Sensor-Assisted Weighted Average Ensemble Model for Detecting Major Depressive Disorder


 , , , and
, , , and
Abstract
:1. Introduction
- (i)
- To the best of our knowledge, a Weighted Average Ensemble machine learning model is developed for the first time in this paper detecting Major Depressive Disorder (MDD) using an integrated feature set, and its performance is justified through experimental results.
- (ii)
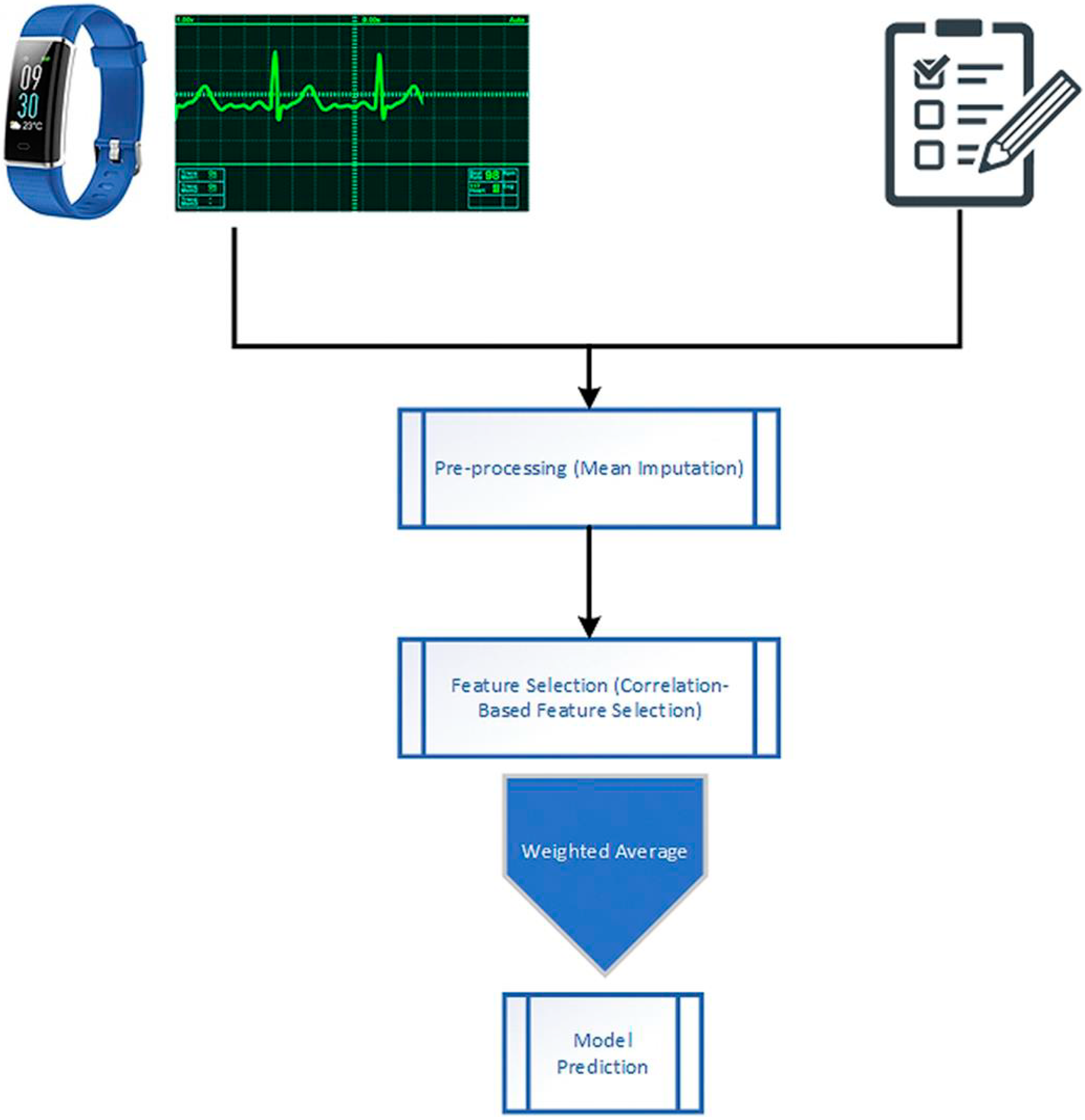
- A unique integrated feature set is formulated by combining the features from the questionnaire, and the smartwatch sensor encompassing a heart rate monitor.
- (iii)
- The gathered data is pre-processed to handle the missing values with the help of Mean Imputation, and then the significant features are selected using the Correlation-based Feature Selection technique.
