1. Introduction
Determining the accurate spatial distribution of winter wheat is of great significance for agricultural production management, crop yield estimation, and national food security [
1,
2]. Remote sensing imagery has become the main source of such data characterizing this information. Image segmentation technology is now widely used to produce pixel-by-pixel classification results that can extract a wide range of spatial distribution information [
3,
4]. The specific pixel feature extraction method and the classifier both have decisive impacts on the accuracy of the classification results [
5].
Effective features can improve the accuracy of the classification result. The fundamental goal of feature extraction methods is to clearly differentiate the feature value of a given object type from that of other types [
6,
7]. Based on statistical analysis, an effective feature extraction method can be obtained. For example, spectral indexes, which have been widely used in the classification of middle- and low-resolution remote sensing imagery, are obtained by statistical analysis of the spectral information of the pixels [
8]. Commonly used methods include various vegetation indexes [
9,
10], the Automated Water Extraction Index (AWEI) [
11], the Normalized Difference Built-up Index (NDBI) [
12], and the Remote Sensing Ecological Index (RSEI) [
13]. The Enhanced Vegetation Index (EVI) [
8], Normalized Different Vegetation Index (NDVI) [
10], and other indexes derived from NDVI are effective at extracting vegetation information and have been widely used for extracting crop spatial distributions from low-resolution remote sensing imagery. Some researchers have taken advantage of the high temporal resolution of middle- and low-spatial resolution remote sensing imagery to obtain the spectral index characteristics of a time series before extracting crop information with good results [
14,
15,
16]. When applying statistical analysis technology to high-resolution remote sensing images, it is necessary to fully consider the impact of increasingly detailed pixel information on the extraction results [
6,
8,
10].
When classifying high spatial resolution remote sensing imagery, information for both the target pixel and adjacent pixels must be considered [
17,
18]. Texture features are commonly used to express information related to adjacent pixels [
19]; these can be extracted by methods including the gray level of co-occurrence matrix (GLCM) [
20], Gabor filters [
21], Markov random fields [
22], and wavelet transforms [
23]. As texture features can accurately express the spatial correlation between pixels, combining these with spectral features can effectively improve the classification accuracy of high-resolution remote sensing imagery [
24]. The combination of traditional texture feature extraction methods can obtain more effective features [
23,
25].
The development of machine learning has allowed researchers to use machine learning abilities to improve pixel feature extraction. However, early machine learning methods such as neural networks [
26,
27], support vector machines [
28,
29], decision trees [
30,
31], and random forests [
32,
33] still use pixel spectral information as input. Although these methods can be effective at obtaining features, these remain single-pixel features, without utilizing the spatial relationships between adjacent pixels.
The development of convolutional neural networks (CNNs) has greatly improved feature extraction. CNNs use trained convolution kernels to form a feature extractor and then generate a feature vector for each pixel in the input image block [
34,
35]. Unlike other feature extraction methods, CNNs can simultaneously extract the features of a given pixel and the spatial correlation features between adjacent pixels [
36,
37]. Classic CNNs include fully convolutional networks (FCNs) [
38], SegNet [
39], DeepLab [
40], RefineNet [
41], and U-Net [
42]. FCNs and SegNet only use high-level semantic features to generate the feature vectors of pixels, yielding very rough object edges [
38,
39]. DeepLab uses CRFs to post-process the segmentation results outputted by CNN; this significantly improves the quality of the results [
40]. RefineNet and U-Net use low-level fine features and high-level rough features to generate pixel-level feature vectors. This strategy is conducive to the expression of multi-depth information [
41,
42].
RefineNet and most other classic CNNs use two-dimensional convolution. The two-dimensional convolution method is suitable for processing images with a small number of channels, such as camera images and optical remote sensing images [
43,
44]. Improved classic CNNs have been widely applied to remote sensing image segmentation [
45] as well as target identification [
46,
47,
48], monitoring [
49,
50,
51], and other fields. For example, CNNs have been successfully used to extract spatial distribution information for various crops, including wheat [
52], rice [
53], and corn [
54]. Two-dimensional convolution methods are unsuitable for processing images with many channels, such as hyperspectral remote sensing images [
55]. Aiming to preserve the spectral and spatial features of hyperspectral remote sensing images, researchers use three-dimensional convolution to extract spectral–spatial information [
55,
56]. Because three-dimensional convolution can fully utilize the abundant spectral and spatial information of hyperspectral imagery, three-dimensional convolution has achieved remarkable success in the classification of hyperspectral images.
When remote sensing images are segmented by CNNs, the intended results can be obtained only by using appropriate feature extraction methods and classification methods according to the characteristics of the images [
57,
58]. CNN and traditional feature extraction methods have different advantages, and CNN cannot completely replace traditional feature extraction methods. The fusion of different feature extraction methods can improve the accuracy of the segmentation results [
59].
