Pruning Optimization over Threshold-Based Historical Continuous Query

Abstract
:1. Introduction
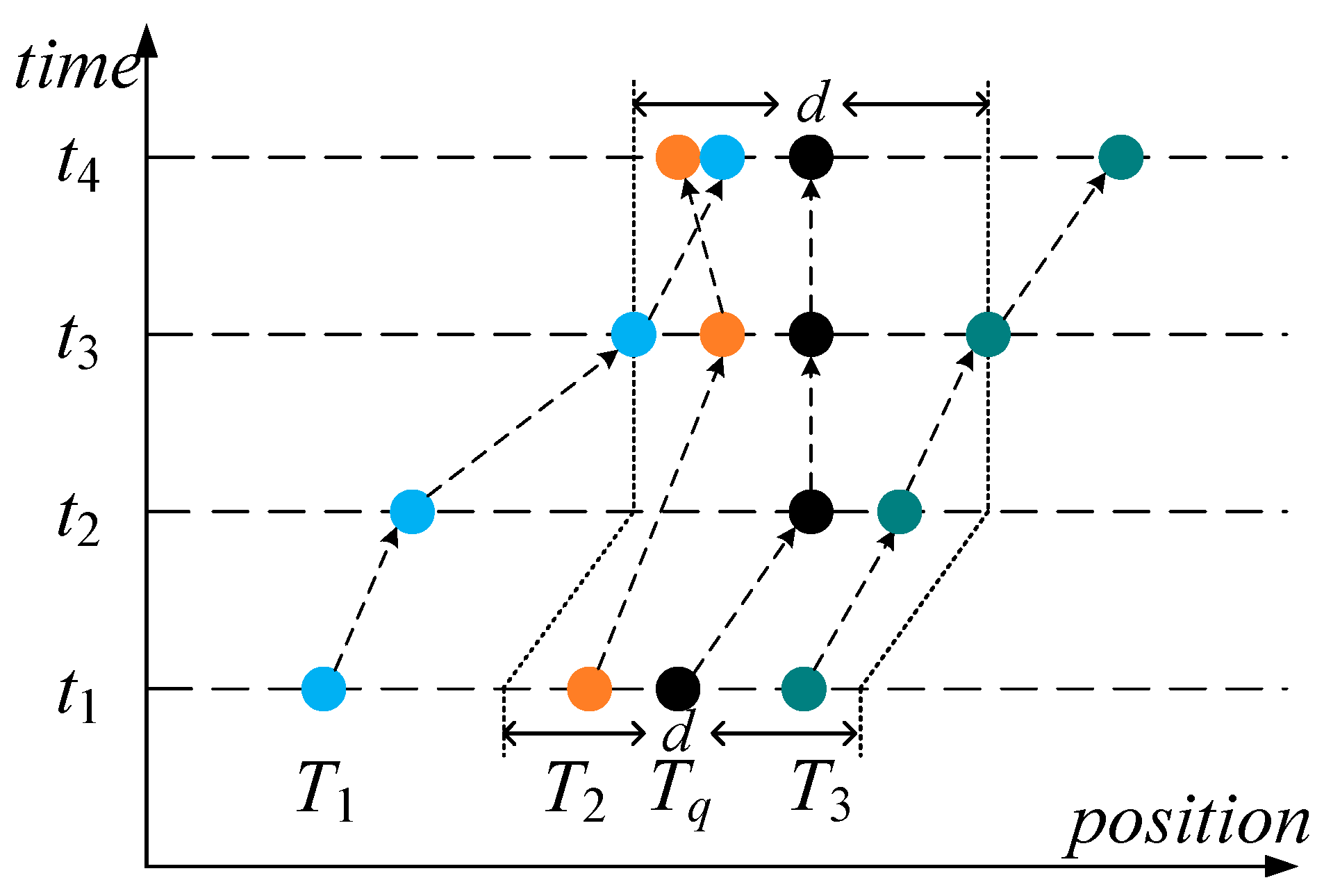
- Find which ships were within one nautical mile from the berth O1 at any time instance of the time period from 10:00 on 11 November 2015 to 10:00 on 12 November 2015.
- Find which ships were within one nautical mile from the ship O2 at any time instance of the time period from 8:00 on 12 November 2015 to 8:00 on 13 November 2015.
- We propose a pruning strategy based on extended MBR overlap to optimize the single pruning check, thereby effectively reducing the processing time.
- We introduce a best-first traversal algorithm based on E3DR tree, to obtain a precise pruning candidate set for refinement processing under the premise of effectively controlling the number of accessed nodes when traversing the indexes.
- We evaluate our method with the dataset of ship trajectory, the experimental results verify the efficiency.
