The Effect of Light Intensity, Sensor Height, and Spectral Pre-Processing Methods When Using NIR Spectroscopy to Identify Different Allergen-Containing Powdered Foods


Abstract
:1. Introduction
1.1. Role of Powdered Foods in the Food Industry
1.2. Powder Food Allergens and Digital Technologies in the Food Industry
1.3. NIR Technology Applications in the Food Manufacturing
1.4. Limitations of Online Applications of the NIR Technology
2. Materials and Methods
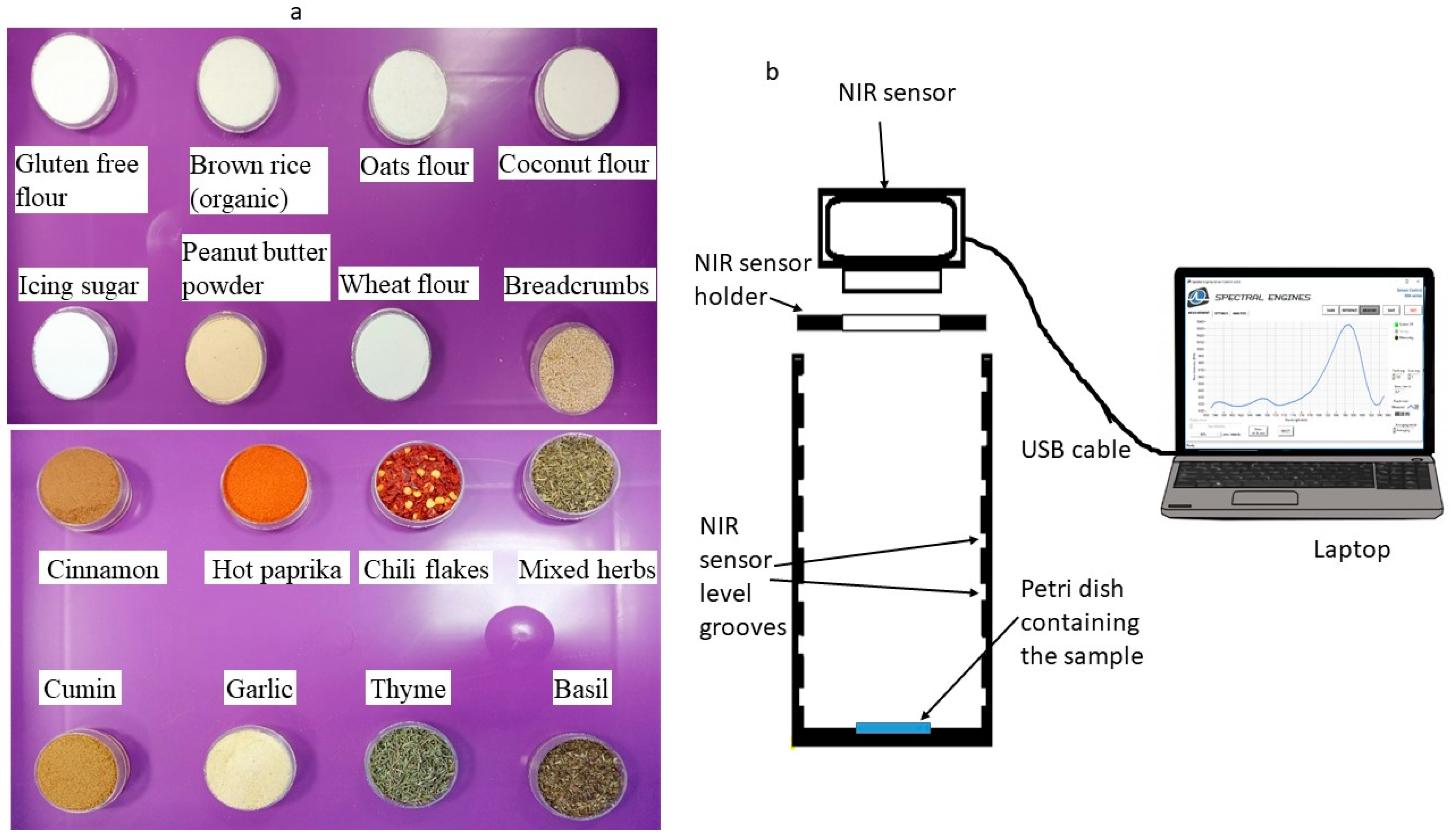
2.1. Raw Materials
2.2. Measurement System and Experimental Procedure
2.3. Data Analysis
3. Results and Discussion
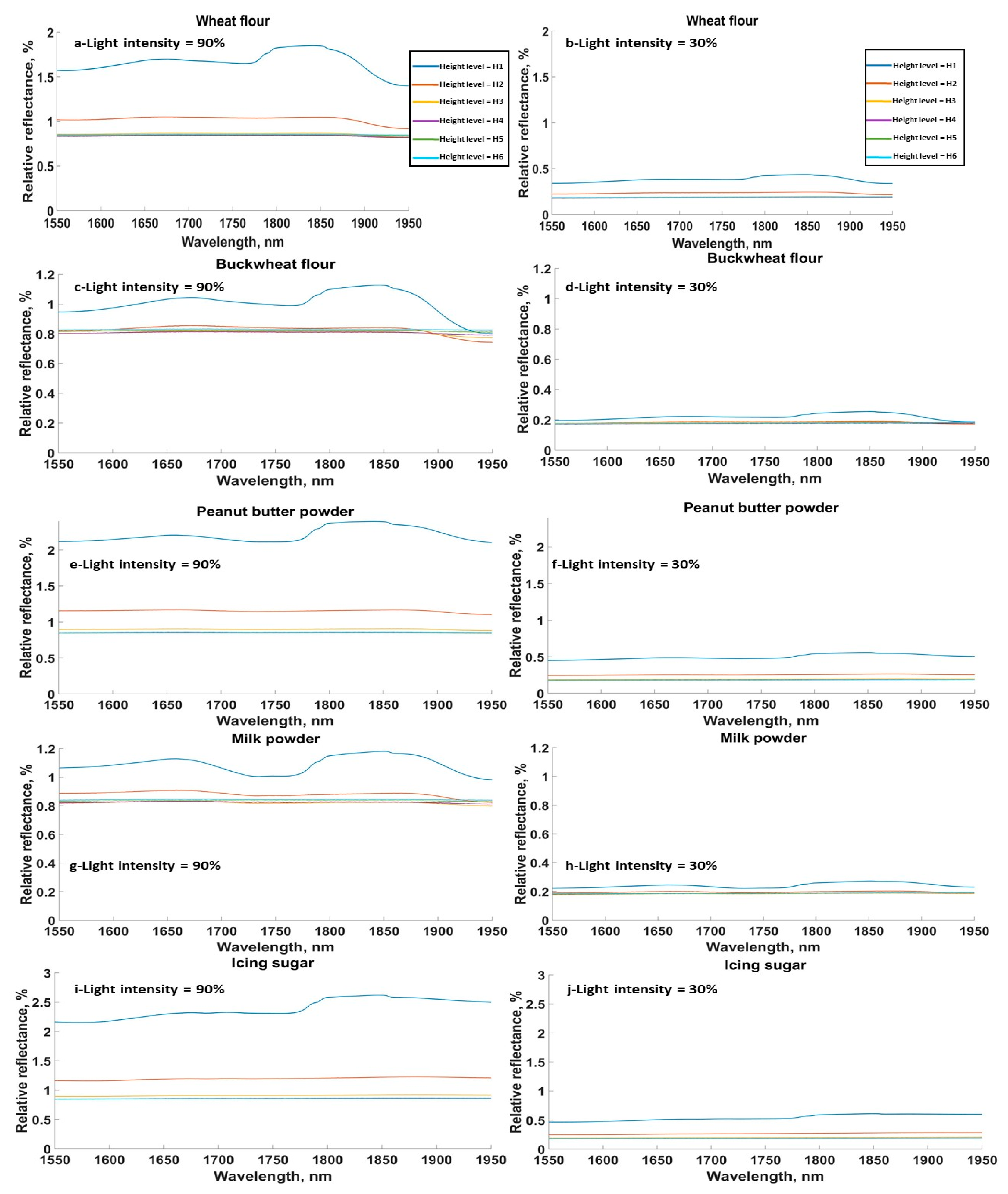
