Low Redundancy Feature Selection of Short Term Solar Irradiance Prediction Using Conditional Mutual Information and Gauss Process Regression


Abstract
:1. Introduction
2. Solar Irradiance Forecasting Using CMI and GPR
2.1. Conditional Mutual Information
2.2. Gauss Process Regression
3. Feature Importance and Election Analysis
3.1. The Construction of the Data Set
3.2. Analysis of Original Feature Set
3.3. Feature Importance Analysis
3.4. Data Description and Evaluation Indicators of Feature Selection
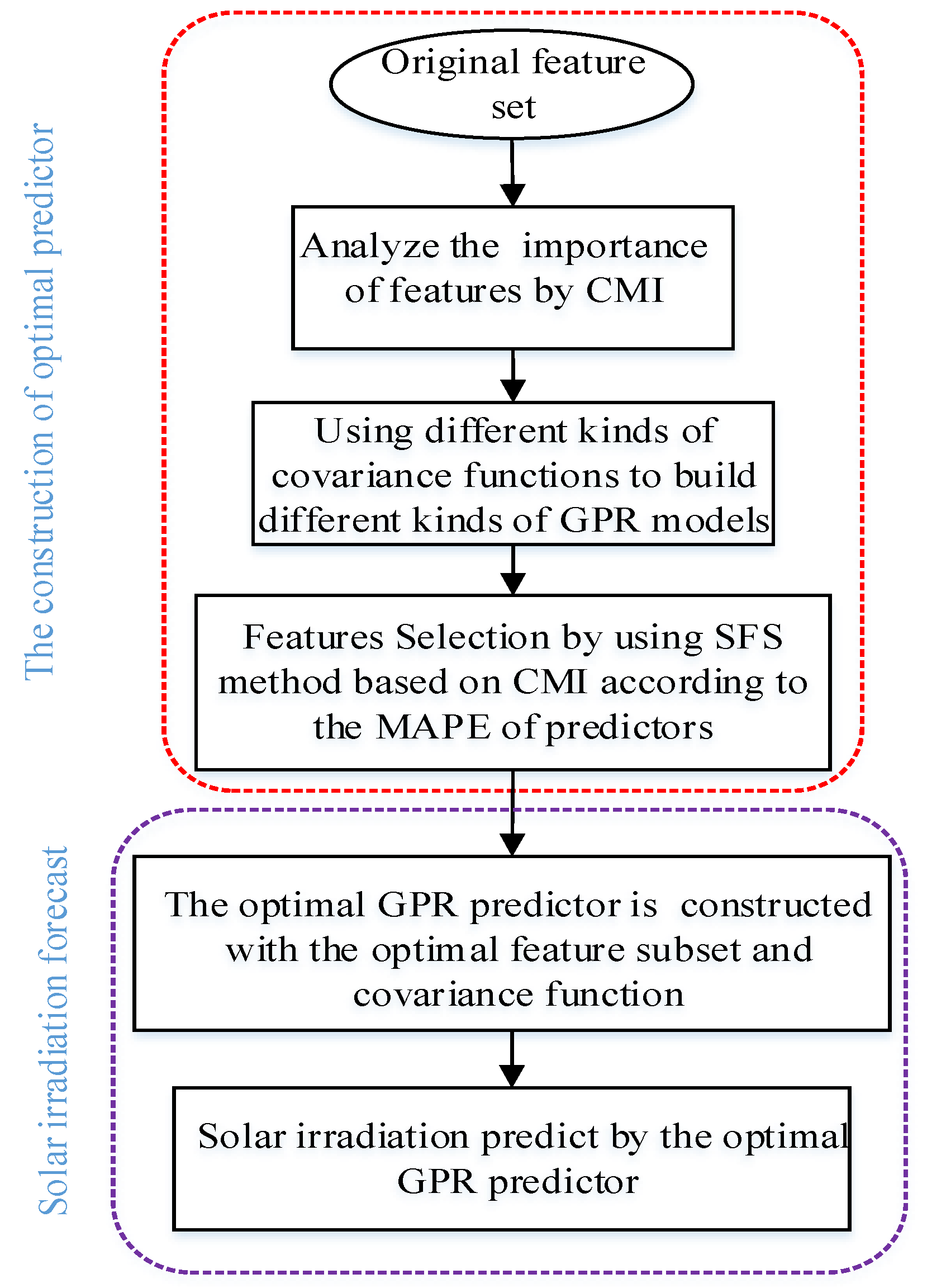
3.5. The Method of Feature Selection Based on CMI and GPR
3.6. Covariance Function Selection and Optimal Predictor Build of GPR
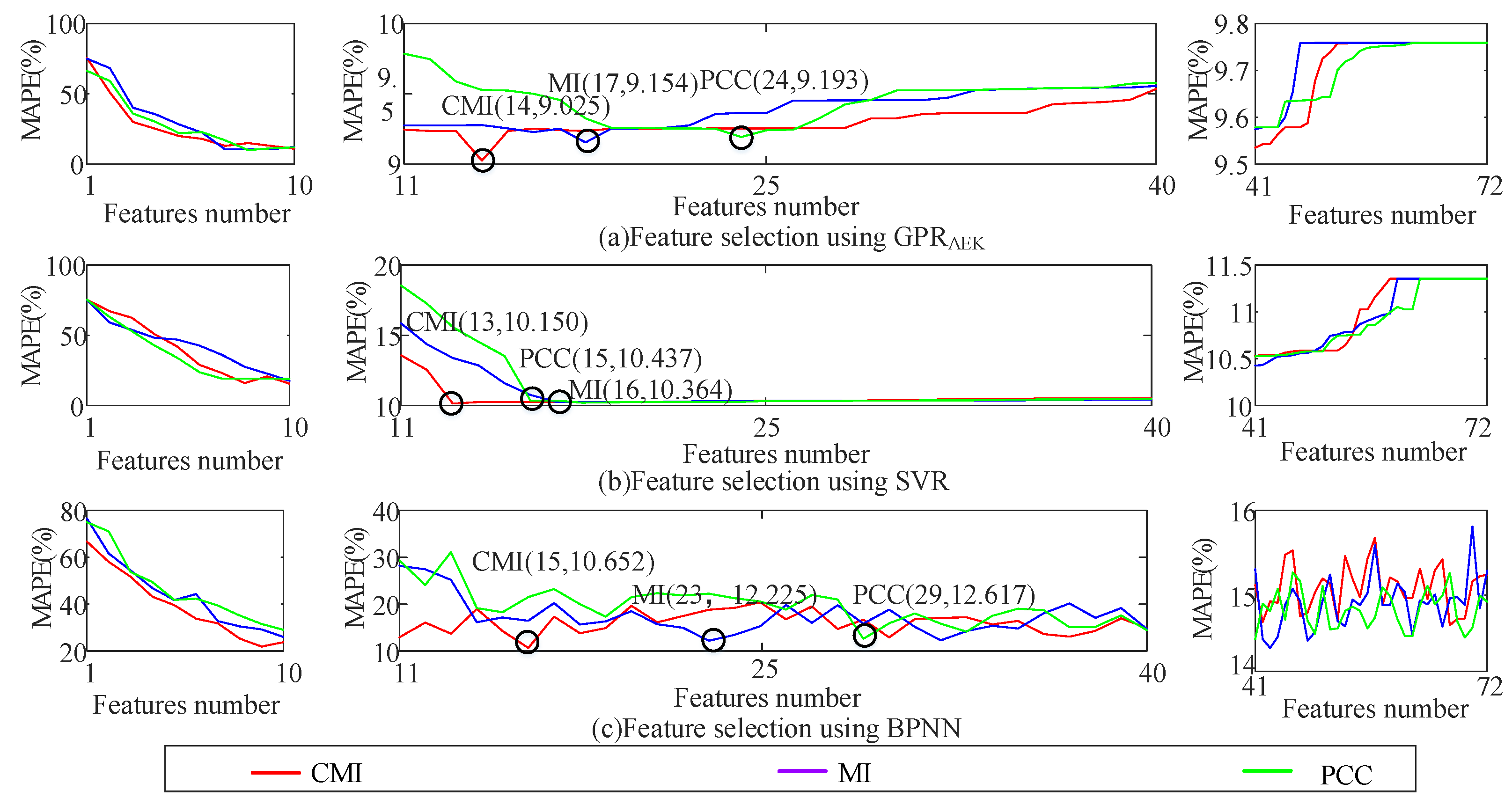
3.7. The Comparison Experiment of Feature Selection
4. Prediction Experiment of Actual Measured Irradiation Data
4.1. Data Description and The Construction of Predictor with Optimal Subset
4.2. Valuation Indicators
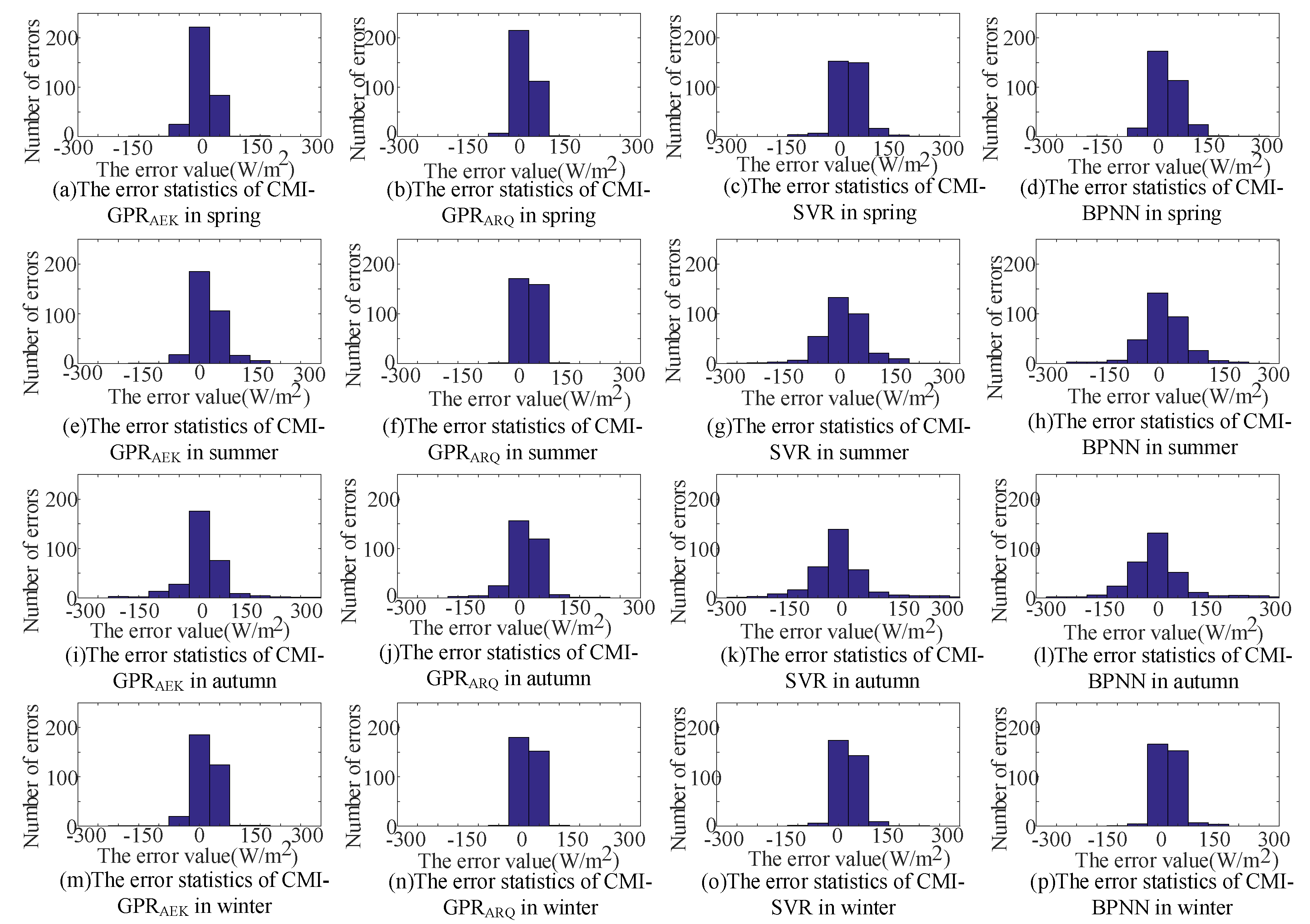
4.3. Prediction Experiment
5. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Arash, A.; Wu, T.X.; Ramos, B. A Hybrid Algorithm for Short-Term Solar Power Prediction—Sunshine State Case Study. IEEE Trans. Sustain. Energy 2017, 8, 582–591. [Google Scholar]
- Emre, A.; Hocaoglu, F.O. A Novel Method Based on Similarity for Hourly Solar Irradiance Forecasting. Renew. Energy 2017, 112, 337–346. [Google Scholar]
- Fidan, M.; Hocaoğlu, F.O.; Gerek, Ö.N. Harmonic analysis based hourly solar radiation forecasting model. IET Renew. Power Gen. 2015, 9, 218–227. [Google Scholar] [CrossRef]
- Jamil, B.; Akhtar, N. Comparative analysis of diffuse solar radiation models based on sky-clearness index and sunshine period for humid-subtropical climatic region of India: A case study. Renew. Sustain. Energy Rev. 2017, 78, 329–355. [Google Scholar] [CrossRef]
