
Real-Time Sound Source Localization for Low-Power IoT Devices Based on Multi-Stream CNN


Abstract
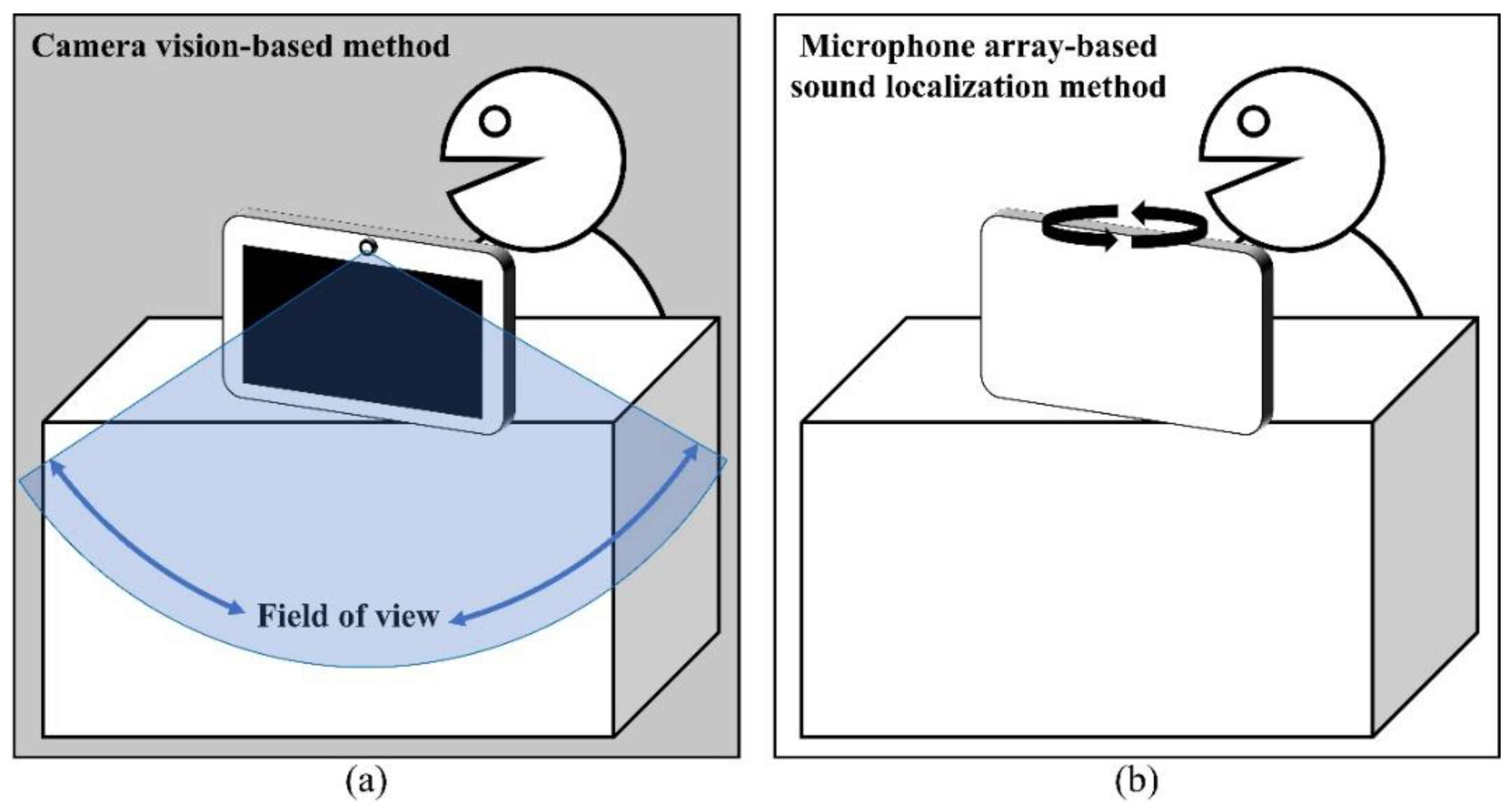
:1. Introduction
2. Materials and Methods
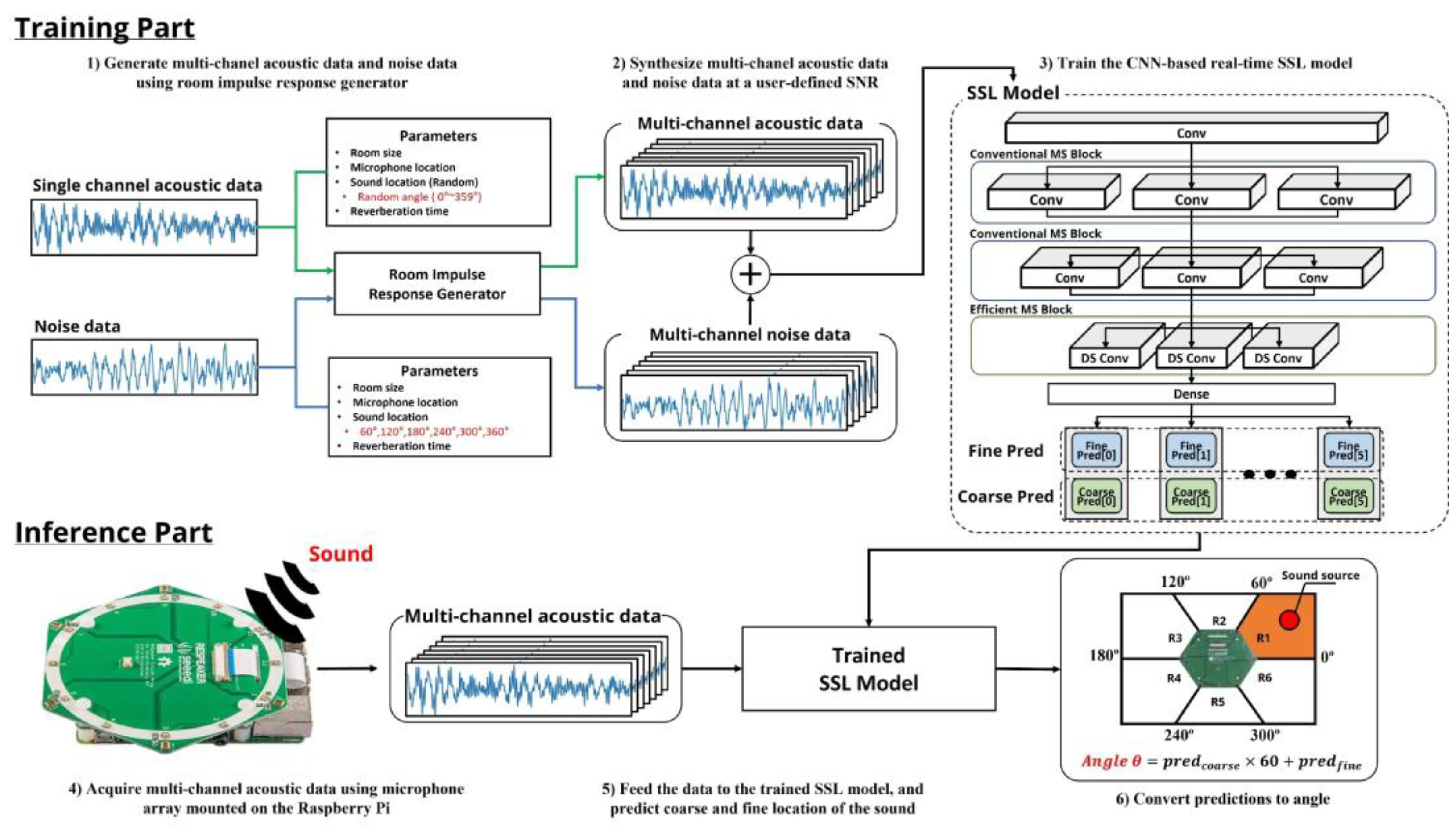
2.1. Overall System Architecture
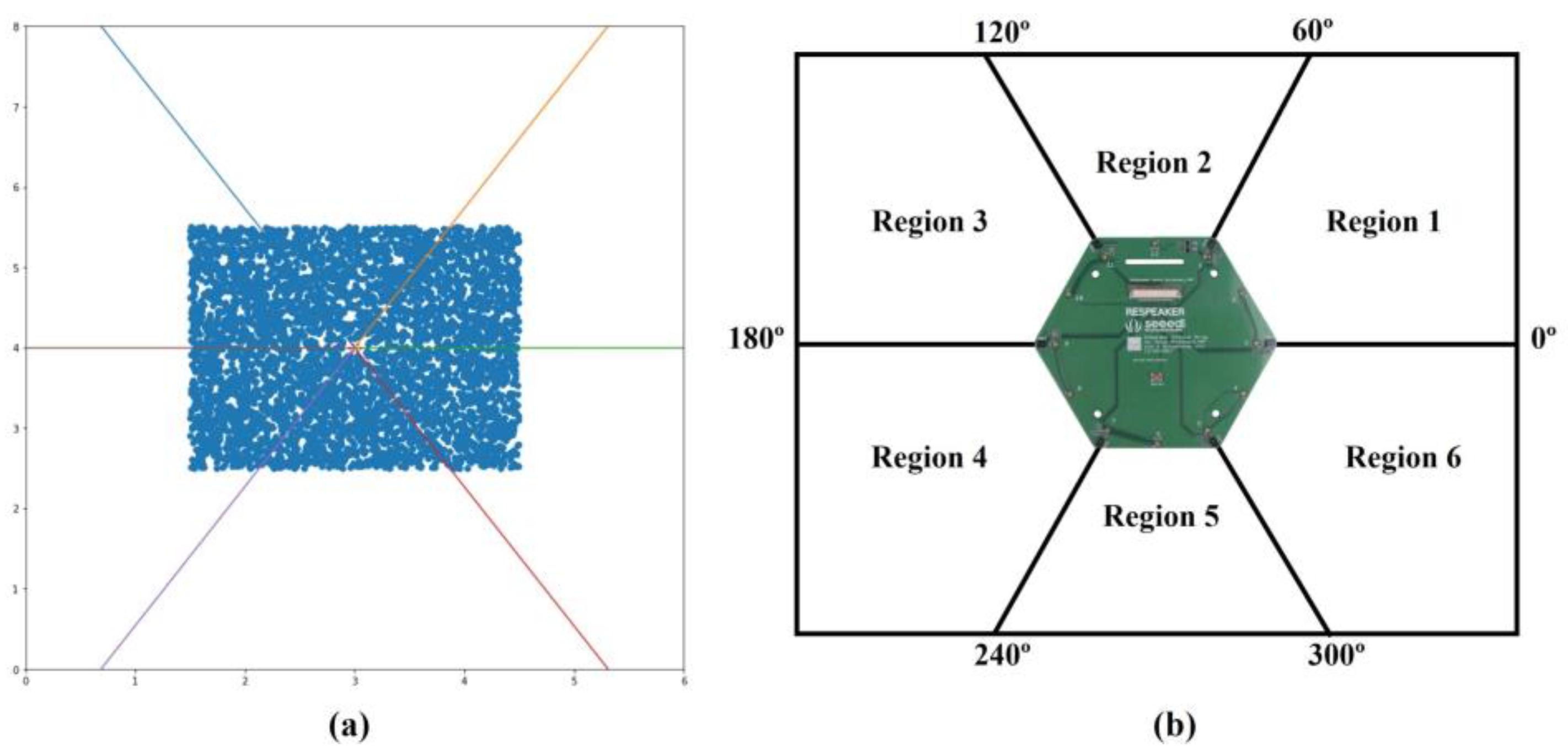
2.2. Dataset
2.3. Classification and Regression together
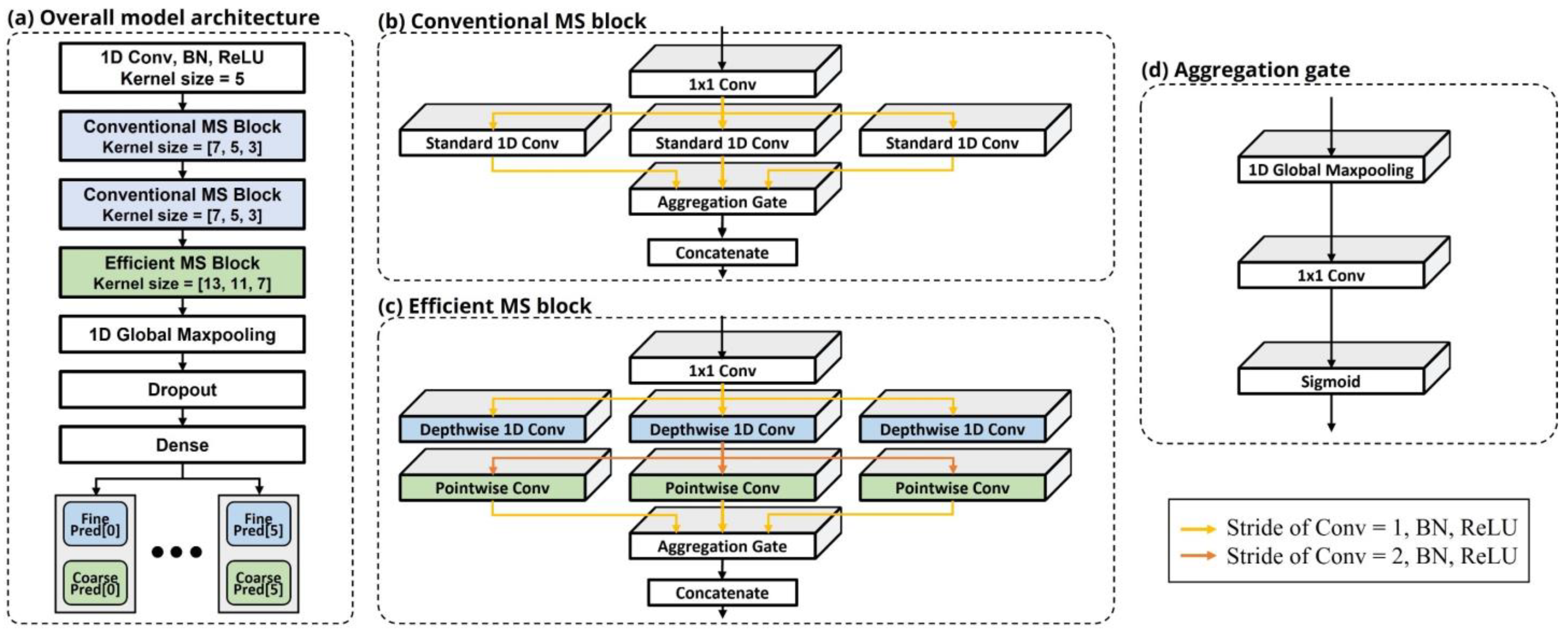
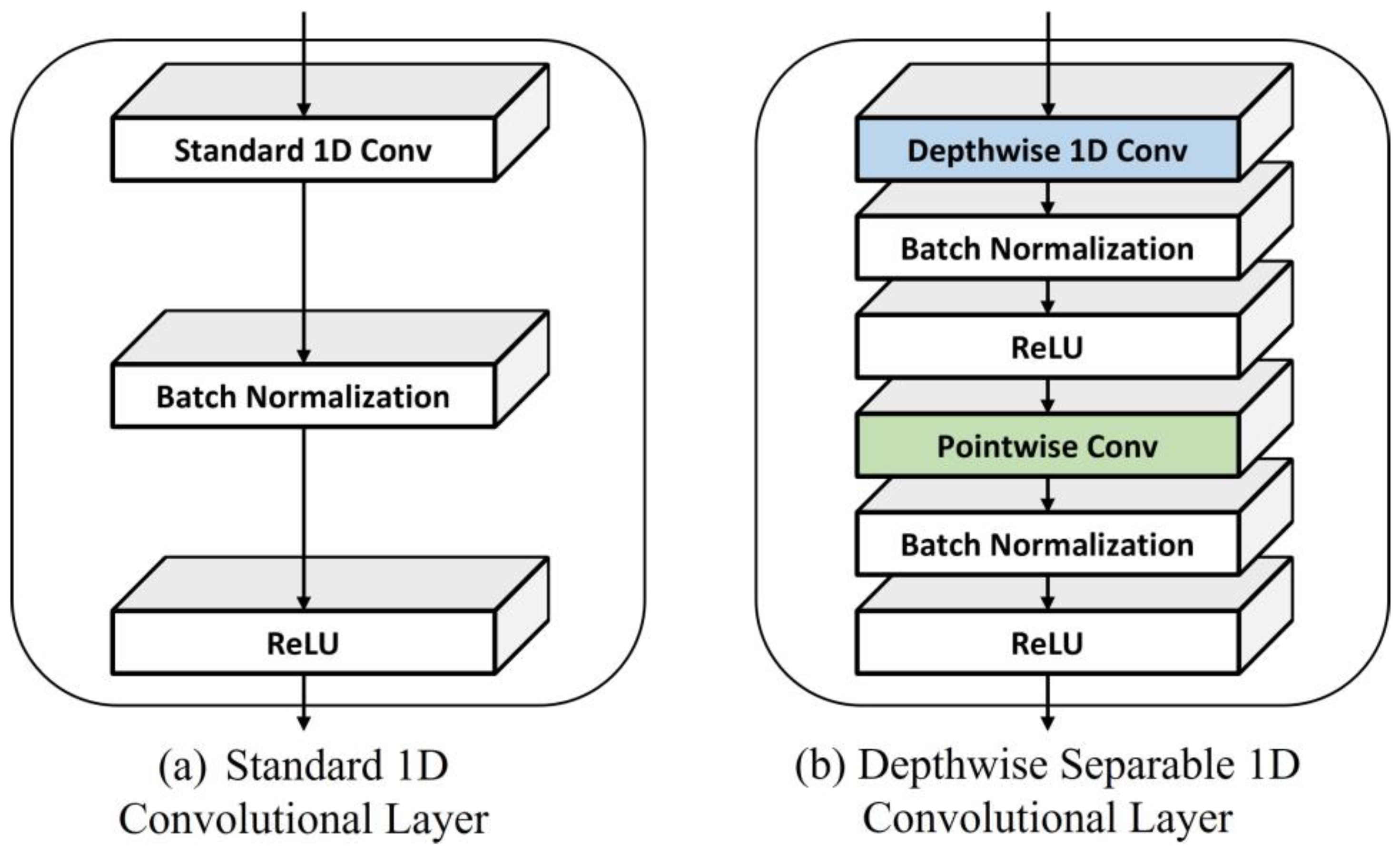
2.4. Conventional Multi-Stream (MS) Block
2.5. Efficient Multi-Stream (MS) Block
2.6. Model Architecture
2.7. Performance Evaluation
3. Results
3.1. Model Performance Measurements
3.2. Model Inference Time Measurements
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| SSL | Sound Source Localization |
| IoT | Internet of Things |
| DNN | Deep Neural Network |
| DOA | Direction of Arrival |
| SPS | Spatial Pseudo-Spectrum |
| CNN | Convolutional Neural Network |
| MS | Multi-Stream |
| AG | Aggregation Gate |
| RIR | Room Impulse Response |
| SNR | Signal-to-Noise Ratio |
| MFCC | Mel-Frequency Cepstral Coefficient |
| AoA | Angle of Arrival |
| ACC | Accuracy |
| ReLU | Rectified Linear Unit |
| BN | Batch Normalization |
