
Fusing Spatial Attention with Spectral-Channel Attention Mechanism for Hyperspectral Image Classification via Encoder–Decoder Networks


 ,
,
Abstract
:
1. Introduction
- To better encode the rich spectral–spatial information of the hyperspectral image, we propose a multi-source fusion attention mechanism. The multi-source fusion attention mechanism can consider the spectral channels and the spatial attention, which can help the network achieve better classification.
- To encode long-range contextual information, we propose our encoder by combining the advantages of a hierarchical transformer. In the encoder, the transformer block and the hierarchical transformer architecture have powerful feature extraction capabilities, which can obtain both shallow local features and high-level global rich semantic information.
- We propose an encoder–decoder transformer framework for hyperspectral image classification. By integrating the multi-source fusion attention mechanism with the transformer framework, our framework can effectively extract and utilize the spectral–spatial information of the hyperspectral images.
2. Related Work
2.1. CNN-Based Methods
2.2. FCN-Based Methods
2.3. Transformer-Based Methods
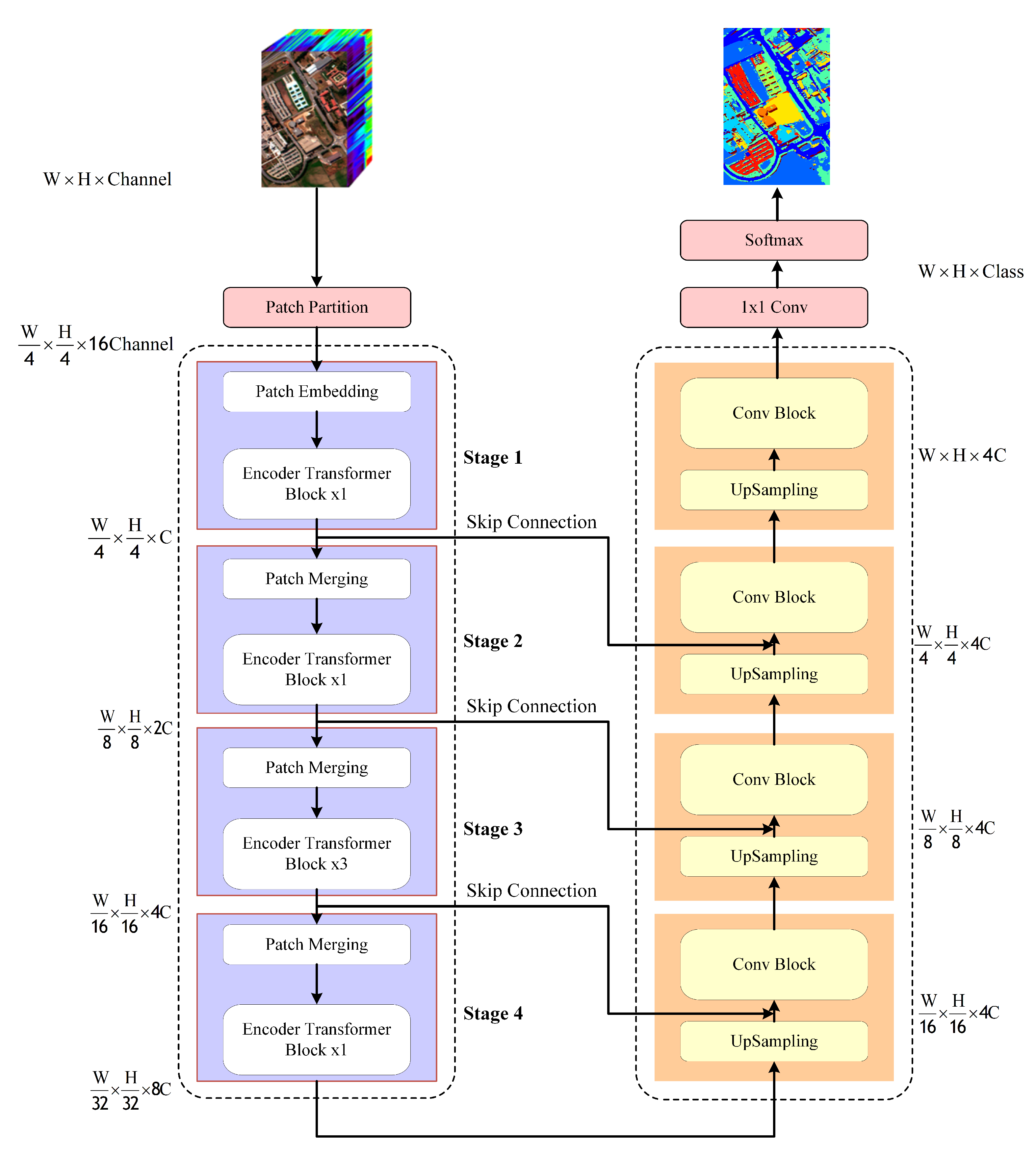
3. Proposed Method
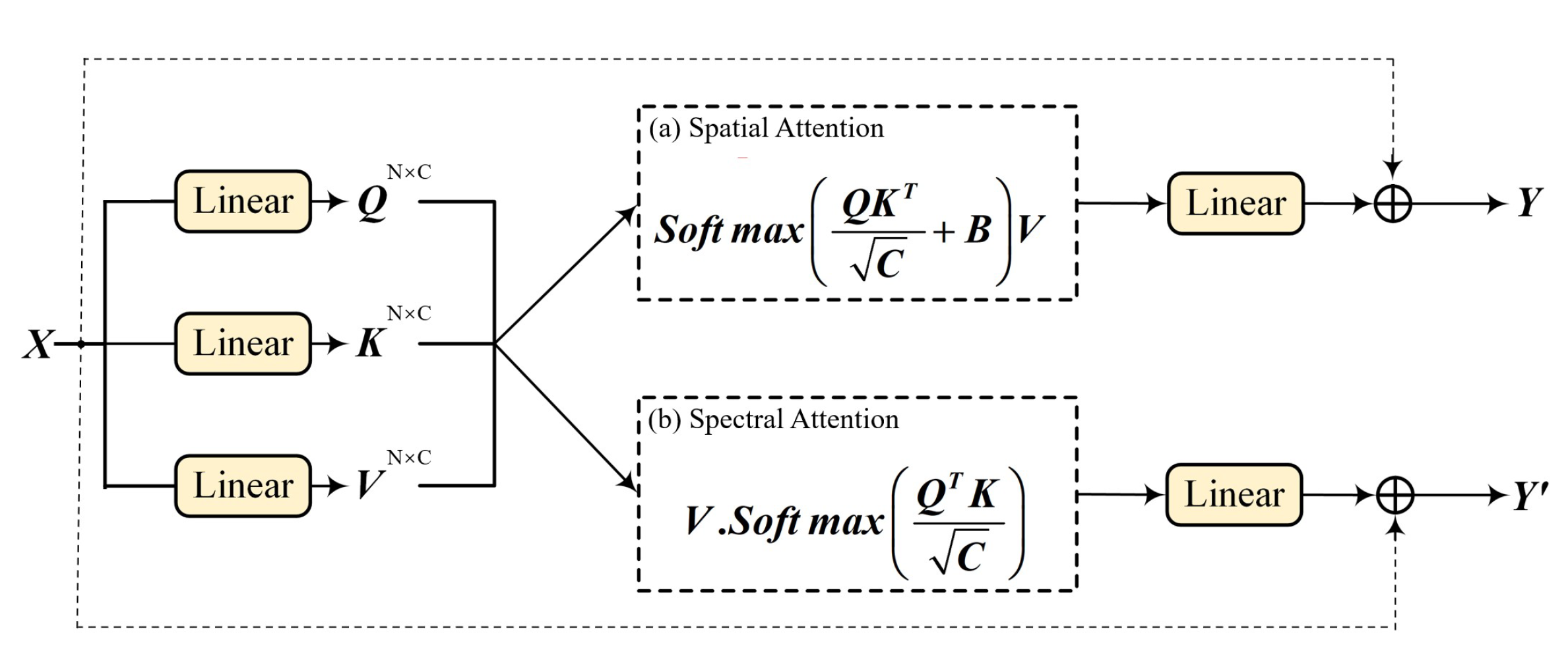
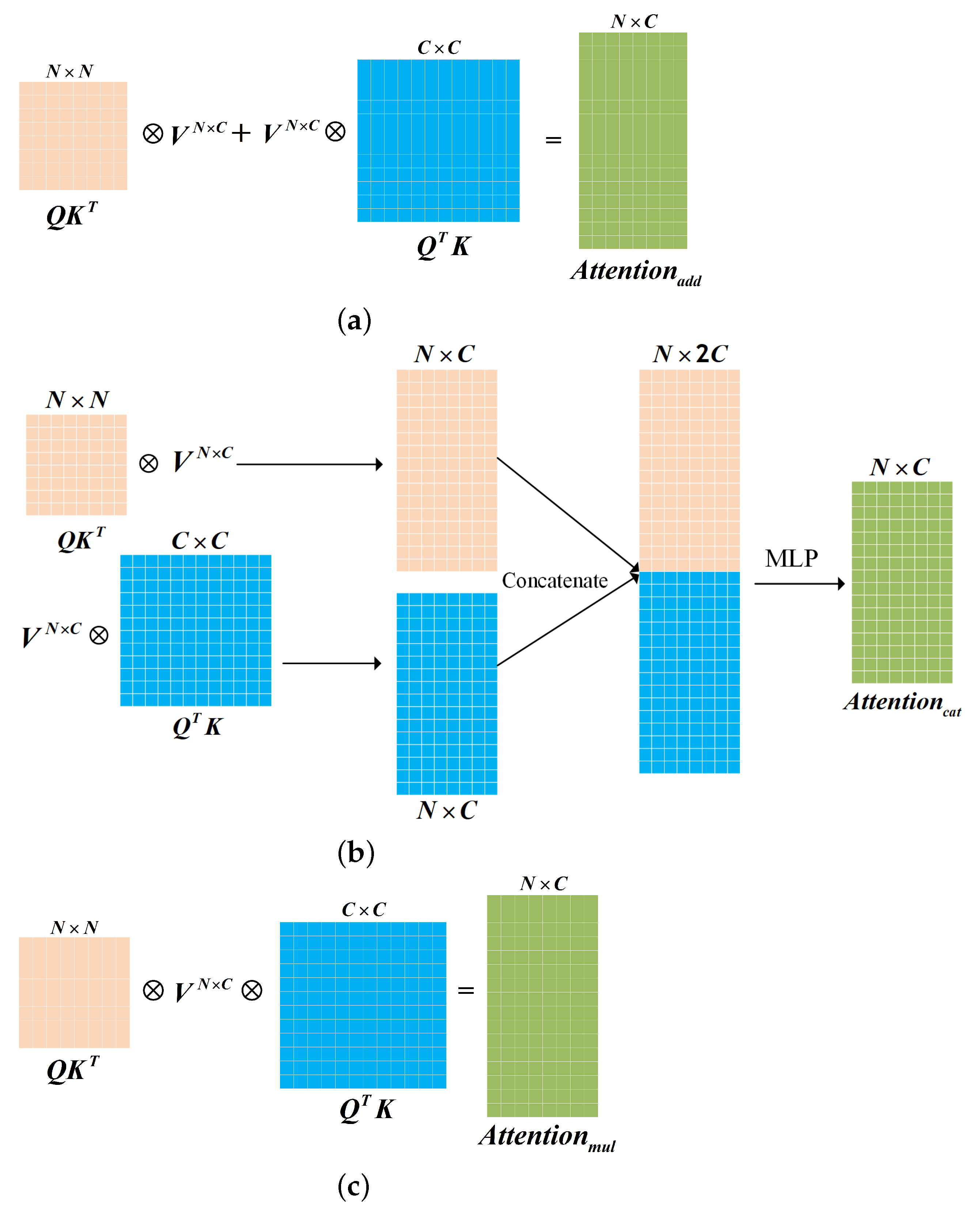
3.1. Multi-Source Fusion Attention Mechanism
3.2. Framework
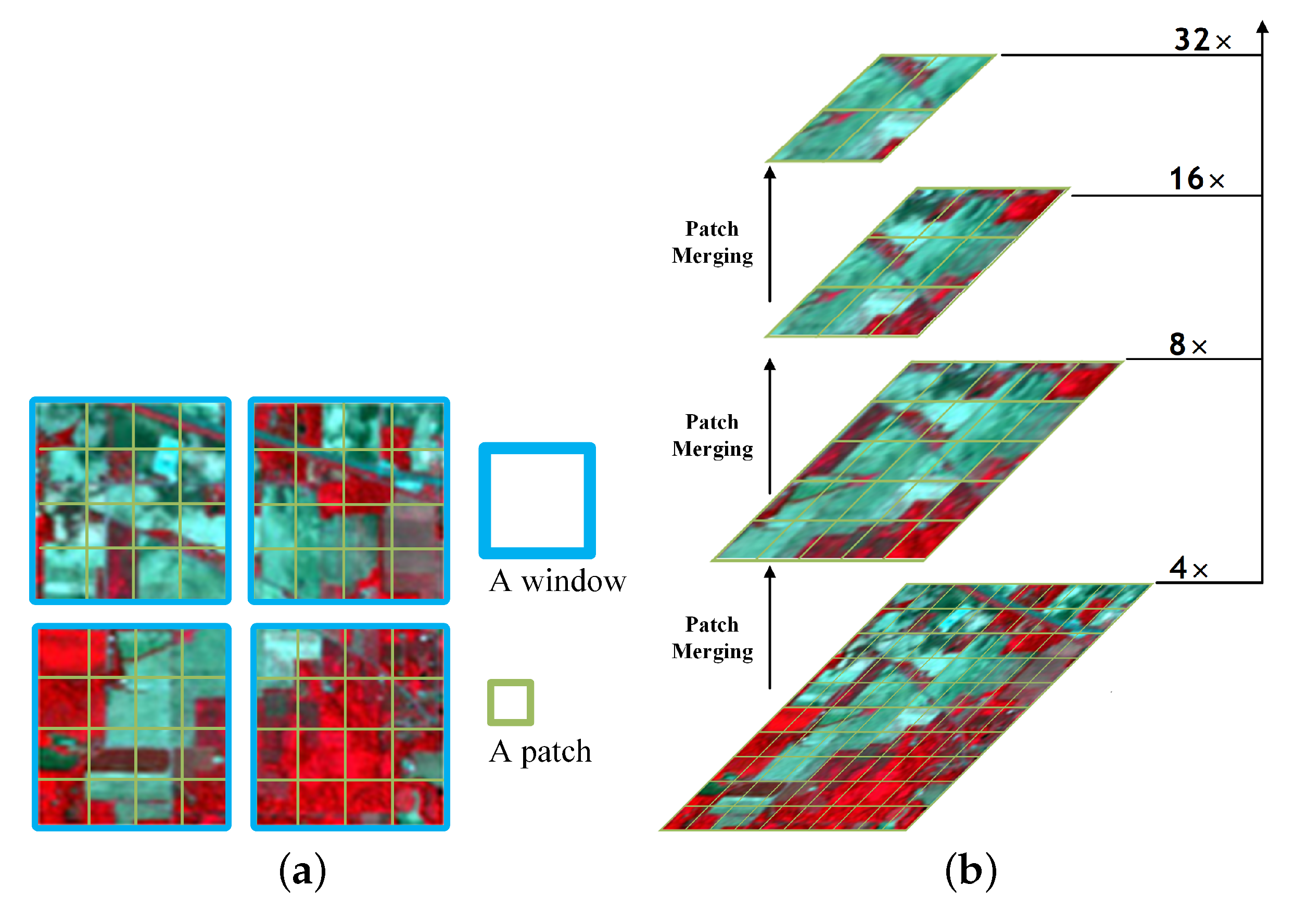
3.2.1. Encoder
3.2.2. Decoder
4. Experimental Results and Analysis
4.1. Experimental Settings
4.1.1. Model Parameters
4.1.2. Optimized Parameters
4.1.3. Metrics
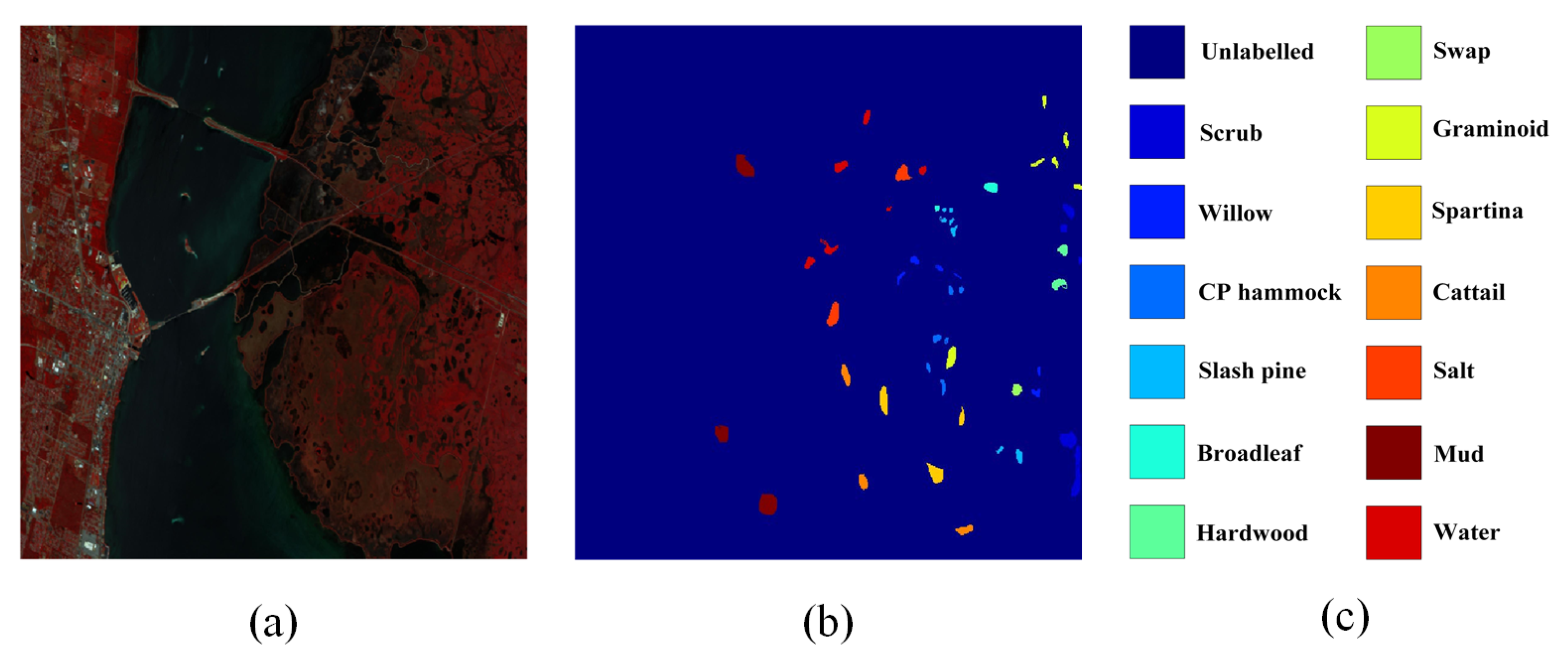
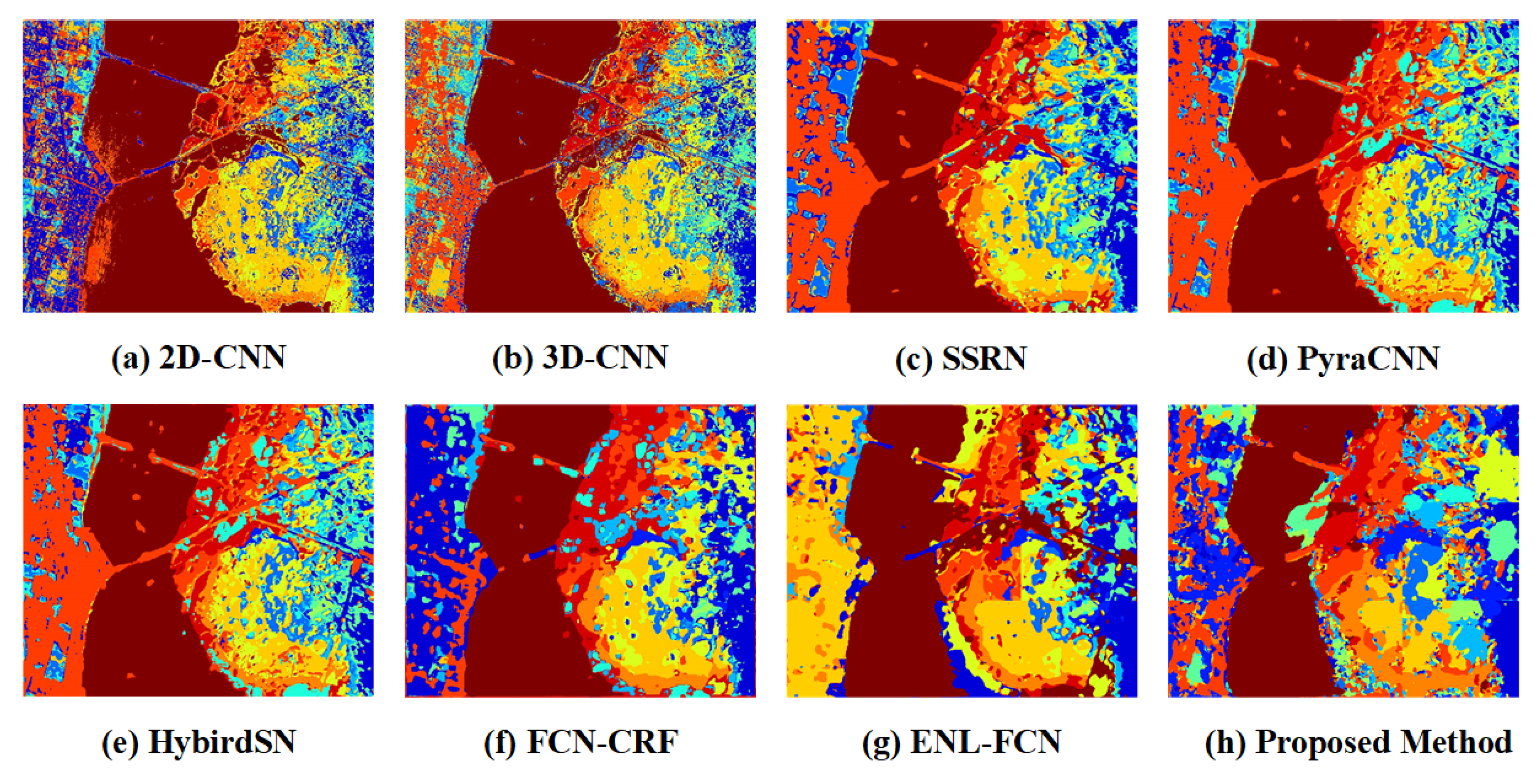
4.2. Experiment 1: Kennedy Space Center
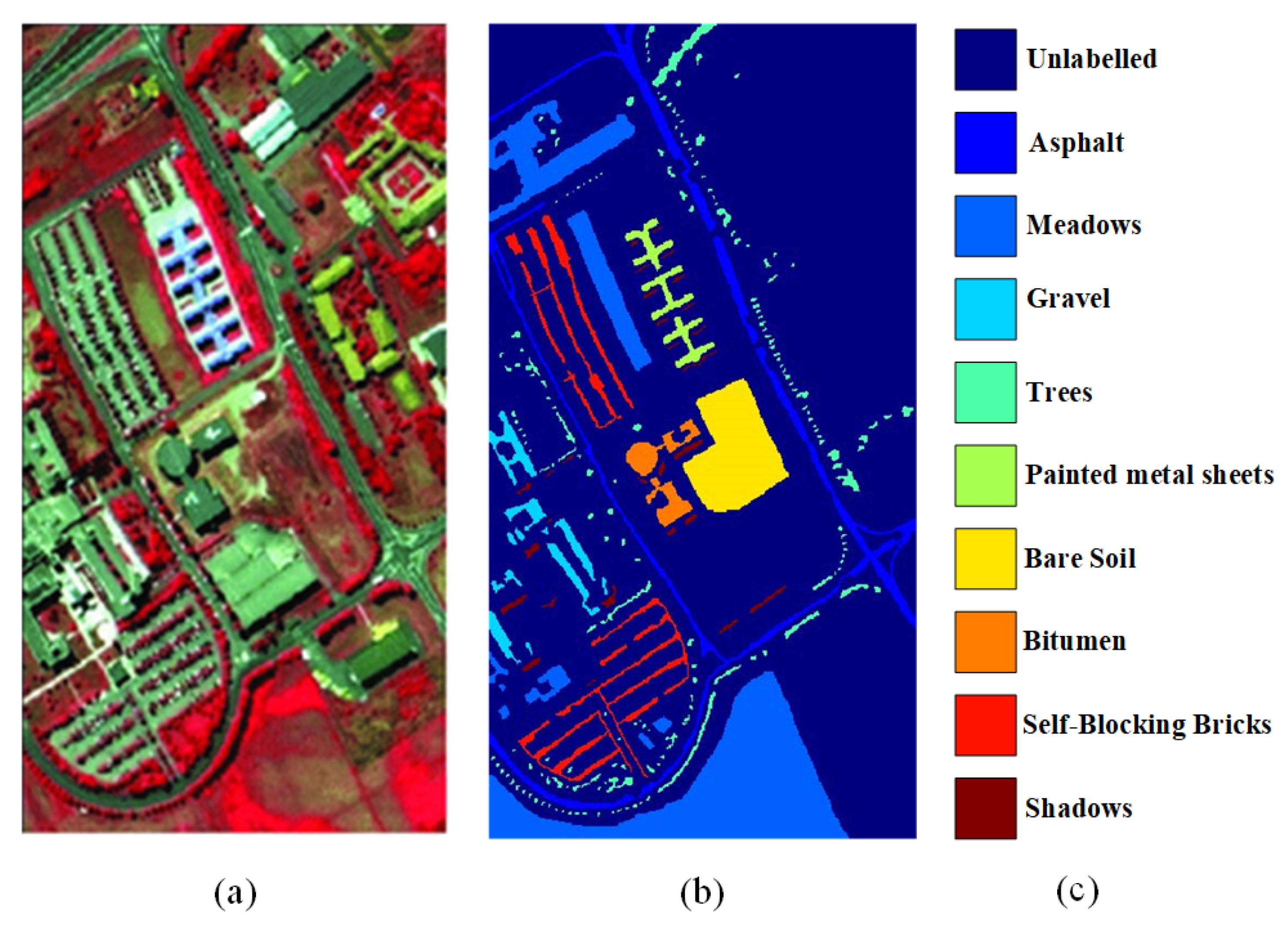
4.3. Experiment 2: Pavia University
4.4. Experiment 3: Indian Pines Dataset
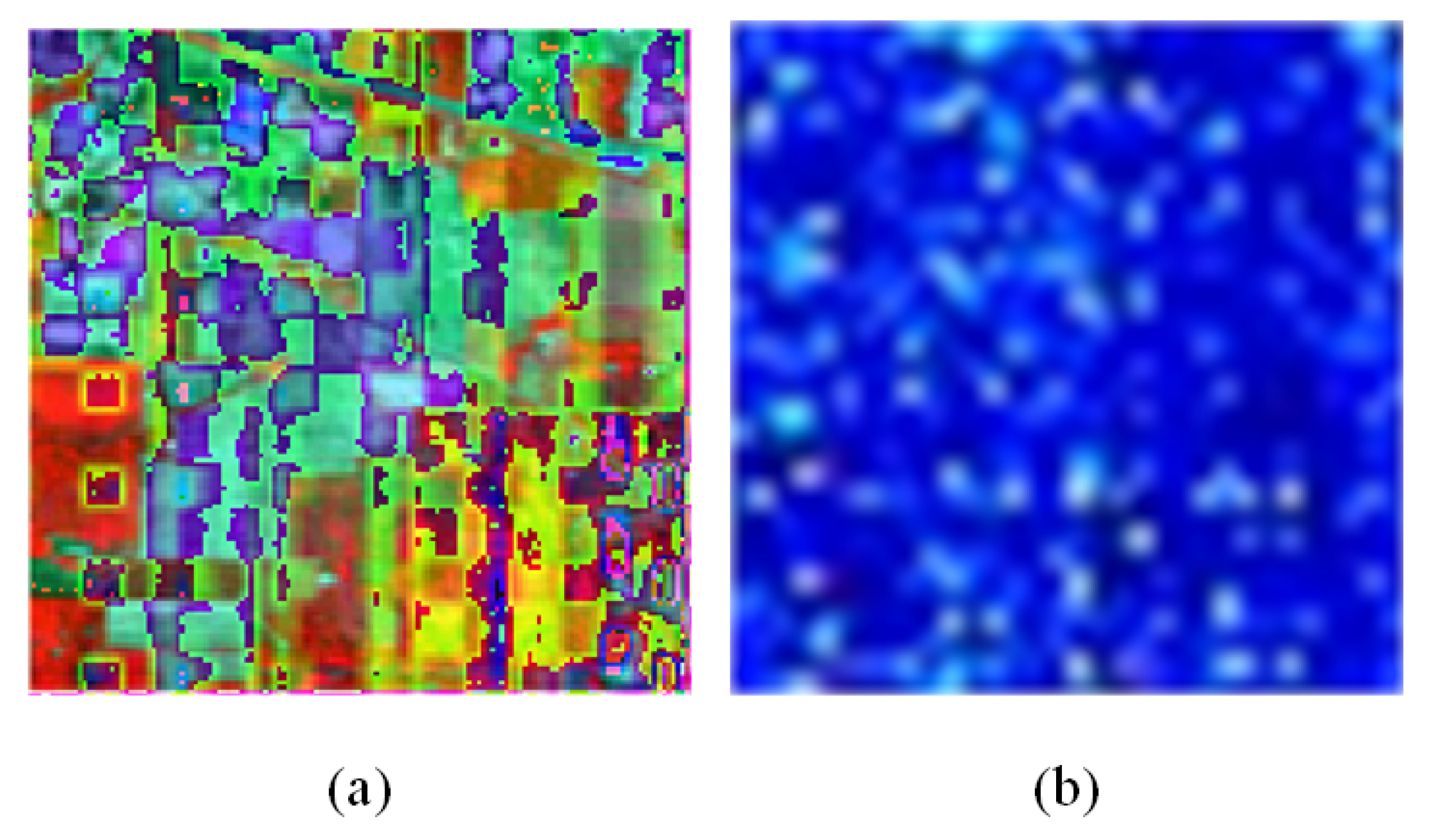
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Sample Availability
References
- Li, S.; Song, W.; Fang, L.; Chen, Y.; Ghamisi, P.; Atli Benediktsson, J. Deep learning for hyperspectral image classification: An overview. IEEE Trans. Geosci. Remote Sens. 2019, 57, 6690–6709. [Google Scholar] [CrossRef] [Green Version]
- Govender, M.; Chetty, K.; Bulcock, H. A review of hyperspectral remote sensing and its application in vegetation and water resource studies. Water Sa 2007, 33, 145–151. [Google Scholar] [CrossRef] [Green Version]
- Adam, E.; Mutanga, O.; Rugege, D. Multispectral and hyperspectral remote sensing for identification and mapping of wetland vegetation: A review. Wetl. Ecol. Manag. 2010, 18, 281–296. [Google Scholar] [CrossRef]
