4.4.1. System Framework of Dynamic reconfigurable RVM
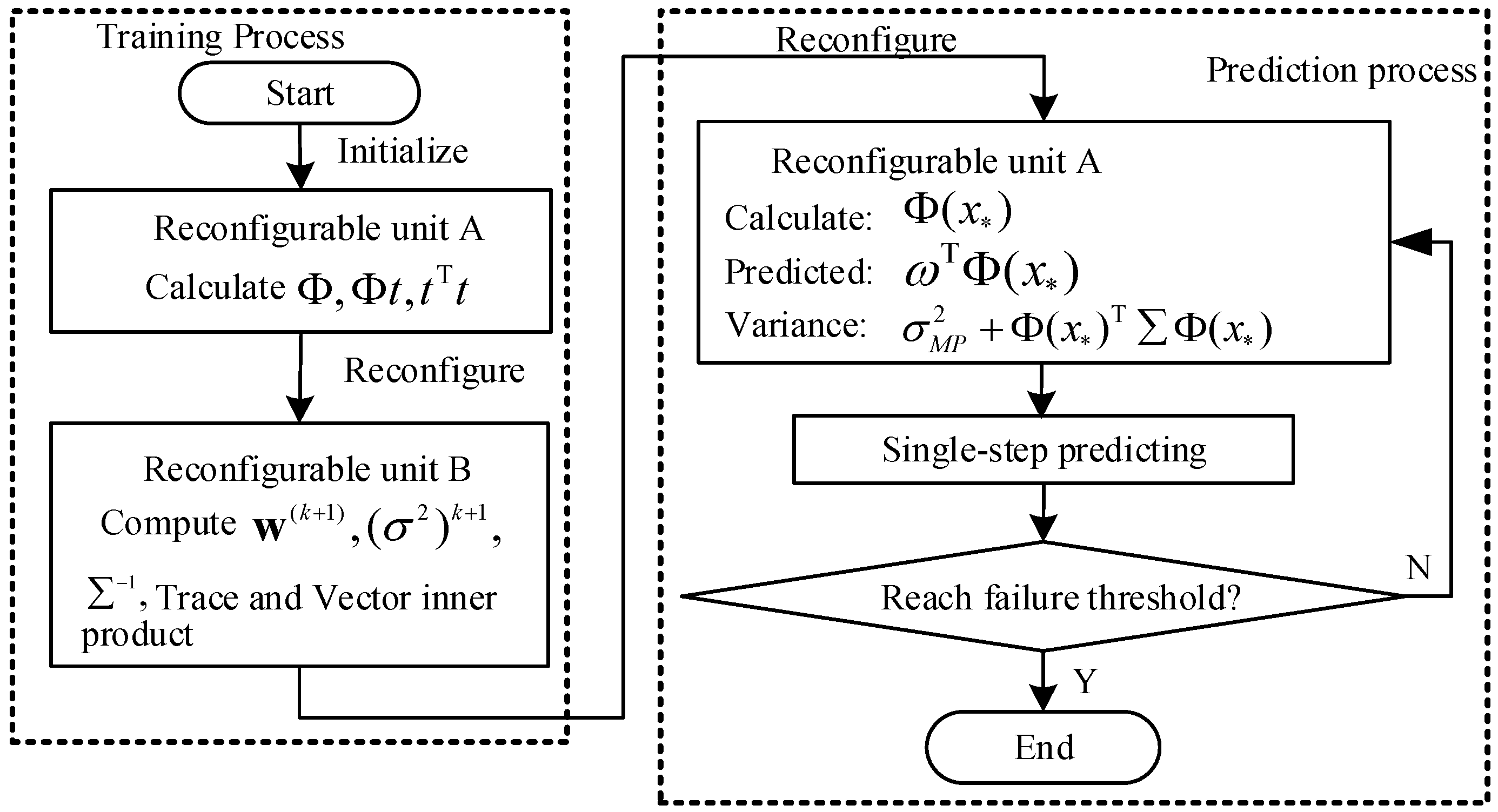
The RVM based RC is divided into two sub-tasks that are denoted as reconfiguration units A and B, respectively. The two sub-tasks are executed in time multiplexing mode in the same reconfigurable partition. Each reconfigurable unit will be configured only once throughout the calculation process.
