


A Self-Supervised Model Based on CutPaste-Mix for Ductile Cast Iron Pipe Surface Defect Classification



Abstract
:1. Introduction
2. Methods
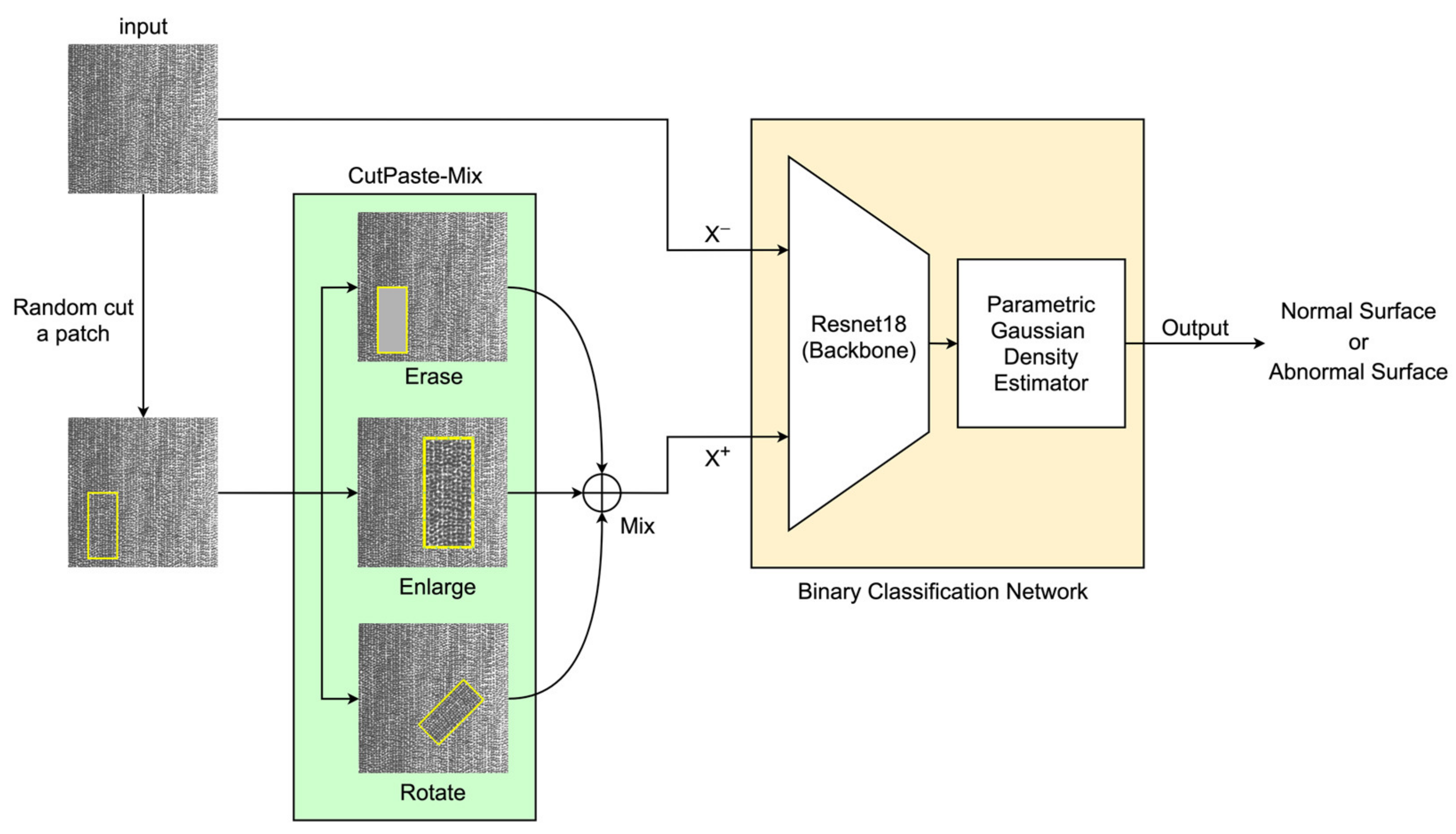
2.1. Definition of Self-Supervised Binary Classifier
2.2. Self-Supervised Learning with CutPaste-Mix
- Erase. Analogous to the Cutout technique, this strategy directly excises a portion from the image, discarding the patch area. Given that DCIP images are grayscale, the residual area’s color adheres to the original grayscale values, with the mean of the original pixels serving as a substitute color. However, this approach engenders appreciable information loss in images and can be harmonized with other methods.