- Emanuele, O. Physical and hybrid methods comparison for the day ahead PV output power forecast. Renew. Energy 2017, 113, 11–21. [Google Scholar] [Green Version]
- Ayush, S. Solar Irradiance Forecasting in Remote Microgrids using Markov Switching Model. IEEE Trans. Sustain. Energy 2016, 99, 1. [Google Scholar]
- Inanlouganji, A.; Reddy, T.A.; Katipamula, S. Evaluation of regression and neural network models for solar forecasting over different short-term horizons. Sci. Technol. Built Environ. 2018, 24, 12–22. [Google Scholar] [CrossRef]
- Tingting, Z. Clear-sky model for wavelet forecast of direct normal irradiance. Renew. Energy 2017, 104, 1–8. [Google Scholar]
- Shahaboddin, S. A comparative evaluation for identifying the suitability of extreme learning machine to predict horizontal global solar radiation. Renew. Sustain. Energy Rev. 2015, 52, 1031–1042. [Google Scholar]
- Tao, H. A Practical Method to Hourly Forecast the Solar Irradiance. Presented at 3rd International Conference on Material, Mechanical and Manufacturing Engineering (IC3ME 2015), Guangzhou, China, 27–28 June 2015. [Google Scholar]
- Stéphanie, M. Hourly forecasting of global solar radiation based on multiscale decomposition methods: A hybrid approach. Energy 2017, 119, 288–298. [Google Scholar]
- Inman, R.H.; Pedro, H.T.C.; Coimbra, C.F.M. Solar forecasting methods for renewable energy integration. Prog. Energy Combust. Sci. 2013, 39, 535–576. [Google Scholar] [CrossRef]
- Bigdeli, N.; Borujeni, M.S.; Afshar, K. Time series analysis and short-term forecasting of solar irradiation, a new hybrid approach. Swarm Evol. Comput. 2016. [Google Scholar] [CrossRef]
