1. Introduction
Nowadays, climate change has seriously threatened sustainable human development. Especially, China, as the world’s biggest emitter of CO
2, is particularly concerned in this regard [
1]. In order to actively implement the Paris Agreement and to contribute to the fight against climate change, China has committed to reducing its carbon intensity by 40–45% per unit of GDP whilst increasing the share of non-fossil energy consumption to 15% by the year of 2020. Since the introduction of the Emissions Trading System (ETS) by the European Union (E.U.) in 2005, carbon emissions trading has become an important market tool for responding to climate change as well as a long-term mechanism to address pollution problems. Advancing with the times, China has successfully established regional pilots for carbon emissions trading and has currently formed eight regional carbon markets, consisting of three provinces and five cities. Moreover, in the carbon trading market, an important corollary factor is carbon price prediction, which helps to reflect the carbon reduction performance and market value [
2]. It is certain that an accurate and a rational prediction of carbon prices would allow us to understand the pattern of carbon price variations and avoid risks in investments [
3]. Therefore, it is meaningful to be concerned with scientific methods for predicting carbon prices in China. In addition, carbon prices in China’s regional markets are time-series-connected with historical data, which also makes it possible to deliver an accurate prediction by using the model that is presented in this paper.
While early-stage research has been conducted on a qualitative analysis of China’s carbon market [
4,
5], more and more carbon price prediction methods have emerged in recent studies. They can be classified into two types that are focused on modeling and forecasting the carbon price volatility: mathematical statistical models and artificial neural networks. The conventional mathematical statistical models include difference-in-difference (DID), the vector auto-regression model (VAR), the autoregressive integrated moving average (ARIMA), and generalized autoregressive conditional heteroscedasticity (GARCH) models. Huang [
