to “mask” out the vehicle and guardrail regions before reconstruction because guardrails have repeating patterns and vehicles move between frames, which subsequently always produce outliers on the image of the guardrail and vehicle regions. In this paper, the images of the vehicle and guardrail regions are collectively called the Mask. The pipeline of 3D reconstruction that utilizes driving recorder data is illustrated in
Figure 2. We can first detect the SIFT [
12] feature points and the Mask in each image, and then we remove the features on the Mask and match the remaining feature points between the pairs of images. Based on the epipolar constraint [
7], we will remove the outliers to further refine the results and finally conduct an incremental SfM procedure [
7] to recover the camera parameters and sparse points.
Figure 2.
The pipeline of 3D reconstruction from driving recorder data. The grey frames show the typical SfM process. The two orange frames are the main improvement steps proposed in this paper.
In order to diminish the adverse impact of outliers on reconstruction, the Mask requires detection as entirely as possible. Therefore, based on the typical vehicle front/back surface detection method in
Section 2.1, the design of the vehicle side surfaces detection method and the blocked-vehicle detection method are described in
Sections 2.2 and
Section 2.4, respectively. The blocked-vehicle is a vehicle moving in the opposite direction partially overlapped by the guardrail. The guardrail region detection method is introduced in
Section 2.3, which is based on the Haar-like classifiers and the position of the vanishing point. Finally, the Mask and the reconstruction process are introduced in
Section 2.5.
2.1. Vehicle Front/Back Surfaces Detection
As the system of vehicle back surface detection [
16] by Haar-like feature-based Adaboost classifier is described in details, we only summarize its main steps here. Classifiers based on Haar-like features can detect objects with a similar appearance. There is a big difference between the front and back surfaces of vehicles and buses; therefore, four types of classifiers were trained to detect the front and back surfaces of vehicles and buses, respectively.
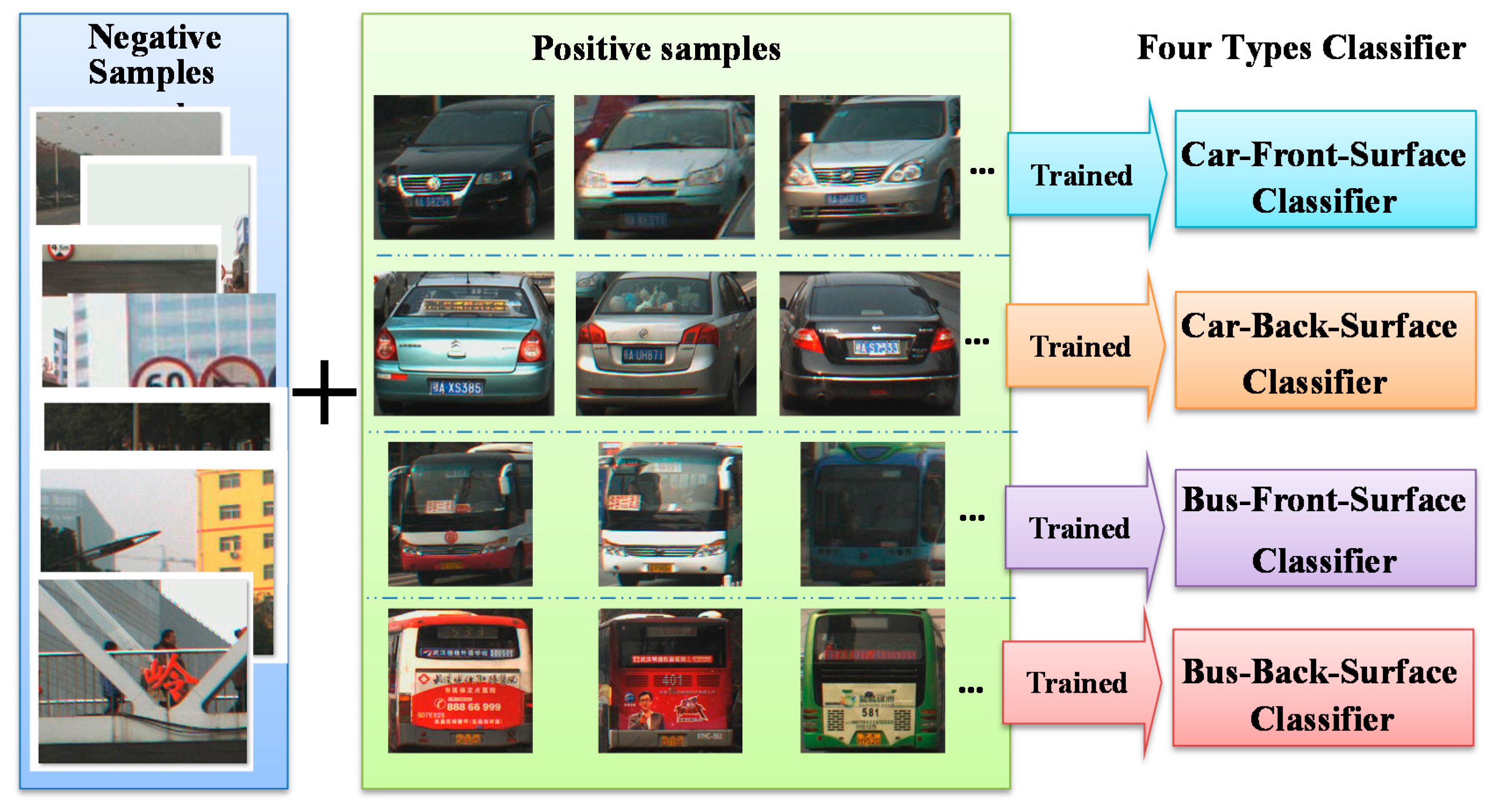
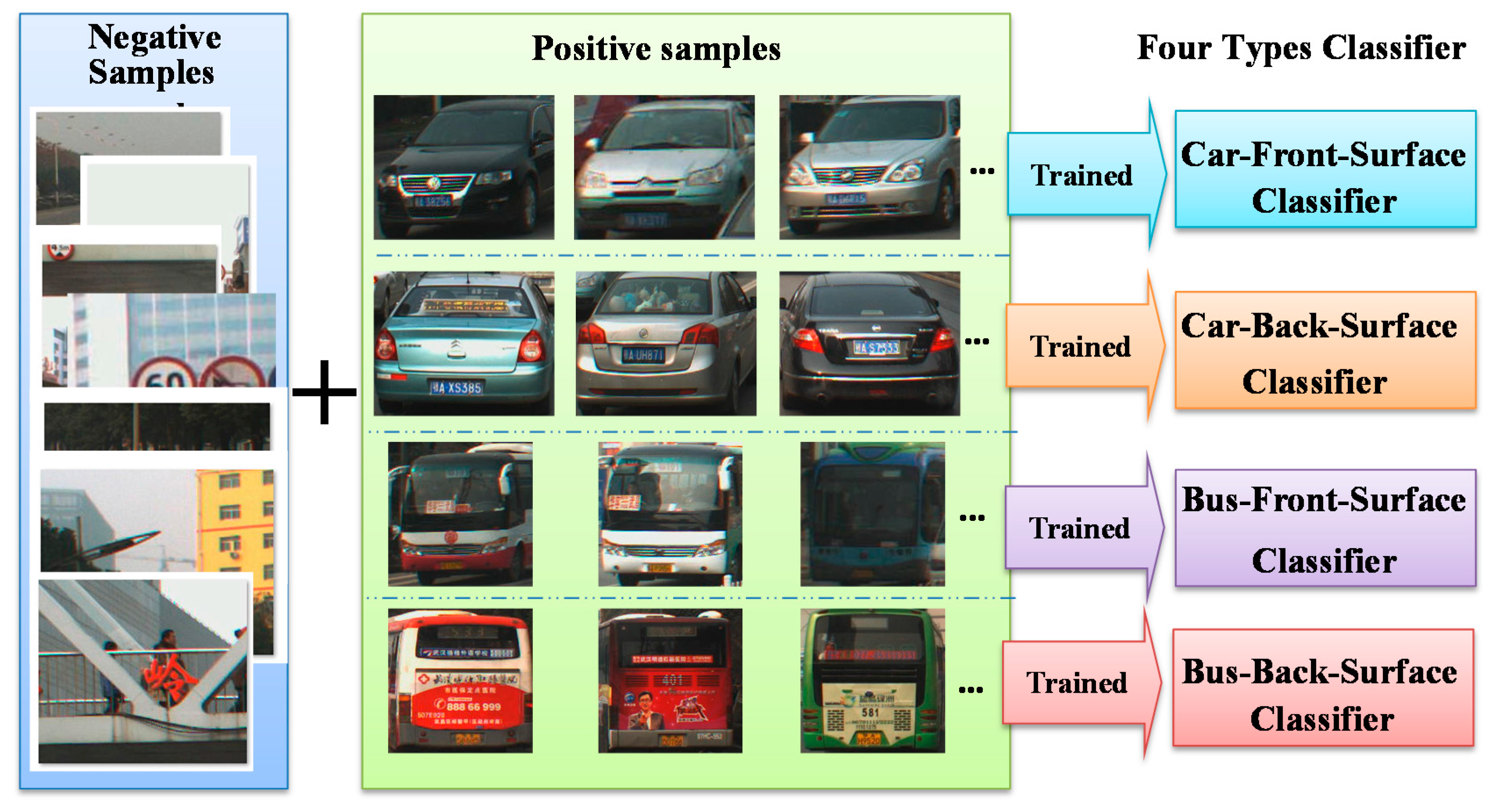
The classifier was trained with sample data. After the initial training, the trained classifier was used to independently detect vehicles. There are two types of samples, positive and negative. A positive sample is a rectangular region cut from an image that contains the target object, and a negative sample is a rectangular region without the target object.