- (iv)
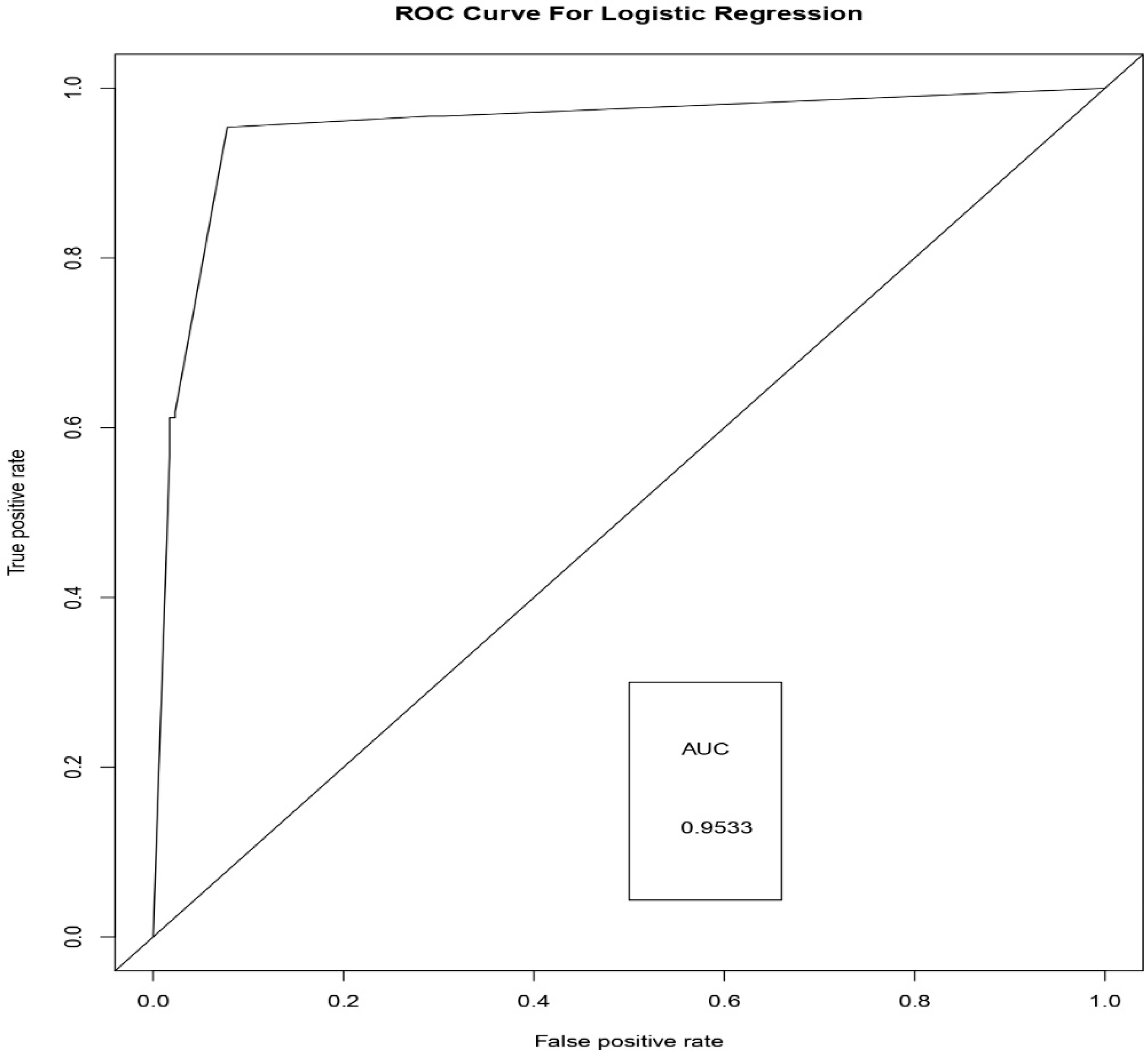
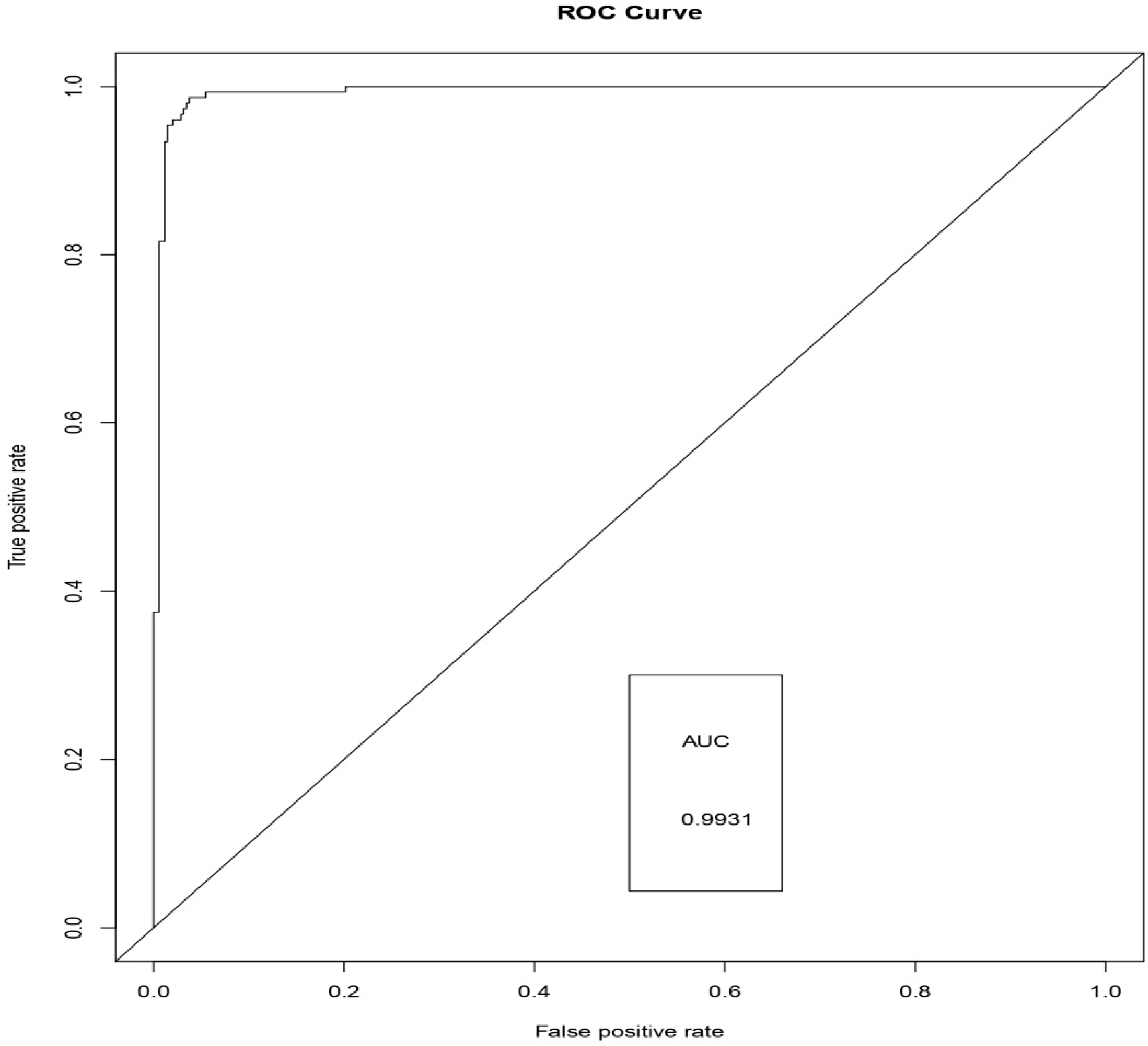
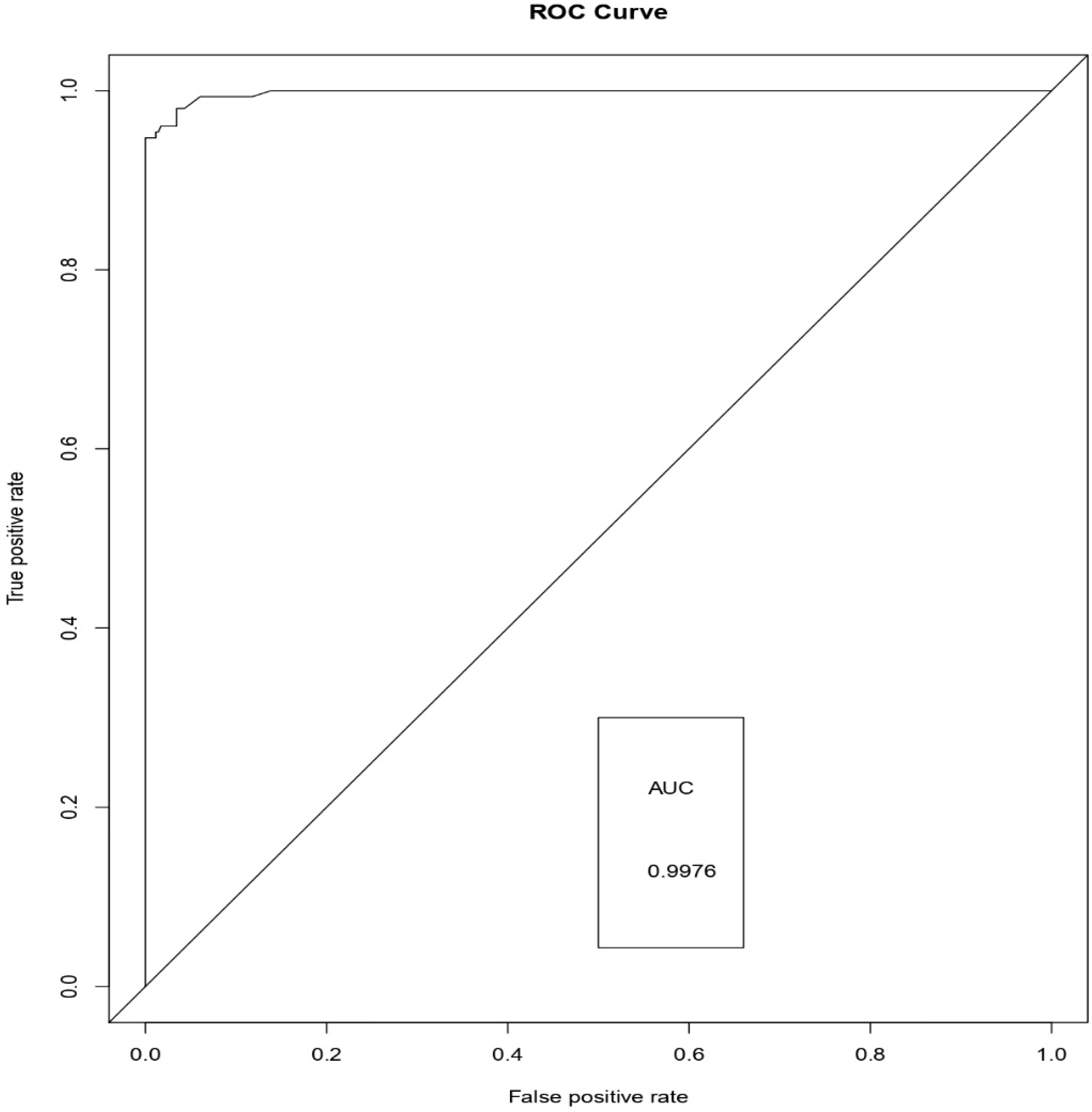
- The proposed Weighted Average Ensemble model surpasses the logistic regression, and the random forest approaches in terms