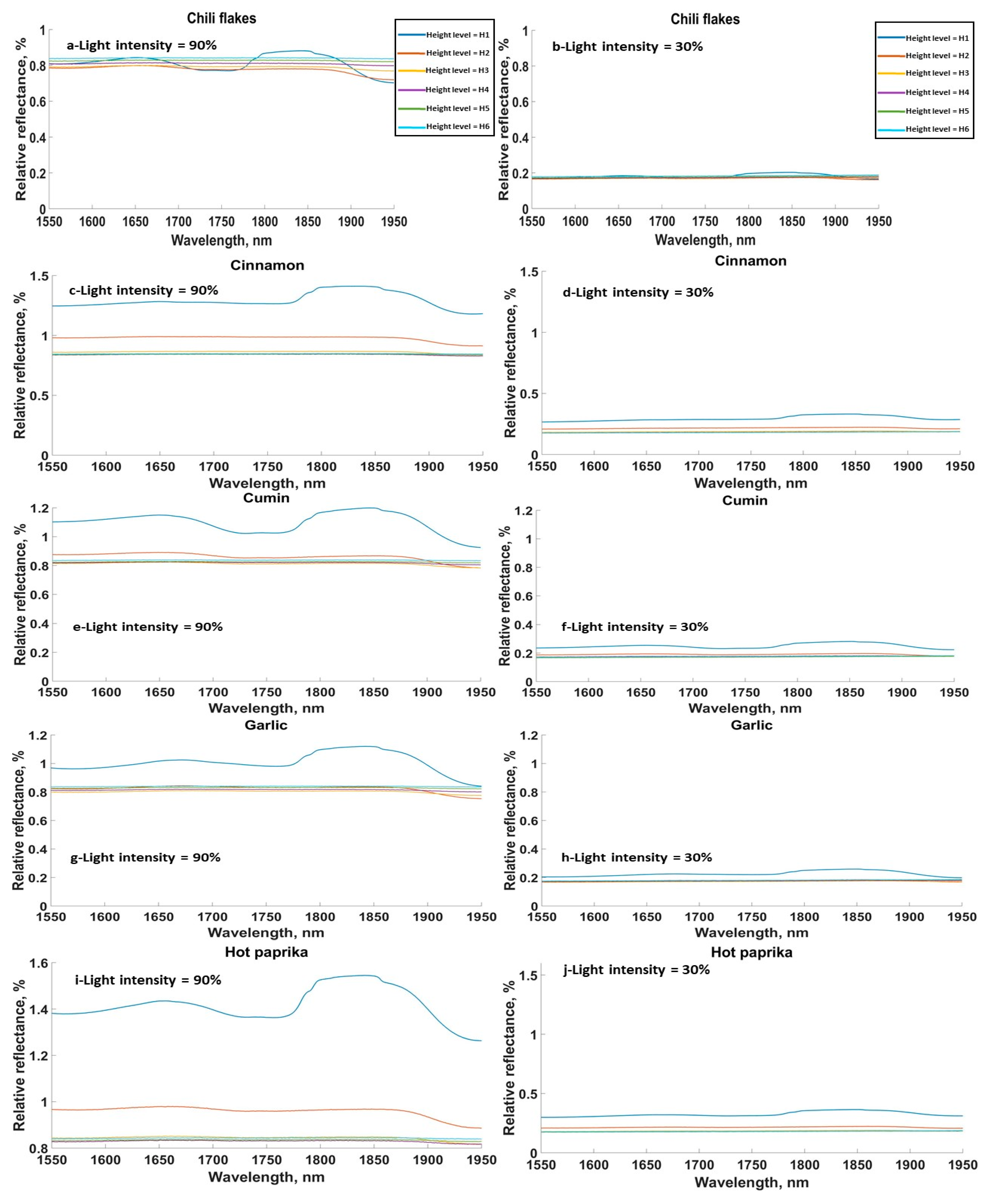
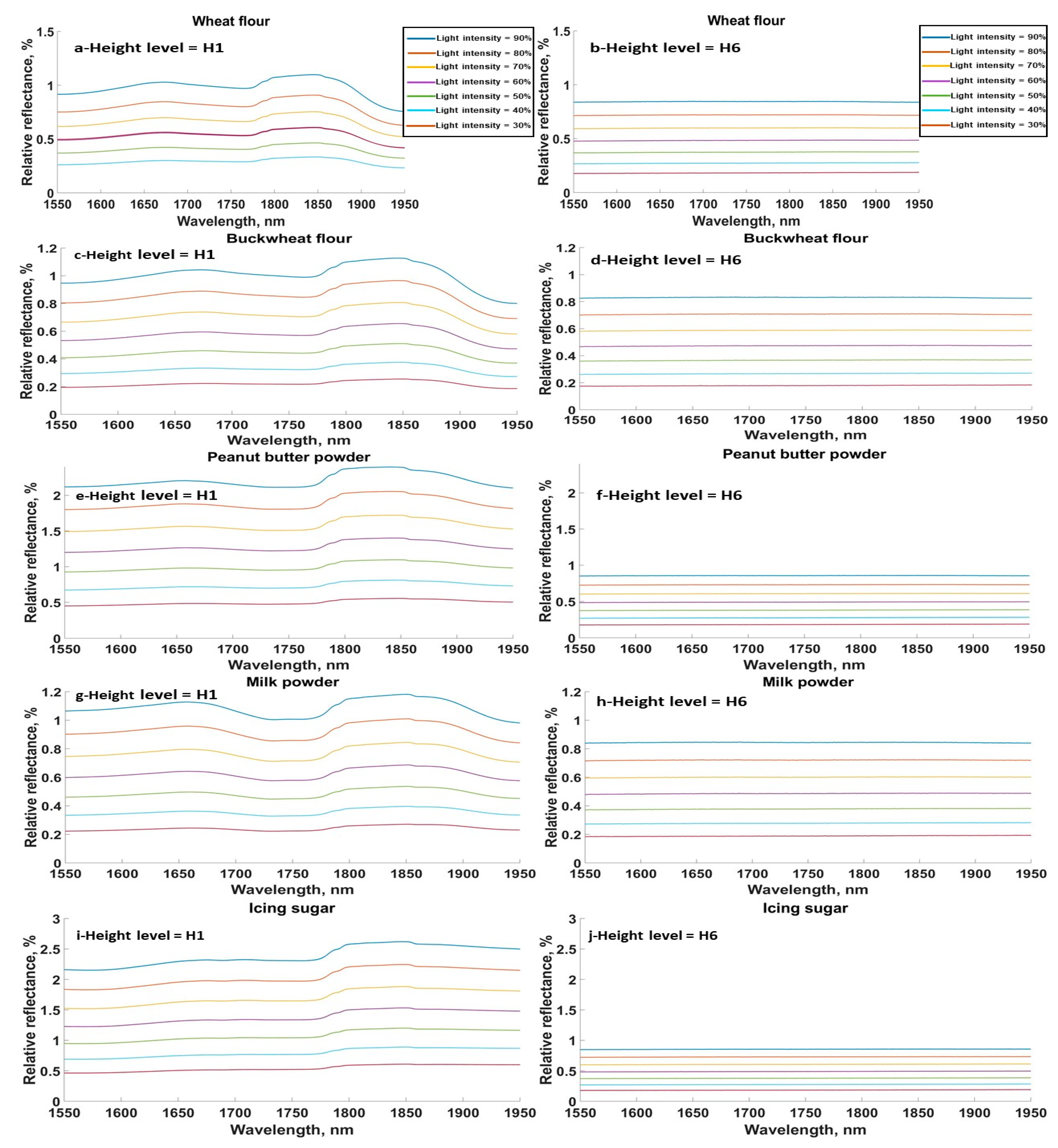
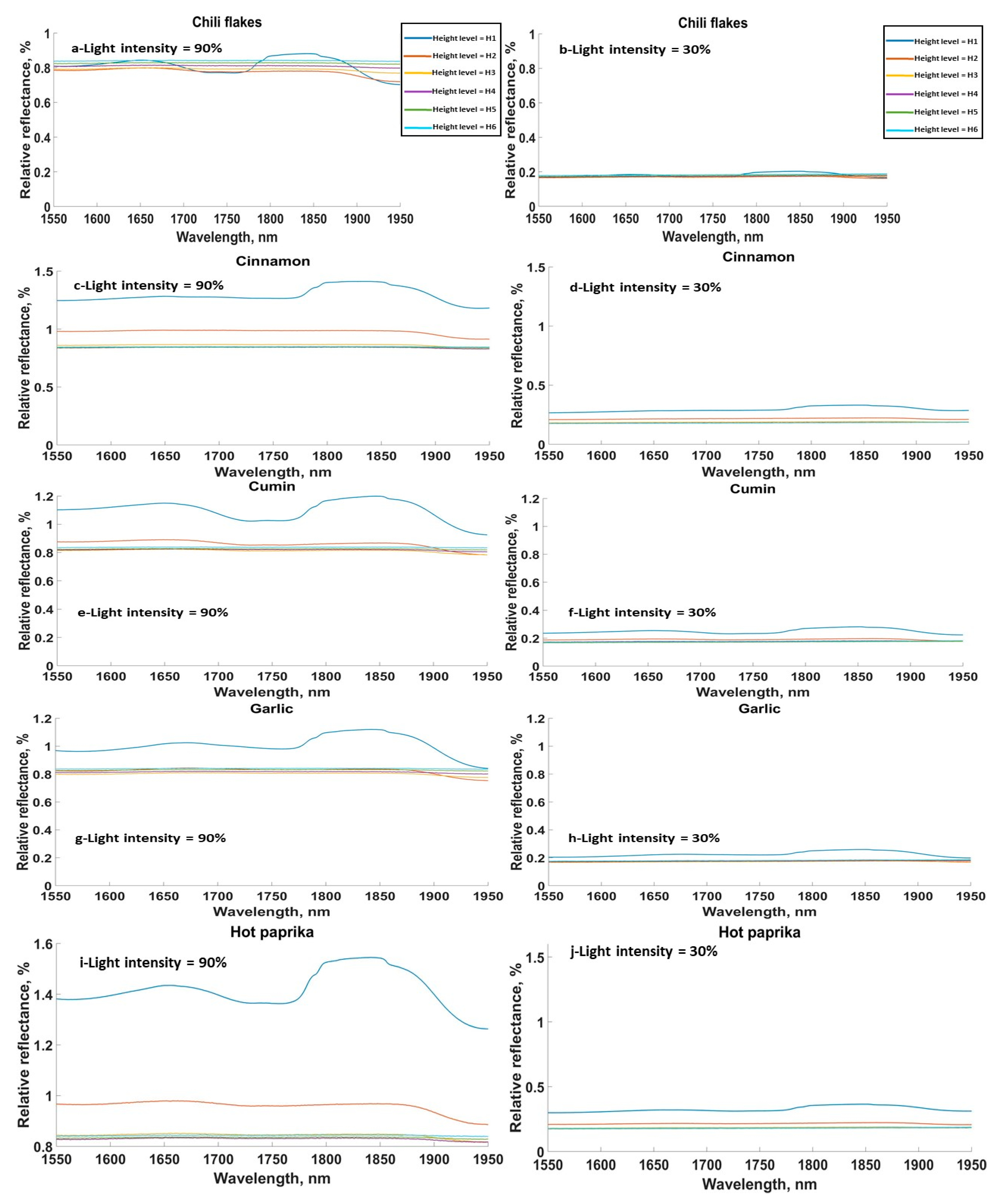
3.1. Effect of Sensor Height on Spectral Signature of Samples
3.2. Effect of Light Intensity on Spectral Signature of Samples
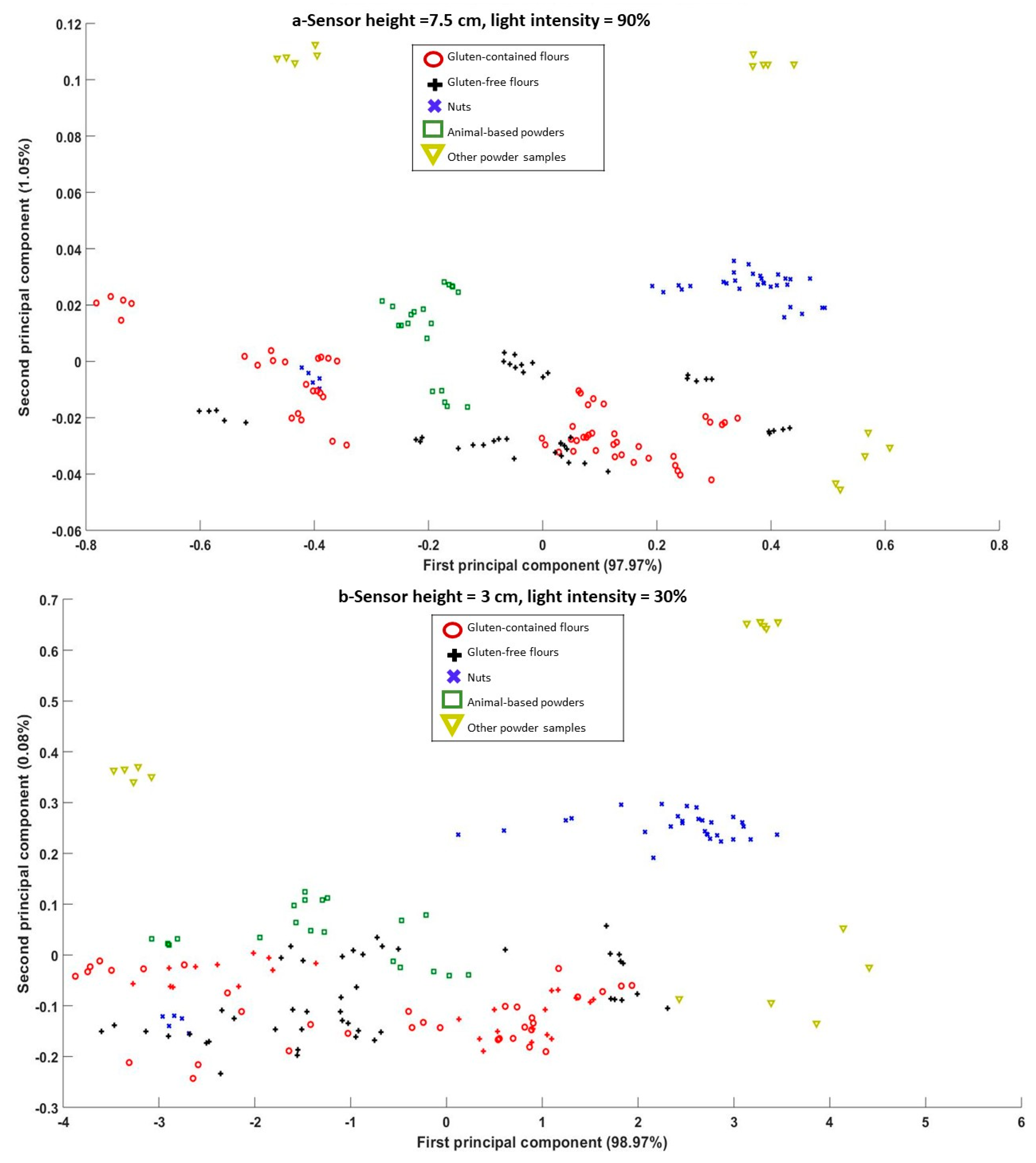
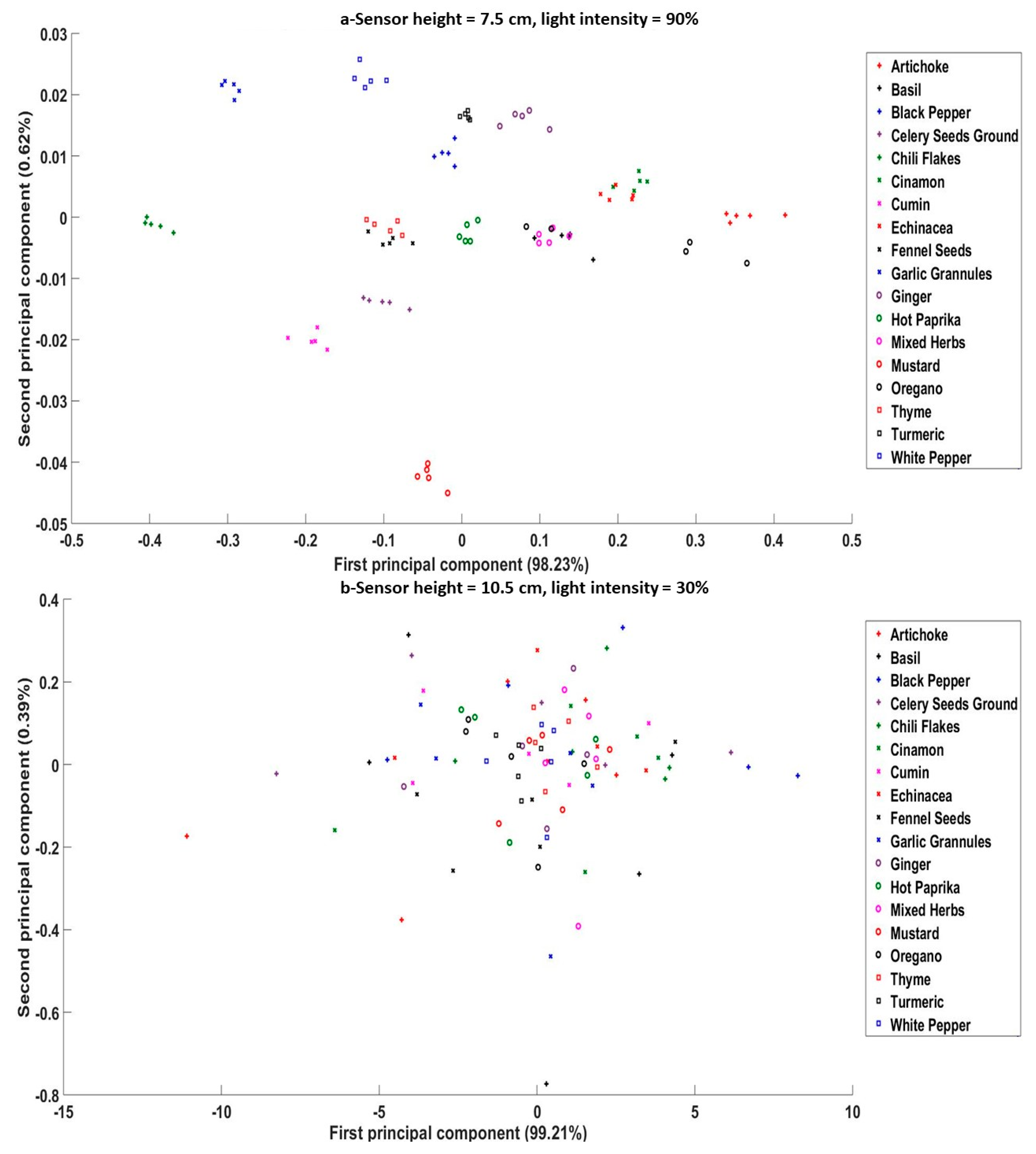
3.3. Effect of Sensor Height and Light Intensity on the Spectra Principle Components
3.4. Effect of Sensor Height, Light Intensity, and Pre-Processing Technique on Classification Prediction Accuracy
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Solar Foods. Food Out of Thin Air. Available online: https://solarfoods.fi (accessed on 8 October 2019).
