1. Introduction
The floods have destroyed the sustainable construction of cities, such as damaging buildings and breaking the city lifeline system, when they suddenly happened with great power [
1]. The frequency of such disasters is increasing globally, according to records, and the economic losses caused by floods are often greater than other natural disasters [
2]. The occurrence of floods is unpredictable, so how to prepare for floods and minimize post-disaster losses are our concerns. The flood disaster evaluation is to explore the non-linear relationship between evaluation indicators and flood levels, and to assess the damage caused by floods. Flood evaluation is fundamental work for flood precaution and mitigation, the conclusions of which can provide important guidance for disaster relief [
3].
The losses caused by floods include both tangible assets, which can be quantified as money, and intangible assets. To accurately evaluate the floods level, both forms should be considered. Robert proposed a quantitative method for assessing the economic losses, according to flood scenarios, and used hydraulic models to ensure the stability of results [
4]. Westen established a training package to use the 1D–2D flood propagation model for flood evaluation [
5]. Ji analyzed the risk levels by taking eight atmospheric circulation indicators as independent variables, and conducted an assessment of floods in the Huaihe River through nonlinear and nonparametric classification [
6]. Some researchers focused on methods and tools for evaluating floods to map, detect, and analyze flood risks [
7]. The research for evaluation of flood disaster and risk generally focused on several aspects: The determination of flood disaster degree, the damage area and the influence extent [
8,
9], and the assessment of economic losses [
10]. Schumann [
11] used SAR images and the USGS Hazards Data Distribution System to describe the flood disaster in Texas [
12]. Rukmana [
13] developed a decision support system to determine the risk level of floods by using the fuzzy method. Kwon [
14] differentiated the risk level of Twitter data and visualized on the map in order to detect signs of flood disaster as soon as possible. Hansson [
15] put forward a framework for the evaluation of flood management strategies. Luino [
16] studied a model for the evaluation of flood damage and described the staged damage curves.
Since the 1980s, the research on disaster sociology and disaster economics emerged rapidly, with the development of the disaster reduction activities worldwide [
17]. They proposed a number of quantitative evaluation methods about the disaster losses, one after another, including the fuzzy comprehensive evaluation method [
18,
19,
20], grey clustering analysis method [
21,
22], intelligent model based on artificial neural network and genetic algorithm [
23,
24], projection pursuit method [
25], and the matter element analysis method [
26], etc. Different methods can evaluate flood disasters from different angles. Those methods have some achievements and applications but there still exists certain limitations, since the index system and influence factors on flood characterized the disunity, randomness, and ambiguity. The evaluation results calculated by different methods generate incompatibility easily, which puzzled the decision makers. The simple and useful evaluation methods for flood disaster with stable and reliable results should be explored, so as to address the vague and uncertain information involved.
In view of many factors leading to floods, only using single index evaluation is unable to make an accurate analysis and support the reasonable suggestions for precaution and reduction of floods. Therefore, the assessment of floods should belong to the problem of multi-index evaluation.
The critical parts for multi-index evaluation are index weights and evaluation methods [
27,
28], and the index weights are always prepared for evaluation methods [
29,
30]. The determination of index weights and evaluation methods are generally divided into qualitative and quantitative. The qualitative evaluation method, including the Delphi method [
31] and expert meeting method [
32], and the quantitative evaluation method including the system engineering method [
33], statistical analysis method [
34,
35], and the operational research method [
36] etc., are the two main comprehensive evaluation methods [
37]. As the appearance of mutual integration from different knowledge areas, new methods including system modeling and simulation method [
38], information theory method [
39], grey theory method [
40,
41], intelligent method [
42,
43,
44], rough set method [
45], matter element analysis method [
46], and a novel MADM approach [
47] for comprehensive evaluation problems emerged. Different evaluation methods suit for different research objects. It can be seen that the index weights usually considered the subjective weights or the objective weights, while few focused on both subjective and objective weights. The fuzzy mathematics method [
48], in numerous evaluation methods, can overcome the disadvantages of “only one solution” and conform to the concept of “flexible management” in modern society because of scalability. Some studies have shown that the fuzzy set theory is suitable for fuzzy control, fuzzy decision making, and fuzzy mathematical programming, which are considered to be the most suitable examples to show the efficiency of the fuzzy set theory [
49].
However, fuzzy set theory is a static concept, which cannot describe the dynamic variability of the fuzzy phenomena. The index system and influencing factors involved in floods are non-uniform, random, and ambiguous. In the 20th century, Chen proposed the concept of relative membership degree and relative membership functions, and established the theory of engineering fuzzy sets and variable fuzzy sets, which was a breakthrough for the static concept of the fuzzy set theory [
50,
51]. The variable fuzzy recognition model has achieved some results in the field of multi-index evaluation [
52,
53].
