2. Literature Review on Related Problems
Electricity demand management applies to effective utilization of the available energy resources, system reliability, energy conservation, and other actions that promote energy efficiency for sustainable development. Managing limited energy resources in an optimal way has become a primary goal among energy suppliers, energy planners, policy makers, and governments. In this context, demand management is supposed to deliver self-sufficiency and cost-effectiveness leading to solid and sustainable economic development. In particular, the motivation of the research stream in this area is focused on, inter alia, demand forecasting, electricity price forecasting, identification of conservation needs, identification of new energy resources, optimized energy utilization, methods for energy efficiency intensification, and strategies for reduced emission of gases.
A considerable amount of research has been dedicated to electricity price forecasting. As investigated by Weron [
10], there were more than 800 publications related to electricity price forecasting in the years 1989–2013, as indexed in the Web of Science and Scopus databases. While there is a high saturation of scientific articles, there are only three books that address electricity price forecasting, which are those of Shahidehpour et al. [
11], Weron [
12], and Zareipour [
13].
Energy forecasting models can be systematized in several ways, categorized as static or dynamic, univariate or multivariate, or as involving various techniques ranging from simple naive methods through a wide range of times series methods to complex hybrid and artificial intelligence models. A wide variety of forecasting approaches has been proposed in the literature, and these fall into several research streams. For the purpose of the review, the approaches are categorized under the following headings: (1) statistical and time series models; (2) computational intelligence models; and (3) hybrid models.
Under the first category of statistical and time series models are a number of approaches which are the applications of statistical or econometric methods including regression models, macro-economic econometric models, cointegration models, autoregressive integrated moving average (ARIMA)-type models, decomposition models, and gray prediction models.
Time series models are the most frequently used methods to represent the future values based on previous observations. The models based on time series have many forms adequate for forecasting electricity consumption volume and peak demand load in the electrical grid. These models are often applied to demand forecasting at the regional/national level. For instance, Himanshu and Lester [
14] used six different time series approaches for predicting electricity demand in Sri Lanka and the forecasts from these techniques look fairly similar considering the horizon of the year 2025. Others, like Gonzalez-Romera et al. [
15] applied an approach to monthly energy forecasting for Spain, in which two time series are considered separately: the trend, and the fluctuation around it.
Regression models are built to capture a relationship between a dependent variable, which is the energy usage, and one or more independent variables (the predictors). These models were used by Jannuzzi and Schipper [
16] to analyze the electrical energy consumption of the residential sector in Brazil. An interesting finding was that the electricity demand increased faster than the income. In [
17], linear and nonlinear effects between energy consumption and economic growth in Taiwan were explored by Lee and Chang, based on data over the period 1955–2013. In [
18], a linear regression model was used by Yumurtaci and Asmaz to predict electricity consumption in Turkey based on the population size and energy consumption increase rates per capita.
Econometric models are built to investigate dependencies between the energy demand and other macro-economic variables such as energy price, gross national product (GNP), technology, investments, and population size. For instance, Samouilidis and Mitropoulos [
19] studied energy and economic growth over the 1960s and the 1970s in industrialized countries, suggesting decreasing income and energy price elasticity. Others, such as Sengupta [
20], have demonstrated that econometric models are effective for forecasting energy patterns in developing countries like India. Quite often the econometric models are proposed to forecast demand for different electricity sources, e.g., coal, oil, and different sectors including industry, transportation, and residential end users in industrialized [
21] and developing [
22] countries.
Among a wide range of econometric methodologies used to capture energy demand relationships, cointegration models were found to change the perception of researchers and practitioners towards electricity demand forecasting [
23]. According to the cointegration concept, non-stationarity of the variables indicates that there is no long-run (cointegrating) relationship between them, and the regression results may be spurious, as concluded by Hasanov et al. [
24]. This indicates that only stationary variables should be considered in the analysis, and, as an alternative, if cointegration is observed amongst non-stationary variables, then the regression results suggest long-run relationships as being present in data.
There are two common approaches to build decomposition models for which energy consumption (EC) and the energy intensity (EI) analysis can be distinguished. The terms EC and EI indicate the energy-related variable subject to decomposition. As explained in [
1], these effects are “associated with the change in aggregate production level, structural change in production, and changes in sectoral energy intensities, while in the energy intensity approach only the last two effects are considered.” For instance, the relevant application issues, including method selection, period-wise against time-series decomposition, and the importance of sectorial disaggregation were analyzed and thoroughly reviewed by Ang [
25].
The ARIMA models describe the approximate model of data sequences over time, assuming the lag term and random error term to explain and to predict the future outcome with a certain mathematical formula [
26]. Univariate Box–Jenkins autoregressive integrated moving average (ARIMA) analysis has been widely applied to forecasting in many fields, including environmental, medical, business and finance, and engineering problems [
1,
26,
27].
Gray models for prediction gained popularity due to their simplicity and ability to describe unknown relations, even when using only a few data points. As argued by Chiang et al. [
28] energy demand forecasting can be considered as a gray system problem, because only a few variables such as GDP, investment, and population size are known to contribute to the energy demand, but the exact relations and the method of affecting the energy demand is not necessary clear or even unknown. The family of gray forecasting models consists of several types and GM(1, 1) is commonly used for forecasting energy demand, as presented by Hsu and Chen [
29].
Within the category of computational intelligence methods, we can distinguish a number of artificial intelligence-based, neural network, support vector machine, non-parametric, and non-linear techniques, which combine elements of learning, evolution, and fuzziness to create robust approaches that are capable of modeling complex and dynamic systems.
Over the last two decades, a great research stream has been dedicated to the application of artificial neural networks (ANNs) and expert systems for electricity load forecasting. ANNs, with their high modeling capability and their ability to generalize non-linear relations, gained widespread popularity for general forecasting in a variety of business, industry, and science applications [
30,
31]. Neural network models have been extensively studied and successfully applied to short-term electricity forecasting [
32,
33,
34,
35]. Some researchers have worked on ANN models applicable to medium- and long-term forecasting [
36,
37]. Cincotti et al. [
38] proposed two computational intelligence techniques, ANN and the support vector machine, to model electricity spot prices of the Italian Power Exchange. The results indicate that support vectors give better forecasting accuracy, closely followed by the econometric models.
Recently, within the smart metering and smart grid initiatives, there has been increasing interest in residential power load forecasting. For this purpose, a number of neural networks and expert systems are applied to load forecasting at the individual household level [
39,
40,
41]. However, this is a challenging task due to the extreme system volatility, which is the result of different dynamic processes composed of the typical, mostly behavioral and socio-demographic, components of many households. Aggregation of individual components reduces the inherent variability of electricity consumption resulting in smoother load shapes; as a result, the forecasting errors observed at the higher aggregation levels (power stations or regions) have been quite low.
Over the last couple years soft computing techniques including genetic algorithms and neuro-fuzzy and fuzzy logic models have been more frequently applied in energy demand forecasting. For instance, Tzafestas and Tzafestas [
42] analyzed eight case studies to show the merits, and validate the performance, of the various computational intelligence techniques constructed under a large repertory of data including geographic and weather features. Ozturk et al. [
43] applied genetic algorithms for forecasting the electricity demand in Turkey. The models were successfully validated with actual data, while future estimation of electricity demand was projected up to 2025. Ying and Pan [
44] proposed an adaptive network based on the fuzzy inference system to forecast electricity loads in four regions of Taiwan.
Based on the available literature, there is a clear and increasingly recognizable research interest that looks at the application of various hybrid models, combining techniques from two or more of the groups listed above. This stream is aimed at increasing the load forecasting accuracy by benefiting from the best features associated with different approaches and their synergy. For instance, in [
45], the authors combined the ARIMA forecasting model, the seasonal exponential smoothing model, and the weighted support vector machines for short-term load forecasting. They demonstrated that the combined solution can effectively account for the nonlinearity and seasonality to benefit from more accurate forecasting results. In [
46], Pao proposed two hybrid nonlinear models as a combination of a linear model with an ANN to create an adjusted forecast. The superiority of the hybrid is due to their flexibility in accounting for complex hidden relationships that are difficult to capture by linear models.
