Adaptive Estimation and Cooperative Guidance for Active Aircraft Defense in Stochastic Scenario


1
School of Electronic and Information Engineering, Xi’an Jiaotong University, Xi’an 710049, China
2
School of Information and Navigation, Air Force Engineering University, Xi’an 710077, China
*
Author to whom correspondence should be addressed.
Sensors 2019, 19(4), 979; https://doi.org/10.3390/s19040979
Submission received: 24 November 2018
/
Revised: 1 February 2019
/
Accepted: 20 February 2019
/
Published: 25 February 2019
(This article belongs to the Special Issue Aerospace Sensors and Multisensor Systems)
Abstract
:The active aircraft defense problem is investigated for the stochastic scenario wherein a defending missile (or a defender) is employed to protect a target aircraft from an attacking missile whose pursuit guidance strategy is unknown. For the purpose of identifying the guidance strategy, the static multiple model estimator (sMME) based on the square-root cubature Kalman filter is proposed, and each model represents a potential attacking missile guidance strategy. Furthermore, an estimation enhancement approach is provided by using pseudo-measurement. For each model in the sMME, the model-matched cooperative guidance laws for the target and defender are derived by formulating the active defense problem as a constrained linear quadratic problem, where an accurate defensive interception and the minimum evasion miss distance are both considered. The proposed adaptive cooperative guidance laws are the result of mixing the model-matched optimal cooperative guidance laws in the criterion of maximum a posteriori probability in the framework of the sMME. By adopting the adaptive cooperative guidance laws, the target can facilitate the defender’s interception with the attacking missile with less control effort. Also, simulation results show that the proposed guidance laws increase the probability of successful target protection in the stochastic scenario compared with other defensive guidance laws.
1. Introduction
With the development of advanced pursuit guidance laws, an attacking missile can intercept a low-maneuverability target accurately. In order to protect the target, a widely discussed topic in recent years is the active defense countermeasure, whereby a defending missile (or a defender) is launched from the target or a target-friendly platform to intercept the attacking missile. There are several approaches to investigating the active defense problem, including optimal control [1,2,3,4,5], differential game [6,7,8,9,10], sliding mode control [11], and line-of-sight guidance [12,13]. In [1,2,3,4,5], the authors used optimal control theory to derive cooperative guidance laws for target and defender with the assumption that the pursuit guidance law of an attacking missile is fixed and known. In [6,7,8,9,10], the authors adopted differential game theory to analyze the dynamic conflicts and design the associated guidance laws. In [11], a cooperative guidance law based on sliding model control was proposed, and its objective was to make the zero-effort miss distance and zero-effort relative velocity of missile–defender engagement both zero. In [12,13], the main idea was the use of line-of-sight guidance to ensure that the defender remains on the line joining the target and attacking missile, and thus, the defender will block the attacking missile.
In all of the above work, the active aircraft defense was discussed for deterministic scenarios, where the maneuvers and state information of each aircraft are exactly known and directly used to calculate the guidance commands. However, in practical applications, the guidance strategy of enemy aircraft is unknown, and the state information needs to be estimated from noisy measurements. Therefore, it is necessary to add a preprocessed module (i.e., estimation module) to deal with the stochastic scenarios of measurement noise and unknown guidance strategy. Also, the performance of the closed loop of guidance and estimation needs further analysis. This is an important motivation for the present effort to investigate the combined estimation and guidance algorithm in the stochastic scenario.
In [14,15], multiple-model adaptive estimators were presented to identify the purist guidance strategy of a homing missile. In [14], a multiple-model adaptive evasion strategy that enables a target’s evasion of a homing missile was proposed, and in [15], cooperative multiple-model adaptive guidance for the defender and target was designed. Inspired by [14,15], adaptive cooperative guidance laws for the target and defender in the stochastic scenario are proposed; the proposed approach combines the sMME-SRCKF and model-matched optimal cooperative guidance laws. The sMME-SRCKF refers to the static multiple model estimator (sMME) that adopts the square-root cubature Kalman filter (SRCKF) as the model-matched nonlinear filter, and each model of the sMME-SRCKF represents a potential guidance law of the attacking missile. The output of the sMME-SRCKF includes a state estimate and model probability, where the former is used to calculate the model-matched cooperative guidance commands, and the latter is used to mix the model-matched guidance laws in the criterion of maximum a posteriori probability. Although the adaptive guidance laws in this paper and in Reference [15] are both designed using a similar approach, which combines an adaptive estimator and model-matched optimal cooperative guidance laws, they are very different. First, the most important difference is that the core of adaptive guidance laws, i.e., the model-matched cooperative guidance laws, are totally different. In [15], the authors designed the defender’s guidance law by using the known future maneuver of the protected target; in the case of a target using a bang–bang maneuver, the optimal switch time of this maneuver was solved to minimize the control effort of the defender. However, in this study, without knowing the information of the future target, the optimal cooperative guidance laws for the defender and target were derived together by solving a constrained linear quadratic problem. Second, the criterion to mix model-matched cooperative guidance laws in this paper is maximum a posteriori probability criterion. Compared with the use of the minimum mean-square-error criterion in [15], the criterion used in this study can reduce the computational burden. Third, the model-matched filter described in this paper is SRCKF, which has two advantages (see Section 3.1 and Section 5.3.1) compared with the extended Kalman filter (EKF) used as a model-matched filter in [15].
The main contribution of this work includes the following aspects. (i) The adaptive cooperative guidance laws can increase the probability of successful target protection in the stochastic active defense scenario, since it is designed to apply to the entire duration of active defense engagement rather than solely the defender–missile engagement, as in [1,2,3,4,15]. Thus, an additional chance for the target to evade the attacking missile is presented if the defender fails to intercept the attacking missile because it is negatively affected by stochastic factors; this issue demonstrated in Section 5.2. (ii) The model-matched cooperative guidance laws are designed to consider the two sufficient conditions of successful active defense, i.e., small defender–missile miss distance and minimum missile–target evasion distance. In [5], the authors also considered both of these conditions, but the two-dimensional generalized dead-zone functions require computation to generate guidance commands, which seems a little complex. On the other hand, the cooperative guidance laws in this paper are easily computed. (iii) Estimation enhancement is analyzed by using pseudo-measurement, and a guideline is provided for adjusting the location geometry of active defense to acquire good-quality estimation and then to improve further the performance of adaptive cooperative guidance laws.
This paper is organized as follows. In Section 2, the kinematic equations and estimation model of active aircraft defense are introduced. In Section 3, the sMME-SRCKF is proposed, and the estimation enhancement analysis is presented. The adaptive cooperative guidance laws for defender and target are derived in Section 4. The performance of the proposed guidance laws and filtering approach is analyzed in Section 5, and some remarkable conclusions are drawn in Section 6.
2. Preliminary
2.1. Kinematic Equations of Active Defense
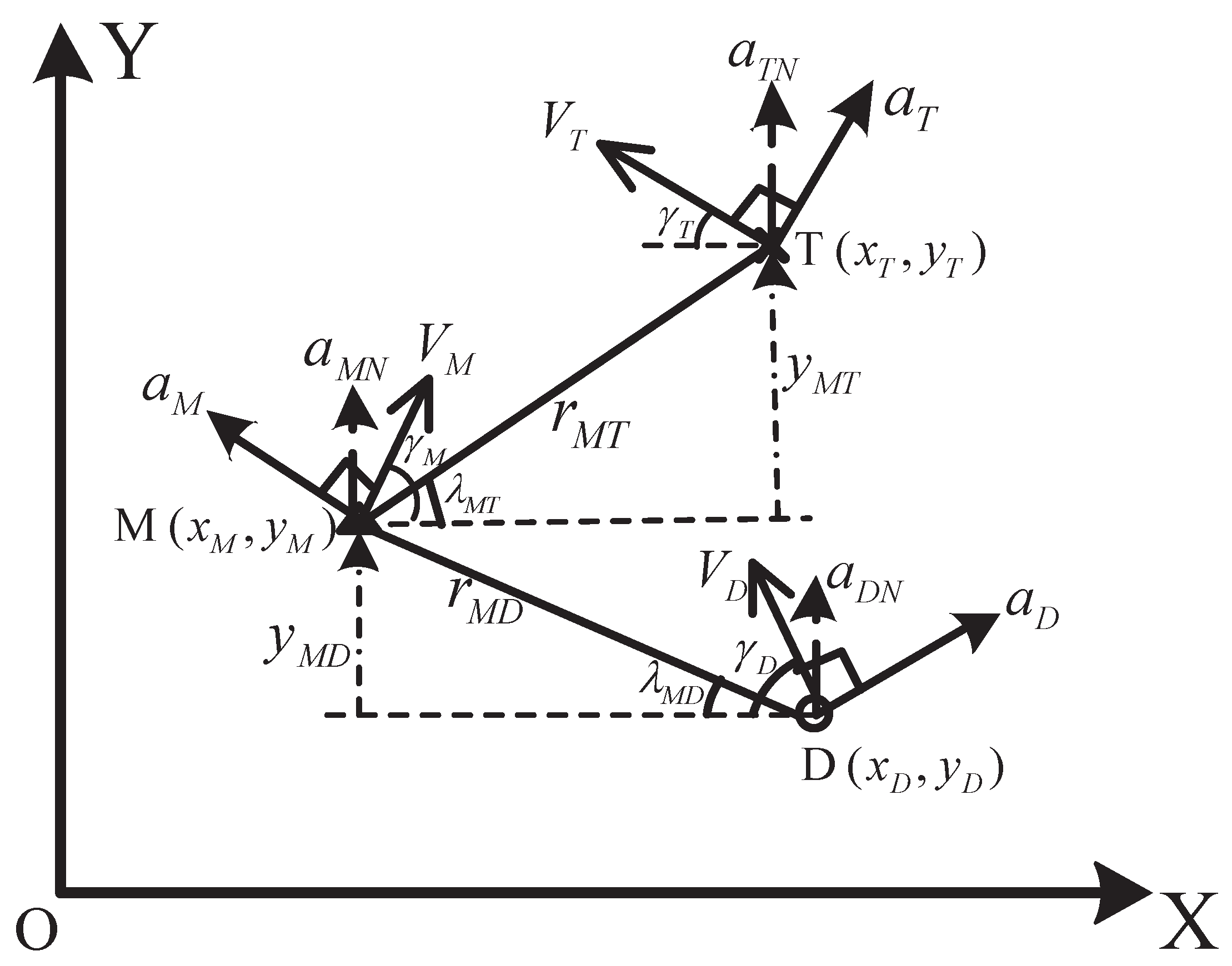
The active aircraft defense contains three aircraft: an attacking missile denoted as M, an evading target denoted as T, and a defender denoted as D. The attacking missile uses an interception guidance law to pursue the evading target. The defender, which is launched from the target or a target-friendly platform, tries to kill the attacking missile before it intercepts the target. The active aircraft defense can be divided into two engagements, which are defender–missile (D–M) engagement and missile–target (M–T) engagement. The geometry of active aircraft defense is shown in Figure 1. The X-axis is selected as the initial line-of-sight (LOS) of M–T engagement, and the Y-axis is normal to the X-axis. The subscripts T, D, and M represent the target, defender, and attacking missile, respectively. , , , and , where , represent the position, velocity, acceleration, and flight-path angle of each aircraft, and is normal to its velocity. is the acceleration component along the Y-axis, and it satisfies , where . and are the LOS angles of M–T and D–M engagements; and are the relative distances of M–T and D–M; and and are the relative displacements along the Y-axis.