6] proved that carbon emission trading has a significant and sustained promotion effect on carbon emission reductions by using the difference-in-difference method. Zeng et al. [
7] employed a structural vector autoregressive (SVAR) model for exploring the dynamic relationships among the carbon emission allowance price, the regional economy, and energy prices in Beijing. Their empirical research results showed that, instead of the energy price, the historical carbon allowance price series was the major influencing factor on the carbon price. Zhu and Wei [
8] examined the forecasting ability of three hybrid ARIMA models under the E.U. ETS. However, the ARIMA model requires a stable time series, which obviously renders it unsuitable for the direct prediction of a carbon price time series. Notably, the different GARCH-type models are popular in this field. Xia [
9] studied the carbon price volatility of five pilot cities in China with the AR-GARCH (1,1) model. The results of experiments showed high consistency. Byun and Cho [
10] compared three methods to predict the related volatility, and concluded that the GARCH-type models were the most suitable method. However, Zhang et al. [
11] found that GARCH-type models are only satisfactory for in-sample forecasting and have limited significance for out-of-sample results. As described in the abovementioned studies, a single statistical model may not satisfy the condition of flexibility for an appropriate simulation due to the dynamic characteristics of carbon price volatility.
Today, with the growing data volume and algorithms’ ability to learn, machine learning algorithms are prevailing. The most essential feature of machine learning is to learn the data, which means to build a system to parse data so as to excavate the laws that hold between the data. The main advantage of a machine learning algorithm is that it can consider multiple attributes or features at one time and capture the hidden relationship between them that is difficult for a statistical model to reveal [
12,
13,
14,