When CNNs are used for pixel classification, the accuracy is high in the inner area but low in the edge area, resulting in rough edges [
60,
61]. Because the rough edges are caused by the differences in feature values between pixels of the same type, it is necessary to introduce appropriate post-processing methods to improve the accuracy of edge pixel classification [
62,
63,
64]. The fully connected CRF comprehensively uses the pixel spatial distance information and the semantic information generated by the CNN to effectively improve the edge accuracy of segmentation, but the amount of data required for model calculation is too large. Researchers used recurrent neural networks [
62] and convolution [
63] to improve the calculation efficiency. Reference [
65] comprehensively used the pixel spatial distance information and category information as constraints for network training to improve the accuracy of image segmentation results.
Object-level information is an information category commonly used in post-processing methods; it includes object shape information [
65] and position information [
65,
66]. Using object-level information to post-process the CNN segmentation results can improve the fineness of the edges. Multiresolution segmentation algorithms [
67] and patch-based learning [
65,
68] have been used to successfully generate image object information. Classifiers are equally important; using more powerful classifiers such as decision trees, the results obtained are better than those obtained by simple linear classifiers [
69]. Methods for extracting more knowledge and more suitable post-processing methods still require further research.
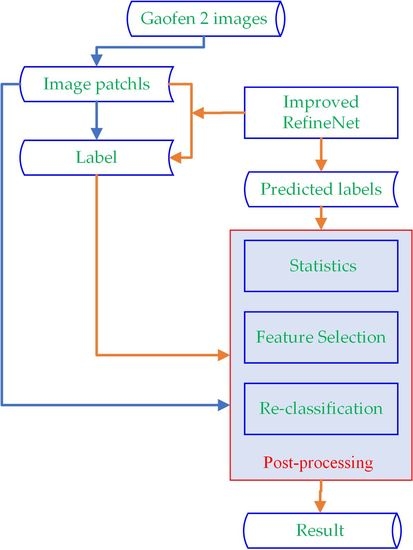
In order to obtain fine winter wheat spatial distribution information from high spatial resolution remote sensing imagery using CNNs, we proposed a post-process CNN (PP-CNN) that uses prior knowledge of the similarity in color and texture between the inner and edge pixels of the target type and their differences from other types to post-process CNN segmentation results and effectively improve the accuracy of edge pixel classification (and thus overall classification). The main contributions of this work are as follows.
PP-CNN uses confidence to evaluate the reliability of the pixel-by-pixel classification results obtained using CNN and clarifies the calculation method of confidence.
PP-CNN proposes a new hierarchical classification strategy. Features generated by standard CNN from the large receipt fields are used for the first-level classifier; features generated from the small receipt fields are used for the second-level classifier. As this hierarchical classification strategy combines the advantage of the large receipt field and the small receipt field, it thus achieves the goal of obtaining fine edges.
3. Method
Our method consisted of three steps. First, the improved RefineNet generated the initial segmentation and outputted a category probability vector for each pixel (
Section 3.1). Second, these initial segmentations were statistically analyzed using manual labels as a reference to determine the confidence threshold (
Section 3.2). Third, all pixels below the confidence threshold were post-processed to generate their final category label (
Section 3.3).
3.1. Initial Segmentation by CNN
In the common CNN structure, the feature extractor comprises multiple overlapping convolutional layers, each of which was followed by pooling, batch normalization, and activation layers (
Figure 4). The convolution layer contained several convolution kernels, most of which were 3 × 3. The pooling layer aggregated the features, which was beneficial for screening out features with good discrimination. The batch normalization layer was used to normalize the feature values. The activation layer adopted a nonlinear function. According to Hornik [
70], the use of an activation layer facilitates better expressions of the correlation features between similar pixels and better optimization of features.
The feature vector generator is generally composed of deconvolution layers, which can generate feature vectors of equal length for each pixel. These generated feature vectors are used as the inputs for the classifier to determine the pixel category. Therefore, the deconvolution performance directly determines the model performance. At present, most CNNs used for image segmentation have similar feature extractor structures; they are mainly distinguished by their feature vector generators. For example, FCN uses the interpolation method as a feature vector generator, while SegNet uses the deconvolution kernel. More recent CNNs generate pixel-level feature vectors using trained deconvolution kernels.
Unlike other CNNs, RefineNet [
42] uses a new “multipath” structure to fuse fine low-level features and rough high-level features, effectively improving the distinguishability of features and greatly improving the accuracy of segmentation results. The RefineNet feature vector generator consists of four levels. Each level uses the results of both the higher-level semantic feature deconvolution and the feature extractor at the same level as the input. This multi-level feature fusion strategy improves the distinguishability of features.
