Figure 1.
Pseudocode of two-stage language identification (LI).
Figure 1.
Pseudocode of two-stage language identification (LI).
Figure 2.
Pseudocode of three-stage LI-1.
Figure 2.
Pseudocode of three-stage LI-1.
Figure 3.
Pseudocode of three-stage LI-1.
Figure 3.
Pseudocode of three-stage LI-1.
Figure 4.
Pseudocode of four-stage LI.
Figure 4.
Pseudocode of four-stage LI.
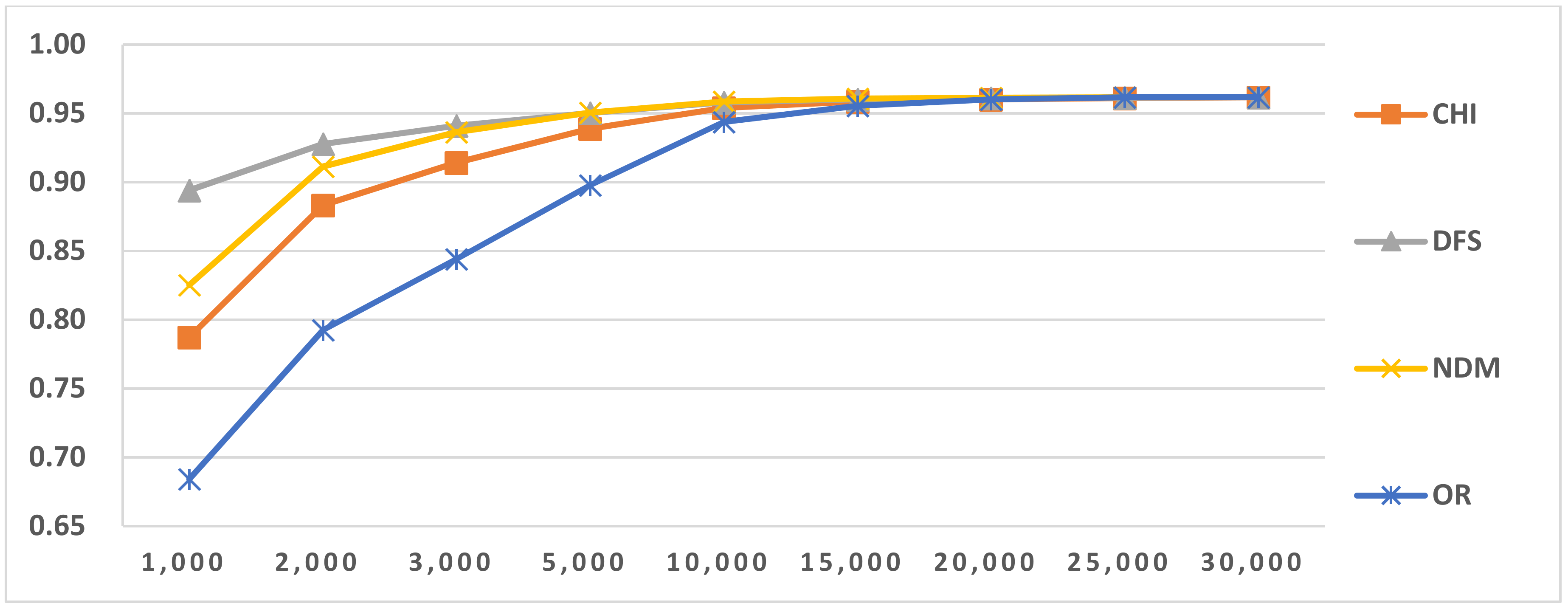
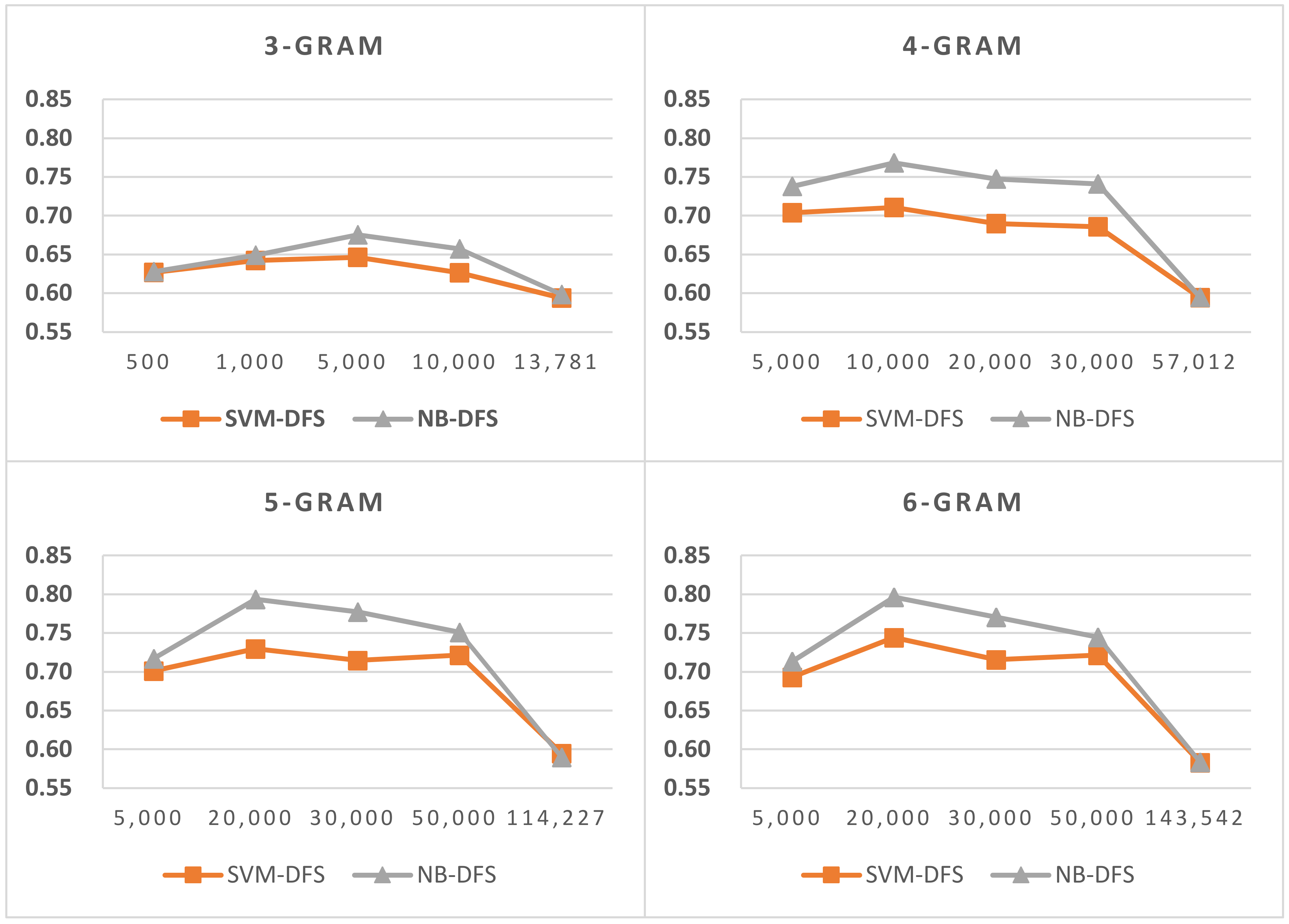
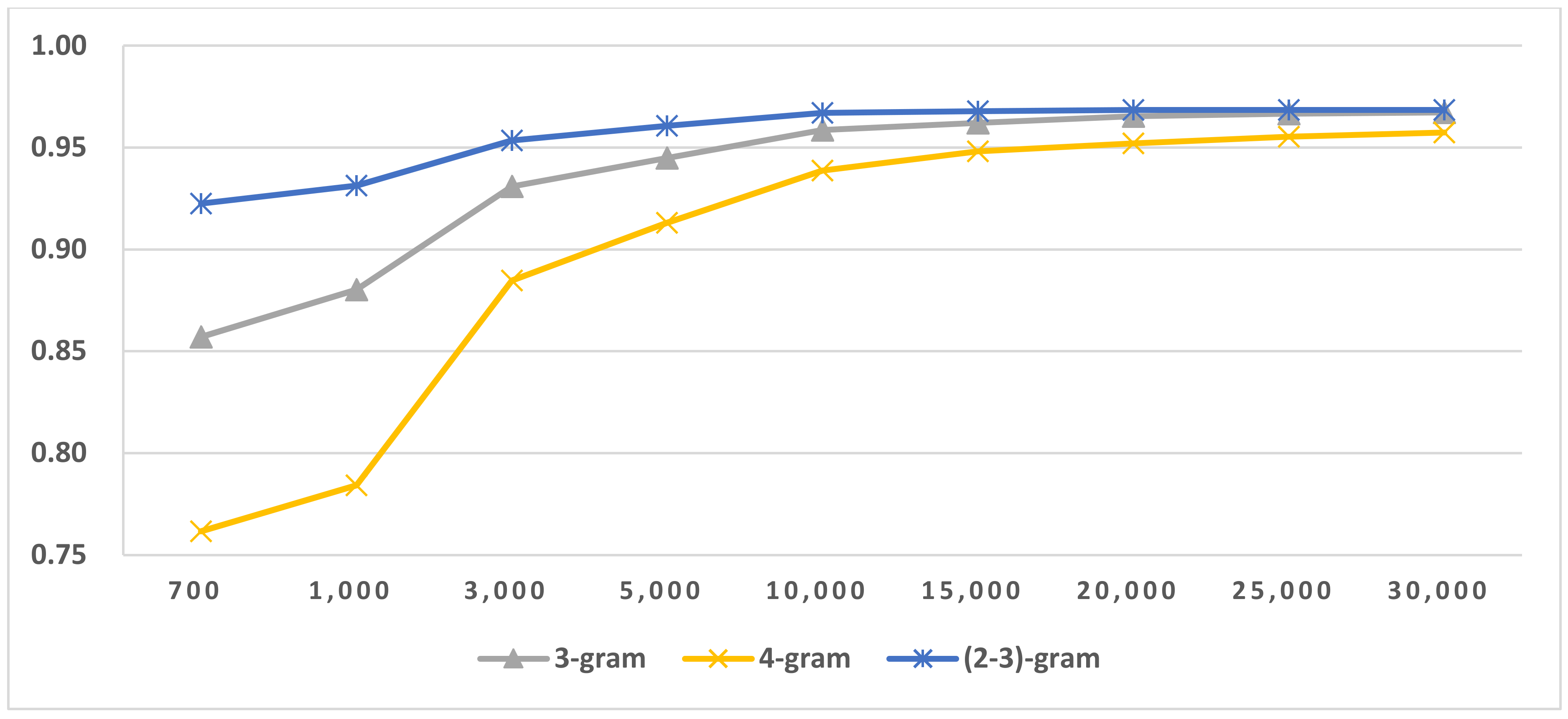
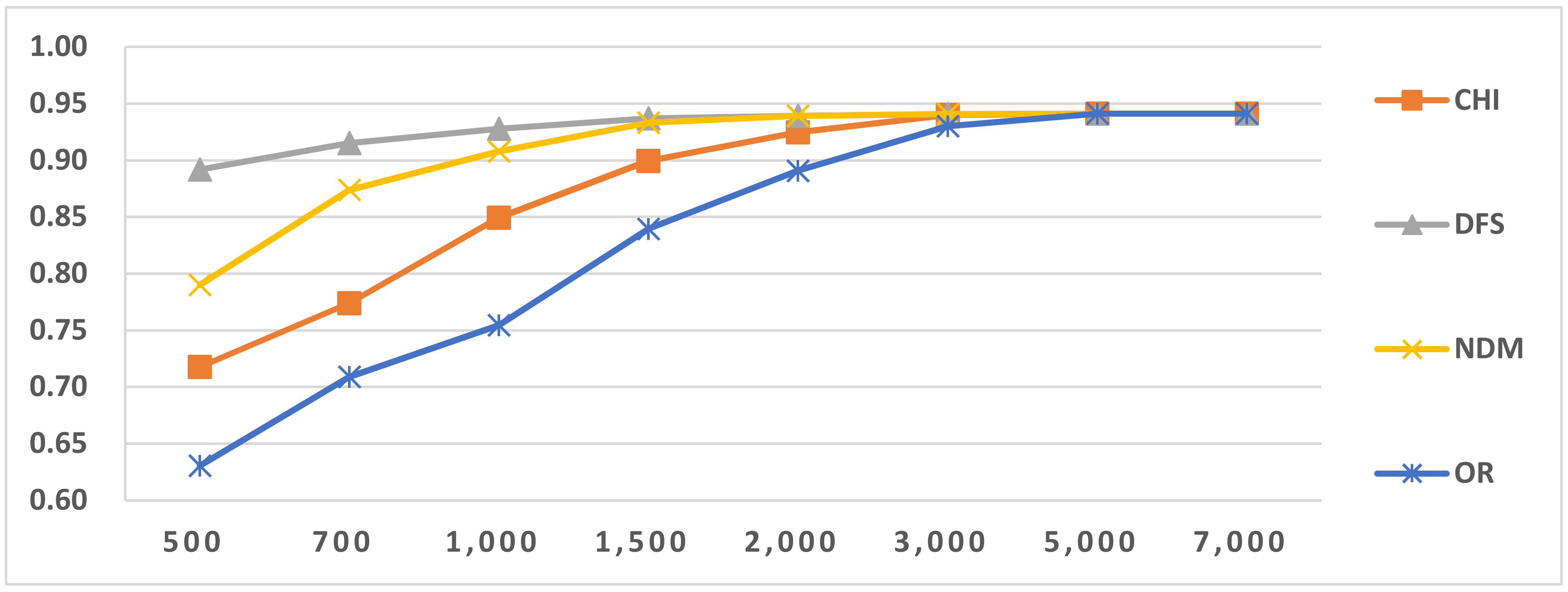
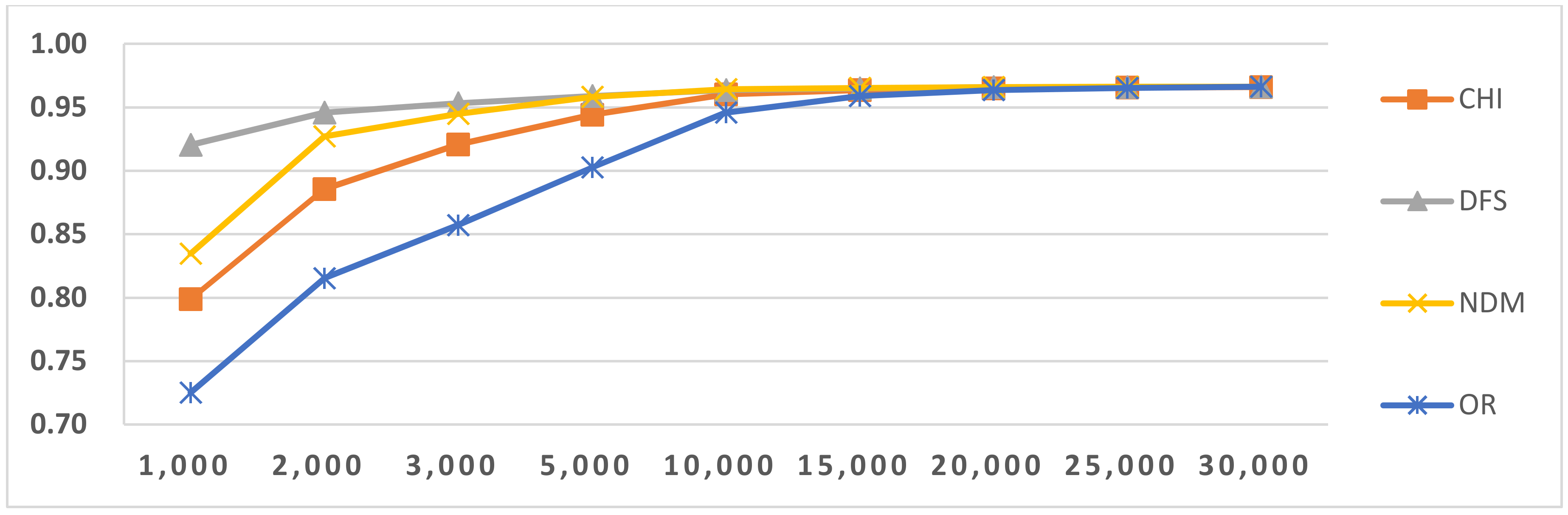
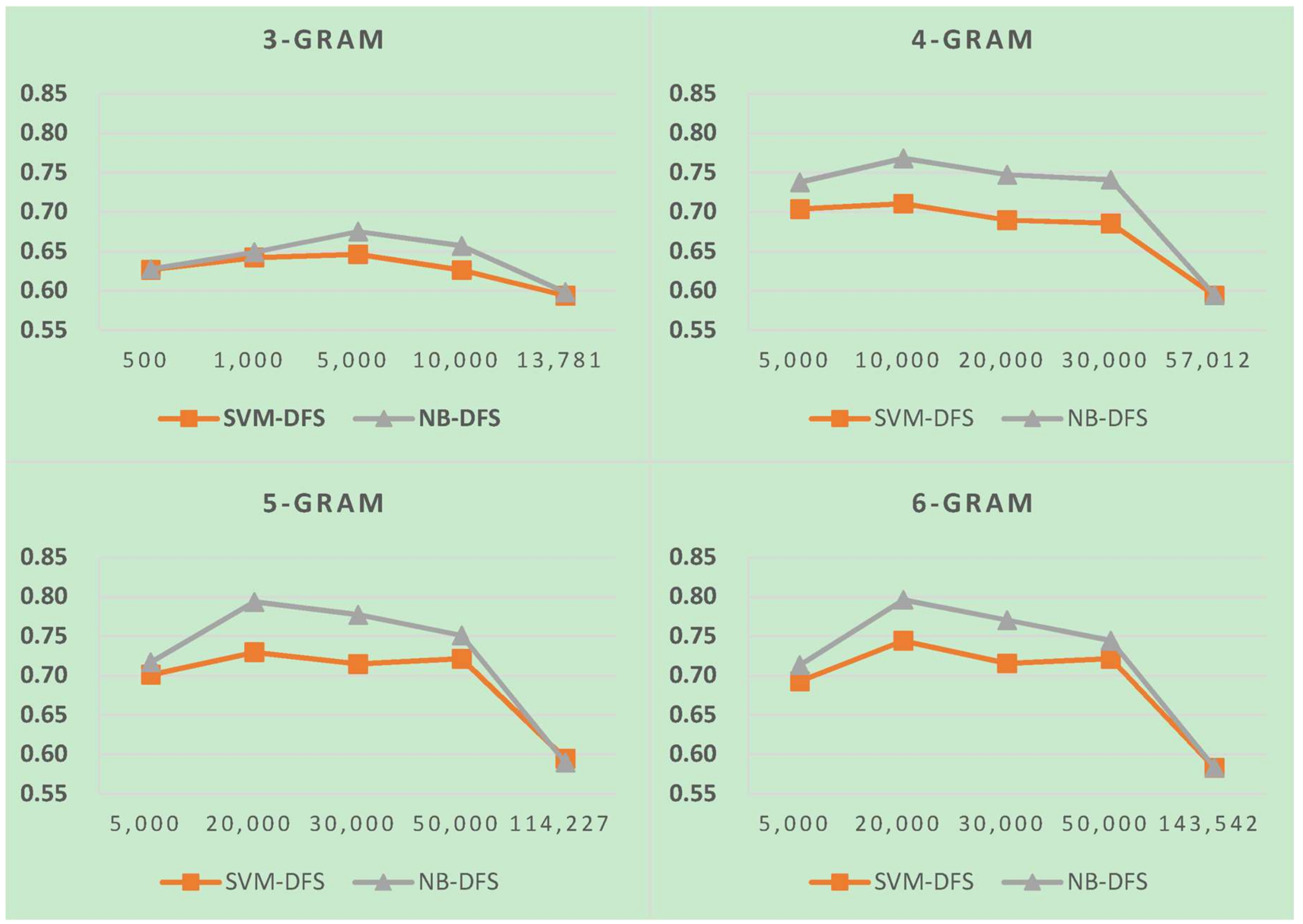
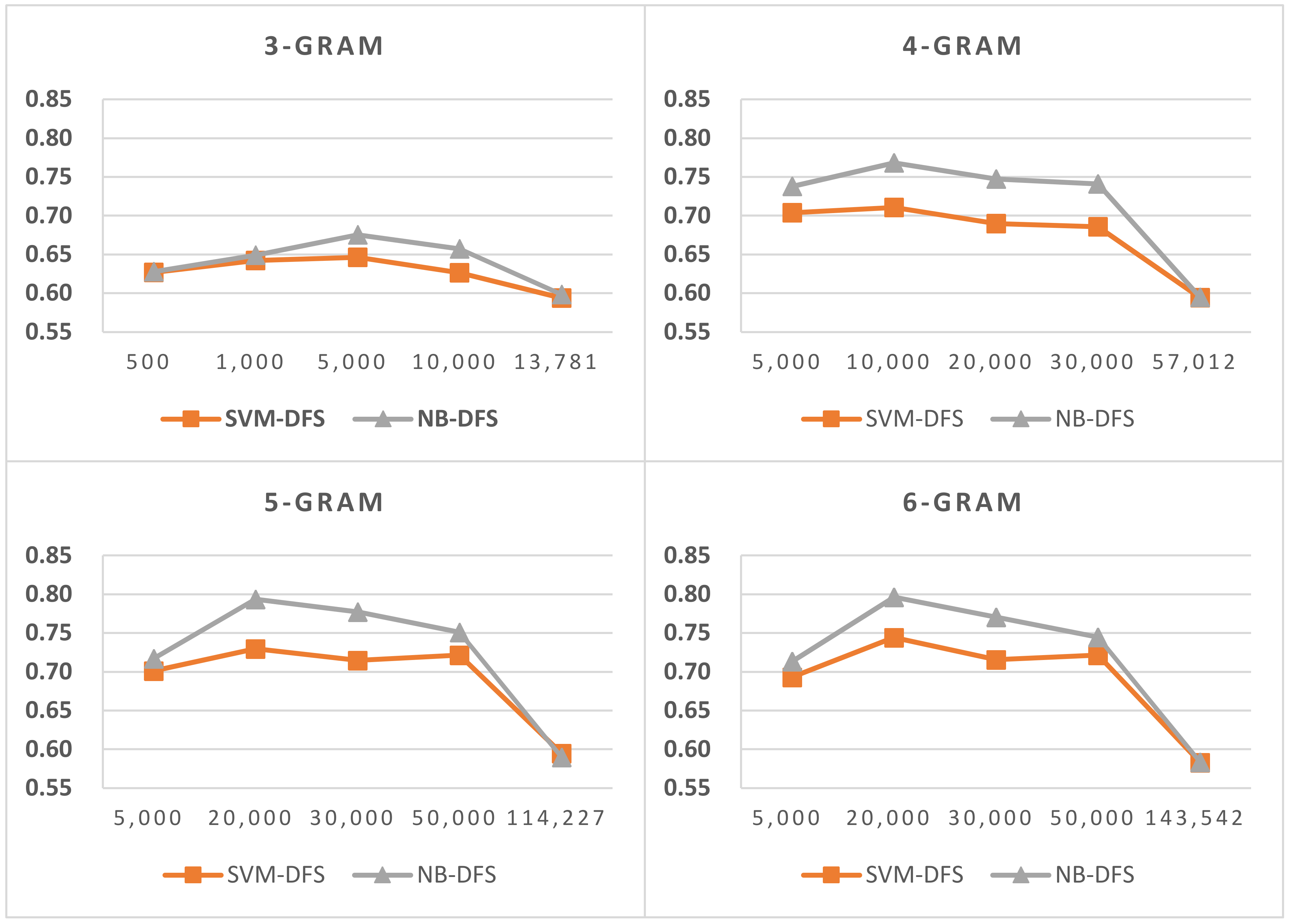
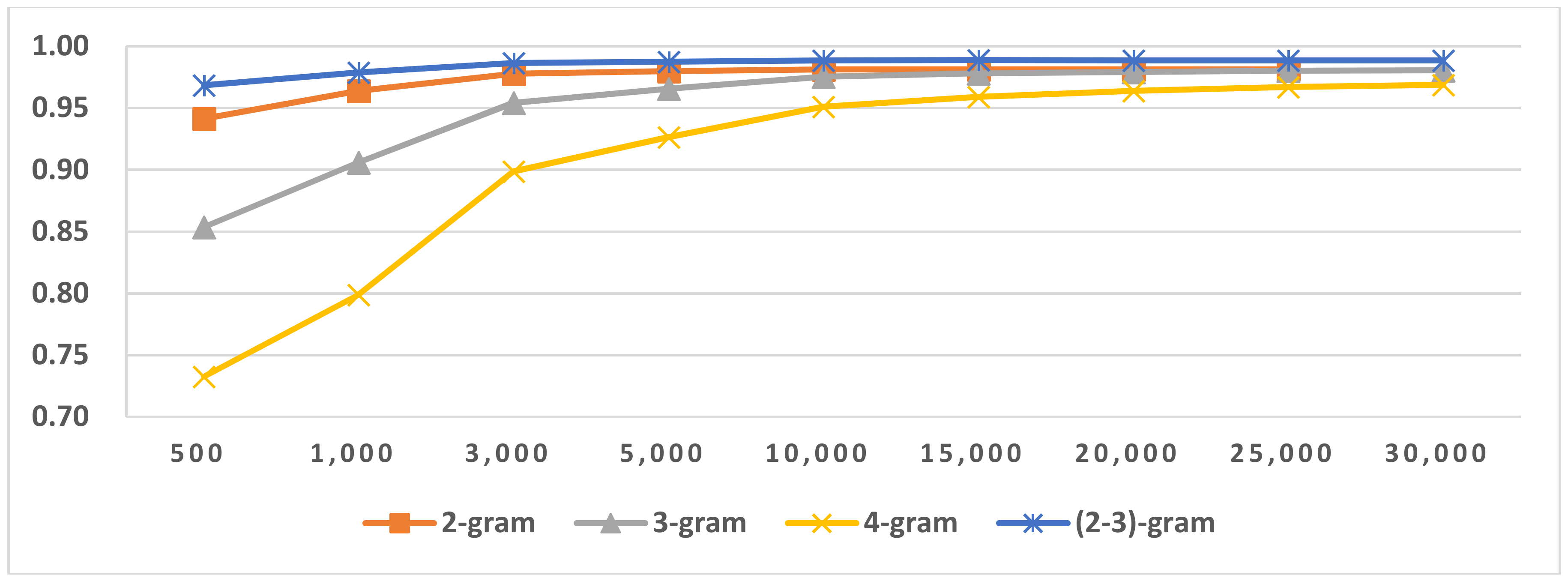
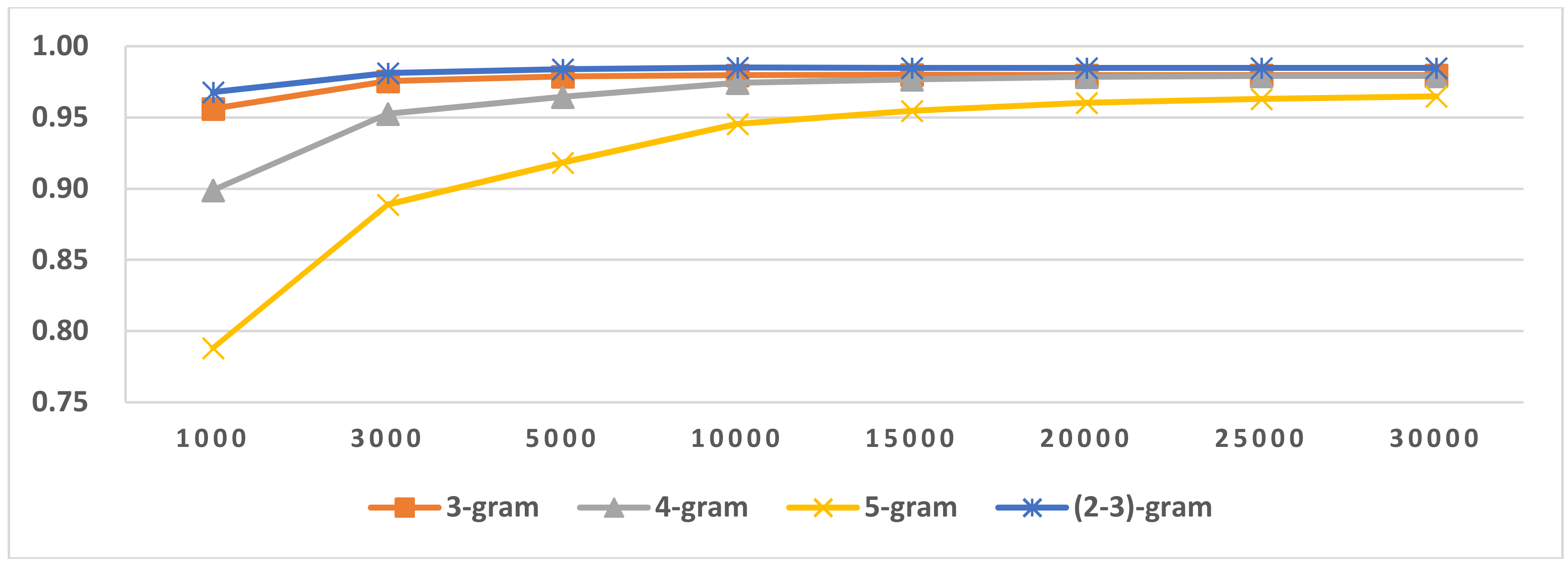
Figure 5.