In [
47], Amjady and Kenya proposed a hybrid method composed of cascaded forecasters where each block consists of an ANN and an evolutionary algorithm. Such a structure was able to deliver high effectiveness and outperformed a combination of similar day and ANN techniques.
Within the research stream dedicated to load forecasting, there is considerable interest in electrical peak load forecasting. Peaks may cause serious challenges to the electricity grid because it needs to support the abnormally high consumption load. Managing these peaks is crucial for the utility providers since energy deficiency can lead to severe consequences such as power outages. Electricity consumption peaks appear in the electricity system as a consequence of the joint behavior of end users, which is influenced by many external factors [
6,
7,
48]. An example of an aggregate behavior is when a relatively large group of individual consumers turns on air conditioners within a short time span because of high temperatures. This behavior is easy to notice since temperature increase affects a large population, which might cause the peak. However, there are other factors that are likely to influence users’ electrical consumption; therefore, it is not trivial to detect high loads in advance. Luckily, peak loads usually follow similar patterns [
49,
50], and these can be identified with, inter alia, classification and pattern recognition algorithms to be further used to improve the accuracy of the forecasts, as presented in our paper. For instance, in [
6], the authors proposed the approach to predict electricity consumption peaks as an input to load balancing and price incentive strategies. This was done by mapping the prediction activities into a two-labeled classification problem. The authors declared that the solution was able to detect about 80% of consumption peaks considering a forecasting horizon of up to one week. A different approach was chosen in [
7] to find some characteristic patterns in data that may determine changes in the demand peaks. Then, the classification of the load curves into groups was proposed to give the analytical space for couple of functional linear models used to make peak load forecasts. Another interesting proposal was presented by Hyndman and Fan in [
48] as an application to forecast probability distributions, including 10%, 50%, and 90%, of weekly and annual peak electricity demand up to 10 years ahead for South Australia.
Based on the literature review, research on electricity load forecasting is maturing, with numerous approaches and attempts proposed throughout the last several decades. However, there is still an increasing and recognizable need to look at the challenges associated with behavioral factors that influence the energy usage considered at different aggregations, including individual end users, micro-grids, and region or country levels. Since peak load forecasting plays an important role in the effective management of power utilities, it falls under one of the current research streams focused on predicting the peaks as an input into load balancing and smart management strategies. These are intended to achieve, in the future, automatic behavior at the customer end, including automatic management of smart electrical appliances (controlled switch on–off events), supporting local level load balancing.
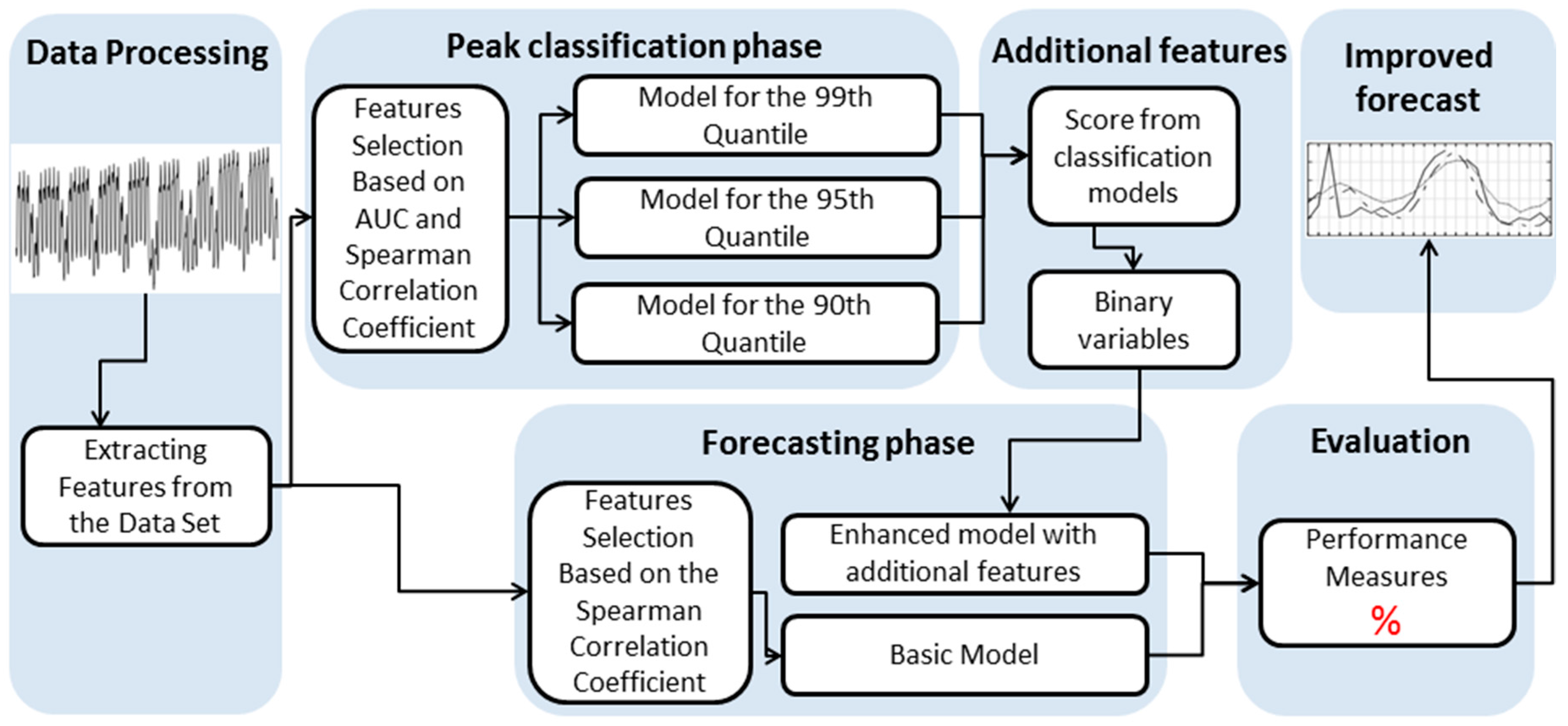
With this paper, it is expected that the proposed two-stage modeling approach will help energy planners to forecast more accurately and to utilize energy resources in a sustainable way by reducing the cost of operating power systems.
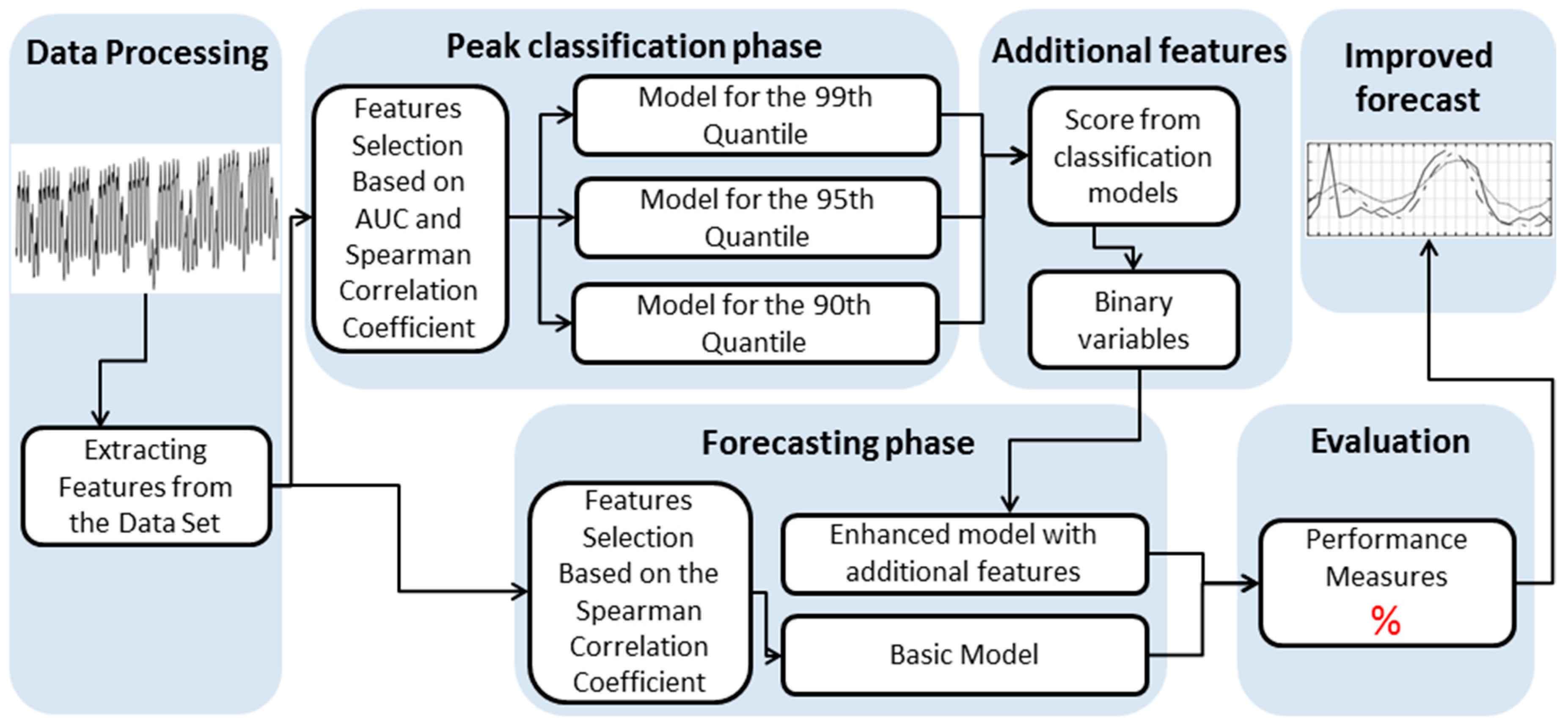
5. Results
5.1. Classification Results
The classification results for all machine learning algorithms obtained on training, validation, and testing datasets are presented in
Table 8.
