


Industrial Product Surface Anomaly Detection with Realistic Synthetic Anomalies Based on Defect Map Prediction

Abstract
1. Introduction
- A methodology for creating more realistic synthetic defect images is designed.
- An image reconstruction network with depth feature consistency is constructed.
- A defect prediction network with a widely effective receptive field is being constructed.
2. Related Work
2.1. The Study of Anomaly Synthesis
2.2. The Study of Defect Detection
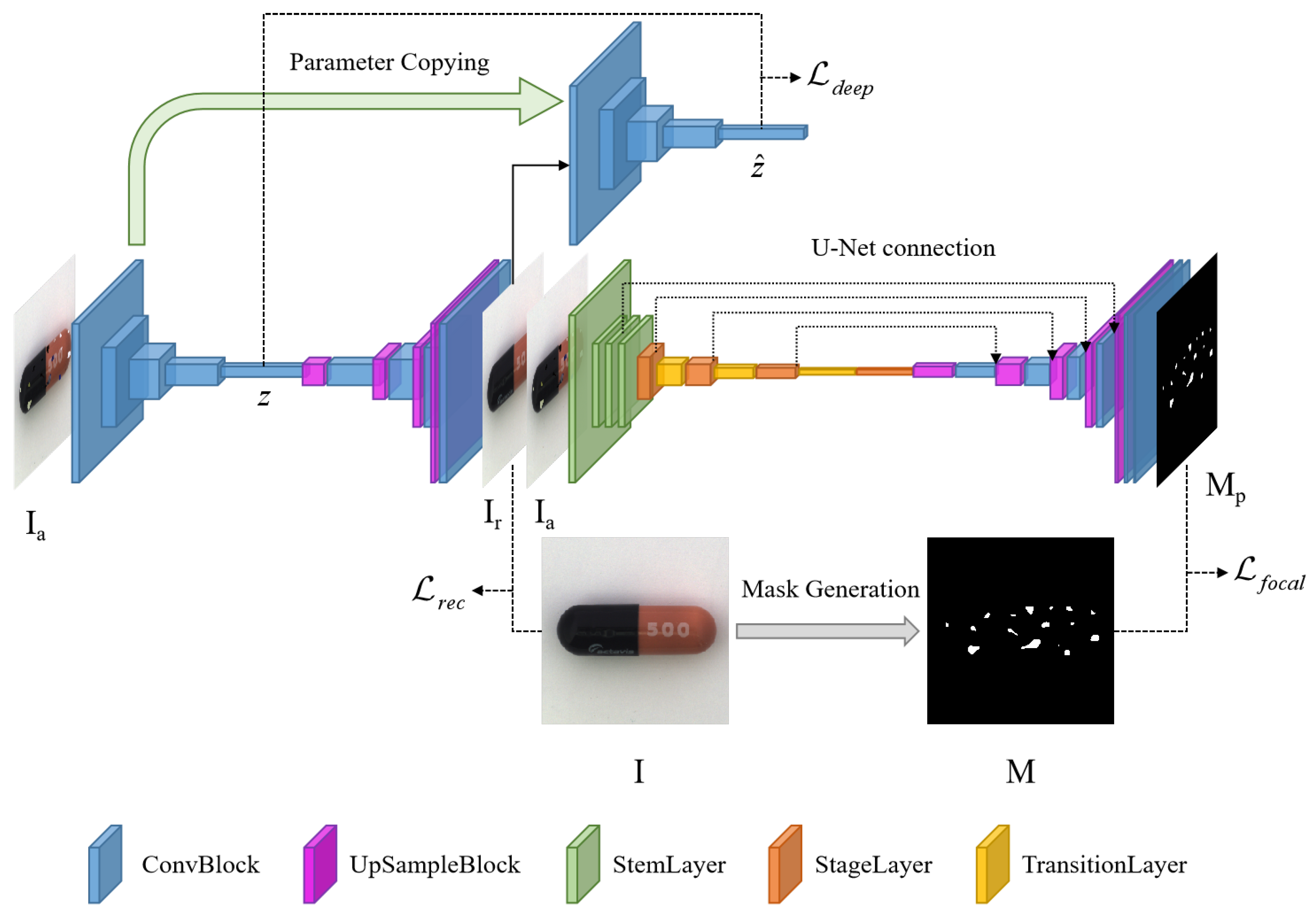
3. Method
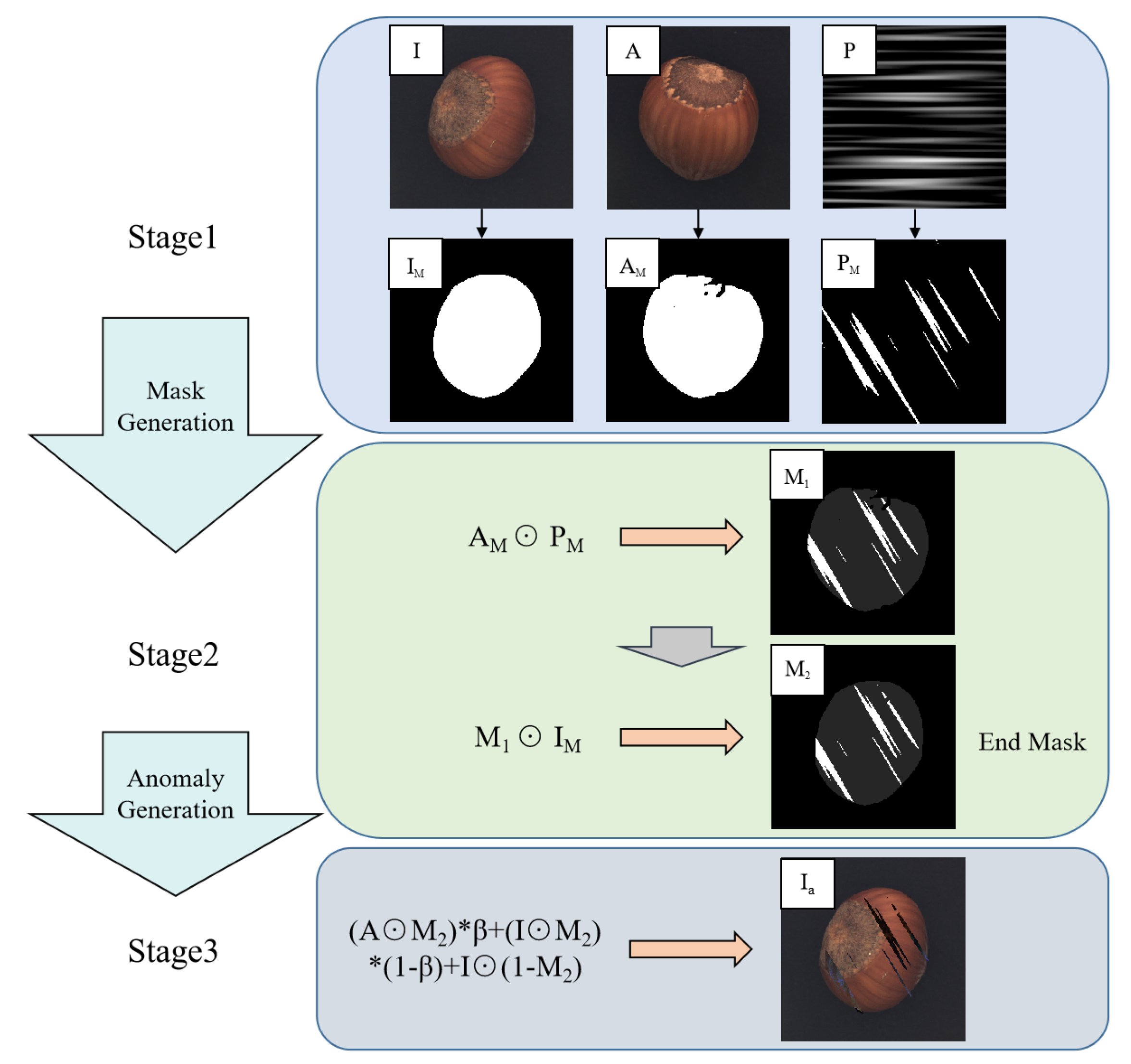
3.1. Abnormal Synthesis Process
3.2. Image Reconstruction Network
3.3. The Large Convolutional Kernel Defect Prediction Network
3.4. Abnormality Score
4. Experiments
4.1. Experimental Setup
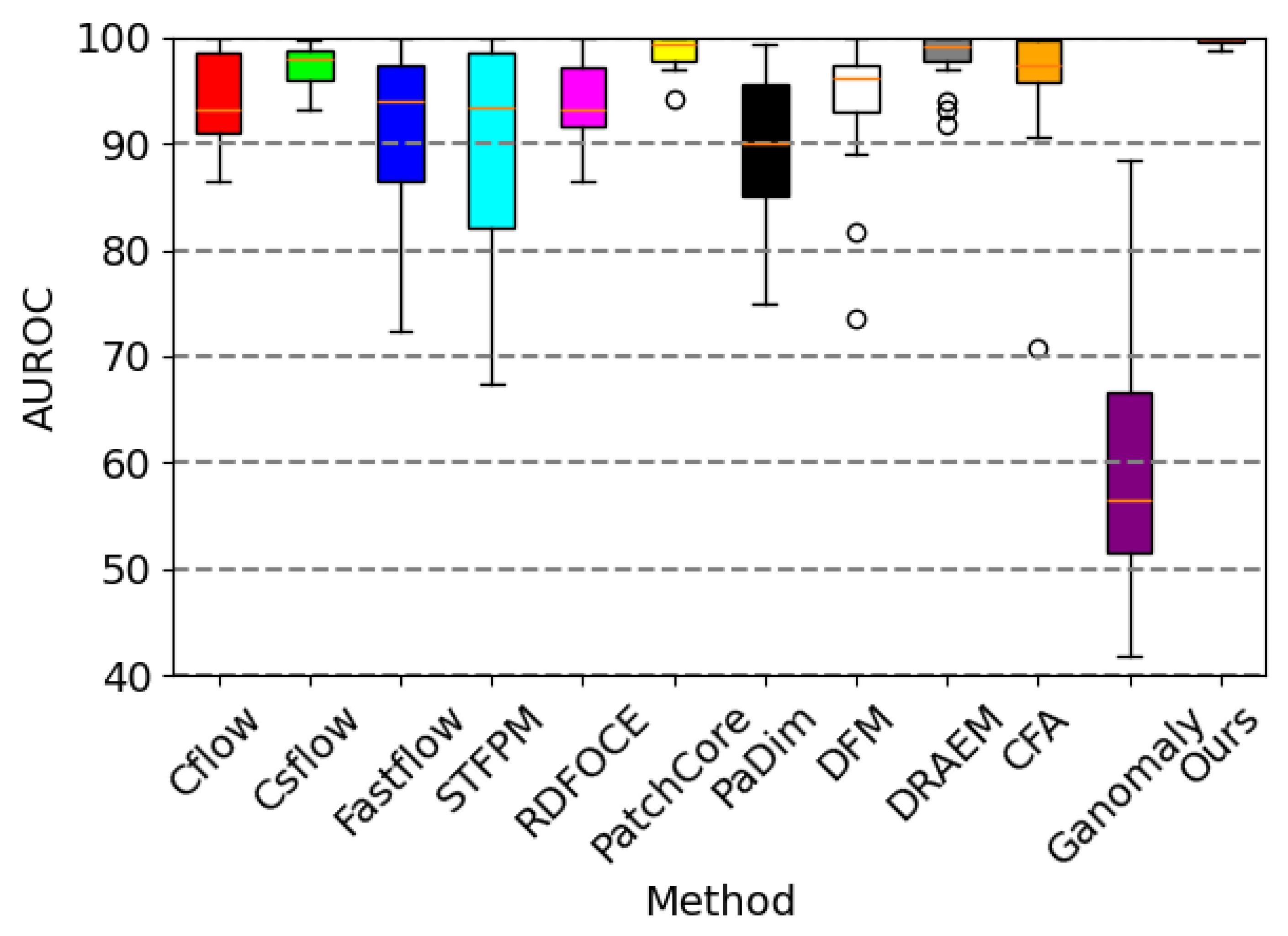
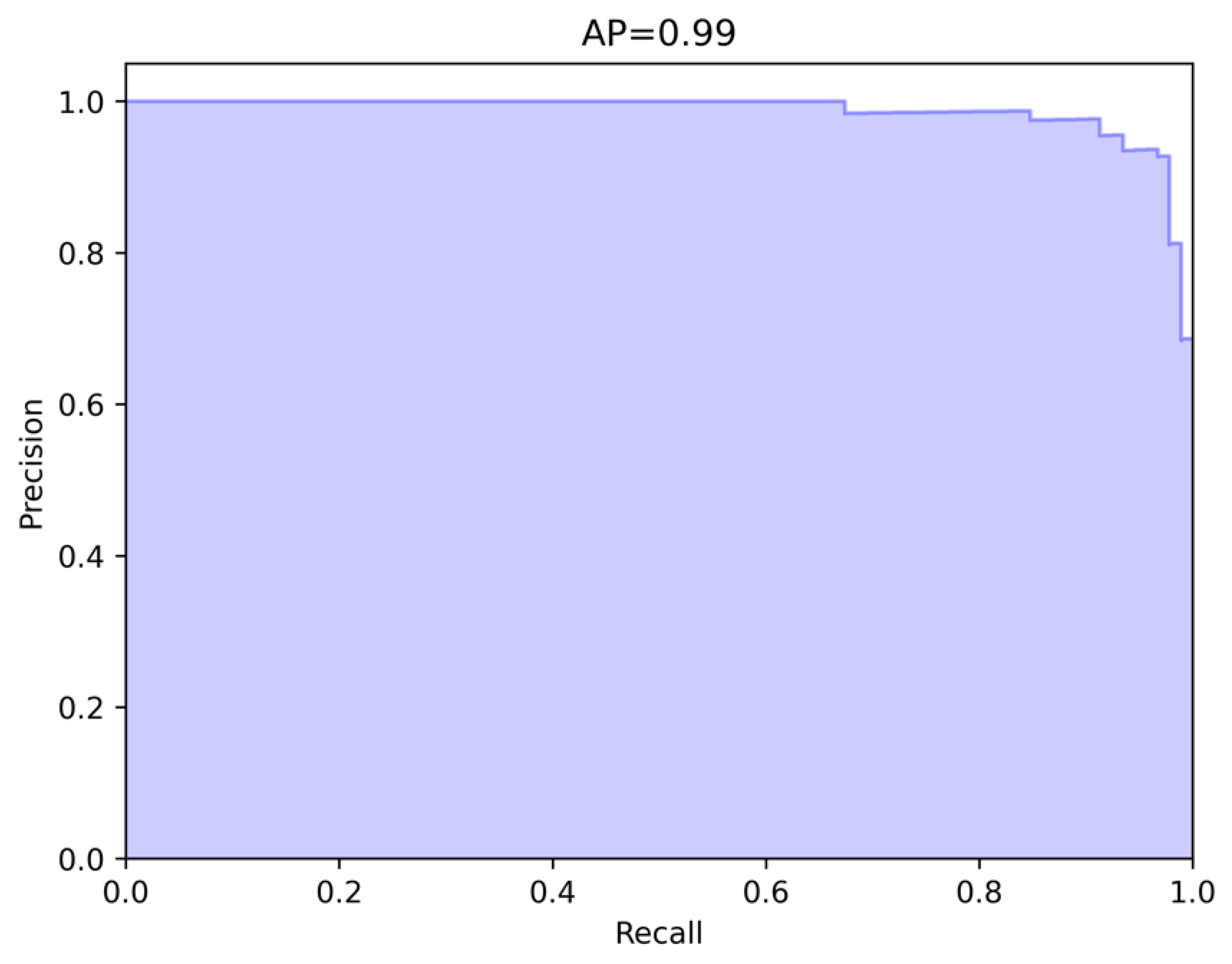
4.2. Anomaly Detection
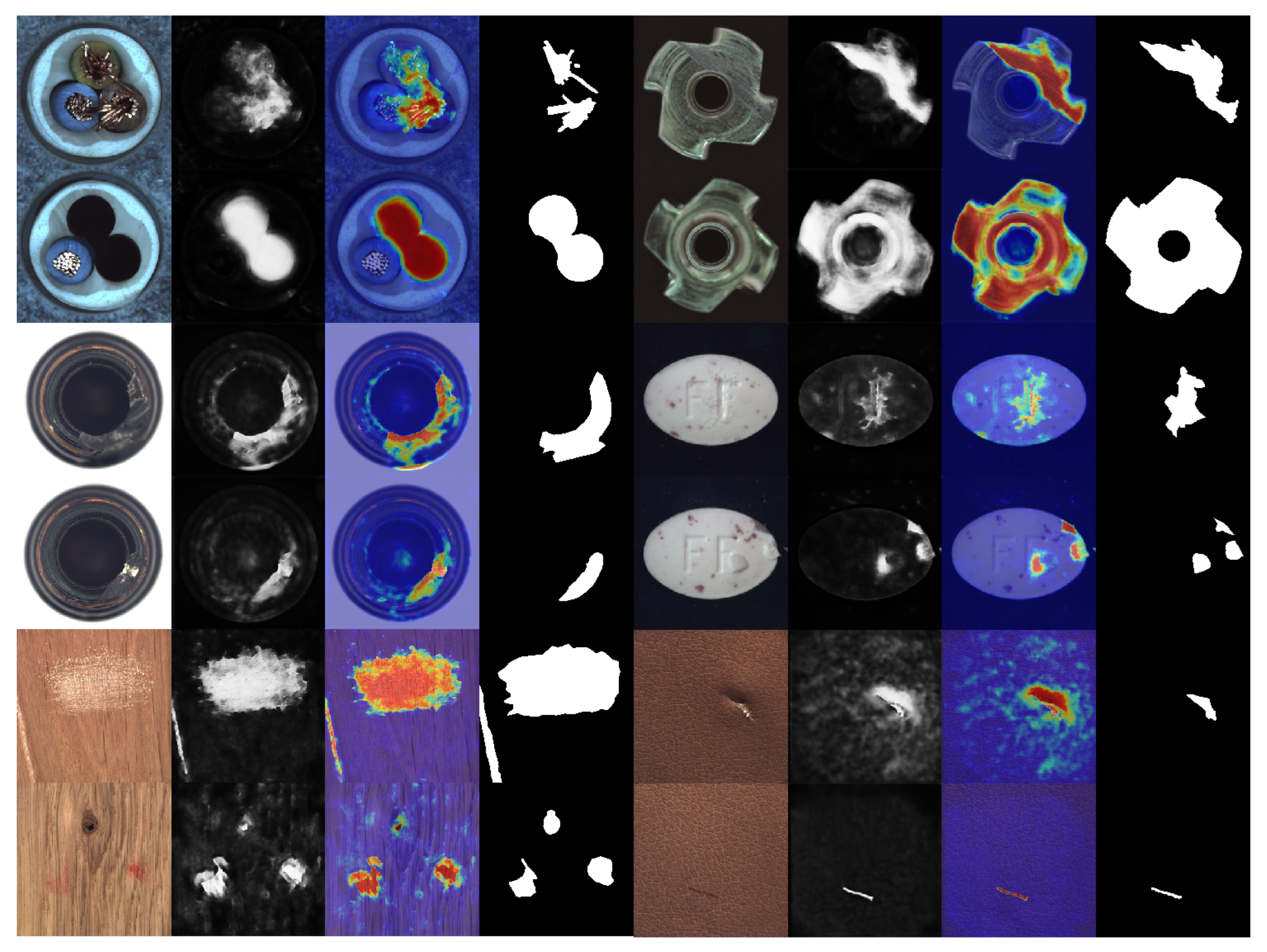
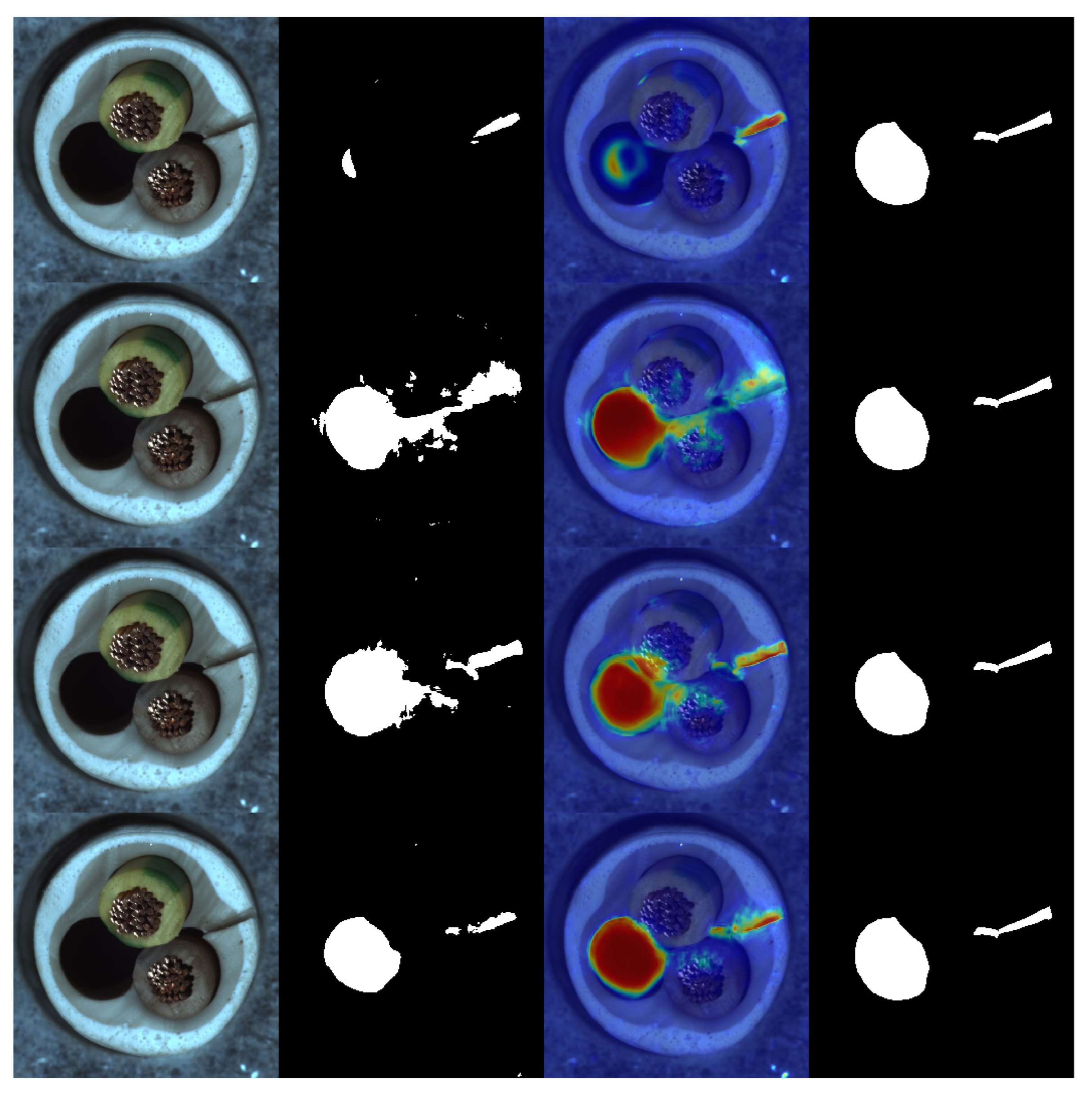
4.3. Defect Localization
4.4. Ablation Experiments
4.4.1. Model Structure
4.4.2. Abnormal Appearance
4.4.3. Training Method
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Catalano, C.; Paiano, L.; Calabrese, F.; Cataldo, M.; Mancarella, L.; Tommasi, F. Anomaly detection in smart agriculture systems. Comput. Ind. 2022, 143, 103750. [Google Scholar] [CrossRef]
- Staar, B.; Lütjen, M.; Freitag, M. Anomaly detection with convolutional neural networks for industrial surface inspection. Procedia CIRP 2019, 79, 484–489. [Google Scholar] [CrossRef]
