1. Introduction
LiDAR systems are rapidly becoming an integral part of automated and intelligent vehicles for environmental awareness. The price of LiDAR sensors is reducing, and automakers are increasingly installing LiDAR in production vehicles for advanced intelligent functions [
1,
2]. LiDAR measures the distance and direction of the surrounding environment by emitting laser pulses in certain directions and measuring the time-of-flight (ToF) of each laser pulse reflected by the environment. The directions and distances can be converted to a digital 3D representation called a point cloud to express the spatial information of the surrounding environment. Because LiDAR uses light waves, the measured point cloud can represent spatial information very accurately. In addition, LiDAR point clouds can be fused with data from other sensors, such as radars, and cameras, to gain more meaningful information about the vehicle’s environment.
All objects in the driving environment are classified as dynamic or static according to the moving conditions. Therefore, the LiDAR point cloud from detected objects can also be classified as dynamic or static point-wise depending on the motion state of the object. Such point-wise classification of point cloud states can be used for safety and convenience functions in automated and intelligent vehicles. For instance, points classified as static are measured from the surfaces of static objects, such as curbs, poles, buildings, and parked vehicles. Such a static point cloud can be applied to various automated and intelligent driving functions, such as mapping, localization, and collision avoidance systems [
3,
4,
5]. Points classified as dynamic are detected from objects that have speeds above a certain level, such as nearby moving vehicles, motorcycles, and pedestrians. These points can be used for object tracking or motion prediction, which are necessary functions for automated and intelligent vehicles for tasks such as autonomous emergency braking (AEB), lane keeping, traffic jam assistance, and adaptive cruise control (ACC) systems.
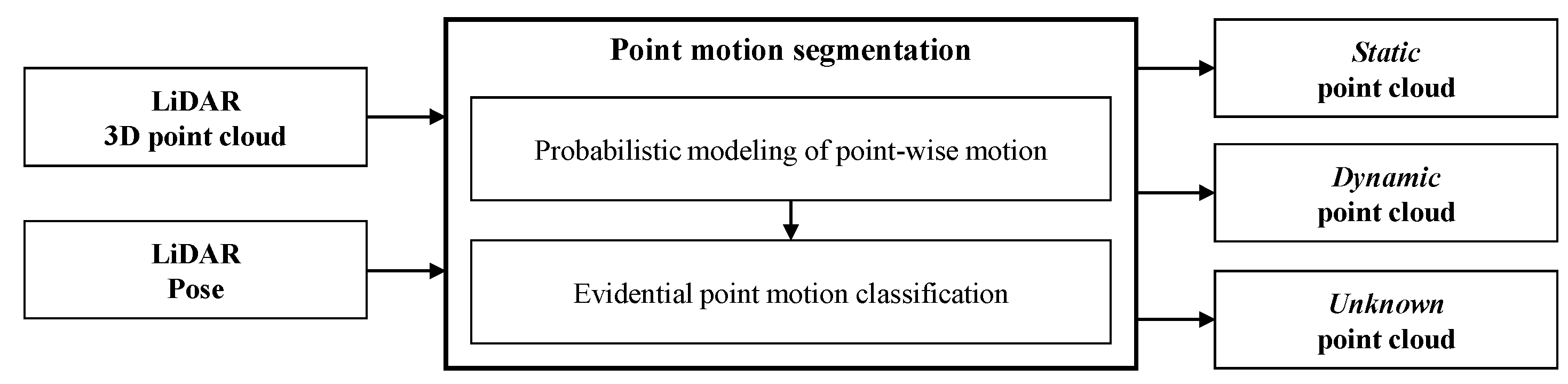
As shown in the previous examples, the information of the point cloud state is classified according to the motion is useful for automated and intelligent vehicles. This paper proposes an algorithm to rapidly segment the motion states of a point cloud detected by LiDAR in real-time. The overall process of the proposed algorithm is shown in
Figure 1. The rapid motion segmentation algorithm has inputs of LiDAR’s 3D point cloud and the 3D pose (position and direction) of the LiDAR sensor. The sensor pose can be estimated from an inertial measurement unit (IMU) or the vehicle’s on-board motion sensors (such as wheel speed sensors or steering angle sensor). Then, point motion segmentation is performed by applying the laser beam characteristics to the pose correlation between consecutive LiDAR point clouds. A combination of probability theory and evidence theory is applied to accurately and reliably update the motion state of points. The algorithm performs point-wise segmentation of the point cloud into three states:
,
, and
.
information is detected from an object moving above a certain speed, and
information is detected from a stationary object. If there are insufficient consecutive LiDAR point clouds for motion classification, some points are classified as
. The performance of the proposed algorithm was evaluated quantitatively and qualitatively through comparison with existing methods.
This research has three main contributions: (1) reflecting the laser characteristics of LiDAR, (2) applying a combination of probabilistic and evidential approaches to update the motion state of points, and (3) online motion updated for real-time applications. This paper focuses on the characteristics of lasers, such as multi-echo, beam divergence, and horizontal and vertical resolution, so that it can segment the motion of points more accurately than existing algorithms, such as occupancy grid mapping. In addition, when updating the state information, a combination of probabilistic and evidential modeling is applied to more accurately reflect the actual LiDAR characteristics to update motion in a point-wise manner. Because all the proposed updating processes are real-time, they are suitable for real-time application in automated and intelligent vehicle systems.