- Koch, B. Status and future of laser scanning, synthetic aperture radar and hyperspectral remote sensing data for forest biomass assessment. ISPRS J. Photogramm. Remote Sens. 2010, 65, 581–590. [Google Scholar] [CrossRef]
- Camps-Valls, G.; Tuia, D.; Bruzzone, L.; Benediktsson, J.A. Advances in hyperspectral image classification: Earth monitoring with statistical learning methods. IEEE Signal Process. Mag. 2013, 31, 45–54. [Google Scholar] [CrossRef] [Green Version]
- Gislason, P.O.; Benediktsson, J.A.; Sveinsson, J.R. Random forests for land cover classification. Pattern Recognit. Lett. 2006, 27, 294–300. [Google Scholar] [CrossRef]
- Melgani, F.; Bruzzone, L. Classification of hyperspectral remote sensing images with support vector machines. IEEE Trans. Geosci. Remote Sens. 2004, 42, 1778–1790. [Google Scholar] [CrossRef] [Green Version]
- Rainforth, T.; Wood, F. Canonical correlation forests. arXiv 2015, arXiv:1507.05444. [Google Scholar]
- Xia, J.; Yokoya, N.; Iwasaki, A. Hyperspectral image classification with canonical correlation forests. IEEE Trans. Geosci. Remote Sens. 2016, 55, 421–431. [Google Scholar] [CrossRef]
- Krishnapuram, B.; Carin, L.; Figueiredo, M.A.T.; J Hartemink, A. Sparse multinomial logistic regression: Fast algorithms and generalization bounds. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 957–968. [Google Scholar] [CrossRef] [Green Version]
- Xia, J.; Du, P.; He, X.; Chanussot, J. Hyperspectral remote sensing image classification based on rotation forest. IEEE Geosci. Remote Sens. Lett. 2013, 11, 239–243. [Google Scholar] [CrossRef] [Green Version]
- Fauvel, M.; Benediktsson, J.A.; Chanussot, J.; R Sveinsson, J. Spectral and spatial classification of hyperspectral data using svms and morphological profiles. IEEE Trans. Geosci. Remote Sens. 2008, 46, 3804–3814. [Google Scholar] [CrossRef] [Green Version]
- Tarabalka, Y.; Benediktsson, J.A.; Chanussot, J. Spectral–spatial classification of hyperspectral imagery based on partitional clustering techniques. IEEE Trans. Geosci. Remote Sens. 2009, 47, 2973–2987. [Google Scholar] [CrossRef]
- Li, J.; Bioucas-Dias, J.M.; Plaza, A. Spectral–spatial classification of hyperspectral data using loopy belief propagation and active learning. IEEE Trans. Geosci. Remote Sens. 2012, 51, 844–856. [Google Scholar] [CrossRef]
- Yue, J.; Zhao, W.; Mao, S.; Liu, H. Spectral—spatial classification of hyperspectral images using deep convolutional neural networks. Remote Sens. Lett. 2015, 6, 468–477. [Google Scholar] [CrossRef]
