
Evolving Protected-Area Impacts in Mexico: Political Shifts as Suggested by Impact Evaluations

Abstract
:1. Introduction
2. Background and Related Literature
2.1. Evaluating PA Impacts
2.2. Evaluating Conservation Impacts in Mexico
3. Modeling PA Impact
3.1. PA Impact by Location
3.2. PA Impact by Type
4. Data and Matching Methods
4.1. Land Cover Data
4.2. Land Characteristics Data
4.3. Matching Methods
5. Results
5.1. Descriptive Statistics
5.2. Drivers of Protection
5.3. Drivers of Land-Cover Change
5.4. Matching on Drivers of Land-Cover Change
5.5. Average PA Impact
5.6. Impacts by PA Type
6. Conclusions
Supplementary Materials
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Pfaff, A.; Amacher, G.S.; Sills, E.O. Realistic REDD: Improving the forest impacts of domestic policies in different settings. Rev. Envir. Eco. Policy 2013, 7, 114–135. [Google Scholar] [CrossRef]
- Joppa, L.; Pfaff, A. Re-assessing the forest impacts of protection: The challenge of non-random protection & a corrective method. Annal. NY Acad. Sci 2010, 1185, 135–149. [Google Scholar]
- Joppa, L.; Pfaff, A. Global Park Impacts. Proc. Royal Society B. 2010. [Google Scholar] [CrossRef]
- Pfaff, A.; Robalino, J.A.; Sanchez-Azofeifa, G.A.; Andam, K.; Ferraro, P. Park Location Affects Forest Protection: Land Characteristics Cause Differences in Park Impacts across Costa Rica. BE J. Econ. Anal. Poli. 2009. Available online: http://www.bepress.com/bejeap/vol9/iss2/art5 (accessed on 24 December 2016).
- Joppa, L.; Pfaff, A. High & Far: Biases in the location of protected areas. PLoS ONE 2009, 4, e8273. [Google Scholar] [CrossRef]
- Pfaff, A.; Robalino, J. Protecting Forests, Biodiversity and the Climate: Predicting policy impact to improve policy choice. Oxford Rev. Econ. Policy 2012, 28, 164–179. [Google Scholar] [CrossRef]
- Blackman, A.; Pfaff, A.; Robalino, J. Paper Park Performance: Mexico’s natural protected areas in the 1990s. Glob. Environ. Chang. 2015, 31, 50–61. [Google Scholar] [CrossRef]
- Johnson, T.; Alatorre, C.; Romo, Z.; Feng, L. Low-Carbon Development for Mexico; The World Bank: Washington, DC, USA, 2010. [Google Scholar]
- The REDD Desk. REDD in Mexico. 2011. Available online: www.theredddesk.org/countries/mexico/readiness_overview (accessed on 3 February 2013).
- The Forest Carbon Partnership. REDD Readiness Progress Fact Sheet. 2012. Available online: www.forestcarbonpartnership.org/ (accessed on 3 February 2013).
- Naughton-Treves, L.; Holland, M.B.; Brandon, K. The role of protected areas in conserving biodiversity and sustaining local livelihoods. Annual Rev. Environ. Resour. 2005, 30, 219–252. [Google Scholar] [CrossRef]
- Nagendra, H. Do Parks Work? Impact of Protected Areas on Land Cover Clearing. Ambio 2008, 37, 330–337. [Google Scholar] [CrossRef] [PubMed]
- Campbell, A.; Clark, S.; Coad, L.; Miles, L.; Bolt, K.; Roe, D. Protecting the future: Carbon, forests, protected areas and local livelihoods. Biodiversity 2008, 9, 117–122. [Google Scholar] [CrossRef]
- Fuller, D.; Jessup, T.; Salim, A. Loss of forest cover in Kalimantan, Indonesia, since the 1997–1998 El Nino. Conserv. Biol. 2004, 18, 249–254. [Google Scholar] [CrossRef]
- Sanchez-Azofeifa, G.A.; Quesada-Mateo, C.; Gonzalez-Quesada, P.; Dayanandan, S.; Bawa, K.S. Protected areas and conservation of biodiversity in the tropics. Conserv. Biol. 1999, 13, 407–411. [Google Scholar] [CrossRef]
- DeFries, R.; Hansen, A.; Newton, A.C.; Hansen, M.C. Increasing isolation of protected areas in tropical forests over the past twenty years. Ecol. Appl. 2005, 15, 19–26. [Google Scholar] [CrossRef]
