
A Multi-Dimensional Goal Aircraft Guidance Approach Based on Reinforcement Learning with a Reward Shaping Algorithm


1
College of Computer Science, Sichuan University, Chengdu 610065, China
2
School of Aeronautics and Astronautics, Sichuan University, Chengdu 610065, China
*
Author to whom correspondence should be addressed.
Sensors 2021, 21(16), 5643; https://doi.org/10.3390/s21165643
Submission received: 9 July 2021
/
Revised: 6 August 2021
/
Accepted: 9 August 2021
/
Published: 21 August 2021
(This article belongs to the Topic Intelligent Transportation Systems)
Abstract
:Guiding an aircraft to 4D waypoints at a certain heading is a multi-dimensional goal aircraft guidance problem. In order to improve the performance and solve this problem, this paper proposes a multi-layer RL approach. The approach enables the autopilot in an ATC simulator to guide an aircraft to 4D waypoints at certain latitude, longitude, altitude, heading, and arrival time, respectively. To be specific, a multi-layer RL approach is proposed to simplify the neural network structure and reduce the state dimensions. A shaped reward function that involves the potential function and Dubins path method is applied. Experimental and simulation results show that the proposed approach can significantly improve the convergence efficiency and trajectory performance. Furthermore, the results indicate possible application prospects in team aircraft guidance tasks, since the aircraft can directly approach a goal without waiting in a specific pattern, thereby overcoming the problem of current ATC simulators.
1. Introduction
Aircraft guidance [1,2,3,4], especially high-dimensional aircraft guidance, has gradually emerged as a significant research focus in academic circles, owing to the application prospects in complex flight tasks and under realistic conditions. In military exercises, pilots usually need to fly to a series of 4D waypoints [5], which are arranged by air traffic controllers (ATCOs) in advance when performing complex flight tasks. For example, in team aircraft landing tasks, aircraft will sequentially arrive at landing 4D waypoints, and the arrival heading angle of the aircraft is required. The aircraft guidance becomes complicated when the arrival heading angle is taken into account, especially when the arrival time is also considered. Thus, it is essential to seek an approach to solve the multi-dimensional goal aircraft guidance problem, so as to guide an aircraft to 4D waypoints at a certain heading.
Researchers have made significant contributions to aircraft guidance. New local quadratic-biquadratic quality functions [6] were used to obtain more general linear-cubic control laws for aircraft guidance. For altitude and position control, in a previous study [7], incremental nonlinear dynamic inversion control was proposed, which is able to track the desired acceleration of the vehicle across the flight envelope. In another previous study [8], a visual/inertial integrated carrier landing guidance algorithm was proposed for aircraft carrier landing, of which the simulation results showed satisfactory accuracy and high efficiency in carrier landing guidance.
The aforementioned prior research is of positive significance in aircraft guidance. In the actual flight, pilots conduct flight tasks with rich experience and skills. However, in ATC simulators, the aircraft is controlled by an autopilot, not by a real pilot, who is usually not well trained to guide the aircraft on 4D flight tasks. The main issue is that autopilot is unable to generate a 4D trajectory [9,10] to meet the requirement of the multi-dimensional goal task, wherein 4D waypoints of certain latitude, longitude, altitude, and heading and arrival time must be reached.
Consequently, ATCOs call for an intelligent approach to solve the aforementioned problem. In this paper, a possible reinforcement learning (RL) [11] approach with a shaped reward function is proposed to achieve the multi-dimensional goal aircraft guidance task, by formulating the problem as a Markov decision process problem.
RL solves sequential decision-making problems by iteratively estimating value functions and optimal control strategies, which represents the long-term optimal performance of the system. Much attention has been shifted towards RL owing to the performance thereof in a wide range of applications. Thus, the capabilities of RL have stimulated research on aircraft guidance tasks.
As a result of RL development, researchers have proposed deep reinforcement learning (DRL) approaches to solve the problems of aircraft guidance. In a previous study [12], to solve the aircraft sequencing and separation problem, the author explored the possibilities of applying RL techniques for ’time in trail’ tasks. A similar approach was proposed in another study [13], which used DRL to train the aircraft by heading commands and constant speed to guide the aircraft. A trajectory generating method was proposed by using a DQN algorithm to perform a perched landing on the ground [14]. In the above DQN algorithm, noise is considered by the model, which is more in line with the actual scenario in the training process.
In previous studies, RL has been shown to have beneficial application prospects in aircraft guidance. However, some results are inconsistent and further research is required for verification, and, at the same time, there are still a number of limitations. First, RL is a method of constantly trying and exploring from the environment, wherein the complexity of state space will directly affect the difficulty of the task. In prior research, aircraft heading was not taken into account in guidance, which reduced the convergence difficulty due to low-level dimensional state space. When aircraft heading and velocity are considered, convergence is usually difficult as aircraft guidance tasks are performed in a high-dimensional state space. Second, the reward function [15,16,17] is vital and will directly affect the converge efficiency; however, the reward function is usually hard to define and needs reward shaping methods.
The high-dimensional state space has an effect on RL training efficiency, which will lead to a considerable amount of calculations and sparse rewards. To reduce the state space dimensions and difficulties, the multi-level hierarchical RL method and nested policies [18] were proposed. Researchers [19] proposed a nested RL model capable of determining both aircraft route and velocity, using an air traffic controller simulator created by NASA. The latter was employed as a testing environment to evaluate RL techniques, to provide tactical decision support to an air traffic controller, to select the proper route, and to change the velocity for each aircraft. Ultimately, RL methods were evaluated in the aforementioned testing environment to solve the autonomous air traffic control problem for aircraft sequencing and separation. The results revealed that, in the whole training process, the total score tended to oscillate and rise, which limited the application of the above method in practice. Another disadvantage of this approach is that it restricts the position of the aircraft in a fixed place and moves the aircraft in a limited route without considering the effect of aircraft aerodynamics on the flight path.
To design an effective reward function through reward shaping algorithms, it is necessary to speed up the convergence. Two types of reward functions [20] are proposed to assist ATCOs in ensuring the safety and fairness of airlines, by solving the problems of both holding on ground and in air. To solve the problem of aircraft guidance, a new reward function was proposed in [21], to improve the performance of the generated trajectories and the training efficiency.
Recent RL development for nonlinear control systems has implications for aircraft guidance tasks. A Virtual State-feedback Reference Feedback Tuning (VSFRT) method [22] was applied to unknown observable systems control. In [23], a hierarchical soft actor–critic algorithm was proposed for task allocation which significantly improved the efficiency of the intelligent system. In another study [24], a strategy based on heuristic dynamic programming (HDP) () was used to solve the event-triggered control problem in a nonlinear system and improve the system stability, where the one-step-return value was approximated by an actor–critic neural network structure.