- Reikard, G.; Haupt, S.E.; Jensen, T. Forecasting ground-level irradiance over short horizons: Time series, meteorological and time-varying models. Renew. Energy 2017. [Google Scholar] [CrossRef]
- Bracale, A.; Carpinelli, G.; De Falco, P. A Probabilistic Competitive Ensemble Method for Short-Term Photovoltaic Power Forecasting. IEEE Trans. Sustain. Energy 2016, 99, 1. [Google Scholar] [CrossRef]
- Fatih Onur, H.; Serttas, F. A novel hybrid (Mycielski-Markov) model for hourly solar radiation forecasting. Renew. Energy 2016, 108, 635–643. [Google Scholar]
- Michael, K.; Kluge, J. A new hybrid support vector machine–wavelet transform approach for estimation of horizontal global solar radiation. Energy Convers. Manag. 2015, 92, 162–171. [Google Scholar]
- Amit Kumar, D. A new hybrid feature selection approach using feature association map for supervised and unsupervised classification. Expert Syst. Appl. 2017, 88, 81–94. [Google Scholar]
- Leily, S.; Alizadeh, S.H. A note on pearson correlation coefficient as a metric of similarity in recommender system. In Proceedings of the AI & Robotics, Qazvin, Iran, 12 April 2015; pp. 1–6. [Google Scholar]
- Jianzhou, W. Forecasting solar radiation using an optimized hybrid model by Cuckoo Search algorithm. Energy 2015, 81, 627–644. [Google Scholar]
- Li, S.; Ping, W.; Goel, L. Wind Power Forecasting Using Neural Network Ensembles With Feature Selection. IEEE Trans. Sustain. Energy 2017, 6, 1447–1456. [Google Scholar] [CrossRef]
- Haomiao, Z. A new sampling method in particle filter based on Pearson correlation coefficient. Neurocomputing 2016, 216, 208–215. [Google Scholar]
