
A Smart Mirror for Emotion Monitoring in Home Environments

 ,
,  ,
,  , ,
, ,  ,
, 
Abstract
:1. Introduction
- The design of a general purpose smart mirror that is easily extendable using ad-hoc modules and the integration of Alexa’s Skills;
- The integration of our deep learning-based modules for the user’s identification, facial attributes estimation, and emotional recognition from visual data;
- The design and implementation of the deep learning-based modules for both speaker identification and emotional recognition from audio signal;
- The evaluation of the audio-based recognition modules under the speaker-dependent and speaker-independent scenarios;
- The definition of a double authentication protocol for a more secure user identification;
- An extended system usability survey to evaluate the final system and gather user feedback for future improvements.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | Field | Features | Technologies |
|---|---|---|---|
| Our | G | General information, email notifications, face identification, speaker identification, emotional states monitoring, Joybar, virtual avatars, multimedia, Alexa’s Skill integration | face recognition, voice recognition, speech recognition, emotion recognition |
| [4] | G | General information, email notifications, daily schedules, graphical keyboard | speech recognition |
| [5] | G | General information, multimedia, two languages, mobile app. | - |
| [6] | G | General information, road traffic, voice commands | face detection, speech recognition |
| [7] | G | General information, voice commands | speech recognition |
| [8] | G | General information, web browsing, face identification, mobile app. | face recognition, speech recognition |
| [9] | G | General information, face identification | face recognition |
| [10] | G | General information, 3D graphics, voice commands | speech recognition, face tracking |
| [11] | G | General information | eye tracking |
| [12] | G | General information, Alexa’s Skill integration | speech recognition |
| [13] | G | Track faces, video playback | face detection |
| [14] | G | 3D visualization | gestures recognition, augmented reality |
| [15] | G | General information, voice commands, face identification | face recognition, speech recognition |
| [16] | G | General information, voice commands, home device control | speech recognition |
| [17] | G | General information, mood detection | emotion recognition |
| [18] | G | General information, voice commands | speech recognition |
| [19] | G | General information, voice commands, face identification | face recognition, speech recognition |
| [20] | G | General information, home devices control, chat assistant, face identification | Speech recognition, Face recognition |
| [21] | G | General information, voice commands | speech recognition |
| [22] | G | General information, voice commands | speech recognition |
| [23] | G | General information, voice commands | speech recognition |
| [24] | F | Fashion recommendation | gesture recognition, augmented reality |
| [25] | F | Virtual try-on, 3D visualization | virtual reality, body tracking |
| [26] | F | Virtual try-on, 3D visualization | body tracking, augmented reality |
| [27] | F | Makeup recommendation | face detection |
| [28] | F | General information, face identification, emotion detection, clothes recommendation | face recognition, emotions recognition |
| [29] | M | 3D scanning, face identification | facial expressions detection, face recognition, 3D face reconstruction |
| [30] | M | 3D graphics, fatigue detection, user fitness, digital measurements | face detection, 3D face reconstruction, face tracking |
| [31] | M | Therapy exercises | body pose tracking |
| [32] | M | Mood detection | emotion recognition |
| [33] | M | General information, health monitoring, BMI calculator (w/ sensors), face identification | face recognition |
| [34] | M | General information, smart posture assistant, face identification | face recognition, Posture recognition |
| [35] | M | General information, face identification, health monitor (w/ sensors) | face recognition |
| [36] | M | General information, music therapy | emotion recognition, face detection |
| [37] | M | General information, color therapy | emotion recognition, face detection |
| [38] | M | General information, face identification, music therapy | face recognition, emotion recognition |
| [39] | M | General information, music therapy | emotion recognition, face detection |
| Ref. | Field | Features | Technologies |
|---|---|---|---|
| [1] | G | General information, multimedia, cooking helper | hand gesture recognition |
| [40] | G | Bill payment, TV, pay per View, screen for PC applications | – |
| [41] | G | General information, health tracker, TV, weather, photos viewer, social networks feeds, mobile app | – |
| [42] | G | General information, weather, multimedia, mobile app | face recognition, hand gesture recognition |
| [43] | G | General information, weather, mobile App | – |
| [44] | F | Clothes management and recommendation, mobile App | augmented reality |
| [45] | F | Makeup recommendation, personal improvement plan | skin imperfection detection |
| [46] | H | General information, weather, transport information, events, shop, social network integration, mobile app | – |
| [47] | H | General information, hotel services, local transportation | based on IBM Watson AI |
2. Related Work
2.1. Smart Mirror Prototypes
2.2. Commercial Smart Mirrors
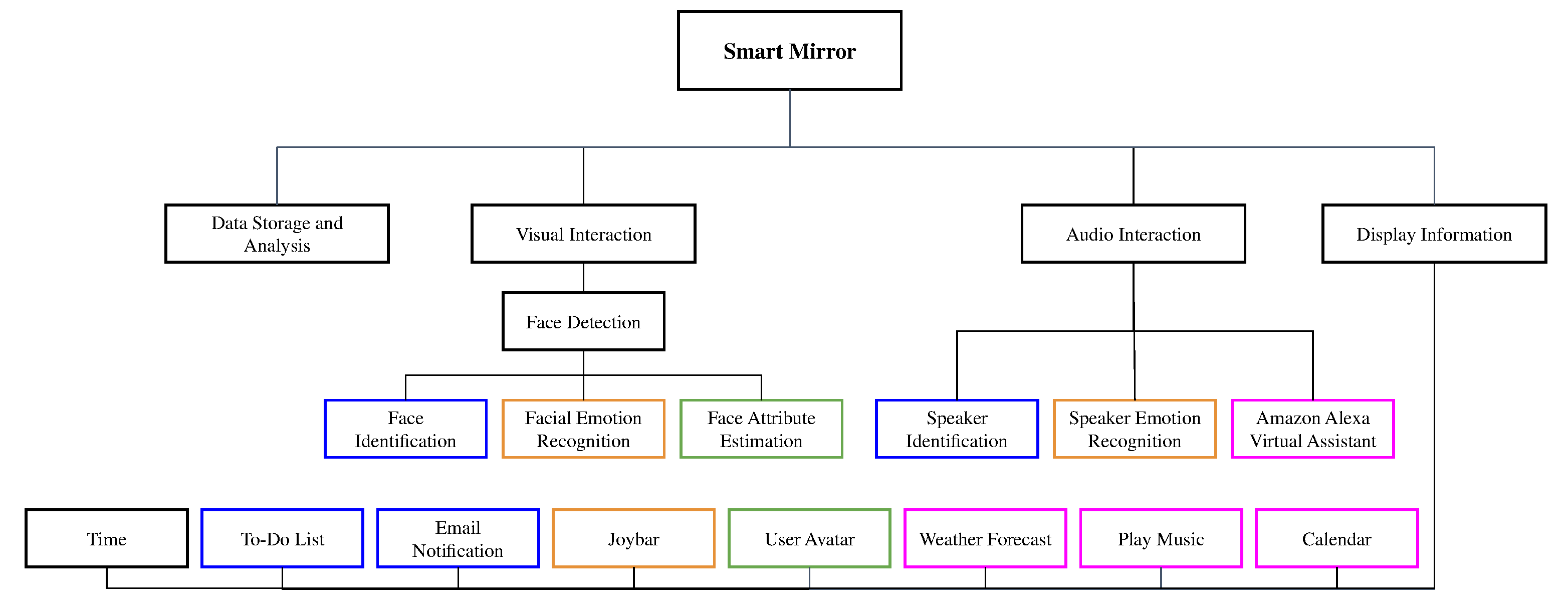
3. The Proposed Smart Mirror
3.1. Functional Requirements
- Face measurement. The subject whose detected face has the highest resolution is selected (usually the user closest to the mirror).
- User identification. The subject whose identity is known since it was previously registered is chosen. In the case of multiple registered users, the face measurement policy is also applied to them.