2. Previous Studies
With the development of autonomous vehicles, LiDAR is being more widely used, and many studies of LiDAR are accordingly being conducted. However, there have not been many studies that classify the point-wise motion of LiDAR measurements themselves in real-time. In the field of autonomous and intelligent vehicle systems, studies related to the proposed algorithm aim to generate static environment maps or remove nonstatic points based on tracking results.
An occupancy grid map is a typical method for generating a static environment map using LiDAR measurements. The occupancy grid map divides the environment around the vehicle into a 2D grid or 3D voxel cells with uniform size. The occupancy level of each cell can be updated through the laser’s ray tracing. The occupancy level of a grid (or voxel) cell passing by the laser becomes lower because the physical space of the cell is likely to be free. Conversely, the levels of cells located on the reflecting surface become higher. Based on these principles, static objects are classified as occupied when the occupancy level exceeds a certain threshold. Contrarily, for a moving object, the occupancy level of the cell is not constantly accumulated, so it is not classified as occupied. The numerical value of each cell’s occupancy level is updated based on probability theory [
6] or belief theory [
7]. Static maps in large-scale traffic environment are constructed using LiDAR sensors with probabilistic and belief approaches [
8,
9,
10]. Moras et al. presented an occupancy grid framework that generates a global static map and classifies local moving objects simultaneously [
11,
12,
13]. Classification of traffic objects (such as vehicles, pedestrians, road curbs, and poles) is used to classify the motion of a point cloud [
14,
15,
16].
The advantages of occupancy grid-based static point cloud classification are that its implementation is relatively straightforward and its performance is stable because it has been studied for a long time in various applications. However, occupancy grid mapping has several disadvantages for use in real-time automated and intelligent vehicle applications. Large memory is required because the driving environment must be represented by a grid or voxel cells. Also, the ray tracing method takes a long time to update all cells related to all LiDAR beams. In addition, because space is represented by discrete cells, a discretization error occurs when the resolution is coarse.
Research on the detection and tracking of moving objects using LiDAR has been conducted to recognize the driving environment of automated and intelligent vehicles [
17,
18]. Object detection algorithms detect surrounding objects by clustering the point cloud and generate a bounding box for the each detected object. Tracking algorithms generate tracks for detected objects to estimate their position, direction, velocity, and acceleration. Using the tracking results, we can classify the motion of a point cloud into dynamic and static states. Points in a track bounding box above a certain speed are classified as dynamic, and the remaining points are classified as static. This tracking-based point motion classification is straightforward, and the tracking results can be reused. However, it has some limitations. The point cloud clustering groups the detected points on the same object in the object detection step. Although many clustering methods have been studied, it is difficult to obtain accurate results using point cloud information alone. Incorrect clustering causes incorrect point motion classification. In addition, because the tracking has an initialization time to generate new track, it struggles to satisfy real-time motion classification. Furthermore, because it is difficult for tracking to accurately estimate the speed of slow objects, the point motion of objects is likely to be misclassified near the threshold speed.
The point motion classification algorithm presented in this paper has many advantages over previously proposed ones. First, the proposed method directly segments the point cloud into dynamic and static states using the laser beam model. Therefore, there is no chance of misclassification due to discretization error in the occupancy grid method and erroneous clustering of the tracking-based method. In addition, the proposed method does not require a large amount of memory like the occupied grid approach because it simply buffers recent point clouds. Finally, the proposed method is able to satisfy the real-time requirements of point motion classification because it does not need to update all of the gird cells to initialize a new track.
3. System Architecture
The objective of the proposed point motion segmentation algorithm is to classify the latest LiDAR point, , into motion states, , in real-time. The notation of the LiDAR point and motion states are and , respectively. The n describes the index of the laser beam from 1 to N. The m represents the order of multi-echo for the laser beam and usually has a value of 2 or less. The t represents the time for the LiDAR scan measurement. The “motion state” has three possible values: . The state indicates the points detected as moving objects, and the state represents points detected as stationary objects. The state means that there is not sufficient evidence to classify the motion state as or .
The basic principle of the proposed algorithm is to classify the motion state of the current point cloud by applying the laser characteristic model to the registration relationship between the previously measured point cloud and the current point cloud. The inputs of the proposed algorithm are the current point cloud, ; the previously buffered point clouds, ; and the sensor pose, , for each point cloud. W denotes the time window size of the previous data buffer to be used for motion classification of the current point cloud. There are several methods for obtaining the sensor pose , such as inertial measurement unit (IMU) dead reckoning, scan matching, a high-definition (HD) map-based localization, and simultaneous localization and mapping (SLAM). To avoid loss of generality, we assume that the sensor’s pose and its uncertainty are provided. The output of the algorithm is the motion state of .
The point motion segmentation algorithm consists of two steps: (1) probabilistic modeling of point motion and (2) evidential point motion classification. In the first step, the probability of
, which is a motion classification of
against
, is updated.
