
Development of YOLOv5-Based Real-Time Smart Monitoring System for Increasing Lab Safety Awareness in Educational Institutions

 , ,
, ,  ,
,
Abstract
:1. Introduction
- (1)
- The creation of a novel, labeled PPE dataset named SLS (Student Lab Safety) containing four different classes, including mask, lab coat, safety glass, and gloves. The dataset contains 481 images and the corresponding annotations of these four classes.
- (2)
- The performance evaluation of various versions of the YOLOv5 [27] (YOLOv5l, YOLOv5m, YOLOv5n, YOLOv5s, and YOLOv5x) and YOLOv7 (YOLOv7 and YOLOv7X) on the proposed dataset for the detection and monitoring of students’ PPE in academic laboratories.
- (3)
- The performance evaluation of the YOLOv5 and YOLOv7 model variant based on instance size of the object, i.e., large instances (lab coat and gloves) and small instances (masks and goggles).
2. System Overview
2.1. Student Laboratory Safety (SLS) Dataset
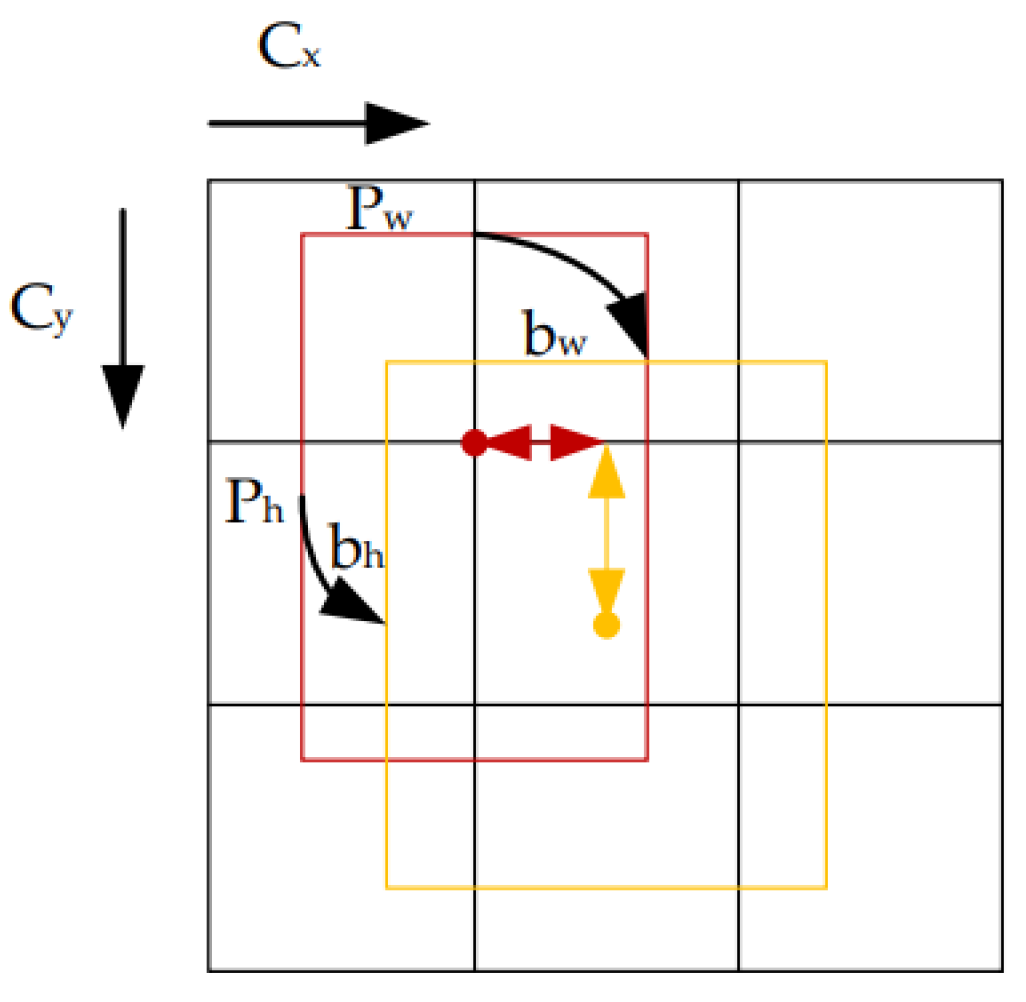
2.2. YOLOv5 Model
2.3. YOLOv7 Model
3. Experimental Results
3.1. Environmental Setup
3.2. Evaluation Metrics
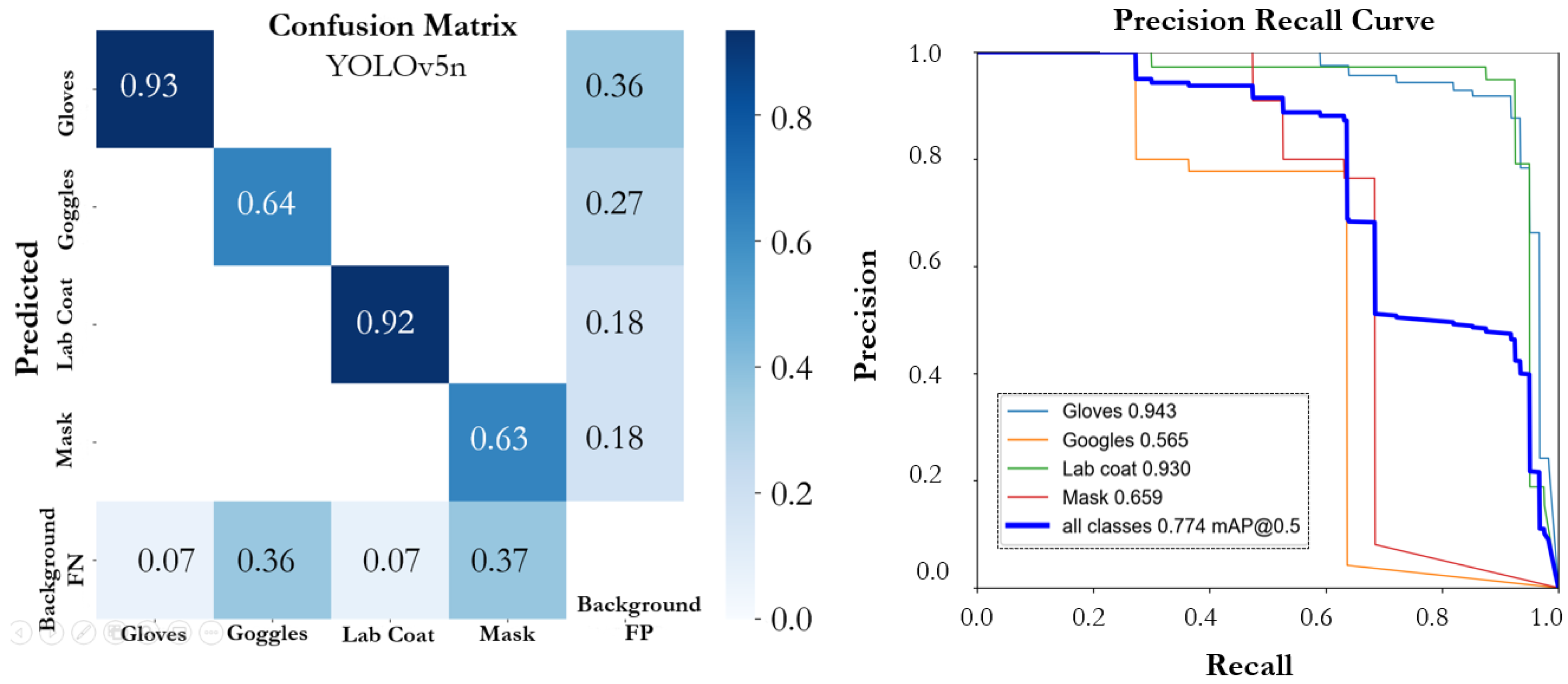
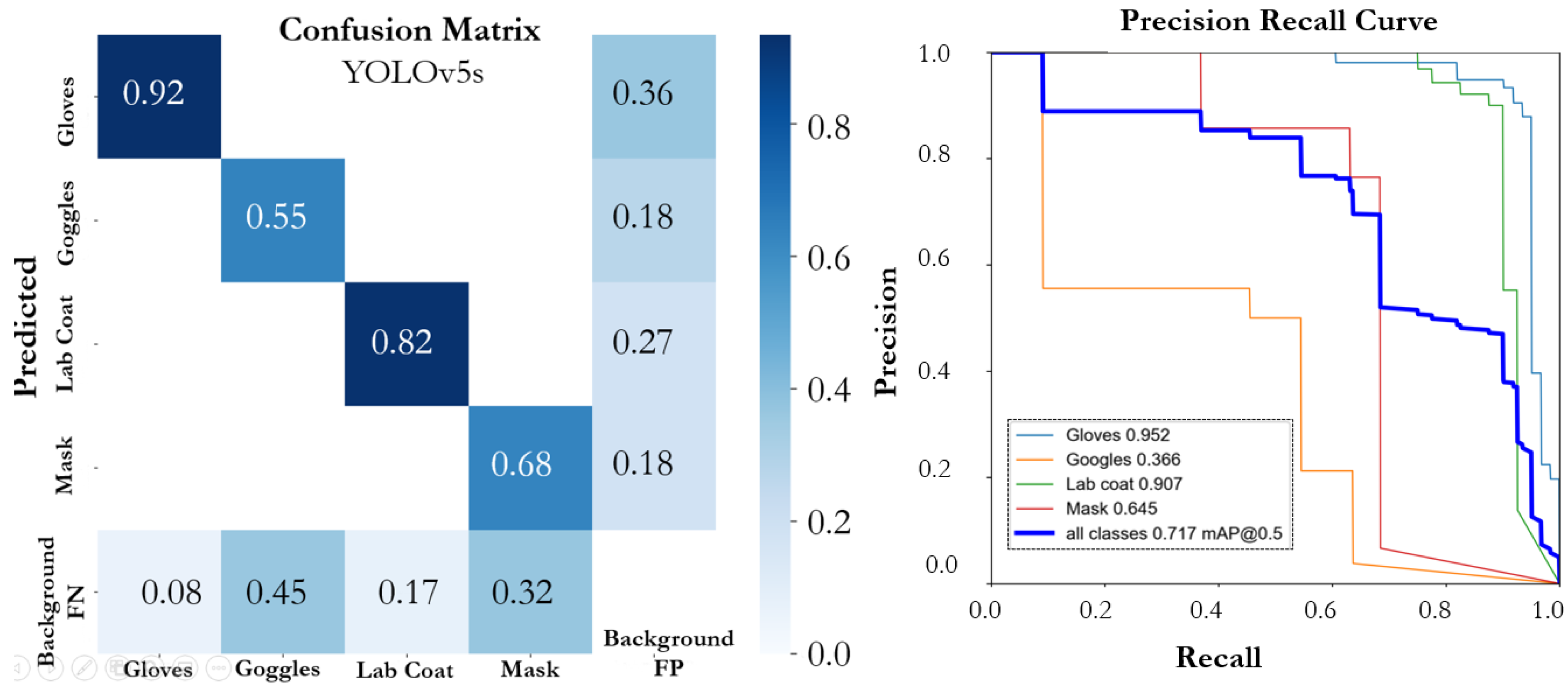
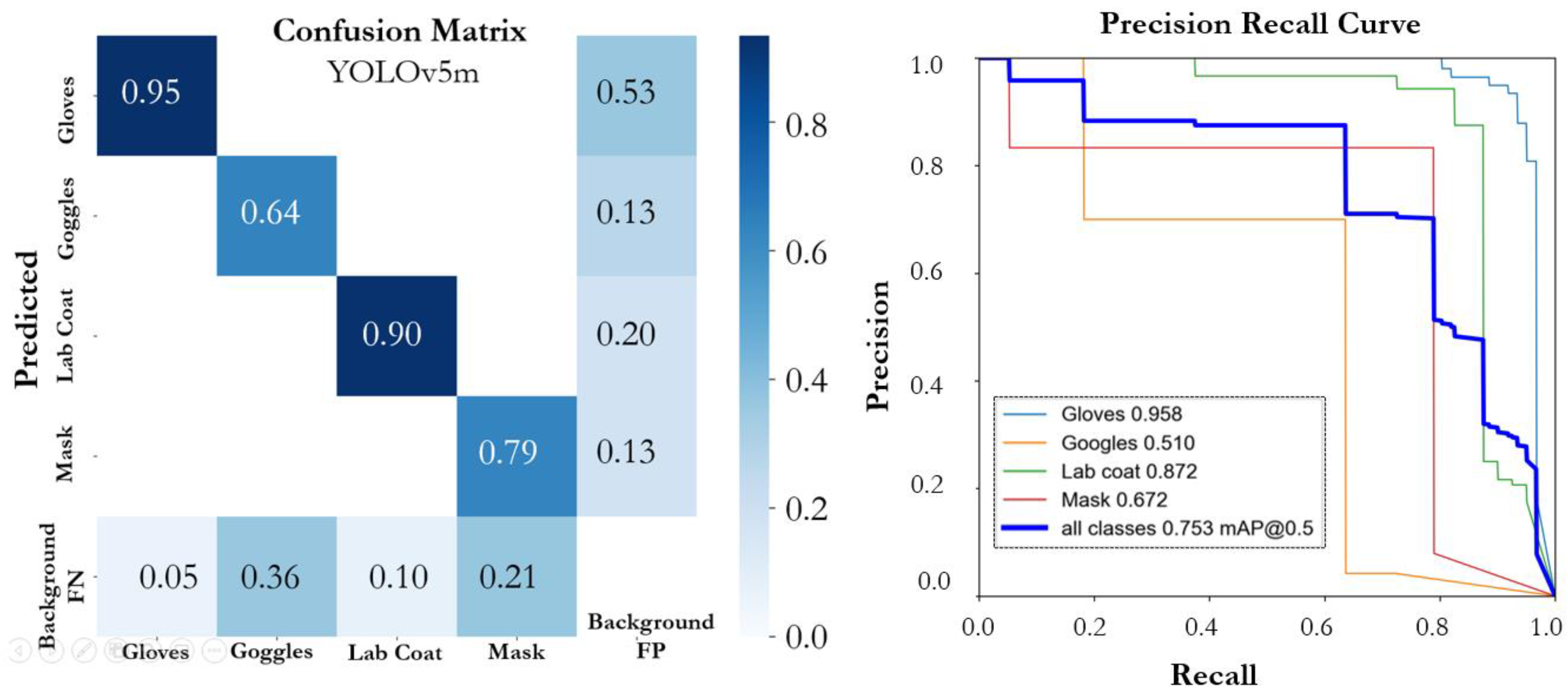
3.3. Analysis of Experimental Results and Discussion
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wu, T.-C.; Liu, C.-W.; Lu, M.-C. Safety Climate in University and College Laboratories: Impact of Organizational and Individual Factors. J. Saf. Res. 2007, 38, 91–102. [Google Scholar] [CrossRef]
- Negligence Caused UCLA Death. Available online: https://cen.acs.org/articles/87/i19/Negligence-Caused-UCLA-Death.html (accessed on 16 September 2022).
- Van Noorden, R. A Death in the Lab. Nature 2011, 472, 270–271. [Google Scholar] [CrossRef] [Green Version]
