1. Introduction
Consumer returns [
1] are a common phenomenon in today’s business, and they become much more frequent as the rapid growth of e-commerce and the intense competition in the retailing industry. According to the National Retail Federation, the amounts of merchandise returned were
$260.5 and
$28.3 billion dollars in the U.S. and Canadian in 2015, respectively [
2]. The average return rate for online products has reached 22% and it is still increasing [
3], and at least 30% of all the products ordered online are returned as compared to 8.89% of that sold in traditional offline stores [
4]. Particularly, for fashion products such as fashion apparel, it can be as high as 75% [
5].
Consequently, considerable attention is paid to customer returns to improve the sustainability and efficiency of traditional supply chains. Closed-loop supply chains (CLSCs) [
6] are an emerging concept that considers returned products in a logistics system. In a CLSC, there are reverse flows of used products (postconsumer use) back to manufacturers as well as the forward flow which is unidirectional from suppliers to manufacturers to distributors to retailers, and to consumers [
7]. To further improve the sustainability of CLSCs, returned products can be disposed by considering their life cycles and the related services. In practice, secondary markets are important for retailers to sell off excess inventory and used items, and returned products can be reconditioned or refurbished [
8] and then sold to secondary markets [
9]. For example, automotive companies tend to provide whole life cycle service to the cars sold to their customers, and hence they can make profits from the service in early days and then from the sales of the used cars in the secondary market. In the consumer electronics industry, it is also a common practice to determine whether a product should be disposed or resold according to its life cycle. Usually, an end-of-life product will be disassembled into components or parts, but a new or fairly new product will be resold in the secondary market for more profits. Currently, many retailers have entered secondary markets to extend their business. For example, JD.com, which is one of the two largest B2C online retailers in China by transaction volume and revenue, launched a new program called “Paipai second-hand” to sell used products in secondary markets, and its main competitor, Alibaba Group, also invested in MEI.COM that sells discounted luxury products in those markets. Although secondary markets are very important and have a close relationship with CLSCs in practice, they are rarely considered in the CLSC literature. Therefore, it will be greatly beneficial to study CLSCs by incorporating secondary markets to represent the real-world business of significant interest and value.
This paper studies a joint location-inventory problem in a closed-loop supply chain by considering the secondary market. In such a system, a retailer will make three types of business decisions: (i) Choosing locations for its hybrid distribution-collection centers (HDCCs); (ii) Assigning HDCCs to customer zones in the forward and reverse flows; and (iii) Planning inventory replenishment for the primary and secondary markets. We develop a mix-integer nonlinear programming model to optimize the facility location, facility-customer assignment, and inventory replenishment decisions simultaneously, and we also design a novel self-adaptive differential evolution algorithm to solve this model efficiently. From a practical perspective, the research questions and gaps that motivate this study are summarized as follows:
How can the logistics flows and interaction between the primary and secondary markets be formulated?
What are the optimal facility location, facility-customer assignment, and inventory replenishment decisions in a CLSC when the primary and secondary markets are both considered?
Which parameters are significant to the cost functions and business decisions in such a system?
The rest of this paper is organized as follows:
Section 2 reviews the literature related to location-inventory problems, closed-loop supply chains, and secondary markets.
Section 3 describes the research problem under study and formulates it as a mixed-integer nonlinear programming model.
Section 4 proposes an improved self-adaptive differential evolution algorithm to solve the model efficiently.
Section 5 presents the numerical study and computational results.
Section 6 concludes this paper and provides directions for future research.
2. Literature Review
Sustainable supply chain design plays an important role in many industries, and it is greatly beneficial to pollution reduction and environmental protection. Currently, customer returns [
10] are a common phenomenon in the real-world business, and they become much more frequent as the rapid growth of e-commerce. To enhance the disposal of returned products and improve the sustainability of today’s supply chains, this paper studies a location-inventory problem (LIP) in a closed-loop supply chain (CLSC) by incorporating the secondary market. Therefore, our study is related to three research streams, which are closed-loop supply chain, secondary market, and location inventory problem.
The closed-loop supply chain is an important topic of significant impact in practice because of the rising awareness of environmental issues. In the literature, CLSCs are extensively studied by incorporating many real-world businesses such as manufacturing and remanufacturing [
11,
12], dual recycling channels [
13], environmental regulations [
14], material management [
15], and disruption risks [
16]. They are also investigated from the perspective of supply chain coordination [
17,
18], and Govindan et al. [
19] presents a comprehensive and thorough review on the related works. Since a main motivation to study CLSCs come from governmental legislation that forced producers to take care of their end-of-life (EOL) products, most research efforts on CLSCs are focused on the disposal of EOL products [
20,
21] without considering the life cycles of the products and services. However, nowadays, many returned products are in new or fairly new conditions, and they represent a large body of the reverse logistics in reality. Therefore, there will be a big gap if it is assumed that the reverse logistics in a CLSC only consists of EOL products that need to be recycled and disposed, and it is greatly beneficial to consider the whole life cycle and study how to handle the returned products in new or good conditions effectively to improve the performance and sustainability of modern supply chains.
Secondary markets have become an important marketplace for business organizations to sell off excess inventory or used products, and it is a common practice to resell returned products of good quality at a discounted price in a secondary market. Because of their great importance in practice, secondary markets have attracted much research attention in the literature [
22]. For example, Angelus [
23] investigates how to dispose excess inventory of new products in secondary markets, and more recent works are extended to refurbished products by considering refurbishing authorization strategy [
9], product upgrade decisions [
24], and consumer return policies [
25]. To study the impact of secondary markets on supply chains, Lee and Whang [
26] find that the secondary market creates two interdependent effects, i.e., a quantity effect regarding the sales by a manufacturer and an allocation effect that is related to supply chain performance. He and Zhang [
27] also show that the secondary market will have a positive impact on supply chain performance in general. In practice, an important consideration for the sales of used products in a secondary market is their sources, and it is not unusual to see that those products come from the returned or recycled items in a CLSC. However, the interaction between CLSCs and secondary markets is rarely studied in the literature. To fill this gap, we consider such interaction dynamically in this study, and hence it can well represent the reality.