In the present paper, a multi-layer RL approach with a reward shaping algorithm is proposed for the multi-dimensional goal aircraft guidance flight task, wherein an aircraft is guided to waypoints at certain latitude, longitude, altitude, heading angle, and arrival time. In the proposed approach, a trained agent is adopted to control the aircraft by selecting the heading, changing the vertical velocity, and altering the horizontal velocity, based on an improved multi-layer RL algorithm with a shaped reward function. The present solution can solve the aircraft guidance problem intelligently and efficiently, and thus is applicable in a continuous environment where an aircraft moves in a continuous expanse of space.
The key contributions of the proposed deep RL approach are multifold:
a. A multi-layer RL model and an intelligent aircraft guidance approach are presented to perform the multi-dimensional goal aircraft guidance flight task, by reducing the state space dimensions and simplifying the neural network structure.
b. A shaped reward function is proposed to enhance the performance of aircraft trajectory, while considering Dubin’s path method.
c. The proposed work provides possible application prospects for the research on aircraft guidance while considering arrival time.
The remainder of the present study is organized as follows: in Section 2, the background concepts on Dubins path and RL are introduced, along with the variants used in the present work; in Section 3, the RL formulation of the aircraft guidance task is presented; in Section 4, the environment settings and structure of model are introduced in detail; in Section 5, numerical simulation results and discussion are given; and, in Section 6, the conclusions of the present study are provided.
2. Background
2.1. Dubins Path
The Dubins path [25,26,27] is the shortest path between any two configurations, and can be more precisely characterized as: , and , where L denotes “turn left”, R denotes “turn right”, and S denotes “go straight”. The six classes of Dubins path mentioned can be divided into and curves, which are shown in Figure 1.
For CSC curves, the length of the shortest path is defined as:
For CCC curves, the length of the shortest path is defined as:
2.2. Reinforcement Learning
2.2.1. Basics of Reinforcement Learning
RL research belongs to the category of Markov decision process (MDP) [28], which attempts to solve the problem of decision optimization and can be defined as , where S is the set of environment states; A is all possible actions the agent can select from the environment; R is the set of obtained rewards from the environment; P is the transition probabilities function; is the discount factor that determines the contribution of future rewards. , and respectively represent the current state, selected action, transition probability, and reward obtained from the environment.
RL is a method to maximize long-term rewards during interaction with the environment. At one time step, the agent selects an action according to the state . Subsequently, the agent gains a reward and steps to the next state . The state-value function is used to estimate the long-term rewards. The updating of can be defined as:
where is the learning rate.
2.2.2. Policy-Based RL
In the value-based RL approach [29], the agent selects an action to maximize the value function using greedy strategy. The strategy is a mapping from state space to action space, which is the optimal strategy.
Policy-based RL [30,31] is to parameterize the policy , where is the parameter of policy neural network. Then, the total rewards can be defined as:
Policy-based RL adopts parameterized linear function and nonlinear function (such as neural network) as the strategy. The optimal policy can be defined as:
where T is the total time.
In the policy-based RL method, a critic network and a policy network are adopted, where and are the parameters. Critic network is to evaluate the current policy . The strategy is directly iterated by iteratively updating critic parameters and policy parameters . The critic network updates through minimizing , which is the expected square error of new estimate value function and old estimate value function , which is:
The policy network maximizes which includes advantage function and entropy regularization term to obtain maximum long-term rewards. can be defined as:
where is the parameter of value function is the entropy regularization term which represents , the strategy used for encouraging exploration and preventing premature convergence to sub-optimal polices, and is the coefficient.
3. RL Formulation
To guide aircraft to the 4D waypoints at a certain heading, it is necessary to design 4D waypoints series and guide the aircraft to 4D waypoints at a certain heading.
3.1. 4D Waypoints Design
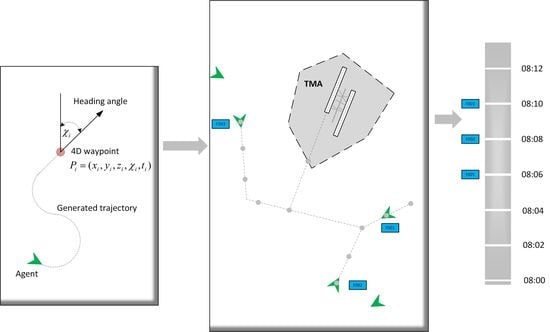
4D waypoints are waypoints with attributes of coordinates (latitude, longitude, altitude) and arrival time, as shown in Figure 2, wherein an aircraft is flying through a series of 4D waypoints. A 4D waypoint can be defined as: , where are the longitude, latitude, altitude, and arrival time of aircraft at 4D waypoint , respectively.
Assuming that there are 4D waypoints on the flight route from the departure airport to the arrival airport , which is shown in Figure 3, the 4D waypoints are sequenced and numbered from the arrival airport to the departure airport: . The 4D waypoints divide the route L into n segments, , where is the segment between 4D waypoint and 4D waypoint . The time can be calculated from each position to the landing site , respectively: .
The time from 4D waypoint to 4D waypoint is:
where is the distance and is the velocity of aircraft.
The flight segment can only be a straight line or an arc. The attribute of is determined by the two 4D waypoints and , and the connection attribute between them, where is the radius of the flight segment between with . Let represent the distance from to , and can be defined as . When , the flight segment is a straight line, whereas, when , the flight segment is an arc. Each 4D waypoint of the route has unique inherent attributes: , which respectively represent the longitude, latitude, altitude, and arrival time. The arrival time is the time when aircraft arrives at from current position .
When the flight segment is a straight line, the radius is 0. The length of the flight segment is:
where (X, Y, Z) are geocentric coordinates of (x,y,z).
When the flight segment is an arc: , where . will be determined by four known points: and , . Segments and are straight line segments, and is a circular arc with point O as the center and as the radius. is the central angle of the arc.
The length of the flight segment is:
From (8)–(10), an observation can be made that, when the velocity distribution of a route is determined, the arrival time of an aircraft moving from 4D waypoint to 4D waypoint can be determined as:
where is the current time of . The interval between 4D waypoints is determined according to the actual airline requirements. Figure 4 shows a series of 4D waypoints. For example, if the current time at is 08:00:00 and is 2 min, the arrival time at of an aircraft departure from can be calculated by (11), which is 08:12:00.
3.2. Fly to Waypoints
Flying to 4D waypoints is an aircraft guidance problem. Figure 5 shows the kinematic model of the aircraft, wherein an agent guides an aircraft from a current position to the target position . , and t are the longitude, latitude, altitude, heading angle, and arrival time, respectively. is the pitch angle of aircraft. The subscripts a and g denote the aircraft and goal. During movement, velocity and heading directly affect the position, and thus the kinematic equations and mathematical relationship can be defined as:
where , and are the delta of the 3D coordinates of the aircraft, v is the velocity, is the pitch angle, is the heading angle (with respect to the geographical north) of the aircraft, is the Earth radius, and z is the current altitude of aircraft (with respect to sea level).
