
Deep Learning Based Prediction on Greenhouse Crop Yield Combined TCN and RNN





Abstract
:1. Introduction
2. Literature Works
- (i)
- There are many intrinsic model parameters associated with a biophysical model and the performance of an explanatory model is highly sensitive to its model parameters (as shown in [13]). Moreover, the model parameter setting suitable for predicting greenhouse crop yield in one region may not be workable for other regions [13].
- (ii)
- (i)
- Features extracted from data for building the classical machine learning models may not be optimal and most representative, thus deteriorating the performance for yield prediction (as shown by our experiment, in most cases, the classical machine learning models perform worse than the deep learning-based ones).
- (ii)
- The classical machine learning models cannot effectively handle data with either high volume or high complexity.
3. Methodology
3.1. Input Data Normalization
3.2. Recurrent Neural Network
3.3. Temporal Convolutional Network
3.4. Fully Connected Layer
4. Experimental Studies
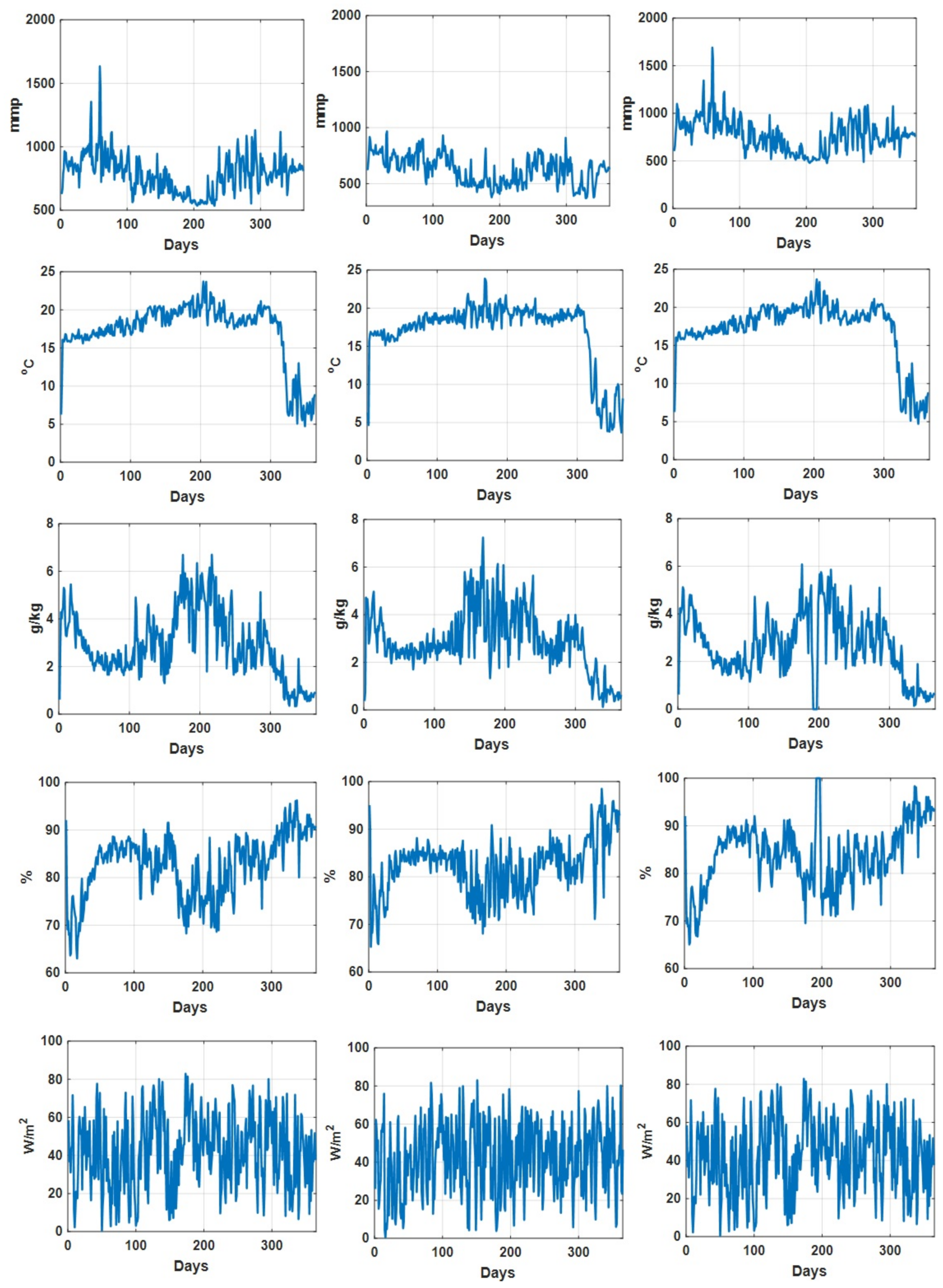
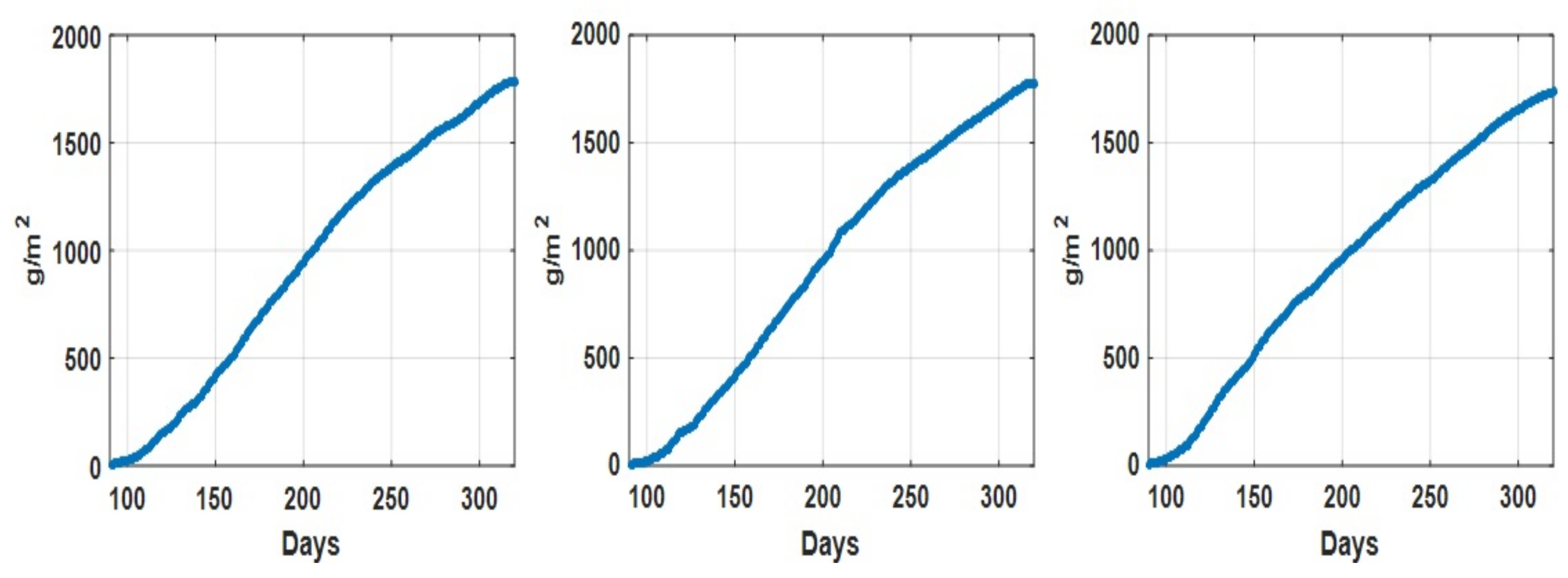
4.1. Datasets Descriptions
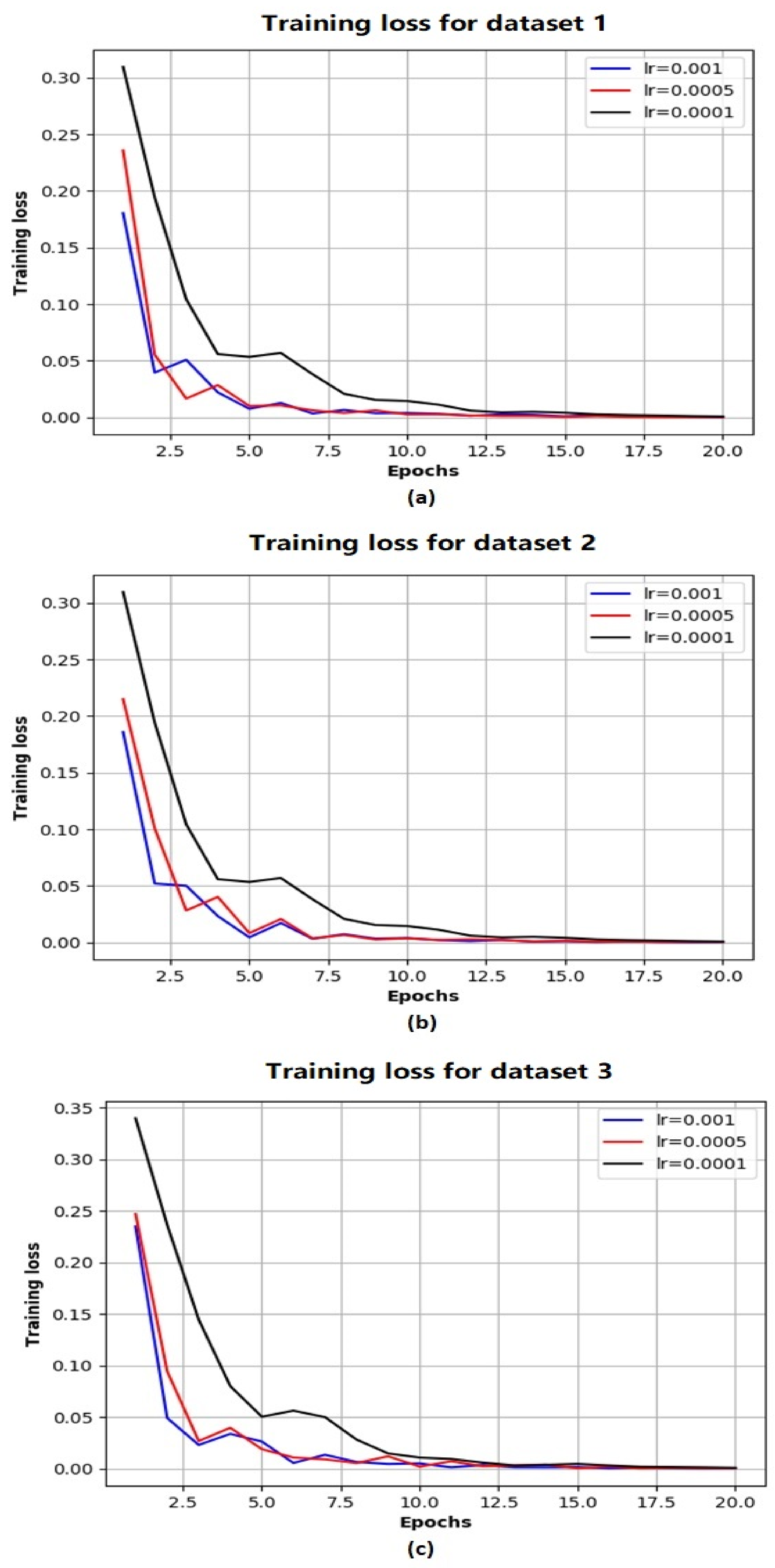
4.2. Experimental Design
4.3. Network Performance
4.4. Comparison Studies
5. Conclusions
- (i)
- The proposed approach can be applied for accurate greenhouse crop yield prediction, based on both historical environmental and yield information.
- (ii)
- The proposed approach can achieve much more accurate prediction than other counterparts of both traditional machine learning and deep learning methods.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Vanthoor, B.; Stanghellini, C.; Van Henten, E.; De Visser, P. A methodology for model-based greenhouse design: Part 1, description and validation of a tomato yield model. Biosyst. Eng. 2011, 110, 363–377. [Google Scholar] [CrossRef]
- Ponce, P.; Molina, A.; Cepeda, P.; Lugo, E.; MacCleery, B. Greenhouse Design and Control; CRC Press: Boca Raton, FL, USA, 2014. [Google Scholar]