Results of LI in Latin script languages when selecting SVM and two-gram.
Figure 5.
Results of LI in Latin script languages when selecting SVM and two-gram.
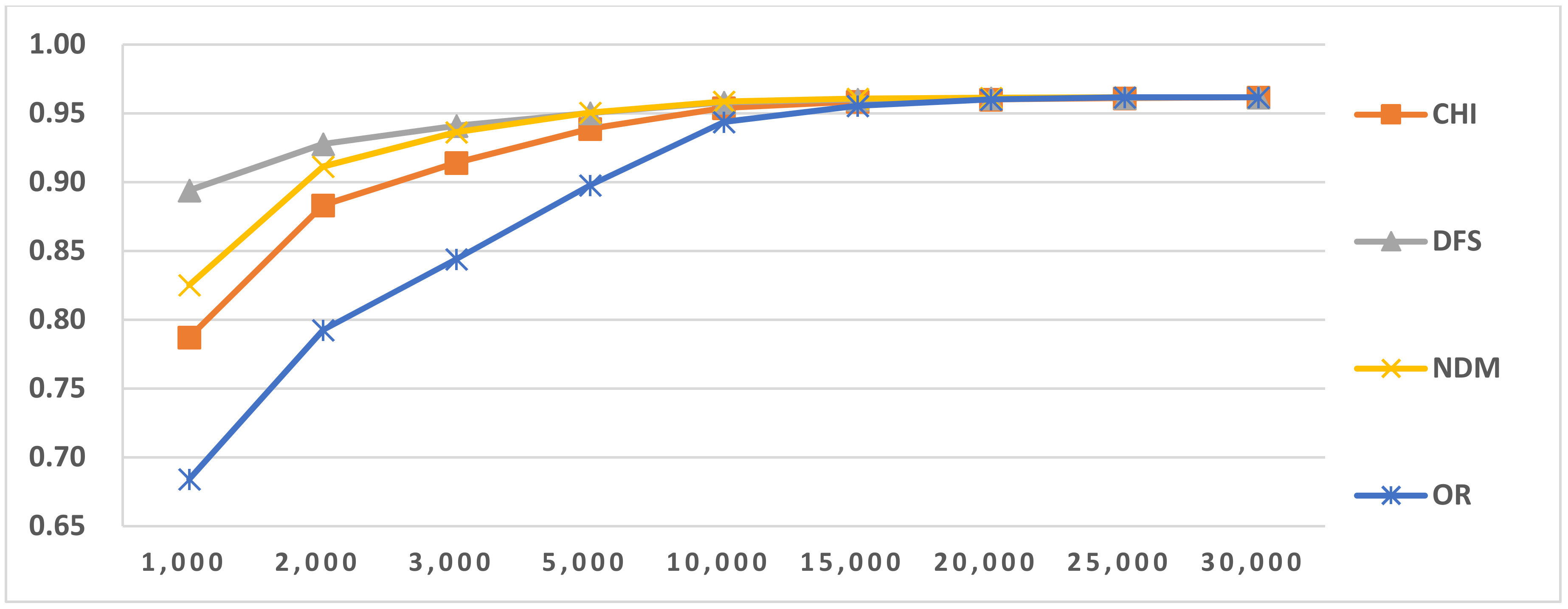
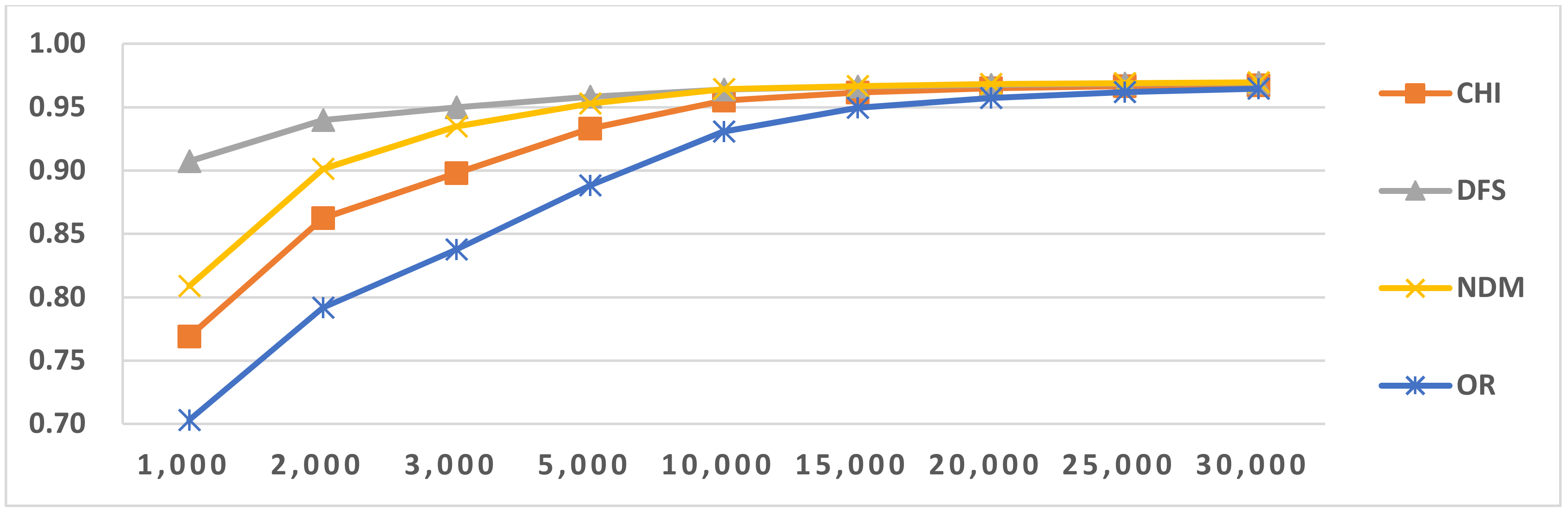
Figure 6.
Results of LI in Latin script languages when selecting SVM and three-gram.
Figure 6.
Results of LI in Latin script languages when selecting SVM and three-gram.
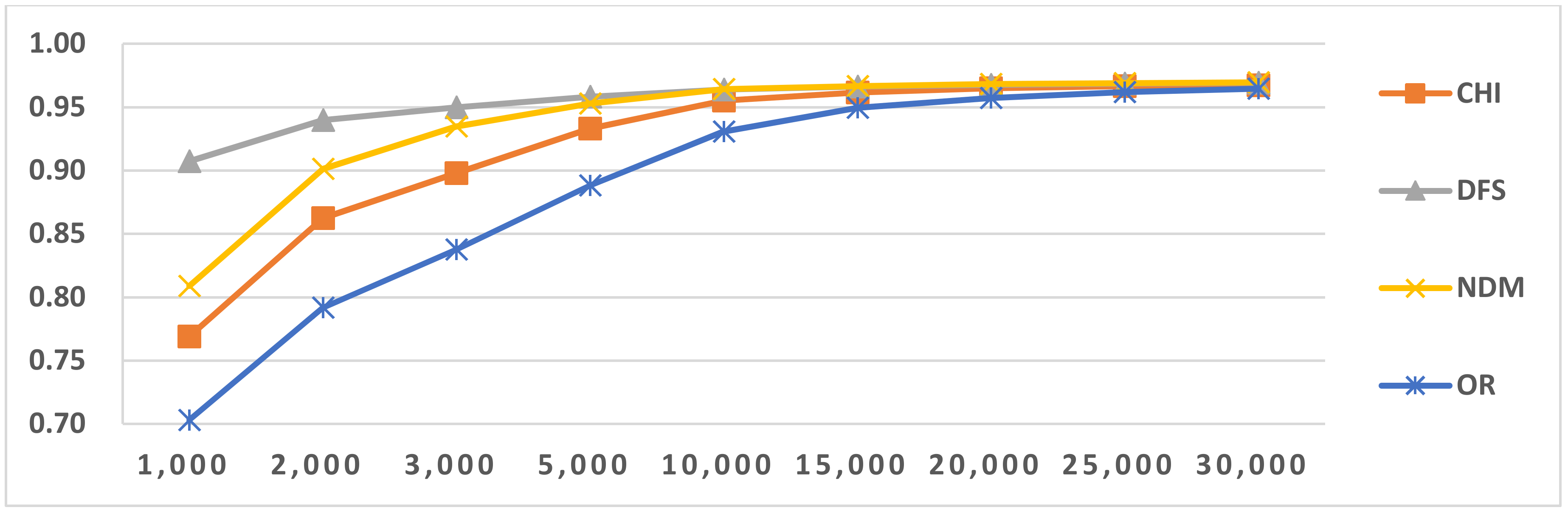
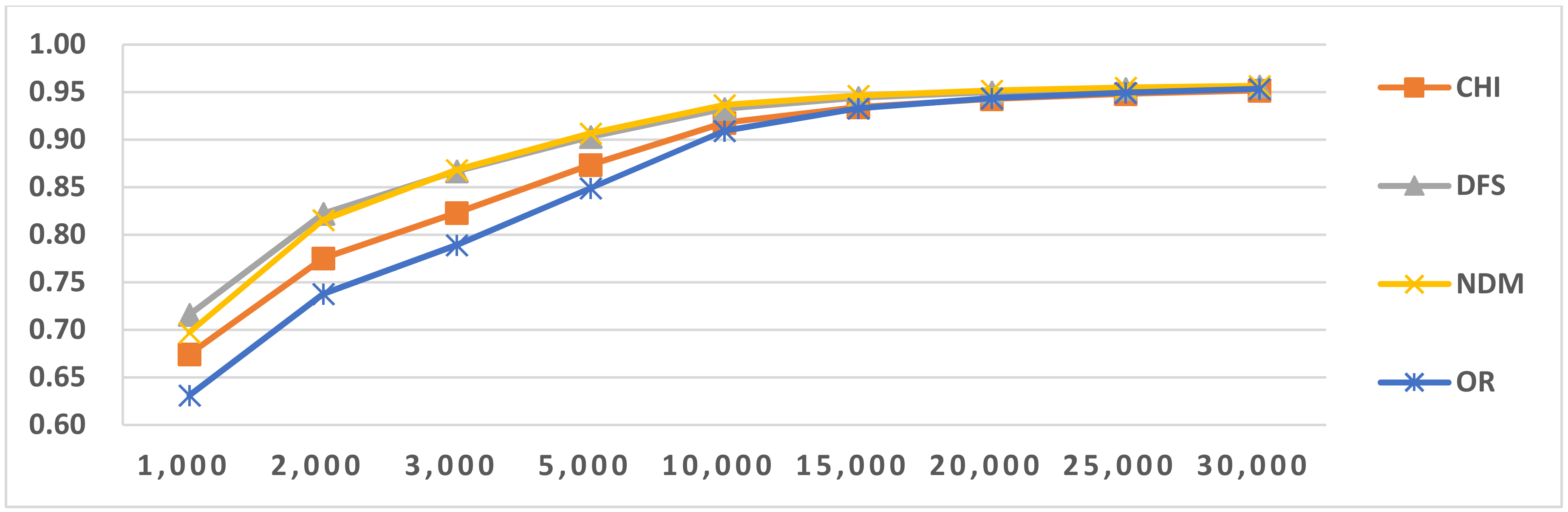
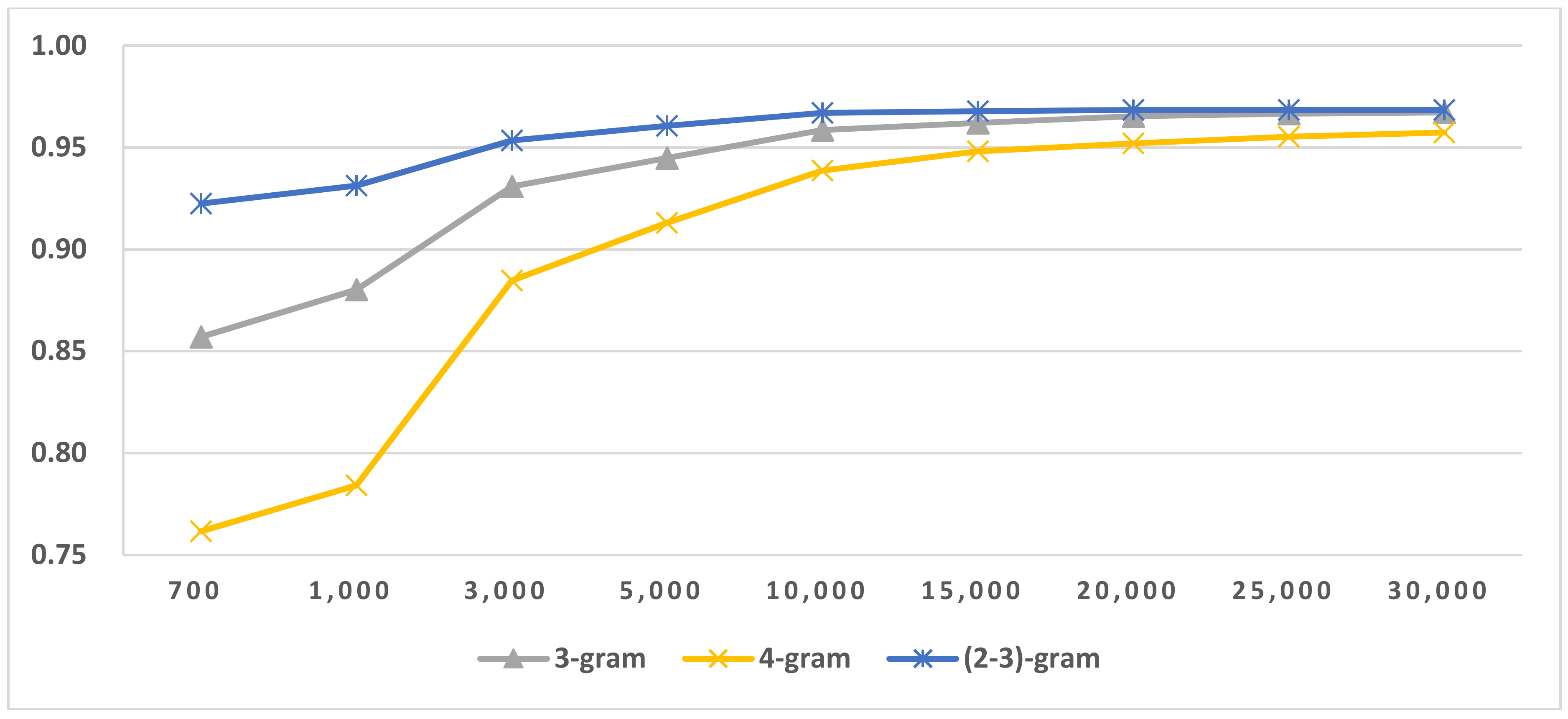
Figure 7.
