A Hardware-Friendly Optical Flow-Based Time-to-Collision Estimation Algorithm


Abstract
1. Introduction
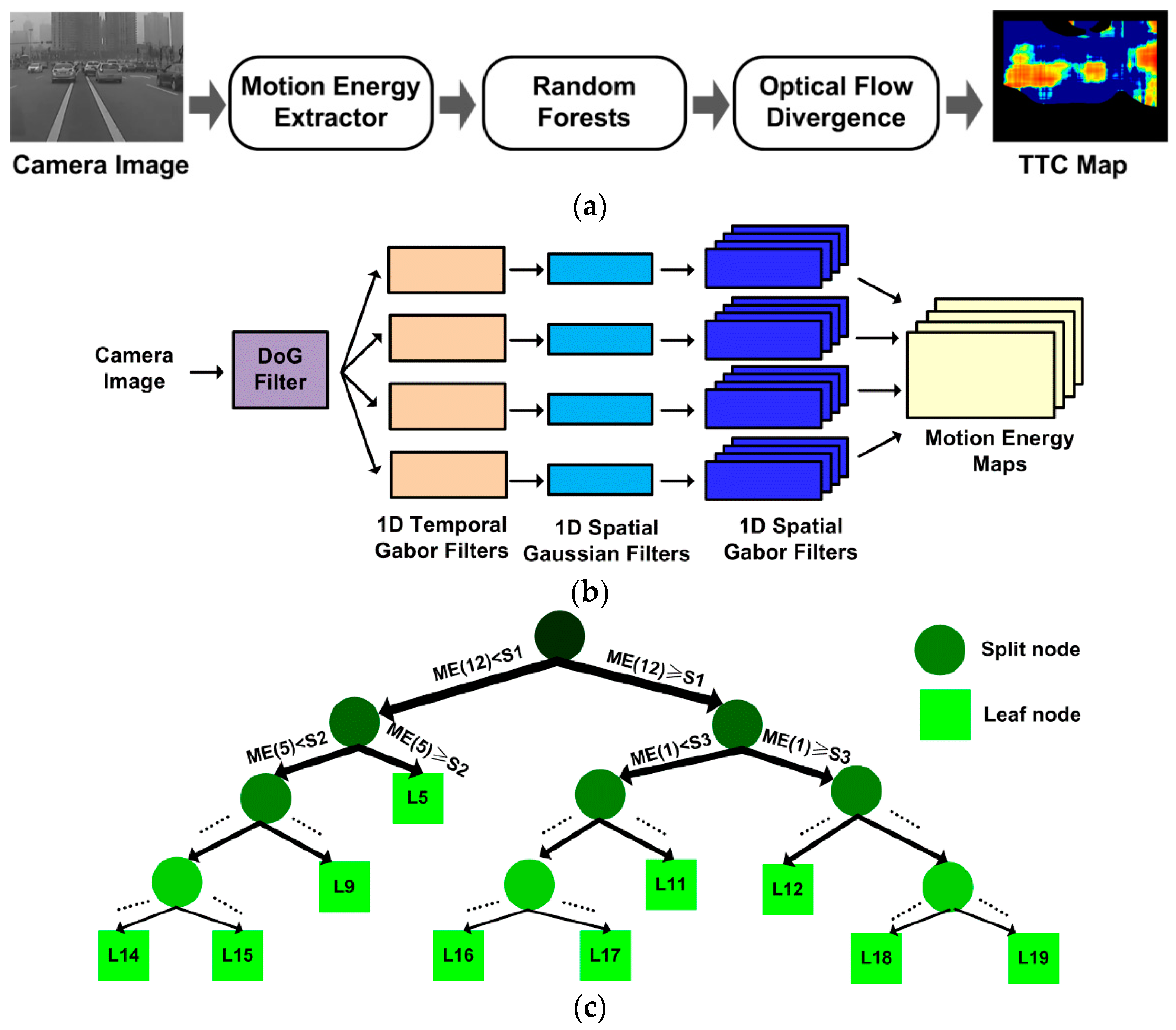
2. Proposed TTC Estimation Algorithm
2.1. Biological Motion Energy Extraction
2.2. Optical Flow Computation by Random Forests
2.3. TTC Estimation from Optical Flow Field
3. Experimental Results
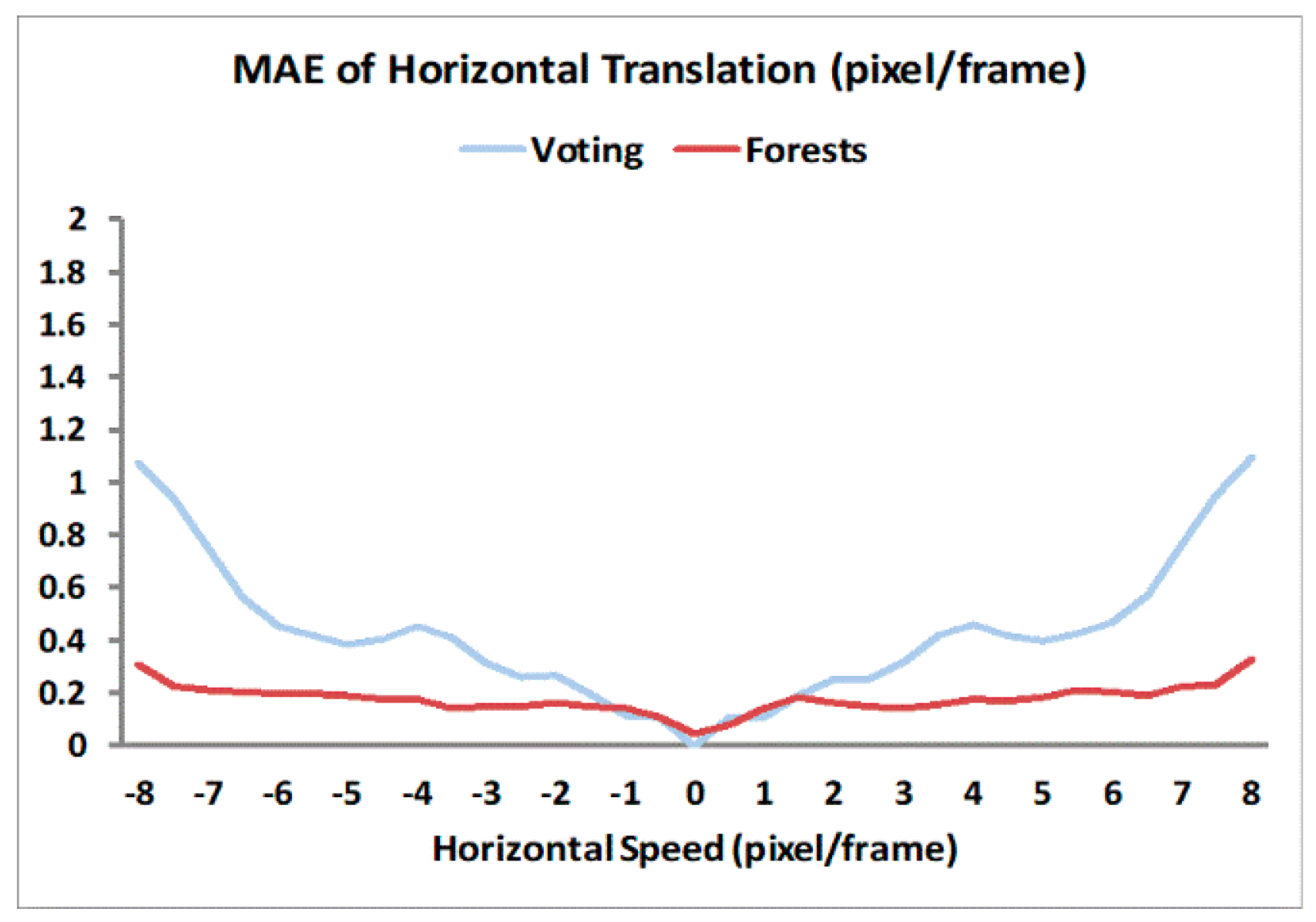
3.1. Optical Flow Accuracy
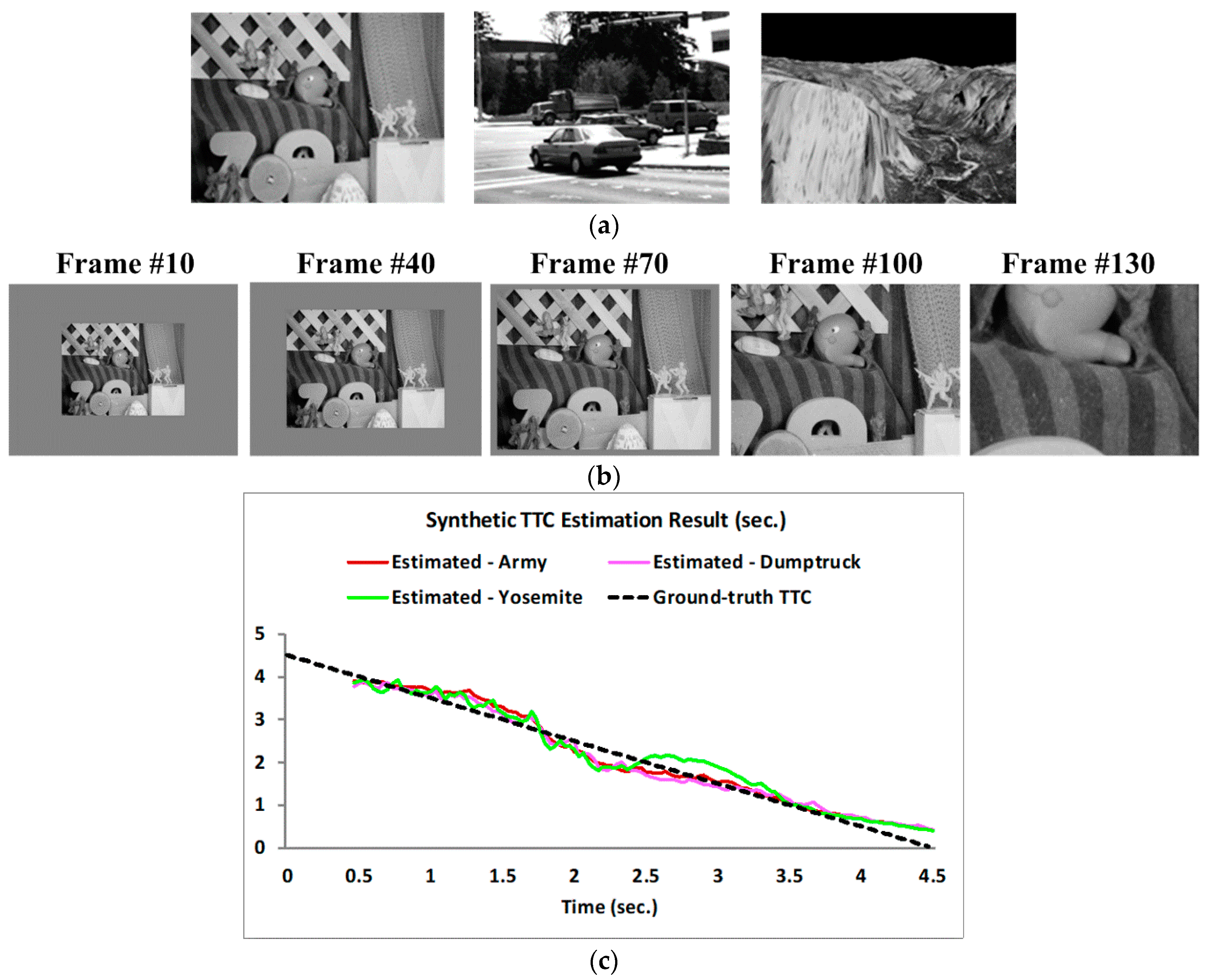
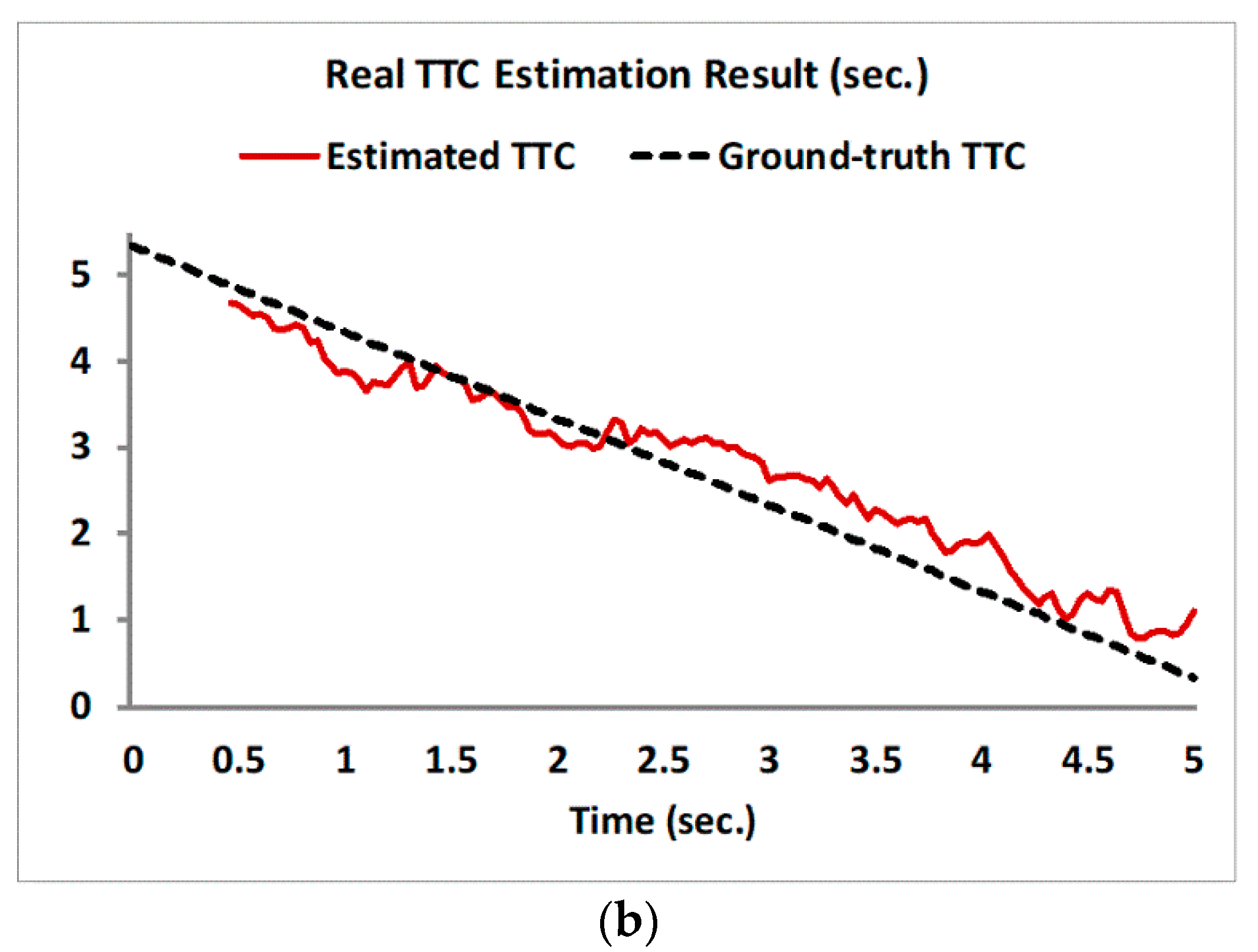
3.2. TTC Estimation Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Sanchez-Garcia, A.J.; Rios-Figueroa, H.V.; Marin-Hernandez, A.; Contreras-Vega, G. Decision making for obstacle avoidance in autonomous mobile robots by time to contact and optical flow. In Proceedings of the Decision Making for Obstacle Avoidance in Autonomous Mobile Robots by Time to Contact and Optical Flow, Cholula, Mexico, 25–27 February 2015; pp. 130–134. [Google Scholar]
- Zhang, H.; Zhao, J. Bio-inspired vision based robot control using featureless estimations of time-to-contact. Bioinspir. Biomim. 2017, 12, 025001. [Google Scholar] [CrossRef] [PubMed]
- Pundlik, S.; Tomasi, M.; Luo, G. Collision detection for visually impaired from a body-mounted camera. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Portland, OR, USA, 23–28 June 2013; pp. 41–47. [Google Scholar]
