
Hybrid 3D Reconstruction of Indoor Scenes Integrating Object Recognition



Abstract
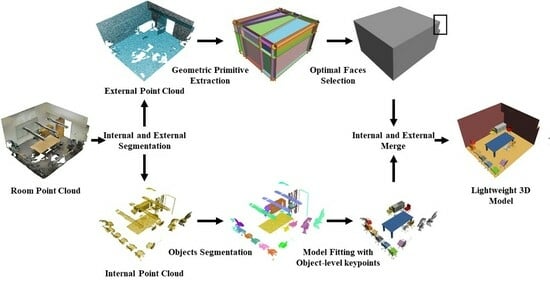
1. Introduction
- We provide a divide-and-conquer reconstruction method based on object-level features to generate models including indoor objects and room shapes from point clouds. We segment the room point cloud into internal and external for reconstruction, respectively, and the reconstruction is carried out in light of the geometric primitive of intersecting faces.
- The proposed method takes the reconstruction of external point cloud as a binary labeling problem. We seek for an appropriate combination of intersecting faces to obtain a lightweight and manifold polygonal surface model for room shapes.
- The method uses instance segmentation to assist in modeling individual indoor objects. We design a random forest classifier to recognize objects using shape features, spatial features, statistical features, and proprietary features. The reconstruction problem is approached as a model fitting problem, wherein object-level key points are extracted and subsequent optimization is performed to minimize the distance between corresponding key points, thus accurately placing the CAD models in target positions.

2. Related Work
2.1. Geometric Primitive-Based Modeling
2.2. Instance Segmentation-Based Modeling
3. Method
3.1. Internal and External Segmentation
| Algorithm 1 Internal and External Segmentation | |
| Require: point cloud | |
| 1: | tree ← kdtree(P) |
| 2: | while |
| 3: | index_0 ← rand(sizeof(P)) |
| 4: | for k = 1 to 10 do |
| 5: | index_k ← RecoverNeighborhood(tree) |
| 6: | end for |
| 7: | plane ← FitPlane(index_0, index_9, index_10) |
| 8: | for i = 1 to n do |
| 9: | if distance(pi, plane) ≤ ε then |
| 10: | S ← Pushback(pi) |
| 11: | end if |
| 12: | end for |
| 13: | if Num(S) ≥ threshold and centroid(S) ≥ centroid_threshold then |
| 14: | Pex ← Pushback(S) |
| 15: | P ← Erase(P, S) |
| 16: | else |
| 17: | if Size(P) ≤ size_threshold then |
| 18: | Pin ← Pushback(P) |
| 19: | break |
| 20: | else |
| 21: | continue |
| 22: | end if |
| 23: | end if |
| 24: | end while |
3.2. Room Shape Reconstruction
3.2.1. Candidate Face Extraction
3.2.2. Optimal Faces Selection
3.3. Indoor Object Reconstruction
3.3.1. Objects Segmentation
3.3.2. Model Fitting
4. Results and Discussion
4.1. Qualitative Comparisons
4.1.1. Object Reconstruction
4.1.2. Scene Reconstruction
4.1.3. The Effect of Occlusion
4.2. Quantitative Comparisons
4.2.1. Scene Completeness
4.2.2. Fitting Error
4.2.3. Efficiency
4.3. Exploring Complex Scenes
5. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Cheng, D.; Zhang, J.; Zhao, D.; Chen, J.; Tian, D. Automatic Extraction of Indoor Structural Information from Point Clouds. Remote Sens. 2021, 13, 4930. [Google Scholar] [CrossRef]
- Oesau, S.; Lafarge, F.; Alliez, P. Indoor Scene Reconstruction Using Feature Sensitive Primitive Extraction and Graph-cut. ISPRS J. Photogramm. Remote Sens. 2014, 90, 68–82. [Google Scholar] [CrossRef]
- Tran, H.; Khoshelham, K. A Stochastic Approach to Automated Reconstruction of 3D Models of Interior Spaces from Point Clouds. ISPRS Ann. Photogramm. Remote Sens. Spatial Inf. Sci. 2019, IV-2/W5, 299–306. [Google Scholar] [CrossRef]
- Xiong, H.; Ma, W.; Zheng, X.; Gong, J.; Abdelalim, D. Indoor Scene Texturing Based on Single Mobile Phone Images and 3D Model Fusion. Int. J. Digit. Earth 2019, 12, 525–543. [Google Scholar] [CrossRef]