In the actual environment, the above variables can be obtained by multi sensors; however, in ATC simulators, the aircraft information can be obtained directly without error. (13) defines the change rates of velocity and heading angle:
where , and are the delta of horizontal velocity, vertical velocity, and heading angle turn rate, respectively. , , , , and are the minimum and maximum of acceleration of horizontal velocity, vertical velocity, and heading angle, respectively.
For aircraft guidance, the generated trajectory is required to be smooth, and other factors should be considered, which will be analyzed in the reward shaping subsection.
In the present study, the decision-making problem can be formulated as finite horizon MDP, which can be defined as . S and A denote the state space and action space, respectively, and both are defined as high-dimensional continuous spaces. For example, the aircraft state and the destination state are composed of 10 dimensions. Generally, the arrival time of goal state is zero, whose state space dimension can be reduced to 9. Additionally, by expressing the actions performed by the agent performing the task in terms of heading, velocity, and altitude commands, the action space also becomes a multi-dimensional continuous space. P denotes the state transition probabilities function. is the discount factor. R denotes the set of rewards that the agent obtains from the environment.
Figure 6 shows the flow chart of the training process. The total steps from when the aircraft starts from the initialization state to the termination state are referred to as an episode. In the initialization process, information such as the position and movement model of the aircraft and the goal state are initialized, in addition to the reward shaping value, which will be explained in detail in the next section. After the initialization of the environment, in each step that does not reach the termination state, the agent selects an action from current state , then the environment steps in next state and returns the reward . The tuple is stored into the replay buffer until the environment reaches the termination state to update the policy while training the agent.
3.3. Training Optimization
3.3.1. Multi-Layer RL Algorithm
In consideration of the flight task as a multi-dimensional goal task, it is necessary to involve the multi-layer RL algorithm. The multi-layer RL algorithm can divide the flight task into several sub tasks, which also decreases both the dimensions of state space and action space. The sub control layers are divided as follows:
- Position control layer: control the heading angle of aircraft;
- Altitude control layer: control the vertical velocity of aircraft;
- Velocity control layer: control the horizontal velocity of aircraft.
The three sub control layers have their own structure, which can be seen as three single neural networks and are integrated into a main neural network. Sub layers are updated by updating the main neural network, so they run sequentially. Figure 7 shows the framework of the algorithm, from which it can be seen that the main neural network consists of “Actor Model” and “Critic Model”. Both of the two models have three sub layers, and they update the parameters in the same training step. The algorithm is shown in Algorithm 1. In every training step of one episode, the agent selects three actions to control position, altitude, and velocity of the aircraft by the “Actor Model”. Then, the environment obtains the selected actions and steps into next state, during which the rewards of three sub control tasks are respectively calculated by (22)–(27). Finally, the agent will learn from the data in replay buffer.
| Algorithm 1 Multi-layer RL algorithm. |
|
3.3.2. State Space
In the present experiment, all possible states have an impact on the final results in the RL environment. Therefore, it is important to consider all parameters that may have an impact on the experimental results when setting the state space. The present experimental goal was to reach a target position (latitude, longitude, altitude, and heading) at the correct time. For the above purpose, a multi-layer RL model was introduced with three layers: a position control layer to select the heading, a velocity control layer to change the velocity, and an altitude control layer to alter the aircraft altitude. The state space was designed separately for each of the layers.
For the position control layer, which aimed to lead the aircraft towards the target position (latitude, longitude) having a goal heading, the state space was designed as:
where Δx denotes the delta longitude of the target and the aircraft Δy denotes the delta latitude of the target and the aircraft, represents the aircraft heading, and represents the goal heading. The domain of , and are and , in degrees, respectively.
For the velocity control layer, which aimed to reach the target position (latitude, longitude, and heading) at certain time, the state space was designed as:
where denotes horizontal velocity of the aircraft, is the arrival time, and is the distance of aircraft to goal. The domain of will be introduced in the “Numerical Experiment” section.
For the altitude control layer, which aimed to reach the target altitude, the state space was designed as:
where is the delta of and , denotes the current altitude, and denotes the goal altitude. The domain of the altitude z is from 0 m to 10,000 m.
3.3.3. Action Space
In the multi-layer RL algorithm, three layers that output actions, heading angle, vertical velocity, and horizontal velocity, respectively, were included.
The action space of the position control layer can be defined as:
where 1 means the aircraft remains at the current heading; 0 and 2 represent the left turn and right turn of the aircraft, respectively.
The action space of the vertical velocity control layer can be defined as:
where 1 means the aircraft remains at the current altitude and the vertical velocity is zero; 0 and 2 represent descending and climbing, respectively.
The action space of the horizontal velocity control layer can be defined as:
where 1 means the aircraft remains at the current horizontal velocity; 0 and 2 represent deceleration and acceleration, respectively.
3.3.4. Termination State
The environment resets when entering a termination state. The following termination states were designed:
- Running out of time. The agent is trained every 300 steps, and, if the agent is trained for more than 300 steps, time runs out and the environment resets.
- Reaching the goal. If the agent-goal distance is less than 2 km and the delta of the heading angle is lower than 28°, the aircraft is assumed to have reached the goal.
3.3.5. Reward Function Design
To learn a policy for an MDP , the reinforcement learning algorithm could instead be run on a transformed MDP.
, where is the transformed reward function, and is the shaping reward function.
Potential function [32,33] is possible applied to reward shaping, which will modify the reward function to accelerate the agent’s learning to move straight forward to the goal. For each state s, we added the difference of potentials to the reward of a transition. Figure 8 shows an agent learning to reach goal, with a +3 reward for going up to a higher potential value state, a −3 reward for going down to a lower potential value state, and an additional −1 reward for losing time at each step.
A shaping reward function is potential-based if there exists :
Owing to F being a potential-based shaping function, every optimal policy in will also be an optimal policy in .
At every step, the agent takes an action from current state and transits to the next state . The reward function can be defined as:
where is the terminal state reward, which is defined as:
The aircraft guidance task involves five demands: latitude, longitude, altitude, arrival time, and heading angle. Thus, is defined as:
where is the horizontal distance reward function, which denotes the distance to the target. is the direction reward function, which denotes the heading angle to the target; is the altitude reward function, which denotes the distance in altitude to the target; is the arrival time reward function, which denotes the arrival time to the target; is the length of Dubins path and can be calculated by (1) and (2); and are coefficients.
However, too many factors considered in the reward function will lead to low convergence efficiency and local region of application. There are four sub functions in (25), and in the present study, a shaped reward function was proposed, wherein the reward function form was simplified using the multi-layer reward function.
In (25), and are merged into one function. Thus, can be redefined by three parts:
where is the coefficient. Table 1 shows all the coefficients of reward functions.
4. Numerical Experiment
In this section, we will first describe the experiment setup. Then, the training model will be introduced in detail.
4.1. Experiment Setup
In the present study, three guidance simulation experiments were conducted and compared. Firstly, an experiment was conducted, wherein four models guided aircraft to 3D waypoints (heading angle was also considered) in a constant velocity without considering the arrival time of the aircraft. The four models were: a multi-layer model without reward shaping, a multi-layer model with reward shaping, a not layered model without reward shaping and a not layered model with reward shaping, respectively. For comparison, the not layered model did not have sub control layers and directly selected a three-dimensional vector as heading action, vertical velocity action, and horizontal velocity action, respectively, where the reward function was also not layered. Secondly, arrival time and velocity changes were considered and the models guided aircraft to 4D waypoints (heading angle was also considered). Finally, the well trained model was used to verify the team performance by guiding aircraft to a series of 4D waypoints, as shown in Figure 9. In this experiment, three aircraft were guided to 4D waypoints, which were distributed in advance, in the same or different aerospace.
In real air guidance, information of an aircraft is obtained by sensors. In the present study, an aircraft was trained under an ATC simulator, wherein aircraft information could be obtained directly and without error.
The experiment settings and details were as follows:
The experimental environment utilized in the present paper was mainly based on the Bluesky simulator [34], which is an open-source air traffic control simulator using OpenAP [35] aircraft performance models. The training environment was set in ZUUU airport terminal aerospace, located at latitude 30.5635165° North, and longitude 103.939946° East, with the runway oriented at 22°. The scenario involved an F-16 aircraft under training, the task of which was to fly towards the series of 4D waypoints for landing preparation. The initial position of the aircraft was at the ZUUU south aerospace field and the aircraft was to fly towards the north direction.
As shown in Table 2, x, y, and z are longitude, latitude, and altitude of aircraft. The maximum and minimum horizontal velocity were set as 500 km/h and 270 km/h, respectively. As such, the maximum turn rate of the aircraft was set to ±6° per second and the maximum acceleration was set to ±2 m per second. The simulation had a time interval of one second. To speed-up the simulation and effectively process the large amount of sampling data, the maximum simulation speed was used during training.
At the start of an episode, the initialization of the environment involved multiple parameters. The system generated a series of 4D waypoints at the landing direction of the ZUUU airport, and, at the same time, an arrival time sequence was generated. The arrival time should not be too high or too low, which would make the speed of the aircraft to become unreasonably high or low. The initial position of the aircraft was established in the ZUUU south airspace, with a random heading, at horizontal velocity 500 km/h and altitude 1000 m. During the simulation, the arrival time of aircraft guided to the aimed for navigation 4D waypoint decreased as the simulation time evolved. The aircraft guidance was considered to be successful when the distance to the current navigation 4D waypoint was less than 2 km, and the delta heading angle of aircraft and 4D waypoint was less than 28°, where we could use heading commands to control an aircraft to reach goal, or the arrival time to the current navigation 4D waypoint was less than zero.
4.2. Models and Training
In this section, the parameters and models are introduced. The time steps T were 300 and the mini batch size M was 1000, and discount factor was 0.98. Table 3 lists all the parameters.
In the present RL method, a multi-layer RL architecture is exploited to effectively manage the complex air traffic control task examined in the present study. In the next section, the design details and the training process of the multi-layer models will be described.
4.2.1. Models
There are three sub layers (position control layer, velocity control layer, and altitude control layer) which select actions to control the aircraft position, velocity, and altitude.
In the position control layer, the Adam optimizer and mean squared error loss function were adopted to learn the neural network parameters with a learning rate of . The critic network had two hidden layers with 128 and 32 units, adopting ReLU [36] and tanh as activation functions [37], respectively. The policy network had two hidden layers with 64 and 32 units, respectively, with ReLU as the activation function. For the output layer, softmax activation function was adopted. During the training of the position control layer, the rewards obtained from the environment should be preprocessed. At every step, the average reward of all possible actions should be calculated; then, the selected action reward should subtract the average reward and be normalized to the sign value.
Both the velocity control layer and the altitude control layer were simple in policy network structure, with 32 units of the hidden layer. Given the distribution of the output, ReLU and the softmax [38] were chosen as the activation functions, respectively, for the two layers. The critic network contained a hidden layer of 64 units. ReLU activation function was adopted as well. Finally, the three control layers were trained using the gradient descent method.
Appropriately setting the model hyperparameters is a crucial factor for optimal performance. Table 3 lists all the hyperparameters in the present network.
The interplay between the model and the environment were also vital to the experiment. The sampling [39] effect in the training process directly affected the convergence efficiency and thus the performance of the algorithm. The aim of the present study was that every sample included valuable data contributing towards a good solution. Thus, the hindsight experience replay (HER) [40] method was adopted to optimize the randomly sampled data so that the neural network could have a better convergence direction and solve the problem of sparse rewards.
4.2.2. Training
In this paper, the actor–critic RL algorithm is adapted to train the agent. The training process is: at the beginning of every training process, initialize critic network V and policy network with weights and .
In each iteration, use old policy to interact with the environment and calculate loss function by (6), then update the critic network by minimizing loss :
where is the step length of gradient descent.
The policy is updated by maximizing in :
where is the step length of gradient descent.
5. Analysis of Results
In this section, analysis is first conducted on the performance without considering the arrival time and the aircraft being under a constant velocity at 500 km/h. Then, the arrival time is taken into consideration, and the results are analyzed. Finally, the well trained model is used to perform the team aircraft guidance task, and the results are analyzed.
5.1. Training Performance
5.1.1. Without Considering Arrival Time