15,
16,
17]. Compared with a traditional statistical model, machine learning algorithms have a stronger self-learning ability, a generalization ability, fast calculation speed, an associative memory ability that can fit a nonlinear relationship, and more flexible applicability to the amount of sample data. Based on these advantages, machine learning algorithms are applied in many fields [
18,
19,
20,
21,
22,
23,
24]. For example, many algorithms have been developed to predict carbon prices, such as the back propagation neural network (BPNN), the support vector machine (SVM), and the radial basis function neural network (RBF). Liu and Sun [
25] applied a BPNN to forecast the carbon price and the carbon trading volume in Shanghai. Zhang et al. [
26] proposed a grey neural network improved by the ant colony algorithm (GNN-ACA) for carbon spot price forecasting. The results showed that the selected model performed significantly better than single ARIMA and least squares support vector machine (LSSVM) models by using data collected from the E.U. ETS. Tsai [
27] proposed a carbon price forecasting system using the radial basis function neural network (RBF), which can supply precise and real-time predictions of carbon prices. Moreover, the SVM and LSSVM, individually or in combination with plenty of other algorithms, have been widely adopted to predict the carbon trading price. Gao and Li [
28] compared some different prediction models in accordance with the daily EU emission allowance (EUA) futures prices from March 2008 to September 2013 (DEC12). The results indicated that the proposed EMD-PSO-SVM model performed better than other artificial neural networks (ANNs) in carbon price forecasting. Razak et al. [
29] and Zhu et al. [
30] used LSSVM as their main forecasting model. Their conclusions indicated that the LSSVM model seems to be a superior method for forecasting highly nonlinear and nonstationary carbon prices.
Huang et al. [
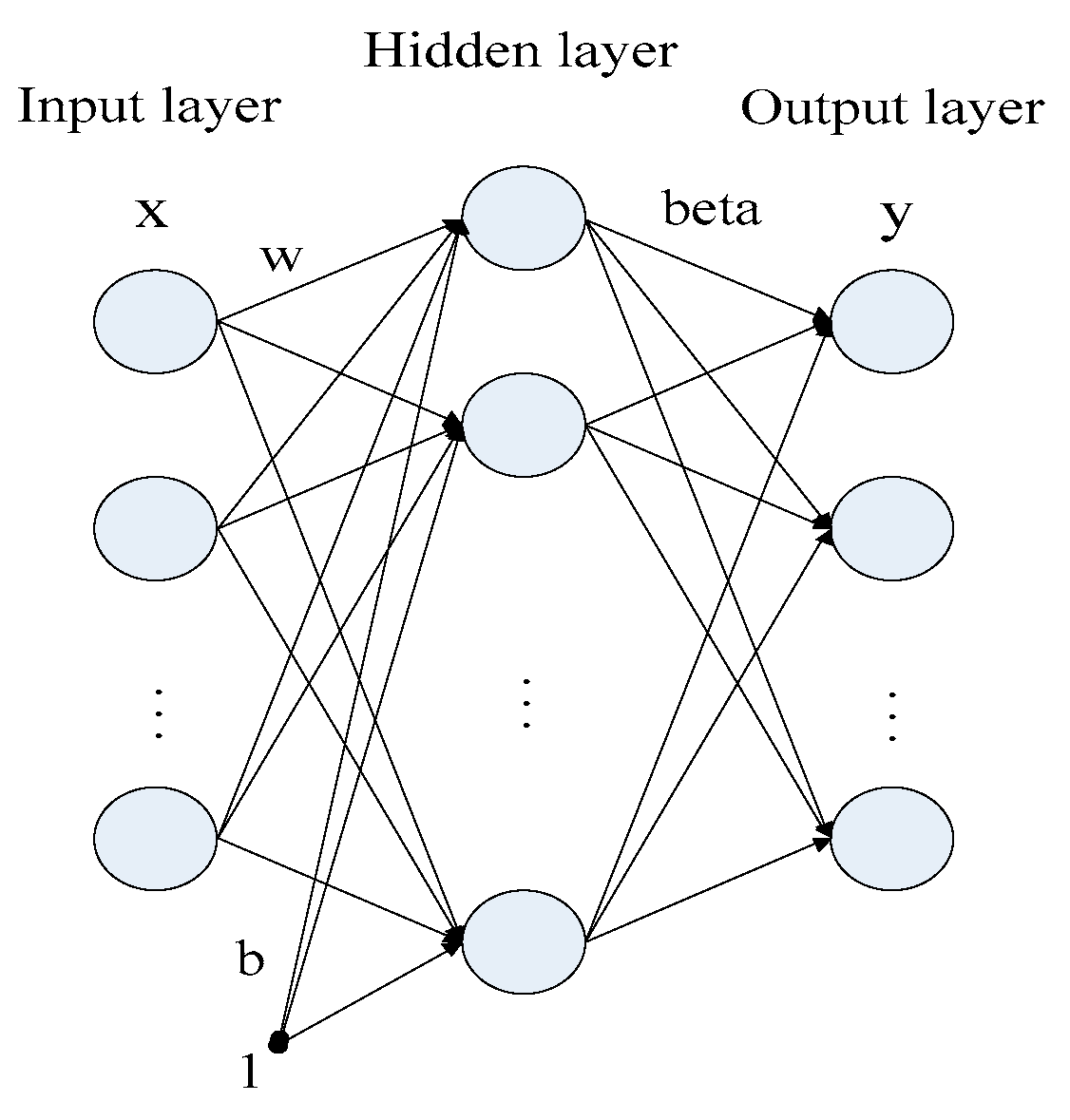