- Tran, H.; Khoshelham, K. Procedural Reconstruction of 3D Indoor Models from LiDAR Data Using Reversible Jump Markov Chain Monte Carlo. Remote Sens. 2020, 12, 838. [Google Scholar] [CrossRef]
- Li, M.; Nan, L.; Liu, S. Fitting Boxes to Manhattan Scenes Using Linear Integer Programming. Int. J. Digit. Earth 2016, 9, 806–817. [Google Scholar] [CrossRef]
- Li, M.; Nan, L.; Smith, N.G.; Wonka, P. Reconstructing Building Mass Models from UAV Images. Comput. Graph. 2016, 54, 84–93. [Google Scholar] [CrossRef]
- Han, J.; Rong, M.; Jiang, H.; Liu, H.; Shen, S. Vectorized Indoor Surface Reconstruction from 3D Point Cloud with Multistep 2D Optimization. ISPRS J. Photogramm. Remote Sens. 2021, 177, 57–74. [Google Scholar] [CrossRef]
- Dai, A.; Qi, C.R.; Nießner, M. Shape Completion Using 3D-Encoder-Predictor CNNs and Shape Synthesis. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Qi, C.; Su, H.; Mo, K.; Guibas, L.J. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Nie, Y.; Hou, J.; Han, X.; Nießner, M. RfD-Net: Point Scene Understanding by Semantic Instance Reconstruction. arXiv 2021, arXiv:2011.14744. [Google Scholar]
- Lai, K.; Bo, L.; Ren, X.; Fox, D. A Large-Scale Hierarchical Multi-View RGB-D Object Dataset. In Proceedings of the 2011 IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011. [Google Scholar]
- Armeni, I.; Sener, O.; Zamir, A.R.; Jiang, H.; Brilakis, I.; Fischer, M.; Savarese, S. 3D Semantic Parsing of Large-Scale Indoor Spaces. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1534–1543. [Google Scholar]
- University of Zurich. UZH 3D Dataset. 2014. Available online: https://www.ifi.uzh.ch/en/vmml/research/datasets.html (accessed on 1 December 2023).
- Pintore, G.; Mura, C.; Ganovelli, F.; Fuentes-Perez, L.; Pajarola, R.; Gobbetti, E. State-of-the-art in Automatic 3D Reconstruction of Structured Indoor Environments. Comput. Graph. Forum 2020, 39, 667–699. [Google Scholar] [CrossRef]
- Wang, T.; Wang, Q.; Ai, H.; Zhang, L. Semantics-and-Primitives-Guided Indoor 3D Reconstruction from Point Clouds. Remote Sens. 2022, 14, 4820. [Google Scholar] [CrossRef]
- Schnabel, R.; Wahl, R.; Klein, R. Efficient RANSAC for Point-Cloud Shape Detection. Comput. Graph. Forum 2007, 26, 214–226. [Google Scholar] [CrossRef]
- Lin, H.C.; Gao, J.; Zhou, Y.; Lu, G.; Ye, M.; Zhang, C.; Liu, L.; Yang, R. Semantic Decomposition and Reconstruction of Residential Scenes from LiDAR Data. ACM Trans. Graph. 2013, 32, 66. [Google Scholar] [CrossRef]
- Ai, M.; Li, Z.; Shan, J. Topologically Consistent Reconstruction for Complex Indoor Structures from Point Clouds. Remote Sens. 2021, 13, 3844. [Google Scholar] [CrossRef]
- Wei, J.; Wu, H.; Yue, H.; Jia, S.; Li, J.; Liu, C. Automatic Extraction and Reconstruction of A 3D Wireframe of An Indoor Scene from Semantic Point Clouds. Int. J. Digit. Earth 2023, 16, 3239–3267. [Google Scholar] [CrossRef]
- Chauve, A.L.; Labatut, P.; Pons, J.-P. Robust Piecewise-Planar 3D Reconstruction and Completion from Large-Scale Unstructured Point Data. In Proceedings of the 2010 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA, 13–18 June 2010. [Google Scholar]
- Mura, C.; Mattausch, O.; Pajarola, R. Piecewise-Planar Reconstruction of Multi-Room Interiors with Arbitrary Wall Arrangements. Comput. Graph. Forum 2016, 35, 179–188. [Google Scholar] [CrossRef]