- Hu, W.; Huang, Y.; Wei, L.; Zhang, F.; Li, H. Deep convolutional neural networks for hyperspectral image classification. J. Sens. 2015, 2015, 258619. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y.; Jiang, H.; Li, C.; Jia, X.; Ghamisi, P. Deep feature extraction and classification of hyperspectral images based on convolutional neural networks. IEEE Trans. Geosci. Remote Sens. 2016, 54, 6232–6251. [Google Scholar] [CrossRef] [Green Version]
- Yu, S.; Jia, S.; Xu, C. Convolutional neural networks for hyperspectral image classification. Neurocomputing 2017, 219, 88–98. [Google Scholar] [CrossRef]
- Audebert, N.; Saux, B.L.; Lefèvre, S. Deep learning for classification of hyperspectral data: A comparative review. IEEE Geosci. Remote Sens. Mag. 2019, 7, 159–173. [Google Scholar] [CrossRef] [Green Version]
- Xu, Q.; Xiao, Y.; Wang, D.; Luo, B. Csa-mso3dcnn: Multiscale octave 3d cnn with channel and spatial attention for hyperspectral image classification. Remote Sens. 2020, 12, 188. [Google Scholar] [CrossRef] [Green Version]
- Mou, L.; Ghamisi, P.; Zhu, X.X. Deep recurrent neural networks for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3639–3655. [Google Scholar] [CrossRef] [Green Version]
- Hang, R.; Liu, Q.; Hong, D.; Ghamisi, P. Cascaded recurrent neural networks for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 5384–5394. [Google Scholar] [CrossRef] [Green Version]
- Hamida, A.B.; Benoit, A.; Lambert, P.; Amar, C.B. 3-d deep learning approach for remote sensing image classification. IEEE Trans. Geosci. Remote Sens. 2018, 56, 4420–4434. [Google Scholar] [CrossRef] [Green Version]
- Wu, H.; Prasad, S. Convolutional recurrent neural networks forhyperspectral data classification. Remote Sens. 2017, 9, 298. [Google Scholar] [CrossRef] [Green Version]
- Lee, H.; Kwon, H. Going deeper with contextual cnn for hyperspectral image classification. IEEE Trans. Image Process. 2017, 26, 4843–4855. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- He, X.; Chen, Y.; Ghamisi, P. Heterogeneous transfer learning for hyperspectral image classification based on convolutional neural network. IEEE Trans. Geosci. Remote Sens. 2019, 58, 3246–3263. [Google Scholar] [CrossRef]
- Gong, Z.; Zhong, P.; Yu, Y.; Hu, W.; Li, S. A cnn with multiscale convolution and diversified metric for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 3599–3618. [Google Scholar] [CrossRef]