- Manzano, A. A single method to estimate the daily global solar radiation from monthly data. Atmos. Res. 2015, 166, 70–82. [Google Scholar] [CrossRef]
- Xinguang, H.; Guan, H.; Qin, J. A hybrid wavelet neural network model with mutual information and particle swarm optimization for forecasting monthly rainfall. J. Hydrol. 2015, 527, 88–100. [Google Scholar]
- Estevez, P.A.; Tesmer, M.; Perez, C.A.; Zurada, J.M. Normalized mutual information feature selection. IEEE Trans. Neural Netw. 2009, 20, 189–201. [Google Scholar] [CrossRef] [PubMed]
- François, F. Fast Binary Feature Selection with Conditional Mutual Information. J. Mach. Learn. Res. 2003, 5, 1531–1555. [Google Scholar]
- Abderrezak, L.; Mordjaoui, M.; Dib, D. One-hour ahead electric load and wind-solar power generation forecasting using artificial neural network. In Proceedings of the Sixth International Renewable Energy Congress, Sousse, Tunisia, 24–26 March 2015; pp. 1–6. [Google Scholar]
- Che, J.; Yang, Y.; Li, L.; Bai, X.; Zhang, S.; Deng, C. Maximum relevance minimum common redundancy feature selection for nonlinear data. Inf. Sci. 2017, 409–410, 68–86. [Google Scholar]
- Chao, H.; Zhang, Z.; Bensoussan, A. Forecasting of daily global solar radiation using wavelet transform-coupled Gaussian process regression: Case study in Spain. In Proceedings of the Innovative Smart Grid Technologies—Asia (ISGT-Asia), Sousse, Tunisia, 28 Novemver–1 December 2016; pp. 799–804. [Google Scholar]
- Zhang, C. A Gaussian process regression based hybrid approach for short-term wind speed prediction. Energy Convers. Manag. 2016, 126, 1084–1092. [Google Scholar] [CrossRef]
- NREL Website. Available online: http://midcdmz.nrel.gov/nelha/ (accessed on 9 August 2018).