References
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems, Montréal, QC, Canada, 7–12 December 2015. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal Loss for Dense Object Detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- DiBiase, J. A High-Accuracy, Low-Latency Technique for Talker Localization in Reverberant Environments Using Microphone Arrays. Ph.D. Thesis, Brown University, Providence, RI, USA, 2000. [Google Scholar]
- Schmidt, R. Multiple emitter location and signal parameter estimation. IEEE Trans. Antennas Propag. 1986, 34, 276–280. [Google Scholar] [CrossRef] [Green Version]
- Yalta, N.; Nakadai, K.; Ogata, T. Sound source localization using deep learning models. J. Robot. Mechatron. 2017, 29, 37–48. [Google Scholar] [CrossRef]
- Adavanne, S.; Politis, A.; Virtanen, T. Direction of arrival estimation for multiple sound sources using convolutional recurrent neural network. arXiv 2017, arXiv:1710.10059. [Google Scholar]
- Vera-Diaz, J.M.; Pizarro, D.; Macias-Guarasa, J. Towards End-to-End Acoustic Localization Using Deep Learning: From Audio Signals to Source Position Coordinates. Sensors 2018, 18, 3418. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sundar, H.; Wang, W.; Sun, M.; Wang, C. Raw Waveform Based End-to-end Deep Convolutional Network for Spatial Localization of Multiple Acoustic Sources. In Proceedings of the ICASSP 2020–2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 4642–4646. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Kim, T.; Lee, J.; Nam, J. Comparison and Analysis of SampleCNN Architectures for Audio Classification. IEEE J. Sel. Top. Signal Process. 2019, 13, 285–297. [Google Scholar] [CrossRef]
- Lopez-Ballester, J.; Alcaraz Calero, J.M.; Segura-Garcia, J.; Felici-Castell, S.; Garcia-Pineda, M.; Cobos, M. Speech Intelligibility Analysis and Approximation to Room Parameters through the Internet of Things. Appl. Sci. 2021, 11, 1430. [Google Scholar] [CrossRef]
- Garofolo, J.S.; Lamel, L.F.; Fisher, W.M.; Fiscus, J.G.; Pallett, D.S. DARPA TIMIT acoustic-phonetic continous speech corpus CD-ROM. NIST speech disc 1-1.1. NASA STI/Recon Tech. Rep. 1993, 93, 27403. [Google Scholar]
- Allen, J.B.; Berkley, D.A. Image method for efficiently simulating small-room acoustics. J. Acoust. Soc. Am. 1979, 65, 943–950. [Google Scholar] [CrossRef]