Nowadays, many business decisions are made jointly instead of separately to improve supply chain performance, and it is a common practice to integrate facility location [
28], inventory management, and vehicle routing problems and solve them together. Correspondingly, the first two problems can be integrated into location-inventory problems (LIPs) [
29], and all of them can be combined as location-inventory-routing problems [
30]. In the literature, LIPs were first proposed by Daskin et al. [
31] and Shen et al. [
32], and they have been studied extensively in several directions thereafter. For example, location-inventory models are extended to consider difference inventory control strategies [
33], uncertain or correlated demands [
34,
35], lateral transshipment [
36], product attributes (e.g., perishable products, seasonal products, substitutable products, etc.) [
37,
38], and third-party logistics [
39]. As the emergence of CLSCs, LIPs are also studied by considering reverse logistics. For example, Li et al. [
40] study a LIP in a CLSC with third-party logistics and proposed a novel heuristic approach based on differential evolution and genetic algorithm to solve the problem. Diabat et al. [
8] investigate a LIP in an uncapacitated CLSC where returns are remanufactured as spare parts. Asl-Najafi et al. [
41] develop a dynamic closed-loop location-inventory model under facility disruption risks. Zhang and Unnikrishnan [
42] propose a capacitated location-inventory model with bidirectional flows. Kaya and Urek [
43] develop a mixed-integer nonlinear facility location inventory pricing model to maximize the total profit of a CLSC.
Although LIPs are studied extensively with the presence of CLSCs, such efforts are usually focused on the primary market and hence the secondary market is ignored. Since secondary markets are growing rapidly and become very important in reality, it will be of great interest to connect the primary and secondary markets by CLSCs and study the work and logistics flows within such a system. In this paper, we make a remarkable contribution to the literature by introducing the secondary market into the study of LIPs and CLSCs. More specifically, we optimize facility location and inventory management decisions jointly in a closed-loop supply chain network by considering both primary and secondary markets, and the logistics flows between the two markets are modelled precisely in this closed-loop system. This work extends the study of CLSCs by covering the whole life cycle of a product, and it also makes a significant contribution to the literature by consolidating the three research streams above.
4. Solution Approach
The location problem is NP-hard in general [
47], and the joint location-inventory problems are usually more complex to solve. Therefore, evolutionary algorithms (EAs) are extensively used to solve LIPs in the literature [
39,
40]. Differential evolution (DE) [
48] shares similar characteristics with other population-based EAs, and it has been widely applied to solve global optimization problems [
49] such as LIPs because of its simplicity and effectiveness [
40]. Although DE has a strong global search ability, its performance is not always guaranteed because of its prematurity and weak local search ability. To obtain a more robust and effective approach, an improved self-adaptive differential evolution (ISaDE) algorithm is designed to overcome those shortcomings. The parameters and operators in the ISaDE algorithm are introduced in
Table 1.
Generally, DE contains four operations: initialization, mutation, crossover, and selection. After initialization, DE enters a loop of mutation, crossover and selection operations to update the population. The main operations in ISaDE are described in details as follows.
4.1. Initialization
4.1.1. Individuals
In a DE scheme, individuals in a population represent the candidate solutions to an optimization problem, and they will evolve to better solutions iteratively. Therefore, the form of individuals plays an important role in the development of a DE algorithm, and an encoding-decoding scheme is needed to translate individuals in a population to the solutions to the MINLP model, and vice versa. In ISaDE, an individual is represented by a vector with 2
N elements, where the first
N elements are related to the forward logistics flow, and the last
N elements are related to the reverse flow. Mathematically, an individual is represented by Equation (13):
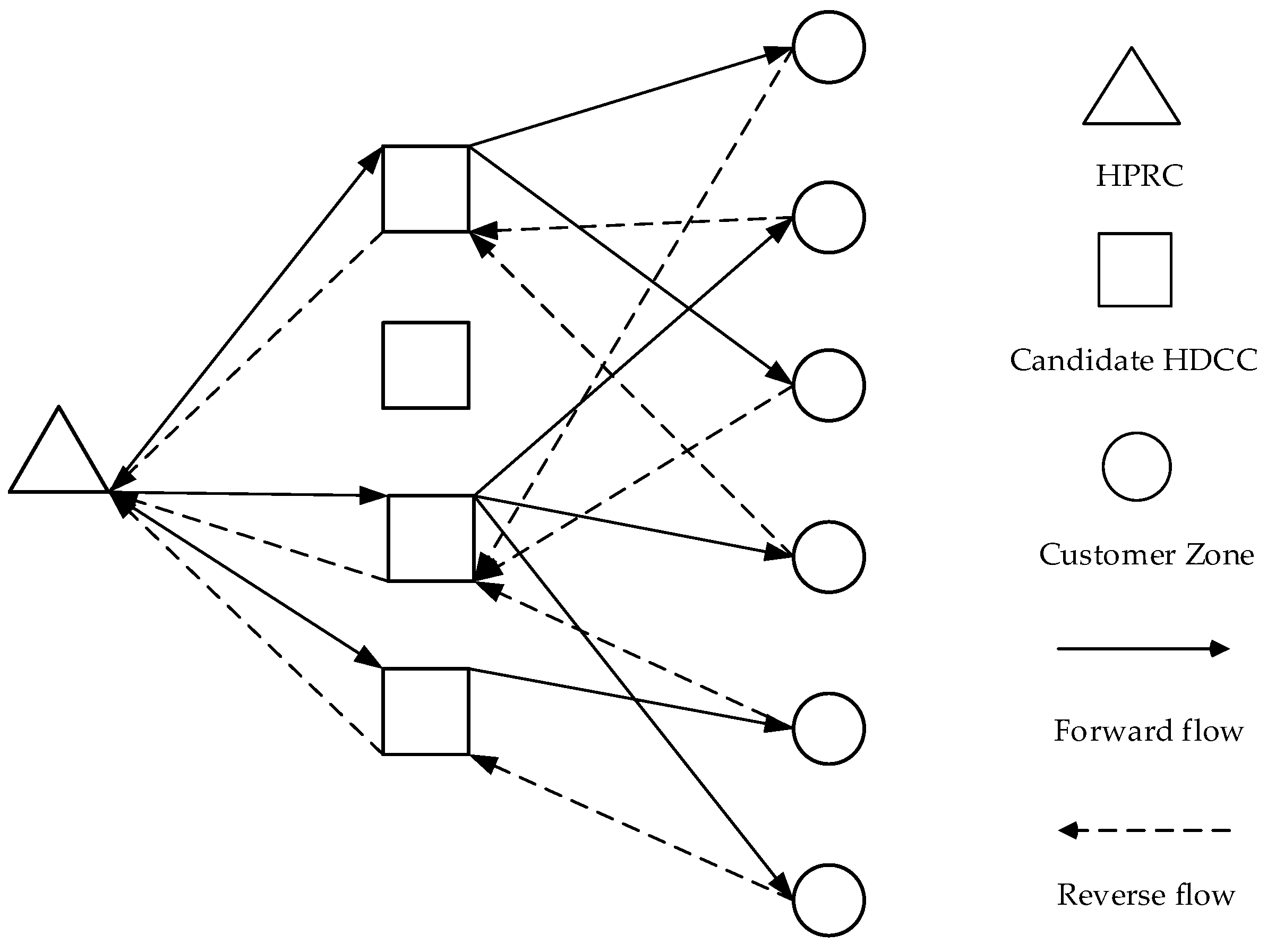