- Hoogenboom, G. Contribution of agrometeorology to the simulation of crop production and its applications. Agric. For. Meteorol. 2000, 103, 137–157. [Google Scholar] [CrossRef]
- Vanthoor, B.; De Visser, P.; Stanghellini, C.; Van Henten, E. A methodology for model-based greenhouse design: Part 2, description and validation of a tomato yield model. Biosyst. Eng. 2011, 110, 378–395. [Google Scholar] [CrossRef]
- Alhnait, B.; Pearson, S.; Leontidis, G.; Kollias, S. Using deep learning to predict plant growth and yield in greenhouse environments. arXiv 2019, arXiv:1907.00624. [Google Scholar]
- Jones, J.; Dayan, E.; Allen, L.; VanKeulen, H.; Challa, H. A dynamic tomato growth and yield model (tomgro). Trans. ASAE 1998, 34, 663–672. [Google Scholar] [CrossRef]
- Heuvelink, E. Evaluation of a dynamic simulation model for tomato crop growth and development. Ann. Bot. 1999, 83, 413–422. [Google Scholar] [CrossRef] [Green Version]
- Lin, D.; Wei, R.; Xu, L. An integrated yield prediction model for greenhouse tomato. Agronomy 2019, 9, 873. [Google Scholar] [CrossRef] [Green Version]
- Seginer, I.; Gary, C.; Tchamitchian, M. Optimal temperature regimes for a greenhouse crop with a carbohydrate pool: A modelling study. Sci. Hortic. 1994, 60, 55–80. [Google Scholar] [CrossRef]
- Kuijpers, W.; Molengraft, M.; Mourik, S.; Ooster, A.; Hemming, S.; Henten, E. Model selection with a common structure: Tomato crop growth models. Biosyst. Eng. 2019, 187, 247–257. [Google Scholar] [CrossRef]
- Ni, J.; Mao, H. Dynamic simulation of leaf area and dry matter production of greenhouse cucumber under different electrical conductivity. Trans. Chin. Soc. Agric. Eng. 2011, 27, 105–109. [Google Scholar]
- Ni, J.; Liu, Y.; Mao, H.; Zhang, X. Effects of different fruit number and distance between sink and source on dry matter partitioning of greenhouse tomato. J. Drain. Irrig. Mach. Eng. 2019, 47, 346–351. [Google Scholar]