- Ravanelli, M.; Bengio, Y. Speaker recognition from raw waveform with sincnet. In Proceedings of the 2018 IEEE Spoken Language Technology Workshop (SLT), Athens, Greece, 18–21 December 2018; pp. 1021–1028. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.Q.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; IEEE: New York, NY, USA, 2015; pp. 1–9. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the 32nd International Conference on Machine Learning, ICML, Lille, France, 6–11 July 2015; International Machine Learning Society (IMLS): Washington, DC, USA, 2015; Volume 1, pp. 448–456. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the 27th International Conference on Machine Learning (ICML-10), Haifa, Israel, 21–24 June 2010; pp. 807–814. [Google Scholar]
- Zhou, K.; Yang, Y.; Cavallaro, A.; Xiang, T. Omni-scale feature learning for person re-identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 28 October 2019; pp. 3702–3712. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications; Technical Report; Google Inc.: Menlo Park, CA, USA, 2017. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst. 2019, 32, 8026–8037. [Google Scholar]
- Chen, T.; Moreau, T.; Jiang, Z.; Zheng, L.; Yan, E.; Cowan, M.; Shen, H.; Wang, L.; Hu, Y.; Ceze, L.; et al. TVM: An Automated End-to-End Optimizing Compiler for Deep Learning. In Proceedings of the 13th USENIX Conference on Operating Systems Design and Implementation, Carlsbad, CA, USA, 8–10 October 2018; pp. 579–594. [Google Scholar]
- Gibson, P.; Cano, J.; Turner, J.; Crowley, E.J.; O’Boyle, M.; Storkey, A. Optimizing Grouped Convolutions on Edge Devices. 2020 IEEE 31st International Conference on Application-specific Systems, Architectures and Processors (ASAP); IEEE Computer Society: Los Alamitos, CA, USA, 2020; pp. 189–196. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Item | Value |
|---|---|
| Number of speakers | 220 |
| Sampling rate | 16 kHz |
| Room size | (m) |
| Reverberation time | 0.4 s |
| Distance | 0.1 m–2.12 m |
| Angle | 0–360° |
| Input duration | 40 ms |
| Total number of samples | 90,767 |
| Type of Module | Input | Output |
|---|---|---|
| Conv block | (640, 8) | (320, 32) |
| Conventional MS block | (320, 32) | (160, 48) |
| Conventional MS block | (160, 48) | (80, 96) |
| Efficient MS block | (80, 96) | (40, 144) |
