1. Introduction
The sustainable development of energy has a huge influence on regional stability and economic growth [
1]. Governments regulate relevant policies to drive the energy sustainability, but it usually takes a long time from the formulation of a policy to its implementation. For example, a new energy law transposed the European Union third energy package and energy development strategy of Serbia by 2025, with projections to 2030, and it was up to five years [
2]. Although many policies advocate for the use of renewable energy, oil is still the main fuel in the current world (in the first quarter of 2017, the total consumption of OECD liquid fuels was 46.78 million barrels per day—data from the U.S. Energy Information Administration,
https://www.eia.gov/outlooks/steo/tables/pdf/3dtab.pdf). Moreover, oil prices could lead to the implementation of policies. For example, interest in energy-related policy was revived with the high oil prices in the late 2000s, and the composition of governmental supports across sectors shifted tectonically with the American Recovery and Reinvestment Act, away from fossil fuels and toward unprecedented levels of support for renewable energy [
3]. Therefore, accurate price forecasting of oil could provide some valuable information for making policies and relieve the time-lag problems of polices.
The volatility of oil prices is affected by many issues, including supply and demand, the futures market, and political stability and geopolitics. Hamilton (2009) documented that the causes of the different volatility were differences in supply and demand [
4]. Hamilton found that previous oil price shocks were primarily caused by physical disruptions in supply, whereas the price run-up of 2007–2008 was caused by strong demand. Huang (2017) studied the world economy, oil stocks, futures market, and political stability in the Middle East with regard to oil price fluctuations in multiple time horizons [
5]. Huang found that these factors have some influence on the volatility of oil prices in one or more horizons. In contrast, oil shocks have a great impact on the economy. Hamilton (1983) supported the idea that oil shocks were a contributing factor to at least some of the U.S. recessions prior to 1972 [
6]. Wong and El (2017) suggested the need for more economic diversification at the country level in the Gulf Corporation Council region to mitigate high volatility in the event of oil shocks [
7]. Hence, an accurate forecast of oil prices is of great interest to investors and policymakers, and it is a big challenge for researchers. This paper proposes a new time-varying weight combination approach.
Recently, there have been two main methods for predicting the price of oil. One method is based on dynamic model averaging (DMA). In 2010, Raftery et al. [
8] developed the DMA model to predict the output strip thickness for a cold rolling mill, and Koop and Korobilis (2012) applied it to an economic variable’s forecast [
9]. For oil forecasting, Drachal (2016), Naser (2016), and Wang et al. (2015) used the DMA model predict different class of oil prices [
10,
11,
12]. The superiority of the DMA model not only captures the time-varying property of the variables, but could also select the optimum model automatically. However, this method will meet the curse of dimensionality when the predictor variables are larger. The other method is to model the combination method. In 2015, Baumeister and Kilian [
13] proposed a forecast combination approach with inverse recursive mean-squared prediction error (MSPE). (Manescu and Van Robays (2016) utilized this method to predict real Brent oil prices [
14]). Their method significantly improved the accuracy with a combination of six models: a vector autoregression model of the global oil market, a forecast based on the price of non-oil industrial raw materials, a no-change forecast, a forecast based on oil futures prices, the spread between the spot prices of gasoline and crude oil, and the time-varying parameter model of the gasoline and heating oil spreads. However, the increases in the MPSE with the different models may contribute to overlooking the truth that the different models themselves may lead to differences. To overcome these, all the models that we use have the same single-variable time-varying parameter to fit the data.
In this paper, we follow Baumeister and Kilian’s [
13] idea and propose a new time-varying weight combination method with some special dependence (this method is similar to Kendall’s tau and Spearman’s rho). The capture of this special dependence is carried concordantly between the predictor variable and the oil prices. Additionally, the weight is built on the assumption that the dependence is stronger and the weight is higher, and vice versa. The steps for constructing the model are portrayed below. First, we used five single-variable time-varying parameter models to predict the crude oil prices separately. These variables were oil production, oil inventory, the Kilian’s index, non-energy commodity prices, and crack spread selected from four aspects supply, demand, non-energy, and energy-related. Second, every special model was assigned a time-varying weight by the new combination approach. Finally, the forecasting results of the oil prices were calculated. Our method, compared to random walk (here we follow Alquist and Kilian (2010) and treat the random walk as the benchmark for comparison purposes [
15]). behaves better in terms of accuracy. Furthermore, our method is robust compared to the inverse recursive MPSE weight method.
