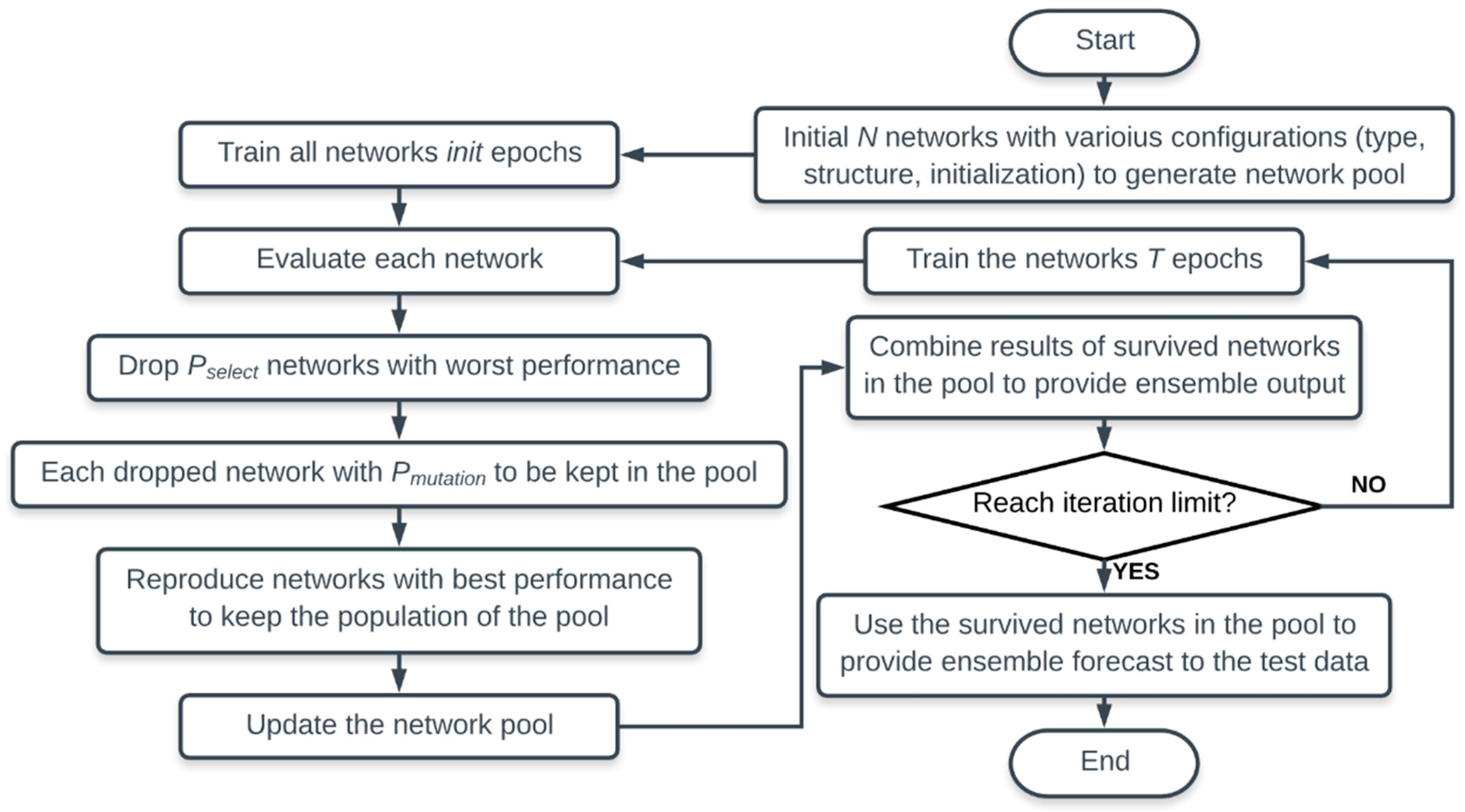
5.1. Optimizing Potential Network Configuration Set Using EENNP
To implement the proposed method, a set of potential network configurations based on a former research should be built, while EENNP itself can be utilized on the building of potential network configuration set for a specific problem as well.
A potential configuration set includes network types, structures, and other configurations (such as activation functions of the neurons) that can form a network fit the problem properly. As discussed in
Section 2. DNN and RNN with LSTM or GRU units are the three candidates on the network types. However, for the specific case regarding household power demand prediction, it is hard to clearly state which network type and structure is undoubted outstanding. Therefore, EENNP can be adopted to select the potential network configuration set.