Therefore, the goal of this study is to make a scientific and reasonable evaluation for floods by a variable fuzzy recognition model based on combined weights, and to provide supports for government authorities on flood precaution and mitigation. In the next section, the authors will introduce the methodology for evaluating the floods. Considering the importance of weights on the results of the comprehensive evaluation [
54], we compare the evaluation results of subjective weights (AHP (Analytic Hierarchy Process), binary comparison method andFCM (Fuzzy Cognitive Map)) and objective weights (entropy method and variable fuzzy method), respectively, and combine the subjective weights and objective weights using the principle of minimum identification information, and then put the combined weights to the variable fuzzy recognition model. Then, the effectiveness of the model is validated through a case study. The floods evaluation by variable fuzzy recognition model, based on combined weights, can provide supports for disaster precaution and relief decision-making. The floods distribution map can also be used for land use planning. Moreover, the model proposed by this study can be applicable to the multi-index evaluation in other fields—with a good promotion.
2. Methodology
Variable Fuzzy Recognition Model
Variable fuzzy recognition model [
55] will be demonstrated in detail as follows.
Setting
m characteristic value vectors of the known objects to be evaluated as Equation (1).
Making a comprehensive evaluation based on standard interval matrices of
m indicators with
c grades.
For the indicators which are the type of “bigger is better”, a > b; For the indicators which are the type of “smaller is better”, a < b. In the Equation (2), .
By judging the left or right side of which falls in, the relative membership degree of to the grade can be calculated by the Equations (3)–(6).
When
falls in the left of
:
When
falls in the right of
:
. In the Equations (3)–(6): is an important parameter, setted as different values in different contexts. When and . If c is an odd number, . When , should be replaced by from the Equations (3)–(6).
According to Equations (3)–(6), the relative membership degree matrix of the object index characteristics value to each grade can be determined, and then the integrated relative membership degree of grade can be solved using the variable fuzzy recognition model, as Equation (7). At last, make a comprehensive evaluation for the object by Equation (8) of level characteristic value.
Definition 1. Setting the contradictory fuzzy concept on domain , the rejection properties on domain of attraction is represented by and . Domain of attraction is a collection that is closely related to a particular attracting set. For any element , in , at any points in the continuum interval referred (to ) and (to .), the relative membership degrees of attraction and rejection are and , respectively, satisfying , and = 1. The integrated relative membership degree of to all grades can be calculated by variable fuzzy recognition model, as Equation (7) [38]: In Equation (7),
is the weight of index
. There are two parameters
in Equation (7),
is the parameter as model optimization criteria, and
means the minimum one power criteria, while
indicates the minimum two powers criteria.
is the parameter as distance, and
means the Hamming distance, while
indicates the Euclidean distance. So there are four combinations of the parameters for the model, which are variable. Normalize
to
and applies Equation (8) to get the grade of
belonging to.
3. Index Weights Calculation Methods
The accurate and reasonable weights are critical when using the variable fuzzy recognition model to make a comprehensive evaluation for the sample data. Generally, decision makers determine the weights in accordance with their subjective cognition and judgement, which has a strong individual disturbance because of different preferences and experiences for indicators despite being close to reality. In contrast, the objective weights totally depend on the sample data. If the sample data changes, the objective weights will change correspondingly. When the quality and quantity of the sample data cannot be guaranteed, simply using objective weights is inaccurate. The combined weights considering both subjective and objective weights can minimize the loss of information, which makes the evaluation results conform with objective data and are as close to the actuality as much as possible. Therefore, we determine the target weights by the combination of subjective weights and objective weights in this paper. In order to make comparative analysis more obviously, we choose AHP, binary comparison method, and FCM to solve the subjective weights, meanwhile, the entropy method and variable fuzzy method for the objective weights then form six kinds of combined weights according to the principle of minimum identification information.
3.1. Objective Weighting Method
3.1.1. Entropy Method
The concept of entropy created by Clausius [
56], which is a measurement of disorder degree of the system, derives from thermodynamics. While the concept of information entropy proposed by Shannon in 1948 [
57] describes the discrete degree of some index data. The bigger the discrete degree, the greater the influence of the indicator on evaluation results, and the bigger the index weight [
58].
Calculation steps of entropy method [
12]:
Step 1: Normalization of the original data. Setting the matrix of original data with schemes and evaluation indexes being and normalizing it in light of the column to . in the normalized matrix denotes the contribution of the scheme under the indicator .
For the indicators of “bigger is better”, the normalized formula is Equation (9):
For the indicators of “smaller is better”, the normalized formula is Equation (10):
Step 2: Definition of entropy. In the evaluation problem with
schemes and
indicators, the entropy of the indicator
is Equation (11):
indicates the total contribution of all samples to indicator . In Equation (11), , and the constant ; when , set . From the formula, when the contribution of each scheme under some indicator tends to be uniform, converges to 1; in particular, when they are all equal, the weight of the indicator is zero.
