1. Introduction
Energy plays a vital part in modern social and economic development. Along with the rapid development of technology in the last few decades, energy demands continue to increase rapidly [
1]. In accordance with the IEA World Energy Outlook 2010, China and India will be responsible for approximately 50% of the growth in global energy demand by 2050. The consumption of energy in China will be close to 70% greater than the energy consumed by the United States today. Second only to America, China will become the second leading energy-consuming country in the world. Nevertheless, China’s per capita energy consumption will remain lower than 50% of that of the USA [
2]. Since conventional energy sources such as coal, natural gas, and oil for electricity generation are being quickly depleted, sufficient energy reserves and sustainable energy problems are garnering increased attention. Additionally, using traditional resources produces large amounts of carbon dioxide, which may lead to global warming, and is considered an international security threat. Therefore, it not only affects the environment, it also threatens the safety of individuals and the planet [
3].
Consequently, to alleviate the pressure of this energy shortage, renewable energy sources are being explored and the sustainable development of green energy has become a significant measure of global energy development success [
4]. Obviously, it has become necessary to seek and develop new environmentally friendly sources of renewable energy. Wind energy, the most significant new type of green renewable energy [
5], is steady, abundantly available, reliable, inexhaustible, widespread, pollution-free, and economical. It contains enormous power and its usage does not harm the environment by creating greenhouse gas emissions. Furthermore, it has been considered or applied in the production and development for energy in a host of countries. In modern times, wind energy has become the most indispensable and vital renewable energy source globally. The fast growth of the power system enables the absorption of large amounts of wind power. However, in consideration of stochastic factors such as temperature, atmospheric pressure, elevation, and terrain, it is still difficult to make an accurate forecast, which can also give rise to trouble in terms of the energy transmission and the balance of the power grid. Hence, developing an effective approach to overcome these challenges is necessary.
In order to reduce time series prediction errors, thousands of methods have already been studied. First, many effective data denoising tools, including the Wavelet Transform (WT), the Empirical Mode Decomposition (EMD) [
6,
7,
8], the Wavelet Packet Transform (WPT), the Singular Spectrum Analysis (SSA) [
9], and the Fast Ensemble Empirical Mode Decomposition (FEEMD) algorithm [
10], have been applied to process the original data to achieve a relatively higher forecasting accuracy. For instance, SSA, as a novel analytical method, is especially suitable for research into periodic oscillation, which has proven to be an effective tool for time series analysis in diverse applications; the results indicate that it can effectively remove the noise of the wind speed data to improve forecasting performance. Secondly, different prediction approaches are applied to time series forecasting, including SVM, ARMA, ANNS, etc. According to various researchers, these methods can be categorized into four classes [
11]: (i) purely physical arithmetic [
12,
13,
14]; (ii) mathematical and statistical arithmetic [
15,
16,
17,
18,
19,
20,
21]; (iii) spatial correlation arithmetic; and (iv) artificial intelligence arithmetic [
22].
