An In-Networking Double-Layered Data Reduction for Internet of Things (IoT)

Abstract
1. Introduction
2. Related Work
Kalman Filter
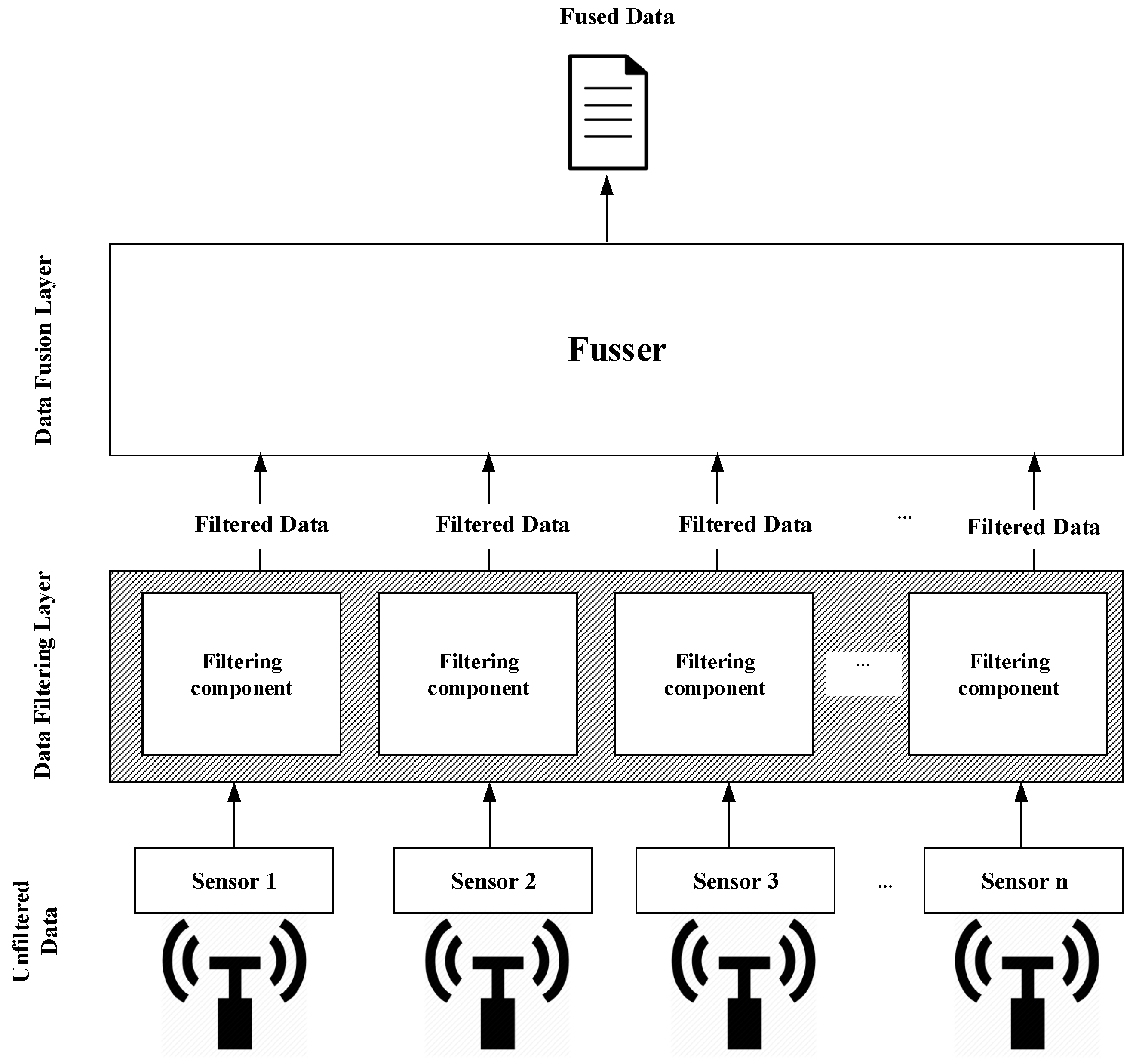
3. Proposed Approach
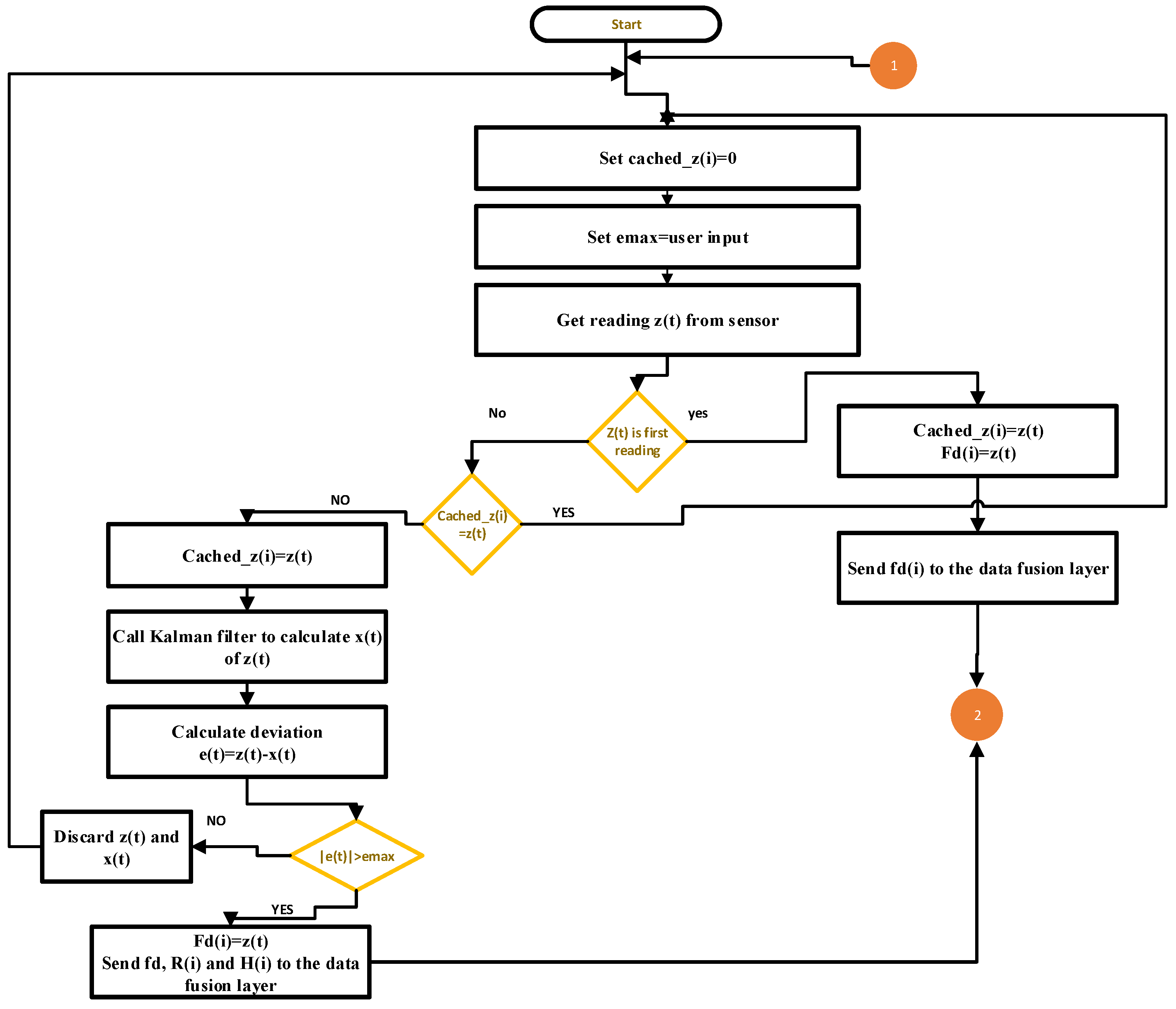
3.1. Data Filtering Layer
| Algorithm 1 Data filtering operation |