- University of Hawaii Fined $115,500 for Lab Explosion. Available online: https://cen.acs.org/articles/94/web/2016/09/University-Hawaii-fined-115500-lab.html (accessed on 16 September 2022).
- Texas Tech University Chemistry Lab Explosion|CSB. Available online: https://www.csb.gov/texas-tech-university-chemistry-lab-explosion/ (accessed on 16 September 2022).
- Schröder, I.; Huang, D.Y.Q.; Ellis, O.; Gibson, J.H.; Wayne, N.L. Laboratory Safety Attitudes and Practices: A Comparison of Academic, Government, and Industry Researchers. J. Chem. Health Saf. 2016, 23, 12–23. [Google Scholar] [CrossRef] [Green Version]
- Rubaiyat, A.; Toma, T.; Kalantari-Khandani, M.; Rahman, S.A.; Chen, L.; Ye, Y.; Pan, C. Automatic Detection of Helmet Uses for Construction Safety. In Proceedings of the 2016 IEEE/WIC/ACM International Conference on Web Intelligence Workshops (WIW), Omaha, NE, USA, 13–16 October 2016; pp. 135–142. [Google Scholar]
- Shrestha, K.; Shrestha, P.; Bajracharya, D.; Yfantis, E. Hard-Hat Detection for Construction Safety Visualization. J. Constr. Eng. 2015, 2015, 721380. [Google Scholar] [CrossRef]
- Qiu, Z.; Zhao, Z.; Chen, S.; Zeng, J.; Huang, Y.; Xiang, B. Application of an Improved YOLOv5 Algorithm in Real-Time Detection of Foreign Objects by Ground Penetrating Radar. Remote Sens. 2022, 14, 1895. [Google Scholar] [CrossRef]
- Xiong, C.; Hu, S.; Fang, Z. Application of Improved YOLOV5 in Plate Defect Detection. Int. J. Adv. Manuf. Technol. 2022. [Google Scholar] [CrossRef]
- Hindawi Swin-YOLOv5: Research and Application of Fire and Smoke Detection Algorithm Based on YOLOv5. Available online: https://www.hindawi.com/journals/cin/2022/6081680/ (accessed on 17 September 2022).