- Moso, J.C.; Cormier, S.; de Runz, C.; Fouchal, H.; Wandeto, J.M. Anomaly detection on data streams for smart agriculture. Agriculture 2021, 11, 1083. [Google Scholar] [CrossRef]
- Roth, K.; Pemula, L.; Zepeda, J.; Schölkopf, B.; Brox, T.; Gehler, P. Towards total recall in industrial anomaly detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 14318–14328. [Google Scholar]
- Qin, K.; Wang, Q.; Lu, B.; Sun, H.; Shu, P. Flight anomaly detection via a deep hybrid model. Aerospace 2022, 9, 329. [Google Scholar] [CrossRef]
- Memarzadeh, M.; Akbari Asanjan, A.; Matthews, B. Robust and Explainable Semi-Supervised Deep Learning Model for Anomaly Detection in Aviation. Aerospace 2022, 9, 437. [Google Scholar] [CrossRef]
- Albasheer, H.; Md Siraj, M.; Mubarakali, A.; Elsier Tayfour, O.; Salih, S.; Hamdan, M.; Khan, S.; Zainal, A.; Kamarudeen, S. Cyber-attack prediction based on network intrusion detection systems for alert correlation techniques: A survey. Sensors 2022, 22, 1494. [Google Scholar] [CrossRef] [PubMed]
- Yang, Z.; Liu, X.; Li, T.; Wu, D.; Wang, J.; Zhao, Y.; Han, H. A systematic literature review of methods and datasets for anomaly-based network intrusion detection. Comput. Secur. 2022, 116, 102675. [Google Scholar] [CrossRef]
- Akcay, S.; Atapour-Abarghouei, A.; Breckon, T.P. Ganomaly: Semi-supervised anomaly detection via adversarial training. In Proceedings of the Computer Vision—ACCV 2018: 14th Asian Conference on Computer Vision, Perth, Australia, 2–6 December 2018; Revised Selected Papers, Part III 14. Springer: Berlin/Heidelberg, Germany, 2019; pp. 622–637. [Google Scholar]