| INPUT: sensor reading = user input while true do if is the first reading then zt(i) Send to the fuser else if ! = then z(t) Call kalman filter to calculate estimated value if then Send , and to the data fusion layer else Discard and values end if end if end if end while |
3.2. Data Fusion Layer
| Algorithm 2 Data fusion operation |
| INPUT: The output data stream of algorithm_1 Covariance matrix calculated by Kalman filter in data filtering layer Identity Matrix Calculated by Kalman filter in data filtering layer if then 2: Exit else 4: 5: 6: Calculate total estimated value using Kalman filter based on total , and send z(t) to cloud. 7: if there is a missing data then 8: send the estimated value calculated by Kalman filter is sent the cloud. 9: end if end if |
4. Implementation and Evaluation of the Proposed Approach
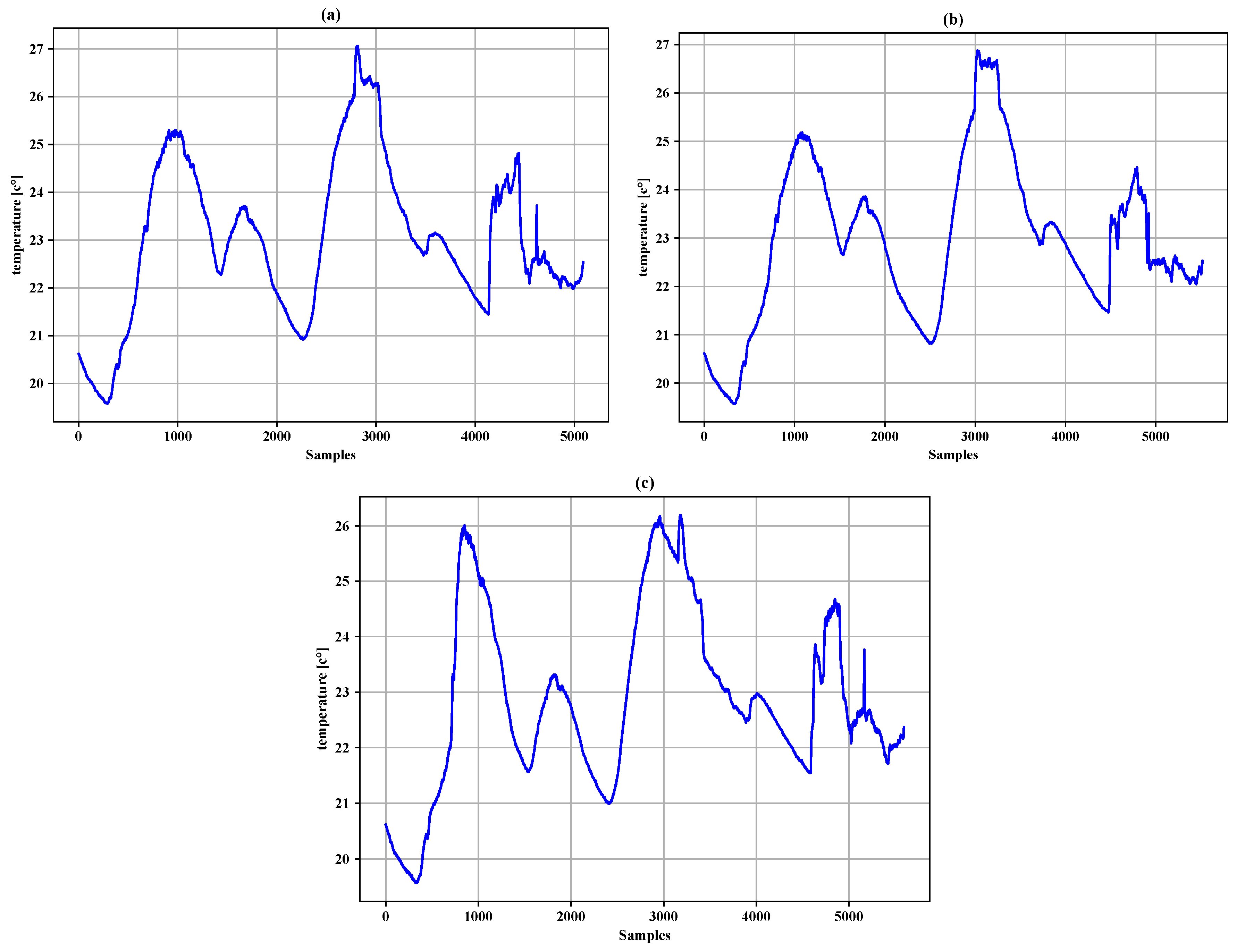
4.1. Datasets
4.2. Simulation Environment
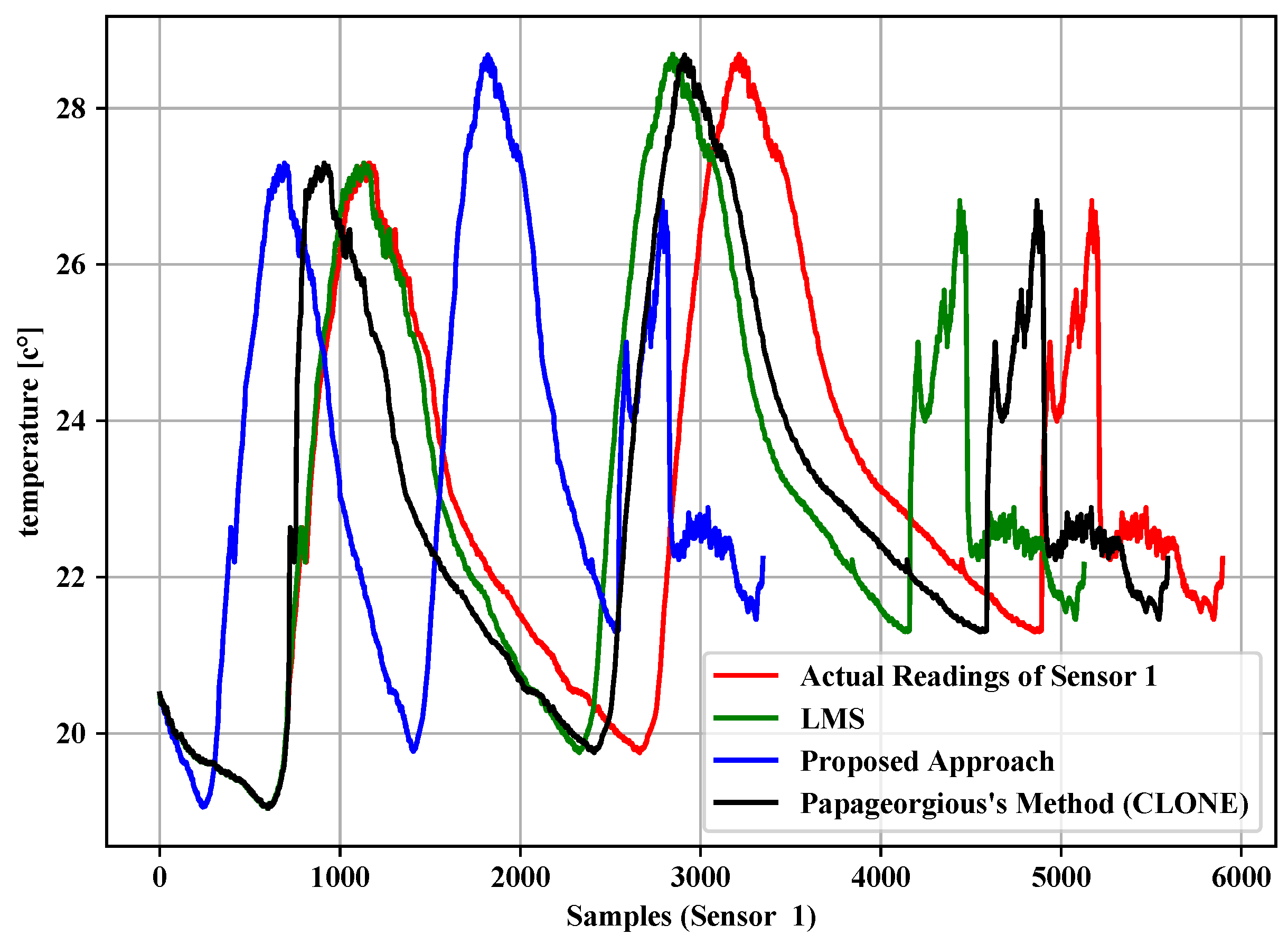
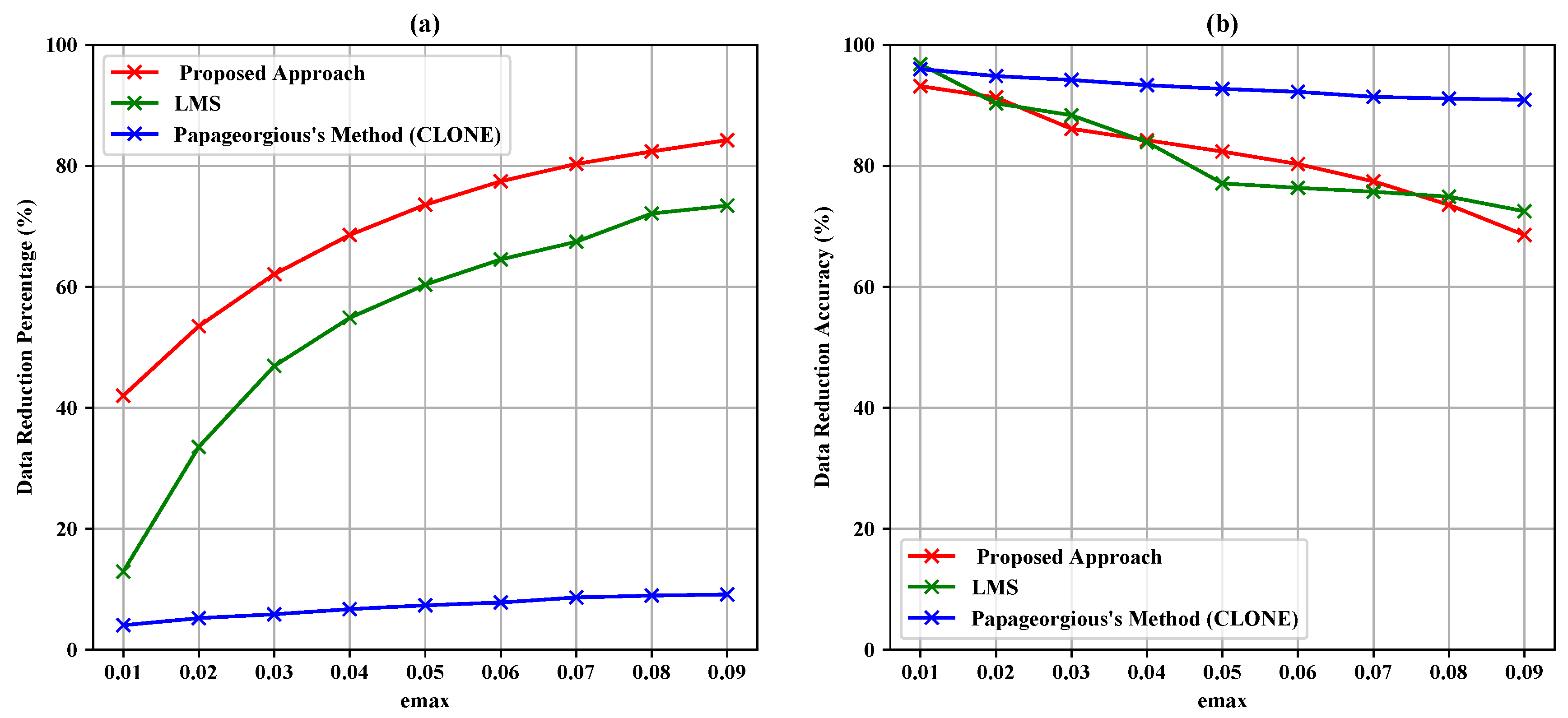
5. Study Results and Evaluation
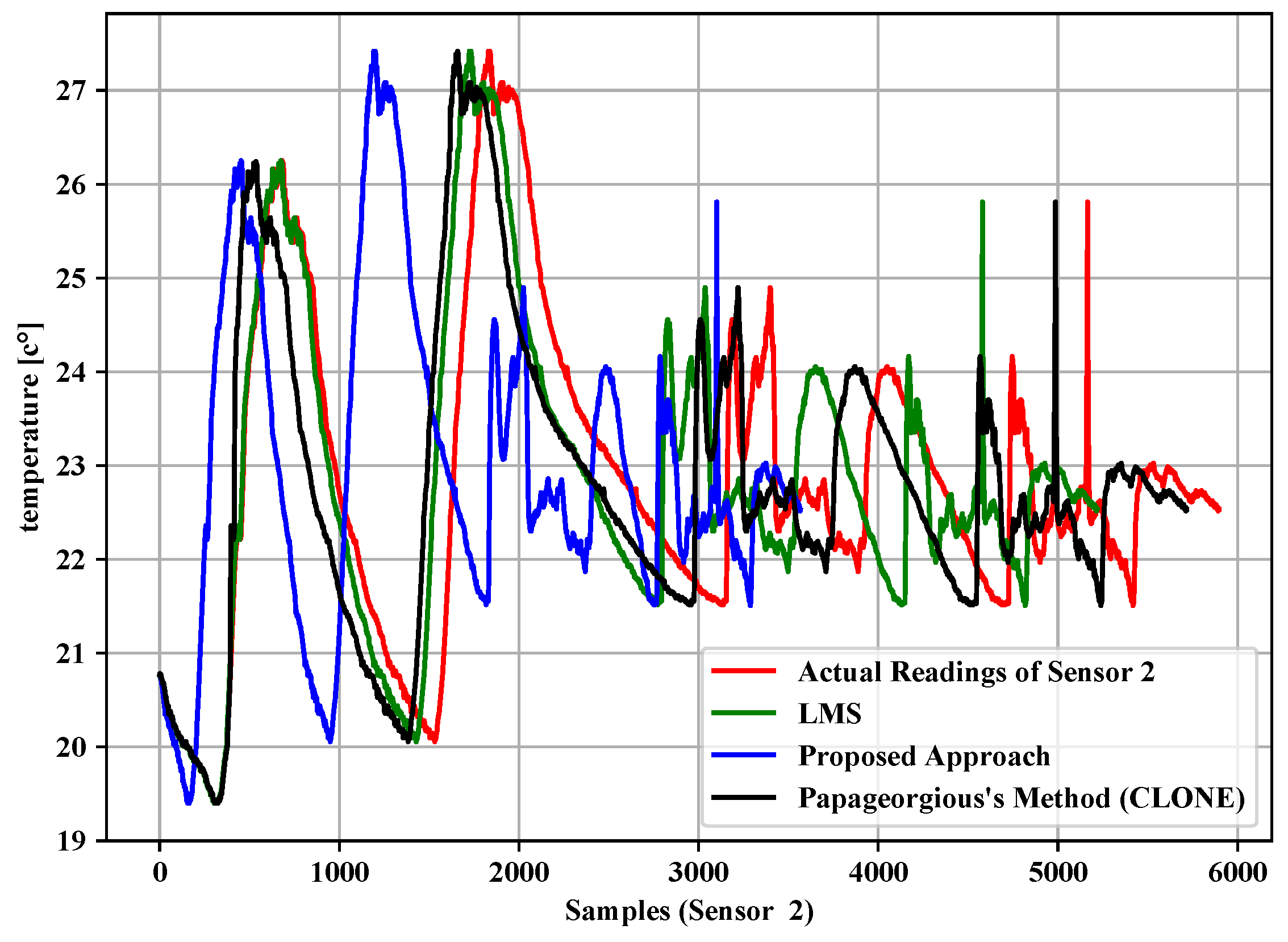