31] put forward the extreme learning machine (ELM) model in 2004, which has a higher precision of generalization as well as a faster convergence speed than the abovementioned models. Moreover, it can avoid many of the problems that may arise in gradient-based learning methods; for instance, stopping criteria and learning periods. As a consequence, it has been widely employed to make predictions in a variety of fields since its introduction. Shrivastava and Panigrahi [
32] investigated the performance of a combination of ELM and the Wavelet technique (WELM) in price forecasting in electricity markets. The empirical research demonstrated that this model is appropriate for price forecasting. Liu et al. [
33] applied the ELM model in wind speed forecasting. In this study, the ARIMA model and the SVM model were involved in a comparison of the prediction performance. The experimental results showed that the proposed WPD-EMD-ELM model performed the best among the compared models. Furthermore, an ELM’s input weights matrix and hidden layer bias are key parameters in the ELM’s generalization capability. Based on this, it is essential to utilize an optimization algorithm to obtain the optimal parameters. Rocha et al. [
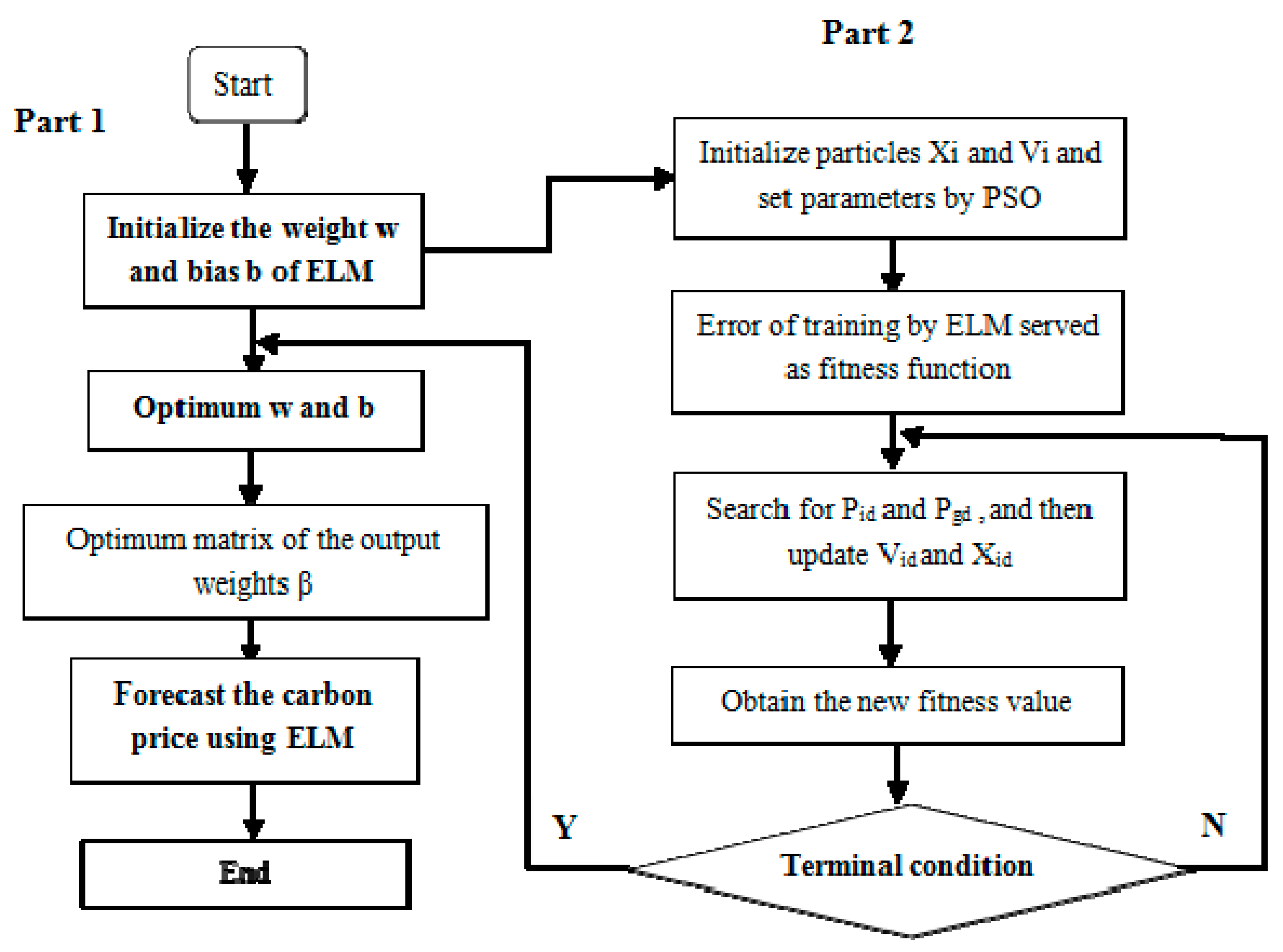
34] implemented parameter selection for an ELM improved by Particle Swarm Optimization (PSO-ELM) in the forecasting of a distributed electrical generation system’s capacity. Fan et al. [
35] proposed a PSO-ELM model for short-term power load forecasting. The results proved that the improved model showed a higher learning rate and prediction accuracy compared with the traditional ELM model. From the above, it can be found that the ELM-type models have been well-employed in a variety of forecasting scenarios. Therefore, one of the purposes of this paper is to verify the feasibility of the PSO-ELM model for carbon price prediction.
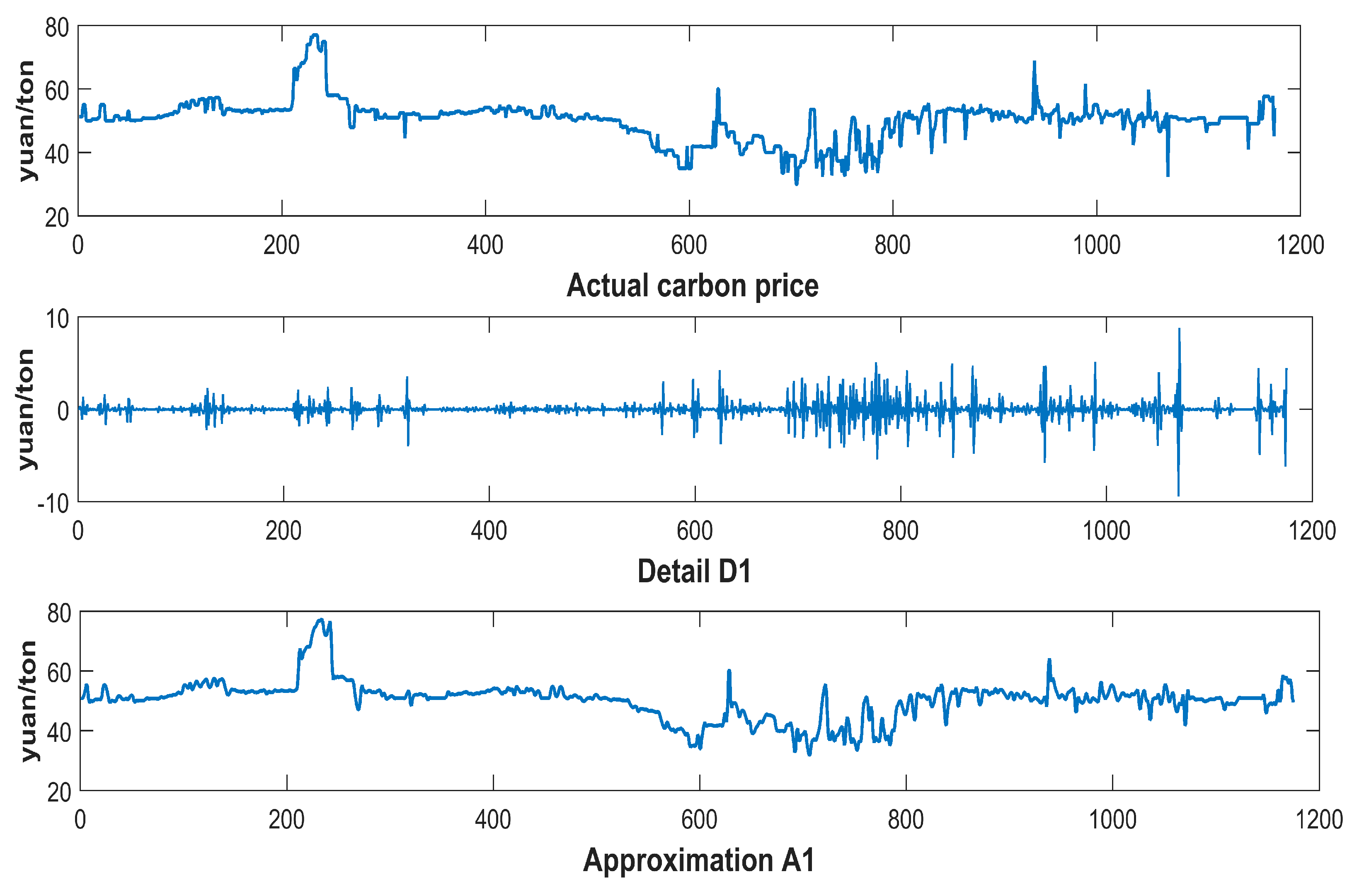
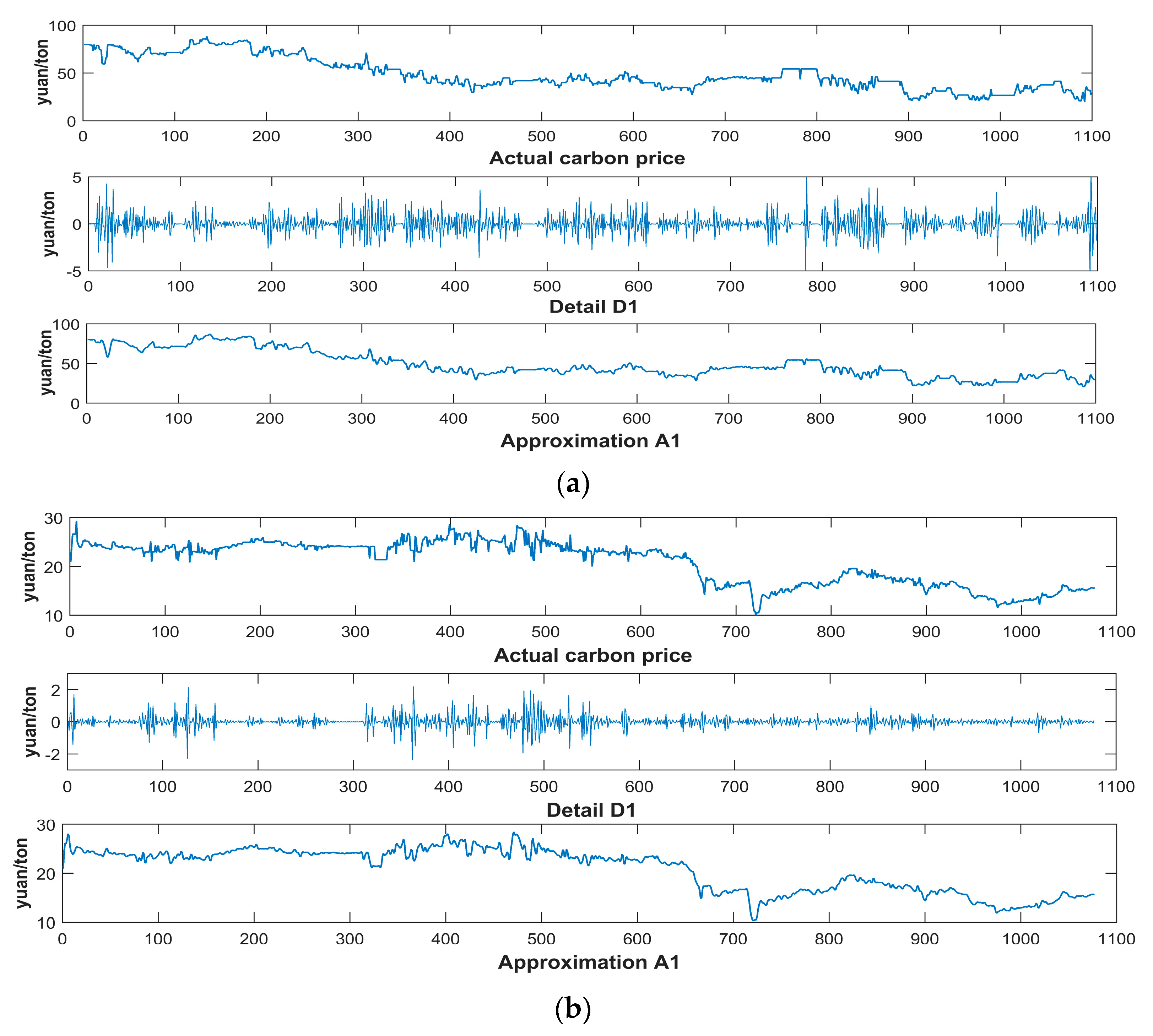
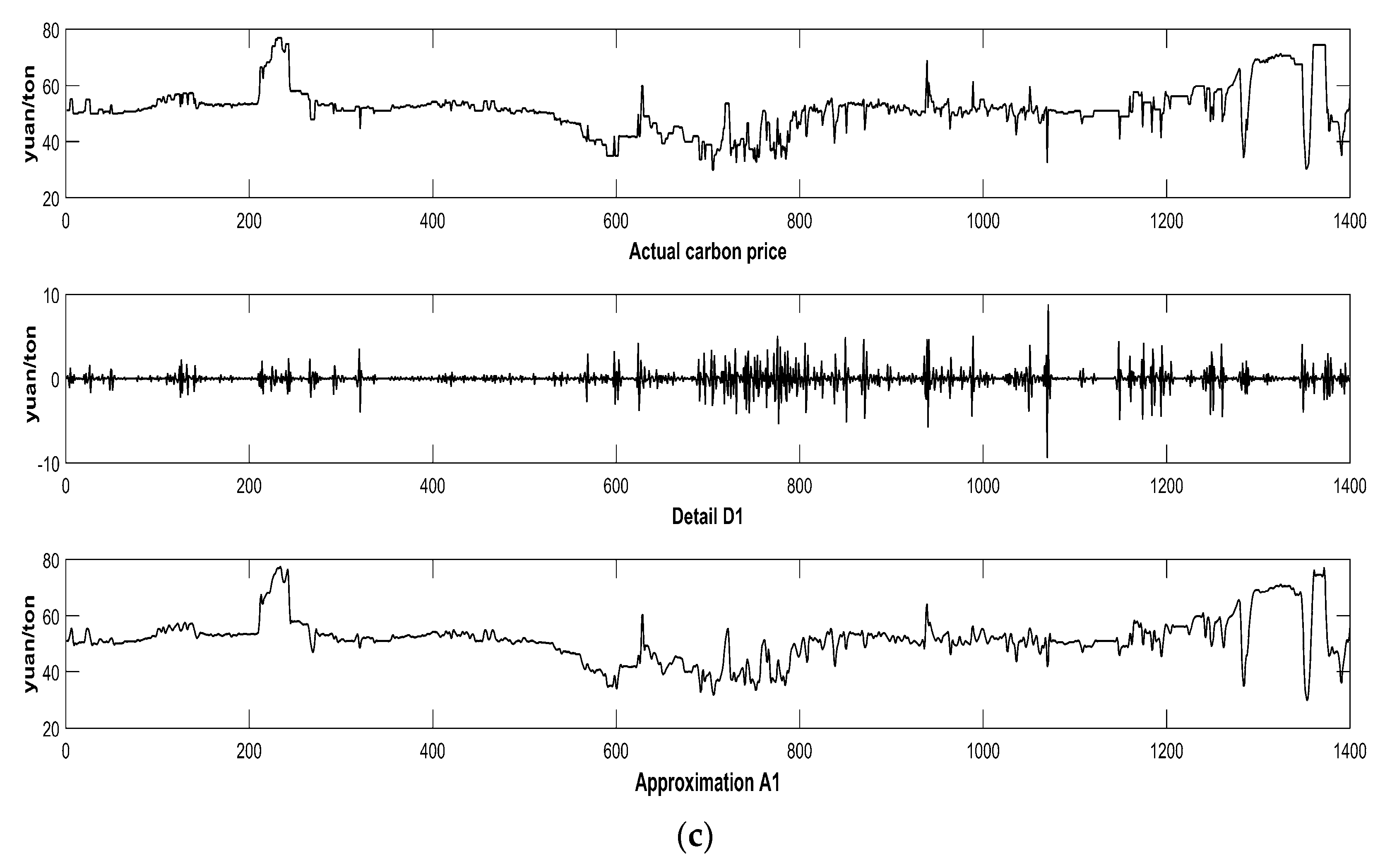
Given the chaotic property and intrinsic complexity of carbon prices, it may not be appropriate to directly forecast carbon prices before data preprocessing. Presently, empirical mode decomposition (EMD) and the wavelet transform (WT) are considered to be the common data preprocessing approaches for decomposing the initial series and eliminating the random volatility. WT was applied to signal processing in electricity market price forecasting by Saber et al. [