2. Related Work
3. Background
4. Pruning Optimization
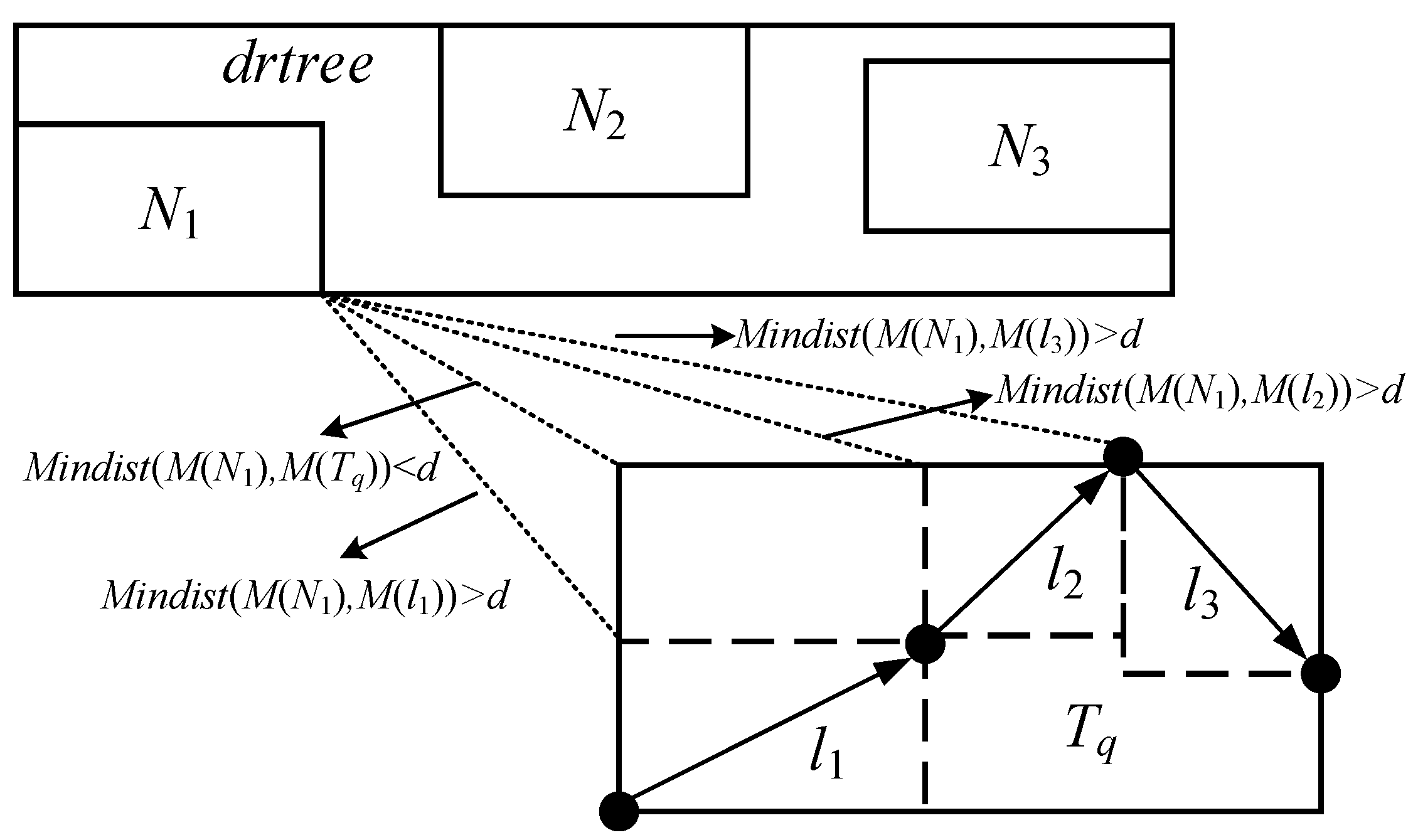
4.1. Extended MBR Overlap Based Pruning Strategy
- Check whether the time interval of Nd overlaps with the time interval of Tq, if , then Nd should be pruned.
- Determine whether the Mindist between the MBR of Nd and the MBR of Tq is not greater than the distance threshold d, if , then Nd should be pruned.
- The algorithm first determines whether the time interval of Nd overlaps with the time interval of Tq. If there is overlap between the two, the algorithm will perform the next step, and return false otherwise (line 1 to 3).
- Whether overlaps with is checked. If any exist, the algorithm will continue to the next step. Otherwise, the false is returned (line 4 to 6).
- The algorithm judges whether overlaps with or . If no overlaps exist, the next step will be performed. Otherwise true is returned (line 7 to 9).
- Whether the value of is not larger than d is checked. The return value is true if . Otherwise false is returned (line 10 to 14).
| Algorithm 1. EMOB Pruning Strategy |
| Input: Query trajectory Tq, drtree node Nd, Distance Threshold d; Output: The true value means retaining Nd, the false value means pruning Nd;
|
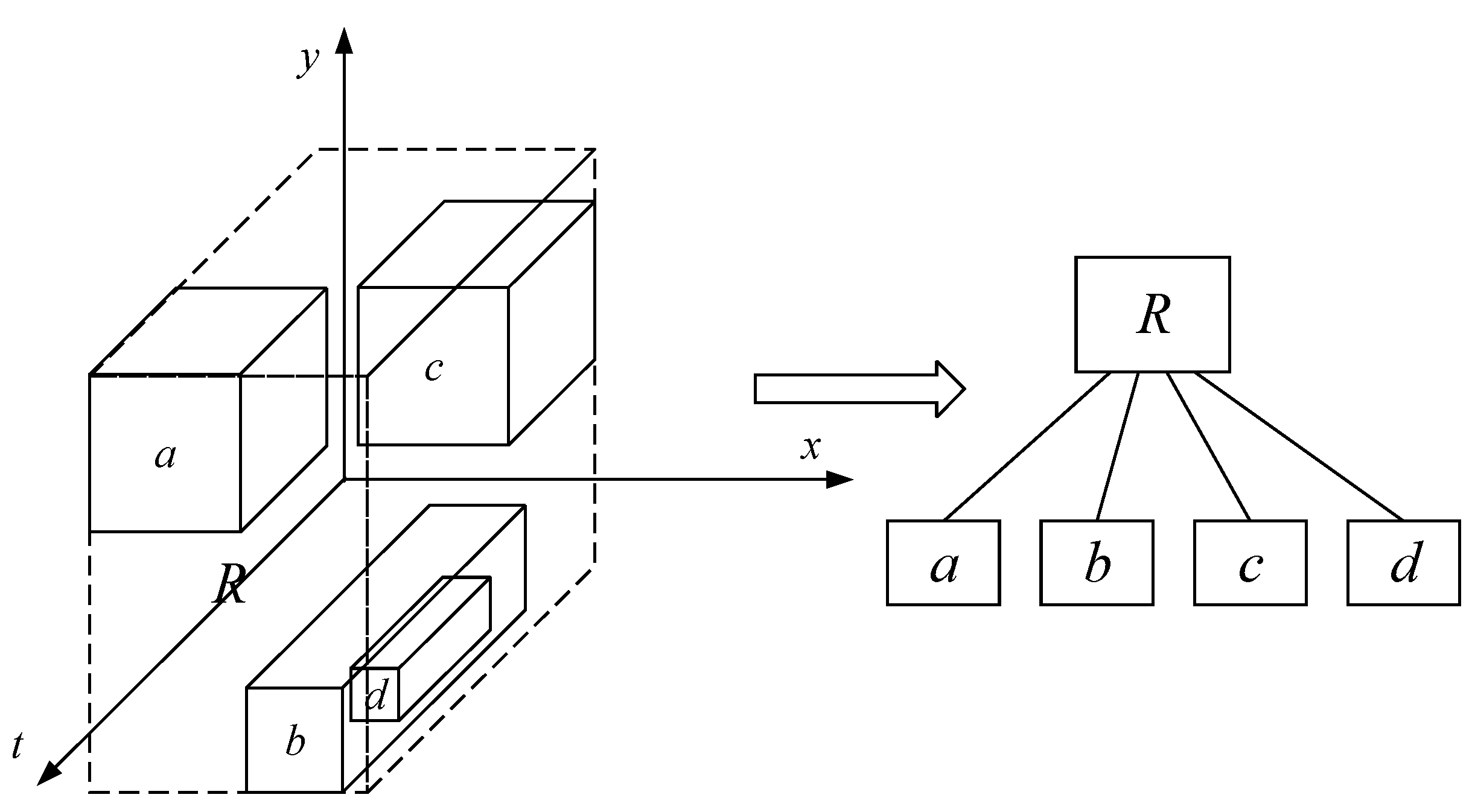
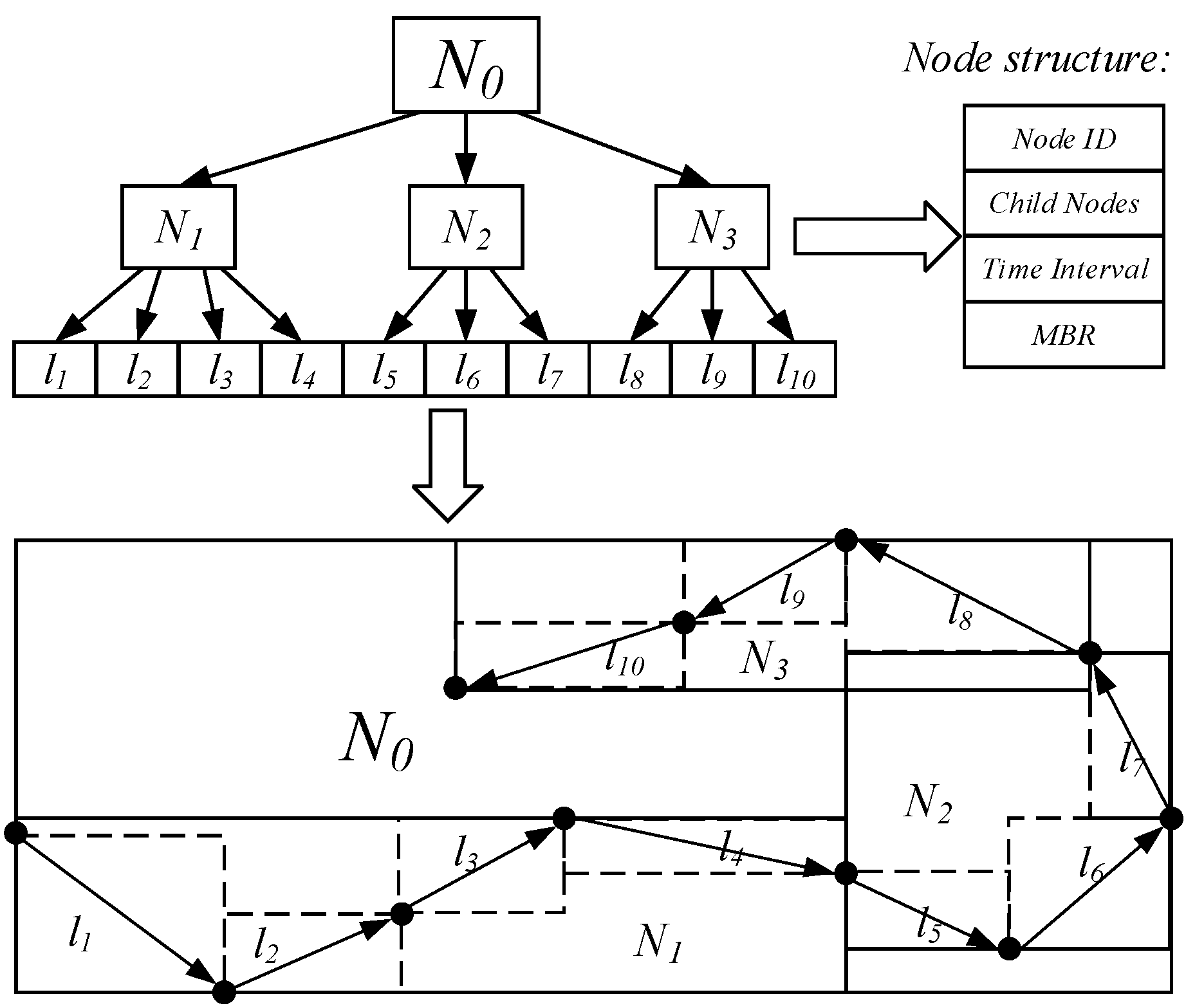
4.2. E3DR-Tree
- Node selection condition. Whenever a trajectory segment is inserted, the node with the smallest change in the time interval is selected as the inserted node.
- Node split processing. When a node needs to be split, while balancing the number of child nodes included in the new nodes, it is also necessary to ensure that the time intervals of new nodes have no overlap.