3.1.1. Visual Interaction
Face Detection
Face Identification
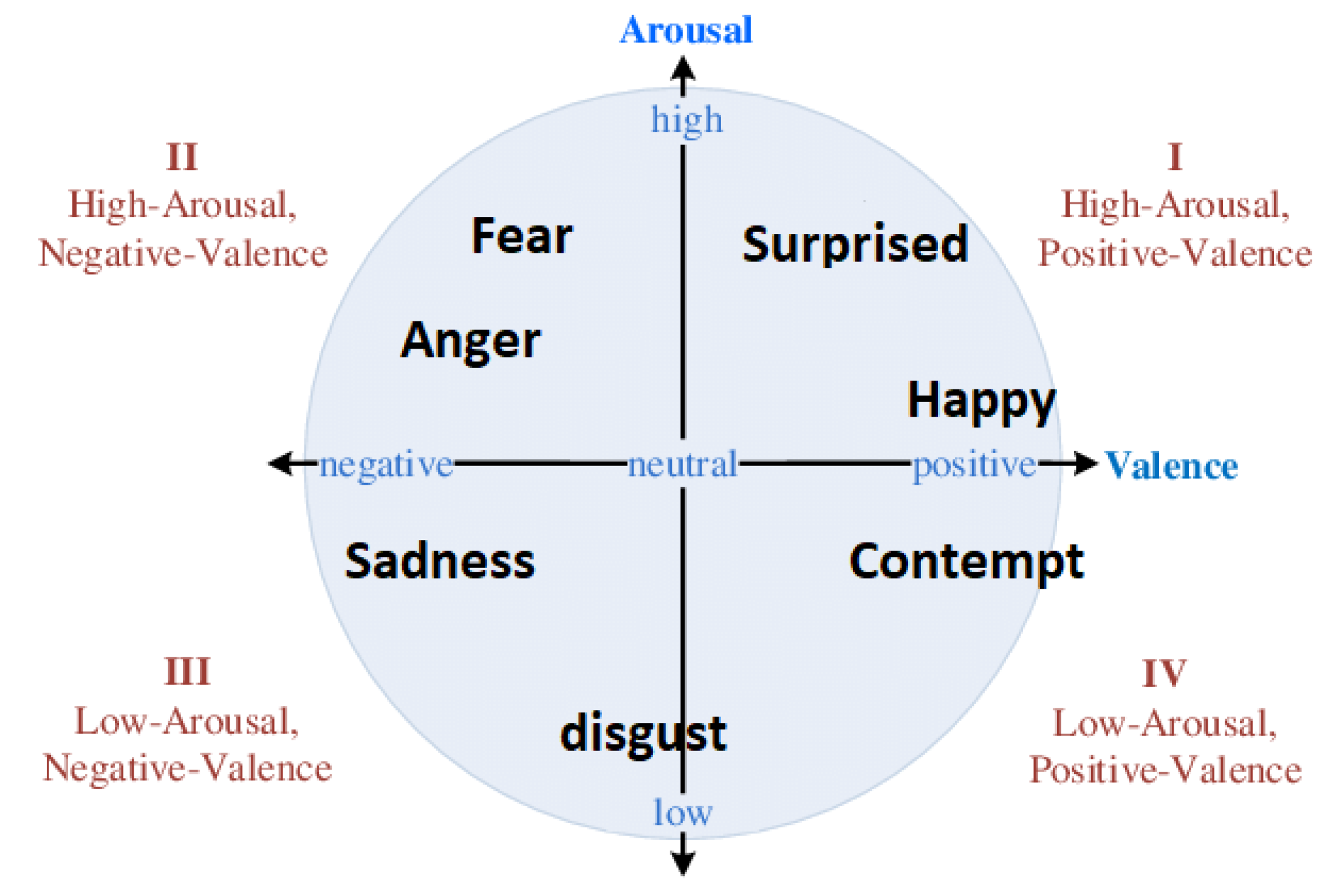
Facial Emotion Recognition
Face Attribute Estimation
3.1.2. Audio Interaction
Speaker Identification
Speaker Emotion Recognition
Amazon Alexa Virtual Assistant
3.1.3. Display Information
3.1.4. Data Storage and Analysis
3.2. Technology Deployment
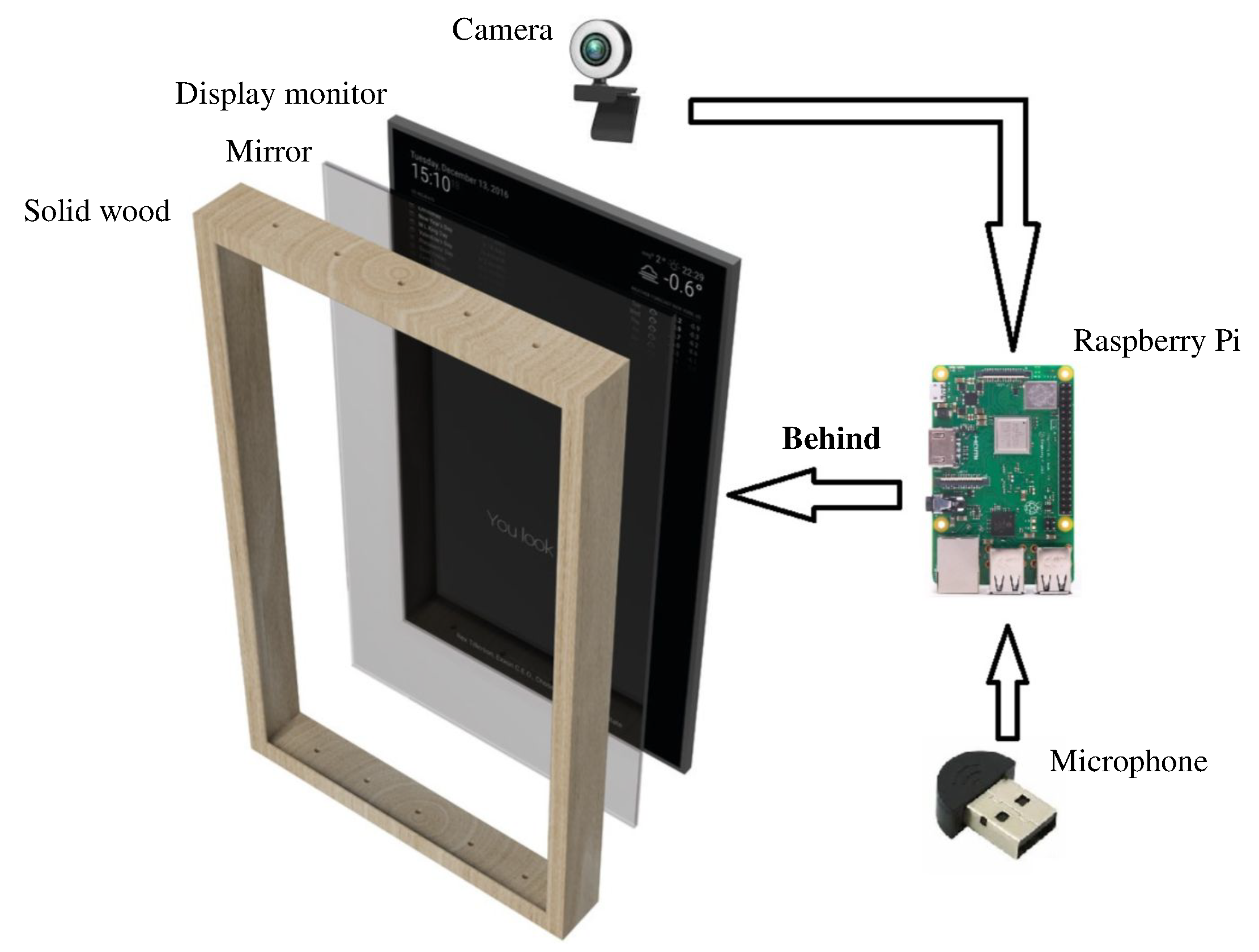
3.2.1. Hardware
- Display monitor: 27 Inch LCD monitor is used as display set.
- Micro-controller: Raspberry Pi 3B, one of the most popular single-board computer, for the role of the client.
- Camera and Microphone: 720P WebCam and Micro Microphone are employed to fulfill the visual- and audio-based functionalities.
- Mirror: A two-way surface with reflector surface properties is chosen.
- Frame: A solid wood frame box is built to cover internal components and place the display monitor.