Thus, the weights of indexes are determined by the value of differences among all schemes, then defining to be the degree of consistency of contribution of each scheme under the indicator , .
Step 3: Calculation of the entropy weights. The entropy weight of the indicator
can be solved by Equation (12).
When , the indicator whose weight is zero, can be deleted.
3.1.2. Variable Fuzzy Method
The derivation process of variable fuzzy model [
55] computing objective weights is as follows.
Firstly, determining the initial solution of the target weights vector, and at this time the target weights
and
are both unknown. According to Equation (13), the difference between scheme
and grades
can be represented by the weighted generalized Euclidean weighted distance quadratic sum.
For the schemes sets to be the optimized as Equation (14).
Obviously, the smaller
is, the smaller the difference of the scheme
to grade
is, that is, the better the recognition to grade
is. So the optimization problems of multi-objective decision-making for unlimited schemes can be established, and the objective function is shown as Equation (15):
All the schemes in schemes sets are on equal status and there is no emphasis. Making use of the linear weighted average method with the same weights for schemes to solve the objective function, and transferring the multi-objective decision-making optimization problem into a single objective optimization problem, just as follows:
It should satisfy the same constraint conditions as Equation (16).
Aiming at the single objective optimization problem, constructing the Lagrangian function:
The iterative model of objective weights can be obtained from Equations (20) and (21),
.
The specific iterative steps are shown as follows:
Step 1: Given that the iteration tolerance of is ;
Step 2: Setting the goal initial weights vector at random ;
Step 3: Putting into Equation (20), and solving the corresponding initial matrix ;
Step 4: Putting the matrix into Equation (21) to solve vector . Comparing and , and if , then the iteration ends and the final results can be calculated. Otherwise, continuing the iteration to times. Because Equations (20) and (21) are proved to be convergent in theory, it will be able to meet the scheduled accuracy, namely .
3.2. Subjective Weighting Method
3.2.1. Analytic Hierarchy Process
Analytic Hierarchy Process (AHP) was proposed by professor T L Saaty in the 1970s [
59,
60], and its specific algorithm steps are shown as follows:
Step 1: Establishment of the hierarchical structure model.
Step 2: Construction of the judgment matrix. Comparing the relative importance of every two indicators in the same grade to get the ratio of relative weights, on the basis of which constructing the judgment matrix
,
means the ratio of the relative weight between the indicator
and
. There are two common patterns of judgment matrix scale, including the 1~9 scale method and the index scale method. This paper selects the 1~9 scale method in light of isotonicity and handleability, as shown in
Table 1.
Step 3: Calculation of the weights using the arithmetic average method.
Normalizing each column vector of the judgment matrix
, and then getting the row vector by summarizing the row data.
Step 4: Consistency check. Calculating the largest eigenvalue of matrix
, and then working out the consistency indicator and consistency ratio. When
, the consistency of judgment matrix is regarded to be acceptable. The corresponding values of RI are listed in
Table 2.
Consistency indicator and consistency ratio: , .
3.2.2. Binary Comparison Method
The calculation process of binary comparison method [
61] will be elaborated as follows.
In the limited schemes and target decisions, noting the decision set , the target set of each scheme , the weight vector of the target , and the set of the target value in decisions set .
Making sure of all targets in targets set
on importance using the binary comparison method [
38], and getting the ordering results of
targets on the importance degree, which subject to sorting consistency, we suppose
.
Definition 2. Making a binary comparison for and on the importance degree in the targets set .
- Step 1:
When is more important than , ;
- Step 2:
When is more important than , and ;
- Step 3:
When is as important as , , in particular, .
We call fuzzy scale value of relative importance between adjacent target and . Particularly, setting the sort of targets on importance and calling fuzzy scale value of relative importance for adjacent targets.
The value of
can be get by tone operator table [
38] of the importance degree between target
and
.
Through the derivation, the formula of calculating the target weights is obtained as follows:
3.2.3. Fuzzy Cognitive Map
Fuzzy cognitive map (FCM), proposed by Kosko (1986) [
62], is dynamic system analysis and modeling approach through causal reasoning based on the cognitive map method [
63] and the fuzzy set theory [
64]. FCM combines both fuzzy logic and neural networks, which indicates intuitive expression and good reasoning skills [
65]. Therefore, FCM can be used to simulate complex and dynamic systems.
The feature of FCM is that the causal relationship between nodes is fuzzy and there is a dynamic feedback mechanism. The reasoning process of FCM mainly depends on the adjacency matrix composed on weights and the state matrix of nodes, which will be introduced specifically as follows.
First, setting the concept set of FCM
, where
indicates the
concept or attribute.
is the adjacency matrix which reflects the interaction between concepts.
is the state matrix of the concepts, where
represents the initial state vector and
is the state vector of the
iteration.