- Forum, W.E. NASA Worked Out How to Make Food Out of Thin Air—and It Could Feed Billions. Available online: https://www.weforum.org/agenda/2019/08/nasas-idea-for-making-food-from-thin-air-just-became-a-reality-it-could-feed-billions/ (accessed on 8 November 2019).
- Bhandari, B. Introduction to food powders. In Handbook of Food Powders; Elsevier: Amsterdam, The Netherlands, 2013; pp. 1–25. [Google Scholar]
- Barbosa-Cánovas, G.V.; Ortega-Rivas, E.; Juliano, P.; Yan, H. Food Powders: Physical Properties, Processing, and Functionality; Springer: Berlin/Heidelberg, Germany, 2005; Volume 86. [Google Scholar]
- Van Hengel, A.J. Introdcution. In Food Allergens: Analysis Instrumentation and Methods; Nollet, L.M., van Hengel, A.J., Eds.; CRC Press: Boca Raton, FL, USA, 2016. [Google Scholar]
- Agency, F.S. Allergen Guidance for Food Businesses. Available online: https://www.food.gov.uk/business-guidance/allergen-guidance-for-food-businesses (accessed on 19 August 2019).
- Taylor, S.L. The nature of food allergy. In Detecting Allergens in Food; Elsevier Ltd.: Amsterdam, The Netherlands, 2006; pp. 3–20. [Google Scholar]
- Mills, E.C.; Johnson, P.; Alexeev, Y.; Breiteneder, H. Identification and characterisation of food allergens. Manag. Food Allerg. 2009, 42–69. [Google Scholar] [CrossRef]
- NHS. Food Allergy Treatment. Available online: https://www.nhs.uk/conditions/food-allergy/treatment/ (accessed on 16 August 2019).
- Koppelman, S.J.; Hefle, S.L. Detecting Allergens in Food; Woodhead Publishing Ltd.: Cambridge, UK, 2006. [Google Scholar]
- Rateni, G.; Dario, P.; Cavallo, F. Smartphone-based food diagnostic technologies: A review. Sensors 2017, 17, 1453. [Google Scholar] [CrossRef]
- Fisher, O.; Watson, N.; Porcu, L.; Bacon, D.; Rigley, M.; Gomes, R.L. Cloud manufacturing as a sustainable process manufacturing route. J. Manuf. Syst. 2018, 47, 53–68. [Google Scholar] [CrossRef]
- Pasquini, C. Near infrared spectroscopy: A mature analytical technique with new perspectives–A review. Anal. Chim. Acta 2018, 1026, 8–36. [Google Scholar] [CrossRef] [PubMed]
- Qu, J.H.; Liu, D.; Cheng, J.H.; Sun, D.W.; Ma, J.; Pu, H.; Zeng, X.A. Applications of near-infrared spectroscopy in food safety evaluation and control: A review of recent research advances. Crit. Rev. Food Sci. Nutr. 2015, 55, 1939–1954. [Google Scholar] [CrossRef]
- Xie, L.; Wang, A.; Xu, H.; Fu, X.; Ying, Y. Applications of near-infrared systems for quality evaluation of fruits: A review. Trans. ASABE 2016, 59, 399–419. [Google Scholar]
- Liu, Y.; Gao, R.; Sun, X. Review of portable NIR instruments for detecting fruit interior quality. Guang Pu Xue Yu Guang Pu Fen Xi Guang Pu 2010, 30, 2874–2877. [Google Scholar]
- Rady, A.M.; Guyer, D.E. Rapid and/or nondestructive quality evaluation methods for potatoes: A review. Comput. Electron. Agric. 2015, 117, 31–48. [Google Scholar] [CrossRef]
- Sánchez, M.-T.; Pérez-Marín, D.; Flores-Rojas, K.; Guerrero, J.-E.; Garrido-Varo, A. Use of near-infrared reflectance spectroscopy for shelf-life discrimination of green asparagus stored in a cool room under controlled atmosphere. Talanta 2009, 78, 530–536. [Google Scholar] [CrossRef]
- Prieto, N.; Roehe, R.; Lavín, P.; Batten, G.; Andrés, S. Application of near infrared reflectance spectroscopy to predict meat and meat products quality: A review. Meat Sci. 2009, 83, 175–186. [Google Scholar] [CrossRef]
- Ballin, N.Z. Authentication of meat and meat products. Meat Sci. 2010, 86, 577–587. [Google Scholar] [CrossRef] [PubMed]
- González-Martín, M.I.; Moncada, G.W.; González-Pérez, C.; San Martín, N.Z.; López-González, F.; Ortega, I.L.; Hernández-Hierro, J.-M. Chilean flour and wheat grain: Tracing their origin using near infrared spectroscopy and chemometrics. Food Chem. 2014, 145, 802–806. [Google Scholar] [CrossRef] [PubMed]
- Ma, H.-L.; Wang, J.-W.; Chen, Y.-J.; Lai, Z.-T. Rapid authentication of starch adulterations in ultrafine granular powder of Shanyao by near-infrared spectroscopy coupled with chemometric methods. Food Chem. 2017, 215, 108–115. [Google Scholar] [CrossRef] [PubMed]
- Cocchi, M.; Durante, C.; Foca, G.; Marchetti, A.; Tassi, L.; Ulrici, A. Durum wheat adulteration detection by NIR spectroscopy multivariate calibration. Talanta 2006, 68, 1505–1511. [Google Scholar] [CrossRef]
- Ghosh, S.; Mishra, P.; Mohamad, S.N.H.; de Santos, R.M.; Iglesias, B.D.; Elorza, P.B. Discrimination of peanuts from bulk cereals and nuts by near infrared reflectance spectroscopy. Biosys. Eng. 2016, 151, 178–186. [Google Scholar] [CrossRef]
- Haughey, S.A.; Graham, S.F.; Cancouët, E.; Elliott, C.T. The application of near-infrared reflectance spectroscopy (NIRS) to detect melamine adulteration of soya bean meal. Food Chem. 2013, 136, 1557–1561. [Google Scholar] [CrossRef]
