Estimation of Cross-Lingual News Similarities Using Text-Mining Methods

Abstract
:1. Introduction
2. Related Work and Theories
2.1. Embedding Techniques for Words and Documents
2.2. Text Similarities Using Siamese LSTM
3. Methods for Extracting Cross-Lingual News Pairs
3.1. Distribution Representation
3.2. Term Frequency-Inversed Document Frequency (TF-IDF)
3.3. TF-IDF Weighting for Word Vectors
3.4. Feature Engineering
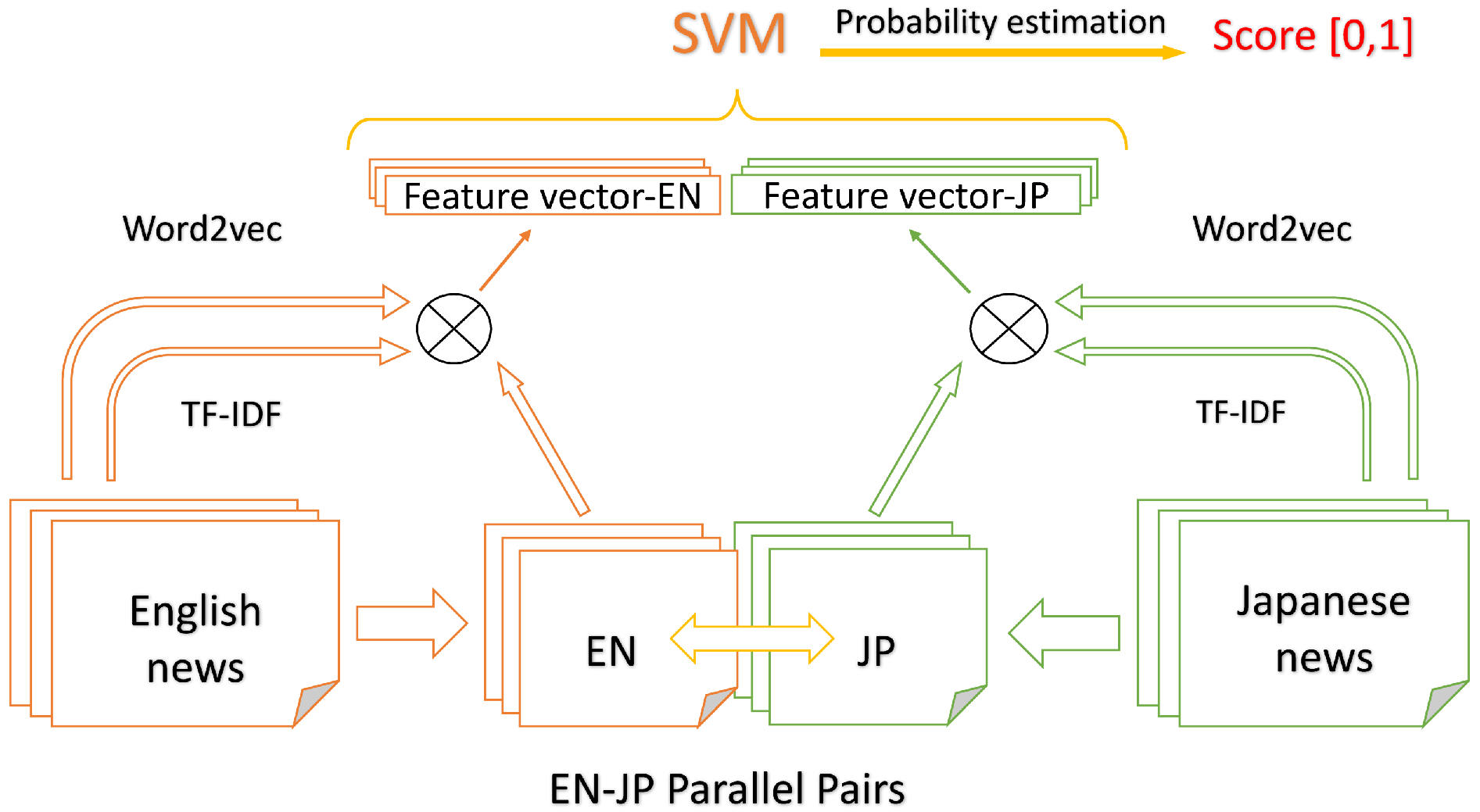
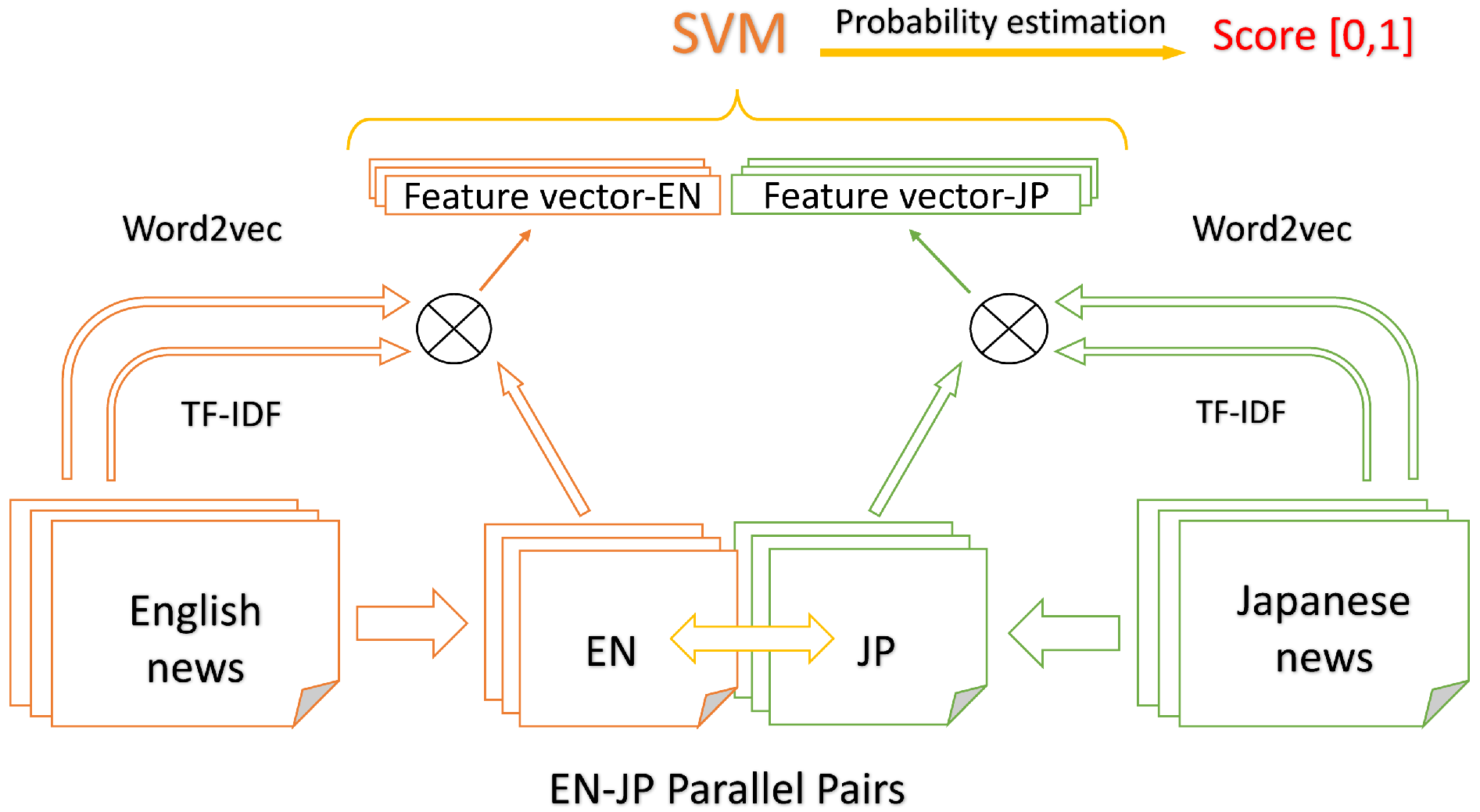
3.5. The SVM-Based Method
- Use the cross-lingual training data in the form of pre-trained word vectors as input, which is discussed in detail in Section 3.1.
- Weight the word vectors for each of language models using TF-IDF, as introduced in Subsection 3.2 and Subsection 3.3.
- Train the proposed model using SVM with Platt’s probability estimation for the connected cross-lingual document features, each of which are the naive join of two weighted word sum vectors in English and Japanese. This is explained in Section 3.4.
