Abstract
Fault diagnosis is critical to ensuring the safety and reliable operation of rotating machinery systems. Long short-term memory networks (LSTM) have received a great deal of attention in this field. Most of the LSTM-based fault diagnosis methods have too many parameters and calculation, resulting in large memory occupancy and high calculation delay. Thus, this paper proposes a low-delay lightweight recurrent neural network (LLRNN) model for mechanical fault diagnosis, based on a special LSTM cell structure with a forget gate. The input vibration signal is segmented into several shorter sub-signals in order to shorten the length of the time sequence. Then, these sub-signals are sent into the network directly and converted into the final diagnostic results without any manual participation. Compared with some existing methods, our experiments illustrate that the proposed method has less memory space occupancy and lower computational delay while maintaining the same level of accuracy.
1. Introduction
Mechanical fault diagnosis—analysing data collected by sensors and predicting the health of mechanical systems—has become a research hotspot in industry [,]. The existing methods can be approximately divided into three categories: physics-based “white-box” models, data-driven artificial intelligence (AI) methods (“black-box”), and the combination of above two kinds, referred to as “grey-box” models. The performance of physics-based models is heavily dependent on the quality of domain knowledge about the practical mechanical systems. In reality, mechanical equipment works in complex production environments, and the collected data are seriously disturbed by a variety of noise. The models built in an ideal environment may not work in such a complex environment. A data-driven model can update parameters using real-time data []. This flexibility has made them become the focus of fault diagnosis research. Although white-box models are dependent on the quality of domain knowledge, this additional information could reduce the solution space and enhance the performance of black-box models. Some grey-box models have earned relatively good results in fault diagnosis. Zhou et al. [] used neighbourhood components analysis to reduce the dimensionality of original features, then applied coupled hidden Markov model (CHMM) to bearing fault diagnosis. Jung et al. [] exploit the multi-scale energy analysis of discrete wavelet transformation to obtain a low-dimensional feature subset of data as the input of a k-nearest neighbours ( k-NN) algorithm for bearing fault classification. Gangsar et al. [] proposed a method for the fault diagnosis of induction motors by combining the wavelet packet transform (WPT) and support vector machine (SVM).
The traditional AI methods are also shallow models and always work on the original feature representation without creating new features during the learning process []. It is difficult to characterise the inherent non-linear relationship of complex mechanical systems effectively while using them. In order to further improve the diagnostic performance, deep learning has recently been applied to mechanical fault diagnosis []. Deep learning can automatically extract advanced features from the original data through hierarchical learning, and achieve end-to-end learning without any manual participation. Compared with the traditional AI methods, the deep learning method has lower dependence on the knowledge of feature design. At present, there are three main methods that are widely used in the field of mechanical fault diagnosis: automatic encoder (AutoEncoder), convolutional neural network (CNN), and recurrent neural network (RNN). The AutoEncoder can learn rich representation features and reduce data dimensionality, and has has received a great deal of attention in this research field. Ahmed et al. [] proposed an unsupervised feature learning algorithm using stacked AutoEncoders to learn feature representations from compressed measurements. Lu et al. [] presented a detailed empirical study of stacked denoising AutoEncoders with three hidden layers for fault diagnosis. Junbo et al. [] used a digital wavelet frame and nonlinear soft threshold method to process vibration signals and used an AutoEncoder on the preprocessed signal to carry out roller bearing fault diagnosis. However, adjusting the model parameters requires a large amount of data and time, and it is difficult to judge whether the learned features are related to the target task.
CNNs can automatically select the feature of data without any artificial designs, and has been widely applied in fault diagnosis. Wen et al. [] transformed a raw signal into a square matrix through non-overlapping cutting and normalised the value to 0–255, which was regarded as an image directly using 2D LeNet-5 for the fault prediction of gears and bearings. Liu et al. [] cut the raw signal into a square matrix by changing the interval distance, which was used directly for fault detection in the 2D-CNN structure training. Sun et al. [] used multi-scale information extracted by dual tree-complex wavelet transform (DT-CWT) to form a matrix and combined it with a CNN for gear fault diagnosis. Guo et al. [] used a novel diagnosis method involving a CNN to directly classify a continuous wavelet transform scalogram (CWTS). CNNs can effectively extract local features of data and process high-dimensional data, but most CNN architectures are heavily over-parametrised and computationally complex, taking a lot of time to train the network [].
The initial parameter values affect the final performance of a CNN. Besides, CNNs are unable to remember historical data information. When predicting, a CNN must process historical input data repeatedly, bringing unnecessary computational consumption. The RNN is a framework for processing sequence data. It analyses the combination of historical data feature and current input data, then extracts the new feature information and makes decisions. The processing form of RNNs is more suitable for mechanical fault diagnosis. RNNs have the ability to memorise historical information, and only need to process the input data once. Therefore, they can detect the health status of mechanical systems in real time. However, the vanishing gradient problem during the back-propagation of model training hinders the performance of RNNs. This means that traditional RNNs may not capture long-term dependencies. Long short-term memory networks (LSTMs), which can extract long-term dependence features, avoid the gradient disappearance problem cleverly through the gate mechanism and have been successfully applied in various fields, including image captioning [], speech recognition [], and natural language processing []. Nevertheless, it is also difficult to train LSTMs when the data sequence is too long. LSTM-based methods also have the problem of excessive parameters and computational complexity. The LSTM structure can be further simplified to reduce the calculation time. In order to solve the above problems, this paper proposes a low-delay lightweight recurrent neural network (LLRNN) model for mechanical fault diagnosis, making the following two main contributions: (1) The design of a lightweight network structure based on a special LSTM cell with only a forget gate, reducing the parameters and calculation of the network. (2) It studies the influence of step length (i.e., the length of each sub-segment of a sequence signal, as shown in Figure 1 ) and step number (number of sub-segment of a sequence signal as shown in Figure 1 L/) of the sequence data on the performance of the model, including accuracy, noise immunity, and calculation delay, on the basis of the characteristics of the vibration signal. Two bearing data sets, provided by Case Western Reserve University (CWRU)’s Bearing Data Center and the Center for Intelligent Maintenance Systems (IMS), University of Cincinnati, respectively, were used to verify the performance of the proposed algorithm. Compared with the LSTM-based methods and some CNN-based models, in our experiments the proposed algorithm took up less storage space and had shorter calculation delay under the same accuracy and noise immunity, and was more suitable for real-time fault diagnosis.

