



Power Efficient Machine Learning Models Deployment on Edge IoT Devices

 , ,
, , 

Abstract
:1. Introduction
2. Related Work
3. System Setup and Methodology
3.1. Digital Multimeter & Power Measurements Setup
- To perform accurate measurements, we follow the methodology that is presented below: The 3A current port was selected as input
- Trigger mode was selected with external triggering on the negative edge
- The DMM was set on Continuous Acquire Mode
- A delay of 50 uS was set as a measurement delay after triggering
- The sampling rate was set for each model in such a way that it was possible to take at least three samples during the inference time
- Display mode switched to trend chart
- Added a linear math function that converted Current input (mA) to Power Input (mW)
3.2. Development Boards and MCU Architectures
- a high-performance, single-cycle 32-bit floating-point unit (FPU) for efficient handling of complex mathematical operations
- advanced interrupt handling capabilities, including support for up to 240 external interrupts and a nested vectored interrupt controller (NVIC)
- high-speed memories, including a Harvard architecture instruction cache, data cache, and tightly-coupled memory (TCM) for fast access to frequently used data
- a large number of peripheral interfaces, including multiple serial communication interfaces, timers, analog-to-digital converters, and digital-to-analog converters
- Each feature may affect the power consumption of ML models in different ways.
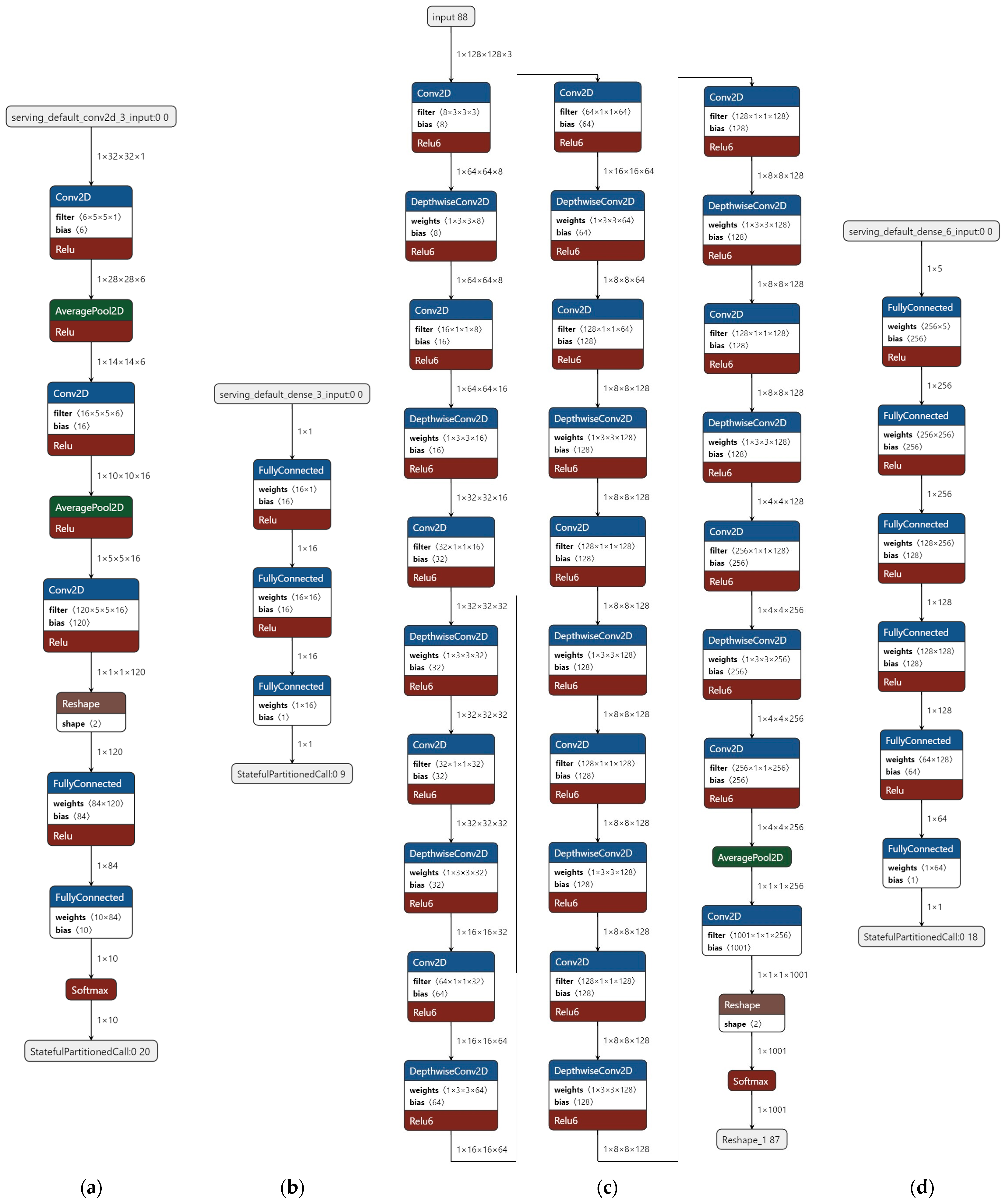
3.3. Selected ML Models
- Each model is required to belong to a group of well-defined and well-known ML models. Specifically, all selected models should be popular models whose behavior is well known (their features and parameters are understood) or models that have been used in other scientific research in microcontroller-based systems [13,14,15]. This criterion will help to make our results meaningful and easier to understand.
- Each model should support at least one version of TensorFlow Micro Framework Operations to run in at least one of the selected MCUs with minimal alterations.
- Each model should be small enough to fit at least in one of the selected devices, preferably uncompressed, no external or added memory is permitted. This criterion maximizes the possibility that the results will contain pairs of compressed-uncompressed models on the same device to compare them while keeping the power measurements for the MCU unimpacted from any external device power consumption.