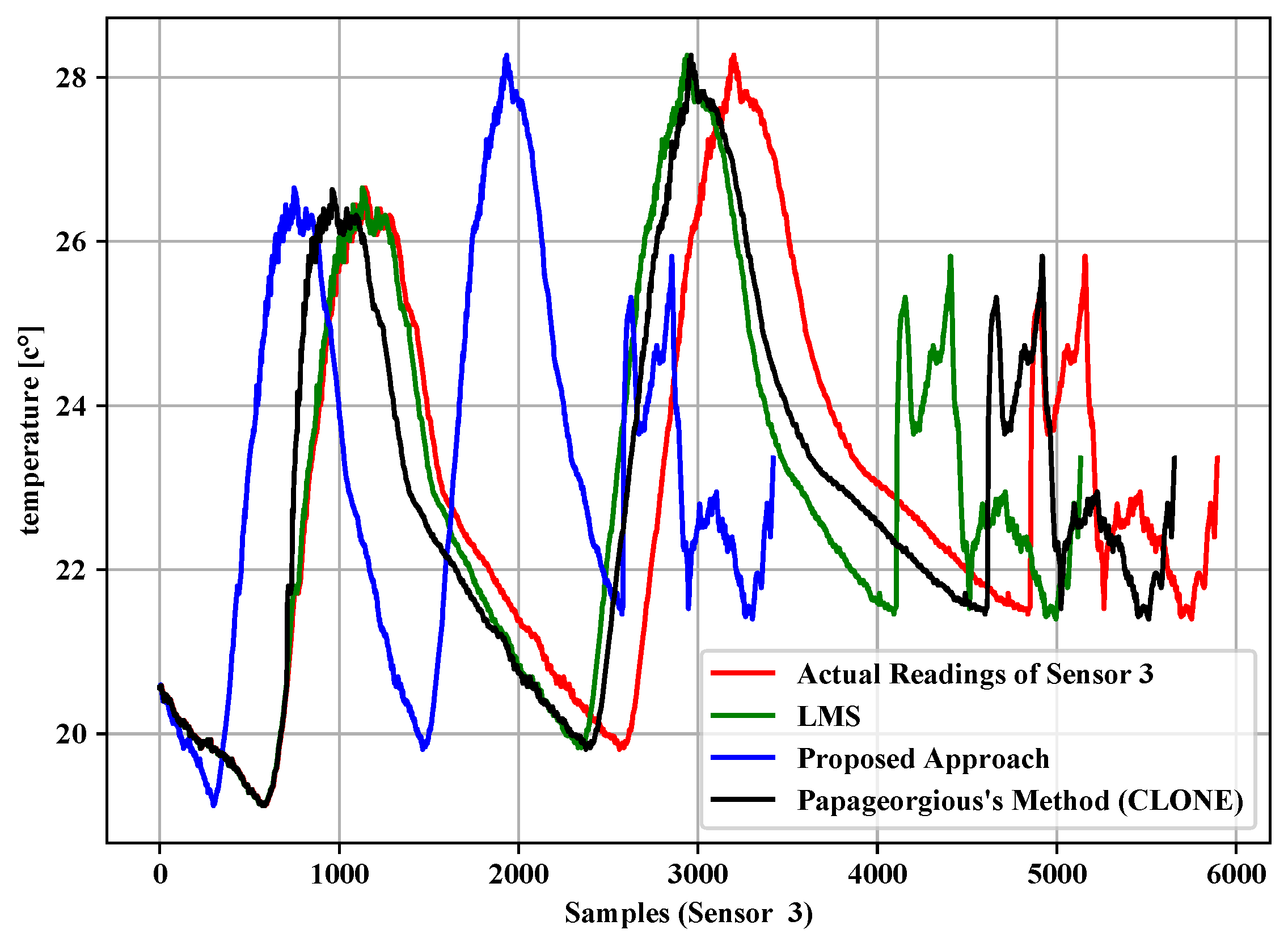
5.1. Data Filtering Layer
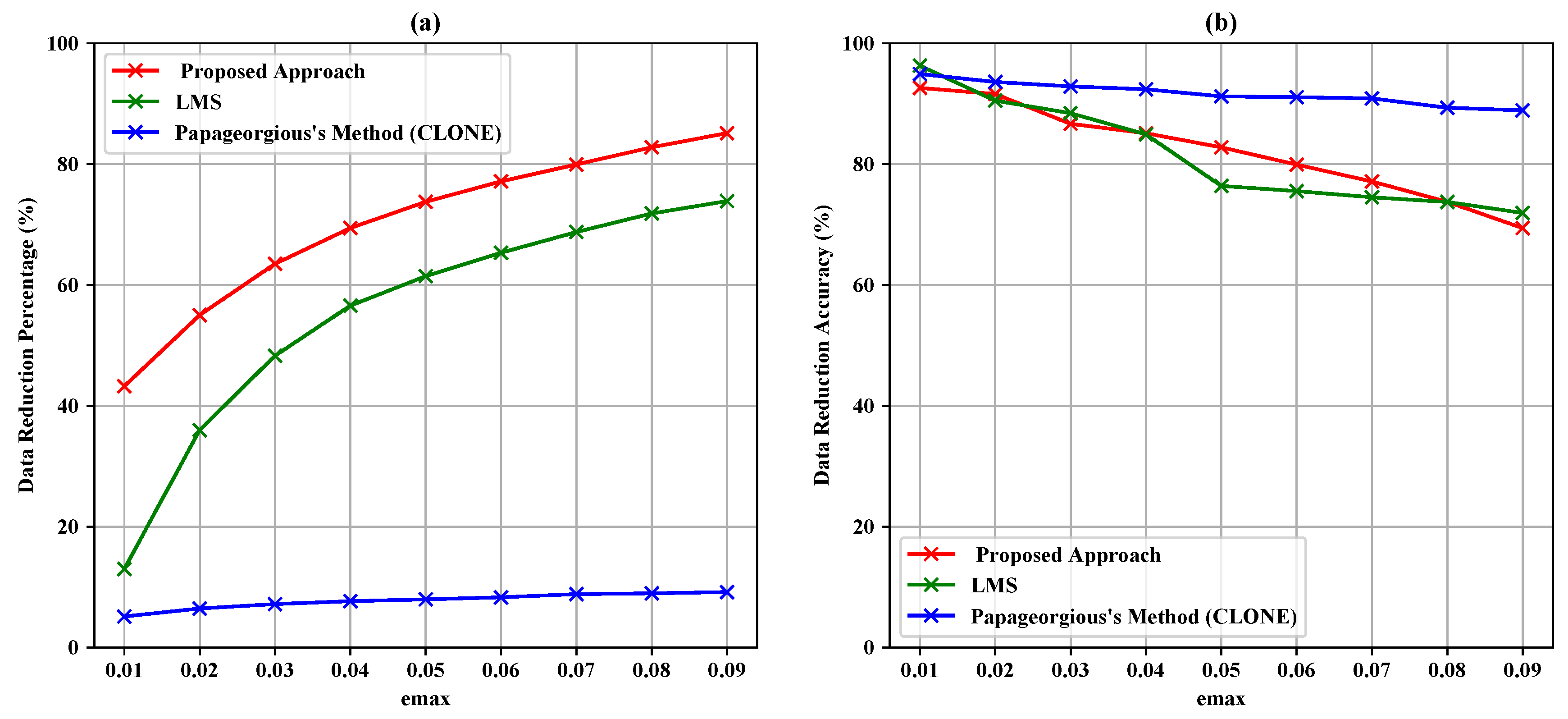
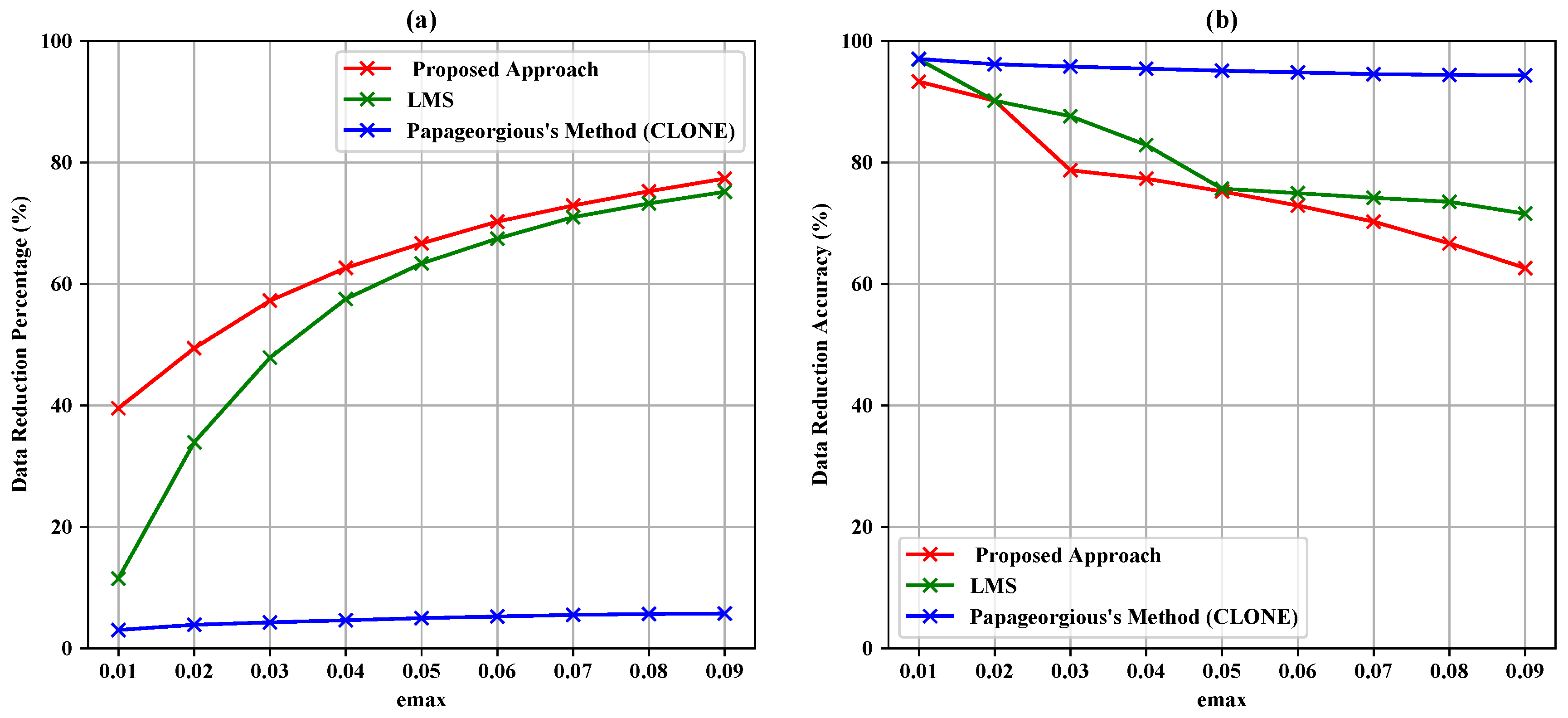
- Data reduction percentage is obtained by:where SP is the saving percentage, AD represents the actual data, TD represents the transmitted data, and DRP is the data reduction percentage.
