1. Introduction
Grapevine trunk diseases involve a complex group of fungi colonizing the trunk, which leads to slow degradation of perennial organs, and often ends with the death of a part of the plant or the entire plant. One side effect of that degradation is the expression of typical “striped” foliar symptoms during the summer period [
1]. However, esca disease remains quite elusive because of the periodicity of the expression of these symptoms. Diseased plants do not necessarily express symptoms, and plant death (apoplexy) may suddenly happen during hot and dry summers [
2]. Because of its toxicity, sodium arsenite was banned from french vineyards in 2001, ruling out the only effective chemical product against the fungi complex [
3]. Since then, many research efforts were conducted to find new ways of preventing the spread of the disease in vineyards, which for instance led to commercial biocontrol products (Esquive WP). In France, approximately 10% of vine plants are affected by those diseases [
4], meaning a need to replace them in the next few years. This results in huge economic losses for the viticulture profession but also in younger vineyards, endangering the local identity of historic wine-growing regions.
Esca foliar symptoms exhibit a particular pattern allowing in many cases accurate disease diagnosis. For instance, red cultivar esca symptoms appear as red spots turning yellow or necrotic [
1]. These spots follow the shape of the leaf’s primary and secondary veins, resulting in the well known tiger-stripe pattern and its green → yellow → red → brown color gradient (
Figure 1a–d). However, symptoms tend to appear differently between white cultivars and red cultivars. White cultivars usually show a wide strip of chlorotic yellow tissues (
Figure 1a,b) while red cultivars show a narrow yellow strip (
Figure 1c,d). In the case of apoplexy, leaves quickly turn to a pale green and wilt in a few days. Wilting is however not specific to esca and could be related to many other issues.
Typical tiger-striped esca patterns are however not so frequent in the vineyard as most leaves found on symptomatic grapevines show attenuated patterns, appearing only partly on the leaf and with varying intensity (
Figure 1e) or partly wilted (
Figure 1f). Circular patterns can also be observed in some cases (
Figure 1g,h)
A year after year cartography of symptomatic plants could help disease management in the long term, allowing better replacement cycles and specific treatments. However, in reality, the exhaustive location list of these symptomatic plants is unknown. The random expression of yearly symptoms renders disease tracking even more confusing. Vine growers are usually unable to keep data of vineyard evolution between years. The only known solution is plant-by-plant human notation, a time-consuming task prone to errors (missed plants, symptoms appearing on one side of the row only, etc.).
These issues motivate for the conception of an automated esca detection device, which may prove to be a significant challenge. Indeed, the presence of wilting, reddening and yellowing zones on the limb is not specific to esca. Actually, most grapevine diseases and deficiencies involve similar colorations, only the spatial patterns of these colors are different. Powdery Mildew/Black Rot (
Figure 2a), Flavescence Dorée (
Figure 2c-d), wilted leaves (
Figure 2e), deficiencies (
Figure 2f) and insect damages are among the other confounding factors found in the vineyard.
Sensors and computer vision are strong candidates to answer these questions in a non-destructive and automatic way. Another inherent advantage of imagery is that it allows a localized diagnostic in the plant, only pointing the symptomatic areas and quantifying the symptomatic portion of the plant. Huge improvements in the field of image analysis these last 15 years brought new promising tools for a great variety of tasks involving agriculture, which are referenced in numerous recent reviews [
5,
6]. More notably, deep learning methods have become increasingly popular, motivating a comparison between that novel state-of-the-art approach and more classical ones. These enhancements are used in this paper in the form of Scale Invariant Feature Transform (SIFT) based encoding and pre-trained deep learning convolutional neural network, allowing to generate sets of features describing in a compact way the composition of grapevine plant images. Thus, the main contributions of this paper are:
This paper is divided into four main sections.
Section 2 describes related works about computer vision methods and examples of agricultural applications.
Section 3 describes the experimental design and image labeling steps leading to the creation of a custom database. In
Section 4, we tackle the classification of leaf image patches from the databases, using the two distinct above-mentioned feature extraction approaches. Finally,
Section 5 addresses the plant-scale detection problem on the basis of the classification step.
2. Related Works
Imagery using airborne or ground cameras is a popular choice for the detection of diseases or plant stresses in the field, whether it uses visible, multispectral [
8], hyperspectral [
9], thermal [
10] or fluorescence [
11] imagery. In-field esca detection is mainly studied using aerial multispectral imagery [
12]. In this work, multispectral aerial imagery allows exhaustive vineyard cover and brings rich spectral information but suffers from geometric problems (stitching of images from different viewpoints) and lacking resolution for precise symptomatic leaves imaging. Differentiation between esca and flavescence dorée, another threatening disease with similar foliar symptoms, is also considered in some works, showing a will to differentiate target disease from other diseases [
13,
14]. The latter uses a combination of hyperspectral measurements and RGB imagery with textural analyses, in laboratory conditions. RGB imagery may seem less attractive at first glance but is actually a cost-effective choice. While it does not include rich spectral information (three-channel broadband sensor), spatial information may be used for disease detection problems involving symptoms with defined patterns, such as esca. We chose to study the problem using proximal sensing to propose a complementary application to remote sensing surveys.