Figure 3 shows the relation of the four classifier types and their trained samples. Each classifier is trained with 1000–2000 positive samples and at least 8000 negative samples. All the samples were manually compiled; and we separated the images containing vehicles as positive samples and the remaining images were used as negative samples. Although diverse samples can produce better classifier performance, a small amount of duplications are acceptable. Therefore, the positive samples of the same vehicle cut from different images are effective samples, and the samples from the same images with a slightly adjusted position are allowable as well. Two samples can even be totally duplicated, which will have a minimal adverse effect on the performance of the classifier when the number of samples is large enough. After inputting the samples into the OpenCV 2.4.9 [
17] training procedure, the classifier can be trained with the default parameters automatically. A cascade classifier is composed of many weak classifiers. Each classifier is trained by adding features until the overall samples are correctly classified. This process can be iterated up to construct a cascade of classification rules that can achieve the desired classification ratios [
16]. Adaboost classifier is more likely to overfit on small and noisy training data. Too many iterative training processes may cause the overfitting problem, too. Therefore, we need to control the maximum number of iteration in the training processes. In OpenCV training procedure, there are some constraints designed to avoid the overfitting problem. For example, the numStages parameter limits the stage number of classifier, and the maxWeakCount parameter helps to limit the count of trees. These parameters could prevent classifiers from the overfitting. Besides these parameter-constraints, we can also use more training data to minimize the possibility of overfitting.
Figure 3.
Example of samples and classifiers.
Figure 3.
Example of samples and classifiers.
A strong cascade classifier consists of a series of weak classifiers in the order of sparse to strict. A sparse classifier has few constraints and low classification accuracy but a high computational speed; while a strict classifier has many constraints and high classification accuracy but a low computational speed. When an image area is input into a strong cascade classifier, it is first detected by the initial sparse classifier. Only a positive result from the previous classifier triggers the evaluation of the next classifier. Negative results (e.g., background regions of the image) therefore are quickly discarded so the classifier can spend more computational time on more promising object-like regions [
13]. Most image areas without the target object can be easily identified and eliminated at the very beginning of the process with minimal effort. Therefore, a cascade classifier is able to enhance computational efficiency [
18].
2.2. Vehicle Side-Surface Detection
The side-surfaces of vehicles cannot be detected by feature-based classifiers since a vehicle’s appearance changes with the angle of view. Poor matching points on these regions inevitably have adverse effects on the reconstruction, especially the side-surfaces of large vehicles that are close to the survey vehicle.
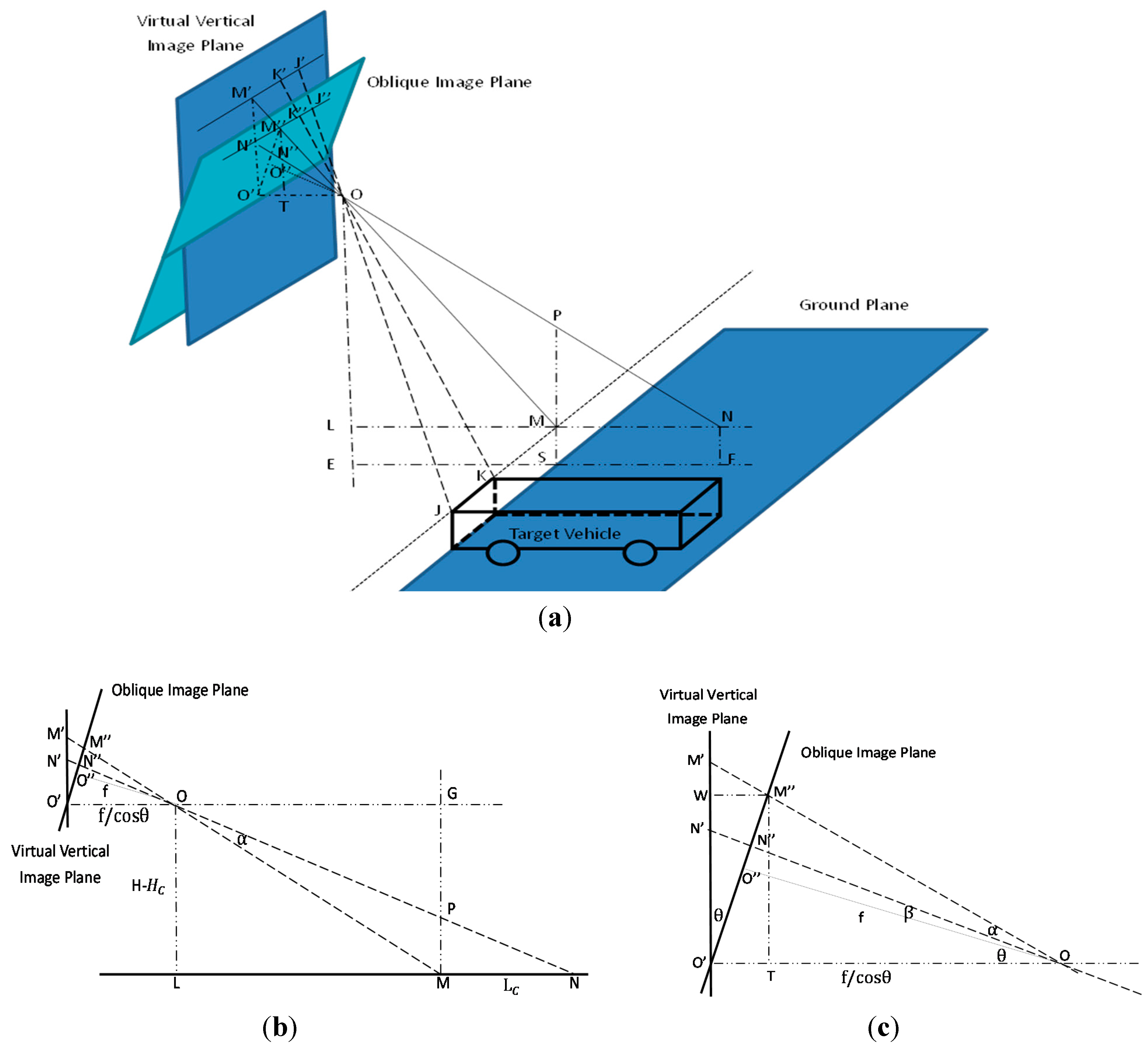
The side-surface region can be determined if the interior orientation parameters, the rough size of the vehicles, and the position of the front/back surfaces of vehicles on the images are known. However, most driving recorders do not contain accurate calibration parameters so we deduced the equations described in this section to compute the rough position of the vehicle side-surface region based on the position of the front/back-surfaces and the vanishing point in the image, the approximate height H of the recorder, the rough value of focal length f, and the pitch angle of recorder
. The vanishing point used in this section was located using the [
19,
20] method and the position of the vehicle front/back-surface was detected with the method described in
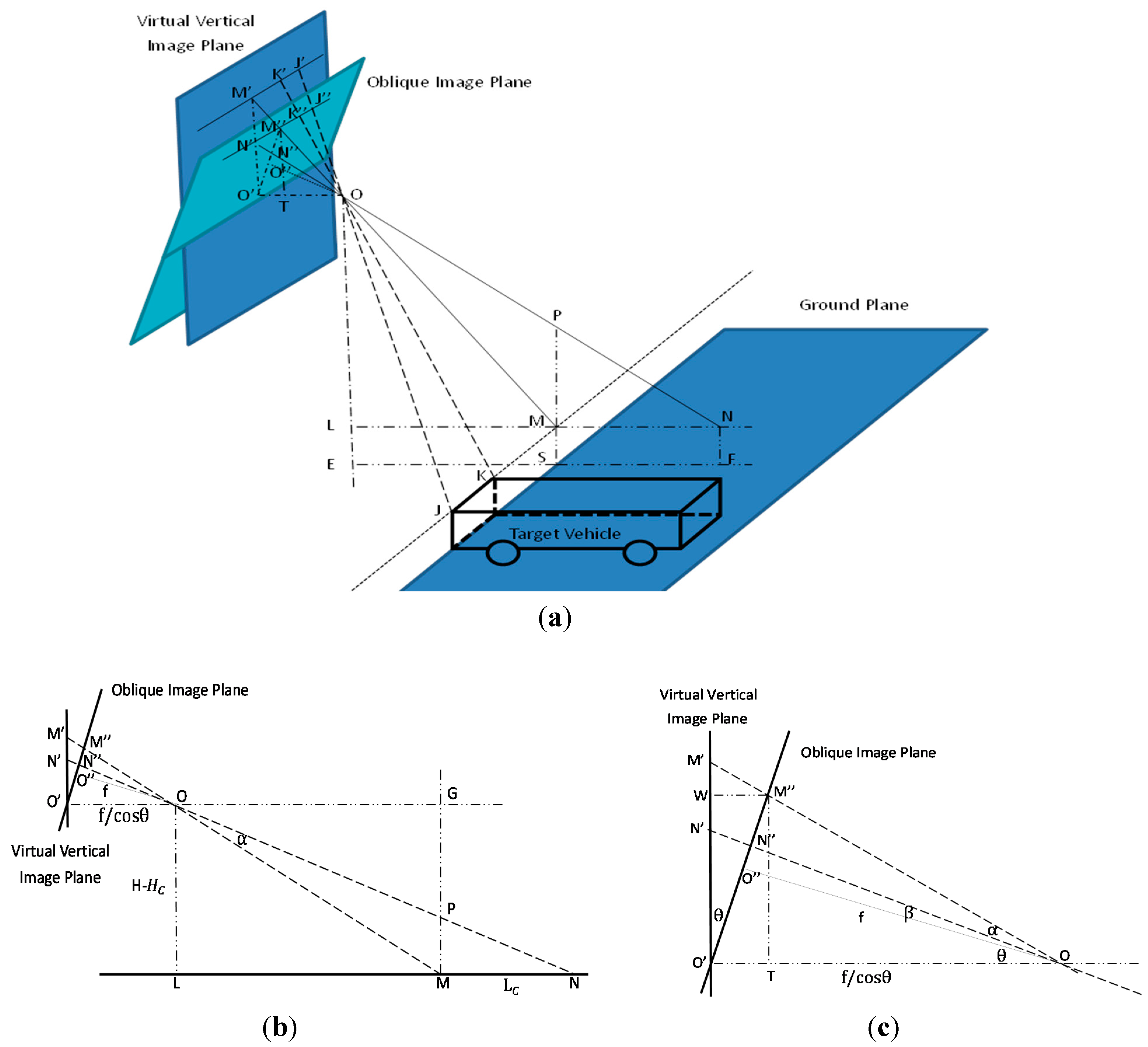
Section 2.1. The vanishing point is considered a point in the picture plane that is the intersection of a set of parallel lines in space on the picture plane. Although the vehicle side-surface detection method proposed in this section can only locate the approximate position of the vehicle side-surface, it is adequate for masking out the features on vehicles to improve the reconstruction results. The length of M″N″ is the key step in the vehicle side-surface detection method. The process of computing the length of M″N″ is described below:
Figure 4.