Figure 1.
The step length () and step number (L/) of a data sequence.
The rest of this paper is arranged as follows. In Section 2, the RNN variants and their applications are reviewed. Then, the LLRNN and its analysis are presented in Section 3. In the following Section 4, the experimental results using two data sets are illustrated. Finally, the conclusion is provided in Section 5.
2. Related Work
2.1. Application of RNN in Fault Detection
RNNs are mainly used to process sequence data, because they can store the feature information of historical data in the internal state (i.e., memory). Then, they combine current input data with memory and extract new features, as shown in Figure 2a. RNNs can be trained via backpropagation through time, but the vanishing gradient problem during backpropagation makes it difficult to capture long-term dependencies. The LSTM is an efficient RNN variant structure to solve this problem. It avoids long-term dependence problems through the gate mechanism and has the ability to extract long-term dependent feature information effectively []. The LSTM cell structure is shown in Figure 2b, and the calculation process is shown in Equation (1).
where denotes the forget gate, the input gate, the output gate, and the new candidate memory state. and denote the hidden states of the previous moment and the current moment. denotes the input of the current moment. and denote the memory states of the previous moment and the current moment. and denote the parameters related to and in the corresponding gate. and denotes the bias in the corresponding gate. “·” and “⊙” denote the operations of matrix multiplication and point multiplication, respectively.
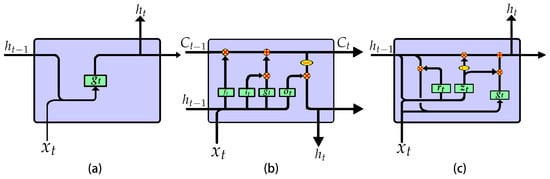
Figure 2.
The inner structures of different recurrent neural network (RNN) cells: (a) RNN; (b) Long short-term memory network (LSTM); (c) Gated recurrent unit (GRU)
The gate mechanism of LSTM is redundant, causing excessive parameters and calculations. In order to solve this problem, researchers have proposed several variants [,,,]. Gated recurrent unit (GRU) [], the most successful variant, combines the forget gate and the input gate into an update gate and mixes the memory state and the hidden state. The GRU cell structure is shown in Figure 2c and the calculation process is shown in Equation (2):
where denotes the reset gate, controlling the influence level of on . denotes the update gate, controlling the update of the memory state. The GRU can achieve performance comparable to LSTM with one less gate.
LSTMs have been successfully applied in many fields, and have also received much attention in the field of mechanical fault detection. Zhao et al. [] combined a CNN with a bi-directional LSTM to propose a novel machine health monitoring system used for tool wearing prediction. Park et al. [] employed an LSTM model in an edge device for industrial robot manipulator fault detection. Yuan et al. [] applied an LSTM for aero engine fault diagnosis and remaining useful life (RUL) prediction. Zhang et al. [] combined LSTM with Monte Carlo simulation for lithium-ion batteries’ RUL prediction. Cui et al. [] combined fast Fourier transform (FFT) and RNN for bearing fault diagnosis. Wang et al. [] applied LSTM to gear fault diagnosis. Liu et al. [] proposed a GRU-based method for rolling bearings fault diagnosis by comparing the reconstruction errors generated from multiple-dimension time-sequence data. This paper proposes a lightweight model with low delay based on a special LSTM cell structure for rotating mechanism fault diagnosis.
2.2. Introduction of JANET
Der Westhuizen et al. [] proposed a new LSTM cell structure with only one forget gate, namely, “just another network” (JANET). Not only does JANET provide computational savings, but also outperforms the standard LSTM on multiple benchmark data sets and competes with some of the best contemporary models. The JANET cell structure is shown in Figure 3, and the calculation process is shown in Equation (3).
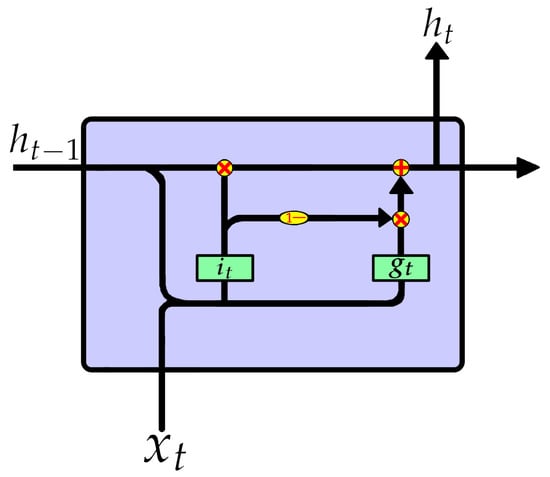
Figure 3.