Figure 2 shows the flowchart of the proposed dynamic reconfigurable RVM based on the RC platform. The RVM in this platform has a training phase and a prediction phase, which compose a typical online retraining process. The FPGA is initially configured as unit A in the training phase and store the intermediate results in unit A. Then, the FPGA is reconfigured as unit B and store the calculated results in unit B. In the prediction phase, the unit A is reconfigured to predict the fault growth and estimate the RUL. From this figure, it is obvious that the training phase involves one reconfiguration from unit A to unit B and the prediction phase involves one reconfiguration from unit B to unit A. The online re-training process of RVM needs two dynamic reconfigurations for each cycle of computation.
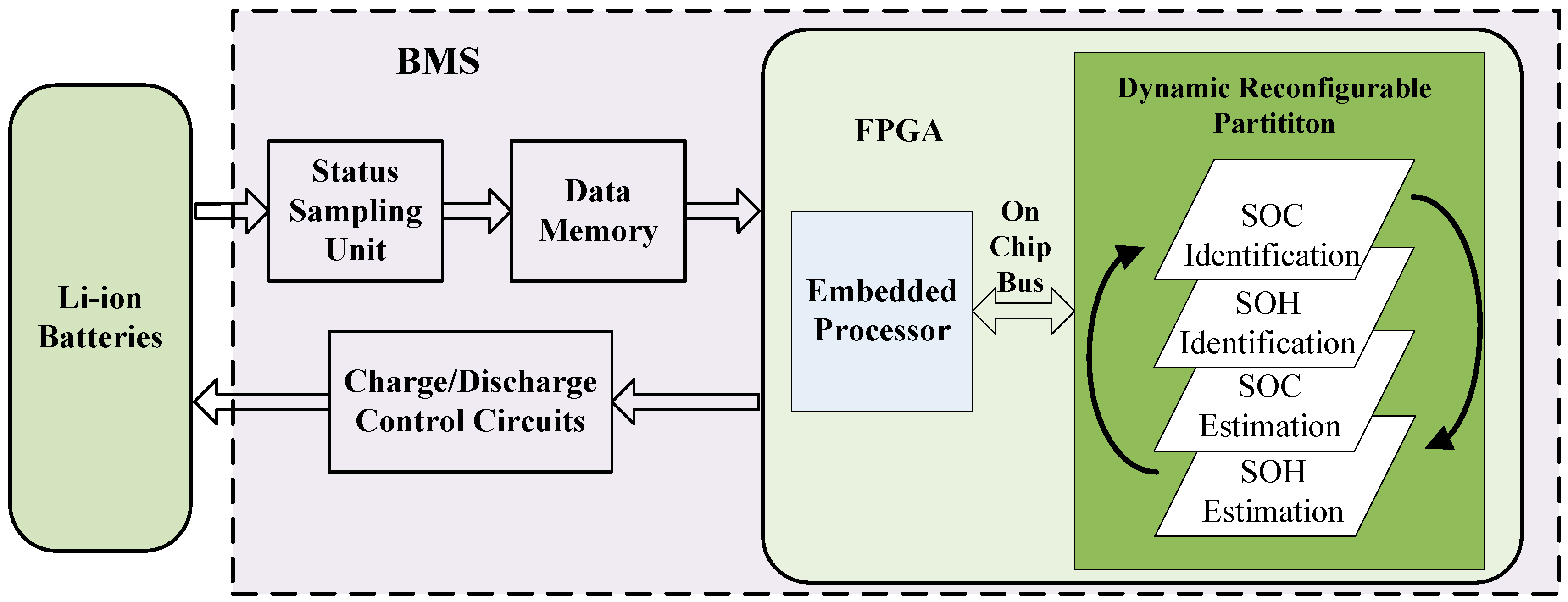
Figure 3 shows a general framework of dynamic RC system on Virtex-5 FPGA [
24]. The dynamic RC system consists of FPGA, off-chip memory, and configuration memory.