Photographic model of driving recorder. (a) Integrated photographic model of driving recorder. (b) Side view of model. (c) Partial enlargement of side view model. The oblique image plane is the driving recorder image plane. Point O is the projective center, and
is the principal point on the driving recorder image plane. The focal length f is
. Point
is the principal point on the virtual vertical image plane. Line OE is perpendicular to the ground. Point E is the intersection point of the ground and line OE. The plane
OOEF can be drawn perpendicular to both the image plane and the ground.
is perpendicular to
, and OM is perpendicular to MJ. Line LN is perpendicular to OE. MP is a vertical line for the ground, and P is the intersection point of line MP and line ON. Line
T is perpendicular to
. The angle between the oblique plane and the vertical plane is
. Angles MON and
are
and
, respectively.
Figure 4.
Photographic model of driving recorder. (a) Integrated photographic model of driving recorder. (b) Side view of model. (c) Partial enlargement of side view model. The oblique image plane is the driving recorder image plane. Point O is the projective center, and
is the principal point on the driving recorder image plane. The focal length f is
. Point
is the principal point on the virtual vertical image plane. Line OE is perpendicular to the ground. Point E is the intersection point of the ground and line OE. The plane
OOEF can be drawn perpendicular to both the image plane and the ground.
is perpendicular to
, and OM is perpendicular to MJ. Line LN is perpendicular to OE. MP is a vertical line for the ground, and P is the intersection point of line MP and line ON. Line
T is perpendicular to
. The angle between the oblique plane and the vertical plane is
. Angles MON and
are
and
, respectively.
In
Figure 4a, we suppose that the real length, height, and width of the vehicle are
,
and
, respectively. The width of the target on image
is
. H is the height of projective center O to ground OE. Therefore, it can be seen that the length of target MN is
, the length of LE is
and OL is H −
.
Figure 4a shows that triangle
TO is similar to OLM and triangle
O is similar to KJO. We therefore can deduce the following equations from the triangle similarity theorem:
So the length of
can be described with Equation (2):
It can be seen from △W
in
Figure 4c that, angle W
is
, and the length of
is equal to
in rectangle
. Then, Equation (3) can be established with the length of
in Equation (2):
In
Figure 4c, the length of
is equal to W
in rectangle
, so the length of
is equal to M″T add
. Then, Equation (4) can be established based on △
∽△
:
Equation (5) is transformed from Equation (4), and the length of
is expressed below:
Equation (6) is established from rectangle
in
Figure 4c.
In
Figure 4a, since
is the height of triangle
, we can infer that:
We know that,
is
, therefore with the calculations of M″T (Equation (2)) and O′M′ (Equation (6)), the length of
can be established from the transformation of Equation (8):
KJ and
are parallel; therefore, we can infer that triangle
O and triangle KMO are similar triangles from
Figure 4a.
is the height of triangle
O and OM is the height of triangle KMO. Meanwhile,
and LN are parallel lines so triangle
is similar to triangle OML. Therefore, based on the triangle similarity theorem, Equation (10) can be established:
The length of
is
and KJ is
so LM can be calculated based on Equations (9) and (10):
In
Figure 4b, Equation (12) can be established since triangle PMN is similar to OLM:
OL and MN are H −
and
, respectively. Then, MP can be described with Equations (11) and (12)
In order to compute the length of M’’N’’, we suppose that:
Based on cosine theorem, Equation (15) can be established:
In
Figure 4b, OG is equal to LM, and OL has the same length as GM in rectangle OGML. The length of OL is H −
. Based on the Pythagoras theorem, Equations (16) and (17) were deduced from △OGP and △OLM.
Taking Equations (16) and (17) into Equation (15), angle
can be described as follow:
In
Figure 4b,c,
so in triangle OML:
Equation (20) is the transformation of Equation (19), with OL= H−
:
Since
is perpendicular to
, the following equations can be established based on thesine theorem in
Figure 4c.
Based on Equation (21), since
is f, the following equation can be transformed:
Finally, the length of
can be calculated by taking Equations (11), (13), (18), and (20) into (22).
We have supposed that
is the length of the vehicle. In
Figure 5,
on line l is the projection length of
, which can be computed by the Equation (22). With the known positions of the vehicle front/back-surfaces, the vanishing point on the image, the length of
, and the rough regions of the vehicle side-surfaces can be located with the following step.
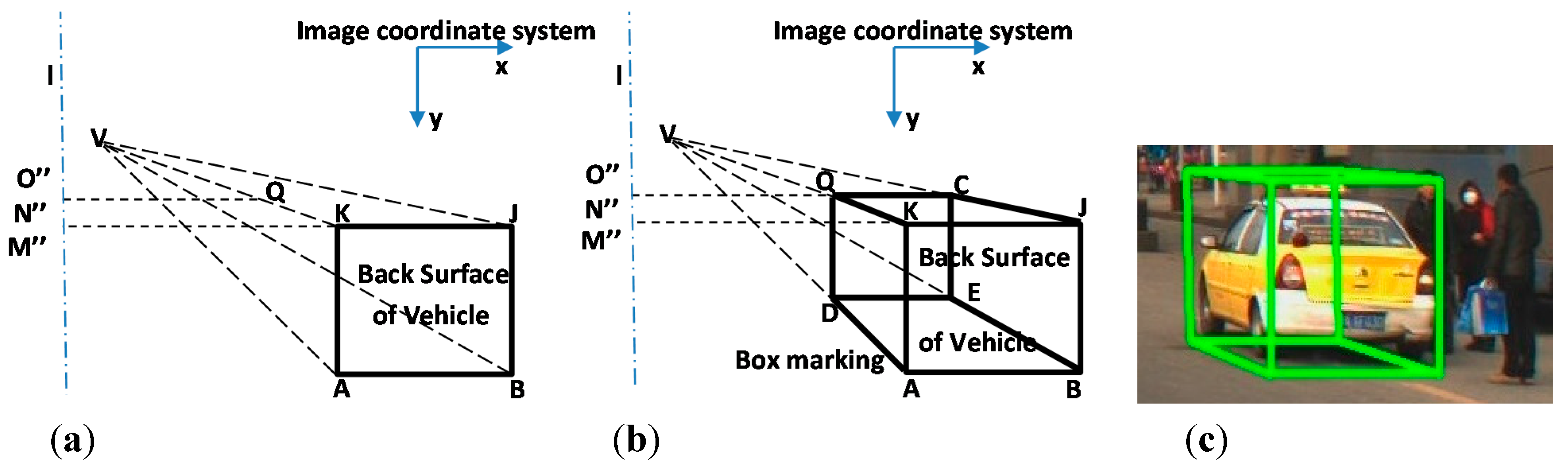
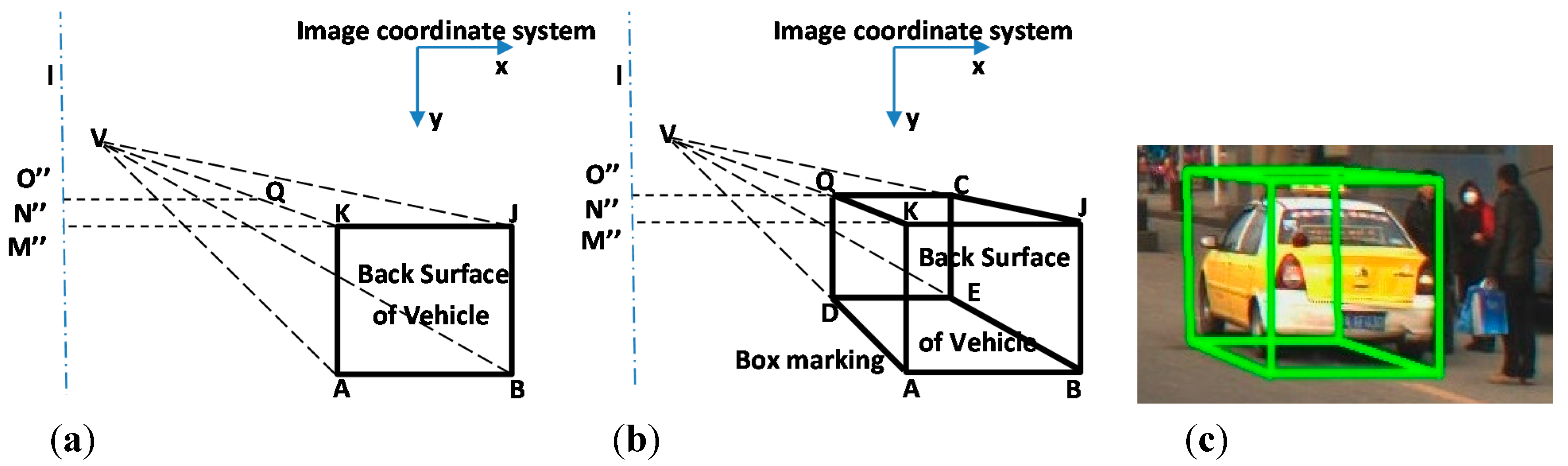
Figure 5.
(
a) and (
b) depictions of the box marking drawing method. (
c) Example of box marking in an image. The principal point
is the center point of the image, and the black rectangle KJAB is the vehicle back surface in the image plane, which are detected by the classifier described in
Section 2.1. Point V is the vanishing point in the image. Line l is the perpendicular bisector of the image passing through principal point
. Line K
is parallel to the x axis of the image and
is the intersection point on l. Line
Q intersects lines VK and VJ at points Q and C, respectively.