Results of LI in Latin script languages when selecting SVM and four-gram.
Figure 7.
Results of LI in Latin script languages when selecting SVM and four-gram.
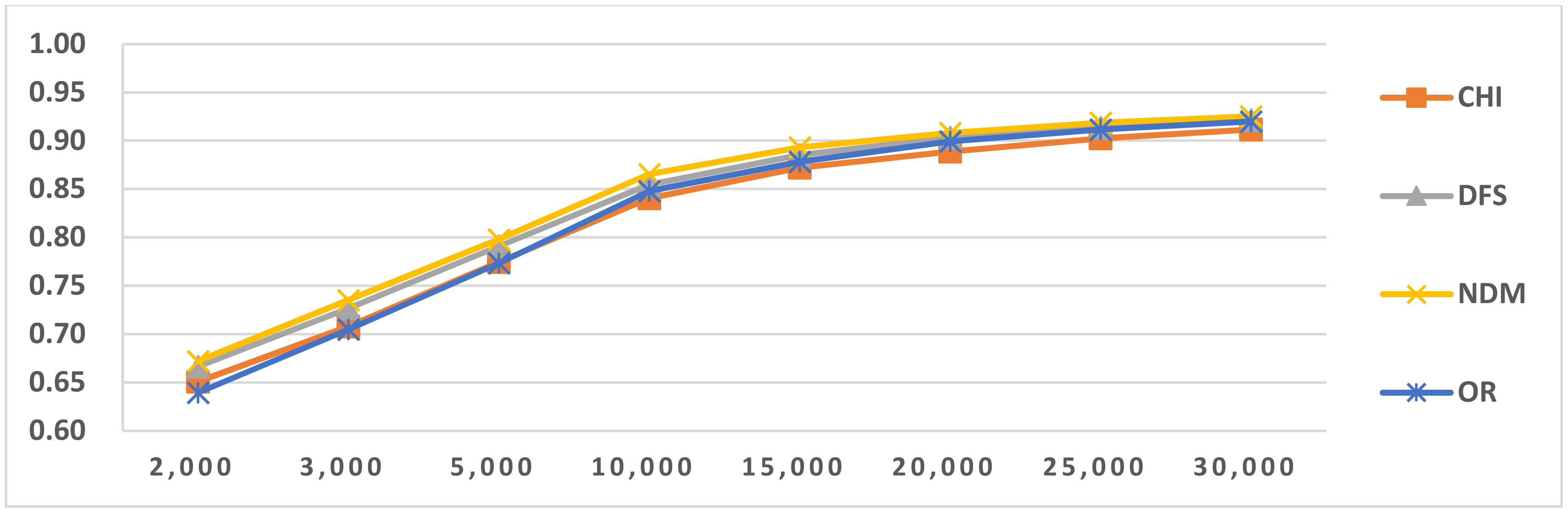
Figure 8.
Results of LI in Latin script languages when select SVM and five-gram.
Figure 8.
Results of LI in Latin script languages when select SVM and five-gram.
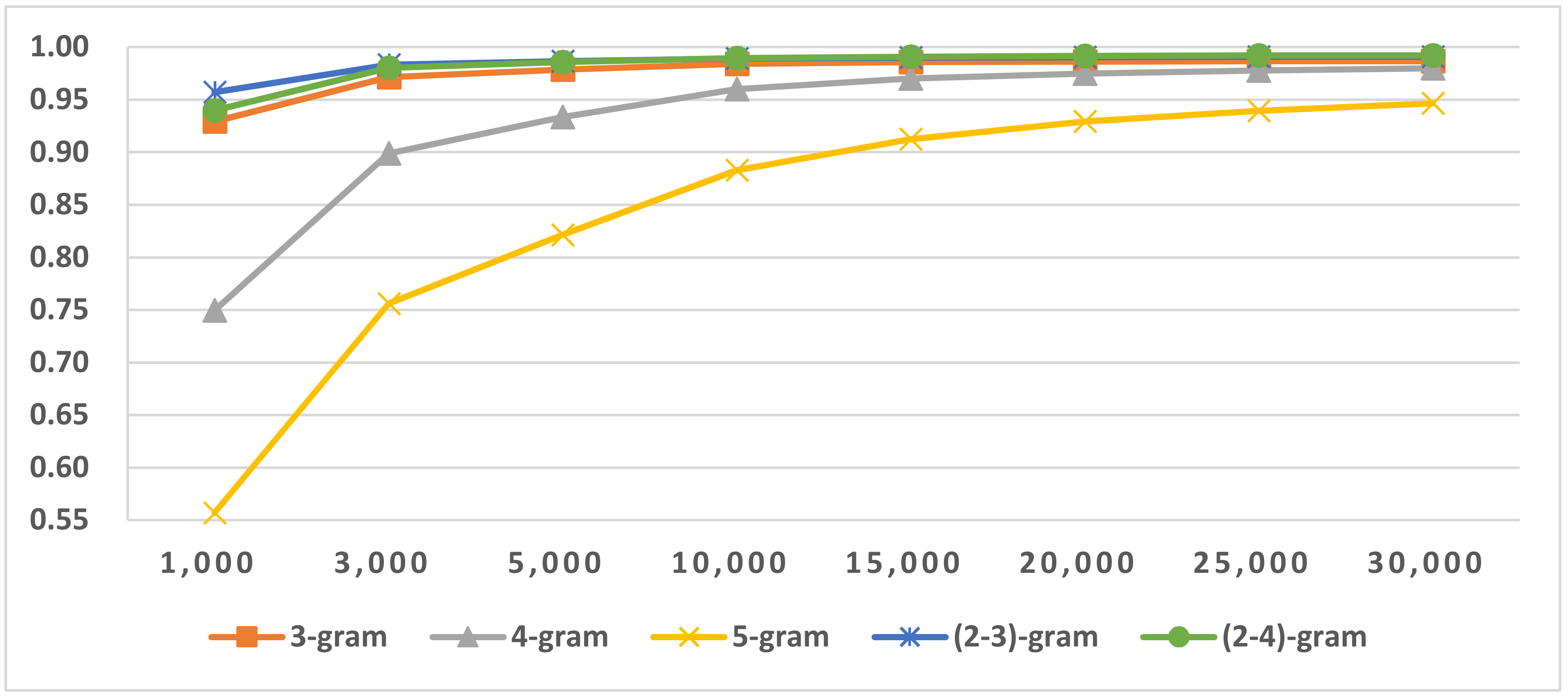
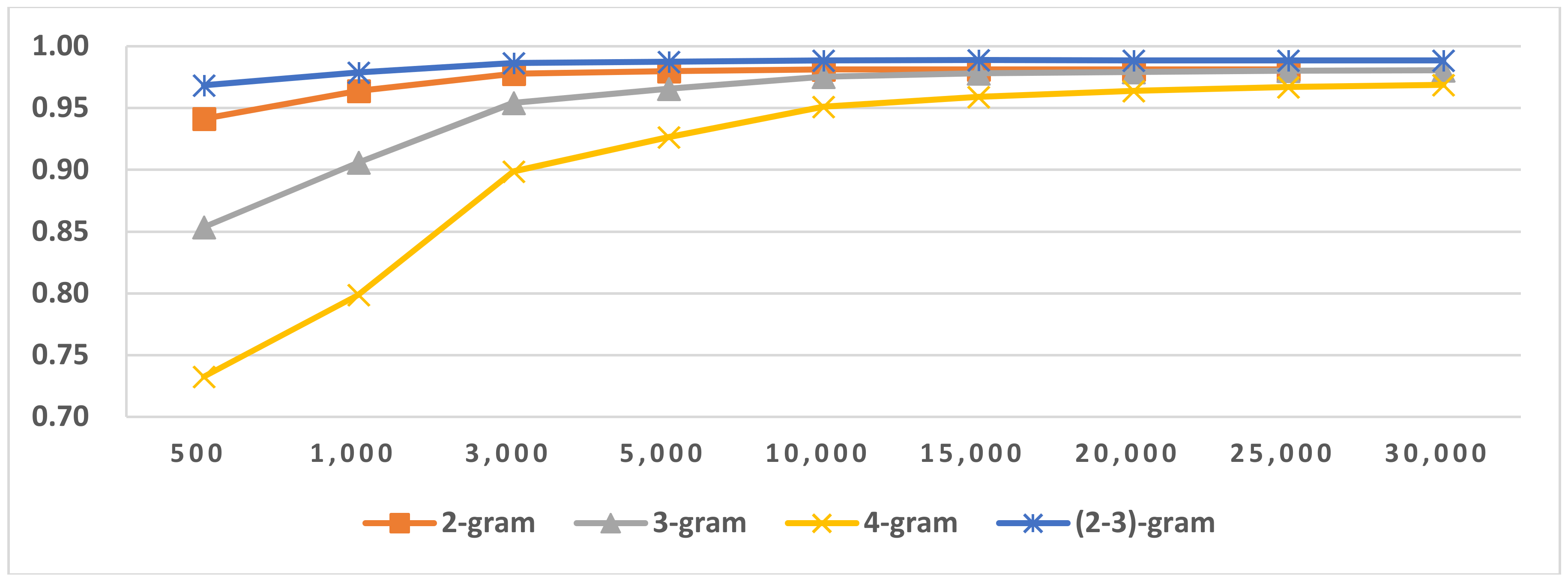
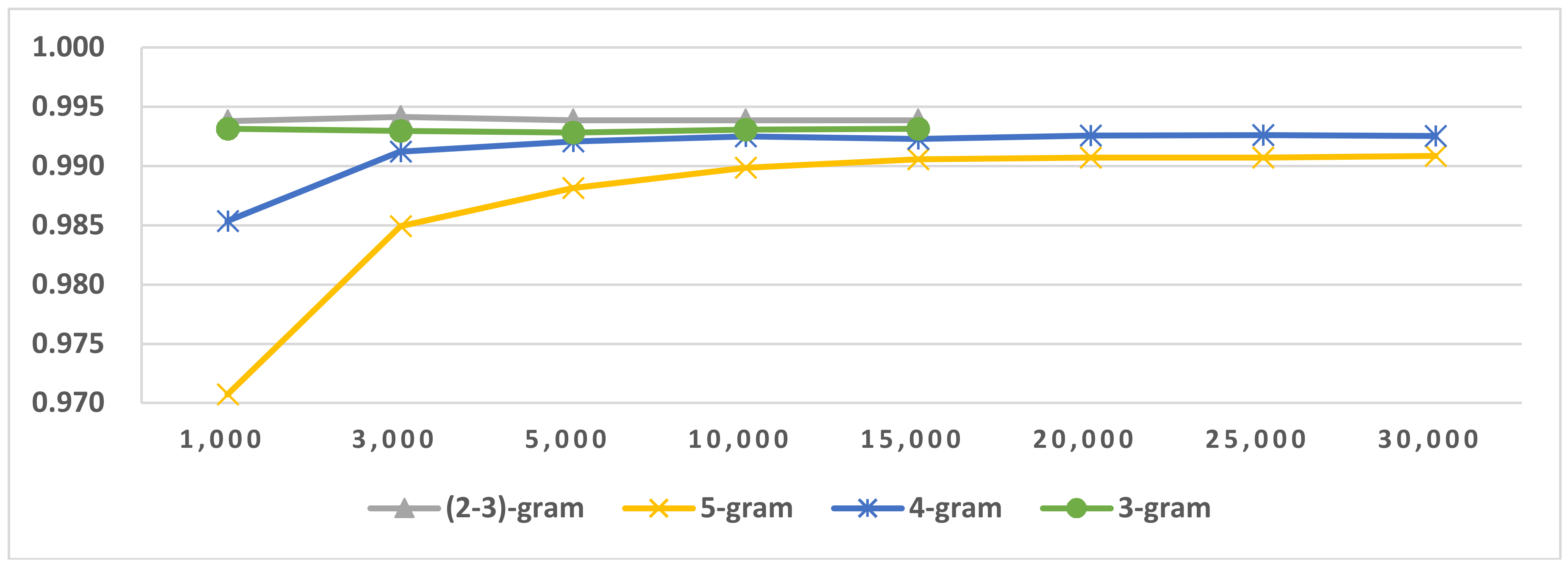
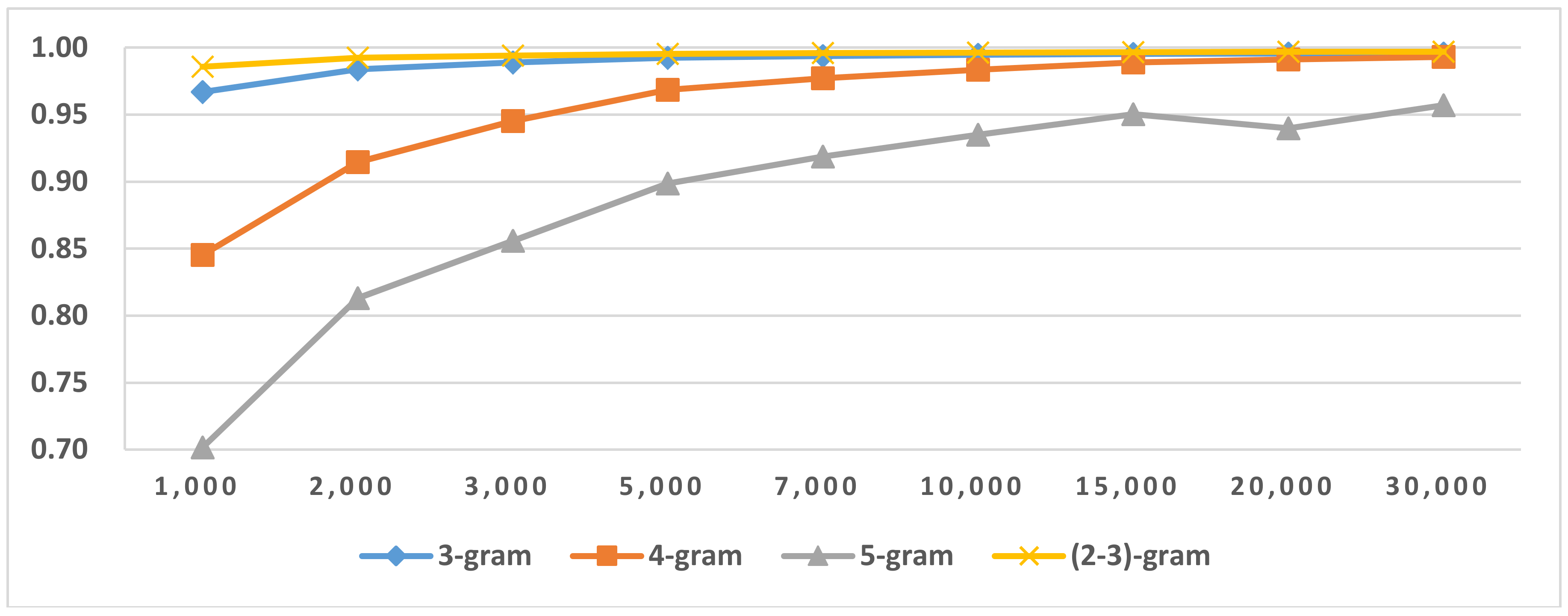
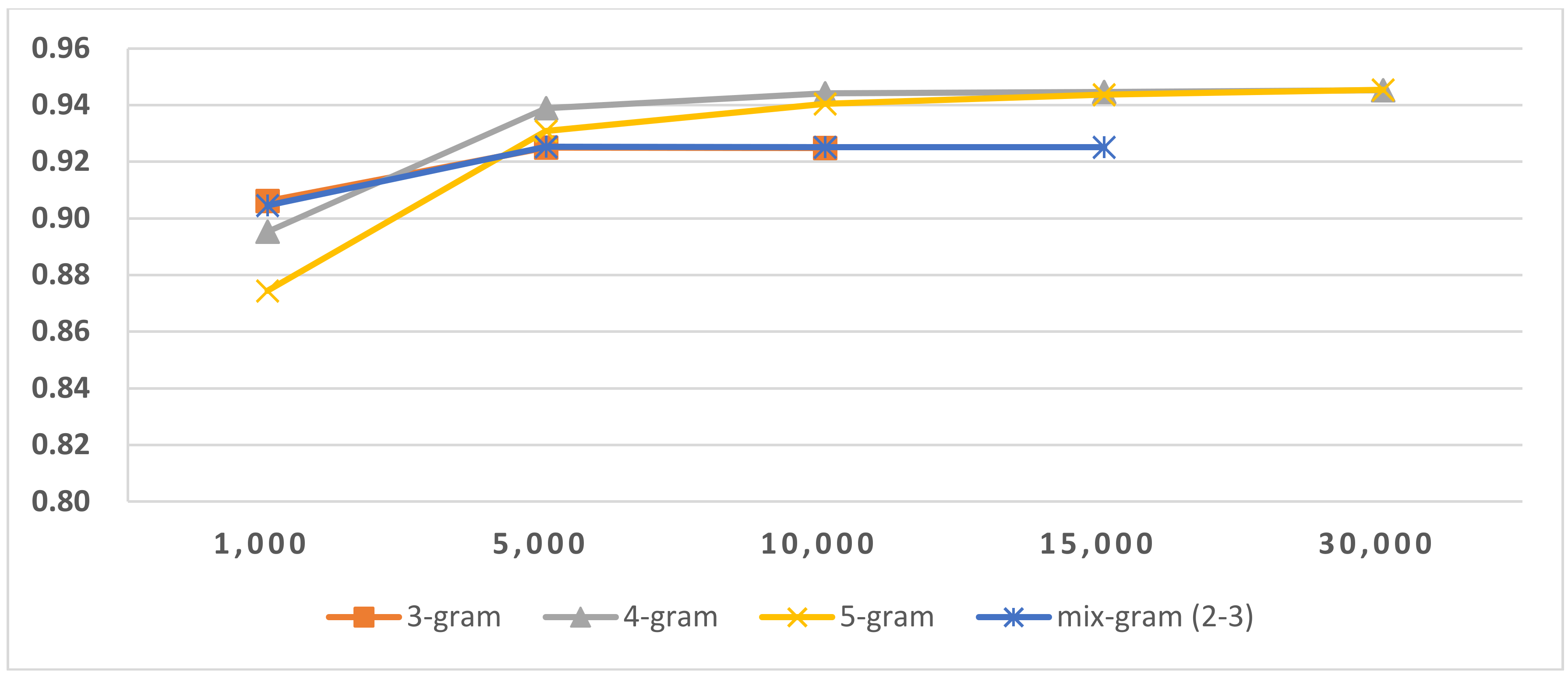
Figure 9.
Results of LI in Latin script languages when selecting SVM and mix-gram (2–3).
Figure 9.
Results of LI in Latin script languages when selecting SVM and mix-gram (2–3).
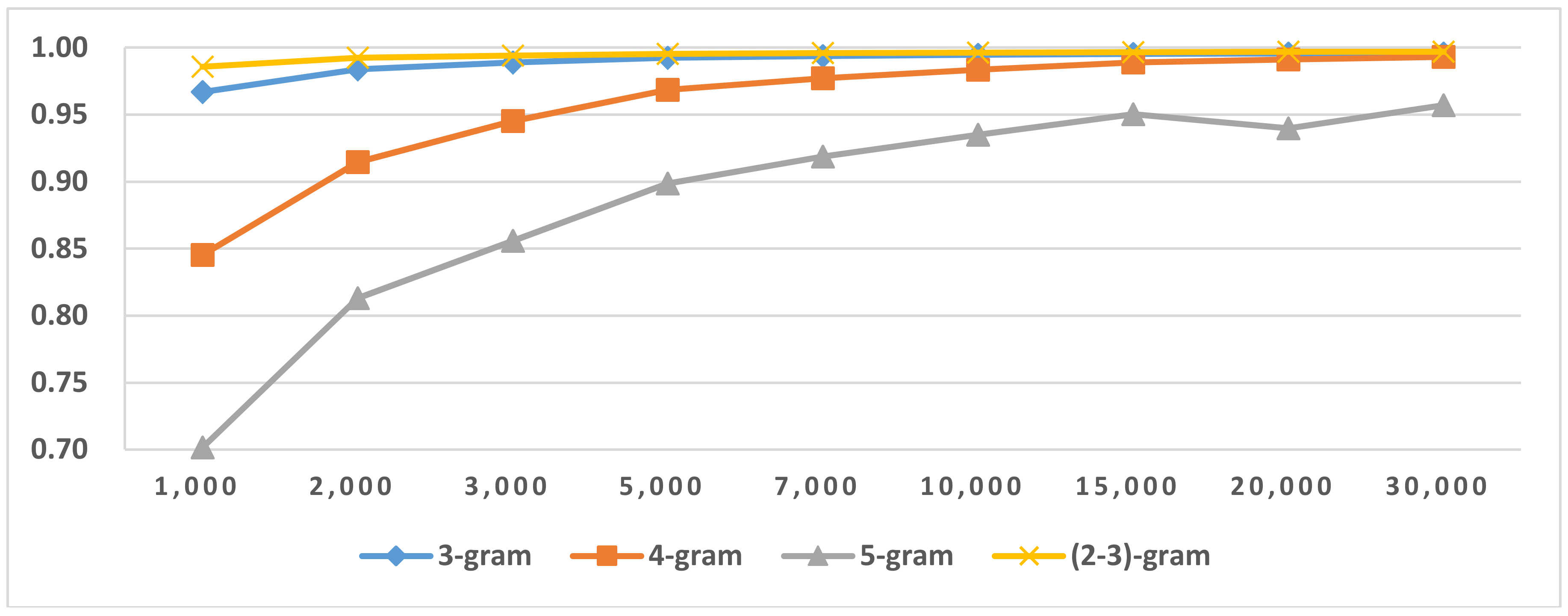
Figure 10.
Results of LI in Latin mix-gram (2–4) Latin script languages.
Figure 10.
Results of LI in Latin mix-gram (2–4) Latin script languages.
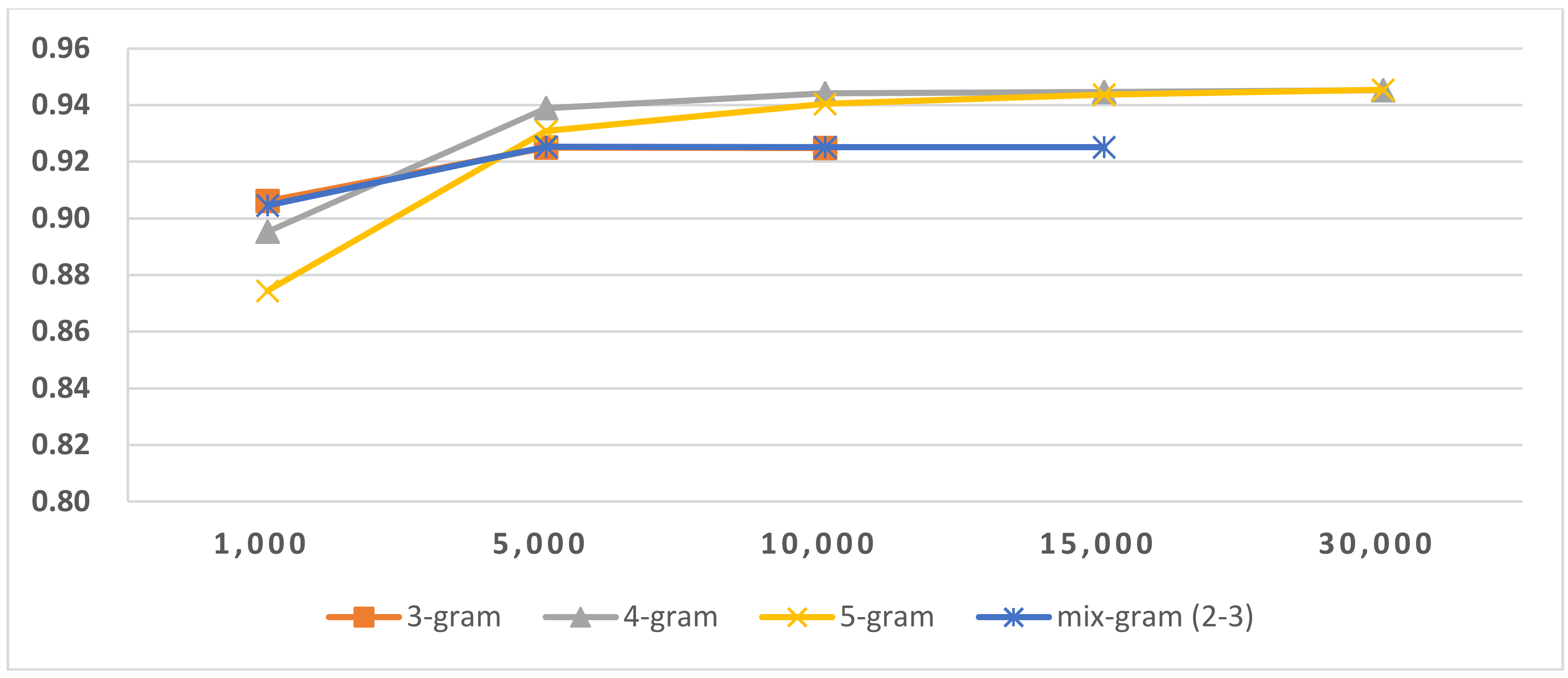
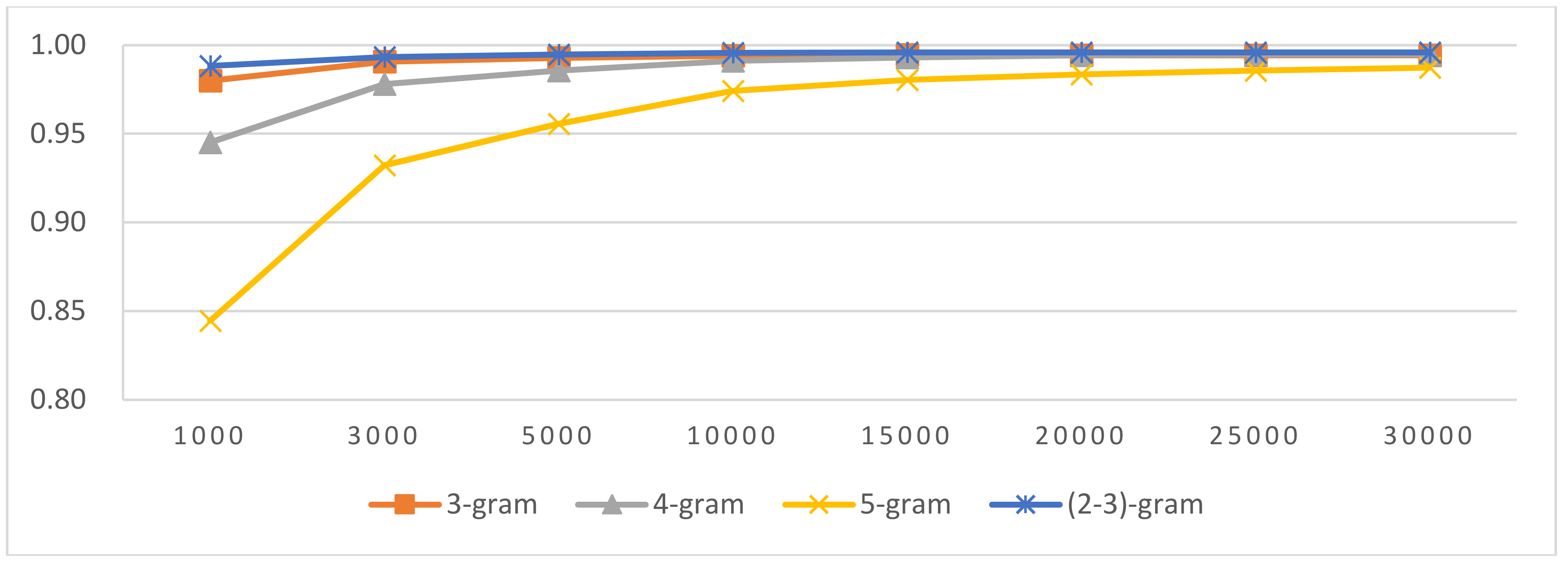
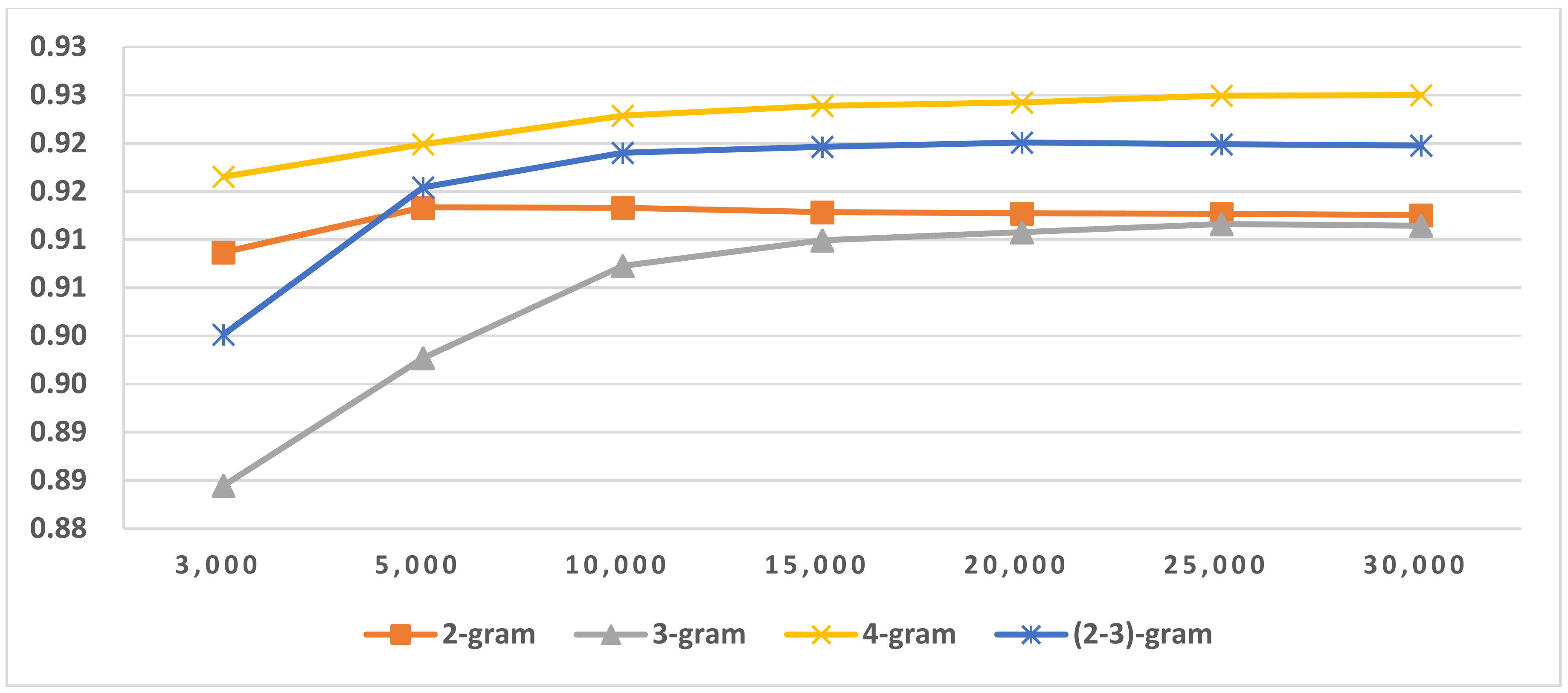
Figure 11.
Results of LI (SLGI) in Latin script languages.
Figure 11.
Results of LI (SLGI) in Latin script languages.
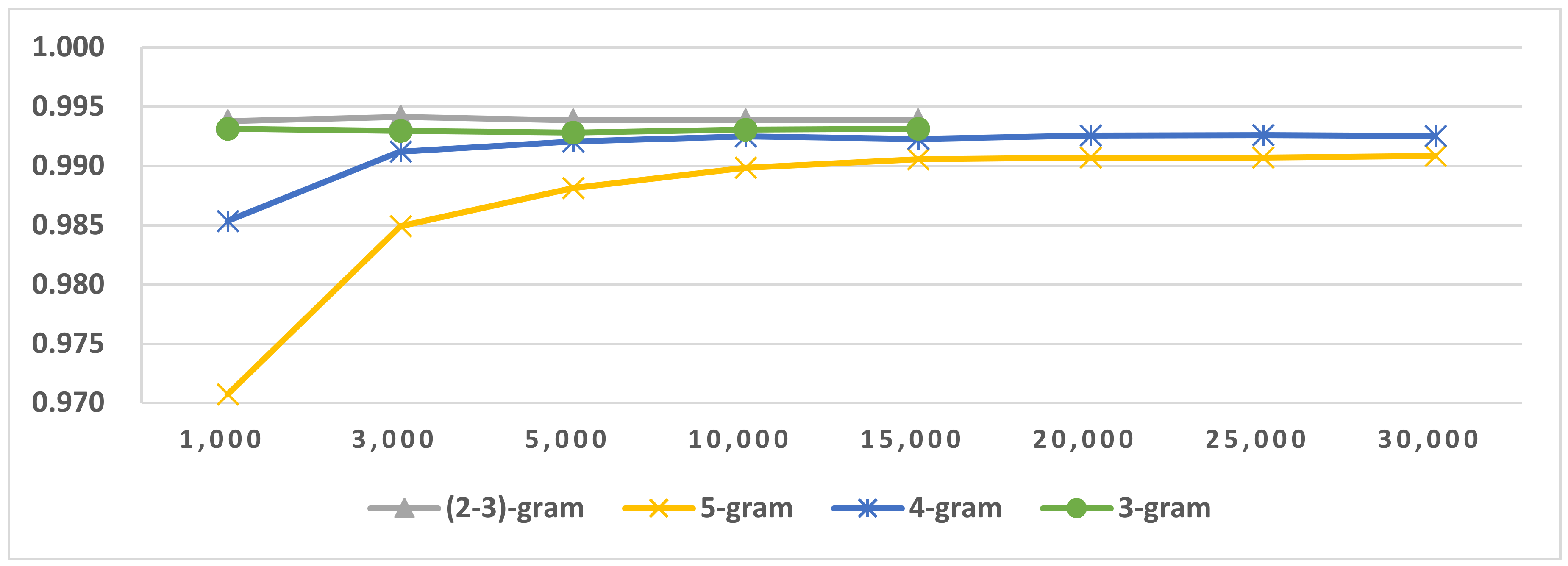
Figure 12.
LI in similar language groups (SLG) including bos and hrv.
Figure 12.
LI in similar language groups (SLG) including bos and hrv.