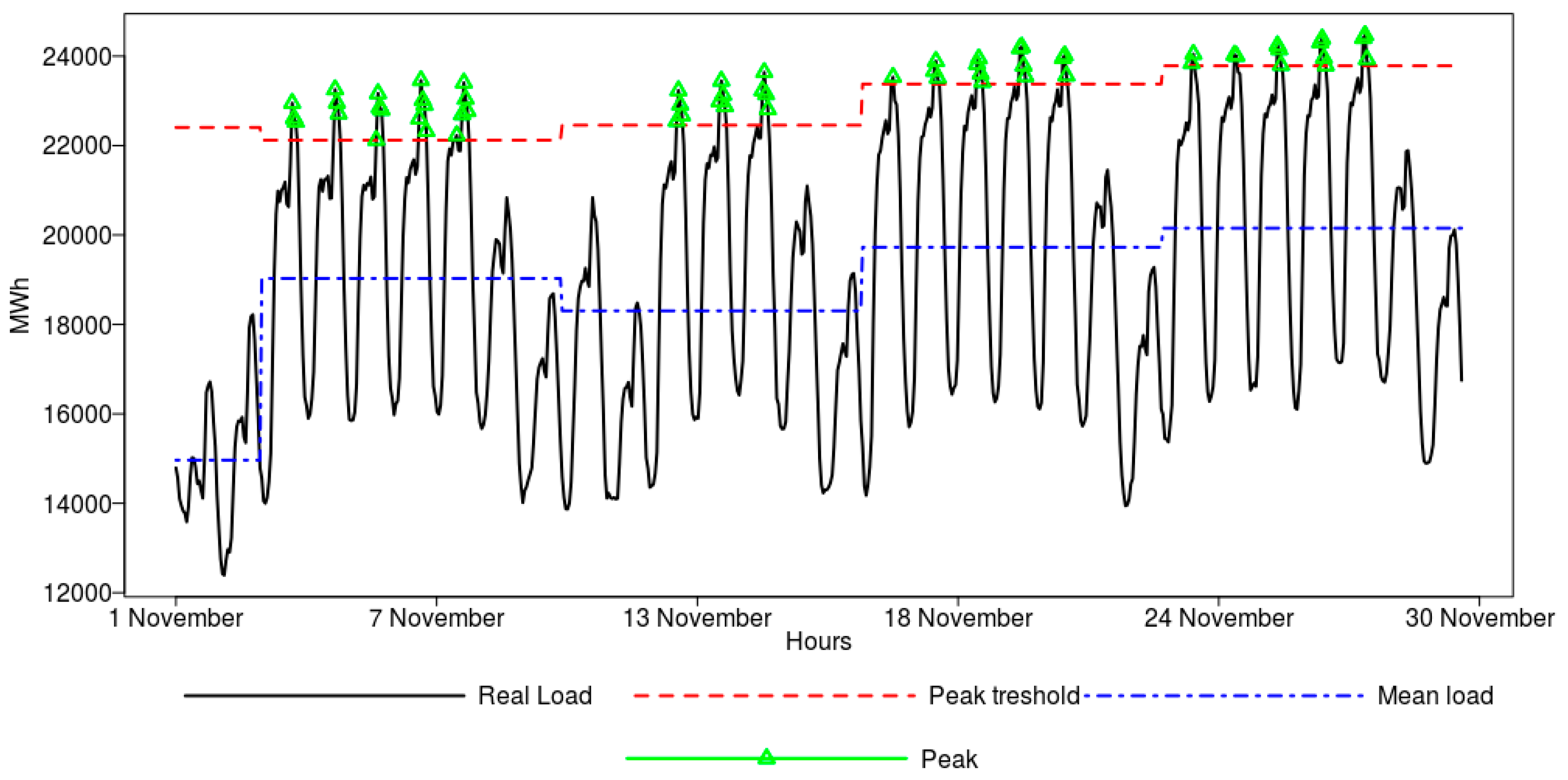
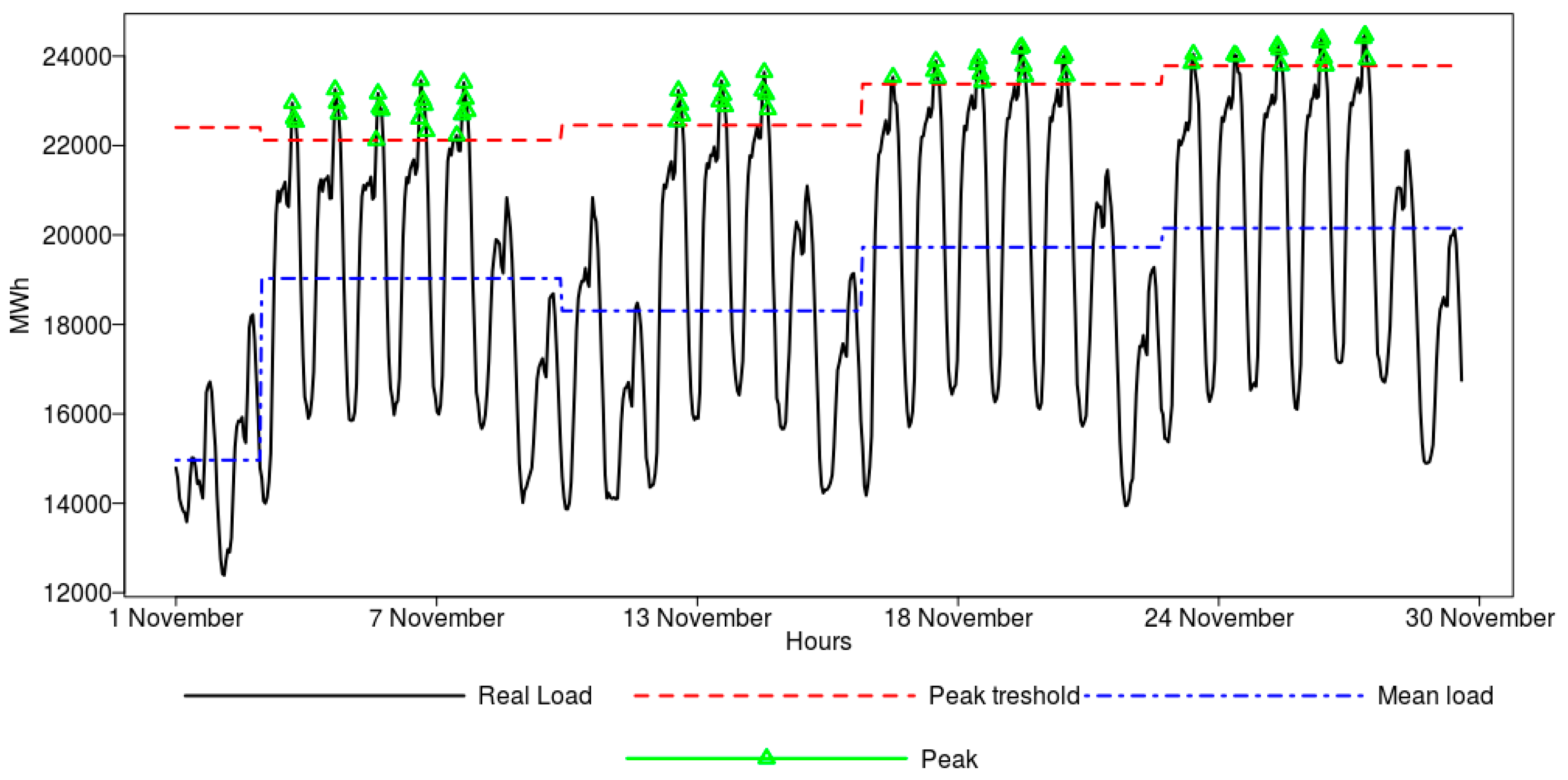
Prior to classification, the benchmarking model was constructed as the reference point to the proposed classification algorithms. The benchmark was prepared in a way that, for each week, and using only working days, the peak was identified based on data of the previous week, taking into account the respective day and hour only when the load data exceeded the 90th, 95th, or 99th quantile of the distribution. If the day of the previous week was a holiday, it was not considered as the forecast, and the week before was taken instead.