Q is parallel with
K. Line QD intersects line VA at point D, and line DE intersects line VB at point E. Line QC and DE are parallel to the x axis and QD is parallel to the y axis of the image.
Figure 5.
(
a) and (
b) depictions of the box marking drawing method. (
c) Example of box marking in an image. The principal point
is the center point of the image, and the black rectangle KJAB is the vehicle back surface in the image plane, which are detected by the classifier described in
Section 2.1. Point V is the vanishing point in the image. Line l is the perpendicular bisector of the image passing through principal point
. Line K
is parallel to the x axis of the image and
is the intersection point on l. Line
Q intersects lines VK and VJ at points Q and C, respectively.
Q is parallel with
K. Line QD intersects line VA at point D, and line DE intersects line VB at point E. Line QC and DE are parallel to the x axis and QD is parallel to the y axis of the image.
With the computed length of
, the position of point
is known, then point C, D, and E can be located with the rules described in
Figure 5. Thereafter, the black bolded-line region QCJBAD on
Figure 5b can be determined. Based on the shape of the black bolded-line region, we defined it as the “box marking”. The region surrounded by the box marking will contain the front, back, and side-surfaces of the vehicle generally. Therefore, according to the description below, the box markings of vehicle side-surfaces can be fixed by
.
Detecting vehicle side-surfaces by the box marking method has the advantage of having a fast speed and reliable results, but it relies on parameters H, f, and
. These parameters can only be estimated crudely on driving recorders. Therefore, the above method can only locate the approximate position of the vehicle side surface. However, it is adequate for the method to reach the goal of eliminating features on the Mask.
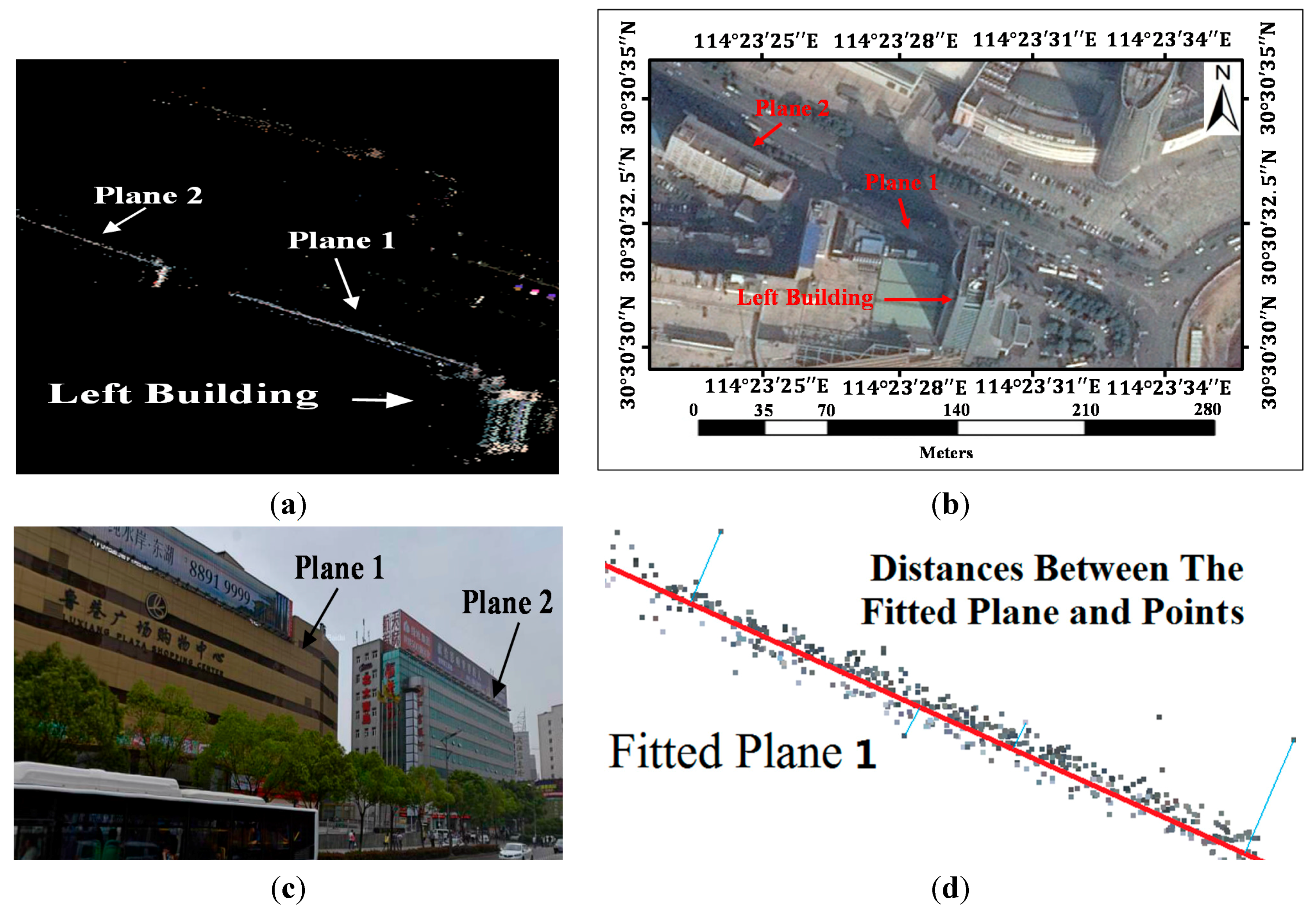
2.3. Guardrail Detection
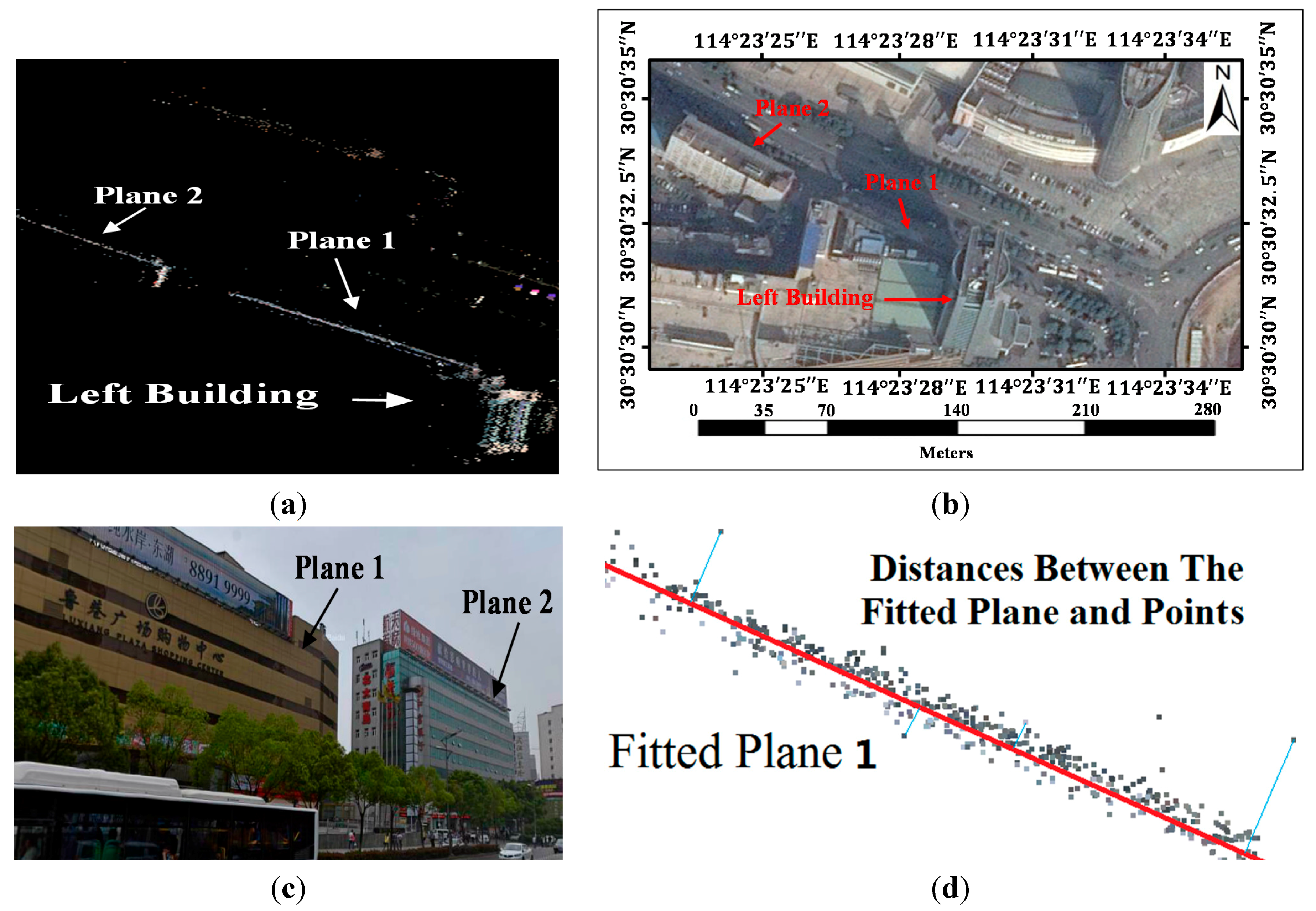
The guardrail is an isolation strip mounted on the center line of the road to separate vehicles running in opposite directions. It also can avoid pedestrian arbitrarily crossing the road. The photos of guardrail are shown in
Figure 6d and
Figure 7c. There are two reasons for detecting and removing the guardrail regions. The main reason is that, due to the repeating patterns of guardrails, they always contribute to poor matches. Furthermore, the views of vehicles moving on the other side of the guardrail are always blocked by the guardrails. This shielding makes vehicles undetectable by the vehicle classifiers. Therefore, in order to detect the blocked-vehicle regions, it was necessary to locate the guardrail regions. The blocked-vehicle regions detection method, which is described in
Section 2.4, is based on the guardrail detection method described below.
