Intelligent Sensor-Cloud in Fog Computer: A Novel Hierarchical Data Job Scheduling Strategy



1
School of Computer Science and Information Engineering, Luoyang Institute of Science and Technology, Luoyang 471023, China
2
Key Laboratory of Intelligent IoT, Luoyang Institute of Science and Technology, Luoyang 471023, China
*
Author to whom correspondence should be addressed.
Sensors 2019, 19(23), 5083; https://doi.org/10.3390/s19235083
Submission received: 6 November 2019
/
Revised: 18 November 2019
/
Accepted: 19 November 2019
/
Published: 21 November 2019
(This article belongs to the Collection Fog/Edge Computing based Smart Sensing System)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:In the Fog Computer (FC), the process of data is prone to problems such as low data similarity and poor data tolerance. This paper proposes a hierarchical data job scheduling strategy Based on Intelligent Sensor-Cloud in Fog Computer (HDJS). HDJS dynamically adjusts the priority of the job to avoid job starvation and maximize the use of resources, uses the key frame to the resource occupied information, distributes the frame sequence to the unit, and then combines the intra frame distribution strategy to balance the load between the nodes. The experimental results show our proposed strategy may be possible to avoid the operation of hunger and resource fragmentation problems, make full use of the advantages of multi-core and multi-thread, improve system resource utilization, and shorten the execution time and response time.
1. Introduction
The job-scheduling of the traditional wireless sensor network usually emphasizes a certain aspect but balances the property of the system from the whole view [1,2,3]. In addition to this, the division strategy of average node job makes the jobs between the nodes imbalanced, which leads to the problem that the nodes which are complicated in the task are put off the whole time of the job. Facing the increase in wireless sensor network data combined with the features of the job, developing a high speed job whose scheduling cost is low and that can also satisfy the users’ QoS needs is the key to improve the concurrent rate and to reduce the waiting time of user jobs. The distribution strategy of the average task is meaningful for reducing the influence of the finishing time of the nodes, wooden pail effect, and for improving the data computing ability [4,5,6]. Because the job scheduling and division strategy are meaningful for the improvement of the system property, scholars from all over the world currently study this area widely in relation to Wireless Sensor Networks (WSNs).
In WSNs, the most usual scheduling strategy, First Come First Service (FCFS), is based on the order of the jobs to schedule or to divide at the source [7]. The serious FCFS scheduling mechanism guarantees the fairness of the users but sacrifices the throughput efficiency and the source using rate of the system, which easily presents the problem of node free and node congestion [8,9,10]. The strategy of FirstFit based on the order that the jobs get into the queue of the jobs and run the first job whose source first satisfies others. Although the strategy can improve the throughput efficiency of the system dramatically, but the job whose source requirement is low can put off the job whose source requirement is high, which makes it not be solved for a long period [11]. The aspect of the fairness is limited, and it can also prolong the average waiting time of the system. Although the Job Scheduling Level Method (JSLM) has high throughput efficiency, it can prolong the time of calculating complicated jobs and also cannot satisfy fairness. BestFit strategy runs the job whose source is the highest and which can satisfy its requirement. At the same time, it can also lead to the phenomenon of job starvation [12,13].
In the WSNs based on sensor-cloud, with the rapid development of the high-performance computing and digital multimedia, the data render job scheduling becomes an important means to solve the single computing node [14,15]. The application has both computational and data intensive hybrid features [16]. At the same time, the emergence of big data technology and cloud computing technology further enhances the WSNs ability to render the extension.
The extension of WSNs computing scale has a high processing capacity, but if there is no system optimization strategy, the system cannot give full play to the computing power [17,18,19]. How to optimize the task scheduling strategy, assign the task to the nodes according to the computation, and improve the resource utilization and system performance is an important challenge for performance optimization research [20,21,22,23]. In addition, the expansion of the scale of the WSNs also means the increase of the energy consumption of the system [24,25,26]. How to design a reasonable scheduling strategy to reduce the energy cost of the system is also a very challenging problem in the WSNs.
2. Related Works
In the WSNs, when optimizing energy consumption, the property also plays an important role as a target. Aiming at the question which is about the balance of energy consumption and the property, there are many researchers currently working on the topic. He et al. [27] reduced the consumption of energy through minimizing the number of activated physical devices. Promoting a resource management framework, which is oriented to the property and the energy, Liu et al. [28] achieved the balance of property and energy by improving the knowledge of the theory. Aiming at the issue about the decreasing of the user service quality, which was caused by excessive integration of the resource, Wang et al. [29] solve the average optimization between the energy and the property by using the dynamic migration of the virtual machine. According to the platform of the SaaS, Zhao et al. [30] proposed a sort of resource scheduling scheme to balance the energy consumption and the property. The technology of Job Scheduling Optimization Strategy (JSOS) appears as a new technology in the current low energy consumption design of the computer system, which leads to many new challenges and chances for the energy-saving scheduling of the progress. Using the feature of JSOS technology to dispatch the task can make the high-performance cluster decrease the cost of energy the most in the whole system, considering the task performance. Sun et al. [31] proposed Heterogeneity-aware Loads Balancing (HLB) technology to balance distribution of the different tasks, which decreases the energy consumption overall, and to set the constraint of the temperature. Based on the Task Distribution Layer Method (TDLM) technology, Wang et al. [32] promoted a sort of heuristic scheduling algorithm to reduce the executive energy consumption, which was produced by the parallel task in the cluster environment. On the condition that this kind of algorithm does not influence the time of the whole tasks, the algorithm reduces the consumption of the energy by reducing the node voltage of the task. Liu [33] also did the same research to put forward a kind of task scheduling algorithm based on the energy-aware in the integrated environment, which reduces the power consumption through controlling the proper level of the voltage. Aiming to the JSLM proposed a sort of task scheduling strategy of the energy-aware, which adjusts the needed voltage dynamically, according to dividing the length of the subtask and minimizing the energy consumption under the condition of satisfying the user’s deadline. Wu et al. [34] promoted a sort of the energy saving system of the energy-aware, which judges whether the users are in the situation of activation or not by setting the dynamic reconfiguration models. Through turning on or turning off the application selectively to achieve the purpose of energy saving, this kind of system can acquire a good energy use rate, and at the same time, it can also provide a different energy scheduling strategy. Aiming to solve the task scheduling problem in the heterogeneous computing environment, Liu et al. [35] put forward an Energy-Conscious Scheduling (ECS) algorithm, which balances the task property and energy consumption by minimizing the value of Relative Superiority (RS) by making the RS of the task property and the cost of the energy consumption the optimization goal. On the basis of the optimization goal of the RS value, Sun et al. [36] combined the algorithm of the genes and proposed a meta-heuristic scheduling algorithm to optimize the property and the energy consumption of the tasks. Wang et al. [37] makes the energy consumption the constraint condition and makes the properties of the concurrent tasks the optimizing goals. Sun et al. [38] put forward a scheduling framework of the heterogeneous energy awareness resource, which makes the heat balance get rid of the ‘heat point’ by adjusting the voltage of the services dynamically. Li et al. [39] put forward energy awareness task fusion technology to optimize the energy consumption of the cluster, which reduces the energy consumption of the system through maximizing the method of using resources. Liu et al. [40] achieves the goal of optimizing the energy consumption by optimizing the free energy consumption and the running energy consumption effectively in the process of running the task. According to the parallel task scheduling, Shao et al. [41] put forward an optimizing algorithm, which concerns the running property, the cost, the reliability, even the energy consumption, and so on. However, this algorithm needs much exploration of the features of the task and even the features of the RS, and in the aspect of optimizing the energy, it also has much knowledge to explore.