- Gaveau, D.L.A.; Wandono, H.; Setiabudi, F. Three decades of deforestation in southwest Sumatra: Have protected areas halted forest loss and logging, and promoted re-growth? Biol. Conserv. 2007, 134, 495–504. [Google Scholar] [CrossRef]
- Messina, J.P.; Walsh, S.J.; Mena, C.F.; Delamater, P.L. Land tenure and deforestation patterns in the Ecuadorian Amazon: Conflicts in land conservation in frontier settings. Appl. Geogra. 2006, 26, 113–128. [Google Scholar] [CrossRef]
- Bruner, A.; Gullison, R.E.; Rice, R.E.; Da Fonseca, G.A. Effectiveness of parks in protecting tropical biodiversity. Science 2001, 291, 125–128. [Google Scholar] [CrossRef] [PubMed]
- Curran, L.; Trigg, S.N.; McDonald, A.K.; Astiani, D.; Hardiono, Y.M.; Siregar, P.; Caniago, I.; Kasischke, E. Lowland forest loss in protected areas of Indonesian Borneo. Science 2004, 303, 1000–1003. [Google Scholar] [CrossRef] [PubMed]
- Kinnaird, M.F.; Sanderson, E.W.; O'Brien, T.G.; Wibisono, H.T.; Woolmer, G. Deforestation trends in a tropical landscape and implications for endangered large mammals. Conserv. Biol. 2003, 17, 245–257. [Google Scholar] [CrossRef]
- Liu, J.G.; Linderman, M.; Ouyang, Z.; An, L.; Yang, J.; Zhang, H. Ecological degradation in protected areas: The case of Wolong Nature Reserve for giant pandas. Science 2001, 292, 98–101. [Google Scholar] [CrossRef] [PubMed]
- Sader, S.; Hayes, D.J.; Hepinstall, J.A.; Coan, M.; Soza, C. Forest change monitoring of a remote biosphere reserve. Int. J. Remote Sens. 2001, 22, 1937–1950. [Google Scholar] [CrossRef]
- Andam, K.; Ferraro, P.J.; Pfaff, A.; Sanchez-Azofeifa, G.A.; Robalino, J.A. Measuring the effectiveness of protected area networks in reducing deforestation. Proc. Natl. Acad. Sci. USA 2008, 105, 16089–16094. [Google Scholar] [CrossRef] [PubMed]
- Shah, P.; Baylis, K. Evaluating Heterogeneous Conservation Effects of Forest Protection in Indonesia. PLoS ONE 2015, 10, e0124872. [Google Scholar] [CrossRef] [PubMed]
- Munoz-Pina, C.; Guevara, A.; Torres, J.M.; Brana, J. Paying for the hydrological services of Mexico’s forests: Analysis, negotiations and results. Ecol. Econ. 2008, 65, 725–736. [Google Scholar] [CrossRef]
- Alix-Garcia, J.M.; Shapiro, E.N.; Sims, K.R.E. Forest Conservation and Slippage: Evidence from Mexico’s National Payments for Ecosystem Services Program. Land Econ. 2012, 88, 613–638. [Google Scholar] [CrossRef]
- Alix-Garcia, J.M.; Sims, K.R.E.; Yanez-Pagans, P. Only One Tree from Each Seed? Environmental effectiveness and poverty alleviation in Mexico’s Payments for Ecosystem Services Program. Am. Econ. J. Econ. Policy 2015, 7, 1–40. [Google Scholar] [CrossRef]
- Rodriguez, L.A. On the Regulation of Small Actors: Three Experimental Essays about Policies based on Voluntary Compliance and Decentralized Monitoring. Ph.D. Thesis, Duke University, Durham, NC, USA, 2016. [Google Scholar]
- Kaczan, D.; Pfaff, A.; Rodriguez, L.; Shapiro, E.N. Increasing the Impact of Collective Incentives: Conditionality on additionality within PES in Mexico. Unpublished work. 2016. [Google Scholar]
- Sims, K.R.E.; Alix-Garcia, J.M. Parks versus PES: Evaluating direct and incentive-based land conservation in Mexico. J. Environ. Econ. Manag. 2016. [Google Scholar] [CrossRef]
- Figueroa, F.; Sánchez-Cordero, V. Effectiveness of Natural Protected Areas to Prevent Land Use and Land Cover Change in Mexico. Biodivers. Cons. 2008, 17, 3223–3240. [Google Scholar] [CrossRef]
- Mas, J.F. Assessing Protected Areas Effectiveness Using Surrounding (Buffer) Areas Environmentally Similar to the Target Area. Envir. Monit. Assess. 2005, 105, 69–80. [Google Scholar] [CrossRef]