- The selected compression methods for a model should result in a smaller memory and/or model size footprint. While this criterion looks like a de-facto result of a compression application, this is not always true for ML models developed using the TensorFlow framework, e.g., pruning a model in TensorFlow framework will result in a more sparse model of the same storage size. To reduce its storage size a classical compression method may later be applied, such as gzip or a custom storage scheme with encoding [6]. The model in TensorFlow framework-based systems should be decompressed before it is usable for inference and this results in wasted computational time and power in the “realm” of microcontrollers. The final memory footprint remains the same and also more “temporary” storage is needed for the decompressed model. These facts defeat any generic usability of this method in TensorFlow Micro Framework.
3.3.1. LeNet-5 Model
3.3.2. Simple Sine Calculation Model
3.3.3. MobileNet 025
3.3.4. AI-Based Indoor Localization System
3.4. Selected Framework
4. Measurements and Results
4.1. LeNet-5 Results
4.2. Sine Model Results
4.3. MobileNet-025 Model Results
4.4. BlueTooth IPS Model Results
5. Conclusions, Discussion, and Future Work
- Decrease the requirements in SRAM that leads to much lower deployment requirements and more efficient power usage
- Decrease the usage of core subsystems (such as hardware FPU) that leads to a wider pool of selectable hardware per application (non-hardware-FPU capable units) and increase power efficiency during inference calculations of ML models.
- Increase the cache hit ratio of the microcontrollers memory system leading to a reduction of internal data traffic and increasing the overall power efficiency
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Conti, M.; Das, S.K.; Bisdikian, C.; Kumar, M.; Ni, L.M.; Passarella, A.; Zambonelli, F. Looking ahead in pervasive computing: Challenges and opportunities in the era of cyber–physical convergence. Pervasive Mob. Comput. 2012, 8, 2–21. [Google Scholar] [CrossRef]
- Dhingra, V.; Anita, A. Pervasive computing: Paradigm for new era computing. In Proceedings of the 2008 First International Conference on Emerging Trends in Engineering and Technology, Nagpur, India, 16–18 July 2008; IEEE: Piscataway, NJ, USA, 2008. [Google Scholar]
- Swief, A.; El-Habrouk, M. A survey of automotive driving assistance systems technologies. In Proceedings of the 2018 International Conference on Artificial Intelligence and Data Processing (IDAP), Malatya, Turkey, 28–30 September 2018; IEEE: Piscataway, NJ, USA, 2018. [Google Scholar]
- Neelakandan, S.; Berlin, M.A.; Tripathi, S.; Devi, V.B.; Bhardwaj, I.; Arulkumar, N. IoT-based traffic prediction and traffic signal control system for smart city. Soft Comput. 2021, 25, 12241–12248. [Google Scholar] [CrossRef]
- Darling. IoT vs. Edge Computing: What’s the Difference? IBM Developer, 2021. Available online: https://developer.ibm.com/articles/iot-vs-edge-computing/ (accessed on 28 December 2022).