- Nan, L.; Wonka, P. PolyFit: Polygonal Surface Reconstruction from Point Clouds. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Hedau, V.; Hoiem, D.; Forsyth, D.A. Thinking Inside the Box: Using Appearance Models and Context Based on Room Geometry. In Proceedings of the European Conference on Computer Vision (ECCV), Heraklion, Greece, 5–11 September 2010. [Google Scholar]
- Cui, Y.; Li, Q.; Yang, B.; Xiao, W.; Chen, C.; Dong, Z. Automatic 3-D Reconstruction of Indoor Environment with Mobile Laser Scanning Point Clouds. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2019, 12, 3117–3130. [Google Scholar] [CrossRef]
- Nan, L.; Xie, K.; Sharf, A. A Search-Classify Approach for Cluttered Indoor Scene Understanding. ACM Trans. Graph. 2012, 31, 137. [Google Scholar] [CrossRef]
- Qi, C.; Yi, L.; Su, H.; Guibas, L.J. PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space. arXiv 2017, arXiv:1706.02413. [Google Scholar] [CrossRef]
- Liu, C.; Furukawa, Y. MASC: Multi-scale Affinity with Sparse Convolution for 3D Instance Segmentation. arXiv 2019, arXiv:1902.04478. [Google Scholar] [CrossRef]
- Liu, Y.; Fan, B.; Xiang, S.; Pan, C. Relation-Shape Convolutional Neural Network for Point Cloud Analysis. In Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Jiang, L.; Zhao, H.; Shi, S.; Liu, S.; Fu, C.-W.; Jia, J. PointGroup: Dual-Set Point Grouping for 3D Instance Segmentation. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- He, T.; Shen, C.; van den Hengel, A. DyCo3D: Robust Instance Segmentation of 3D Point Clouds through Dynamic Convolution. In Proceedings of the 2021 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Nan, L.; Sharf, A.; Zhang, H.; Cohen-Or, D.; Chen, B. SmartBoxes for Interactive Urban Reconstruction. ACM Trans. Graph. 2010, 29, 93–103. [Google Scholar] [CrossRef]
- Hackel, T.; Wegner, J.D.; Schindler, K. Fast Semantic Segmentation of 3D Point Clouds with Strongly Varying Density. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, 3, 177–184. [Google Scholar] [CrossRef]
- Weinmann, M.; Jutzi, B.; Mallet, C. Geometric Features and Their Relevance for 3D Point Cloud Classification. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2017, 4, 157–164. [Google Scholar] [CrossRef]
- Gurobi. Gurobi Optimization. Available online: http://www.gurobi.com/ (accessed on 25 December 2022).
- Jutzi, B.; Gross, H. Nearest Neighbor Classification on Laser Point Clouds to Gain Object Structures from Buildings. ISPRS Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2009, 38, 65–70. [Google Scholar]
- Demantké, J.; Mallet, C.; David, N.; Vallet, B. Dimensionality-Based Scale Selection in 3D Lidar Point Clouds. ISPRS Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2012, 38, 97–102. [Google Scholar] [CrossRef]
- Thomas, H.; Deschaud, J.-E.; Marcotegui, B.; Goulette, F.; Le Gall, Y. Semantic Classification of 3D Point Clouds with Multiscale Spherical Neighborhoods. In Proceedings of the 2018 International Conference on 3D Vision (3DV), Verona, Italy, 5–8 September 2018. [Google Scholar]
- Avetisyan, A.; Dahnert, M.; Dai, A.; Savva, M.; Chang, A.X.; Nießner, M. Scan2CAD: Learning CAD Model Alignment in RGB-D Scans. arXiv 2019, arXiv:1811.11187. [Google Scholar] [CrossRef]
- Li, M.; Lafarge, F. Planar Shape-Based Registration for Multi-Modal Geometry. In Proceedings of the British Machine Vision Conference, Online, 30 August–2 September 2021. [Google Scholar]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature Class | Features | Definitions |
|---|---|---|
| Shape features | Planarity | |