The most simple image processing methods regarding disease detection are image binarization ones, considering a threshold to separate green (healthy) elements from the symptomatic parts, e.g., the work in [
15] estimates virulence of wheat pathogen and compares it to traditional visual estimate methods. For that, colorspace transformations may be applied, such as RGB to HSV transformation (keeping hue information in a single channel) or vegetation indices (greenness index). Morphological operations can also be used to smooth the results and reduce false detections. These approaches are quite limited for more complex applications since they are sensitive to natural conditions (lighting, angle, shades, and organs with similar colors). Because of the absence of spatial information, they also perform badly if the underlying goal is to differentiate between diseases with similar discolorations.
Facing the limitations of color thresholding techniques, spatial information extraction was considered, taking into account the spatial relationships between pixels at first, and then between shapes and objects. Circular Hough transform was used as a powdery mildew spots detector [
16]. Segmentation [
17] allows retaining homogeneous spatial regions and then classify them according to the contained color features. Texture analysis, using for example standard Haralick indices, computed on gray level co-occurrence matrices, can also naturally be used and combined with other color features [
18].
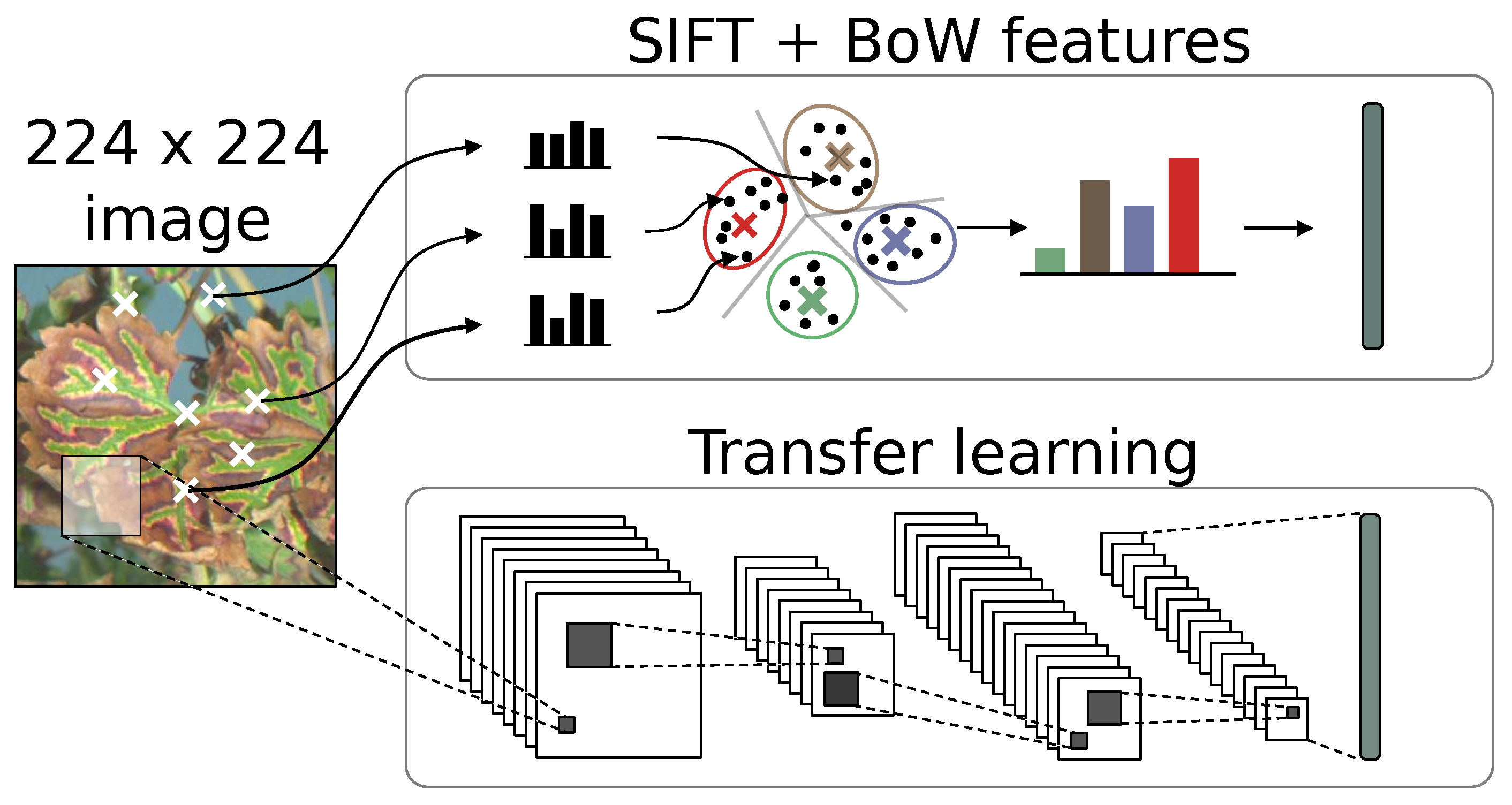
Lately, techniques naturally encoding the object composition of the image have been devised, allowing huge progress on general image classification tasks. SIFT keypoint detection is a powerful method used both for image classification and image correspondence [
19]. The intuition behind SIFT relies on finding “keypoints” in an image and then computing a 128-dimensional descriptor around that point to summarize local gradient histograms information in a scale and rotational invariant way. That wealth of local informations can then be aggregated into a compact image representation using bag of visual word-type approaches [
20]. SIFT descriptors are used for diverse agricultural applications such as leaf species classification [
21]. In that case, the descriptors help to distinguish species based on the architecture of leaf venation and shape. In [
22], species retrieval from a database of roughly 80 species is performed, using a fusion of several features including SIFT and Gabor filter, using HSI colorspace. A smartphone leaf identification system is devised for portable android device in [
23] using SURF (a fast SIFT variant) features with bag of visual words. Similarly, rice flowering steps can be detected using the same SIFT descriptors [
24]. Spatial grids of SIFT descriptors is also used in that study. As for disease detection, a set of three soybean diseases are classified in [
25] on scanned leaves. Best results are achieved using a multiscale grid in the form of the Pyramid Histogram of Words (PHOW) method. Extensive experiments around SIFT variants (including color fusions and different keypoint detectors) are also performed in [
26] for the classification of flowers pictures from three datasets. In the case of esca detection, SIFT/Bag of Words (BoW) combinations are of particular interest. Esca symptoms can be summarized as local patterns on the leaf (following the five main veins) with oriented soft gradients at different scales, meaning SIFT descriptors are good candidates to extract that information. On the other hand, BoW describes the composition of complex images with many objects and shape, similar to natural grapevine images. Other techniques based on local descriptors such as Local Binary Patterns [
27], Gabor Wavelets [
28], Histogram of Gradients [
29] and structure tensor [
30] are also popular methods in the literature.
