1. Introduction
In recent years, remote sensing images have played an important role in many areas, such as surveillance, land-use classification, forest disturbance, and urban planning [
1]. How to exploit the information of remotely-sensed images has been a popular research problem for decades. Hyperspectral images (HSI) have attracted a significant amount of attention due to its high spectral resolution and wide spectral range which make it possible to analyse and distinguish various objects with higher accuracy [
2].
One of the most important applications of HSI is supervised classification which assigns a specific class to each pixel based on the spectral information [
3]. Various techniques have been employed for this task, such as support vector machines (SVM) [
4,
5,
6], random forest (RF) [
7], multinomial logistic regression (MLR) [
8], and neural networks (NN) [
9]. Among these techniques, SVM has shown its effectiveness for HSI classification, especially when dealing with the Hughes phenomenon of very high-dimensional data [
4]. Dimensionality reduction methods were developed to deal with the high dimensionality of HSI data and obtained some promising results [
6,
10,
11]. Although these methods have provided some reasonable solutions to the problem, spatial context has not been fully utilized in those conventional classifiers. Without spatial information being involved, the classification map may produce a more noisy appearance and a lower accuracy [
12]. During the past decade, many attempts have been made to integrate the spatial context in the classification tasks. Some methods have focused on feature extraction, such as extended morphological profiles [
13,
14] and attribute profiles [
15,
16], which improved the classification results by taking the morphological properties into account. Kernel-based methods, such as the one in [
17], use a composite kernel to incorporate spectral and spatial properties, and then images are classified by SVM. In addition, multiple feature learning approaches [
18,
19], which combine different features learned by various methods, are proven to enhance the classification results. Markov random fields (MRF) [
20,
21] focus on developing classifiers that can preserve the spatial context by formulating a minimization function of spatial and spectral energy, and the result changes when different weights are assigned to spectral and spatial energy terms. All these techniques are able to incorporate spatial and spectral information.
In the last few years, sparse representation (SR) has been a promising tool in solving many image processing problems, such as denoising [
22], fusion [
23], and image compression [
24]. In [
25], SR was used to detect the boundary points and outliers from images, which is proven to be very useful for image processing applications. SR assumes that a natural signal can be linearly expressed by a few coefficients from a so-called dictionary [
26]. Now SR has been extended to the classification of HSI based on the assumption that the pixels of a class usually lie in a low-dimensional subspace, despite their high-dimensional characteristics [
27]. This enables a test pixel with an unknown label to be linearly represented by a few elements, and then the label can be determined after the coefficient vectors are recovered from a training dictionary. Many studies [
28,
29,
30] have provided a promising result for HSI classification based on SR. Moreover, SR can also learn the probability for a decision fusion classifier [
31]. It should be noted that the reconstruction work mechanism makes it very efficient, and can easily accommodate new training data by reconstructing the class-specific dictionary (e.g., directly adding the new training data to the dictionary matrix which corresponding to the label class of the training data) without retraining the whole dataset, which is required for other classifiers, such as SVM and MLR. Another advantage of SR compared to other conventional binary classifiers is that it can label the pixels from multiple classes directly. Many studies have been attempted to explore the merits of SR. Cui and Prasad [
32] proposed a class-dependent sparse representation classifier which utilized the k-nearest method to select atoms for SR, and they considered the label information by computing the Euclidean distances between the test sample and k-nearest pixels in a class-specific manner. The class-dependent SR can also be extended to a kernelized variant by using a kernel function. Similar work has been done in [
33]. In the report of [
34], the authors proposed a multi-layer spatial-spectral sparse representation specifically for hyperspectral image classification. The class residual is computed in the first sparse representation layer, and then the sparse coefficients are determined to be updated or not in the next layer based on a class-dependent residual distribution. The multi-layer strategy is implemented sequentially and the selected atoms’ indices are determined by the classes’ rankings within the minimal residuals. The experimental results have demonstrated its superior results when compared to the traditional sparse coding methods.
In order to further exploit the spatial information, a joint sparse model (JSM) has been proposed [
28]. For HSI, neighbouring pixels tend to have similar contextual properties and are highly correlated with each other [
35]. JSM assumes that pixels constrained by a region scale share a common sparsity pattern, and these pixels can be linearly represented by a few common atoms which are associated with different sparsity coefficients. Based on this assumption, the test pixel can be replaced with its surrounding neighbours in the JSM model to seek a more reliable representation. Recently, JSM has achieved a better performance when compared to pixel-wise SR methods [
36]. However, JSM is sensitive to the selected region scale because near-edge areas require a small region scale and smooth areas need a large region scale. Some experiments have shown that, if an oversized area is selected for a specific test pixel, the accuracy tends to decrease [
37]. If the scale is too small, then insufficient contextual properties are included; hence, it is difficult to choose an optimal region scale for JSM.