This paper makes two main contributions. The first is to build five single-variable time-varying parameter models related to the four significant impacts of oil prices. The second is to propose a new time-varying weight combination method. This method behaves better with regard to improving the accuracy of forecasts. The remainder of the paper is designed as follows. In
Section 2, we introduce the methodology of time-varying combination. The data selection and empirical results are introduced in
Section 3.
Section 4 shows the discussion and conclusions.
2. Methodology
In this subsection, we first introduce the general time-varying parameter (TVP) model and Kalman filter (Kim and Nelson 1999 [
16]). Next, a single-variable TVP model is provided. Finally, following the single-variable TVP model, a time-varying weight method is proposed.
TVP models: Consider the following regression model in which the regression coefficients are time-varying with specific dynamics:
where
t is time;
;
;
is a
dependent variable;
is a
vector of independent or exogenous variables (
k is constant). We assume that
is
dimension and
, so
Q is a
matrix and
F is a
matrix.
Kalman filter: The Kalman filter is described by the following six equations:
Updating:
where
is the Kalman gain, which determines the weight assigned to new information about
contained in the prediction error.
is the covariance matrix of
conditional on information up to
and
.
Single-variable TVP model and time-varying weight methods: Assume that
is a vector that only includes itself and its lag terms. Let
and
F be 0 and 1, respectively. The single-variable TVP model transforms as
The single-variable TVP model is estimated with a Gibbs sample algorithm (in oil price forecasting, Baumeister et al. (2013) used product spreads to forecast with this method [
17]). (see Kim and Nelson 1999 [
16]).
Based on the prediction results of all the single-factor TVP models, the time-varying weight combination approach is presented below. Let
and
be two time series.
is
i orders difference operator, namely
,
. Define a score function
,
Then, let
where
n is the length of the rolling window and
is the dynamic value:
,
c is a positive constant, which means that we give a different weight for score function by the distance to
t. Moreover, the closer to time
t it is, the larger the score gets. This is based on the assumption that the current situation has a greater effect than usual. We also assume that it has
m single-variable models to forecast the dependent variable
. Let these single variables be
,
. We gain the
j-th single-variable model with weight
,
Thus, the weight of every single-variable model has a dynamic weight.
3. Empirical Results and Robustness Test
The real price of crude oil—the dependent variable—is the focus of our paper. We consider the West Texas Intermediate crude oil prices (WTI) as a proxy for crude oil. Recently, Alquist and Kilian (2010) [
15], Alquist et al. (2013) [
18], Baumeister et al. (2013, 2014, 2015) [
13,
17,
19], Wang et al. (2015) [
12], Xiong et al. (2013) [
20], Yin and Yang (2016) [
21], Drachal (2016) [
10] and Naser (2016) [
11] all regarded WTI as a proxy variable for oil prices. We selected four factors: supply, demand, crack spread, and non-energy commodity prices. According to economic theory, supply and demand are the key factors for changing the price of a commodity. Therefore, many researchers employ it as an independent variable to forecast oil prices (Baumeister and Kilian (2012) [
22], Fattouh et al. (2013) [
23], Hamilton (2009) [
4], Wang et al. (2015) [
12], Baumeister et al. (2013, 2014, 2015) [
13,
17,
19]), and we follow in their steps. For supply, two factors—oil production and oil inventory—were selected. Oil production and oil inventory reflect the increment and stock of oil prices, respectively, and oil production is a key influencing factor for oil prices because it is directly related to the supply of oil. The oil inventory signals the speculation, and its fluctuation easily bursts the volatility of oil prices. Kilian’s index is a proxy of demand introduced by Kilian (2009) [
24], and is based on the percentage change of growth rates obtained from a panel of single-voyage bulk dry cargo ocean shipping freight rates measured in dollars per metric ton. This index can reflect the global demand of industrial commodities. Since industrial commodities rely primarily on oil, Kilian’s index should be a reasonable and suitable proxy for oil demand. The cost of oil refining technology has a direct impact on oil prices. In general, refined products follow an approximately fixed proportion of 3:2:1, which means obtaining two barrels of gasoline and one barrel of heating oil from three barrels of crude oil. We denote the price changes of the refining process as the crack spread. In commodity markets, energy and non-energy commodity prices are always somewhat interdependent because both of them are necessities in life. We treat non-energy commodity prices as another variable to forecast. The data of the WTI, oil production, oil inventory, and crack spread are all from the U.S. Energy Information Administration (EIA), and the non-energy commodity prices are collected from the World Bank. Kilian’s index comes from his personal webpage (
http://www-personal.umich.edu/~lkilian/). In this paper, all the variables on prices are divided by the Consumer Price Index (CPI), and we follow Drachal (2016) [
10] and consider the U.S. Consumer Price Index (
https://fred.stlouisfed.org/series/CPIAUCSL) a proxy variable for global CPI. In addition, for all variables, we chose the monthly data from June 1986 to December 2016, for a total of 367 observations.