For the purpose of the clarity, the following abbreviations were used: ANN—artificial neural network algorithm, RF—random forests, and SVM—support vector machine algorithm. Moreover, in the brackets, the best parameter settings related to each model are presented.
In the following, the results on the testing dataset are discussed since these are the best proxy of the models performance on new set of the data points.
Model accuracy, which assesses how many correct forecasts the model makes, ranges between 0.812 and 0.906 depending on the algorithm and whether the model is used to classify the load exceeding the 99th, 95th, or 90th percentile on the distribution. An important observation is that the highest accuracy is observed for the SMV model, which is able to detect peaks with accuracy of 0.892, 0.906, and 0.906 for the loads that are equal to or higher than the 90th, 95th, and 99th percentile of the distribution, respectively.
The AUC values for the models range between 0.938 and 0.971. Again, the highest AUC are observed for the SVM models, regardless of the classification problem, since SVM superiority is confirmed in all experiments that include the classification of the peaks greater than or equal to the 90th, 95th, and 99th percentile of the distribution.
In terms of sensitivity, which is the proportion of peaks that are correctly identified as such, the results range between 0.899 and 0.963. In particular, the best model to classify the load exceeding the 99th percentile of the distribution is ANN (0.963), while for the other classification variants, the best model is RF, reaching a sensitivity of 0.933 and 0.945 for the loads exceeding the 95th and 90th percentile of the distribution, respectively.
Finally, the specificity, which measures the proportion of non-peaks that are correctly captured as such, ranges from 0.792 to 0.911. Irrespective of the classification problem, the SVM model delivers the highest specificity values.
Interestingly, the benchmarking models outperformed the machine learning algorithms in terms of accuracy and specificity. However, the ability to identify peaks correctly is very limited since sensitivity is significantly lower as compared to the ANN, RF, and SVM models. The same is reflected by the low AUC values, which means that the benchmark model does not distinguish well between peaks and non-peaks.
Importantly, all proposed models exhibited stable performance in terms of the classification quality on all three datasets. Therefore, the scores from these models can be used in further steps to feed forecasting steps in the proposed approach.
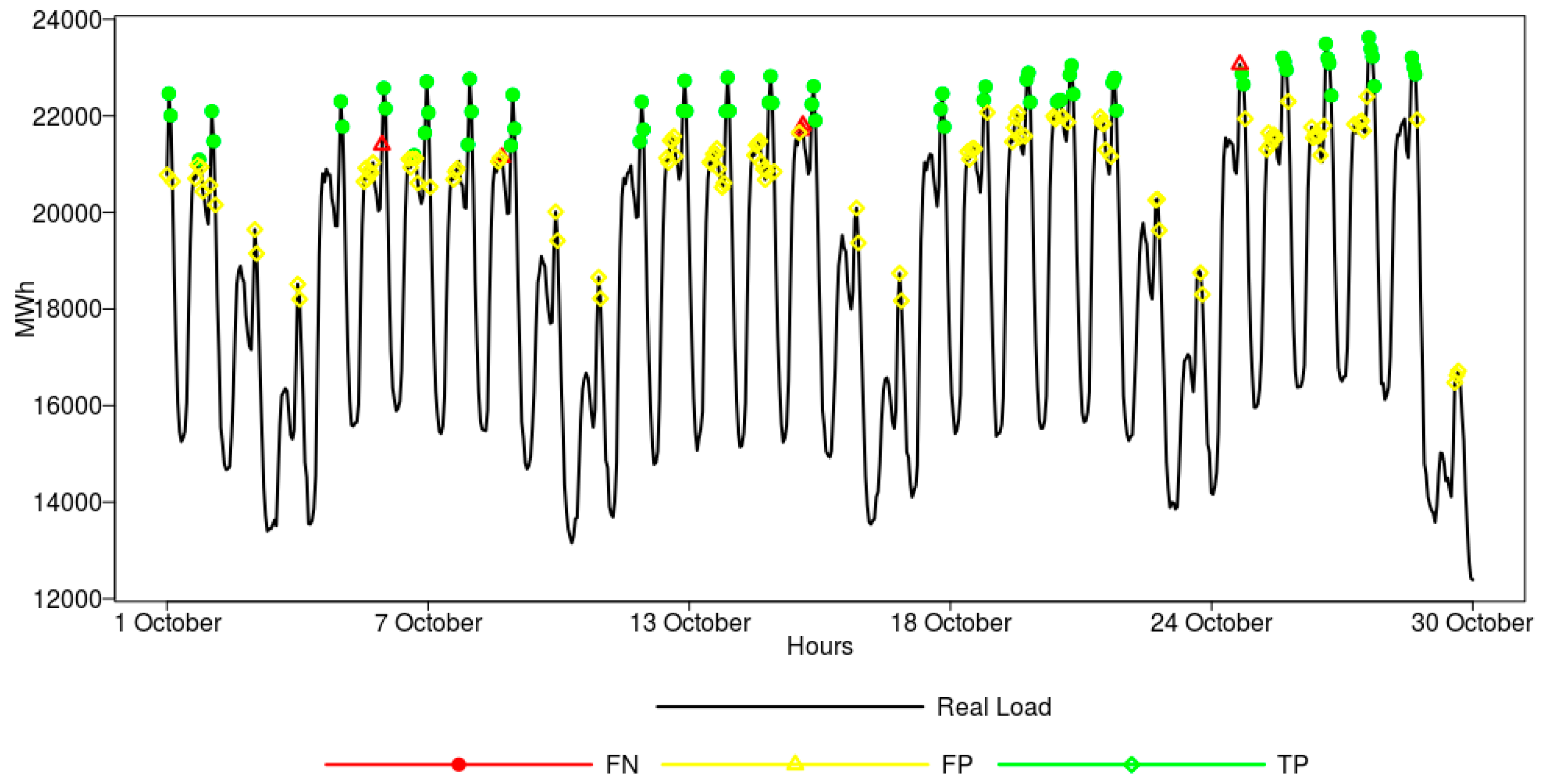
Additionally, to visualize the performance of the models for peak classification (model for the 90th percentile), the results obtained for the randomly drawn test period (five weeks in October 2015) for the ANN model are shown in
Figure 6.
