Using Random Forests to Select Optimal Input Variables for Short-Term Wind Speed Forecasting Models

Abstract
:1. Introduction
2. RF-Based Input Variables Selection
2.1. Basic Principle of the RF Method
2.2. Measuring Feature Importance Based on Out-of-Bag Prediction Accuracy
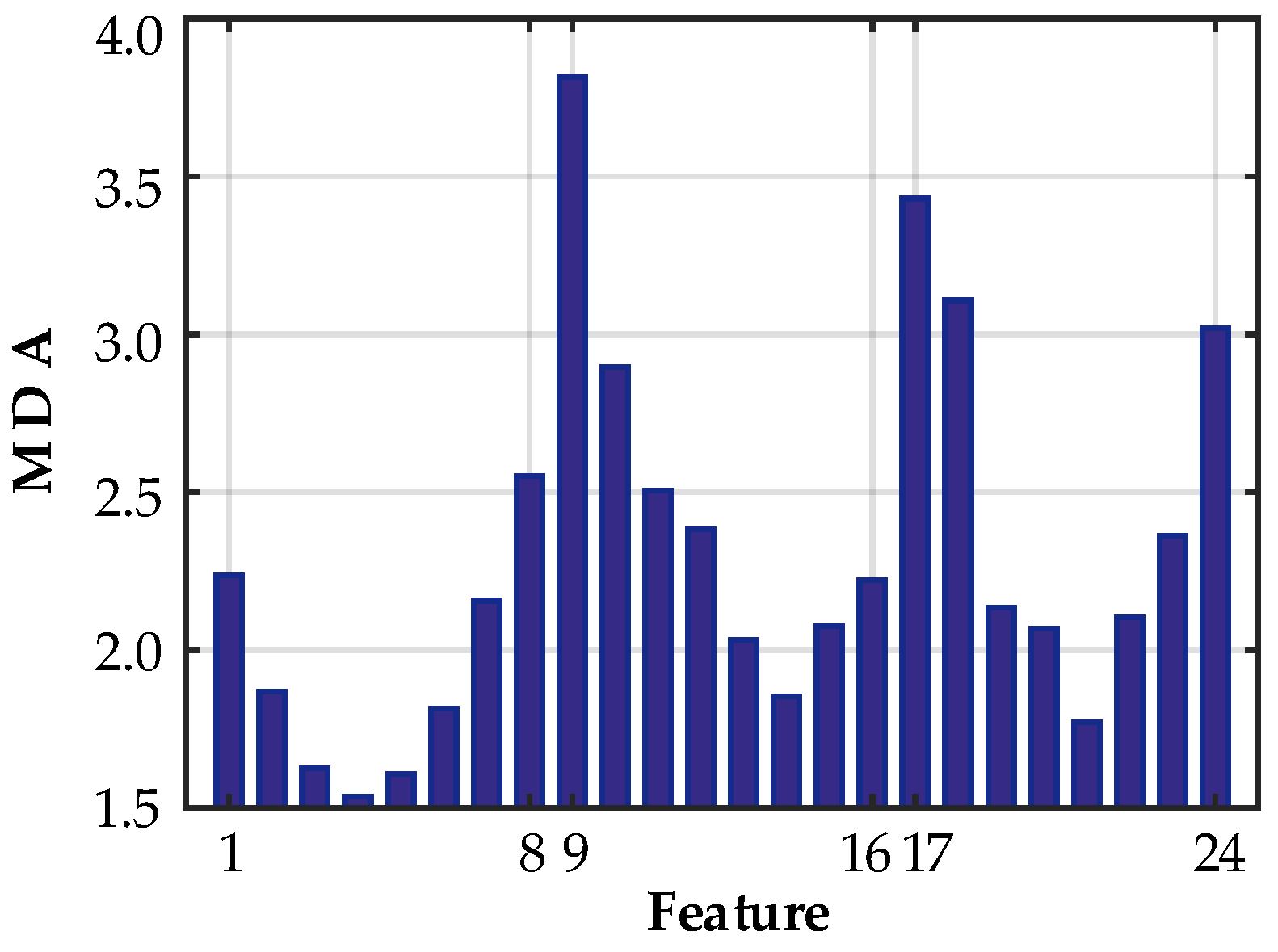
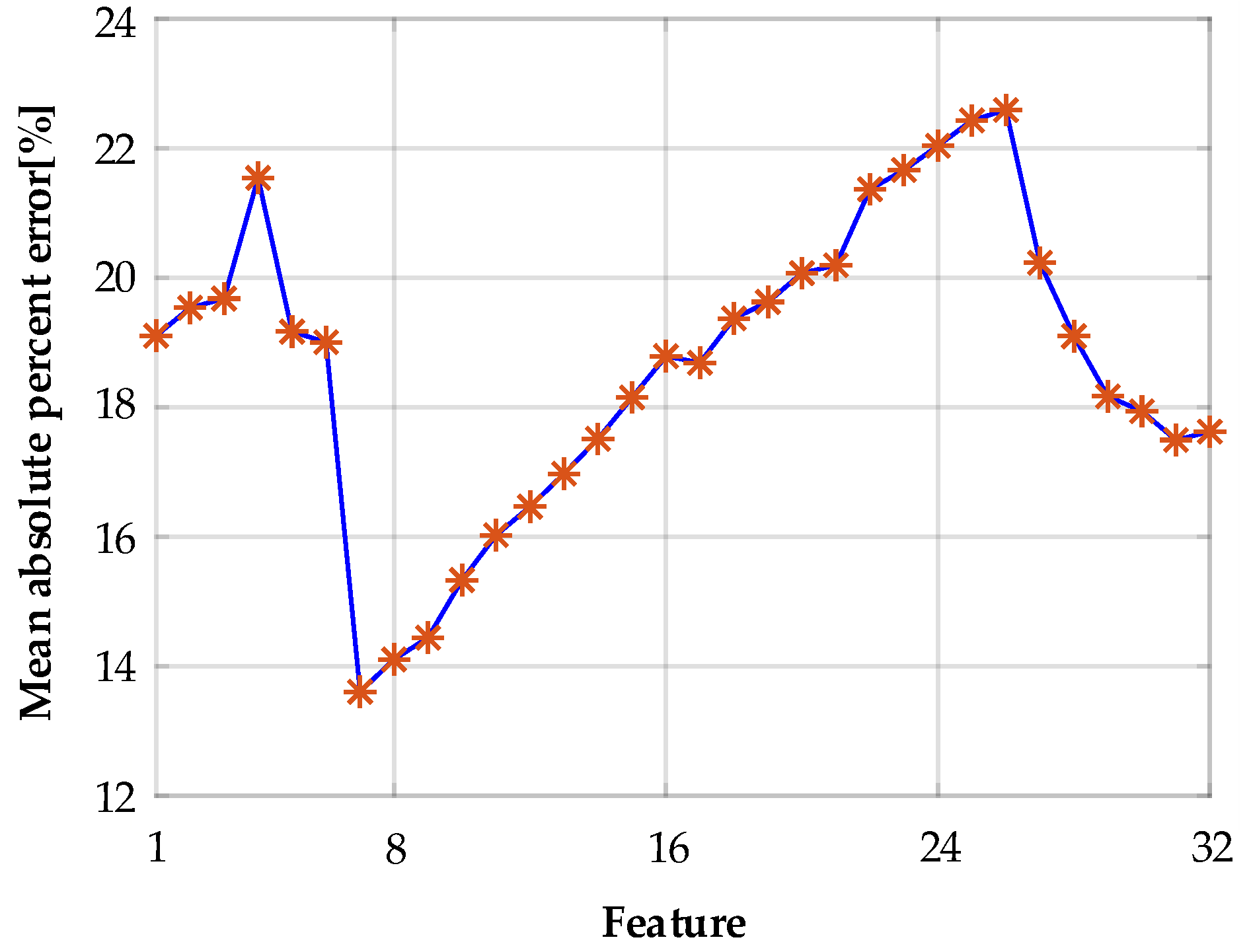
2.3. MDA-Based Input Variable Selection
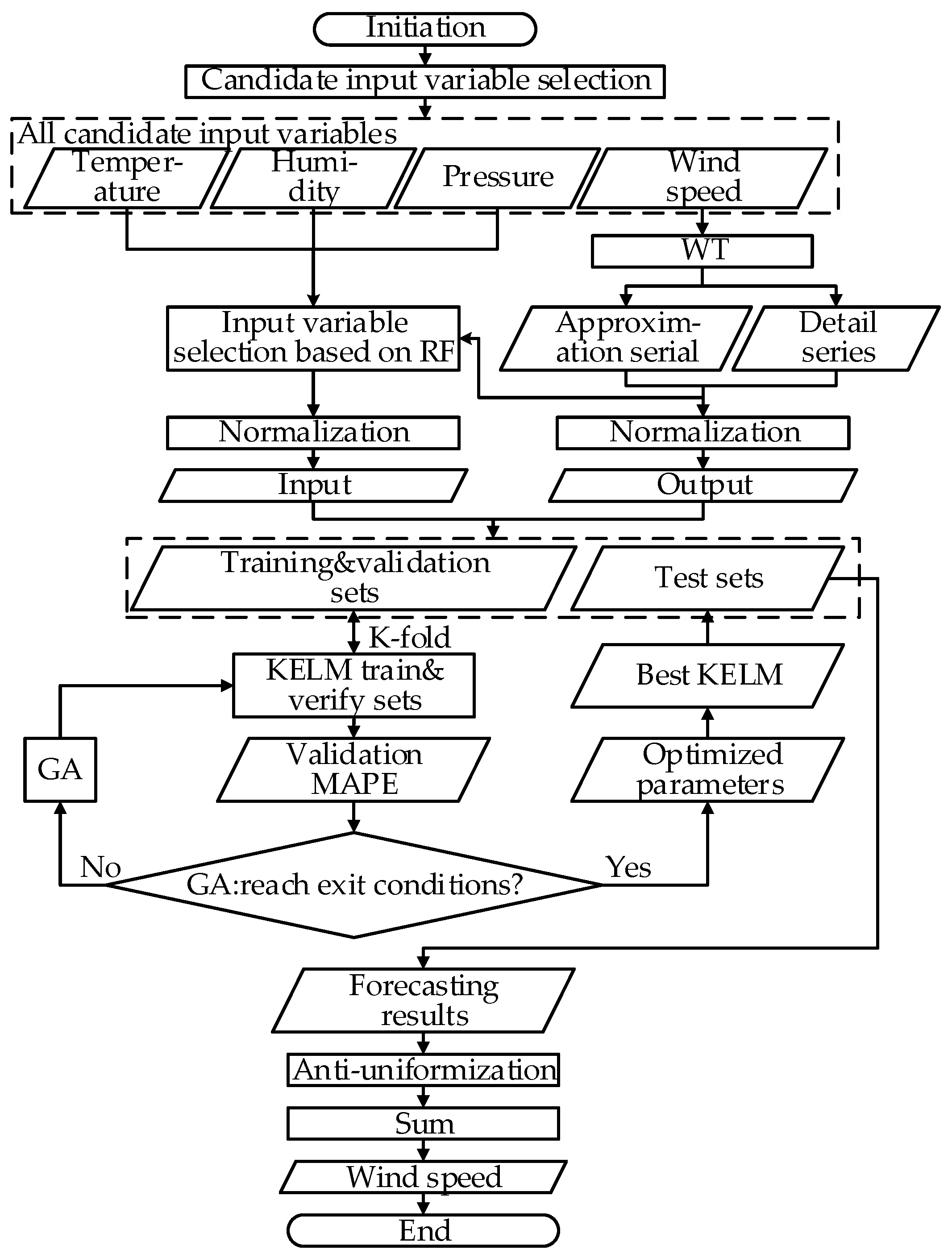
3. Construction of a Wind Speed Forecasting Model Based on Input Variable Selection
3.1. Candidate Input Variable Selection
3.2. KELM Modelling and GA Optimization
3.3. Forecasting Results Evaluation
4. Case Study
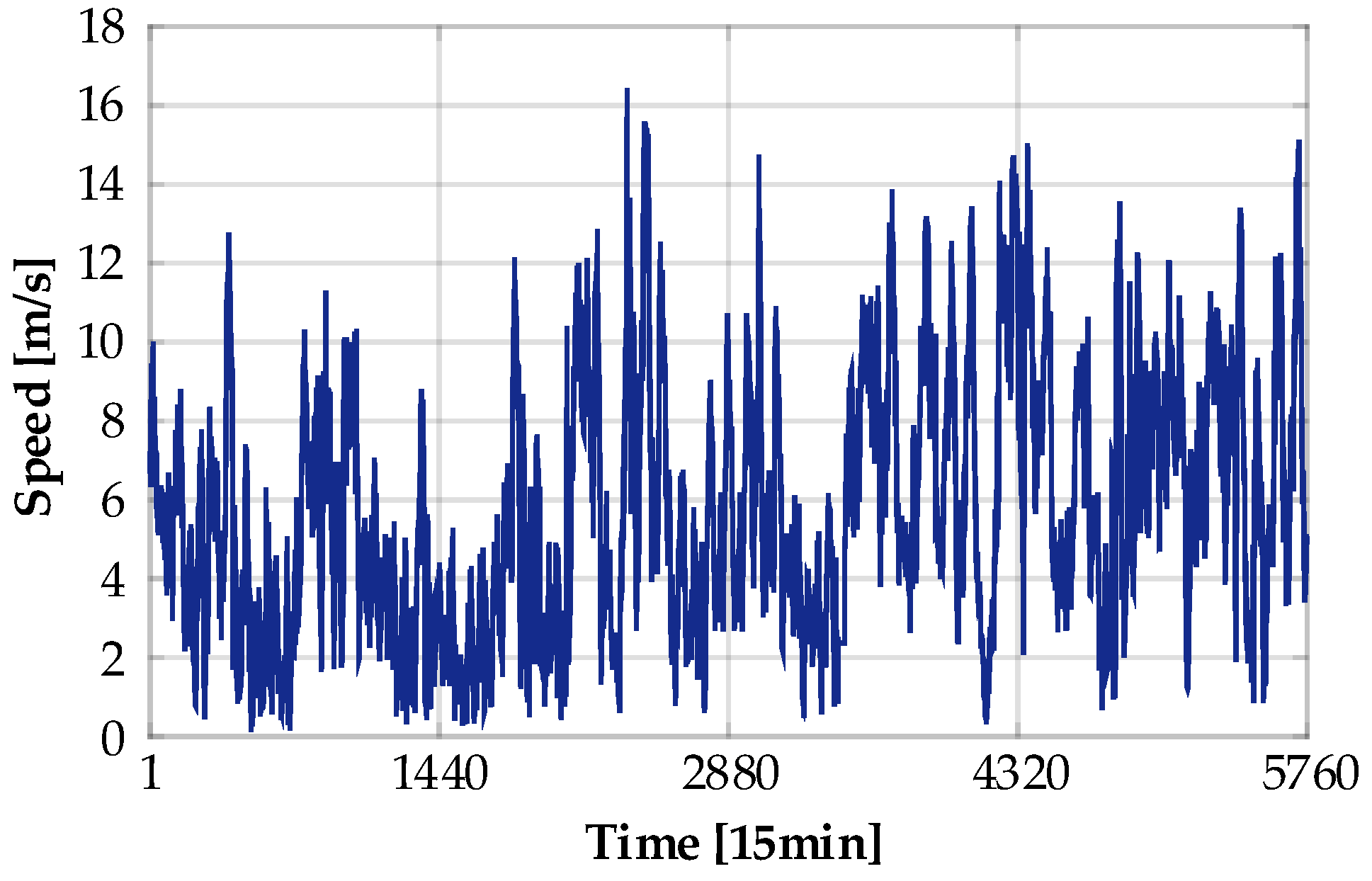
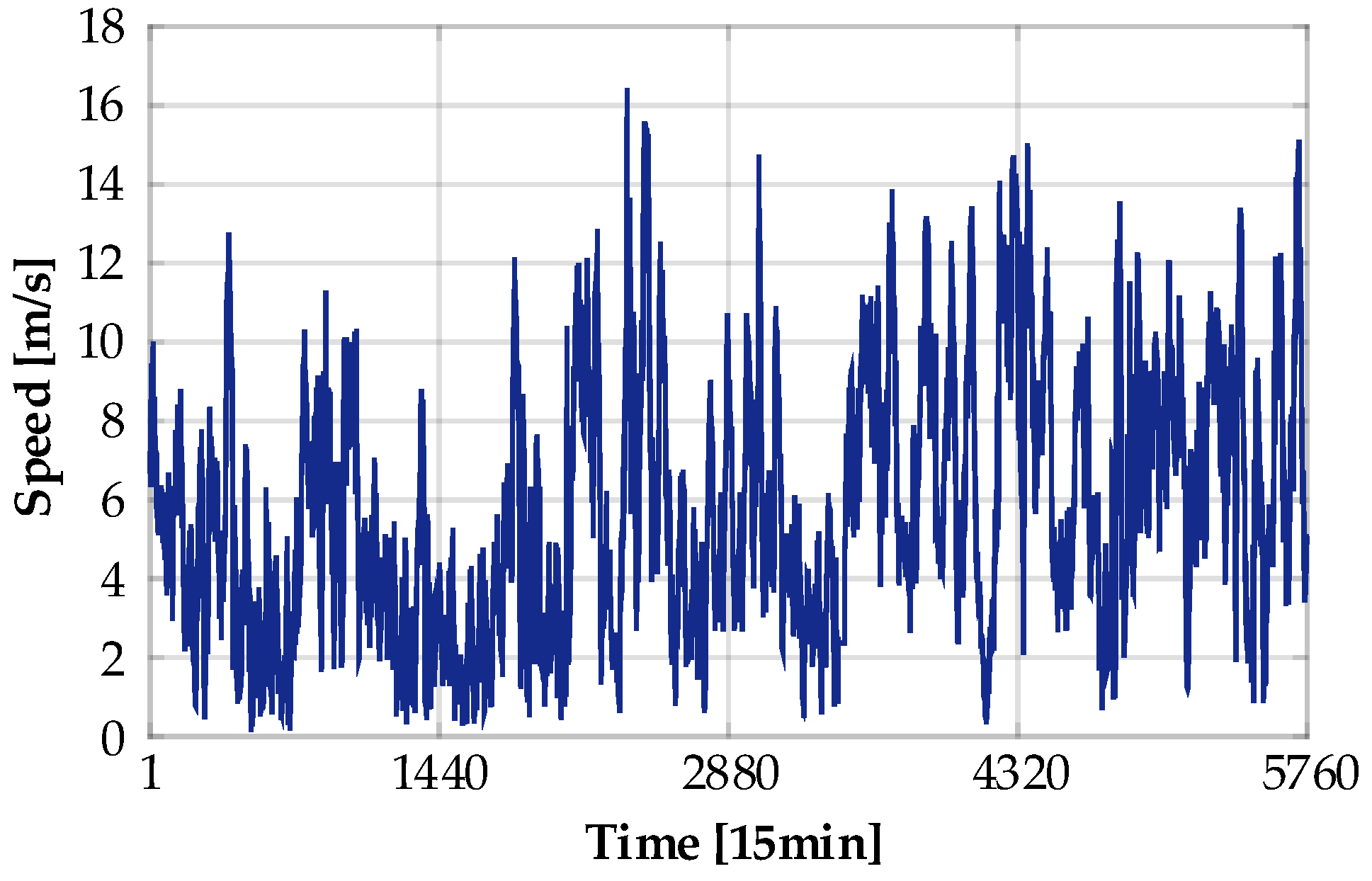
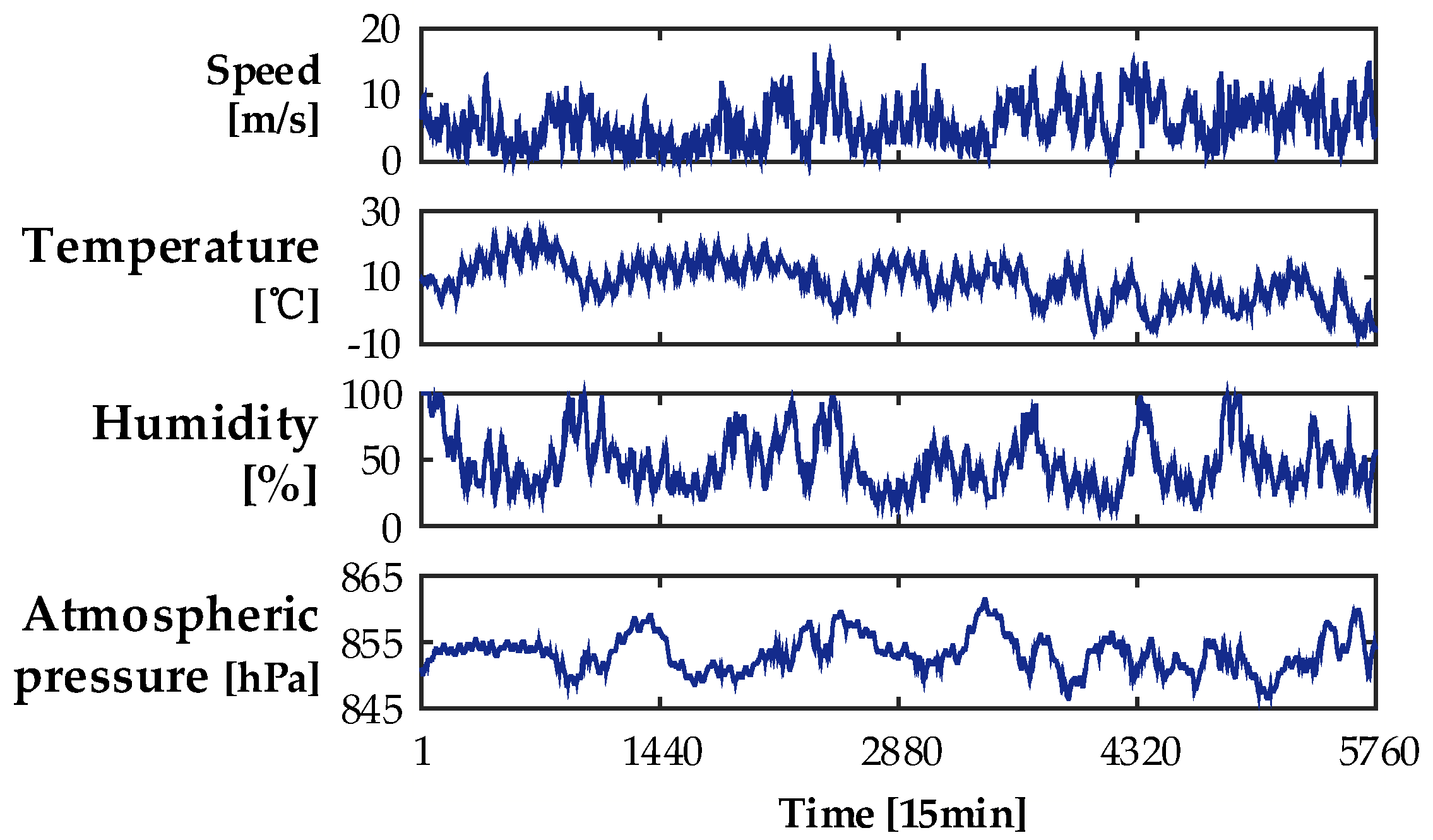
4.1. Data Source and Parameter Initialization
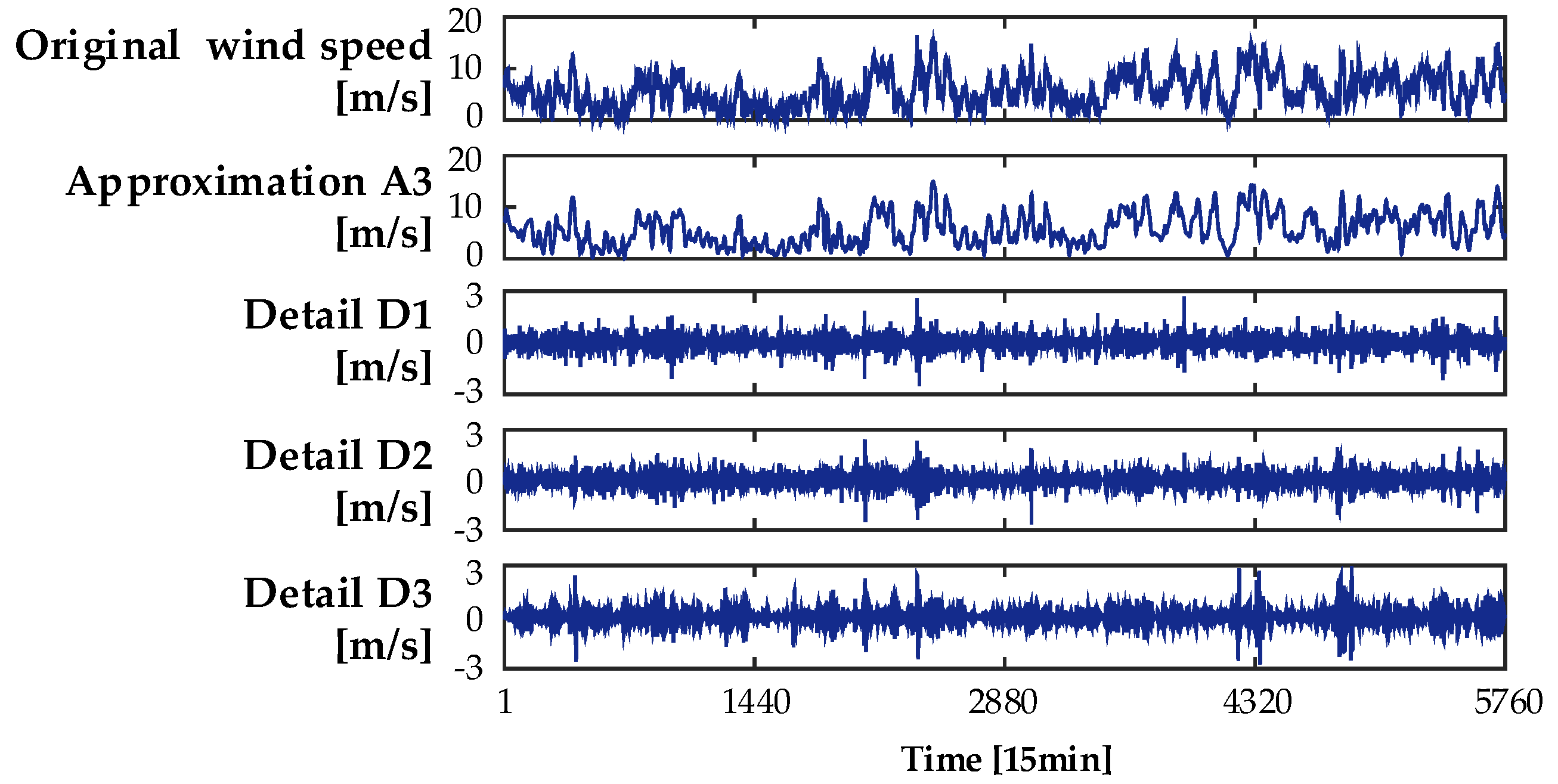
4.2. Candidate Input Variable Selection
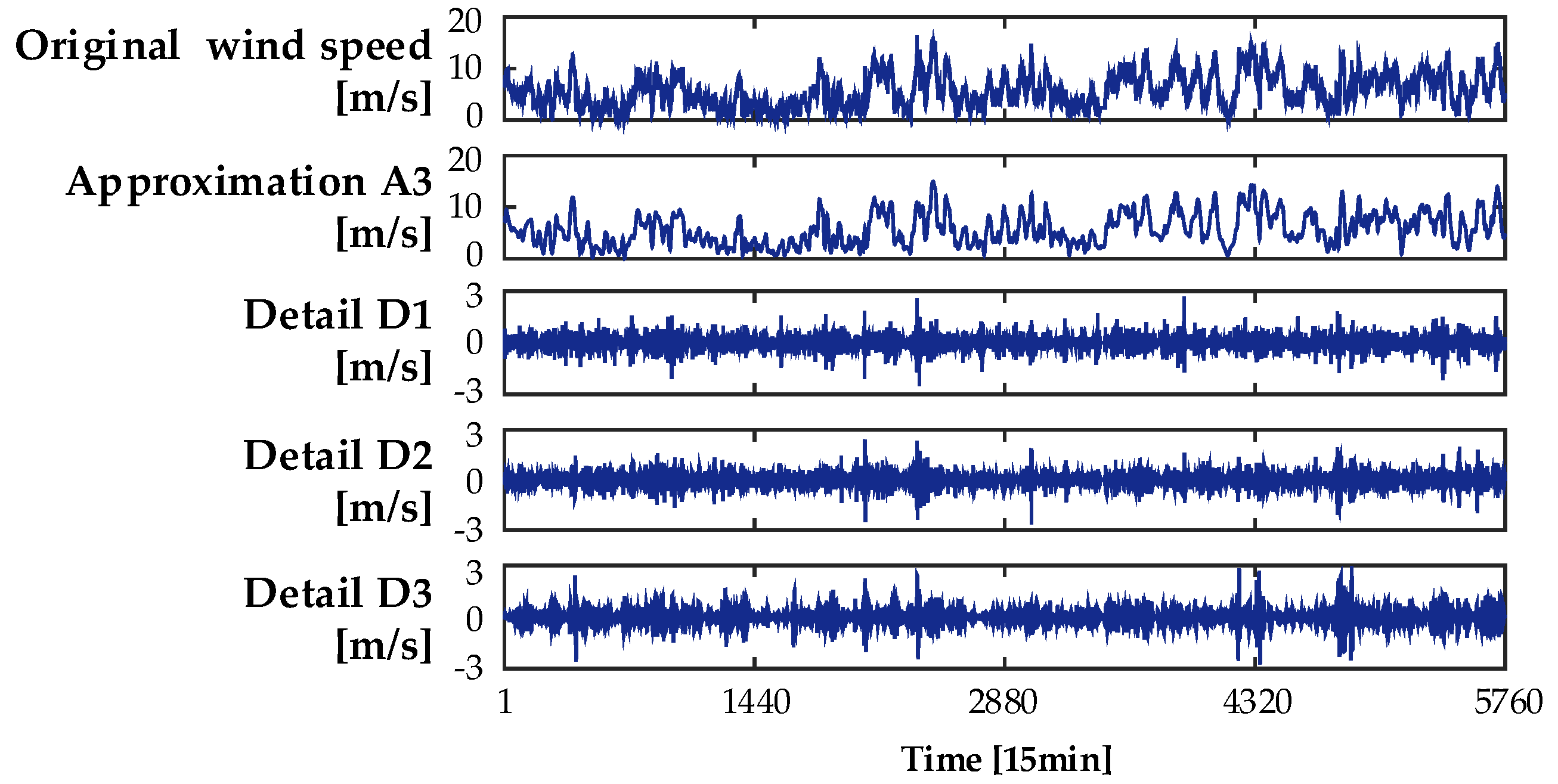
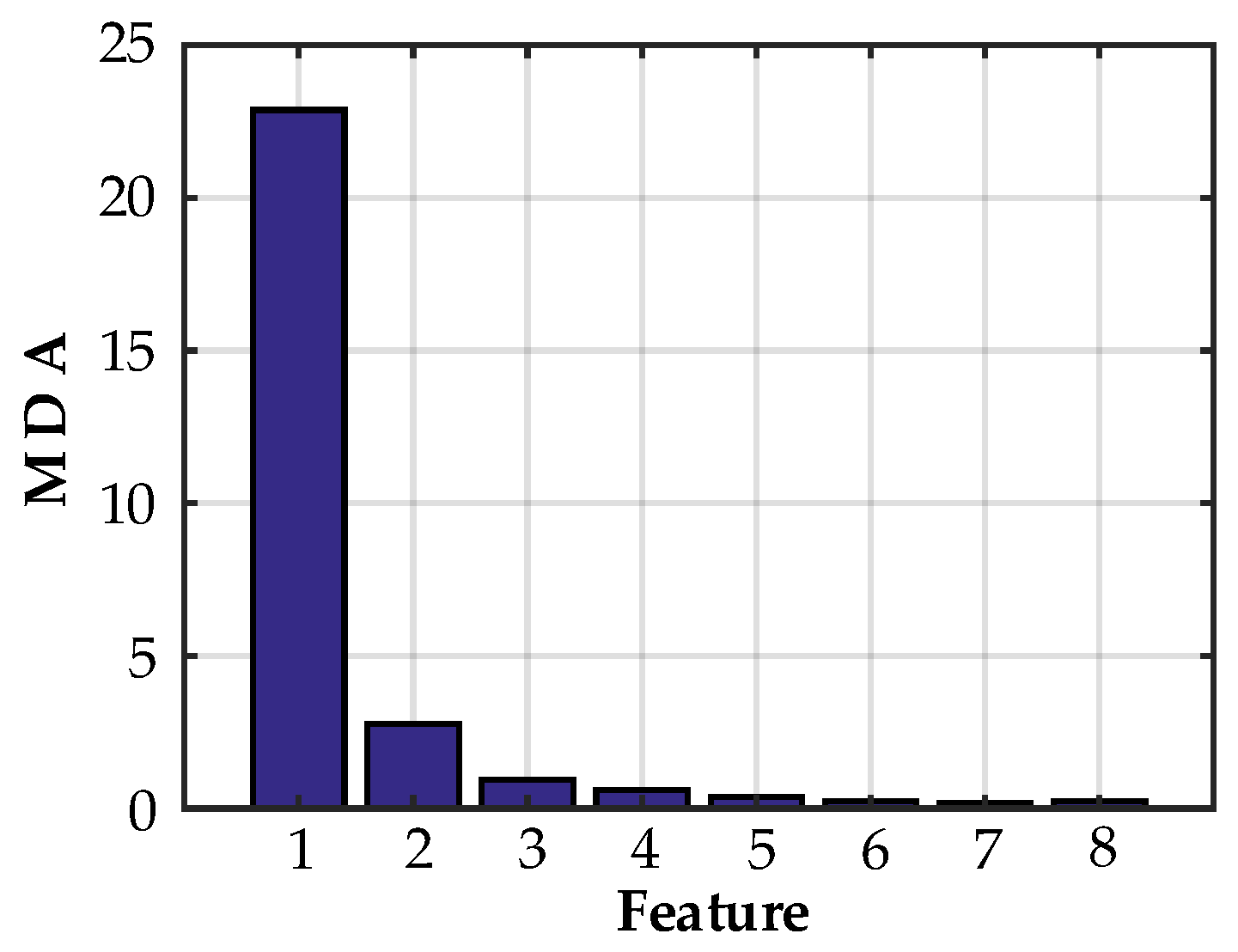
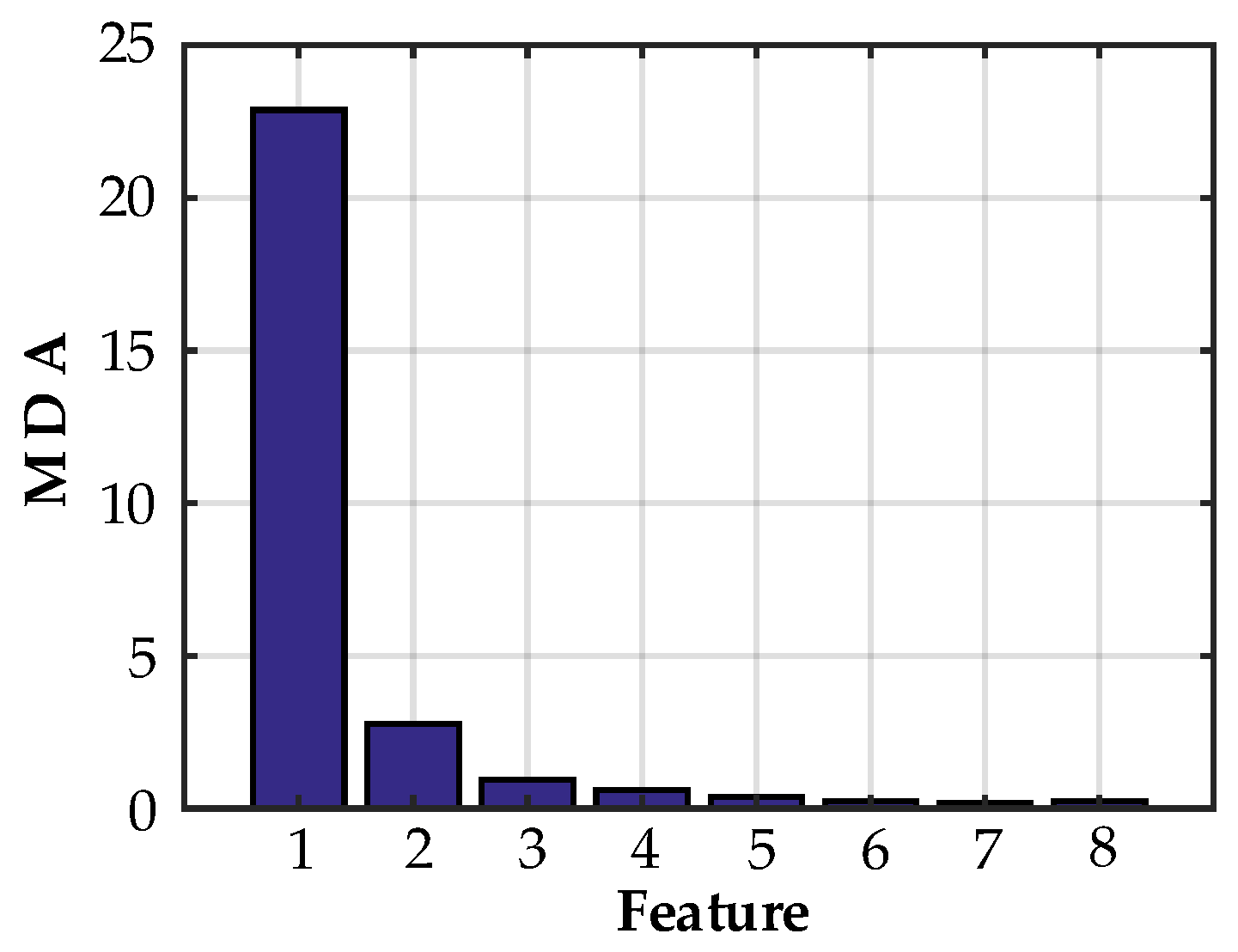
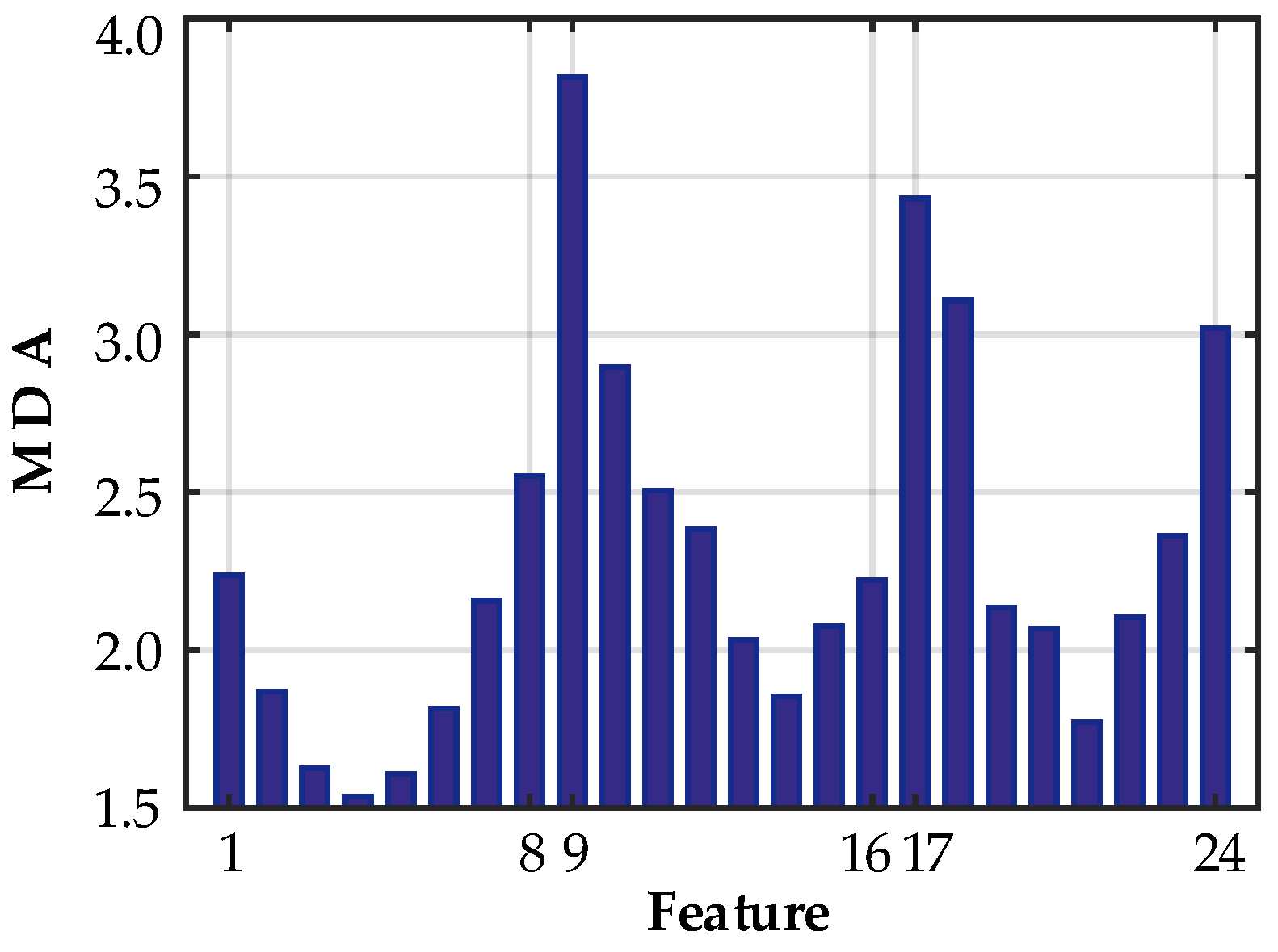
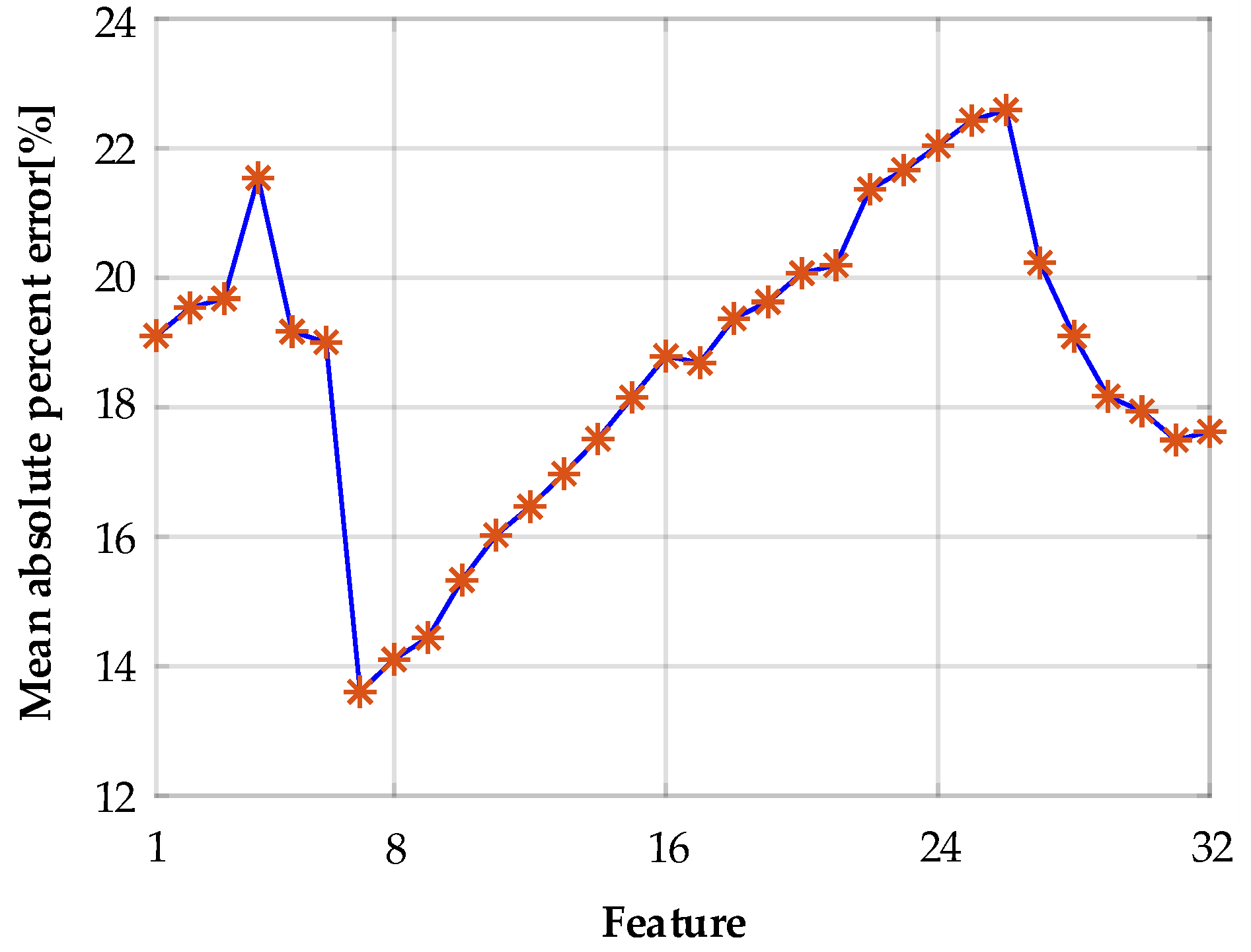