Before the forecasting, it was necessary to test the stationarity of the WTI.
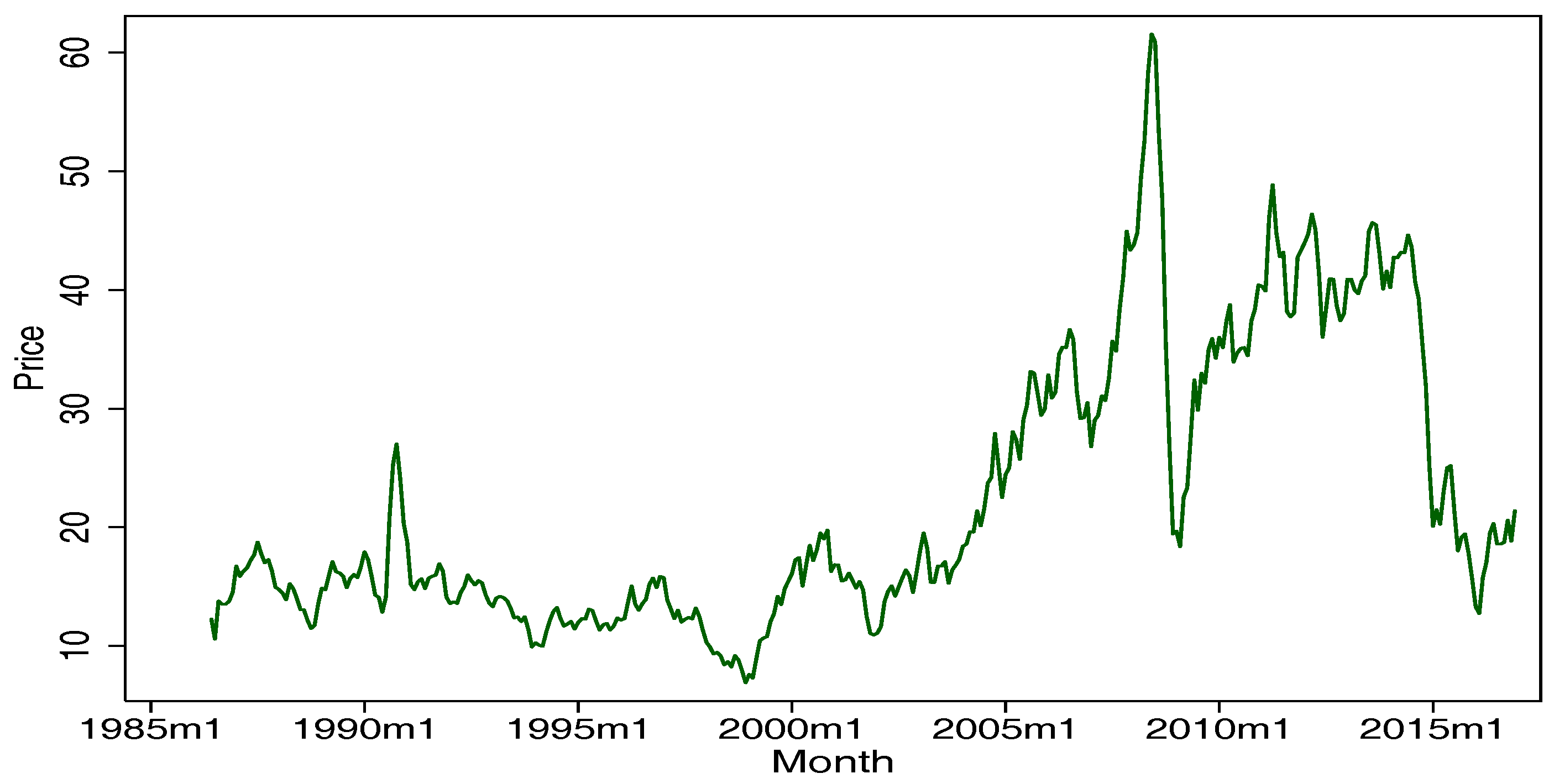
Figure 1 gives the real price of the WTI from June 1986 to December 2016, divided by the U.S. CPI. In
Table 1, the results of the augmented Dickey–Fuller (ADF) test and Phillips–Perron (PP) test both show that a unit root null hypothesis was refused except for the WTI. The Kwiatkowski–Phillips–Schmidt–Shin (KPSS) test also achieved the same results. Therefore, all the WTI differences remained stable, except the WTI demonstrated non-stationarity overall (the methods to test stationarity are various; this paper follows Drachal (2016) [
10] and chooses the ADF, KPSS, and PP tests). Additionally, we selected the first 27 draws as prior data sets, the middle 240 as training sets, and the last 100 as the out-of-sample forecast. By 2000, repeating the Gibbs sample algorithms we gained the coefficients and variance, which discarded the first 500 draws and saved the last 1500.
Next, looking at the individual model:
,
i is the alternative model: global economic activity, crack spread, non-energy commodity prices, oil production, and oil inventory. In
Table 2, compared to random walk, the fitting results for the success ratio are given (the success ratio equals the length of out-of-sample divided by the times of the specified model defeating random walk in out-of-sample forecasting [
15]). Global economic activity presents poor prediction results, except for the horizon 21, with value 51. The model’s crack spread and non-energy commodity prices were optimal compared to random walk in most horizons. There were only two shorter horizons—1 and 6—in terms of crack spread, whereas 1 and 3 in non-energy prices did not exceed 50. In contrast, for oil production, getting rid of two mid-horizons—9 and 12—that were below 50, performed well in other horizons. The last single TVP model, oil inventory, performed normally and had three horizons that were below 50: 6, 9, and 21.
For the MSPE,