For example, HDCCs will be established at four candidate locations to serve ten customer zones, and hence an individual can be encoded as {1, 4, 4, 1, 1, 2, 4, 2, 2, 4, 2, 2, 1, 2, 1, 4, 2, 1, 1, 1}. In this example, the first ten entries in this vector means that in the forward logistics flow, the HDCC at location 1 (or HDCC 1) will server customer zones {1, 4, 5}, HDCC 2 will serve customer zones {6, 8, 9}, and the HDCC 4 serves customer zones {2, 3, 7,10}. The last ten entries in this vector means that, in the reverse logistics, HDCC 1 will collect returns from customer zones {3, 5, 8, 9, 10}, HDCC 2 will collect returns from customer zones {1, 2, 4, 7}, and HDCC 4 will collect returns from customer zones {6}. Therefore, decision variables in the MINLP model, i.e., Xi, Yij and Zji, can be represented by individuals in ISaDE.
4.1.2. Population Initialization
Given
i (1 ≤
i ≤
P), the initial population can be generated by Equation (14):
where
round is the rounding function,
r(
j) ∈ [0,1] is the
jth realization of a uniform random variable.
is a vector whose entries are the unique values of
in ascending order,
xL and
xU are the lower and upper bound of
respectively.
Practically, xL and xU mean the minimum and maximum numbers of HDCCs to be established. Obviously, xL is equal to 1, and xU is the number of candidate HDCC locations. The encoding scheme of the last N entries ensures that an HDCC cannot become a collection center in the reverse logistics unless it functions as a distribution center in the forward logistics.
4.2. Mutation
In DE algorithms, the mutation operation plays a vital role because of its importance to the search capability and convergence rate. The basic mutation scheme (DE/rand/1) produces a new vector by adding a weighted difference of two randomly selected vectors to a random vector in generation
g. In this study, DE/rand/1 is adopted as the basic mutation strategy, and it can be expressed by Equation (15):
where
i ≠
r1 ≠
r2 ≠
r3,
r1,
r2,
r3 are randomly selected from {1, 2, …,
P},
round is the rounding function, and
F ∈ [0,1] is the mutation factor that controls the amplification of differential variation.
To avoid prematurity and accelerate convergence, we design a new adaptive mechanism to choose
F randomly at each iteration, and it is introduced by Equation (16) in the mutation operation:
where
rand1 and
rand2 are two random variables that are uniformly distributed on [0,1],
τ1 is a constant value that represents the probability of updating parameters,
Fmin and
Fmax is the minimum and maximum
F, respectively. Note that, in our experiments, we set
Fmin = 0.1,
Fmax = 0.9 and
τ1 = 0.9.
4.3. Crossover
In ISaDE, the crossover operation is used to generate new individuals and increase the diversity of a population. After the mutation operation, a trial vector
will be generated from a mutate vector
and target vector
by applying the crossover operator. To increase the population diversity and strengthen the searching abilities, we introduce a novel crossover operator in ISaDE. The trial vector
is generated by Equation (17):
where
k ∈ [1, 2,…,
P] is a random integer,
r(
j) ∈ [0,1] is a random number that is generated from the uniform distribution, and
CR ∈ [0,1] is the crossover factor that controls the amplification of differential variation.
To further increase the diversity of a population and improve the robustness of the algorithm, an adaptive mechanism is also introduced in the crossover operator. More specifically, the crossover factor
CR is adaptively changed according to Equation (18):
where
rand3 and
rand4 are two random variables that are uniformly distributed on [0,1], and
τ2 is a constant that represents the probability of updating parameters. Note that we have
τ2 = 0.9 in this study.
4.4. Feasibility Correction
The crossover and mutation operations may create new individuals that are equivalent to infeasible solutions to the MINLP model by violating Constraint (9). To avoid this issue, a screening mechanism is needed to remove infeasible solutions that are generated by ISaDE. In this study, the feasibility correction procedure is designed as follows: A new individual will be checked after it is generated. If it equals to a solution that indicates an HDCC will be established only for collecting returns in the reverse flow, it will be substituted by a new individual that is randomly generated by Equation (12).
4.5. Selection
After a new population is generated from its predecessor by mutation, crossover, and feasibility correction, a selection operation will be performed by evaluating the objective values of all trial vectors because the new population needs to be better than its predecessor. In ISaDE, the objective value of an trial vector
will be compared to the corresponding target vector
by using a greedy criterion [
48], and the selection operation can be expressed by Equation (19):
where
is the objective function shown in Equation (1).