36]. In the process of analyzing the unified interval price of China’s carbon trading market, Li and Lu [
37] applied the GARCH-EMD model to predict carbon prices. The results demonstrate that EMD is an effective method to decompose unstable carbon prices. Zhu et al. [
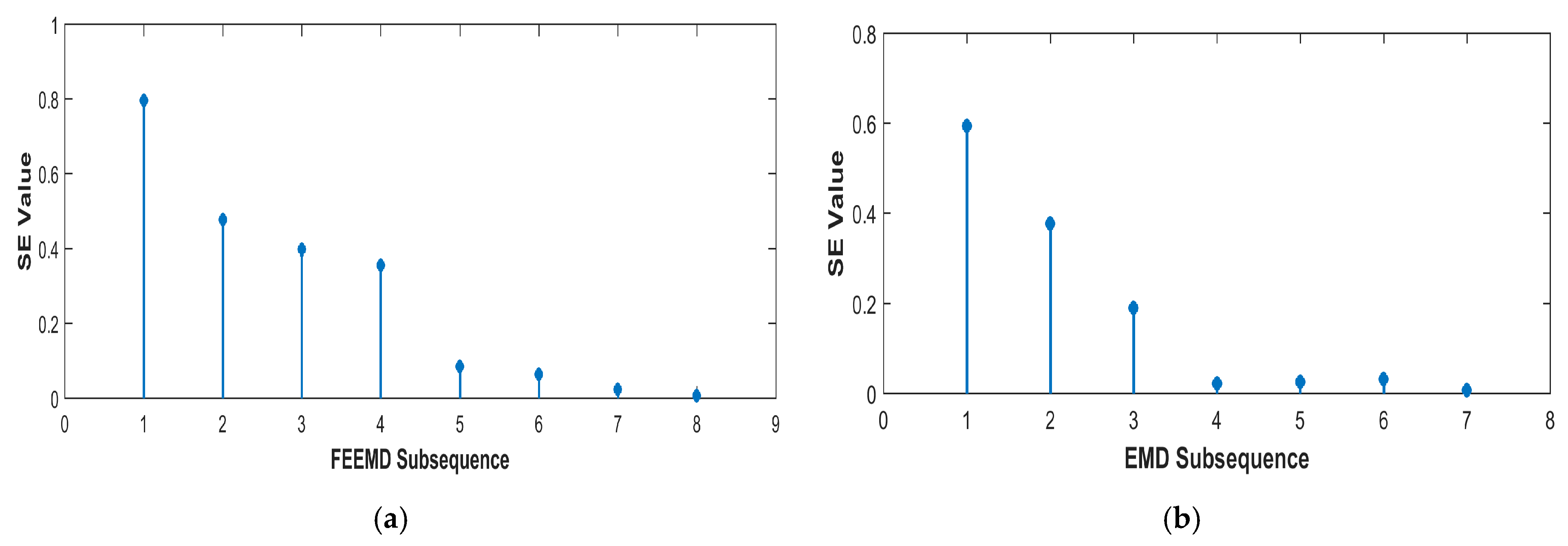
38] built a multiscale model that combined EMD and developmental least squares support vector regression (LSSVR) for carbon price forecasting with a high accuracy. Basing on the data from the E.U. ETS, the empirical results showed that the EMD-LSSVR model performed the best in comparison with other prediction models according to the values of statistical indicators. It is worth noting that EMD may have a mode mixing problem that causes the decomposed intrinsic mode functions (IMFs) to lose their meaning. To tackle the problem, Huang and Wu carried out ensemble empirical mode decomposition (EEMD) via introducing white noise into the original series [
39]. In 2014, fast ensemble empirical mode decomposition (FEEMD) was proposed to improve EEMD’s computing capacity for a large amount of sample data [
40]. They were all used successfully in wind speed forecasting. Heng et al. [
41] reconstructed the initial data for wind speed forecasting by FEEMD. Sun and Liu proposed EMD and FEEMD for processing the original wind speed data, and then combined these methods with different intelligent algorithms for the prediction of wind speed [
42,
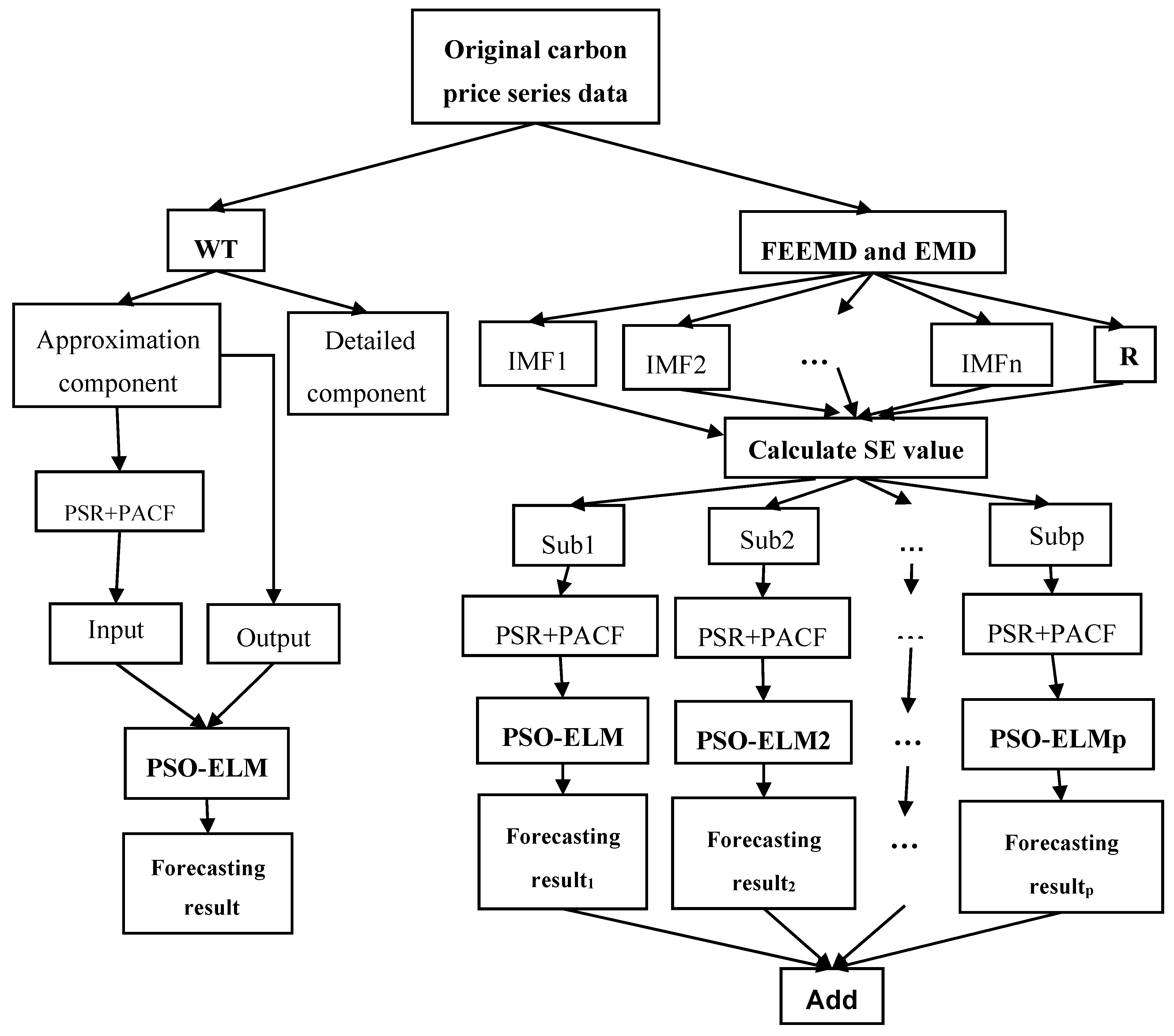
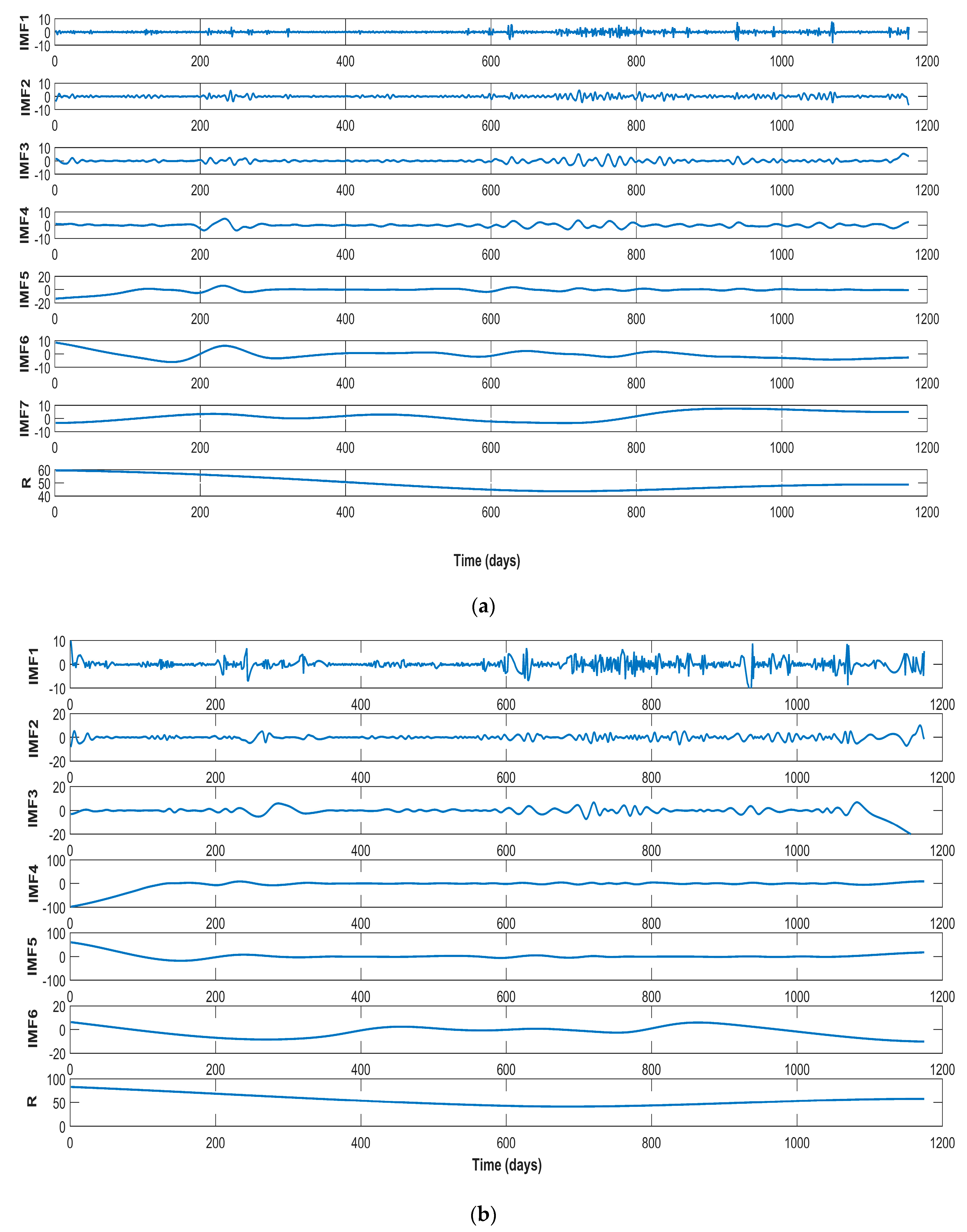
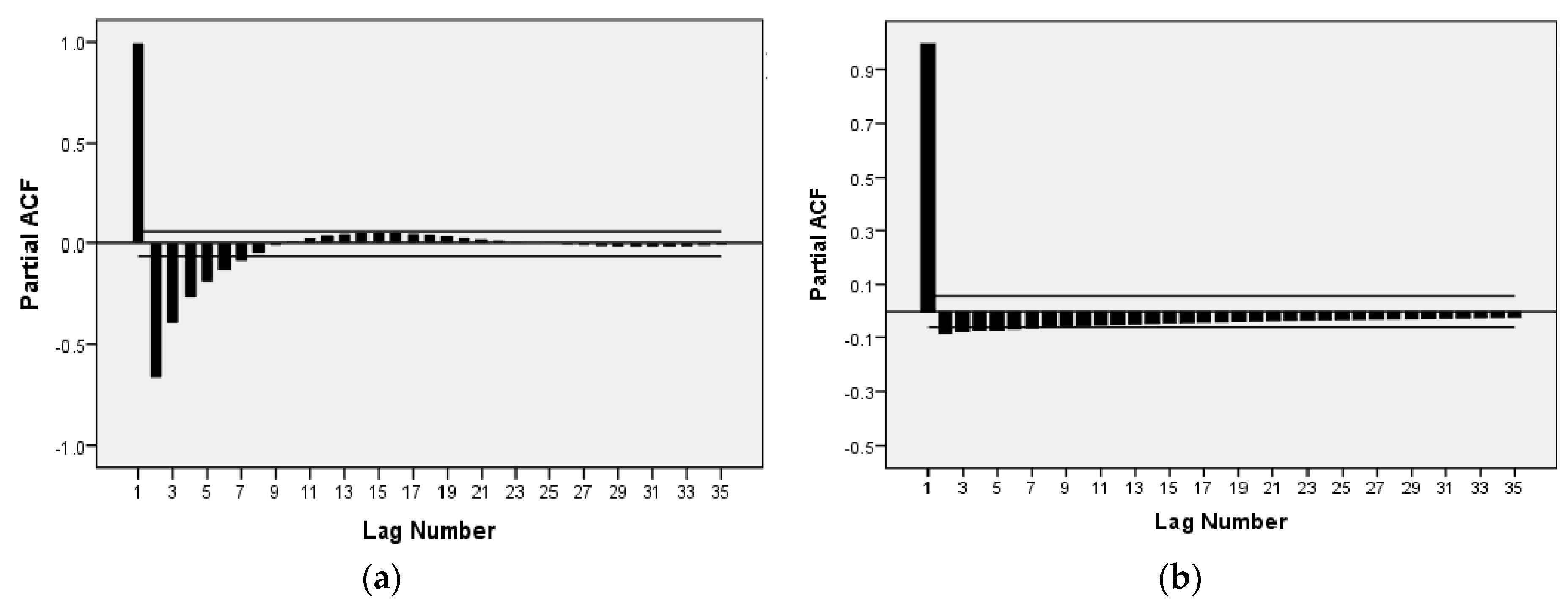
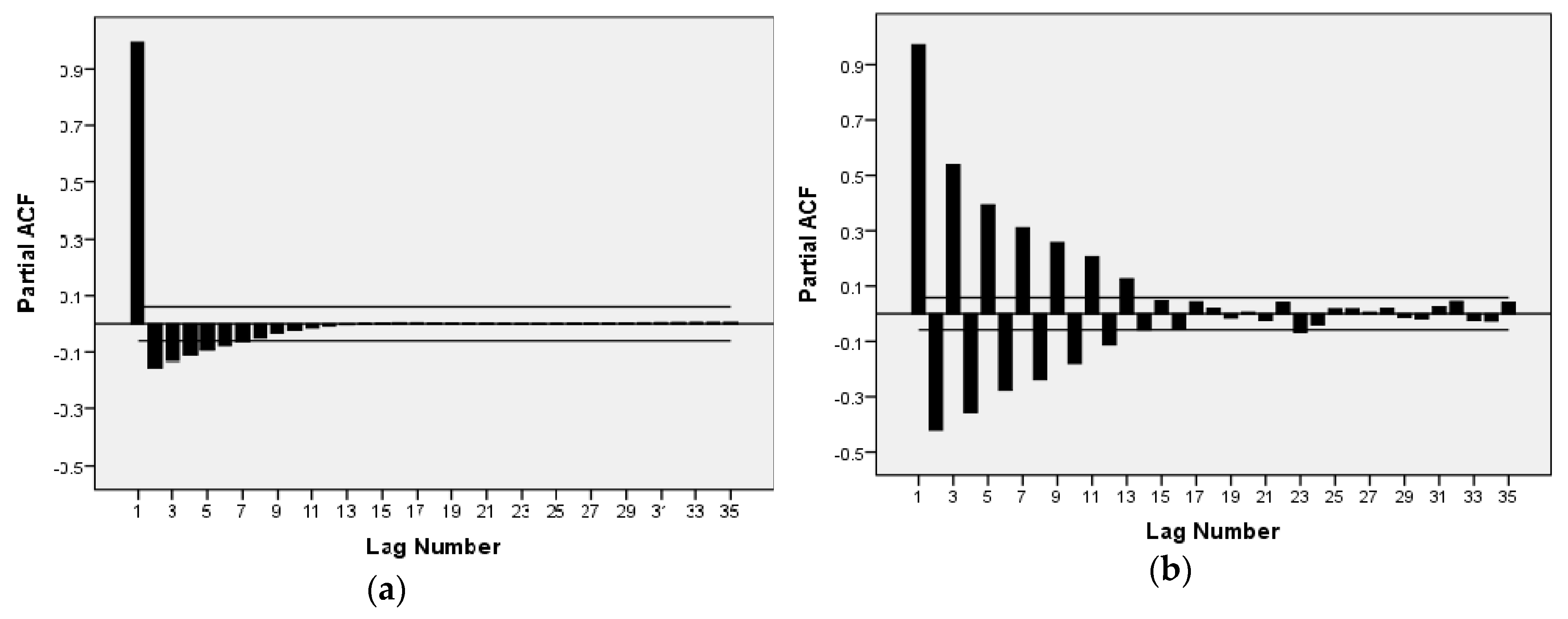
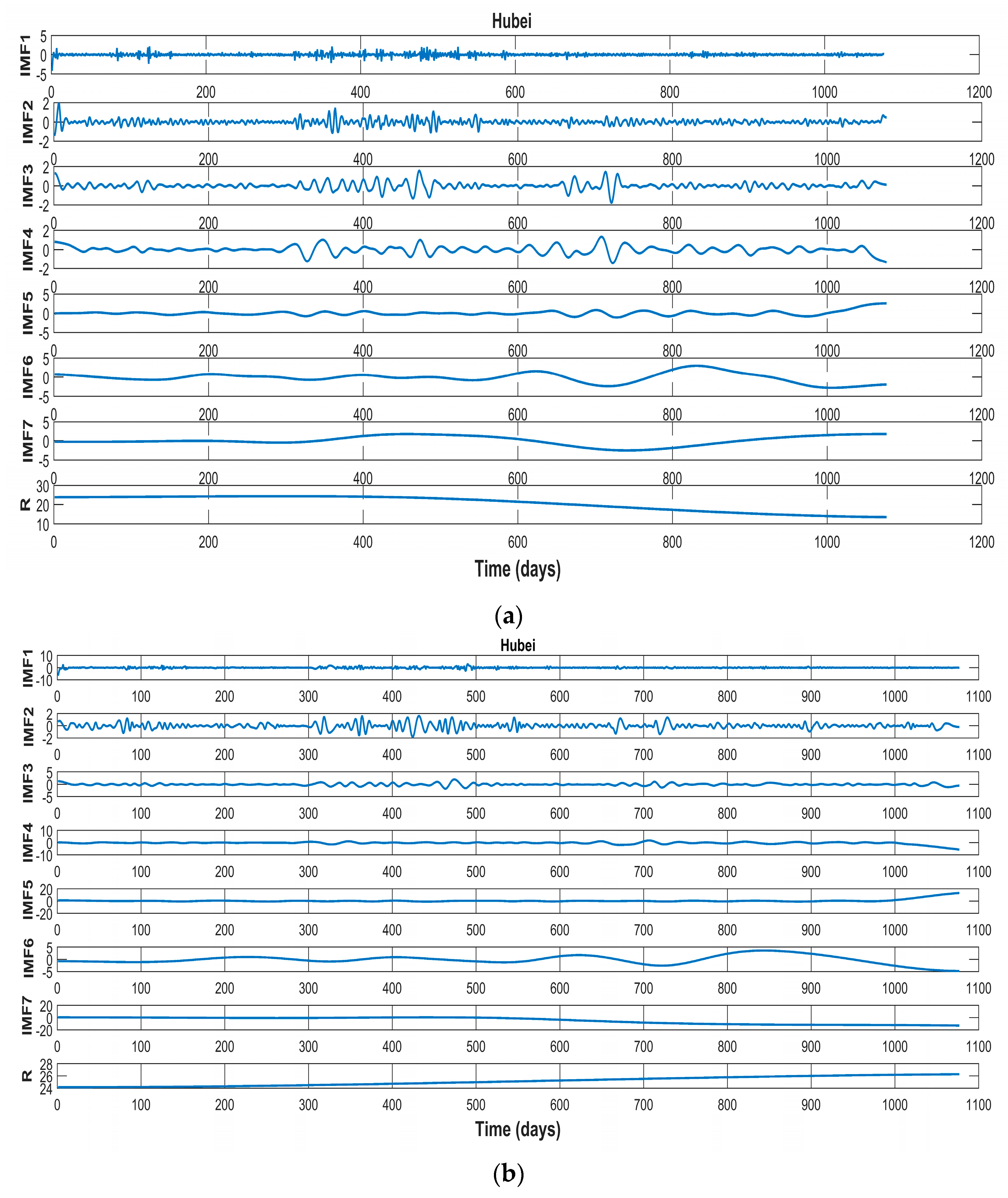
43]. Thanks to carbon prices having dynamic and nonlinear properties that are similar to those of wind speed, this paper proposes EMD and FEEMD to decompose a carbon price series and introduces both a phase space reconstruction theory (PSR) and a partial autocorrelation function (PACF) for the analysis of the decomposed subsequences.