- ORNL Website. Available online: http://midcdmz.nrel.gov/ornl_rsr/ (accessed on 9 August 2018).
- NELHA Website. Available online: http://midcdmz.nrel.gov/nelha/ (accessed on 9 August 2018).
- Rasmussen, C.E.; Nickisch, H. Gaussian Processes for Machine Learning (GPML) Toolbox. J. Mach. Learn. Res. 2010, 11, 3011–3015. [Google Scholar]
- Li, D.; Lam, T.; Chu, C. Relationship between the total solar radiation on tilted surfaces and the sunshine hours in Hong Kong. Sol. Energy 2008, 82, 1220–1228. [Google Scholar] [CrossRef]
- Gagn, D.J., II; McGovern, A.; Haupt, S.E.; Williams, J.K. Evaluation of statistical learning configurations for gridded solar irradiance forecasting. Sol. Energy 2017, 150, 383–393. [Google Scholar] [CrossRef]
- Zhao, E.F.; Jin, Y. Dam Deformation Monitoring Model and Forecast Based on Hierarchical Diagonal Neural Network. In Proceedings of the 2008 4th International Conference on Wireless Communications, Networking and Mobile Computing, Dalian, China, 12–14 October 2008; pp. 1–4. [Google Scholar]
- Maniezzo, V. Genetic evolution of the topology and weight distribution of neural networks. Neural Netw. IEEE Trans. 1994, 5, 39–53. [Google Scholar] [CrossRef] [PubMed]
- Cervone, G. Short-term photovoltaic power forecasting using Artificial Neural Networks and an Analog Ensemble. Renew. Energy 2017, 108, 274–286. [Google Scholar] [CrossRef]
- Jiang, H. A short-term and high-resolution distribution system load forecasting approach using support vector regression with hybrid parameters optimization. IEEE Trans. Smart Grid. 2017, 99, 1. [Google Scholar] [CrossRef]
- He, J.; Yao, D. A nonlinear support vector machine model with hard penalty function based on glowworm swarm optimization for forecasting daily global solar radiation. Energy Conv. Manag. 2016, 126, 991–1002. [Google Scholar]
- Belaid, S.; Mellit, A. Prediction of daily and mean monthly global solar radiation using support vector machine in an arid climate. Energy Conv. Manag. 2016, 118, 105–118. [Google Scholar] [CrossRef]
- He, J.; Yao, D. Forecast of hourly global horizontal irradiance based on structured Kernel Support Vector Machine: A case study of Tibet area in China. Energy Conv. Manag. 2017, 142, 307–321. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data | Method | Importance Ranking of Features (Top 12) |
|---|---|---|
| SRRL | PCC | St-1,St-2,St-3,St-4,St-5,St-6,St-7,St-8,St-9,Tt-1,Ht-1,Tt-2 |
| MI | St-1,St-2,St-3,hour,St-4,St-5,St-6,St-7,St-8,St-9,St-10,Tt-1 | |
| CMI | St-1,Tt-1,Tt-9,Wst-1,St-6,St-10,Tt-4,St-8,St-5,St-4,St-3,hour | |
| ORNL | PCC | St-1,St-2,St-3,St-4,St-5,St-6,Tt-1,Tt-5,Tt-9,Tt-4,St-7,Wdt-3 |
| MI | St-1,St-2,St-3,hour,St-4,St-5,St-6,St-7,St-8,St-9,St-10,Tt-1 | |
| CMI | St-1,hour,St-10,St-9,St-8,St-7,Tt-6,St-4,St-3,St-5,St-2,Wst-1 | |
| LELH | PCC | St-1,St-2,St-3,St-4,St-5,St-6,St-7,Ht-1,Ht-2,St-8,Ht-3,Ht-4 |
| MI | St-1,hour,St-2,St-8,St-3,Tt-1,Ht-2,St-5,St-4,St-3,St-2,St-7 | |
| CMI | St-1,St-2,St-3,St-4,Tt-5,Ht-1,St-6,St-8,hour,Ht-4,St-7,Pt-1 |
| GPR Covariance Function | Mathematical Expression | Function Number |
|---|---|---|
