NMLPA: Uncovering Overlapping Communities in Attributed Networks via a Multi-Label Propagation Approach †

Abstract
:1. Introduction
- We propose a novel overlapping community detection algorithm, which considers both the network structure and node attribute information, to identify underlying community structures in attributed networks.
- We creatively combine the node attribute information with the multi-label propagation process in the way of mapping the node similarity to the edge weight and formulate our Node-similarity-based Multi-Label Propagation Algorithm (NMLPA) to uncover overlapping communities in attributed networks. To the best of our knowledge, NMLPA is the first overlapping community detection method that leverages the node attribute information in the multi-label propagation process. Furthermore, NMLPA uses a pruning strategy to control the number of labels per node when label propagating, which leads to an appropriate range of the final community number.
- We carefully design overlapping community detection experiments in both synthetic networks and real-world networks. Results of these extensive experiments show that our proposed NMLPA significantly outperforms the state-of-the-art methods.
2. Related Work
2.1. Community Detection in Attributed Networks
2.2. Label Propagation Based Community Detection
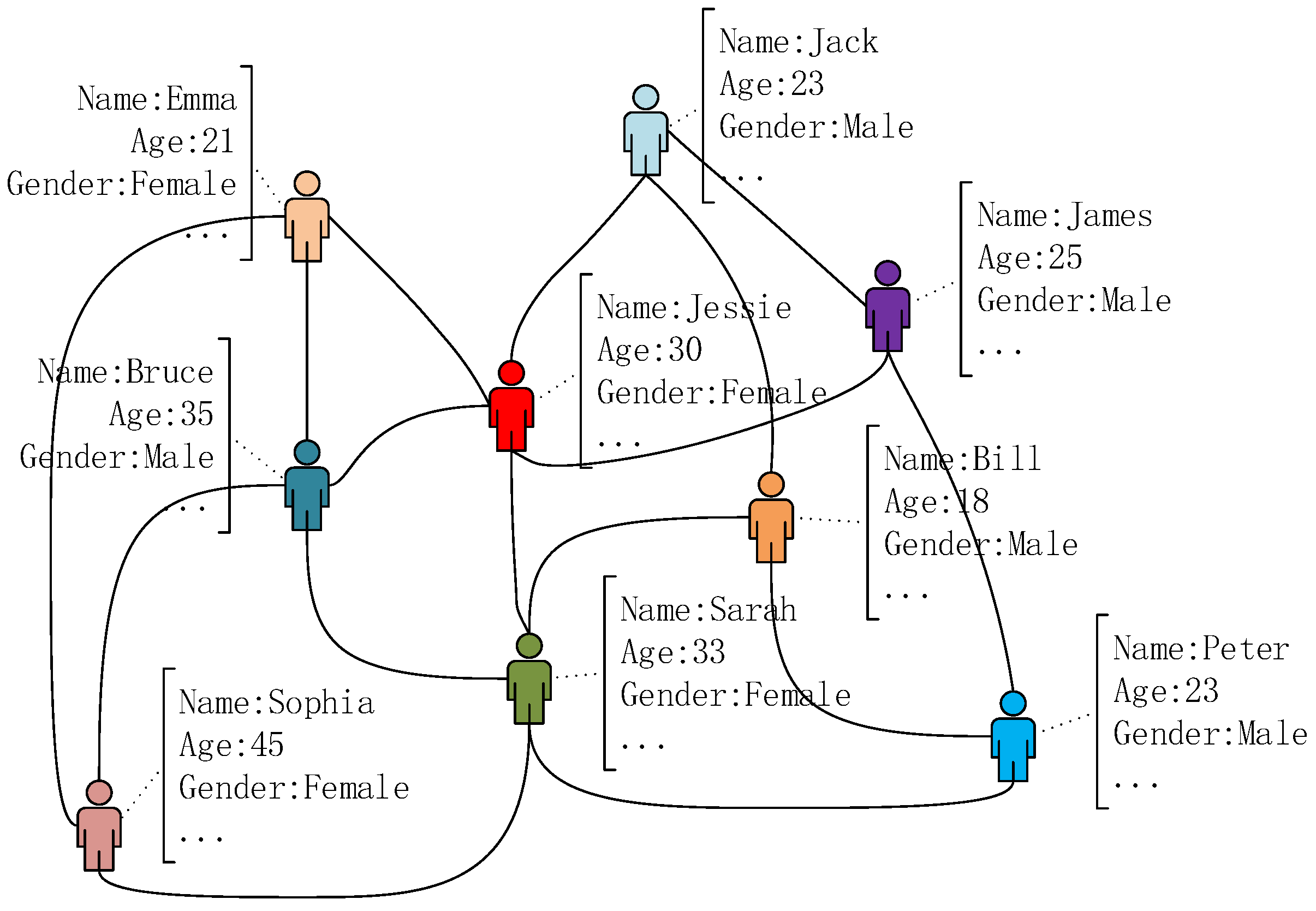
3. Problem Definition
- In terms of network structure, the nodes in the same community are densely connected while the nodes in different communities are sparsely connected.