The guardrail regions are detected based on a specially-designed guardrail-classifier. Except for changes in the training parameters, the guardrail-classifier training process is similar to the vehicle training method, which is described in
Section 2.1. In order to detect an entire region of guardrails, a special guardrail-classifier was trained based on OpenCV Object Detection Lib [
17] with a nearly 0% missing object rate. The price of a low missing rate, however, inevitably is an increase in the false detection rate, which means that the classifier could detect thousands of results that included not only the guardrails but also some background. In the training process, two parameters, the Stages-Number and the desired Min-Hit-Rate of each stage, were decreased. One parameter, the MinNeighbor [
17] (a parameter specifying how many neighbors each candidate rectangle should have to retain it), was set to 0 during the detecting process.
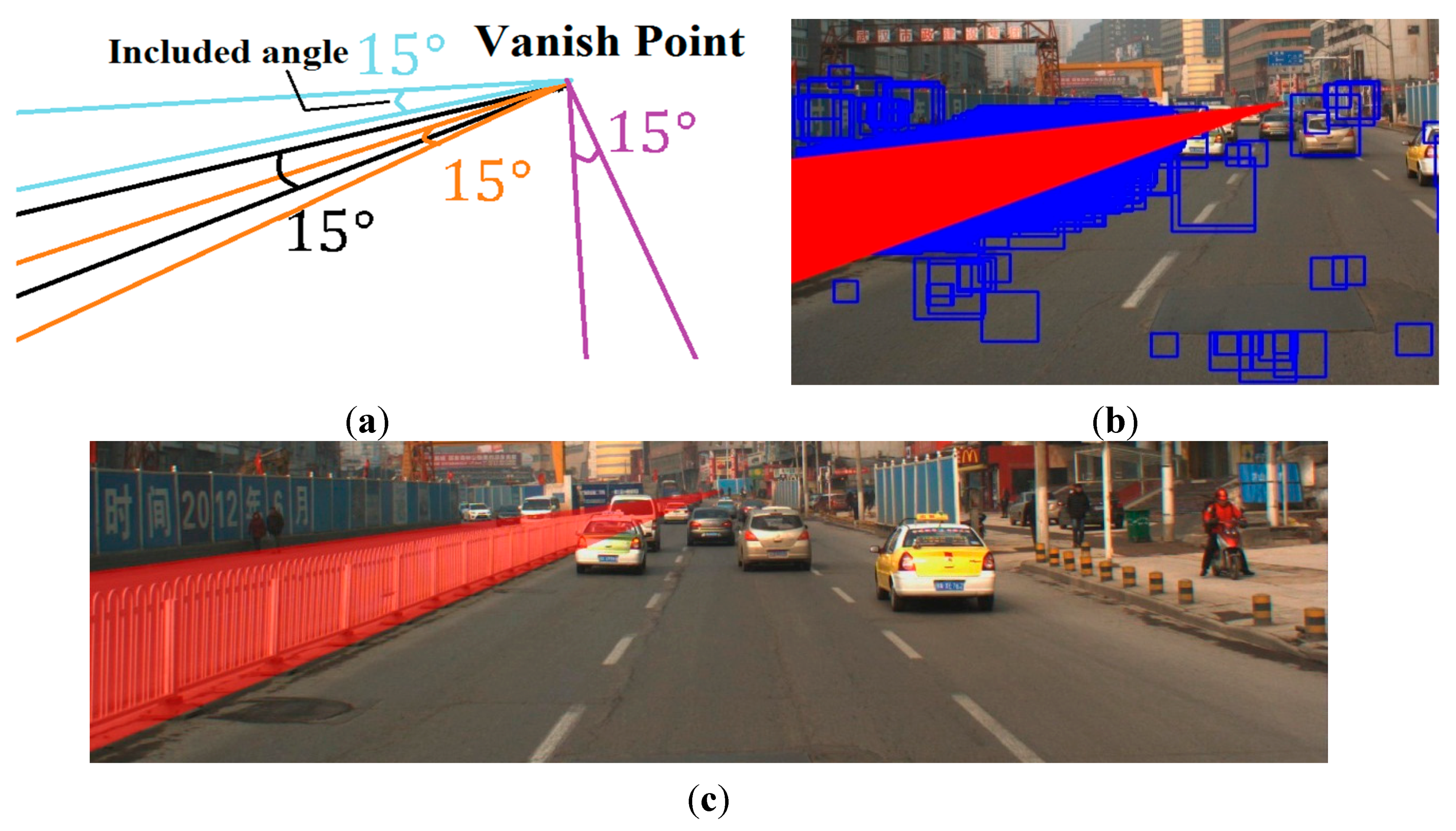
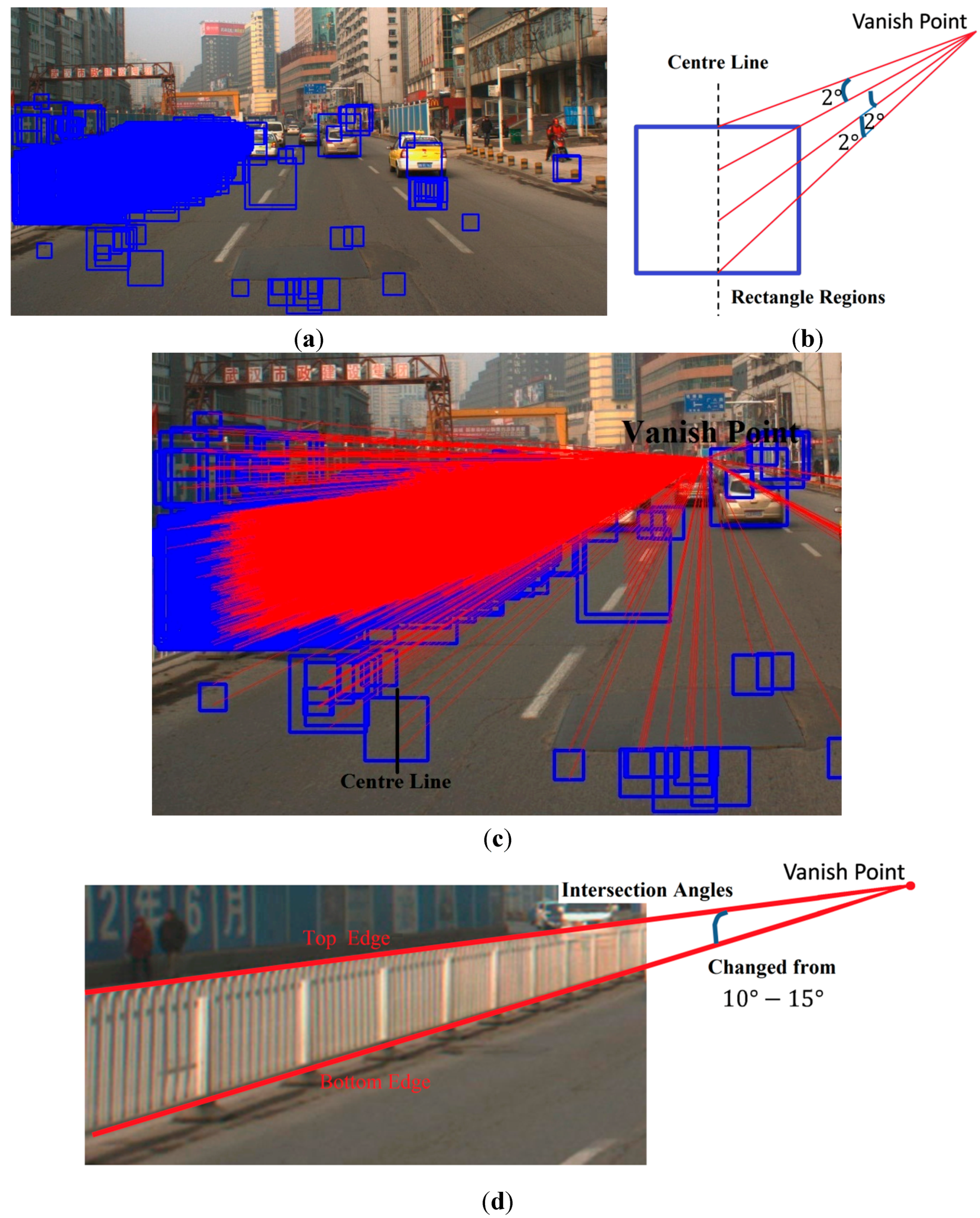
The special-designed guardrail classifier detection results are shown in
Figure 6a as blue rectangles, and many of them are not guardrails. This is a side effect of guaranteeing a low missing object rate, but uses of the statistical analysis method can ensure that these false detections cannot influence the confirmation of the actual guardrail regions in further steps. The vanishing point was fixed by the [
19,
20] method, wherein a vanishing point is considered a point in the picture plane that is the intersection of a set of parallel lines in space on the picture plane. The lines are drawn from the vanishing point to each centre line of the rectangular regions at an interval of
. This drawing approach is shown in
Figure 6b, and the drawing results are shown in
Figure 6c with red lines. Since the heights of the guardrails were fixed and the models in the driving recorder were changed within a certain range, the intersection angles between the guardrail top and bottom edges on the image often changed from
to
as a general rule. An example of the intersection angles is shown in
Figure 6d.
