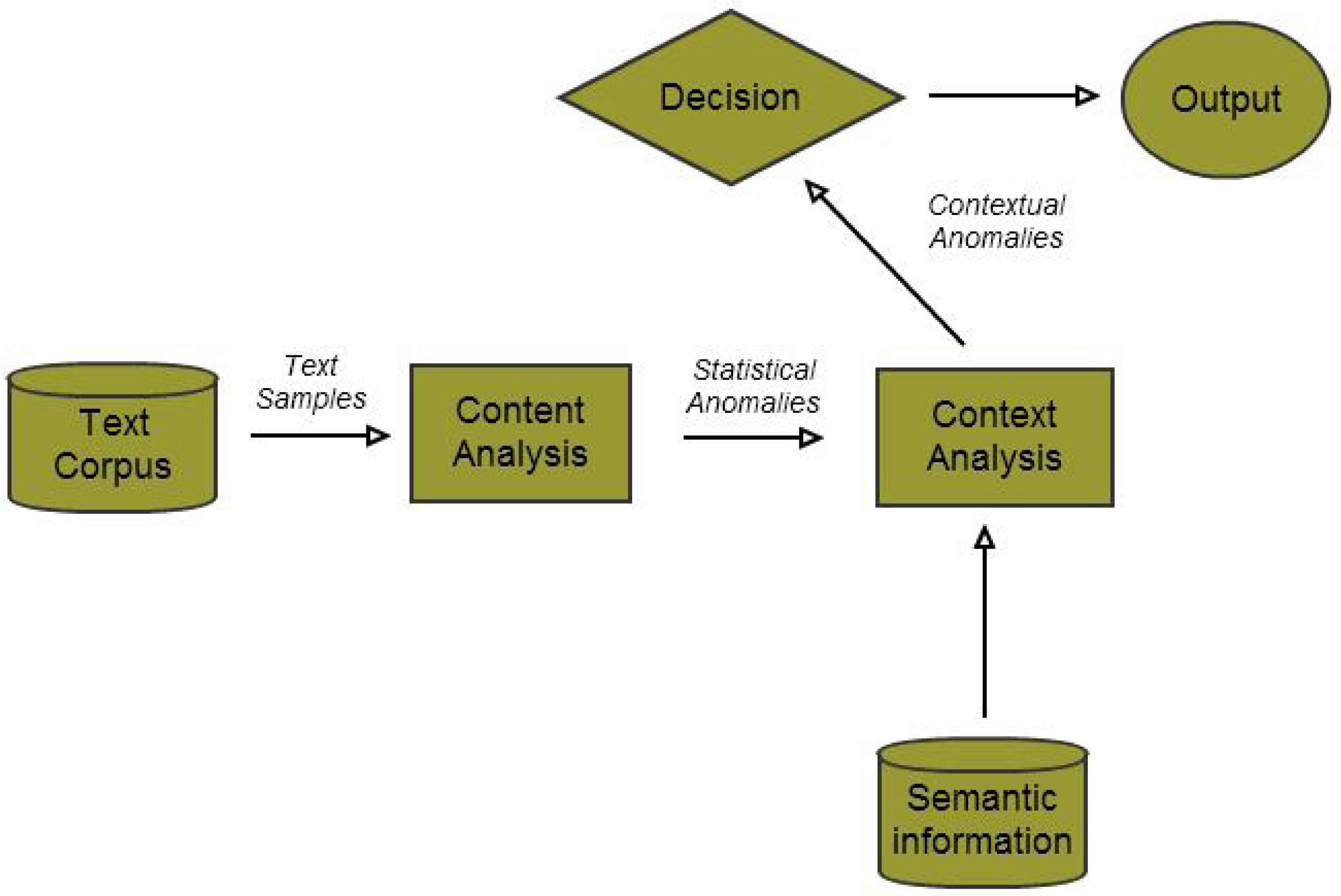
Contextual Anomaly Detection in Text Data

Abstract
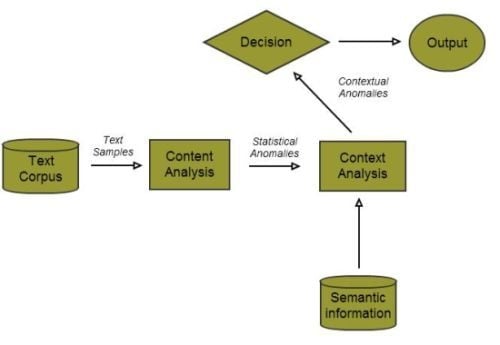
:
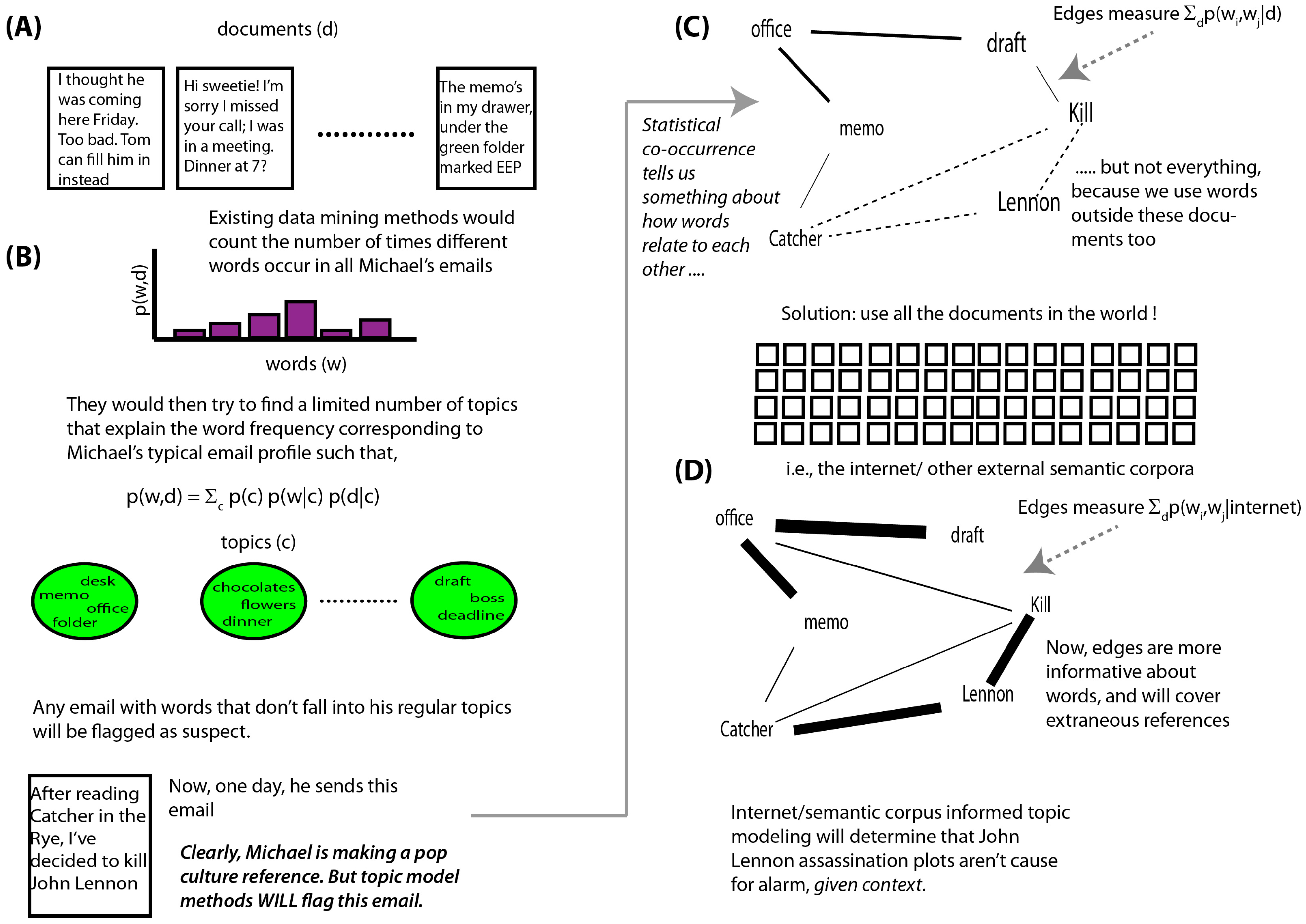
1. Introduction
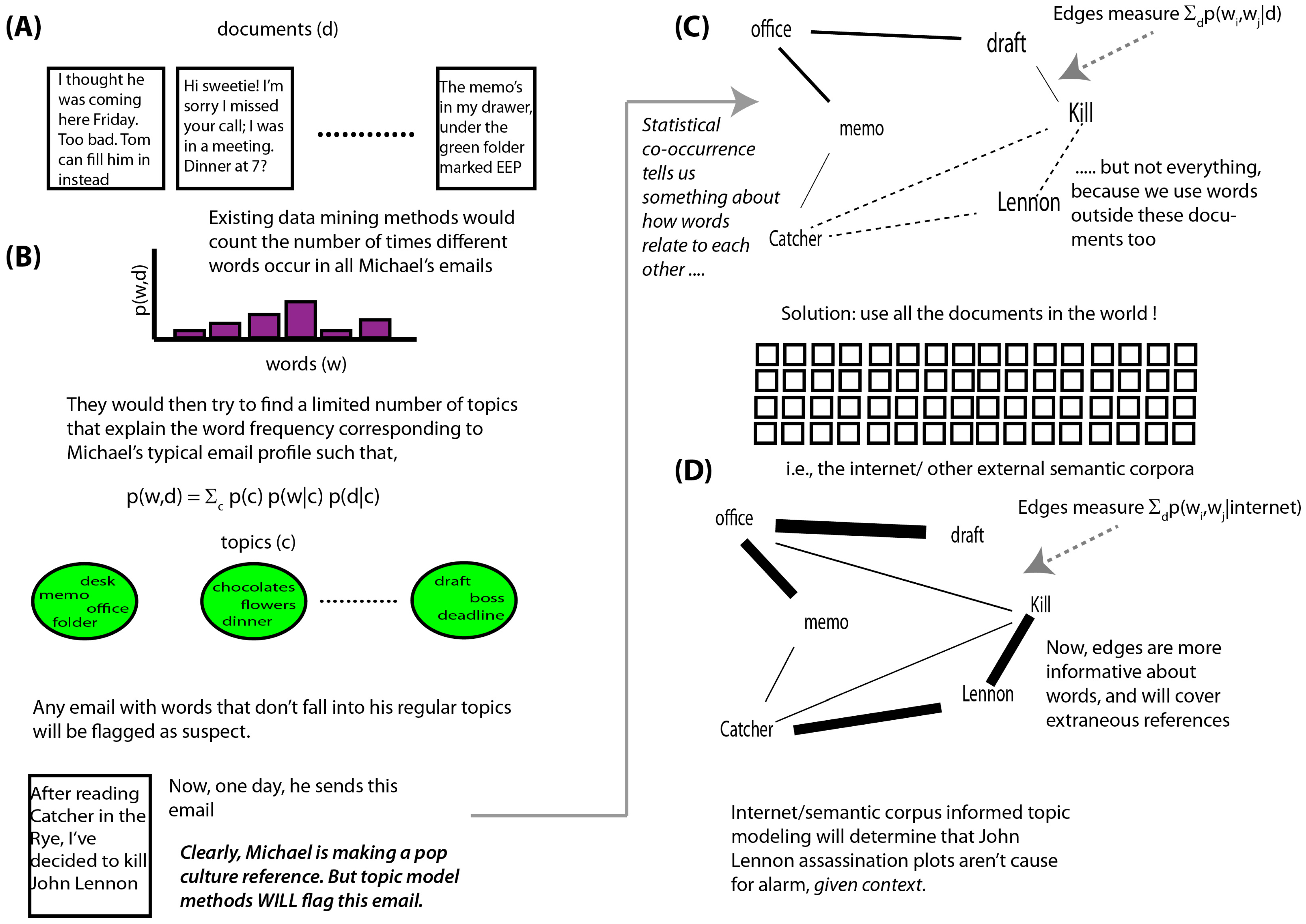
2. Related Work
3. Methods
3.1. Statistical Content Analysis

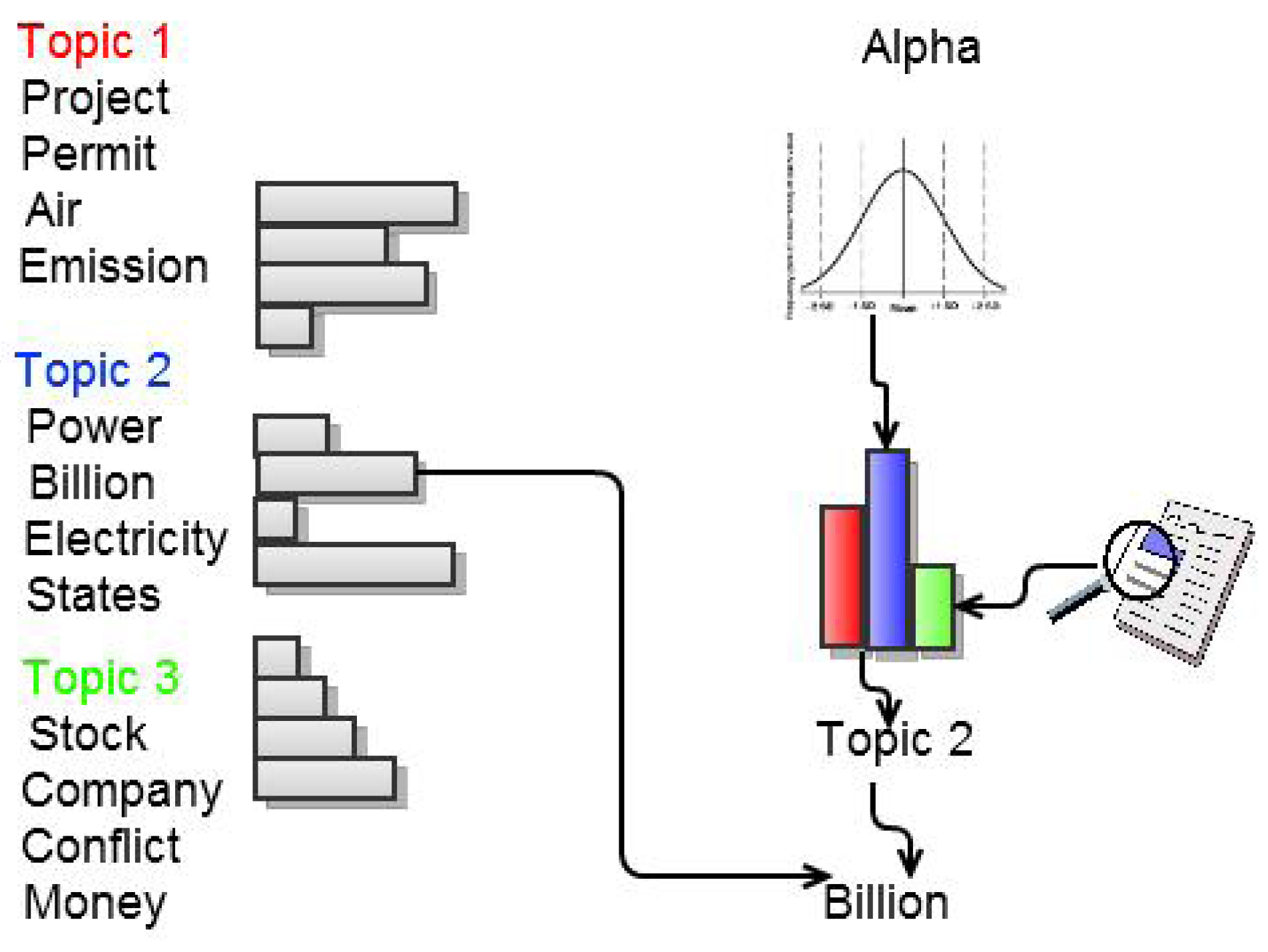

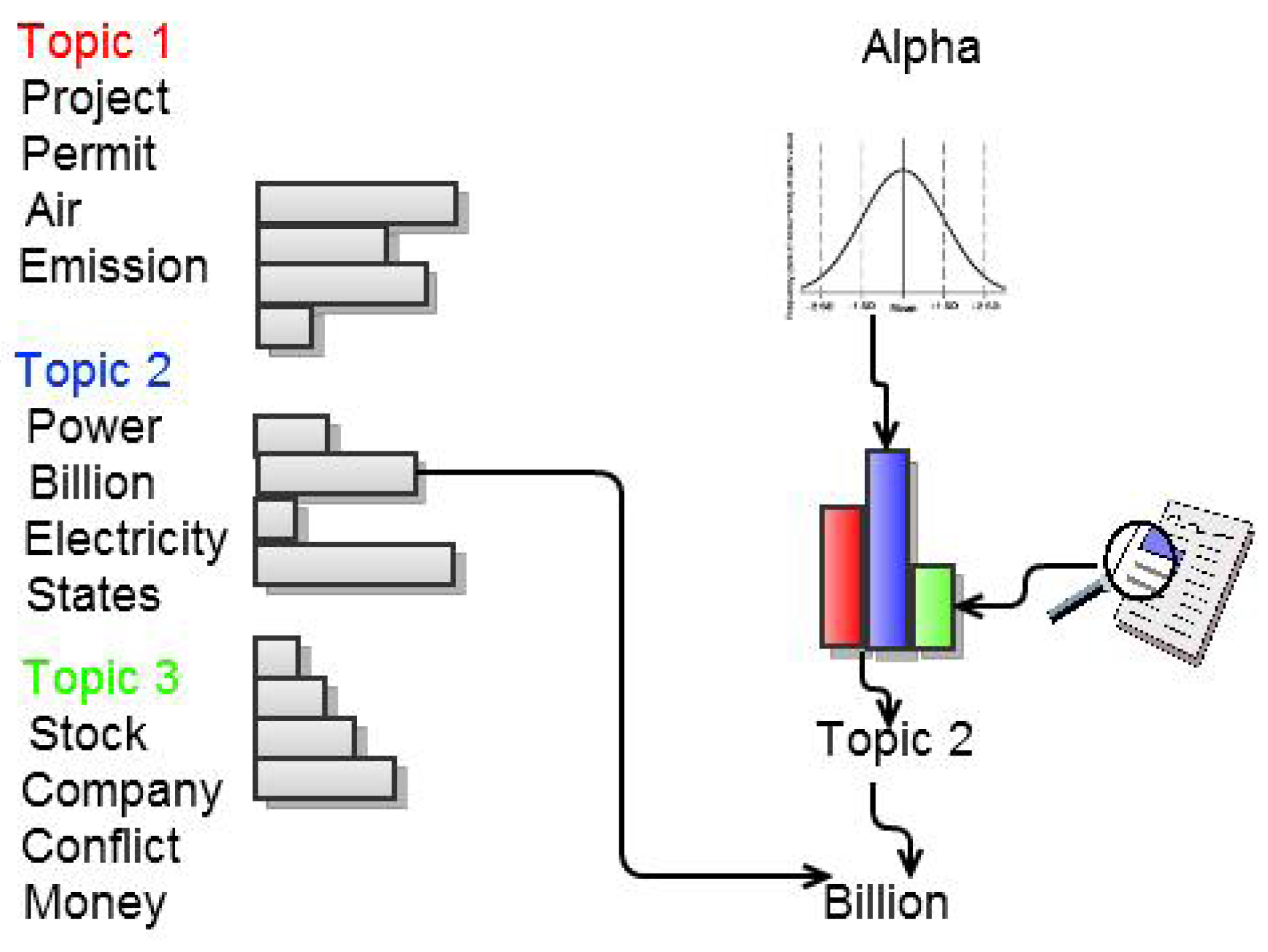
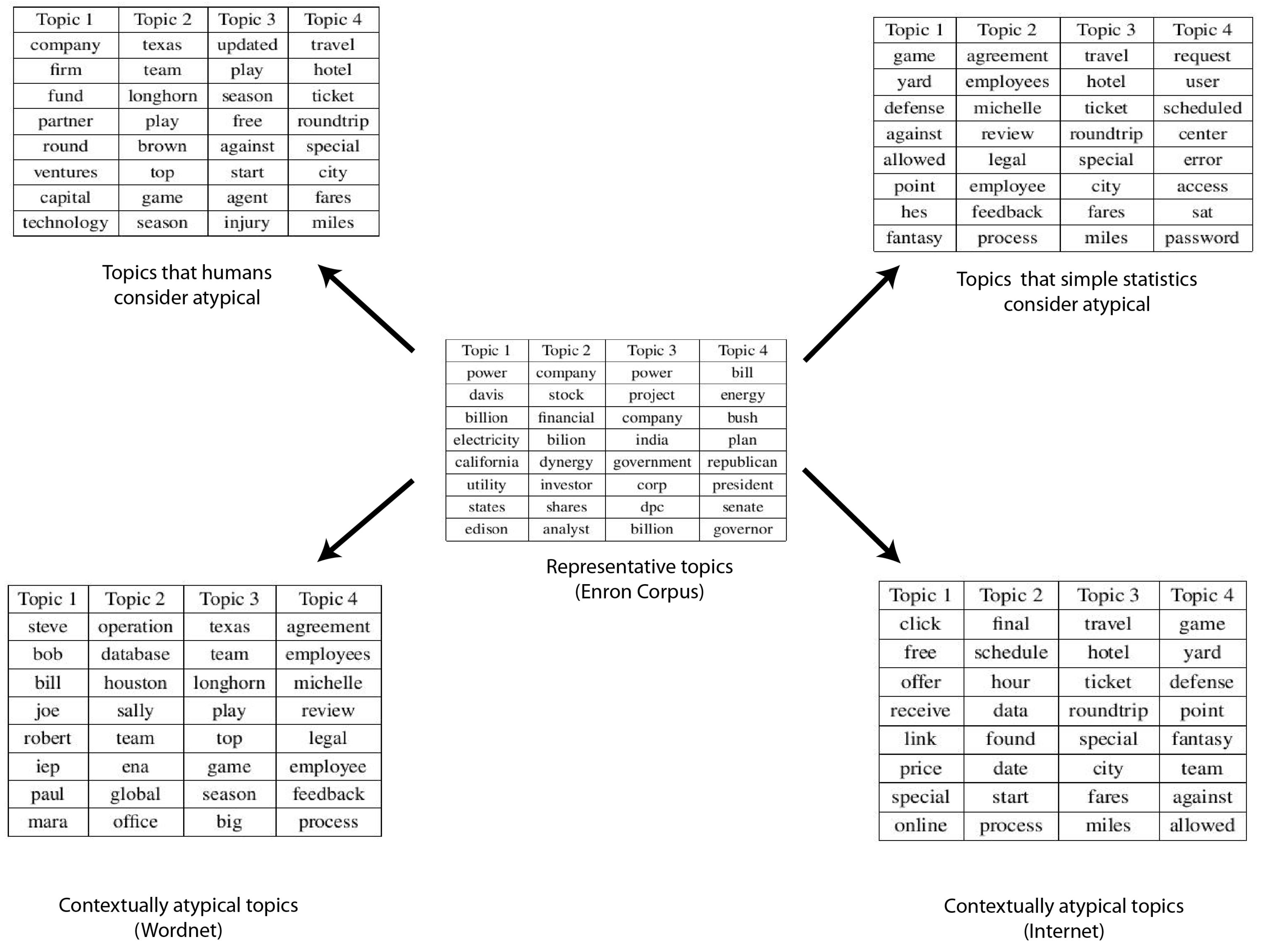
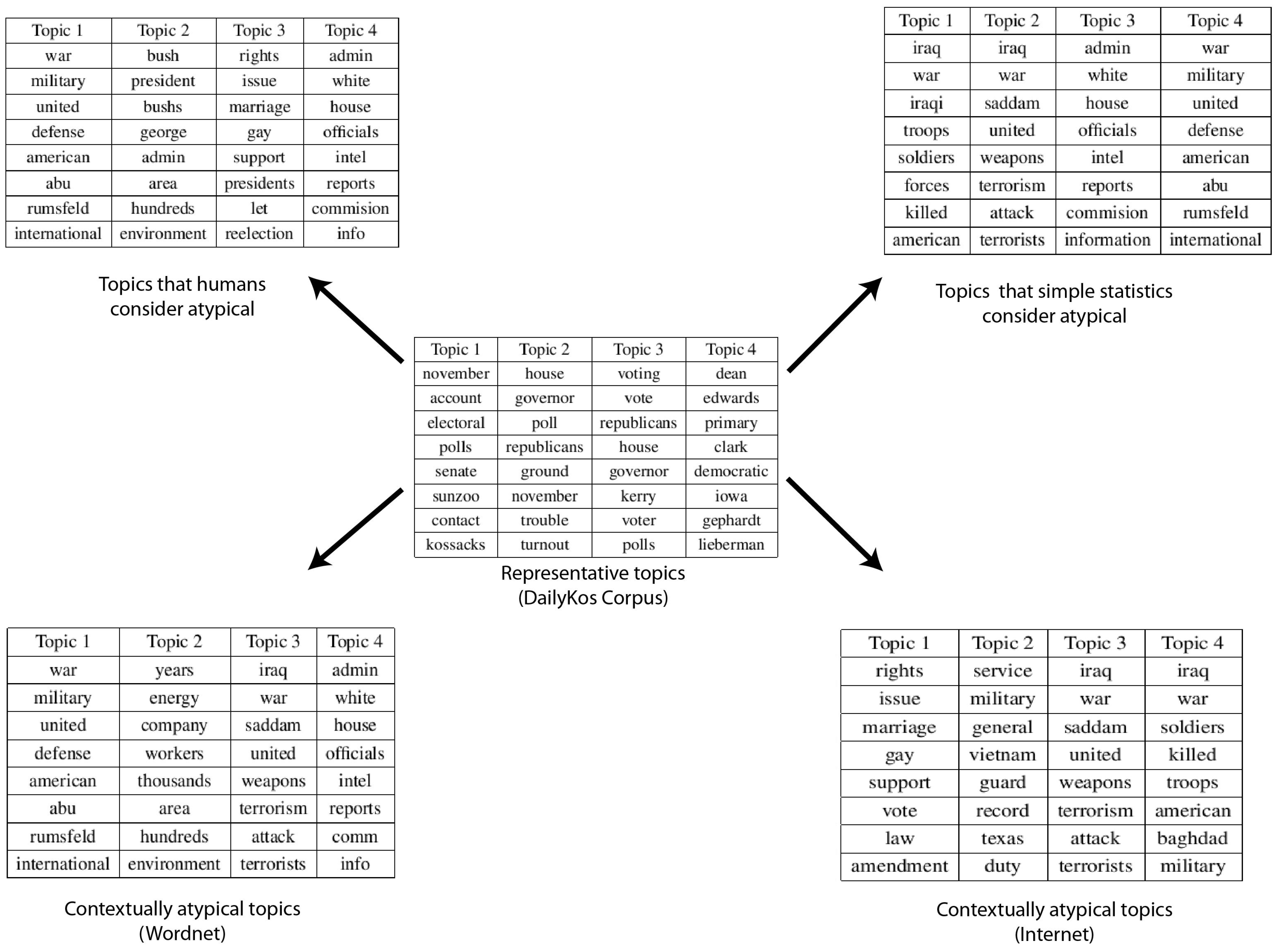
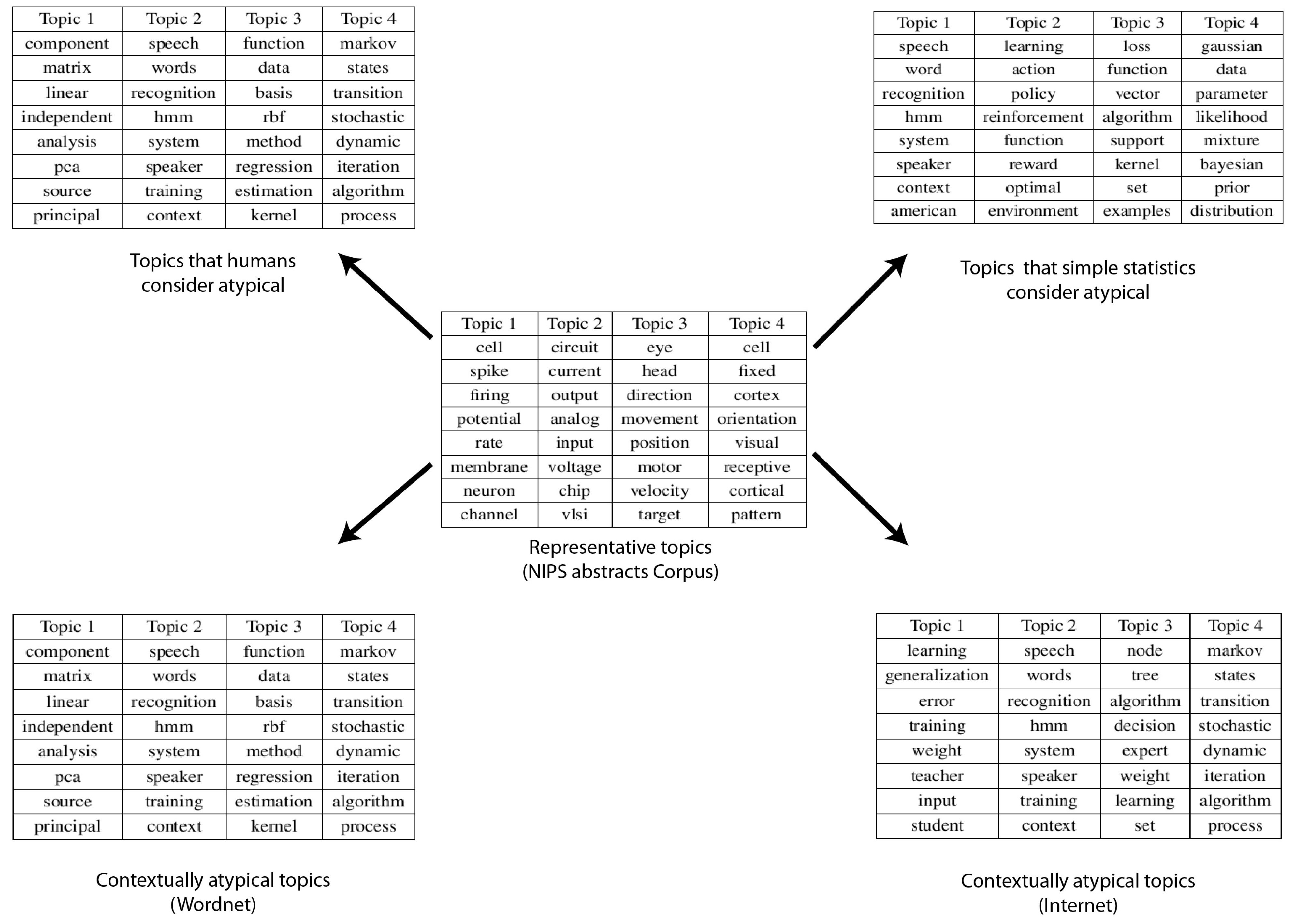
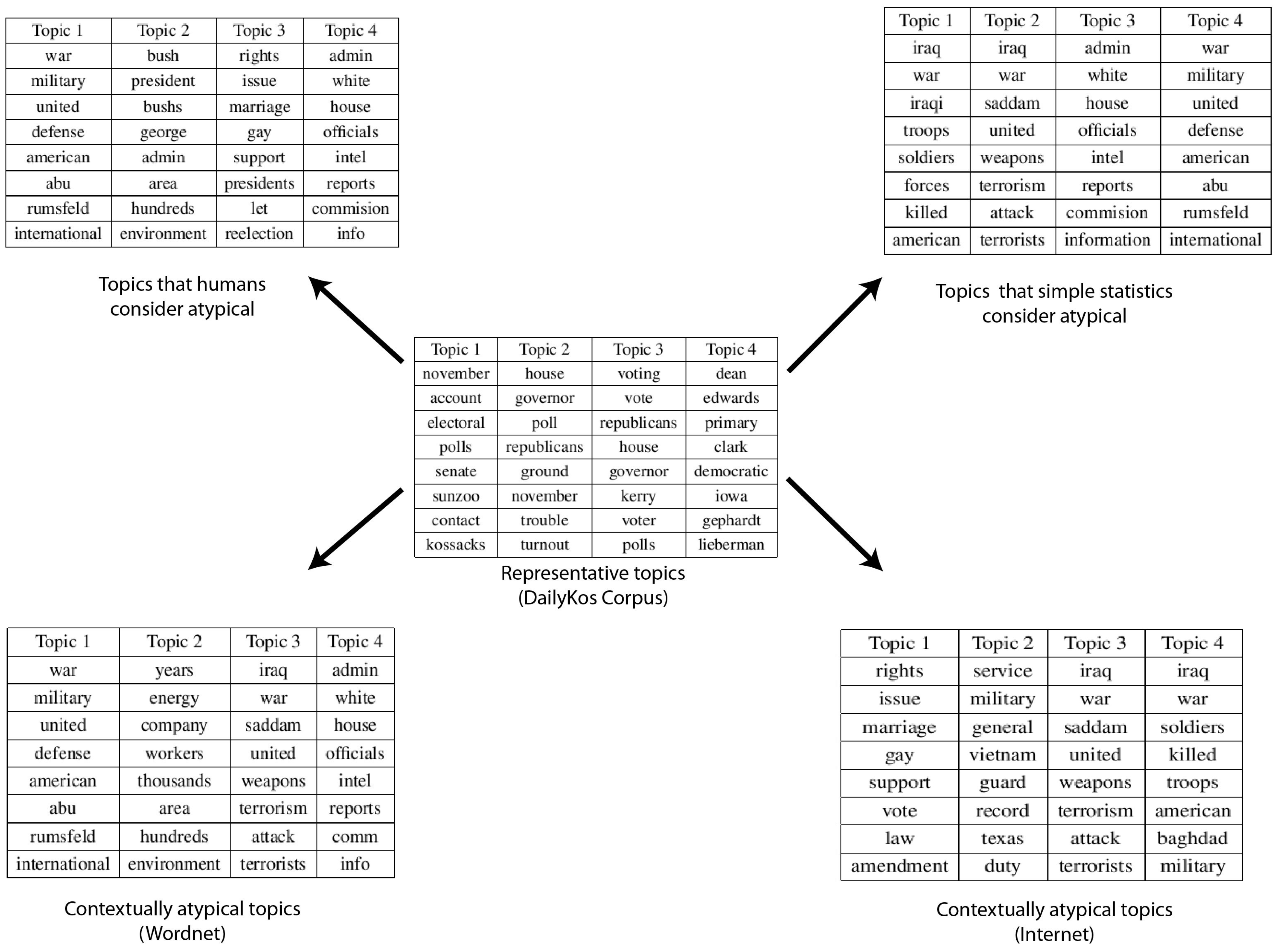
- Clustering: The text log was divided into k-Clusters using the LDA model. The values of k and other parameters (θ, α, etc.) were decided based