The inner structures of JANET.
JANET retains the most important forget gate in LSTM. Since determines which information should be discarded, the information that does not suggest to drop should be retained. Therefore, is approximately regarded as , reducing both the parameters and calculation caused by the input gate. The output gate selects the useful information in the memory state and passes it to the hidden state . In fact, this task can be handed over to the forget gate of the next moment. Based on this idea, JANET cancels the output gate and merges the hidden state and memory state , just like the GRU. JANET has a simpler structure and less calculation.
3. The Proposed Method
3.1. Model Structure
In this paper, a low-delay lightweight recurrent neural network (LLRNN) model for rotating machinery fault diagnosis is designed based on a JANET cell, and the overall flowchart is shown in Figure 4a. The input vibration signal is segmented into several shorter sub-signals. Then, these sub-signals are sent to the network directly and converted into the final classification results, as shown in Figure 4b. As an end-to-end model, the proposed model can turn the data collected by sensors into the finally desired prediction results without any manual participation, which could be used for real-time monitoring and has two improvements: (1) It is based on a simpler cell structure with fewer parameters, and the proposed model consumes less storage space while maintaining its performance. (2) Segmenting the signal before sending it into the network not only reduces the training difficulty of the network, but also improves the noise immunity.
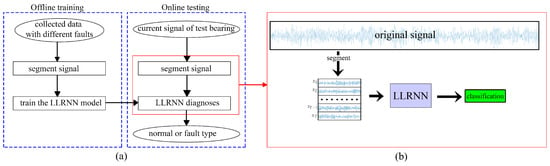
Figure 4.
(a) Flowchart of the proposed method. (b) Diagnostic process of the proposed method. LLRNN: low-delay lightweight recurrent neural network.
3.2. Network Structure
Using the output of the previous layer as the input of next layer, an RNN can also be stacked to form a deeper structure similar to a CNN, as shown in Figure 5a. The feature extraction ability of the model can be improved and the learned features have more semantic information. However, this operation brings a risk of over-fitting and more calculation. After logically expanding, the actual calculation process of an l- RNN is described in Figure 5b. The length of each is , and T = = L/. In subsequent experiments, the effects of various parameters on the performance of the model are verified, including accuracy, noise immunity and computational delay.
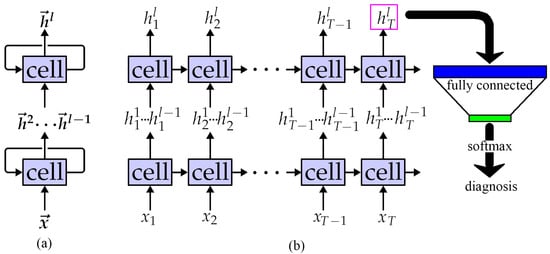
Figure 5.
LLRNN network structure: (a) The real structure; (b) The logically expanding structure.
3.3. Model Analysis
3.3.1. The Parameters and Calculation of Different Cell Structures
As shown in Equation (3), the calculation process of each gate is essentially a fully connected layer. Let denote the quantity of hidden units in each gate, and denote the input data dimension. The parameters and calculation cost are defined as in Equations (4) and (5):
where and (FLOP: floating-point operations) denote the parameters and calculation amount of each gate, respectively.
The parameter quantity of the cell is the sum of that of all the gates inside it. LSTM has four gates, GRU has three, and JANET has only two. Their parameters are shown in Equations (6)–(8). JANET has only half the number of parameters that LSTM does, and two-thirds those of GRU:
The calculation of the cell in each moment equals to the sum of the that of all the gates, plus the calculation cost of information interaction between the respective gates, which essentially are some point addition and point multiplication operations. LSTM has four multiplication interactions, GRU has five, and JANET has four. The total calculations are shown in Equations (9)–(11):
where denotes the number of sub-segments of a sequence signal, and = L/, as shown in Figure 1.
3.3.2. Analysis of Step Length
As shown in Equations (8) and (11), and affect both the calculation and parameters, and steps affects only the calculation. When the signal length L of the input model is fixed, = L/ and the Equations (12) and (13) can be obtained by substituting it into Equations (8) and (11):
Equation (12) shows that the total parameters of the model are positively correlated with , and the occupancy of parameters and storage space increases with . On the contrary, Equation (13) shows that the total calculation of the model is negatively correlated with , and the increment of will reduce the calculation. In addition to the computation, the waiting time caused by data dependencies also affects the total computing time of the model. The RNN has a serious problem of calculation delay when processing long sequence data. Because the calculation of must wait for , the parallel computing power of the GPU cannot solve it. When training the network using a vibration signal , the model takes a long time to process such a long time sequence if every point is used as the input of each moment. It is difficult to train the network. In addition, there is too little effective information that can be extracted, and the extracted features are seriously disturbed by noise if the input vibration signal is single-point. Noise interference not only changes the amplitude information of the signal, but may even change the direction information of the vibration. As a result, the accuracy of the algorithm is reduced.
In order to solve these problems, we segment the vibration signal of length L into steps-segment sub-signals of length , as shown in Figure 1. When -point vibration information is used as the input of each moment, the step number of the time sequence will reduce from L to L/ and the total calculation decreases according to Equation (13).