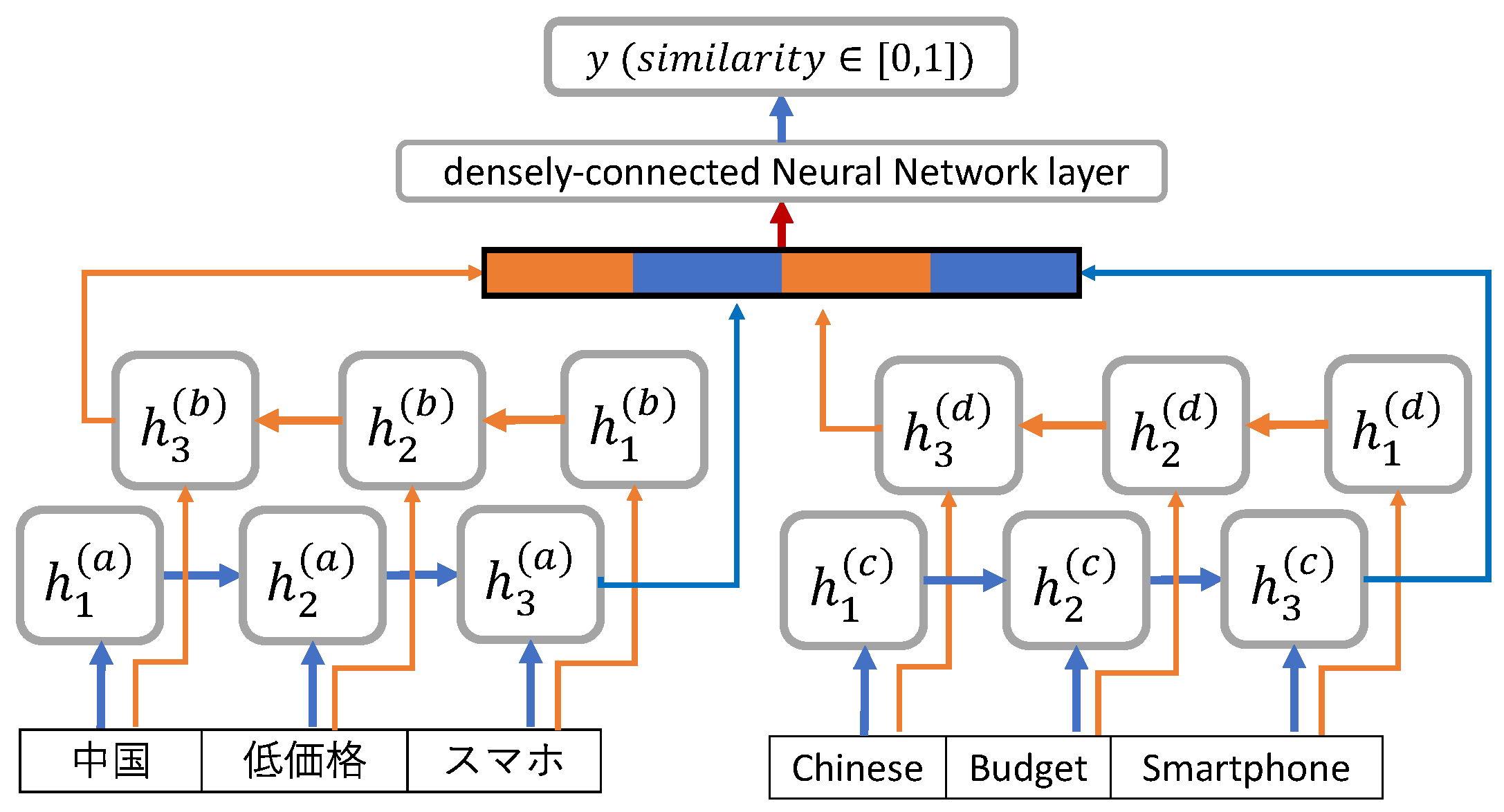
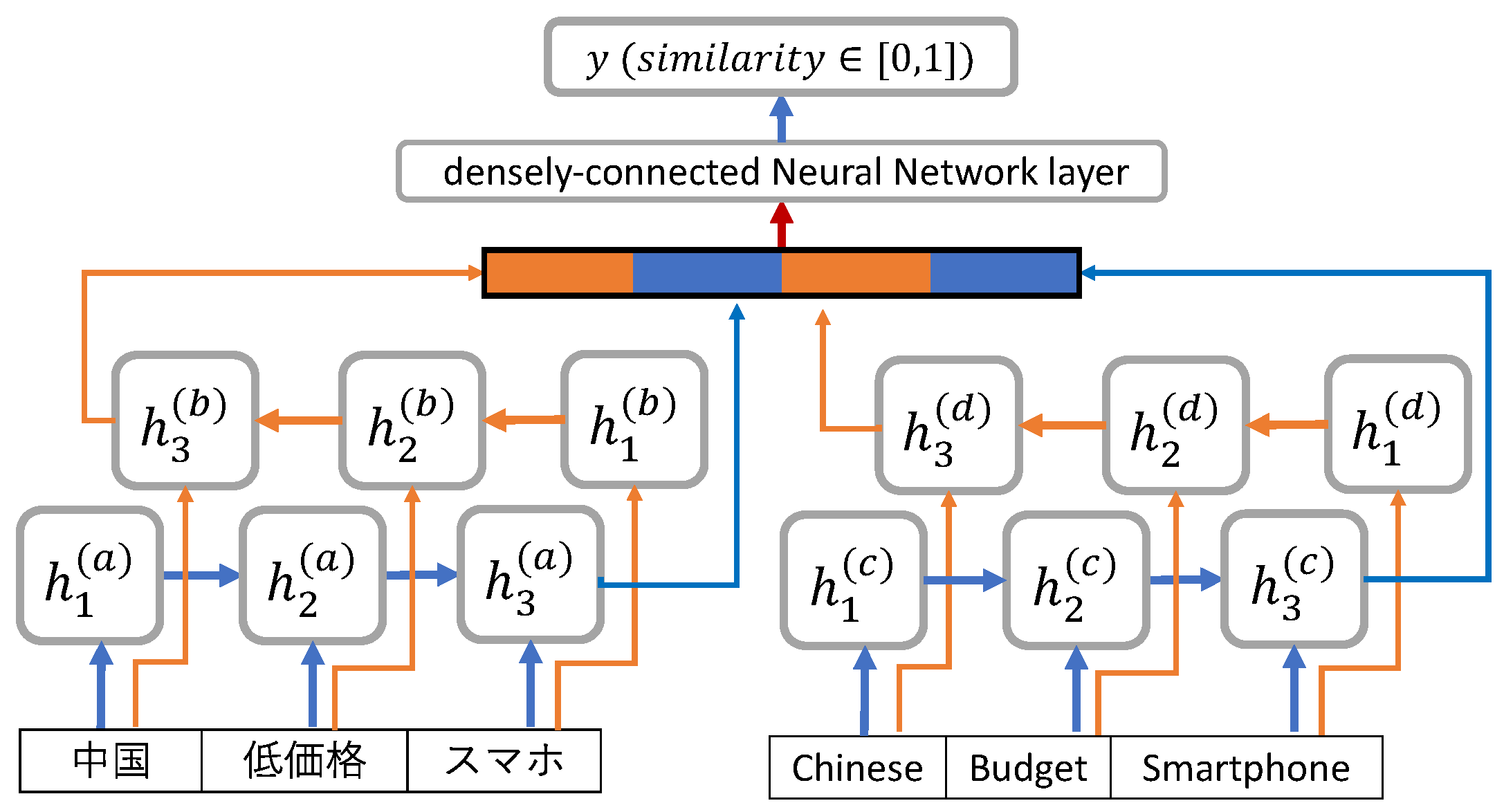
3.6. A Bidirectional LSTM Based Method
3.6.1. The Bi-LSTM Layer
3.6.2. Dense Layer
4. Experiments and Results
4.1. Evaluation Methods
4.2. Baseline: Siamese LSTM with Google-Translation
4.3. Datasets and Pre-Processing
4.4. Experiments on Text Datasets
4.4.1. Training Data
4.4.2. Test Data
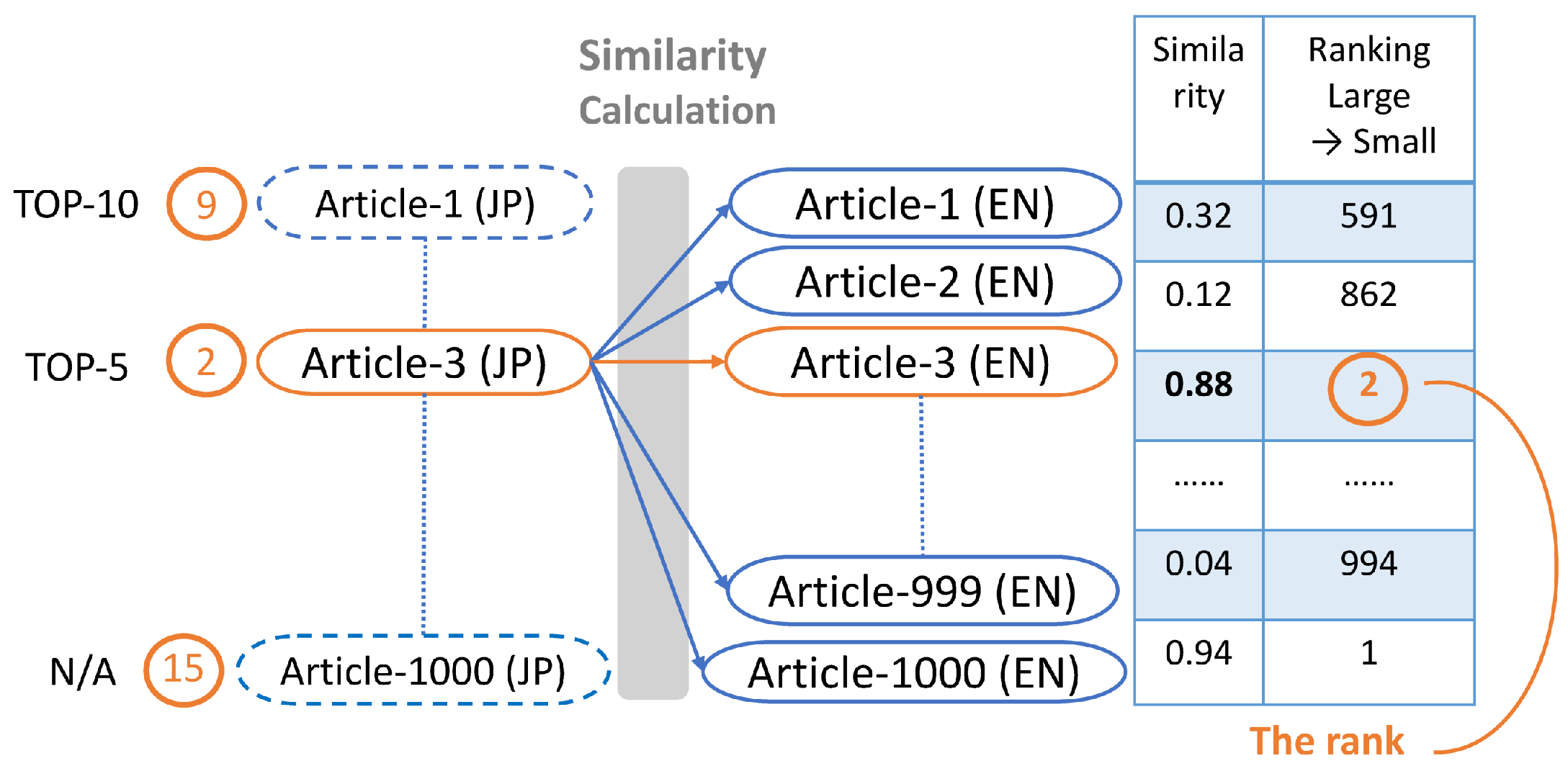
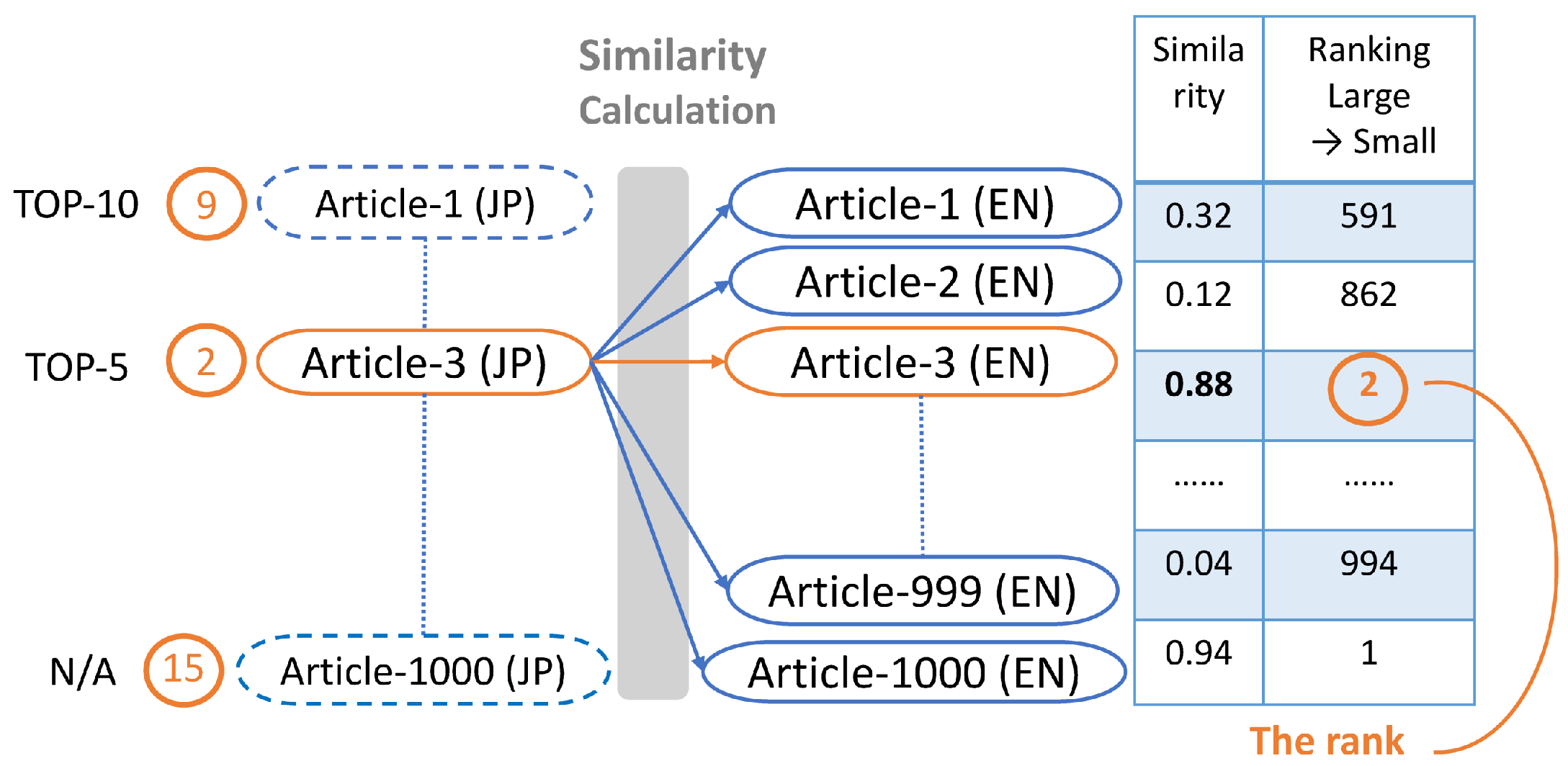
4.4.3. Ranks and TOP-N
5. Discussion
5.1. Comparison of the Baseline and the LSTM-Based Model
5.2. Comparison of the LSTM-Based Model and SVM-Based Model
5.2.1. From the Point of View of the SVM-Based Model
5.2.2. From the Point of View of the LSTM-Based Model
6. Conclusions