- Ajani, T.S.; Agbotiname Lucky, I.; Aderemi, A.A. An overview of machine learning within embedded and mobile devices–optimizations and applications. Sensors 2021, 21, 4412. [Google Scholar] [CrossRef] [PubMed]
- Kugele, A.; Pfeil, T.; Pfeiffer, M.; Chicca, E. Hybrid SNN-ANN: Energy-Efficient Classification and Object Detection for Event-Based Vision. In Proceedings of the DAGM German Conference on Pattern Recognition, Bonn, Germany, 28 September–1 October 2021; Springer: Cham, Germany, 2021. [Google Scholar]
- Han, S.; Huizi, M.; William, J.D. Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding. arXiv 2015, arXiv:1510.00149. [Google Scholar]
- Hu, P.; Peng, X.; Zhu, H.; Aly MM, S.; Lin, J. Opq: Compressing deep neural networks with one-shot pruning-quantization. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual Conference, 2–9 February 2021; Volume 35. [Google Scholar]
- Chen, B.; Bakhshi, A.; Batista, G.; Ng, B.; Chin, T.J. Update Compression for Deep Neural Networks on the Edge. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 24–18 June 2022. [Google Scholar]
- Sudharsan, B.; Sundaram, D.; Patel, P.; Breslin, J.G.; Ali, M.I.; Dustdar, S.; Ranjan, R. Multi-Component Optimization and Efficient Deployment of Neural-Networks on Resource-Constrained IoT Hardware. arXiv 2022, arXiv:2204.10183. [Google Scholar]
- Zou, Z.; Jin, Y.; Nevalainen, P.; Huan, Y.; Heikkonen, J.; Westerlund, T. Edge and fog computing enabled AI for IoT-an overview. In Proceedings of the 2019 IEEE International Conference on Artificial Intelligence Circuits and Systems (AICAS), Hsinchu, Taiwan, 18–20 March 2019; IEEE: Piscataway, NJ, USA, 2019. [Google Scholar]
- Unlu, H. Efficient neural network deployment for microcontroller. arXiv 2020, arXiv:2007.01348. [Google Scholar]
- Liberis, E.; Lane, N.D. Neural networks on microcontrollers: Saving memory at inference via operator reordering. arXiv 2019, arXiv:1910.05110. [Google Scholar]
- Kotrotsios, K.; Fanariotis, A.; Leligou, H.C.; Orphanoudakis, T. Design Space Exploration of a Multi-Model AI-Based Indoor Localization System. Sensors 2022, 22, 570. [Google Scholar] [CrossRef] [PubMed]
- LeCun, Y. LeNet-5, Convolutional Neural Networks. 2015. Available online: http://yann.lecun.com/exdb/lenet (accessed on 30 January 2023).