In order to roughly control the amount of computation for each individual network, the upper limit of the number of weight vectors in an individual is specified. Choosing the number of weight vectors to represent the amount of computation of a network is because both feed-forward and learning process require to operate all the weight vectors in the network. Hence the number of weight vectors is used in the study to roughly count the amount of computation required by a network.
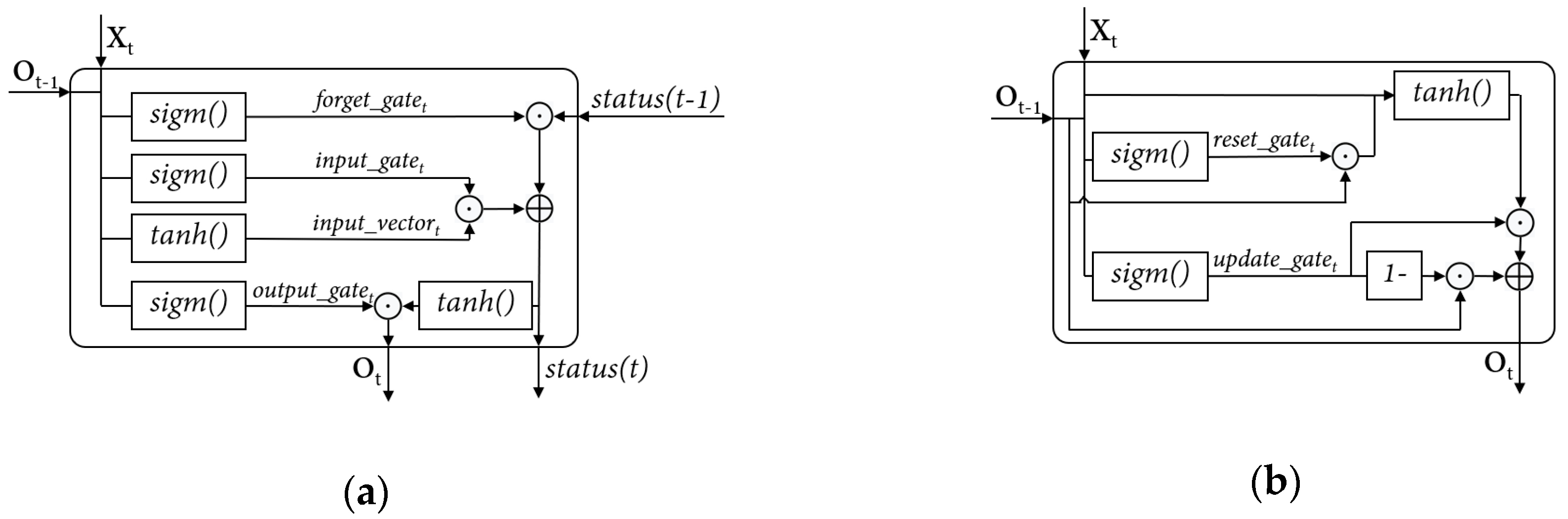
In a DNN, weight vectors exist in each neuron of the network to calculate the weighted summary with the input of the neuron. The number of weight vectors in the network equals the total number of neurons in the network. In an LSTM unit or a GRU, weight vectors emerge together with the activation functions which compute input. An LSTM unit exists 4 weight vectors, and a GRU unit has 3 weight vectors.
Thereupon, based on these relative relationships and considering the time of operating experiments, in this paper, the maximum number of neurons for a DNN individual is set as 384; in an LSTM based RNN, the upper limit of LSTM units can be configured is set as 96; in a GRU base RNN, the number of GRU can be set is equal to or less than 128. All the three types of the networks can be configured with 1 to 10 hidden layers. In RNNs, the activation functions in the units are given by the unit definitions. In a DNN, the activation function in the neurons can be configured from a set of activation functions. In this research, the activation function is configured by layer. Either sigmoid function or hyperbolic tangent function is able to be set as the activation function of all the neurons in a layer.