4.3. Feature Selection Based on the RF Method
4.4. KELM-Based Modelling and Parameter Optimization
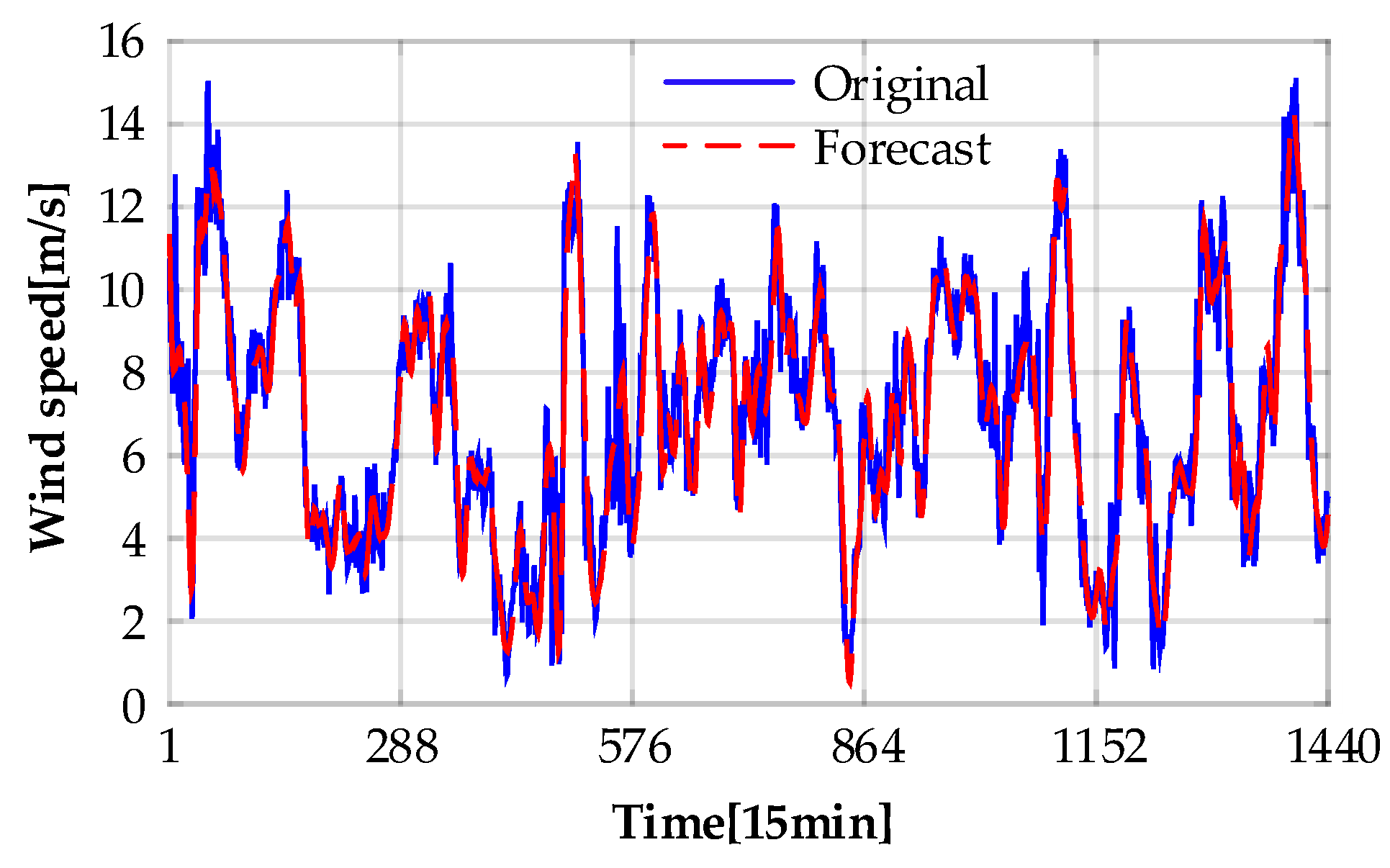
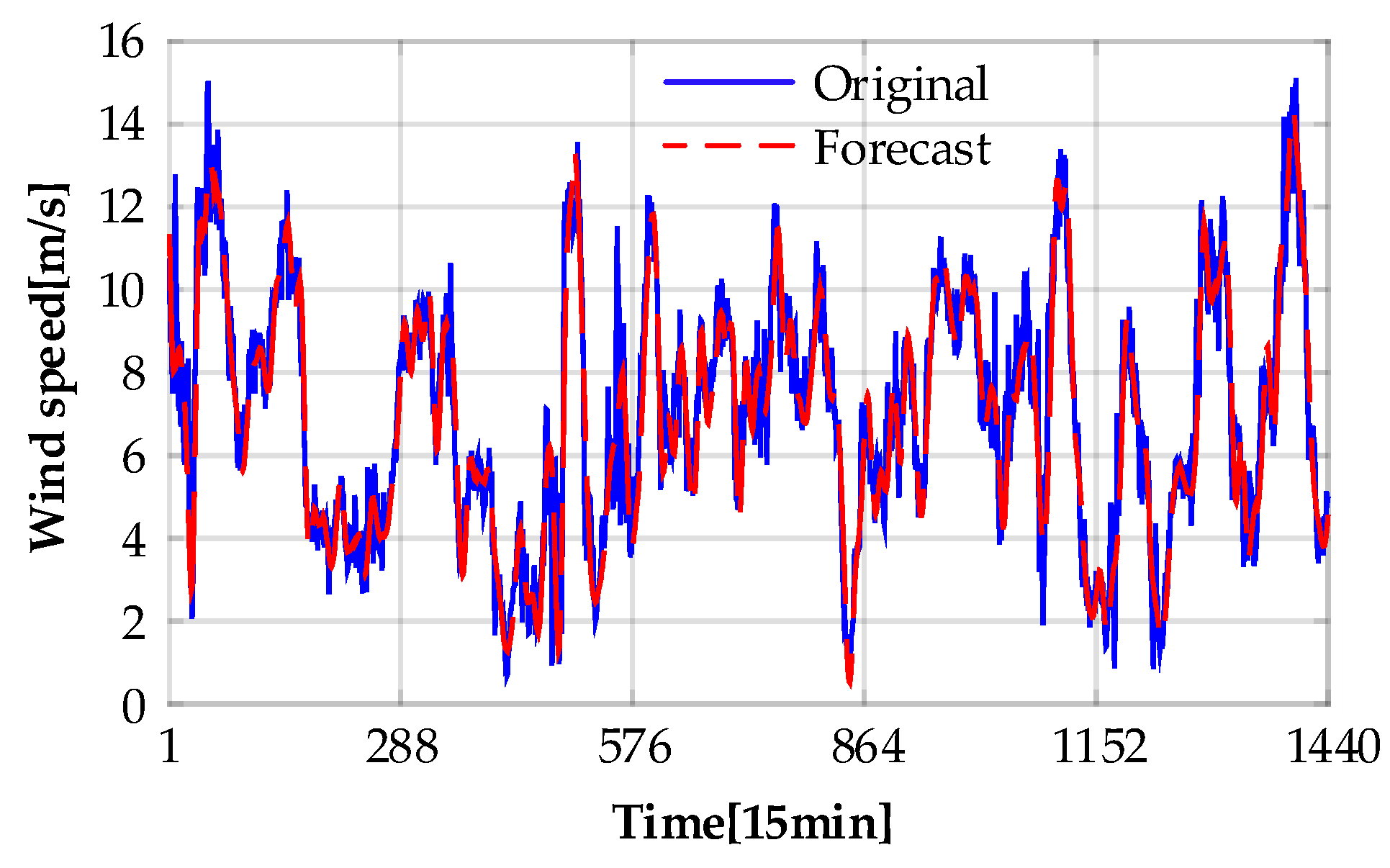
4.5. Forecasting Results and Model Comparisons
5. Conclusions
Author Contributions
Conflicts of Interest
References
- Kavasseri, R.G.; Seetharaman, K. Day-ahead wind speed forecasting using f-arima models. Renew. Energy 2009, 34, 1388–1393. [Google Scholar] [CrossRef]
- Liu, H.; Tian, H.; Li, Y. Comparison of two new ARIMA-ANN and ARIMA-Kalman hybrid methods for wind speed prediction. Appl. Energy 2012, 98, 415–424. [Google Scholar] [CrossRef]
- Filik, T. Improved Spatio-temporal linear models for very short-term wind speed forecasting. Energies 2016, 9, 168. [Google Scholar] [CrossRef]
- Zhang, C.; Wei, H.; Zhao, X.; Liu, T.; Zhang, K. A Gaussian process regression based hybrid approach for short-term wind speed prediction. Energy Convers. Manag. 2016, 126, 1084–1092. [Google Scholar] [CrossRef]