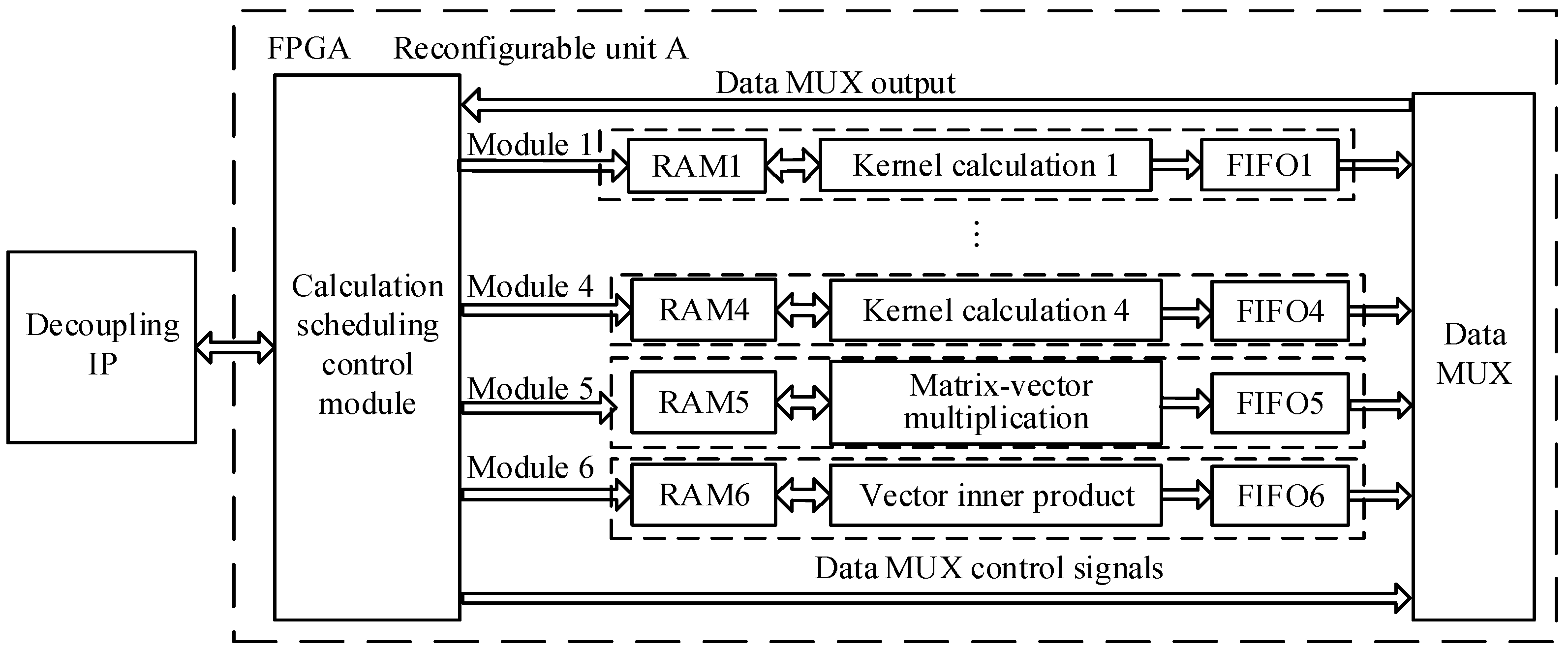
FPGA is the core functional unit that comprises a static logic partition and dynamic reconfigurable partition. The static logic partition includes embedded processors, on-chip bus, and peripheral modules connected to the bus. Dynamic reconfigurable partition executes reconfiguration units A and B in time multiplexing mode for RVM training and prediction. The embedded processors access the dynamic reconfigurable partition through the on-chip bus to control the computing process.
Off-chip memory stores the input data and intermediate results for RUL prediction. Data exchange between the dynamic reconfigurable partition and off-chip memory is implemented in direct memory access (DMA) manner to improve data transmission efficiency. Decoupling IPs are used to avoid disturbing the functions of static logic partition during dynamic reconfiguration. The configuration memory is used to store FPGA configuration files.
4.4.3. Design of Key Modules
The kernel function computing involves calculation of 2-norm and exponential functions. The 2-norm calculation has low computation efficiency since it cannot be executed with pipeline computing while the exponential function is a transcendental function which cannot be directly implemented by multiplier and adder. To achieve high efficiency, a multi-level pipeline calculation method of piecewise linear approximation is proposed. In addition, an improved Cholesky decomposition method is proposed to accommodate the large amount of computations in matrix inversion with lower-upper (LU) decomposition and the instability caused by the round-off error from the Cholesky decomposition.
For Gaussian kernel function
where
is the hyper-parameter determined before training, the kernel matrix
is a symmetric positive definite matrix whose diagonal elements are all 1. Therefore, only the lower triangular elements, as shown below, need to be calculated:
Assuming that the dimension of training samples is
, the 2-norm for vector
and
is:
A multi-level pipelined method is introduced to calculate the 2-norm. Take the first column in Equation (20) as an example, the computing elements are shown in
Table 1.