- Paoletti, M.E.; Haut, J.M.; Plaza, J.; Plaza, A. Deep learning classifiers for hyperspectral imaging: A review. ISPRS J. Photogramm. Remote Sens. 2019, 158, 279–317. [Google Scholar] [CrossRef]
- Feng, Z.; Yang, S.; Wang, M.; Jiao, L. Learning dual geometric low-rank structure for semisupervised hyperspectral image classification. IEEE Trans. Cybern. 2019, 51, 346–358. [Google Scholar] [CrossRef]
- Shen, Y.; Zhu, S.; Chen, C.; Du, Q.; Xiao, L.; Chen, J.; Pan, D. Efficient deep learning of nonlocal features for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2020, 59, 6029–6043. [Google Scholar] [CrossRef]
- Ruck, D.W.; Rogers, S.K.; Kabrisky, M. Feature selection using a multilayer perceptron. J. Neural Netw. Comput. 1990, 2, 40–48. [Google Scholar]
- Makantasis, K.; Karantzalos, K.; Doulamis, A.; Doulamis, N. Deep supervised learning for hyperspectral data classification through convolutional neural networks. In Proceedings of the 2015 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Milan, Italy, 26–31 July 2015; pp. 4959–4962. [Google Scholar]
- Li, Y.; Zhang, H.; Shen, Q. Spectral–spatial classification of hyperspectral imagery with 3d convolutional neural network. Remote Sens. 2017, 9, 67. [Google Scholar] [CrossRef] [Green Version]
- Zhong, Z.; Li, J.; Luo, Z.; Chapman, M. Spectral–spatial residual network for hyperspectral image classification: A 3-d deep learning framework. IEEE Trans. Geosci. Remote Sens. 2017, 56, 847–858. [Google Scholar] [CrossRef]
- Ma, W.; Yang, Q.; Wu, Y.; Zhao, W.; Zhang, X. Double-branch multi-attention mechanism network for hyperspectral image classification. Remote Sens. 2019, 11, 1307. [Google Scholar] [CrossRef] [Green Version]
- Xu, Y.; Du, B.; Zhang, L. Beyond the patchwise classification: Spectral-spatial fully convolutional networks for hyperspectral image classification. IEEE Trans. Big Data 2019, 6, 492–506. [Google Scholar] [CrossRef]
- Xu, Y.; Zhang, L.; Du, B.; Zhang, F. Spectral–spatial unified networks for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2018, 56, 5893–5909. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Berlin, Germany, 2015; pp. 234–241. [Google Scholar]
- Zheng, Z.; Zhong, Y.; Ma, A.; Zhang, L. Fpga: Fast patch-free global learning framework for fully end-to-end hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2020, 58, 5612–5626. [Google Scholar] [CrossRef]
- Zhu, Q.; Deng, W.; Zheng, Z.; Zhong, Y.; Guan, Q.; Lin, W.; Zhang, L.; Li, D. A spectral-spatial-dependent global learning framework for insufficient and imbalanced hyperspectral image classification. IEEE Trans. Cybern. 2021. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 675–686. [Google Scholar]