- Enlarge. Commencing with the random cropping of a rectangular region, this method subsequently enlarges and reattaches it to a random location on the original image. We confine the cropped region’s dimensions to not exceed 20% of the image area, while the enlargement factor remains within the image’s boundaries. This approach often yields significant abnormal regions while mitigating the substantial information loss entailed by erase.
- Rotate. Analogous to Enlarge, this approach involves initial patch cropping, followed by rotation by a random angle before reintegration into the original image. This tactic imposes minimal information loss while concurrently generating abnormal regions.
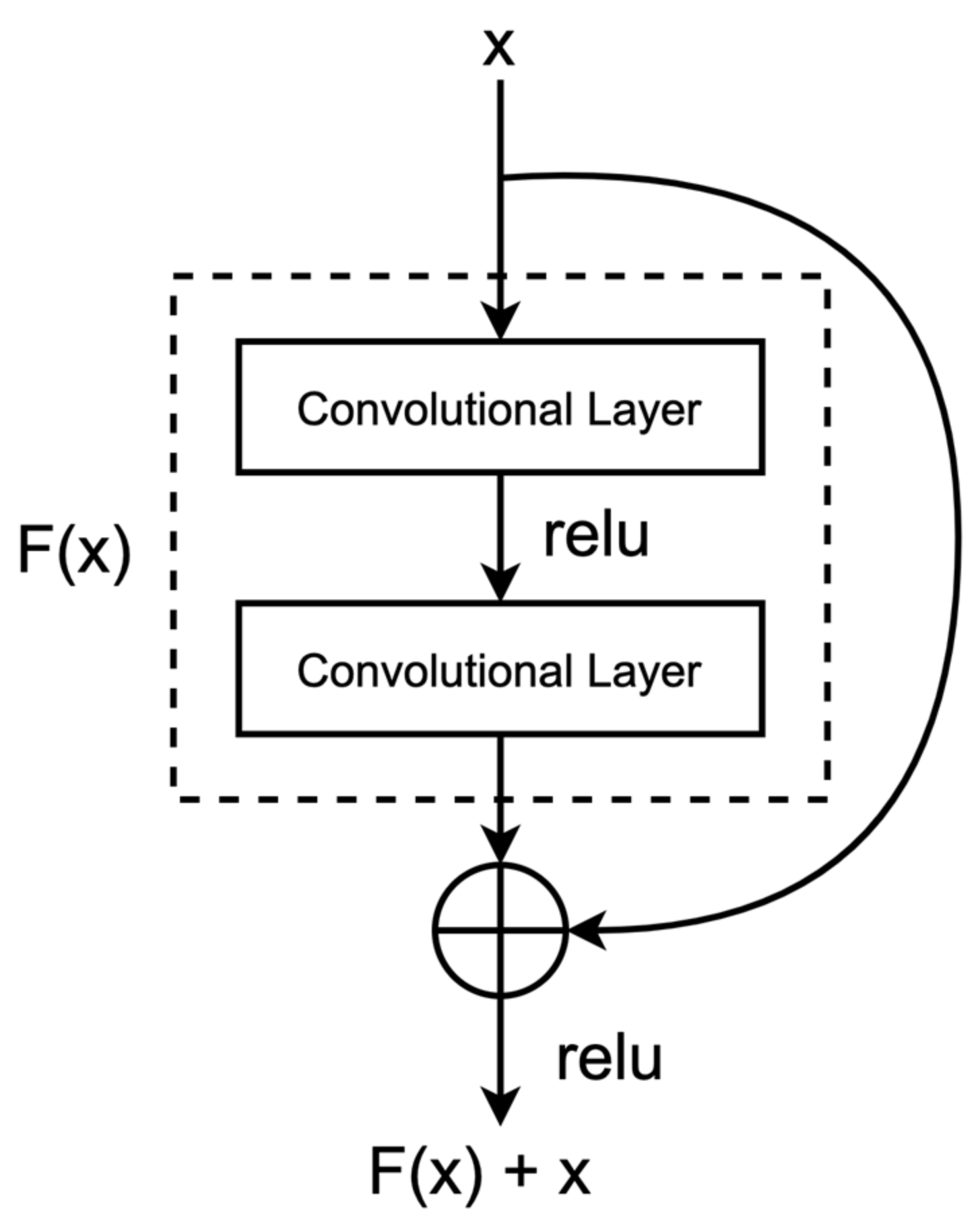
2.3. Deep Residual Learning with ResNet-18
2.4. Computing Anomaly Score for Classification
3. Experiments
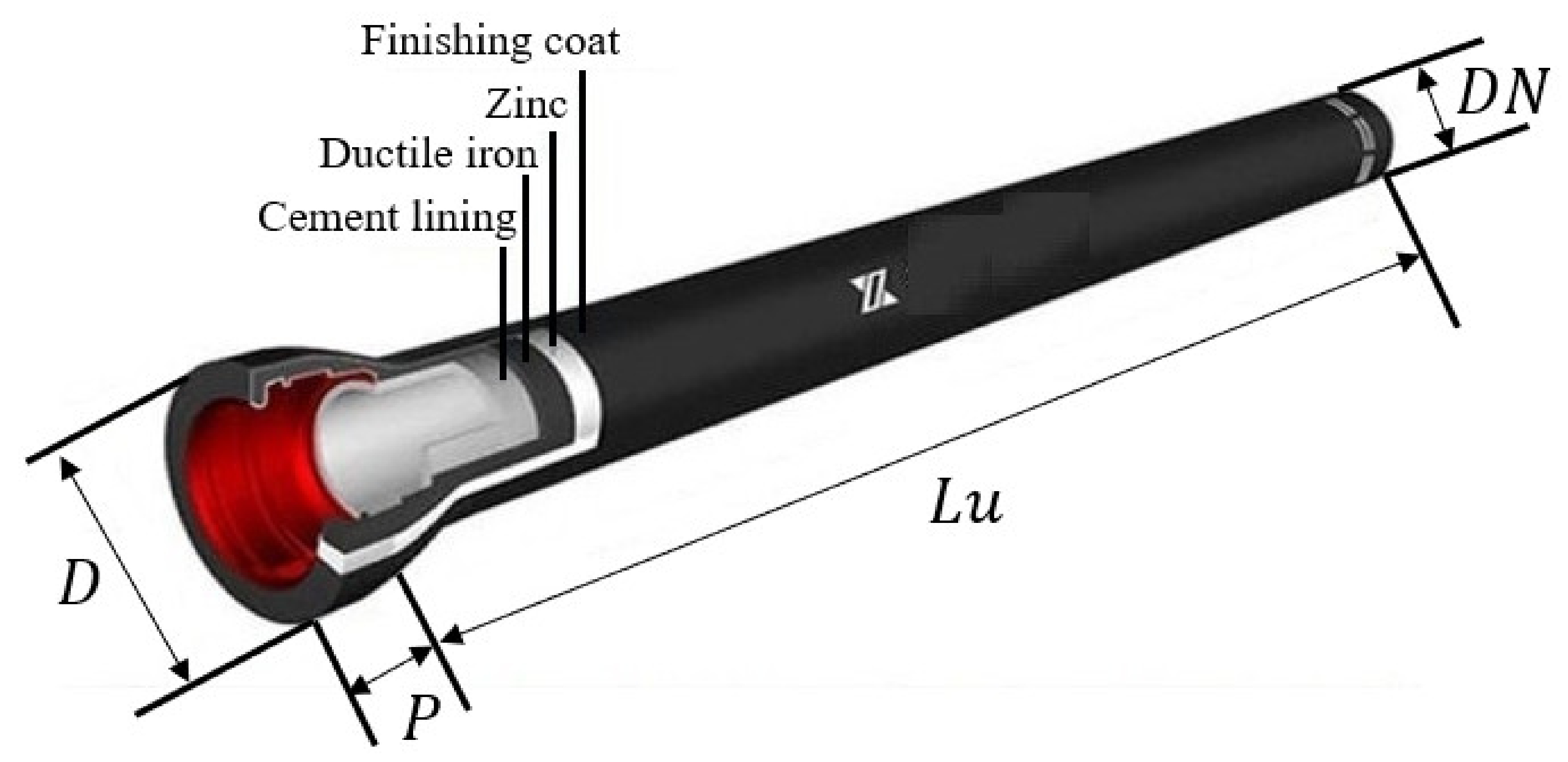
3.1. Description of DCIPs
3.2. Experiment Setup
3.3. Description of Image in Dataset
3.4. Training and Testing Process of Classifier
3.5. Main Results
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhou, D.; Xu, K.; Lv, Z.; Yang, J.; Li, M.; He, F.; Xu, G. Intelligent Manufacturing Technology in the Steel Industry of China: A Review. Sensors 2022, 22, 8194. [Google Scholar] [CrossRef]
- Latif, J.; Shakir, M.Z.; Edwards, N.; Jaszczykowski, M.; Ramzan, N.; Edwards, V. Review on Condition Monitoring Techniques for Water Pipelines. Measurement 2022, 193, 110895. [Google Scholar] [CrossRef]
- Makar, J.M.; Desnoyers, R.; McDonald, S.E. Failure Modes and Mechanisms in Gray Cast Iron Pipes. In Underground Infrastructure Research; Knight, M., Thomson, N., Eds.; CRC Press: Boca Raton, FL, USA, 2020; pp. 303–312. ISBN 978-1-00-307748-0. [Google Scholar]
- Ji, J.; Hong Lai, J.; Fu, G.; Zhang, C.; Kodikara, J. Probabilistic Failure Investigation of Small Diameter Cast Iron Pipelines for Water Distribution. Eng. Fail. Anal. 2020, 108, 104239. [Google Scholar] [CrossRef]