Figure 10 shows the success rates of different approaches during more than 15,000 training episodes. In Figure 10, four success rate curves are presented, which represent the rates of the aircraft reaching the goal, using a multi-layer RL approach without reward shaping, a multi-layer RL approach with reward shaping, a not layered approach without reward shaping, and not layered approach with reward shaping, respectively.
The multi-layer RL approach with reward shaping quickly reached a high success rate at 90% before 8000 training episodes, compared with other approaches. Furthermore, the success rate reached the maximum at around 95% before 14,000 training episodes. Compared with the former approach, without reward shaping, the multi-layer RL approach remained at a low success rate of less than 20%, which suggested a lower efficiency in exploring and exploiting. However, compared with not layered approaches, the multi-layer approach showed a significant performance in the success rate. The curves of the non-layered approaches showed that they cannot achieve the goal without the multi-layer approach because of the sparse rewards and local regions of the applications.
The maximum success rates and average computational times obtained by testing each well trained model in 100 simulations are shown in Table 4. The multi-layer RL approach with reward shaping had the highest maximum success rate of 95%, compared with other approaches. According to the simulation results, the average calculation time of all approaches was less than 10 ms, while the calculation time of the multi-layer approach was longer.
After the four models were trained for 15,000 episodes, we selected the best generated trajectories for comparison when testing each model in 100 simulations. Figure 11 shows the trajectories of the four approaches guiding aircraft to a waypoint at certain latitude, longitude, altitude, and heading, respectively, without considering arrival time. During the guidance, the aircraft maintained a constant horizontal speed.
As shown in Figure 11a, when using a multi-layer approach without reward shaping, the aircraft reached its goal in altitude but kept whirling and failed to reach the goal position. In Figure 11c,d, when the multi-layered approach was not used, the aircraft kept whirling and failed to reach the goal in both altitude and position. Compared with the former approaches, shown in Figure 11b, when using a multi-layer approach with reward shaping, the aircraft successfully reached its goal in both altitude and position, which demonstrated that the performance of aircraft guidance could be significantly improved using a multi-layer approach with reward shaping.
5.1.2. Considering Arrival Time
When considering arrival time, the model action space should take velocity changes into consideration. In this experiment, four approaches were used to guide aircraft to a 4D waypoint at certain latitude, longitude, altitude, heading angle, and arrival time, during which aircraft would alter the horizontal velocity to accommodate the arrival time.
Figure 12 shows the success rates of different approaches during more than 15,000 training episodes. For the approaches considering arrival time, the final success rate decreased as the state space increased. Compared with Figure 10, the curve of the multi-layer approach with reward shaping became unstable. Because of the larger state space, the success rates of other approaches remained low.
As shown in Table 5, compared with approaches without considering arrival time, the final success rates of approaches considering arrival time were 2%, 3%, 1%, and 3% lower, respectively, and the average computational times were slightly increased by 2.1 ms, 2.3 ms, 0.7 ms, and 0.7 ms, respectively.
Figure 13 shows the 4D trajectories of the aircraft. Compared with Figure 11, when considering arrival time, the trajectory was slightly different when the aircraft turned because of the velocity changes and the differences in the turning radius. From Figure 11b and Figure 13b, we can see that the aircraft was farther from the goal when reaching termination state, due to the velocity changes.
5.2. Multi Aircraft Performance
In this experiment, three aircraft were involved and well-trained models were used to test the team guidance performance of multi-aircraft. Figure 14 is a color map figure which shows the 2D trajectories and the arrival times of aircraft, where the color map value such as −100 is the delta of current time and final time in seconds. Figure 15 shows the 3D trajectories how the aircraft flew to the aimed for 4D waypoint, where three aircraft started within the predetermined scope in the same aerospace (Figure 15a) and different aerospaces (Figure 15b), and aircraft aimed at the series landing 4D waypoints, respectively. The simulation results are shown in Table 6, both the average distance and delta heading angle were in the tolerances within 2 km and ±28°. The simulation results show that the trajectories can be generated to guide aircraft to a series of 4D waypoints.
Figure 16, Figure 17 and Figure 18 respectively give the changes of heading angle, altitude, and velocity. According to the figures, heading angle and velocity change more frequently and irregularly, which should be avoided in the actual flight. Since the turning radius varies with the velocity, the flight trajectory is a velocity-dependent curve, which is the reason for frequent changes in the velocity. The change of altitude is linear because the goal altitude is definite and invariable.
6. Conclusions
In the present study, a deep multi-layer RL algorithm is proposed that can overcome the multi-dimensional goal aircraft guidance problem. In the proposed method, the problem is formulated as an MDP problem, and the aircraft is controlled by selecting the heading, changing the vertical velocity, and altering the horizontal velocity. The results of the present numerical experiments reveal that the proposed algorithm has promising prospects in assisting an aircraft to reach a target 4D waypoint at a certain heading, which can be applied in team aircraft guidance tasks. The advantage of the present method is providing a potential solution enabling autonomous 4D aircraft guidance in a structured airspace.
Additionally, a hierarchical architecture is proposed for a multi-layer RL agent, and the capability thereof was demonstrated to solve multi-goal aircraft guidance decision-making problems. The promising results from the present numerical experiments have provided encouragement to conduct future work on more advanced ATC simulators. However, the present experiment and algorithm have limitations. In the actual flight, the flight trajectory should be smooth and simple, and frequent changes of velocity and heading angle are undesirable. The focus of future work will be on continuous action reward shaping to solve the current constraints.
Author Contributions
Conceptualization, W.Z.; Methodology, W.Z.; Project administration, Y.J.; Software, W.Z. and R.L.; Supervision, Y.J.; Validation, W.Z. and H.Y.; Writing—original draft, W.Z., H.Y., and R.L.; Writing—review and editing, Y.J. All authors have read and agreed to the published version of the manuscript.
Funding
This study was supported by the National Natural Science Foundation of China (grant number U20A20161).
Conflicts of Interest
The authors declare no conflict of interest.
References
- Dunn, C.; Valasek, J.; Kirkpatrick, K.C. Unmanned Air System Search and Localization Guidance Using Reinforcement Learning; Infotech@ Aerospace: Garden Grove, CA, USA, 2012; pp. 1–8. [Google Scholar] [CrossRef] [Green Version]
- Verba, V.; Merkulov, V.; Rudenko, E. Linear-cubic locally optimal control of linear systems and its application for aircraft guidance. J. Comput. Syst. Sci. Int. 2020, 59, 768–780. [Google Scholar] [CrossRef]
- Ivler, C.M.; Rowe, E.S.; Martin, J.; Lopez, M.J.; Tischler, M.B. System Identification Guidance for Multirotor Aircraft: Dynamic Scaling and Test Techniques. J. Am. Helicopter Soc. 2021, 66, 1–16. [Google Scholar] [CrossRef]
- Kumar, S.R.; Mukherjee, D. Cooperative active aircraft protection guidance using line-of-sight approach. IEEE Trans. Aerosp. Electron. Syst. 2020, 57, 957–967. [Google Scholar] [CrossRef]