- Zavrtanik, V.; Kristan, M.; Skočaj, D. Draem-a discriminatively trained reconstruction embedding for surface anomaly detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Nashville, TN, USA, 20–25 June 2021; pp. 8330–8339. [Google Scholar]
- Li, C.L.; Sohn, K.; Yoon, J.; Pfister, T. Cutpaste: Self-supervised learning for anomaly detection and localization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 9664–9674. [Google Scholar]
- Bergmann, P.; Fauser, M.; Sattlegger, D.; Steger, C. MVTec AD–A comprehensive real-world dataset for unsupervised anomaly detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9592–9600. [Google Scholar]
- Tan, J.; Hou, B.; Batten, J.; Qiu, H.; Kainz, B. Detecting outliers with foreign patch interpolation. arXiv 2020, arXiv:2011.04197. [Google Scholar] [CrossRef]
- Zimmerer, D.; Petersen, J.; Köhler, G.; Jäger, P.; Full, P.; Roß, T.; Adler, T.; Reinke, A.; Maier-Hein, L.; Maier-Hein, K. Medical out-of-distribution analysis challenge. Zenodo 2020. [Google Scholar] [CrossRef]
- Schlüter, H.M.; Tan, J.; Hou, B.; Kainz, B. Natural synthetic anomalies for self-supervised anomaly detection and localization. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 474–489. [Google Scholar]
- Cimpoi, M.; Maji, S.; Kokkinos, I.; Mohamed, S.; Vedaldi, A. Describing textures in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 3606–3613. [Google Scholar]