Purely physical arithmetic not only utilizes physical data such as temperature, density, speed, and topography information, but also physical methods, including observation, experiment, analogy, and analysis, to forecast the future wind speed. However, these approaches do not possess unique advantages for short-term prediction. Mathematical and statistical methods, such as the famous stochastic time series models, typically make use of historical data to forecast the wind speed, which can be easy to employ and simple to realize. Therefore, some categories of time series models are often used in wind speed forecasting. Some examples that can be utilized to obtain excellent results include the exponential smoothing model, the autoregressive moving average (ARMA) model [
18], filtering methods, and the autoregressive integrated moving average (ARIMA) model [
23,
24]. Distinct from other methods, spatial correlation arithmetic may achieve better prediction performance. Nevertheless, it is extremely difficult to obtain a perfect application due to the abundant amount of information that must be considered and collected. In recent years, as artificial intelligence technology has developed and become widely used, many researchers have utilized intelligence algorithms in their papers, including artificial neural networks (ANNs) [
25,
26,
27,
28,
29], Support Vector Machine (SVM) [
30,
31], and fuzzy logic (FL) methods [
32,
33], which can be applied to combine new algorithms for enhancing wind speed forecasting ability.
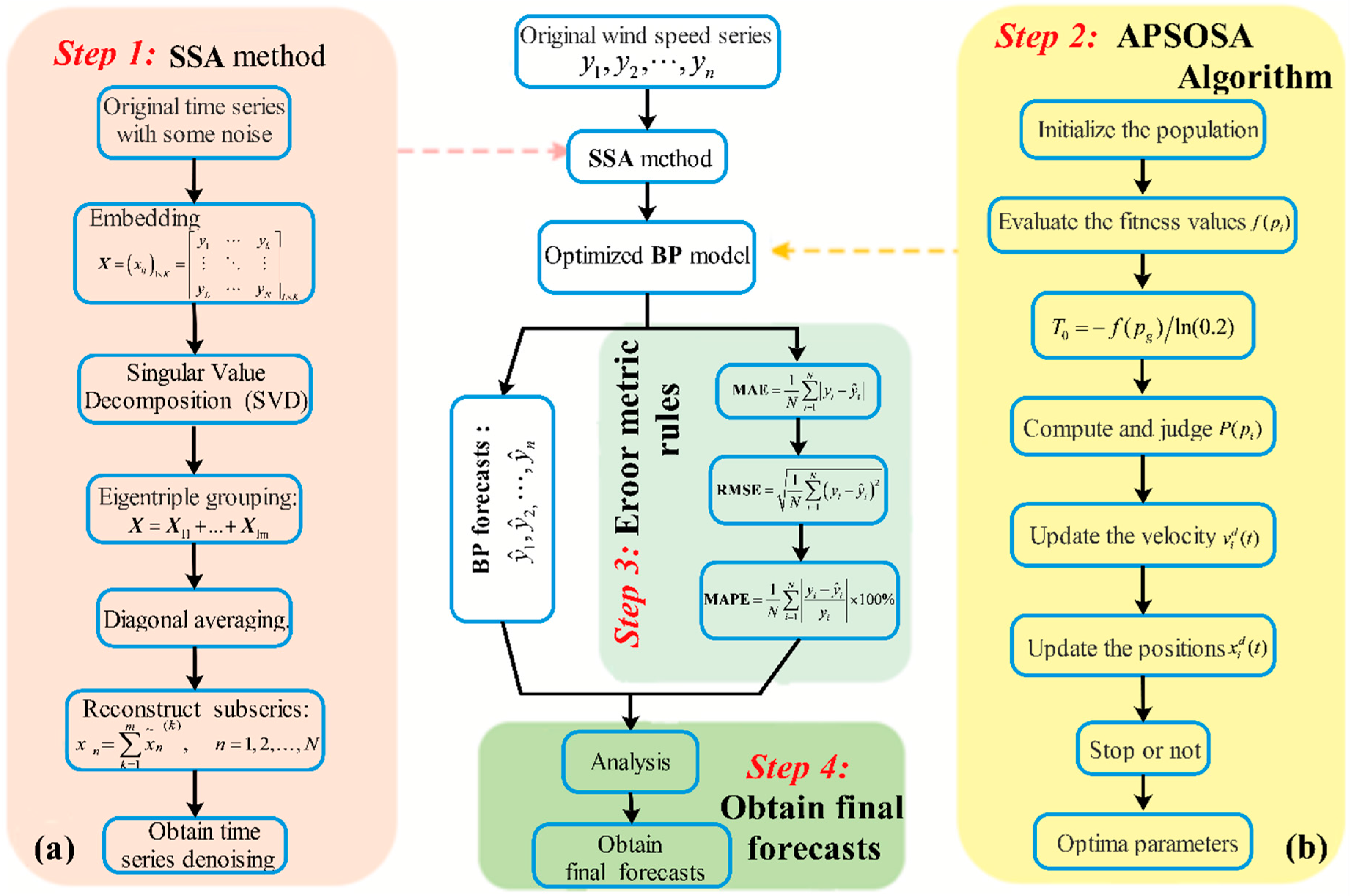
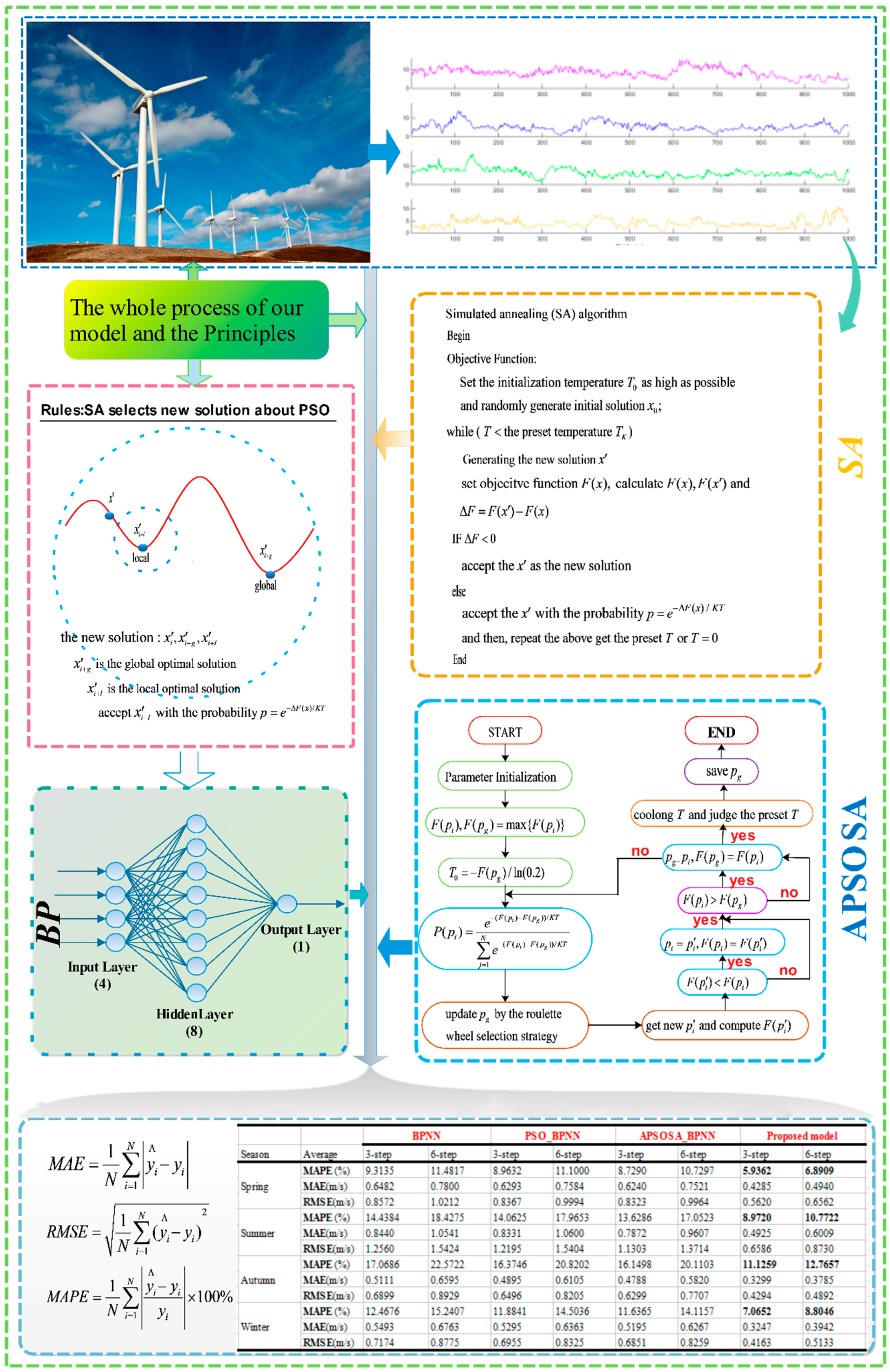
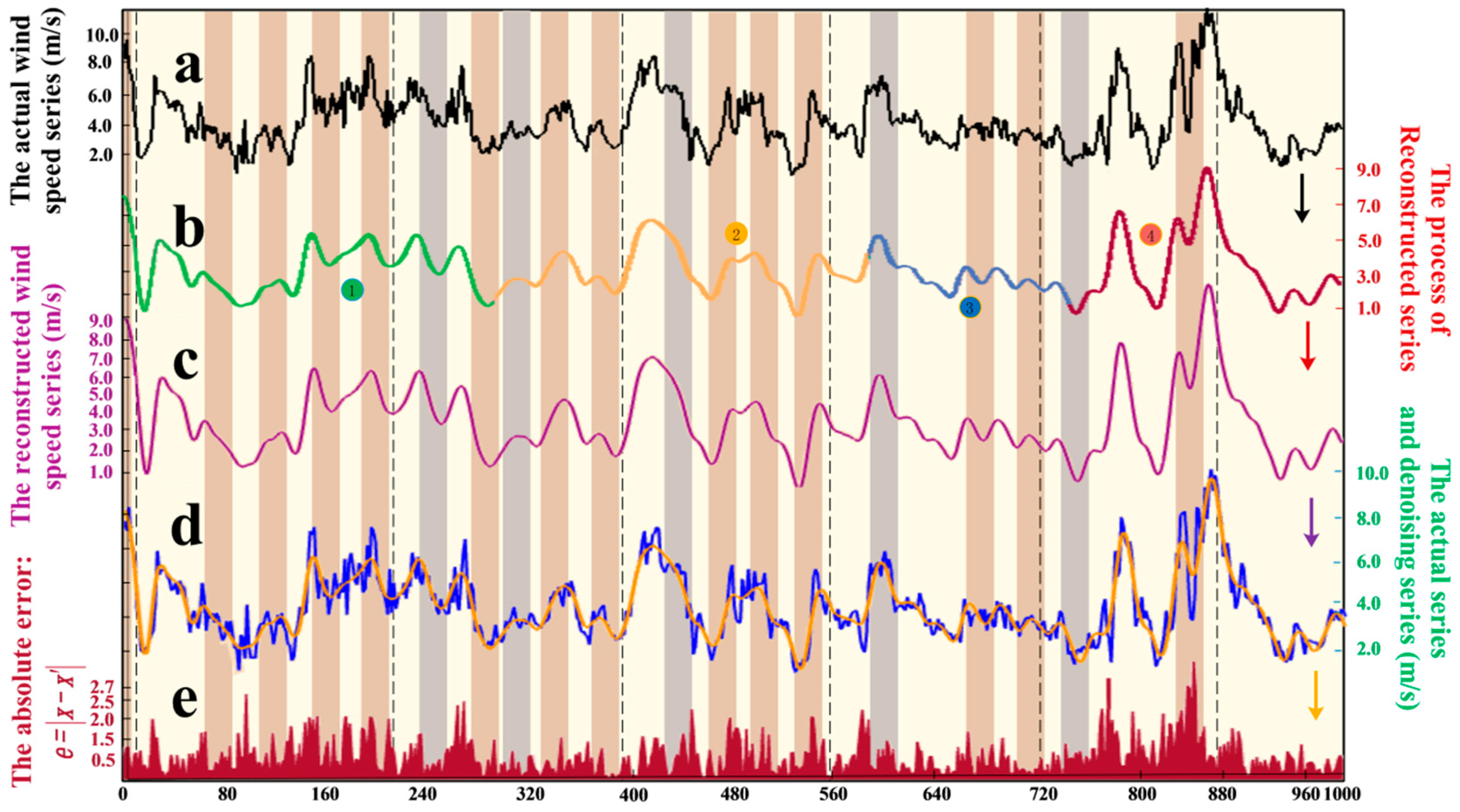
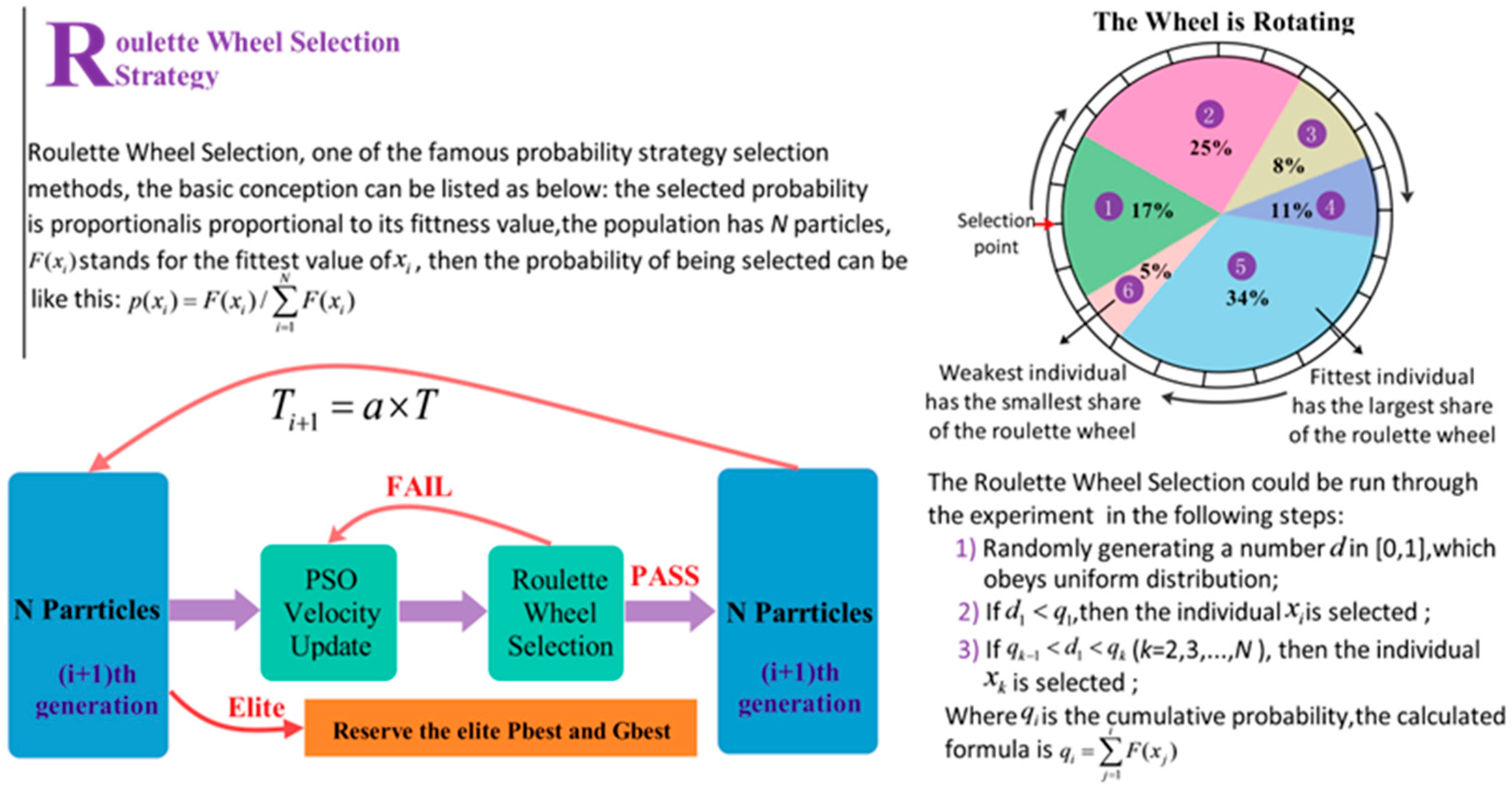
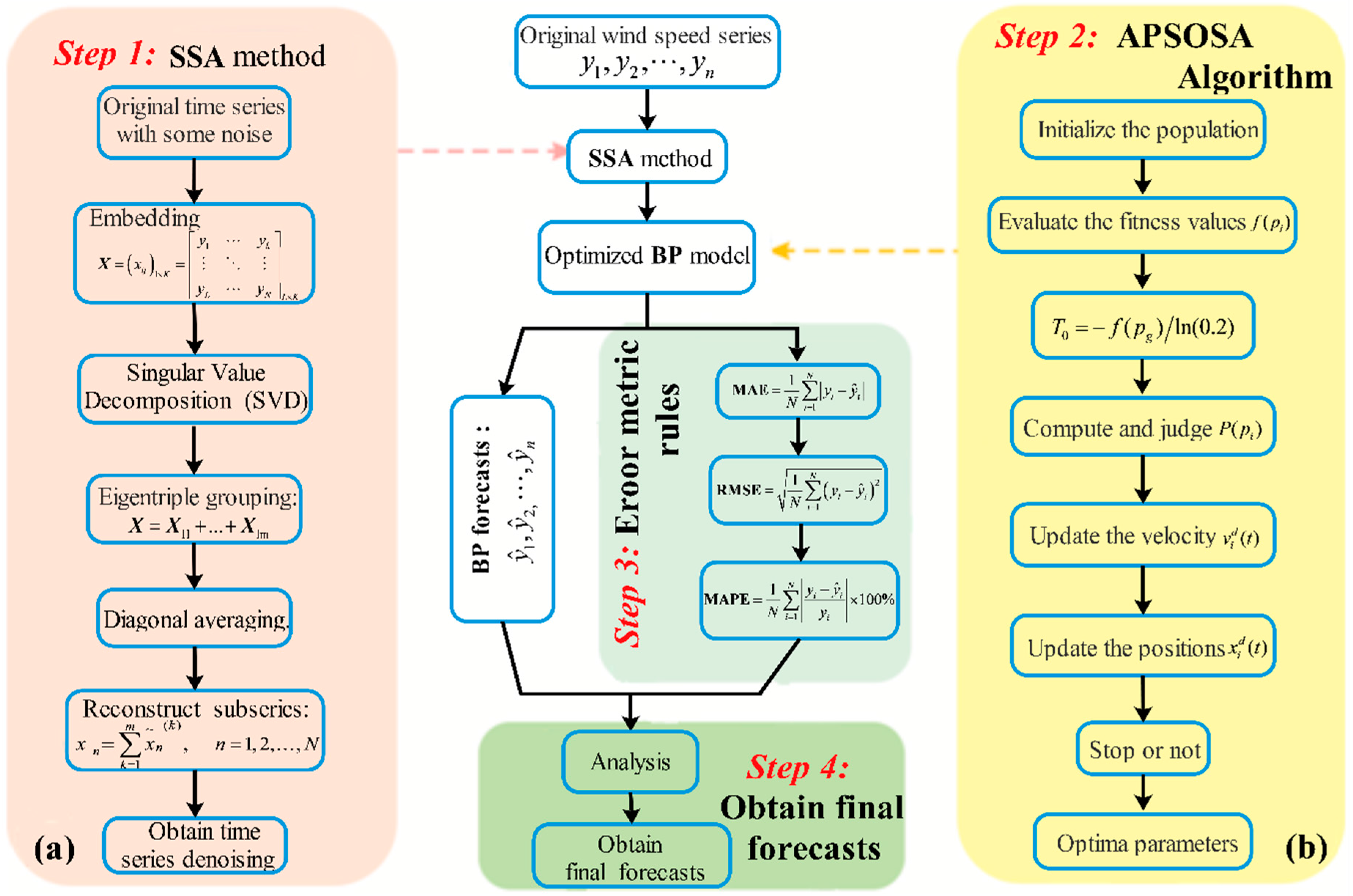
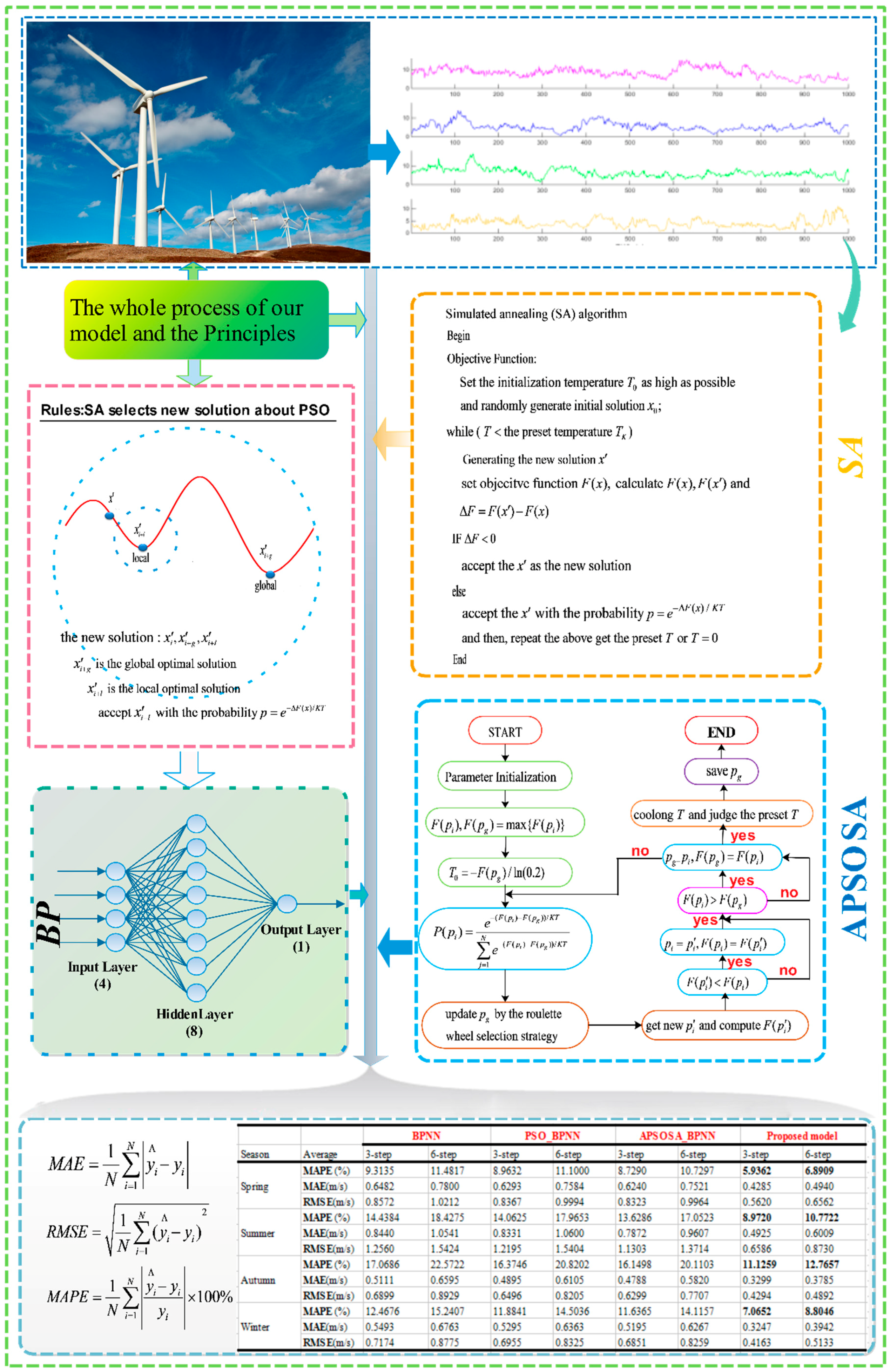