From the figure, we can observe that the peak loads are correctly predicted in sixty cases—green dots represent true positive classification. Three peak loads, marked as red triangles, are incorrectly classified as normal loads (false negative classification). Finally, in some cases (yellow diamonds), the neural network model claims that there will be a peak load one day ahead, but there was in fact no peak (false positive classification). For clarity, in
Figure 6, the true negative class was not provided, as it constitutes the overwhelming majority.
The results of the classification experiments can be summarized as follows:
Peak demands in Poland are mostly affected by such features as the day of the week, temperature, humidity, load in previous hours, and the load trend observed in the previous hours (please see
Table 4 for details).
Predictive power of the models is considered to be excellent, which was confirmed by AUC, accuracy, sensitivity, and specificity measures.
The best results in terms of accuracy, AUC, and specificity were obtained for the SVM model; however, the sensitivity of peak detection (for 95th and 90th percentile) was better captured by the RF model.
Models reflect stable performance in terms of the classification quality on three datasets (training, validation, and testing);
A high true positive rate confirms the models’ ability to classify correctly the real peaks in the system.
5.2. Forecasting Results
The results of the machine learning algorithms for the 24 h forecasting horizon are summarized in
Table 9. There were three measures used to evaluate the quality of the forecasts. In order to check whether the improvements are statistically significant, the confidence intervals for each of the proposed measures were computed. The 95% confidence intervals were estimated using bootstrap resampling procedure implemented in the
boot package. This package estimates equally tailed two-sided nonparametric confidence intervals using normal approximation. For the purpose of clarity in
Table 9, significant improvements in terms of the errors between the enhanced and base models, for the respective algorithms, are indicated by asterisks (*).
Additionally, the benchmarking model was created to give the idea of the improvement space, the achievement of which is feasible when machine learning algorithms are applied. The benchmarking model was constructed in line with the similar-day method [
12], and the forecast value for the particular hour was equal to the value for the same hour and the same day but from the previous week. If the working day of the week before was a holiday, then another, previous week was taken instead. Further, if the forecasted day was a holiday, then the respective hour of the most recent holiday day from the past was used.
In the following, the forecasting results on the testing dataset are discussed.