On the other hand, for a given specific area, distinct structures and characteristics, as well as some irrelevant information, will exhibit; however, some pixels with different spectral structures of the test pixel also exist in this region. If a strategy aims to find the most similar pixels to the test pixel and reject the dissimilar neighbouring pixels, information of correlated spatial context should be more representative for classification. Hence, we propose an adaptive neighbour selection strategy which computes the weights based on distances between pixels, with the labels of training data as a priori information. The structural similarity between the central pixel and its neighbours can be exploited in a more sensible way by considering the different contribution of each spectral band. Based on this, a novel joint sparse model-based classification approach, namely ‘adaptive weighted joint sparse model’ (AJSM) is proposed in this paper. Moreover, we propose a novel classification method with a name ‘multi-level joint sparse representation model’ (MLSR), in order to take advantage of the correlations among neighbouring pixels in a region. The procedures of MLSR are summarized as: (1) Local matrices are obtained by the proposed adaptive neighbour selection strategy. Different thresholds of distances can result in different local matrices corresponding to different levels; therefore (2) different joint sparse representations of the test pixel from different levels can be constructed. Since pixels with similar distances can be simultaneously sparsely represented by the features in the same subspace, and pixels from multiple levels may share different sparsity patterns, MLSR is designed to learn the dictionary for each joint sparse model separately; and (3) a simultaneous orthogonal matching pursuit (SOMP) algorithm is employed to learn the multi-level classification task.
The weight matrix for AJSM and MLSR is constructed by the ratio of the between-class and within-class distances with the consideration of a priori label information. This alleviates the negative impact when we classify the mixed pixels and similar pixels. In addition, the proposed MLSR performs on one region scale with different levels, and the sparse coding procedures at different levels are independent of each other. To sum up the main advantage of the proposed multi-level method, various parameter values can generate multiple sparse models to represent the different inner contextual structures among pixels, thereby improving the HSI classification accuracy.
The remainder of this paper is organized as follows:
Section 2 reviews the sparsity representation and joint sparse models briefly.
Section 3 describes the proposed MLSR method in detail for HSI classification. Experimental results on three benchmark datasets are presented in
Section 4. Finally, conclusions and future work are provided in
Section 5.
3. Adaptive Weight Joint Sparse Model (AJSM) and Multi-Level Sparse Representation Model (MLSR)