4.6. Stopping Criteria
The operations above will be repeated iteratively until a termination criterion is satisfied. The execution of ISaDE will be terminated if any of the two criteria below is satisfied:
Stop if no better solution is obtained in consecutive K iterations (where K is a pre-defined counter value);
Stop if the maximum number of iterations, which is denoted by G, is reached.
4.7. Algorithm Flow
The steps in ISaDE are summarized as follows:
Step 1: Initialization. Create P individuals randomly;
Step 2: Set iteration index G to 1;
Step 3: Set initial target index K to 1;
Step 4: Calculate objective values of individuals in the population. Note that the objective is given by Equation (1);
Step 5: Mutation operation: update mutation factor F using Equation (14) and generate mutation vector by Equation (13);
Step 6: Crossover operation: update crossover factor CR using Equation (16) and generate trail vector by Equation (15);
Step 7: Feasibility correction: identify and remove the individuals that are equivalent to infeasible solutions;
Step 8: Selection operation: generate a new population by Equation (17) and calculate objective values;
Step 9: Stop the algorithm if any stopping criterion is satisfied. Otherwise, go to Step 4.
5. Numerical Experiment
This section presents computational results to study related parameters and validate ISaDE. First, control parameters F and CR are analyzed because they are important for ISaDE. Next, sensitivity analysis is conducted to measure the impact of cost parameters. Last, ISaDE is compared with Lingo 11 to validate its effectiveness and efficiency.
In this study, the locations of candidate HDCCs and customer zones are randomly generated on a grid with the size of (0,100) × (0,100), and the parameters in the MINLP model are shown in
Table 2. All experiments were implemented by using Java JDK 1.7 on a Windows PC (AMD A10-9600P RADEON R5, 10 COMPUTE CORES 4C+6G 2.40GHz; RAM: 4.00 GB DDR; OS: Windows 10).
5.1. Parameter Analysis
In ISaDE, mutation factor
F and crossover probability C
R are two important parameters that have a significant impact on solution accuracy and time efficiency. To evaluate their effects, we use an example network that consists of 10 candidate HDCC locations and 100 customer zones, and execute the algorithm 30 times under each combination of parameters by setting
P = 5
N. The numerical results are shown in
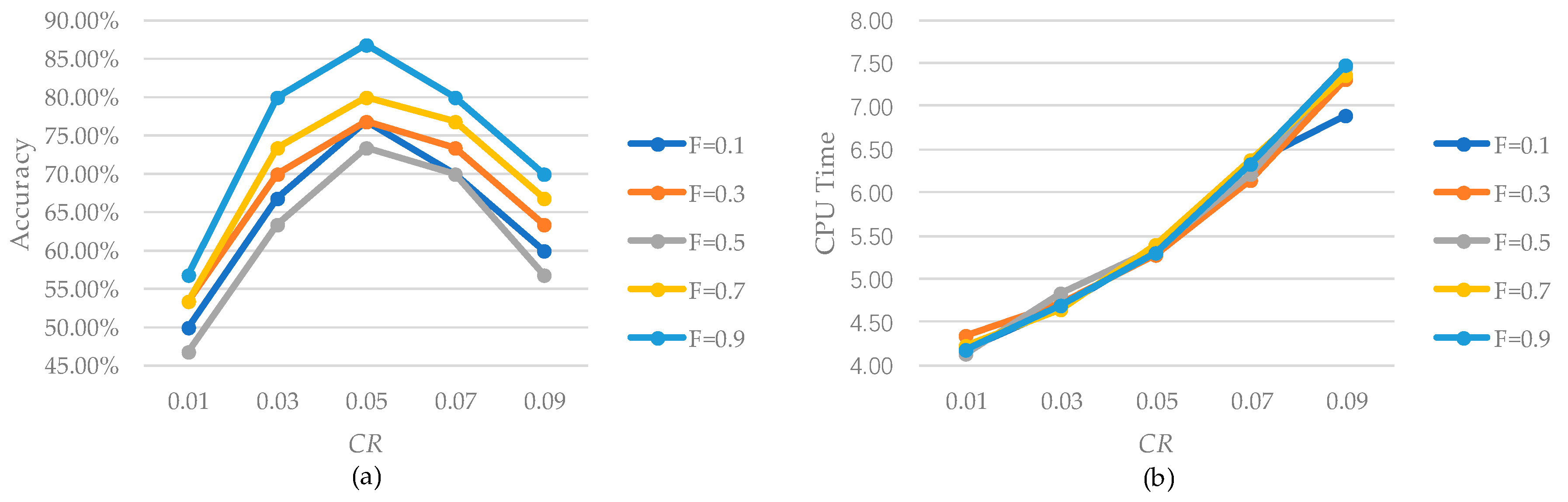
Figure 3.
In
Figure 3, the performance of ISaDE is evaluated by (a) solution accuracy in terms of the probability of finding the optimal solution, and (b) time efficiency in terms of CPU Time. From
Figure 3, we can see that the performance of ISaDE can be affected by
F and
CR individually or jointly.
Figure 3a shows that (i) as
CR increases, solution accuracy will first increase and then decrease, and the best solution accuracy is achieved when
CR = 0.05, and (ii) as
F increases, solution accuracy will always increase, and the best solution accuracy is achieved when
F = 0.9.
Figure 3b shows that time efficiency will always increase as
CR increases, but is almost identical under the different values of
F. Overall, ISaDE has the best performance when
F = 0.9 and
CR = 0.05, and hence this setting will be used in the subsequent analysis.