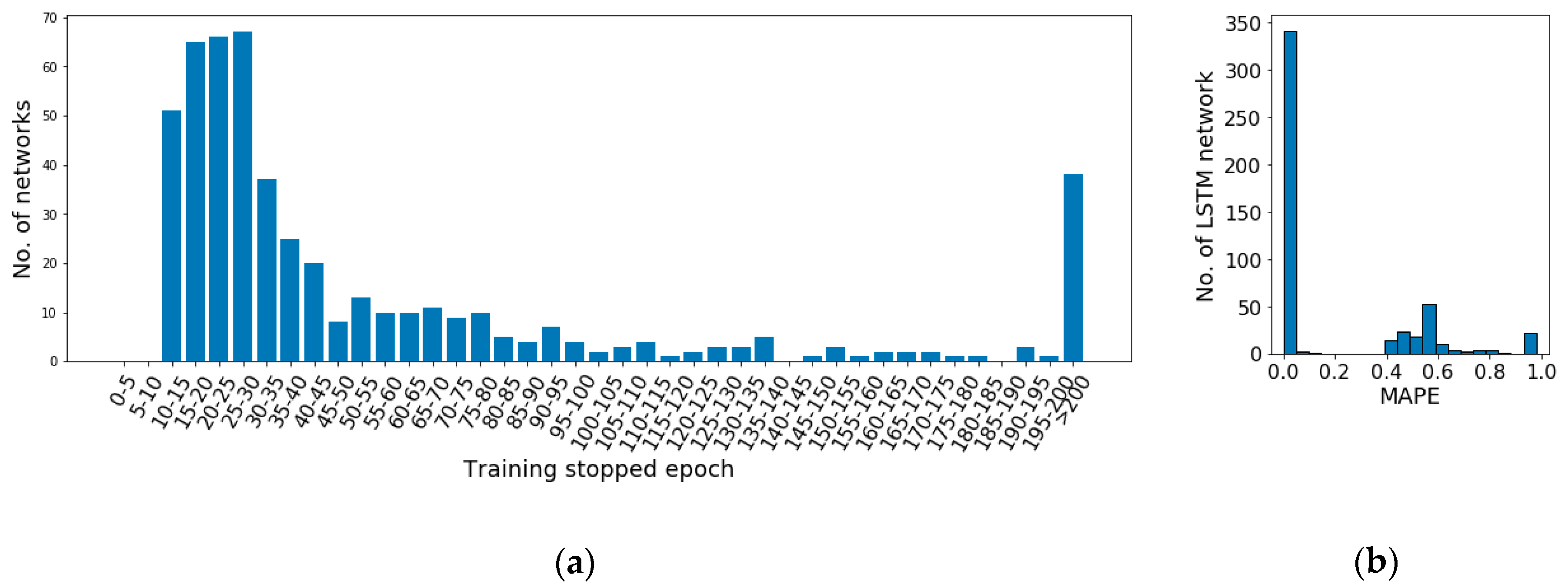
As an example, to illustrate the general performance of the networks in the potential configuration set, 500 random generated networks based on the set are initialized randomly and trained using the same cost function and learning algorithm, which are mean squared error and Adam optimization algorithm respectively. The data of a random household are used as input of the networks. Each network is trained 200 epochs unless early-stopping is triggered. The distribution of training stopping epoch as well as the distribution of performance of the networks are illustrated in
Figure 6.
It can be observed in
Figure 6a that after 10–15 epochs of training, the network stopping epochs widely distribute among the epoch ranges. More than 60% networks stop within 40 epochs. However, the rest of the networks stop gradually along with the training. Even there are 7.6% of the networks which do not trigger early-stopping after 200 epochs of training. Moreover, the performance of the networks on the test set illustrated in
Figure 6b shows that the majority of the networks achieve significantly better performance (MAPE < 0.1) than others. Therefore, an analysis on the potential configuration set is required to remove network configurations normally with weak performance and with too long learning period to improve the model performance. It is required to notice here that network initialization is an important factor on the network performance. It is always possible to achieve a worse random initialization causing a slow or weak learning. The target of this analysis is to remove the commonly emerging weak configurations to improve the overall performance of the pool.
An example of manually optimizing the potential network configuration set is provided as follow:
Through quantitative analysis, for training performance, in the 100 networks with better performance (MAPE < 0.0012), 5% of them are DNNs, LSTM based RNN accounts 49%, GRU based RNN occupies 46%. All the better performing RNNs are with 1–4 layers. It is observed that LSTM and GRU are relatively more suitable for the study on household power demand prediction.
In addition, as shown in
Figure 6b, among all the networks, 31.2% networks achieve MAPE on test set higher than 0.1 (10%). Among them, 86.5% are DNNs, 7.1% are GRU based RNNs, 6.4% are LSTM based RNNs. Within the LSTM and GRU based networks with MAPE higher than 0.1, there are 90.0% and 100% of them with MAPE greater than 0.9 respectively. With a closer observation, all of weak performing RNNs with greater than 0.4 MAPE hold more than 4 layers, while their stopping epochs are with no significant particularity comparing with other networks.