- Kumar, S.; Gupta, H.; Yadav, D.; Ansari, I.A.; Verma, O.P. YOLOv4 Algorithm for the Real-Time Detection of Fire and Personal Protective Equipments at Construction Sites. Multimed. Tools Appl. 2022, 81, 22163–22183. [Google Scholar] [CrossRef]
- Damage detection and localization in masonry structure using faster region convolutional networks. Geomate J. 2019, 17. Available online: https://geomatejournal.com/geomate/article/view/270 (accessed on 17 September 2022).
- Otgonbold, M.-E.; Gochoo, M.; Alnajjar, F.; Ali, L.; Tan, T.-H.; Hsieh, J.-W.; Chen, P.-Y. SHEL5K: An Extended Dataset and Benchmarking for Safety Helmet Detection. Sensors 2022, 22, 2315. [Google Scholar] [CrossRef]
- Delhi, V.S.K.; Sankarlal, R.; Thomas, A. Detection of Personal Protective Equipment (PPE) Compliance on Construction Site Using Computer Vision Based Deep Learning Techniques. Front. Built Environ. 2020, 6, 136. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Tang, S.; Roberts, D.; Golparvar-Fard, M. Human-Object Interaction Recognition for Automatic Construction Site Safety Inspection. Autom. Constr. 2020, 120, 103356. [Google Scholar] [CrossRef]
- Wu, J.; Cai, N.; Chen, W.; Wang, H.; Wang, G. Automatic Detection of Hardhats Worn by Construction Personnel: A Deep Learning Approach and Benchmark Dataset. Autom. Constr. 2019, 106, 102894. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. arXiv 2016, 9905, 21–37. [Google Scholar] [CrossRef] [Green Version]
- Fang, Q.; Li, H.; Luo, X.; Ding, L.; Luo, H.; Rose, T.M.; An, W. Detecting Non-Hardhat-Use by a Deep Learning Method from Far-Field Surveillance Videos. Autom. Constr. 2018, 85, 1–9. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; Curran Associates, Inc.: Montreal, QC, Canada, 2015; Volume 28. [Google Scholar]
- Saudi, M.; Hakim, A.; Ahmad, A.; Mohd Saudi, A.S.; Hanafi, M.; Narzullaev, A.; Ghazali, I. Image Detection Model for Construction Worker Safety Conditions Using Faster R-CNN. Int. J. Adv. Comput. Sci. Appl. 2020, 11, 246–250. [Google Scholar] [CrossRef]
- Nath, N.D.; Behzadan, A.H.; Paal, S.G. Deep Learning for Site Safety: Real-Time Detection of Personal Protective Equipment. Autom. Constr. 2020, 112, 103085. [Google Scholar] [CrossRef]
- Wang, J.; Zhu, G.; Wu, S.; Luo, C. Worker’s Helmet Recognition and Identity Recognition Based on Deep Learning. Open J. Model. Simul. 2021, 9, 135–145. [Google Scholar] [CrossRef]
- Wang, Z.; Wu, Y.; Yang, L.; Thirunavukarasu, A.; Evison, C.; Zhao, Y. Fast Personal Protective Equipment Detection for Real Construction Sites Using Deep Learning Approaches. Sensors 2021, 21, 3478. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Jocher, G. Yolov5. Code Repository. Available online: https://github.com/ultralytics/yolov5 (accessed on 17 September 2022).
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors 2022. arXiv 2022, arXiv:2207.02696. [Google Scholar]
- GitHub—Heartexlabs/LabelImg: LabelImg Is Now Part of the Label Studio Community. The Popular Image Annotation Tool Created by Tzutalin Is No Longer Actively Being Developed, but You Can Check Out Label Studio, the Open Source Data Labeling Tool for Images, Text, Hypertext, Audio, Video and Time-Series Data. Available online: https://github.com/heartexlabs/labelImg (accessed on 1 October 2022).
- Roboflow: Give Your Software the Power to See Objects in Images and Video. Available online: https://roboflow.com/ (accessed on 1 October 2022).