Deep learning methods introduced a new shift in the way we envision features. Convolutional Neural Networks (CNNs) architectures use a network of image filters to extract features from an image [
31]. The weights determining the nature of these filters are learned during the training step. The user only defines the global structure of the CNN. CNNs are successfully used for image classification [
32] and detection problems [
33] on huge image databases (e.g., CalTech101 and Imagenet). The excellent results on these datasets have motivated the use of deep learning for many agricultural applications. For instance, plant identification is performed in [
34]. In that study, two image databases are considered, one being the above-mentioned Flavia dataset and the other a custom database of smartphone images in natural conditions. In [
35], the authors used VGG and AlexNet CNNs for classification on the Plant Village dataset. This database comprises images of different diseases and species in laboratory and infield conditions. It is worth noting that the network trained on laboratory images does not seem to generalize well on real field images. Web images can also be gathered to create a plant disease database such as in [
36]. Using more advanced frameworks, Fuentes et al. performed the detection of tomato diseases using ResNet classification network and Faster R-CNN detection architecture [
37]. In that paper, a data augmentation process is used to generate more samples based on variations of existing samples and reduce the overfitting effect. Fruit detection is also tackled in [
38], merging RGB and NIR Imagery, exhibiting good detection results even for partially occluded fruits. Sometimes authors also try to deeply modify existing methodologies, e.g., in [
39], the LeNet-5 network is used in combination with a novel k-means based weight initialization in order to improve classification performances of different weeds type in a soybean field and, in [
40], a custom network is devised for the quantification of maize tassels on in-field images. CNN’s state-of-the-art performances on many applications motivated the use of deep learning techniques for esca detection.
From these works, several tendencies can be noticed:
Image databases tend to grow bigger and to be more diverse. In parallel, laboratory studies in controlled conditions evolved into field condition acquisitions. Classification and detection problems are getting harder but in the meantime they are closer to potential commercial applications.
Feature extractors become less and less specific. Many agricultural applications actually do not use ad-hoc approaches. Thanks to transfer learning, very general trained feature extractors can be efficiently used for specific tasks.
Classifier importance has been revised downwards. State-of-the art classifiers such as SVM, random forest or artificial neural network provide satisfactory results that almost entirely depend on the two above-mentioned points. This means that, in most cases, noticeable performance gaps can only be achieved using larger databases and better feature extractors.
3. Data Collection and Processing
In field data collection was performed during summer 2017, in mid-august. Two plots from the Bordeaux region of France were used at the basis for the experiment: red cultivar Cabernet-Sauvignon vineyard in Pauillac and white cultivar Sauvignon-Blanc vineyard in Castres-Gironde. In both cases, the 50 first plants were sampled on even numbered rows. Since esca plants represent about 5% of the plants, esca samples are more sparse than healthy samples, thus additional plants presenting esca symptoms were handpicked to complete the database. Cartography of esca prevalence in the last five years was available, allowing to know in advance which plants are diseased.
Images were acquired using a RGB 2592 × 2048 camera; the camera was protected in a sturdy box packed with a microcomputer (image storage and acquisition program) and an electronic flash (
Figure 3).
Data acquisition was then triggered using a custom smartphone app for one-time acquisition or regular acquisitions. The device was then mounted on a transformed wheelbarrow advancing in the vinerow and aiming at the plants on the right side (
Figure 4). This device could also be easily mounted on a tractor for fast and automatic acquisitions. Lens and flash calibration depend on natural conditions and thus were done on the field to obtain a clear image of the grapevine plant foreground with homogeneous lighting and blurry background (next vine rows). A picture was taken for each plant, centered as much as possible on the trunk. Spatial resolution of images is about 1 mm.
The differences in symptom expression shown in
Figure 1 are greatly exacerbated by acquisition geometry and scene complexity. Leaves are visible at different angles and may be partially hidden. Esca symptoms are frequently overlain with stems, wires and other leaves. They may also appear blurry because of their relative position with the foreground, while the out-of-field background may trigger false positives. This means that the proposed classification algorithm should be robust to changes in illumination, rotation and obstructing elements. To take into account these differences, esca symptoms were roughly separated into three subclasses during the labeling process:
Esca3: Very well defined symptoms, most of the foliar area is affected, no occlusions (e.g.,
Figure 1a–d).