Moreover, from the perspective of stopping epoch, 25.4% of networks with longer than 40 epochs training are DNNs, 46.0% are LSTM based RNNs, 28.5% are GRU based RNNs. It is not able to observe that the training period of DNNs hold a significant advantage comparing with RNNs.
To conclude, LSTM and GRU based RNNs with their outstanding performance are considered to suit the prediction of the experimental study case, household power demand prediction. The preferred network structures achieved by enumerative based quantitative analysis, are RNNs with 1–4 layers, which is set as the optimized potential network configuration set.
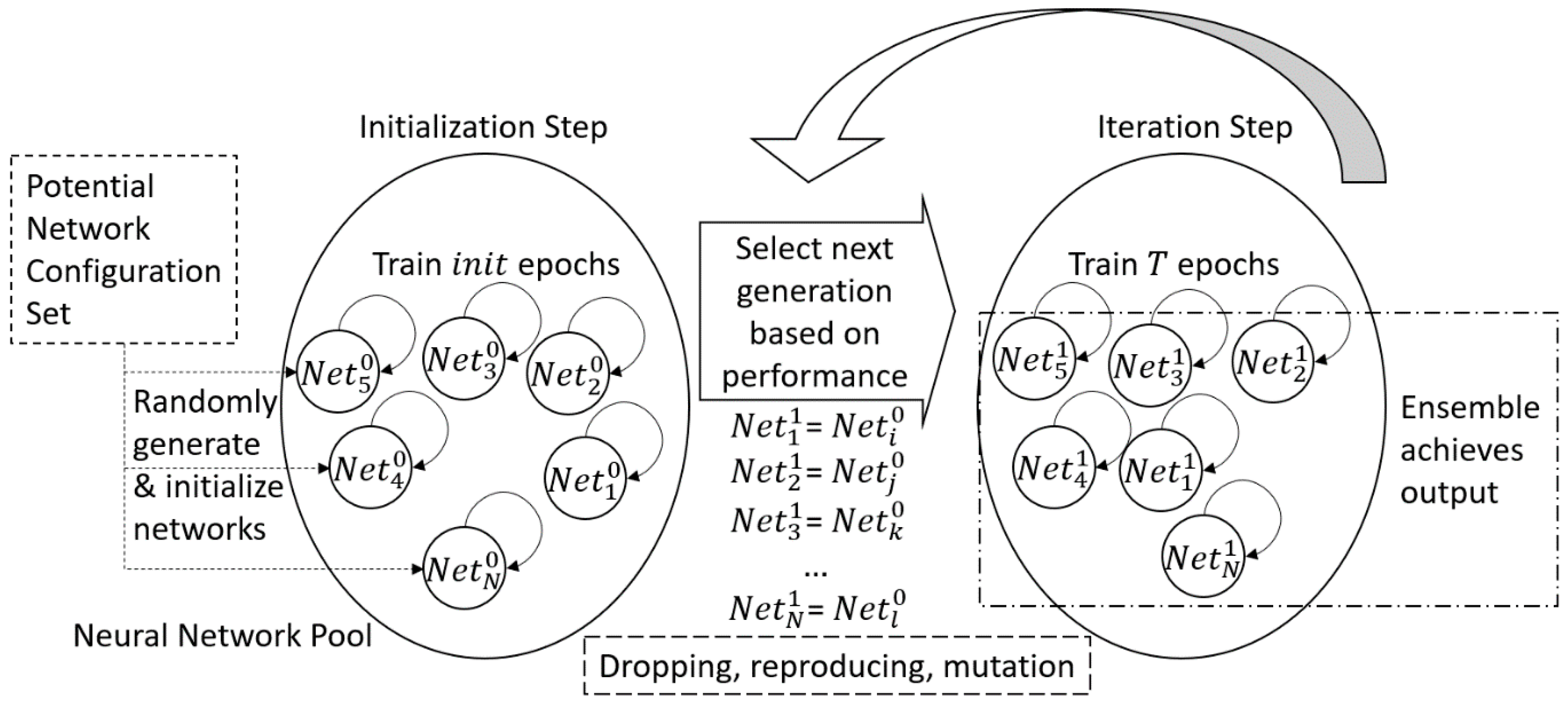
As described above, the entire process of optimizing potential network configuration set could spend a considerable period which has to be done manually. It is hard to be implemented in a HEMS or other distributed scenarios, since it is too costly to provide manual selecting/turning for each distributed located neural network prediction. Therefore, the proposed EENNP method is utilized to realize the optimizing process automatically.