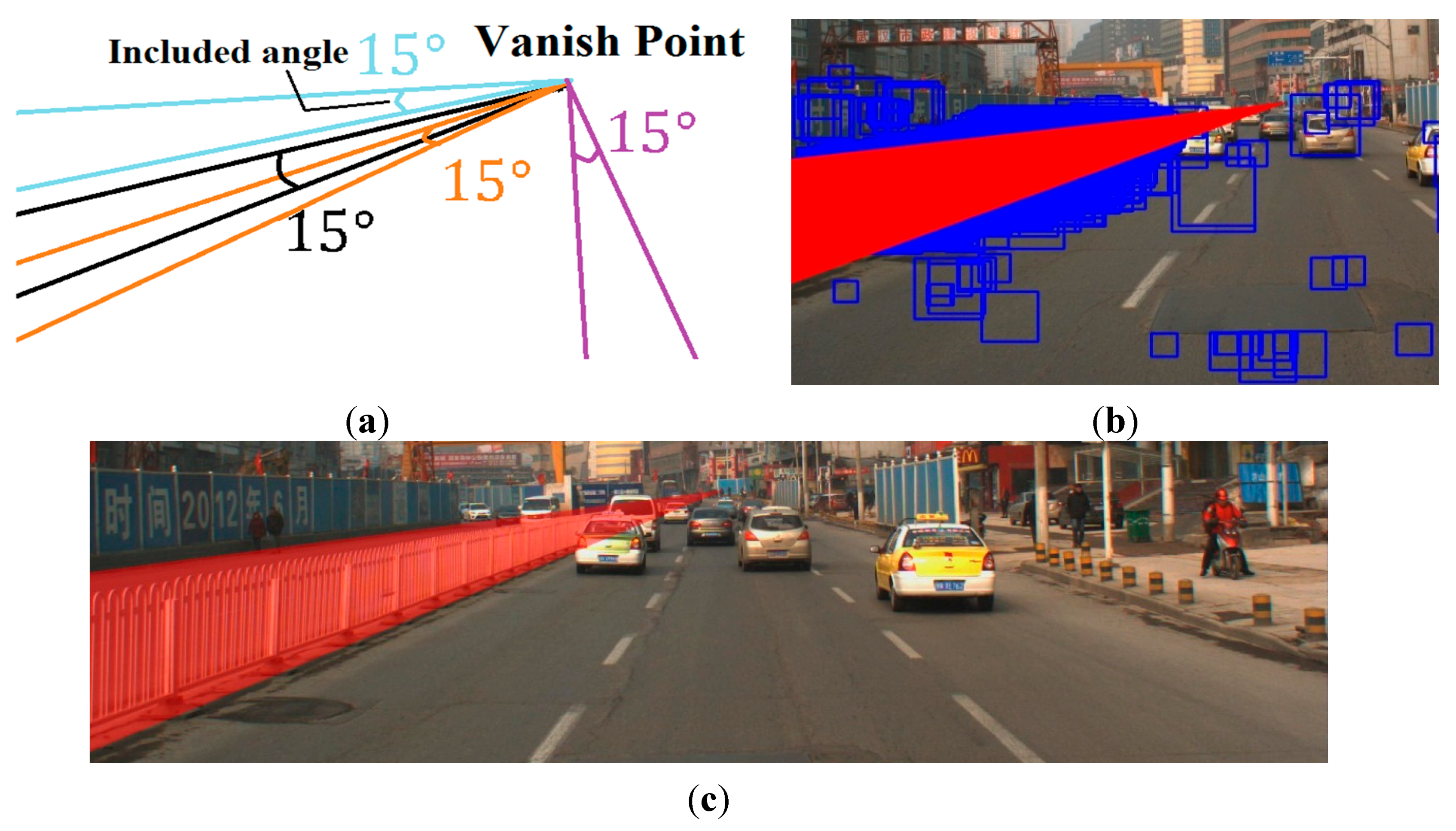
Based on the red lines drawn results, we made a triangle region which included an angle of
and a fixed vertex (the vanishing point). The threshold of
was the maximum potential intersection angle between the top and bottom edges of the guardrail. Then, we shifted the triangle region between
like
Figure 7a. During the shift, the number of red lines included in every triangle region was counted. Then, we considered the triangle region that had the largest line numbers as the guardrail region.
Figure 7b shows the position of the triangle region that had the largest line numbers, and
Figure 7c shows the final detection results of the guardrail.
Figure 6.
Guardrails detection process. (a) Detection results of a specially-designed guardrail-classifier which could detect thousands of results, including not only correct guardrails but many wrong detection regions as well. (b) Example of how to draw the red lines from the vanishing point to the detection regions. (c) Results of red lines drawn from the vanishing point to each centre line of the rectangle regions at an interval of
. An example of a rectangle region’s centre line is shown in the bottom left corner of the (c); and (d) is an example of an intersection angle between the top and bottom edges of the guardrail.
Figure 6.
Guardrails detection process. (a) Detection results of a specially-designed guardrail-classifier which could detect thousands of results, including not only correct guardrails but many wrong detection regions as well. (b) Example of how to draw the red lines from the vanishing point to the detection regions. (c) Results of red lines drawn from the vanishing point to each centre line of the rectangle regions at an interval of