We introduce an adaptive weight joint sparse model (AJSM) and a multi-level joint sparse representation model (MLSR) for HSI classification in this paper. Multiple local signal matrices are constructed using different parameters to realize the similarity learning in MLSR. In fact, AJSM is a simple form of MLSR. The proposed AJSM is expected to improve the classification accuracy in these areas by not taking all the neighbouring pixels to construct the joint sparse matrix. Additionally, MLSR improves the classification results by selecting the neighbour pixels from various levels using the proposed adaptive neighbour selection strategy.
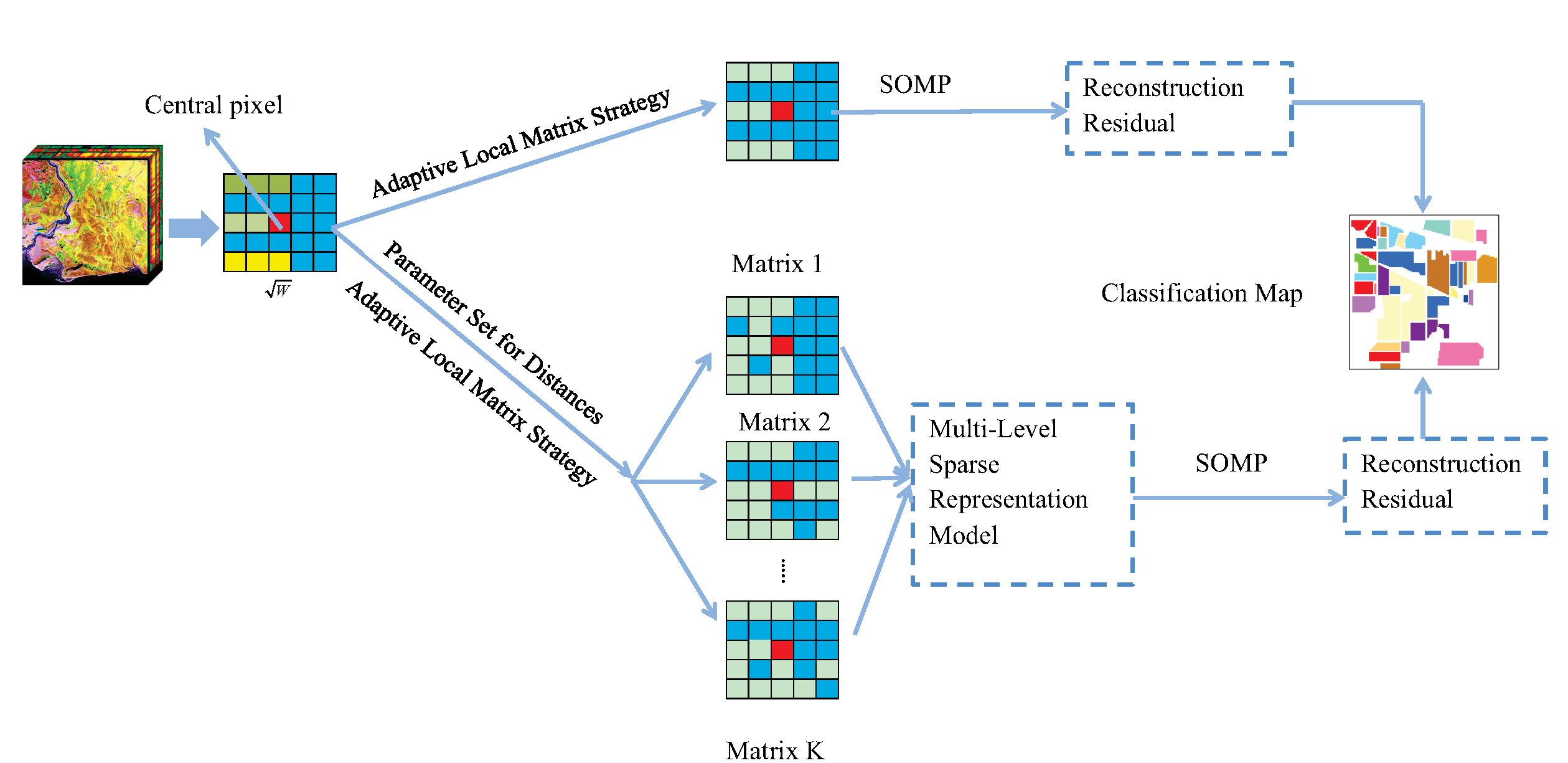
To better understand the procedure of the proposed method, a flowchart is shown in
Figure 1 where each component of the method is explained in detail in the following sections.
3.1. Adaptive Local Signal Matrix
In order to select reasonable neighbours to construct the joint matrix, the weighted Euclidean distances between the test pixel and its neighbours are used. We first select a region with a window size
, which is centred at the test pixel
. Different weights are given to each spectral band according to their contribution to the whole spectral characteristics. The weighting strategy is described as follows:
where
is the weight distance between pixels
and
,
is the weight for the
l-th feature, and
is determined by training samples from different classes.
is a positive parameter that controls the influence of a class-specific distance
. If
, the distance between two pixels decreases to the equal weight Euclidean distance. If
is large enough, the change will be reflected on
.
denotes an indicator function which takes between-class and within-class distances into account.
is the average of the
c-th class of the
l-th feature, and
represents the average of all training samples of the
l-th feature;
represents the label of pixel
.
Pixels with a predefined distance value can be selected as similar neighbours according to this method. In other words, this adaptive neighbour selection strategy can identify the samples with similar characteristics to form a group. The superiority of this weight strategy over other weighting schemes is that it considers the spectral similarities on a pixel level, and the discriminative information among different groups which can be obtained from training samples.
3.2. Adaptive Weight Joint Sparse Model
The goal of Equation (12) is to find the optimal samples to reconstruct the central pixel. Once the appropriate weights are assigned to each spectral band, the weight distances between the test pixel and its neighbouring pixels can be evaluated. Based on the top
N-nearest strategy,
nearest neighbouring pixels can be chosen as the adaptive weight joint sparse matrix to relax the joint sparse model (Equation (9)). Here we define
as the weight matrix chosen from the original joint sparse matrix
. In other words,
nearest pixels are selected from the
pixels based on the previous adaptive weight scheme. The adaptive weight joint sparse model can be expressed as:
The label of central pixel can be identified by minimizing the class residual:
The procedure of AJSM is summarized below in Algorithm 1.
| Algorithm 1. The implementation of AJSM |
Input: training datasets belong to the c-th class: , region scale: , top number of nearest neighbours: , test datasets .
