Coverage-Balancing User Selection in Mobile Crowd Sensing with Budget Constraint


Abstract
:1. Introduction
2. Assumptions and Models
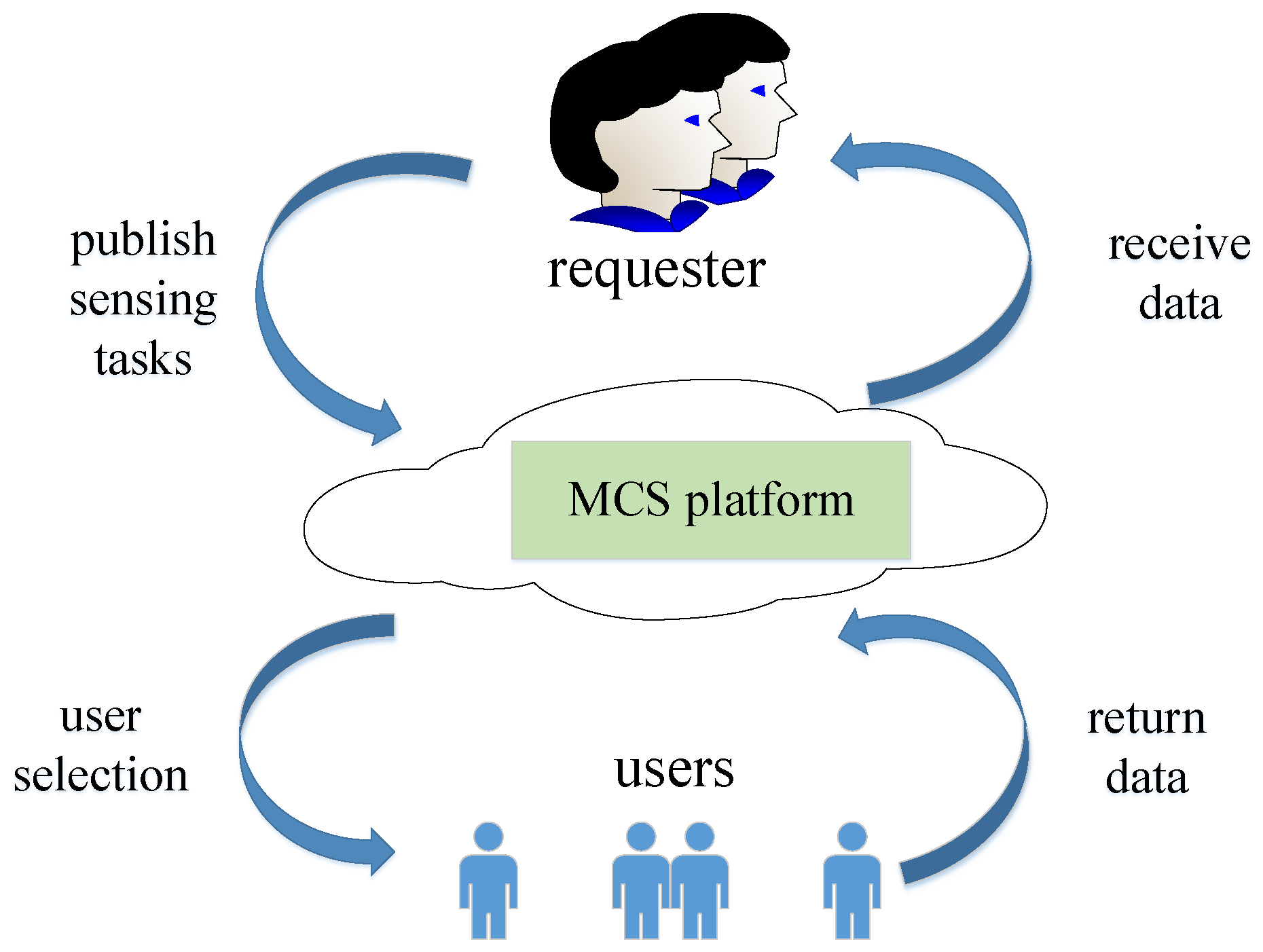
2.1. System Model of MCS
2.2. Models of Sensing Coverage and Sensing Utility
2.3. Problem Description
3. Designs
3.1. Overview of Our Designs
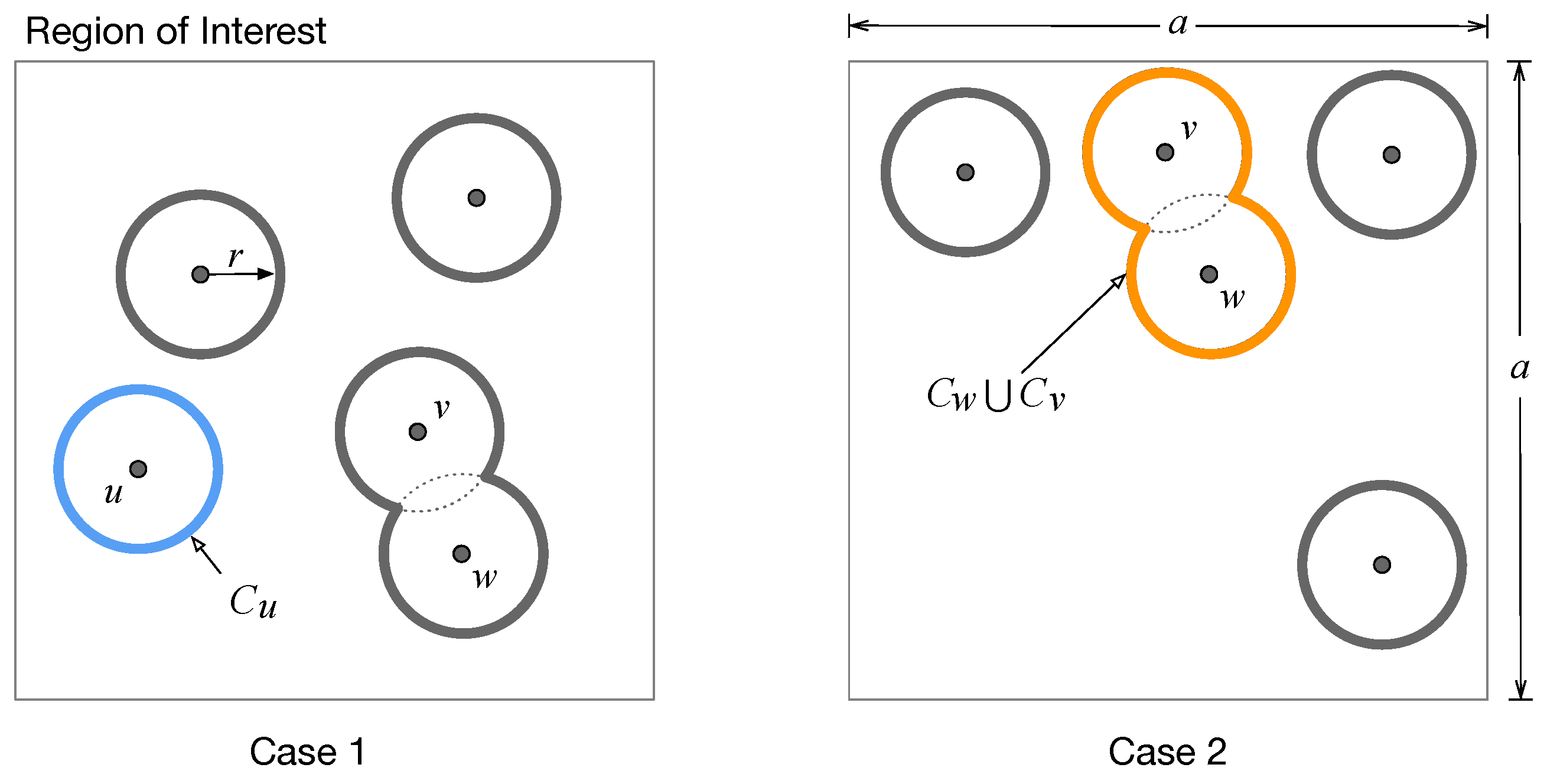
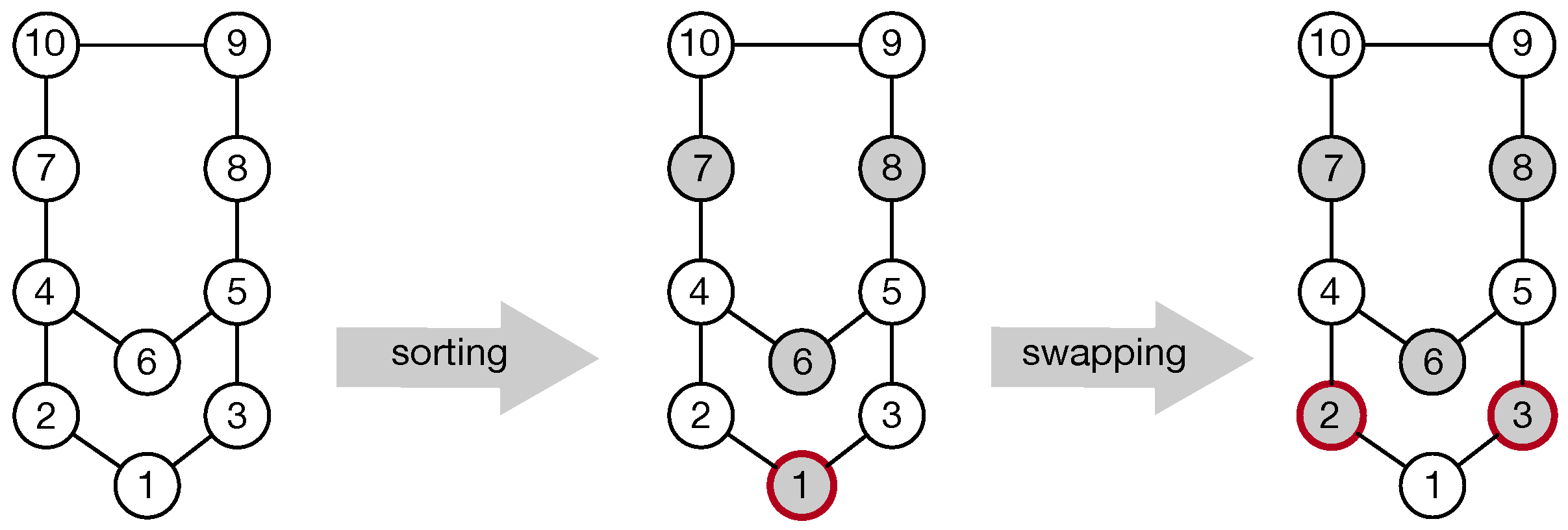
3.2. Determining Maximum Users without Overlaps
3.3. Budget-Based User Adjustments
| Algorithm 1: Deleting Users in the Case of Budget Overrun. |