, ensuring that the outputs of each iteration are in the interval of
, which is the threshold function. This paper uses the following threshold function,
The hyperbolic tangent function is one of the commonly used threshold functions, which can normalize the inputs of the concept nodes and permit the value of the nodes to be negative.
The interaction between a specific concept and other concepts is calculated by the iterative formula.
After a certain number of iterations, if the state value of the concept nodes reaches one of the following three conditions, it is considered that a steady state has been reached, and the iteration is ended. Specifically, (a) the state value is stable at a fixed value, (b) the change in state value is periodic, and (c) presenting a chaotic state, that is, the state value is uncertain and random.
Calculation steps of FCM are shown as follows.
Step 1, getting the local weight vector by the eigenvalue method.
Step 2, depicting the FCM map to reflect the interaction between concepts.
Step 3, getting a steady state matrix by iteration according to Equation (1).
Step 4, calculating the overall weight vector. To obtain the overall weight, the local weight vector
and the steady state matrix
should be normalized as follows.
where,
is the largest element in the vector
and
is the largest row sum in the matrix
.
Then, the overall vector can be got.
FCM has two obvious shortcomings: Strong dependence on expert opinions and the final state may converge to the state outside the expectation. To enhance the validity and robustness of FCM, the learning algorithm is necessary for updating the weight matrix. This study uses Nonlinear Hebbian Learning rules (NHL) [
66].
3.3. Combined Weighting Method
Combination of subjective and objective weights, in general, is determined by linear combination method which lacks explanatory ability. This paper adopts the following method:
Suppose the objective weights vector calculated by the entropy method is
(the objective weights vector calculated by the variable fuzzy method is
), the subjective weights vector by AHP is
(the subjective weights vector calculated by the binary comparison method is
and the subjective weights vector calculated by FCM is
), and the combined weights vector is
. According to the minimum identification information principle [
67], the following objective function is established in order to make the combined weights be as close to the reality as much as possible:
Calculate the function by Lagrange multiplier method, and the combined weights can be solved as follows:
Put the combined weights into Equation (7), and calculate the integrated relative membership degree at all grades, and then normalize them to . In light of Equation (8), calculate the disaster grades where the samples can be.
4. Case Study
Flood evaluation is a fuzzy problem and the evaluation criterion is usually an interval, which means it is suitable for fuzzy recognition. This paper quotes the data example from Reference [
68] to make an analysis and verification, targeting the flood disaster evaluation index system, and realizes recognition and evaluation by the variable fuzzy recognition model.
The original data are listed in
Table 3.
4.1. Objective Weights Results
Since all the indicators are the type “smaller is better”, we normalize the original data by the Equation (10) as shown in
Table 4.
In accordance with Equation (12), the objective weights vector calculated by the entropy method using Matlab programming is .
In light of Equations (20) and (21), the objective weights vector calculated by the variable fuzzy method using Matlab programming is , with the initial weights vector and the target accuracy .