Initialization: initialize dictionary with training samples, and normalize the columns of to have unit norm.
1. Compute the for each spectral band according to Equation (12);
2. For each test pixel in :
Construct the weight matrix according to Equation (12) and normalize the columns of to have a unit norm;
Calculate the sparse coefficient matrix and dictionary from Equation (13) using SOMP;
Determine the class label for each test pixel by Equation (14).
Output: 2-dimensional classification map. |
It has been identified that neighbouring pixels consist of different types of materials in the heterogeneous areas in HSI. JSM cannot perform well on such areas due to its definition of neighbouring pixels, which tend to have similar labels. The proposed AJSM is expected to improve the classification accuracy in these areas by not taking all the neighbouring pixels to construct the joint sparse matrix.
3.3. Multi-Level Weighted Joint Sparse Model
The neighbour pixels selected from a fixed scale using single level criteria as seen in JSM and AJSM may not contain the complementary and accurate information, and the neighbour pixels selected from different criteria levels can help represent the data wholly. Herewith we propose a multi-level weighted joint sparse model to fully integrate the neighbour information, as well as to avoid the outliers dominating in the sparse coding. For a test pixel, its neighbour pixels are selected by the proposed adaptive neighbour selection strategy with different distance threshold level values. Then the multiple joint sparse matrices are constructed by the corresponding neighbour pixels with different distance threshold level values. The details of this method are described as follows.
Assume that
is the
k-th joint sparse matrix constructed for pixel
. Here we define
using a weight matrix i.e.,
where
is a function that determines if pixel
can be preserved to reconstruct
,
is the
j-th sample in the given region which is restricted by the scale
. In (12),
is a monotonously increasing function of the weighted distances. Although there are many ways to define
, we define it as a piecewise constant to simplify the selection of different joint sparse matrices as follows:
where
is a threshold controlling the value of the corresponding element in
. According to (12) and (15), when a pixel in
has the corresponding weighted distance with the test pixel
:
it will not be selected in the joint sparse model. Otherwise, if
, the corresponding term will be selected to reconstruct the test pixel. In other words,
is constructed by the terms that have the weighted distances less than
between itself and the test pixel
.
By using the proposed scheme, we can generate different patches with various values of :
: This is an independent set. In this situation, only the central pixel itself is selected. This means that the joint sparse model becomes a pixel-wise sparse representation model.
: Because in this situation, all the neighbours of the test pixel in the given area are selected.
: The sparsity representation of is satisfied. A smaller number of pixels are selected for the reconstruction of .
As described above, for each test pixel , when different parameters of are applied, different patches can be generated to represent this pixel with the inner contextual information involved. Our next task is to construct the multi-level joint sparse representation model for the test pixel.
3.4. Multi-Level Joint Sparse Representation
The SRC has been successfully used for HSI classification, herein we extend it to a multi-level version for the classification task. After different patches are constructed for each pixel, the patches for the test pixel can be arranged as a feature matrix: (), where be the k-th joint sparsity matrix constructed for the test pixel .
In this paper, let be a set of dictionary which can be learnt from all the training data for patches, and is the dictionary learnt for the k-th level. Each dictionary is composed of all the sub-dictionaries for each labelled class as , where denotes the sub-dictionary of the c-th labelled class.
The sparse representation of the test pixel
with its
k-th patch can be described as:
where
is the sparse representation coefficients for the specific patch
. Equation (16) expresses how to sparsely represent each of the
patches when the sparse coefficient vector is given. Considering all the
patches, Equation (16) can be rewritten as:
where
is composed of
columns of the coefficient vectors. Each column of the matrix is the sparse representation coefficients corresponding to a dictionary over a specific patch.
Since the pixels belonging to the same class should have the dictionary in the same subspace spanned by the training samples, the class-specific level joint representation optimization problem can be written as:
This problem can be decomposed into sub-problems. In this paper, the SOMP is used to solve the optimization function (Equation (18)) and it can efficiently solve this problem in several iterations. Algorithm 2 introduces the implementation of the proposed framework.