- Data reduction accuracy is the similarity between actual data and filtered data mixed with estimated data to make a set of the same length as the original one based on the Jaccard coefficient as follows:
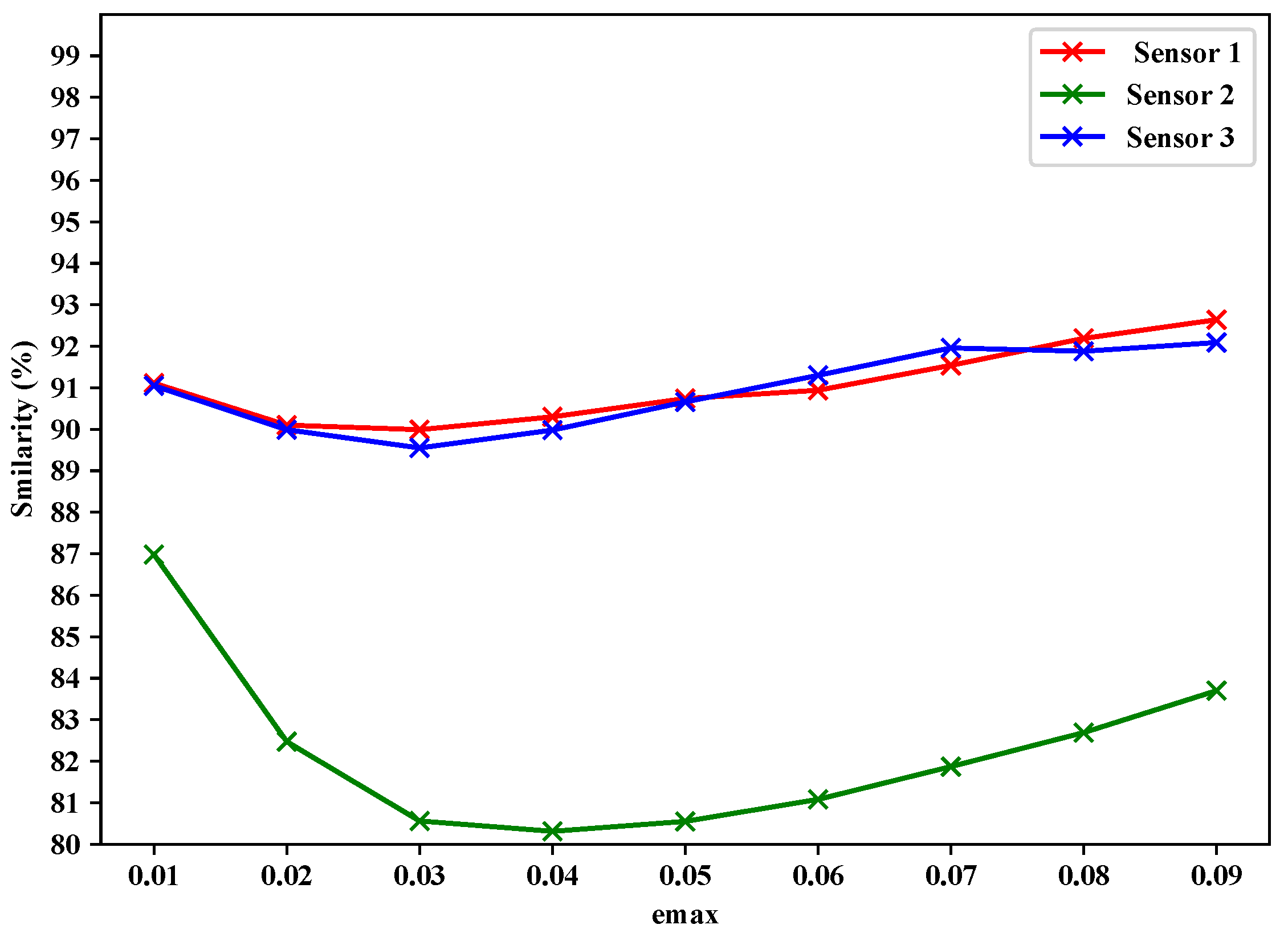
5.2. Data Fusion Layer
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Miorandi, D.; Sicari, S.; De Pellegrini, F.; Chlamtac, I. Internet of things: Vision, applications and research challenges. Ad Hoc Netw. 2012, 10, 1497–1516. [Google Scholar] [CrossRef]
- Wu, J.; Feng, Y.; Sun, P. Sensor Fusion for Recognition of Activities of Daily Living. Sensors 2018, 18, 4029. [Google Scholar] [CrossRef] [PubMed]
- Shahid, N.; Aneja, S. Internet of things: A survey on enabling technologies, protocols, and applications. IEEE Commun. Surv. Tutor. 2015, 17, 2347–2376. [Google Scholar]
- Feng, L.; Kortoçi, P.; Liu, Y. A multi-tier data reduction mechanism for IoT sensors. In Proceedings of the Seventh International Conference on the Internet of Things, Linz, Austria, 22–25 October 2017; ACM: New York, NY, USA, 2017; p. 6. [Google Scholar]
- Papageorgiou, A.; Cheng, B.; Kovacs, E. Real-time data reduction at the network edge of Internet-of-Things systems. In Proceedings of the 2015 11th International Conference on Network and Service Management (CNSM), Barcelona, Spain, 9–13 November 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 284–291. [Google Scholar]
- Rahman, H.; Ahmed, N.; Hussain, I. Comparison of data aggregation techniques in Internet of Things (IoT). In Proceedings of the International Conference on Wireless Communications, Signal Processing and Networking (WiSPNET), Chennai, India, 23–25 March 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 1296–1300. [Google Scholar]
- Lingyun, Y.; Lijing, H.; Manman, Z.; Mingli, Z. RFID data fusion algorithm based on spatio-temporal semantics in internet of things. In Proceedings of the 2017 13th IEEE International Conference on Electronic Measurement & Instruments (ICEMI), Yangzhou, China, 20–22 October 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 179–184. [Google Scholar]
- Stojkoska, B.R.; Nikolovski, Z. Data compression for energy efficient IoT solutions. In Proceedings of the 25th Telecommunication Forum (TELFOR), Belgrade, Serbia, 21–22 November 2017; pp. 1–4. [Google Scholar]
- Ling, W.S.; Yaik, O.B.; Yue, L.S. A novel data reduction technique with fault-tolerance for internet-of-things. In Proceedings of the Second International Conference on Internet of things and Cloud Computing, Cambridge, UK, 22–23 March 2017; ACM: New York, NY, USA, 2017; p. 71. [Google Scholar]
- Papageorgiou, A.; Cheng, B.; Kovacs, E. Reconstructability-aware filtering and forwarding of time series data in internet-of-things architectures. In Proceedings of the 2015 IEEE International Congress on Big Data (BigData Congress), New York, NY, USA, 27 June–2 July 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 576–583. [Google Scholar]
- Narendra, N.; Ponnalagu, K.; Ghose, A.; Tamilselvam, S. Goal-driven context-aware data filtering in IoT-based systems. In Proceedings of the 2015 IEEE 18th International Conference on Intelligent Transportation Systems (ITSC), Las Palmas, Spain, 15–18 September 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 2172–2179. [Google Scholar]
- Bijarbooneh, F.H.; Du, W.; Ngai, E.C.H.; Fu, X.; Liu, J. Cloud-assisted data fusion and sensor selection for internet of things. IEEE Internet Things J. 2016, 3, 257–268. [Google Scholar] [CrossRef]
- Dubey, H.; Yang, J.; Constant, N.; Amiri, A.M.; Yang, Q.; Makodiya, K. Fog data: Enhancing telehealth big data through fog computing. In Proceedings of the ASE BigData & SocialInformatics 2015, Kaohsiung, Taiwan, 7–9 October 2015; ACM: New York, NY, USA, 2015; p. 14. [Google Scholar]
- Xu, X.; Huang, S.; Chen, Y.; Browny, K.; Halilovicy, I.; Lu, W.T. Time series analytics as a service on IoT. In Proceedings of the IEEE International Conference on Web Services (ICWS), Anchorage, AK, USA, 27 June–2 July 2014; Volume 27, pp. 249–256. [Google Scholar]
- Anastasi, G.; Conti, M.; Di Francesco, M.; Passarella, A. Energy conservation in wireless sensor networks: A survey. Ad Hoc Netw. 2009, 7, 537–568. [Google Scholar] [CrossRef]
- Mohamed, M.F.; Shabayek, A.E.R.; El-Gayyar, M.; Nassar, H. An adaptive framework for real-time data reduction in AMI. J. King Saud Univ. Comput. Inf. Sci. 2018, in press. [Google Scholar] [CrossRef]