Considering the superior performance of the RefineNet model, we chose this as the initial segmentation model in our study. Similar to other CNNs, RefineNet also employs the Softmax model as a classifier.
We used a modified Softmax model as a classifier. The modified SoftMax model also takes a pixel-level feature vector as the input, and calculates the probability of classifying the pixel into each category. The category corresponding to the maximum probability value was assigned as the category of the pixel. The probabilities were organized into a category probability vector. The output included the category probability vector and initial category for each pixel.
3.2. Statistics for Initial Classification Results
Statistical analysis showed that the most pixels which had been correctly classified were located inside the winter wheat planting area, and the most pixels which had been incorrectly classified were located at the edge of this area. Statistical analysis also showed that the difference between the maximum probability value and the second-highest probability value was generally large in the category probability vectors of pixels that had been correctly classified, but that it was generally small or nearly equivalent in the category probability vectors of pixels that had been incorrectly classified.
We proposed the confidence level (CL) as an indicator for the credibility of the CNN segmentation results. The CL of a category probability vector was calculated as:
where
p is a category probability vector,
is the maximum value in
p, and
is the second-highest value in
p.
Our analysis showed that the classification result for a pixel could be considered credible if the CL of this pixel was higher than the minimum confidence threshold (minCL); otherwise, it was considered non-credible. Those pixels with CL values lower than minCL required post-processing. In our study, based on the statistical analysis of the training results, 0.21 was selected as minCL.
3.3. Low-Confidence Pixel Post-Processing
3.3.1. Feature Selection
Based on the prior knowledge that the inner pixels and edge pixels in winter wheat planting areas have very similar colors and textures, and the near-infrared (NIR) band is sensitive to crops, we created a feature vector for each pixel using the red, blue, green, and near-infrared bands along with NDVI, uniformity (UNI), contrast (CON), entropy (ENT), and inverse difference (INV). NDVI was calculated following Wang et al. [
10],
UNI, CON, ENT, and INV were extracted using the methods proposed by Yang and Yang, based on GLCM [
23],
In (4)–(7), q is the gray level quantization and g(i,j) is the element of GLCM.
The feature vector
v of each pixel had nine elements, structured as:
3.3.2. Vector Distance Calculation Method
We used the improved Euclidean distance to calculate the vector distance of the two feature vectors. The standard Euclidean distance is defined as:
where
x and
y are the feature vectors to be compared,
xi and
yi are the feature components, and
b is the length of the feature vector. Smaller distances between the two feature vectors correspond to greater similarity. In the standard Euclidean distance, all elements are considered to have equal weight, without considering the influence of the aggregation degree of elements on the distance.
Statistically, among the features of the samples of the same category, a higher concentration of the value of a certain feature corresponds to stronger distinguishability of this feature and greater weight that should be assigned to this feature. Similarly, greater dispersion in the value of a certain feature corresponds to weaker distinguishability and smaller assigned weight of this feature.
Based on prior knowledge, we introduced the reciprocal of the feature value distance as the weight factor to improve the Euclidean distance, thus better reflecting the influence of feature value aggregation on the vector distance. This weight factor was calculated as:
where
i is the position number of the component in the feature vector,
wi is the weight of the component,
maxi is the maximum value of the
ith components of all feature vectors, and
mini is the minimum value of the
ith components of all feature vectors. On this basis, the vector distance calculation formula was:
where
x and
y are the feature vectors to be compared,
xi and
yi are the feature components,
wi is the weight of component
i, and
n is the component number of the feature vector.
3.3.3. Vector Distance Threshold Determination
Firstly, each complete crop planting area in the training image was set as a statistical unit. The vector distance d between each pixel and other pixels was calculated individually, and the maximum vector distance di of the unit was recorded, where i was the number of the statistical unit.
Secondly, the vector distance threshold (
vdt) was obtained by:
where
n is the number of statistical units.
3.3.4. Low-confidence Pixel Classification
We used the following steps to optimize the results of winter wheat planting areas outputted by the improved RefineNet model:
NDVI for each pixel was calculated;
UNI, CON, ENT, and INV for each pixel was calculated;
CL was calculated pixel by pixel;
Winter wheat pixels with continuous position and CL > minCL were divided into a separate group;
For each group, the adjacent pixels for which CL < minCL were processed individually. For a certain adjacent pixel p, we calculated the vector distances between p and each pixel in the adjacent group and then chose the minimum value as the minimum distance mind. If mind < vdt, p was re-classified as a winter wheat pixel.
3.4. Experimental Setup
We conducted a comparative experiment on a graphics workstation with a 12-GB internal graphics card and a Linux Ubuntu 16.04 operating system. TensorFlow 1.10 software was used to write the statistical analysis and post-processing code in the Python language. Using a RefineNet model from the GitHub platform, we modified the output of the SoftMax model used by RefineNet. We used this for initial segmentation and used the output as basic data for statistical analysis.