. An example of a rectangle region’s centre line is shown in the bottom left corner of the (c); and (d) is an example of an intersection angle between the top and bottom edges of the guardrail.
Figure 7.
Guardrail location method. (a) Example of four triangle regions which included the angle of
and the fixed vertex (the vanishing point). (b) Triangle region that had the largest line numbers. (c) Final detection results of guardrail location method.
Figure 7.
Guardrail location method. (a) Example of four triangle regions which included the angle of
and the fixed vertex (the vanishing point). (b) Triangle region that had the largest line numbers. (c) Final detection results of guardrail location method.
2.5. Mask and Structure from Motion
In the SIFT matching algorithm, detecting the feature points on the images is the first step, and the correspondences are then matched between the features. The coordinates of the features were compared with the location of the Mask regions in the image, and then the features located in the Mask were removed from the feature point sets. An example of our removing results is shown in
Figure 9. The Mask was obtained by merging the regions detected in
Section 2.1,
Section 2.2,
Section 2.3 and
Section 2.4. After removing the SIFT feature points on the Mask, the remaining features were matched. Then, the QDEGSAC [
21] algorithm was used to robustly estimate a fundamental matrix for each pair and the outliers were eliminated with a threshold of two pixels by the epipolar constraint [
7,
22]. The QDEGSAC algorithm is a robust model with a selection procedure that accounts for different types of camera motion and scene degeneracies. QDEGSAC is as robust as RANSAC [
23] (the most common technique to deal with outliers in matches), even for (quasi-)degenerate data [
21].