on the size of the dataset and our understanding of the nature of the dataset. The top 10 most likely words were extracted as a representative summary of each topic.
- Ranking: The topics were ordered based on their co-usage in documents. LDA assumes every document to have been created by a mixture of topic distributions. We obtain an ordering of topics based on the assumption that topics that appear together are similar to each other and should have a low relative difference in their rankings. First, the topic distributions for each topic was calculated. Then, for each pair of topics i.e., (P, Q), the symmetrized KL divergence between topic distributions P and Q was calculated. Equation 1 shows the divergence measure between the probability distributions P and Q. Equation 2 shows the symmetrized KL divergence measure (henceforth SD), which has the properties of being symmetric and non-negative (Equations 3 and 4 ). The symmetrized KL divergence was subjected to dimensionality reduction and the first dimension was used to rank the topics [17]. We made use of the “Topic Modeling Toolbox” to conduct out experiments.
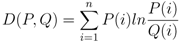
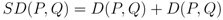
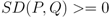
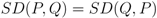
3.2. Computing Contexts
3.2.1. Computing Semantic Similarity Using WordNet
- Path Measure: Path is a network distance measure. It is simply the inverse of the number of nodes that come along the shortest path between the synsets containing the two words. It is a measure between 0 and 1. The path length is 1 if the two words belong to the same synset.
- Gloss Vectors: Gloss is a relatedness measure that uses statistical co-occurrence to compute similarity. Every set of words in WordNet is accompanied by some glossary text. This measure uses the gloss text to find similarity between words. Relatedness between concepts is measured by finding the cosine between a pair of gloss vectors. It is also a measure between 0 and 1. If two concept are exactly the same then the measure is 1 (angle between them is 0 ◦ and Cos(0) is 1).
3.2.2. Computing Semantic Similarity Using the Internet
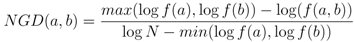
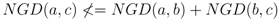
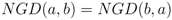
3.3. The Decision Engine
- We find the semantic distance between the first word in an anomalous topic and the first word in one of the normal topics. We aggregate it over all words in the given normal topic and aggregate that over all the words in the given anomalous topic. Let Sm(i, j) denote the similarity between the ith word in a test topic and jth word in the mth typical topic. I and J stand for the total number of words in a test topic and a typical topic respectively (10 in our case). Then relatedness of the test topic with one typical topic is measured as follows. The semantic distances used by us were the ones based on the WordNet and Normalized Google Distance as described above.
![Algorithms 05 00469 i008]()
- We then aggregate that over all the normal topics, which finally gives us a measure of similarity of the given anomalous topic with all the normal topics. M stands for the total number of typical topics. Hence, relatedness between the given pth test topic and all the typical topics is measured as follows:
![Algorithms 05 00469 i009]()
- We repeat the two steps above for all potentially anomalous topics.