3.2.2. Software
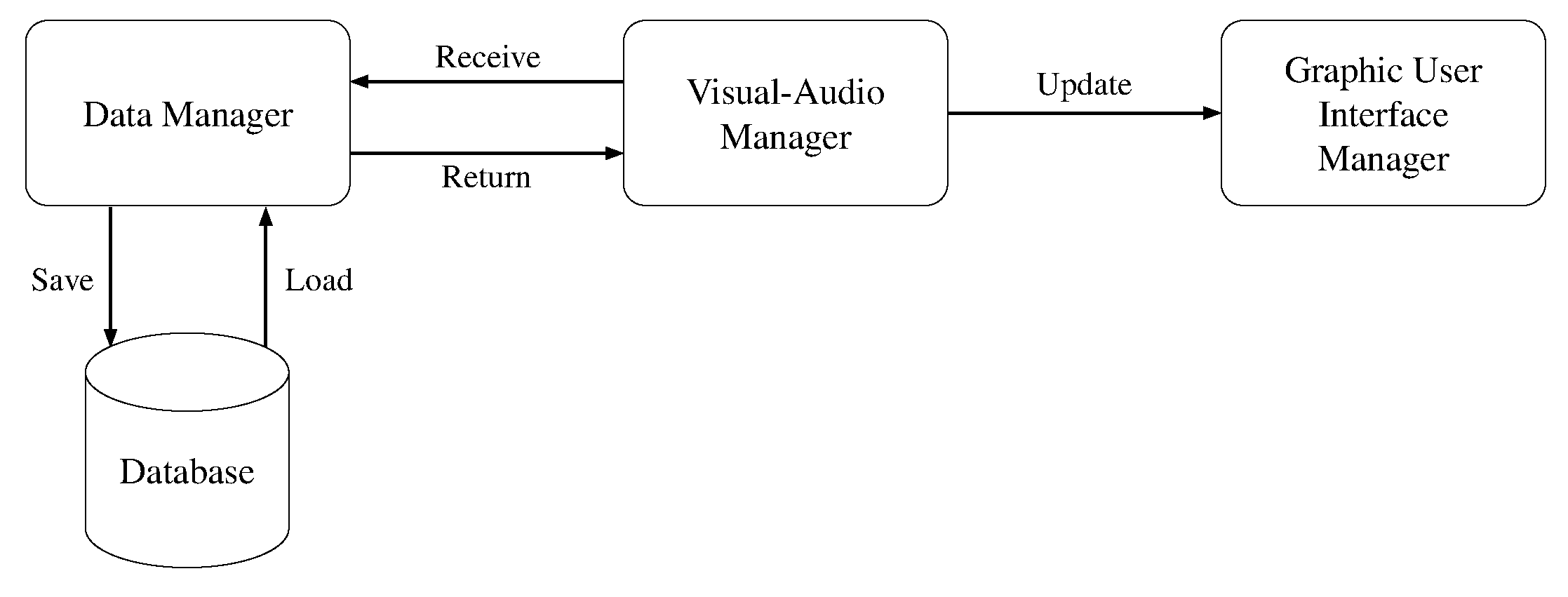
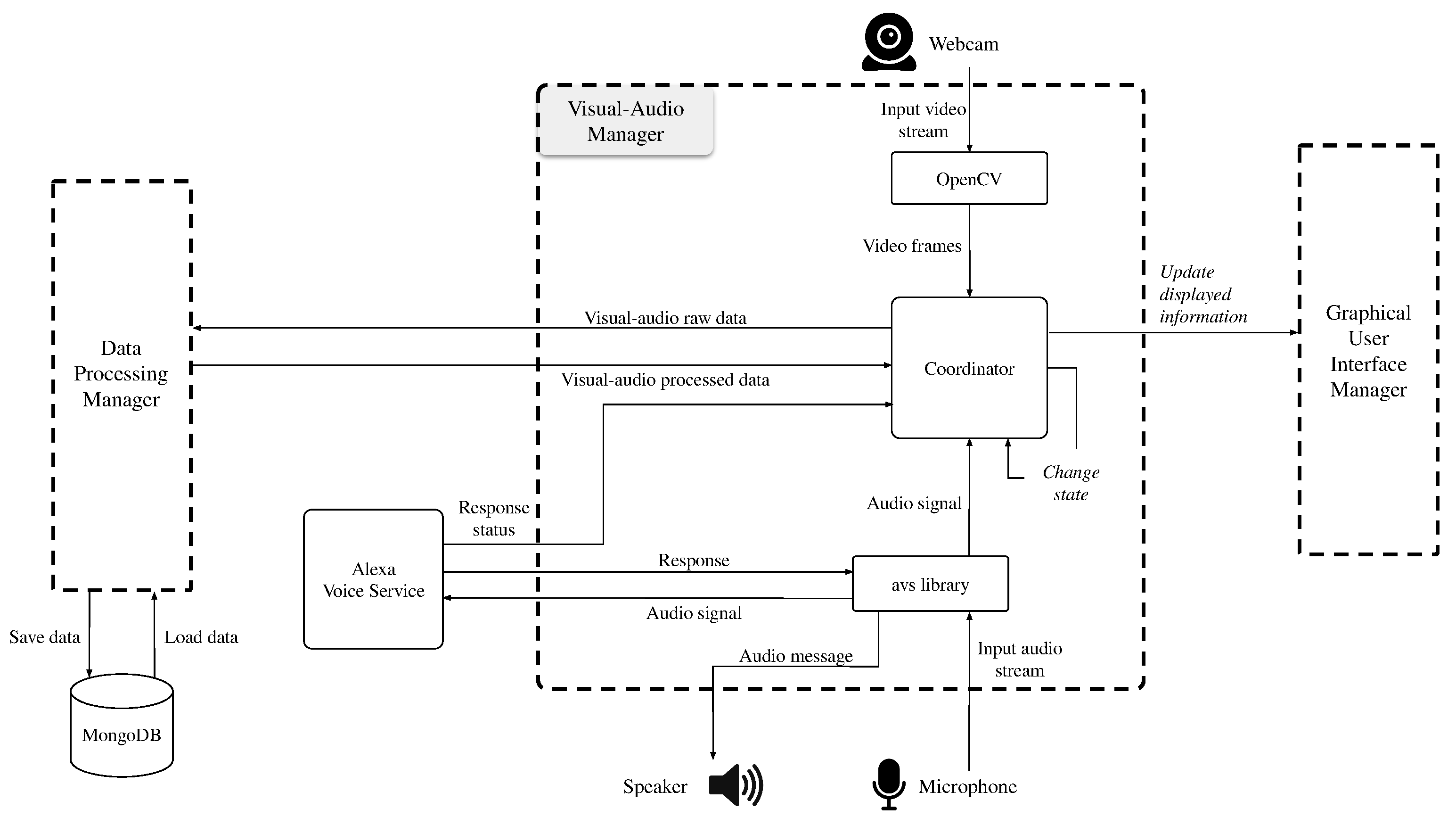
- The Visual-Audio Manager is responsible for the visual/audio inputs and outputs, including the initial interaction with Alexa, recording of audio, and capturing of visual frames.
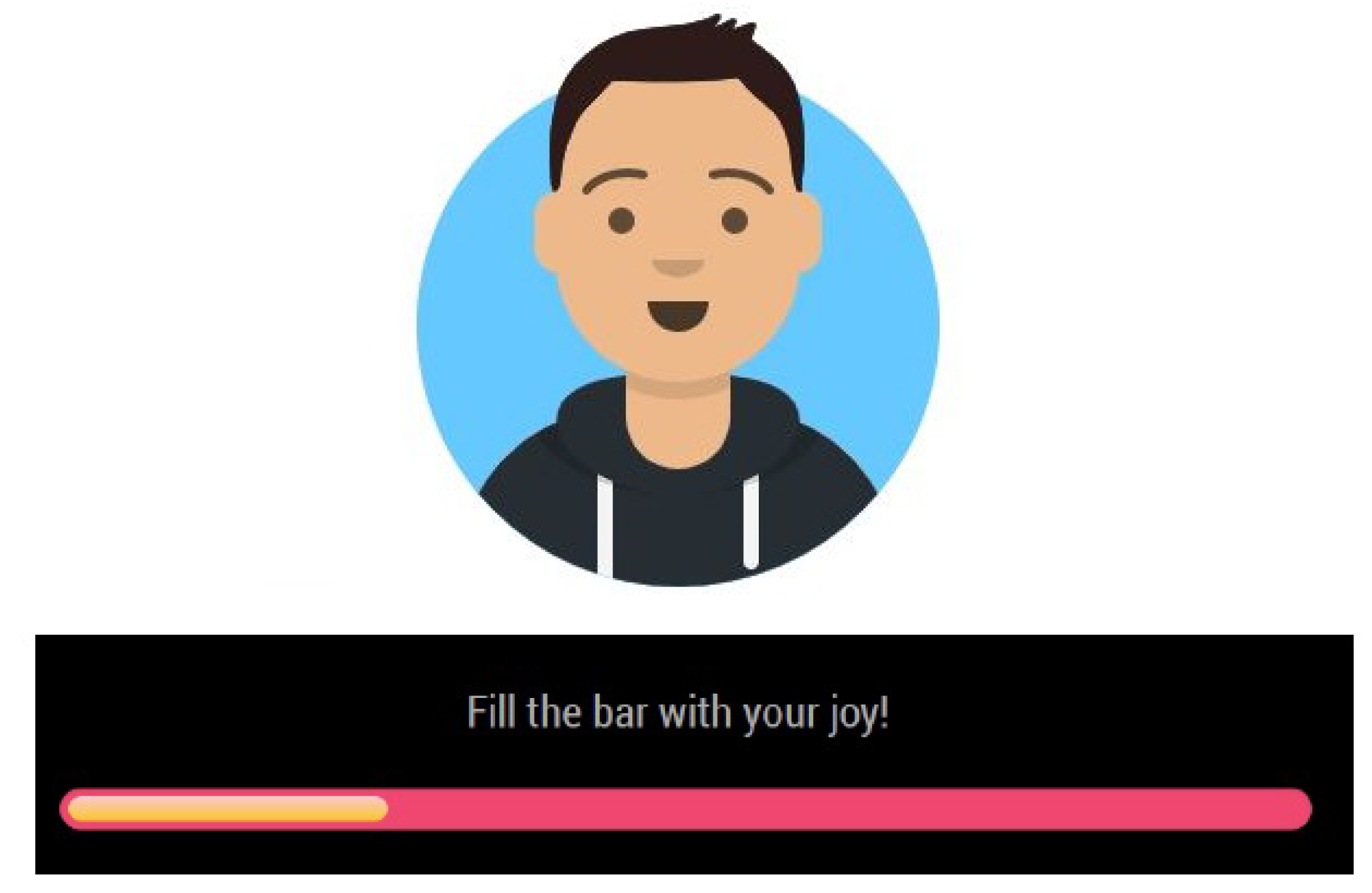
- The Graphical User Interface Manager controls the information displayed in the mirror, including the user’s avatar, messages, joybar, and additional widgets.