Figure 13.
LI in SLG consisting of ind and msa.
Figure 13.
LI in SLG consisting of ind and msa.
Figure 14.
LI in SLG consisting of nob and nor.
Figure 14.
LI in SLG consisting of nob and nor.
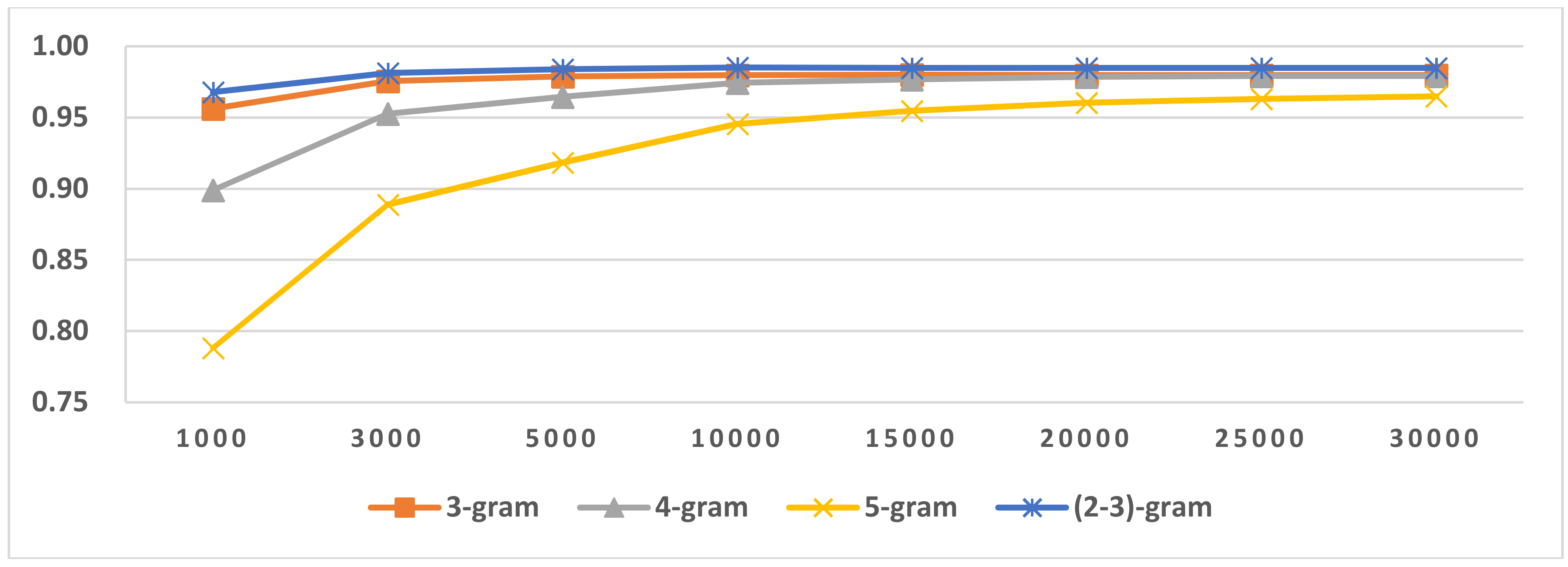
Figure 15.
LGI in Latin script languages.
Figure 15.
LGI in Latin script languages.
Figure 16.
LI in Indo-European/Germanic in Latin script languages.
Figure 16.
LI in Indo-European/Germanic in Latin script languages.
Figure 17.
LI in Indo-European/Italic in Latin script languages.
Figure 17.
LI in Indo-European/Italic in Latin script languages.
Figure 18.
LI in Austronesian/Malayo-Polynesian (MP) in Latin script languages.
Figure 18.
LI in Austronesian/Malayo-Polynesian (MP) in Latin script languages.
Figure 19.
LI in Indo-European/Balto-Slavic in Latin script languages.
Figure 19.
LI in Indo-European/Balto-Slavic in Latin script languages.
Figure 20.
LI in Austronesian-Malayo/Polynesian (MP) in Latin.
Figure 20.
LI in Austronesian-Malayo/Polynesian (MP) in Latin.
Figure 21.
LI in Indo-European/Balto-Slavic in Latin.
Figure 21.
LI in Indo-European/Balto-Slavic in Latin.
Figure 22.
LI in Indo-European/Germanic in Latin.
Figure 22.
LI in Indo-European/Germanic in Latin.
Table 1.
Script datasets with only one member.
Table 1.
Script datasets with only one member.