- In terms of node attributes, the nodes in the same community tend to have similar attribute values while the nodes in different communities tend to have diverse attribute values.
- is allowed to exist.
4. Node Similarity Based Multi-Label Propagation
4.1. Overview
4.2. The NMLPA Algorithm
| Algorithm 1: The NMLPA algorithm. |
 |
4.2.1. Weighted Network Construction
| Algorithm 2: Weighted network construction (G). |
 |
4.2.2. Multi-Label Propagation
| Algorithm 3: Multi label propagation (). |
 |
4.2.3. Post-Processing
4.3. Complexity Analysis
- On Line 1 of Algorithm 1, the construction of the weighted network , shown in Algorithm 2, is divided into two parts: the construction of the node set and the construction of the edge set, which take and time respectively. Thus, the total time is .
- The initialization of label list takes time on Line 2 of Algorithm 1.
- On Lines 3–5 of Algorithm 1, each iteration of the multi-label propagation, shown in Algorithm 3, first takes time to initialize the label dictionary. For each edge in , one iteration of the multi-label propagation takes time to propagate labels from one node to another, where l is minimum of k and . The pruning operation in one iteration needs to initialize the new label list and time to execute the pruning operation since the total number of repeatable labels is not greater than and here we use the quick sorting to select the top-k labels for each node. Therefore, the total time of the multi-label propagation process is .
- In the stage of post-processing on Line 6 of Algorithm 1, using a hash table, our method counts the number of nodes each label belongs to in time since the number of labels for each node is not greater than k. Because the number of distinguishing label is not great than the number of nodes, we need time to select the top-k labels and time to make communities cover all nodes. Thus, the total time of this stage is .
4.4. Parameter Settings
5. Experiments
5.1. Evaluation on Synthetic Networks
5.2. Evaluation on Real-World Networks
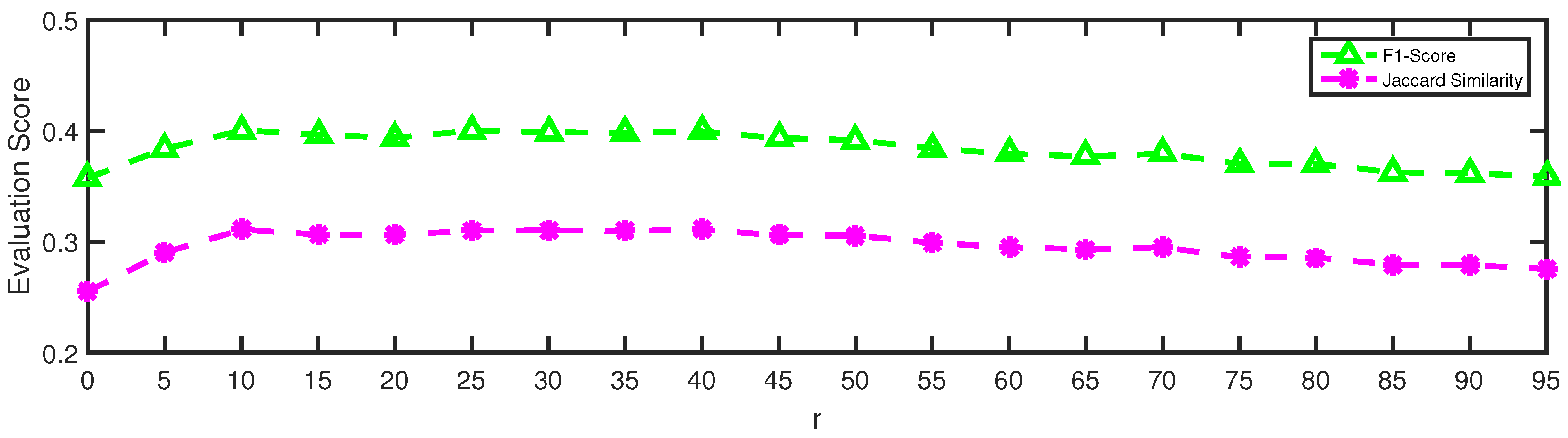
5.3. Parameter Sensitivity Analysis
5.4. Analysis of Detected Communities
6. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Karyotis, V.; Tsitseklis, K.; Sotiropoulos, K.; Papavassiliou, S. Big Data Clustering via Community Detection and Hyperbolic Network Embedding in IoT Applications. Sensors 2018, 18, 1205. [Google Scholar] [CrossRef]
- Bhatti, G. Machine Learning Based Localization in Large-Scale Wireless Sensor Networks. Sensors 2018, 18, 4179. [Google Scholar] [CrossRef]
- Bi, R.; Li, Y.; Tan, G.; Sun, L. Optimizing Retransmission Threshold in Wireless Sensor Networks. Sensors 2016, 16, 665. [Google Scholar] [CrossRef]
- Yang, Y.; Gao, H.; Li, J.; Shi, S. A Distributed and Kernel-Based Scheme for Location Verification in Wireless Sensor Networks. Ad Hoc Sens. Wirel. Netw. 2013, 18, 333–351. [Google Scholar]
- Leng, J.; Jiang, P. Mining and matching relationships from interaction contexts in a social manufacturing paradigm. IEEE Trans. Syst. Man Cybern. Syst. 2017, 47, 276–288. [Google Scholar] [CrossRef]
- Meo, P.D.; Ferrara, E.; Abel, F.; Aroyo, L.; Houben, G.J. Analyzing user behavior across social sharing environments. ACM Trans. Intell. Syst. Technol. 2013, 5, 1–31. [Google Scholar] [CrossRef] [Green Version]