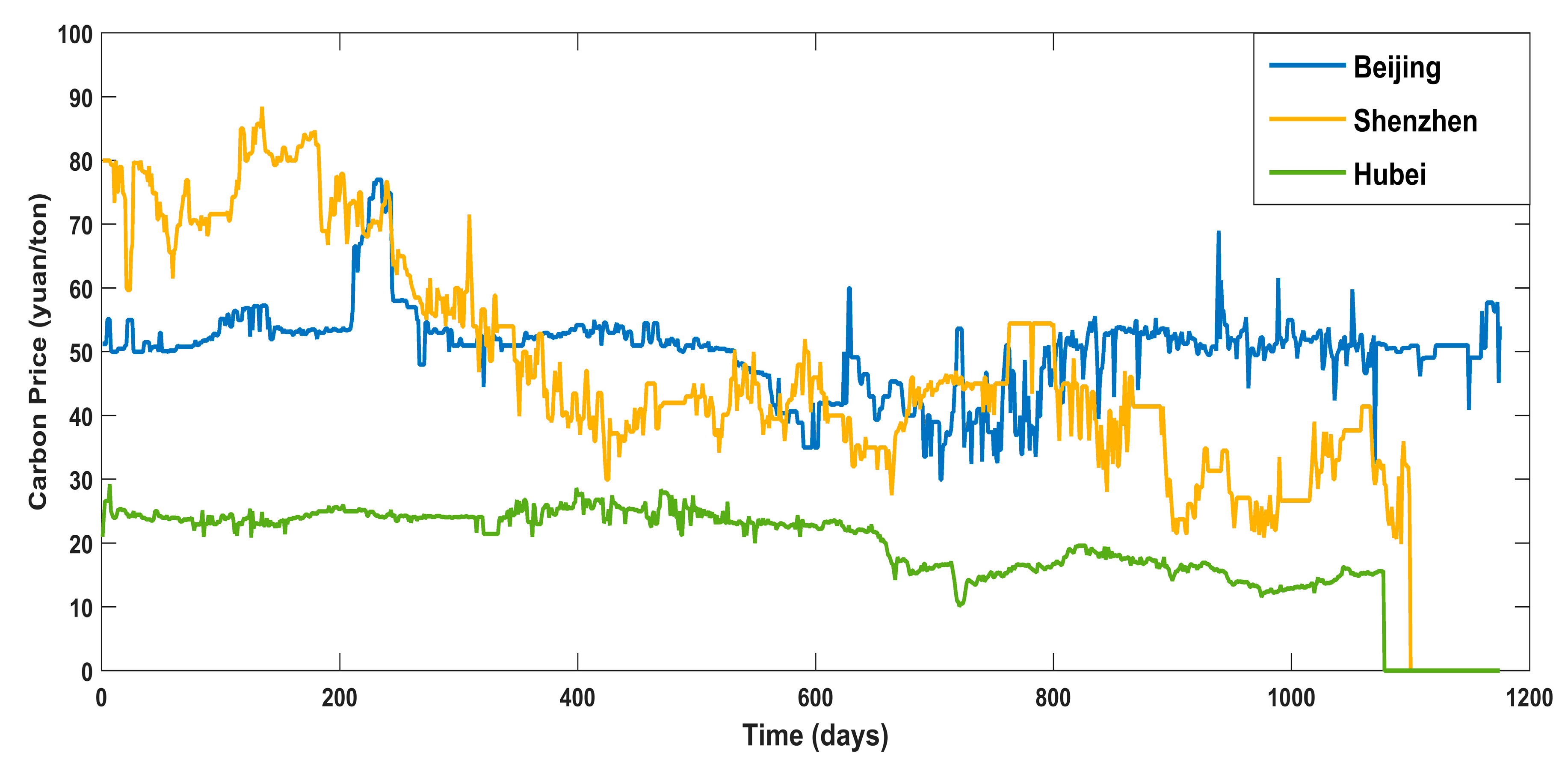
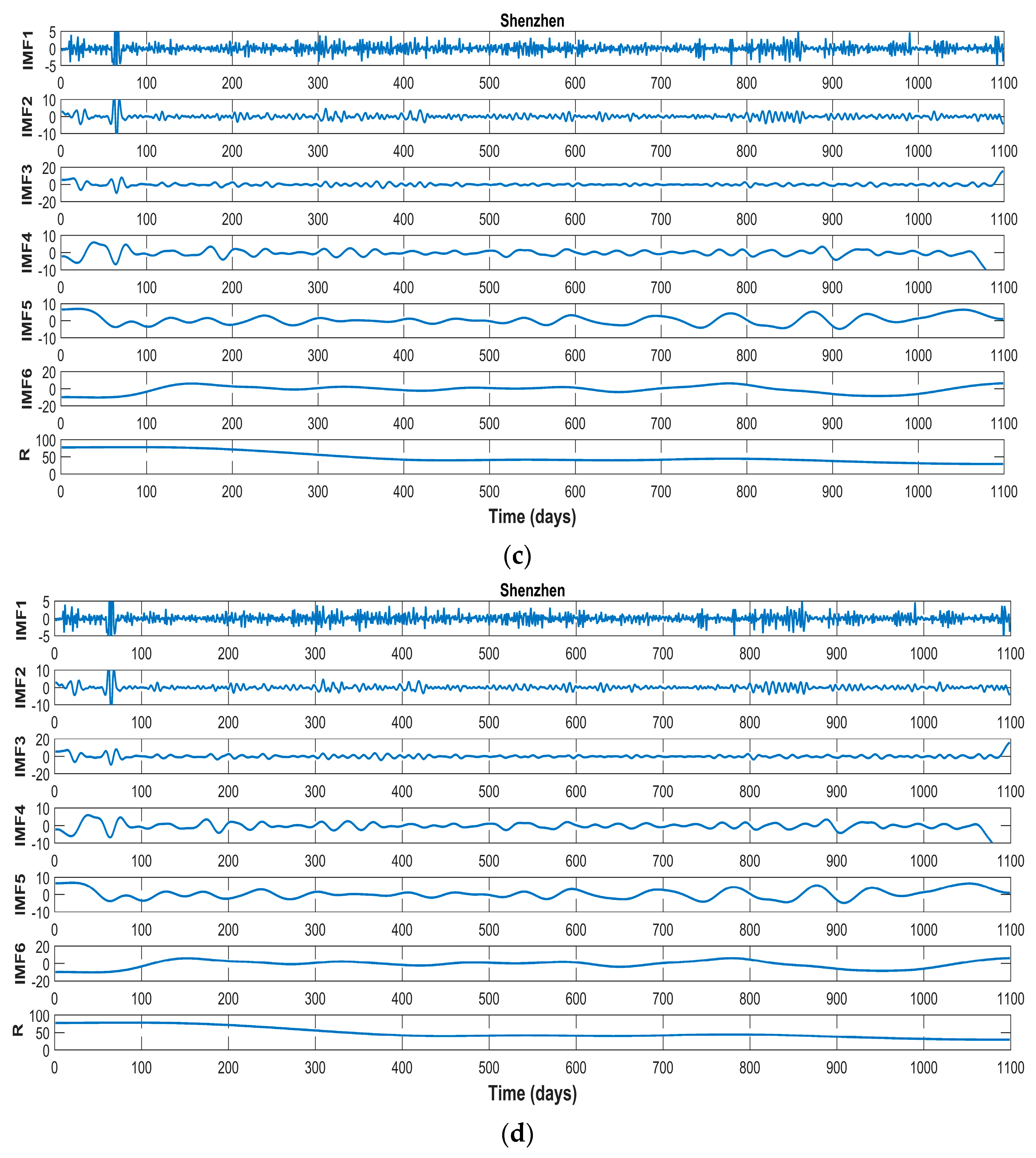
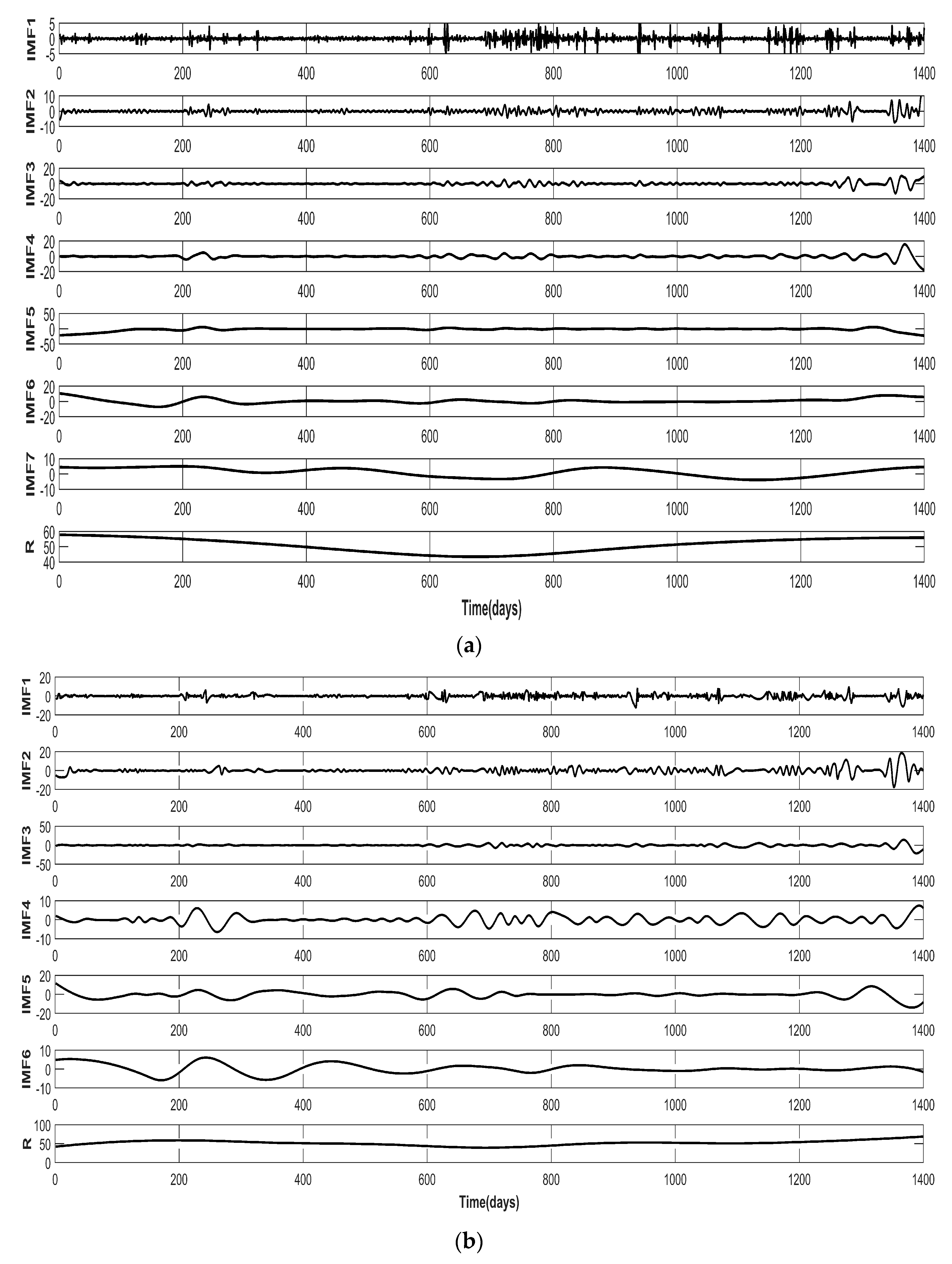
Currently, China has constructed eight regional carbon markets, and, on 19 December 2017, started the construction of the national carbon market. As the earliest pilot markets, the Beijing, Shenzhen, and Hubei carbon markets have been in smooth operation and gradually formed their features in the process of promoting emission reductions.
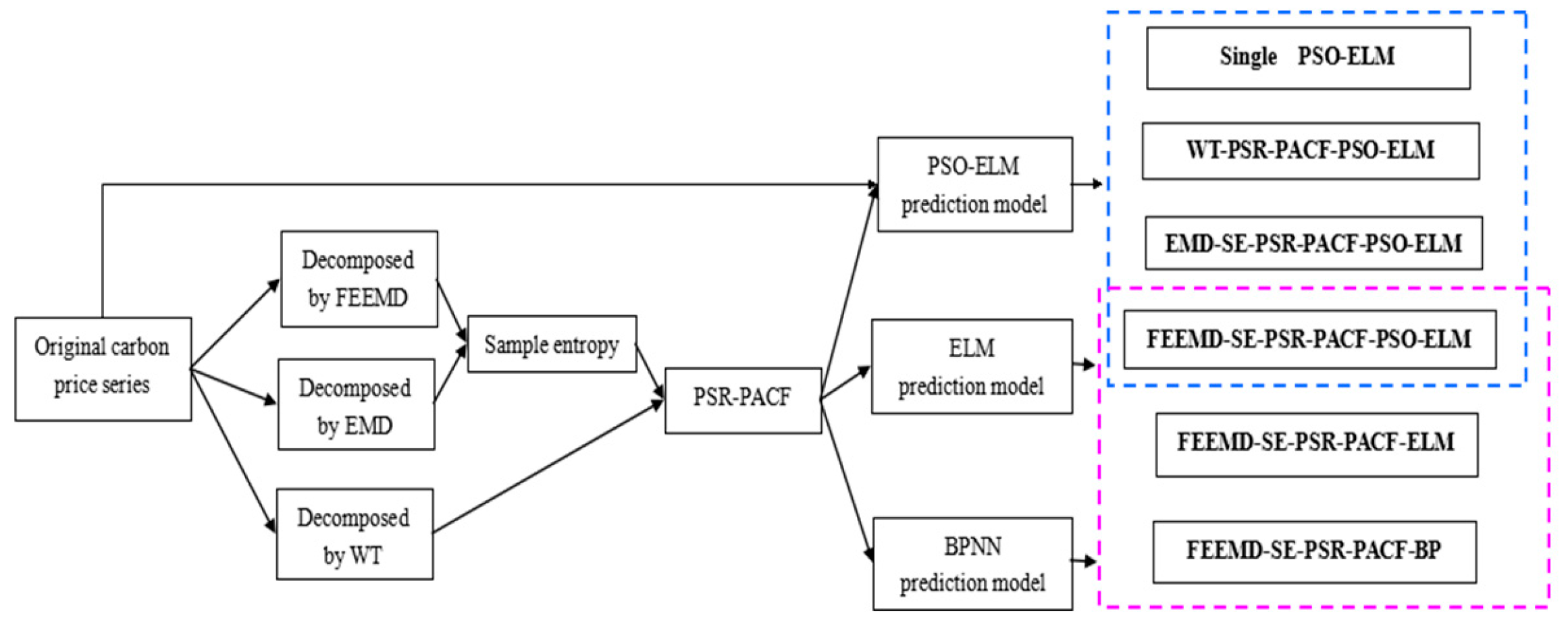
Having summarized the research of our predecessors, this thesis selects the carbon price of Beijing, Shenzhen, and Hubei as the example. We focus on Beijing’s carbon price, and analyze the features through a comparison with the other two typical markets. After being decomposed by the FEEMD, the IMFs are analyzed by phase space reconstruction and a partial autocorrelation function to determine the input of the forecasting models in the next step. Additionally, this paper adopts the PSO-ELM model to forecast carbon prices.
The main contribution of this paper is this new hybrid combination model for carbon price prediction, which is expressed as FEEMD-PSR-PACF-PSO-ELM. Firstly, this paper comprehensively considers the chaotic property and the partial autocorrelation of decomposed carbon price subsequences to reconstruct the input and output variables. Secondly, the research idea, which is based on the FEEMD model combined with the PSO-ELM model to decompose carbon prices, represents a new attempt to predict carbon prices.
The rest of this paper is divided into four sections.
Section 2 presents the methods and models that are applied in this paper, including the decomposition methods, the chaotic series reconstruction, and the hybrid prediction model. An exhaustive explanation of the hybrid forecasting models that are proposed in this paper is given in
Section 3. The data processing and the analysis of carbon price forecasting based on actual data from different regions under China’s ETS are presented in
Section 4. Finally,
Section 5 provides conclusions according to the results of the empirical analysis.