| Script | Code | Script | Code | Script | Code | Script | Code |
|---|
| Armenian | hye | Japanese Braille | jpn | Ge’ez | amh | Georgian | kat |
| Greek | ell | Gujarati | guj | Gurmukhi | pan | Hebrew | heb |
| Kannada | kan | Khmer | khm | Korean | kor | Tamil | tam |
| Lao | lao | Odia | ori | Sinhala | sin | Telugu | tel |
| Thai | tha | Simplified Chinese | zho | Tibetan | dzo | Tirhuta | mal |
Table 2.
Latin script dataset.
Table 2.
Latin script dataset.
| Language Group | ISO Language Code List |
|---|
| Afro-Asiatic/Semitic | Mlt |
| Austroasiatic/Vietic | vie |
| Austronesian/Malayo-Polynesian (MP) | (Ind, msa), jav, mlg, tgl |
| constructed language | vol |
| International auxiliary language | epo |
| Indo-European/Albanian | sqi |
| Indo-European/Balto-Slavic | (bos, hrv), ces, lav, lit, pol, slk, slv |
| Indo-European/Celtic | bre, cym, gle |
| Indo-European/Germanic | afr, dan, deu, eng, fao, isl, ltz, nld, nno, (nob, nor), swe |
| Indo-European/Italic | arg, cat, fra, glg, hat, ita, lat, oci, por, ron, spa, wln |
| Language isolate (Vasconic) | eus |
| Niger–Congo/Atlantic–Congo | swa, xho, zul, kin |
| Quechuan languages/Quechua | que |
| Altaic/Turkic | azj, tur |
| Uralic/Finnic | est, fin |
| Uralic/Finno-Ugric | hun |
| Uralic/Sami | sme |
Table 3.
Arabic script dataset.
Table 3.