Esca2: Strong to medium symptoms (some parts of the leaf may not be affected), possible partial occlusions (e.g.,
Figure 1e,f).
Esca1: Weak symptoms or strongly occluded symptoms (e.g.,
Figure 1g,h). May be confounded with other diseases and abiotic stresses.
Since samples from these subclasses are scarce, these were only used during the testing stage as a way to evaluate more precisely the performances.
Image labeling was manually done using the free software LabelImg, outputting. xml files containing a list of bounding boxes for every labeled image. The files were then processed using a python script in order to create databases of rectangular leaf patches, which were then resized to 224 × 224 patches (
Table 1) during the feature extraction step.
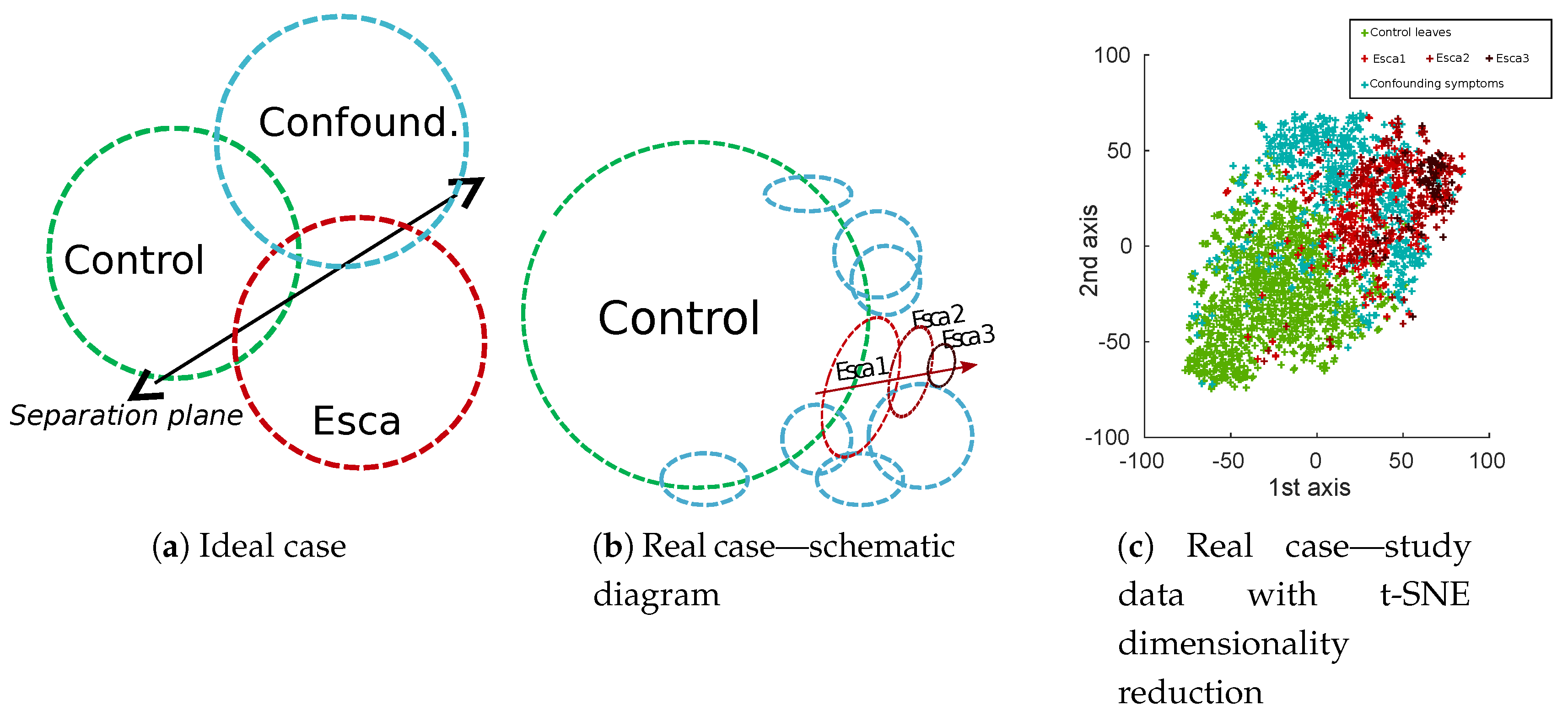
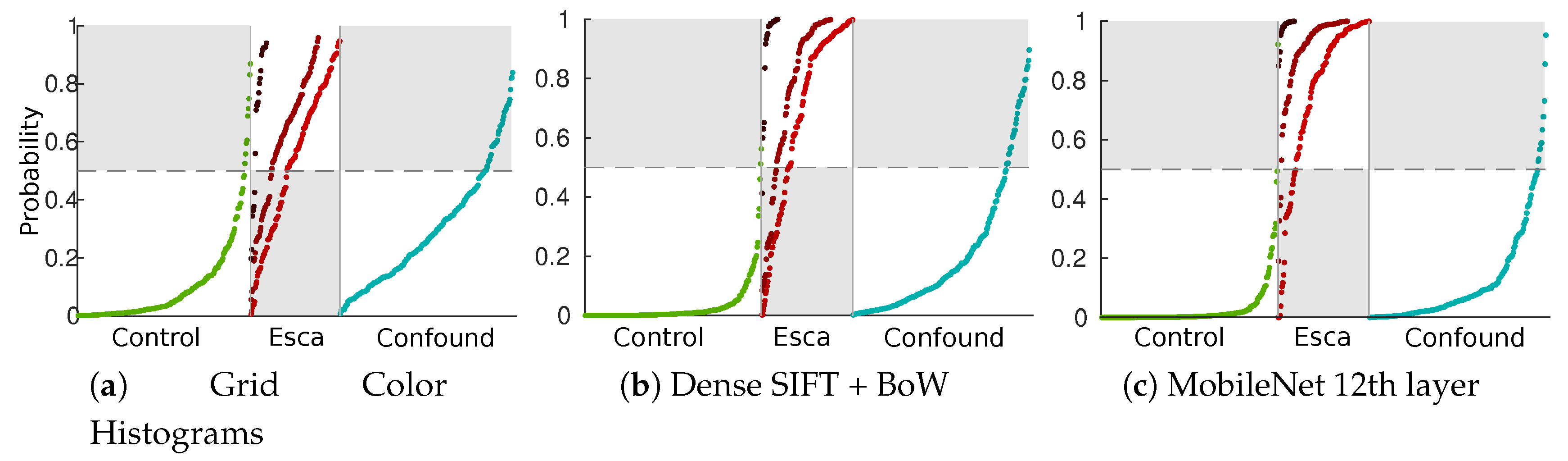