| Global max-pooling | (40, 144) | (1, 144) |
| Dense | (1, 144) | (1, 12) |
| Hyperparameter | Value |
|---|---|
| Total number of epochs | 30 |
| Batch size | 256 |
| Optimizer | Adam |
| Learning rate (LR) | 0.01 |
| Row Number | Training SNR (dB) | Test SNR | |||||||
|---|---|---|---|---|---|---|---|---|---|
| 30 dB | 20 dB | 10 dB | 0 dB | ||||||
| ACC (%) | DOA (°) | ACC (%) | DOA (°) | ACC (%) | DOA (°) | ACC (%) | DOA (°) | ||
| 1 | 30, 20, 10, 0 | 96.01 | 4.6436 | 95.95 | 4.7519 | 95.63 | 4.9653 | 88 | 9.0297 |
| 2 | 30 | 96.53 | 3.9954 | 96.52 | 4.0413 | 92.32 | 6.5589 | 33.58 | 58.1142 |
| 3 | 20 | 96.67 | 3.8748 | 96.62 | 3.9359 | 93.19 | 5.96 | 33.61 | 59.6756 |
| 4 | 10 | 96.41 | 4.0014 | 96.39 | 4.0832 | 95.79 | 4.5159 | 55.28 | 36.6573 |
| 5 | 0 | 96.07 | 4.6869 | 96.09 | 4.6663 | 95.72 | 4.9086 | 91.41 | 7.4289 |
| 6 | X | 96.81 | 3.9654 | 96.68 | 4.0048 | 92.41 | 6.3149 | 32.99 | 57.9033 |
| Types of Blocks (Kernel Sizes) | Test SNR | Computation | |||||||
|---|---|---|---|---|---|---|---|---|---|
| 30 dB | 20 dB | 10 dB | 0 dB | ||||||
| ACC (%) | DOA (°) | ACC (%) | DOA (°) | ACC (%) | DOA (°) | ACC (%) | DOA (°) | ||