- Schlegl, T.; Seeböck, P.; Waldstein, S.M.; Schmidt-Erfurth, U.; Langs, G. Unsupervised anomaly detection with generative adversarial networks to guide marker discovery. In Proceedings of the International Conference on Information Processing in Medical Imaging, Boone, NC, USA, 25–30 June 2017; Springer: Berlin/Heidelberg, Germany, 2017; pp. 146–157. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Gudovskiy, D.; Ishizaka, S.; Kozuka, K. Cflow-ad: Real-time unsupervised anomaly detection with localization via conditional normalizing flows. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2022; pp. 98–107. [Google Scholar]
- Rudolph, M.; Wehrbein, T.; Rosenhahn, B.; Wandt, B. Fully convolutional cross-scale-flows for image-based defect detection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2022; pp. 1088–1097. [Google Scholar]
- Yu, J.; Zheng, Y.; Wang, X.; Li, W.; Wu, Y.; Zhao, R.; Wu, L. Fastflow: Unsupervised anomaly detection and localization via 2d normalizing flows. arXiv 2021, arXiv:2111.07677. [Google Scholar]
- Wang, G.; Han, S.; Ding, E.; Huang, D. Student-teacher feature pyramid matching for unsupervised anomaly detection. arXiv 2021, arXiv:2103.04257. [Google Scholar]
- Deng, H.; Li, X. Anomaly detection via reverse distillation from one-class embedding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 9737–9746. [Google Scholar]
- Defard, T.; Setkov, A.; Loesch, A.; Audigier, R. Padim: A patch distribution modeling framework for anomaly detection and localization. In Proceedings of the International Conference on Pattern Recognition, Bangkok, Thailand, 28–30 July 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 475–489. [Google Scholar]