In this research, a hybrid algorithm was proposed with the goal of achieving better forecasting performance. Firstly, in comparison with other methods, including WNN (Wavelet Neural Network) and GRNN (generalized regression neural network), BPNN provides the best prediction performance for both half-hour and one-hour time frames. Therefore, BPNN was selected for use in our models. Next, as a different analytical method, SSA is employed to construct, decompose, and reconstruct the trajectory matrix. SSA can extract different components of the original signal, such as the long-term trend of the signal, a periodic signal, and noise signals, and is capable of removing the noise from the original signal. Next, the optimization algorithm APSOSA, combining APSO [
34,
35,
36,
37,
38] and SA [
39,
40,
41,
42], can enhance the prediction accuracy and convergence of the basic PSO algorithm. Moreover, APSOSA is able to avoid falling into local extreme points so that the parameters of the Back Propagation neural network (BPNN) can be better optimized. Finally, to achieve better forecasting performances, the wind speed data after noise elimination are input into the BPNN. In addition, four commonly used error criteria (AE, MAE, MAPE, and MSE) are applied to assess the performance of the raised hybrid algorithm. The main aspects of the model are introduced as follows: (1) data preprocessing; (2) the best forecasting method, BPNN, is selected and its parameters are tuned by an artificial intelligence (APSOSA) model; (3) forecasting; and (4) comparison and analysis.
The main contributions of this paper are summarized as follows:
- (1)
With the aim of reducing the randomness and instability of wind speed, the Singular Spectrum Analysis technique is applied to decompose the wind series data, revealing real and useful signals from the wind series.
- (2)
The best prediction system, BPNN, is selected from the different methods, including WNN, GRNN, and BPNN.