- The Data Processing Manager handles and computes results from the given input for both visual and audio modules, including storing the data in the appropriate database.
Visual-Audio Manager
Data Processing Manager
Graphical User Interface Manager
- Standby. It is displayed when no user is detected in front of the mirror. Whenever this page is active, a simple clock is shown, displaying the current date and time.
- User Not Identified. It is shown when an unidentified user is standing in front of the mirror. In this page, the user can see their current avatar, the joybar, which displays their current emotional valence, and a simple message for the user to say if they want to initialize the registration process.
- User Identified. It is shown when the person in front of the mirror was identified. This page is the same as that of the unidentified user except the message displayed.
- Registration. It appears when the person in front of the mirror wants to register their identity in the system. This page guides the user through the registration phase, displaying what the user has to say to complete the process.
- User’s personal page. This page shows the weather for the user’s current location and other generic information. To access this page, the user is required not only to authenticate but also to show a positive emotional value in front of the mirror (for example, smiling). This is done not only as an initiative to ask the user to give a positive stimulus, but also as a therapeutic treatment for the user to be positive more often.
4. Experiments
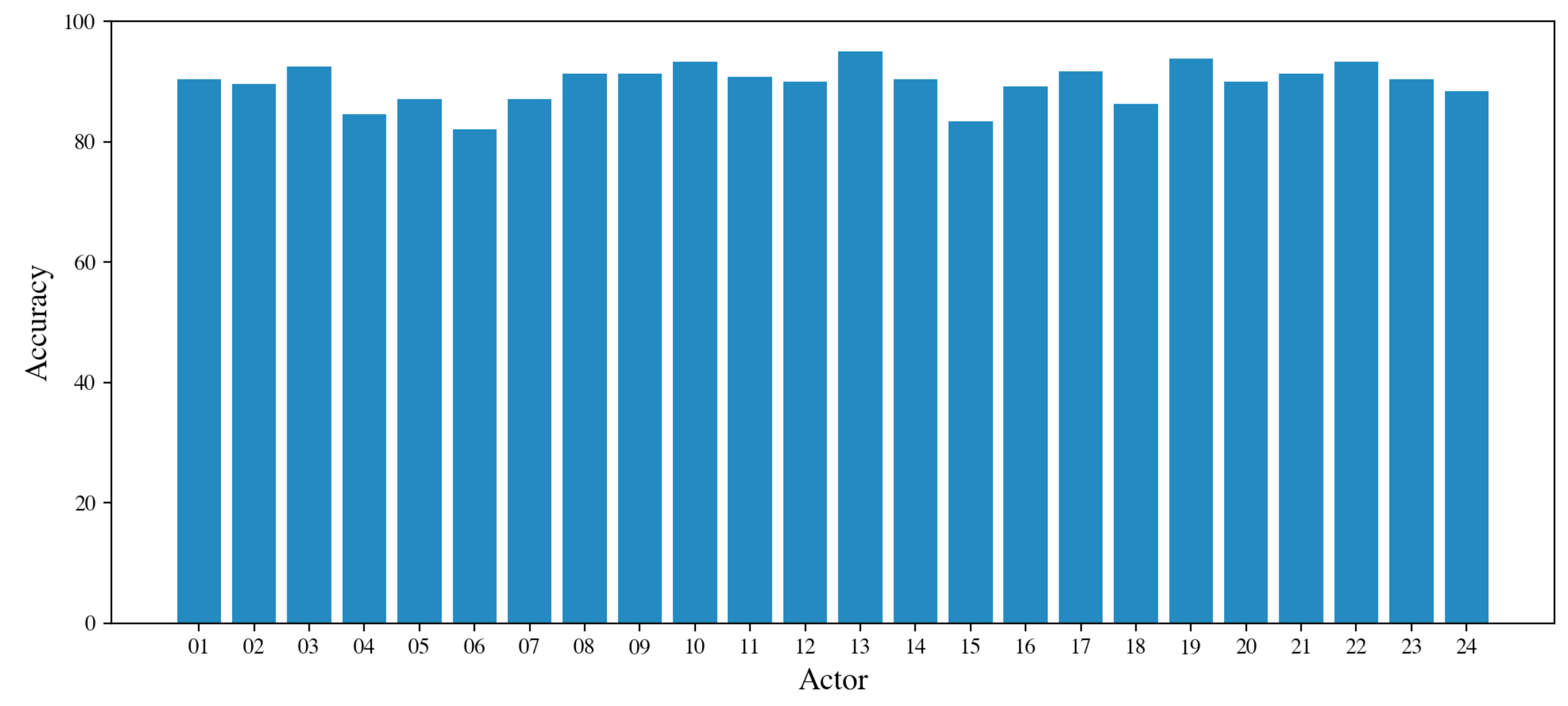
4.1. Results for Speaker Identification
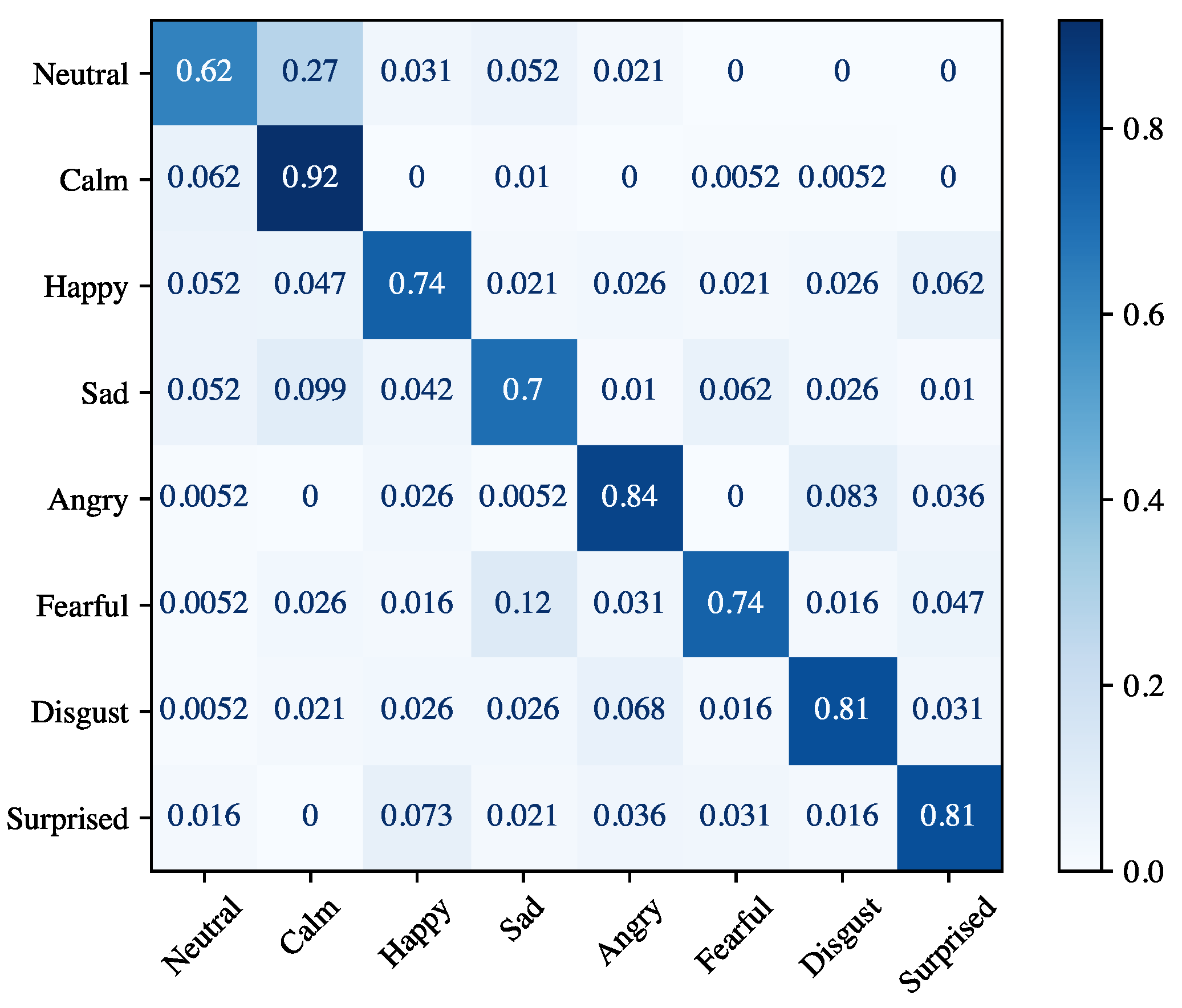
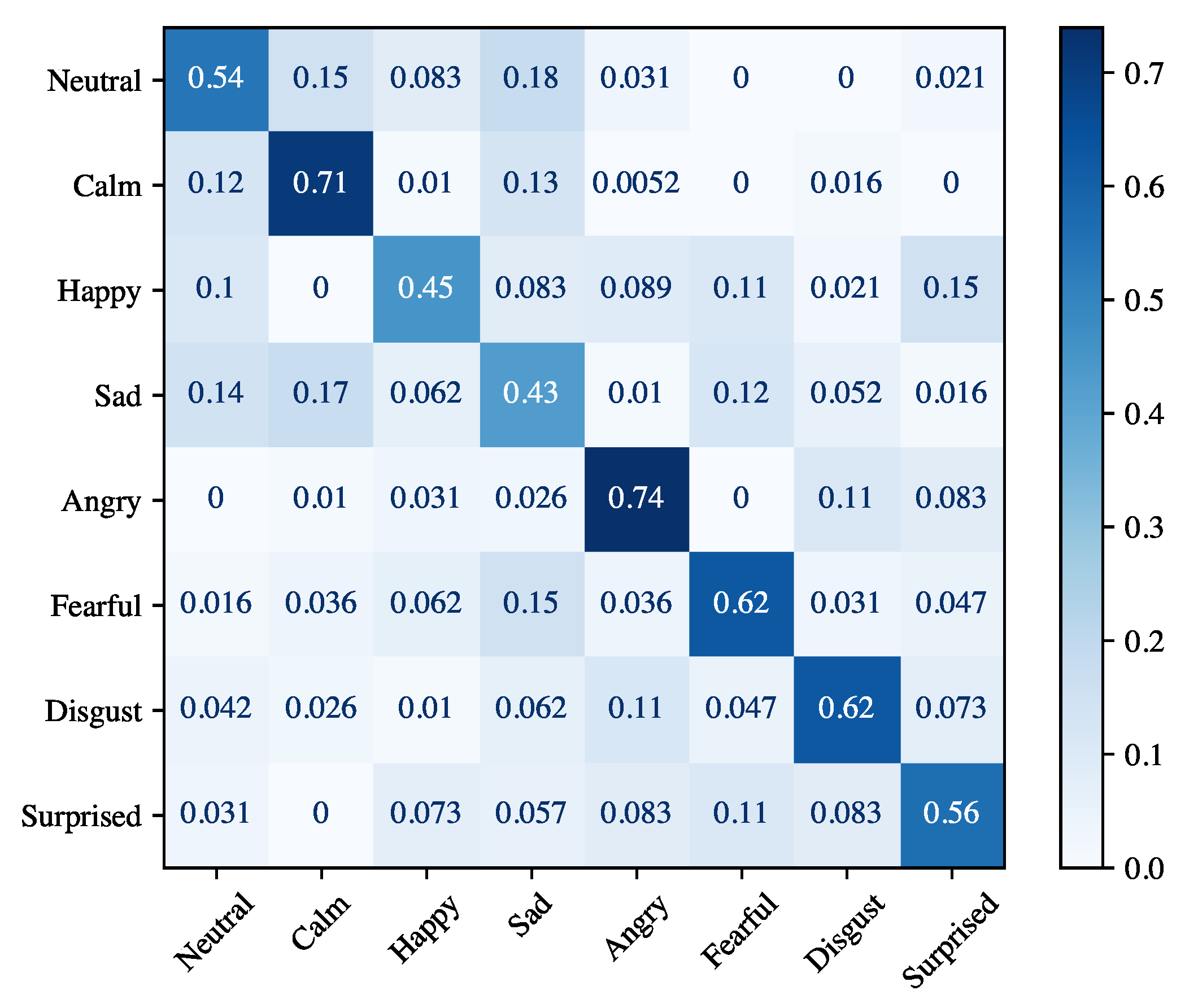
4.2. Results for Speaker Emotion Recognition
Speaker-Dependent
Speaker-Independent
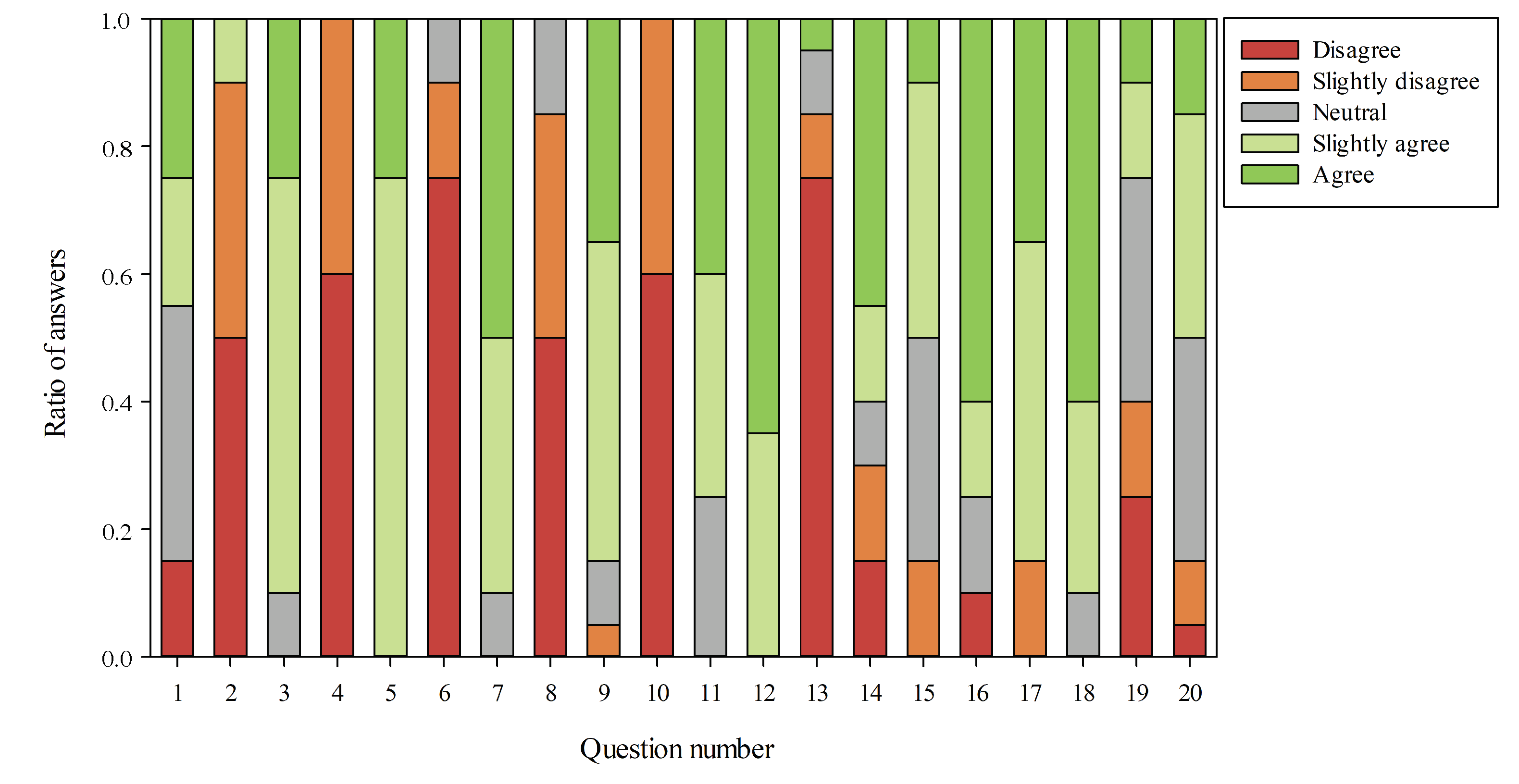
4.3. System Usability Survey
- I think I will often use this device.
- I found this device too complex.
- The device is easy to use.
- I need the support from an expert to use the device.
- I found each feature of the system well integrated.
- There are too many inconsistency in this device.
- I think the majority of the people will be able to quickly learn how to use this device.
- I found this device really uncomfortable to use.
- I felt at ease while using the device.
- I had to learn many things prior starting to use the device.
- I think the device is responsive.
- I found the registration phase easy to complete.
- I found redundant Alexa reading each written phrase on the mirror.
- I think a touchscreen interaction would be useful for the mirror.
- I found the conversation with the device natural and fluid.