Besides parameters
F and
CR, population size
P is another important parameter that can affect the robustness and effectiveness of ISaDE. Therefore,
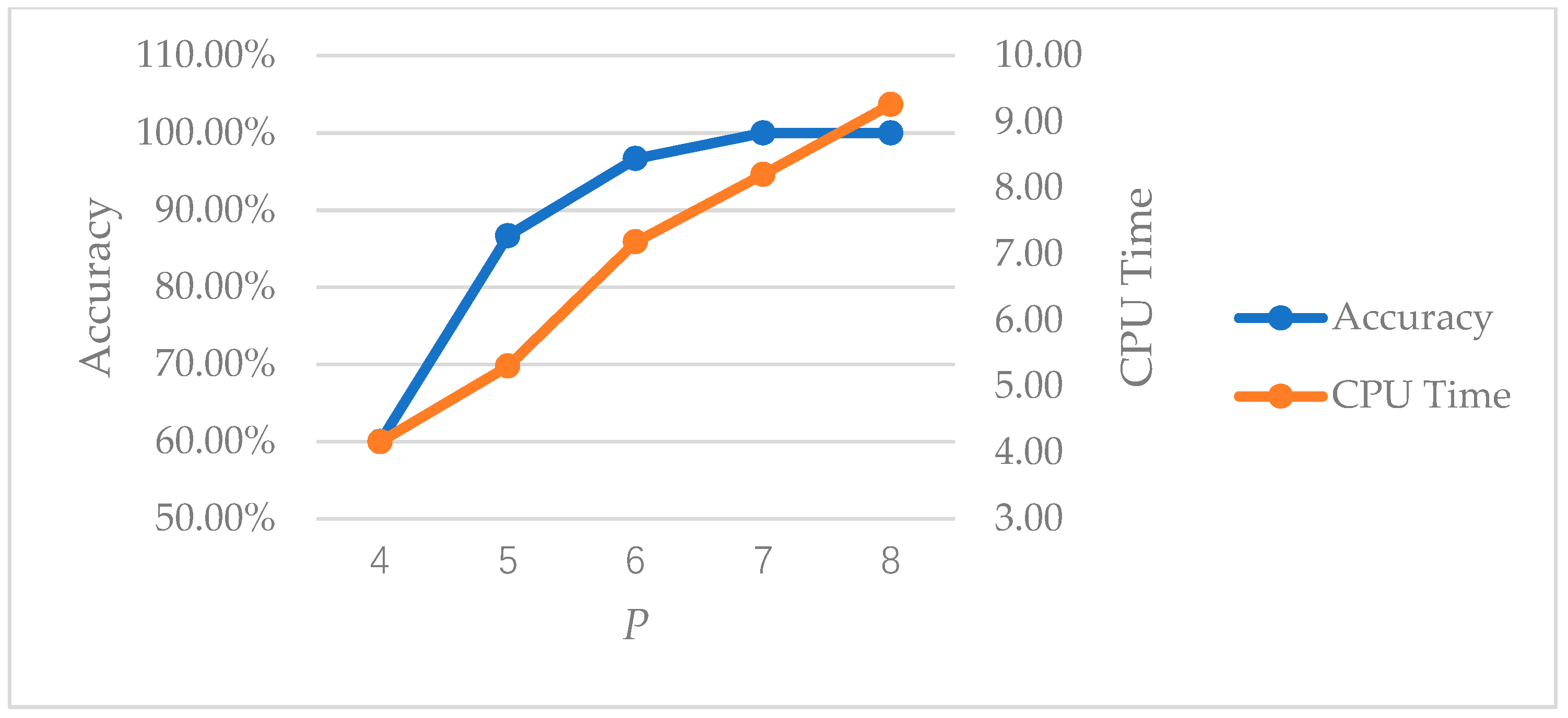
P is also tested at different values by using the example above, and the results are shown in
Figure 4. We can see that, as
P increases, both solution accuracy and CPU time will increase monotonically. This means that a larger population size will lead to a more stable solution, but it will also increase the runtime of the algorithm. Obviously, ISaDE has the best overall performance when
P = 6
N or
P = 7
N, and
P = 6
N will be used in the subsequent analysis.
5.2. Sensitivity Analysis
Sensitivity analysis is an effective means to study how the change of a parameter affects the output of a system. In practice, it provides an efficient way for decision-makers to identify main drivers to improve their supply chain systems. In this study, sensitivity analysis is conducted to measure the impact of the changes of business parameters on the optimal solution. For
dij,
ei,
q1 and
q2, each parameter is analyzed individually by varying its value within the range of [−30%, 30%] and fixing the other paramaters. The numerical results are shown in
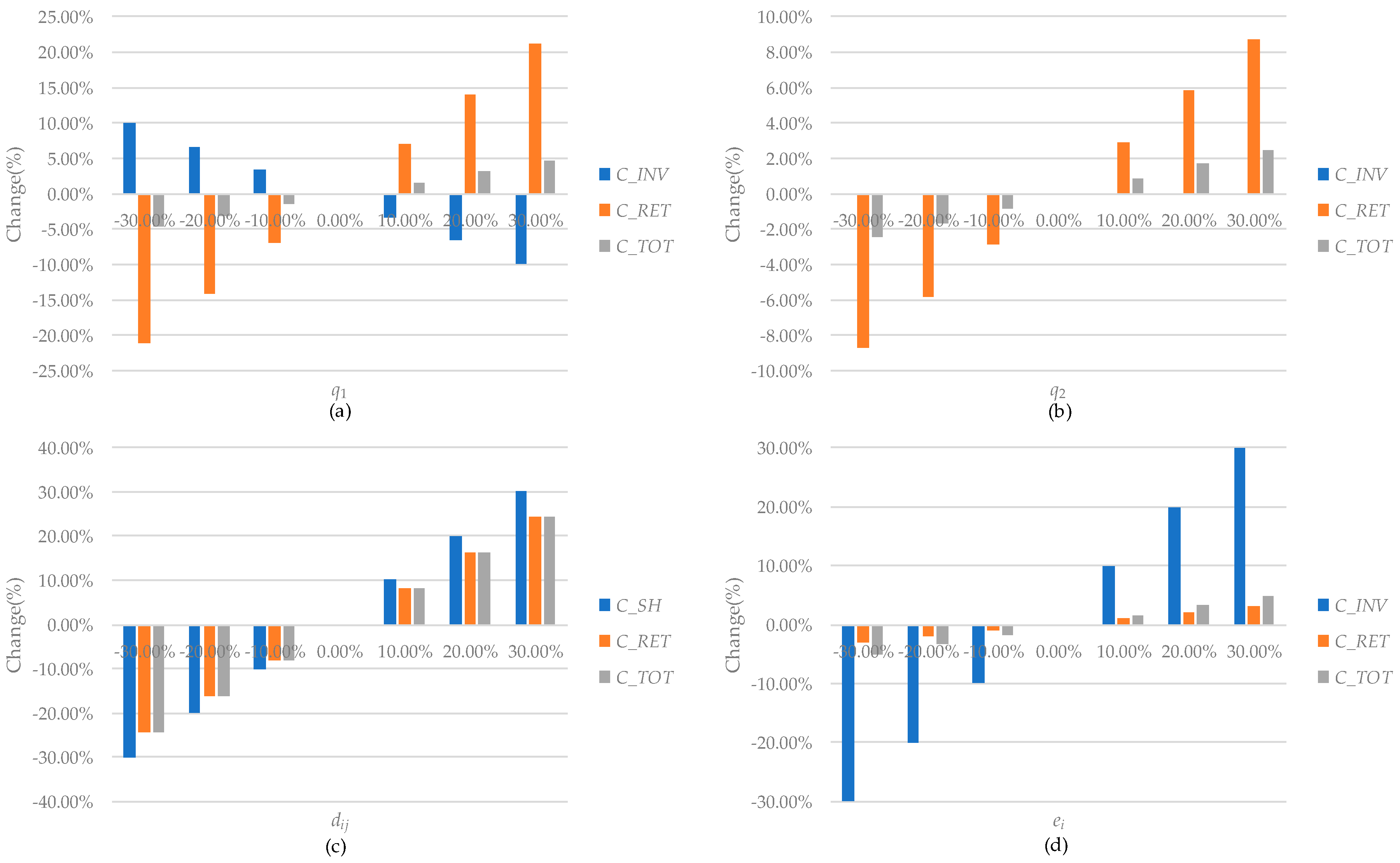
Figure 5, and we can draw the conclusions below:
- (1)
From
Figure 5a, we can see that, as
q1 increases, inventory cost
CINV will decrease but return cost
CRET will increase significantly, and hence total cost
CTOT will increase slightly. We can also see that, as
q1 decreases, inventory cost
CINV will increase but return cost
CRET will decrease significantly, and hence total cost
CTOT will decrease slightly. When
q1 varies from −30% to 30%, the ranges of the changes of
CINV,
CRET, and
CTOT are [−9.89%, 9.89%], [−21.09%, 21.09%] and [−4.65%, 4.65%], respectively.
- (2)
From
Figure 5b, we can see that when
q2 changes, return cost