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Yang, S.J.; Berndl, M.; Michael Ando, D.; Barch, M.; Narayanaswamy, A.; Christiansen, E.; Hoyer, S.; Roat, C.; Hung, J.; Rueden, C.T.; et al. Assessing Microscope Image Focus Quality with Deep Learning. BMC Bioinform. 2018, 19, 77. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Guo, Y.; Zeng, Y.; Gao, F.; Qiu, Y.; Zhou, X.; Zhong, L.; Zhan, C. Improved YOLOV4-CSP Algorithm for Detection of Bamboo Surface Sliver Defects With Extreme Aspect Ratio. IEEE Access 2022, 10, 29810–29820. [Google Scholar] [CrossRef]
- Zhang, Y.; Guo, Z.; Wu, J.; Tian, Y.; Tang, H.; Guo, X. Real-Time Vehicle Detection Based on Improved YOLO V5. Sustainability 2022, 14, 12274. [Google Scholar] [CrossRef]
- Liu, H.; Sun, F.; Gu, J.; Deng, L. SF-YOLOv5: A Lightweight Small Object Detection Algorithm Based on Improved Feature Fusion Mode. Sensors 2022, 22, 5817. [Google Scholar] [CrossRef] [PubMed]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Precision | Recall | [email protected] | [email protected]:0.95 | Weights | No. of Parameters | |
|---|---|---|---|---|---|---|
| YOLOv5n | 0.795 | 0.787 | 0.774 | 0.485 | 3.9 MB | 1.9 M |
| YOLOv5s | 0.798 | 0.702 | 0.717 | 0.476 | 14.5 MB | 7.2 M |
| YOLOv5m | 0.837 | 0.776 | 0.753 | 0.481 | 42.3 MB | 21.2 M |
| YOLOv5l | 0.805 | 0.725 | 0.707 | 0.482 | 92.9 MB | 46.5 M |