The 2-norm computing process is executed by rows. That is,
is first and then
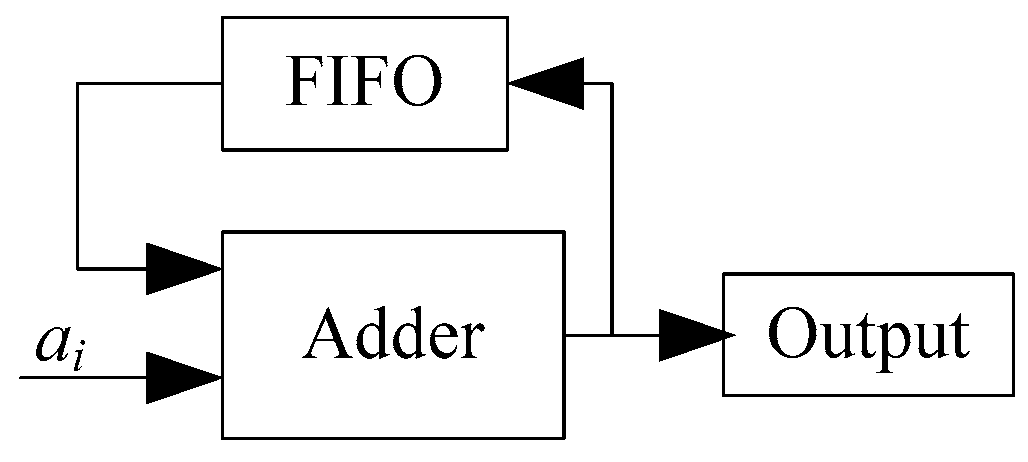
, and so forth. In this process, a fully pipelined accumulator is designed with an fully pipelined adder and a FIFO as shown in
Figure 6.
Figure 7 shows the computing flowchart of the fully pipelined accumulator. In the first stage, data
a1,
a2, ...,
an−1 and “0“ are input to the adder, and the outputs of the adder are stored in the FIFO. In the 2
nd stage, data
an,
an+1, ...,
a2(n−1) and FIFO buffered data from the 1
st stage are then input to the adder. The outputs of the adder are again stored in the FIFO. This process is repeated at the
lth pipeline cycle. Similarly, the 2-norm calculations in other columns can be implemented.
- (b)
Exponential Function Calculation
Since exponential function cannot be implemented directly by adders and multipliers in FPGA, a piecewise linear approximation method, which combines linear polynomial function and LUT, is employed as an approximation [
25]. In this method, the linear polynomial parameters are stored in the LUT while the calculation of linear polynomial is implemented by an adder and a multiplier in FPGA.
The principle of piecewise linear approximation is as follows: for a nonlinear function defined in , the interval is evenly divided into m subintervals [Li, Ui] and . For , is approximated as , where and are linear polynomial parameters stored in the LUT. Note that m introduces trade-off between accuracy and hardware occupation and should be selected properly.
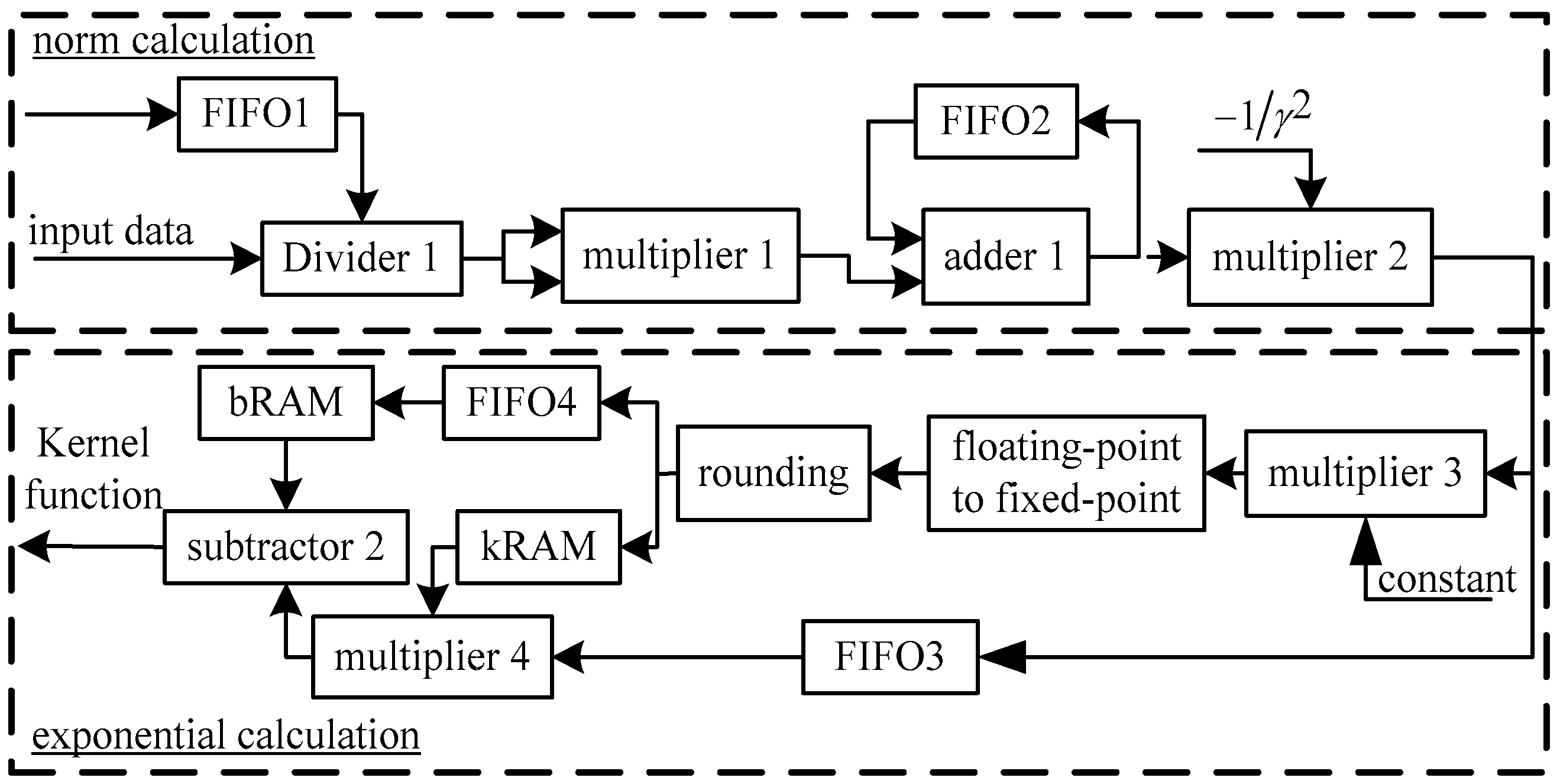
Figure 8 shows the data path of Gaussian kernel function calculation. In this figure, the upper part is for 2-norm calculation while the lower part is for exponential function calculation. In the lower part, bRAM and kRAM store parameters
k and
b for piecewise linear approximation, respectively.