- Durán, E.; Mas, J.F.; Velázquez, A. Land Use/Cover Change in Community-Based Forest Management Regions and Protected Areas in Mexico. In The Community Forests of Mexico; Bray, D.B., Merino-Pérez, L., Barry, D., Eds.; University of Texas Press: Austin, TX, USA, 2005; pp. 215–238. [Google Scholar]
- Honey-Roses, J.; Lopez-Garcia, J.; Rendon-Salinas, E.; Peralta-Higuera, A.; Galindo-Leal, C. To pay or not to pay? Monitoring performance and enforcing conditionality when paying for forest conservation in Mexico. Environ. Conserv. 2009, 36, 120–128. [Google Scholar] [CrossRef]
- Honey-Roses, J.; Baylis, K.; Ramirez, M.I. A Spatially Explicit Estimate of Avoided Forest Loss. Conserv. Biol. 2011, 25, 1032–1043. [Google Scholar] [CrossRef] [PubMed]
- Miteva, D.; Ellis, E.; Ellis, P.; Griscom, B. The role of property rights in resisting forest loss in the Yucatan Peninsula. Unpublished work. 2016. [Google Scholar]
- Von Thünen, J.H. Der Isolierte Staat in Beziehung der Landwirtschaft und Nationalökonomie (1996, trans.). In von Thünen’s The Isolated State; Hall, P., Ed.; Pergamon Press: Oxford, United Kingdom, 1826. [Google Scholar]
- World Bank. Policies and Deforestation in the Brazilian Amazon: Roads, Protected Areas, Their Interactions, and Their Impacts; Technical Paper; World Bank: Washington DC, USA, 2013. [Google Scholar]
- Nelson, A.; Chomitz, K. Effectiveness of Strict vs. Multiple Use Protected Areas in Reducing Tropical Forest Fires: A Global Analysis Using Matching Methods. PLoS ONE 2011, 6, 322722. [Google Scholar] [CrossRef] [PubMed]
- Pfaff, A.; Robalino, J.; Lima, E.; Sandoval, C.; Herrera, L.D. Governance, Location and Avoided Deforestation from Protected Areas: Greater restrictions can have lower impact, due to differences in location. World Develop. 2014. Available online: http://dx.doi.org/10.1016/j.worlddev.2013.01.011 (accessed on 24 December 2016).
- Albers, H.J. Spatial modeling of extraction and enforcement in developing country protected areas. Resour. Energy Econ. 2010, 32, 165–179. [Google Scholar] [CrossRef]
- Borner, J.; Kis-Katos, K.; Hargrave, J.; Konig, K. Post-Crackdown Effectiveness of Field-Based Forest Law Enforcement in the Brazilian Amazon. PLoS ONE 2015, 10, e0121544. [Google Scholar] [CrossRef] [PubMed]
- Bartholome, E.; Belward, A. GLC2000: A new approach to global land cover mapping from Earth observation data. Int. J. Remote Sens. 2005, 26, 1959–1977. [Google Scholar] [CrossRef]
- European Space Agency (ESA); ESA GlobeCover Project lead by MEDIAS-France. Ionia GlobCover. Available online: http://due.esrin.esa.int/page_globcover.php (accessed on 24 December 2009).
- United States Geological Survey. Shuttle Radar Topography Mission, 30 Arc Second scene SRTM_GTOPO_u30, Mosaic. 2006. Available online: http://www2.jpl.nasa.gov/srtm/ (accessed on 24 December 2008). [Google Scholar]
- National Imagery and Mapping Agency (NIMA). Vector Map Level. Available online: http://egsc.usgs.gov/nimamaps/ (accessed on 24 December 2010).
- United Nations Environment Program-Center for International Earth Science Information Network (UNEP-CIESEN). Global Rural-Urban Mapping Project (GRUMP), Alpha Version: Urban Extent. 2006. Available online: http://sedac.ciesin.columbia.edu/gpw/ancillaryfigures.jsp (accessed on 24 December 2010).
- World Conservation Monitoring Center. World Database on Protected Areas (WDPA). World Conservation Union (IUCN) and UNEP-World Conservation Monitoring Center Cambridge, UK. 2007. Available online: http://www.wdpa.org/ (accessed on 24 December 2010).