- Javaid, M.; Haleem, A.; Singh, R.P.; Rab, S.; Suman, R. Exploring Impact and Features of Machine Vision for Progressive Industry 4.0 Culture. Sens. Int. 2022, 3, 100132. [Google Scholar] [CrossRef]
- Smith, M.L.; Smith, L.N.; Hansen, M.F. The Quiet Revolution in Machine Vision—A State-of-the-Art Survey Paper, Including Historical Review, Perspectives, and Future Directions. Comput. Ind. 2021, 130, 103472. [Google Scholar] [CrossRef]
- Gupta, C.; Farahat, A. Deep Learning for Industrial AI: Challenges, New Methods and Best Practices. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Online, 6–10 July 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 3571–3572. [Google Scholar]
- Khalil, R.A.; Saeed, N.; Masood, M.; Fard, Y.M.; Alouini, M.-S.; Al-Naffouri, T.Y. Deep Learning in the Industrial Internet of Things: Potentials, Challenges, and Emerging Applications. IEEE Internet Things J. 2021, 8, 11016–11040. [Google Scholar] [CrossRef]
- Wang, D.; Wang, J.-G.; Xu, K. Deep Learning for Object Detection, Classification and Tracking in Industry Applications. Sensors 2021, 21, 7349. [Google Scholar] [CrossRef] [PubMed]
- Sika, R.; Szajewski, D.; Hajkowski, J.; Popielarski, P. Application of instance-based learning for cast iron casting defects prediction. Manag. Prod. Eng. Rev. 2019, 10, 101–107. [Google Scholar]
- Di, H.; Ke, X.; Peng, Z.; Dongdong, Z. Surface Defect Classification of Steels with a New Semi-Supervised Learning Method. Opt. Lasers Eng. 2019, 117, 40–48. [Google Scholar] [CrossRef]
- Pourkaramdel, Z.; Fekri-Ershad, S.; Nanni, L. Fabric Defect Detection Based on Completed Local Quartet Patterns and Majority Decision Algorithm. Expert Syst. Appl. 2022, 198, 116827. [Google Scholar] [CrossRef]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023. [Google Scholar]