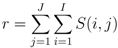
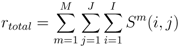
3.4. Anomaly Detection in Tag Space

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Tag Set Number | Tag Set |
|---|---|
| 1 | Education, Tutorial, Teacher, Class, Somersault |
| 2 | Yoga, Health, Exercise, Shocking |
| 3 | Lonely, Island, Holiday, Adventure, Rap |
| 4 | Cute, Babies, Funny, Laughter, Blood |

4. Results
| Dataset | Precision | Recall | F Measure | Sensitivity | Specificity |
|---|---|---|---|---|---|
| Enron without context | 0.62 | 1 | 0.77 | 1 | 0 |
| Enron with WordNet | 0.889 | 0.8 | 0.84 | 0.8 | 0.83 |
| Enron with NGD | 0.77 | 0.7 | 0.73 | 0.7 | 0.67 |
| NIPS without context | 0.25 | 1 | 0.4 | 1 | 0 |
| NIPS with WordNet | 1 | 0.8 | 0.88 | 1 | 0.9167 |
| NIPS with NGD | 0.5 | 0.5 | 0.5 | 0.5 | 0.833 |
| Kos without context | 0.43 | 1 | 0.60 | 1 | 0 |
| Kos with WordNet | 0.8 | 0.57 | 0.67 | 0.57 | 0.89 |
| Kos with NGD | 0.75 | 0.42 | 0.54 | 0.4286 | 0.88 |
4.1. Enron Email Dataset
4.2. DailyKos Blogs Dataset
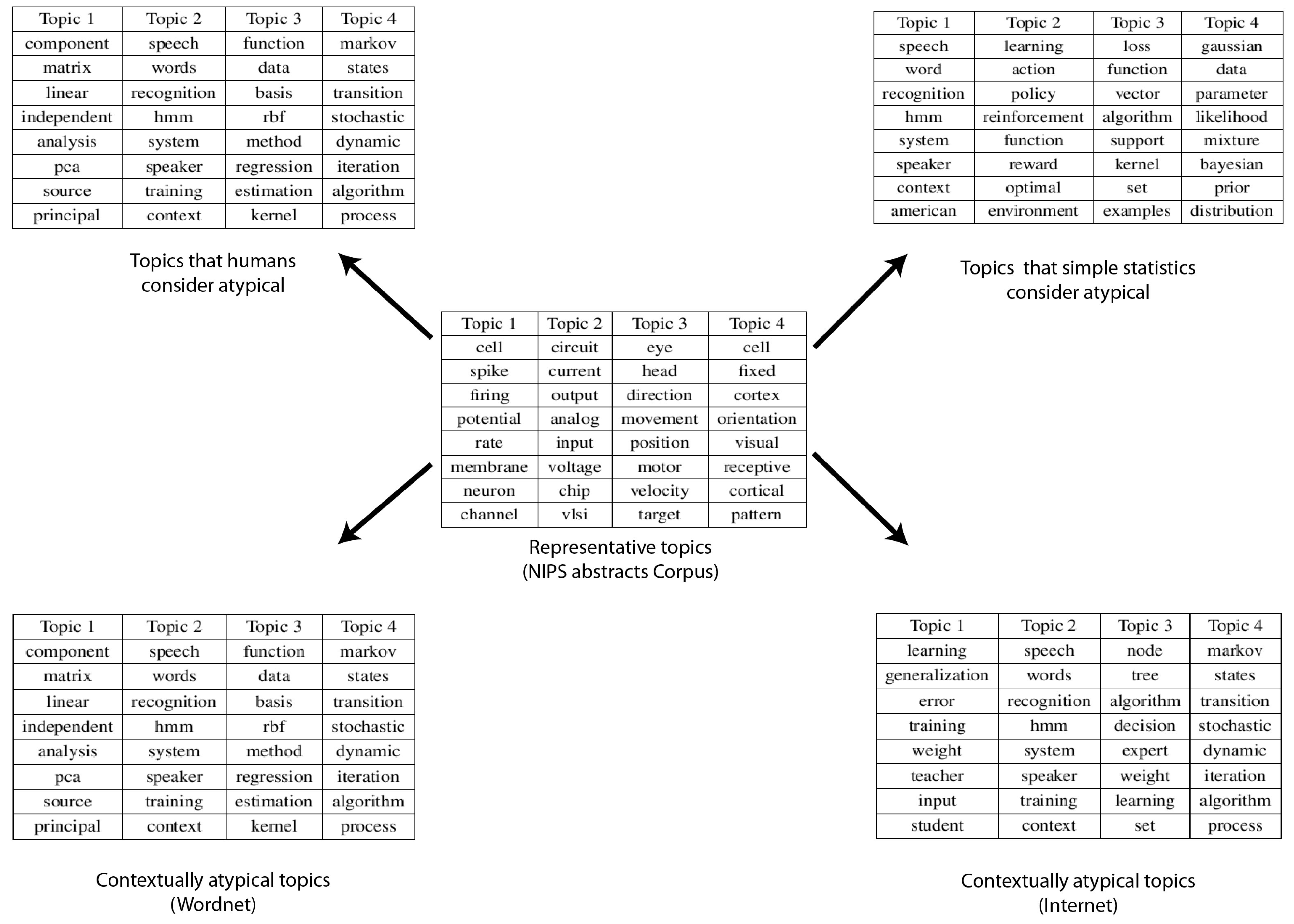
4.3. NIPS Papers Dataset
4.4. YouTube Video Tags Dataset
| Tag Set Number | Tag Set |
|---|---|
| 1 | fish, net, hook, island, U2 |
| 2 | motivational, speaker, speech, inspiration, sony |
| 3 | mouse, computer, monitor, apple, orange |
| 4 | angry, birds, game, mobile, playstation |
5. Discussion
- The first step that clusters the text corpus into topics has a complexity of O(((NT )τ (N + τ)3)) [23], where N is the number of words in the corpus, T is the number of topics in the corpus and τ is the number of topics in a document. This has polynomial run-time if τ is a constant.
- The second step that performs context incorporation has a complexity of O(m ∗n ∗k ∗k), where m is the number of training topics, n is the number of test topics and k is the number of words in a topic (k = 10 in our case).
- The overall complexity is thus O(((NT )τ (N + τ)3)) + O(m ∗n ∗k ∗k). The second step does not affect the overall complexity of the algorithm asymptotically.