- Vazquez-Cruz, M.; Guzman-Cruz, R.; Lopez-Cruz, I.; Cornejo-Perez, O.; Torres-Pacheco, I.; Guevara-Gonzalez, R. Global sensitivity analysis by means of EFAST and Sobol’ methods andcalibration of reduced state-variable TOMGRO model using geneticalgorithms. Comput. Electron. Agric. 2014, 100, 1–12. [Google Scholar] [CrossRef]
- Sim, H.; Kim, D.; Ahn, M.; Ahn, S.; Kim, S. Prediction of strawberry growth and fruit yield based on environmental and growth data in a greenhouse for soil cultivation with applied autonomous facilities. Hortic. Sci. Technol. 2020, 38, 840–849. [Google Scholar]
- Hassanzadeh, A.; Aardt, J.; Murphy, S.; Pethybridge, S. Yield modeling of snap 245 bean based on hyperspectral sensing: A greenhouse study. J. Appl. Remote Sens. 2020, 14, 024519. [Google Scholar] [CrossRef]
- Ehret, D.; Hill, B.; Helmer, T.; Edwards, D. Neural network modeling of green- house tomato yield, growth and water use from automated crop monitoring data. Comput. Electron. Agric. 2011, 79, 82–89. [Google Scholar] [CrossRef]
- Gholipoor, M.; Nadali, F. Fruit yield prediction of pepper using artificial neural network. Sci. Hortic. 2019, 250, 249–253. [Google Scholar] [CrossRef]
- Qaddoum, K.; Hines, E.; Iliescu, D. Yield prediction for tomato greenhouse using EFUNN. ISRN Artif. Intell. 2013, 2013, 430986. [Google Scholar] [CrossRef]
- Salazar, R.; Lpez, I.; Rojano, A.; Schmidt, U.; Dannehl, D. Tomato yield prediction in a semi-closed greenhouse. In Proceedings of the International Horticultural Congress on Horticulture: Sustaining Lives, Livelihoods and Landscapes (IHC2014): International Symposium on Innovation and New Technologies in Protected Cropping, Brisbane, Australia, 18–22 August 2014. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Elavarasan, D.; Vincent, P. Crop yield prediction using deep reinforcement learning model for sustainable agrarian application. IEEE Access 2020, 8, 86886–86901. [Google Scholar] [CrossRef]