Both the fault shock signal and noise signal are superimposed on the normal signal. The operation of each gate in the cell is a vector multiplied by a matrix, which is essentially a weighted summation of each point of input. It plays a certain smoothing effect, the same as a mean operation, as shown in Equation (14):
where denotes the signal of input data, and denote the signal of vibration part and noise part in , and and denote the signal of the normal part and the fault part in . Most noise is subject to the zero-mean distribution and . This means that the larger is, the closer is to 0. Although the , for the most part the value of is 0, except for the moments where a fault shock happens. If is too large, will be very small. It is difficult for a model to extract the feature of faults. Consequently, the should be appropriate—not too large or too small. These analyses were verified in the subsequent experiments.
4. Experiment and Analysis
Two bearing data sets were used to verify the performance of the proposed algorithm and the previous analyses. The data sets were provided by Case Western Reserve University (CWRU)’s Bearing Data Center [] and the Center for Intelligent Maintenance Systems (IMS), University of Cincinnati []. The hardware resources of the computing device used for the experiment were as follows, CPU: Intel Core i7-8700k, 3.7 GHz, six-core twelve threads; GPU: NVIDIA 1080Ti, 11G ; Memory: 32 GB; Storage: 2 TB.
The software environment was as follows, Ubuntu 16.04 system; TensorFlow 1.10 framework, Python programming language.
4.1. The Impact of Model Structure on Performance
4.1.1. Introduction of the CWRU Data Set
To validate the previous analyses, 12-kHz drive-end data collected by Case Western Reserve University (CWRU)’s Bearing Data Center were used. Figure 6 shows the test rig used for data collection. The data set contains four different categories, namely, normal bearings, bearings with a faulty ball (ball), bearings with a faulty inner race (inner) and bearings with a faulty outer race (outer). For each type of fault, there are three fault diameters, 0.007 inch, 0.014 inch and 0.021 inch, respectively. Thus, there are 10 classifications in this dataset.

Figure 6.
Fault simulation test rig of the Case Western Reserve University (CWRU) data set.
Due to the limited experimental data, the overlapping sampling method was used to enhance the data according to references [,], as shown in Figure 7.
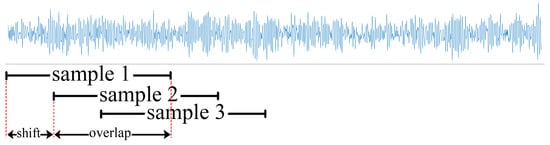
Figure 7.
Diagram of overlapping sampling.
The data set was divided into four subsets, corresponding to four different loads, namely load 0, load 1, load 2, and load 3. As shown in Table 1, every category of data subset under each load contained 800 training samples, 100 test samples, and 100 validation samples, for a total of 8000 training samples, 1000 test samples, and 1000 validation samples.

Table 1.
Classification of the CWRU bearing fault data subsets under each load.
Under normal circumstances, bearing vibration signals are affected by the surrounding ambient noise. The CWRU dataset selected in this study was collected in an environment with a relatively low level of ambient noise and therefore cannot reflect the performance of the fault diagnosis algorithm in an actual environment. In addition, there are a number of noise sources in an actual environment, and it is impossible to obtain training samples under all the conditions in various noise environments. Therefore, noise was added to the samples in the raw test set to simulate data from actual conditions. Using the resultant data for testing could produce results closer to those obtained under actual industrial production conditions. Accordingly, white Gaussian noise from 10 dB to −4 dB was added to the data to simulate actual conditions. Signal-to-noise ratio (SNR) is defined as in Equation (15), and was used when adding noise:
where P and P are the intensities of the raw and noise signals, respectively.
To examine the noise immunity of the proposed algorithm, the learning model with the highest accuracy for the validation set in 1000 iterations was selected. Noise-containing data were randomly generated 10 times for each sample in the test set of the dataset, and were used for testing and statistically analysing the experimental results, which were represented in the form of the mean.
4.1.2. Experimental Results and Analysis
To verify the analysis of the impact of step length on performance in Section 3.3.2, the data subset under load 0 was selected for experimentation, with the network structure having 128 hidden units and 1 layer. We repeated the experiment 10 times with each parameter configuration, and calculated the mean value of the results, as shown in Table 2.
Table 2.
Experimental results for the effects of different step lengths.
As the increased, the validation accuracy and test accuracy slightly increased. When exceeded 256, the accuracy began to decrease due to the smoothing effect caused by the lengthening of , which made the model less sensitive to the detail change information of the vibration signal. When increased from 512 to 1024, the increment of noise immunity was greater than the decrement of feature extraction capability, so the noise immunity ability rebounded. The was set to 64 to preserve the noise immunity of the model.
The number of hidden units determines the ability of the RNN model to extract feature information; too few leads to under-fitting, and too many causes over-fitting. The extracted feature is finally transformed into a vector, which represents the category, through a fully connected layer as shown in Figure 4b. This process also has a smoothing effect and an impact on noise immunity. As shown in Table 3, as the number of hidden units increased, the test accuracy first rose and then fell. The reason for this is that the generalisation ability increased with the complexity of the model, then decreased due to over-fitting when the number of cells exceeded 128. Unlike the impact of , the decrement of noise immunity was not due to the reduced feature extraction capabilities, but to the over-fitting to noise-free training data.
Table 3.
Experimental results for the effects of different hidden units.