4.2. Subjective Weights Results
According to the formula of AHP, the consistency indicator can be solved by using Matlab programming, , which satisfies the consistency test. The subjective weights vector calculated by AHP is .
In a similar way, the subjective weights vector calculated by binary comparison method is .
In order to validate the influence of individual preference on the subjective weights, combined weights and the evaluation results, we choose two groups of experts to fill in the judgment matrix for AHP and the binary comparison method separately.
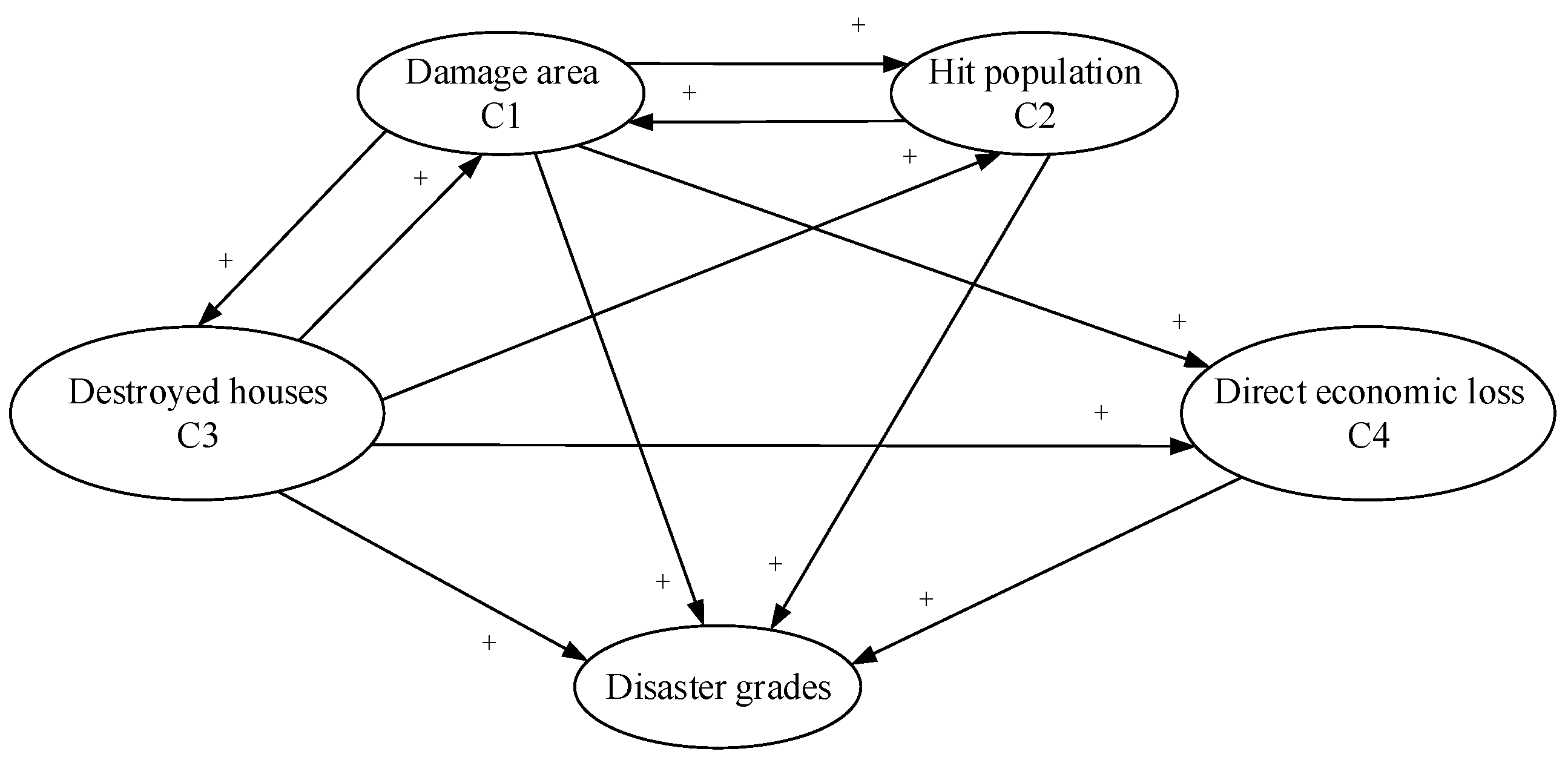
The reasoning process of FCM combines fuzzy logic and neural network, which has more advantages in comparison with AHP and binary comparison method because it considers fuzziness and the interaction between indexes. Firstly, the authors established a FCM model, shown in
Figure 1. Where,
,
,
and
indicate the damage area, hit population, destroyed houses, and direct economic loss, respectively. “+” represents that the interaction between concepts as positive.
The normalized local weights calculated by the eigenvalue method are.
The initial weight matrix can be obtained by experts in the disaster evaluation field, as follows.
Training the weight matrix using the Hebbian learning algorithm, setting learning efficiency parameter to be 0.01 and weight attenuation factor to be 0.95, and the steady matrix can be got as follows:
The overall weights of the concepts (indexes) can be obtained according to the formula.
4.3. Combined Weights Results
Calculating the six kinds of combined weights by Equation (32), using the principle of minimum identification information, the results are shown in
Table 5.
4.4. Variable Fuzzy Evaluation
Both grades indexes and disaster grades of the flood evaluation system are shown in
Table 6.
We put the values of all indicators of 10 regions or 10 schemes into the evaluation model, and calculated the corresponding flood disaster grades by the variable fuzzy recognition model. This paper randomly selects the data of Kezhou (scheme 8) as an example to elaborate the evaluation process, that is, the value sector of indicators is . Make use of the variable fuzzy recognition model based on the combined weights to evaluate the sample data as the following steps.
Firstly, we construct the value matrixes for all parameters
of the variable fuzzy evaluation model, and then get the following domain of attraction
, range domain
, and the value of
on the basis of the variable fuzzy evaluation theory and method.
In light of the direction (left or right) where the matrix and judgment evaluation index lying to the point
, we calculated the relative membership grade of various rank standards
as follows:
The authors put the weights values into Equation (7) and changed the corresponding combinations of different parameters, and then the integrated relative membership degrees of indicators can be obtained by programming in matlab2010a, as shown in
Figure 2.
From the top to the root of the figure, the first line is the integrated relative membership degree of indicators related to the third grade, and the purple one is the comprehensive relative membership degree related to the fourth grade, and the rest can be dealt with in the same manner. Then it is easy to see that the maximum relative membership degree of indicators for different levels is the third grade, and the flood disaster grade of Kezhou can be determined as the third grade, according to the principle of maximum degree of membership, that belongs to moderate disaster specifically. Further confirmation by variable fuzzy numerical calculation is subsequent.