In this paper, there are three assumptions: (i) The M–T and D–M engagements occur around the triangle-collision courses, so both types of engagements can be linearized around the initial LOS of M–T (or the X-axis). This can be realized at the endgame of engagement, since most of the guidance error has been removed after the midcourse guidance. (ii) The set of the attacking missile’s guidance laws contains proportional navigation (PN), augmented proportional navigation (APN), and optimal guidance law (OGL) (shown in Equations (3) and (4)); the attacking missile uses one of them to pursue the target, and it is unknown to the defender–target team. (iii) The aircraft’s dynamics is represented by arbitrary-order linear equations [1]:
where represents the internal state vector of the aircraft with the dimension for ; and is the control command component along the Y-axis and satisfies , where is the total control command perpendicular to the velocity. If an aircraft has first-order dynamics with time constant , then we have , , , and . If an aircraft has ideal dynamics, then we have , , , and . This means that the acceleration is equal to the guidance command, which can be obtained immediately without delay. For example, if an aircraft uses the thrust vector control engine, then the acceleration dynamics is nearly ideal.
On the basis of the linearization assumption, the D–M interception time and M–T interception time are approximately calculated as
where the subscript 0 indicates the initial instant.
According to [1], under the linearization assumption, the traditional attacking missile’s guidance laws can be written in the general form of Equation (3), which is a function of the M–T engagement’s relative variables and possibly the control of the target.
The pursuit guidance laws of PN, APN, and OGL have the following forms:
where , with as the navigation gains; is the time-to-go of M–T engagement, i.e., ; and , with . and are constants between 3 and 5, and satisfies
Defining the state vector of active defense as
and using the attacking missile’s guidance law in Equation (3), the kinematic equation of active defense is
where
and
2.2. Estimation Model
According to Figure 1, the kinematic equation of the attacking missile is described as
Defining the state vector of the attacking missile as , Equation (11) can be rewritten as
Assuming the defender and target track the attacking missile with infrared radar, the measurement model of active defense during D–M engagement (i.e., ) is
where represents the measurements of M–T and D–M LOS angles, and is a mutually independent zero-mean white Gaussian noise. The covariance matrix of measurement noise is
where and are the variances of and , respectively.
After the missile–defender engagement terminates (i.e., ), only the target uses its sensor to track the attacking missile, and then the measurement model becomes
3. Guidance Identification and State Estimation
3.1. Static Multiple Model Estimator
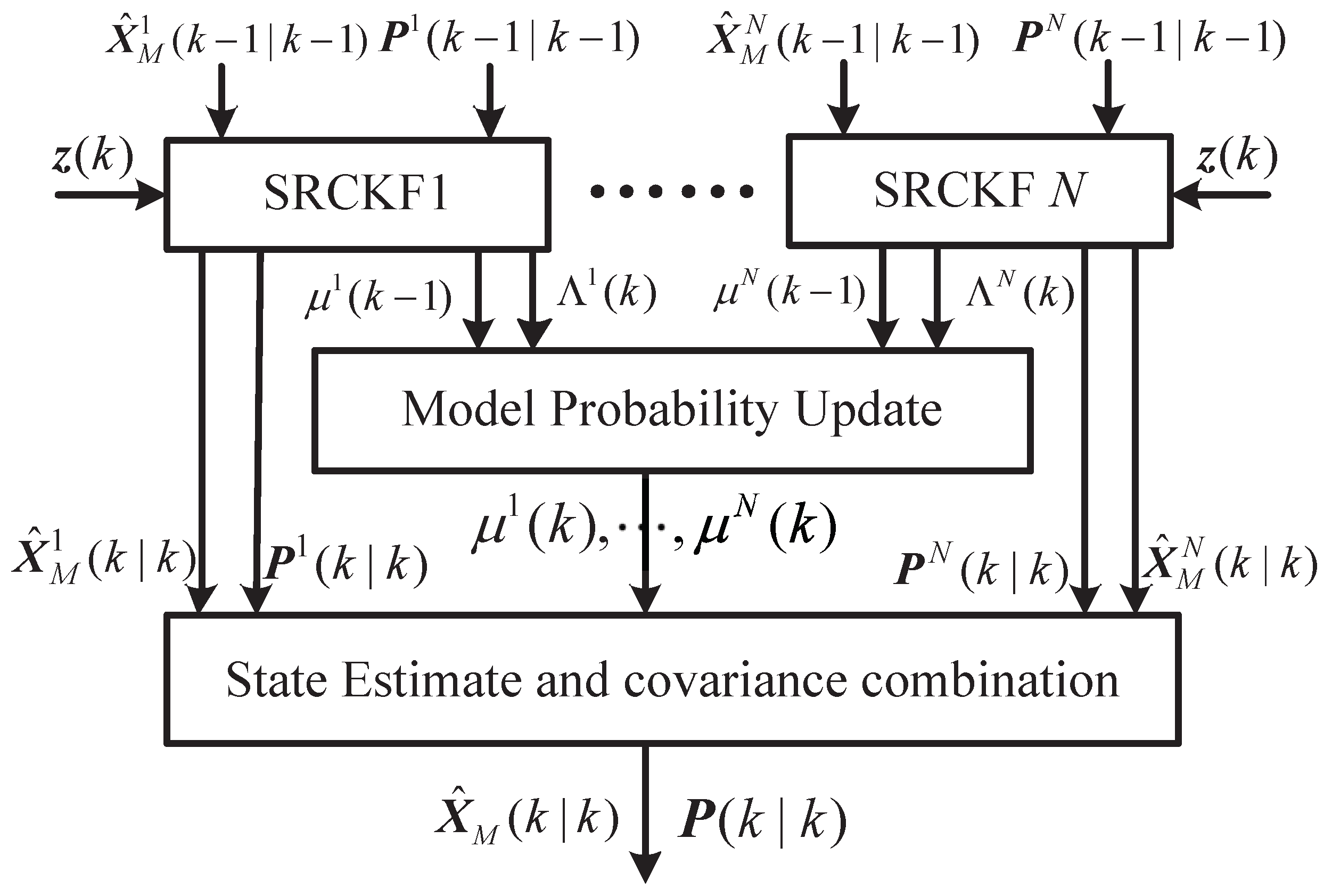
In this subsection, a method called the sMME-SRCKF is proposed to deal with the scenario of an unknown guidance strategy of an attacking missile. The sMME, also known as the multiple-model adaptive estimator [16], is used to identify the guidance law; meanwhile, the square-root cubature Kalman filter (SRCKF) is employed as the model-matched filter. The SRCKF is a square-root version of the cubature Kalman filter, which is proved as a good nonlinear Kalman filter having good numerical stability, low computational complexity, and satisfactory filtering accuracy as compared with other methods [17,18,19]. Because of its good performance, the improved estimation algorithms based on the cubature Kalman filter are widely used in target tracking and navigation systems [20,21,22]. Thus, the SRCKF is adopted as the model-matched filter. The sMME addresses a set of the potential models of the system, and then the model-matched SRCKF is set up to yield model-conditioned state estimate and error covariance. Assuming that there are N potential attacking missile guidance laws, the guidance commands are defined as , with . Then, by substituting into Equation (11), N estimation models are obtained on the basis of the process model shown in Equation (11) and the measurement model shown in Equation (13) or (15). On the basis of these estimation models, the algorithm of the sMME-SRCKF is described in the following three steps.
Step 1: Run N parallel SRCKFs to yield each model-conditioned state estimate and error covariance, namely, and (see Equations (A11) and (A15)). The original work of the SRCKF is introduced in [17]. However, the filtering problem in this section is a little different from the one in [17], since the process equation (shown in Equation (11)) is a differential equation rather than a difference equation, as in [17]. Thus, the evaluation of the propagated cubature points in the time update needs revising. In other words, according to Equation (11), we use the fourth-order Runge–Kutta method to calculate the integration to obtain the propagated cubature points. The details of using the SRCKF to estimate the attacking missile’s state information are given in Appendix A.
Step 2: Model probability update. The jth model probability is obtained according to the Bayes’ formula, which is
where is the jth model-conditioned likelihood function, computed as
where and are the jth model-conditioned innovation and innovation covariance (see Equation (A10)).
Step 3: Update the state estimate (i.e., ) and error covariance (i.e., ) by combining the model-conditioned state estimate and error covariance, as shown in Equations (18) and (19).
According to the above steps of the sMME-SRCKF, the schematic structure of the sMME-SRCKF is shown in Figure 2, where SRCKF1 to SRCKF N represent N parallel Kalman filters.
There are two reasons for adopting the SRCKF to estimate the state of the attacking missile. First, the SRCKF is a more accurate nonlinear filter than the traditional extended Kalman filter (EKF) and unscented Kalman filter (UKF) [17,18,19]. Second, by using the EKF in [15], the authors needed to compute the complex Jacobin matrix of Equation (12), defined as , for the step of state prediction in each model. However, the derivation of the Jacobin matrix is complex, since is a function of . Additionally, the authors needed to compute the transition matrix on the basis of , i.e., , and it is a little hard to calculate. However, the SRCKF adopted here is derivative-free for undesirable Jacobians and the transition matrix, and we only need to compute the cubature points in the state prediction (see Equations (A1) and (A2)), which is easier to calculate. Comparisons between the performance of SRCKF and EKF and between the performance of sMME-SRCKF and sMME-EKF are presented in Section 5.3.1.
3.2. Estimation Enhancement Analysis
In this subsection, the method of enhancing the estimation performance is discussed. The estimation module is processed before the guidance module, and the state estimate is used for computing the adaptive guidance laws (see Section 4.2). Thus, the estimation results have a great impact on the performance of adaptive cooperative guidance. For example, if the sMME-SRCKF can identify the exact guidance strategy of the attacking missile as soon as possible, then the command error of adaptive cooperative guidance will be reduced. Otherwise, a part of the target and defender’s control effort will be wasted as a result of the uncertain strategy of the attacking missile. Also, the more accurate the estimation, the larger the probability that the defender–target team is successful. For this purpose, we analyze the influence of the active defense location geometry on the estimation performance and then use it as a guideline to improve the estimation performance.
The analysis of estimation enhancement is based on the concept of pseudo-measurement described in [23]. According to Figure 1, the position of the attacking missile can be calculated by using the noisy measurements as
where
According to the measurement model of Equation (13), we have and . Since and are small, Equation (21) can be linearized around and as
where and are the true values of the position and are defined as
According to Equation (22), and can be viewed as pseudo-measurements at time step k, which has a non-stationary normal distribution, defined by
where
According to Equation (25), if approaches zero, (i.e., the difference between the M–T LOS angle and the D–M LOS angle is small), then the variances of pseudo-measurement (i.e., and ) will increase significantly, and increased variance causes a deterioration in estimation accuracy, especially in the estimation of position. Thus, the estimation performance depends on the location geometry of the defender and target. In order to achieve a good-quality estimation, the difference between the M–T LOS angle and the D–M LOS angle should remain far from zero, which means that the trajectories of the defender and target should be separated clearly with respect to the attacking missile. This conclusion is used as a guideline for choosing an appropriate initial geometry of active defense to improve estimation performance, which is shown in Section 5.3.2.
4. Adaptive Cooperative Guidance Laws
4.1. Model-Matched Optimal Cooperative Guidance Laws
4.1.1. Optimization Problem Formulation
For the identified guidance law of the attacking missile, the linearized kinematic equations are shown in Equations (7)–(10); on the basis of those, the optimal defensive guidance problem is formulated. The success of the defender–target team is defined as one of the following two sufficient conditions: (i) the D–M miss distance is small, and (ii) the M–T miss distance is larger than the lethal radius of the attacking missile. Here, both conditions are considered in designing cooperative guidance laws to achieve the largest probability of successful target protection, since the defender may fail to intercept the attacking missile due to its poor dynamics, acceleration saturation, or the negative effect of stochastic factors. For this purpose, a further target evasion maneuver is considered to increase the probability of successful active defense.