- Sun, J.; Di, L.; Sun, Z.; Shen, Y.; Lai, Z. County-level soybean yield prediction using deep CNN-LSTM model. Sensors 2019, 19, 4363. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Alhnait, B.; Kollias, S.; Leontidis, G.; Shouyong, J.; Schamp, B.; Pearson, S. An autoencoder wavelet based deep neural network with attention mechanism for multi-step prediction of plant growth. Inf. Sci. 2021, 560, 35–50. [Google Scholar] [CrossRef]
- Sherstinsky, A. Fundamentals of recurrent neural network (RNN) and long short-term memory (LSTM) network. Phys. D Nolinear Phenom. 2020, 404, 132306. [Google Scholar] [CrossRef] [Green Version]
- Lea, C.; Flynn, M.; Vidal, R.; Reiter, A. Temporal convolutional networks for action segmentation and detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Salimans, T.; Kingma, D. Weight normalization: A simple reparameterization to accelerate training of deep neural networks. In Proceedings of the 30th International Conference on Neural Information Processing Systems, Barcelona, Spain, 4–9 December 2016. [Google Scholar]
- Kingma, D.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the 3rd International Conference for Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset 1 | Dataset 2 | Dataset 3 | |
|---|---|---|---|
| Location | Greenhouse 1 | Greenhouse 2 | Greenhouse 2 |
| Time period | 2018 | 2017 | 2018 |
| Information included | yield information (g/m) | ||
| CO concentration (mmp) | |||
| temperature (C) | |||
| humidity deficit (g/kg) | |||
| relative humidity (percentage) | |||
| radiation (W/m) | |||
| Dataset 1 | Dataset 2 | Dataset 3 | ||
|---|---|---|---|---|
| CO (mmp) | Min | 535.97 | 370.94 | 478.05 |
| Max | 1634.10 | 967.40 | 1691.43 | |
| Median | 793.95 | 629.97 | 769.79 | |
| Mean | 785.95 | 624.19 | 770.37 | |
| Standard deviation | 152.52 | 129.58 | 175.61 | |
| Temperature (C) | Min | 4.73 | 3.68 | 4.72 |
| Max | 23.73 | 23.89 | 23.69 | |
| Median | 18.30 | 18.46 | 18.31 | |
| Mean | 17.25 | 17.01 | 17.18 | |
| Standard deviation | 3.97 | 4.25 | 3.94 | |
| Humidity deficit (g/kg) | Min | 0.33 | 0.13 | 0 |