- The child nodes (or trajectory segments) of a node are sorted in the ascending order of the start timestamp of the corresponding time interval.
4.3. Best-First Traversal Algorithm
- (1)
- Node Nq—a qrtree node, which can be an index node or a trajectory segment;
- (2)
- Height hq—the height from Nq to the trajectory segment layer of qrtree. if , then Nq is a trajectory segment. In addition, the F-entries in a FirstPQ are sorted by hq value (largest to smallest).
- (3)
- Timestamp tq—the starting timestamp of the time interval of Nq. In addition, tq is the secondary keyword for sorting F-entries, when two F-entries have the same hq value, they are sorted by tq value (smallest to largest).
- (4)
- SecPQ SPQ—a SecPQ that records the qrtree nodes which pass the pruning check with Nq.
- (1)
- Node Nd—a drtree node, which can be an index node or a trajectory segment;
- (2)
- Height hd—the height from Nd to the trajectory segment layer of drtree. if , then Nd is a trajectory segment. In addition, the S-entries in a SecPQ are sorted by hd value (largest to smallest).
- (3)
- Timestamp td—the starting timestamp of the time interval of Nd. In addition, td is the secondary keyword for sorting S-entries, when two S-entries have the same hd value, they are sorted by td value (smallest to largest).
- Case 1 (At least one of fe1.hq and se1.hd is not 0, and -): The child nodes of fe1.Nq are traversed by the function TRA-Q(FPQ, fe1, d), and when each child node is accessed, the pruning check is performed for the drtree node of each S-entry in fe1.SPQ (lines 12 to 13). The pseudo code of the function TRA-Q(FPQ, fe1, d) is shown in Algorithm 3.