5. Conclusions
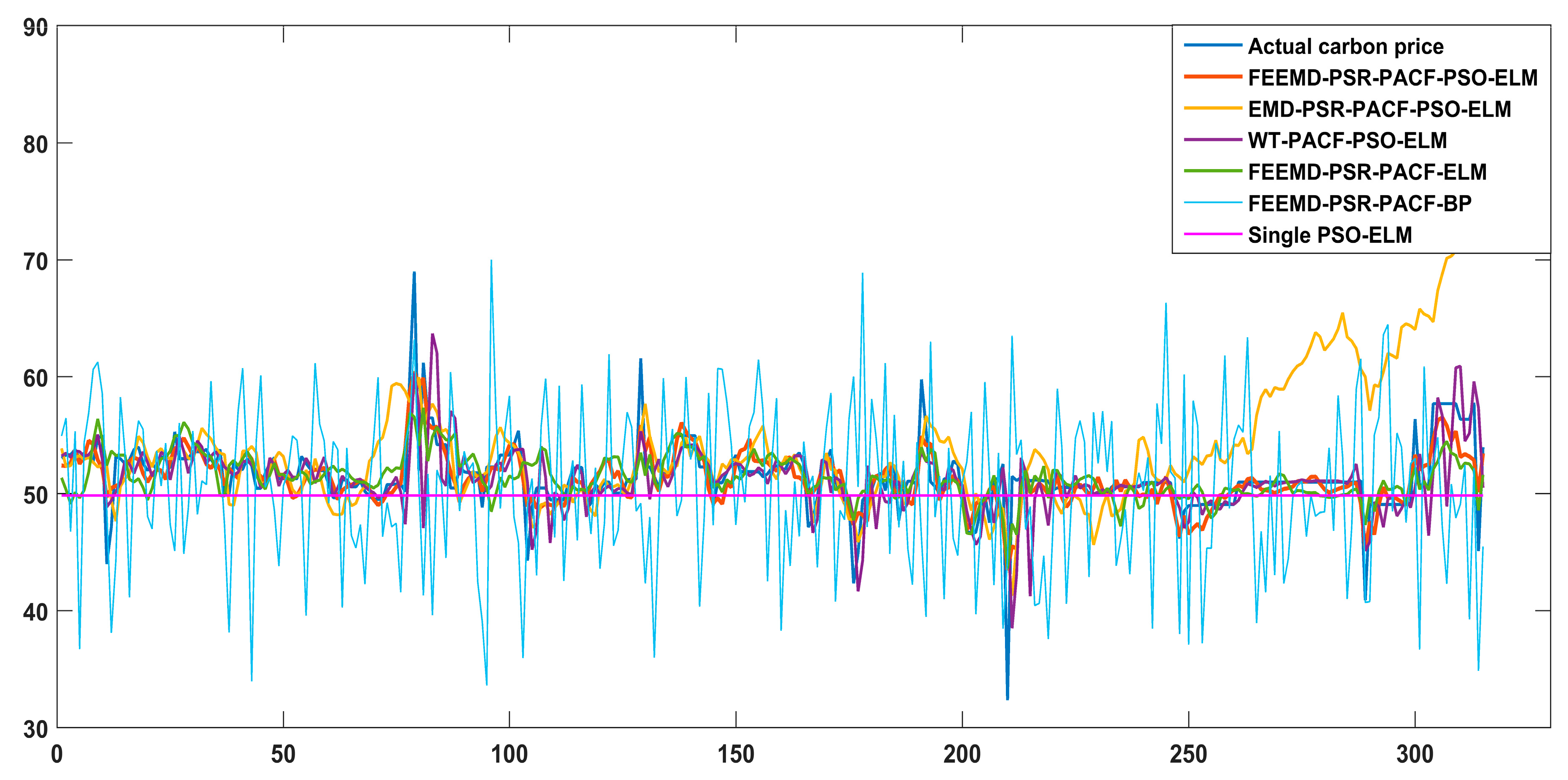
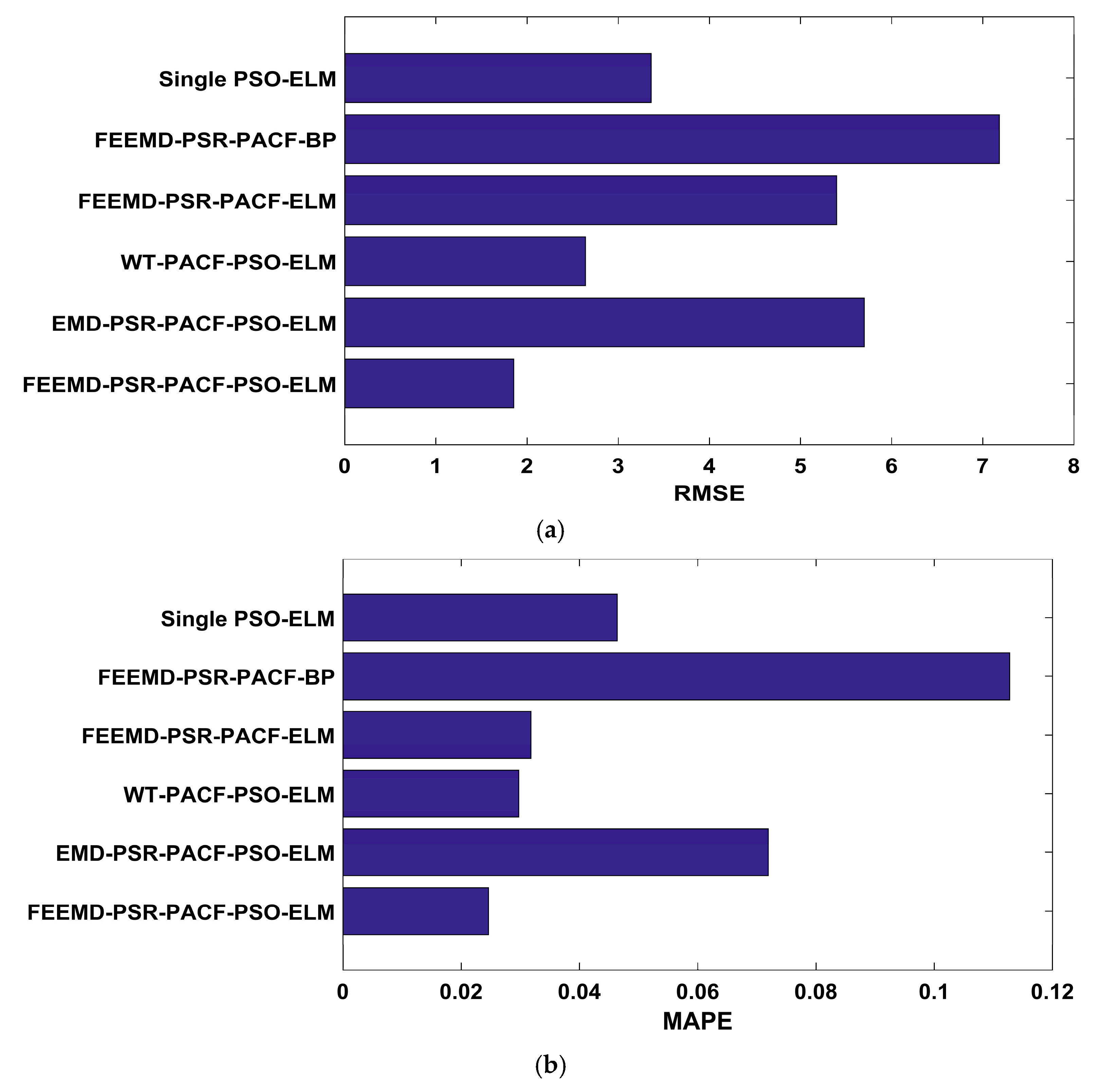
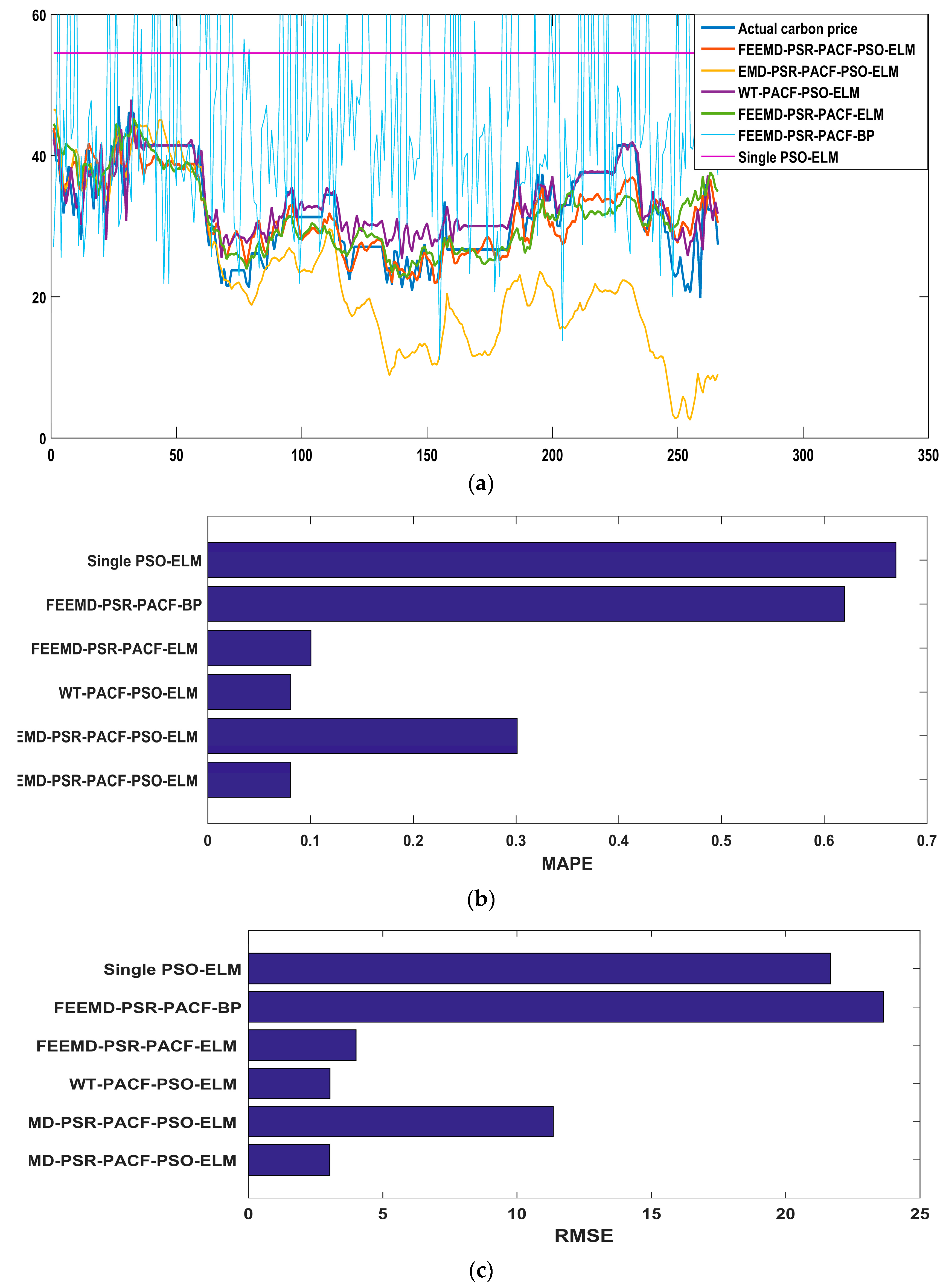
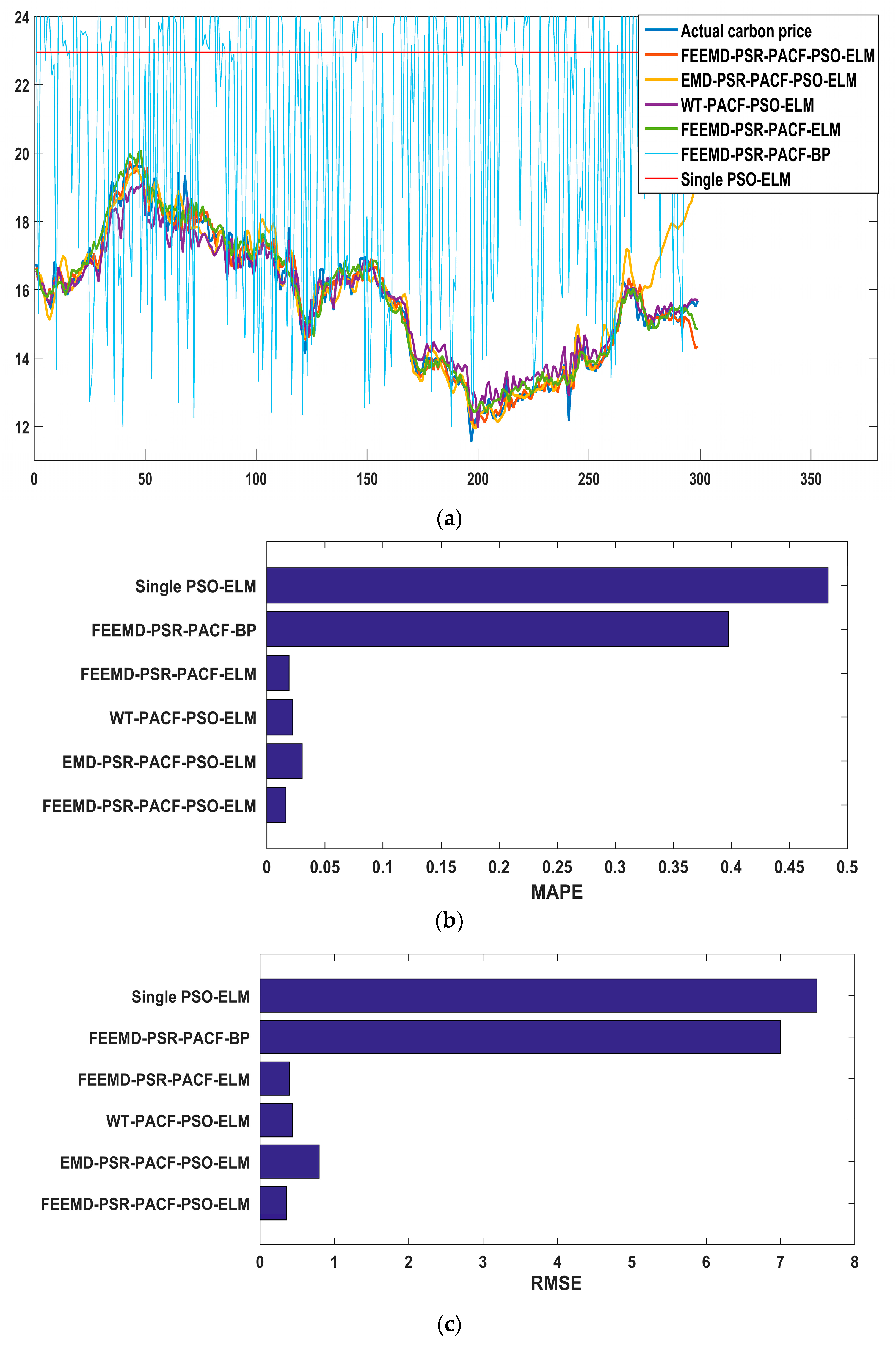
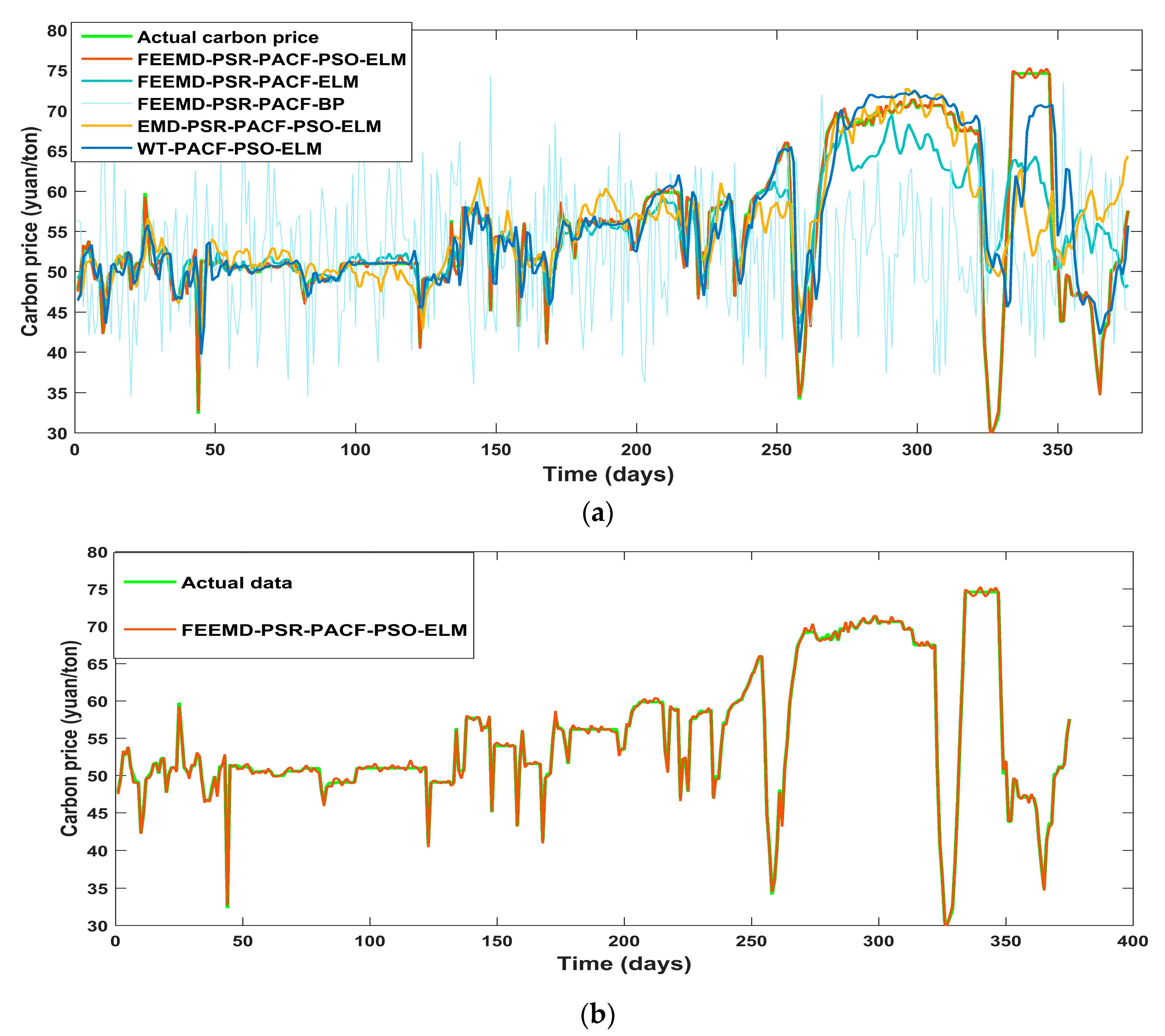
The promotion of the carbon market is a requirement for the high-quality development of China’s economy. An accurate carbon price forecasting method is helpful for the stability of the carbon market. This paper proposed a new hybrid model for carbon price prediction based on fast ensemble empirical mode decomposition, sample entropy, phase space reconstruction, and a partial autocorrelation function that utilizes an extreme learning machine improved by particle swarm optimization. Due to the nonlinearity and volatility of carbon price time series, this paper combined a decomposition method and a phase space reconstruction theory for data analysis and processing. FEEMD was introduced to decompose the original carbon price to reduce the noise signal. The sample entropy was calculated to merge the series decomposed by FEEMD to form new subsequences, which reduced the overall computational workload. Based on Chaos theory, a phase space reconstruction and the maximum Lyapunov exponent were employed to determine the input and output variables of the prediction models. In particular, this paper tested the chaotic property of each subsequence by calculating the maximum Lyapunov exponent, and performed a PACF analysis of the subsequences that were not suitable for PSR. This paper forecast the carbon price using the PSO-ELM model. The decomposition methods and prediction models, including WT, EMD, single ELM, and BP, were compared. To verify the performance and validity of FEEMD-PSR-PACF-PSO-ELM, case studies of three different carbon markets were used. Moreover, we focused on the carbon price forecast under Beijing’s ETS. The conclusions that can be drawn according to the empirical results are summarized below.
(a) Through the performance of the forecasting models in the case studies, we can infer that the decomposition methods (FEEMD, EMD, WT) can improve the forecasting accuracy by reducing the noise interference in the initial data on the carbon price. In the comparison of the decomposition methods, the FEEMD method has better applicability for forecasting the carbon price when applying the same prediction models.
(b) Integrating the Chaos and PACF methods leads to an effective method for processing nonstationary and nonlinear carbon prices that takes full account of the characteristics of the carbon price subsequences.
(c) The PSO-ELM model has the best performance in forecasting the carbon price compared with the other models that were considered in this paper. Taking only historical data into account to determine the input and output of the forecasting models, and following the above-described technical route, we can obtain future carbon price changes in regional carbon markets in China through the proposed model, which contributes to policy development and investment. Moreover, it may be useful for the analysis of the national carbon market.
This paper focuses on the study of historical time series of carbon prices, and fully considers the instability and nonlinear properties of carbon price series. The applicability of the proposed hybrid model was also verified by case studies. However, we did not analyze possible influencing factors in this paper. Therefore, subsequent research may focus on external influencing factors of the carbon price in China’s carbon market.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
