Figure 9.
SIFT feature points removing results. (a) Original SIFT feature points set on image. (b) Mask results, which show the masked out features on the vehicle and guardrail regions.
Figure 9.
SIFT feature points removing results. (a) Original SIFT feature points set on image. (b) Mask results, which show the masked out features on the vehicle and guardrail regions.
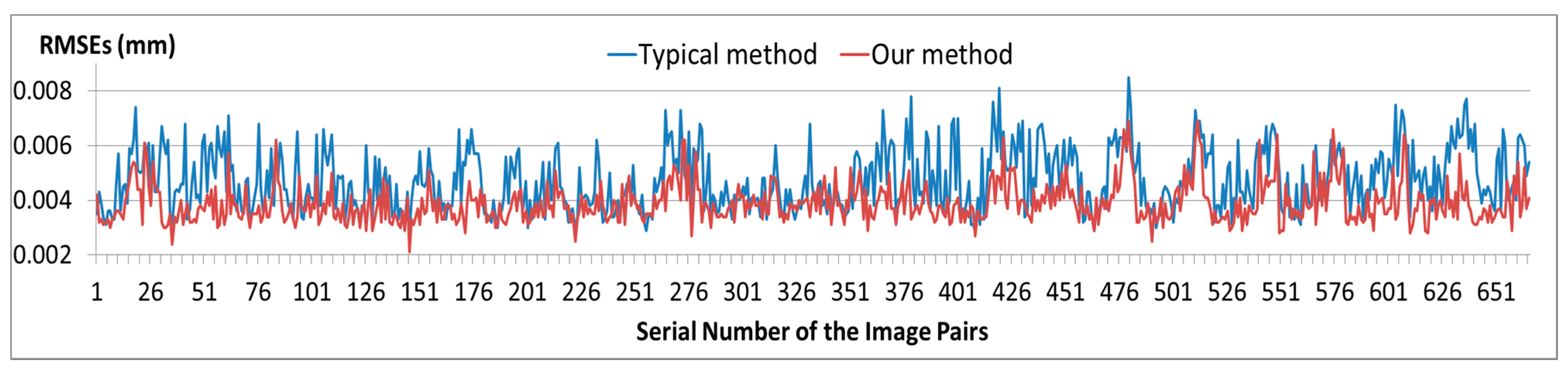
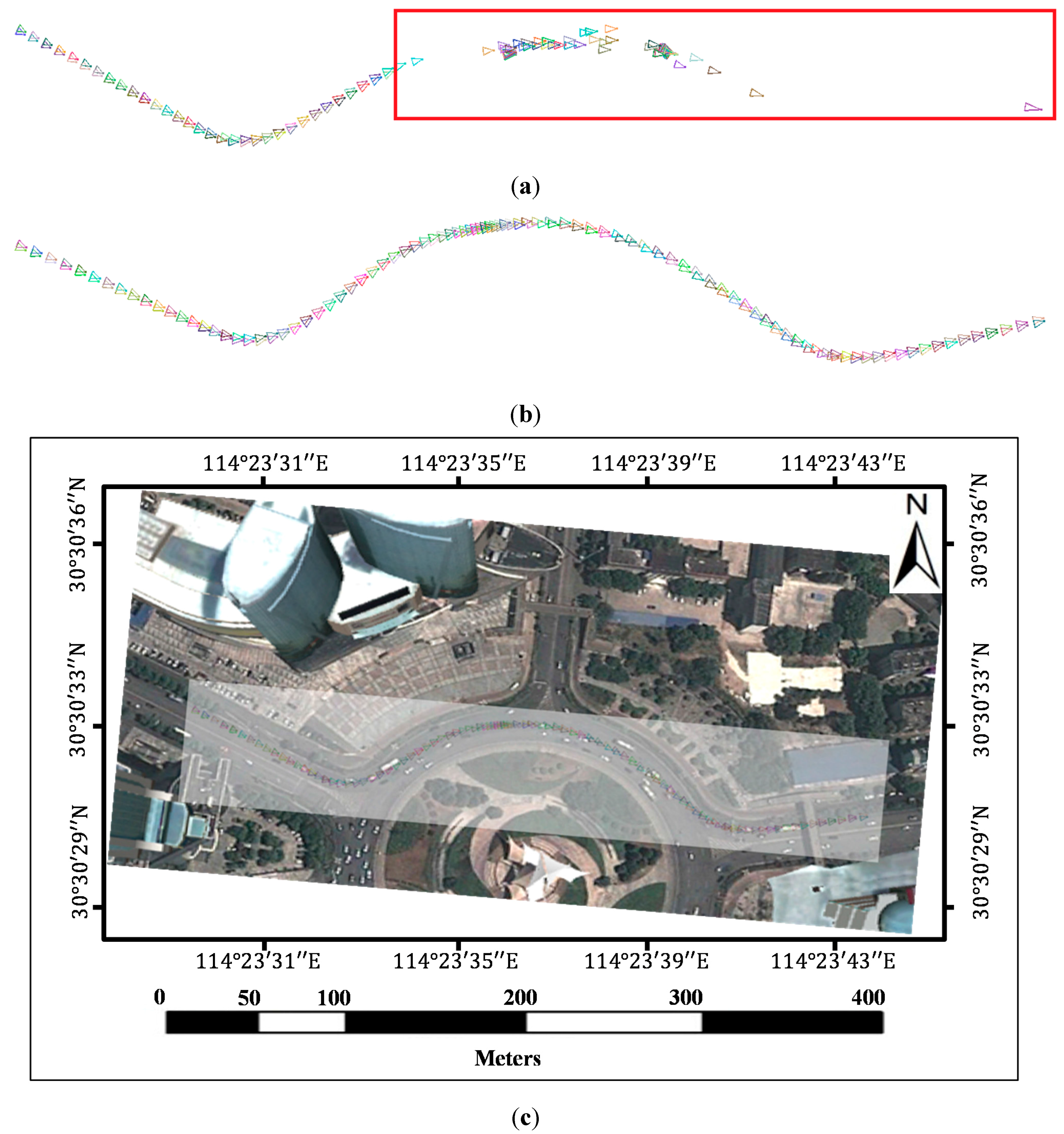
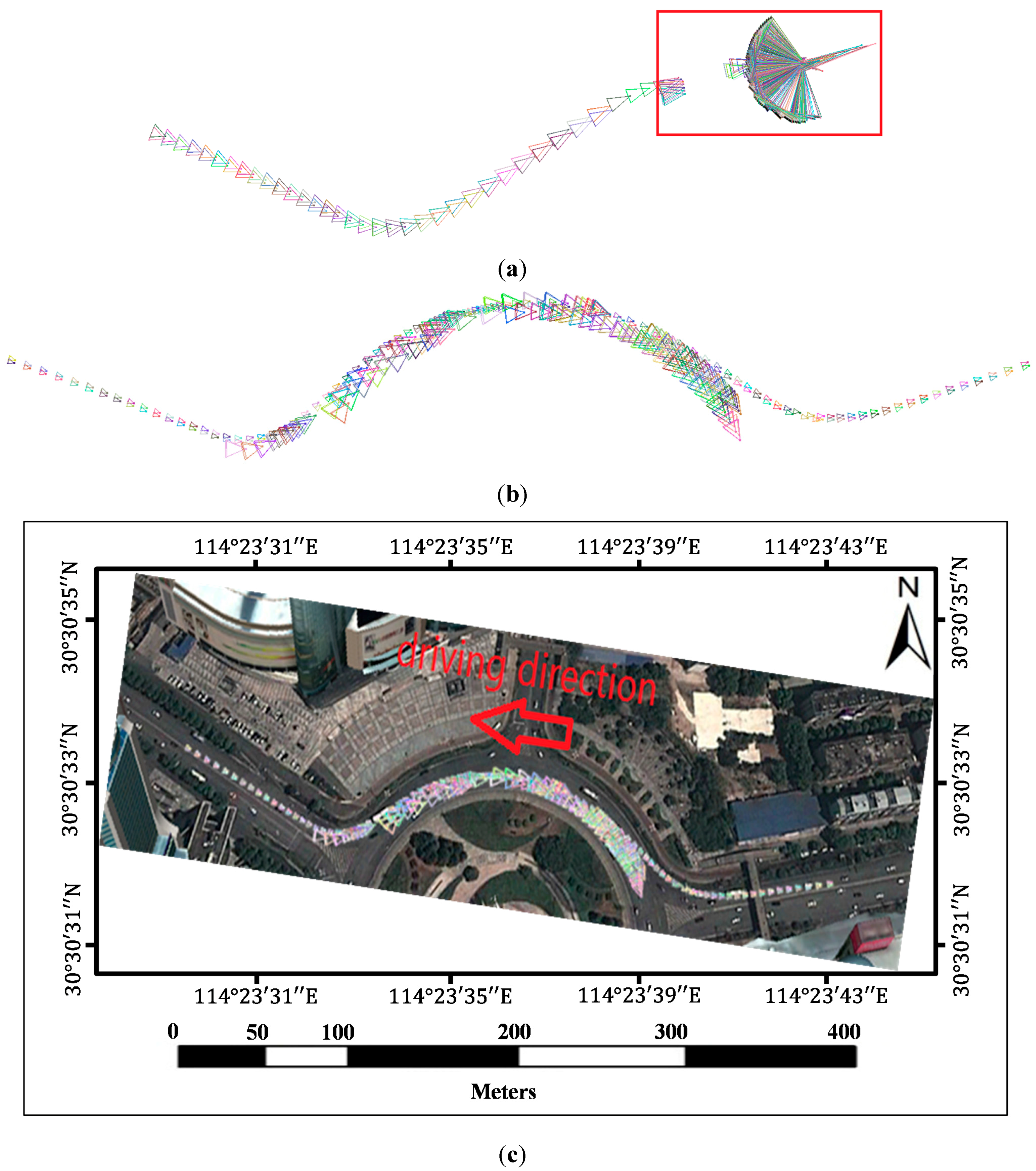
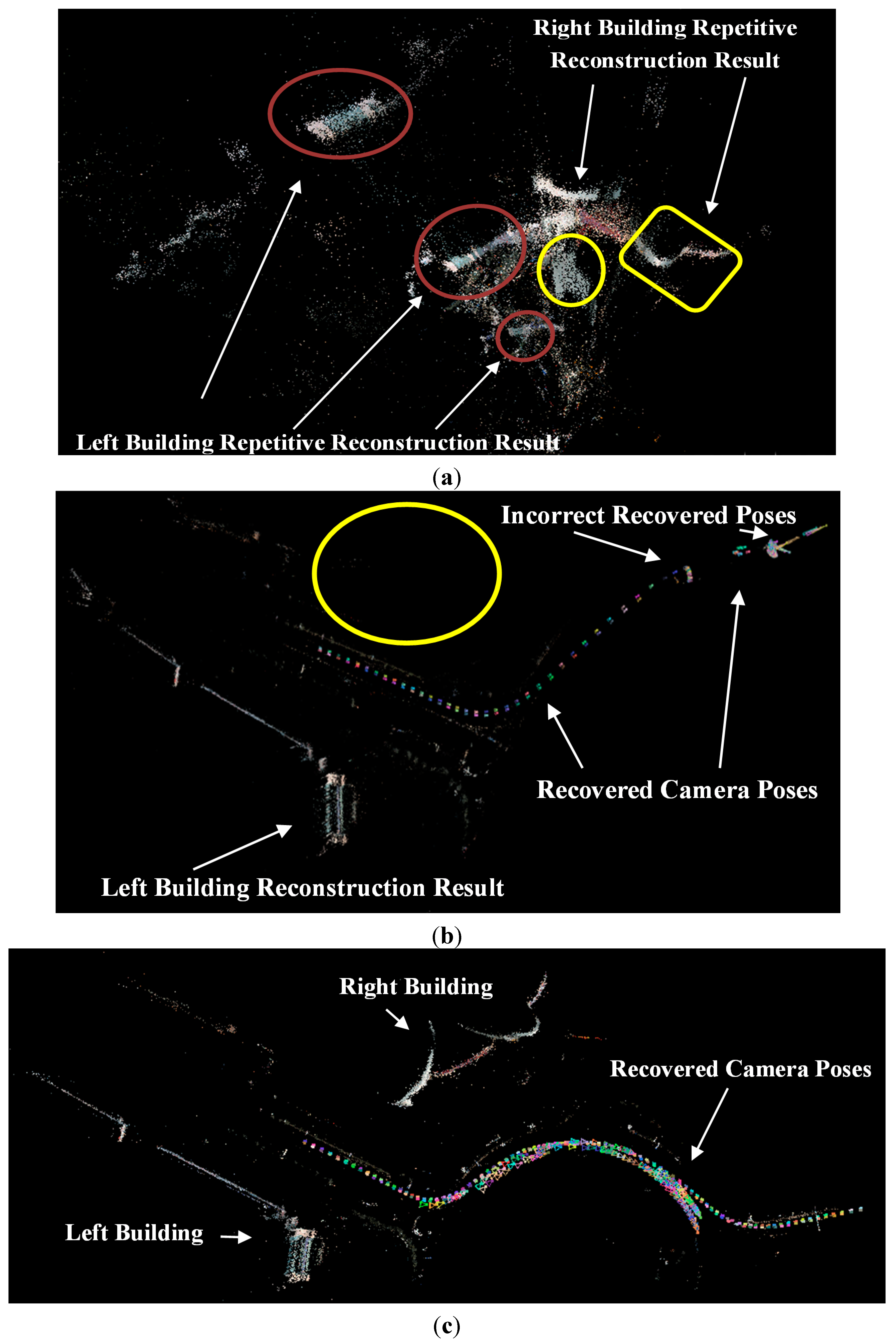
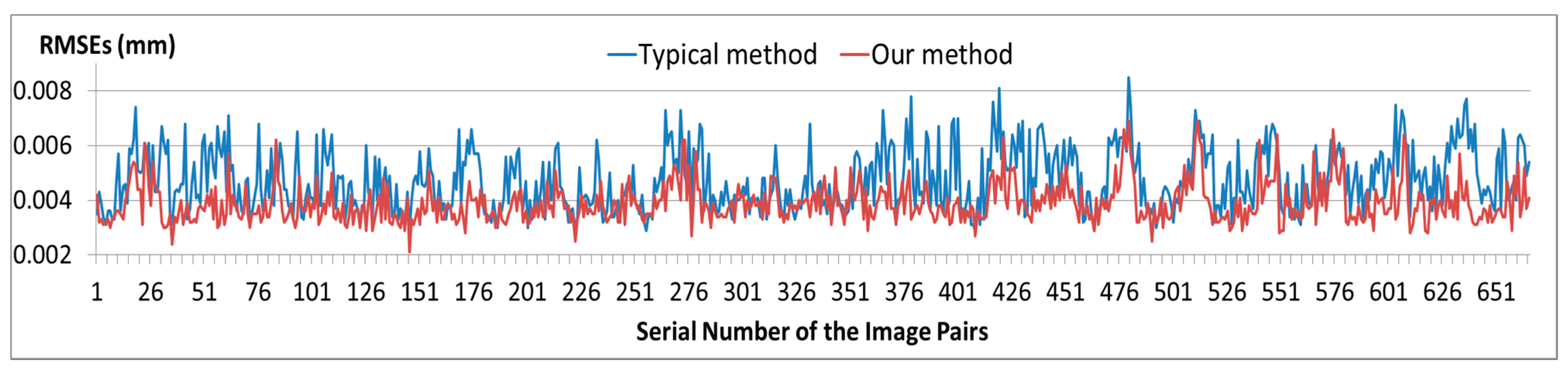
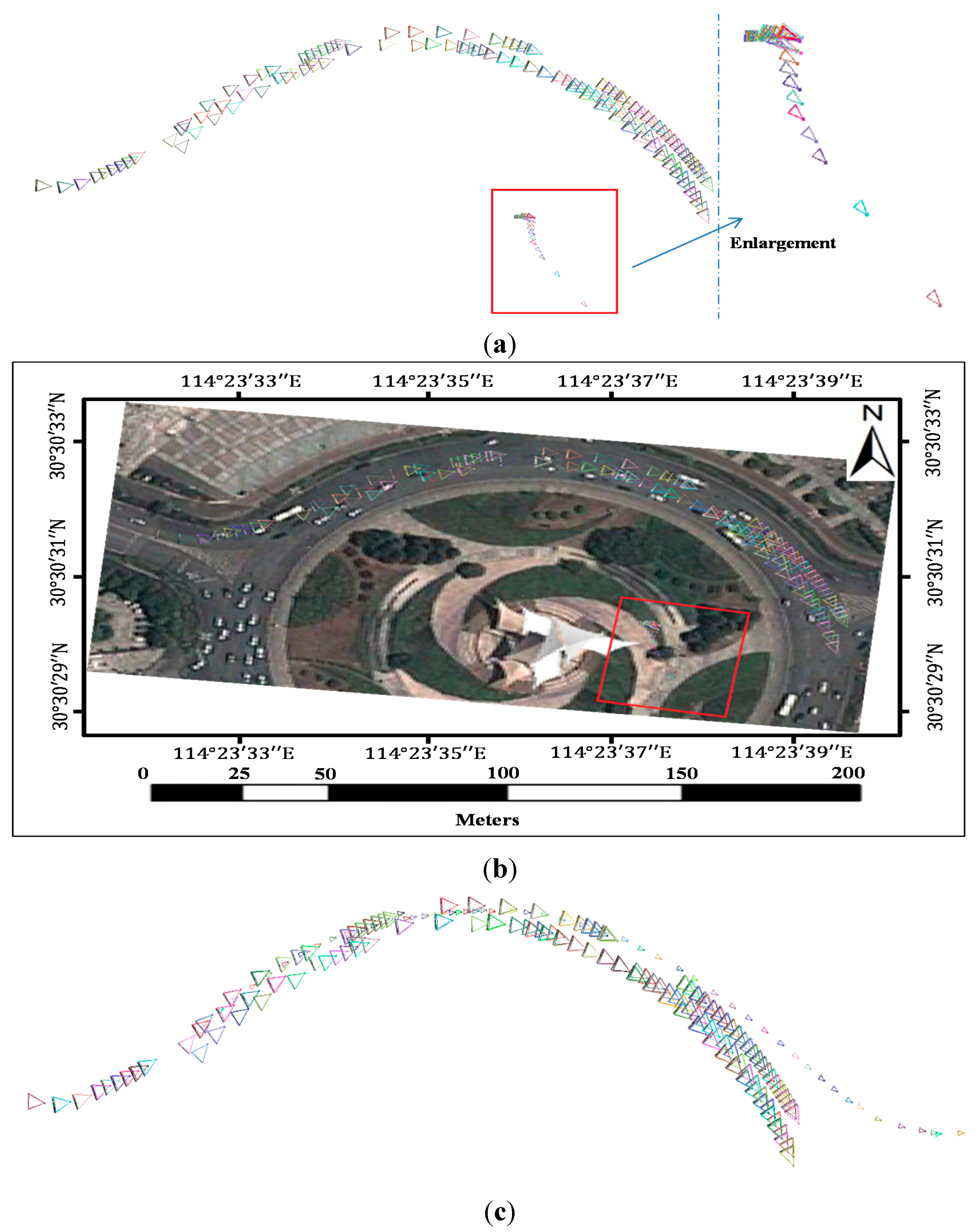
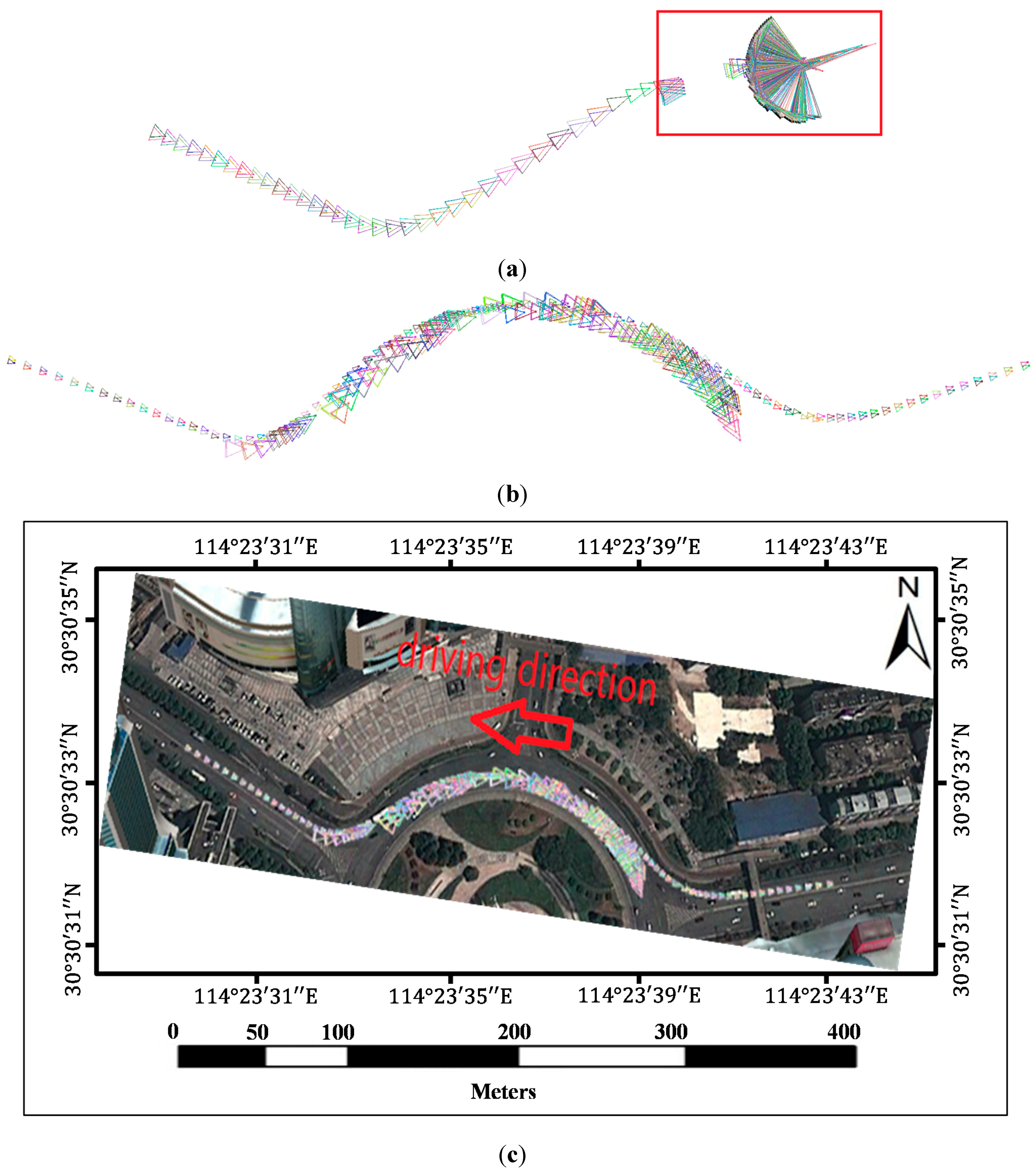
In a typical SfM reconstruction method, pairwise images are matched with the SIFT algorithm without any added process. Then, the inlier matches are determined by the epipolar constraint algorithm (similar to the QDEGSAC algorithm), and a sparse point cloud is reconstructed with the inliers by the SfM algorithm. However, in our method, during the pairwise matching process, the SIFT feature points on the vehicle and guardrail regions are masked out before matching. The remaining features are then matched by the SIFT algorithm. After the outliers were eliminated by the epipolar constraint algorithm, the SfM reconstruction process proceeds with the remaining matches.
Both in the typical method and our proposed method, the QDEGSAC algorithm was used as an epipolar constraint algorithm to select the inliers, and the SfM process was conducted in VisualSFM [
24,
25]. Visual SFM is a GUI application of the incremental SfM system. It runs very fast by exploiting multi-core acceleration. The features mask out process in our method is the only difference from the typical method.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}