 |
| Algorithm 2: Adding Users in the Case of Budget Surplus. |
 |
3.4. Calculation of Coverage Union
4. Evaluation
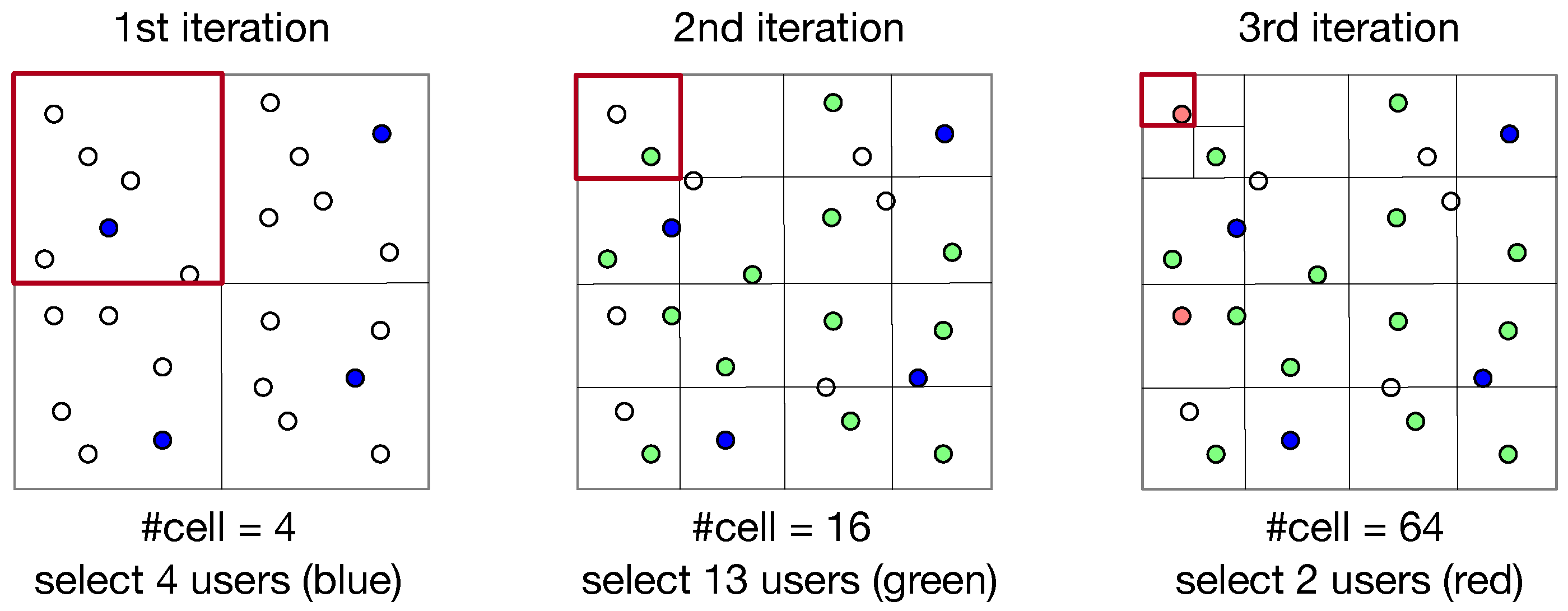
4.1. Baseline Algorithms
| Algorithm 3: (ParRand) Partition-Based Random User Selection. |
 |
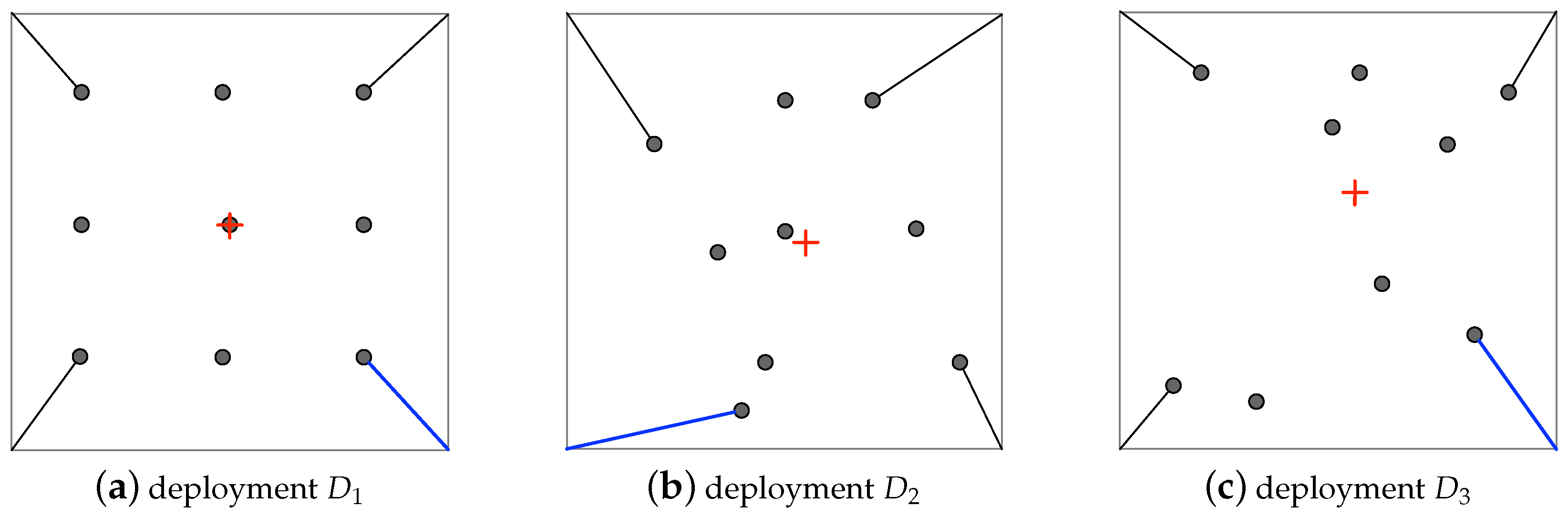
4.2. Experimental Setup
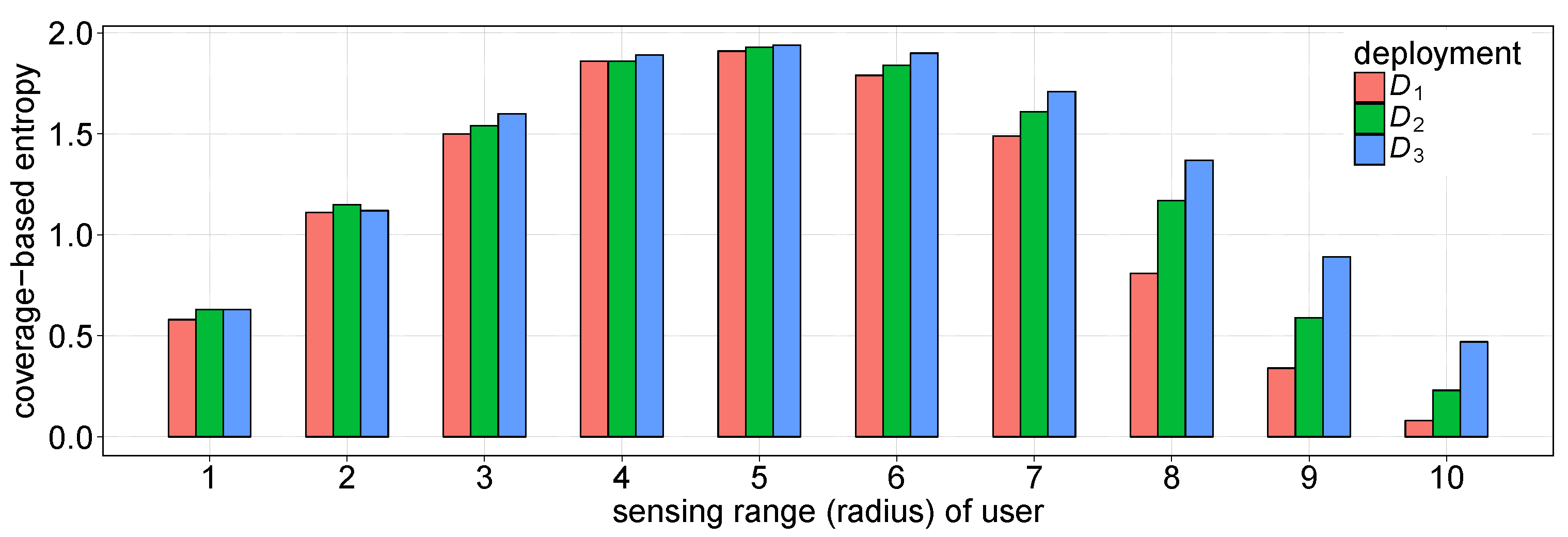
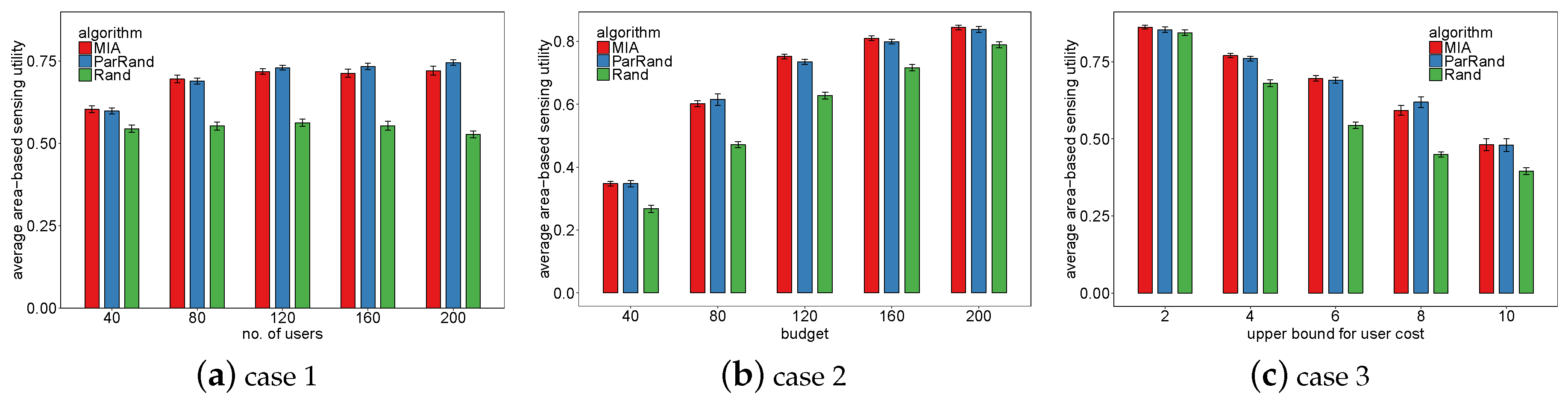
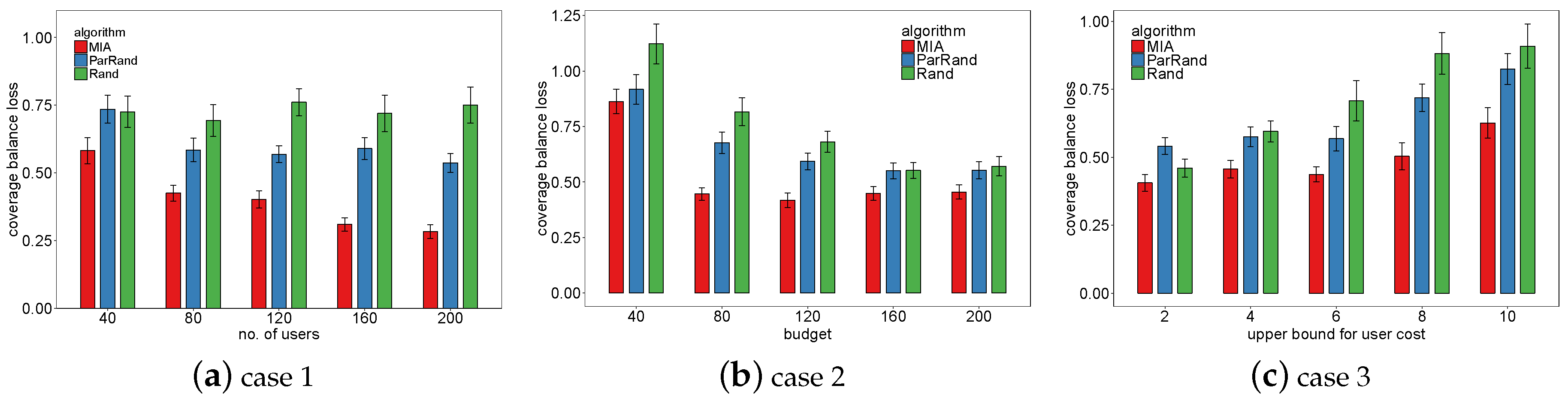
4.3. Results and Analyses
5. Related Work