- Case 2 (At least one of fe1.hq and se1.hd is not 0, and ): The child nodes of se1.Nd are traversed by the function TRA-D(FPQ, fe1, d), and the pruning check is performed when each child node is accessed (lines 14 to 15). The pseudo code of the function TRA-D(FPQ, fe1, d) is shown in Algorithm 4.
- Case 3 (Both of fe1.hq and se1.hd are 0): Namely both of fe1.Nq and se1.Nd are the trajectory segments. Moreover, according to the ordering rule of SecPQ, the drtree node of any S-entry in fe1.SPQ is also a trajectory segment and is a candidate of fe1.Nq. Therefore, fe1 can be regarded as a pruning result and added to Ps (line 16 to 17).
| Algorithm 2. Best-First Traversal Algorithm |
| Input: Query Trajectory Tq, distance threshold d, drtree; Output: Pruning results Ps;
|
- Initialize a SecPQ CSPQ (line 2);
- Loop read each S-entry of fe1.SPQ (without dequeuing), let cse be the current read S-entry if cse.Nd is not pruned, then cse is inserted into CSPQ (lines 3 to 7).
- Create a new F-entry for Cq by using the relevant parameters and insert it into FPQ (line 8).
| Algorithm 3. TRA-Q(FPQ, fe1, d) |
| Input: FirstPQ FPQ, F-entry fe1, distance threshold d; Output: Null;
|
- Dequeue the head S-entry se1 from fe1.SPQ (line);
- Traverse the child nodes of se1.Nd, and perform the pruning check for each child node Cd, if Cd is not pruned, then an S-entry is created for Cd and inserted into fe1.SPQ (line 2 to 6);
- Insert fe1 into FPQ again (line 7).
| Algorithm 4. TRA-D(FPQ, fe1, d) |
| Input: FirstPQ FPQ, F-entry fe1, distance threshold d; Output: Null;
|
4.4. Performance Analysis
5. Experiment
5.1. Experimental Set Up
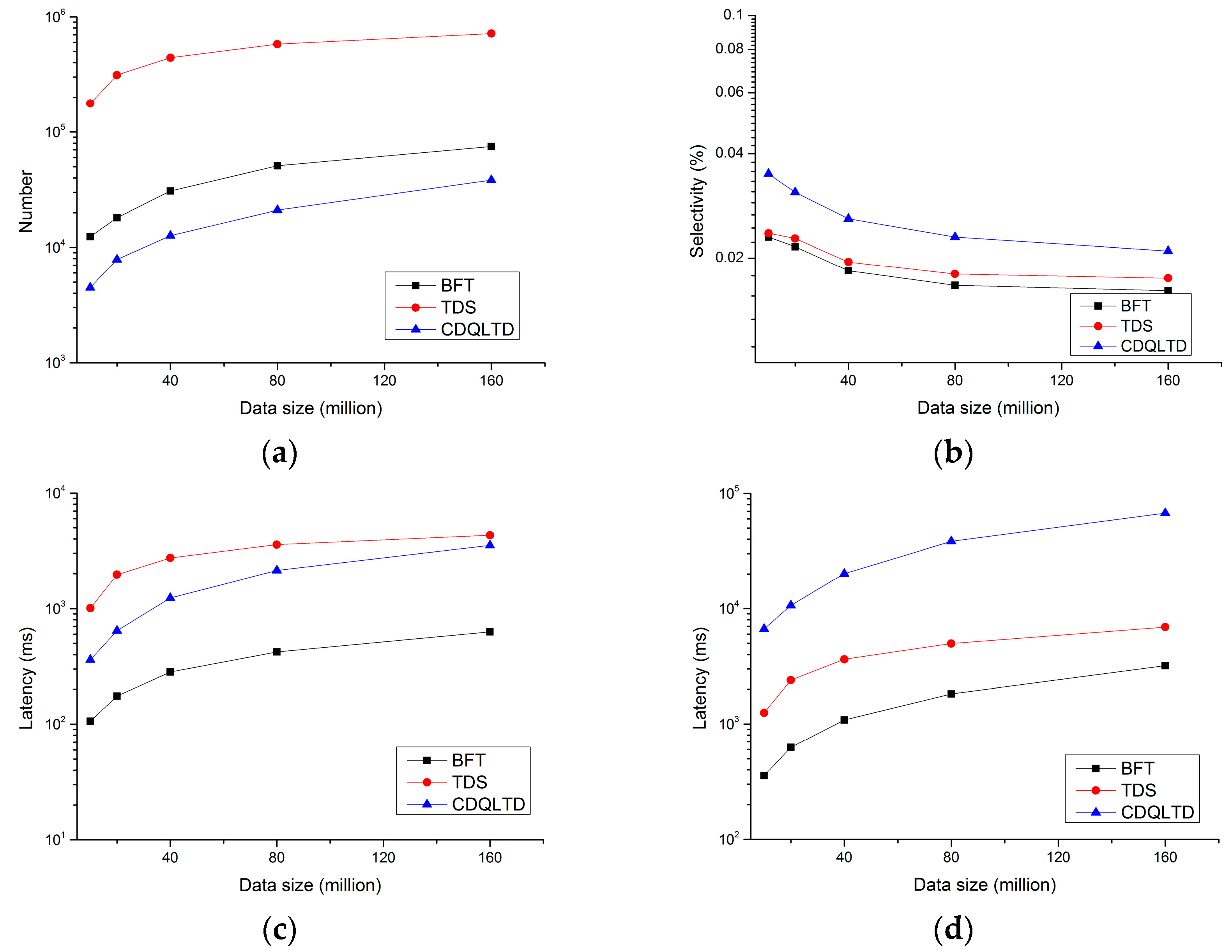
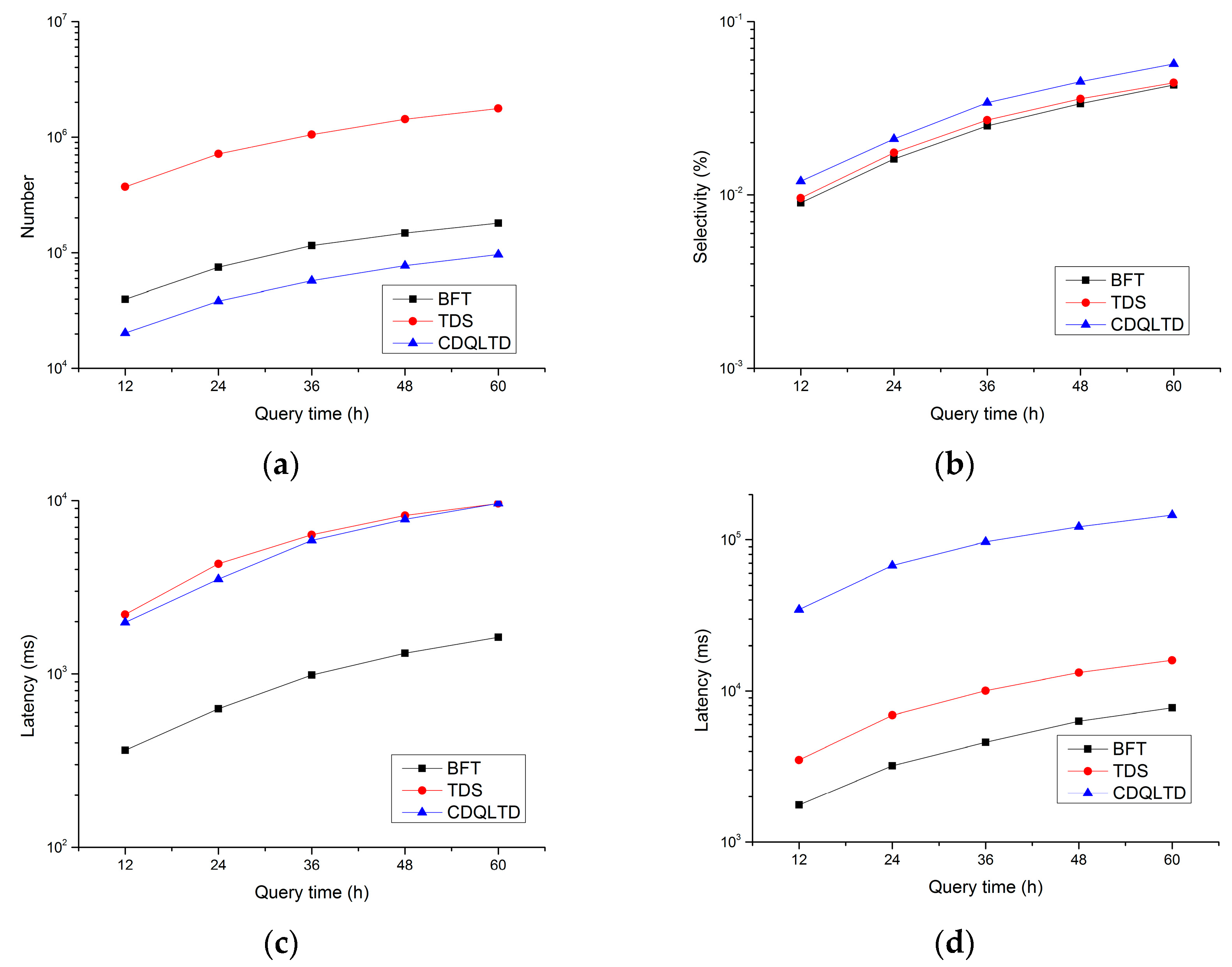
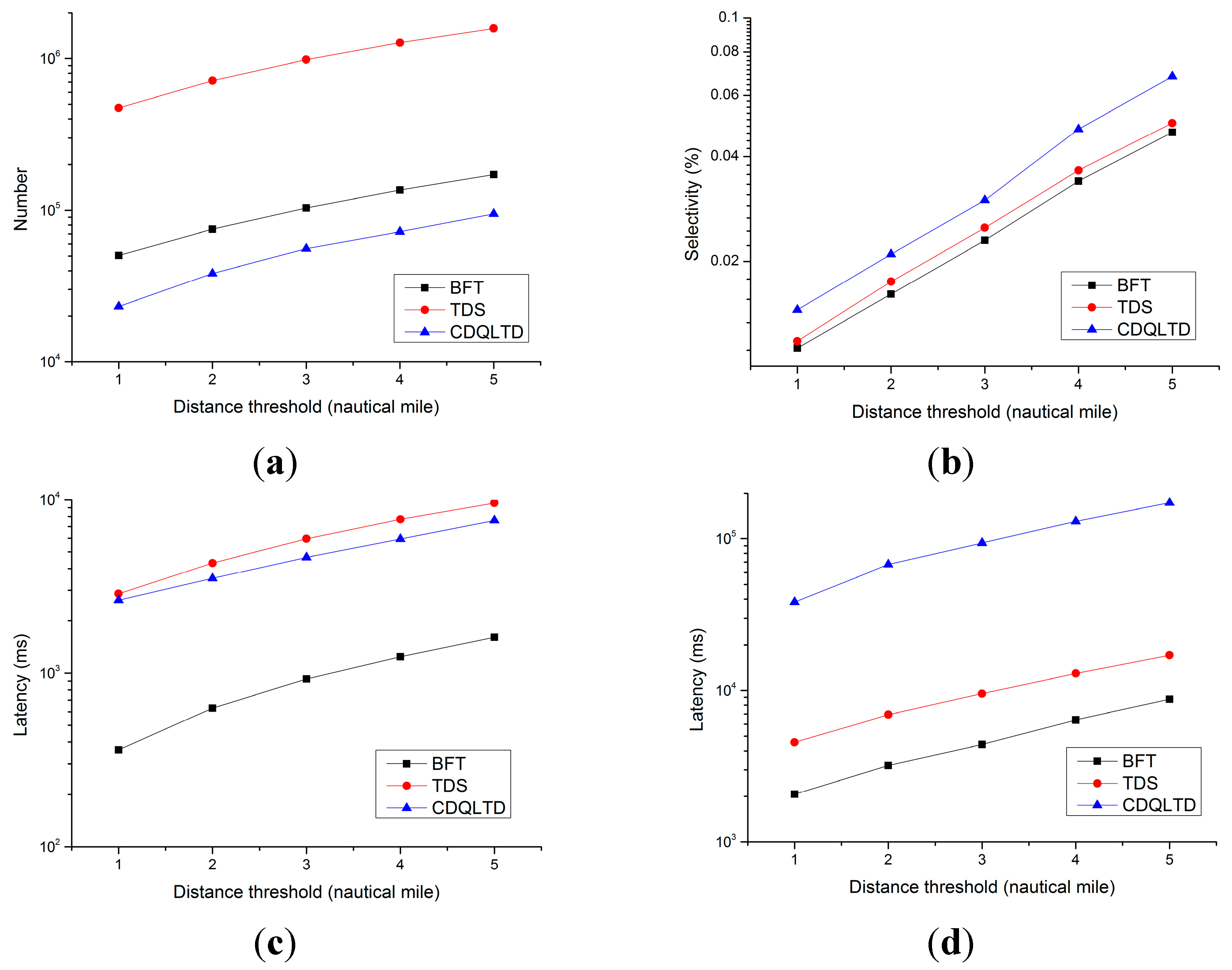
- Number of the accessed nodes: The sum of the number of index nodes and the number of trajectory segments checked during pruning;
- Selectivity: The ratio of the number of candidate trajectory segments obtained by pruning to the number of trajectory segments contained in the dataset;
- Pruning Latency: The execution time of the pruning step during a query;
- Query Latency: The execution time of a query.