- Ahuja, N.A.; Ndiour, I.; Kalyanpur, T.; Tickoo, O. Probabilistic modeling of deep features for out-of-distribution and adversarial detection. arXiv 2019, arXiv:1909.11786. [Google Scholar]
- Lee, S.; Lee, S.; Song, B.C. Cfa: Coupled-hypersphere-based feature adaptation for target-oriented anomaly localization. IEEE Access 2022, 10, 78446–78454. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Ding, X.; Zhang, X.; Han, J.; Ding, G. Scaling up your kernels to 31 × 31: Revisiting large kernel design in cnns. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11963–11975. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the Computer Vision—ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part V 13. Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Zhou, B.; Zhao, H.; Puig, X.; Xiao, T.; Fidler, S.; Barriuso, A.; Torralba, A. Semantic understanding of scenes through the ade20k dataset. Int. J. Comput. Vis. 2019, 127, 302–321. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Proceedings, Part III 18. Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Akcay, S.; Ameln, D.; Vaidya, A.; Lakshmanan, B.; Ahuja, N.; Genc, U. Anomalib: A deep learning library for anomaly detection. In Proceedings of the 2022 IEEE International Conference on Image Processing (ICIP), Bordeaux, France, 16–19 October 2022; pp. 1706–1710. [Google Scholar]
- Bergmann, P.; Fauser, M.; Sattlegger, D.; Steger, C. Uninformed students: Student-teacher anomaly detection with discriminative latent embeddings. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 4183–4192. [Google Scholar]