- Jiang, P.; Wang, Z.; Zhang, K.; Yang, W. An innovative hybrid model based on data pre-processing and modified optimization algorithm and its application in wind speed forecasting. Energies 2017, 10, 954. [Google Scholar] [CrossRef]
- Meng, A.; Ge, J.; Yin, H.; Chen, S. Wind speed forecasting based on wavelet packet decomposition and artificial neural networks trained by crisscross optimization algorithm. Energy Convers. Manag. 2016, 114, 75–88. [Google Scholar] [CrossRef]
- Wang, Z.; Wang, C.; Wu, J. Wind energy potential assessment and forecasting research based on the data pre-processing technique and swarm intelligent optimization algorithms. Sustainability 2016, 8, 1191. [Google Scholar] [CrossRef]
- Liu, D.; Niu, D.; Wang, H.; Fan, L. Short-term wind speed forecasting using wavelet transform and support vector machines optimized by genetic algorithm. Renew. Energy 2014, 62, 592–597. [Google Scholar] [CrossRef]
- Kong, X.; Liu, X.; Shi, R.; Lee, K.Y. Wind speed prediction using reduced support vector machines with feature selection. Neurocomputing 2015, 169, 449–456. [Google Scholar] [CrossRef]
- Santamaria-Bonfil, G.; Reyes-Ballesteros, A.; Gershenson, C. Wind speed forecasting for wind farms: A method based on support vector regression. Renew. Energy 2016, 85, 790–809. [Google Scholar] [CrossRef]
- Huang, G.B.; Zhu, Q.Y.; Siew, C.K. Extreme learning machine: Theory and applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef]
- Salcedo-Sanz, S.; Pastor-Sánchez, A.; Prieto, L.; Blanco-Aguilera, A.; García-Herrera, R. Feature selection in wind speed prediction systems based on a hybrid coral reefs optimization - Extreme learning machine approach. Energy Convers. Manag. 2014, 87, 10–18. [Google Scholar] [CrossRef]
- Zhang, C.; Zhou, J.; Li, C.; Fu, W.; Peng, T. A compound structure of elm based on feature selection and parameter optimization using hybrid backtracking search algorithm for wind speed forecasting. Energy Convers. Manag. 2017, 143, 360–376. [Google Scholar] [CrossRef]
- Liu, D.; Wang, J.; Wang, H. Short-term wind speed forecasting based on spectral clustering and optimised echo state networks. Renew. Energy 2015, 78, 599–608. [Google Scholar] [CrossRef]