CRET will change reversely and the other individual costs will remain the same. Hence, total cost
CTOT will increase. When
q2 varies from −30% to 30%, the ranges of the changes of
CRET and
CTOT are [−8.72%, 8.72%] and [−2.48%, 2.48%], respectively.
- (3)
From
Figure 5c, we can see that, as
dij increases, shipping cost
CSH and return cost
CRET will increase significantly, and, as
dij decreases,
CSH and
CRET will decrease significantly. When
dij changes, although the other individual costs will remain the same, total cost
CTOT will still change significantly because of the changes of
CSH and
CRET. When
dij varies from −30% to 30%, the ranges of the changes of
CSH,
CRET, and
CTOT are [−30.00%, 30.00%], [−24.42%, 24.42%] and [−24.31%, 24.31%], respectively.
- (4)
From
Figure 5d, we can see that, as
ei increases, inventory cost
CINV and return cost
CRET will increase significantly and slightly, respectively. We can also see that, as
ei decreases, inventory cost
CINV and return cost
CRET will decrease significantly and slightly, respectively. When
ei varies from −30% to 30%, the ranges of the changes of
CINV,
CRET, and
CTOT are [−29.86%, 29.86%], [−3.03%, 3.03%] and [−4.94%, 4.94%], respectively.
In this study, sensitivity analysis is also conducted on bi, ci, hi, gi, fi, k and δ, but the numerical results are not shown because their impacts are not significant.
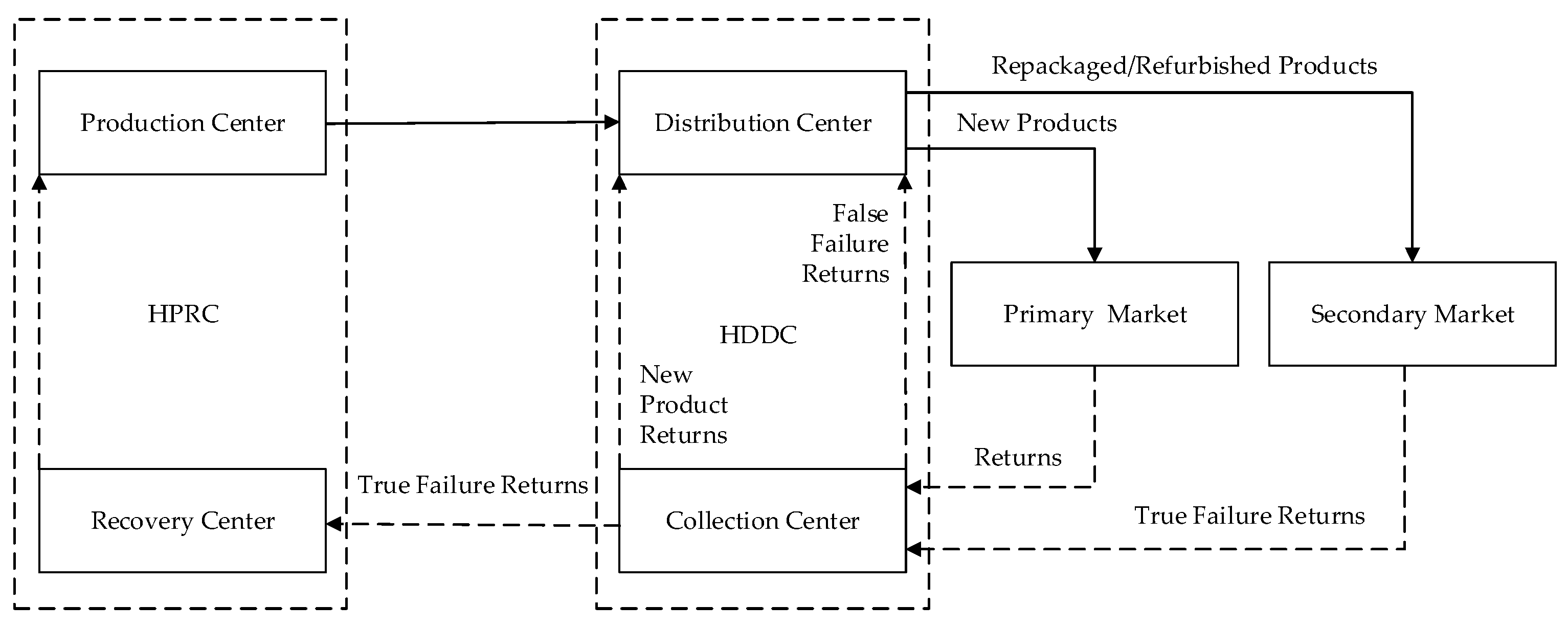
Although it is well known that returns are causing tremendous loss in the industry, it is not clear how the loss is driven by different types of returns. To support important business decisions such as return policies, it will be greatly beneficial to analyze the sensitivity of the cost functions to different types of returns in the primary market. Since the sum of
θ,
β, and
γ always equals 1, a parameter cannot be changed without affecting others. Therefore, sensitivity analysis is conducted on
θ,
β,
γ in pairs, and the numerical results are shown in
Figure 6,
Figure 7 and
Figure 8.