Supplementary Materials
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Agirrea, Eneko, Carmen Baneab, Daniel Cerd, Mona Diabe, Aitor Gonzalez-Agirrea, Rada Mihalceab, German Rigaua, and Janyce Wiebe. 2016. Semeval-2016 task 1: Semantic textual similarity, monolingual and cross-lingual evaluation. Paper presented at the SemEval-2016, San Diego, CA, USA, June 16–17; pp. 497–511. [Google Scholar]
- Baroni, Marco, Georgiana Dinu, and German Kruszewski. 2014. Don’t count, predict! a systematic comparison of context-counting vs. context-predicting semantic vectors. Paper presented at the 52nd Annual Meeting of the Association for Computational Linguistics, Baltimore, MD, USA, June 23–25; pp. 238–47. [Google Scholar]
- Béchara, Hanna, Hernani Costa, Shiva Taslimipoor, Rohit Gupta, Constantin Orasan, Gloria Corpas Pastor, and Ruslan Mitkov. 2015. Miniexperts: An svm approach for measuring semantic textual similarity. Paper presented at the 9th International Workshop on Semantic Evaluation (SemEval 2015), Denver, CO, USA, June 4–5; pp. 96–101. [Google Scholar]
- Burges, Christopher J. C. 1998. A tutorial on support vector machines for pattern recognition. Data Mining and Knowledge Discovery 2: 121–67. [Google Scholar] [CrossRef]
- Gouws, Stephan, Yoshua Bengio, and Greg Corrado. 2015. Bilbowa: Fast bilingual distributed representations without word alignments. Paper presented at the 32nd International Conference on Machine Learning (ICML-15), Lille, France, July 7; pp. 748–56. [Google Scholar]
- Graves, Alex. 2012. Supervised Sequence Labelling with Recurrent Neural Networks. Berlin and Heidelberg: Springer, vol. 385. [Google Scholar]
- Greff, Klaus, Rupesh K. Srivastava, Jan Koutník, Bas R. Steunebrink, and Jürgen Schmidhuber. 2017. Lstm: A search space odyssey. IEEE Transactions on Neural Networks and Learning Systems 28: 2222–32. [Google Scholar] [CrossRef] [PubMed]
- Hochreiter, Sepp, and Jürgen Schmidhuber. 1997. Long short-term memory. Neural Computation 9: 1735–80. [Google Scholar] [CrossRef] [PubMed]
- Kingma, Diederik P., and Jimmy Ba. 2014. Adam: A Method for Stochastic Optimization. Available online: https://arxiv.org/abs/1412.6980 (accessed on 16 August 2017).