- Huang, G.B.; Zhou, H.; Ding, X.; Zhang, R. Extreme learning machine for regression and multiclass classification. IEEE Trans. Syst. Man Cybern. Part B 2012, 42, 513. [Google Scholar] [CrossRef] [PubMed]
- Wong, P.K.; Wong, K.I.; Chi, M.V.; Cheung, C.S. Modeling and optimization of biodiesel engine performance using kernel-based extreme learning machine and cuckoo search. Renew. Energy 2015, 74, 640–647. [Google Scholar] [CrossRef]
- You, C.X.; Huang, J.Q.; Lu, F. Recursive reduced kernel based extreme learning machine for aero-engine fault pattern recognition. Neurocomputing 2016, 214, 1038–1045. [Google Scholar] [CrossRef]
- Lu, F.; Jiang, C.; Huang, J.; Wang, Y.; You, C. A novel data hierarchical fusion method for gas turbine engine performance fault diagnosis. Energies 2016, 9, 828. [Google Scholar] [CrossRef]
- Hu, M.; Hu, Z.; Yue, J.; Zhang, M.; Hu, M. A Novel Multi-Objective Optimal Approach for Wind Power Interval Prediction. Energies 2017, 10, 419. [Google Scholar] [CrossRef]
- Lin, L.; Wang, F.; Xie, X. Random forests-based extreme learning machine ensemble for multi-regime time series prediction. Expert Syst. Appl. 2017, 83, 164–176. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, C.; Li, L. Electricity price forecasting by a hybrid model, combining wavelet transform, ARMA and kernel-based extreme learning machine methods. Appl. Energy 2017, 190, 291–305. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Masetic, Z.; Subasi, A. Congestive heart failure detection using random forest classifier. Comput. Methods Program Biomed. 2016, 130, 54–64. [Google Scholar] [CrossRef] [PubMed]
- Elyan, E.; Gaber, M.M. A genetic algorithm approach to optimising random forests applied to class engineered data. Inf. Sci. 2017, 384, 220–234. [Google Scholar] [CrossRef]
- Ibrahim, I.A.; Khatib, T. A novel hybrid model for hourly global solar radiation prediction using random forests technique and firefly algorithm. Energy Convers. Manag. 2017, 138, 413–425. [Google Scholar] [CrossRef]
- Wei, Z.S.; Han, K.; Yang, J.Y.; Shen, H.B.; Yu, D.J. Protein-protein interaction sites prediction by ensembling SVM and sample-weighted random forests. Neurocomputing 2016, 193, 201–212. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Matrix | Meaning | Dimension | Total Dimension |