- Albanell, E.; Miñarro, B.; Carrasco, N. Detection of low-level gluten content in flour and batter by near infrared reflectance spectroscopy (NIRS). J. Cereal Sci. 2012, 56, 490–495. [Google Scholar] [CrossRef]
- Shi, H.; Yu, P. Comparison of grating-based near-infrared (NIR) and Fourier transform mid-infrared (ATR-FT/MIR) spectroscopy based on spectral preprocessing and wavelength selection for the determination of crude protein and moisture content in wheat. Food Control 2017, 82, 57–65. [Google Scholar] [CrossRef]
- Badaró, A.T.; Morimitsu, F.L.; Ferreira, A.R.; Clerici, M.T.P.S.; Barbin, D.F. Identification of fiber added to semolina by near infrared (NIR) spectral techniques. Food Chem. 2019, 289, 195–203. [Google Scholar] [CrossRef]
- Wesley, I.; Larroque, O.; Osborne, B.; Azudin, N.; Allen, H.; Skerritt, J. Measurement of gliadin and glutenin content of flour by NIR spectroscopy. J. Cereal Sci. 2001, 34, 125–133. [Google Scholar] [CrossRef]
- Mao, X.; Sun, L.; Hui, G.; Xu, L. Modeling research on wheat protein content measurement using near-infrared reflectance spectroscopy and optimized radial basis function neural network. J. Food Drug Anal. 2014, 22, 230–235. [Google Scholar] [CrossRef] [Green Version]
- Ornelas-Soto, N.; Barbosa-García, O.; Lopez-de-Alba, P.L. Procedures of Food Quality Control: Analysis Methods, Sampling and Sample Pretreatment. In Quality Control of Herbal Medicines and Related Areas; IntechOpen: London, UK, 2011. [Google Scholar]
- Penner, M.H. Basic principles of spectroscopy. In Food Analysis; Springer: Berlin/Heidelberg, Germany, 2017; pp. 79–88. [Google Scholar]
- Nicolai, B.M.; Beullens, K.; Bobelyn, E.; Peirs, A.; Saeys, W.; Theron, K.I.; Lammertyn, J. Nondestructive measurement of fruit and vegetable quality by means of NIR spectroscopy: A review. Postharvest Biol. Technol. 2007, 46, 99–118. [Google Scholar] [CrossRef]
- Varmuza, K.; Filzmoser, P. Introduction to Multivariate Statistical Analysis in Chemometrics; CRC Press: Boca Raton, FL, USA, 2016. [Google Scholar]
- Brereton, R.G. Chemometrics: Data Analysis for the Laboratory and Chemical Plant; John WIlley & Sons: Hoboken, NJ, USA, 2003. [Google Scholar]
- Siesler, H.W.; Ozaki, Y.; Kawata, S.; Heise, H.M. Near-Infrared Spectroscopy: Principles, Instruments, Applications; John Wiley & Sons: Hoboken, NJ, USA, 2008. [Google Scholar]
- Ekramirad, N.; Rady, A.; Adedeji, A.A.; Alimardani, R. Application of Hyperspectral Imaging and Acoustic Emission Techniques for Apple Quality Prediction. Trans. ASABE 2017, 60, 1391–1401. [Google Scholar] [CrossRef]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Workman, J., Jr.; Weyer, L. Practical Guide and Spectral Atlas for Interpretive Near-Infrared Spectroscopy; CRC Press: Boca Raton, FL, USA, 2012. [Google Scholar]
- Li, D.; Hu, X. Fatty acid content of commonly available nuts and seeds. In Nuts and Seeds in Health and Disease Prevention; Elsevier: Amsterdam, The Netherlands, 2011; pp. 35–42. [Google Scholar]
- Guerra, M.J.; Mujica, M.V. Physical and chemical properties of granulated cane sugar“panelas”. Food Sci. Technol. 2010, 30, 250–257. [Google Scholar] [CrossRef] [Green Version]
- McKevith, B. Nutritional aspects of cereals. Nutr. Bull. 2004, 29, 111–142. [Google Scholar] [CrossRef]
- NHS. Echinacea Allergy Warning for Children under 12. 2012. Available online: https://www.nhs.uk/news/medication/echinacea-allergy-warning-for-children-under-12/ (accessed on 15 October 2019).
- Nawi, N.M.; Atomi, W.H.; Rehman, M. The effect of data pre-processing on optimized training of artificial neural networks. Procedia Technol. 2013, 11, 32–39. [Google Scholar] [CrossRef] [Green Version]
- Ziegler, J.U.; Leitenberger, M.; Longin, C.F.H.; Würschum, T.; Carle, R.; Schweiggert, R.M. Near-infrared reflectance spectroscopy for the rapid discrimination of kernels and flours of different wheat species. J. Food Compos. Anal. 2016, 51, 30–36. [Google Scholar] [CrossRef]
- Hu, L.; Yin, C.; Ma, S.; Liu, Z. Assessing the authenticity of black pepper using diffuse reflectance mid-infrared Fourier transform spectroscopy coupled with chemometrics. Comput. Electron. Agric. 2018, 154, 491–500. [Google Scholar] [CrossRef]
- Di Anibal, C.; Rodriguez, M.S.; Albertengo, L. UV-visible spectroscopy and multivariate classification as a screening tool to identify adulteration of culinary spices with Sudan I and blends of Sudan I + IV dyes. Food Anal. Methods 2014, 7, 1090–1096. [Google Scholar] [CrossRef]
- Garnett, J. Using Infrared Spectroscopy to Evaluate Physiological Ageing in Stored Potatoes (Solanum Tuberosum). Ph.D. Thesis, University of East Anglia, Norwich, UK, 2018. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Flours Group (FG) | Spices Group (SG) | ||||