When hidden units increased from 16 to 256, the theoretical calculation increased by 50 times, but the real training time only increased by less than three percent, and the test time nearly doubled. These gaps were caused by the following two reasons: (1) The increment of hidden units only brought the calculation for each moment without increasing the waiting time. (2) The GPU has parallel computing power; 16 units or 256 units were calculated synchronously, and the time consumed was the same as that for calculating only one unit. Only when calculating the sum of all the results of each unit did the calculating time increase slightly.
RNNs can also be stacked like CNNs to build deeper models, as shown in Figure 5b. The number of hidden units in the network was set to 128 for the experiment due to the highest noise immunity performance, and the effects of different layer numbers on the model performance are shown in Table 4.
Table 4.
Experimental results for the effects of different numbers of layers.
The model had the highest test accuracy and noise immunity at two layers due to the appropriate model complexity. The model with more layers had lower performance caused by over-fitting, and both space occupancy and calculation delay increased without any increment of test accuracy or noise immunity.
As shown in the above experiments, all the analyses of the impact of network structure and step length on performance were verified. As increased, the calculation delay decreased, the accuracy first rose then fell, and the noise immunity increased. As increased, the calculation delay on the CPU decreased, and both the accuracy and noise immunity increased then decreased. As the number of layers increased, the calculation delay increased, and both the accuracy and noise immunity increased then decreased. The trend of performance was almost the same as assumed in Section 3. The proposed method had the most satisfactory result for fault diagnosis on the CWRU data set in the condition that was equal to 64, was equal to 128, and was equal to 2.
4.2. The Universality of the Proposed Method
In the previous experiments, the analyses of the impact of network parameters on the performance were verified, and the proposed method had a satisfactory result on the CWRU data set. However, the mechanical system in the CWRU bearing data experiment was relatively simple, and the fault was also caused by human damage, whose vibration characteristics may be different from that of natural wear in an actual production environment. To verify the universality of the model, extra experiments were performed using the IMS data set, which was collected in a more complex mechanical system with natural wear faults. LSTM and GRU were used for experimental comparison to verify whether the simplification of the cell structure would reduce the network performance.
4.2.1. Introduction of the IMS Data Set
This dataset was provided by the Center for Intelligent Maintenance Systems (IMS), University of Cincinnati, and shared on the website of the Prognostic Data Repository of NASA []. The structure of the mechanical system is shown in Figure 8, and the data records the entire wear process of the bearing.
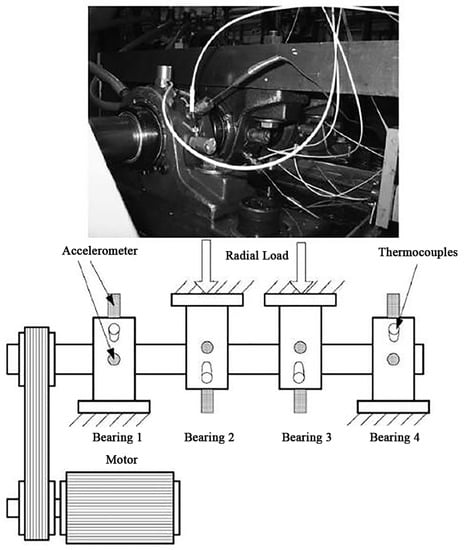
Figure 8.
Test rig and sensor placement of the Center for Intelligent Maintenance Systems (IMS) dataset.
The bearings experienced “increase–decrease–increase” degradation trends. This behaviour was due to the “self-healing” nature of the damage []. First, the amplitude of vibration increased because of the impact caused by the initial surface defect (e.g., spalling or cracks). Then, the initial defect was smoothed by continuous rolling contact, leading to the decrease of the impact amplitude. Finally, the damage spread over a broader area, and the vibration amplitude increased again. During the self-healing period, the amplitude of the fault bearing was similar to that of the normal bearing, making it difficult to detect the fault during the self-healing period, as shown in Figure 9.
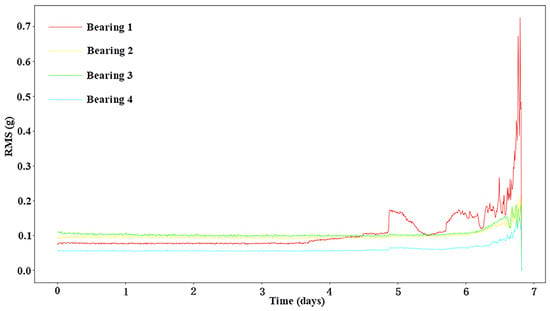
Figure 9.
The root mean square (RMS) values in dataset 2 of IMS.
At the end of the experiment, the inner race defect, outer race defect, and roller element defect were detected manually []. As shown in Figure 9, the red curve indicates the wear process of the outer race defect in bearing 1. The self-healing appeared after the failure on the fifth day, and its amplitude was basically the same as that of the normal bearing (green curve). In order to increase the difficulty of diagnosis, we chose the bearings in the self-healing period as fault data, and the normal bearing with similar amplitude as normal data. Also, a length of 1024 was directly sampled as a sample instead of overlapping sampling due to the relatively sufficient size of the IMS data set. The fault data categories are shown in Table 5.
Table 5.
Classification of the IMS bearing fault data set.
4.2.2. Experimental Results and Analysis
In order to verify whether the simplification of the cell structure had too much of a negative impact on performance, a comparison experiment was performed using GRU and LSTM with the same number of hidden units and almost-calculated quantities.