| Squared Exponential Kernel | ① | |
| Exponential Kernel | ② | |
| Matern 3/2 | ③ | |
| Matern 5/2 | ④ | |
| Rational Quadratic Kernel | ⑤ | |
| ARD Squared Exponential Kernel | ⑥ | |
| ARD Exponential Kernel | ⑦ | |
| ARD Matern 3/2 | ⑧ | |
| ARD Matern 5/2 | ⑨ | |
| ARD Rational Quadratic Kernel | ⑩ |
| Location | Covariance Function | Predictor | |||||
|---|---|---|---|---|---|---|---|
| PCC-GPR | MI-GPR | CMI-GPR | |||||
| MAPE min | Feature Dimension | MAPE min | Feature Dimension | MAPE min | Feature Dimension | ||
| SRRL | Squared Exponential | 10.546 | 23 | 10.056 | 35 | 9.246 | 12 |
| Exponential | 10.727 | 13 | 10.984 | 34 | 9.027 | 20 | |
| Matern3/2 | 10.687 | 29 | 10.546 | 36 | 9.951 | 18 | |
| Matern5/2 | 10.469 | 28 | 10.479 | 42 | 9.096 | 19 | |
| Rational Quadratic | 10.165 | 29 | 10.099 | 40 | 9.294 | 21 | |
| ARD Squared Exponential | 10.046 | 34 | 10.058 | 35 | 10.278 | 17 | |
| ARD Exponential Kernel | 9.825 | 15 | 9.860 | 36 | 8.707 | 14 | |
| ARD Matern 3/2 | 10.752 | 13 | 9.944 | 34 | 10.517 | 19 | |
| ARD Matern 5/2 | 10.241 | 13 | 10.078 | 32 | 8.730 | 11 | |
| ARD Rational Quadratic | 9.932 | 33 | 9.957 | 30 | 9.396 | 12 | |
| ORNL | Squared Exponential | 13.518 | 40 | 9.541 | 36 | 7.872 | 18 |
| Exponential | 11.480 | 41 | 9.058 | 34 | 7.279 | 23 | |
| Matern3/2 | 11.871 | 41 | 9.481 | 33 | 7.130 | 20 | |
| Matern5/2 | 11.999 | 41 | 9.498 | 35 | 7.562 | 20 | |
| Rational Quadratic | 11.253 | 41 | 8.456 | 37 | 6.862 | 13 | |
| ARD Squared Exponential | 11.130 | 34 | 8.284 | 34 | 7.025 | 16 | |
| ARD Exponential Kernel | 10.078 | 33 | 7.732 | 32 | 6.668 | 16 | |
| ARD Matern 3/2 | 10.840 | 36 | 8.978 | 32 | 6.699 | 20 | |
| ARD Matern 5/2 | 11.314 | 46 | 9.489 | 30 | 6.839 | 24 | |
| ARD Rational Quadratic | 10.276 | 33 | 8.048 | 34 | 7.2726 | 26 | |
| LELH | Squared Exponential | 15.581 | 40 | 12.792 | 37 | 12.180 | 13 |
| Exponential | 13.869 | 51 | 12.479 | 40 | 12.548 | 13 | |
| Matern3/2 | 14.173 | 51 | 12.588 | 29 | 13.090 | 17 | |
| Matern5/2 | 14.372 | 51 | 11.789 | 30 | 12.554 | 23 | |
| Rational Quadratic | 12.663 | 51 | 11.588 | 33 | 12.215 | 17 | |
| ARD Squared Exponential | 12.507 | 50 | 11.546 | 32 | 11.743 | 17 | |
| ARD Exponential Kernel | 12.386 | 52 | 10.843 | 33 | 11.806 | 16 | |
| ARD Matern 3/2 | 12.941 | 50 | 11.548 | 34 | 12.011 | 13 | |
| ARD Matern 5/2 | 12.840 | 46 | 10.954 | 35 | 12.303 | 20 | |
| ARD Rational Quadratic | 12.709 | 42 | 10.901 | 32 | 10.115 | 16 | |
| Data | Predictor | MAPE | Dimension |
|---|---|---|---|
| ORNL | CMI-GPRAKE | 6.668 | 16 |
| MI-GPRAEK | 7.732 | 20 | |
| PCC-GPRAEK | 10.078 | 25 | |
| CMI-SVR | 8.735 | 14 | |
| MI-SVR | 9.738 | 21 | |
| PCC-SVR | 9.962 | 25 | |
| CMI-BPNN | 8.565 | 16 | |
| MI-BPNN | 7.428 | 23 | |
| PCC-BPNN | 9.655 | 26 | |
| LELH | CMI-GPRARQ | 10.176 | 13 |
| MI-GPRAEK | 10.843 | 23 | |
| PCC-GPRAEK | 12.386 | 25 | |
| CMI-SVR | 17.410 | 14 | |
| MI-SVR | 17.956 | 20 | |
| PCC-SVR | 18.732 | 28 | |
| CMI-BPNN | 13.412 | 24 | |
| MI-BPNN | 13.655 | 28 | |
| PCC-BPNN | 14.237 | 31 |