Arabic script dataset.
| Language Group | ISO Code List | Language Group | ISO Code |
|---|
| Afro-Asiatic/Semitic | ara | Altaic/Turkic | uig |
| Indo-European/Indo-Iranian | fas, kur, pus, urd | | |
Table 4.
Cyrillic script dataset.
Table 4.
Cyrillic script dataset.
| Language Group | ISO Code |
|---|
| Indo-European/Balto-Slavic | bel, bul, mkd, srp, rus, ukr |
| Altaic/Mongolic | mon |
| Altaic/Turkic | kaz, kir |
Table 5.
Nagari and Devanagari script dataset.
Table 5.
Nagari and Devanagari script dataset.
| Script | Language Group | ISO Language Code List |
|---|
| Devanagari | Indo-European/Indo-Iranian | hin, mar, nep |
| Eastern Nagari | Indo-European/Indo-Iranian | asm, ben |
Table 6.
Toy example sentences. SLG, similar language group.
Table 6.
Toy example sentences. SLG, similar language group.
| ID | Content | Language | Script | LG | SLG |
|---|
| A | 저는 유학생입니다 | Korean | Korean | | |
| B | Egy nemzetközi diák vagyok. | Hungarian | Latin | Finno-Ugric | |
| C | I’m an international student. | English | Latin | Germanic | |
| D | Jeg er en internasjonal student. | Norwegian | Latin | Germanic | nor-nob |
Table 7.
Example of the decomposition of a sentence into character N-grams.
Table 7.
Example of the decomposition of a sentence into character N-grams.
| N-Gram Type | N-Gram |
|---|
| 1-gram | g, o, o, d, b, o, y |
| 2-gram | -g, go, oo, od, d-, -b, bo, oy, y- |
| 3-gram | -go, goo, ood, od-, d-b, -bo, -boy, oy- |
| 4-gram | -goo, good, ood-, od-b, d-bo, -boy, boy- |
Table 8.
Preliminary notations.
Table 8.
Preliminary notations.
| Notation | Value | Meaning |
|---|
| M | | M is the number of classes |
| | Number of documents belonging to class and containing term . |
| | Number of documents not belonging to class and containing term . |
| | Number of documents belonging to class and not containing term . |
| | Number of documents not belonging to class and not containing term . |
| N | | Total number of documents in the training corpora. |
| | The probability of class when word is present. |
| | The probability of other items when class is present. |
| or | | The probability of item when other class is present. |
| or | | The probability of item when other class is present. |
Table 9.
Script identification results.
Table 9.
Script identification results.
| REMSI | Score | Time | SI | Macro F1 | Time |
|---|
| F1 score | 0.9986 | 0.978 | 0.00:58.26 | 0.9981 | 0.03:53.50 |
Table 10.
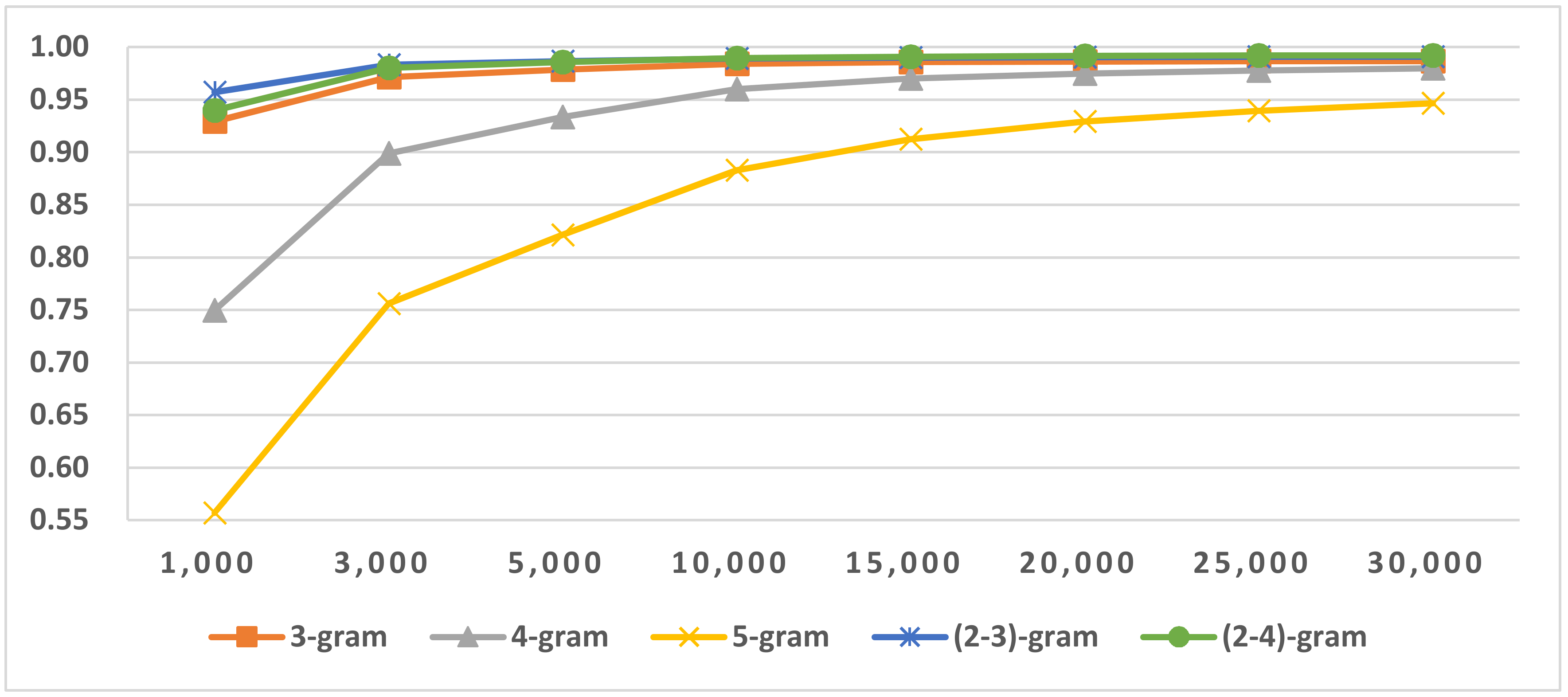
Different N-gram numbers in different LI corpora.
Table 10.
Different N-gram numbers in different LI corpora.
| ID | In All 97 Languages | In Latin Script | In Germanic LG | In Nor-Nob SLG |
|---|
| 2-gram | 256,629 | 7389 | 3203 | 1706 |
| 3-gram | 973,319 | 78,320 | 31,516 | 13,781 |
| 4-gram | 2,342,861 | 438,945 | 164,640 | 57,012 |
| 5-gram | 4,174,524 | 1,391,955 | 445,814 | 114,227 |
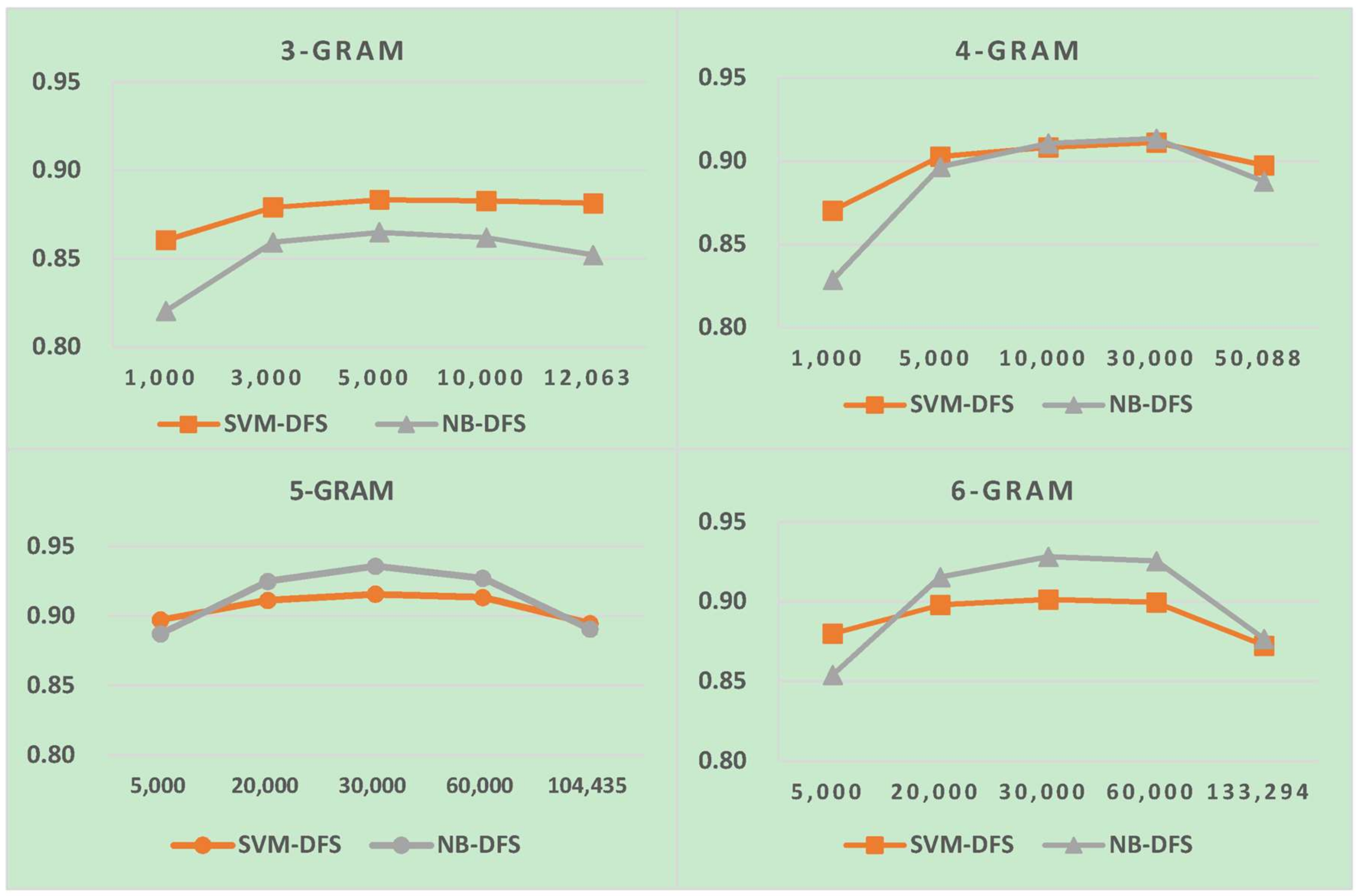
Table 11.
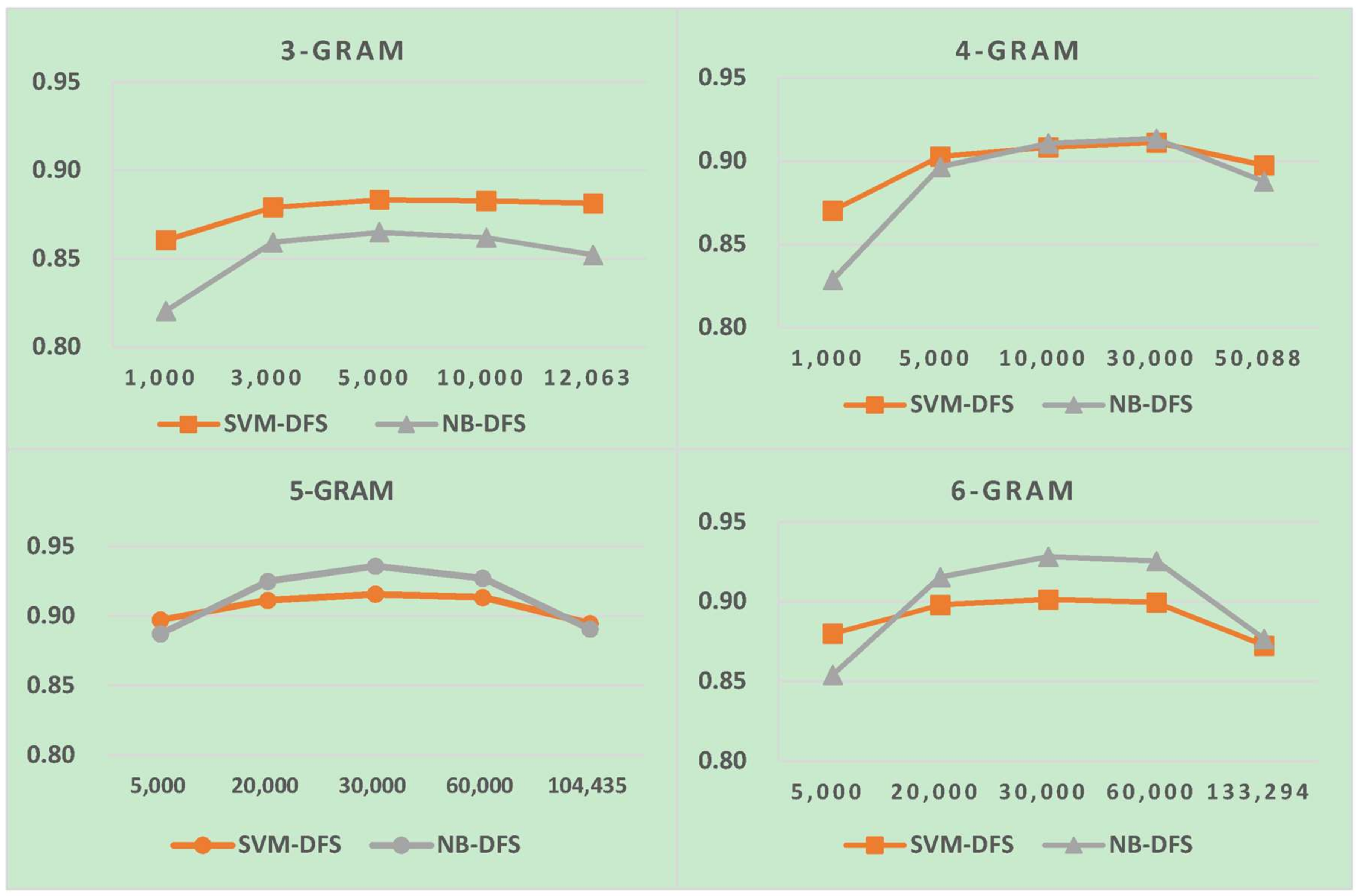
Results of LI in one-stage LI. FS, feature size.