- Tian, L.; Tu, Z.; Zhang, D.; Liu, J.; Li, B.; Yuan, J. Unsupervised learning of optical flow with cnn-based non-local filtering. IEEE Trans. Image Process. 2020, 29, 8429–8442. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; Jégou, H. Training data-efficient image transformers & distillation through attention. In Proceedings of the International Conference on Machine Learning, Virtual Event, 18–24 July 2021; pp. 10347–10357. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual Event, 12 October 2021; pp. 10012–10022. [Google Scholar]
- Han, K.; Xiao, A.; Wu, E.; Guo, J.; Xu, C.; Wang, Y. Transformer in transformer. Adv. Neural Inf. Process. Syst. 2021, 34, 1056–1067. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Fan, D.-P.; Song, K.; Liang, D.-P.; Lu, T.; Luo, P.; Shao, L. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual Event, 12 October 2021; pp. 568–578. [Google Scholar]
- Bao, H.; Dong, L.; Wei, F.; Wang, W.; Yang, N.; Liu, X.; Wang, Y.; Gao, J.; Piao, S.; Zhou, M.; et al. Unilmv2: Pseudo-masked language models for unified language model pre-training. In Proceedings of the International Conference on Machine Learning, Vienna, Austria, 13–18 July 2020; PMLR: Stockholm, Sweden, 2020; pp. 642–652. [Google Scholar]
- Hu, H.; Gu, J.; Zhang, Z.; Dai, J.; Wei, Y. Relation networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3588–3597. [Google Scholar]
- Hu, H.; Zhang, Z.; Xie, Z.; Lin, S. Local relation networks for image recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 3464–3473. [Google Scholar]
- Gardner, M.W.; Dorling, S.R. Artificial neural networks (the multilayer perceptron)—A review of applications in the atmospheric sciences. Atmos. Environ. 1998, 32, 2627–2636. [Google Scholar] [CrossRef]
- Kim, S.W.; Kook, H.K.; Sun, J.Y.; Kang, M.C.; Ko, S.J. Parallel feature pyramid network for object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 234–250. [Google Scholar]
- Paoletti, M.E.; Haut, J.M.; Fernandez-Beltran, R.; Plaza, J.; Plaza, A.J.; Pla, F. Deep pyramidal residual networks for spectral–spatial hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2018, 57, 740–754. [Google Scholar] [CrossRef]
- Roy, S.K.; Krishna, G.; Dubey, S.R.; Chaudhuri, B.B. Hybridsn: Exploring 3-d–2-d cnn feature hierarchy for hyperspectral image classification. IEEE Geosci. Remote Sens. Lett. 2019, 17, 277–281. [Google Scholar] [CrossRef] [Green Version]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Land Cover Class | Training | Testing | Total |