- Liu, Z.; Hu, H.; Lin, Y.; Yao, Z.; Xie, Z.; Wei, Y.; Ning, J.; Cao, Y.; Zhang, Z.; Dong, L.; et al. Swin Transformer V2: Scaling Up Capacity and Resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–24 June 2022. [Google Scholar]
- Zhao, P.; Lin, Q. RLNF: Reinforcement Learning Based Noise Filtering for Click-Through Rate Prediction. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, Online, 11–15 June 2021. [Google Scholar]
- Ruff, L.; Vandermeulen, R.; Goernitz, N.; Deecke, L.; Siddiqui, S.A.; Binder, A.; Müller, E.; Kloft, M. Deep One-Class Classification. PMLR 2018, 80, 4393–4402. [Google Scholar]
- Masci, J.; Meier, U.; Cireşan, D.; Schmidhuber, J. Stacked Convolutional Auto-Encoders for Hierarchical Feature Extraction. In Proceedings of the Artificial Neural Networks and Machine Learning—ICANN, Espoo, Finland, 14–17 June 2011; Honkela, T., Duch, W., Girolami, M., Kaski, S., Eds.; Springer: Berlin, Heidelberg, 2011; pp. 52–59. [Google Scholar]
- Bergman, L.; Hoshen, Y. Classification-Based Anomaly Detection for General Data. arXiv 2020, arXiv:2005.02359. [Google Scholar]
- Schlegl, T.; Seeböck, P.; Waldstein, S.M.; Schmidt-Erfurth, U.; Langs, G. Unsupervised Anomaly Detection with Generative Adversarial Networks to Guide Marker Discovery. In Proceedings of the Information Processing in Medical Imaging, Boone, NC, USA, 25–30 June 2017; Niethammer, M., Styner, M., Aylward, S., Zhu, H., Oguz, I., Yap, P.-T., Shen, D., Eds.; Springer International Publishing: Cham, Switzerland, 2017; pp. 146–157. [Google Scholar]
- Sohn, K.; Li, C.-L.; Yoon, J.; Jin, M.; Pfister, T. Learning and Evaluating Representations for Deep One-Class Classification. arXiv 2021, arXiv:2011.02578. [Google Scholar]