The integrated relative membership degree of each indicator for different risk grades can be normalized to
, which is shown as follows:
Use Equation (8) to calculate the grade characteristic value of this sample, as shown in
Table 7.
Therefore, the flood disaster grade of Kezhou is the third, which is the same as the conclusion of
Figure 1. From
Table 7, we can see that although the model parameters are changed, the evaluation results are stable, which demonstrates the stability and effectiveness of the model.
Similarly, we get the same evaluation conclusions of flood disaster grades by the variable fuzzy recognition mode based on the other combined weights, which will be elaborated on in part 4.5. Calculating the grades in other regions in the same way, and the summary conclusions can be got in
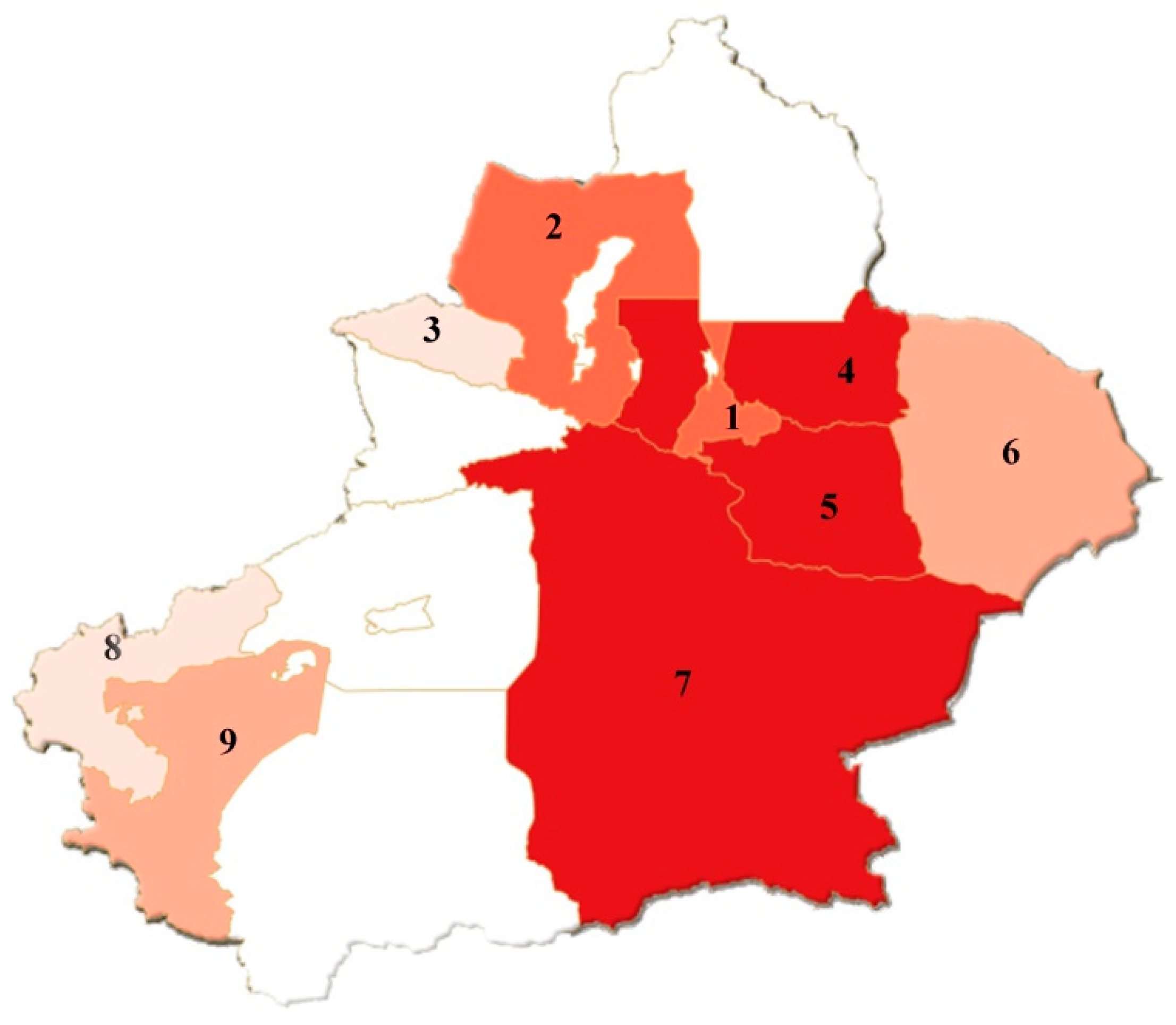
Table 8. The flood disaster level of each damage area can also be represented by a map, where different colors indicate corresponding disaster level. The distribution of floods in the nine cities of Xinjiang Uygur Autonomous Region can be seen in
Figure 3. Scheme 10, Bingtuan, is not a regular administrative area, so it is not shown on the map.