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Pau, D.; Lattuada, M.; Loro, F.; De Vita, A.; Licciardo, G.D. Comparing industry frameworks with deeply quantized neural networks on microcontrollers. In Proceedings of the 2021 IEEE International Conference on Consumer Electronics (ICCE), Las Vegas, NV, USA, 10–12 January 2021; IEEE: Piscataway, NJ, USA, 2021. [Google Scholar]
- Ray, P.P. A review on TinyML: State-of-the-art and prospects. J. King Saud Univ. Comp. Inf. Sci. 2021, 34, 1595–1623. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Device | Model | Optimization | Inference Time (uS) | Inference Power (mW) | NoOp Power | SRAM (Tensor Arena Size) | Model Size | Total Power Per Inference (uWh) | Pure Inference Power (uWh) | Virtual Runtime (h) |
|---|---|---|---|---|---|---|---|---|---|---|
| ESP32 | Lenet-5 | NO | 313,715 | 193.8 | 124 | 23 k | 245 k | 16.88832417 | 6.082585278 | 18.09 |
| STM32H7 | Lenet-5 | QA | 6665 | 545.6 | 469.4 | 5.8 k | 72 k | 1.010117778 | 0.141075833 | 302.49 |
| STM32H7 | Lenet-5 | NO | 19,393 | 606.5 | 469.4 | 23 k | 245 k | 3.267181806 | 0.738550083 | 93.52 |
| Device | Model | Optimization | Inference Time (uS) | Inference Power (mW) | NoOp Power | SRAM (Tensor Arena Size) | Model Size | Total Power Per Inference (uWh) | Pure Inference Power (uWh) | Virtual Runtime (h) |
|---|---|---|---|---|---|---|---|---|---|---|
| STM32H7 | Sine | NO | 13 | 526.2 | 469.4 | 240 | 3 k | 0.001900167 | 0.000205111 | 160,804 |
| STM32H7 | Sine | QA | 12 | 524.6 | 469.4 | 144 | 3 k | 0.001748667 | 0.000184 | 174,736 |
| STM32H7 | Sine | PQ | 12.5 | 524.8 | 469.4 | 120 | 3 k | 0.001822222 | 0.000192361 | 167,683 |
| Device | Model | Optimization | Inference Time (uS) | Inference Power (mW) | NoOp Power | SRAM (Tensor Arena Size) | Model Size | Total Power Per Inference (uWh) | Pure Inference Power (uWh) | Virtual Runtime (h) |
|---|---|---|---|---|---|---|---|---|---|---|
| STM32H7 | MobileNet 025 | PQ | 464,400 | 615.3 | 469.4 | 128 K | 497 k | 79.3737 | 18.8211 | 3849 |
| Device | Model | Optimization | Inference Time (uS) | Inference Power (mW) | NoOp Power | SRAM (Tensor Arena Size) | Model Size | Total Power Per Inference (uWh) | Pure Inference Power (uWh) | Virtual Runtime (h) |
|---|---|---|---|---|---|---|---|---|---|---|
| ESP32 | BT-IPS | No | 24,850 | 190.3 | 124 | 3 k | 492 k | 1.313598611 | 0.457654167 | 232.6 |
| STM32H7 | BT-IPS | No | 2624 | 516.2 | 469.4 | 3 k | 492 k | 0.376252444 | 0.034112 | 812.1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fanariotis, A.; Orphanoudakis, T.; Kotrotsios, K.; Fotopoulos, V.; Keramidas, G.; Karkazis, P. Power Efficient Machine Learning Models Deployment on Edge IoT Devices. Sensors 2023, 23, 1595. https://doi.org/10.3390/s23031595
Fanariotis A, Orphanoudakis T, Kotrotsios K, Fotopoulos V, Keramidas G, Karkazis P. Power Efficient Machine Learning Models Deployment on Edge IoT Devices. Sensors. 2023; 23(3):1595. https://doi.org/10.3390/s23031595
Chicago/Turabian StyleFanariotis, Anastasios, Theofanis Orphanoudakis, Konstantinos Kotrotsios, Vassilis Fotopoulos, George Keramidas, and Panagiotis Karkazis. 2023. "Power Efficient Machine Learning Models Deployment on Edge IoT Devices" Sensors 23, no. 3: 1595. https://doi.org/10.3390/s23031595
APA StyleFanariotis, A., Orphanoudakis, T., Kotrotsios, K., Fotopoulos, V., Keramidas, G., & Karkazis, P. (2023). Power Efficient Machine Learning Models Deployment on Edge IoT Devices. Sensors, 23(3), 1595. https://doi.org/10.3390/s23031595