| YOLOv5x | 0.794 | 0.688 | 0.725 | 0.488 | 173.2 MB | 86.7 M |
| YOLOv7 | 0.700 | 0.654 | 0.609 | 0.366 | 74.8 MB | 36.9 M |
| YOLOv7X | 0.775 | 0.652 | 0.616 | 0.400 | 142.1 MB | 71.3 M |
| YOLOv5n | |||||
|---|---|---|---|---|---|
| Class | Instance Size | Precision | Recall | [email protected] | [email protected]:0.95 |
| Gloves | L | 0.918 | 0.918 | 0.943 | 0.610 |
| Goggles | S | 0.566 | 0.636 | 0.565 | 0.286 |
| Lab Coat | L | 0.937 | 0.925 | 0.93 | 0.602 |
| Mask | S | 0.761 | 0.67 | 0.659 | 0.440 |
| YOLOv5s | |||||
| Gloves | L | 0.942 | 0.902 | 0.952 | 0.638 |
| Goggles | S | 0.519 | 0.455 | 0.366 | 0.247 |
| Lab Coat | L | 0.968 | 0.775 | 0.907 | 0.620 |
| Mask | S | 0.763 | 0.677 | 0.645 | 0.400 |
| YOLOv5m | |||||
| Gloves | L | 0.934 | 0.929 | 0.958 | 0.629 |
| Goggles | S | 0.666 | 0.636 | 0.510 | 0.242 |
| Lab Coat | L | 0.93 | 0.825 | 0.872 | 0.622 |
| Mask | S | 0.819 | 0.713 | 0.672 | 0.431 |
| YOLOv5l | |||||
| Gloves | L | 0.957 | 0.951 | 0.954 | 0.668 |
| Goggles | S | 0.553 | 0.545 | 0.339 | 0.207 |
| Lab Coat | L | 0.966 | 0.719 | 0.915 | 0.644 |
| Mask | S | 0.743 | 0.684 | 0.621 | 0.408 |
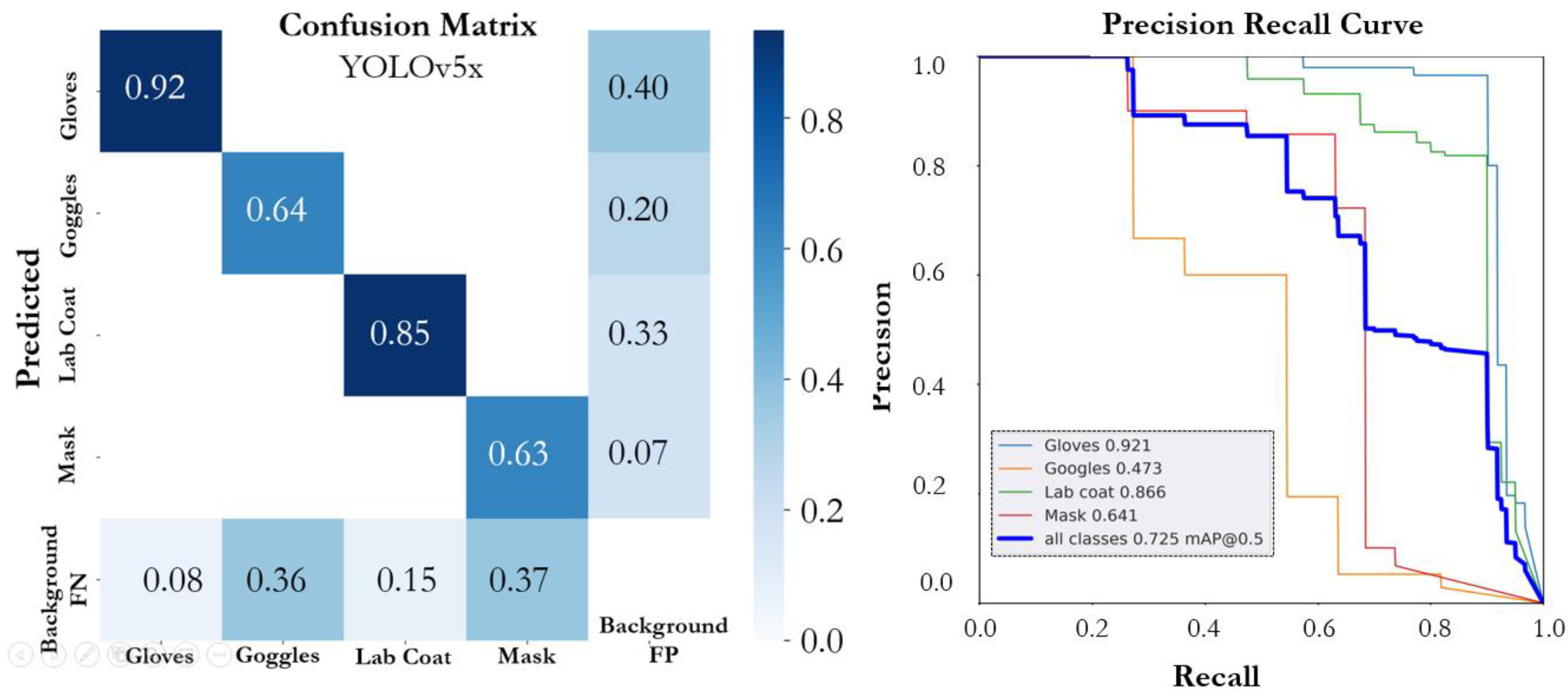
| YOLOv5x | |||||
| Gloves | L | 0.963 | 0.902 | 0.921 | 0.617 |
| Goggles | S | 0.53 | 0.545 | 0.473 | 0.282 |
| Lab Coat | L | 0.906 | 0.675 | 0.866 | 0.612 |
| Mask | S | 0.776 | 0.632 | 0.641 | 0.439 |