Figure 2 illustrates the concept of the probability update of
based on a geometrical relationship between
and
. The likelihood field of the motion can be updated using
and the characteristics of the laser (such as beam divergence and multi-echo). The
probability for
and
will be higher when they are located in the path of the laser (green region) for the previous point cloud
, and the
probability for
will be higher if it is located near the previous point (red region).
In the second step, the probabilities of each motion classification
are integrated to estimate the final motion classification
, as shown in
Figure 3. However, the probability of
cannot be updated by previous points if the current points are not in the likelihood field of the previous points. In this case, it should be classified as
. However, because
cannot be expressed clearly using probability theory, evidence theory, which can handle the
state explicitly, is employed. The probabilities of
are converted into mass (degree of belief) with consideration of LiDAR and sensor pose uncertainty and then integrated into a mass of
using Dempster’s combination rule. The motion states
of each point
are determined using the integrated mass of
.
4. Probabilistic Modeling of LiDAR Point Motion
4.1. Characteristics of LiDAR Point Cloud
LiDAR uses rotating laser beams to measure the distances and angles from surrounding objects. A laser pulse is emitted at a specific angle, and the distance to the object for that angle can be measured using the time-of-flight (ToF) principle, as demonstrated in
Figure 4. ToF represents the difference between the time the laser pulse is emitted from the diode and the time it returns to the object. The distance is calculated by multiplying this time by the speed of the laser light. Using the horizontal–vertical emitted angles and the measured distances, 3D information of surrounding objects can be reconstructed in the form of point data.
The actual LiDAR’s laser is not emitted in a straight line, as shown in the
Figure 4a. The laser has a characteristic of “beam divergence”, which increases the beam’s cross section over the distance. Because of this characteristic, the farther away from the laser source an object is, the wider the area objects can be detected in. In addition, beam divergence enables multi-echoing of the emitted laser pulse, as shown in
Figure 4b, and the multi-echo allows simultaneous measurement of distances to various objects. Another important characteristic of LiDAR is the uncertainty of the distance and angular measurement. Despite the use of lasers, the distance measurement is not infinitely accurate. The distance measurement accuracy is proportional to the measuring capability of the time the laser pulse takes to return. Conversely, the angular accuracy (vertical and horizontal) is discretely accurate because LiDAR is able to control and configure the emission angle. Many previous studies that used LiDAR measurements did not properly account for the above-mentioned characteristics of LiDAR (i.e., beam divergence and distance uncertainty); they treated LiDAR measurements as points with no volume and constant 3D Gaussian uncertainty. To classify LiDAR point motion with high accuracy and reliability, the proposed algorithm accurately reflects these characteristics of LiDAR.
The LiDAR point cloud measurement must be representable in both spherical and Cartesian coordinates for processing by the point motion segmentation algorithm. The measurement can be represented in spherical coordinates as . The point is represented as , where r is distance to a point with a second echo, is the vertical (polar) angle of the point, is the horizontal (azimuthal) angle of the point, and m is the number of echos. The Cartesian coordinate representation is , where .
4.2. Probabilistic Modeling for LiDAR Point Motion
The point motion segmentation classifies the latest N LiDAR points into the motion states , respectively, in real-time, where consists of three states . The motion state of the latest point cloud is segmented based on the registration relationship for the previously buffered point cloud. In other words, the latest point cloud is segmented into based on the W-buffered point clouds and the sensor pose of each point cloud. The sensor pose can be obtained using several methods, such as an IMU dead reckoning, scan matching, HD map-based localization, and SLAM. However, the proposed algorithm assumes that the sensor’s pose information and its uncertainty is abstracted regardless of the type of pose estimation method.
Probabilistic motion modeling of the point cloud
can be estimated using the LiDAR sensor pose
of
and the previously detected LiDAR point cloud
and its sensor pose
, as shown in
Figure 2. The probabilistic motion model of
to
,
, and
can be described as
. The probability
can be represented by a conditional probability for the given conditions, the past and present point cloud pairs
, and their sensor pose
, as represented in Equation (
1).
is composed of each independent point motion
, so
can be represented by the set of conditional probabilities of each point, as described by
consists of two states
, and the sum of
and
is always one.
The conditional probability of one point motion can be reorganized by the Bayes rule, as represented by Equation (
3).
is the likelihood of the LiDAR point measurement for the given motion state.
is the predicted probability density function. The motion for given
,
, and
can be represented by a uniform distribution, so
is
.
can be a normalization factor by applying marginalization, as described by Equation (
4).
By summarizing the above equations, the posterior probability of one point motion can be represented by the following equation,
where
is the normalization factor
of Equation (
4). Equation (
5) is the conditional probability of one LiDAR point motion being expressed by the likelihood of the given point motion. Therefore, the motion probability estimation problem is converted to a likelihood estimation problem for LiDAR point cloud.
4.3. Likelihood of LiDAR Point Measurement
We know that the point cloud motion probability
can be obtained from the likelihood of the point cloud
, as described by Equation (
5). The likelihood
represents a statistical state when
is determined as
or
for given
,
, and
. The likelihood field of one point
can be represented intuitively, as shown in
Figure 5. The likelihood field of the LiDAR point
, measured at sensor pose
at time
t, is represented by points
in point cloud
measured at pose
at the previous time
. The intensity of the green color indicates the likelihood of the point
in the green region being in dynamic motion, and the intensity of the red region represents the likelihood of the point
in the red region being in static motion. The likelihood field is represented in the local spherical coordinates of the previous sensor pose
. The point cloud
is represented in spherical coordinates as
. The likelihood field for the point
is constructed in a triangular-pyramid form by each previous point
with consideration of the beam divergence characteristics of the LiDAR laser, as shown in
Figure 5.