|---|---|---|---|---|---|
| Gluten-Containing Flours | Non-Gluten-Containing Flours | Nuts | Animal-Based Flours | Other | |
| Barley flour Breadcrumbs Oatmeal Oats flour Rye flour Spelt flour Wheat flour (six brands) Wheat gluten | Buckwheat flour Brown rice flour Brown rice flour (organic) Coconut Corn flour Gluten free flour (two brands) Tapioca flour (organic) | Almond ground Peanut butter powder (four brands) Peanut flour (two brands) | Egg white Egg yolk Egg whole Powdered milk | Casting sugar Icing sugar Table salt | Artichoke powder Basil flakes Black pepper ground Celery ground Chili flakes Cinnamon ground Cumin ground Echinacea powder Fennel seeds Garlic powder Ginger ground Mixed herbs flakes Hot paprika ground Mustard powder Oregano flakes Thyme flakes Turmeric powder White pepper ground |
| 13 | 8 | 7 | 4 | 3 | 18 |
| Material | Ingredients |
|---|---|
| Barley Flour | 100% barely flour |
| Breadcrumbs | Wheat flour, salt, yeast |
| Oatmeal | Wholegrain rolled oats |
| Oats Flour | Wholegrain oat flour |
| Rye Flour | Rye flour (organic) |
| Spelt Flour | Spelt flour |
| Wheat Flour (Brands 1–3) | Wheat flour, calcium carbonate, iron, niacin, thiamine |
| Wheat Flour (Brand 4) | Wheat flour, calcium carbonate, iron, niacin, thiamine + ascorbic acid |
| Wheat Flour (Brand 5) | Wheat flour, calcium carbonate, iron, niacin, thiamine |
| Wheat Flour (Brand 5) | Wheat flour, calcium carbonate, iron, niacin, thiamine, raising agents: sodium carbonates, calcium phosphates |
| Wheat Gluten | Powder wheat gluten |
| Buckwheat Flour | 100% buckwheat flour |
| Brown Rice Flour (Organic) | 100% rice flour |
| Coconut | Organic coconut flour |
| Corn Flour | Cornflour |
| Gluten Free Flour | Rice, potato, tapioca, maize, buckwheat, raising agent (mono-calcium phosphate, sodium bicarbonate, thickener (xanthan gum) |
| Tapioca Flour (Organic) | Tapioca flour |
| Almond Ground | Almond ground |
| Peanut Butter Powder (Brands 1 and 2) | Peanut, coconut palm sugar, salt |
| Peanut Butter Powder (Brand 3) | Peanut flour, Palmyra nectar powder, mineral sea salt |
| Peanut Butter Powder (Brand 4) | Roasted peanut, sugar, salt |
| Peanut Flour | 100% peanut flour |
| Egg White | 100% pure egg white powder |
| Egg Yolk | 99.7% Egg yolk powder, 0.3% anti-caking agent |
| Egg Whole | 100% pure powdered whole egg |
| Powdered Milk | Whole milk powder, emulsifier (soya lecithin) |
| Casting Sugar | Cane sugar |
| Table Salt | Salt, anticaking agent: sodium ferrocyanide |
| Icing Sugar | Cane sugar powder |
| Light Intensity (%) | Classification Range for the Test Set (Minimum–Maximum) (%) | ||||
|---|---|---|---|---|---|
| KNN | PLSDA | SIMCA | ANN | ||
| Height Level H1 | 90 | 77–97 | 34–77 | 34–77 | 51–54 |
| 80 | 71–100 | 37–69 | 37–69 | 51–54 | |
| 70 | 71–100 | 26–83 | 37–80 | 54–57 | |
| 60 | 77–100 | 23–83 | 31–74 | 54 | |
| 50 | 77–100 | 17–80 | 31–80 | 54 | |
| 40 | 80–100 | 17–74 | 34–74 | 37–54 | |
| 30 | 74–100 | 6–66 | 6–66 | 43–57 | |
| Height Level H2 | 90 | 71–97 | 20–63 | 3–60 | 46–54 |
| 80 | 63–97 | 6–60 | 6–69 | 49–54 | |
| 70 | 77–100 | 6–69 | 6–69 | 54 | |
| 60 | 51–97 | 9–74 | 9–74 | 34–54 | |
| 50 | 54–100 | 3–54 | 3–54 | 51–54 | |
| 40 | 51–97 | 6–57 | 6–57 | 34–54 | |
| 30 | 34–89 | 3–49 | 3–46 | 43–54 | |
| Height Level H3 | 90 | 46–94 | 6–54 | 6–54 | 43–54 |
| 80 | 40–91 | 11–57 | 11–60 | 37–54 | |
| 70 | 40–94 | 6–57 | 6–57 | 34–54 | |
| 60 | 51–89 | 6–57 | 6–57 | 34–54 | |
| 50 | 31–86 | 6–49 | 6–49 | 34–54 | |
| 40 | 31–83 | 6–54 | 6–54 | 34–54 | |
| 30 | 31–94 | 3–46 | 3–46 | 14–60 | |
| Height Level H4 | 90 | 49–97 | 6–46 | 6–54 | 43–54 |
| 80 | 34–94 | 3–37 | 3–40 | 43–54 | |
| 70 | 31–91 | 6–51 | 6–51 | 37–54 | |
| 60 | 29–89 | 6–43 | 3–49 | 40–54 | |
| 50 | 26–94 | 3–34 | 3–34 | 31–54 | |
| 40 | 49–83 | 3–43 | 3–43 | 34–54 | |
| 30 | 23–83 | 3–46 | 3–40 | 34–54 | |
| Height Level H5 | 90 | 17–83 | 6–49 | 6–46 | 34–54 |
| 80 | 26–83 | 3–46 | 3–40 | 34–51 | |
| 70 | 29–89 | 6–37 | 6–46 | 26–54 | |
| 60 | 29–80 | 3–40 | 6–40 | 34–54 | |
| 50 | 40–89 | 3–46 | 3–46 | 26–51 | |
| 40 | 23–94 | 3–37 | 3–37 | 34–51 | |
| 30 | 20–83 | 6–31 | 6–31 | 31–54 | |
| Height Level H6 | 90 | 20–89 | 6–40 | 6–40 | 34–54 |
| 80 | 31–83 | 9–40 | 9–40 | 34–54 | |
| 70 | 26–77 | 0–40 | 0–40 | 31–54 | |
| 60 | 26–69 | 0–34 | 0–34 | 34–60 | |
| 50 | 29–74 | 0–31 | 0–31 | 29–57 | |
| 40 | 17–69 | 6–46 | 6–46 | 23–54 | |
| 30 | 23–66 | 0–23 | 0–29 | 26–43 | |
| Light Intensity (%) | Classification Range for the Test Set (Minimum–Maximum) (%) | ||||
|---|---|---|---|---|---|
| LDA | KNN | PLSDA | ANN | ||
| Height Level H1 | 90 | 39–100 | 44–89 | 50–89 | <20 |
| 80 | 39–100 | 44–89 | 61–89 | <20 | |
| 70 | 39–100 | 50–100 | 50–83 | <20 | |