- Li, C.-L.; Sohn, K.; Yoon, J.; Pfister, T. CutPaste: Self-Supervised Learning for Anomaly Detection and Localization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Online, 19–25 June 2021; pp. 9664–9674. [Google Scholar]
- Otneim, H.; Tjøstheim, D. The Locally Gaussian Density Estimator for Multivariate Data. Stat. Comput. 2017, 27, 1595–1616. [Google Scholar] [CrossRef]
- Varanasi, M.K.; Aazhang, B. Parametric Generalized Gaussian Density Estimation. J. Acoust. Soc. Am. 1989, 86, 1404–1415. [Google Scholar] [CrossRef]
- Lobo, J.M.; Jiménez-Valverde, A.; Real, R. AUC: A Misleading Measure of the Performance of Predictive Distribution Models. Glob. Ecol. Biogeogr. 2008, 17, 145–151. [Google Scholar] [CrossRef]
- Sazzed, S.; Jayarathna, S. SSentiA: A Self-Supervised Sentiment Analyzer for Classification from Unlabeled Data. Mach. Learn. Appl. 2021, 4, 100026. [Google Scholar] [CrossRef]
- Kinakh, V.; Taran, O.; Voloshynovskiy, S. ScatSimCLR: Self-Supervised Contrastive Learning with Pretext Task Regularization for Small-Scale Datasets. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops, Online, 11–17 October 2021; pp. 1098–1106. [Google Scholar]
- Albelwi, S. Survey on Self-Supervised Learning: Auxiliary Pretext Tasks and Contrastive Learning Methods in Imaging. Entropy 2022, 24, 551. [Google Scholar] [CrossRef]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. Proc. AAAI Conf. Artif. Intell. 2016, 31, 4278–4284. [Google Scholar] [CrossRef]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1800–1807. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2015, arXiv:1409.1556. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- He, F.; Liu, T.; Tao, D. Why ResNet Works? Residuals Generalize. IEEE Trans. Neural Netw. Learn. Syst. 2020, 31, 5349–5362. [Google Scholar] [CrossRef] [PubMed]
- Terrell, G.R.; Scott, D.W. Variable Kernel Density Estimation. Ann. Stat. 1992, 20, 1236–1265. [Google Scholar] [CrossRef]