| Max | 6.70 | 7.27 | 6.08 | |
| Median | 2.27 | 2.78 | 2.58 | |
| Mean | 2.91 | 2.91 | 2.65 | |
| Standard deviation | 1.40 | 1.29 | 1.33 | |
| Relative humidity (%) | Min | 63.04 | 65.31 | 65.09 |
| Max | 96.24 | 98.50 | 100 | |
| Median | 83.87 | 83.22 | 84.73 | |
| Mean | 82.49 | 82.19 | 83.99 | |
| Standard deviation | 6.57 | 5.88 | 6.72 | |
| Radiation (W/m) | Min | 0.59 | 0.58 | 0.59 |
| Max | 82.91 | 83.02 | 82.91 | |
| Median | 42.81 | 43.41 | 42.81 | |
| Mean | 42.17 | 42.19 | 42.17 | |
| Standard deviation | 19.37 | 18.92 | 19.37 |
| 50 | 100 | 200 | 250 | |||
|---|---|---|---|---|---|---|
| Dataset 1 | 50 | 16.20 ± 5.25 | 8.24 ± 0.78 | 13.84 ± 0.72 | 10.82 ± 0.80 | |
| 100 | 16.51 ± 0.87 | 11.45 ± 0.64 | 9.62 ± 0.04 | 9.96 ± 1.78 | ||
| 200 | 19.57 ± 2.80 | 18.54 ± 1.57 | 16.30 ± 1.56 | 11.11 ± 0.13 | ||
| 250 | 10.48 ± 0.64 | 16.99 ± 0.22 | 10.45 ± 0.94 | 9.98 ± 0.27 | ||
| Dataset 2 | 50 | 8.91 ± 1.78 | 9.01 ± 0.73 | 7.16 ± 0.50 | 7.26 ± 1.21 | |
| 100 | 11.81 ± 1.22 | 8.47 ± 0.52 | 8.81 ± 1.85 | 8.23 ± 0.27 | ||
| 200 | 10.62 ± 1.58 | 7.07 ± 1.90 | 7.96 ± 0.25 | 6.33 ± 1.48 | ||
| 250 | 11.62 ± 0.02 | 8.78 ± 0.12 | 6.76 ± 0.45 | 7.95 ± 0.44 | ||
| Dataset 3 | 50 | 11.96 ± 2.29 | 8.54 ± 0.71 | 8.21 ± 0.99 | 8.02 ± 0.20 | |
| 100 | 11.08 ± 4.61 | 8.58 ± 1.40 | 8.18 ± 0.44 | 8.88 ± 0.53 | ||
| 200 | 8.85 ± 1.52 | 7.41 ± 1.48 | 8.67 ± 1.15 | 8.77 ± 1.20 | ||
| 250 | 9.35 ± 1.57 | 7.46 ± 1.78 | 7.40 ± 1.88 | 10.06 ± 0.99 | ||
| Average | 50 | 12.36 ± 3.11 | 8.60 ± 0.74 | 9.74 ± 0.74 | 8.70 ± 0.74 | |
| 100 | 13.13 ± 2.27 | 9.50 ± 0.85 | 8.87 ± 0.78 | 9.02 ± 0.85 | ||
| 200 | 13.01 ± 1.97 | 11.01 ± 1.65 | 10.98 ± 1.00 | 8.74 ± 0.94 | ||
| 250 | 10.48 ± 0.74 | 11.08 ± 0.71 | 8.20 ± 1.09 | 9.33 ± 0.57 | ||
| Layer Number | 1 | 2 | ||
|---|---|---|---|---|
| Block Number | ||||
| Dataset 1 | 1 | 10.45 ± 0.94 | 10.93 ± 2.73 | |
| 2 | 22.52 ± 10.08 | 15.58 ± 8.27 | ||
| Dataset 2 | 1 | 6.76 ± 0.45 | 6.50 ± 0.45 | |
| 2 | 9.18 ± 1.60 | 7.12 ± 0.18 | ||
| Dataset 3 | 1 | 7.40 ± 1.88 | 13.41 ± 2.09 | |