- Pundlik, S.; Tomasi, M.; Moharrer, M.; Bowers, A.R.; Luo, G. Preliminary Evaluation of a Wearable Camera-based Collision Warning Device for Blind Individuals. Optometry Vision Sci. 2018, 95, 747–756. [Google Scholar] [CrossRef] [PubMed]
- Alenyà, G.; Nègre, A.; Crowley, J.L. Time to contact for obstacle avoidance. In Proceedings of the 4th European Conference on Mobile Robots, Mlini/Dubrovnik, Croatia, 23–25 September 2009; pp. 19–24. [Google Scholar]
- Chae, S.-H.; Sun, J.-Y.; Kang, M.-C.; Son, B.-J.; Ko, S.-J. Collision detection based on scale change of image segments for the visually impaired. In Proceedings of the 2015 IEEE International Conference on Consumer Electronics (ICCE), Las Vegas, NV, USA, 9–12 January 2015; pp. 511–512. [Google Scholar]
- Muller, D.; Pauli, J.; Nunn, C.; Gormer, S.; Muller-Schneiders, S. Time to contact estimation using interest points. In Proceedings of the 2009 12th International IEEE Conference on Intelligent Transportation Systems, St. Louis, MO, USA, 4–7 October 2009. [Google Scholar]
- Negre, A.; Braillon, C.; Crowley, J.L.; Laugier, C. Real-time time-to-collision from variation of intrinsic scale. In Experimental Robotics; Springer: Berlin/Heidelberg, Germany, 2008; pp. 75–84. [Google Scholar]