In order to guarantee the fairness of the users’ work, the promoted work scheduling level method sets the dynamic priority for the work to guarantee the work priority scheduling method whose priority is high. When the source is limited, in the situation of not delaying the running of the original high priority work, the work priority of adjusting high priority dynamically will dispatch the work whose priority is low in advance, and at the same time, it will save resources for the work whose original priority is high [42]. Once the work requirement whose source satisfies the high level priority stopped the work whose priority is low and restarted to patch the work whose priority is high, the mission will send the frame sequence to the unit by way of making the unit the source particle size basic unit based on scene geometry, to choose the key frame. This uses the feedback of the source occupying information of the key frame and the related feature between the frames, combining the distributing strategy among the frames. The innovative points are as follows:
- (1)
- Setting the dynamic priority to guarantee the scheduling fairness.
- (2)
- Allowing the work whose priority is low and whose source requirement is small to run in advance to guarantee the adequate usage of the source, which also preserves the source for the work whose priority is high or whose requirement of source is big, and which also prevents situations of work starvation and reduction of source fragments.
- (3)
- The mission will send the frame sequence to the unit by way of making the unit the source particle size basic unit, based on scene geometry to choose the key frame, using the feedback of the source occupying information of the key frame and the related feature of between the frames. It combines the distributing strategy among the frames to render the work load between the nodes in balance.
3. Job Scheduling Level Method
3.1. Basic Concept
In the WSNs, the job scheduling layer mainly deals with the task submitted by the user. According to the needs of the users, the job is scheduled to the corresponding resource [43,44,45]. In order to better describe the method of job scheduling layer, the following definitions are introduced.
Definition 1.
In the queue waiting for the scheduling job, the fill-in job is the job that, at the back of the queue, is scheduled first.
Definition 2.
The unit is a collection of CPU cores in the node.
Definition 3.
The use rate shows the extent to which the sources in the system are busy. In general, we use the percentage of using source. However, it uses the percentage of the CPU usage to show the source’s use rate in the paper.
The use rate of the system includes the real-time source use rate and the average source use rate. We assume that the real-time source use rate is Pr, and the average source use rate is Pr_T in the time period T. So that the real-time source use rate is the following:
Pr = Nb/N
In the Formula, Nb indicates the amount of the CPU that is working; N shows the whole number of the CPU.
From the time period of Ta to Tb, the average source use rate is the following:
Dividing this period of time into m areas, the time in every area is Δt, and the result is as follows:
By using the conception of infinite segmentation, when n→∞, Δt→0, the average source rate can be shown as:
So that the average real-time source use rate in this paper states the source use rate in a certain time approximately.
Assuming a certain work Ji whose original time of moment is TJI(i) is the moment that the work Ji was submitted to the system by the users. Assuming that the start moment of the work is TJS(i, k), deadline moment is TJF(i, k), k is the number of the CPU that is needed. Therefore, the time of the work Ji which needs k CPU is:
Definition 4.
The whole time of the work indicates the whole finishing time of all the work in the work queue. It can also see it as the gap between the latest moment and the earliest moment.
Therefore, the whole finishing time TAJF(n) of the n works in the work queue is:
Definition 5.
The response time of the work is the gap of the time between the original and the first time it starts, and it is also the waiting time of the work.
Definition 6.
The turnover time of the work is the time gap between the start moment and the over moment. It not only includes the running time but the response time as well.
Assuming that TJres(i,k) shows the response time of k CPU source works Ji, and TJave_res(n) shows the average response time of n works, we can conclude that:
Assuming that TJturn(i,k) is the finishing time of k CPU source work Ji, and TJave_turn(n) is the average turnover time of n works, we can conclude that:
The analysis of the characteristics of operation is a sequence of frames, a group of mutual dependence and parallel split, in the WSNs [46]. Therefore, this method can be adjusted by dynamic priority and preemption mechanism to ensure fairness. The idea is to ensure maximizing the utilization of resources so that the free resources can be low priority and resources need little homework ahead of time, at the same time that resources are set aside for high priority and resource demanding work, in the WSNs.
3.2. Constraint Conditions for Data Jobs
Due to it being a data intensive application in terms of the memory requirements of the distribution of a wide range, there are dozens of MB of memory occupied by a simple scene, and it also has more than a dozen GB of memory of complex scenes [47,48]. Therefore, it is necessary to take account of the memory footprint in relation to the unit’s size. If you run a unit through all nodes of the process of the physical memory, the operating system will use the swap partition to ensure the normal operation of the process; so frequently, the disk data exchange will bring an extra-heavy overhead, and it will greatly extend the time. Therefore, the unit partition strategy needs to satisfy the following constraints:
- (1)
- The memory of all the processes running on the unit does not exceed the physical memory capacity of the node,in which mi is the memory for each process, M is the machine memory capacity, p is the number of processes running simultaneously, and σ is the memory of the system.In addition, it is also a computationally intensive application processor; task switching overhead will usually offset the boost processor sharing performance and even lead to performance decline. Therefore, the unit partition strategy should satisfy the following constraints:
- (2)
- The sum of the number of threads that run on the unit cannot exceed the number of processors in the node,in which ti is the number of threads in the i process, C is the number of processor cores for the node, and p is the number of simultaneous processes.
According to the above two constraints, the switching cost and the lack of memory can be eliminated. Therefore, to maximize the use of resources, the goal of the division of the unit needs to meet the above two constraints to start the concurrent process to reduce the time as much as possible. Assume that the optimal number of units in each node is Co, the number of units corresponding to Nu, then the optimal process number Po and the number of threads allocated by each process can be given as
According to the above analysis, it can be seen that the unit partition strategy first selects the corresponding resource for the user according to the parameters of the task submitted by the user. Here the use of CPU as a resource for the number of units and then the method of scene geometry selection based on key frames and key frames from the pre-rendered are used to estimate resource usage according to the resource of that unit optimal kernel number, and each CPU is assigned a number of processes, and finally, assigned tasks according to a certain strategy in the WSNs.
After submitting the task, the schedule that every node finishes all tasks is:
Giving the example of the node i, the paper describes the energy consumption of the single node. Assuming that Ti is the whole time of the node i, it is as follows:
Therefore, the finishing time Tmax of the whole nodes are the latest nodes. The accurate calculating process is as follows:
In order to illustrate the energy consumption Ei of the node, which is number i, Equation (17) illustrates the process of the calculation.
In the Equation (17), Wi is the whole energy consumption of the node i which finishes the task list L:{lir,lir+1,…,l(i+1)r-1}. This part of energy consumption is decided by the power Pi of the node i and the running time of the task. Ii shows the energy consumption of the node i in this scheduling, which is in the free situation; this part of the energy consumption is decided by the free power pi of the node i and the free waiting time. This paper assumes that if and only if the nodes finish the whole task in the queue, they can be in the situation which is free. The Equations (18) and (19) describe two kinds of counting process of the energy consumption which are above.
Then, if we put the Equations (8) and (9) into (10), then we can conclude the energy consumption of the number i node:
According to the energy consumption model of the node i, in the nodes list (R1,R2,…,Rn), the Equation (21) describes the counting process of the whole nodes’ energy consumption.