Table 3 shows the fitting results. Though only one horizon of success ratio was better than random walk, global economic activity had horizons 3, 6, 9, and 12 performing better in the MSPE. However, the MSPE ratio of the crack spread was not good in many horizons. Nonetheless, it acted well in the success ratio. Non-energy commodity prices and oil production displayed coherent results between the success ratio and the MSPE, but the MSPE exceeded 1 in horizon 12. Oil inventory also maintained coherent results with regard to the success ratio; i.e., the MSPE performance equaled that of random walk.
Because these single-variable models cannot perform well in all horizons, the paper proposes the new combination weight model referred to in
Section 2. The three-model combination is composed of crack spread, non-energy price, and oil production. A five-model combination is used that includes all the single models the paper referred to before. The results of the two-combination models are shown in
Table 4. In order to determine whether the rolling window has an effect on the results, we chose two rolling window lengths, 24 months and 36 months, and the slope
. From the values of column 2 in panel A, three models were combined with weight rolling window 24 (abbreviated as 3-CE
24; we use the same abbreviating methods below), which has very ideal results compared to random walk since the success ratios all exceed 0.5, except for horizon 1. With reference to column 3 of panel A, 3-CE
36 also performed well, except for horizons 2 and 21. Though the 3-CE
36 were slightly inferior to 3-CE
24 in the number of horizons, the value of the 3-CE
36 was better than 3-CE
24 in horizons that performed well. Thus, the three-model combination with two different rolling windows showed an equal ability with regard to the success ratio. The MSPE of 3-CE
36 and 3-CE
24—except for horizon 12—performed well in columns 2 and 3 of panel B. For testing the robustness of the three-model combination results, the paper gives the results of the inverse recursive error weight. From the results of the success ratio in columns 6–7 of panel A, the three-model combination method with the inverse recursive weight was not better than 3-CE
24 and 3-CE
36. Although the MPSE values of column 6 in panel B are all less one, column 7 shows poor results, except for horizon 3. Overall, the paper’s three-model combination approach was slightly superior to the inverse recursive error weight by the three-model combination, and was more stable in general.