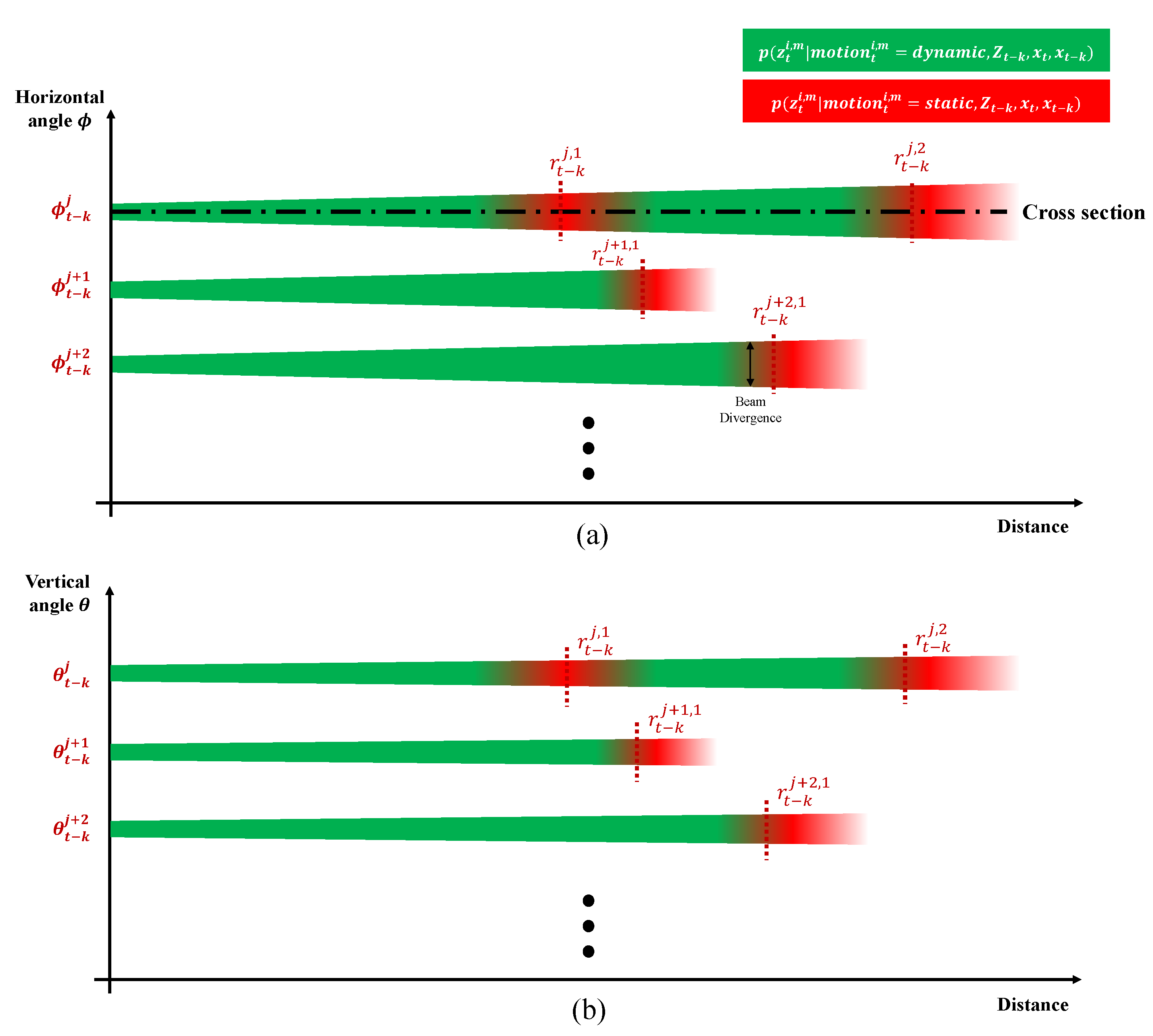
The 3D likelihood distribution of
can be divided by two 2D likelihood fields. The first one is a likelihood field for the distance–horizontal angle (
) plane,
, and the second is a likelihood field of the distance-vertical angle (
) plane,
.
Figure 6 shows the 2D likelihood field in the (
) and (
) planes for the previous measurements
and
. For each horizontal and vertical angle, the likelihood field is distributed discretely based on the resolution of the horizontal and vertical laser pulses. Due to the beam divergence of the laser, the likelihood fields gradually disperse.
The cross-section of the likelihood field for one laser beam
in
Figure 6a can be represented by the likelihood value in
Figure 7. Through this figure, we can more accurately analyze the distribution of likelihood for each motion.
Figure 7a shows the likelihood
when a measured point
is
for given previous measurement
and given poses
and
. Here, the previous measurement
can be expressed in spherical coordinates as
. The region where the previous LiDAR point was detected is likely to be static. LiDAR is measured using ToF, so the uncertainty of the measured distance,
, depends on the accuracy of the ToF sensor. Considering this uncertainty, the likelihood of static motion can be expressed as a Gaussian distribution, as described by
Figure 7a and Equation (
6).
is the standard deviation of the distance measurement, which are different depending on the LiDAR.