- The avatar represented on the mirror is what I look like.
- I found easy to access the user’s personal page.
- I found useful the reminder feature.
- I think this device might violate my privacy.
- I would use this device on my daily life.
4.4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Mack, E. Toshiba’s Smart Mirror Concept Puts the Future on Display. 2014. Available online: https://newatlas.com/toshiba-smart-mirror-concept-ces-2014/30574/ (accessed on 15 October 2021).
- Riva, G.; Baños, R.M.; Botella, C.; Wiederhold, B.K.; Gaggioli, A. Positive technology: Using interactive technologies to promote positive functioning. Cyberpsychol. Behav. Soc. Netw. 2012, 15, 69–77. [Google Scholar] [CrossRef]
- Grossi, G.; Lanzarotti, R.; Napoletano, P.; Noceti, N.; Odone, F. Positive technology for elderly well-being: A review. Pattern Recognit. Lett. 2019, 137, 61–70. [Google Scholar] [CrossRef]
- Johri, A.; Jafri, S.; Wahi, R.N.; Pandey, D. Smart mirror: A time-saving and affordable assistant. In Proceedings of the International Conference on Computing Communication and Automation (ICCCA), Greater Noida, India, 14–15 December 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–4. [Google Scholar]
- Ghazal, M.; Al Hadithy, T.; Al Khalil, Y.; Akmal, M.; Hajjdiab, H. A mobile-programmable smart mirror for ambient iot environments. In Proceedings of the International Conference on Future Internet of Things and Cloud Workshops (FiCloudW), Prague, Czech Republic, 21–23 August 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 240–245. [Google Scholar]
- Sun, Y.; Geng, L.; Dan, K. Design of smart mirror based on Raspberry Pi. In Proceedings of the International Conference on Intelligent Transportation, Big Data & Smart City (ICITBS), Xiamen, China, 25–26 January 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 77–80. [Google Scholar]
- Athira, S.; Francis, F.; Raphel, R.; Sachin, N.; Porinchu, S.; Francis, S. Smart mirror: A novel framework for interactive display. In Proceedings of the International Conference on Circuit, Power and Computing Technologies (ICCPCT), Nagercoil, India, 18–19 March 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 1–6. [Google Scholar]
- García, I.C.A.; Salmón, E.R.L.; Riega, R.V.; Padilla, A.B. Implementation and customization of a smart mirror through a facial recognition authentication and a personalized news recommendation algorithm. In Proceedings of the IEEE International Conference on Signal-Image Technology & Internet-Based Systems (SITIS), Jaipur, India, 4–7 December 2017; pp. 35–39. [Google Scholar]
- Mohamed, A.S.A.; Wahab, M.A.; Suhaily, S.; Arasu, D.B.L. Smart mirror design powered by raspberry pi. In Proceedings of the Artificial Intelligence and Cloud Computing Conference, Tokyo, Japan, 21–23 December 2018; pp. 166–173. [Google Scholar]
- Ding, J.R.; Huang, C.L.; Lin, J.K.; Yang, J.F.; Wu, C.H. Interactive multimedia mirror system design. IEEE Trans. Consum. Electron. 2008, 54, 972–980. [Google Scholar] [CrossRef]
- Park, K.H.; Tae-Seon, K.; Heo, C.R.; Kim, M.Y.; Kim, T.K. Smart Mirror with Focus Control. U.S. Patent 10,134,370, 20 November 2018. [Google Scholar]
- Sarnin, S.S.; Akbar, A.; Mohamad, W.N.W.; Idris, A.; Fadzlina Naim, N.; Ya’acob, N. Maleficent mirror with alexa voice services as an internet of things implement using raspberry pi 3 model b. In Proceedings of the TENCON 2018–2018 IEEE Region 10 Conference, Jeju, Korea, 28–31 October 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1202–1207. [Google Scholar]
- Darrell, T.; Gordon, G.; Woodfill, J.; Harville, M. A virtual mirror interface using real-time robust face tracking. In Proceedings of the International Conference on Automatic Face and Gesture Recognition, Nara, Japan, 14–16 April 1998; IEEE: Piscataway, NJ, USA, 1998; pp. 616–621. [Google Scholar]
- Fiala, M. Magic mirror and hand-held and wearable augmentations. In Proceedings of the 2007 IEEE Virtual Reality Conference, Charlotte, NC, USA, 10–14 March 2007. [Google Scholar]
- Jin, K.; Deng, X.; Huang, Z.; Chen, S. Design of the smart mirror based on raspberry pi. In Proceedings of the Advanced Information Management, Communicates, Electronic and Automation Control Conference (IMCEC), Xi’an, China, 25–27 May 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1919–1923. [Google Scholar]
- Ganesh, H.; Sharmila, S. IoT Based Home Automation using Smart Mirror. Int. J. Innov. Sci. Res. Technol. 2019, 4, 607–612. [Google Scholar]
- Strickland, E.; Hatrie, H.H.M. HomeMirror. 2016. Available online: https://github.com/HannahMitt/HomeMirror (accessed on 15 October 2021).
- Yeo, U.C.; Park, S.H.; Moon, J.W.; An, S.W.; Han, Y.O. Smart Mirror of Personal Environment using Voice Recognition. J. Korea Inst. Electron. Commun. Sci. 2019, 14, 199–204. [Google Scholar]
- D’souza, A.A.; Kaul, P.; Paul, E.; Dhuri, M. Ambient Intelligence Using Smart Mirror-Personalized Smart Mirror for Home Use. In Proceedings of the Bombay Section Signature Conference (IBSSC), Mumbai, India, 26–28 July 2018; IEEE: Piscataway, NJ, USA, 2019; pp. 1–5. [Google Scholar]
- Mathivanan, P.; Anbarasan, G.; Sakthivel, A.; Selvam, G. Home automation using smart mirror. In Proceedings of the International Conference on System, Computation, Automation and Networking (ICSCAN), Pondicherry, India, 29–30 March 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–4. [Google Scholar]
- Bahendwar, I.; Bhardwaj, R.; Hindaria, S.; Rathod, V. Mirr-Active An Aritificially Intelligent Interactive Mirror. In Proceedings of the International Conference on Advanced Computation and Telecommunication (ICACAT), Bhopal, India, 28–29 December 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–6. [Google Scholar]
- Kafi, A.; Alam, M.S.A.; Hossain, S.B. Artificially intelligent smart mirror using Raspberry Pi. Int. J. Comput. Appl. 2018, 180, 15–18. [Google Scholar] [CrossRef]
- Kawale, J.; Chaudhari, P. IoT based Design of Intelligent Mirror using Raspberry Pi. In Proceedings of the International Conference for Convergence in Technology (I2CT), Pune, India, 29–31 March 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–4. [Google Scholar]
- Liu, Y.; Jia, J.; Fu, J.; Ma, Y.; Huang, J.; Tong, Z. Magic mirror: A virtual fashion consultant. In Proceedings of the International Conference on Multimedia, Amsterdam, The Netherlands, 15–19 October 2016; pp. 680–683. [Google Scholar]
- Wang, L.; Villamil, R.; Samarasekera, S.; Kumar, R. Magic mirror: A virtual handbag shopping system. In Proceedings of the Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Providence, RI, USA, 16–21 June 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 19–24. [Google Scholar]
- Saakes, D.; Yeo, H.S.; Noh, S.T.; Han, G.; Woo, W. Mirror mirror: An on-body t-shirt design system. In Proceedings of the CHI Conference on Human Factors in Computing Systems, San Jose, CA, USA, 7–12 May 2016; pp. 6058–6063. [Google Scholar]
- Nguyen, T.V.; Liu, L. Smart mirror: Intelligent makeup recommendation and synthesis. In Proceedings of the International Conference on Multimedia, Mountain View, CA, USA, 23–27 October 2017; ACM: New York, NY, USA, 2017; pp. 1253–1254. [Google Scholar]
- Sethukkarasi, C.; HariKrishnan, V.; PalAmutha, K.; Pitchian, R. Interactive mirror for smart home. Int. J. Adv. Intell. Syst. 2016, 9, 148–160. [Google Scholar]
- Andreu, Y.; Chiarugi, F.; Colantonio, S.; Giannakakis, G.; Giorgi, D.; Henriquez, P.; Kazantzaki, E.; Manousos, D.; Marias, K.; Matuszewski, B.J.; et al. Wize Mirror-a smart, multisensory cardio-metabolic risk monitoring system. Elsevier Comput. Vis. Image Underst. 2016, 148, 3–22. [Google Scholar] [CrossRef] [Green Version]
- Henriquez, P.; Matuszewski, B.J.; Andreu-Cabedo, Y.; Bastiani, L.; Colantonio, S.; Coppini, G.; D’Acunto, M.; Favilla, R.; Germanese, D.; Giorgi, D.; et al. Mirror mirror on the wall... an unobtrusive intelligent multisensory mirror for well-being status self-assessment and visualization. IEEE Trans. Multimed. 2017, 19, 1467–1481. [Google Scholar] [CrossRef]