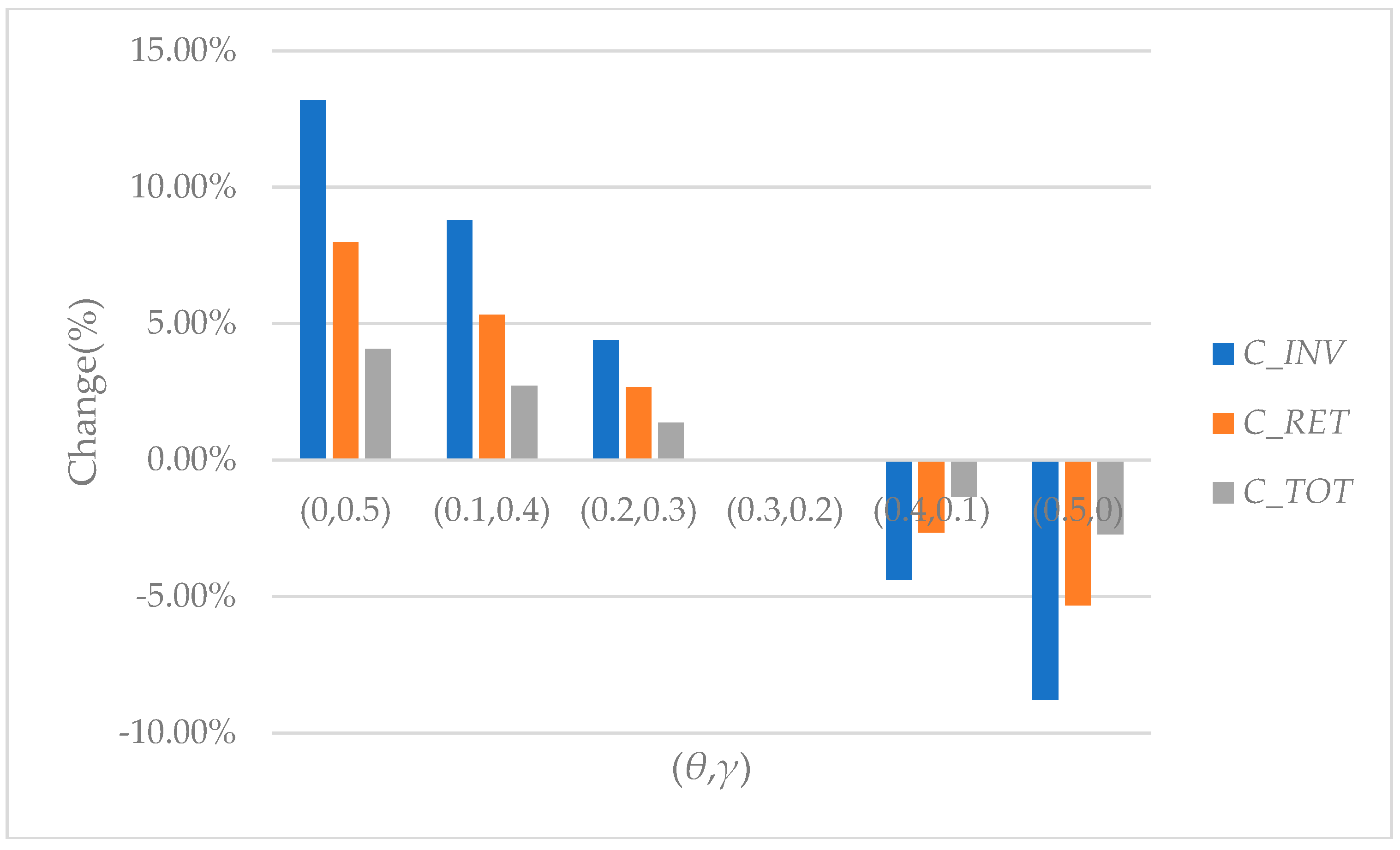
From
Figure 6, we can see that when
γ is fixed, the change of (
θ,
β) has a great impact on the inventory, return and total costs, and those costs will decrease significantly as
θ increases and
β decreases. More specifically, when
γ = 0.2 and (
θ,
β) changes from (0, 0.8) to (0.8, 0), the ranges of the changes of
CINV,
CRET, and
CTOT are [1.32%, −2.20%], [2.28%, −3.80%] and [0.83%, −1.38%], respectively. From
Figure 7, we can see that when
β is fixed, the change of (
θ,
γ) has a great impact on the inventory, return and total costs, and those costs will decrease significantly as
θ increases and
γ decreases. More specifically, when
β = 0.5 and (
θ,
γ) changes from (0, 0.5) to (0.5, 0), the ranges of the changes of
CINV,
CRET, and
CTOT are [13.19%, −8.79%], [7.98%, −5.32%] and [4.07%, −2.72%], respectively. From
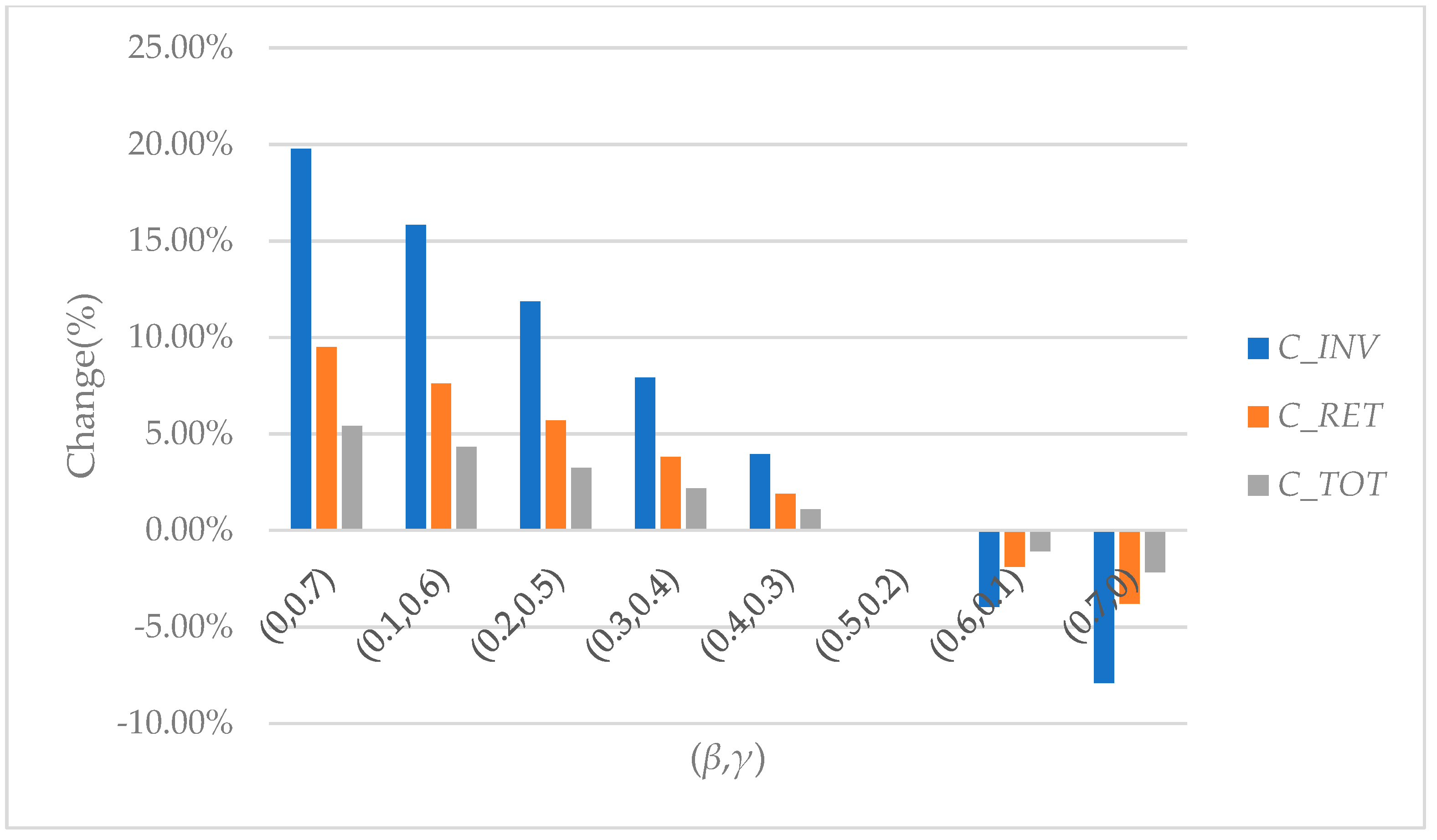
Figure 8, we can see that when
θ is fixed, the change of (
β,
γ) has a significant impact on the return and total costs. More specifically, when
θ = 0.3 and (
β,
γ) changes from (0, 0.7) to (0.7, 0), the ranges of the changes of
CINV,
CRET, and
CTOT are [19.78%, −7.91%], [9.50%, −3.80%] and [5.41%, −2.16%], respectively.
5.3. Performance Comparison
In this sub-section, ISaDE is compared with Lingo 11 to validate its performance in terms of solution accuracy and time efficiency, and the numerical results are shown in
Table 3. To compare their performances thoroughly, ISaDE and Lingo are tested on a set of problems in small (i.e., 20 × 5, 40 × 5, 60 × 5), medium (i.e., 80 × 10, 100 × 10, 120 × 10) and large (i.e., 140 × 15, 160 × 15, 180 × 15) sizes. Moreover, there are two instances for each size, and the coordinates of HDCC locations and customer zones are different in the two instances. For each problem, ISaDE is executed 30 times, but Lingo is executed only once because of their different natures. From
Table 3, we can see that ISaDE is much faster than Lingo for all instances, and hence it has great time efficiency to solve those problems. Moreover, for each instance, the mean optimal value from 30 runs of ISaDE is almost identical to the optimal value given by Lingo, which indicates that ISaDE has a good capability to search the global optimums. We can also see that the standard deviation of the optimal values given by ISaDE is very small in all test cases, and this indicates that ISaDE has a good consistency to find the optimal solution. Therefore, we can conclude that ISaDE is a robust and efficient approach to solve the LIP problem under study.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}