Figure 7b shows the likelihood
when a measured point
is
for given
, and
. The region where the previous LiDAR beam
passed is likely to be free, and the location of the current LiDAR point
in the region means that this point is more likely to be detected from a dynamic object. This characteristic can be represented by the following equation:
Here,
denotes the maximum likelihood value for the previous point measurement
and can be represented by the following equation:
When the point
is located in the likelihood field for the given
, we can obtain the likelihood through Equations (
6) and (
7). Then, the probability of the point motion can be calculated through Equation (
5). However, if the point
is located outside of the likelihood field, we cannot obtain the likelihood using the above equations. The area outside of the likelihood field must be dealt with as
, but probability theory cannot handle the
state explicitly. Therefore, in the next chapter, we apply evidence theory to deal with the
state explicitly.
5. Evidential Point Motion Classification
5.1. Evidential Modeling of LiDAR Point Motion
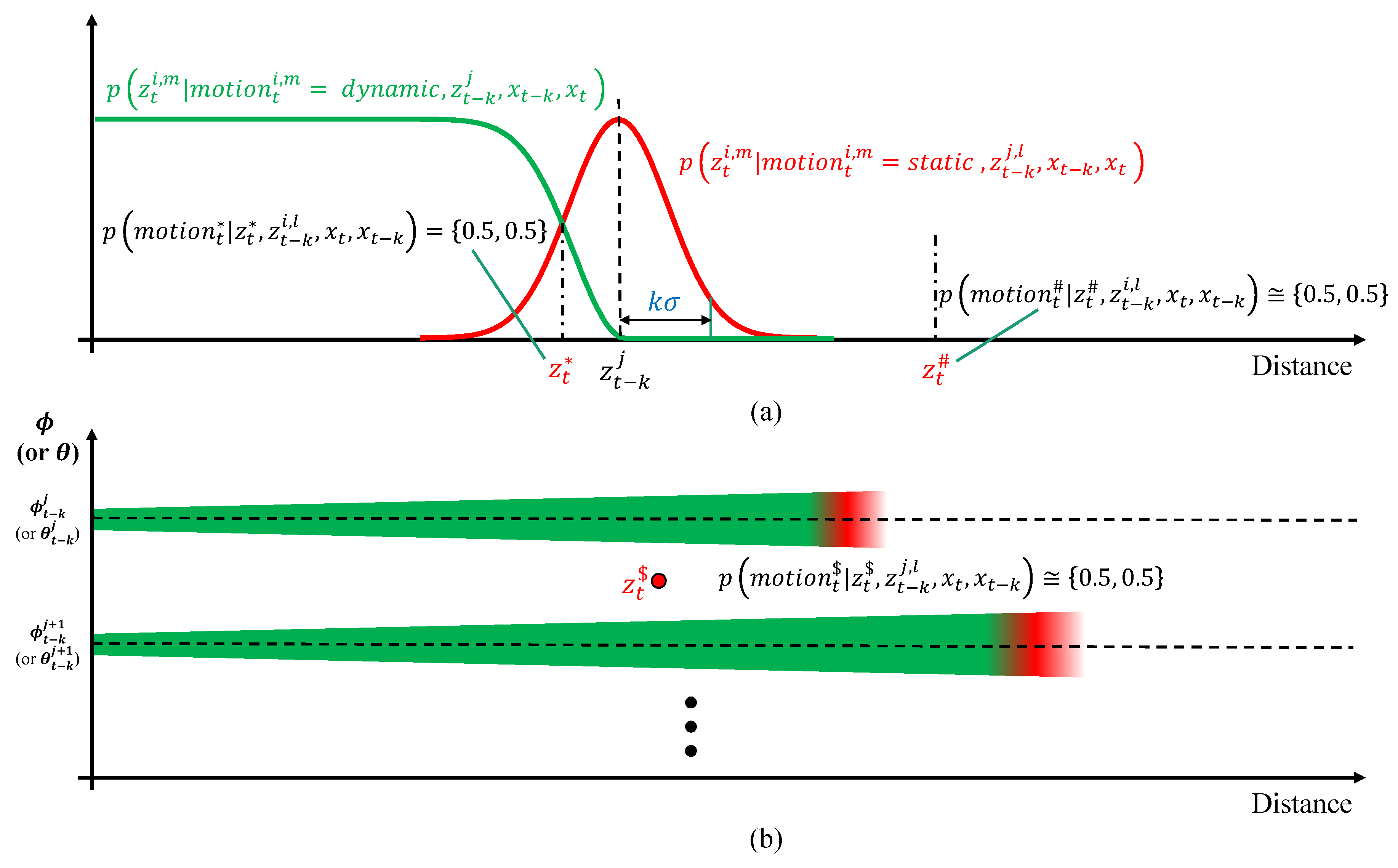
The process of point-wise probabilistic motion estimation achieved through the likelihood field was described in the previous section. However, there is a limitation to the probabilistic method if the point
is not located above the likelihood field. We can see this limitation in
Figure 8. In
Figure 8a, the measurement
represents a normal case because the point is located inside the likelihood field. The point motion probability
can be
because the likelihoods for
and
are the same. However, the probabilities of motion for
in
Figure 8a and
in
Figure 8b are not included in the likelihood field close to
, because both likelihoods for
and
are zero. This means that we cannot distinguish the difference between
,
, and
in the probabilistic approach. To overcome this limitation, an evidential approach (Dempster–Shafer theory) is applied to explicitly distinguish the motion of points that are not located in the likelihood field.