of the area under the receiver operating characteristic (ROC) curves measure.
- (v)
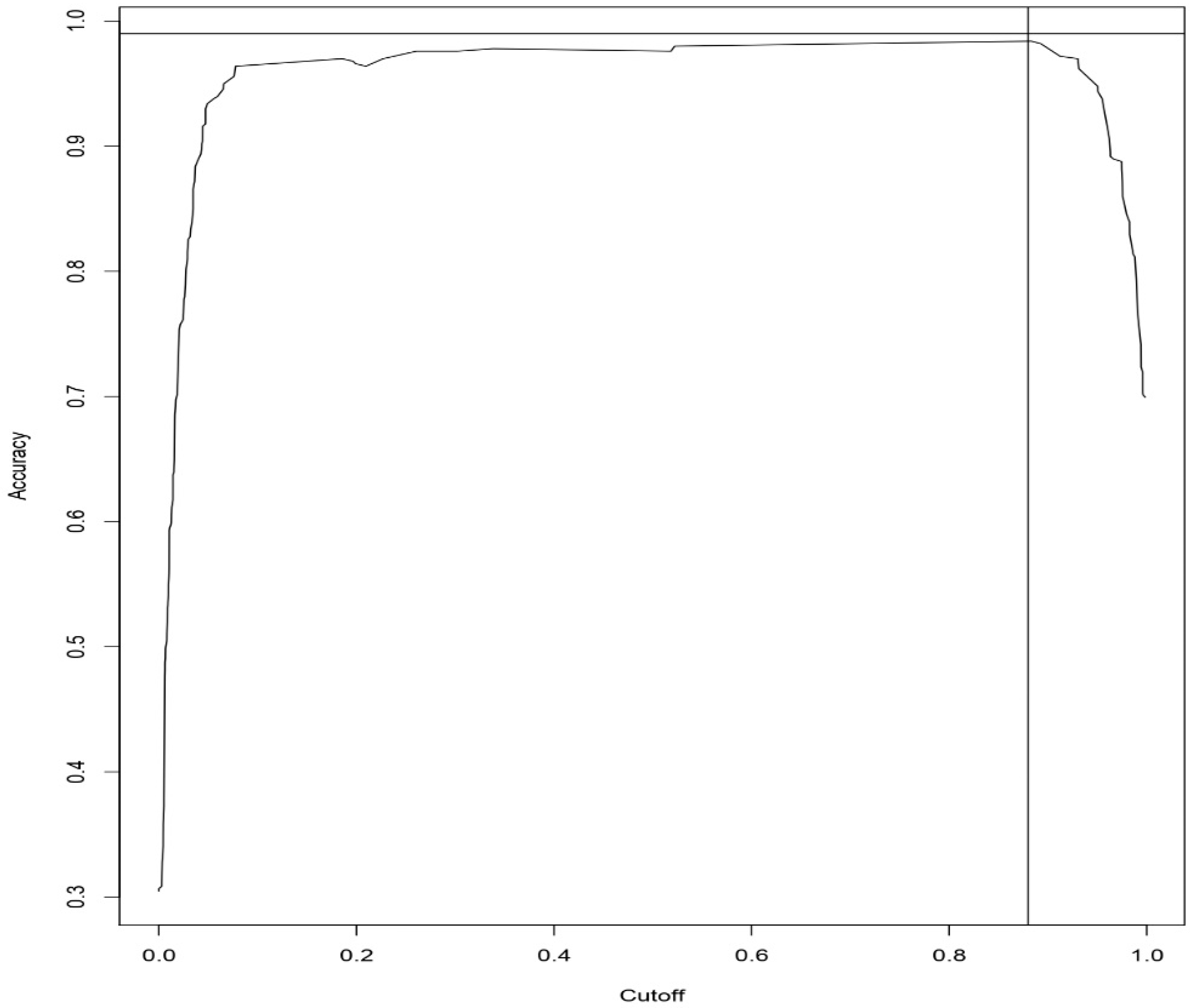
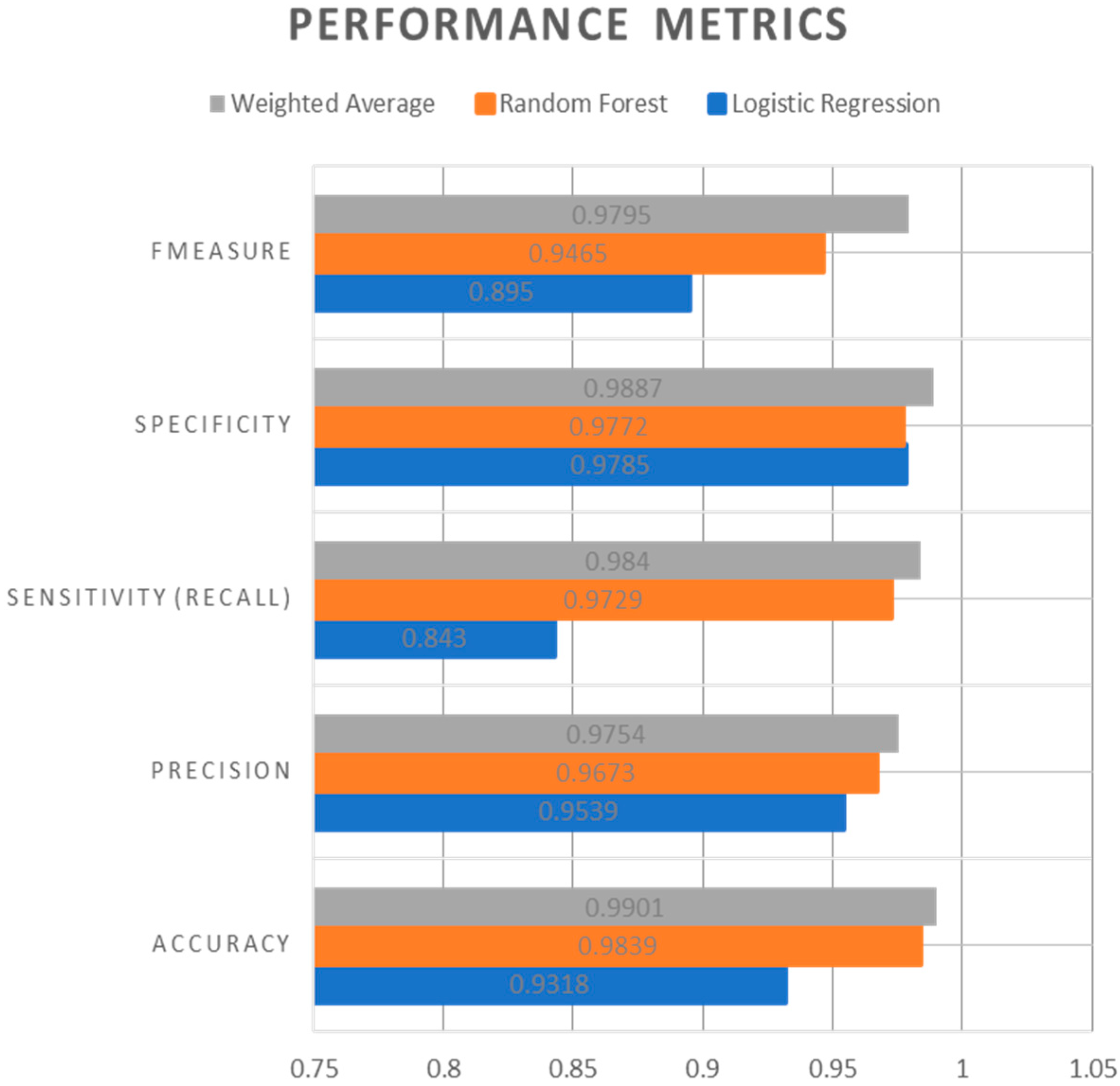
- It can be observed from the experimental results that the Weighted Average Ensemble model performs better in terms of accuracy, precision, recall, specificity, and FMeasure in due comparison with Logistic regression and Random Forest Models. Furthermore, the proposed model also illustrates a superior performance with an accuracy of 99.01%.