As an operating example suitable for the data we have as well as our experimental equipment, the total number of network individuals in the pool is configured as
. The evolutionary parameters are set as
, and the iteration limit is set as 50 epochs. Comprehensive considering the data we have and the requirement of evolutionary process, 30% of the time series data at beginning is set to the initialization step. Successively, each iteration uses the subsequent 10% data for further process, among them 9% are for training and 1% are for validation and evaluation. The validation and evaluation of the networks use a same dataset. Then, the next 10% of the data are utilized for testing. Within the evolutionary training, 78 among the 100 networks are dropped. The surviving ones with their types and number of layers are illustrated in
Table 2, where 3.1% are DNNs, 37.5% are LSTM based RNNs, 59.4% are GRU based RNNs. Thereinto, the 93.5% of RNNs are with 1–4 layers. Therefore, 1–4 layers RNNs are selected as the optimized potential network configuration set for the training of the other application scenarios.
It can be observed that the selection result achieved by using EENNP is very similar with the manual analysis result, but with much less manual operating time.
5.2. Power Demand Prediction Using EENNP
Adopting the optimized potential network configuration set achieved in the last subsection, the performance of EENNP on specific households is discussed in this subsection. The impact of picking different evolutionary parameters on the model performance is investigated as well. Input data preparation process is mentioned in
Section 4.
As an operating example suitable for the data we have as well as our experimental equipment, the total number of network individuals in the pool is configured as
. The evolutionary parameters are set as
, and the iteration limit is set as 50 epochs. Same training, evaluation and test datasets are determined as in the scenario of optimizing potential network configuration set. The proposed method is utilized to train the available data of a household 2 times. The performance of the two experiments are illustrated as EENNP_1 and EENNP_2 in
Figure 7a by solid lines. The performance of two predictors are introduced here as comparisons. The MAPE of a naïve predictor, which uses the power reading now to forecast the next, is 0.0868. A simple 1-layer, 1-neuron ANN model, which is trained by all the training data 50 epochs and then evaluated by the test dataset, has MAPE = 0.0589. It is observed that the proposed method achieves better performance comparing with naïve or simple predictors.
Two neural networks within the final survival population in the pool are shown in
Figure 7a as Neural Network_1 and Neural Network_2 using dotted lines. It is observed that comparing with neural network individuals within the final survival population, the proposed method usually can achieve a better performance. In addition, comparing with the unexpectable performance achieved by using a network individual to forecast power demand, the results obtained through the proposed ensemble method demonstrate a relatively better stability. The performance of EENNP using the unoptimized potential network configuration set (1–10 layers DNN/RNN) on the same data with the same evolutionary parameters are tested 2 times. The prediction results of the test set are illustrated in
Figure 7b,c as EENNP_3 and EENNP_4 by dash lines. The performance of EENNP_3, EENNP_4 indicates a similar stability as EENNP_1 and EENNP_2. A possible source of the stability could come from the potential network configuration set. The possibility of obtaining a proper prediction within a set of configurations could be relatively steady. With the same evolutionary parameters, the better performing networks are gradually selected out through iteration steps.
Based on this reason, although it could happen that within a population of networks do not exist any with a proper combination of configuration and initialization, the possibility of obtaining a better prediction by using EENNP is significantly higher that using one neural network with a randomly chosen type and structure. Moreover, without manually tuning a network initialized by random numbers, EENNP provides an automatic method to achieve a better prediction.
In addition, the comparison between curves of EENNP_1&2 and EENNP_3&4 (in
Figure 7b,c) illustrates the difference on performance using different potential network configuration sets. By using the optimized configuration set, the pools perform significantly better than the pools using the unoptimized set at the beginning iteration steps. Their performance becomes closer at the last steps. This phenomenon is reasonable since within the bigger but unoptimized set of potential configurations, the possibility of achieving an individual which is generated and initialized properly is lower than within a smaller, optimized set. Therefore, more weak performing individuals are generated in EENNP_3&4, which requires more iteration steps to be removed. With better performing individuals generated in EENNP_1&2, the possibility of achieving even more excelling performing individuals is higher. In addition, with better performing individuals in the pool, it is reasonable to achieve better ensemble results through tradeoff among the survival individuals.