The objective function is defined as
where is the D–M miss distance, and and are positive penalty weights. The terminal constraint is defined as
where is the M–T miss distance, and is the expected evasion miss distance, which is larger than the lethal radius of the attacking missile. The guidance optimization problem is the minimization of the cost function in Equation (26) with the terminal constraint of Equation (27) based on the kinematic equation in Equation (7).
The M–T and D–M zero-effort miss distances, i.e., and , are introduced to reduce the optimization problem’s order; they are defined as
where , and are the transition matrices associated with Equation (7). The physical meaning of and is the miss distance that the defender and target would achieve under the following condition: neither the defender nor the target would apply any control commands, while the attacking missile would still employ the guidance law from the current time instant to the final interception time. From Equation (28), we have and . Since the defender’s guidance command only works in the D–M engagement, then for is obtained. Therefore, the cost function of Equation (26) can be rewritten as
The derivatives of zero-effort miss distances with respect to time are
where
and The derivation of Equations (30) and (31) is shown in Appendix B.
4.1.2. Derivation of Optimal Cooperative Guidance Laws
Before solving the above optimal guidance problem, the following auxiliary optimization problem is considered: the terminal inequality constraint (i.e., Equation (32)) is replaced with the equality constraint of fixed M–T missile distance, i.e., , where is an arbitrary real number satisfying . The Hamilton of the auxiliary problem is
By applying and [24], the optimal control commands are obtained as
Using adjoint equation and transversal condition , we have
Integrating Equation (30), the following equations are obtained:
Thus, the optimal control commands of the auxiliary problem are determined by substituting Equations (37) and (38) into Equation (34).
Then, the optimal guidance problem can be solved by looking for the optimal value of in to minimize the cost function. Substituting Equations (34) and (37) into Equation (29), we can rewrite the cost function as
where
According to Equation (38), we have and . According to Equation (40), we have , which is proved in Appendix C. Therefore, is obtained, and the optimal value is solved as
where
and
Replacing with in Equation (37) and then substituting it into Equation (34), the optimal cooperative guidance laws for the defender and the target are
Here, a special case is considered, which is . By substituting into Equation (41), the following equation is obtained as
Then, substituting Equation (45) into Equation (44), the optimal cooperative guidance laws become
Remark 1.
For the D–M engagement, the cooperative guidance laws in the special case of (i.e., Equation (46)) are equal to the cooperative guidance laws presented in [2] (see (53)∼(54) in [2]). This is because if , the terminal constraint of Equation (32) is removed, and the optimization problem becomes the minimization of the cost function of Equation (26) on the basis of Kinematic Equations (7)–(10); this problem is identical to the one presented in [2]. Therefore, the cooperative guidance laws in this special case can be regarded as the guidance laws that consider only one sufficient condition of successful active defense, i.e., small D–M miss distance.
4.1.3. Target Evasion Guidance after Termination of Missile–Defender Engagement
After D–M engagement terminates, the active defensive engagement becomes M–T pursuit–evasion engagement. In this engagement, the flight time satisfies . According to Equations (31) and (38), we have , , and . Then, substituting them into Equation (44), the guidance command of the target can be written as
The guidance law in Equation (47) has the same form of the optimal evasion guidance law with a specific miss distance in [25] (see (20) in [25]). This is because after the D–M terminates, the optimization problem becomes one of minimizing the control effort of the target with the M–T miss distance constraint, and this is the same as the minimum-effort evasion guidance problem in [25]. If the attacking missile or pursuer uses the same pursuit guidance law shown in Equation (3), then both of the evasion guidance laws are same.
4.2. Adaptive Cooperative Guidance Laws
In Section 4.1, the model-matched optimal cooperative guidance laws are derived with perfect information. However, in the stochastic scenario, perfect information is unavailable. Thus, the estimated information of the filter is used to compute the guidance laws. In the sMME-SRCKF, the model-conditioned state estimation of the jth model can be obtained as , and it is used to calculate the estimated state of active defense as
where
Then, the model-conditioned estimation of zero-effort miss distances is
The jth model-matched cooperative guidance laws (i.e., and ) are obtained by replacing and with and in Equation (44).
The adaptive cooperative guidance laws are derived by mixing the model-matched optimal guidance laws in the criterion of maximum a posteriori probability as
Equation (51) shows that the model-matched cooperative guidance commands with the largest model probability are chosen as the adaptive cooperative guidance commands. If there are multiple models that have the same maximum probability, then we choose an arbitrary one to generate the adaptive cooperative guidance laws. For example, the simple way is to always choose the smallest value of j when there are multiple values.
In [15], the authors used the minimum mean-square-error criterion to generate the adaptive guidance commands, which are formulated as
where the adaptive guidance commands are weighted sums of all model-matched guidance commands. According to Equation (52), at each guidance time instant, each model-matched cooperative guidance law needs calculating, and the calculation burden is a little heavy. The advantage of using the criterion of maximum a posteriori probability is that only one model-matched optimal cooperative guidance law needs computing at each guidance time instant. Thus, this will reduce the computational burden.
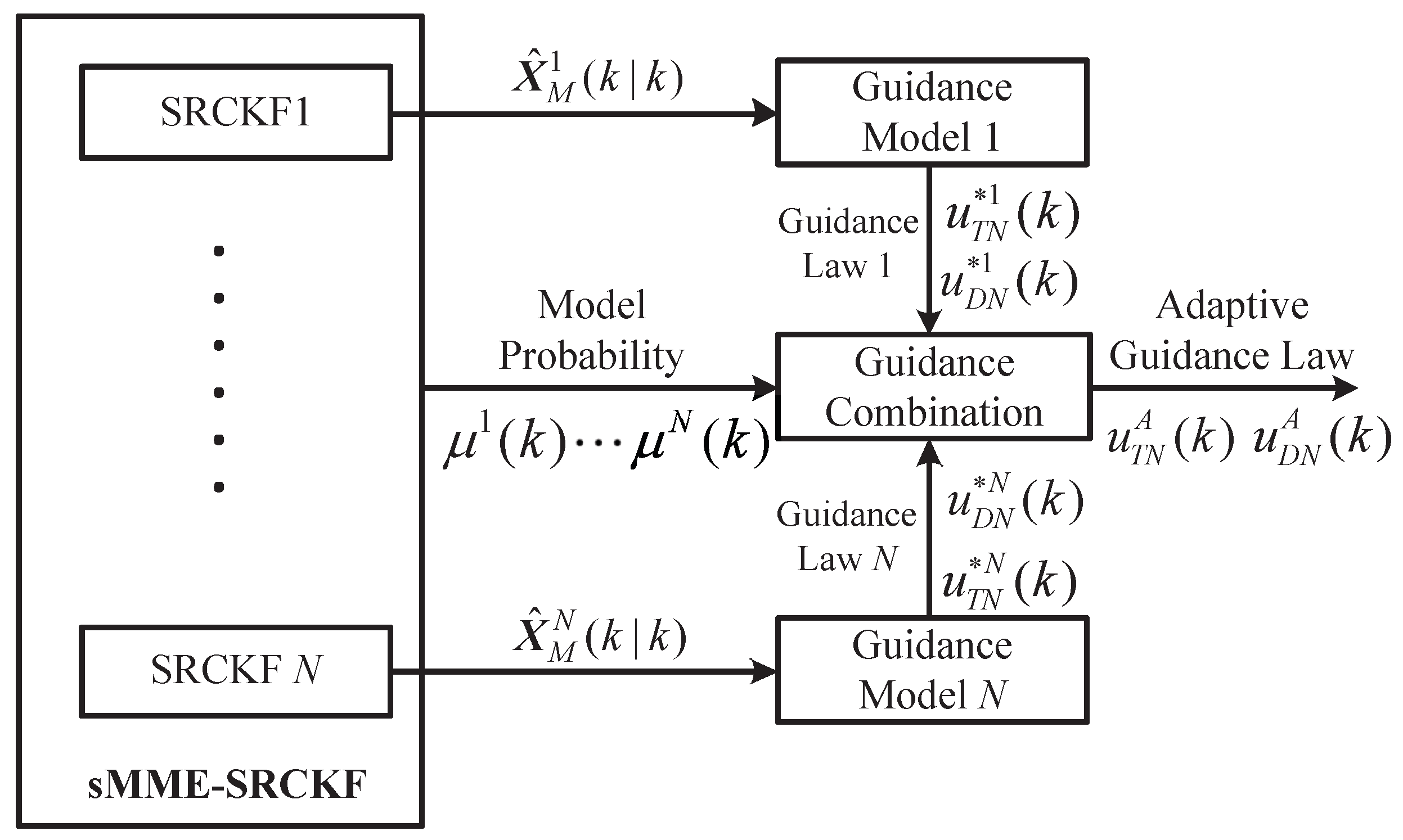
The structure of adaptive cooperative guidance laws in the framework of the sMME-SRCKF is shown in Figure 3, where the output of the sMME-SRCKF (i.e., model-conditioned state estimation and model probability ) is used to generate the adaptive guidance law. In Figure 3, guidance models 1–N represent N models based on Kinematic Equations (7)–(10) with the associated guidance law of the attacking missile. On the basis of the guidance model, the matched cooperative guidance laws (i.e., and ) are obtained by using Equation (44). The adaptive cooperative guidance laws are obtained by combining the model-matched cooperative guidance laws in the criterion of maximum a posteriori probability.
5. Simulations
In this section, the performance of the adaptive cooperative guidance laws and estimation approach is analyzed. The simulation conditions are as follows. The initial positions of three aircraft are , , and ; and the velocities are , , and . It is assumed that the three aircraft have first-order dynamics with time constants of , , and . The accelerations of the attacking missile, defender, and target are limited to , , and , respectively. The penalty weights in the cost function are set as and . The control efforts of the three aircraft are defined as , with . It is assumed that the maximum miss distance for successful interception is 5 m, so the defender or attacking missile will fail to intercept their targets beyond this range. Thus, the condition for successful active defense is or .