In the WSNs, the whole energy consumption includes the energy consumption of all tasks and time of node and even the free waiting energy consumption. If Equation (15) is put into Equation (20), eventually we can get the energy consumption computing model.
The accurate estimation of resource occupancy is the premise of the efficient implementation of the multi-process mode, and how to divide the granularity of computing resources based on the feedback resource information is the key to improve the performance of multi-process [49,50]. The traditional way of dividing the resources of the unit is to improve the performance of the node; dividing it into coarse granularity and multi-thread is not obvious, therefore, this paper puts forward the concept of "unit" as the resource partition unit.
Multi-frame sequences are usually assigned to this set for multi thread, and the unit contains the number of cores that show how many threads are rendered. In this paper, we assume that a kernel corresponds to a thread, and each sub job (4 frames) is rendered in the order of the number of frames. Therefore, for nodes with multi-core processors, according to the resource information feedback, the number of nuclear units is the optimal unit allocation by starting a process to render sequence frame multi-thread allocation and resource utilization and by maximizing the increased efficiency.
In order to eliminate the influence of the accumulation of inter frame differences on the load balance among the nodes, the allocation strategy uses the correlation between the frame and the frame to allocate the frame to the unit. In the traditional way, the continuous frames are assigned to the nodes sequentially, and the correlation between frames can only guarantee the difference between adjacent frames. However, if both ends of the sequence, frame node 1 and node R, are assigned to the total operation in the sequence frame, this will bring a larger load imbalance; especially in the abrupt shot explosion, some background conversion, the unbalanced phenomenon is more serious. Therefore, in the unit distribution frame, according to the frame number, staggered modes are allocated for each node frame number of successive frames will be assigned to the unit adjacent to the purpose is to use inter frame correlation to minimize the load of each unit. Therefore, the unit r is assigned to the frame sequence set Sr can be given as
The frame allocation strategy based on unit belongs to a static strategy, while dynamic strategy needs to start the new process and reload the additional cost of the scene file. The implementation of this strategy is relatively simple; there is no preprocessing or task migration overhead.
3.3. Data Job Scheduling
The user submits 5 jobs to the system. According to the job scheduling strategy proposed in this paper, the job scheduling process is shown in Figure 1.
Figure 1a shows the initial state of the scheduling, the current system has idle resources, the user submitted to the 5 jobs, J1–J5, waiting for job management system scheduling. J1, J3, and J5 have the highest priority, priority scheduling; the current system has 15 idle states of CPU, to meet the needs of the resources of these three operations. As a result, T0, J1, J3, and J5 are assigned resources to perform. Since the current system does not have an idle resource, it cannot meet the resource requirements of job J2 and J4, so job J2 and J4 remain in the waiting queue.
Figure 1b represents that time T1 is the scheduling state. At this time, Job J5 has finished the rendering, and there are 4 idle CPUs. According to the order of priority, J2 should be scheduled and allocated resources. However, J2 requires 8 CPUS, which cannot be met by the system. For the job J4 with lower priority, its resource requirement can be met by the system. Therefore, in order to maximize the throughput and the resource efficiency, the job scheduling strategy schedules J4 in advance. Henceforth, the job J4 with lower priority is executed before J2 with higher priority.
Figure 1c represents that time T2 is the scheduling state. At this time, the data fusion for J3 is finished, and the number of idle CPUs is 5 for the system. Therefore, the resource requirement of J2 still fails to be satisfied. However, the number of appointed CPUs is 4, and the total number of idle CPUs and appointed CPUs is 9, which could satisfy the requirement of J2. Meanwhile, the progress of J4 is smaller than 90%. Therefore, J4 is paused, and the CPUs occupied by J4 are now changed into idle state. Then, 8 idle CPUs are allocated to J2, and J4 is now in the queue waiting to be scheduled. At this time, since all the jobs in the queue require more than 1 CPU, the system will generate 1 idle CPU.
Figure 1d represents that time T3 is the scheduling state. At this time, the data fusion task for J2 is finished, and there are 9 idle CPUs in the system, which could satisfy the requirement of J4. Then, resources are allocated to J4 for the unfinished jobs. At this time, the scheduling queue is empty. The sensor-cloud computation system waits for users to submit jobs.
In order to compare the scheduling process and the problems of the strategy, the scheduling results of FCFS and FirstFit job scheduling policies for the 5 jobs are shown in Figure 2. FCFS scheduling strategy of operating is in strict accordance with the arrival order (priority) scheduling; the resources are idle, and due to the blocking phenomenon in the job scheduling process, job completion time is longer, and the system resource utilization rate is not high. The scheduling results are shown in Figure 2a. FirstFit job scheduling policy can also generate resource idling and also cannot guarantee fairness; scheduling results are shown in Figure 2b.
When the job scheduling layer assigns the resource to the task in the WSNs, the task distribution layer decomposes the job into a task and distributes it evenly to the resource. The task distribution layer method is divided into 3 steps:
- (1)
- First of all, it is based on the key frame before rendering the granularity of the resources.
- (2)
- Secondly, the correlation based on frame will render the frame sequence assigned to the unit.
- (3)
- Finally, combined with intra partition strategy, it will not be divisible by the number of the remaining frames unit assigned to the unit.
Aiming at the problems such as low data similarity and poor data tolerance, this paper proposes a hierarchical job scheduling strategy (HDJS). The implementation of the proposed HDJS is as follows (Algorithm 1):
| Algorithm 1 Hierarchical Job Scheduling Strategy |
| Input: Wait for scheduling job queue |
| Output: Job scheduling sequence |
| 1. Set flag = 0; |
| 2. Sort jobs in SJobs by priority from high to low; |
| 3. for each Ji in SJobs do |
| 4. if NumJi <= freeNum then |
| 5. Allocate the free CPUs to Ji; |
| 6. Update the state of CPUs and Rjobs; |
| 7 if flag ==1 then |
| 8. Set Ji as fill-in job and corresponding CPUs as reservation CPUs; |
| 9. Update order N; |
| 10. endif |
| 11. break |
| 12. else |
| 13. if NumJi > freeN && NumJi <= (freeN + orderN) then |
| 14. Select jobs paused in IJobs and put them to bJobs; |
| 15. Select CPUs corresponding to jobs in bJobs and put them to bCs; |
| 16. Update bCsN; |
| 17. if bCs ! = NULL then |
| 19. Change the state of CPUs to free and CPUs as no reservation CPUs; |
| 20. Update freeN, orderN; |
| 21. endif |
| 22. endif |
| 22. if NumJi <= freeN then |
| 23. Allocate the free CPUs to Ji and update the state of CPUs; |
| 24. Update busyN; |
| 25. if flag == 1 then |
| 26. Set Ji as fill-in job and corresponding CPUs as reservation CPUs; |
| 27. Update orderN; |
| 28. |
| 29. endif |
| 30. endif |
| 33. flag = 1; |
| 34. endfor |
The Algorithm 1 is used to judge whether the current job initialization is a sign of queue operations (flag) algorithm simulation having completed the process of scheduling a period in the WSNs. If the current idle state of the CPU resource is able to meet the resource requirements of the job Ji, the idle state CPU is assigned to the job Ji, and then the resource state and the busy state CPU number are updated. If the next one and the reservation status of homework then set the Ji queue operations, and the corresponding CPU is set to CPU resources reservation number at the same time, update the appointment booking status CPU. The time complexity of the algorithm is O(nlogn), and the time is mainly consumed in the job priority ranking of the waiting list. In this paper, we use a stable merge sort, and the space complexity is O(n).