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Guo, B.; Wang, Z.; Yu, Z.; Wang, Y.; Yen, N.; Huang, R.; Zhou, X. Mobile Crowd Sensing and Computing: The Review of an Emerging Human-Powered Sensing Paradigm. ACM Comput. Surv. 2015, 48, 7. [Google Scholar] [CrossRef]
- Antonic, A.; Marjanovic, M.; Pripuzic, K.; Zarko, I. A Mobile Crowd Sensing Ecosystem Enabled by CUPUS: Cloud-based Publish/Subscribe Middleware for the Internet of Things. Future Gener. Comput. Syst. 2016, 56, 607–622. [Google Scholar] [CrossRef]
- Guo, B.; Chen, H.; Yu, Z.; Xie, X.; Huangfu, S.; Zhang, D. FlierMeet: A mobile crowdsensing system for cross-space public information sharing. IEEE Trans. Mob. Comput. 2015, 14, 2020–2033. [Google Scholar] [CrossRef]
- Gregoria, E.; Improta, A.; Lenzini, L.; Luconi, V.; Redini, N.; Vecchio, A. Smartphone-based crowdsourcing for estimating the bottleneck capacity in wireless networks. J. Netw. Comput. Appl. 2016, 64, 62–75. [Google Scholar] [CrossRef] [Green Version]