- Morani, G.; Di Vito, V.; Corraro, F.; Grevtsov, N.; Dymchenko, A. Automatic Guidance through 4D Waypoints with time and spatial margins. In Proceedings of the AIAA Guidance, Navigation, and Control (GNC) Conference, Boston, MA, USA, 19–22 August 2013; p. 4892. [Google Scholar] [CrossRef]
- Verba, V.; Merkulov, V.; Rudenko, E. Optimization of automatic support systems of air objects based on local quadratic-biquadratic functionals. I. Synthesis of optimum control. J. Comput. Syst. Sci. Int. 2021, 60, 22–27. [Google Scholar] [CrossRef]
- Wang, X.; Van Kampen, E.J.; Chu, Q.; Lu, P. Stability analysis for incremental nonlinear dynamic inversion control. J. Guid. Control. Dyn. 2019, 42, 1116–1129. [Google Scholar] [CrossRef] [Green Version]
- Meng, Y.; Wang, W.; Han, H.; Ban, J. A visual/inertial integrated landing guidance method for UAV landing on the ship. Aerosp. Sci. Technol. 2019, 85, 474–480. [Google Scholar] [CrossRef]
- Ma, L.; Tian, S. A hybrid CNN-LSTM model for aircraft 4D trajectory prediction. IEEE Access 2020, 8, 134668–134680. [Google Scholar] [CrossRef]
- Juntama, P.; Chaimatanan, S.; Alam, S.; Delahaye, D. A Distributed Metaheuristic Approach for Complexity Reduction in Air Traffic for Strategic 4D Trajectory Optimization. In Proceedings of the 2020 International Conference on Artificial Intelligence and Data Analytics for Air Transportation (AIDA-AT), Singapore, 3–4 February 2020; pp. 1–9. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Vonk, B. Exploring Reinforcement Learning Methods for Autonomous Sequencing and Spacing of Aircraft. 2019. Available online: https://repository.tudelft.nl/islandora/object/uuid:2e776b60-cd4e-4268-93e3-3fcc81cd794f (accessed on 6 August 2021).
- Wang, Z.; Li, H.; Wu, H.; Shen, F.; Lu, R. Design of agent training environment for aircraft landing guidance based on deep reinforcement learning. In Proceedings of the 2018 11th International Symposium on Computational Intelligence and Design (ISCID), Hangzhou, China, 8–9 December 2018; Volume 2, pp. 76–79. [Google Scholar] [CrossRef]
- Waldock, A.; Greatwood, C.; Salama, F.; Richardson, T. Learning to perform a perched landing on the ground using deep reinforcement learning. J. Intell. Robot. Syst. 2018, 92, 685–704. [Google Scholar] [CrossRef] [Green Version]
- Dong, Y.; Tang, X.; Yuan, Y. Principled reward shaping for reinforcement learning via lyapunov stability theory. Neurocomputing 2020, 393, 83–90. [Google Scholar] [CrossRef]
- Zou, H.; Ren, T.; Yan, D.; Su, H.; Zhu, J. Learning Task-Distribution Reward Shaping with Meta-Learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 2–9 February 2021; Volume 35, pp. 11210–11218. [Google Scholar]
- du Preez-Wilkinson, N.; Gallagher, M. Fitness Landscape Features and Reward Shaping in Reinforcement Learning Policy Spaces. In International Conference on Parallel Problem Solving from Nature; Springer: Berlin, Germany, 2020; pp. 500–514. [Google Scholar] [CrossRef]
- Levy, A.; Konidaris, G.; Platt, R.; Saenko, K. Learning multi-level hierarchies with hindsight. arXiv 2017, arXiv:1712.00948. Available online: https://arxiv.org/abs/1712.00948 (accessed on 6 August 2021).
- Brittain, M.; Wei, P. Autonomous Aircraft Sequencing and Separation with Hierarchical Deep Reinforcement Learning. 2018. Available online: https://lib.dr.iastate.edu/cgi/viewcontent.cgi?article=9470&context=etd#page=91 (accessed on 6 August 2021).
- Cruciol, L.L.; de Arruda, A.C., Jr.; Weigang, L.; Li, L.; Crespo, A.M. Reward functions for learning to control in air traffic flow management. Transp. Res. Part C Emerg. Technol. 2013, 35, 141–155. [Google Scholar] [CrossRef]
- Wang, Z.; Li, H.; Wu, Z.; Wu, H. A pretrained proximal policy optimization algorithm with reward shaping for aircraft guidance to a moving destination in three-dimensional continuous space. Int. J. Adv. Robot. Syst. 2021, 18, 1729881421989546. [Google Scholar] [CrossRef]
- Radac, M.B.; Borlea, A.I. Virtual State Feedback Reference Tuning and Value Iteration Reinforcement Learning for Unknown Observable Systems Control. Energies 2021, 14, 1006. [Google Scholar] [CrossRef]
- Tang, H.; Wang, A.; Xue, F.; Yang, J.; Cao, Y. A novel hierarchical soft actor–critic algorithm for multi-logistics robots task allocation. IEEE Access 2021, 9, 42568–42582. [Google Scholar] [CrossRef]
- Li, T.; Yang, D.; Xie, X.; Zhang, H. Event-triggered control of nonlinear discrete-time system with unknown dynamics based on HDP (λ). IEEE Trans. Cybern. 2021. [Google Scholar] [CrossRef] [PubMed]
- Manyam, S.G.; Casbeer, D.; Von Moll, A.L.; Fuchs, Z. Shortest Dubins path to a circle. In Proceedings of the AIAA Scitech 2019 Forum, San Diego, CA, USA, 7–11 January 2019; p. 0919. [Google Scholar] [CrossRef] [Green Version]
- Zhou, Y.; Zhou, W.; Fei, M.; Wang, S. 3D Curve Planning Algorithm of Aircraft Under Multiple Constraints. In Recent Featured Applications of Artificial Intelligence Methods; LSMS 2020 and ICSEE 2020 Workshops; Springer: Berlin, Germany, 2020; pp. 236–249. [Google Scholar] [CrossRef]
- Kučerová, K.; Váň, P.; Faigl, J. On finding time-efficient trajectories for fixed-wing aircraft using dubins paths with multiple radii. In Proceedings of the 35th Annual ACM Symposium on Applied Computing, Brno, Czech Republic, 30 March–3 April 2020; pp. 829–831. [Google Scholar] [CrossRef] [Green Version]
- Van Otterlo, M.; Wiering, M. Reinforcement learning and markov decision processes. In Reinforcement Learning; Springer: Berlin, Germany, 2012; pp. 3–42. [Google Scholar] [CrossRef]
- Szepesvári, C.; Littman, M.L. A unified analysis of value-function-based reinforcement-learning algorithms. Neural Comput. 1999, 11, 2017–2060. [Google Scholar] [CrossRef]
- Yu, M.; Sun, S. Policy-based reinforcement learning for time series anomaly detection. Eng. Appl. Artif. Intell. 2020, 95, 103919. [Google Scholar] [CrossRef]
- Brittain, M.; Wei, P. Autonomous separation assurance in an high-density en route sector: A deep multi-agent reinforcement learning approach. In Proceedings of the 2019 IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, 27–30 October 2019; pp. 3256–3262. [Google Scholar] [CrossRef]
- Lee, S.; Kil, R.M. A Gaussian potential function network with hierarchically self-organizing learning. Neural Netw. 1991, 4, 207–224. [Google Scholar] [CrossRef]
- Huang, W.H.; Fajen, B.R.; Fink, J.R.; Warren, W.H. Visual navigation and obstacle avoidance using a steering potential function. Robot. Auton. Syst. 2006, 54, 288–299. [Google Scholar] [CrossRef]
- Hoekstra, J.M.; Ellerbroek, J. Bluesky ATC simulator project: An open data and open source approach. In Proceedings of the 7th International Conference on Research in Air Transportation, Philadelphia, PA, USA, 20–24 June 2016; Volume 131, p. 132. [Google Scholar]
- Sun, J.; Hoekstra, J.M.; Ellerbroek, J. OpenAP: An open-source aircraft performance model for air transportation studies and simulations. Aerospace 2020, 7, 104. [Google Scholar] [CrossRef]
- Hara, K.; Saito, D.; Shouno, H. Analysis of function of rectified linear unit used in deep learning. In Proceedings of the 2015 International Joint Conference on Neural Networks (IJCNN), Killarney, Ireland, 12–17 July 2015; pp. 1–8. [Google Scholar] [CrossRef]
- Agostinelli, F.; Hoffman, M.; Sadowski, P.; Baldi, P. Learning activation functions to improve deep neural networks. arXiv 2014, arXiv:1412.6830. Available online: https://arxiv.org/abs/1412.6830 (accessed on 6 August 2021).
- Gao, B.; Pavel, L. On the properties of the softmax function with application in game theory and reinforcement learning. arXiv 2017, arXiv:1704.00805. Available online: https://arxiv.org/abs/1704.00805 (accessed on 6 August 2021).
- Kakade, S.M. On the Sample Complexity of Reinforcement Learning; University of London, University College London: London, UK, 2003. [Google Scholar]
- Andrychowicz, M.; Wolski, F.; Ray, A.; Schneider, J.; Fong, R.; Welinder, P.; McGrew, B.; Tobin, J.; Abbeel, P.; Zaremba, W. Hindsight experience replay. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5055–5065. [Google Scholar]
Figure 1.
Dubins path: (a) CSC curve and (b) CCC curve.