- Erazo, O.; Pino, J.A.; Pino, R.; Asenjo, A.; Fernández, C. Magic mirror for neurorehabilitation of people with upper limb dysfunction using kinect. In Proceedings of the Hawaii International Conference on System Sciences, Waikoloa, HI, USA, 6–9 January 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 2607–2615. [Google Scholar]
- Von Hollen, S.; Reeh, B. Smart Mirror Devices. In Proceedings of the International Conference on Innovations for Community Services, Bhubaneswar, India, 24–26 June 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 194–204. [Google Scholar]
- Muneer, A.; Fati, S.M.; Fuddah, S. Smart health monitoring system using IoT based smart fitness mirror. Telkomnika 2020, 18, 317–331. [Google Scholar] [CrossRef]
- Cvetkoska, B.; Marina, N.; Bogatinoska, D.C.; Mitreski, Z. Smart mirror E-health assistant—Posture analyze algorithm proposed model for upright posture. In Proceedings of the International Conference on Smart Technologies, Bengaluru, India, 17 August 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 507–512. [Google Scholar]
- Moon, Y.B.; Oh, S.W.; Kang, H.J.; Lee, H.S.; Kim, S.J.; Bang, H.C. Smart mirror health management services based on iot platform. In Proceedings of the International Conference on Applications of Computer Engineering (ACE’15), Seoul, Korea, 5–7 September 2015; pp. 87–89. [Google Scholar]
- Iyer, S.R.; Basu, S.; Yadav, S.; Vijayanand, V.M.; Badrinath, K. Reasonably intelligent mirror. In Proceedings of the International Conference on Computational Systems and Information Technology for Sustainable Solutions (CSITSS), Karnataka, India, 20–22 December 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 302–306. [Google Scholar]
- Yang, R.P.; Liu, Z.T.; Zheng, L.D.; Wu, J.P.; Hu, C.C. Intelligent Mirror System Based on Facial Expression Recognition and Color Emotion Adaptation——iMirror. In Proceedings of the Chinese Control Conference (CCC), Wuhan, China, 25–27 July 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 3227–3232. [Google Scholar]
- Yu, Y.C.; You, S.D.; Tsai, D.R. Magic mirror table for social-emotion alleviation in the smart home. IEEE Trans. Consum. Electron. 2012, 58, 126–131. [Google Scholar] [CrossRef]
- Honnali, V.; Honnali, M.P.; Vibhuti, M.A.; Malakannavar, M.R. Design and Implementation of Magic Mirror for Social-Emotion Alleviation in the Smart Home Using GSM. Available online: http://www.kscst.iisc.ernet.in/spp/41_series/SPP41S/02_Exhibition_Projects/234_41S_BE_1440.pdf (accessed on 6 November 2021).
- Hanlon, M. Philips HomeLab Creates Mirror TV. 2004. Available online: https://newatlas.com/philips-homelab-creates-mirror-tv/2003/ (accessed on 15 October 2021).
- Groups Inc., C. Mango Mirror. Available online: https://www.mangomirror.com/ (accessed on 15 October 2021).
- Hanlon, M. Ekko Smart Mirror Puts a Wealth of Information Right in Front of Your Face. 2016. Available online: https://www.digitaltrends.com/home/ekko-smart-mirror-integrates-functional-technology-everyday-object/ (accessed on 15 October 2021).
- Crist, R. Griffin Technology Takes a Stab at the Smart Mirror at CES 2017. 2017. Available online: https://www.cnet.com/reviews/griffin-technology-connected-mirror-preview/ (accessed on 15 October 2021).
- Memomi. Memory Mirror. Available online: https://memorymirror.com/ (accessed on 15 October 2021).
- Carman, A. The HiMirror Plus Scanned My Face and Told Me I Have Wrinkles. 2017. Available online: https://www.theverge.com/2017/1/4/14166064/himirror-plus-scan-smart-mirror-ces-2017/ (accessed on 15 October 2021).
- Airnodes. Anna Smart Mirror. Available online: https://www.miroir-anna.com/ (accessed on 15 October 2021).
- Panasonic. Digital Concierge—Advanced Smart Mirror with IBM Watson. 2017. Available online: https://channel.panasonic.com/contents/19698/ (accessed on 15 October 2021).
- Tater, L.; Pranjale, S.; Lade, S.; Nimbalkar, A.; Mahalle, P. IoT based Assistive Smart Mirror with Human Emotion Recognition System. Int. J. Eng. Res. Technol. (IJERT) 2020, 9, 381–385. [Google Scholar]
- Bianco, S.; Celona, L.; Napoletano, P. Visual-based sentiment logging in magic smart mirrors. In Proceedings of the International Conference on Consumer Electronics-Berlin (ICCE-Berlin), Berlin, Germany, 2–5 September 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–4. [Google Scholar]
- Bhosale, S.; Deshmukh, P.; Daware, M.; Pawar, R.; Boraste, P. An Industrial Purpose Smart Mirror For Mood Detection. Int. J. Emerg. Trends Technol. 2019, 6, 13044–13046. [Google Scholar]
- Miotto, R.; Danieletto, M.; Scelza, J.R.; Kidd, B.A.; Dudley, J.T. Reflecting health: Smart mirrors for personalized medicine. NPJ Digit. Med. 2018, 1, 62. [Google Scholar] [CrossRef]
- Silapasuphakornwong, P.; Uehira, K. Smart Mirror for Elderly Emotion Monitoring. In Proceedings of the Global Conference on Life Sciences and Technologies (LifeTech), Nara, Japan, 9–11 March 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 356–359. [Google Scholar]
- Yu, H.; Bae, J.; Choi, J.; Kim, H. LUX: Smart Mirror with Sentiment Analysis for Mental Comfort. Sensors 2021, 21, 3092. [Google Scholar] [CrossRef]
- CareOS. CareOS—The First Smart Health & Beauty Platform for the Bathroom. 2021. Available online: https://care-os.com/themis/ (accessed on 15 October 2021).
- King, D.E. Dlib-ml: A machine learning toolkit. J. Mach. Learn. Res. 2009, 10, 1755–1758. [Google Scholar]
- Kazemi, V.; Sullivan, J. One millisecond face alignment with an ensemble of regression trees. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; IEEE: Piscataway, NJ, USA, 2014. [Google Scholar]
- Bianco, S.; Celona, L.; Schettini, R. Who Is in the Crowd? Deep Face Analysis for Crowd Understanding. In Proceedings of the International Conference on Pattern Recognition, Chengdu, China, 16–18 July 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 487–494. [Google Scholar]
- Mollahosseini, A.; Hasani, B.; Mahoor, M.H. Affectnet: A database for facial expression, valence, and arousal computing in the wild. IEEE Trans. Affect. Comput. 2017, 10, 18–31. [Google Scholar] [CrossRef] [Green Version]
- Celona, L.; Bianco, S.; Schettini, R. Fine-grained face annotation using deep multi-task cnn. Sensors 2018, 18, 2666. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, Z.; Luo, P.; Wang, X.; Tang, X. Deep learning face attributes in the wild. In Proceedings of the International Conference on Computer Vision, Las Condes, Chile, 11–18 December 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 3730–3738. [Google Scholar]
- Bianco, S.; Cereda, E.; Napoletano, P. Discriminative Deep Audio Feature Embedding for Speaker Recognition in the Wild. In Proceedings of the International Conference on Consumer Electronics-Berlin (ICCE-Berlin), Berlin, Germany, 2–5 September 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–5. [Google Scholar]
- Nagrani, A.; Chung, J.S.; Zisserman, A. VoxCeleb: A large-scale speaker identification dataset. arXiv 2017, arXiv:1706.08612. [Google Scholar]
- Cao, H.; Cooper, D.G.; Keutmann, M.K.; Gur, R.C.; Nenkova, A.; Verma, R. Crema-d: Crowd-sourced emotional multimodal actors dataset. IEEE Trans. Affect. Comput. 2014, 5, 377–390. [Google Scholar] [CrossRef] [Green Version]
- Burkhardt, F.; Paeschke, A.; Rolfes, M.; Sendlmeier, W.F.; Weiss, B. A database of German emotional speech. In Proceedings of the European Conference on Speech Communication and Technology, Lisbon, Portugal, 4–8 September 2005. [Google Scholar]
- Wang, W. Machine Audition: Principles, Algorithms and Systems: Principles, Algorithms and Systems; IGI Global: Hershey, PA, USA, 2010. [Google Scholar]
- Pichora-Fuller, M.K.; Dupuis, K. Toronto Emotional Speech Set (TESS); Draft Version; Scholars Portal Dataverse: Toronto, ON, Canada, 2020. [Google Scholar]
- React Component for Avataaars. Available online: https://github.com/fangpenlin/avataaars (accessed on 15 October 2021).