2. Review of Literature
3. Methodology
3.1. Dataset Description
3.2. Hamilton Depression Rating Scale
3.3. Smart Watch Sensors
3.3.1. Accelerometer
3.3.2. Gyroscope
3.3.3. Heart-Rate Monitor
3.4. Pre-Processing
3.5. Feature Selection
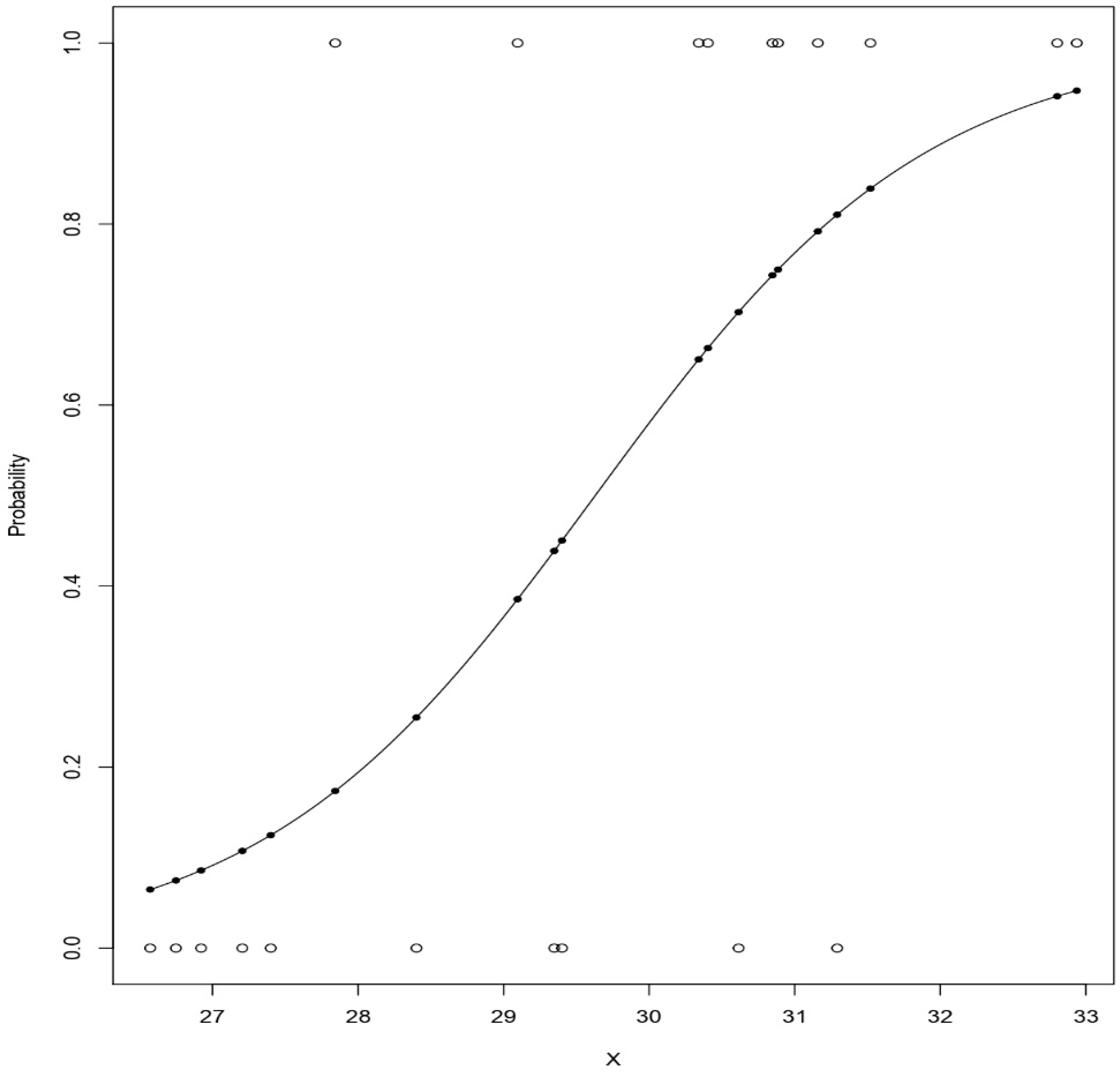
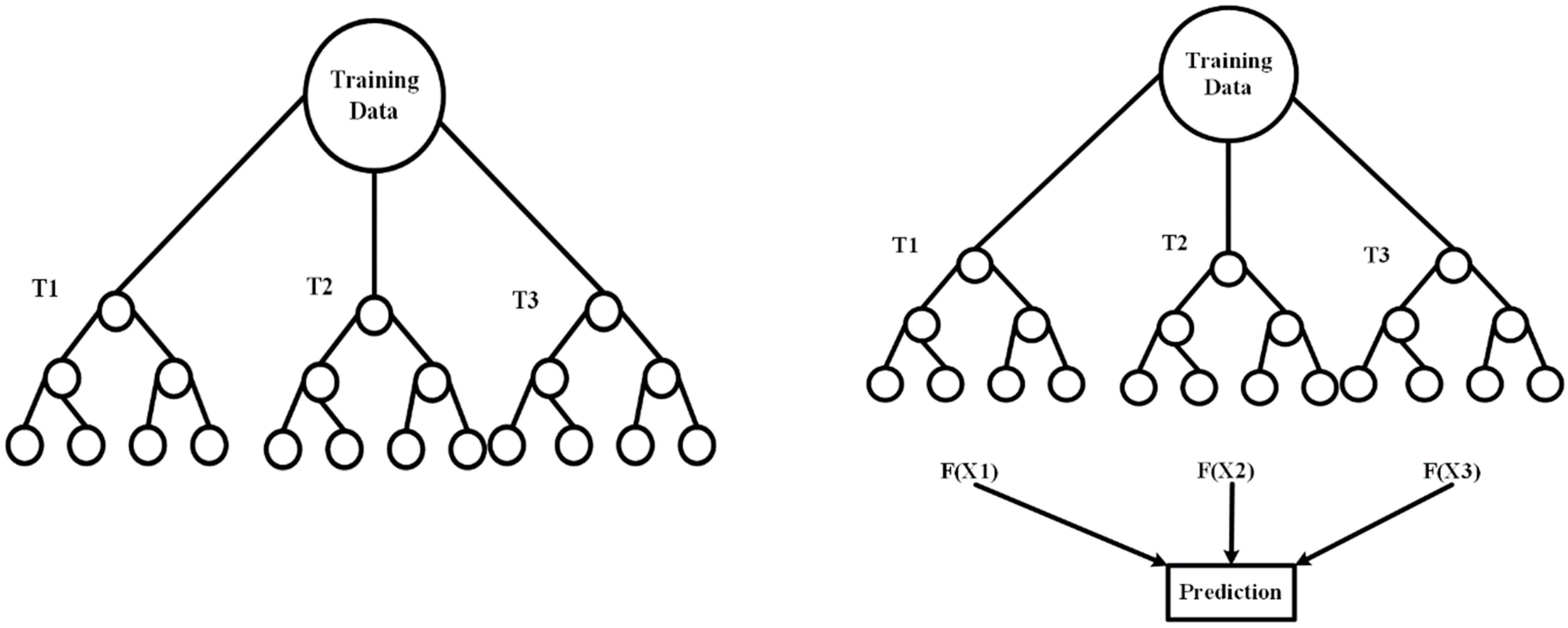
3.6. Machine Learning Models
- P(A)—Is the probability of A (Dependent Variable)
- a0—moves the curve right and left
- a1—Slope
- B—Nominal Variable or Independent Variable.