Figure 2.
Aircraft fly towards 4D waypoints series.

Figure 3.
Line and arc flight segments.

Figure 4.
Arrival time of the 4D waypoint.

Figure 5.
Kinematic model of aircraft: (a) kinematic model on a vertical plane and (b) kinematic model on a horizontal plane.
Figure 5.
Kinematic model of aircraft: (a) kinematic model on a vertical plane and (b) kinematic model on a horizontal plane.

Figure 6.
Flow chart of the planning algorithm.

Figure 7.
Framework of the planning algorithm.

Figure 8.
Potential value associated with each state.

Figure 9.
Team aircraft guidance in different aerospaces.

Figure 10.
Training success rates, without considering arrival time: multi layer approach without reward shaping; multi layer approach with reward shaping; not layered approach without reward shaping and not layered approach with reward shaping.
Figure 10.
Training success rates, without considering arrival time: multi layer approach without reward shaping; multi layer approach with reward shaping; not layered approach without reward shaping and not layered approach with reward shaping.

Figure 11.
Trajectories of aircraft without considering arrival time: (a) multi-layer approach without reward shaping; (b) multi-layer approach with reward shaping; (c) not layered approach without reward shaping; and (d) not layered approach with reward shaping.
Figure 11.
Trajectories of aircraft without considering arrival time: (a) multi-layer approach without reward shaping; (b) multi-layer approach with reward shaping; (c) not layered approach without reward shaping; and (d) not layered approach with reward shaping.

Figure 12.
Training success rates, considering arrival time: multi layer approach without reward shaping; multi layer approach with reward shaping; not layered approach without reward shaping and not layered approach with reward shaping.
Figure 12.
Training success rates, considering arrival time: multi layer approach without reward shaping; multi layer approach with reward shaping; not layered approach without reward shaping and not layered approach with reward shaping.