4.5. Robustness Test
4.5.1. Comparative Analysis of Evaluation Methods
This paper had the comprehensive evaluation results calculated by the multi-index evaluation model of variable fuzzy recognition, based on the combined weights according to a case. When changing the parameters of the variable fuzzy evaluation model, the results are all uniform, which demonstrates the stability of the variable fuzzy recognition model. In order to further verify the robustness of the model, we compared it with the principal component projection method [
69] and the grey clustering method [
21].
The results in
Table 9 show that there are differences in flood disaster evaluation among the three methods. For this paper, the evaluation results of Changji, Turpan, Bazhou, and Bingtuan are all the same as Reference [
69], but different from Reference [
21]. According to the analysis of the original data, taking Changji as an example, we find that the four indicators in Changji, except “destroyed houses”, belonged to a range of extremely serious disasters are all in the interval of serious disaster and the indicator weight of destroyed houses is less than one third. Therefore, the evaluation result of the disaster grade, serious disaster, is reasonable and extremely serious disaster grade is too pessimistic. The evaluation results of this paper and Reference [
69] are closer to the actuality than Reference [
21].
For Hami and Kashgar, the evaluation results of this paper are different from the two comparative References [
21,
69]. Analyzing the original data once again, the four indicators in Hami, except damage area belonging to the range of moderate disaster, are all in the interval of serious disaster and the indicator weight of the damage area is relatively low. Therefore, the evaluation result of the disaster grade, serious disaster, is reasonable and the moderate disaster grade is unable to reflect the severity. In a similar way, the three indicators in Kashgar are all in the interval of serious disaster, only one falling in the range of moderate disaster. Therefore, the evaluation result of the disaster grade, serious disaster, is reasonable and moderate disaster grade is unable to reflect the severity.
According to the comparison of the results among different evaluation methods, we found that the projection values of the principal component projection method has a certain subjectivity, and the whitening function of the grey clustering method is unable to reflect the internal changes of disaster grades because of the theory’s limitation itself. The variable fuzzy recognition model, based on the combined weights, precisely describes the differences of the disaster losses among those evaluation objects in the form of a continuous real numbers, which makes the evaluation results more reliable and stable.
4.5.2. Discussions of Weights
The variable fuzzy recognition model shows robustness well in multi-index decision-making for flood disaster as a result of the discussions in
Section 4.5.1. Next, we will verify the rationality of the weights of this paper.
This paper uses the classic methods of the subjective and objective weights determination, combining them in proper order to form six kinds of combined weights according to the principle of minimum identification information, and then carries out the variable fuzzy evaluation. Simply applying the subjective weights, the evaluation results calculated by AHP, binary comparison method, and FCM are inconsistent. Since the subjective weights are easily affected by preferences and experiences from experts, the evaluation results are unreliable. While only applying the objective weights, different principle, and the mechanism of the entropy method and variable fuzzy method lead to different evaluation results in spite of the same original data. Because the objective weights are influenced by the accuracy of the iteration and the collected data, the evaluation results calculated are not creditable either. However, after the two kinds of objective weights, being corrected by the AHP or binary comparison method or FCM, the evaluation results, based on the combined weights, are all consistent. Therefore, simply relying on subjective weights or objective weights will not describe the evaluation results accurately, and the combined weights have a stronger explanatory ability and application validity. The results are summarized in
Table 10.
As mentioned above, the multi-index evaluation model of variable fuzzy recognition based on the combined weights, having a good robustness, can be applied in the multi-index evaluation of flood disaster.
5. Conclusions
This paper established the multi-index evaluation model of variable fuzzy recognition for floods based on the combined weights. According to a specific case of Xianjiang in China, we not only verified the effectiveness and reliability targeting in the variable fuzzy recognition model itself, but also validated the rationality and robustness of the variable fuzzy recognition model based on the combined weights aiming at different weights and their combinations.
The variable fuzzy recognition model obtained four groups of evaluation values by means of changing parameter combinations, which improved the reliability and credibility of the evaluation results. When simply relying on the subjective weights, the evaluation results will be of great difference because of experts’ different preferences and experiences for indicators are not accurate enough. When only depending on the objective weights, the evaluation results can describe the internal relations of the objective data with high requirements on the accuracy of the data samples, and different calculation principles will lead to the instability of the evaluation results. Therefore, the combined weights considering both subjective and objective weights can not only reflect all the information of the decision matrix but can also avoid the distortion of the data by subjective experience, which makes the evaluation results more stable and rational, closer to the reality as much as possible.
The analysis of the case demonstrates that the model is simple and effective. The evaluation conclusions are reliable to be applied in the multi-index evaluation of flood disaster and provide reasonable suggestions for floods precaution and relief to management authorities.