- Watanabe, Y.; Sakaue, F.; Sato, J. Time-to-Contact from Image Intensity. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 4176–4183. [Google Scholar]
- Horn, B.K.P.; Fang, Y.; Masaki, I. Time to contact relative to a planar surface. In Proceedings of the 2007 IEEE Intelligent Vehicles Symposium, Istanbul, Turkey, 13–15 June 2007; pp. 68–74. [Google Scholar]
- Horn, B.K.P.; Fang, Y.; Masaki, I. Hierarchical framework for direct gradient-based time-to-contact estimation. In Proceedings of the 2009 IEEE Intelligent Vehicles Symposium, Xi’an, China, 3–5 June 2009; pp. 1394–1400. [Google Scholar]
- Coombs, D.; Herman, M.; Hong, T.-H.; Nashman, M. Real-time obstacle avoidance using central flow divergence, and peripheral flow. IEEE Trans. Rob. Autom 1998, 14, 49–59. [Google Scholar] [CrossRef]
- Galbraith, J.M.; Kenyon, G.T.; Ziolkowski, R.W. Time-to-collision estimation from motion based on primate visual processing. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 1279–1291. [Google Scholar] [CrossRef] [PubMed]
- Shi, C.; Luo, G. A Compact VLSI System for Bio-Inspired Visual Motion Estimation. IEEE Trans. Circuits Syst. Video Technol. 2018, 28, 1021–1036. [Google Scholar] [CrossRef] [PubMed]
- Chessa, M.; Solari, F.; Sabatini, S.P. Adjustable Linear Models for Optic Flow based Obstacle Avoidance. Comput. Vision Image Underst. 2013, 117, 603–619. [Google Scholar] [CrossRef]