If frames cannot be divisible by the number of nodes, there are some nodes in idle state when there is a residual frame; resources cannot be fully utilized, and finishing time will be a prolonged operation. Fine grained intra frame distribution is helpful to balance the load of each node, but the efficiency is not high. As a result, an intra-frame distribution strategy is used to render a smaller residual frame, to avoid the idle resources, to further balance the load between nodes, and to reduce the completion time of the job.
By assigning the fine-grained task to the unit, the number of blocks per frame N-tile can be given as:
4. Experimental Results and Analysis
In order to evaluate the proposed scheduling strategy performance in the WSNs, this paper builds WSNs based on B/S architecture using local server. In the simulation of the WSNs, the management node undertakes the management job and resource management functions. The system deployed on the management node is the Tomcat version 6.02; the version of the database is mysql-5.32. In addition, the 200 nodes responsible for the hardware configuration of each node are the same, belonging to the isomorphic WSNs.
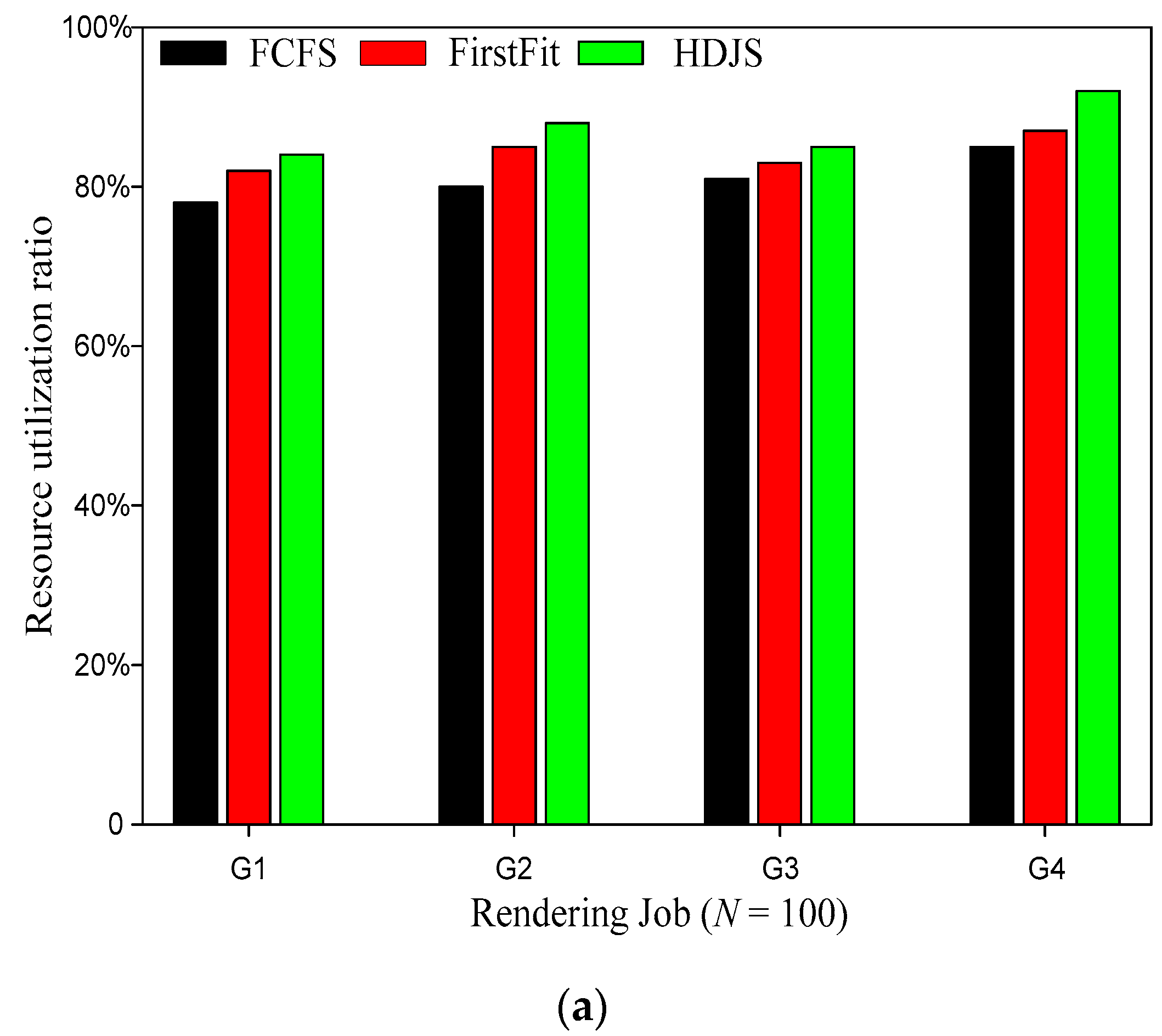
First, Systems test the resource utilization, and the priority of each task, and the proportion of resource requirements is different. Figure 3 shows the comparison of resource utilization ratio for different strategy. It is clearly evident from Figure 3 that our proposed HDJS has better performance and higher resource utilization. When the number of jobs is 100, the resource utilization ratio of HDJS is increased by an average of 8.8% compared with FCFS, and the best case is increased by 10.28%. When the number of jobs is 200, the resource utilization ratio of HDJS is increased by an average of 8.51% compared with FCFS, and the best case is increased by 10.02%. With the increase of job resources and high priority, the HDJS can obtain higher resource utilization ratio in the WSNs.
Figure 4 shows the comparison of average completion times for different strategies. As shown in Figure 4, when the number of jobs is 100, the average execution time of HDJS is reduced compared with FCFS average execution time. When the amount of jobs is 200, the average execution time of HDJS is reduced compared with FCFS average execution time. Although FirstFit is based on the principle of matching the system resources, the task can be scheduled as soon as possible so as to avoid the resource congestion caused by the lack of system resources. However, in the process of matching resources, FirstFit will produce the phenomenon of idle resources, which cannot make full use of the resources. HDJS can achieve the operations and does not make the resources idle in idle waiting state, while the low priority and high degree of idle resources work to fill in this part for resources, not only to improve their utilization rate but also to make sure the operations can complete part of the schedule. In this way, each job has the opportunity to run ahead of time not because of low priority and long wait for the scheduling state. Of course, this part of the low priority and early scheduling of the work in the system resources to meet the needs of high priority resources will automatically release the resources, also to meet the principle of fairness. This kind of advance plug in execution can reduce the average turnaround time in the WSNs.