After the sparsity coefficients are obtained, for a given test pixel
, it would be assigned to the class which gives the smallest reconstruction residual:
where
is the reconstruction residual of
, as:
where
is the dictionary for the
c-th class over the
k-th patch, and
denotes the sparse coefficient matrix corresponding to
.
| Algorithm 2. The implementation of the proposed algorithm. |
Input: training datasets belonging to the c-th class: , region scale: , number of levels: , distance threshold controlling parameter: , test datasets
Initialization: initialize dictionary , and normalize the columns of dictionary to have unit
1. Compute according to Equation (12) using the training data sets and the corresponding labels
2. For each test pixel
Compute adaptive weight distances between the test pixel and all the pixels in the selected neighbour region to construct based on Equation (12)
3. Compute based on Equation (15).
4. For
Compute for each level for each class using SOMP.
5. Compute the class label for test pixel based on Equations (19) and (20).
Output: 2-dimensional classification map. |
4. Experimental Results and Analysis
4.1. Data Description
To validate the proposed methods, three benchmark datasets are used in the experiments.
1. Airborne Visible/Infrared Imaging Spectrometer (AVIRIS) dataset: Indian Pines, which was obtained by an AVIRIS sensor over the site in Northwest Indiana, United States of America (USA). This imagery has 16 labelled classes. The dataset has 220 spectral bands ranging from 0.2 to 2.4 wavelength, and each channel has 145145 pixels with a spatial resolution of 20 m. Twenty water absorption bands (no. 104–108, 150–163, and 220) are removed in the experiments. This data is widely used due to the presence of mixed pixels in available classes and the unbalanced number of training samples per class.
2. Reflective Optics System Imaging Spectrometer (ROSIS) data set: University of Pavia, Italy. This image was acquired during a fight campaign over Pavia in Northern Italy. It has nine labelled ground truth classes with 610340 pixels. This dataset contains urban features, as well as vegetation and soil features. Each pixel has a 1.3 m spatial resolution. With water absorption bands removed, 103 bands are used in the experiments.
3. AVIRIS data set: Salinas. The image was also acquired by an AVIRIS sensor over Salinas Valley, CA, USA. The image is of 512217 size with 224 spectral bands. In the experiments, 20 water absorption bands (no. 108–112, 154–167, and 224) are removed. Salinas has a 3.7 m resolution per pixel and 16 different classes. It includes vegetables, bare soils, and vineyard fields. Due to the spectral similarity of most classes, this dataset has been frequently used as a benchmark for HSI classification.
The ground truths of three datasets, as well as the false colour composite images are illustrated in
Figure 2.
4.2. Description of Comparative Classifiers and Parameters Setting
In this paper, the proposed AJSM and MLSR are compared with several benchmark classifiers: pixel-wise SVM (referred to as SVM), EMP with SVM (referred to as EMP), pixel-wise SRC (referred to as SRC), and JSM with a greedy pursuit algorithm [
28]. Pixel-wise SVM and pixel-wise SRC classify the images with only spectral information, while JSM, AJSM, and MLSR are sparse representation-based classifiers with spatial information utilized.
During the experiments, the range of parameters is empirically determined and the optimal values are determined by cross-validation. The parameters for pixel-wise SVM are set as the default ones in [
4] and implemented using the SVM library with Gaussian kernels [
41]. Parameters for EMP and pixel-wise SRC are set up by following the instructions in [
14] and [
28], respectively. The selected regions for JSM, AJSM, and MLSR are set as 3
3, 5
5, 7
7, 9
9, 11
11, 13
13 and 15
15, and the best result is described in this paper. For AJSM, the number of pixels selected in the given region is set as: 7, 20, 40, 50, 50, 50, and 50 for the abovementioned scales, respectively. For the proposed MLSR, the number of threshold parameter
is set as seven, and the threshold values are:
. The predefined sparsity level is set as 3 for each dataset.
Quantitative analysis metrics, overall accuracy (OA), average accuracy (AA), and Kappa coefficient are adopted to validate the proposed method. All the experiments in this paper are repeatedly implemented ten times and the mean accuracy is presented.
4.3. Experimental Results
The first experiment was performed on the Indian Pines image. We randomly selected 10% of the samples from each class as training data and the remaining as a test dataset. The optimal parameters in this experiment are set as:
= 0.2,
. The numbers of training and test data for each class are described in
Table 1. Classification results are listed in
Table 2, and the classification maps are shown in
Figure 3. One can observe that the classification maps obtained by pixel-wise SVM and pixel-wise SRC have a more noisy appearance than other classifiers, which confirms that the contextual information is important for hyperspectral image classification. Considering the spatial information, JSM gives a smoother result; however, it still fails to classify some near-edge areas. EMP, AJSM, and the proposed MLSR deliver better results, and MLSR shows the highest classification accuracy. From
Figure 3, one can see that MLSR further provides a smoother classification result and preserves more useful information for HSI.