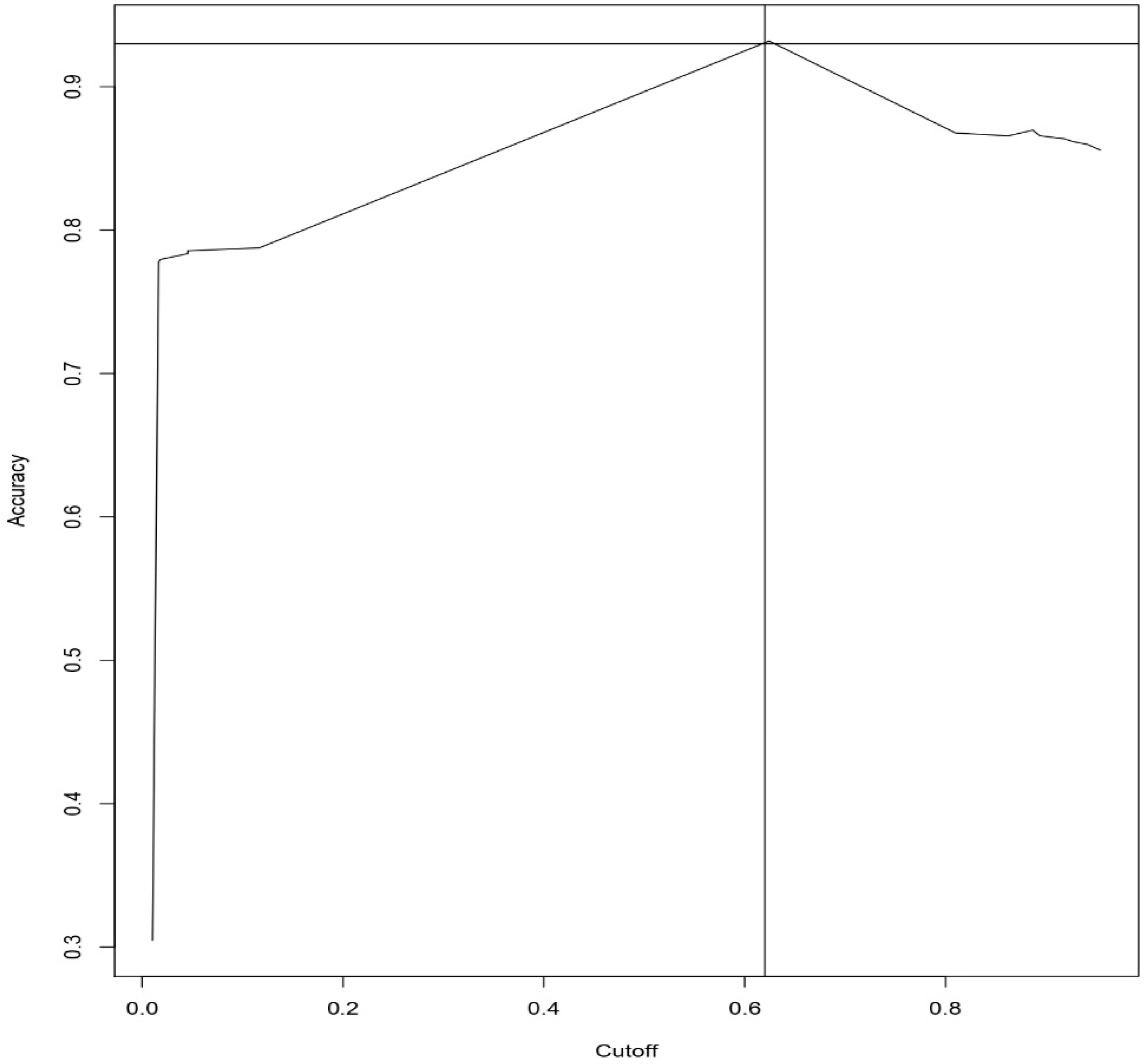
4. Results and Discussion
- Feeling Sad
- Feeling Irritable
- Feeling Anxious about Tense
- Response to Mood to Good or Desired Events
- The mood in Relation to the Time of Day
- Thoughts of Death or Suicide
- Capacity for Pleasure or Enjoyment
- Bodily Symptoms
- Panic/Phobic Symptoms
- Standard Deviation
- Root Mean Square
- Root Sum Square
- Upper Quartile
- Lower Quartile
- Kurtosis
5. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Moreno, M.A.; Jelenchick, L.A.; Egan, K.G.; Cox, E.; Young, H.; Gannon, K.E.; Becker, T. Feeling bad on Facebook: Depression disclosures by college students on a social networking site. Depress. Anxiety 2010, 28, 447–455. [Google Scholar] [CrossRef] [PubMed]
- McElroy, E.; Fearon, P.; Belsky, J.; Fonagy, P.; Patalay, P. Networks of Depression and Anxiety Symptoms Across Development. J. Am. Acad. Child Adolesc. Psychiatry 2018, 57, 964–973. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fried, E.I.; Nesse, R.M. Depression is not a consistent syndrome: An investigation of unique symptom patterns in the STAR*D study. J. Affect. Disord. 2015, 172, 96–102. [Google Scholar] [CrossRef] [PubMed]
- Fried, E.; Nesse, R.; Zivin, K.; Guille, C.; Sen, S. Depression is more than the sum score of its parts: Individual DSM symptoms have different risk factors. Psychol. Med. 2014, 44, 2067–2076. [Google Scholar] [CrossRef] [PubMed]
- Mahendran, N.; Vincent, D.R. Effective Classification of Major Depressive Disorder Patients Using Machine Learning Techniques. Recent Pat. Comput. Sci. 2019, 12, 41–48. [Google Scholar] [CrossRef]
- Klakk, H.; Kristensen, P.L.; Andersen, L.B.; Froberg, K.; Møller, N.C.; Grøntved, A. Symptoms of depression in young adulthood is associated with unfavorable clinical- and behavioral cardiovascular disease risk factors. Prev. Med. Rep. 2018, 11, 209–215. [Google Scholar] [CrossRef]
- Gerrits, M.M.; van Oppen, P.; van Marwijk, H.W.; Penninx, B.W.; van der Horst, H.E. Pain and the onset of depressive and anxiety disorders. Pain 2014, 155, 53–59. [Google Scholar] [CrossRef]
- Dietterich, T.G. Machine learning for sequential data: A review. In Proceedings of the Joint IAPR International Workshops on Statistical Techniques in Pattern Recognition (SPR) and Structural and Syntactic Pattern Recognition (SSPR), Windsor, ON, Canada, 6–9 August 2002; Springer: Berlin/Heidelberg, Germany, 2002; pp. 15–30. [Google Scholar]
- Cohn, J.F.; Kruez, T.S.; Matthews, I.; Yang, Y.; Nguyen, M.H.; Padilla, M.T.; Zhou, F.; De la Torre, F. Detecting depression from facial actions and vocal prosody. In Proceedings of the 2009 3rd International Conference on Affective Computing and Intelligent Interaction and Workshops, Amsterdam, The Netherlands, 10–12 September 2009; pp. 1–7. [Google Scholar]
- Karasz, A.; Dowrick, C.; Byng, R.; Buszewicz, M.; Ferri, L.; Hartman TC, O.; Reeve, J. What we talk about when we talk about depression: Doctor-patient conversations and treatment decision outcomes. Br. J. Gen. Pract. 2012, 62, e55–e63. [Google Scholar] [CrossRef]
- Papakostas, G.I.; Petersen, T.; Mahal, Y.; Mischoulon, D.; Nierenberg, A.A.; Fava, M. Quality of life assessments in major depressive disorder: A review of the literature. Gen. Hosp. Psychiatry 2004, 26, 13–17. [Google Scholar] [CrossRef]
- Lu, T.C.; Fu, C.M.; Ma MH, M.; Fang, C.C.; Turner, A.M. Healthcare applications of smart watches. Appl. Clin. Inform. 2016, 7, 850–869. [Google Scholar] [CrossRef]
- Bonino, D.; Corno, F.; De Russis, L. Dwatch: A personal wrist watch for smart environments. Procedia Comput. Sci. 2012, 10, 300–307. [Google Scholar] [CrossRef]
- Weiss, G.M.; Timko, J.L.; Gallagher, C.M.; Yoneda, K.; Schreiber, A.J. Smartwatch-based activity recognition: A machine learning approach. In Proceedings of the 2016 IEEE-EMBS International Conference on Biomedical and Health Informatics (BHI), Las Vegas, NV, USA, 25–27 February 2016; pp. 426–429. [Google Scholar]
- Morganti, E.; Angelini, L.; Adami, A.; Lalanne, D.; Lorenzelli, L.; Mugellini, E. A smart watch with embedded sensors to recognize objects, grasps and forearm gestures. Procedia Eng. 2012, 41, 1169–1175. [Google Scholar] [CrossRef]