5.1. Optimal Cooperative Guidance with Perfect Information
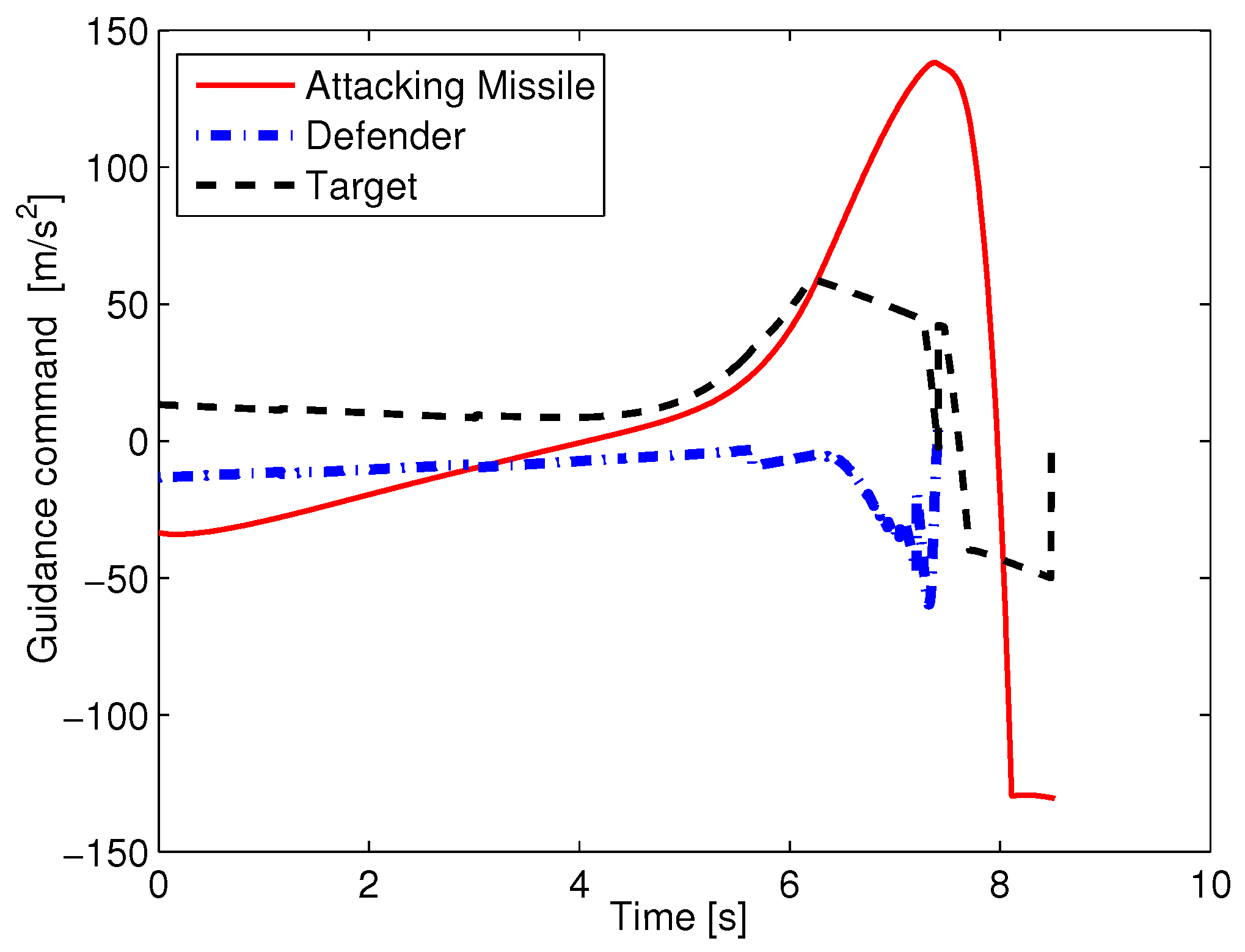
In this subsection, the performance of model-matched optimal cooperative guidance with perfect information is tested. The attacking missile uses the proportional navigation (PN) guidance law, and . First, the performance of optimal cooperative guidance laws with different initial flight-path angles is discussed. The initial flight-path angle of the attacking missile is set as , and the initial flight-path angles of the defender and target are obtained from the sets and , respectively. The minimum expected evasion distance is set as . In the simulation, although the defender intercepts the attacking missile at the end of D–M engagement, we continue simulating the M–T engagement until it is completed in order to see the results of M–T engagement. The simulation results are shown in Table 1 and Figure 4 and Figure 5. In Table 1, we see that the D–M miss distances all approach zero, which demonstrates that the defender intercepts the attacking missile accurately. The M–T miss distance is almost equal to or a little larger than 10 m, which illustrates that the target achieves the expected minimum evasion distance. The reason that all of the M–T miss distances are close to the expected minimum evasion distance (i.e., 10 m) is as follows. After D–M engagement terminates, according to the evasion guidance law shown in Equation (47), if , then the maneuver of the target becomes zero, which makes decrease; after , then the defender will execute an evasion maneuver to increase until again. Thus, oscillates around within a very small range, and the resultant M–T miss distances are close to . Figure 4 and Figure 5 give the trajectories and guidance commands of the three aircraft in the case of . In Figure 4, the solid lines represent the trajectories during the D–M engagement, and the dotted lines represent the trajectories after the D–M engagement. In Figure 4, the defender intercepts the attacking missile at the end of D–M engagement, and meanwhile, the target evades the attacking missile at the end of M–T engagement. In Figure 5, the guidance commands refer to . The defender’s guidance command terminates at about 7.41 s because the D–M engagement terminates at that time. In the first 5.5 s, the guidance command of the target is small, and then the pursuit guidance command of the attacking missile is also small. As a result, the defender uses a small guidance command to pursue the attacking missile. After that, the target employs a larger evasion maneuver; then, the guidance command of the attacking missile increases, and this makes the defender use an aggressive maneuver to intercept the attacking missile.
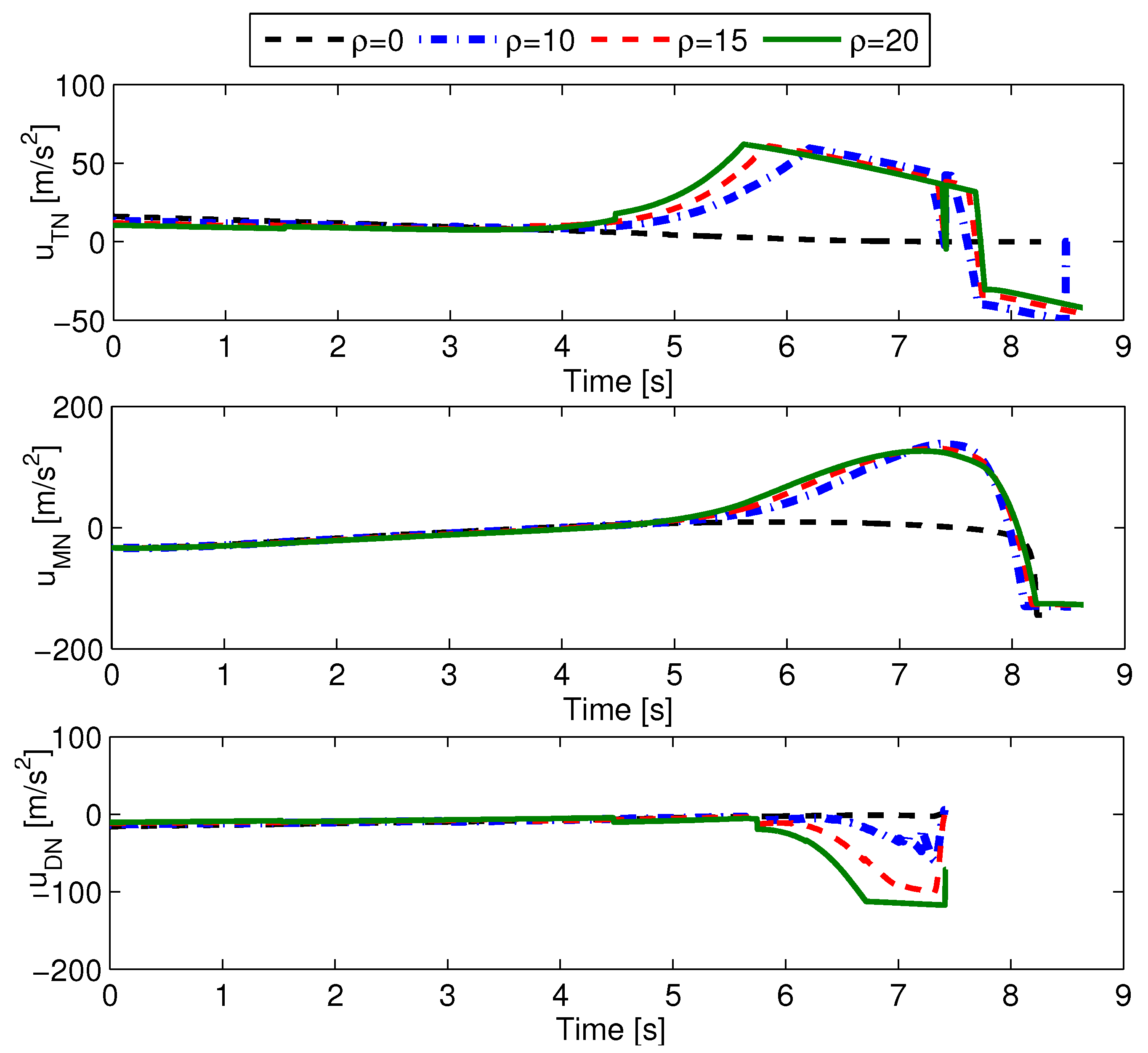
Next, the performance of optimal cooperative guidance laws with different minimum evasion distances is presented. The minimum evasion distances are set as , and the initial flight-path angles are . The simulation results are shown in Table 2 and Figure 6. In Table 2, and represent the D–M and M–T miss distances. From Table 2, we see that the larger the value of , the more control effort each aircraft needs. Also, except for the case of , for which the D–M miss distance is a little large, all the other D–M miss distances are almost equal to zero. In the cases of and , the M–T miss distances are smaller than the expected minimum evasion miss distances. These results can be explained by Figure 6. In Figure 6, it is seen that the larger the value of , the more aggressive the evasion maneuver used by the target uses, and as a consequence, the attacking missile and defender need more control effort to pursue their targets. Also, it is seen that the defender suffers command saturation for the longest time period in the case of , and that leads to a somewhat large D–M miss distance. Also, the target suffers relatively severe guidance command saturation in the case of and , and as a result, the target fails to reach the expected evasion miss distance. According to Table 2 and Figure 6, guidance command saturation is an important factor that influences the results of cooperative guidance laws.
In addition, there is another important factor that has a great impact on guidance performance via numerous simulations: the time constant of first-order dynamics. For example, increasing the time constant of the attacking missile to s, and keeping the other parameters the same, then in the case of , the simulation results are and . This example demonstrates that the defender can intercept the attacking missile accurately while the target meets the requirement for evasion miss distance. This is because the attacking missile becomes slow to respond to the guidance command in the case of a large time constant, and thus, the defender easily intercepts the attacking missile while the agile target is able to evade the attacking missile easily.
As a conclusion, guidance command limits and time constants both have an influence on the performance of optimal cooperative guidance laws. Here, we suggest setting the parameter in cooperative guidance as follows: if the command limits of the defender and target are much larger than the attacking missile, or if the time constants of the target are much smaller than that of the attacking missile, then we can choose a large to achieve both accurate defensive interception and large evasion miss distance. Otherwise, we need to choose a small or even to focus on achieving accurate missile–defender miss distance. Additionally, according to the simulation results, the advantage of cooperative guidance laws is that the defender can intercept the maneuverable attacking missile with relatively smaller control effort with the help of the target. This advantage stems from the fact that the target employs a "lure" maneuver so that the attacking missile flies toward the defender.
5.2. Adaptive Cooperative Guidance Laws
Two adaptive cooperative guidance laws are defined, i.e., ACGL1 and ACGL2, and the expected minimum evasion distances in ACGL1 and ACGL2 are set as and , respectively. According to Remark 1, ACGL2 can be regarded as the adaptive guidance law that only considers a small D–M miss distance, which is identical to the cooperative guidance law considered in [2]. ACGL1 is the proposed cooperative guidance that considers both successful conditions, namely, a small D–M miss distance and the minimum M–T evasion distance.
The simulation conditions are as follows: the attacking missile uses the PN guidance law with , and the initial flight path angles are ; both the measurement sampling period and guidance command period are 0.02 s, and the blind range is 500 m. The blind range refers to the minimal measuring range. When the defender approaches the attacking missile with a distance of less than 500 m, then the measurement model changes from Equations (13) to (15). The initial condition of the filter is sampled from a Gaussian distribution, i.e., , where is the true initial state of the attacking missile, and is the initial covariance.
First, the stochastic case in which measurement noise exists, and the attacking missile’s guidance law is known, is considered. In this case, the number of models in the sMME-SRCKF is 1, and thus, the filter becomes the SRCKF. Four cases with different measurement noises are considered—Case 1: ; Case 2: ; Case 3: ; and Case 4: . The success probability of ACGL1 and ACGL2 are shown in Table 3. From Table 3, it is seen that if the measurement noise is small (i.e., Case 1), the success probabilities of ACGL1 and ACGL2 are both 100%. However, as the measurement noise increases, the success probability of ACGL1 becomes larger than that of ACGL2. When the measurement noise increases, it generates a larger estimation error and, as a result, a larger error in the guidance commands. ACGL2 only considers the accurate interception by the defender. Thus, once the defender misses the attacking missile because of guidance error, the active defense fails. On the contrary, for ACGL1, the target will take evasive measures after the failed D–M engagement, thus increasing the probability of success. This is the advantage of ACGL1 that can lead to a better performance in a noisy environment compared with ACGL2.