- Olson, D.; Dinerstein, E.; Wikramanayake, E.D.; Burgess, N.D.; Powell, G.V.; Underwood, E.C.; D’Amico, J.A.; Itoua, I.; Strand, H.E.; Morrison, J.C.; et al. Terrestrial ecoregions of the world: A new map of life on Earth. BioScience 2001, 51, 933–938. [Google Scholar] [CrossRef]
- Fischer, G.; van Velthuizen, H.; Nachtergaele, F.; Medow, S. Global Agro-Ecological Zones. 2002. Available online: http://www.fao.org/nr/gaez/en/ (accessed on 24 December 2010).
- Rosenbaum, P.R.; Rubin, D.B. The central role of the propensity score in observational studies for causal effects. Biometrika 1983, 70, 41–55. [Google Scholar] [CrossRef]
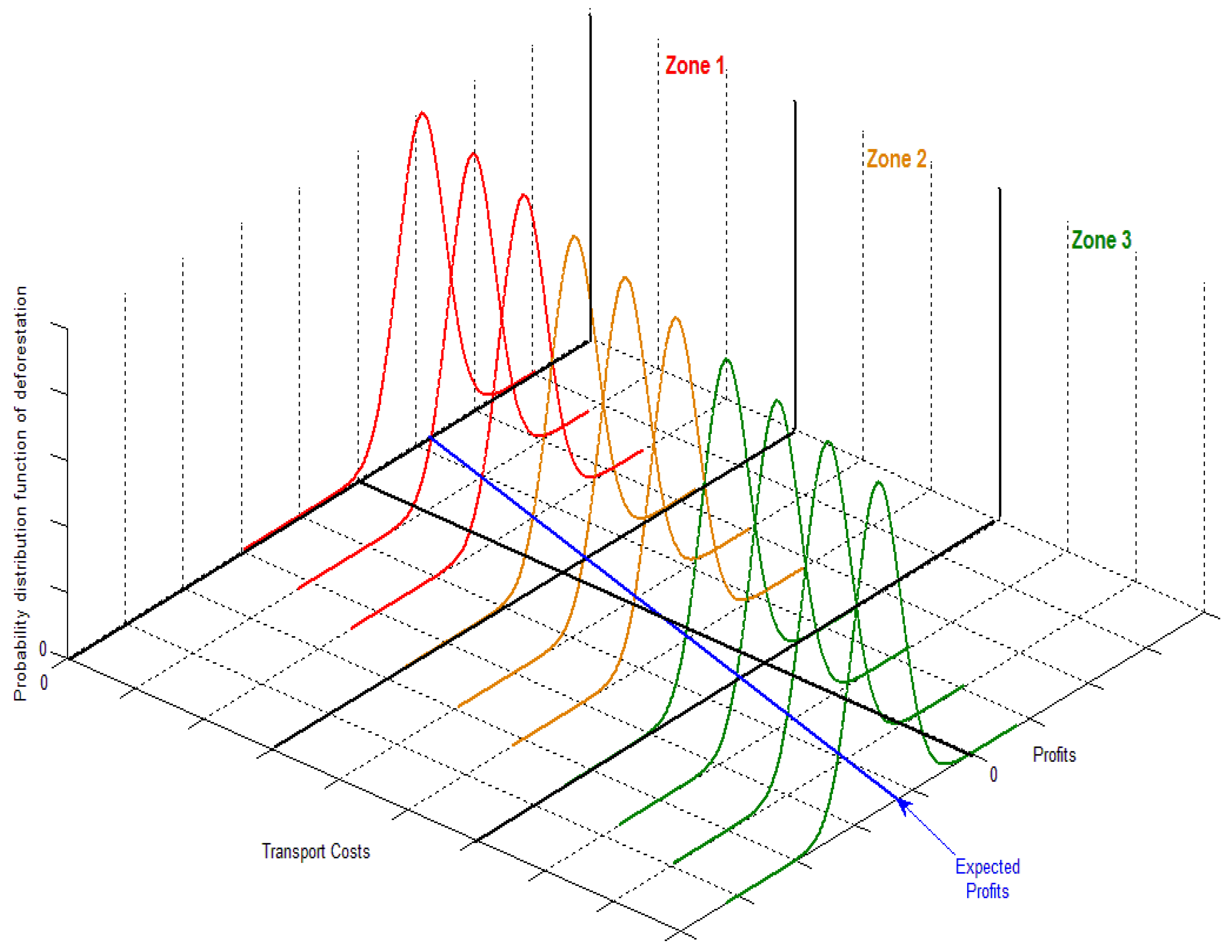

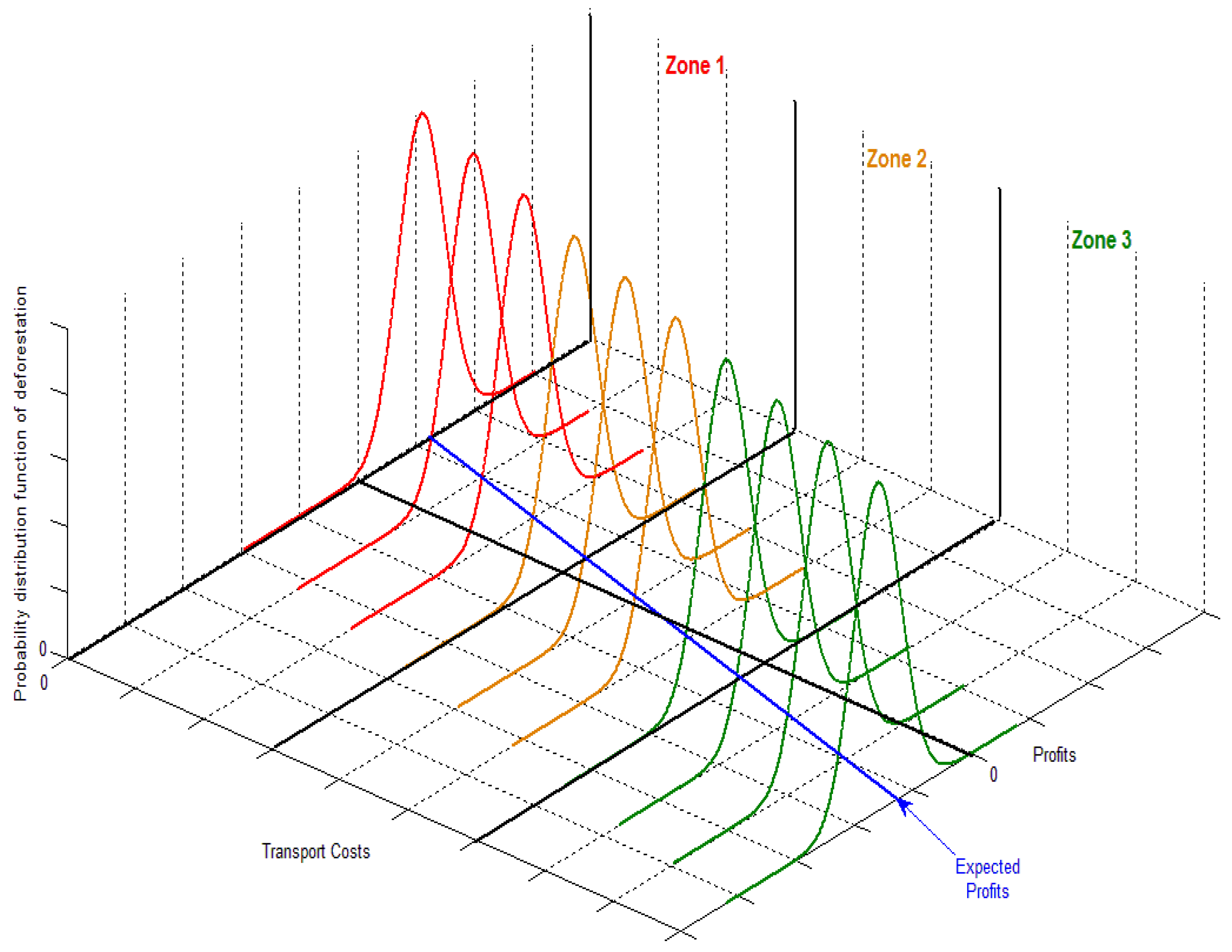{kind=link}
| Unprotected | Protected | Protected–Stricter | Protected–Mixed-Use | |
|---|---|---|---|---|
| Protected, Stricter Subset (1/0) | 0 | 0.21 | 1 | 0 |
| Protected, Mixed-use Subset (1/0) | 0 | 0.79 | 0 | 1 |
| IUCN Category (1–6) | 0 | 5.0 | 1.3 | 6.0 |
| Distance Outside PA Edge (km) | 55.8 | −14.0 | −10.5 | −15.0 |
| Urban Distance (km) | 35.6 | 95.7 | 58.4 | 105.3 |
| Road Distance (km) | 8.5 | 12.6 | 14.3 | 12.2 |
| Elevation (m) | 1081 | 622 | 885 | 554 |
| Slope (degrees) | 2.81 | 2.85 | 3.42 | 2.70 |
| Agricultural Suitability (0–9) | 6.17 | 6.81 | 6.57 | 6.88 |
| Relatively Low Agric. Suitability (1/0) | 0.39 | 0.56 | 0.38 | 0.60 |
| Relatively High Agric. Suitability (1/0) | 0.37 | 0.21 | 0.22 | 0.21 |
| Fires (number detected in 2000–2006) | 0.005 | 0.003 | 0.004 | 0.003 |
| Dummy for Whether Any Fires (1/0) | 0.005 | 0.003 | 0.004 | 0.003 |
| Pine Oak Forest Dummy (1/0) | 0.115 | 0.003 | 0.005 | 0.003 |
| Chihuahua Desert Dummy (1/0) | 0.163 | 0.064 | 0.012 | 0.078 |
| GLC 2000 Natural Land Cover (1/0) | 0.840 | 0.920 | 0.912 | 0.921 |