- Fu, T.C.; Hung, Y.K.; Chung, F.L. Improvement algorithms of perceptually important point identification for time series data mining. In Proceedings of the 2017 IEEE 4th International Conference on Soft Computing & Machine Intelligence (ISCMI), Port Louis, Mauritius, 23–24 November 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 11–15. [Google Scholar]
- Jugel, U.; Jerzak, Z.; Hackenbroich, G.; Markl, V. VDDA: Automatic visualization-driven data aggregation in relational databases. VLDB J. Int. J. Very Large Data Bases 2016, 25, 53–77. [Google Scholar] [CrossRef]
- Yu, T.; Wang, X.; Shami, A. A Novel Fog Computing Enabled Temporal Data Reduction Scheme in IoT Systems. In Proceedings of the GLOBECOM 2017–2017 IEEE Global Communications Conference, Singapore, 4–8 December 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–5. [Google Scholar]
- Fathy, Y.; Barnaghi, P.; Tafazolli, R. An Adaptive Method for Data Reduction in the Internet of Things. Proceedings of IEEE 4th World Forum on Internet of Things, Singapore, 5–8 February 2018; IEEE: Piscataway, NJ, USA, 2018. [Google Scholar]
- Chen, Y.; Si, X.; Li, Z. Research on Kalman-filter based multisensor data fusion. J. Syst. Eng. Electron. 2007, 18, 497–502. [Google Scholar]
- Soman, R.; Ostachowicz, W. Kalman Filter Based Load Monitoring in Beam Like Structures Using Fibre-Optic Strain Sensors. Sensors 2018, 19, 103. [Google Scholar] [CrossRef] [PubMed]
- Singh, R.; Mehra, R.; Sharma, L. Design of Kalman filter for wireless sensor network. In Proceedings of the International Conference on Internet of Things and Applications (IOTA), Pune, India, 22–24 January 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 63–67. [Google Scholar]
- Gan, Q.; Harris, C.J. Comparison of two measurement fusion methods for Kalman-filter-based multisensor data fusion. IEEE Trans. Aerosp. Electron. Syst. 2001, 37, 273–279. [Google Scholar] [CrossRef]
- Coppin, P.R.; Bauer, M.E. Digital change detection in forest ecosystems with remote sensing imagery. Remote Sens. Rev. 1996, 13, 207–234. [Google Scholar] [CrossRef]
- Castanedo, F. A review of data fusion techniques. Sci. World J. 2013, 2013. [Google Scholar] [CrossRef] [PubMed]
- Bodik, P.; Hong, W.; Guestrin, C.; Madden, S.; Paskin, M.; Thibaux, R. Intel Lab Data. Available online: http://db.csail.mit.edu/labdata/labdata.html (accessed on 15 February 2019).














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Definition |
|---|---|
| cache for Sensor reading when data change detected | |
| Maximum absolute deviation of observation from its estimated value | |
| Data stream produced by a sensor at time | |
| state value at time | |
| error between the observation and the estimated value | |
| filtered data at time t | |
| t | Time index = 1,2,…,t |
| Parameter | Definition |
|---|---|
| The data stream of sensors passed from the data filtering layer at time t | |
| Covariance matrices of each sensor calculated by Kalman filter at time t | |
| Identity matrices of each sensor calculated by Kalman filter at time t | |
| The total covariance matrix at time t | |
| The total measurement vector at time t | |
| identity matrix of fused measurement vector at time t |
| Sensor | Initial Value of x |
|---|---|
| Sensor 1 | 20.5078 |
| Sensor 2 | 20.7724 |
| Sensor 3 | 20.5666 |
| MAE | Incoming Data | Proposed Approach | LMS | Papageorgious’s Method (CLONE) | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Forwarded Data No. | Reduction Percentage of Incoming Data | Reduction Accuracy | Forwarded Data No. | Reduction Percentage of Incoming Data | Reduction Accuracy | Forwarded Data No. | Reduction Percentage of Incoming Data | Reduction Accuracy | ||
| 0.01 | 5896 | 3346 | 43.25% | 92.61% | 5129 | 13.01% | 96.30% | 5593 | 5.14% | 94.91% |
| 0.02 | 5896 | 2652 | 55.02% | 91.59% | 3774 | 35.99% | 90.50% | 5515 | 6.46% | 93.59% |
| 0.03 | 5896 | 2152 | 63.50% | 86.67% | 3049 | 48.29% | 88.42% | 5472 | 7.19% | 92.86% |
| 0.04 | 5896 | 1803 | 69.42% | 85.11% | 2560 | 56.58% | 84.91% | 5444 | 7.67% | 92.38% |
| 0.05 | 5896 | 1547 | 73.76% | 82.77% | 2273 | 61.45% | 76.39% | 5426 | 7.97% | 91.21% |
| 0.06 | 5896 | 1348 | 77.14% | 79.92% | 2044 | 65.33% | 75.53% | 5406 | 8.31% | 91.07% |
| 0.07 | 5896 | 1183 | 79.94% | 77.12% | 1842 | 68.76% | 74.51% | 5375 | 8.84% | 90.87% |
| 0.08 | 5896 | 1015 | 82.78% | 73.75% | 1661 | 71.83% | 73.73% | 5367 | 8.97% | 89.33% |
| 0.09 | 5896 | 877 | 85.13% | 69.41% | 1540 | 73.88% | 71.92% | 5355 | 9.18% | 88.89% |