- Bergmann, P.; Fauser, M.; Sattlegger, D.; Steger, C. Uninformed Students: Student-Teacher Anomaly Detection with Discriminative Latent Embeddings. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 4182–4191. [Google Scholar]
- Yi, J.; Yoon, S. Patch SVDD: Patch-Level SVDD for Anomaly Detection and Segmentation. In Proceedings of the Asian Conference on Computer Vision (ACCV), Kyoto, Japan, 30 November–4 December 2020; pp. 375–390. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| DN/mm | D/mm | P/mm | Lu/m |
|---|---|---|---|
| 350 | 448 | 110 | 6 |
| 400 | 500 | 110 | 6 |
| 450 | 540 | 120 | 6 |
| 500 | 604 | 120 | 6 |
| 600 | 713 | 120 | 6 |
| 700 | 824 | 150 | 6 |
| 800 | 943 | 160 | 6 |
| 900 | 1052 | 175 | 6 |
| 1000 | 1158 | 185 | 6 |
| Erase | Enlarge | Rotate | AUC |
|---|---|---|---|
| * | 84.3 ± 2.3 | ||
| * | 95.8 ± 1.1 | ||
| * | 92.5 ± 1.8 | ||
| * | * | 88.6 ± 0.5 | |
| * | * | 97.2 ± 0.7 | |
| * | * | 98.9 ± 0.2 | |
| * | * | 94.8 ± 1.5 | |
| * | * | * | 99.4 ± 0.1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, H.; Sun, Q.; Xu, K. A Self-Supervised Model Based on CutPaste-Mix for Ductile Cast Iron Pipe Surface Defect Classification. Sensors 2023, 23, 8243. https://doi.org/10.3390/s23198243
Zhang H, Sun Q, Xu K. A Self-Supervised Model Based on CutPaste-Mix for Ductile Cast Iron Pipe Surface Defect Classification. Sensors. 2023; 23(19):8243. https://doi.org/10.3390/s23198243
Chicago/Turabian StyleZhang, Hanxin, Qian Sun, and Ke Xu. 2023. "A Self-Supervised Model Based on CutPaste-Mix for Ductile Cast Iron Pipe Surface Defect Classification" Sensors 23, no. 19: 8243. https://doi.org/10.3390/s23198243
APA StyleZhang, H., Sun, Q., & Xu, K. (2023). A Self-Supervised Model Based on CutPaste-Mix for Ductile Cast Iron Pipe Surface Defect Classification. Sensors, 23(19), 8243. https://doi.org/10.3390/s23198243