- (3)
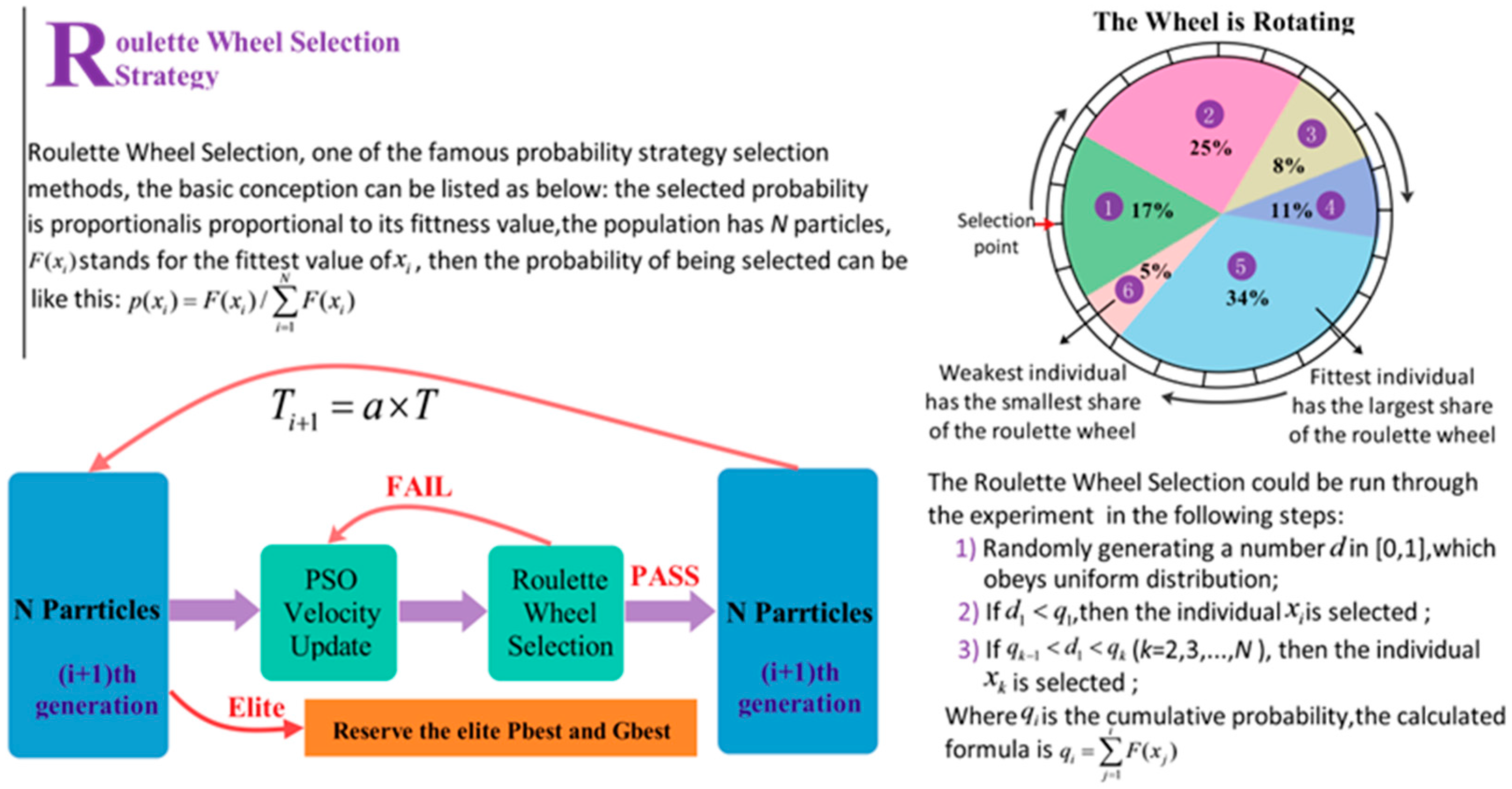
In view of the shortcomings of the PSO algorithm, APSOSA is developed to optimize parameters, which can assist the individual PSO in jumping out of the local optimum. Ultimately, parameters are selected and optimized by combining their respective advantages.
- (4)
To examine the stability and accuracy of the new combined forecasting algorithm, 10-min wind speed series from three different stations are used in the experimental simulations. The experimental results indicate that the novel hybrid algorithm has a higher performance, significantly outperforming the other forecasting algorithms.
- (5)
Giving full consideration to the other influential factors in the experiments, such as the seasonal factors, the geographical factors, etc., according to the results, this action proves that the new combined algorithm has a powerful adaptive capacity, which can be widely applied to the prediction field.
- (6)
The Bias-Variance Framework and statistical hypothesis testing are employed to further illustrate the stability and performance of the proposed algorithm.
The remainder of this paper is designed as follows. The methodology is described specifically in
Section 2. To verify the prediction accuracy of the raised algorithm, a case study is examined in
Section 3. Next, the wind farms area and datasets are introduced in
Section 3.1, whereas
Section 3.2 displays the performance criteria of the forecast results. In
Section 3.3, the results of the different algorithms are listed and compared with the proposed algorithm. In order to further illustrate the stability and performance of the proposed algorithm, in
Section 4, the Bias-Variance Framework and statistical hypothesis testing are employed. Finally, the conclusions are provided in
Section 5.
3. Case Study
To examine the accuracy of the novel combined algorithm, four different multi-step forecasting algorithms are compared by analyzing the three-step-ahead-prediction (half–1-h-ahead) and the six-step-ahead-prediction (1-h-ahead) of a 10-min wind speed series at three different wind power stations.