In terms of the MAPE, regardless of the forecasting algorithm used, all models enhanced by the peak identification features delivered lower errors than their respective base models. The lowest MAPE error of 3.10% was observed for the Enhanced ANN model, while the highest error of 3.58% was recorded for an base SVM model. However, for the enhanced RF and SVM models, the difference in terms of the error reduction observed on the test dataset as compared to the base model was not statistically significant. For the ANN model, the improvement was considered statistically significant for the testing dataset (3.30% vs. 3.10%).
When it comes to SMAPE, it was the ANN model that outperformed other algorithms and delivered forecast characterized by the lowest SMAPE error of 3.11% (vs. 3.27% for the base model), and the improvement was statistically significant. Once again, the highest error of 3.54% was observed for the base SVM model, but an improved version of the model resulted in a lower SMAPE of 3.40%. However, the reduction of the error was not confirmed to be statistically significant.
As far as r-MAPE is concerned, the results revealed that the ANN model enhanced by the peak identification features achieved statistically significant forecasting improvement when compared to the base model. The ANN model delivered a forecast with an r-MAPE of 2.70% (vs. 2.80% for the base model). The lowest errors were observed for the RF model—2.53% (vs. 2.70% for the base model)—but the error reduction was not statistically significant. For the SVM model, the use of peak identification features resulted in a slight error decrease from 2.89% (base model) to 2.81% (enhanced model), but the difference was not found to be statistically significant.
Lastly, the lowest RMSE error was observed for the ANN—800.9 vs. 895.7 for the base model—but the error reduction was not statistically significant on the testing dataset. The same finding was observed for RF and SVM—the errors of the enhanced models were slightly lower, but the reduction was not confirmed to be significant.
Importantly, all of the proposed models can be characterized by low errors, and, in general, an improvement in terms of the forecasting ability was observed, when the results delivered by the enhanced models and the base models are compared, not to mention the benchmarking forecasts. The benchmarking model exhibited error values up to two times as high in comparison to the results delivered by machine learning algorithms. For the ANN models, the greatest stability in results was observed on all three datasets while delivering the forecast with the lowest errors. Therefore, it can be considered as a tool for supporting short-term forecasting exercises.
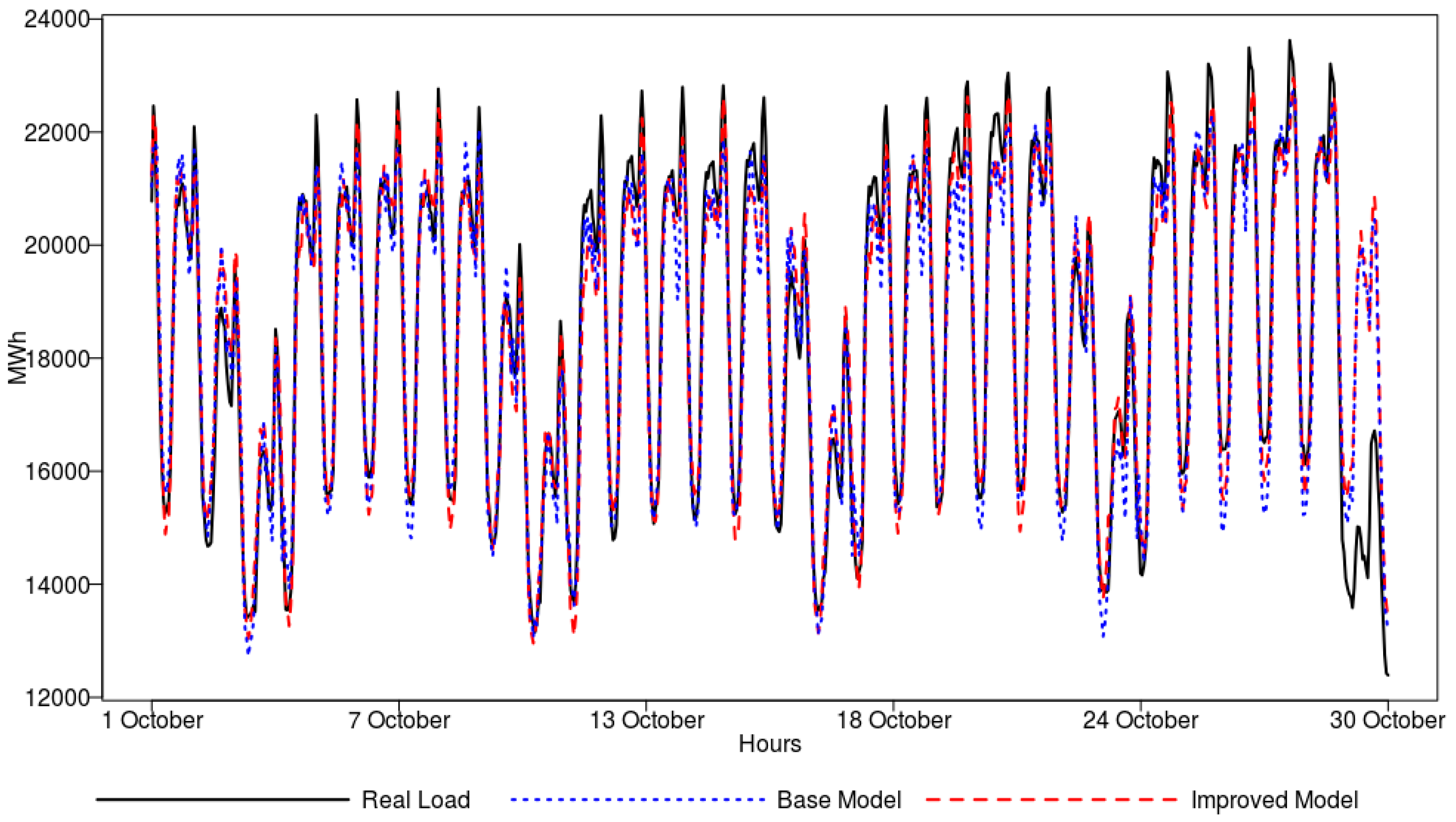
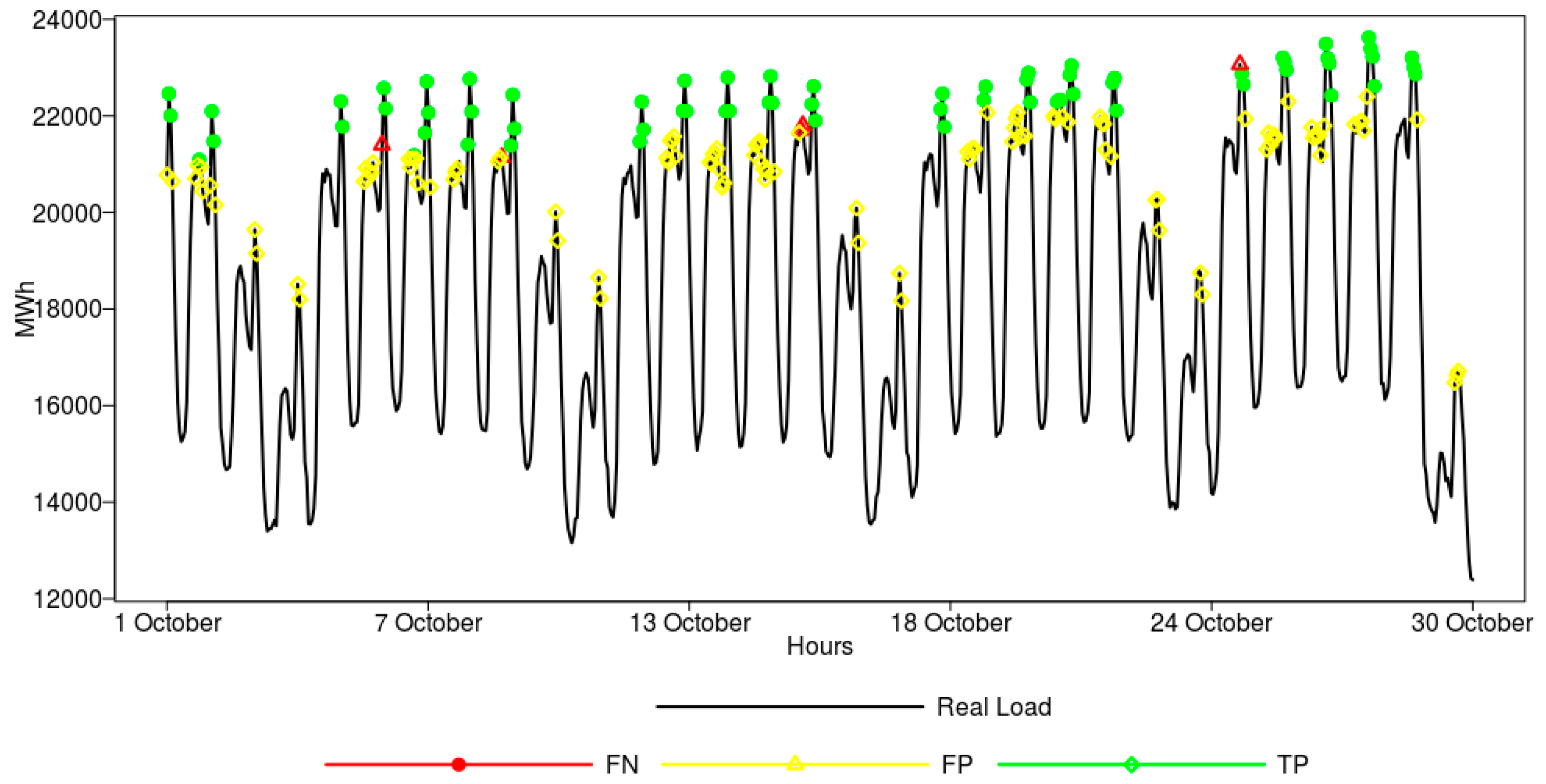
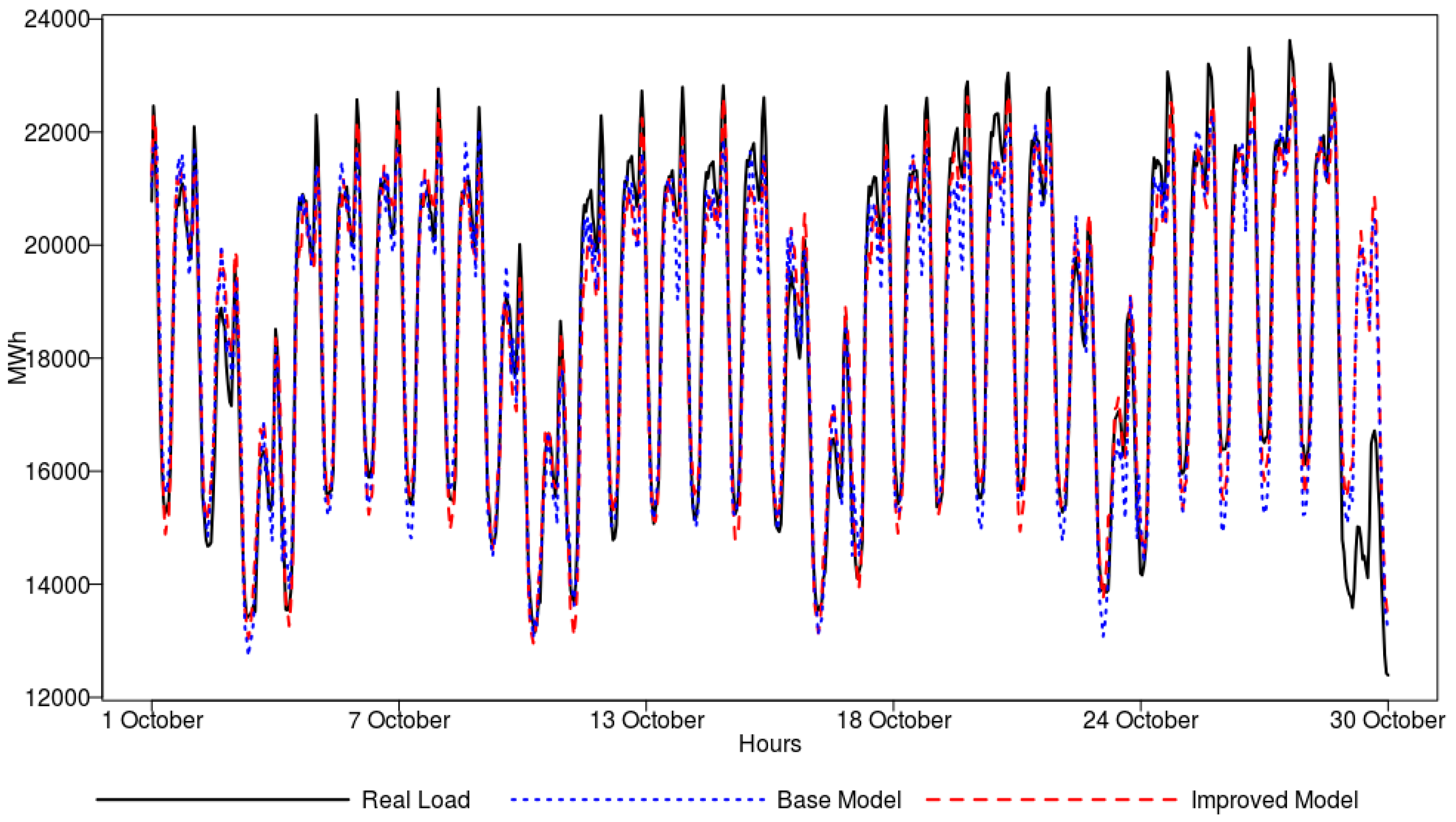
To give a graphical view on model performance, a one-day-ahead forecast obtained for the randomly drawn test period (five weeks in October 2015) by the ANN model is shown in
Figure 7. In general, the real load is followed well by the forecasting model. In the figure, we can observe that the peak loads are better captured by the improved model, which is supported by the peak identification features.