Moreover, it is able to be observed in
Figure 7a,c that the performance of test set could be worse than the learning period. It is because that the test data are always brand-new data rows for the models, which could lead unstable on model performance. The decline of performance could cause by the rising of new behavior pattern in the data, model over-fitting, etc. One reason of new behavior pattern rising could be that the available data are only for 4 months, new power demand patterns maybe arise when a new season comes. About over-fitting, it can happen on any neural network-based models (as shown in
Figure 7a: Neural network_1), even though new evaluation data are kept introduced into the input dataset. Among the tested EENNPs, this phenomenon is not particularly serious.
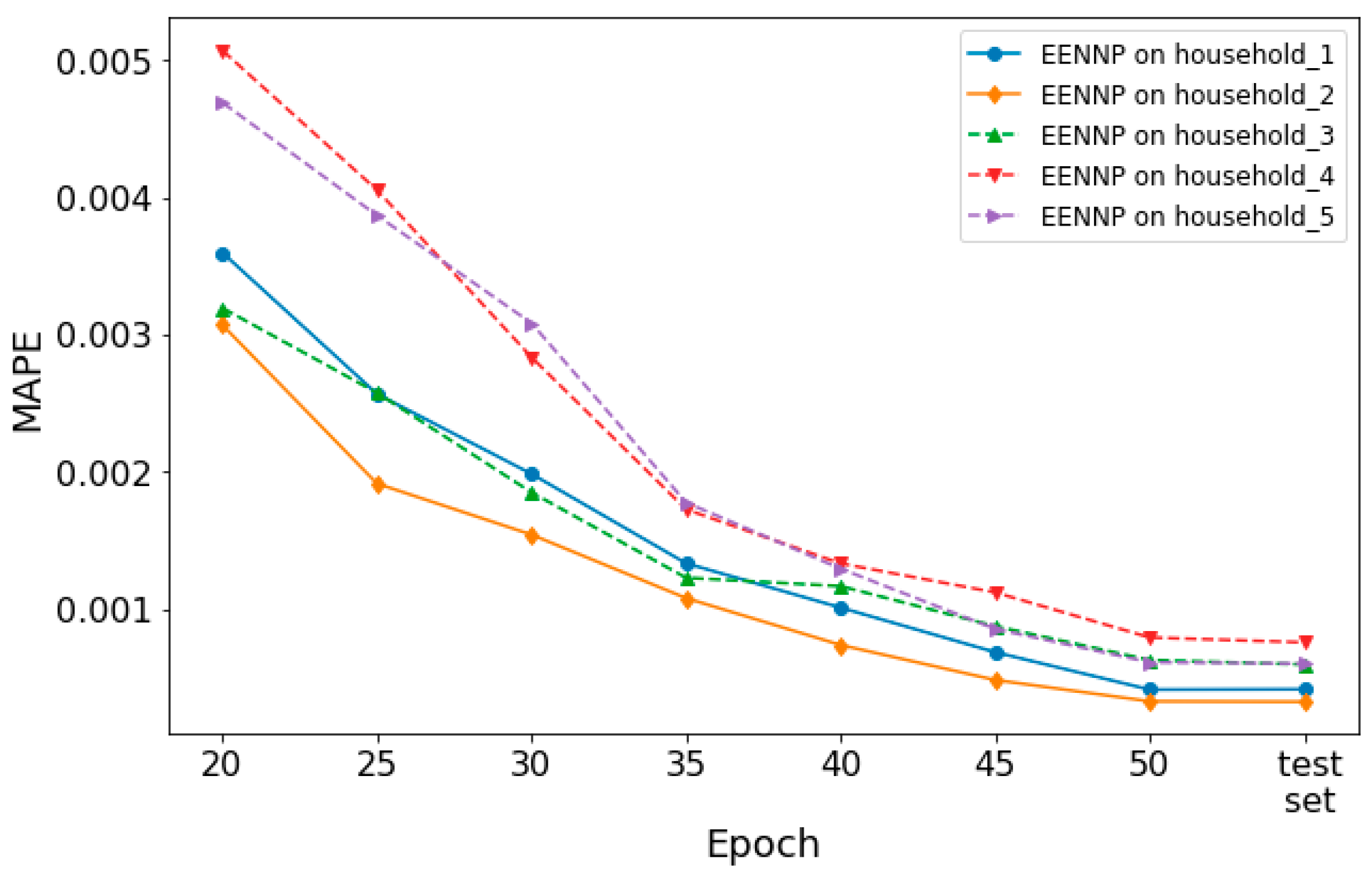
Additionally, the performance of the optimized potential configuration set based EENNPs on different households is tested. In
Figure 8, the performance of EENNP on 5 different households is illustrated. It is observed that the performance curves of the networks are with a similar trend. If we look into the details of their performance, the 5 EENNPs can be divided into two groups. The performance on household 4&5 is weaker than on household 1&2&3 at beginning. Then during the iteration steps, household 4&5 catches up the others. This phenomenon is similar with the comparison between EENNPs using optimized and unoptimized configuration sets in
Figure 7b,c (EENNP_1&2 and EENNP_3&4), but with less performance gaps. Hence it is deduced that the cause of having this phenomenon could be that the households have different patterns of power demand individualities, which can be influenced by the number of persons living in the household, their ages, habits, etc. For instance, the power demand pattern of young couples with two children could be very different with single retired persons. It is possible to have more specific potential network configuration sets for households with different patterns. However, it is not the main focus of this paper. The corresponding research will be conducted in our future studies.