Figure 13.
Trajectories of aircraft considering arrival time: (a) multi-layer approach without reward shaping; (b) multi-layer approach with reward shaping; (c) not layered approach without reward shaping; and (d) not layered approach with reward shaping.
Figure 13.
Trajectories of aircraft considering arrival time: (a) multi-layer approach without reward shaping; (b) multi-layer approach with reward shaping; (c) not layered approach without reward shaping; and (d) not layered approach with reward shaping.

Figure 14.
Color maps of aircraft trajectories: (a) three aircraft starting in the same aerospace, flying to the aimed for 4D waypoints, respectively, and (b) three aircraft starting in different aerospaces, flying to the aimed for 4D waypoints, respectively.
Figure 14.
Color maps of aircraft trajectories: (a) three aircraft starting in the same aerospace, flying to the aimed for 4D waypoints, respectively, and (b) three aircraft starting in different aerospaces, flying to the aimed for 4D waypoints, respectively.

Figure 15.
Trajectories of aircraft trained in team aircraft guidance: (a) three aircraft starting in the same aerospace, flying to the aimed for 4D waypoints, respectively, and (b) three aircraft starting in different aerospaces, flying to the aimed for 4D waypoints, respectively.
Figure 15.
Trajectories of aircraft trained in team aircraft guidance: (a) three aircraft starting in the same aerospace, flying to the aimed for 4D waypoints, respectively, and (b) three aircraft starting in different aerospaces, flying to the aimed for 4D waypoints, respectively.

Figure 16.
Headings of aircraft trained in team aircraft guidance: (a) three aircraft starting in the same aerospace, flying to the aimed for 4D waypoints, respectively, and (b) three aircraft starting in different aerospaces, flying to the aimed for 4D waypoints, respectively.
Figure 16.
Headings of aircraft trained in team aircraft guidance: (a) three aircraft starting in the same aerospace, flying to the aimed for 4D waypoints, respectively, and (b) three aircraft starting in different aerospaces, flying to the aimed for 4D waypoints, respectively.

Figure 17.
Altitudes of aircraft trained in team aircraft guidance: (a) three aircraft starting in the same aerospace, flying to the aimed for 4D waypoints, respectively, and (b) three aircraft starting in different aerospaces, flying to the aimed for 4D waypoints, respectively.
Figure 17.
Altitudes of aircraft trained in team aircraft guidance: (a) three aircraft starting in the same aerospace, flying to the aimed for 4D waypoints, respectively, and (b) three aircraft starting in different aerospaces, flying to the aimed for 4D waypoints, respectively.

Figure 18.
Velocities of aircraft trained in team aircraft guidance: (a) three aircraft starting in the same aerospace, flying to the aimed for 4D waypoints, respectively, and (b) three aircraft starting in different aerospaces, flying to the aimed for 4D waypoints, respectively.
Figure 18.
Velocities of aircraft trained in team aircraft guidance: (a) three aircraft starting in the same aerospace, flying to the aimed for 4D waypoints, respectively, and (b) three aircraft starting in different aerospaces, flying to the aimed for 4D waypoints, respectively.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Coefficients of reward functions.
| Coefficients | Value |
|---|---|
| 0.02 | |
| 0.006 | |
| 0.5 | |
| 1 | |
| 0.02 |
Table 2.
Simulation environment settings.
| Parameters | Value |
|---|---|
| Airport latitude | |
| Airport longitude | |
| Airport runway orientation | |
| Aircraft type | F-16 |
| x range | [103.4°, 104.5°] |
| y range | [30.1°, 30.6°] |
| z range | [0 m, 1000 m] |
| Time interval | 1 s |
| Initial horizontal velocity | 500 km/h |
| Maximum horizontal velocity | 500 km/h |
| Minimum horizontal velocity | 270 km/h |
| Maximum climb velocity | 3 m/s |
| Minimum descent velocity | m/s |
| Maximum turn rate | m/s |
| Maximum acceleration | m/s |
| Termination | distance < 2 km and delta heading |
| angle < 28° or arrival time < 0 |
Table 3.
Hyperparameters of the multi-layer RL model.
| Parameters | Value |
|---|---|
| Replay buffer size | 200,000 |
| Discount factor | 0.98 |
| Learning rate | |
| Mini batch size | 1000 |
Table 4.
Simulation results of algorithm without considering arrival time.
| Algorithm | Maximum Success Rate (%) | Average Computational Time (ms) |
|---|---|---|
| Multi-layer approach | 17 | 3.4 |
| without reward shaping | ||
| Multi-layer approach | 95 | 3.5 |
| with reward shaping | ||
| Not layered approach | 6 | 2.9 |
| without reward shaping | ||
| Not layered approach | 5 | 2.7 |
| with reward shaping |
Table 5.
Simulation results of algorithm considering arrival time.
| Algorithm | Maximum Success Rate (%) | Average Computational Time (ms) |
|---|---|---|
| Multi-layer approach | 15 | 5.5 |
| without reward shaping | ||
| Multi-layer approach | 92 | 5.8 |
| with reward shaping | ||
| Not layered approach | 5 | 3.6 |
| without reward shaping | ||
| Not layered approach | 2 | 3.4 |
| with reward shaping |
Table 6.
Average distance and delta heading angle to goal.
| Born Place | Average Distance (km) | Average Delta Heading Angle (°) |
|---|---|---|
| Aircraft in the same aerospace | 0.360 | 13.7 |
| Aircraft in different aerospaces | 0.598 | 14.7 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Zu, W.; Yang, H.; Liu, R.; Ji, Y. A Multi-Dimensional Goal Aircraft Guidance Approach Based on Reinforcement Learning with a Reward Shaping Algorithm. Sensors 2021, 21, 5643. https://doi.org/10.3390/s21165643
AMA Style
Zu W, Yang H, Liu R, Ji Y. A Multi-Dimensional Goal Aircraft Guidance Approach Based on Reinforcement Learning with a Reward Shaping Algorithm. Sensors. 2021; 21(16):5643. https://doi.org/10.3390/s21165643
Chicago/Turabian StyleZu, Wenqiang, Hongyu Yang, Renyu Liu, and Yulong Ji. 2021. "A Multi-Dimensional Goal Aircraft Guidance Approach Based on Reinforcement Learning with a Reward Shaping Algorithm" Sensors 21, no. 16: 5643. https://doi.org/10.3390/s21165643
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.