Table 11.
Results of LI in one-stage LI. FS, feature size.
| FS | 1000 | 3000 | 5000 | 10,000 | 15,000 | 20,000 | 25,000 | 30,000 |
|---|
| NB-2 | 0.440 | 0.870 | 0.920 | 0.942 | 0.952 | 0.952 | 0.952 | 0.957 |
| SVM-2 | 0.423 | 0.879 | 0.933 | 0.955 | 0.964 | 0.964 | 0.964 | 0.964 |
| NB-3 | 0.590 | 0.763 | 0.874 | 0.916 | 0.932 | 0.935 | 0.936 | 0.950 |
| SVM-3 | 0.588 | 0.768 | 0.886 | 0.932 | 0.949 | 0.952 | 0.952 | 0.963 |
| NB-4 | 0.446 | 0.667 | 0.776 | 0.864 | 0.878 | 0.899 | 0.905 | 0.914 |
| SVM-4 | 0.448 | 0.672 | 0.781 | 0.878 | 0.892 | 0.913 | 0.919 | 0.928 |
| NB-5 | 0.334 | 0.560 | 0.670 | 0.775 | 0.800 | 0.822 | 0.840 | 0.851 |
| SVM-5 | 0.339 | 0.566 | 0.676 | 0.786 | 0.813 | 0.836 | 0.855 | 0.866 |
| NB-30 | 0.690 | 0.834 | 0.920 | 0.945 | 0.950 | 0.952 | 0.952 | 0.963 |
| SVM-30 | 0.697 | 0.845 | 0.937 | 0.953 | 0.968 | 0.970 | 0.970 | 0.970 |
| NB-40 | 0.692 | 0.815 | 0.899 | 0.937 | 0.947 | 0.949 | 0.949 | 0.961 |
| SVM-40 | 0.698 | 0.829 | 0.918 | 0.957 | 0.966 | 0.968 | 0.968 | 0.969 |
Table 12.
Confusion matrix and F1-scores related to similar languages in one-stage LI.
Table 12.
Confusion matrix and F1-scores related to similar languages in one-stage LI.
| ID | Bos | Hrv | ID | Ind | Msa | ID | Nob | Nor |
|---|
| bos | 768 | 207 | ind | 714 | 262 | nob | 555 | 322 |
| hrv | 205 | 710 | msa | 229 | 756 | nor | 407 | 428 |
| F1-score | 0.771 | 0.735 | | 0.772 | 0.744 | | 0.544 | 0.468 |
Table 13.
Results of LI in non-Latin script languages when using SVM, distinguishing feature DFS and 2-gram.
Table 13.
Results of LI in non-Latin script languages when using SVM, distinguishing feature DFS and 2-gram.
| FS | 300 | 500 | 700 | 1000 | 1500 | 2000 |
|---|
| Arabic | 0.997 | 0.998 | 0.998 | 0.998 | 0.998 | 0.998 |
| Cyrillic | 0.978 | 0.988 | 0.990 | 0.991 | 0.992 | 0.992 |
| Devanagari | 0.992 | 0.992 | 0.993 | 0.993 | 0.993 | 0.993 |
| Nagari | 0.999 | 0.999 | 0.999 | 0.999 | 0.999 | 0.999 |
Table 14.
Optimal classification method (OCM) for LI in different scripts in two-stage LI.
Table 14.
Optimal classification method (OCM) for LI in different scripts in two-stage LI.
| ID | Model | FS | F1-Score | ID | Model | FS | F1-Score |
|---|
| Arabic | SVM-2 | 500 | 0.998 | Cyrillic | SVM-2 | 1500 | 0.992 |
| Devanagari | SVM-2 | 700 | 0.993 | Latin | SVM-(2–3) | 10,000 | 0.965 |
| Nagari | SVM-2 | 300 | 0.999 | | | | |
Table 15.
Confusion matrix and F1-scores related to similar languages in two-stage LI.
Table 15.
Confusion matrix and F1-scores related to similar languages in two-stage LI.
| ID | Bos | Hrv | ID | Ind | Msa | ID | Nob | Nor |
|---|
| bos | 758 | 236 | ind | 770 | 218 | nob | 528 | 414 |
| hrv | 52 | 940 | msa | 167 | 828 | nor | 330 | 588 |
| F1-score | 0.836 | 0.842 | | 0.784 | 0.801 | | 0.562 | 0.578 |
Table 16.
Selected OCM for LI in Latin script and SLI in three SLG in three-stage LI-1.
Table 16.
Selected OCM for LI in Latin script and SLI in three SLG in three-stage LI-1.
| ID | Model | FS | F1-Score | ID | Model | FS | F1-Score |
|---|
| LI in Latin | SVM-(2–3) | 10,000 | 0.989 | LI in bos-hrv | NB-5 | 30,000 | 0.936 |
| LI in ind-msa | NB-5 | 20,000 | 0.930 | LI in nob-nor | NB-5 | 20,000 | 0.794 |
Table 17.
Confusion matrix and F1-score related to similar languages in three-stage LI-1.
Table 17.
Confusion matrix and F1-score related to similar languages in three-stage LI-1.
| ID | Bos | Hrv | ID | Ind | Msa | ID | Nob | Nor |
|---|
| bos | 914 | 81 | ind | 889 | 101 | nob | 595 | 367 |
| hrv | 145 | 837 | msa | 120 | 877 | nor | 407 | 549 |
| F1 score | 0.886 | 0.867 | | 0.876 | 0.886 | | 0.583 | 0.562 |
Table 18.
LGI in different script languages when using DFS and two-gram.
Table 18.
LGI in different script languages when using DFS and two-gram.
| FS | 300 | 500 | 700 | 1000 | 2000 | 3000 | 5000 | 7000 |
|---|
| Arabic | 0.999 | 0.999 | 0.999 | 0.999 | 0.999 | 0.999 | | |
| Cyrillic | 0.998 | 0.999 | 0.999 | 0.999 | 0.999 | | | |
| Latin | 0.960 | 0.980 | 0.986 | 0.989 | 0.991 | 0.992 | 0.992 | 0.992 |
Table 19.
LI in LG when using two-gram.
Table 19.
LI in LG when using two-gram.
| FS | 100 | 300 | 500 | 700 | 1000 | 3000 |
|---|
| Arabic | Indo-European/Indo-Iranian | 0.993 | 0.997 | 0.998 | 0.998 | 0.998 | |
| Cyrillic | Altaic/Turkic | 0.993 | 0.997 | 0.998 | 0.998 | 0.998 | |
| Indo-European/Balto-Slavic | 0.946 | 0.982 | 0.986 | 0.989 | 0.989 | |
| Latin | Niger-Congo/Atlantic-Congo | 0.996 | 0.999 | 0.999 | 0.999 | 0.999 | |
| Indo-European/Celtic | 0.997 | 0.999 | 0.999 | 0.999 | 0.999 | |
| Altaic/Turkic | 0.977 | 0.981 | 0.982 | 0.981 | 0.981 | |
| Uralic/Finnic | 0.996 | 0.997 | 0.998 | 0.998 | 0.998 | |
| Indo-European/Germanic | 0.778 | 0.849 | 0.872 | 0.878 | 0.883 | 0.882 |
| Indo-European/Italic | 0.883 | 0.953 | 0.965 | 0.969 | 0.971 | 0.971 |
| Austronesian/Malayo-Polynesian | 0.832 | 0.865 | 0.871 | 0.872 | 0.872 | |
| Indo-European/Balto-Slavic | 0.795 | 0.888 | 0.912 | 0.920 | 0.927 | 0.935 |
Table 20.
Selected OCM for LGI and LI in LG in three-stage LI-2.
Table 20.
Selected OCM for LGI and LI in LG in three-stage LI-2.
| ID | Model | FS | F1-score |
|---|
| LGI in Arabic script languages | SVM-2 | 300 | 0.999 |
| LGI in Cyrillic script languages | SVM-2 | 500 | 0.999 |
| LGI in Latin-script languages | SVM-(2–3) | 5000 | 0.995 |
| LI in Indo-European/Indo-Iranian in Arabic script | SVM-2 | 500 | 0.998 |
| LI in Indo-European/Balto-Slavic in Cyrillic script | SVM-(2–3) | 5000 | 0.995 |
| LI in Turkic-Common/Turkic in Cyrillic in Cyrillic | SVM-2 | 300 | 0.999 |
| LI in Indo-European/Germanic in Latin | SVM-(2–3) | 15,000 | 0.924 |
| LI in Indo-European/Italic in Latin | SVM-(2–3) | 10,000 | 0.989 |
| LI in Niger-Congo/Atlantic-Congo in Latin | SVM-2 | 300 | 0.999 |
| LI in Austronesian/Malayo-Polynesian (MP) in Latin | SVM-(2–3) | 10,000 | 0.945 |
| LI Indo-European/Celtic in Latin | SVM-2 | 300 | 0.999 |
| LI in Turkic-Common/Turkic in Latin | SVM-3 | 3000 | 0.983 |
| LI in Indo-European/Balto-Slavic in Latin | SVM-(2–3) | 10,000 | 0.966 |
| LI in Uralic/Finnic Latin | SVM-3 | 500 | 0.999 |
Table 21.
Confusion matrix and F1-score related to similar languages in three-stage LI-1.
Table 21.
Confusion matrix and F1-score related to similar languages in three-stage LI-1.
| ID | Bos | Hrv | ID | Ind | Msa | ID | Nob | Nor |
|---|
| bos | 739 | 227 | ind | 852 | 144 | nob | 572 | 404 |
| hrv | 35 | 957 | msa | 131 | 865 | nor | 380 | 598 |
| F1-score | 0.851 | 0.863 | | 0.850 | 0.857 | | 0.580 | 0.589 |
Table 22.
Selected OCM for SLGI in three LG in four-stage LI.
Table 22.
Selected OCM for SLGI in three LG in four-stage LI.
| ID | Model | FS | F1-Score |
|---|
| LI in Austronesian-Malayo/Polynesian (MP) in Latin | SVM-(2–3) | 1000 | 0.994 |
| LI in Indo-European/Balto-Slavic in Latin | SVM-(2–3) | 5000 | 0.995 |
| LI in Indo-European/Germanic in Latin | SVM-(2–3) | 5000 | 0.984 |
Table 23.
Confusion matrix between similar languages in LI in LG.
Table 23.
Confusion matrix between similar languages in LI in LG.
| ID | Bos | Hrv | ID | Ind | Msa | ID | Nob | Nor |
|---|
| bos | 915 | 81 | ind | 894 | 102 | nob | 609 | 376 |
| hrv | 145 | 847 | msa | 120 | 874 | nor | 414 | 568 |
| F1 score | 0.885 | 0.877 | | 0.879 | 0.883 | | 0.594 | 0.576 |
Table 24.
Comparison results for different levels of hierarchical LI.
Table 24.
Comparison results for different levels of hierarchical LI.
| Type | One-Stage | Two-Stage | Three-Stage 1 | Three-Stage 2 | Four-Stage | Langid.py |
|---|
| Macro-F1 | 0.9659 | 0.9757 | 0.9792 | 0.9797 | 0.9799 | 0.8766 |
| Time | 0:00:44.41 | 0:00:42.70 | 0:00:47.64 | 0:01:15.81 | 0:01:18.97 | 0:01:18.97 |
Table 25.
F1-score for Indo-European/Germanic languages in Latin for different levels of hierarchical LI.
Table 25.
F1-score for Indo-European/Germanic languages in Latin for different levels of hierarchical LI.
| ID | Afr | Dan | Deu | Eng | Fao | Isl | Ltz | Nld | Nno | Nob | Nor |
|---|
| One-stage | 0.989 | 0.908 | 0.983 | 0.962 | 0.969 | 0.973 | 0.980 | 0.978 | 0.872 | 0.543 | 0.468 |
| Two-stage | 0.995 | 0.965 | 0.989 | 0.980 | 0.988 | 0.989 | 0.982 | 0.991 | 0.934 | 0.562 | 0.577 |
| Three-stage 1 | 0.994 | 0.968 | 0.990 | 0.981 | 0.990 | 0.992 | 0.986 | 0.990 | 0.946 | 0.583 | 0.561 |
| Three-stage 2 | 0.993 | 0.983 | 0.992 | 0.977 | 0.992 | 0.996 | 0.886 | 0.994 | 0.973 | 0.579 | 0.588 |
| Four-stage | 0.994 | 0.980 | 0.991 | 0.977 | 0.994 | 0.997 | 0.985 | 0.995 | 0.974 | 0.594 | 0.576 |
| langid.py | 0.893 | 0.868 | 0.916 | 0.900 | 0.693 | 0.811 | 0.926 | 0.904 | 0.811 | 0.217 | 0.552 |
Table 26.
Xhosa corpora statistics.
Table 26.
Xhosa corpora statistics.
| Length Unit | Max | Min | Average |
|---|
| Character | 260 | 19 | 112.14 |
| Word | 61 | 2 | 15.78 |
Table 27.
Comparative results of the effect of noisy content on LI.
Table 27.
Comparative results of the effect of noisy content on LI.
| Test Type | One-Stage | Two-Stage | Three-Stage 1 | Three-Stage 2 | Four-Stage | Langid.py |
|---|
| Macro-F1 | 0.9620 | 0.9726 | 0.9748 | 0.9753 | 0.9754 | 0.8736 |
| Time | 0:00:45.167 | 0:00:44.537 | 0:00:44.376 | 0:01:19.102 | 0:01:20.765 | 0:01:20.960 |
Table 28.
Confusion matrix related to Xhosa.
Table 28.
Confusion matrix related to Xhosa.
| Including Xhosa | Not Including Xhosa |
|---|
| | afr | kin | swa | xho | zul | | afr | kin | swa | zul |
| afr | 948 | | | 47 | | afr | 996 | | | |
| kin | | 996 | | 2 | | kin | | 998 | | |
| swa | | | 996 | | | swa | | | 998 | |
| xho | 90 | | | 839 | 25 | zul | | | | 1000 |
| zul | | | | 16 | 984 | | | | | |
| Macro-F1 | 0.927 | 0.997 | 0.996 | 0.861 | 0.977 | | 0.995 | 0.998 | 0.998 | 0.999 |













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}