The results of the forecasting experiments can be summarized as follows:
Electric power load in Poland is mostly affected by such features as the hour of the day, day of the week, month, temperature, humidity, the load trend observed in previous hours and, interestingly, by the sunset variable (please see
Table 6 for details).
The use of peak classification features in the models, in general, led to forecast improvement, which was confirmed by MAPE, SMAPE, r-MAPE, and RMSE.
The best results in terms of forecasting accuracy were obtained for the ANN model, which exhibited stable performance on all three datasets used for training, validation, and testing. The ANN model was able to benefit from additional peak classification features to the greatest extent, which significantly improved its ability to follow the real load curve, especially when the extraordinary load was observed.
6. Summary and Concluding Remarks
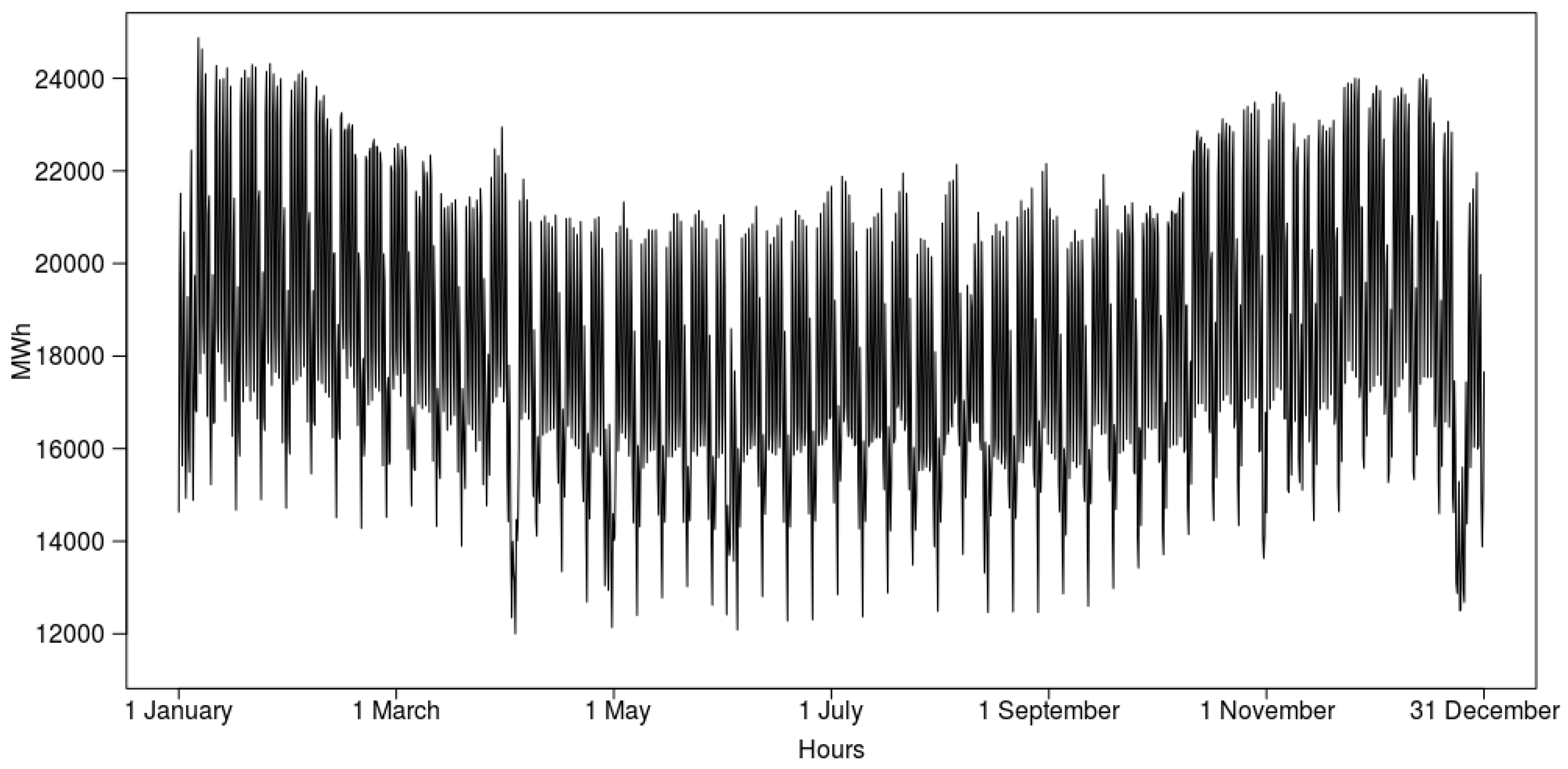
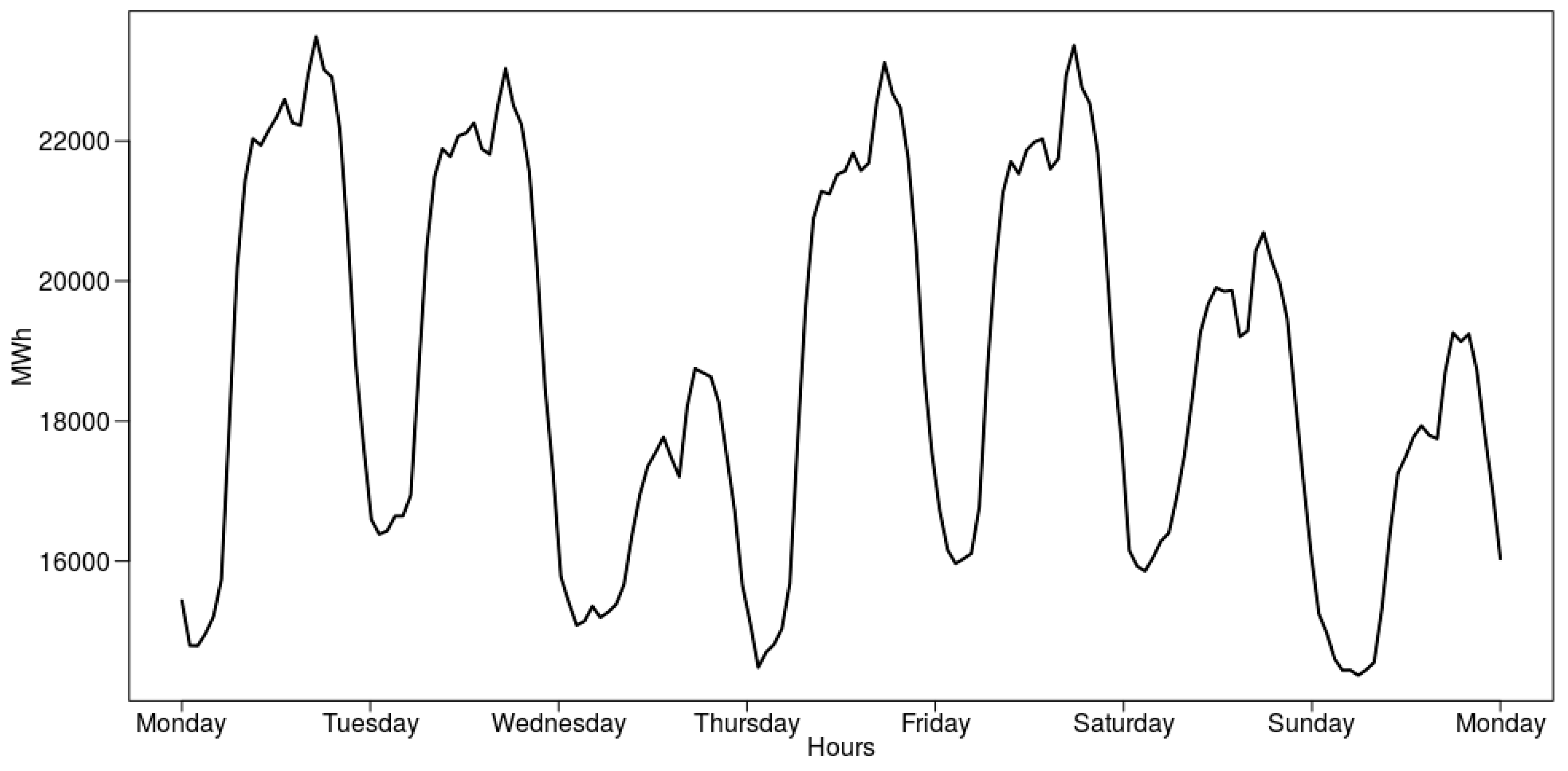
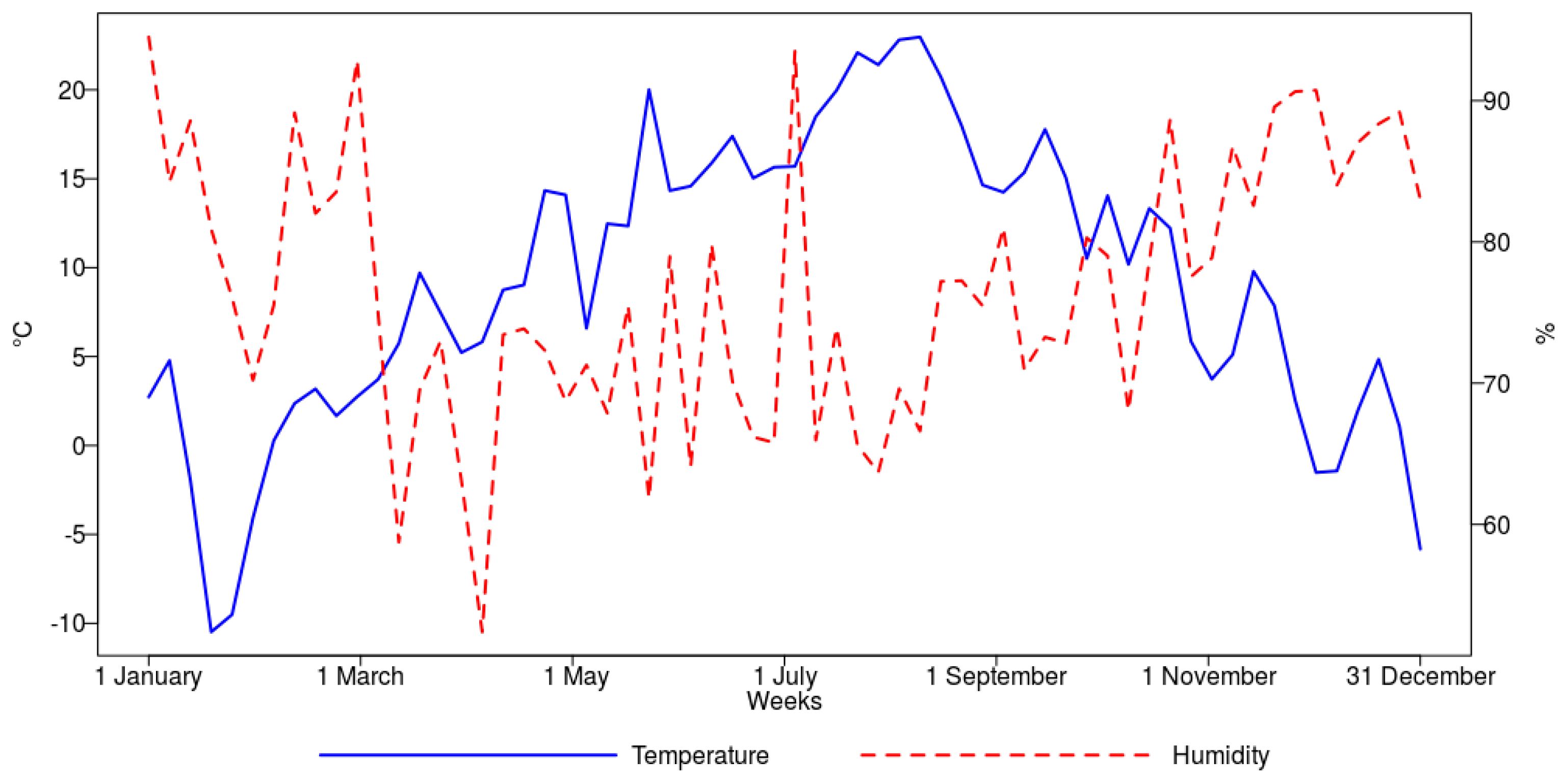
In this paper, we have focused on the short-term forecasting of hourly electricity load in the Polish Power System based on data between 1 January 2008 and 31 December 2015. For this purpose, we have proposed an algorithmic scheme to load modeling through peak detection and use this information to feed the forecasting system. This was done by mapping the time series data into a binary classification problem. The peaks are defined as the extraordinary load levels equal to or above the 99th, 95th, or 90th percentile for the respective load distribution when weekly time windows are considered. These three peak variants were modeled using classification algorithms, and their outcome was used to enhance the forecasting models. There were several additional factors considered in the modeling besides the load data, such as weather temperature, humidity, sunrises, and sunsets, in order to enhance both peak classification and the quality of the forecasts.
The most promising results were produced by applying the SVM algorithm to peak classification and ANN for forecasting. In fact, this approach is able to predict more than 90% of the electricity peaks correctly and to deliver accurate forecasts with the errors as low as 2–3%. It is important to underline that the algorithms were trained to favor false positives over false negatives, since the latter have less of an impact on power grids, as predicting a peak that is not materialized has fewer consequences than not predicting peaks that are materialized.
To conclude, all numerical analyses were designed to provide answers to the questions raised at the very beginning of the research. In particular, the findings are as follows:
Based on the experiments, we observed that it is possible to attain accurate peak load classification up to 24 h ahead, and this can be obtained with high precision. The best machine learning algorithms, on the testing dataset, were able to deliver an accuracy reaching 0.906, AUC of 0.971, a sensitivity equal to 0.963, and a specificity of 0.911.