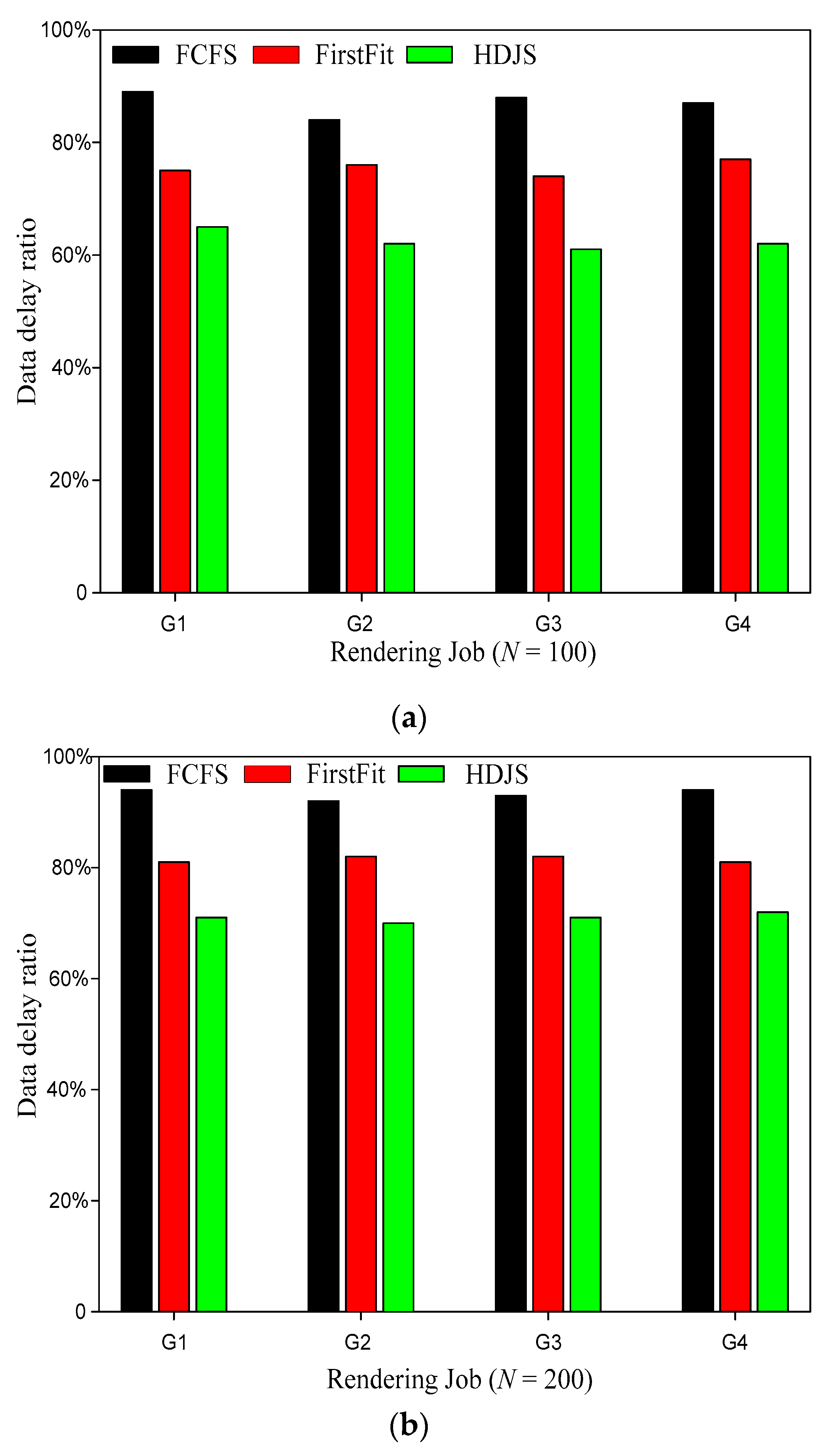
Figure 5 shows the comparison of data delay ration for a different strategy. It is clearly evident from Figure 5 that our proposed HDJS is superior to the other two algorithms in data delay ration. The user experience is not only the number of hours of work but also includes the fairness factor. Usually, the user’s needs are not only related to the resources but also to the fairness of their request. For users, fairness is a very important factor. Users usually, from their own point of view, do not want to submit their own work whose execution has been delayed, which is the key point to render the user needs to deal with WSNs. The total completion time is one of the key indicators to evaluate the performance of the system. Compared with the traditional job scheduling strategies FCFS and FirstFit, HDJS can achieve higher performance and better user experience in WSNs management in the WSNs. The traditional FCFS job scheduling strategy can guarantee absolute fairness, which is strictly based on the order of the user submitted jobs. However, the algorithm does not consider the improvement of system performance. FirstFit scheduling strategy with respect to the FCFS strategy readjusts the scheduling queue in order to achieve the purpose of increasing the throughput of the system, but its consideration in terms of fairness is poor; this is often not acceptable for users. In this paper, job scheduling strategy, according to the job priority scheduling, will break absolute fairness only when the job is blocked. With high priority, resource needs work temporarily to wait; when the priority is low, resource needs little homework ahead of time scheduling, thus speeding up the process of scheduling, reduce the resource idle time, and make full use of the current free system resources. For the scheduling jobs in the current system, the dynamic priority policy can improve the throughput of the system, and the reservation mechanism ensures the fairness of job scheduling with high priority and large resource requirements. Therefore, the method of this paper can shorten the total completion time of the work and can provide the overall performance of the system.
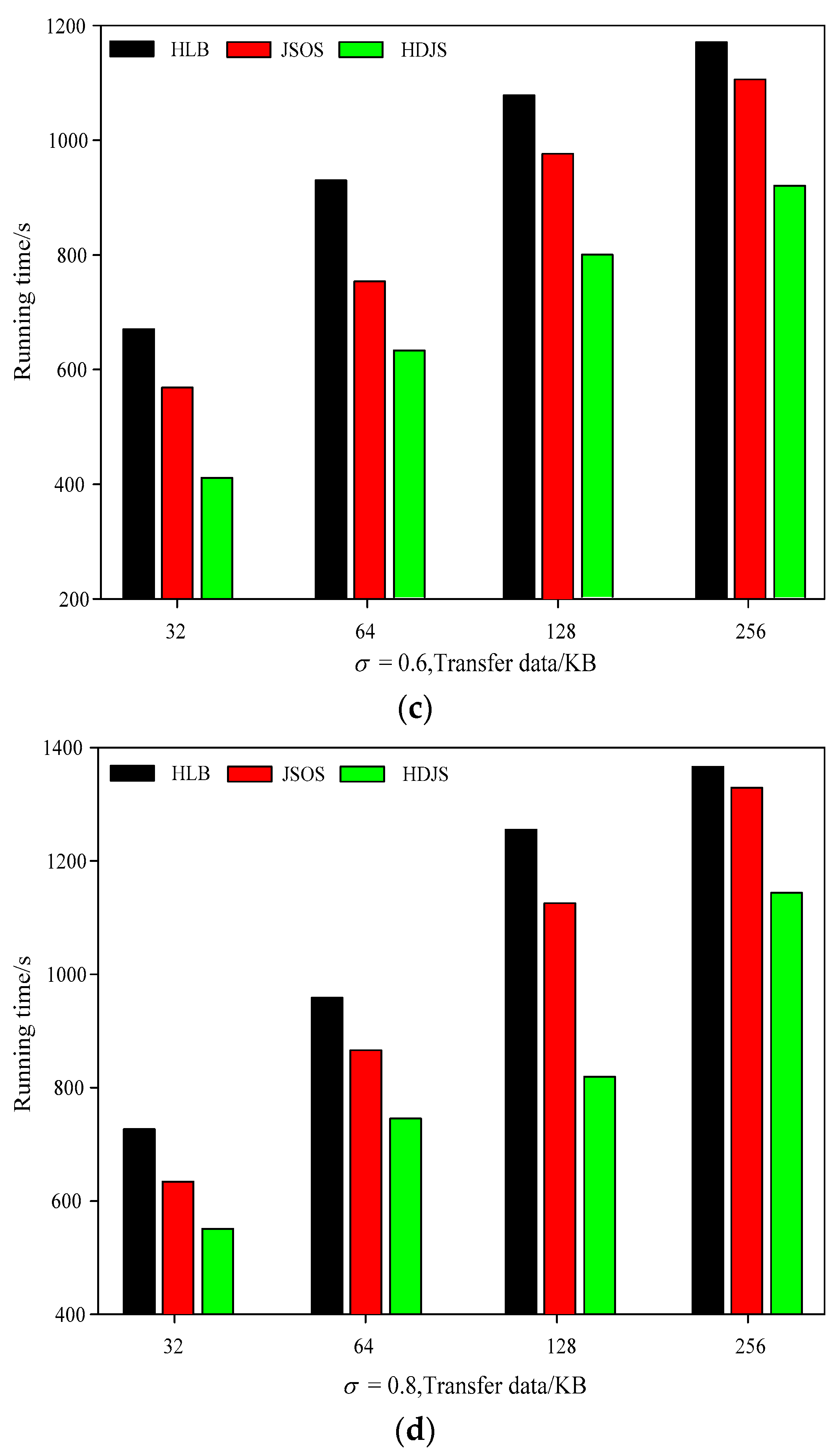
Figure 6 shows the sensor-cloud processing time of the different testing cases in the low cyber conditions. From Figure 6a,b, we can conclude that HDJS has the superior property, compared with other two optimizing approaches. In the best situation, the property of the HDJS increased by 13%, compared with HLB, and increased by 7%, compared with JSOS. Figure 6c,d shows the localization execution rate of the different testing cases in WSNs period. From Figure 6, it can be concluded that the HDJS has the highest localization execution rate, compared with other two kinds of approaches. For example, when the data block is 64 KB, the localization execution rate of the HDJS can increase to 23.7%; however, the localization execution rates of the HLB and JSOS are only 12.28% and 15.51%, respectively. Compared with the HLB, the property of the HDJS and localization execution rate of it increased dramatically. This is because, in the approach of the HLB, the data blocks were put on the working nodes randomly according to the hard disk of the nodes using rate. This strategy does not concern the differences of the working nodes calculating in WSNs, which caused that, after the nodes whose calculating abilities finish the local mission stole the local sensor-cloud tasks of the working nodes which have low computing abilities, which leads to abundant non-localization