Natural class unbalance is easily noticeable, which can be explained by the low prevalence of esca symptoms in vineyards compared to the huge amount of control plants. It is also obvious that most of labeled esca symptoms are not “textbook examples” symptoms. Very well-defined symptoms are actually sparse, roughly 50 samples per cultivar in our database, which is not only caused by actual symptoms themselves but also by acquisition geometry. More generally, in real applications, background samples are often numerous, while targeted disease are scarce and present with varying intensity (displayed with green and red circles in
Figure 5). Confounding factors (blue circles in
Figure 5) could be separated in many different subclasses but most of them would have very few samples. In some cases, these subclasses are likely to be confounded with targeted esca class in the feature space (deficiencies) and in some cases not (powdery mildew, wilted leaves). A 2D visualization of features extracted from the database using t-distributed Stochastic Neighbor Embedding algorithm (t-SNE) algorithm can be found in
Figure 5c. The t-SNE is a non-supervised dimensionality reduction technique known for its ability to find relevant embeddings in high dimensional spaces [
41].
6. Conclusions and Perspectives
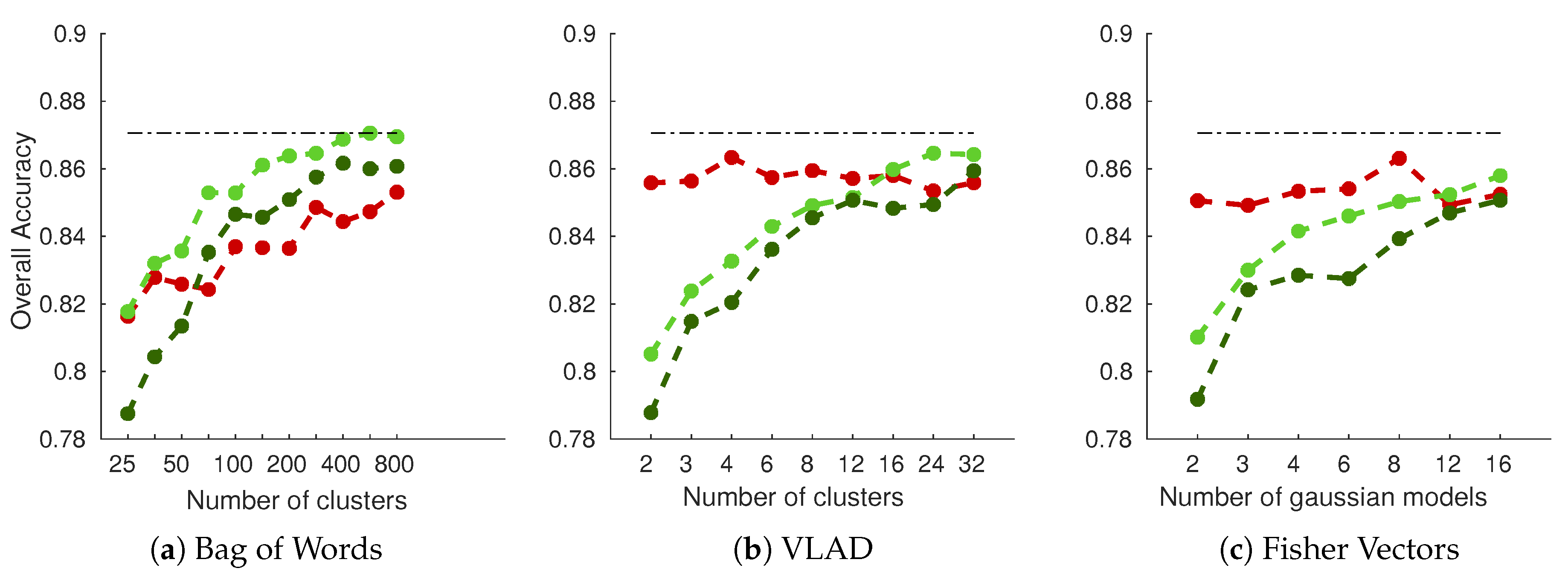
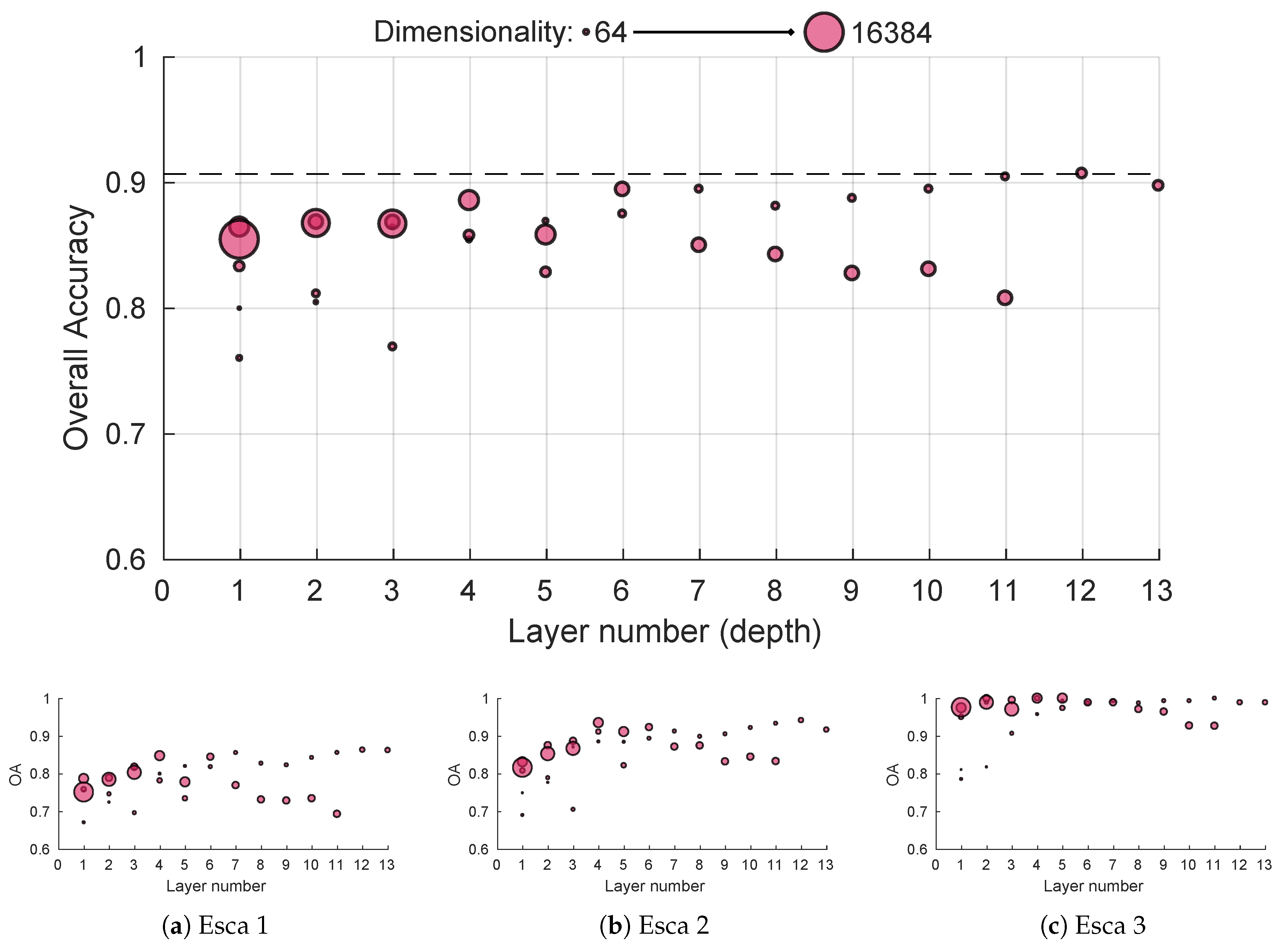
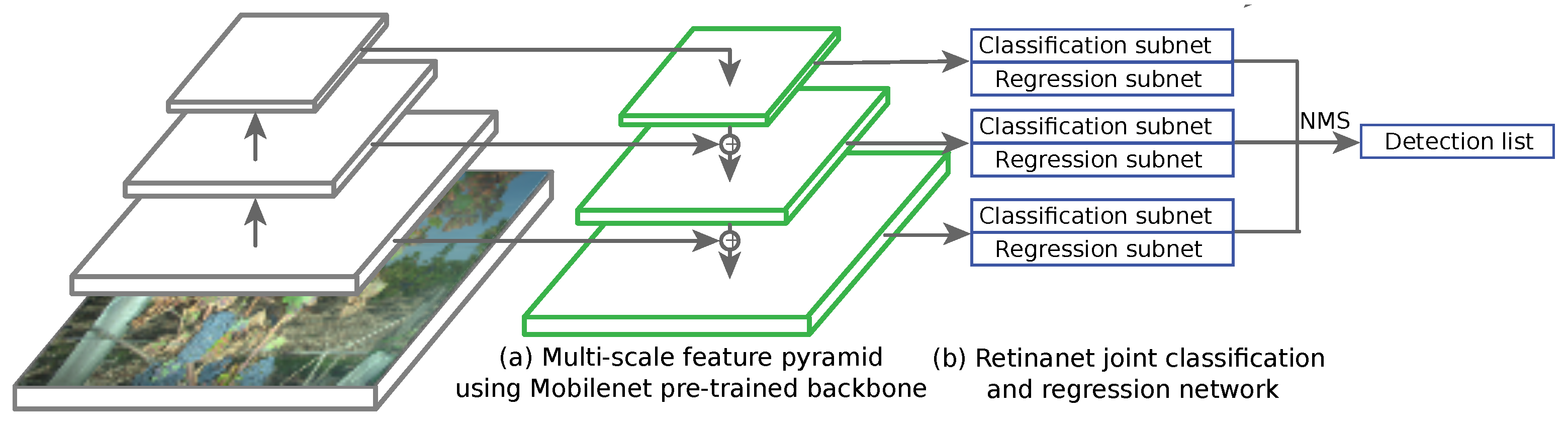
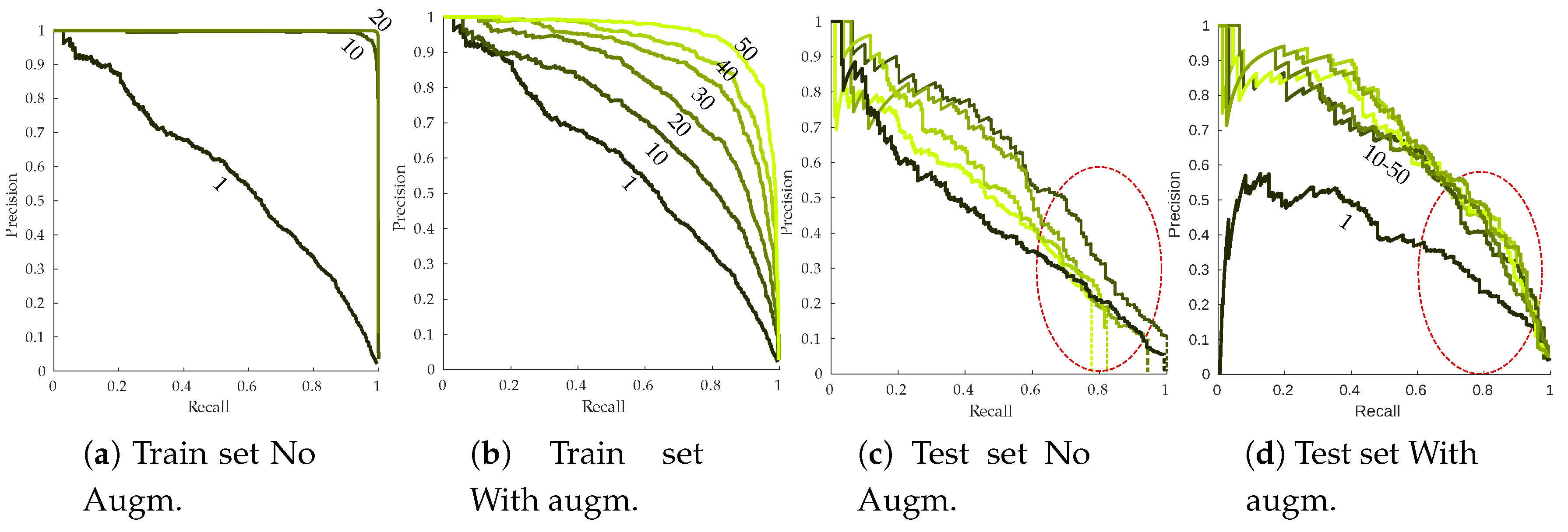
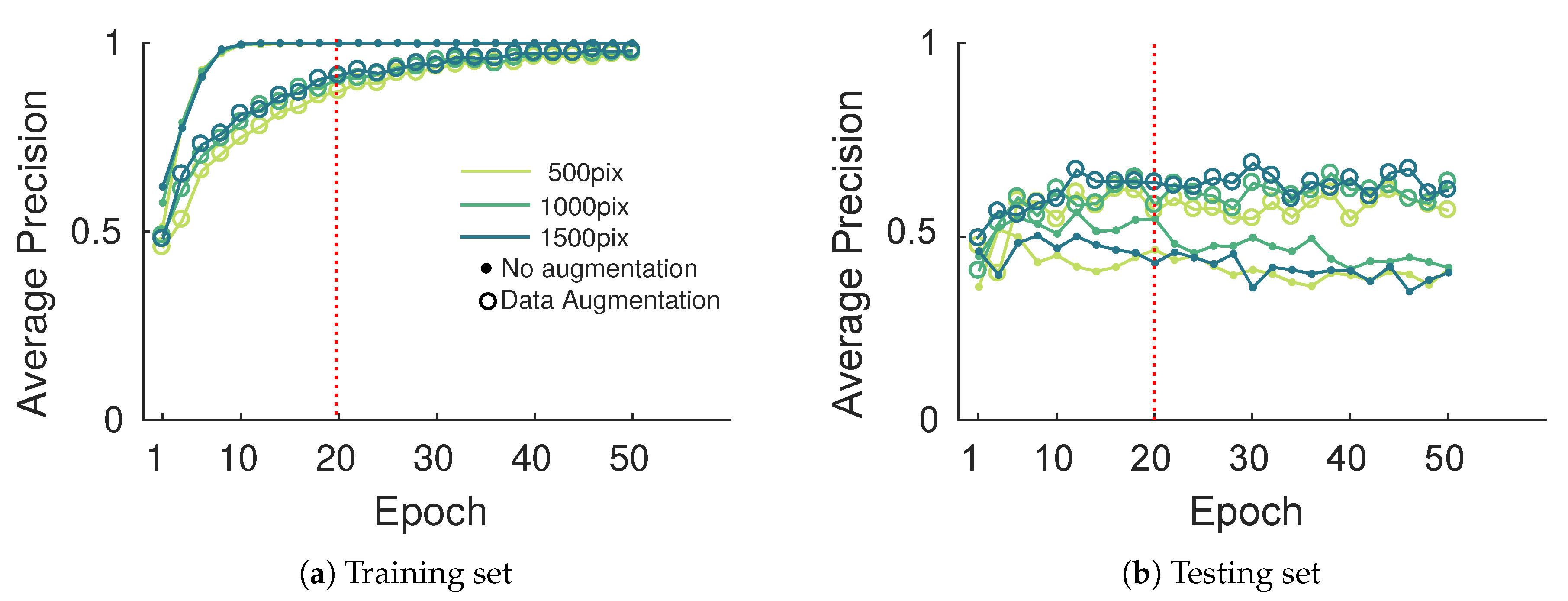
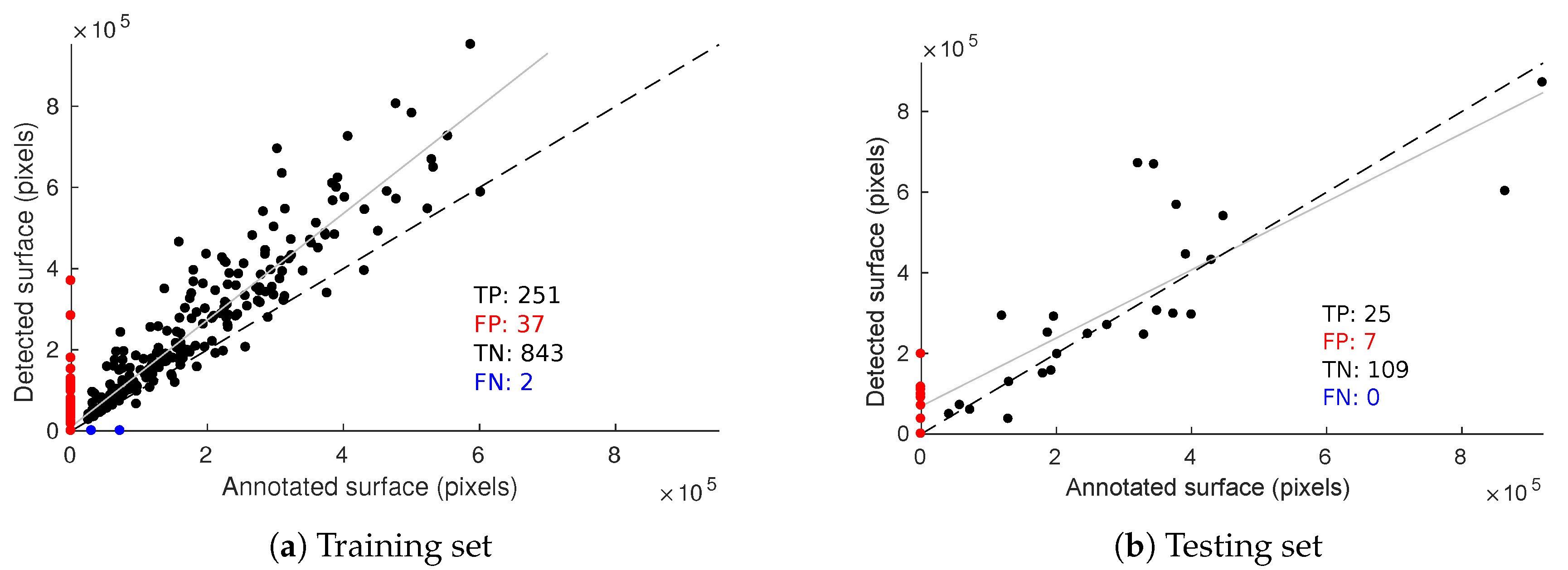
Plant diagnostic relies on the observation of the whole plant; it allows human observers to give, most of the time, accurate predictions about the plant status, although it is still error prone. In this paper, we propose a novel in-field esca symptom detector taking into account the differentiation with confounding factors. The first objective was to compare leaf-scale classification performances using state-of-the-art feature extractors. While SIFT based approaches using detected keypoints or grid of keypoints yielded good performances on challenging datasets, feature maps extracted from trained convolutional network (transfer learning) gave better results. Highest accuracy was thus achieved using deep mobilenet feature maps with global max pooling. In that case, spatial information allowed better discriminating esca from healthy leaves and other symptoms, especially for harder samples. While perfect classification on well-defined esca symptoms was easily achieved using these approaches, classification of less defined esca symptom remains a challenging task. The second objective was to exploit the discriminative power of the feature extractor to use it as the backbone in a detection algorithm at the plant scale. Based on the RetinaNet object segmentation model, the presented algorithm yields good results with an high correlation between the annotated esca surface and the detected surface for each plant. Furthermore, no esca annotated plant was missed during the prediction, meaning each symptomatic plant was correctly detected for a detection threshold of 0.5. Proximal sensing is thus a promising tool for precise disease detection, its rich spatial information can be used to discriminate between similar diseases in the vineyards, serving as a complementary tool to remote sensing surveys. Future works may include the construction of a broader in-field image database including more leaf symptoms and more grapevine cultivars, which is the next step for automatic and robust in-field grapevine disease detection.






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