Acknowledgments
References
- Chandola, V.; Banerjee, A.; Kumar, V. Anomaly detection: A survey. ACM Comput. Surv. 2009, 41, 1–58. [Google Scholar]
- Manevitz, L.; Yousef, M. Document Classification on Neural Networks Using Only Positive Examples. In Proceedings of the 23rd Annual International ACM SIGIR Conference Research and Development in Information Retrieval, New Orleans, USA, 24-28 July 2000; 34, pp. 304–306.
- Manevitz, L.; Yousef, M. One-class SVMs for document classification. J. Mach. Learning Res. 2002, 2, 139–154. [Google Scholar]
- Srivastava, A.; Zane-Ulman, B. Discovering Recurring Anomalies in Text Reports Regarding Complex Space Systems. In Proceedings of IEEE Aerospace Conference, Los Alamitos, CA, USA, 5-12 March 2005; pp. 55–63.
- Agovic, A.; Shan, H.; Banerjee, A. Analyzing Aviation Safety Reports: From Topic Modeling to Scalable Multi-label Classification. In Proceedings of the Conference on Intelligent Data Understanding, Mountain View, CA, USA, 5-6 October 2010; pp. 83–97.
- Guthrie, D.; Guthrie, L.; Allison, B.; Wilks, Y. Unsupervised Anomaly Detection. In Proceedings of the Twentieth International Joint Conference on Artificial Intelligence, Hyderabad, India, 9-12 January 2007; pp. 1626–1628.
- Lin, D. An Information-Theoretic Definition of Similarity. In Proceedings of the 15th International Conference on Machine Learning, Madison, WI, USA, 24-27 July 1998; pp. 296–304.
- Resnik, P. Using Information Content to Evaluate Semantic Similarity in a Taxonomy. In Proceedings of the 14th International Joint Conference on Artificial Intelligence, Montreal, CA, USA, 20-25 August 1995 ; pp. 448–453.
- Jiang, J.J.; Conrath, D.W. Semantic Similarity Based on Corpus Statistics and Lexical Taxonomy. In Proceedings of the International Conference on Research in Computational Linguistics, Taiwan; 1997; pp. 19–33. [Google Scholar]
- Mangalath, P.; Quesada, J.; Kintsch, W. Analogy-making as Predication Using Relational Information and LSA Vectors. In Proceedings of the 26th Annual Meeting of the Cognitive Science Society, Chicago, USA, 5-7 August 2004.
- Cilibrasi, R.; Vitanyi, P. The google similarity distance. IEEE Trans. Knowl. Data Eng. 2007, 19, 370–383. [Google Scholar]
- Bollegala, D.; Matsuo, Y.; Ishizuka, M. Measuring the Similarity between Implicit Semantic Relations from the Web. In Proceedings of the 18th International Conference on World Wide Web, ACM, Madrid, Spain, 20-24 April 2009; pp. 651–660.
- Liu, D.; Hua, X.; Yang, L.; Wang, L.; Zhang, H. Tag Ranking. In Proceedings of the 18th International Conference on The World Wide Web, Madrid, Spain, 20-24 April 2009; pp. 351–360.
- Gligorov, R.; Kate, W.; Aleksovski, Z.; Harmelen, F. Using Google Distance to Weight Approximate Ontology Matches. In Proceedings of the 16th International Conference on the World Wide Web, Banff ALberta, Canada, 8–12 May, 2007; pp. 767–776.
- Blei, D.; Ng, A.; Jordan, M. Latent Dirichlet allocation. J. Mach. Learning Res. 2003, 3, 993–1022. [Google Scholar]
- Newman, D.; Asuncion, A.; Smyth, P.; Welling, M. Distributed Inference for Latent Dirichlet Allocation. In Proceedings of NIPS 2008, Vancouver, Canada, 8-11 December 2008; MIT Press: Cambridge, MA, USA, 2008; pp. 1081–1088. [Google Scholar]
- Topic Modelling toolbox. Available online: http://psiexp.ss.uci.edu/research/programsdata (accessed on 10 August 2011).
- WordNet. Available online: http://wordnet.princeton.edu/ (accessed on 10 August 2011).
- Pedersen, T.; Patwardhan, S.; Michelizzi, J. WordNet: Similarity-measuring the Relatedness of Concepts. In Proceedings of the 19th National Conference on Artificial Intelligence, San Jose CA, USA, 25-29 July 2004; pp. 1024–1025.
- Frank, A.; Asuncion, A. UCI Machine Learning Repository. University of California: Irvine, CA, USA, 2010. Available online: http://archive.ics.uci.edu/ml (accessed on 5 July 2011).
- Srivastava, N.; Srivastava, J. A hybrid-logic Approach Towards Fault Detection in Complex Cyber-Physical Systems. In Proceedings of the Annual Conference of the Prognostics and Health Management Society, Portland, Oregon, USA, 13-16 October 2010.
- Wagstaff, K.; Rogers, S.; Schroedl, S. Constrained K-Means Clustering With Background Knowledge. In Proceedings of the International Conference on Machine Learning, Williamstown, MA, USA, 28 June-1 July 2001; pp. 577–584.
- Sontag, D.; Roy, D. Complexity of inference in Latent Dirichlet Allocation; NIPS: Grenada, Spain, 2011; pp. 1008–1016. [Google Scholar]
- Petrovi, S.; Osborne, M.; Lavrenko, V. Streaming First Story Detection with Application to Twitter. In Proceedings of the Human Language Technologies: The 2010 Annual Conference of the North American Chapter of the Association for Computational Linguistics, LA, USA, 1-6 June 2010; pp. 181–189.
- WordNet: Similarity. Available online: http://marimba.d.umn.edu/ (accessed on 10 August 2011).
© 2012 by the authors; licensee MDPI, Basel, Switzerland. This article is an open-access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Mahapatra, A.; Srivastava, N.; Srivastava, J. Contextual Anomaly Detection in Text Data. Algorithms 2012, 5, 469-489. https://doi.org/10.3390/a5040469
Mahapatra A, Srivastava N, Srivastava J. Contextual Anomaly Detection in Text Data. Algorithms. 2012; 5(4):469-489. https://doi.org/10.3390/a5040469
Chicago/Turabian StyleMahapatra, Amogh, Nisheeth Srivastava, and Jaideep Srivastava. 2012. "Contextual Anomaly Detection in Text Data" Algorithms 5, no. 4: 469-489. https://doi.org/10.3390/a5040469
APA StyleMahapatra, A., Srivastava, N., & Srivastava, J. (2012). Contextual Anomaly Detection in Text Data. Algorithms, 5(4), 469-489. https://doi.org/10.3390/a5040469