execution of the task sensor-cloud. The non-localization execution of the sensor-cloud task caused the distant communication of the nodes in WSNs, so that it can prolong the time that the jobs stay in WSNs. The property of the HDJS and the localization execution rate of the sensor-cloud have improved to some extent, compared with JSOS. This is because when the JSOS starts to select the input data nodes, according to the calculating rate of different working nodes, it preserves the proper amount of the data block, and the nodes whose calculating ability is high preserve a bigger number of the sensor-cloud task inputting data blocks, which reduced the number of the data blocks movement. However, in the approach of JSOS, the execution time of the task has a linear relation with the amount of the data that is inputted.
According to the analysis in the third chapter, the execution time of the task has no simple linear relationship with the amount of data that is imputed. It also has some relationship with the features of the loads and the features of the working nodes. Therefore, the JSOS approach can also lead to that part of the working nodes to execute the non-localization sensor-cloud task. The HDJS proposed in the paper uses the property forecasting model to test the process abilities of the working nodes, whose forecast accuracy is higher than JSOS. In addition to this, in the period of sensor-cloud, the HDJS can dynamically monitor different working nodes in the local sensor-cloud task list execution process. Because of this, it reduces the waiting cost of the inputting data node-hop cyber communication that was caused by the non-localization sensor-cloud mission in the WSNs.
5. Conclusions
In big data environments and WSNs, data plays an important role in improving system performance and job scheduling. With the strategy proposed in this paper, it may be possible to avoid the operation of hunger and resource fragmentation problems, make full use of the advantages of multi-core and multi-thread, and improve system resource utilization, considering the idle energy consumption of the system and the energy consumption of the task runtime; according to the natural parallelism of the rendering application frame and the frame, the rendering task energy consumption model is established. According to this model, the task scheduling queue is split into sub-queues, and the sub-sequence is optimized. Task scheduling improves node utilization; avoids waste of idle node energy consumption, thus completing the optimization of energy consumption of the rendering system’s global task; and shortens the execution time and response time. In future work, we will combine simulated annealing algorithm and GPGPU platform with the proposed strategy so as to reduce the system execution time more effectively.
Author Contributions
Conceptualization and methodology: Z.S., C.L., and G.Z.; data curation: Z.S., L.W., Z.L., and Z.M.; writing—original draft preparation: Z.S., C.L., and Z.M.; writing—review and editing: Z.S., Z.L., Z.M., and G.Z.; experiment analyses: Z.S., C.L., L.W., and G.Z.; funding acquisition: Z.S.
Funding
This work was supported in part by the Henan Province Education Department Cultivation Young Key Teachers in University under Grant 2016GGJS-158, in part by the Luoyang Institute of Science and Technology High-Level Research Start Foundation under Grant 2017BZ07, in part by the Henan Province Education Department Natural Science Foundation under Grant 19A520006 and 20A520027, and in part by the Key Science and Technology Program of Henan Province under Grant 192102210116 and 182102210428.