| Season | Error | Predictor | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CMI-GPRAEK | CMI-GPRARQ | CMI-SVR | CMI-BPNN | MI- GPRAEK | PCC- GPRAEK | MI- GPRARQ | PCC- GPRARQ | GPRAEK | GPRARQ | SVR | BPNN | ||
| Spring | MAPE | 5.365 | 5.887 | 4.776 | 7.235 | 6.008 | 6.245 | 5.994 | 7.310 | 6.987 | 7.412 | 10.545 | 12.461 |
| RMSE | 36.925 | 78.450 | 61.080 | 58.243 | 62.842 | 57.472 | 64.752 | 69.221 | 57.158 | 76.637 | 89.445 | 96.575 | |
| MAE | 18.387 | 55.834 | 43.595 | 35.807 | 46.724 | 39.258 | 52.100 | 62.438 | 40.264 | 51.942 | 70.452 | 75.683 | |
| rRMSE | 6.032 | 9.688 | 10.432 | 9.524 | 9.685 | 13.759 | 12.563 | 13.117 | 7.002 | 23.451 | 18.028 | 20.076 | |
| rMAE | 3.004 | 6.357 | 6. 568 | 5.850 | 6.421 | 5.973 | 7.697 | 8.082 | 9.916 | 6.237 | 16.47 | 17.648 | |
| Summer | MAPE | 8.978 | 10.537 | 22.123 | 16.800 | 12.824 | 14.742 | 14.496 | 14.059 | 15.056 | 15.266 | 18.481 | 22.630 |
| RMSE | 40.497 | 55.041 | 90.407 | 118.294 | 45.630 | 63.179 | 59.730 | 67.872 | 68.415 | 72.702 | 96.014 | 124.720 | |
| MAE | 23.901 | 31.393 | 77.140 | 75.693 | 29.087 | 52.476 | 40.381 | 57.274 | 60.174 | 69.974 | 78.099 | 84.269 | |
| rRMSE | 8.766 | 13.185 | 18.293 | 28.332 | 7.925 | 10.510 | 16.217 | 11.033 | 12.548 | 12.630 | 29.239 | 34.305 | |
| rMAE | 4.529 | 9.519 | 18.476 | 16.129 | 5.693 | 10.286 | 10.458 | 12.131 | 13.735 | 14.804 | 17.642 | 22.244 | |
| Autumn | MAPE | 12.184 | 19.142 | 25.747 | 29.458 | 20.369 | 23.075 | 24.259 | 25.116 | 30.409 | 33.547 | 30.257 | 32.275 |
| RMSE | 62.950 | 73.656 | 98.408 | 101.067 | 89.716 | 90.070 | 88.646 | 92.437 | 89.617 | 77.908 | 96.154 | 135.002 | |
| MAE | 26.252 | 39.790 | 75.497 | 86.193 | 50.435 | 73.492 | 48.482 | 75.668 | 53.225 | 51.715 | 61.390 | 79.841 | |
| rRMSE | 11.307 | 18.512 | 24.785 | 34.456 | 14.510 | 18.439 | 16.803 | 19.042 | 18.319 | 17.865 | 20.544 | 35.562 | |
| rMAE | 7.838 | 9.999 | 18.999 | 23.671 | 12.168 | 17.067 | 11.374 | 18.659 | 12.693 | 12.374 | 13.732 | 18.275 | |
| Winter | MAPE | 12.472 | 16.628 | 16.942 | 16.992 | 15.561 | 17.041 | 18.418 | 18.475 | 17.862 | 18.300 | 19.931 | 22.070 |
| RMSE | 43.921 | 64.568 | 81.133 | 116.209 | 72.364 | 75.290 | 78.821 | 80.056 | 77.827 | 81.273 | 64.754 | 98.680 | |
| MAE | 25.784 | 40.487 | 62.840 | 78.233 | 42.640 | 64.741 | 62.456 | 68.671 | 59.470 | 61.151 | 64.754 | 72.680 | |
| rRMSE | 7.384 | 10.853 | 15.542 | 19.524 | 17.993 | 18.813 | 19.003 | 15.300 | 13.010 | 14.726 | 15.533 | 17.206 | |
| rMAE | 4.325 | 6.804 | 9.249 | 13.820 | 7.062 | 14.029 | 13.998 | 13.766 | 11.973 | 12.266 | 12.739 | 14.507 | |
| All Year | MAPE | 9.750 | 13.049 | 17.397 | 17.621 | 13.691 | 15.776 | 15.792 | 16.990 | 17.579 | 18.631 | 22.304 | 18.859 |
| RMSE | 46.073 | 67.929 | 82.757 | 98.453 | 67.649 | 71.503 | 72.987 | 77.397 | 73.254 | 77.130 | 86.592 | 113.744 | |
| MAE | 23.581 | 41.877 | 64.768 | 68.982 | 42.222 | 57.492 | 50.855 | 66.0128 | 53.283 | 58.700 | 68.674 | 78.118 | |
| rRMSE | 8.372 | 13.060 | 17.263 | 22.959 | 12.778 | 15.380 | 16.147 | 14.623 | 12.720 | 17.168 | 20.836 | 26.787 | |
| rMAE | 4.924 | 8.170 | 13.323 | 14.868 | 7.836 | 11.839 | 10.882 | 13.160 | 12.079 | 11.420 | 15.146 | 18.169 | |