Next, another stochastic case is considered: the attacking missile’s guidance strategy is unknown, and we use the sMME-SRCKF to identify the guidance strategy. The set of guidance laws contains PN with , APN with , and OGL. The initial probability of each guidance model is . The actual guidance law of the attacking missile is PN with . Three cases of measurement noise are set as follows. Case 1: ; Case 2: ; and Case 3: . For each case, a 1000-run Monte Carlo simulation was completed. The success probability of ACGL1 in Case 1, Case 2, and Case 3 is 86.6%, 67.8%, and 57.2%, respectively; that of ACGL2 in Case 1, Case 2, and Case 3 is 84.5%, 47.1%, and 36.1%, respectively. These results show that ACGL1 still performs better than ACGL2. The simulation results of ACGL1 in Case 1 are shown in Figure 7 and Figure 8. Figure 7 shows the root-mean-square error (RMSE) of the estimator. The RMSE of the estimated scalar is defined as [16]
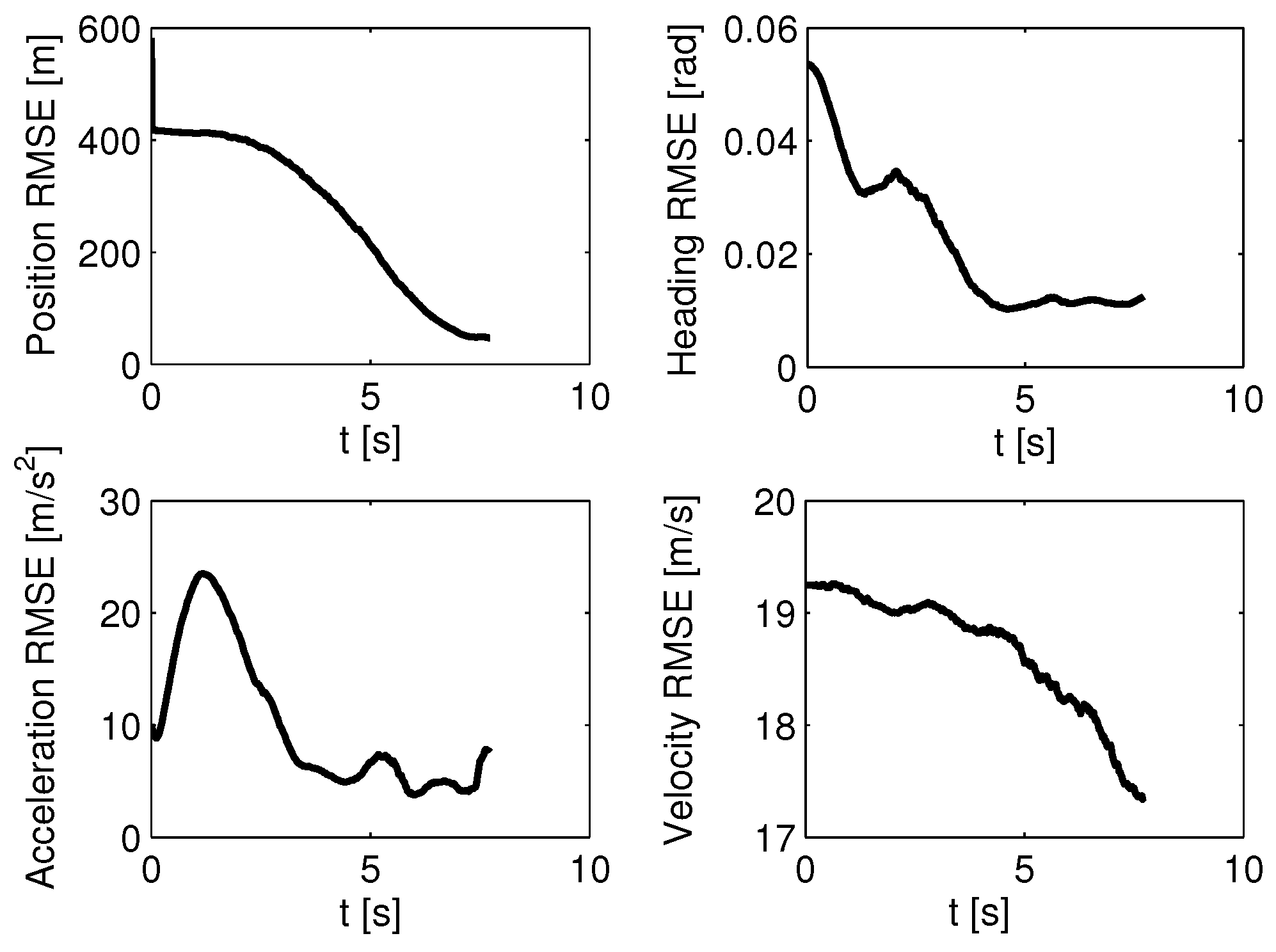
where represents the number of Monte Carlo simulations. For example, the position RMSE is defined as
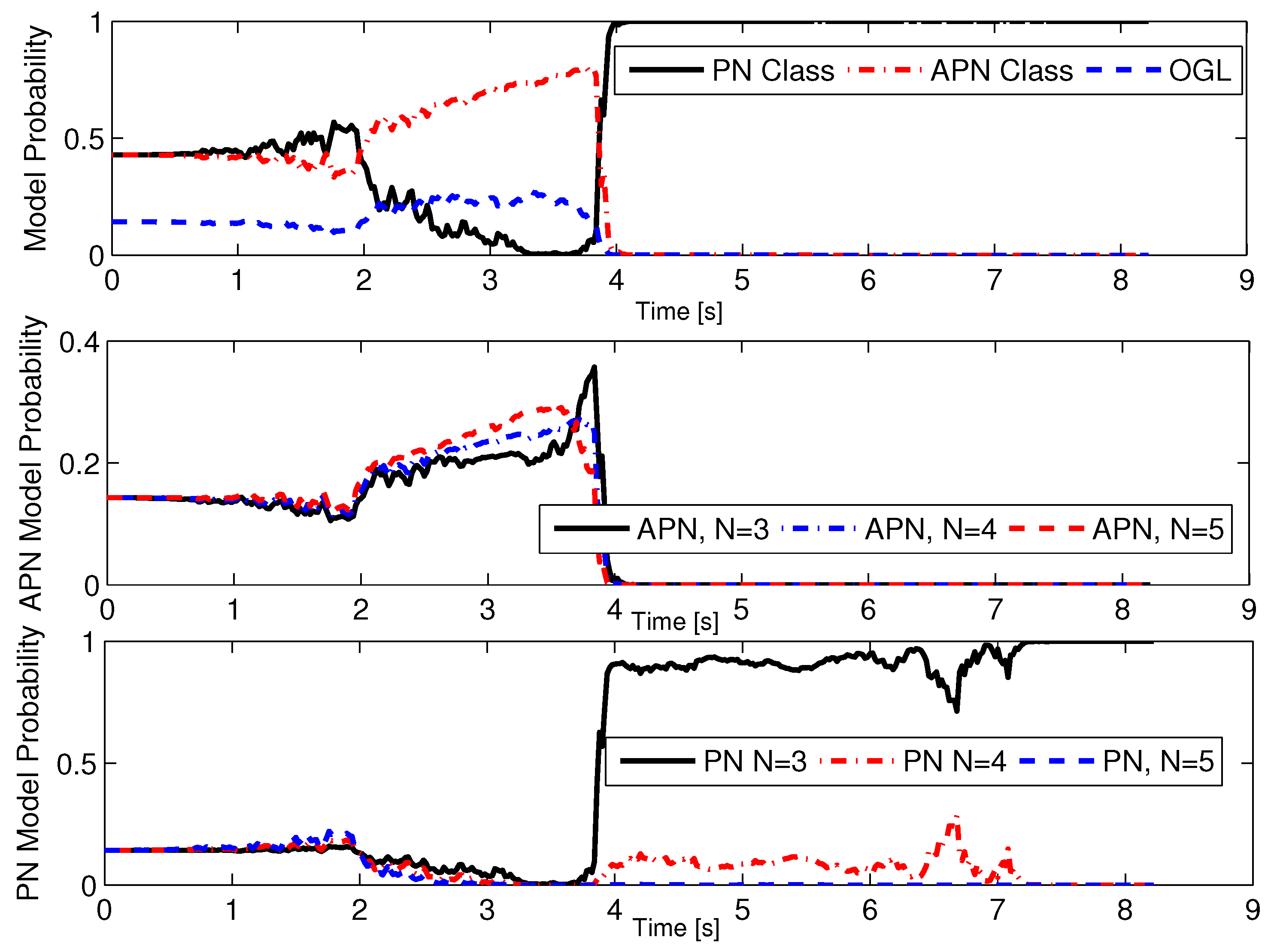
where is the estimated position for the ith Monte Carlo simulation. In Figure 7, each RMSE converges as time moves forward, which demonstrates that the sMME-SRCKF works well. In Figure 8, the model probability of the sMME-SRCKF in a single simulation is presented, and the PN class refers to PN guidance laws with , and the APN class refers to APN guidance laws with . Figure 8 shows that the model probability of the PN class increases to 1, and the other model’s probability reduces to zero at about 4 s. The sMME-SRCKF can be assumed to identify the correct guidance law of the attacking missile at about 4 s, since the model probability of PN with plays a dominant role, i.e., the model probability of PN with is larger than 85% for the most time from 4 s to the end.
As a conclusion, it is demonstrated that the proposed adaptive guidance law that considers two successful conditions has a larger probability of a successful active defense compared with the adaptive guidance law that only considers one successful condition.