3.1. Study Area and Datasets
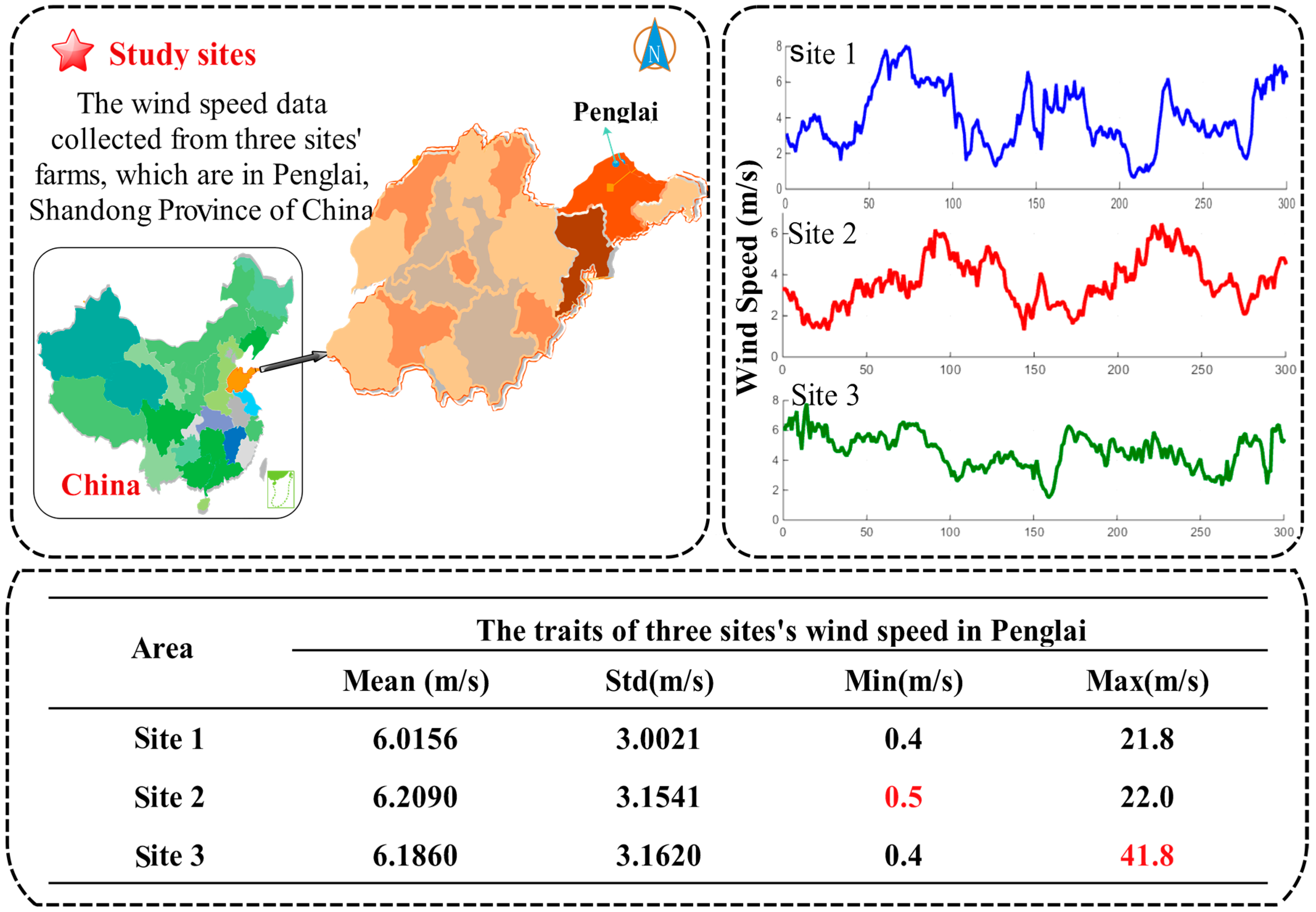
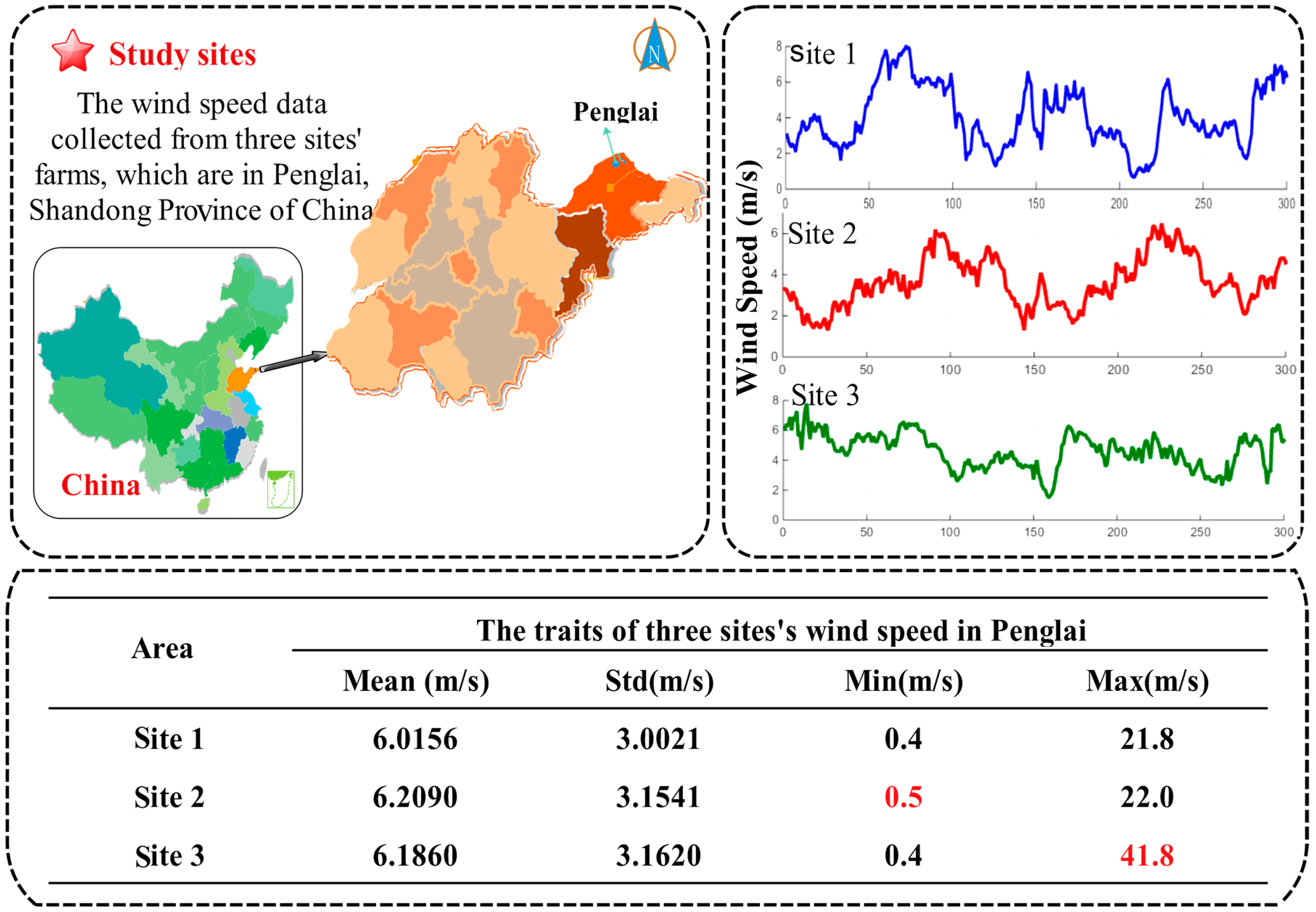
Shandong, located on the east coast of China, is not only one of the provinces with the largest economy, but also one of the biggest energy consumers. However, 99% of the electrical energy comes from coal power generation. As a result, Shandong faces enormous energy pressures.
However, as a coastal province, Shandong possesses one of China’s largest wind farms, with an installed capacity of 58 million kilowatts. A simple map of the research area is depicted in
Figure 4. With the aim of satisfying social development, achieving energy conservation, and protecting the environment, Shandong has begun developing wind power stations. Due to the area’s unique geographical advantages, capacity reached 260 billion KWH in 2007. In addition, the Shandong Province Bureau of Meteorology assessment notes that the entire output of wind energy resources in Shandong province is 67 million kilowatts, which is equivalent to the installed capacity of 3.68 times the capacity of the Three Gorges Hydro-power Station (18.20 million kilowatts), which ranks in the top three. To actively build wind power green energy bases, promote wind energy development, and protect the environment, Shandong has been focusing on building large-scale wind farms in Weihai, Yantai, Dongying, Weifang, Qingdao, and other coastal areas, and is gradually developing offshore wind power projects.
In this work, Penglai, which is located north of Shandong and lies north of the Yellow Sea and the Bohai Sea, was chosen as the area of study. It has tremendous, potentially valuable wind resources. The specific advantages are as follows: (i) higher elevation but relatively flat hilltops, ridges, and a special terrain that has much potential as an air strip; (ii) longer cycle of efficient power generation; (iii) suitable climatic conditions that are conducive to the normal operation of wind turbines; and (iv) small diurnal and seasonal variations of wind speed, which can reduce the impact on power.