Acknowledgments
We are grateful to the experimental foundation provided by the Key Laboratory of Intelligent IoT.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Sun, Z.Y.; Wang, H.H.; Liu, B.L.; Li, C.F.; Pan, X.Y.; Nie, Y.L. CS-FCDA: A compressed sensing-based on fault-tolerant data aggregation in sensor networks. Sensors 2018, 18, 3749. [Google Scholar] [CrossRef] [PubMed]
- Bittencourt, L.F.; Diaz-Montes, J.; Buyya, R.; Rana, O.F.; Rarashar, M. Mobility-aware application scheduling in fog computing. IEEE Cloud Comput. 2017, 4, 26–35. [Google Scholar] [CrossRef]
- Bitam, S.; Zeadally, S.; Mellouk, A. Fog computing job scheduling optimization based on bees swarm. Enterp. Inf. Syst. 2018, 12, 373–397. [Google Scholar] [CrossRef]
- Wang, T.; Zhang, G.X.; Liu, A.F.; Alam Bhuiyan, M.Z.; Jin, Q. A Secure IoT Service architecture with an efficient balance dynamics based on cloud and edge computing. IEEE Internet Things J. 2019, 6, 4831–4843. [Google Scholar] [CrossRef]
- Zhang, G.X.; Wang, T.; Wang, G.J.; Liu, A.F.; Jia, W.J. Detection of hidden data attacks combined fog computing and trust evaluation method in sensor-cloud systems. Concurr. Comp. Pract. E. 2018. [Google Scholar] [CrossRef]
- Sun, Z.Y.; Liu, J.; Xing, X.F.; Li, C.F.; Pan, X.Y. A dynamic cluster job scheduling optimization algorithm based on data irreversibility in sensor networks. Int. J. Embedded Syst. 2019, 11, 551–561. [Google Scholar] [CrossRef]
- Li, Q.; Wu, W.G.; Sun, Z.Y.; Wang, L.; Huang, J.H.; Zhou, X.X. A novel hierarchal scheduling strategy for rendering system. In Proceedings of the International Conference on Identification, Information, and Knowledge in the Internet of Things (IIKI 2015), Beijing, China, 22–23 October 2015; pp. 206–209. [Google Scholar]
- Liu, X.X.; Qiu, T.; Zhou, X.B.; Wang, T.; Yang, L.; Chang, V. Latency-aware anchor-point deployment for disconnected sensor networks with mobile sinks. IEEE Trans. Ind. Inf. 2019. [Google Scholar] [CrossRef]
- Liu, X.M.; Guo, Y.; Li, W.; Hua, M.; Ding, E.J. A complete feasible and nodes-grouped scheduling algorithm for wireless rechargeable sensor networks in tunnels. Sensors 2018, 18, 3410. [Google Scholar] [CrossRef]
- Sun, Z.Y.; Lv, Z.G.; Hou, Y.; Xu, C.; Yan, B. MR-DFM: A multi-path routing algorithm based on data fusion mechanism in sensor networks. Comput. Sci. Inf. Syst. 2019, 16, 867–890. [Google Scholar] [CrossRef]
- Li, Q.; Wu, W.G.; Zhou, X.X.; Sun, Z.Y.; Huang, J.H. R-FirstFit: A reservation based firstfit priority job scheduling strategy and its application for rendering. In Proceedings of the 17th IEEE International Conference on Computation Science and Engineering (CSE 2014), Chengdu, China, 19–21 December 2014; pp. 1078–1085. [Google Scholar]
- Stavrinides, G.L.; Karatza, H.D. A hybrid approach to scheduling real-time IoT workflows in fog and cloud environments. Multimed. Tools. Appl. 2019, 78, 24639–24655. [Google Scholar] [CrossRef]
- Biason, A.; Pielli, C.; Zanella, A.; Zorzi, M. Access control for IoT nodes with energy and fidelity constraints. IEEE Trans. Wirel. Commun. 2018, 17, 3242–3257. [Google Scholar] [CrossRef]
- Wang, T.; Luo, H.; Zheng, X.; Xie, M.D. Crowdsourcing mechanism for trust evaluation in CPCS based on intelligent mobile edge computing. ACM Trans. Intel. Syst. Tec. 2019, 10. [Google Scholar] [CrossRef]
- Sun, Z.Y.; Wei, L.L.; Song, B.; Nie, Y.L.; Shao, H.X. Mobile intelligent computing in internet of things: An optimized data gathering method based on compressive sensing. IEEE Access 2019, 7, 66110–66122. [Google Scholar] [CrossRef]
- Lyu, X.C.; Ni, W.; Tian, H.; Liu, R.P.; Wang, X.; Giannakis, G.B.; Paulraj, A. Distributed online optimization of fog computing for selfish devices with out-of-data information. IEEE Trans. Wirel. Commun. 2018, 17, 7704–7717. [Google Scholar] [CrossRef]
- Wang, T.; Ke, H.X.; Zheng, X.; Wang, K.; Sangaiah, A.K.; Liu, A.F. Big data cleaning based on mobile edge computing in industrial sensor-cloud. IEEE Trans. Ind. Inf. 2019. [Google Scholar] [CrossRef]
- Sthapit, S.; Thompson, J.; Robertson, N.M.; Hopgood, J.R. Computational load balancing on the edge in absence of cloud and fog. IEEE Trans. Mob. Comput. 2019, 18, 1499–1512. [Google Scholar] [CrossRef]
- Wang, T.; Zhang, G.X.; Alam Bhuiyan, M.Z.; Liu, A.F.; Jia, W.J.; Xie, M.D. A novel trust mechanism based on fog computing in sensor-cloud system. Future Gener. Comput. Syst. 2018. [Google Scholar] [CrossRef]
- Zeng, D.Z.; Gu, L.; Guo, S.; Cheng, Z.X.; Yu, S. Joint optimization of task scheduling and image placement in fog computing supported software-defined embedded systems. IEEE Trans. Comput. 2016, 65, 3702–3712. [Google Scholar] [CrossRef]
- Wang, T.; Zhou, J.Y.; Liu, A.F.; Alam Bhuiyan, M.Z.; Wang, G.J.; Jia, W.J. Fog-based computing and storage offloading for data synchronization in IoT. IEEE Internet Things J. 2019, 6, 4272–4282. [Google Scholar] [CrossRef]
- Wang, X.L.; Veeravalli, B.; Rana, O.F. An optimal task-scheduling strategy for large-scale astronomical workloads using in-transit computation model. Int. J. Comput. Int. Sys. 2018, 11, 600–607. [Google Scholar] [CrossRef]
- Yang, Y.; Wang, K.L.; Zhang, G.W.; Chen, X.; Luo, X.L.; Zhou, M.T. MEETS: Maximal energy efficient task scheduling in homogeneous fog networks. IEEE Internet Things J. 2018, 5, 4076–4087. [Google Scholar] [CrossRef]
- Wang, T.; Zeng, J.D.; Lai, Y.X.; Cai, Y.Q.; Tian, H.; Chen, Y.H.; Wang, B.W. Data collection from WSNs to the cloud based on mobile fog elements. Future Gener. Comput. Syst. 2017. [Google Scholar] [CrossRef]
- Wang, T.; Liang, Y.Z.; Jia, W.J.; Muhammad, A.; Liu, A.F.; Xie, M.D. Coupling resource management based on fog computing in smart city systems. J. Netw. Comput. Appl. 2019, 135, 11–19. [Google Scholar] [CrossRef]
- Liu, X.X.; Zhang, P.Y. Data drainage: A novel load balancing strategy for wireless sensor networks. IEEE Commun. Lett. 2018, 22, 125–128. [Google Scholar] [CrossRef]
- He, S.; Dong, M.X.; Ota, K.; Wu, J.; Li, J.H.; Li, G.L. Software-defined efficient service reconstruction in fog using content awareness and weighted graph. In Proceedings of the 2017 IEEE Global Communications Conference, Singapore, 4–8 December 2017; pp. 1–6. [Google Scholar]
- Liu, Z.; Zhang, J.W.; Li, Y.N.; Bai, L.; Ji, Y.F. Joint jobs scheduling and lightpath provisioning in fog computing micro datacenter networks. J. Opt. Commun. Netw. 2018, 10, B152–B163. [Google Scholar] [CrossRef]