| 2 | 9.95 ± 0.72 | 16.85 ± 3.11 | ||
| Excluding CO2 Concentration | 11.88 ± 2.01 |
| Excluding temperature | 12.45 ± 0.87 |
| Excluding HD | 14.17 ± 2.98 |
| Excluding RH | 14.98 ± 3.88 |
| Excluding radiation | 12.84 ± 4.55 |
| Excluding historical yield information | 831.54 ± 73.02 |
| Dataset 1 | Dataset 2 | Dataset 3 | ||
|---|---|---|---|---|
| Classical models | LR | 23.77 ± 0 | 21.20 ± 0 | 17.88 ± 0 |
| RF | 28.84 ± 1.02 | 27.69 ± 0.56 | 26.47 ± 1.44 | |
| SVR | 55.10 ± 0 | 46.62 ± 0 | 49.12 ± 0 | |
| DT | 28.93 ± 1.33 | 28.93 ± 1.96 | 27.03 ± 2.64 | |
| GBR | 28.93 ± 0.65 | 27.07 ± 0.52 | 23.98 ± 0.44 | |
| MLANN | 95.81 ± 43.33 | 60.27 ± 19.03 | 47.01 ± 13.37 | |
| DL models | LSTM–RNN (single layer) [5] | 25.34 ± 5.62 | 13.12 ± 4.31 | 15.65 ± 4.01 |
| LSTM–RNN (multiple layers) [5] | 14.16 ± 0.86 | 10.08 ± 0.84 | 12.38 ± 0.58 | |
| LSTM–RNN with attention [23] | 20.18 ± 1.87 | 13.20 ± 2.67 | 13.60 ± 1.50 | |
| TCN | 51.67 ± 29.87 | 30.79 ± 8.24 | 26.20 ± 7.54 | |
| TCN (multiple blocks) | 16.96 ± 0.76 | 14.12 ± 3.06 | 11.41 ± 5.61 | |
| Ours | 10.45 ± 0.94 | 6.76 ± 0.45 | 7.40 ± 1.88 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gong, L.; Yu, M.; Jiang, S.; Cutsuridis, V.; Pearson, S. Deep Learning Based Prediction on Greenhouse Crop Yield Combined TCN and RNN. Sensors 2021, 21, 4537. https://doi.org/10.3390/s21134537
Gong L, Yu M, Jiang S, Cutsuridis V, Pearson S. Deep Learning Based Prediction on Greenhouse Crop Yield Combined TCN and RNN. Sensors. 2021; 21(13):4537. https://doi.org/10.3390/s21134537
Chicago/Turabian StyleGong, Liyun, Miao Yu, Shouyong Jiang, Vassilis Cutsuridis, and Simon Pearson. 2021. "Deep Learning Based Prediction on Greenhouse Crop Yield Combined TCN and RNN" Sensors 21, no. 13: 4537. https://doi.org/10.3390/s21134537
APA StyleGong, L., Yu, M., Jiang, S., Cutsuridis, V., & Pearson, S. (2021). Deep Learning Based Prediction on Greenhouse Crop Yield Combined TCN and RNN. Sensors, 21(13), 4537. https://doi.org/10.3390/s21134537