The comparison results of the CWRU data set are shown in Table 6 and Table 7. When the number of hidden units was 128 and the number of layers was 1, neither the test accuracy nor noise immunity of GRU and LSTM were improved much compared with LLRNN. However, the parameter quantity of GRU increased by one-half and that of LSTM increased by one time, the test delay of GRU increased by 50%, and that of LSTM increased by 25%. The GRU had less calculation than the LSTM but the calculation delay of GRU was higher than that of LSTM. This is because the four gates of the LSTM were independent and could be calculated in parallel, while the calculation of in GRU must wait for the output of , as shown in Figure 2c, resulting in more calculation time than LSTM.
Table 6.
Experimental results of various methods in the CWRU dataset.
Table 7.
Noise immunity of various methods in the CWRU dataset.
Under a structure of one layer with parameter quantity and calculation amount similar to LLRNN, the performances of GRU and LSTM were slightly lower than that of LLRNN, while the delay of LSTM was 13% higher and that of GRU was 30% higher. In the cell structure work flow, the calculation of the LSTM activation function tanh brought calculation and computational delays, resulting in the calculation time of LSTM being longer than that of LLRNN. Under the structure of two layers with the parameter quantity and calculation amount similar to LLRNN, the performances of GRU and LSTM were improved compared with GRU and LSTM. Although the performance was similar to that of LLRNN, the delay of LSTM increased by 24% and that of GRU increased by 37%. As shown in Table 6, CNN-based models [,,,] gained competitive performance in no-noise test data, but they took up more storage and consumed more computing time due mainly to the over-complexity of the network structure. Although reference [] had similar parameters to LLRNN, its theoretical calculation was six times greater and its real computing time was approximately ten times greater compared with the proposed method. Besides, the accuracies of CNN models fell rapidly in the noisy environment while the accuracy of LLRNN still exceeded 90%, as shown in Table 7. The model structure and training method of SVM both differ from those for neural networks, so it is meaningless to discuss the training time of reference []. Not only were the test accuracies and noise immunities of SVM much lower than those of LLRNN, but also the test time of the former was dozens of times greater than that of the latter. The primary reason is that the multi-category task of SVM is broken down into several binary tasks, which results in extra computation.
The experimental results of the IMS data set are shown in Table 8. The self-repair of the mechanical system made the data characteristics of the faulty bearing similar to those of the normal bearing. Although the test accuracy gained satisfactory results, the complexity of the system made the data more difficult to distinguish in high-noise environments. The test accuracy in the simulation environment of 0 dB was lower than that of the CWRU data set at least 6%. Like the experimental results of the CWRU dataset, the performance of LLRNN was not worse than any structure using LSTM or GRU.
Table 8.
Experimental results of various methods in the IMS dataset.
In contrast to the experimental results of the CWRU data, two CNN models gained competitive noise immunity. However, their computing time was still much higher than that of proposed method. The other two still could not work in a noisy environment—especially reference [], whose prediction accuracy was similar to random guess in a severely noisy environment, at around 25%. The SVM model also behaved poorly; its performance was similar to that in the CWRU data set. However, its test time was much lower than that in the CWRU data set. Because there are four categories of IMS data and the quantity of decomposed binary tasks is only four-tenths that of CWRU, it had much less calculation. According to the results of the above experiments, the ingenious simplification of the JANET cell did not cause serious performance degradation. The calculation delay of LLRNN was at least 10% lower than any network structure using LSTM or GRU while maintaining a satisfactory performance. Compared with some CNN and SVM models, the proposed method not only gained higher prediction accuracy and noise immunity, but also spent the least amount of computing time.
5. Conclusions
In this paper, a low-delay lightweight recurrent neural network (LLRNN) model is proposed for mechanical fault diagnosis, which is an end-to-end processing model. From input data to output diagnostics, the process executes automatically without any manual involvement. Thus, the diagnostic quality is not dependent on expert experience. According to the work flow of the JANET cell structure, this paper analysed the influence of several factors (e.g., , , , and ) on the performance of the model, including accuracy, noise immunity, and calculation delay. The relationship between these factors and performance was verified in the experiment. The proposed method obtained the highest accuracy and noise immunity performance when = 2, = 64, and = 128. This could give some guidance to model design in related fields. The experimental results of the two data sets CWRU and IMS prove that the simplified structure of LLRNN could achieve performance comparable to any network model using LSTM or GRU, and the computational delay decreased by at least 10%, which is more suitable for real-time fault detection systems.
The proposed method still requires some improvements due to the data dependencies of the RNN work flow. As shown in Figure 5b and Equation (3), the calculation of must wait for . Let denote the time consumed in calculating each gate. Although the GPU has parallel computing power, it could only calculate each gate synchronously with the limitation of data dependencies. Ignoring the consumption of communication between each gate, the time consumed each moment could approximate . When dealing with time series data with length of steps, the GPU must wait steps times caused by the data dependencies, so the time of calculating each data sample is . If the dependence between and could be eliminated, the calculation of each moment could be performed independently and the GPU could fully utilise its parallel computing power without any waiting. The calculation of steps moments could be dealt with at the same time. Consequently, the time of calculating each data sample could be further reduced to approximately . Now that the CPU of the edge device is basically multi-core and has certain parallel computing capabilities, it means that the test time could decrease as well.