The proposed AJSM improves the classification capability of JSM by exploring the different contributions of the neighbouring pixels in the selected region. This confirms the effectiveness of the adaptive weight matrix scheme. However, one can see that AJSM produces a relatively lower accuracy for oats, which has limited training samples. The improvement of MLSR-based classification of alfalfa and oats, which have been considered as small classes, indicates that the proposed method can perform well on classes with fewer training samples. In addition, the adaptive local matrix imposes the local constraint on the sparsity, which would improve the performance. As can be observed from the classification maps, our proposed method has a better capability to identify the near-edge areas and it benefits from the selection of most similar pixels to reconstruct the test pixel. The accuracies for MLSR are very high, which indicates that JSM can be significantly improved by multiple feature extraction approaches.
The second experiment is conducted on the Pavia University image, and
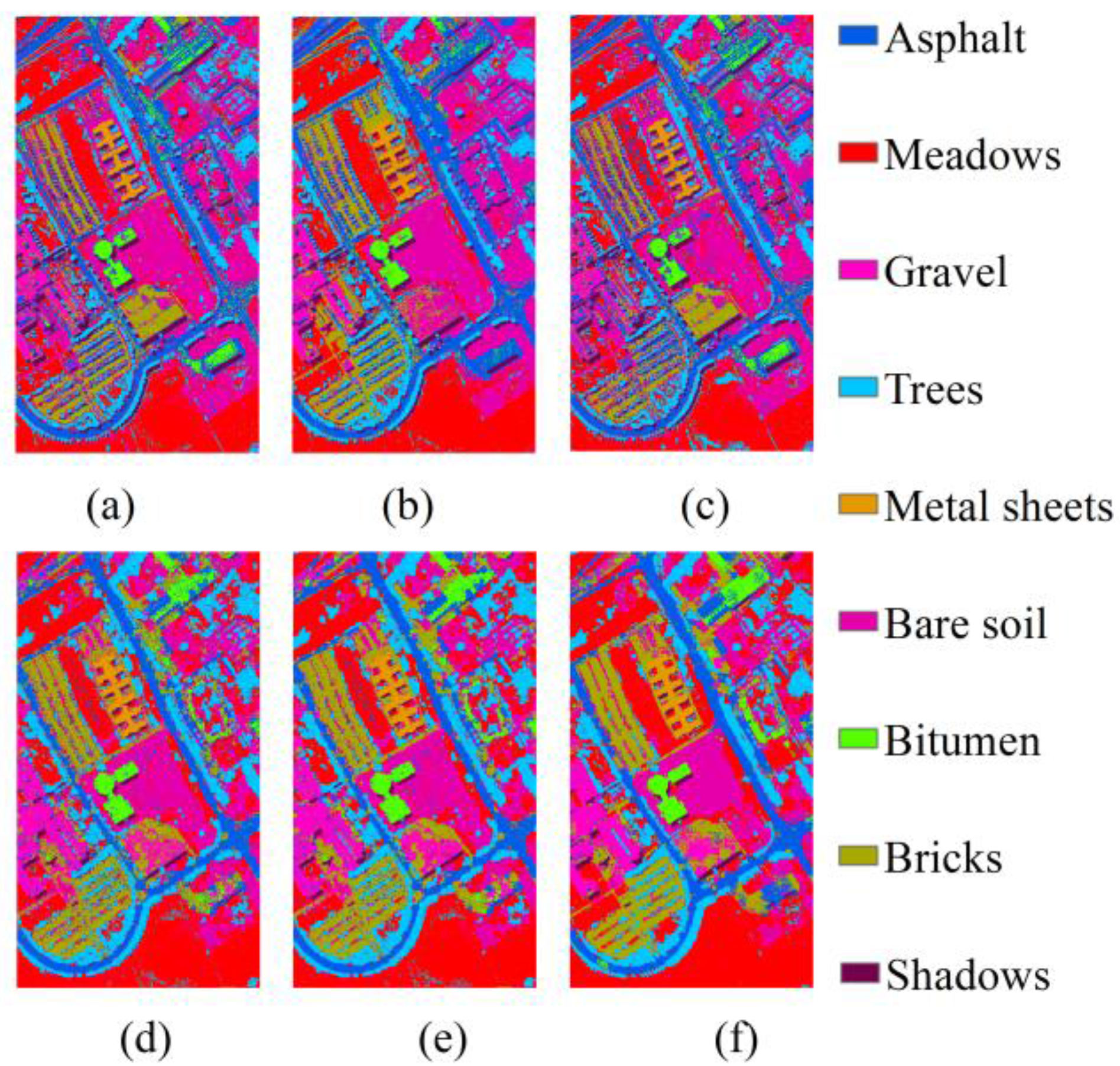
Table 3 shows the class information. We randomly selected 250 samples as the training data, and the rest as test data. The optimal parameters in this experiment are set as:
= 0.2,
. Classification results and maps are illustrated in
Table 4 and
Figure 4, respectively. It is obvious that the multi-level information can, indeed, improve the results of classification of the Pavia University image compared to other SRC based methods and the popular SVMs. The improvement of MLSR compared to JSM suggests that the local adaptive matrix can preserve the most useful information and reduce the redundant information. The result is consistent with the previous experiment on the Indian Pines image where the edge pixels are predicted more precisely.