- Cannons, K.J.; Wildes, R.P. The applicability of spatiotemporal oriented energy features to region tracking. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 784–796. [Google Scholar] [CrossRef] [PubMed]
- Fortun, D.; Bouthemy, P.; Kervrann, C. Optical flow modeling and computation: a survey. Comput. Vision Image Understanding 2015, 134, 1–21. [Google Scholar] [CrossRef]
- Adelson, E.H.; Bergen, J.R. Spatiotemporal energy models for the perception of motion. J. Opt. Soc. Am. A 1985, 2, 284–299. [Google Scholar] [CrossRef] [PubMed]
- Grzywacz, N.M.; Yuille, A.L. A model for the estimate of local image velocity by cells in the visual cortex. In Proc. Royal Society B Biol. Sci. 1990, 239, 129–161. [Google Scholar] [CrossRef] [PubMed]
- Solari, F.; Chessa, M.; Medathati, N.V.K.; Kornprobst, P. What can we expect from a V1-MT feedforward architecture for optical flow estimation? Signal Process. Image Commun. 2015, 39, 342–354. [Google Scholar] [CrossRef]
- Medathati, N.K.; Neumann, H.; Masson, G.S.; Kornprobst, P. Bio-inspired computer vision: Towards a synergistic approach of artificial and biological vision. Comput. Vision Image Understanding 2016, 150, 1–30. [Google Scholar] [CrossRef]
- Brinkworth, R.S.A.; O’Carroll, D.C. Robust Models for Optic Flow Coding in Natural Scenes Inspired by Insect Biology. PLoS Comput. Biol. 2009, 5, e1000555. [Google Scholar]