5.2. Performance of Different Data Scales
5.3. Performance of Different Time Ranges
5.4. Performance of Different Distance Thresholds
5.5. Summary of the Experiments
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Zhang, Z.; Jin, C.; Mao, J.; Yang, X.; Zhou, A. TrajSpark: A Scalable and Efficient In-Memory Management System for Big Trajectory Data. In Proceedings of the Asia-Pacific Web (APWeb) and Web-Age Information Management (WAIM) Joint Conference on Web and Big Data, Beijing, China, 7–9 July 2017. [Google Scholar]
- Salmon, L.; Ray, C. Design principles of a stream-based framework for mobility analysis. GeoInformatica 2017, 21, 237–261. [Google Scholar] [CrossRef]
- Nutanong, S.; Ali, M.E.; Tanin, E.; Mouratidis, K. Dynamic Nearest Neighbor Queries in Euclidean Space. Encycl. GIS 2015, 1–7. [Google Scholar]
- Trajcevski, G.; Tamassia, R.; Cruz, I.F.; Scheuermann, P.; Hartglass, D.; Zamierowski, C. Ranking continuous nearest neighbors for uncertain trajectories. VLDB J. 2011, 20, 767–791. [Google Scholar] [CrossRef]
- Theodoridis, Y.; Vazirgiannis, M.; Sellis, T. Spatio-temporal indexing for large multimedia applications. In Proceedings of the Third IEEE International Conference on Multimedia Computing and Systems, Hiroshima, Japan, 17–23 June 1996. [Google Scholar]
- Frentzos, E.; Gratsias, K.; Pelekis, N.; Theodoridis, Y. Algorithms for nearest neighbor search on moving object trajectories. Geoinformatica 2007, 11, 159–193. [Google Scholar] [CrossRef]
- Papadias, D.; Zhang, J.; Mamoulis, N.; Tao, Y. Query processing in spatial network databases. In Proceedings of the 29th International Conference on Very Large Data Bases, Berlin, Germany, 9–12 September 2003. [Google Scholar]
- Pfoser, D.; Jensen, C.S.; Theodoridis, Y. Novel Approaches in Query Processing for Moving Object Trajectories. In Proceedings of the 26th International Conference on Very Large Data Bases, Cairo, Egypt, 10–14 September 2000. [Google Scholar]