5.3. Estimation Performance Evaluation
5.3.1. Comparison of Filtering Approaches
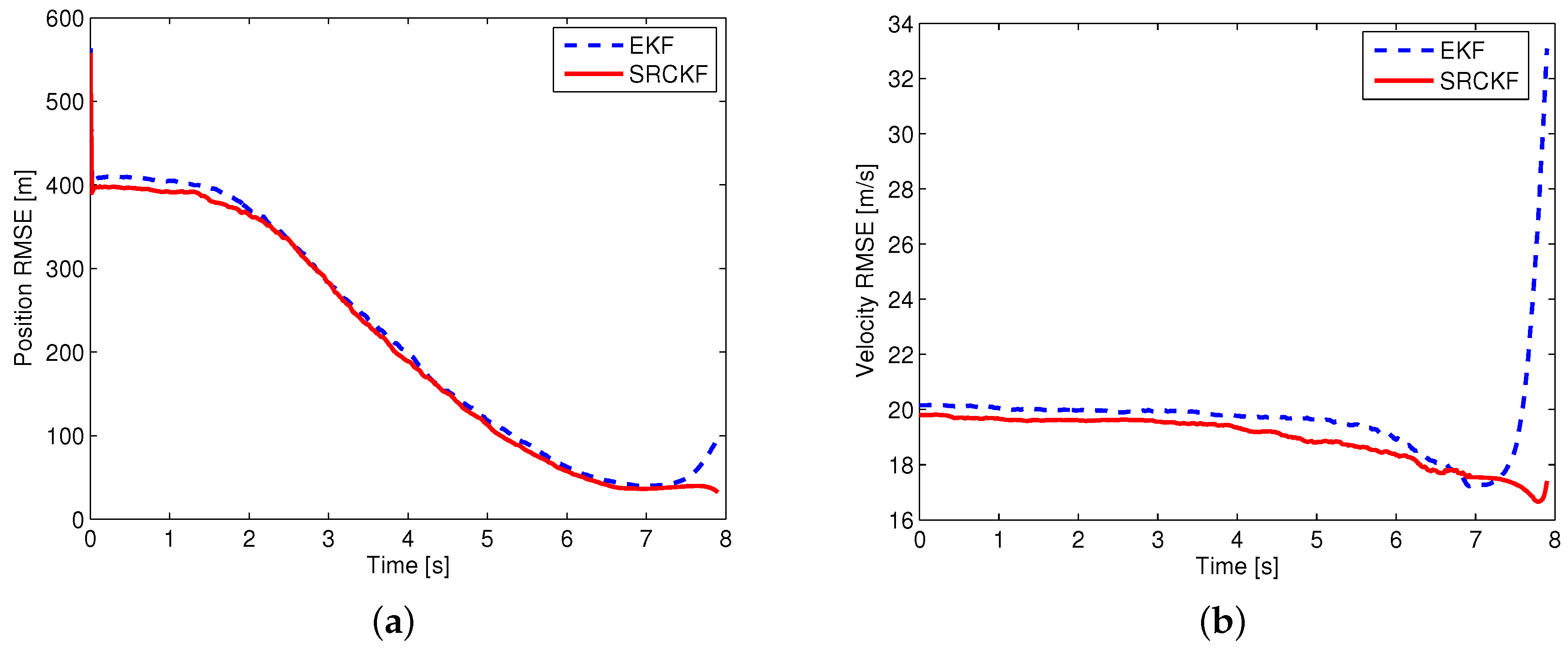
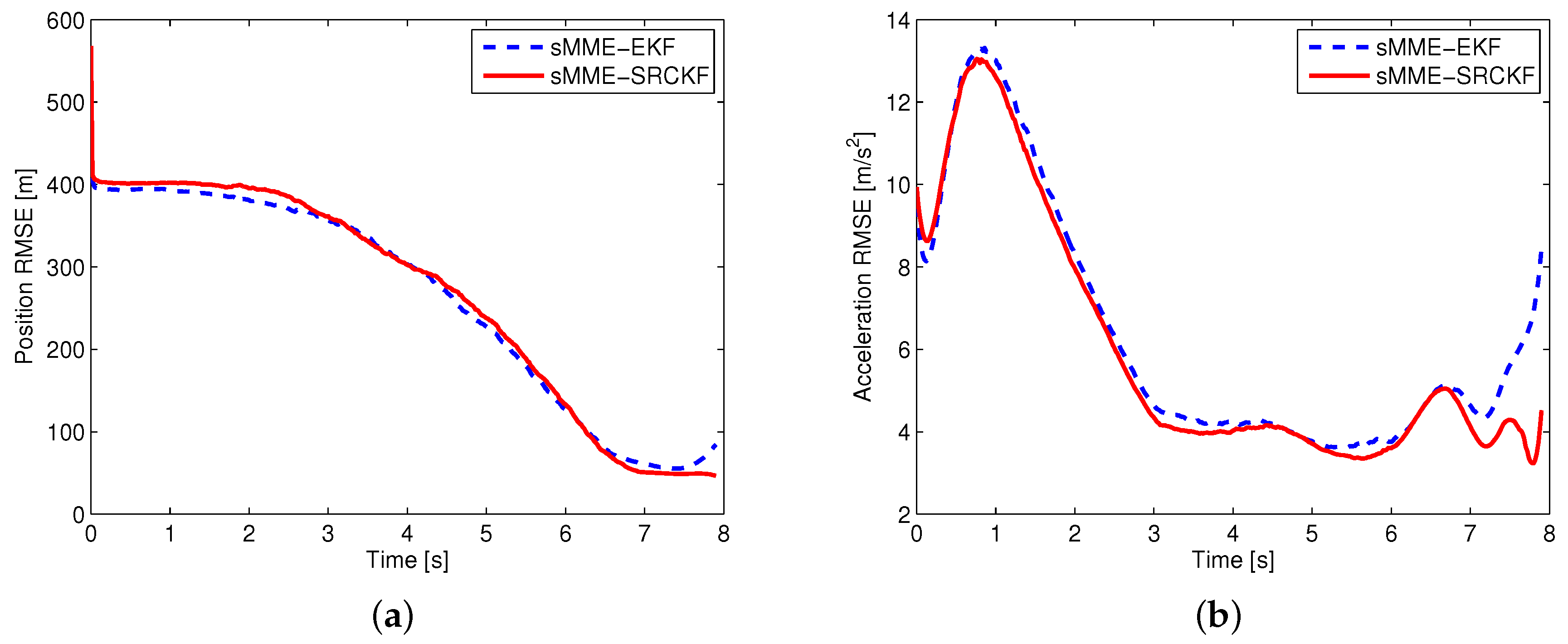
For a fair comparison of different filtering approaches, perfect information is used for calculating the cooperative guidance laws. Using this approach, the performance evaluation of the filter is separated from the closed-loop system of guidance and estimation. Two scenarios are simulated for evaluating the performance of different filtering approaches. In the first scenario, it is assumed that the guidance law of the attacking missile is known, and the measurement noise is . Then, the EKF and SRCKF are used to estimate the state of the attacking missile. In the second scenario, it is assumed that the guidance law of the attacking missile is unknown, and the measurement noise is . The sMME-EKF and sMME-SRCKF are used to track the attacking missile. Except for the measurement noise, the simulation conditions of the two scenarios are the same as those shown in Section 5.2. The attacking missile uses PN with , and the expected minimum evasion distance of the cooperative guidance laws is set as . As indicated in Section 3.1, the complex Jacobian matrix needs computing to implement the EKF and sMME-EKF. For the sake of brief exposition, the derivation of the Jacobian matrix is omitted here, and the process of the sMME-EKF can be referred to [15]. A 1000-run Monte Carlo simulation was performed in both scenarios, and the simulation results are shown in Figure 9 and Figure 10.
According to the simulation results, D–M engagement is terminated at 6.94 s, and M–T engagement is terminated at 7.9 s. Note that during D–M engagement, two sensors are used to track the attacking missile; after the termination of D–M engagement, only a sensor on the target works to track the attacking missile. From Figure 9, it is seen that the performance of the SRCKF is a little better than that of EKF during the D–M engagement (i.e., 0–6.94 s); after that, the performance of the SRCKF is much better than that of EKF (i.e., 6.94–7.9 s). In Figure 10, it is seen that the performance of the sMME-SRCKF is almost the same as that of the sMME-EKF during the D–M engagement (i.e., 0–6.94 s), while the sMME-SRCKF performs better than the sMME-EKF after the termination of D–M engagement (i.e., 6.94–7.9 s). The simulation results demonstrate the superiority of the SRCKF or sMME-SRCKF, especially after the termination of D–M engagement. This is because only one sensor with angular measurement is used to track the attacking missile at this phase, and then the nonlinearity of the estimation problem becomes more serious. Furthermore, the SRCKF and sMME-SRCKF are derivative-free for undesirable Jacobians and the transition matrix. It is convenient to implement the SRCKF and sMME-SRCKF for various guidance laws of attacking missile. For example, if a new guidance law is added to the sMME filter, then the additional derivation of the Jacobian matrix and calculation of the transition matrix are needed for the sMME-EKF. However, this is not required in the sMME-SRCKF.
5.3.2. Estimation Enhancement Test
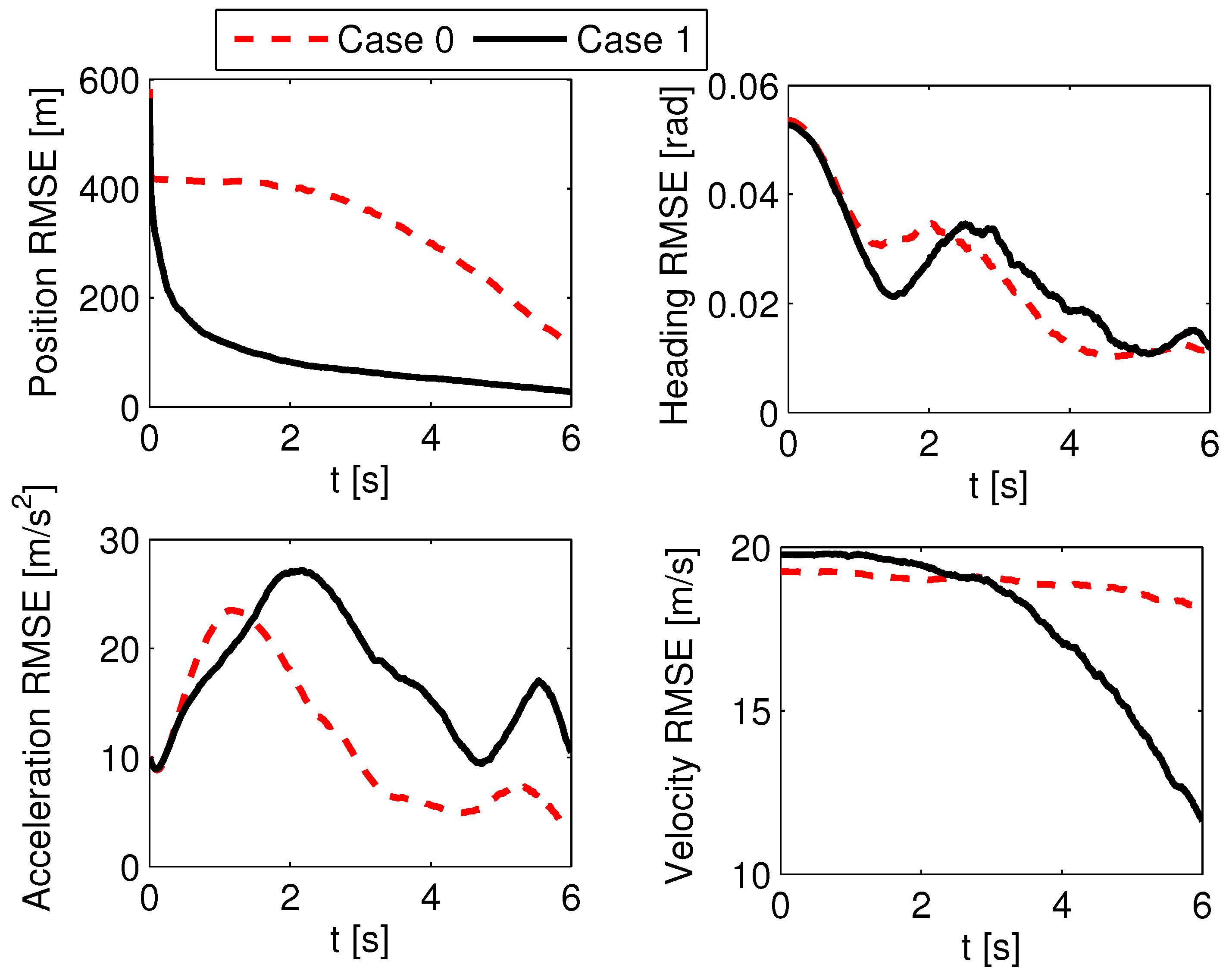
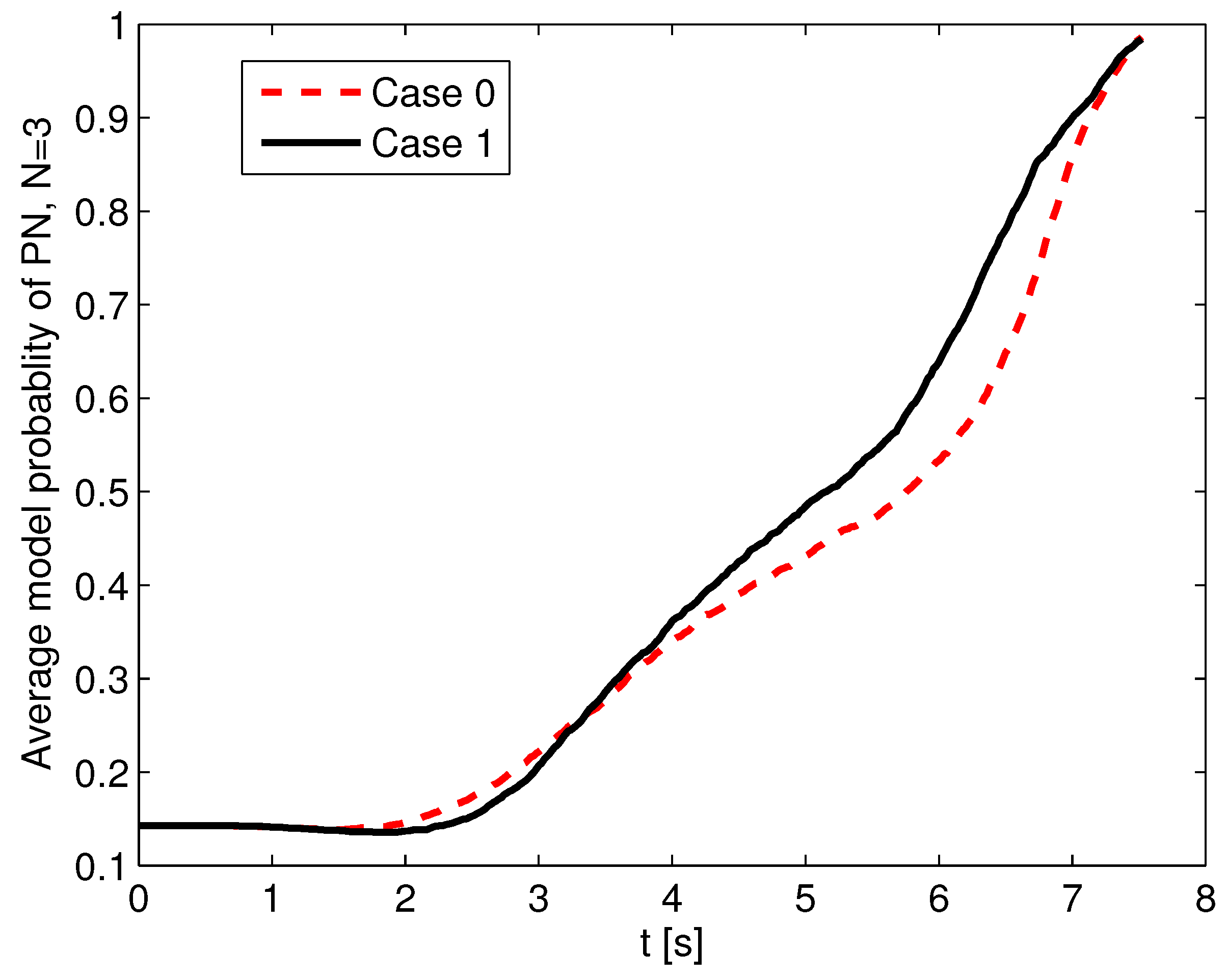
According to the analysis in Section 3.2, it is concluded that the LOS angle difference will influence the estimation performance. Thus, the estimation performance is tested with different initial LOS angles. Here, two cases are compared. In Case 0, all the initial conditions are as shown at the beginning of Section 5. In Case 1, the initial position and flight-path angle of the defender are changed to and , and the rest of the initial conditions are the same as those of Case 0. The absolute initial LOS angle differences in Case 0 and Case 1 are and , respectively. The stochastic scenario of an unknown guidance strategy of the attacking missile is considered. The set of guidance laws contains PN with , APN with , and OGL, and the initial probability of each guidance model is set as . The measurement noise is , and the attacking missile uses the PN guidance law with . ACGL1 in Section 5.2 is used as the adaptive guidance law. A 1000-run Monte Carlo simulation was completed, and the probability of success in Case 1 is 91.2%, which is better than that in Case 0 (i.e., 86.6%). Also, the probability of in Case 1 is 68.9%, which is larger than that of 63.1% in Case 0. The increased success probability in Case 1 benefits from the estimation enhancement, whose results are shown in Figure 11 and Figure 12. Figure 11 shows the RMSEs of position, flight-path angle, acceleration, and velocity in the first 6 s. It shows that the RMSEs of position and velocity in Case 1 converge more rapidly than those in Case 0. The position RMSE in Case 1 at 6 s is 27 m, which is much smaller than that of 115 m in Case 0. The RMSEs of flight-path angle and acceleration in Case 0 and Case 1 perform in a similar way. In Figure 12, the average model probabilities of PN with in Case 0 and Case 1 are shown. The average model probability is introduced as an index to represent the change in model probability in the Monte Carlo simulation, and it is more reliable to use this index than to use the model probability in a single Monte Carlo simulation. The average model probability of the jth model is defined as
where is the jth model probability at the ith MC simulation, and is the number of Monte Carlo simulations. From Figure 12, it is seen that the average model probability of PN guidance law with in Case 1 is always larger than that in Case 0 after 4 s, so the sMME-SRCKF in Case 1 can identify the right guidance strategy faster on the average. The faster the sMME-SRCKF identifies the right model, the more accurate the generated guidance command, and the larger the probability of a successful active defense. Thus, it is helpful to choose an engagement geometry with a large initial LOS angle difference to yield good estimation and guidance performance.
6. Conclusions