The third experiment is conducted on the Salinas imagery. For each class, 1.5% samples are selected as the training data, and the remaining as the test dataset. The optimal parameters in this experiment are set as:
= 0.2,
. The class information and classification results are given in
Table 5 and
Table 6, respectively. The results are also visualized in classification maps as shown in
Figure 5. One can observe that the proposed MLSR yields the best accuracy for most of the classes, especially for classes 15 and 16. Furthermore, the proposed MLSR identified the edge areas best.
4.4. Effects of Different Kinds of Parameters
This section focuses on the effects of the parameters setting on the classification performance. We first varied the value of positive parameter
that controls the influence of the ratio of the between-class and within-class distances, and the value was varied from 0 to 1 at 0.2 intervals. The experiments were conducted with AJSM on three datasets and the window sizes were fixed as the corresponding optimal values. In
Figure 6, the overall accuracies for three datasets fluctuate in a small range, and the best performances were obtained when
was set as 0.2 for all three datasets though the trends for them were different. As
only controls the influence of each feature band, it is reasonable to apply the same value for MLSR in the experiments.
The effect of region scales for JSM, AJSM, and MLSR has also been analysed in the experiments. In order to simply show the trends, the numbers of training and test datasets are selected to be the same as in the previous experiments. OA is shown in
Figure 7. For JSM, AJSM, and MLSR, the region scales ranging from 3
3 to 29
29 at 2
2 intervals. As shown in
Figure 7, the best OA is achieved for JSM when the scale is set as 7
7, 11
11, and 15
15 for Indian Pines, Pavia University, and Salinas, respectively. If the scale increases, the accuracy decreases dramatically. In most situations, AJSM performs better than JSM because the most useful information is preserved and the redundant information is rejected by the selection strategy. The accuracy for MLSR becomes stable when a larger region is selected. More specifically, the proposed MLSR performs better than other joint sparsity-based models in most regions. This result actually benefits from its mechanism of discarding outliers in the specific area, which provides a more reliable dictionary.
Another consideration is the number of patches that should be tested, i.e., is having more patches better? To evaluate this, the adaptive framework is used to generate more patches. Especially, with
set to
, we can define 11 patches. In each experiment, we randomly selected a patch subset with the number of
from these 11 patches and evaluated the performance of the method on three datasets. For each value of
, the experiment procedure is repeated 10 times with different subset selection.
Figure 8 shows the average OA result of the 10 iterations. As
increases, the performance of the framework also increases when
; however, it slightly decreases when
. This trend shows that a certain number of patches are necessary for the improvement of the performance of the proposed method. However, too many patches can also result in a slight decrease in performance. In the experiment, we fixed five values {0.1, 0.2, 0.3, 0.4, 0.5}, and the last two values are determined from the remaining five values {0.6, 0.7, 0.8, 0.9, 1} by cross-validation.