- Güting, R.H.; Behr, T.; Xu, J. Efficient k-nearest neighbor search on moving object trajectories. VLDB J. 2010, 19, 687–714. [Google Scholar]
- Gowanlock, M.; Casanova, H. In-memory distance threshold queries on moving object trajectories. In Proceedings of the Sixth International Conference on Advances in Databases, Knowledge, and Data Applications, Chamonix, France, 20–25 April 2014. [Google Scholar]
- Dagum, L.; Menon, R. OpenMP: An industry-standard API for shared-memory programming. CiSE 1998, 1, 46–55. [Google Scholar] [CrossRef]
- Huorong, H.; Jianqiu, X.; Xiaolin, Q. Continuous Distance Queries over Large Trajectory Data. J. Chin. Comput. Syst. 2017, 38, 2505–2510. (In Chinese) [Google Scholar]
- Chakka, V.P.; Everspaugh, A.; Patel, J.M. Indexing large trajectory data sets with SETI. CIDR 2003, 75, 76. [Google Scholar]
- Gowanlock, M.; Casanova, H. Distance threshold similarity searches on spatiotemporal trajectories using GPGPU. In Proceedings of the 2014 21st International Conference on High Performance Computing (HiPC), Goa, India, 17–20 December 2014. [Google Scholar]
- Gowanlock, M.; Casanova, H. Indexing of spatiotemporal trajectories for efficient distance threshold similarity searches on the GPU. In Proceedings of the 2015 IEEE International Parallel and Distributed Processing Symposium, Hyderabad, India, 25–29 May 2015. [Google Scholar]
- Gowanlock, M.; Casanova, H. Distance threshold similarity searches: Efficient trajectory indexing on the GPU. IEEE Trans. Parallel Distrib. Syst. 2016, 27, 2533–2545. [Google Scholar] [CrossRef]
- Mahmood, A.R.; Punni, S.; Aref, W.G. Spatio-temporal access methods: A survey (2010–2017). GeoInformatica 2019, 23, 1–36. [Google Scholar] [CrossRef]
- Nutanong, S.; Jacox, E.H.; Samet, H. An Incremental Hausdorff Distance Calculation Algorithm. Proc. VLDB Endow. 2011, 4, 506–517. [Google Scholar] [CrossRef]