In this paper, adaptive cooperative guidance for a target and defender is proposed to deal with the stochastic active defense problem. Adaptive cooperative guidance combines a multiple-model adaptive estimator and optimal control. The sMME-SRCKF is designed as a nonlinear adaptive estimator that can identify the guidance strategy and estimate the state of the attacking missile efficiently. By solving the optimal defensive problem, the model-matched cooperative guidance laws are obtained that can satisfy criteria of both an accurate defensive interception and the expected minimum evasion distance. The cooperation between the target and defender is established by using the cooperative guidance laws, and the advantage of this cooperation makes it possible to use a low-maneuverability defending missile (the cost of this low-maneuverability missile is cheap) to intercept an advanced and high-maneuverability attacking missile. Also, the adaptive cooperative guidance law performs better in the stochastic scenario, and it is more robust than the adaptive guidance law that only considers small D–M miss distance. Furthermore, the estimation enhancement analysis provides an approach to improving the performance of the estimation and guidance.
This paper focuses on the design of cooperative guidance laws in planar active defense engagement. For the general three-dimensional active defense engagement, it can be decoupled into two perpendicular planar engagements, and then the proposed guidance laws can be applied to both planar engagements. Further work lies in extending this proposed solution to three-dimensional engagement.
Author Contributions
F.F., Y.C., and Z.Y. provided insights into formulating the ideas, F.F. performed the simulations and analyzed the simulation results. F.F. wrote the paper.
Funding
This research was funded by the National Natural Science Foundation of China Grant Numbers 61873277 and 71571190. The authors gratefully acknowledge all of the support.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviation
| , , , , , , | state-space model matrices of active defense |
| , , , | state-space model matrices of aircraft’s internal dynamics |
| , , | acceleration of attacking missile, target, and defender |
| , , | acceleration component of attacking missile, target, and defender along the Y-axis |
| , , , , | guidance parameters of the attacking missile |
| , , | navigation gains of PN, APN, and OGL |
| , , | dimension of the internal state vector of the attacking missile, target, and defender |
| , , | internal state vector of the attacking missile, target, and defender |
| measurement noise covariance matrix at time instant k | |
| , , | D–M and M–T interception time, time-to-go of M–T engagement |
| , , | guidance command of the attacking missile, target, and defender |
| , , | guidance command of the attacking missile, target, and defender along the Y-axis |
| , | adaptive guidance laws of the target and defender |
| , | state vector of active defense kinematic model and state vector of the attacking missile |
| jth model-conditioned state estimate of active defense | |
| , | state estimate and error covariance of attacking missile |
| , | jth model-conditioned state estimate and error covariance of the attacking missile |
| , , , | D–M and M–T relative displacements and relative velocity along the Y-axis |
| , | D–M and M–T zero-effort miss distances |
| , , | measurement vector, D–M and M–T angle measurement at time instant k |
| , | jth model-conditioned innovation and innovation covariance at time instant k |
| , | penalty weights in the cost function |
| , , | flight-path angle of the attacking missile, target, and defender |
| , | jth model-conditioned likelihood function and jth model probability |
| , | D–M and M–T line-of-sight angle |
| , , | white Gaussian noise vector, D–M and M–T angle measurement noise |
| , | expected evasion miss distance, transition matrix |
| , , | time constant of the attacking missile, target and defender |
Appendix A.
The algorithm for using the SRCKF to estimate the model-conditioned state of the attacking missile is shown as follows. The variables with the subscript j represent the variables of the jth model. According to [17], the SRCKF is described by two steps: time update and measurement update.
In the time update, the cubature points are firstly evaluated:
with , where is the number of cubature points, and represents the dimension of . and are the attacking missile state estimate and the square-root factor of error covariance at the time instant; , where is the ith point/column of the complete fully symmetric set of points defined as . The process equation in this section is a continuous differential equation rather than a difference equation as shown in [17]. Thus, according to Equation (12), the evaluation of the propagated cubature points in this section can be calculated as
with , where is the ith cubature point at time t, and T is the sampling period. The integration in Equation (A2) can be computed by using the fourth-order Runge–Kutta method. Then, the predicted state and square-root factor of the predicted error covariance are
where
and is a square-root of the covariance of process noise satisfying with representing the covariance of process noise. According to Equation (11), we have , which means that there is no process noise. represents a general triangularization algorithm, and we have , where is an upper triangular matrix obtained from the QR decomposition on .
In the measurement update, the predicted measurement and the square root of the innovation covariance are firstly estimated:
where
and
and is the square-root factor of (i.e., measurement noise covariance) satisfying . The innovation and the innovation covariance are computed as
Then, the updated state estimate and the square-root factor of the error covariance are
where
and
The error covariance of the estimation can be obtained as
This completes the algorithm for using the SRCKF to estimate the model-conditioned state of the attacking missile.
Appendix B.
The derivation of Equations (30) and (31) is shown in this appendix. Since is the transition matrix associated with Equation (7), it has the following property:
In Equation (A17), we have
This can be proved by the following steps. Defining the first row of as , where for , we therefore have
According to Equation (A16), we have
Then, on the basis of Equation (A20), the following equation is obtained:
Appendix C.
This appendix gives the proof of . According to Equation (38), we have and
First, the auxiliary inequality, i.e., , is proved via the following steps. Assuming and , then we have . Since , the following equation is obtained.
By using the Cauchy–Buniakowsky–Schwarz Inequality, the right side of Equation (A24) satisfies
Thus, is proved. By using , , , and , then is proved.