For the 24 h load forecasting, it was observed that the models showed good projection characterized by low errors. The errors on the testing dataset were as low as 3.10%, 3.11%, 2.70%, and 800.9 for MAPE, SMAPE, r-MAPE, and RMSE, respectively. The best results in terms of forecasting accuracy were obtained for the ANN, which exhibited stable performance on all three datasets used for training, validation and testing.
We showed through experiments that additional peak classification variables applied on the top of the load and the weather data can enhance forecasting capability. The richer data set helped to reduce the MAPE error from 3.30 to 3.10%, the SMAPE from 3.27 to 3.11%, the r-MAPE from 2.80 to 2.70%, and the RMSE from 895.7 to 800.9 as observed on the testing dataset for the ANN model. In case of other techniques, only the RF model delivered a statistically significant error reduction in terms of SMAPE (3.33% vs. 3.17%) on the testing dataset.
The results revealed that there are significant differences in forecasting quality in favor of the machine learning algorithms, namely, ANN, RF, and SVM, in comparison to the proposed benchmarking model. When it comes to the comparison between the algorithms the most promising results are produced by applying SVM algorithm to peak classification and ANN for forecasting. In particular, artificial neural networks, through their ability to approximate complex nonlinear functions, as well as their generalization capability, seem to be very effective tools for capturing hidden trends in the load data and delivering stable short-term forecasting, which was observed on all three datasets when the richer data was considered.
There are a number of practical applications for use of the next-day peak demand, identification, and load forecasting. Such peak-based forecasts are useful for both network capacity planning and investment decisions. In addition, the knowledge on the timing of the peak demand is important for network maintenance planning. An accurate classification can be used to improve decision-making since the correct classification can reduce both costs and risks for the entities operating on the electricity markets.
As for any other approaches, there are some areas for possible improvement. For example, the data points related to temperature, humidity, sunrises, and sunsets were found important for peak identification and forecasting. However, these were gathered for Warsaw only and thus do not necessarily represent the weather conditions for the entire country. Therefore, additional data representing weather conditions in different regions would be beneficial. Additionally, we are endeavoring to analyze and incorporate socio-demographic features related to citizens’ wealth (like disposable incomes, savings, housing conditions) into the models, since these may affect the electricity consumption patterns not only on the individual user level but globally as well [
60,
61].





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}