|---|---|---|---|---|
| 1 | Scrub | 18 | 329 | 347 |
| 2 | Willow swamp | 13 | 230 | 243 |
| 3 | CP hammock | 13 | 243 | 256 |
| 4 | Slash pine | 13 | 239 | 252 |
| 5 | Oak/broadleaf | 9 | 152 | 161 |
| 6 | Hardwood | 12 | 217 | 229 |
| 7 | Swamp | 6 | 99 | 105 |
| 8 | Graminoid marsh | 20 | 370 | 390 |
| 9 | Spartina marsh | 26 | 494 | 520 |
| 10 | Cattail marsh | 21 | 383 | 404 |
| 11 | Salt marsh | 21 | 398 | 419 |
| 12 | Mud flats | 26 | 477 | 503 |
| 13 | Water | 47 | 880 | 927 |
| Total | 245 | 4511 | 4756 |
| Class | 2D-CNN | 3D-CNN | SSRN | PyraCNN | HybridSN | FCN-CRF | ENL-FCN | Proposed (add) | Proposed (cat) | Proposed (mul) |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 97.65 | 88.58 | 98.84 | 98.93 | 98.47 | 100 | 99.62 | 100 | 100 | 100 |
| 2 | 88.78 | 82.31 | 97.07 | 92.54 | 93.75 | 99.34 | 100 | 98.25 | 100 | 97.38 |
| 3 | 64.38 | 73.55 | 97.13 | 95.12 | 89.08 | 99.17 | 99.59 | 100 | 100 | 100 |
| 4 | 67.29 | 60.33 | 89.77 | 81.55 | 89.93 | 71.94 | 98.10 | 100 | 100 | 100 |
| 5 | 65.42 | 64.64 | 87.78 | 81.30 | 90.48 | 68.33 | 100 | 100 | 100 | 100 |
| 6 | 79.15 | 79.29 | 99.32 | 89.86 | 92.98 | 99.30 | 100 | 100 | 100 | 100 |
| 7 | 80.14 | 77.98 | 93.55 | 95.27 | 91.07 | 33.16 | 100 | 100 | 100 | 100 |
| 8 | 88.49 | 93.37 | 98.59 | 99.28 | 93.59 | 99.01 | 100 | 100 | 99.75 | 100 |
| 9 | 90.87 | 88.06 | 98.50 | 99.76 | 94.12 | 100 | 100 | 100 | 100 | 98.78 |
| 10 | 99.52 | 98.36 | 99.32 | 99.09 | 98.36 | 100 | 99.93 | 100 | 100 | 100 |
| 11 | 99.64 | 99.69 | 99.74 | 99.97 | 97.69 | 100 | 100 | 100 | 100 | 100 |
| 12 | 97.98 | 89.44 | 98.16 | 99.46 | 99.19 | 99.36 | 96.18 | 99.79 | 100 | 100 |
| 13 | 98.98 | 98.56 | 100 | 100 | 99.47 | 100 | 100 | 100 | 100 | 100 |
| OA | 91.06 | 89.98 | 97.88 | 97.04 | 96.04 | 96.08 | 99.46 | 99.90 | 99.98 | 99.75 |
| AA | 86.02 | 84.93 | 96.75 | 94.78 | 94.47 | 89.97 | 99.49 | 99.85 | 99.98 | 99.70 |
| kappa | 90.04 | 88.84 | 97.64 | 96.70 | 95.59 | 95.64 | 99.40 | 99.89 | 99.98 | 99.73 |
| No. | Land Cover Class | Training | Testing | Total |
|---|---|---|---|---|
| 1 | Asphalt | 67 | 6564 | 6631 |
| 2 | Meadows | 187 | 18,462 | 18,649 |
| 3 | Gravel | 21 | 2078 | 2099 |
| 4 | Trees | 31 | 3033 | 3064 |
| 5 | Metal sheets | 14 | 1331 | 1345 |
| 6 | Bare Soil | 51 | 4978 | 5029 |
| 7 | Bitumen | 14 | 1316 | 1330 |
| 8 | Bricks | 37 | 3645 | 3682 |
| 9 | Shadows | 10 | 937 | 947 |
| Total | 432 | 42,344 | 42,776 |