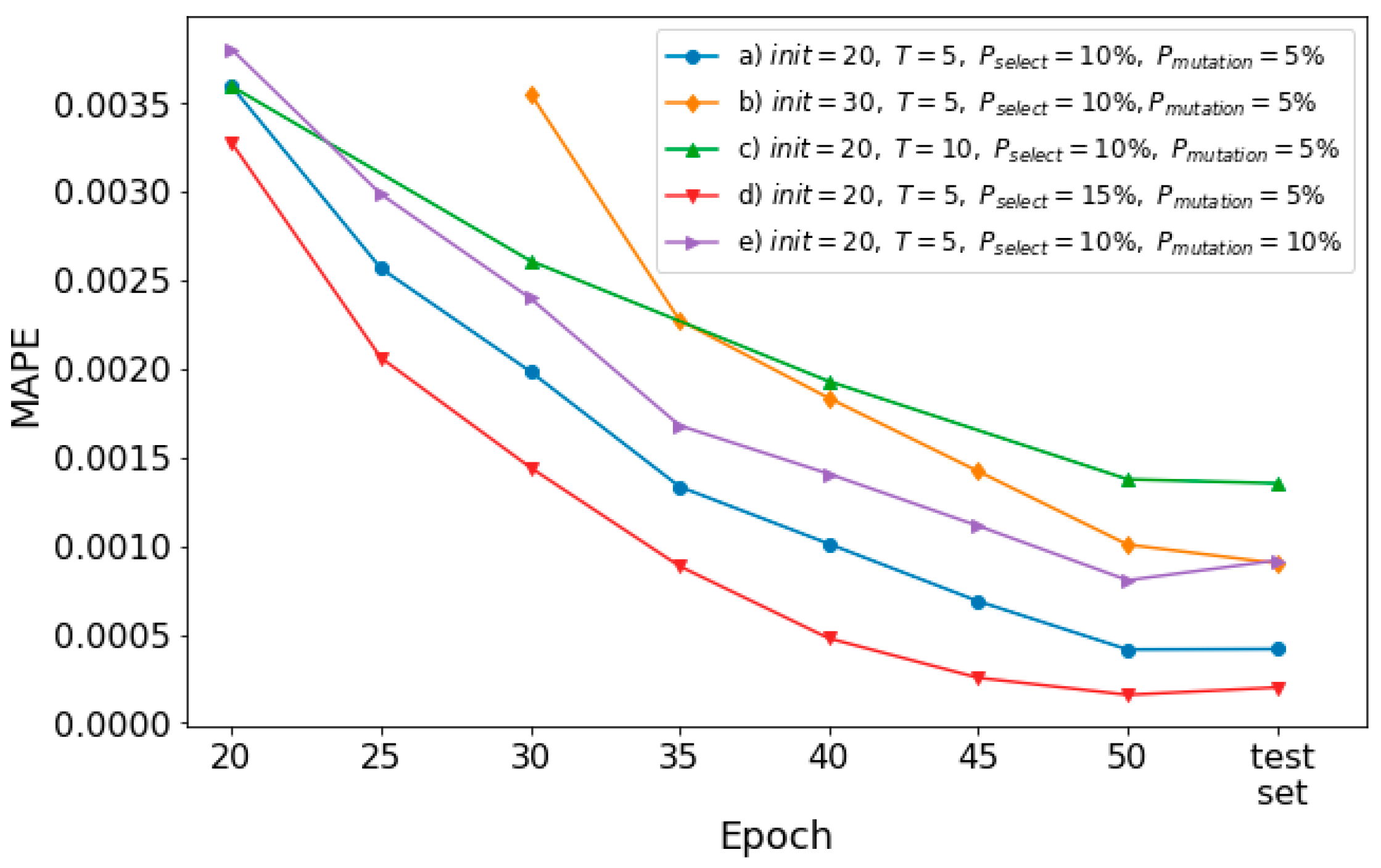
In the following, the impact of evolutionary parameters on the model performance is investigated. Using the optimized configuration set, 5 EENNPs are tested using the data of a household with different evolutionary parameter sets, which are: a)
; b)
; c)
; d)
; e)
. To keep the pace of learning among the experiments with different evolutionary parameter sets, the set b) uses the first 50% of available data for the initialization step. In each iteration step in the experiment on set c), 20% of data are used. The performance of the models is demonstrated in
Figure 9.