- Sanchez-Riera, J.; Srinivasan, K.; Hua, K.; Cheng, W.; Hossain, M.A.; Alhamid, M.F. Robust RGB-D Hand Tracking Using Deep Learning Priors. IEEE Trans. Circuits Syst. Video Technol. 2017, 28, 2289–2301. [Google Scholar] [CrossRef]
- Stetco, A.; Dinmohammadi, F.; Zhao, X.; Robu, V.; Flynn, D.; Barnes, M.; Keane, J.; Nenadic, G. Machine learning methods for wind turbine condition monitoring: A review. Renew. Energy 2019, 133, 620–635. [Google Scholar] [CrossRef]
- Lison, P. An Introduction to Machine Learning; Language Technology Group: Edinburgh, UK, 2015. [Google Scholar]
- Mitchell, T.; Buchanan, B.; DeJong, G.; Dietterich, T.; Rosenbloom, P.; Waibel, A. Machine learning. Annu. Rev. Comput. Sci. 1990, 4, 417–433. [Google Scholar] [CrossRef]
- Carbonell, J.G.; Michalski, R.S.; Mitchell, T.M. An overview of machine learning. In Machine Learning; Morgan Kaufmann: Burlington, MA, USA, 1983; pp. 3–23. [Google Scholar]
- Hänsel, K.; Alomainy, A.; Haddadi, H. Large scale mood and stress self-assessments on a smartwatch. In Proceedings of the 2016 ACM International Joint Conference on Pervasive and Ubiquitous Computing: Adjunct, Heidelberg, Germany, 12–16 September 2016; pp. 1180–1184. [Google Scholar]
- Wile, D.J.; Ranawaya, R.; Kiss, Z.H. Smart watch accelerometry for analysis and diagnosis of tremor. J. Neurosci. Methods 2014, 230, 1–4. [Google Scholar] [CrossRef] [PubMed]
- Chang, C.Y.; Chang, C.W.; Kathiravan, S.; Lin, C.; Chen, S.T. DAG-SVM based infant cry classification system using sequential forward floating feature selection. Multidimens. Syst. Signal Process. 2017, 28, 961–976. [Google Scholar] [CrossRef]
- Chen, S.; Srinivasan, K.; Lin, C.; Chang, C. Chapter 10—Neonatal Cry Analysis and Categorization System Via Directed Acyclic Graph Support Vector Machine. In Intelligent Data-Centric Systems, Big Data Analytics for Sensor-Network Collected Intelligence; Hsu, H., Chang, C., Hsu, C., Eds.; Academic Press: Cambridge, MA, USA, 2017; pp. 205–222. [Google Scholar] [CrossRef]
- Lin, Y.C.; Wei, K.C. An electronic smart watch monitors heart rate of an extremely preterm baby. Pediatrics Neonatol. 2018, 59, 214–215. [Google Scholar] [CrossRef] [Green Version]
- Shin, D.; Shin, D.; Shin, D. Ubiquitous health management system with watch-type monitoring device for dementia patients. J. Appl. Math. 2014, 2014, 878741. [Google Scholar] [CrossRef]
- Gutierrez, M.A.; Fast, M.L.; Ngu, A.H.; Gao, B.J. Real-time prediction of blood alcohol content using smartwatch sensor data. In ICSH; Springer: Cham, Switzerland, 2015; pp. 175–186. [Google Scholar]
- Hosseinifard, B.; Moradi, H.M.; Rostami, R. Classifying depression patients and normal subjects using machine learning techniques and nonlinear features from EEG signal. Comput. Methods Programs Biomed. 2013, 109, 339–345. [Google Scholar] [CrossRef]
- Hamilton, M. The Hamilton rating scale for depression. In Assessment of Depression; Springer: Berlin/Heidelberg, Germany, 1986; pp. 143–152. [Google Scholar]
- Williams, J.B. A structured interview guide for the Hamilton Depression Rating Scale. Arch. Gen. Psychiatry 1988, 45, 742–747. [Google Scholar] [CrossRef] [PubMed]
- Mekruksavanich, S.; Hnoohom, N.; Jitpattanakul, A. Smartwatch-based sitting detection with human activity recognition for office workers syndrome. In Proceedings of the 2018 International ECTI Northern Section Conference on Electrical, Electronics, Computer and Telecommunications Engineering (ECTI-NCON), Chiang Rai, Thailand, 25–28 February 2018; pp. 160–164. [Google Scholar]
- Lee, Y.; Song, M. Recognizing problem behaviors of children with developmental disabilities using smartwatch. In Proceedings of the 2016 IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), San Francisco, CA, USA, 10–14 April 2016; pp. 1001–1002. [Google Scholar]
- Kotsiantis, S.B.; Kanellopoulos, D.; Pintelas, P.E. Data preprocessing for supervised leaning. Int. J. Comput. Sci. 2006, 1, 111–117. [Google Scholar]
- Huang, J.; Li, Y.; Xie, M. An empirical analysis of data preprocessing for machine learning-based software cost estimation. Inf. Softw. Technol. 2015, 67, 108–127. [Google Scholar] [CrossRef]