| Class | 2D-CNN | 3D-CNN | SSRN | PyraCNN | HybridSN | FCN-CRF | ENL-FCN | Proposed (add) | Proposed (cat) | Proposed (mul) |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 92.72 | 87.21 | 99.66 | 94.94 | 95.13 | 91.89 | 99.40 | 97.96 | 97.96 | 99.30 |
| 2 | 97.14 | 94.10 | 98.70 | 99.41 | 99.16 | 95.83 | 100.00 | 99.99 | 99.99 | 100 |
| 3 | 87.91 | 64.08 | 93.95 | 81.90 | 88.73 | 95.82 | 91.45 | 99.47 | 99.47 | 96.56 |
| 4 | 99.35 | 96.82 | 99.72 | 93.75 | 98.18 | 98.23 | 97.55 | 96.73 | 96.73 | 96.60 |
| 5 | 98.92 | 95.13 | 99.93 | 99.78 | 98.98 | 99.67 | 100.00 | 100 | 100 | 100 |
| 6 | 97.41 | 94.07 | 98.52 | 93.91 | 98.66 | 94.76 | 99.28 | 100 | 100 | 100 |
| 7 | 91.99 | 58.80 | 96.84 | 83.03 | 96.64 | 95.42 | 98.66 | 99.77 | 99.77 | 99.62 |
| 8 | 88.41 | 77.11 | 88.85 | 89.20 | 90.69 | 94.95 | 99.26 | 99.78 | 99.78 | 98.81 |
| 9 | 99.41 | 84.19 | 99.53 | 99.84 | 97.21 | 99.77 | 98.24 | 99.79 | 99.79 | 99.46 |
| OA | 95.35 | 88.69 | 97.54 | 95.44 | 97.01 | 95.36 | 99.08 | 99.38 | 99.38 | 99.34 |
| AA | 94.81 | 83.50 | 97.30 | 92.86 | 95.93 | 96.26 | 98.20 | 99.28 | 99.28 | 98.93 |
| kappa | 93.81 | 84.86 | 96.74 | 93.93 | 96.02 | 93.83 | 98.78 | 99.18 | 99.18 | 99.14 |
| No. | Land Cover Class | Training | Testing | Total |
|---|---|---|---|---|
| 1 | Alfalfa | 5 | 49 | 54 |
| 2 | Corn-notill | 143 | 1291 | 1434 |
| 3 | Corn-mintill | 83 | 751 | 834 |
| 4 | Corn | 23 | 211 | 234 |
| 5 | Grass-pasture | 49 | 448 | 497 |
| 6 | Grass-trees | 74 | 451 | 525 |
| 7 | Grass-pasture-mowed | 2 | 24 | 26 |
| 8 | Hay-windrowed | 48 | 441 | 489 |
| 9 | Oats | 2 | 18 | 20 |
| 10 | Soybean-notill | 96 | 872 | 968 |
| 11 | Soybean-mintill | 246 | 2222 | 2468 |
| 12 | Soybean-clean | 61 | 553 | 614 |
| 13 | Wheat | 21 | 191 | 212 |
| 14 | Woods | 129 | 1165 | 1294 |
| 15 | Buildings-Grass-Trees | 38 | 342 | 380 |
| 16 | Stone-Steel-Towers | 9 | 86 | 95 |
| Total | 1029 | 9337 | 10,366 |
| Class | 2D-CNN | 3D-CNN | SSRN | PyraCNN | HybridSN | FCN-CRF | ENL-FCN | Proposed (add) | Proposed (cat) | Proposed (mul) |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 100 | 99.41 | 98.18 | 97.26 | 97.16 | 96.76 | 97.15 | 100 | 100 | 100 |
| 2 | 94.11 | 96.07 | 96.25 | 98.99 | 97.15 | 95.46 | 97.86 | 97.80 | 99.06 | 98.19 |
| 3 | 93.69 | 94.65 | 96.84 | 98.96 | 98.25 | 94.78 | 99.75 | 98.51 | 99.06 | 98.51 |
| 4 | 95.40 | 97.65 | 97.16 | 95.54 | 97.9 | 90.40 | 96.60 | 99.53 | 99.53 | 96.21 |
| 5 | 96.87 | 98.76 | 99.03 | 98.79 | 98.49 | 94.24 | 99.26 | 100 | 99.30 | 99.06 |
| 6 | 98.35 | 98.00 | 98.61 | 99.43 | 98.92 | 98.42 | 99.13 | 99.39 | 99.69 | 99.54 |