The corresponding values of k and b can be obtained by accessing the addresses for these two RAMs. Then the kernel function can be calculated with subtractor 2 and multiplier 4. To get the right addresses of bRAM and kRAM, the output of the 2-norm calculation is mapped to the RAM address by multiplication, “floating-point to fixed-point” and rounding units.
Since the computing delay of multiplier 4 is one clock cycle larger than subtractor 2, FIFO4 is used to synchronize them by introducing a clock delay to access the bRAM. FIFO3 is used to store the output of 2-norm calculation and its depth should be larger than the delay of multiplier 4, which is 8 clock cycles in this design. The multiplier and adder are implemented with Xilinx floating-point arithmetic IP core, and the data are in single-precision floating point format.
To make computations affordable and deal with the instability caused by rounding error in of matrix inversion computing process, an improved Cholesky decomposition [
26] is introduced for the inversion of symmetric positive definite Gaussian kernel matrix
. The improved Cholesky decomposition method decomposes matrix
as follows:
where
L is a lower triangular matrix whose diagonal elements are all 1,
D is a diagonal matrix (its diagonal elements are not 0). Matrices
L and
D can be obtained as:
where
and
is the element of
.
Assuming
, we have
, where
P is a lower triangular matrix with elements of:
where
.
The implementation of the improved Cholesky decomposition and matrix inversion is shown in
Figure 8. The elements in diagonal matrix
D−1 is the reciprocal of corresponding elements in matrix
D and this only requires division. The computation of matrix
P, i.e., the inverse matrix of
L, is given by Equation (24), in which
and
is the negative value of the result from a multiply accumulator:
In
Figure 9, the calculation of
D−1 is achieved with divider 1 and the results are stored into FIFO1. Multiplier 1, subtractor 1 and FIFO2 are used to calculate the
pij, in which FIFO2 buffers the results from the subtractor 1, which is initialized as 0. The memory depth of FIFO1 and FIFO2 is
n. With
D−1 and
P,
can be calculated by
.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}