We selected the SegNet and unmodified RefineNet models as standard CNN and CRF as the post-process method for comparison with PP-CNN (
Table 1). SegNet works like RefineNet, except it uses only high-level semantic features to generate feature vectors for each pixel.
By comparing the results from SegNet and RefineNet, we hoped to verify that the strategy of generating features with RefineNet was better than that of generating features with SegNet. By comparing the results of SegNet-CRF, RefineNet, and RefineNet-CRF with PP-CNN, we hoped to show that post-processing could effectively improve the accuracy of segmentation results. By comparing the results of SegNet with PP-SegNet, we hoped to show that the proposed post-processing method had strong adaptability.
We applied data augmentation techniques onto the training dataset, including horizontal flip, color adjustment, and vertical flip steps. The color adjustment factors used included brightness, hue, saturation, and contrast. Each image in the training dataset was processed 10 times. All images created by the data augmentation techniques were only used in training the CNNs.
We used cross-validation techniques in the comparative experiments. Each CNN model was trained over four rounds; in each round, 87 images were selected as test images and the other images were used as training images. Each image was used at least once as the test image (
Table 2).
Table 3 shows the hyper-parameter setup we used to train our model. In the comparison experiments, the hyper-parameters were also applied to the comparison model.
4. Results
We randomly selected ten test images from the test data set and assessed their segmentation results using the SegNet, SegNet-CRF, PP-SegNet, RefineNet, RefineNet-CRF, and PP-CNN models (
Figure 5).
The six methods had very similar performances within the winter wheat planting areas, with virtually no misclassifications. However, differences were obvious at the edges of these areas. PP-CNN and PP-SegNet misclassified only very small numbers of discrete pixels, while SegNet had the most errors in a more continuous pattern, with errors being more common at corners than at edges. RefineNet had significantly fewer errors than the SegNet model, with most located near corners and few in continuous patterns.
Comparing SegNet-CRF and PP-SegNet, RefineNet, and PP-CNN, respectively, it can be seen that, on the premise that the initial segmentation results are the same, the results obtained by post-processing using the proposed method are better than those obtained by using CRF. Considering that CRF has very good performance in processing camera images, this may be because the resolution of remote sensing images is lower than that of camera images, which reduces the performance of CRF. It shows that the appropriate post-processing method should be selected according to the image characteristics.
Whether using CRF or the method proposed in this paper, the accuracy of the results after post-processing is improved, which also shows the importance of post-processing methods when CNN is applied to image segmentation.
We then produced a confusion matrix for the segmentation results for all four methods (
Table 4), where each column represents the classification result obtained from the segmentation results and each row represents the actual category defined by manual classification. PP-CNN was clearly superior, with classification errors accounting for only 5.6%, lower than the 13.7% for SegNet, 9.8% for SegNet-CRF, 6.2% for PP-SegNet, 7.2% for RefineNet, and 5.9% for RefineNet-CRF.
We used the accuracy, precision, recall, and Kappa coefficient to evaluate the performance of the four models [
45] (
Table 5). The average accuracy of PP-CNN was 13.7% higher than SegNet, 7.2% higher than RefineNet, and 6.2% higher than PP-SegNet.
Table 6 shows the average time required for each method to complete the testing of one image. The proposed post-processing method requires an approximate increase of 2% in time and improves the accuracy by 7.2%. The time consumed by CRF is higher than that consumed by the proposed method because the CRF must calculate the distances between all pixel–pixel pairs for a single image, while the proposed method must calculate the distances for only a small number of pixel–pixel pairs.
6. Conclusions
Using CNNs to extract crop spatial distribution information from satellite remote sensing imagery has become increasingly common. However, the use of CNNs alone usually results in very rough edge areas, with a corresponding negative influence on overall accuracy. We used prior knowledge and statistical analysis to optimize winter wheat CNN extraction results, especially with regard to edge areas.
We analyzed the root cause of increased errors in CNN edge pixel classification, then used the category probability vector output to calculate the results’ credibility, dividing these into high-credibility and low-credibility pixels for subsequent processing. We then optimized the accuracy of the latter’s classification by analyzing the characteristics of planting area pixels using prior knowledge of the segmentation results. This new extraction strategy effectively improved the accuracy of crop extraction results.
Although the PP-CNN post-processing method proposed here was mainly established for crop extraction, it could be applied to the extraction of water, forest, grassland, and other land-use types with small internal pixel differences. However, for land-use types with larger internal differences, such as residential land, other post-treatment feature organization methods must be developed. The main disadvantage of our approach is the need for more manually classified images; future research should test the use of semi-supervised classification to reduce this dependence.

 ,
, 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}