- Zavrtanik, V.; Kristan, M.; Skočaj, D. Reconstruction by inpainting for visual anomaly detection. Pattern Recognit. 2021, 112, 107706. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Cflow [19] | Csflow [20] | Fastflow [21] | STFPM [22] | RDFOCE [23] | Ours |
|---|---|---|---|---|---|---|
| bottle | 100.0 | 99.4 | 100.0 | 99.8 | 93.2 | 99.5 |
| cable | 93.1 | 97.3 | 90.8 | 93.4 | 92.9 | 98.8 |
| capsule | 90.3 | 97.7 | 87.6 | 67.5 | 90.5 | 99.5 |
| carpet | 94.8 | 97.9 | 97.2 | 98.4 | 98.3 | 99.8 |
| grid | 86.5 | 99.3 | 98.3 | 93.8 | 94.7 | 100.0 |
| hazelnut | 99.3 | 93.2 | 81.0 | 99.1 | 100.0 | 100.0 |
| leather | 99.9 | 99.7 | 100.0 | 100.0 | 86.5 | 100.0 |
| metal nut | 97.9 | 94.6 | 95.7 | 98.5 | 97.4 | 100.0 |
| pill | 90.2 | 93.3 | 91.4 | 76.7 | 95.7 | 98.8 |
| screw | 91.0 | 98.1 | 72.4 | 79.5 | 88.6 | 100.0 |
| tile | 91.0 | 98.1 | 72.4 | 79.5 | 88.6 | 100.0 |
| toothbrush | 95.0 | 94.3 | 82.2 | 86.3 | 97.0 | 100.0 |
| transistor | 91.4 | 98.0 | 91.0 | 91.8 | 93.1 | 99.2 |
| wood | 99.6 | 98.7 | 96.8 | 98.7 | 99.2 | 100.0 |
| zipper | 92.1 | 98.6 | 94.0 | 84.6 | 92.7 | 99.9 |
| Average | 94.7 | 97.3 | 91.6 | 90.9 | 93.3 | 99.7 |
| Category | PC * [4] | PaDim [25] | DFM [26] | DRAEM [10] | CFA [27] | Ganomaly [9] | Ours |
|---|---|---|---|---|---|---|---|
| bottle | 100.0 | 99.4 | 100.0 | 99.2 | 99.8 | 54.6 | 99.5 |
| cable | 98.7 | 84.3 | 95.6 | 91.8 | 97.2 | 56.6 | 98.8 |
| capsule | 97.2 | 90.1 | 94.4 | 98.5 | 90.7 | 66.6 | 99.5 |