- Ahn, Y.Y.; Bagrow, J.P.; Lehmann, S. Link communities reveal multiscale complexity in networks. Nature 2010, 466, 761–764. [Google Scholar] [CrossRef]
- Balasubramanyan, R.; Cohen, W.W. Block-LDA: Jointly modeling entity-annotated text and entity-entity links. In Proceedings of the 2011 SIAM International Conference on Data Mining, Mesa, AZ, USA, 28–30 April 2011; pp. 450–461. [Google Scholar]
- Coscia, M.; Rossetti, G.; Giannotti, F.; Pedreschi, D. Demon: A local-first discovery method for overlapping communities. In Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Beijing, China, 12–16 August 2012; pp. 615–623. [Google Scholar]
- Li, J.; Wang, X.; Deng, K.; Yang, X.; Sellis, T.; Yu, J.X. Most influential community search over large social networks. In Proceedings of the 2017 IEEE 33rd International Conference on Data Engineering, San Diego, CA, USA, 19–22 April 2017; pp. 871–882. [Google Scholar]
- Chen, L.; Liu, C.; Zhou, R.; Li, J.; Yang, X.; Wang, B. Maximum Co-located Community Search in Large Scale Social Networks. Proc. VLDB Endow. 2018, 11, 1233–1246. [Google Scholar] [CrossRef]
- Chong, C.Y.; Kumar, S.P. Sensor networks: Evolution, opportunities, and challenges. Proc. IEEE 2003, 91, 1247–1256. [Google Scholar] [CrossRef] [Green Version]
- Zhou, Y.; Cheng, H.; Yu, J.X. Graph clustering based on structural/attribute similarities. Proc. VLDB Endow. 2009, 2, 18–729. [Google Scholar] [CrossRef]
- Zhou, Y.; Cheng, H.; Yu, J.X. Clustering large attributed graphs: An efficient incremental approach. In Proceedings of the 10th IEEE International Conference on Data Mining, Sydney, Australia, 14–17 December 2010; pp. 689–698. [Google Scholar]
- Huang, X.; Cheng, H.; Yu, J.X. Attributed Community Analysis: Global and Ego-centric Views. IEEE Data Eng. Bull. 2016, 39, 29–40. [Google Scholar]
- Raghavan, U.N.; Albert, R.; Kumara, S. Near linear time algorithm to detect community structures in large-scale networks. Phys. Rev. E 2007, 76, 036106. [Google Scholar] [CrossRef]
- Xie, J.; Szymanski, B.K.; Liu, X. Slpa: Uncovering overlapping communities in social networks via a speaker-listener interaction dynamic process. In Proceedings of the 11th IEEE International Conference on Data Mining Workshops, Vancouver, BC, Canada, 11–14 December 2011; pp. 344–349. [Google Scholar]
- Akoglu, L.; Tong, H.; Meeder, B.; Faloutsos, C. Pics: Parameter-free identification of cohesive subgroups in large attributed graphs. In Proceedings of the 2012 SIAM International Conference on Data Mining, Anaheim, CA, USA, 26–28 April 2012; pp. 439–450. [Google Scholar]
- Ester, M.; Ge, R.; Gao, B.J.; Hu, Z.; Ben-Moshe, B. Joint cluster analysis of attribute data and relationship data: The connected k-center problem. In Proceedings of the 2006 SIAM International Conference on Data Mining, Bethesda, MD, USA, 20–22 April 2006; pp. 246–257. [Google Scholar]
- Moser, F.; Colak, R.; Rafiey, A.; Ester, M. Mining cohesive patterns from graphs with feature vectors. In Proceedings of the 2009 SIAM International Conference on Data Mining, Sparks, NV, USA, 30 April–2 May 2009; pp. 593–604. [Google Scholar]