Author Contributions
Conceptualization, W.L.; Validation, W.L.; Writing—original draft, W.L.; Writing—review and editing, L.Y., and P.G.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
| LLRNN | Low-Delay Lightweight Recurrent Neural Network |
| LSTM | Long Short-Term Memory Network |
| AutoEncoder | Automatic Encoder |
| DT-CWT | Dual Tree-Complex Wavelet Transform |
| CWTS | Continuous Wavelet Transform Scalogram |
| AI | Artificial Intelligence |
| CHMM | Coupled Hidden Markov Model |
| k-NN | k-Nearest Neighbour |
| WPT | Wavelet Packet Transform |
| SVM | Support Vector Machine |
| CNN | Convolutional Neural Network |
| RNN | Recurrent Neural Network |
| GRU | Gated Recurrent Unit |
| RUL | Remaining Useful Life |
| FFT | Fast Fourier Transform |
| JANET | Just Another NETwork |
| FLOPs | FLOating-Point Operations |
| CPU | Central Processing Unit |
| GPU | Graphics Processing Unit |
References
- Yin, S.; Li, X.; Gao, H.; Kaynak, O. Data-Based Techniques Focused on Modern Industry: An Overview. IEEE Trans. Ind. Electron. 2015, 62, 657–667. [Google Scholar] [CrossRef]
- Qiao, W.; Lu, D. A Survey on Wind Turbine Condition Monitoring and Fault Diagnosis—Part I: Components and Subsystems. IEEE Trans. Ind. Electron. 2015, 62, 6536–6545. [Google Scholar] [CrossRef]
- Khan, S.; Yairi, T. A review on the application of deep learning in system health management. Mech. Syst. Signal Process. 2018, 107, 241–265. [Google Scholar] [CrossRef]
- Zhou, H.; Chen, J.; Dong, G.; Wang, H.; Yuan, H. Bearing fault recognition method based on neighbourhood component analysis and coupled hidden Markov model. Mech. Syst. Signal Process. 2016, 66–67, 568–581. [Google Scholar] [CrossRef]
- Jung, U.; Koh, B.H. Wavelet energy-based visualization and classification of high-dimensional signal for bearing fault detection. Knowl. Inf. Syst. 2015, 44, 197–215. [Google Scholar] [CrossRef]
- Gangsar, P.; Tiwari, R. Multi-fault Diagnosis of Induction Motor at Intermediate Operating Conditions using Wavelet Packet Transform and Support Vector Machine. J. Dyn. Syst. Meas. Control 2018, 140, 081014. [Google Scholar] [CrossRef]
- Zhou, Z.; Feng, J. Deep Forest. arXiv 2018, arXiv:1702.08835v1. [Google Scholar] [CrossRef]
- Liu, R.; Yang, B.; Zio, E.; Chen, X. Artificial intelligence for fault diagnosis of rotating machinery: A review. Mech. Syst. Signal Process. 2018, 108, 33–47. [Google Scholar] [CrossRef]
- Ahmed, H.; Wong, M.; Nandi, A. Intelligent condition monitoring method for bearing faults from highly compressed measurements using sparse over-complete features. Mech. Syst. Signal Process. 2018, 99, 459–477. [Google Scholar] [CrossRef]
- Lu, C.; Wang, Z.Y.; Qin, W.L.; Ma, J. Fault diagnosis of rotary machinery components using a stacked denoising autoencoder-based health state identification. Signal Process. 2017, 130, 377–388. [Google Scholar] [CrossRef]
- Junbo, T.; Weining, L.; Juneng, A.; Xueqian, W. Fault diagnosis method study in roller bearing based on wavelet transform and stacked auto-encoder. In Proceedings of the 27th Chinese Control and Decision Conference (2015 CCDC), Qingdao, China, 23–25 May 2015; pp. 4608–4613. [Google Scholar] [CrossRef]
- Wen, L.; Li, X.; Gao, L.; Zhang, Y. A New Convolutional Neural Network-Based Data-Driven Fault Diagnosis Method. IEEE Trans. Ind. Electron. 2018, 65, 5990–5998. [Google Scholar] [CrossRef]
- Liu, R.; Meng, G.; Yang, B.; Sun, C.; Chen, X. Dislocated Time Series Convolutional Neural Architecture: An Intelligent Fault Diagnosis Approach for Electric Machine. IEEE Trans. Ind. Electron. 2017, 13, 1310–1320. [Google Scholar] [CrossRef]
- Sun, W.; Yao, B.; Zeng, N.; Chen, B.; He, Y.; Cao, X.; He, W. An Intelligent Gear Fault Diagnosis Methodology Using a Complex Wavelet Enhanced Convolutional Neural Network. Materials 2017, 10, 790. [Google Scholar] [CrossRef] [PubMed]
- Guo, S.; Yang, T.; Gao, W.; Zhang, C. A Novel Fault Diagnosis Method for Rotating Machinery Based on a Convolutional Neural Network. Sensors 2018, 18, 1429. [Google Scholar] [CrossRef] [PubMed]
- Denil, M.; Shakibi, B.; Dinh, L.; Ranzato, M.; De Freitas, N. Predicting Parameters in Deep Learning. In Proceedings of the Advances in Neural Information Processing Systems 26 (NIPS 2013), Lake Tahoe, NV, USA, 5–8 December 2013; pp. 2148–2156. [Google Scholar]
- Gao, L.; Guo, Z.; Zhang, H.; Xu, X.; Shen, H.T. Video Captioning With Attention-Based LSTM and Semantic Consistency. IEEE Trans. Multimed. 2017, 19, 2045–2055. [Google Scholar] [CrossRef]