| Globcover 2005 Natural Land Cover (1/0) | 0.862 | 0.957 | 0.970 | 0.954 |
| 2000–2005 Loss of Natural Cover (1/0) | 0.092 | 0.029 | 0.022 | 0.031 |
| # observations | 1,801,935 | 121,847 | 25,096 | 96,751 |
| Protected | Protected–Stricter Subset | Protected–Mixed-Use Subset | |
|---|---|---|---|
| Urban Distance | 0.00251 *** | 0.00032 *** | 0.00248 *** |
| (0.000) | (0.000) | (0.000) | |
| Road Distance | 0.00031 * | 0.00066 *** | −0.00035 *** |
| (0.000) | (0.000) | (0.000) | |
| Elevation | −0.00001 *** | 0.00000 *** | −0.00001 *** |
| (0.000) | (0.000) | (0.000) | |
| Slope | 0.00120 *** | 0.00048 *** | −0.00044 *** |
| (0.000) | (0.000) | (0.000) | |
| High Agricultural Suitability | −0.01533 *** | −0.01053 *** | −0.00564 *** |
| (0.000) | (0.000) | (0.000) | |
| Pine Oak Forest | −0.10585 *** | −0.03090 *** | −0.08272 *** |
| (0.000) | (0.000) | (0.000) | |
| Chihuahuan Desert | −0.10554 *** | −0.03271 *** | −0.08405 *** |
| (0.000) | (0.000) | (0.000) | |
| constant | −0.00390 *** | −0.00566 *** | 0.00461 *** |
| (0.000) | (0.000) | (0.000) | |
| # obs | 1,923,782 | 1,827,031 | 1,898,686 |
| R2 | 0.182 | 0.021 | 0.196 |
| Adjusted R2 | 0.182 | 0.021 | 0.196 |
| Natural Land Cover Loss 2000–2005 | Natural Land Cover Amount 2005 | |
|---|---|---|
| Urban Distance | −0.00101 *** | 0.00137 *** |
| (0.000) | (0.000) | |
| Road Distance | −0.00074 *** | 0.00064 *** |
| (0.000) | (0.000) | |
| Elevation | −0.00004 *** | 0.00006 *** |
| (0.000) | (0.000) | |
| Slope | −0.00445 *** | 0.00572 *** |
| (0.000) | (0.000) | |
| High Agricultural Suitability | 0.03979 *** | −0.06338 *** |
| (0.001) | (0.001) | |
| Pine Oak Forest | 0.06457 *** | −0.06964 *** |
| (0.001) | (0.001) | |
| Chihuahuan Desert | −0.02074 *** | 0.01979 *** |
| (0.001) | (0.001) | |
| Constant | 0.19813 *** | 0.75283 *** |