| Season | Error | Predictor | |||||||
|---|---|---|---|---|---|---|---|---|---|
| CMI-GPRAEK | MI-GPRAEK | PCC-GPRAEK | GPRAEK | ||||||
| ORNL | LELH | ORNL | LELH | ORNL | LELH | ORNL | LELH | ||
| Spring | MAPE | 12.472 | 7.204 | 14.151 | 8.410 | 16.277 | 8.203 | 16.832 | 9.242 |
| RMSE | 43.925 | 24.491 | 54.581 | 37.423 | 49.488 | 42.996 | 51.755 | 48.666 | |
| MAE | 25.786 | 20.036 | 34.574 | 33.824 | 26.154 | 30.674 | 30.287 | 29.825 | |
| rRMSE | 7.387 | 5.968 | 11.586 | 6.652 | 11.262 | 6.746 | 12.131 | 7.023 | |
| rMAE | 4.321 | 4.122 | 9.478 | 8.776 | 6.469 | 6.409 | 7.247 | 6.371 | |
| Summer | MAPE | 12.183 | 9.595 | 15.616 | 10.867 | 16.458 | 10.020 | 16.026 | 10.547 |
| RMSE | 62.954 | 23.357 | 71.623 | 25.023 | 72.090 | 25.176 | 70.249 | 26.739 | |
| MAE | 26.256 | 9.209 | 34.472 | 18.135 | 36.534 | 16.694 | 37.012 | 18.274 | |
| rRMSE | 11.305 | 3.280 | 13.767 | 5.516 | 17.902 | 5.552 | 16.866 | 5.951 | |
| rMAE | 7.839 | 2.251 | 6.798 | 5.627 | 9.514 | 7.475 | 9.335 | 7.923 | |
| Autumn | MAPE | 5.367 | 9.192 | 6.319 | 10.809 | 7.282 | 9.762 | 7.873 | 10.686 |
| RMSE | 36.924 | 34.457 | 47.640 | 45.290 | 49.051 | 37.621 | 55.525 | 42.684 | |
| MAE | 18.383 | 19.085 | 29.716 | 26.008 | 32.112 | 26.725 | 35.647 | 30.007 | |
| rRMSE | 6.031 | 5.457 | 7.014 | 6.473 | 6.384 | 6.636 | 6.561 | 7.012 | |
| rMAE | 3.004 | 3.162 | 6.312 | 4.204 | 7.275 | 6.279 | 7.144 | 7.034 | |
| Winter | MAPE | 8.974 | 6.622 | 11.845 | 8.971 | 10.497 | 9.322 | 11.709 | 9.297 |
| RMSE | 40.497 | 21.305 | 54.428 | 26.435 | 49.569 | 30.111 | 56.688 | 29.725 | |
| MAE | 23.900 | 8.487 | 32.379 | 15.094 | 29.630 | 17.263 | 31.120 | 17.242 | |
| rRMSE | 8.762 | 4.878 | 10.002 | 5.002 | 9.833 | 6.265 | 11.196 | 6.241 | |
| rMAE | 4.523 | 3.654 | 6.725 | 4.204 | 5.742 | 7.537 | 6.915 | 7.638 | |
| All Year | MAPE | 9.749 | 8.153 | 11.983 | 9.764 | 12.629 | 9.327 | 13.110 | 9.943 |
| RMSE | 46.075 | 25.903 | 57.068 | 33.543 | 55.050 | 33.976 | 58.554 | 36.954 | |
| MAE | 23.581 | 14.204 | 32.785 | 23.265 | 31.108 | 22.839 | 33.517 | 23.837 | |
| rRMSE | 8.371 | 4.896 | 10.592 | 5.911 | 11.345 | 6.300 | 11.689 | 6.557 | |
| rMAE | 4.922 | 3.297 | 7.328 | 5.703 | 7.250 | 6.925 | 7.660 | 7.242 | |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, N.; Li, R.; Lin, L.; Yu, Z.; Cai, G. Low Redundancy Feature Selection of Short Term Solar Irradiance Prediction Using Conditional Mutual Information and Gauss Process Regression. Sustainability 2018, 10, 2889. https://doi.org/10.3390/su10082889
Huang N, Li R, Lin L, Yu Z, Cai G. Low Redundancy Feature Selection of Short Term Solar Irradiance Prediction Using Conditional Mutual Information and Gauss Process Regression. Sustainability. 2018; 10(8):2889. https://doi.org/10.3390/su10082889
Chicago/Turabian StyleHuang, Nantian, Ruiqing Li, Lin Lin, Zhiyong Yu, and Guowei Cai. 2018. "Low Redundancy Feature Selection of Short Term Solar Irradiance Prediction Using Conditional Mutual Information and Gauss Process Regression" Sustainability 10, no. 8: 2889. https://doi.org/10.3390/su10082889