- Beauchemin, S.S.; Barron, J.L. The computation of optical flow. ACM Comput. Surv. 1995, 27, 433–466. [Google Scholar] [CrossRef]
- Lecoeur, J.; Baird, E.; Floreano, D. Spatial Encoding of Translational Optic Flow in Planar Scenes by Elementary Motion Detector Arrays. Sci. Rep. 2018, 8, 5821. [Google Scholar] [CrossRef] [PubMed]
- Etienne-Cummings, R.; Spiegel, J.V.; Mueller, P. Hardware implementation of a visual-motion pixel using oriented spatiotemporal neural filters. IEEE Trans. Circuits Syst. 1999, 46, 1121–1136. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Criminisi, A.; Shotton, J. Decision Forests for Computer Vision and Medical Image Analysis; Springer Science & Business Media: Berlin, Germany, 2013. [Google Scholar]
- Sabatini, S.P.; Gastaldi, G.; Solari, F.; Pauwels, K.; Van Hulle, M.M.; Diaz, J.; Eduardo Ros, E.; Nicolas Pugeault, N.; Krüger, N. A compact harmonic code for early vision based on anisotropic frequency channels. Comput. Vision Image Understanding 2010, 6, 681–699. [Google Scholar] [CrossRef]
- Prince, S.J.D. Computer Vision: Models, Learning, and Inference; Cambridge University Press: Cambridge, UK, 2012. [Google Scholar]
- Regression Tree Ensembles. Available online: https://www.mathworks.com/help/stats/regression-tree-ensembles.html (accessed on 22 November 2018).