In this study, the 10-min wind speed data from Penglai wind farms are used to obtain a detailed example for evaluating the performance of the proposed model. First, the wind speed data are divided into four parts according to the seasons, so that the impact of seasonal variations can be considered to increase the stability of the proposed model. Next, every seasonal wind speed dataset is divided into three parts: a training set, a validation set, and a testing set. Additionally, the noise is removed from the data by using SSA. Finally, the processed data are entered into the model and, judging from the forecasting results, we determine whether the raised algorithm can be widely employed for real-world farm use. In this study, the experiment is applied to three different sites (Site 1, 2, and 3). The above-described experiment is scientific and is used to validate the performance of the proposed model.
3.2. Performance Criteria of Forecast Accuracy
To evaluate the prediction accuracy of the raised hybrid algorithm, four indexes are applied to measure the quality of the forecasting methods: absolute error (AE), mean absolute error (MAE), root mean square error (RMSE), and mean absolute percent error (MAPE), shown in
Table 4 (here
N is the number of test samples, and
and
represent the real and forecast values, respectively). Here, the absolute error (AE) and the mean absolute error (MAE) are both selected so that the level of error can be more clearly reflected. RMSE is chosen because it can easily reflect the degree of changes between the actual and forecasted value. Additionally, MAPE is chosen because of its ability to reveal the credibility of the forecasting model. Wind speed forecasting errors are related to not only the forecasting models but the selected samples. Consequently, the forecasting errors within a certain scientific range can be accepted. Moreover, in order to better evaluate performance, four percentage error criterions are also applied in this study, listed in
Table 5.
3.3. Experimental Simulations
In this subsection, three single models, WNN, GRNN, and BPNN, are compared to obtain the best prediction approach. As a result, whether for half-hour (rolling three-step) or one-hour (rolling six-step) predictions, BPNN gives the best prediction accuracy (see
Table 6 and
Table 7) of the four proposed models. Next, the APSOSA-BPNN is selected from BPNN, PSO-BPNN as the best prediction algorithm. Finally, the hybrid SSA–APSOSA–BP algorithm was proposed as our best prediction model.
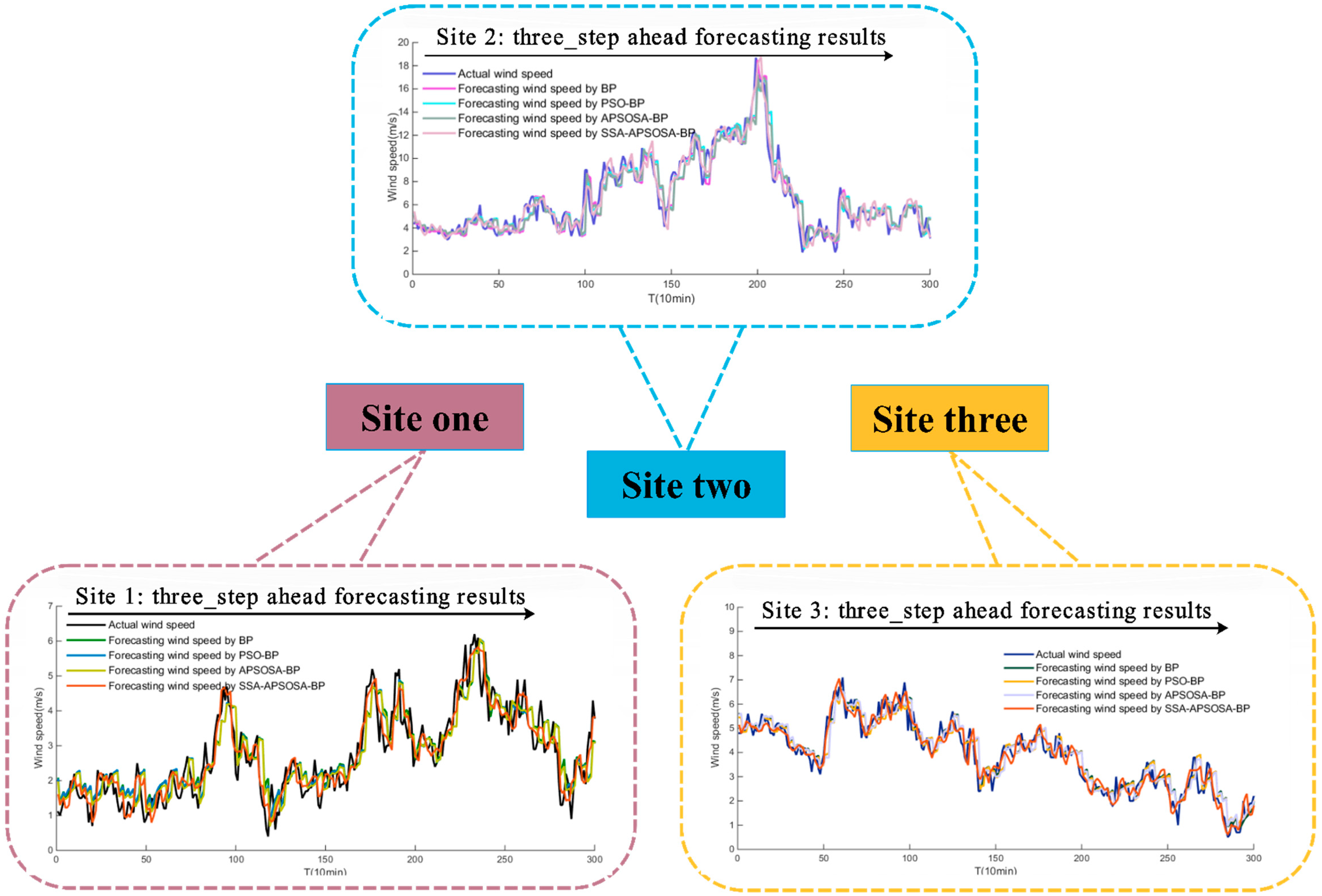
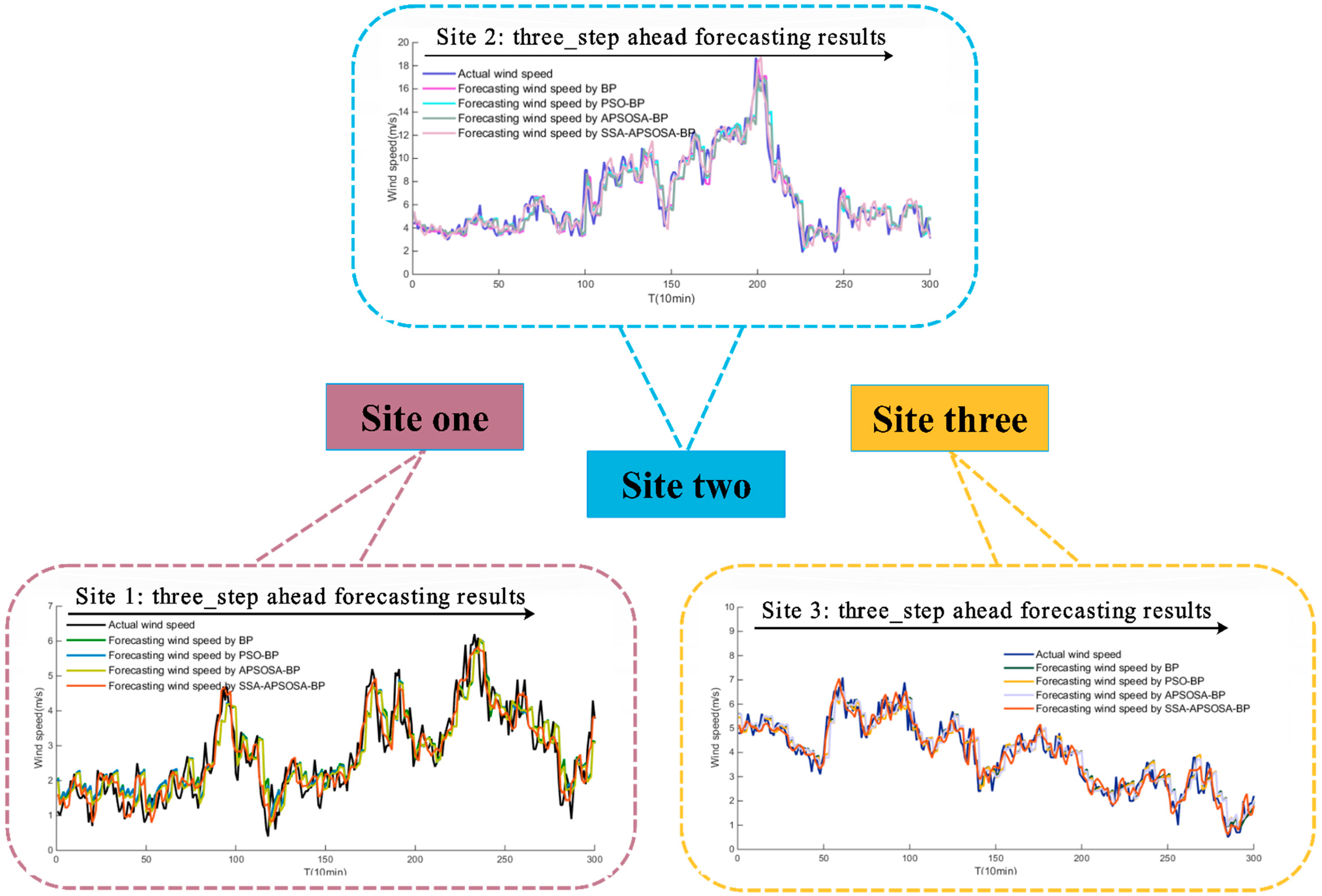
The BPNN, PSO-BPNN, and APSOSA–BPNN hybrid algorithms were selected to compare the forecasting results. Three sites from the Shandong–Penglai wind farms were selected, and then a sample (the 10-min wind speed series) of every season from each site was selected and entered into the above algorithms. Next, the multi-step predicted results were displayed. The specific results of the three sites are shown in
Table 6 and
Table 7, respectively. Additionally, the results from Site 1 are displayed in
Figure 5 and the absolute errors of the three sites are shown in
Table 6 and
Table 7. Using the four percentage error criteria, the improvement percentages between each set of algorithms are shown in
Table 8 and
Table 9.
From
Table 6 and
Table 7, we can see following:
- (a)
Different forecasting algorithms have different forecasting results;
- (b)
All the algorithms’ forecasting results from the three sites are effective. Examples are included in
Figure 5;
- (c)
For different seasons at the same site, the hybrid algorithms show strong forecasting stability;
- (d)
Among the algorithms studied, the hybrid SSA–PSOSA–BP algorithm (see in
Figure 6) obtained better accuracy than the others. Moreover, to further illustrate the quality of the proposed hybrid algorithm, four percentage error criterions are used in
Table 5.
It can be analyzed in detail that:
- (a)