| (0.001) | (0.001) | |
| # obs | 1,514,249 | 1,801,935 |
| R2 | 0.03 | 0.06 |
| Adjusted R2 | 0.03 | 0.06 |
| Propensity Score Matching | Protected–Unprotected Characteristics Differences | Protected–Stricter Subset | Protected–Mixed-Use Subset |
|---|---|---|---|
| Urban Distance | |||
| Pre-match difference | 60.064 *** | 19.273 *** | 69.409 *** |
| Post-match difference | −2.580 *** | −0.817 | −2.759 *** |
| % residual difference | −4.3% | −4.2% | −4.0% |
| Road Distance | |||
| Pre-match difference | 4.128 *** | 5.584 *** | 3.622 *** |
| Post-match difference | 0.223 *** | 0.174 | −0.029 |
| % residual difference | 5.4% | 3.1% | −0.8% |
| Elevation | |||
| Pre-match difference | −459.298 *** | −169.814 *** | −524.714 *** |
| Post-match difference | −126.659 *** | 26.358 ** | −61.156 *** |
| % residual difference | 27.6% | −15.5% | 11.7% |
| Slope | |||
| Pre-match difference | 0.039 *** | 0.617 *** | −0.118 *** |
| Post-match difference | −0.684 *** | −0.133 ** | −0.003 |
| % residual difference | † | −21.6% | 2.5% |
| High Agric. Suitability | |||
| Pre-match difference | −0.163 *** | −0.139 *** | −0.165 *** |
| Post-match difference | −0.049 *** | 0.013 ** | −0.002 |
| % residual difference | 30% | −9.4% | 1.2% |
| Pine Oak Forest | |||
| Pre-match difference | −0.111 *** | −0.105 *** | −0.110 *** |
| Post-match difference | −0.007 *** | −0.002 ** | −0.005 *** |
| % residual difference | 6.3% | 1.9% | 4.5% |
| Chihuahuan Desert | |||
| Pre-match difference | −0.099 *** | −0.147 *** | −0.084 *** |
| Post-match difference | −0.021 *** | −0.001 | −0.025 *** |
| % residual difference | 21.2% | 0.7% | 29.8% |
| Protected | Protected–Strict Subset | Protected–Mixed-Use Subset | |
|---|---|---|---|
| 2000–2005 Natural Land Cover Loss | |||