- Ruan, Y.; Fuhry, D.; Parthasarathy, S. Efficient community detection in large networks using content and links. In Proceedings of the 22nd International Conference on World Wide Web, Rio de Janeiro, Brazil, 13–17 May 2013; pp. 1089–1098. [Google Scholar]
- Wang, X.; Jin, D.; Cao, X.; Yang, L.; Zhang, W. Semantic Community Identification in Large Attribute Networks. In Proceedings of the 30th AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; pp. 265–271. [Google Scholar]
- Li, Y.; Sha, C.; Huang, X.; Zhang, Y. Community Detection in Attributed Graphs: An Embedding Approach. In Proceedings of the 32th AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Available online: https://aaai.org/ocs/index.php/AAAI/AAAI18/paper/view/17142 (accessed on 23 November 2018).
- Leskovec, J.; Mcauley, J.J. Learning to discover social circles in ego networks. In Proceedings of the 26th Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–8 December 2012; pp. 539–547. [Google Scholar]
- Sun, Y.; Aggarwal, C.C.; Han, J. Relation strength-aware clustering of heterogeneous information networks with incomplete attributes. Proc. VLDB Endow. 2012, 5, 394–405. [Google Scholar] [CrossRef] [Green Version]
- Xu, Z.; Ke, Y.; Wang, Y.; Cheng, H.; Cheng, J. A model-based approach to attributed graph clustering. In Proceedings of the 2012 ACM SIGMOD International Conference on Management of Data, Scottsdale, AZ, USA, 20–24 May 2012; pp. 505–516. [Google Scholar]
- Yang, J.; McAuley, J.; Leskovec, J. Community detection in networks with node attributes. In Proceedings of the 13th IEEE International Conference on Data Mining, Dallas, TX, USA, 7–10 December 2013; pp. 1151–1156. [Google Scholar]
- Chang, J.; Blei, D. Relational topic models for document networks. In Proceedings of the 12th International Conference on Artificial Intelligence and Statistics, Clearwater Beach, FL, USA, 16–18 April 2009; pp. 81–88. [Google Scholar]
- Liu, Y.; Niculescu-Mizil, A.; Gryc, W. Topic-link LDA: Joint models of topic and author community. In Proceedings of the 26th Annual International Conference on Machine Learning, Montreal, QC, Canada, 14–18 June 2009; pp. 665–672. [Google Scholar]
- Yang, J.; Leskovec, J. Structure and overlaps of communities in networks. arXiv, 2012; arXiv:1205.6228. [Google Scholar]
- Günnemann, S.; Färber, I.; Boden, B.; Seidl, T. Subspace clustering meets dense subgraph mining: A synthesis of two paradigms. In Proceedings of the 10th IEEE International Conference on Data Mining, Sydney, Australia, 14–17 December 2010; pp. 845–850. [Google Scholar]
- Günnemann, S.; Boden, B.; Färber, I.; Seidl, T. Efficient mining of combined subspace and subgraph clusters in graphs with feature vectors. In Proceedings of the 17th Pacific-Asia Conference on Knowledge Discovery and Data Mining, Gold Coast, Australia, 14–17 April 2013; pp. 261–275. [Google Scholar]
- Wang, Y.; Gao, L. An Edge-based Clustering Algorithm to Detect Social Circles in Ego Networks. J. Comput. 2013, 8, 2575–2582. [Google Scholar] [CrossRef]
- Gregory, S. Finding overlapping communities in networks by label propagation. New J. Phys. 2010, 12, 103018. [Google Scholar] [CrossRef] [Green Version]