|---|---|---|---|---|
| Input | 8 | 32 | ||
| 8 | ||||
| 8 | ||||
| 8 | ||||
| Output | 4 | 4 |
| Variable | Matrix | Meaning | Dimension | Total Dimension |
|---|---|---|---|---|
| Input | 2 | 7 | ||
| - | 0 | |||
| 2 | ||||
| 3 | ||||
| Output | 4 | 4 |
| Model | Configuration Details |
|---|---|
| RBF | Transfer function: Gaussian, spread of RBF: 1. |
| NN | Sizes of hidden layers: 5, transfer function: tansig. Parameters by GA: initial weights and thresholds. |
| SVM | Transfer function: Gaussian RBF. Parameters by GA: width of kernel, penalty coefficient. |
| ELM | Number of hidden neurons: 20, transfer function: sigmoidal. Parameters by GA: weights of input layer, bias of hidden layer. |
| Model | MAE (m/s) | MAPE (%) | RMSE (m/s) |
|---|---|---|---|
| Persistence | 1.1782 | 21.83 | 1.1693 |
| WT-RBF | 1.3169 | 22.05 | 1.7152 |
| WT-RF-RBF | 1.0568 | 19.76 | 1.3803 |
| WT-NN-GA | 1.4018 | 23.36 | 1.6628 |
| WT-RF-NN-GA | 0.7373 | 13.80 | 0.9776 |
| WT-SVM-GA | 1.1319 | 21.09 | 1.5676 |