The results of the five-model combination are given in columns 4 and 5 of
Table 4. The success ratio also maintained its good performance for some short horizons: 1 and 6 of 5-CE24 and 1, 6, and 9 of 5-CE36 in columns 4 and 5, respectively. The performance of the success ratio in the five-model combination was worse than that of the three-model combination, but it obtained amazing results for the MPSE ratio in Panel B. The values of two models—5-CE24 and 5-CE36—were both less than 1. Therefore, the five-model combination represents a higher ability to improve accuracy. Furthermore, we have a robust test compared to the inverse recursive error weight. The results of the combination model are provided in columns 8–9. From the values of the two methods, regardless of the success ratio or MSPE ratio, the five-model combination was robust.
Overall, three- and five-model combinations were both clearly superior to a single model. The success ratio of the three-model combination was better, but the five-model combination behaved better with regard to the MSPE ratio. The combination models both had robust results compared to the recursive error weight combination model.
4. Discussion and Conclusions
In this paper, a new time-varying weight combination approach is explored to enhance the forecasting accuracy of crude oil prices. Accurate forecasting prices of oil is a good reference for governments or organizations to document relevant policies on energy sustainability. Additionally, investors can apply predicted prices to make decisions. Moreover, oil is a crucial energy source globally, and the fluctuation of oil prices has a significant impact on economies. Therefore, improving the prediction accuracy of oil prices is very meaningful and valuable.
A time-varying approach—specifically a time-varying combination approach—was used for price forecasting [
10,
11,
12,
13,
14]. The time-varying model—regardless of coefficients or variances—could better capture the character of a time series and gain forecasting performance. The combination model considers more influencing factors and makes it more closely match reality. As shown before, there are two popular methods: DMA and combination methods with recursive MSPE. The key point of DMA lies that it allows both the model and parameters to vary at each point in time. However, the economic implications of forecasting are hard to explain, because the best influencing factor is selected from the big data. The superiority of the combination model with the recursive MSPE can solve the problem that a special model may only perform well in short-horizons or long-horizons. However, we are hard to exclude the difference among models; i.e., the different models themselves may lead to differences. So, this will lead to bias when we give the weight to every model. Based on the existing approaches, we proposed a new time-varying weight combination approach. Since the weight of our method is given by capturing the dependence between the variables and the combination model is built with five single-variable TVP models, it is better able to solve the mentioned problems above. Our model has the following three merits. Firstly, we built the time-varying weight by dependence, which catches the correlations of variables well. Secondly, supply, demand, crack spread, and non-energy commodity prices are used in our model as the influencing factors of oil prices. These factors were popular for forecasting oil and could be easily explained in economic theory [
10,
11,
12,
13]. Finally, Wang et al. (2015) considered 18 different econometric models and found that a simple model can reduce the effects of estimation error and model misspecification [
26]. Thus, we applied a simple single-variable model to forecast oil prices, and it could reduce the computing and estimating errors. Besides, a limitation of our model deserves to be mentioned—that is, our weighting method is only appropriate for single-variable models.
Alquist and Kilian (2010) documented that random walk was a plausible measure of the oil prices [
15]. Since then, many researchers have devoted their best efforts to beating random walk [
10,
11,
12,
13]. Likewise, we treated random walk as a benchmark model. The empirical results indicate that the combination methods were robust and performed well in mid-horizons and long-horizons. Specially, the five-model combination had amazing results with regard to the MSPE ratio; i.e., they defeated random walk in all horizons. Therefore, we have the conclusion that our approach gained forecasting accuracy in mid-horizons and long-horizons. In addition, our model may provide some help for policymakers and investors. For policymakers, some policies or agreements need a long time and forecasting prices may give more useful information. For investors, the forecasting prices may lead to better decision-making.



{kind=link}