Both probabilistic and evidential approaches are based on the concept of assigning weights to the hypothesized states of the measurement. However, the evidential approach allows sets of alternatives, which means new states can be created by combining existing states. The probabilistic approach deals with the two states . In the evidential approach, the two states form a frame of discernment . Dempster–Shafer theory can manage more states explicitly (, ) by extending the frame of discernment to the power set . is the set , which means that the point motion is or . However, because the point motion cannot be and simultaneously, the state indicates an state. is an empty set, which means that the point motion is not both and . However, because this situation is physically impossible, the state indicates a situation. For each state of the power set in the evidential approach, a mass function is used to quantify the belief of the hypothesis. The mass functions of and represent the belief of point being and , respectively. The mass function of is the union of the beliefs of and , and represents the belief that the point is conflicted by different measurements. The sum of mass functions for the power set must be based on its definition in the evidential framework.
Based on the evidential approach, we can explicitly handle the points located outside the likelihood field for the given point
as an
state. The boundary between the inside and outside is
, as shown in
Figure 8.
k is the tuning factor, which determines the size of the likelihood boundary, and we used
. The point
is located inside the likelihood field, but
and
are located outside the likelihood field. The
of point
motion for the given
, and
is denoted by
for each
.
can be calculated based on whether the point
is located inside or outside of the likelihood field using the following equation.
The
values of the
and
states are calculated by the motion probability
and its confidence,
. The confidence
can be determined using Equation (
10).
describes the confidence of the pose registration between
and
. This value is determined by the performance of the registration method, such as IMU, scan matching, and HD mapping. If the registration is very accurate, the value is close to one; however, if it is not good, it is close to zero. The confidence
is also affected by the time difference
k. Because the confidence of the probabilistic model decreases as the time difference
k increases, the confidence
also decreases by
, where
is the time constant that determines the decay rate.
5.2. Point Motion Segmentation by Integrating the Point Motion Masses
For the given point
and the given poses
and
, the point motion of
can be described by mass function
. For all given previous scan points
and the given poses
and
, several mass functions
can be calculated. We must integrate the mass functions into one mass function
. In addition, for the previously buffered point clouds
in the time window
W, several mass functions
can be obtained, and these mass functions should be integrated into a single mass function
to represent the motion of one point
. To integrate two different mass values from different laser scans and times, Dempster’s combination rule (Equation (
11)) is applied.