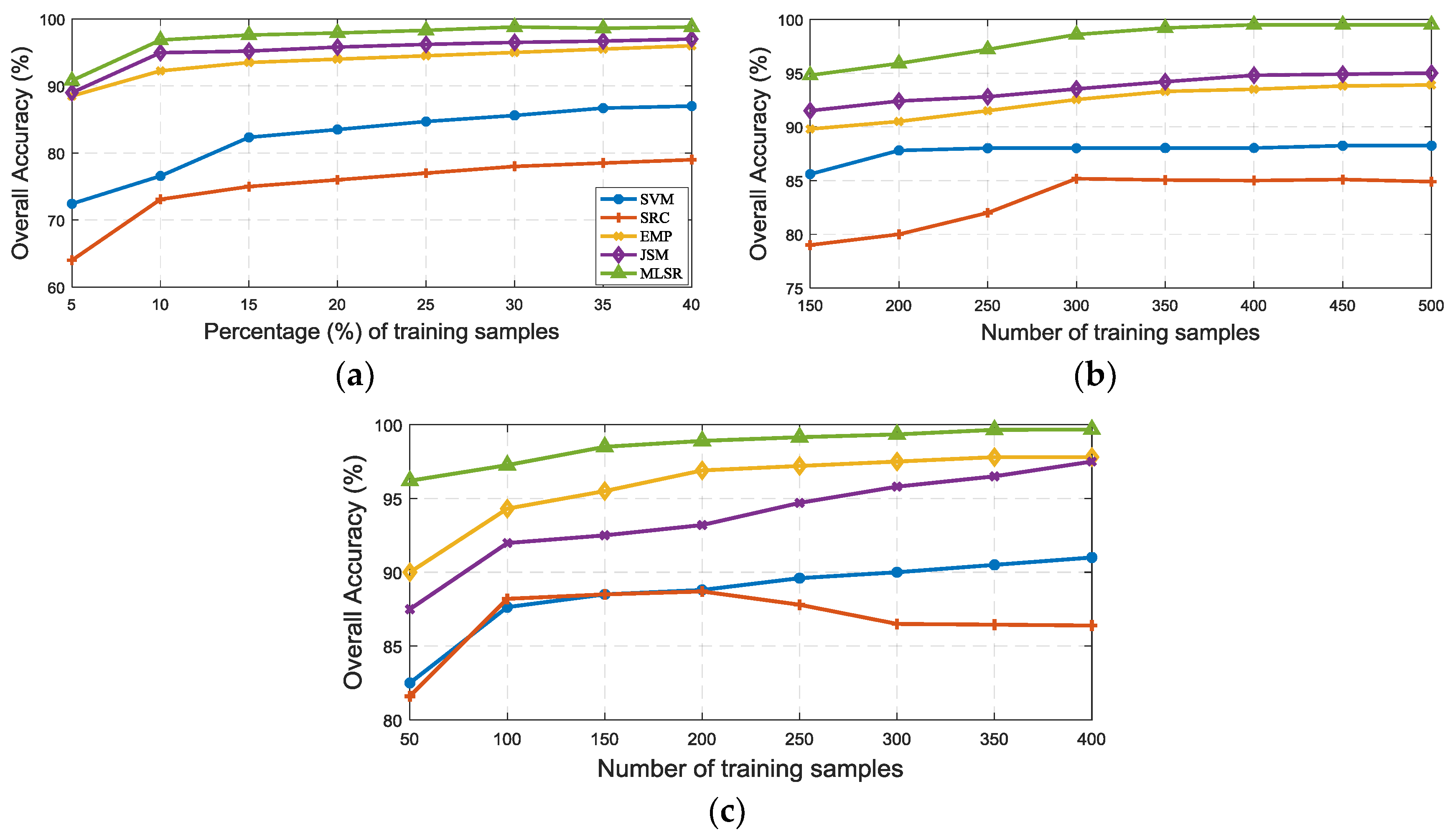
We also conducted the experiments to evaluate the impact of the number of training samples per class for pixel-wise SVM, pixel-wise SRC, EMP with SVM, single-scale JSM, and the proposed MLSR. AJSM is not considered in this experiment as they exhibit a similar trend with JSM. Training samples are randomly chosen, and the rest are used as test samples. For the Indian Pines dataset, the number of training data ranges from 5% to 40% of the whole pixel counts at 5% intervals; for the Pavia University dataset, the number of training samples per class ranges from 150 to 500 at 50 intervals; For the Salinas dataset, the number of training samples per class ranges from 50 to 400 at 50 intervals.
Figure 9 illustrates the classification results (OA) for these three datasets. As can be observed, less than 5% of the samples are needed for each class to obtain an OA over 90% for the Indian Pines datasets using the proposed MLSR. This is very promising because it is often difficult to collect a large training datasets in practice. For the Pavia University dataset, only 150 training samples are needed to obtain an OA of 95%. In fact, this accuracy is 3% higher than that by JSM and 4.5% higher than that by EMP with SVM. This is due to the fact that the local information included by the proposed MLSR outperforms the others. The same trend can be concluded for the Salinas dataset. In addition, the proposed MLSR produces very high accuracy and shows robustness with an increase of the number of training samples, and it can be observed that MLSR performs very well when training samples are limited.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}