| MAE | Incoming Data | Proposed Approach | LMS | Papageorgious’s Method (CLONE) | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Forwarded Data No. | Reduction Percentage of Incoming Data | Reduction Accuracy | Forwarded Data No. | Reduction Percentage of Incoming Data | Reduction Accuracy | Forwarded Data No. | Reduction Percentage of Incoming Data | Reduction Accuracy | ||
| 0.01 | 5896 | 3566 | 39.52% | 93.30% | 5219 | 11.48% | 96.96% | 5718 | 3.02% | 97.03% |
| 0.02 | 5896 | 2983 | 49.41% | 90.16% | 3896 | 33.92% | 90.15% | 5667 | 3.88% | 96.16% |
| 0.03 | 5896 | 2522 | 57.23% | 78.70% | 3075 | 47.85% | 87.60% | 5644 | 4.27% | 95.77% |
| 0.04 | 5896 | 2204 | 62.62% | 77.32% | 2505 | 57.51% | 82.86% | 5623 | 4.63% | 95.42% |
| 0.05 | 5896 | 1965 | 66.67% | 75.22% | 2160 | 63.36% | 75.67% | 5603 | 4.97% | 95.09% |
| 0.06 | 5896 | 1754 | 70.25% | 72.89% | 1919 | 67.45% | 74.93% | 5587 | 5.24% | 94.81% |
| 0.07 | 5896 | 1598 | 72.90% | 70.24% | 1711 | 70.98% | 74.16% | 5571 | 5.51% | 94.53% |
| 0.08 | 5896 | 1460 | 75.24% | 66.66% | 1578 | 73.24% | 73.51% | 5563 | 5.65% | 94.40% |
| 0.09 | 5896 | 1336 | 77.34% | 62.60% | 1465 | 75.15% | 71.54% | 5558 | 5.73% | 94.32% |
| MAE | Incoming Data | Proposed Approach | LMS | Papageorgious’s Method (CLONE) | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Forwarded Data No. | Reduction Percentage of Incoming Data | Reduction Accuracy | Forwarded Data No. | Reduction Percentage of Incoming Data | Reduction Accuracy | Forwarded Data No. | Reduction Percentage of Incoming Data | Reduction Accuracy | ||
| 0.01 | 5896 | 3420 | 41.99% | 93.17% | 5135 | 12.91% | 96.79% | 5658 | 4.04% | 96.01% |
| 0.02 | 5896 | 2742 | 53.49% | 91.30% | 3919 | 33.53% | 90.33% | 5589 | 5.21% | 94.84% |
| 0.03 | 5896 | 2235 | 62.09% | 86.13% | 3131 | 46.90% | 88.37% | 5551 | 5.85% | 94.20% |
| 0.04 | 5896 | 1853 | 68.57% | 84.24% | 2661 | 54.87% | 83.91% | 5501 | 6.70% | 93.34% |
| 0.05 | 5896 | 1559 | 73.56% | 82.36% | 2338 | 60.35% | 77.09% | 5464 | 7.33% | 92.72% |
| 0.06 | 5896 | 1330 | 77.44% | 80.29% | 2092 | 64.52% | 76.36% | 5436 | 7.80% | 92.24% |
| 0.07 | 5896 | 1161 | 80.31% | 77.43% | 1919 | 67.45% | 75.72% | 5387 | 8.63% | 91.41% |
| 0.08 | 5896 | 1039 | 82.38% | 73.54% | 1644 | 72.12% | 74.90% | 5369 | 8.94% | 91.11% |
| 0.09 | 5896 | 928 | 84.26% | 68.56% | 1567 | 73.42% | 72.49% | 5358 | 9.12% | 90.92% |
| MAE | Proposed Approach | LMS | Papageorgious’s Method (CLONE) | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Filtered Data No. | Fused Data No. | DRP | Filtered Data No. | Fused Data No. | DRP | Filtered Data No. | Fused Data No. | DRP | |||||||
| Sensor 1 | Sensor 2 | Sensor 3 | Sensor 1 | Sensor 2 | Ssensor 3 | Sensor 1 | Sensor 2 | Sensor 3 | |||||||
| 0.01 | 3346 | 3566 | 3420 | 5372 | 69.63% | 5129 | 5219 | 5135 | 5877 | 66.78% | 5593 | 5718 | 5658 | 5897 | 66.67% |
| 0.02 | 2652 | 2983 | 2742 | 4836 | 72.66% | 3774 | 3896 | 3919 | 5444 | 69.23% | 5515 | 5667 | 5589 | 5897 | 66.67% |
| 0.03 | 2152 | 2522 | 2235 | 4324 | 75.56% | 3049 | 3075 | 3131 | 4907 | 72.26% | 5472 | 5644 | 5551 | 5897 | 66.67% |
| 0.04 | 1803 | 2204 | 1853 | 3873 | 78.11% | 2560 | 2505 | 2661 | 4363 | 75.34% | 5444 | 5623 | 5501 | 5897 | 66.67% |
| 0.05 | 1547 | 1965 | 1559 | 3495 | 80.24% | 2273 | 2160 | 2338 | 4019 | 77.28% | 5426 | 5603 | 5464 | 5897 | 66.67% |
| 0.06 | 1348 | 1754 | 1330 | 3167 | 82.10% | 2044 | 1919 | 2092 | 3700 | 79.09% | 5406 | 5587 | 5436 | 5897 | 66.67% |
| 0.07 | 1183 | 1598 | 1161 | 2883 | 83.70% | 1842 | 1711 | 1919 | 3428 | 80.62% | 5375 | 5571 | 5387 | 5897 | 66.67% |
| 0.08 | 1015 | 1460 | 1039 | 2644 | 85.05% | 1661 | 1578 | 1644 | 3119 | 82.37% | 5367 | 5563 | 5369 | 5897 | 66.67% |
| 0.09 | 877 | 1336 | 928 | 2420 | 86.32% | 1540 | 1465 | 1567 | 2917 | 83.51% | 5355 | 5558 | 5358 | 5897 | 66.67% |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ismael, W.M.; Gao, M.; Al-Shargabi, A.A.; Zahary, A. An In-Networking Double-Layered Data Reduction for Internet of Things (IoT). Sensors 2019, 19, 795. https://doi.org/10.3390/s19040795
Ismael WM, Gao M, Al-Shargabi AA, Zahary A. An In-Networking Double-Layered Data Reduction for Internet of Things (IoT). Sensors. 2019; 19(4):795. https://doi.org/10.3390/s19040795
Chicago/Turabian StyleIsmael, Waleed M., Mingsheng Gao, Asma A. Al-Shargabi, and Ammar Zahary. 2019. "An In-Networking Double-Layered Data Reduction for Internet of Things (IoT)" Sensors 19, no. 4: 795. https://doi.org/10.3390/s19040795
APA StyleIsmael, W. M., Gao, M., Al-Shargabi, A. A., & Zahary, A. (2019). An In-Networking Double-Layered Data Reduction for Internet of Things (IoT). Sensors, 19(4), 795. https://doi.org/10.3390/s19040795