- Kudo, Taku, Kaoru Yamamoto, and Yuji Matsumoto. 2004. Applying conditional random fields to japanese morphological analysis. Paper presented at the 2004 Conference on Empirical Methods in Natural Language Processing, Barcelona, Spain, July 25; vol. 4, pp. 230–37. [Google Scholar]
- Le, Quoc, and Tomas Mikolov. 2014. Distributed representations of sentences and documents. Paper presented at the 31st International Conference on Machine Learning (ICML-14), Beijing, China, June 23; pp. 1188–96. [Google Scholar]
- Lo, Chi-kiu, Meriem Beloucif, Markus Saers, and Dekai Wu. 2014. Xmeant: Better semantic mt evaluation without reference translations. Paper presented at the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Baltimore, MD, USA, June 23–25; vol. 2, pp. 765–71. [Google Scholar]
- Malakasiotis, Prodromos, and Ion Androutsopoulos. 2007. Learning textual entailment using svms and string similarity measures. Paper presented at the ACL-PASCAL Workshop on Textual Entailment and Paraphrasing, Prague, Czech Republic, June 28–29; Stroudsburg: Association for Computational Linguistics, pp. 42–47. [Google Scholar]
- Mikolov, Tomas, Ilya Sutskever, Kai Chen, Greg Corrado, and Jeffrey Dean. 2013. Distributed representations of words and phrases and their compositionality. Paper presented at the 26th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, December 5–10; pp. 3111–19. [Google Scholar]
- Mueller, Jonas, and Aditya Thyagarajan. 2016. Siamese recurrent architectures for learning sentence similarity. Paper presented at the 30th AAAI Conference on Artificial Intelligence (AAAI 2016), Phoenix, AZ, USA, February 16; pp. 2786–92. [Google Scholar]
- Nair, Vinod, and Geoffrey E. Hinton. 2010. Rectified linear units improve restricted boltzmann machines. Paper presented at the 27th International Conference on Machine Learning (ICML-10), Haifa, Israel, June 21–24; pp. 807–14. [Google Scholar]
- Rupnik, Jan, Andrej Muhic, Gregor Leban, Blaz Fortuna, and Marko Grobelnik. 2016. News across languages-cross-lingual document similarity and event tracking. Journal of Artificial Intelligence Research 55: 283–316. [Google Scholar]
- Schroff, Florian, Dmitry Kalenichenko, and James Philbin. 2015. Facenet: A unified embedding for face recognition and clustering. In Paper presented at Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, June 7–12; pp. 815–23. [Google Scholar]
- Taghva, Kazem, Rania Elkhoury, and Jeffrey Coombs. 2005. Arabic stemming without a root dictionary. Paper presented at International Conference on Information Technology: Coding and Computing, 2005 (ITCC 2005), Las Vegas, NV, USA, April 4–6; vol. 1, pp. 152–157. [Google Scholar]
- Tang, Duyu, Furu Wei, Nan Yang, Ming Zhou, Ting Liu, and Bing Qin. 2014. Learning sentiment-specific word embedding for twitter sentiment classification. Paper presented at the 52nd Annual Meeting of the Association for Computational Linguistics, Baltimore, MD, USA, June 23–25; pp. 1555–65. [Google Scholar]