- Donders AR, T.; Van Der Heijden, G.J.; Stijnen, T.; Moons, K.G. A gentle introduction to imputation of missing values. J. Clin. Epidemiol. 2006, 59, 1087–1091. [Google Scholar] [CrossRef] [PubMed]
- Chang, C.; Srinivasan, K.; Chen, S.; Chang, M.; Sharma, V. An Efficient SVM Based Lymph Node Classification Approach Using Intelligent Communication Ant Colony Optimization. J. Med. Imaging Health Inform. 2018, 8, 1077–1086. [Google Scholar] [CrossRef]
- Hira, Z.M.; Gillies, D.F. A Review of Feature Selection and Feature Extraction Methods Applied on Microarray Data. Adv. Bioinform. 2015, 2015, 198363. [Google Scholar] [CrossRef]
- Kira, K.; Rendell, L.A. A practical approach to feature selection. In Machine Learning Proceedings 1992; Morgan Kaufmann: Burlington, MA, USA, 1992; pp. 249–256. [Google Scholar]
- Blum, A.L.; Langley, P. Selection of relevant features and examples in machine learning. Artif. Intell. 1997, 97, 245–271. [Google Scholar] [CrossRef] [Green Version]
- Mursalin, M.; Zhang, Y.; Chen, Y.; Chawla, N.V. Automated epileptic seizure detection using improved correlation-based feature selection with random forest classifier. Neurocomputing 2017, 241, 204–214. [Google Scholar] [CrossRef]
- Dreiseitl, S.; Ohno-Machado, L. Logistic regression and artificial neural network classification models: A methodology review. J. Biomed. Inform. 2002, 35, 352–359. [Google Scholar] [CrossRef]
- Harrington, P. Machine Learning in Action; Manning: Greenwich, UK, 2012; Volume 5. [Google Scholar]
- Tabaei, B.P.; Herman, W.H. A multivariate logistic regression equation to screen for diabetes: Development and validation. Diabetes Care 2002, 25, 1999–2003. [Google Scholar] [CrossRef]
- Ham, J.; Chen, Y.; Crawford, M.M.; Ghosh, J. Investigation of the random forest framework for classification of hyperspectral data. IEEE Trans. Geosci. Remote Sens. 2005, 43, 492–501. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Confusion Matrix | Definition | Formula |
|---|---|---|
| Accuracy | It is the ratio of correctly classified to the whole set. For instance, which answers the question: How many patients did we correctly diagnosed as depressed out of all the patients? | TN + TP/All |
| Precision | It is the ratio of correctly classified positive subjects to all the positive subjects. For instance, which answers the question: How many of the patients whom we named as depressed are actually depressed? | TP/TP + FP |
| Sensitivity (Recall) | It is the ratio of correctly classified positive subjects to all those who have the disease in reality. Which answers the question: Of all the depressed people in the dataset, how many did we correctly predict as depressed? | TP/TP + FN |
| Specificity | It is the ratio of correctly classified negative subjects to all the healthy subjects in reality. Which answers the question: Of all the healthy people in the dataset, how many we correctly predict as not depressed? | TN/TN + FP |
| FMeasure | It is a combination of both recall and precision. Harmonic average. | 2 × (Precision × Recall)/(Recall + Precision) |
| Performance Metrics | Logistic Regression | Random Forest | Weighted Average |
|---|---|---|---|
| Accuracy | 0.9318 | 0.9839 | 0.9901 |
| Precision | 0.9539 | 0.9673 | 0.9754 |
| Sensitivity (Recall) | 0.8430 | 0.9729 | 0.9840 |
| Specificity | 0.9785 | 0.9772 | 0.9887 |
| FMeasure | 0.8950 | 0.9465 | 0.9795 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mahendran, N.; Vincent, D.R.; Srinivasan, K.; Chang, C.-Y.; Garg, A.; Gao, L.; Reina, D.G. Sensor-Assisted Weighted Average Ensemble Model for Detecting Major Depressive Disorder. Sensors 2019, 19, 4822. https://doi.org/10.3390/s19224822
Mahendran N, Vincent DR, Srinivasan K, Chang C-Y, Garg A, Gao L, Reina DG. Sensor-Assisted Weighted Average Ensemble Model for Detecting Major Depressive Disorder. Sensors. 2019; 19(22):4822. https://doi.org/10.3390/s19224822
Chicago/Turabian StyleMahendran, Nivedhitha, Durai Raj Vincent, Kathiravan Srinivasan, Chuan-Yu Chang, Akhil Garg, Liang Gao, and Daniel Gutiérrez Reina. 2019. "Sensor-Assisted Weighted Average Ensemble Model for Detecting Major Depressive Disorder" Sensors 19, no. 22: 4822. https://doi.org/10.3390/s19224822