- Harati-Mokhtari, A.; Wall, A.; Brooks, P.; Wang, J. Automatic Identification System (AIS): Data reliability and human error implications. J. Navig. 2007, 60, 373–389. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Description |
|---|---|
| the time interval of x | |
| the spatial MBR of x | |
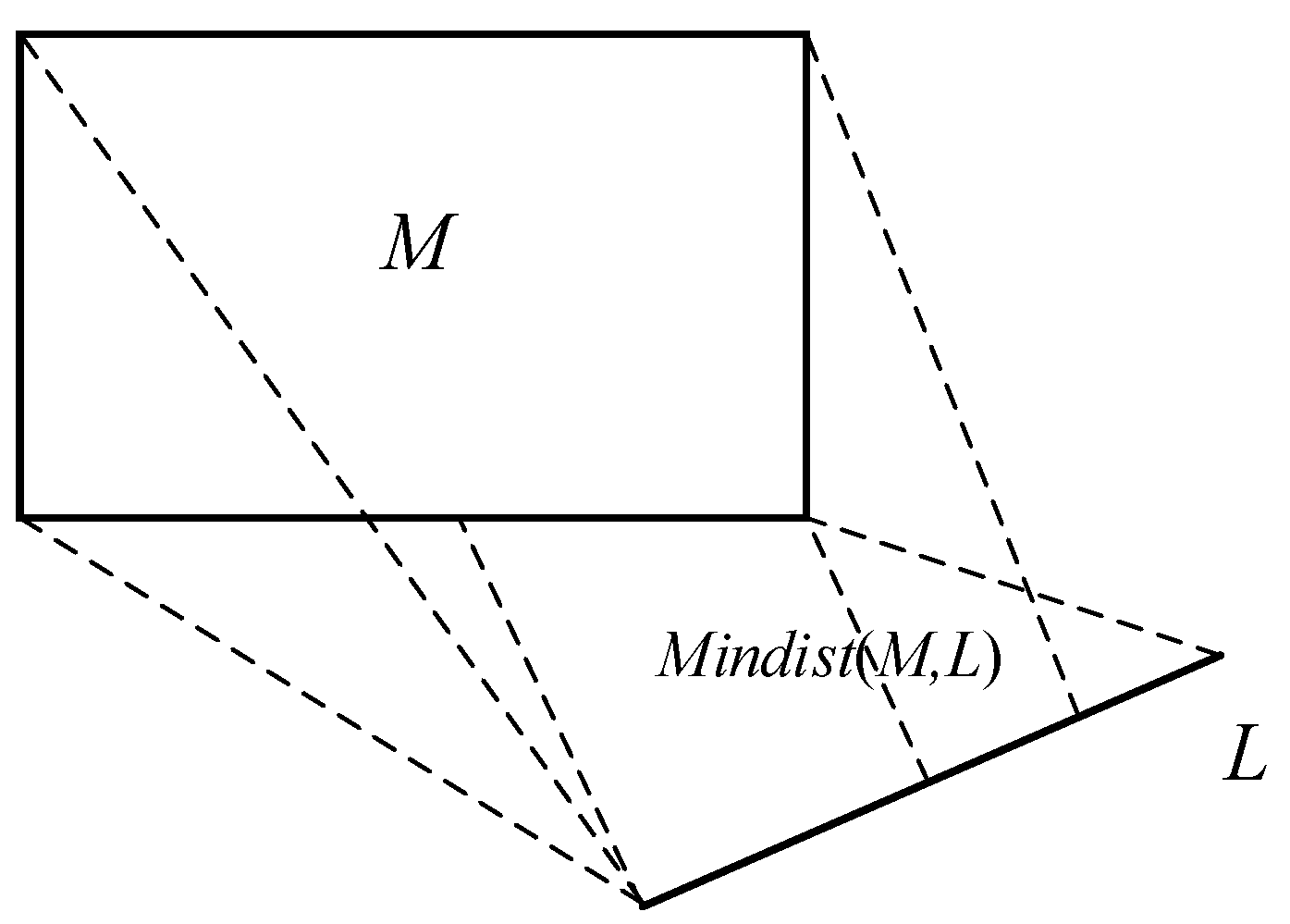
| minimum distance from spatial area Md to spatial area Mq | |
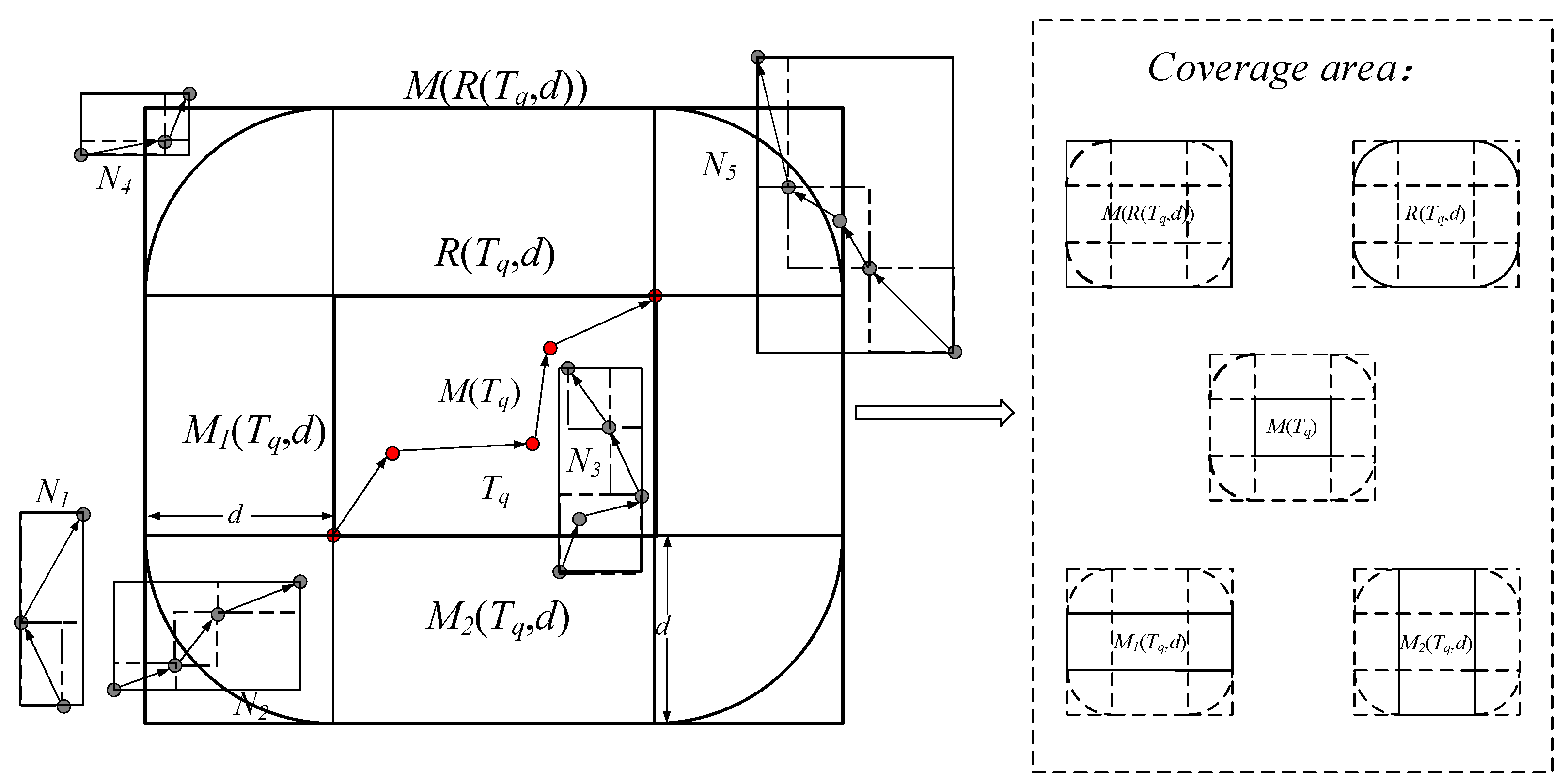
| the coverage area by extending the MBR of x with the distance threshold d | |
| the rectangular spatial area by expanding the k-dimensional spatial range of the MBR of x with the distance threshold d | |
| Root(tree) | the root node of the index tree |
| H(N) | the height from N to the trajectory segment layer of the index |
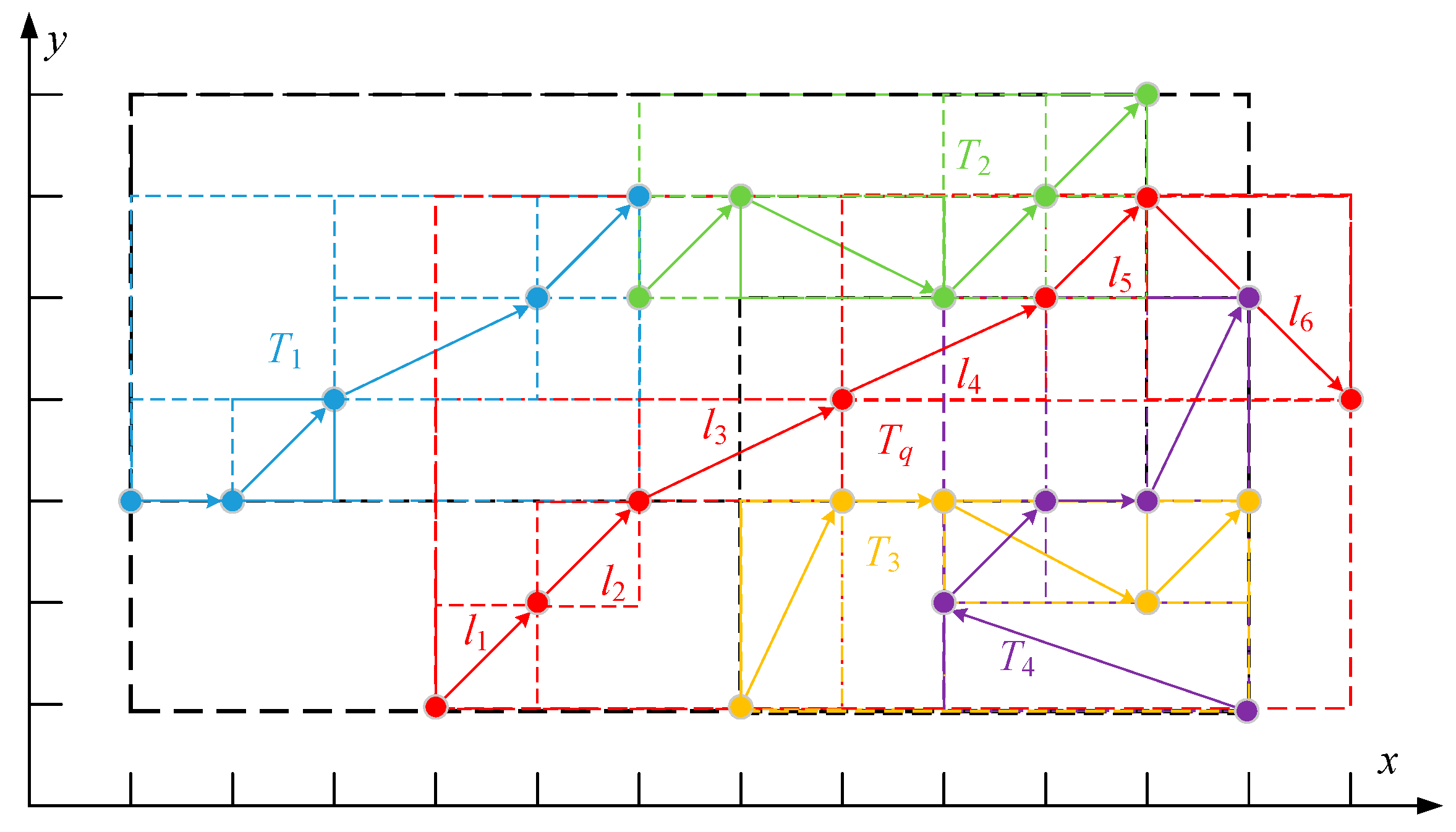
| Trajectory Segment | Candidate Quantity (BFT) | Candidate Quantity (TDS) | Candidate Quantity (CDQLTD) |
|---|---|---|---|
| l1 | 0 | 1 | 15 |
| l2 | 2 | 2 | 15 |
| l3 | 8 | 10 | 15 |
| l4 | 10 | 11 | 15 |
| l5 | 4 | 4 | 15 |
| l6 | 6 | 7 | 15 |
| Name | No. of Moving Objects | No. of AIS Messages |
|---|---|---|
| AIS01 | 73,490 | 10,000,000 |
| AIS02 | 95,732 | 20,000,000 |
| AIS03 | 110,566 | 40,000,000 |
| AIS04 | 136,932 | 80,000,000 |
| AIS05 | 152,807 | 160,000,000 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qin, J.; Ma, L.; Liu, Q. Pruning Optimization over Threshold-Based Historical Continuous Query. Algorithms 2019, 12, 107. https://doi.org/10.3390/a12050107
Qin J, Ma L, Liu Q. Pruning Optimization over Threshold-Based Historical Continuous Query. Algorithms. 2019; 12(5):107. https://doi.org/10.3390/a12050107
Chicago/Turabian StyleQin, Jiwei, Liangli Ma, and Qing Liu. 2019. "Pruning Optimization over Threshold-Based Historical Continuous Query" Algorithms 12, no. 5: 107. https://doi.org/10.3390/a12050107
APA StyleQin, J., Ma, L., & Liu, Q. (2019). Pruning Optimization over Threshold-Based Historical Continuous Query. Algorithms, 12(5), 107. https://doi.org/10.3390/a12050107