Comparison between a) (the blue line with circle markers) and b) (the yellow line with diamond markers) illustrates that with a longer initialization step, the model performance is getting weak. It is because a) obtains 2 more iteration steps than b), within which 10 weak performing individuals are dropped from the pool and 10 better performing individuals are reproduced (if no mutation happens). It could cause a difference on model final performance. In addition, with 10 more epochs of initialization without dropping, the amount of computation utilized by b) is more than a), which leads b) as a worse evolutionary parameter set. However, depending on different research questions, the suitable could be various. A very less could also cause that potentially better performing individuals are dropped at early steps.
If we compare a) and c) (the green line with triangle_up markers), it is observed that with more epochs of training on each iteration step, the performance of the model declines. It is reasonable since a) achieves 2 more rounds of selections with the same amount of computation. However, similar as for , a too short training time could also not good for the individuals to learn the environment.
The impact of increasing dropping and reproducing rate is demonstrated by a) and d) (the red line with triangle_down markers) in
Figure 9. With a greater rate of selection, a better model performance is achieved. Based on our quantitative analysis illustrated in
Figure 6a, where the majority of networks achieve their first early-stopping before epoch-40. It means the individuals with proper combinations of configuration and initialization are most likely able to show out their fitness before epoch-40. Therefore, the iteration steps could easily select these individuals out, to lead a better performing model than using d). However, for situations that the potential better performing ones cannot show out their fitness at beginning, a greater
could lead a reduction on model performance. Moreover, a greater
may also lead the diversity of the pool decreasing. If the number of individuals of one combination of configuration and initialization is too large in the entire population, it could also weaken the stability of the prediction performance. The purple line with triangle_right markers illustrates the model performance using e). Comparing e) and a), it is observed that with a higher
, the model performance decreases. It is because that a higher
could cause weak performing individuals are remained in the pool through the iteration steps. However, for situations that potential proper networks do not clearly emerge at early steps, a certain rate of mutation could be useful to keep the potential networks within the pools.
5.3. Missing Data Refilling using EENNP
Data correctness is the basis of a good prediction. In order to handle the missing data in the achieved raw datasets in a more reliable way to imitate the power demand during the missing period, the use of EENNP is discussed in this subsection to generate refilling rows for the missing power demands.
A potential use case of the missing data refilling is at the cloud server part. Some real-time analyses could be operating on the cloud which require the real-time power readings as an input. Data missing in this situation could influence the real-time analyses. At the same time, as a rare happening event, data missing is not necessary for the cloud server to have an always-on refilling method to handle. Therefore, a lightweight mechanism is required to be triggered whenever missing data happens to generate a relatively reliable substitute for the missing power reading.
Based on the requirements discussed above, the refilling method we used in data preprocessing (
Section 4.2) is no longer available, since we cannot obtain the required information on real-time. For instance, when the next data reading will be received by the cloud server. Therefore, a missing data refilling method using EENNP method is developed here: A pool with well-performing individuals for a specific household is achieved beforehand by using EENNP method, as described in
Section 5.2. Then the pool is frozen there until a data missing is detected. A total of 20 min of historical data before the missing point (about 120 rows) are used to reheat the pool
epochs before a forecast of the missing data is given.
The household utilized to train the EENNP illustrated in
Figure 7 is employed to build a test. The pool is initialized and evolutionarily trained as described in
Section 5.2. For the testing set, 5 portions of raw data without duplicate and missing rows are randomly picked from the test period (last 10% of available data) to organize the missing rows as well as the corresponding reheating sets, as described in
Section 4.3. EENNP_1 illustrated in
Figure 7 with
is utilized to execute the experiments. The test results show that with reheating, the performance of missing data refilling is similar with prediction. The average MAPE of the 5 tests is 0.0005, which is significantly better than the naive predictor, which is another missing data refilling method capable for (near) real-time treatment.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}