Dempster’s combination rule is based on the conjunctive combination rule described by Equation (
13).
6. Experiments
6.1. Experimental Environments
An autonomous vehicle (A1) was used for the experiment to evaluate the proposed algorithm. A1 was equipped with two LiDARs (Velodyne VLP-16) and an IMU, as shown in
Figure 9. The LiDARs provided point cloud data with a 10 Hz sampling frequency and their maximum detection range is 100 m.
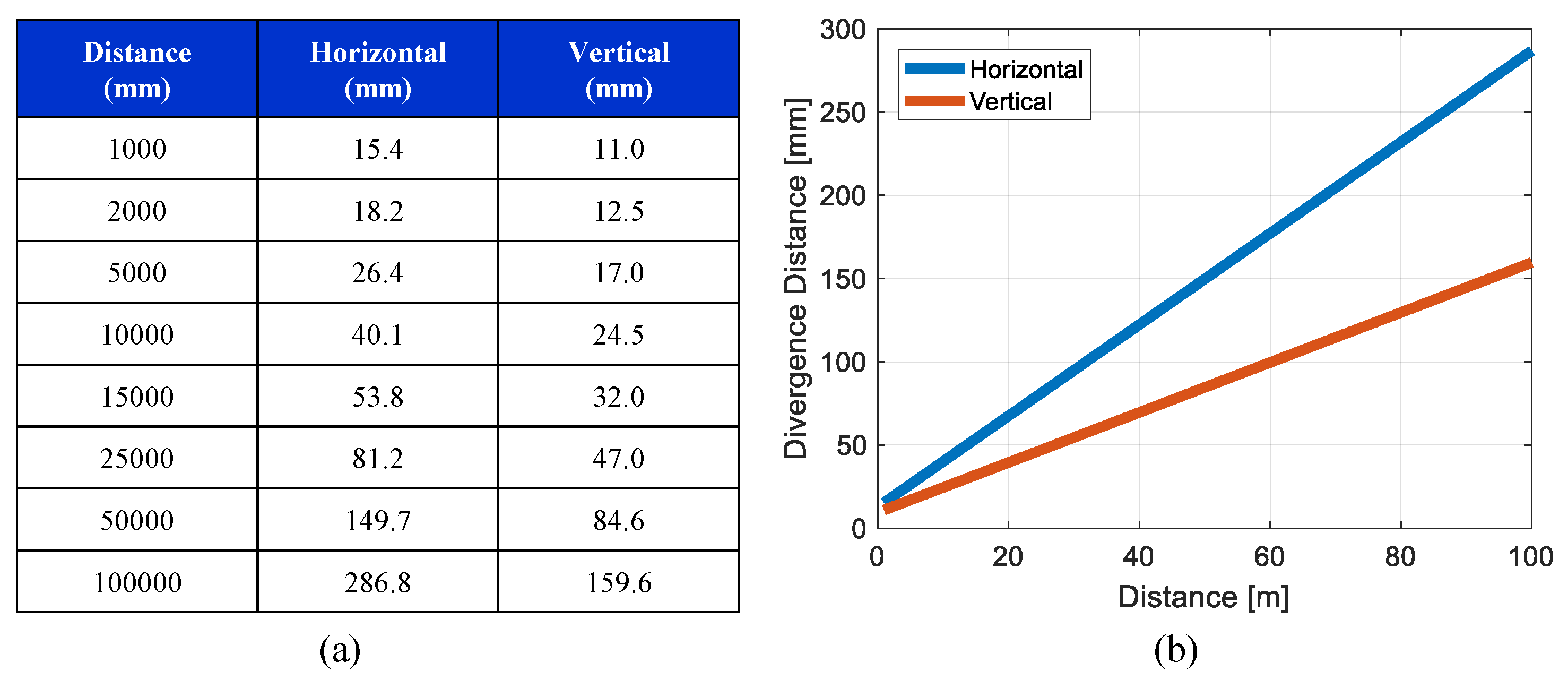
LiDAR lasers beams have beam divergence, which means the beam cross section is increased over time. We designed a beam divergence model based on the specification of the LiDAR sensors, as shown in
Figure 10. The horizontal and vertical beam divergence characteristics were different. The standard deviation
of the distance accuracy was set to 3 cm. Because the distance accuracy can vary based on factors such as temperature and target reflectivity, the selection of the standard deviation
for the probabilistic LiDAR model must consider the uncertainty. The horizontal field of view (FoV) was 360
, and the horizontal angular resolution was set to 0.2
. The vertical FoV was 30
, and the vertical resolution was 2
. Because the LiDAR controls the laser emitting angle, it was assumed that the angular uncertainties (vertical and horizontal) were negligible.
Dead reckoning was implemented using the IMU to estimate the LiDAR pose for each time step. For the experiments, raw IMU data (acceleration and gyro) from the RT3002 sensor were used without real-time kinematic (RTK) GNSS correction. The specifications of the MEMS IMU are listed in
Table 1. Although the IMU was not sufficiently accurate to estimate the long-term pose of the LiDAR sensor, it can provide stable performance in short windows of approximately 50 or less (five seconds or less). In addition, the evidential integration algorithm was able to account for the inaccuracy of the IMU-based pose estimation by tuning the registration confidence
. By considering the installed MEMS IMU, we set
to 0.9.
The synchronization between the LiDAR, IMU, and point motion classification algorithm was measured by a pulse per second (PPS) signal from an RT3002. The LiDARs and IMU were precisely calibrated to be located in the same coordinate system.
6.2. Segmentation Performance Evaluation through Comparative Analysis
To evaluate the performance of the point-wise motion segmentation, experiments were conducted under various scenarios (e.g., cities and highways). The total length of the experiment road is more than two kilometers.
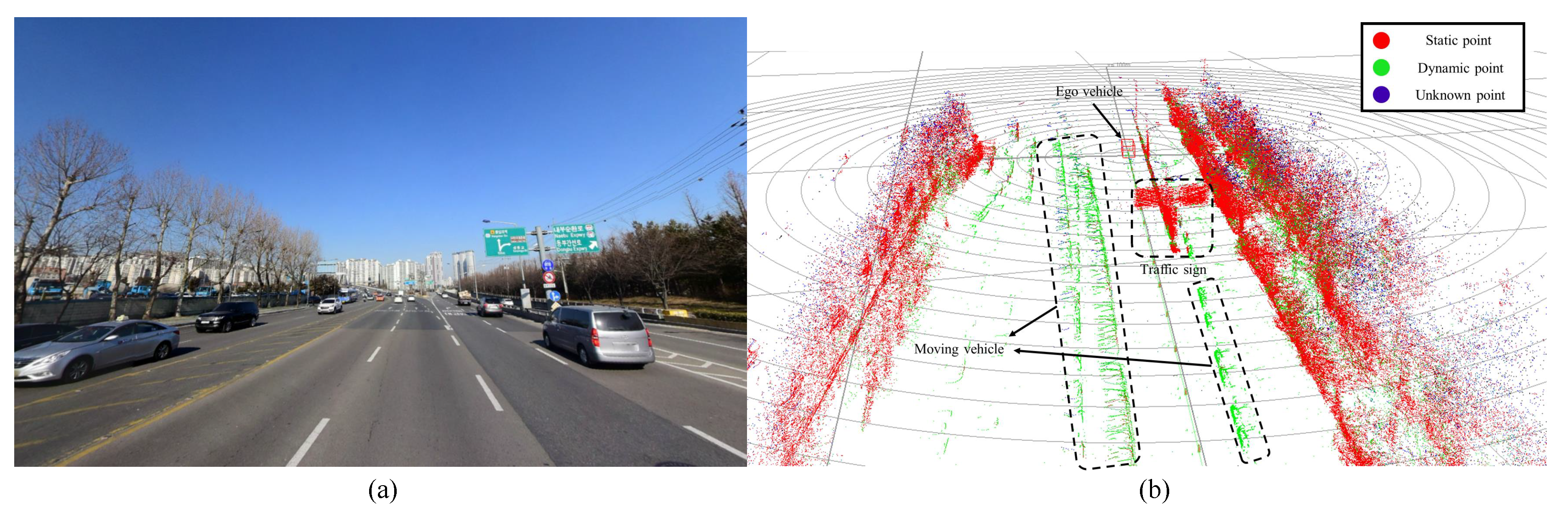
Figure 11a shows single scene of the experimental condition, where moving cars and stationary road structures were mixed. The result of segmentation through the proposed algorithm is shown in
Figure 11b. The RGB value for each point is set using the proposed motion belief algorithm. The red values represent
state belief, the green values represent
state belief, and the blue values represent
state belief. Therefore, the objects that have a high probability of stopping will appear red, moving objects will appear green, and unsegmented objects will appear blue. As shown in
Figure 11b, traffic signs and roadside trees are segmented as red, and moving cars are classified as green.