| carpet | 98.1 | 94.5 | 81.7 | 97.0 | 97.3 | 55.8 | 99.8 |
| grid | 97.0 | 85.7 | 73.6 | 99.9 | 95.0 | 86.0 | 100.0 |
| hazelnut | 100.0 | 75.0 | 99.4 | 100.0 | 100.0 | 88.5 | 100.0 |
| leather | 100.0 | 98.2 | 99.3 | 100.0 | 100.0 | 43.8 | 100.0 |
| metal nut | 99.6 | 96.1 | 92.2 | 98.7 | 99.1 | 48.7 | 100.0 |
| pill | 94.2 | 86.3 | 96.1 | 98.9 | 94.9 | 66.7 | 98.8 |
| screw | 97.3 | 75.9 | 89.0 | 93.9 | 70.8 | 44.3 | 100.0 |
| tile | 98.7 | 95.0 | 96.6 | 99.6 | 99.8 | 59.3 | 100.0 |
| toothbrush | 100.0 | 88.9 | 96.9 | 100.0 | 100.0 | 41.9 | 100.0 |
| transistor | 100.0 | 92.0 | 93.9 | 93.1 | 96.5 | 58.2 | 99.2 |
| wood | 99.4 | 97.6 | 97.7 | 99.1 | 99.5 | 86.9 | 100.0 |
| zipper | 99.4 | 77.9 | 96.9 | 100.0 | 96.7 | 56.2 | 99.9 |
| Average | 98.6 | 89.1 | 93.6 | 98.0 | 95.8 | 60.9 | 99.7 |
| Category | US [35] | RIAD [36] | PaDim | DRAEM | Ours |
|---|---|---|---|---|---|
| bottle | 74.2 | 76.4 | 77.3 | 86.5 | 99.8 |
| cable | 48.2 | 24.4 | 45.4 | 52.4 | 99.6 |
| capsule | 25.9 | 38.2 | 46.7 | 49.4 | 99.9 |
| carpet | 52.2 | 52.2 | 60.7 | 53.5 | 100.0 |
| grid | 10.1 | 36.4 | 35.7 | 65.7 | 100.0 |
| hazelnut | 57.8 | 33.8 | 61.1 | 92.9 | 100.0 |
| leather | 40.9 | 49.1 | 53.5 | 75.3 | 100.0 |
| metal nut | 83.5 | 64.3 | 77.4 | 96.3 | 100.0 |
| pill | 62.0 | 51.6 | 61.2 | 48.5 | 99.8 |
| screw | 7.8 | 43.9 | 21.7 | 58.2 | 100.0 |
| tile | 65.3 | 52.6 | 52.4 | 92.3 | 100.0 |
| toothbrush | 37.7 | 50.6 | 54.7 | 44.7 | 100.0 |
| transistor | 27.1 | 39.2 | 72.0 | 50.7 | 98.9 |
| wood | 53.3 | 38.2 | 46.3 | 77.7 | 100.0 |