- Zou, Will Y., Richard Socher, Daniel Cer, and Christopher D. Manning. 2013. Bilingual word embeddings for phrase-based machine translation. Paper presented at the 2013 Conference on Empirical Methods in Natural Language Processing, Seattle, WA, USA, October 19; pp. 1393–98. [Google Scholar]
| 1 | Google Translation Web API could be accessed from https://github.com/aditya1503/Siamese-LSTM. |
| 2 | The open source code for Siamese LSTM can be accessed from https://github.com/aditya1503/Siamese-LSTM. |
| 3 | Official websites of Thomson Reuters: http://www.reuters.com/. |
| 4 | To see more specific of the configuration of word2vec model, see the documentation of Word2Vec class from https://radimrehurek.com/gensim/models/word2vec.html. |

{kind=link}
{kind=link}
{kind=link}
| Toyota | Sony | |||
|---|---|---|---|---|
| TOP | Word | Similarity | Word | Similarity |
| 1 | Honda | 0.612 | PlayStation | 0.612 |
| 2 | Toyota corp | 0.546 | Entertainment | 0.546 |
| 3 | Hyundai corp | 0.536 | SonyBigChance | 0.536 |
| 4 | Chrysler | 0.524 | Game console | 0.524 |
| 5 | Nissan | 0.519 | Nexus | 0.519 |
| 6 | motor | 0.511 | X-BOX | 0.511 |
| 7 | LEXUS | 0.506 | spring | 0.506 |
| 8 | Acura | 0.493 | Windows | 0.493 |
| 9 | Mazda | 0.492 | Compatibility | 0.492 |
| 10 | Ford | 0.486 | application software | 0.486 |
| Lexus | Lenovo | |||
|---|---|---|---|---|
| TOP | Word | Similarity | Word | Similarity |
| 1 | acura | 0.636 | huawei | 0.636 |
| 2 | corolla | 0.588 | zte | 0.588 |
| 3 | camry | 0.571 | xiaomi | 0.571 |
| 4 | 2002–2005 | 0.570 | dell | 0.570 |
| 5 | sentra | 0.541 | handset | 0.541 |
| 6 | prius | 0.539 | smartphone | 0.539 |
| 7 | 2003–2005 | 0.537 | hannstar | 0.537 |
| 8 | sedan | 0.533 | thinkpad | 0.533 |
| 9 | mazda | 0.530 | tcl | 0.530 |
| 10 | altima | 0.524 | medison | 0.524 |
| TOP-10 | ||||
| SHORT | LONG | |||
| TEST-1S | TEST-2S | TEST-1L | TEST-1L | |
| LSTM | 511 | 495 | 456 | 432 |
| SVM | 453 | 422 | 685 | 654 |
| baseline | 243 | - | 302 | - |
| TOP-5 | ||||
| SHORT | LONG | |||
| TEST-1S | TEST-2S | TEST-1L | TEST-1L | |
| LSTM | 339 | 338 | 284 | 278 |
| SVM | 324 | 295 | 520 | 491 |
| baseline | 134 | - | 192 | - |
| TOP-1 | ||||
| SHORT | LONG | |||
| TEST-1S | TEST-2S | TEST-1L | TEST-1L | |
| LSTM | 90 | 106 | 61 | 58 |
| SVM | 101 | 96 | 128 | 179 |
| baseline | 39 | - | 50 | - |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Z.; Liu, E.; Sakaji, H.; Ito, T.; Izumi, K.; Tsubouchi, K.; Yamashita, T. Estimation of Cross-Lingual News Similarities Using Text-Mining Methods. J. Risk Financial Manag. 2018, 11, 8. https://doi.org/10.3390/jrfm11010008
Wang Z, Liu E, Sakaji H, Ito T, Izumi K, Tsubouchi K, Yamashita T. Estimation of Cross-Lingual News Similarities Using Text-Mining Methods. Journal of Risk and Financial Management. 2018; 11(1):8. https://doi.org/10.3390/jrfm11010008
Chicago/Turabian StyleWang, Zhouhao, Enda Liu, Hiroki Sakaji, Tomoki Ito, Kiyoshi Izumi, Kota Tsubouchi, and Tatsuo Yamashita. 2018. "Estimation of Cross-Lingual News Similarities Using Text-Mining Methods" Journal of Risk and Financial Management 11, no. 1: 8. https://doi.org/10.3390/jrfm11010008