- Wang, T.; Qiu, L.; Sangaiah, A.K.; Xu, G.Q.; Liu, A.F. Energy-efficient and Trustworthy Data Collection Protocol Based on Mobile Fog Computing in Internet of Things. IEEE Trans. Ind. Informat. 2019. [Google Scholar] [CrossRef]
- Zhao, G.Z.; Gao, X.; Zheng, W.D.; Lv, Z.G. A novel optimization strategy for job scheduling based on double hierarchy. J. Eng. Sci. Technol. Rev. 2017, 10, 61–67. [Google Scholar] [CrossRef]
- Sun, Z.Y.; Zhao, G.Z.; Li, M.; Lv, Z.G. Job performance optimization method based on data balance in the wireless sensor networks. Int. J. Online Eng. 2017, 13, 4–17. [Google Scholar] [CrossRef]
- Wang, T.; Luo, H.; Jia, W.J.; Liu, A.F.; Xie, M.D. An intelligent trust evaluation scheme in sensor-cloud enabled industrial internet of things. IEEE Trans.. Ind. Inform. 2019. [Google Scholar] [CrossRef]
- Liu, X.X. Node deployment based on extra path creation for wireless sensor networks on mountain roads. IEEE Commun. Lett. 2017, 21, 2376–2379. [Google Scholar] [CrossRef]
- Wu, Y.K.; Huang, N.Y.; Wang, Y.; Alam Bhuiyan, M.Z.; Wang, T. An incentive-based protection and recovery strategy for secure big data in social networks. Inf. Sci. 2020, 508, 79–91. [Google Scholar]
- Liu, X.X.; Wang, T.; Jia, W.J.; Liu, A.F.; Chi, K.K. Quick convex hull-based rendezvous planning for delay-harsh mobile data gathering in disjoint sensor networks. IEEE Trans. Syst. Man Cybern. B Cybern. 2019. [Google Scholar] [CrossRef]
- Sun, Z.Y.; Ji, X.H. HDAC: High-dimensional data aggregation control algorithm for big data in wireless sensor networks. Int. J. Inf. Technol. Web. Eng. 2017, 12, 72–86. [Google Scholar] [CrossRef]
- Wan, J.F.; Chen, B.T.; Wang, S.Y.; Xia, M.; Li, D.; Liu, C.L. Fog computing for energy aware load balancing and scheduling in smart factory. IEEE Trans. Ind. Inf. 2018, 14, 4548–4556. [Google Scholar] [CrossRef]
- Sun, Z.Y.; Li, L.X.; Xing, X.F.; Lv, Z.G.; Xiong, N.N. A novel nodes deployment assignment scheme with data association attributed in wireless sensor networks. J. Internet Technol. 2019, 20, 509–520. [Google Scholar]
- Li, Z.X.; Su, D.D.; Zhu, H.J.; Li, W.; Zhang, F.; Li, R.R. A fast synthetic aperture radar raw data simulation using cloud computing. Sensors 2017, 17, 113. [Google Scholar] [CrossRef] [Green Version]
- Liu, X.X.; Qiu, T.; Wang, T. Load-balanced data dissemination for wireless sensor networks: A nature- Inspired approach. IEEE Internet Things J. 2019. [Google Scholar] [CrossRef]
- Shao, Y.L.; Li, C.L.; Fu, Z.; Jia, L.Y.; Luo, Y.L. Cost-effective replication management and scheduling in edge computing. J. Netw. Comput. Appl. 2019, 129, 46–61. [Google Scholar] [CrossRef]
- Sun, Z.Y.; Tao, R.; Xiong, N.X.; Pan, X.Y. CS-PLM: Compressive sensing data gathering algorithm based on packet loss matching in sensor networks. Wirel. Commun. Mob. Comput. 2018. [Google Scholar] [CrossRef]
- Wang, T.; Wang, X.; Zhao, Z.M.; He, Z.X.; Xia, T.S. Measurement data classification optimization based on a novel evolutionary kernel clustering algorithm for multi-target tracking. IEEE Sens. J. 2018, 18, 3722–3733. [Google Scholar] [CrossRef]
- Hou, X.J.; Zhao, G.Z. Resource Scheduling and load balancing fusion algorithm with deep learning based on cloud computing. Int. J. Inf. Technol. Web. Eng. 2018, 13, 54–72. [Google Scholar] [CrossRef]
- Wang, T.; Alam Bhuiyan, M.D.Z.; Wang, G.J.; Rahman, M.A.; Wu, J.; Cao, J.N. Big data reduction for smart city’s critical infrastructural health monitoring. IEEE Commun. Mag. 2018, 56, 128–133. [Google Scholar] [CrossRef]
- Sun, Z.Y.; Zhang, Y.S.; Nie, Y.L.; Wei, W.; Lloret, J.; Song, H.B. CASMOC: A novel complex alliance strategy with multi-objective optimization of coverage in wireless sensor networks. Wirel. Netw. 2017, 23, 1201–1222. [Google Scholar] [CrossRef]
- Wang, T.; Zhao, D.; Cai, S.B.; Jia, W.J.; Liu, A.F. Bidirectional prediction based underwater data collection protocol for end-edge-cloud orchestrated system. IEEE Tran. Ind. Inform. 2019. [Google Scholar] [CrossRef]
- Sun, Z.Y.; Zhao, G.Z.; Xing, X.F. ENCP: A new energy-efficient nonlinear coverage control protocol in mobile sensor networks. EURASIP J. Wirel. Commun. Netw. 2018, 1. [Google Scholar] [CrossRef] [Green Version]
- Wang, Q.Y.; Guo, S.T.; Liu, J.D.; Yang, Y.Y. Energy-efficient computation offloading and resource allocation for delay-sensitive mobile edge computing. Sustainable Comput. Inf. Sys. 2019, 21, 154–164. [Google Scholar] [CrossRef]
- Wu, Y.K.; Huang, H.Y.; Wu, Q.; Liu, A.F.; Wang, T. A risk defense method based on microscopic state prediction with partial information observations in social networks. J. Parallel Distrib. Comput. 2019, 131, 189–199. [Google Scholar] [CrossRef]
Figure 1.
Job scheduling instance based on HDJS; (a) t = 10 s; (b) t = 20 s; (c) t = 30 s; (d) t = 40 s.
Figure 1.
Job scheduling instance based on HDJS; (a) t = 10 s; (b) t = 20 s; (c) t = 30 s; (d) t = 40 s.

Figure 2.
The process of FCFS and FirstFit job scheduling (a) t = 100 s; (b) t = 150 s.

Figure 3.
Comparison of resource utilization ratio for different strategies; (a) N = 100; (b) N = 200.
Figure 3.
Comparison of resource utilization ratio for different strategies; (a) N = 100; (b) N = 200.


Figure 4.
Comparison of average completion time for different strategies; (a) N = 100; (b) N = 200.


Figure 5.
Comparison of data delay ration for different strategies; (a) N = 100; (b) N = 200.

Figure 6.
Comparison of data transmission and running time under different parameters; (a) σ = 0.2; (b) σ = 0.4; (c) σ = 0.6; (d) σ = 0.8.
Figure 6.
Comparison of data transmission and running time under different parameters; (a) σ = 0.2; (b) σ = 0.4; (c) σ = 0.6; (d) σ = 0.8.


© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Sun, Z.; Li, C.; Wei, L.; Li, Z.; Min, Z.; Zhao, G. Intelligent Sensor-Cloud in Fog Computer: A Novel Hierarchical Data Job Scheduling Strategy. Sensors 2019, 19, 5083. https://doi.org/10.3390/s19235083
AMA Style
Sun Z, Li C, Wei L, Li Z, Min Z, Zhao G. Intelligent Sensor-Cloud in Fog Computer: A Novel Hierarchical Data Job Scheduling Strategy. Sensors. 2019; 19(23):5083. https://doi.org/10.3390/s19235083
Chicago/Turabian StyleSun, Zeyu, Chuanfeng Li, Lili Wei, Zhixian Li, Zhiyu Min, and Guozeng Zhao. 2019. "Intelligent Sensor-Cloud in Fog Computer: A Novel Hierarchical Data Job Scheduling Strategy" Sensors 19, no. 23: 5083. https://doi.org/10.3390/s19235083
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.