| zipper | 36.1 | 63.4 | 58.2 | 81.5 | 100.0 |
| Average | 45.5 | 48.2 | 55.0 | 68.4 | 99.9 |
| Structure | Abnormal Appearance | Training Approach | Result | |||||
|---|---|---|---|---|---|---|---|---|
| Number |
Deep Features |
Large Kernel | MVTec AD | DTD |
Parameter Copying |
Gradient Update | AUROC | AP |
| 1 | ✓ | 98.00 | 68.40 | |||||
| 2 | ✓ | ✓ | 99.23 | 99.62 | ||||
| 3 | ✓ | ✓ | 99.61 | 99.78 | ||||
| 4 | ✓ | 99.25 | 99.54 | |||||
| 5 | ✓ | ✓ | 99.58 | 99.79 | ||||
| 6 | ✓ | ✓ | ✓ | 99.27 | 99.49 | |||
| 7 | ✓ | ✓ | ✓ | ✓ | 99.70 | 99.87 | ||
| 8 | ✓ | ✓ | ✓ | ✓ | 99.33 | 99.69 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Peng, T.; Zheng, Y.; Zhao, L.; Zheng, E. Industrial Product Surface Anomaly Detection with Realistic Synthetic Anomalies Based on Defect Map Prediction. Sensors 2024, 24, 264. https://doi.org/10.3390/s24010264
Peng T, Zheng Y, Zhao L, Zheng E. Industrial Product Surface Anomaly Detection with Realistic Synthetic Anomalies Based on Defect Map Prediction. Sensors. 2024; 24(1):264. https://doi.org/10.3390/s24010264
Chicago/Turabian StylePeng, Tao, Yu Zheng, Lin Zhao, and Enrang Zheng. 2024. "Industrial Product Surface Anomaly Detection with Realistic Synthetic Anomalies Based on Defect Map Prediction" Sensors 24, no. 1: 264. https://doi.org/10.3390/s24010264
APA StylePeng, T., Zheng, Y., Zhao, L., & Zheng, E. (2024). Industrial Product Surface Anomaly Detection with Realistic Synthetic Anomalies Based on Defect Map Prediction. Sensors, 24(1), 264. https://doi.org/10.3390/s24010264