However, there are still some limitations. Firstly, we only validate the robustness and rationality of the model itself, but lack adequate argument for the quality of the data and evaluation index system, which use an existing case from the reference. We should further explore much more actual flood data from other regions in China and conduct comparative analysis between regions. In addition, we will collect data of floods in Xinjiang, in different years, for comparative analysis on time series. Through the comparison of horizontal and vertical, the verification and application of the model proposed is more fully expanded. The establishment of the index system should be further discussed, and previous research and actual floods investigations will be comprehensively considered to ensure that the indicators can accurately evaluate the floods level. Secondly, although the floods evaluation model proposed in this study is an effective means for floods precaution and relief because of quickness, accuracy, and easiness, we can combine the traditional evaluation methods and those visualization technologies, such as remote sensing technology, to make real-time and dynamic evaluation for flood disaster. Additionally, we can use the machine learning method to predict floods and optimize indexes by social network analysis.

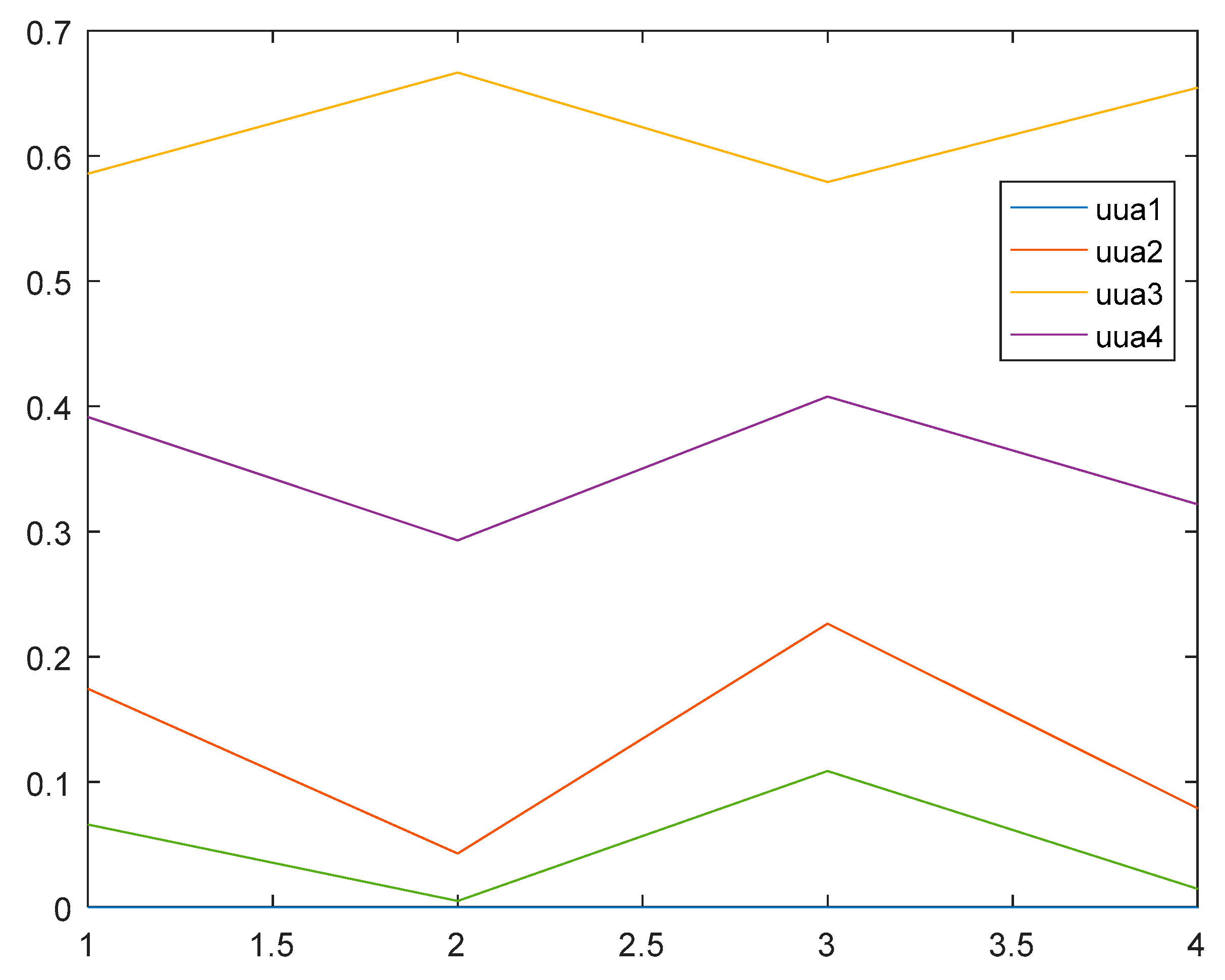

{kind=link}
{kind=link}
{kind=link}