| 60 | 39–100 | 50–100 | 56–94 | <20 | |
| 50 | 44–100 | 44–94 | 39–83 | <20 | |
| 40 | 50–100 | 56–100 | 22–83 | <20 | |
| 30 | 61–100 | 50–94 | 28–72 | <20 | |
| Height Level H2 | 90 | 61–100 | 61–100 | 11–44 | <20 |
| 80 | 61–100 | 61–100 | 11–67 | <20 | |
| 70 | 56–100 | 22–94 | 17–44 | <20 | |
| 60 | 33–100 | 6–94 | 6–39 | <20 | |
| 50 | 33–89 | 11–89 | 6–39 | <20 | |
| 40 | 39–100 | 44–94 | 6–28 | <20 | |
| 30 | 44–100 | 0–72 | 6–44 | <20 | |
| Height Level H3 | 90 | 28–94 | 11–94 | 6–61 | <20 |
| 80 | 39–94 | 17–94 | 11–56 | <20 | |
| 70 | 28–94 | 11–83 | 0–17 | <20 | |
| 60 | 17–94 | 6–78 | 6–22 | <20 | |
| 50 | 11–78 | 6–72 | 6–33 | <20 | |
| 40 | 6–56 | 6–72 | 0–22 | <20 | |
| 30 | 11–67 | 11–67 | 0–22 | <20 | |
| Height Level H4 | 90 | 44–89 | 6–83 | 6–22 | <20 |
| 80 | 50–78 | 28–83 | 6–22 | <20 | |
| 70 | 56–72 | 11–83 | 0–22 | <20 | |
| 60 | 33–72 | 17–83 | 0–17 | <20 | |
| 50 | 33–67 | 17–78 | 0–11 | <20 | |
| 40 | 28–61 | 6–78 | 0–17 | <20 | |
| 30 | 6–44 | 0–50 | 0–6 | <20 | |
| Height Level H5 | 90 | 17–67 | 11–61 | 0–22 | <20 |
| 80 | 17–61 | 6–61 | 0–28 | <20 | |
| 70 | 11–72 | 11–67 | 0–6 | <20 | |
| 60 | 22–44 | 6–61 | 0–17 | <20 | |
| 50 | 6–44 | 0–50 | 0–6 | <20 | |
| 40 | 11–33 | 11–39 | 0–17 | <20 | |
| 30 | 0–28 | 0–33 | 0–6 | <20 | |
| Height Level H6 | 90 | 22–72 | 11–78 | 6–17 | <20 |
| 80 | 11–61 | 6–72 | 0–22 | <20 | |
| 70 | 17–61 | 0–56 | 0–11 | <20 | |
| 60 | 17–50 | 11–56 | 0–6 | <20 | |
| 50 | 0–50 | 0–67 | 0–6 | <20 | |
| 40 | 6–50 | 6–56 | 0 | <20 | |
| 30 | 0–56 | 0–56 | 0 | <20 | |
| Gluten-Containing Flours | Gluten-Free Flours | Nuts | Animal-Based Powders | Other Powder Samples | Overall Classification | |
|---|---|---|---|---|---|---|
| Gluten-Containing Flours | 11 | 1 | 0 | 0 | 0 | |
| Gluten-Free Flours | 0 | 9 | 0 | 0 | 0 | |
| Nuts | 0 | 0 | 7 | 0 | 0 | |
| Animal-Based Powders | 0 | 0 | 0 | 4 | 0 | |
| Other Powder Samples | 0 | 0 | 0 | 0 | 3 | |
| 94% | ||||||
| Light Intensity (%) | Maximum Classification Range for the Test Set (%) | ||||
|---|---|---|---|---|---|
| Flours Group Using KNN | Spices Group Using LDA | ||||
| SNV | Second Derivative | SNV | Second Derivative | ||
| Height Level H1 | 90 | 97 | 94 | 83 | 100 |
| 80 | 100 | 100 | 83 | 100 | |
| 70 | 100 | 91 | 78 | 100 | |
| 60 | 100 | 94 | 78 | 100 | |
| 50 | 100 | 91 | 78 | 94 | |
| 40 | 97 | 89 | 78 | 89 | |
| 30 | 100 | 77 | 78 | 83 | |
| Height Level H2 | 90 | 97 | 71 | 100 | 50 |
| 80 | 97 | 63 | 100 | 61 | |
| 70 | 100 | 69 | 100 | 56 | |
| 60 | 97 | 51 | 94 | 33 | |
| 50 | 97 | 54 | 89 | 33 | |
| 40 | 97 | 51 | 100 | 39 | |
| 30 | 83 | 34 | 100 | 44 | |
| Height Level H3 | 90 | 94 | 46 | 94 | 28 |
| 80 | 89 | 40 | 94 | 39 | |
| 70 | 91 | 40 | 94 | 28 | |
| 60 | 77 | 51 | 94 | 17 | |
| 50 | 71 | 31 | 78 | 11 | |
| 40 | 74 | 31 | 56 | 06 | |
| 30 | 74 | 31 | 67 | 06 | |
| Height Level H4 | 90 | 83 | 49 | 78 | 44 |
| 80 | 80 | 34 | 78 | 50 | |
| 70 | 86 | 31 | 61 | 56 | |
| 60 | 69 | 29 | 56 | 33 | |
| 50 | 51 | 26 | 33 | 39 | |
| 40 | 57 | 49 | 33 | 44 | |
| 30 | 49 | 23 | 06 | 11 | |
| Height Level H5 | 90 | 63 | 17 | 56 | 28 |
| 80 | 69 | 26 | 44 | 17 | |
| 70 | 66 | 29 | 33 | 11 | |
| 60 | 46 | 40 | 39 | 22 | |
| 50 | 43 | 40 | 6 | 28 | |
| 40 | 43 | 23 | 11 | 17 | |
| 30 | 34 | 20 | 11 | 0 | |
| Height Level H6 | 90 | 57 | 20 | 50 | 22 |
| 80 | 40 | 31 | 22 | 17 | |
| 70 | 46 | 26 | 17 | 17 | |
| 60 | 31 | 34 | 22 | 22 | |
| 50 | 31 | 29 | 33 | 06 | |
| 40 | 31 | 20 | 6 | 17 | |
| 30 | 31 | 23 | 0 | 6 | |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rady, A.; Fischer, J.; Reeves, S.; Logan, B.; James Watson, N. The Effect of Light Intensity, Sensor Height, and Spectral Pre-Processing Methods When Using NIR Spectroscopy to Identify Different Allergen-Containing Powdered Foods. Sensors 2020, 20, 230. https://doi.org/10.3390/s20010230
Rady A, Fischer J, Reeves S, Logan B, James Watson N. The Effect of Light Intensity, Sensor Height, and Spectral Pre-Processing Methods When Using NIR Spectroscopy to Identify Different Allergen-Containing Powdered Foods. Sensors. 2020; 20(1):230. https://doi.org/10.3390/s20010230
Chicago/Turabian StyleRady, Ahmed, Joel Fischer, Stuart Reeves, Brian Logan, and Nicholas James Watson. 2020. "The Effect of Light Intensity, Sensor Height, and Spectral Pre-Processing Methods When Using NIR Spectroscopy to Identify Different Allergen-Containing Powdered Foods" Sensors 20, no. 1: 230. https://doi.org/10.3390/s20010230
APA StyleRady, A., Fischer, J., Reeves, S., Logan, B., & James Watson, N. (2020). The Effect of Light Intensity, Sensor Height, and Spectral Pre-Processing Methods When Using NIR Spectroscopy to Identify Different Allergen-Containing Powdered Foods. Sensors, 20(1), 230. https://doi.org/10.3390/s20010230