- Wu, Z.H.; Lin, Y.F.; Gregory, S.; Wan, H.Y.; Tian, S.F. Balanced multi-label propagation for overlapping community detection in social networks. J. Comput. Sci. Technol. 2012, 27, 468–479. [Google Scholar] [CrossRef]
- Hu, W. Finding statistically significant communities in networks with weighted label propagation. Soc. Netw. 2013, 2, 138–146. [Google Scholar] [CrossRef]
- Agreste, S.; De Meo, P.; Ferrara, E.; Piccolo, S.; Provetti, A. Analysis of a heterogeneous social network of humans and cultural objects. IEEE Trans. Syst. Man Cybern. Syst. 2015, 45, 559–570. [Google Scholar] [CrossRef]
- Vörös, A.; Snijders, T.A. Cluster analysis of multiplex networks: Defining composite network measures. Soc. Netw. 2017, 49, 93–112. [Google Scholar] [CrossRef]
- Ma, J.; Qiao, Y.; Hu, G.; Huang, Y.; Wang, M.; Sangaiah, A.K.; Zhang, C.; Wang, Y. Balancing user profile and social network structure for anchor link inferring across multiple online social networks. IEEE Access 2017, 5, 12031–12040. [Google Scholar] [CrossRef]
- Lancichinetti, A.; Fortunato, S. Benchmarks for testing community detection algorithms on directed and weighted graphs with overlapping communities. Phys. Rev. E 2009, 80, 016118. [Google Scholar] [CrossRef] [Green Version]
- Yang, J.; Leskovec, J. Overlapping community detection at scale: A nonnegative matrix factorization approach. In Proceedings of the 6th ACM International Conference on Web Search and Data Mining, Rome, Italy, 4–8 February 2013; pp. 587–596. [Google Scholar]
- Blondel, V.D.; Guillaume, J.L.; Lambiotte, R.; Lefebvre, E. Fast unfolding of communities in large networks. J. Stat. Mech. Theory Exp. 2008, 2008, P10008. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | n | m | s | k | AD | AS | AN |
|---|---|---|---|---|---|---|---|
| 4039 | 176,468 | 10 | 193 | 43.69 | 21.93 | 1.05 | |
| Flickr | 16,710 | 1,432,126 | 1156 | 5436 | 85.70 | 273.10 | 88.84 |
| 81,306 | 2,420,766 | 50 | 4065 | 29.77 | 12.51 | 0.63 |
| Dataset | F1-Score | Jaccard Similarity | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| SLPA | CESNA | SCI | CDE | NMLPA | SLPA | CESNA | SCI | CDE | NMLPA | |
| 0.3058 | 0.3233 | 0.0854 | 0.3506 | 0.3905 | 0.2311 | 0.2244 | 0.0462 | 0.2408 | 0.2947 | |
| Flickr | 0.0237 | 0.1041 | 0.0532 | 0.1324 | 0.1444 | 0.0122 | 0.0559 | 0.0246 | 0.0722 | 0.0804 |
| 0.1028 | 0.2223 | NA | NA | 0.2370 | 0.0667 | 0.1374 | NA | NA | 0.1542 | |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, B.; Wang, C.; Wang, B. NMLPA: Uncovering Overlapping Communities in Attributed Networks via a Multi-Label Propagation Approach. Sensors 2019, 19, 260. https://doi.org/10.3390/s19020260
Huang B, Wang C, Wang B. NMLPA: Uncovering Overlapping Communities in Attributed Networks via a Multi-Label Propagation Approach. Sensors. 2019; 19(2):260. https://doi.org/10.3390/s19020260
Chicago/Turabian StyleHuang, Bingyang, Chaokun Wang, and Binbin Wang. 2019. "NMLPA: Uncovering Overlapping Communities in Attributed Networks via a Multi-Label Propagation Approach" Sensors 19, no. 2: 260. https://doi.org/10.3390/s19020260
APA StyleHuang, B., Wang, C., & Wang, B. (2019). NMLPA: Uncovering Overlapping Communities in Attributed Networks via a Multi-Label Propagation Approach. Sensors, 19(2), 260. https://doi.org/10.3390/s19020260