| Pre-match difference in means | –6.3 % *** | –7.0 % *** | –6.1%*** |
| # observations | 1,923,782 | 1,827,031 | 1,898,686 |
| Pre-match regression (all the data) | –3.5 % *** | –5.8 % *** | –2.6 % *** |
| SE | (0.001) | (0.001) | (0.001) |
| # observations | 1,626,295 | 1,537,139 | 1,603,405 |
| Post-match regression (most similar) | –3.2 % *** | –5.2 % *** | –2.7 % *** |
| SE | (0.002) | (0.003) | (0.001) |
| # observations | 181,844 | 38,633 | 143,318 |
| 2005 Natural Land Cover | |||
| Pre-match difference in means | 9.5 % *** | 10.8 % *** | 9.2 % *** |
| # observations | 1,923,782 | 1,827,031 | 1,898,686 |
| Pre-match regression (all the data) | 3.7 % *** | 6.8 % *** | 2.5 % *** |
| SE | (0.001) | (0.001) | (0.001) |
| # observations | 1,923,782 | 1,827,031 | 1,898,686 |
| Post-match regression (most similar) | 3.5 % *** | 6.3 % *** | 2.9 % *** |
| SE | (0.002) | (0.003) | (0.001) |
| # observations | 201,569 | 43,655 | 157,826 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pfaff, A.; Santiago-Ávila, F.; Joppa, L. Evolving Protected-Area Impacts in Mexico: Political Shifts as Suggested by Impact Evaluations. Forests 2017, 8, 17. https://doi.org/10.3390/f8010017
Pfaff A, Santiago-Ávila F, Joppa L. Evolving Protected-Area Impacts in Mexico: Political Shifts as Suggested by Impact Evaluations. Forests. 2017; 8(1):17. https://doi.org/10.3390/f8010017
Chicago/Turabian StylePfaff, Alexander, Francisco Santiago-Ávila, and Lucas Joppa. 2017. "Evolving Protected-Area Impacts in Mexico: Political Shifts as Suggested by Impact Evaluations" Forests 8, no. 1: 17. https://doi.org/10.3390/f8010017
APA StylePfaff, A., Santiago-Ávila, F., & Joppa, L. (2017). Evolving Protected-Area Impacts in Mexico: Political Shifts as Suggested by Impact Evaluations. Forests, 8(1), 17. https://doi.org/10.3390/f8010017