- Baker, S.; Scharstein, D.; Lewis, J.P.; Roth, S.; Black, M.J.; Szeliski, R. A database and evaluation methodology for optical flow. Int. J. Comput. Vision 2011, 92, 1–31. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Avg MAE (pixel/frame) | Horizontal Translation | 2D Translation | Rotation | Looming | Global |
|---|---|---|---|---|---|
| Voting | 0.435 | 0.712 | 0.815 | 0.740 | 0.676 1 |
| Forests | 0.179 | 0.320 | 0.519 | 0.658 | 0.419 1 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shi, C.; Dong, Z.; Pundlik, S.; Luo, G. A Hardware-Friendly Optical Flow-Based Time-to-Collision Estimation Algorithm. Sensors 2019, 19, 807. https://doi.org/10.3390/s19040807
Shi C, Dong Z, Pundlik S, Luo G. A Hardware-Friendly Optical Flow-Based Time-to-Collision Estimation Algorithm. Sensors. 2019; 19(4):807. https://doi.org/10.3390/s19040807
Chicago/Turabian StyleShi, Cong, Zhuoran Dong, Shrinivas Pundlik, and Gang Luo. 2019. "A Hardware-Friendly Optical Flow-Based Time-to-Collision Estimation Algorithm" Sensors 19, no. 4: 807. https://doi.org/10.3390/s19040807
APA StyleShi, C., Dong, Z., Pundlik, S., & Luo, G. (2019). A Hardware-Friendly Optical Flow-Based Time-to-Collision Estimation Algorithm. Sensors, 19(4), 807. https://doi.org/10.3390/s19040807