| XXO (3, 5, 7) | 95.91 | 4.7539 | 95.85 | 4.7132 | 95.52 | 4.9142 | 90.74 | 7.6871 | 3,258,868 |
| XXO (7, 9, 13) | 96.07 | 4.6869 | 96.09 | 4.6663 | 95.72 | 4.9086 | 91.41 | 7.4289 | 3,285,748 |
| Item | Batch Size | |
|---|---|---|
| 1 | 16 | |
| Inference time (ms) using Pytorch | 426.93 | 7.677 |
| Inference time (ms) using TVM | 7.811 | 5.772 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ko, J.; Kim, H.; Kim, J. Real-Time Sound Source Localization for Low-Power IoT Devices Based on Multi-Stream CNN. Sensors 2022, 22, 4650. https://doi.org/10.3390/s22124650
Ko J, Kim H, Kim J. Real-Time Sound Source Localization for Low-Power IoT Devices Based on Multi-Stream CNN. Sensors. 2022; 22(12):4650. https://doi.org/10.3390/s22124650
Chicago/Turabian StyleKo, Jungbeom, Hyunchul Kim, and Jungsuk Kim. 2022. "Real-Time Sound Source Localization for Low-Power IoT Devices Based on Multi-Stream CNN" Sensors 22, no. 12: 4650. https://doi.org/10.3390/s22124650
APA StyleKo, J., Kim, H., & Kim, J. (2022). Real-Time Sound Source Localization for Low-Power IoT Devices Based on Multi-Stream CNN. Sensors, 22(12), 4650. https://doi.org/10.3390/s22124650