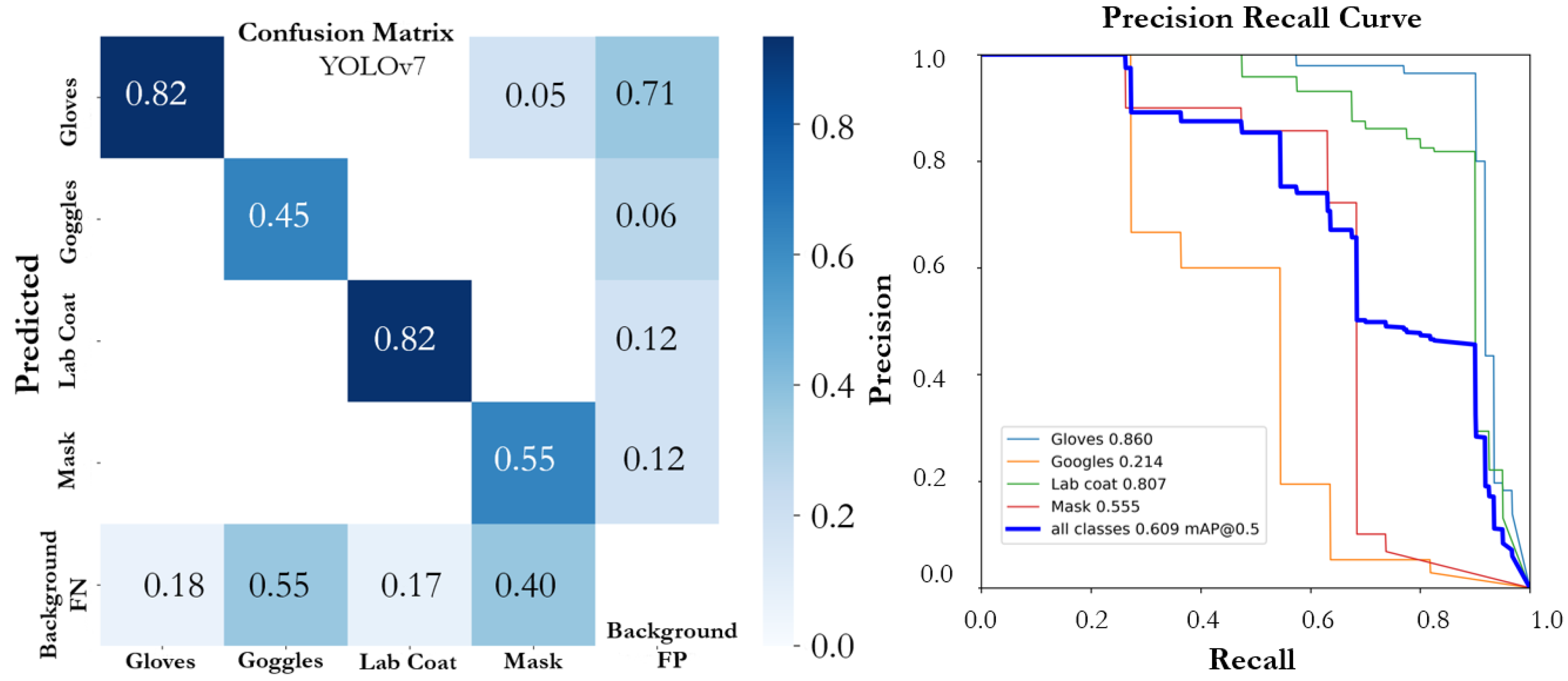
| YOLOv7 | |||||
| Gloves | L | 0.795 | 0.803 | 0.860 | 0.505 |
| Goggles | S | 0.483 | 0.364 | 0.214 | 0.079 |
| Lab Coat | L | 0.892 | 0.825 | 0.807 | 0.522 |
| Mask | S | 0.628 | 0.622 | 0.555 | 0.357 |
| YOLOv7X | |||||
| Gloves | L | 0.874 | 0.836 | 0.855 | 0.565 |
| Goggles | S | 0.599 | 0.544 | 0.327 | 0.162 |
| Lab Coat | L | 0.891 | 0.65 | 0.707 | 0.495 |
| Mask | S | 0.736 | 0.579 | 0.574 | 0.376 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ali, L.; Alnajjar, F.; Parambil, M.M.A.; Younes, M.I.; Abdelhalim, Z.I.; Aljassmi, H. Development of YOLOv5-Based Real-Time Smart Monitoring System for Increasing Lab Safety Awareness in Educational Institutions. Sensors 2022, 22, 8820. https://doi.org/10.3390/s22228820
Ali L, Alnajjar F, Parambil MMA, Younes MI, Abdelhalim ZI, Aljassmi H. Development of YOLOv5-Based Real-Time Smart Monitoring System for Increasing Lab Safety Awareness in Educational Institutions. Sensors. 2022; 22(22):8820. https://doi.org/10.3390/s22228820
Chicago/Turabian StyleAli, Luqman, Fady Alnajjar, Medha Mohan Ambali Parambil, Mohammad Issam Younes, Ziad Ismail Abdelhalim, and Hamad Aljassmi. 2022. "Development of YOLOv5-Based Real-Time Smart Monitoring System for Increasing Lab Safety Awareness in Educational Institutions" Sensors 22, no. 22: 8820. https://doi.org/10.3390/s22228820