| Anisotropy | ||
| Eigenentropy | ||
| Change in Curvature | ||
| Spatial features | Longest Distance within Neighborhood | |
| Local Point Density | ||
| Average Height within Neighborhood | ||
| Statistical features | Absolute Moment (×2) | |
| Vertical Moment (×6) | ||
| Proprietary features | Oriented Bounding Box Height–Size Ratio | |
| Object Face and Corresponding Parallel OBB Face Axis–Size Ratio | ||
| Angle between Object Faces (Chair) |
| Scenes in Figure 11 | Points | Points of the Largest Object | Object Number |
|---|---|---|---|
| Room 1 | 1,136,617 | 35,627 | 15 |
| Room 2 | 2,314,634 | 21,161 | 33 |
| Room 3 | 1,266,990 | 34,325 | 20 |
| Room 4 | 1,138,116 | 15,221 | 23 |
| Room 5 | 1,067,709 | 29,523 | 14 |
| Room 6 | 2,065,834 | 33,060 | 16 |
| Scenes in Figure 11 | Polyfit [23] | Polyfit (Bbox) | RfD-Net [11] (Data-Driven) | Ours |
|---|---|---|---|---|
| Room 1 | 13 (−2) | 13 (−2) | 12 (−3) | 13 (−2) |
| Room 2 | 25 (−8) | 30 (−3) | 19 (−14) | 30 (−3) |
| Room 3 | 15 (−5) | 17 (−3) | 21 (+1) | 17 (−3) |
| Room 4 | 17 (−6) | 21 (−2) | 5 (−18) | 21 (−2) |
| Room 5 | 11 (−3) | 12 (−2) | 9 (−5) | 12 (−2) |
| Room 6 | 13 (−3) | 14 (−2) | 15 (−1) | 14 (−2) |
| Scenes in Figure 11 | Polyfit [23] | Polyfit (Bbox) | RfD-Net [11] (Data-Driven) | Ours |
|---|---|---|---|---|
| Room 1 | 0.11 | 0.11 | 0.07 | 0.05 |
| Room 2 | 0.34 | 0.09 | 0.10 | 0.11 |
| Room 3 | 0.29 | 0.21 | 0.12 | 0.05 |
| Room 4 | 0.02 | 0.02 | 0.28 | 0.06 |
| Room 5 | 0.05 | 0.05 | 0.09 | 0.03 |
| Room 6 | 0.44 | 0.38 | 0.22 | 0.04 |
| Objects in Figure 10 | Polyfit [23] | Polyfit (Bbox) | RfD-Net [11] (Data-Driven) | Ours |
|---|---|---|---|---|
| Chair 1 in 1st row | 0.02 | 0.02 | 0.05 | 0.04 |
| Chair 2 in 2nd row | 0.02 | 0.02 | 0.05 | 0.04 |
| Chair 3 in 2nd row | 0.01 | 0.01 | 0.06 | 0.03 |
| Table in 3rd row | 0.10 | 0.10 | 0.28 | 0.02 |
| Cabinet in 4th row | 0.53 | 0.48 | 0.49 | 0.02 |
| Sofa in 5th row | 0.01 | 0.01 | 0.11 | 0.03 |
| Scenes in Figure 11 | Scene Segmentation (s) | Room Shape Reconstruction (s) | Instance Segmentation (s) | Model Fitting (s) |
|---|---|---|---|---|
| Room 1 | 8.54 | 35.88 | 2.61 | 205.45 |
| Room 2 | 23.62 | 69.36 | 7.28 | 381.08 |
| Room 3 | 9.12 | 40.38 | 2.80 | 254.99 |
| Room 4 | 6.54 | 40.02 | 2.05 | 265.06 |
| Room 5 | 5.14 | 33.86 | 2.48 | 186.92 |
| Room 6 | 10.80 | 43.04 | 4.94 | 406.23 |
| Scenes in Figure 11 | Polyfit | Polyfit (Bbox) | Ours |
|---|---|---|---|
| Room 1 | 409.47 | 179.24 | 39.87 |
| Room 2 | 288.55 | 99.22 | 13.60 |
| Room 3 | 563.45 | 117.44 | 39.91 |
| Room 4 | 168.78 | 97.33 | 13.67 |
| Room 5 | 352.49 | 156.65 | 33.71 |
| Room 6 | 388.64 | 161.76 | 37.40 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, M.; Li, M.; Xu, L.; Wei, M. Hybrid 3D Reconstruction of Indoor Scenes Integrating Object Recognition. Remote Sens. 2024, 16, 638. https://doi.org/10.3390/rs16040638
Li M, Li M, Xu L, Wei M. Hybrid 3D Reconstruction of Indoor Scenes Integrating Object Recognition. Remote Sensing. 2024; 16(4):638. https://doi.org/10.3390/rs16040638
Chicago/Turabian StyleLi, Mingfan, Minglei Li, Li Xu, and Mingqiang Wei. 2024. "Hybrid 3D Reconstruction of Indoor Scenes Integrating Object Recognition" Remote Sensing 16, no. 4: 638. https://doi.org/10.3390/rs16040638
APA StyleLi, M., Li, M., Xu, L., & Wei, M. (2024). Hybrid 3D Reconstruction of Indoor Scenes Integrating Object Recognition. Remote Sensing, 16(4), 638. https://doi.org/10.3390/rs16040638