| WT-RF-SVM-GA | 0.7598 | 13.55 | 1.0289 |
| WT-ELM-GA | 1.2156 | 21.98 | 1.5857 |
| WT-RF-ELM-GA | 0.7688 | 13.83 | 1.0350 |
| WT-KELM-GA | 1.1694 | 21.54 | 1.5303 |
| WT-RF-KELM-GA | 0.7047 | 12.54 | 0.9518 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, H.; Sun, J.; Sun, J.; Wang, J. Using Random Forests to Select Optimal Input Variables for Short-Term Wind Speed Forecasting Models. Energies 2017, 10, 1522. https://doi.org/10.3390/en10101522
Wang H, Sun J, Sun J, Wang J. Using Random Forests to Select Optimal Input Variables for Short-Term Wind Speed Forecasting Models. Energies. 2017; 10(10):1522. https://doi.org/10.3390/en10101522
Chicago/Turabian StyleWang, Hui, Jingxuan Sun, Jianbo Sun, and Jilong Wang. 2017. "Using Random Forests to Select Optimal Input Variables for Short-Term Wind Speed Forecasting Models" Energies 10, no. 10: 1522. https://doi.org/10.3390/en10101522
APA StyleWang, H., Sun, J., Sun, J., & Wang, J. (2017). Using Random Forests to Select Optimal Input Variables for Short-Term Wind Speed Forecasting Models. Energies, 10(10), 1522. https://doi.org/10.3390/en10101522