- Sollfrank, T.; Kohnen, O.; Hilfiker, P.; Kegel, L.C.; Jokeit, H.; Brugger, P.; Loertscher, M.L.; Rey, A.; Mersch, D.; Sternagel, J.; et al. The effects of dynamic and static emotional facial expressions of humans and their avatars on the EEG: An ERP and ERD/ERS study. Front. Neurosci. 2021, 15, 459. [Google Scholar] [CrossRef] [PubMed]
- Fabri, M.; Elzouki, S.Y.A.; Moore, D. Emotionally expressive avatars for chatting, learning and therapeutic intervention. In Proceedings of the International Conference on Human-Computer Interaction, Beijing, China, 22–27 July 2007; Springer: Berlin/Heidelberg, Germany, 2007; pp. 275–285. [Google Scholar]
- Rehm, I.C.; Foenander, E.; Wallace, K.; Abbott, J.A.M.; Kyrios, M.; Thomas, N. What role can avatars play in e-mental health interventions? Exploring new models of client–therapist interaction. Front. Psychiatry 2016, 7, 186. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Python Alexa Voice Service App. Available online: https://pypi.org/project/avs/ (accessed on 15 October 2021).
- Livingstone, S.R.; Russo, F.A. The Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS): A dynamic, multimodal set of facial and vocal expressions in North American English. PLoS ONE 2018, 13, e0196391. [Google Scholar]
- Brooke, J. SUS-A quick and dirty usability scale. Usability Eval. Ind. 1996, 189, 4–7. [Google Scholar]
- Vakhshiteh, F.; Nickabadi, A.; Ramachandra, R. Adversarial attacks against face recognition: A comprehensive study. IEEE Access 2021, 9, 92735–92756. [Google Scholar] [CrossRef]
- Joshi, S.; Villalba, J.; Żelasko, P.; Moro-Velázquez, L.; Dehak, N. Study of Pre-processing Defenses against Adversarial Attacks on State-of-the-art Speaker Recognition Systems. IEEE Trans. Inf. Forensics Secur. 2021, 16, 4811–4826. [Google Scholar] [CrossRef]
- Chen, Z.; Gu, S.; Zhu, F.; Xu, J.; Zhao, R. Improving Facial Attribute Recognition by Group and Graph Learning. In Proceedings of the International Conference on Multimedia and Expo (ICME), Shenzhen, China, 5–9 July 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–6. [Google Scholar]
- Kwon, S. Optimal feature selection based speech emotion recognition using two-stream deep convolutional neural network. Int. J. Intell. Syst. 2021, 36, 5116–5135. [Google Scholar]
- Kalhor, E.; Bakhtiari, B. Speaker independent feature selection for speech emotion recognition: A multi-task approach. Multimed. Tools Appl. 2021, 80, 8127–8146. [Google Scholar] [CrossRef]
- Bianco, S.; Cadene, R.; Celona, L.; Napoletano, P. Benchmark analysis of representative deep neural network architectures. IEEE Access 2018, 6, 64270–64277. [Google Scholar] [CrossRef]












| Index | Attribute | Index | Attribute | Index | Attribute | Index | Attribute |
|---|---|---|---|---|---|---|---|
| 1 | 5o’Clock Shadow | 11 | Blurry | 21 | Male | 31 | Sideburns |
| 2 | Arched Eyebrows | 12 | Brown Hair | 22 | Mouth Slightly Open | 32 | Smiling |
| 3 | Attractive | 13 | Bushy Eyebrows | 23 | Mustache | 33 | Straight Hair |
| 4 | Bags Under Eyes | 14 | Chubby | 24 | Narrow Eyes | 34 | Wavy Hair |
| 5 | Bald | 15 | Double Chin | 25 | No Beard | 35 | Wearing Earrings |
| 6 | Bangs | 16 | Eyeglasses | 26 | Oval Face | 36 | Wearing Hat |
| 7 | Big Lips | 17 | Goatee | 27 | Pale Skin | 37 | Wearing Lipstick |
| 8 | Big Nose | 18 | Gray Hair | 28 | Pointy Nose | 38 | Wearing Necklace |
| 9 | Black Hair | 19 | Heavy Makeup | 29 | Receding Hairline | 39 | Wearing Necktie |
| 10 | Blond Hair | 20 | High Cheekbones | 30 | Rosy Cheeks | 40 | Young |
| CREMA-D | EMO-DB | SAVEE | TESS | |
|---|---|---|---|---|
| # samples | 7442 | 535 | 480 | 2800 |
| # actors | 91 | 10 | 4 | 2 |
| # male | 48 | 5 | 4 | 0 |
| # female | 43 | 5 | 0 | 2 |
| # of Emotions | 6 | 7 | 7 | 7 |
| Age Range | 20–74 | 21–35 | 27–31 | 26–64 |
| Actors first Language | English | German | English | English |
| Actors Origin Accent | Multiethnic | Germany | South-East England | North American |
| Sample rate | 16,000 | 16,000 | 44,100 | 24,414 |
| Precision | Recall | F1-Score | Accuracy | |
|---|---|---|---|---|
| Average | 99.70 ± 1.70 | 99.65 ± 2.06 | 99.66 ± 1.48 | 99.97 ± 0.12 |
| Precision | Recall | F1-Score | Accuracy | |
|---|---|---|---|---|
| Angry | 85.63 ± 13.02 | 84.24 ± 5.84 | 84.09 ± 5.78 | 95.47 ± 2.32 |
| Calm | 74.23 ± 6.06 | 91.78 ± 5.00 | 81.74 ± 2.62 | 94.51 ± 0.99 |
| Disgust | 83.68 ± 7.52 | 80.26 ± 7.27 | 81.42 ± 3.50 | 95.14 ± 0.97 |
| Fearful | 86.14 ± 9.13 | 73.55 ± 15.43 | 77.70 ± 9.45 | 94.72 ± 1.53 |
| Happy | 80.47 ± 9.72 | 74.63 ± 7.94 | 76.84 ± 6.02 | 93.97 ± 1.65 |
| Neutral | 62.29 ± 2.77 | 61.97 ± 13.93 | 61.11 ± 6.92 | 94.88 ± 1.50 |
| Sad | 77.02 ± 9.51 | 69.70 ± 14.71 | 71.44 ± 7.28 | 92.91 ± 0.97 |
| Surprised | 83.49 ± 12.96 | 79.22 ± 17.13 | 78.89 ± 10.65 | 94.91 ± 1.71 |
| Average | 79.12 ± 12.00 | 76.92 ± 14.58 | 76.65 ± 9.82 | 94.56 ± 1.69 |
| Precision | Recall | F1-Score | Accuracy | |
|---|---|---|---|---|
| Angry | 78.64 ± 20.78 | 73.96 ± 24.45 | 70.29 ± 19.91 | 91.81 ± 5.83 |
| Calm | 79.18 ± 19.48 | 71.35 ± 30.93 | 66.38 ± 24.95 | 91.94 ± 4.21 |
| Disgust | 69.70 ± 23.63 | 62.50 ± 28.64 | 61.28 ± 23.24 | 90.83 ± 3.97 |
| Fearful | 74.10 ± 22.93 | 62.50 ± 27.24 | 60.86 ± 22.53 | 89.86 ± 7.13 |
| Happy | 77.35 ± 26.44 | 44.79 ± 29.52 | 47.30 ± 24.14 | 88.75 ± 4.60 |
| Neutral | 50.44 ± 35.06 | 54.17 ± 41.25 | 40.22 ± 30.81 | 90.83 ± 6.70 |
| Sad | 61.74 ± 33.27 | 42.71 ± 30.39 | 39.58 ± 23.84 | 84.44 ± 11.35 |
| Surprised | 73.74 ± 23.39 | 56.25 ± 30.41 | 55.64 ± 20.91 | 89.17 ± 6.38 |
| Average | 70.61 ± 27.77 | 58.53 ± 32.47 | 55.19 ± 26.35 | 89.70 ± 7.03 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bianco, S.; Celona, L.; Ciocca, G.; Marelli, D.; Napoletano, P.; Yu, S.; Schettini, R. A Smart Mirror for Emotion Monitoring in Home Environments. Sensors 2021, 21, 7453. https://doi.org/10.3390/s21227453
Bianco S, Celona L, Ciocca G, Marelli D, Napoletano P, Yu S, Schettini R. A Smart Mirror for Emotion Monitoring in Home Environments. Sensors. 2021; 21(22):7453. https://doi.org/10.3390/s21227453
Chicago/Turabian StyleBianco, Simone, Luigi Celona, Gianluigi Ciocca, Davide Marelli, Paolo Napoletano, Stefano Yu, and Raimondo Schettini. 2021. "A Smart Mirror for Emotion Monitoring in Home Environments" Sensors 21, no. 22: 7453. https://doi.org/10.3390/s21227453