| 7 | 100 | 98.82 | 98.03 | 89.00 | 100 | 83.33 | 100.00 | 100 | 100 | 100 |
| 8 | 96.58 | 99.09 | 99.45 | 100 | 99.67 | 99.56 | 99.84 | 100 | 100 | 100 |
| 9 | 100 | 95.00 | 97.64 | 91.67 | 92.38 | 88.54 | 85.19 | 83.33 | 88.89 | 83.33 |
| 10 | 94.27 | 96.18 | 95.21 | 95.37 | 98.74 | 95.88 | 98.22 | 98.95 | 99.19 | 99.07 |
| 11 | 95.81 | 96.08 | 96.68 | 98.98 | 99.16 | 98.22 | 99.82 | 99.77 | 99.50 | 99.68 |
| 12 | 93.74 | 97.02 | 96.04 | 95.23 | 97.47 | 92.46 | 99.40 | 99.43 | 98.86 | 99.62 |
| 13 | 99.68 | 99.78 | 99.58 | 100.00 | 98.02 | 98.57 | 98.91 | 97.81 | 98.36 | 97.81 |
| 14 | 98.39 | 98.82 | 99.30 | 98.34 | 99.32 | 98.36 | 99.91 | 100 | 100 | 100 |
| 15 | 95.67 | 94.72 | 95.71 | 94.60 | 97.64 | 93.71 | 93.00 | 98.26 | 99.13 | 98.84 |
| 16 | 94.48 | 95.48 | 95.48 | 96.43 | 91.02 | 96.44 | 93.57 | 96.39 | 95.18 | 96.39 |
| OA | 95.79 | 96.84 | 97.19 | 98.12 | 98.44 | 96.48 | 98.85 | 99.34 | 99.37 | 99.36 |
| AA | 96.69 | 97.22 | 97.45 | 96.79 | 97.58 | 94.80 | 97.35 | 98.20 | 98.65 | 98.07 |
| kappa | 95.10 | 96.40 | 96.80 | 97.85 | 98.23 | 95.98 | 98.69 | 99.25 | 99.29 | 99.27 |
| KSC | |||
| OA | AA | Kappa | |
| Baseline | 99.48 | 99.27 | 99.42 |
| Attention add | 99.90 | 99.85 | 99.89 |
| Attention cat | 99.98 | 99.98 | 99.98 |
| Attention mul | 99.75 | 99.70 | 99.73 |
| PU | |||
| OA | AA | Kappa | |
| Baseline | 99.32 | 99.13 | 99.11 |
| Attention add | 99.38 | 99.28 | 99.18 |
| Attention cat | 99.38 | 99.28 | 99.18 |
| Attention mul | 99.34 | 98.93 | 99.14 |
| IP | |||
| OA | AA | Kappa | |
| Baseline | 99.40 | 98.30 | 99.34 |
| Attention add | 99.34 | 98.20 | 99.25 |
| Attention cat | 99.37 | 98.65 | 99.29 |
| Attention mul | 99.36 | 98.07 | 99.27 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, J.; Zhang, J.; Gao, X.; Wang, M.; Ou, D.; Wu, X.; Zhang, D. Fusing Spatial Attention with Spectral-Channel Attention Mechanism for Hyperspectral Image Classification via Encoder–Decoder Networks. Remote Sens. 2022, 14, 1968. https://doi.org/10.3390/rs14091968
Sun J, Zhang J, Gao X, Wang M, Ou D, Wu X, Zhang D. Fusing Spatial Attention with Spectral-Channel Attention Mechanism for Hyperspectral Image Classification via Encoder–Decoder Networks. Remote Sensing. 2022; 14(9):1968. https://doi.org/10.3390/rs14091968
Chicago/Turabian StyleSun, Jun, Junbo Zhang, Xuesong Gao, Mantao Wang, Dinghua Ou, Xiaobo Wu, and Dejun Zhang. 2022. "Fusing Spatial Attention with Spectral-Channel Attention Mechanism for Hyperspectral Image Classification via Encoder–Decoder Networks" Remote Sensing 14, no. 9: 1968. https://doi.org/10.3390/rs14091968