To quantitatively analyze the segmentation performance, confusion matrices for the tracking-based classification algorithm and the proposed algorithm with various time window configurations were created, as shown in
Table 2. Using the occupancy grid map, static point segmentation is possible, but dynamic point classification is not possible. Therefore, the performance of the segmentation algorithm based on the occupancy grid map is not included in the confusion matrix. For the segmentation using the proposed algorithm, the point motion is classified as static or dynamic when the belief of static and dynamic is over 0.8, respectively. The true class of points used as a reference for evaluation was classified manually. Although public data is more appropriate for comparing performance with other algorithms, there is no public data labeled by point-wise motion to verify the performance of real-time motion classification. The object tracking-based point motion segmentation algorithm segments a point as
when it is located inside the bounding box of the track above a certain speed, and the remaining points not included in the moving track are segmented as
. However, the performance of point-wise motion segmentation is not superior due to incorrect bounding boxes and inaccurate speed estimation by the tracker. The segmentation accuracy of the proposed algorithm is better than that of the tracking-based segmentation algorithm when the time window
W is 20, 30, 50, and 100, as shown in
Table 2. The segmentation performance for a time window of 50 is better than that of 100 because the drift error of pose estimation affects the segmentation performance.
6.3. Real-Time Performance Evaluation
The algorithm was verified in an RTMaps environment with a QuadCore Intel Core i5-3570K, 3600 MHz (
) CPU. Hard real-time performance could not be fully evaluated because it is not an embedded environment, but it can be optimized later by checking the soft real-time performance in the RTMaps environment. To evaluate the real-time performance of the algorithm, the occupancy grid map-based segmentation algorithm was compared with the proposed algorithm. As shown in
Figure 12, the algorithm based on occupancy grid maps took a long time because all cells in the area the LiDAR beam passed were constantly updated. The larger the window size of the proposed algorithm, the more computation is required. The most appropriate time window setting for the proposed algorithm is 50, as illustrated by the confusion matrix, and its computation time is below the sampling period of the Velodyne LiDAR (100 milliseconds).
7. Conclusions
This paper proposed a segmentation algorithm to rapidly classify the motion states of a LiDAR point cloud in real-time. The motion segmentation algorithm requires inputs of point clouds and 3D pose (position and direction) of the LiDAR sensor. The point-wise motion segmentation is performed based on the laser beam characteristics and the 3D pose correlation between consecutive LiDAR points. A combination of probability and evidence theory is used to accurately and reliably segment the motion state of points into , , and .
(1) The point motion segmentation algorithm considers the characteristics of the LiDAR laser beam, such as multi-echo, beam divergence, and horizontal and vertical resolution. Therefore, the point motions are segmented more accurately and reliably than by conventional algorithms (e.g., occupancy grid mapping and tracking-based segmentation algorithm).
(2) To update the motion state of each LiDAR point, a combination of probability theory and evidence theory is applied to point motion modeling to accurately reflect the LiDAR characteristics. Probability theory is used to model the likelihood fields of LiDAR point clouds, taking into account the uncertainty of LiDAR measurements. Evidence theory is used to incorporate multipoint motion probabilities, taking into account pose uncertainty and the state.
(3) The proposed point motion segmentation algorithm was evaluated experimentally. The segmentation accuracy was for a time window of . This is better than the accuracy of the tracking-based algorithm (). Because the proposed algorithm can handle one LiDAR point clouds in a one-step process, when operating under 100 ms, it is suitable for real-time applications in automated and intelligent vehicle systems.
The performance of the algorithm is related to the positioning algorithm that estimates the pose of the LiDAR sensor. In future research, we plan to analyze the quantitative relationship between the LiDAR sensor positioning and the proposed algorithm performance, and to study the SLAM algorithm that classifies the point motion and simultaneously estimates the pose of the LiDAR sensor.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