References
- Shima, T. Optimal cooperative pursuit and evasion strategies against a homing missile. J. Guid. Control Dyn. 2011, 34, 414–425. [Google Scholar] [CrossRef]
- Prokopov, O.; Shima, T. Linear quadratic optimal cooperative strategies for active aircraft protection. J. Guid. Control Dyn. 2013, 36, 753–764. [Google Scholar] [CrossRef]
- Weiss, M.; Shima, T.; Castaneda, D. Minimum effort intercept and evasion guidance algorithms for active aircraft defense. J. Guid. Control Dyn. 2016, 39, 2297–2311. [Google Scholar] [CrossRef]
- Fang, F.; Cai, Y. Optimal cooperative guidance with guaranteed miss distance in three-body engagement. Proc. Inst. Mech. Eng. Part G J. Aerosp. Eng. 2018, 232, 492–504. [Google Scholar] [CrossRef]
- Weiss, M.; Shima, T.; Castaneda, D. Combined and cooperative minimum-effort guidance algorithms in an active aircraft defense scenario. J. Guid. Control Dyn. 2017, 40, 1241–1254. [Google Scholar] [CrossRef]
- Perelman, A.; Shima, T.; Rusnak, I. Cooperative differential games strategies for active aircraft protection from a homing missile. J. Guid. Control Dyn. 2011, 34, 761–773. [Google Scholar] [CrossRef]
- Rubinsky, S.; Gutman, S. Three-player pursuit and evasion conflict. J. Guid. Control Dyn. 2014, 37, 98–110. [Google Scholar] [CrossRef]
- Rubinsky, S.; Gutman, S. Vector guidance approach to three-player conflict in exoatmospheric interception. J. Guid. Control Dyn. 2015, 38, 2270–2286. [Google Scholar] [CrossRef]
- Garcia, E.; Casbeer, D.W.; Pachter, M. Active target defence differential game: fast defender case. IET Control Theory Appl. 2017, 11, 2985–2993. [Google Scholar] [CrossRef]
- Garcia, E.; Casbeer, D.W.; Fuchs, Z.E.; Pachter, M. Cooperative missile guidance for active defense of air vehicles. IEEE Trans. Aerosp. Electron. Syst. 2018, 54, 706–721. [Google Scholar] [CrossRef]
- Kumar, S.R.; Shima, T. Cooperative nonlinear guidance strategies for aircraft defense. J. Guid. Control Dyn. 2017, 40, 124–138. [Google Scholar] [CrossRef]
- Ratnoo, A.; Shima, T. Line-of-sight interceptor guidance for defending an aircraft. J. Guid. Control Dyn. 2011, 34, 522–532. [Google Scholar] [CrossRef]
- Yamasaki, T.; Balakrishnan, S.N.; Takano, H. Modified command to line-of-sight intercept guidance for aircraft defense. J. Guid. Control Dyn. 2013, 36, 901–905. [Google Scholar] [CrossRef]
- Fonod, R.; Shima, T. Multiple model adaptive evasion against a homing missile. J. Guid. Control Dyn. 2016, 39, 1578–1592. [Google Scholar] [CrossRef]
- Shaferman, V.; Shima, T. Cooperative multiple-model adaptive guidance for an aircraft defending missile. J. Guid. Control Dyn. 2010, 33, 1801–1813. [Google Scholar] [CrossRef]
- Bar-Shalom, Y.; Li, X.R.; Kirubarajan, T. Estimation with Applications to Tracking and Navigation; Wiley: New York, NY, USA, 2001; pp. 243–244. [Google Scholar]
- Arasaratnam, I.; Haykin, S. Cubature Kalman Filters. IEEE Trans. Autom. Control 2009, 54, 1254–1269. [Google Scholar] [CrossRef]
- Jiang, H.; Cai, Y. Adaptive Fifth-Degree Cubature Information Filter for Multi-Sensor Bearings-Only Tracking. Sensors 2018, 18, 3241. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Huang, Y.; Li, N.; Zhao, L. Interpolatory cubature Kalman filters. IET Control Theory Appl. 2015, 9, 1731–1739. [Google Scholar] [CrossRef]
- Wu, H.; Chen, S.; Yang, B.; Chen, K. Feedback Robust Cubature Kalman Filter for Target Tracking Using an Angle Sensor. Sensors 2016, 16, 629. [Google Scholar] [CrossRef] [PubMed]
- Liu, H.; Wu, W. Interacting Multiple Model (IMM) Fifth-Degree Spherical Simplex-Radial Cubature Kalman Filter for Maneuvering Target Tracking. Sensors 2017, 17, 1374. [Google Scholar] [CrossRef] [PubMed]
- Zhao, X.; Li, J.; Yan, X.; Ji, S. Robust Adaptive Cubature Kalman Filter and Its Application to Ultra-Tightly Coupled SINS/GPS Navigation System. Sensors 2018, 18, 2352. [Google Scholar] [CrossRef] [PubMed]
- Song, T.L.; Ahn, J.Y.; Park, C. Suboptimal filter design with pseudomeasurements for target tracking. IEEE Trans. Aerosp. Electron. Syst. 1988, 24, 28–39. [Google Scholar] [CrossRef]
- Bryson, A.E.; Ho, Y.C. Applied Optimal Control; Blaisdell Publishing Company: Waltham, UK, 1969. [Google Scholar]
- Weiss, M.; Shima, T. Minimum Effort Pursuit/Evasion Guidance with Specified Miss Distance. J. Guid. Control Dyn. 2016, 39, 1069–1079. [Google Scholar] [CrossRef]
Figure 1.
The geometry of active aircraft defense.

Figure 2.
The structure of adaptive cooperative guidance laws.

Figure 3.
The structure of adaptive cooperative guidance laws.

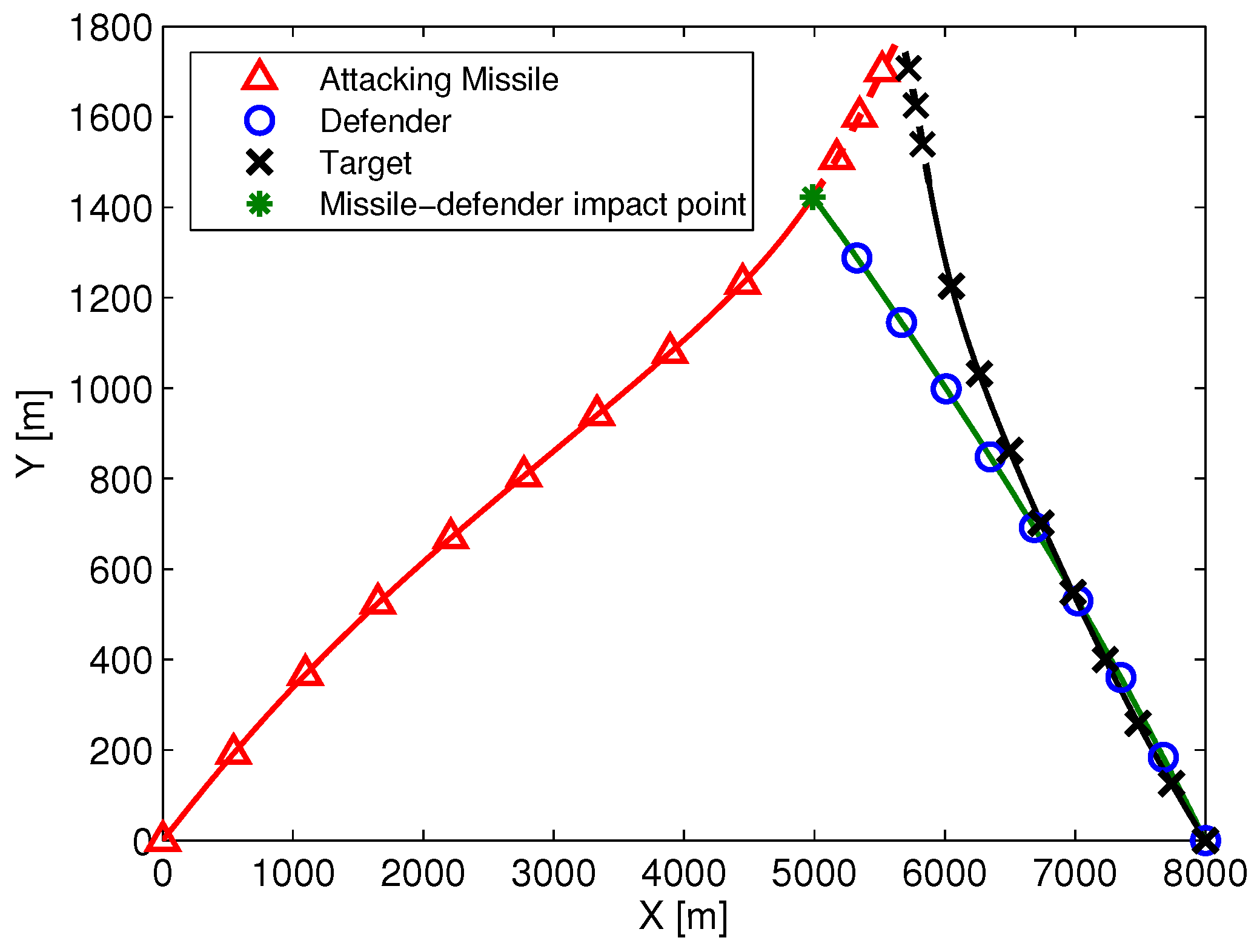
Figure 4.
The trajectories of three aircraft in the case of .

Figure 5.
The guidance commands of three aircraft in the case of .

Figure 6.
Guidance commands of three aircraft with different .

Figure 7.
Estimation error of the sMME-SRCKF (static multiple model estimator with square-root cubature Kalman filter) in Case 1.
Figure 7.
Estimation error of the sMME-SRCKF (static multiple model estimator with square-root cubature Kalman filter) in Case 1.

Figure 8.
Model probability of the sMME-SRCKF for one Monte Carlo simulation in Case 1.

Figure 9.
Estimation errors of the extended Kalman filter (EKF) and SRCKF: (a) position root-mean-square error (RMSE), (b) velocity RMSE.
Figure 9.
Estimation errors of the extended Kalman filter (EKF) and SRCKF: (a) position root-mean-square error (RMSE), (b) velocity RMSE.

Figure 10.
Estimation errors of the sMME-EKF and sMME-SRCKF: (a) position RMSE, (b) acceleration RMSE.
Figure 10.
Estimation errors of the sMME-EKF and sMME-SRCKF: (a) position RMSE, (b) acceleration RMSE.

Figure 11.
Estimation RMSE of the sMME-SRCKF in Case 0 and Case 1.

Figure 12.
Average model probability of PN with in Case 0 and Case 1.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Simulation results with different flight-path angles. D—defender; M—missile; T—target.
| D–M Miss Distance (m) | M–T Miss Distance (m) | |
|---|---|---|
| 0.0022 | 10.3023 | |
| 0.0027 | 11.5965 | |
| 0.006 | 10.7112 | |
| 0.0017 | 11.1289 | |
| 0.0014 | 11.0299 | |
| 0.0164 | 10.4282 |
Table 2.
Simulation results in different cases.
| Simulation Case | (m) | (m) | (m/s) | (m/s) | (m/s) |
|---|---|---|---|---|---|
| 0.0031 | 0.071 | 109.6531 | 56.8811 | 59.8561 | |
| 0.0017 | 11.1289 | 354.9131 | 193.5426 | 81.5393 | |
| 0.0619 | 10.2815 | 379.1928 | 204.7415 | 129.7482 | |
| 2.7552 | 9.5650 | 393.9062 | 208.7452 | 173.0856 |
Table 3.
Successful probability of two adaptive cooperative guidance laws (ACGL) with different measurement noise.
Table 3.
Successful probability of two adaptive cooperative guidance laws (ACGL) with different measurement noise.
| Case 1 | Case 2 | Case 3 | Case 4 | |
|---|---|---|---|---|
| ACGL1 | 100% | 99.9% | 93.9% | 83.1% |
| ACGL2 | 100% | 88% | 57.5% | 47.4% |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Fang, F.; Cai, Y.; Yu, Z. Adaptive Estimation and Cooperative Guidance for Active Aircraft Defense in Stochastic Scenario. Sensors 2019, 19, 979. https://doi.org/10.3390/s19040979
AMA Style
Fang F, Cai Y, Yu Z. Adaptive Estimation and Cooperative Guidance for Active Aircraft Defense in Stochastic Scenario. Sensors. 2019; 19(4):979. https://doi.org/10.3390/s19040979
Chicago/Turabian StyleFang, Feng, Yuanli Cai, and Zhenhua Yu. 2019. "Adaptive Estimation and Cooperative Guidance for Active Aircraft Defense in Stochastic Scenario" Sensors 19, no. 4: 979. https://doi.org/10.3390/s19040979
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.