When comparing the hybrid PSO–BP algorithm with the single BP algorithm, we can make a conclusion that the PSO selects excellent parameters to run BP model, but the prediction accuracy of PSO–BP is increased only slightly. From
Table 6 and
Table 7, in the spring, the three-step MAPE results of the PSO–BP and the BP are 7.2490% and 7.4083%, respectively. For the six-step, they are 9.0061% and 9.3530%, respectively.
- (b)
When comparing the hybrid PSOSA–BP algorithm with the combined PSO–BP algorithm, the former combines the advantages of simulated annealing, and further optimizes the parameters; as a result, with respect to (a), the predicted quality rises again, but not particularly clearly. The specific upgrade percentages are provided in
Table 8 and
Table 9.
- (c)
When comparing the hybrid SSA–APSOSA–BP algorithm with the hybrid PSOSA–BP algorithm, the former MAPE results are better than the latter. In other words, the forecasting quality of the new combined algorithm is better because of the higher accuracy when comparing it with the BP, PSO–BP, and PSOSA–BP algorithms.
- (d)
The forecasting quality of the hybrid SSA–APSOSA–BP algorithm is better than that of the hybrid PSO–BP algorithm. The decreases in MAPE results in comparison with the PSO–BP and SSA–APSOSA–BP algorithm of three-step and six-step forecasts are 37.4439% and 36.9998% in
Table 8 and
Table 9 for the spring season, respectively.
- (e)
When comparing the hybrid SSA–APSOSA–BP algorithm with the single BP algorithm, the accuracy of the wind speed forecasting, is improved more obviously. As an example, in
Table 6, the three-step forecasting MAPE results for the latter are 9.4392%, 13.8388%, 13.0224%, and 11.4632%, respectively. However, for the former, the three-step forecasting MAPE results are 6.4101%, 9.0027%, 9.7494%, and 6.7077%, respectively.
- (f)
From (a) to (e), the reasons include:
- (1)
The combination of the SA algorithm and the PSO algorithm has increased the forecasting ability and accuracy of the single BP algorithm effectively.
- (2)
The SSA algorithm removes the noise signal from the original wind speed data and, due to the APSOSA algorithm, the best initial weights and thresholds are given to optimize the BP algorithm, which can lead to high-precision forecasting results.
- (3)
The scientific and rational data selection used in this paper is also one of the paramount reasons for the outstanding performance achieved.
In different seasons at the same site, the proposed algorithms’ forecasting qualities can also be different. This phenomenon indicates that wind speed can be affected by seasonal factors. In this paper, we also consider this factor, and the different seasons’ forecasting results are listed in
Table 6 and
Table 7.
Table 10 and
Table 11 are chosen as examples, and the detailed descriptions of this phenomenon are as follows:
- (a)
Different sites can give different results. In
Table 10, for the hybrid SSA–PSOSA–BP algorithm, the MAPE results of the three-step and six-step are 8.9477% and 10.8290%, respectively, at Site 1. However, for Sites 2 and 3, they are 7.9093% and 7.0741% vs. 7.9675% and 9.5219%, respectively.
- (b)
In
Table 11, for the hybrid SSA–APSOSA–BP algorithm in spring and winter, the MAPE of the three-step and six-step are 5.9362% and 6.8909% vs. 7.0652% and 8.8046%, respectively. However, in summer and autumn, they are 8.9720% and 10.7722% vs. 11.1259% and 12.7657%, respectively. Obviously, in spring and winter, the MAPE results are less than 9%, but in summer and autumn, the wind speed forecasting errors are all more than 10%, especially in autumn when they are close to 12%.
- (c)
As can be clearly observed from the circumstances described above, geographical and seasonal factors must be considered in the wind speed prediction. From (b), it can be concluded that the prediction accuracy in spring and winter is better than that in summer and autumn. However, comparing with the other proposed algorithms, the forecasting errors of the hybrid algorithm are still effectively less.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}