- Zhang, Y.; Lu, X. A Speech Recognition Acoustic Model Based on LSTM -CTC. In Proceedings of the 2018 IEEE 18th International Conference on Communication Technology (ICCT), Chongqing, China, 8–11 October 2018; pp. 1052–1055. [Google Scholar] [CrossRef]
- Palangi, H.; Deng, L.; Shen, Y.; Gao, J.; He, X.; Chen, J.; Song, X.; Ward, R. Deep Sentence Embedding Using Long Short-Term Memory Networks: Analysis and Application to Information Retrieval. IEEE/ACM Trans. Audio Speech Lang. Process. 2016, 24, 694–707. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Zhang, S.; Wu, Y.; Che, T.; Lin, Z.; Memisevic, R.; Salakhutdinov, R.; Bengio, Y. Architectural complexity measures of recurrent neural networks. In Proceedings of the Advances in Neural Information Processing Systems 29 (NIPS 2016), Barcelona, Spain, 5–10 December 2016; pp. 1830–1838. [Google Scholar]
- Arjovsky, M.; Shah, A.; Bengio, Y. Unitary evolution recurrent neural networks. In Proceedings of the 33rd International Conference on Machine Learning (ICML 2016), New York, NY, USA, 19–24 June 2016; pp. 1120–1128. [Google Scholar]
- Ororbia, A.G.; Mikolov, T.; Reitter, D. Learning Simpler Language Models with the Differential State Framework. Neural Comput. 2017, 29, 3327–3352. [Google Scholar] [CrossRef]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Gated Feedback Recurrent Neural Networks. In Proceedings of the 32nd International Conference on Machine Learning (ICML 2015), Lille, France, 6–11 July 2015; pp. 2067–2075. [Google Scholar]
- Zhao, R.; Yan, R.; Wang, J.; Mao, K. Learning to Monitor Machine Health with Convolutional Bi-Directional LSTM Networks. Sensors 2017, 17, 273. [Google Scholar] [CrossRef]
- Park, D.; Kim, S.; An, Y.; Jung, J. LiReD: A Light-Weight Real-Time Fault Detection System for Edge Computing Using LSTM Recurrent Neural Networks. Sensors 2018, 18, 2110. [Google Scholar] [CrossRef]
- Yuan, M.; Wu, Y.; Lin, L. Fault diagnosis and remaining useful life estimation of aero engine using LSTM neural network. In Proceedings of the 2016 IEEE International Conference on Aircraft Utility Systems (AUS), Beijing, China, 10–12 October 2016; pp. 135–140. [Google Scholar]
- Zhang, Y.; Xiong, R.; He, H.; Pecht, M.G. Long Short-Term Memory Recurrent Neural Network for Remaining Useful Life Prediction of Lithium-Ion Batteries. IEEE Trans. Veh. Technol. 2018, 67, 5695–5705. [Google Scholar] [CrossRef]
- Cui, Q.; Li, Z.; Yang, J.; Liang, B. Rolling bearing fault prognosis using recurrent neural network. In Proceedings of the 29th Chinese Control And Decision Conference (CCDC), Chongqing, China, 28–30 May 2017; pp. 1196–1201. [Google Scholar] [CrossRef]
- Wang, W.; Qiu, X.; Chen, C.; Lin, B.; Zhang, H. Application Research on Long Short-Term Memory Network in Fault Diagnosis. In Proceedings of the 2018 International Conference on Machine Learning and Cybernetics (ICMLC), Chengdu, China, 15–18 July 2018; Volume 2, pp. 360–365. [Google Scholar] [CrossRef]
- Liu, H.; Zhou, J.; Zheng, Y.; Jiang, W.; Zhang, Y. Fault diagnosis of rolling bearings with recurrent neural network-based autoencoders. ISA Trans. 2018, 77, 167–178. [Google Scholar] [CrossRef]
- Der Westhuizen, J.V.; Lasenby, J. The unreasonable effectiveness of the forget gate. arXiv 2018, arXiv:1804.04849. [Google Scholar]
- Case Western Reserve University. Bearing Data Center. Available online: http://csegroups.case.edu/bearingdatacenter/pages/welcome-case-western-reserve-university-bearing-data-center-website (accessed on 10 July 2019).
- Qiu, H.; Lee, J.; Lin, J.; Yu, G. Wavelet filter-based weak signature detection method and its application on rolling element bearing prognostics. J. Sound Vib. 2006, 289, 1066–1090. [Google Scholar] [CrossRef]
- Jia, F.; Lei, Y.; Lin, J.; Zhou, X.; Lu, N. Deep neural networks: A promising tool for fault characteristic mining and intelligent diagnosis of rotating machinery with massive data. Mech. Syst. Signal Process. 2016, 72, 303–315. [Google Scholar] [CrossRef]
- Chen, K.; Zhou, X.; Fang, J.; Zheng, P.; Wang, J. Fault Feature Extraction and Diagnosis of Gearbox Based on EEMD and Deep Briefs Network. Int. J. Rotating Mach. 2017, 2017, 9602650. [Google Scholar] [CrossRef]
- Acoustics and Vibration Database. NASA Bearing Dataset. Available online: https://ti.arc.nasa.gov/tech/dash/groups/pcoe/prognostic-data-repository/ (accessed on 10 July 2019).
- Williams, T.; Ribadeneira, X.; Billington, S.A.; Kurfess, T.R. Rolling element bearing diagnostics in run-to-failure lifetime testing. Mech. Syst. Signal Process. 2001, 15, 979–993. [Google Scholar] [CrossRef]
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).