- Elhamshary, M.; Youssef, M.; Uchiyama, A.; Yamaguchi, H.; Higshino, T. TransitLabel: A Crowd-Sensing System for Automatic Labeling of Transit Stations Semantics. In Proceedings of the 14th ACM International Conference on Mobile Systems, Applications, and Services (MobiSys), Singapore, 26–30 June 2016; pp. 193–206. [Google Scholar]
- Azzam, R.; Mizouni, R.; Otrok, H.; Ouali, A.; Singh, S. GRS: A Group-Based Recruitment System for Mobile Crowd Sensing. J. Netw. Comput. Appl. 2016, 72, 38–50. [Google Scholar] [CrossRef]
- Wang, Z.; Huang, D.; Wu, H.; Deng, Y.; Aikebaier, A.; Teranishi, Y. QoS-Constrained Sensing Task Assignment for Mobile Crowd Sensing. In Proceedings of the 2014 IEEE Global Communications Conference (Globecom), Austin, TX, USA, 8–12 December 2014; pp. 311–316. [Google Scholar]
- Zhang, M.; Yang, P.; Tian, C.; Tang, S.; Gao, X.; Wang, B.; Xiao, F. Quality-aware Sensing Coverage in Budget Constrained Mobile Crowdsensing Networks. IEEE Trans. Veh. Technol. 2015, 65, 7698–7707. [Google Scholar] [CrossRef]
- Xiong, H.; Zhang, D.; Chen, G.; Wang, L.; Gauthier, V.; Barnes, L. iCrowd: Near-Optimal Task Allocation for Piggyback Crowdsensing. IEEE Trans. Mob. Comput. 2016, 15, 2010–2022. [Google Scholar] [CrossRef]
- Yu, Z.Y.; Zhou, J.; Guo, W.; Guo, L.; Yu, Z.W. Participant selection for t-sweep k-coverage crowd sensing tasks. World Wide Web 2018, 21, 741–758. [Google Scholar] [CrossRef]
- Huang, P.; Zhu, W.; Guo, L. Optimizing Movement for Maximizing Lifetime of Mobile Sensors for Covering Targets on a Line. Sensors 2019, 19, 273. [Google Scholar] [CrossRef] [PubMed]
- Goto, K.; Sasaki, Y.; Hara, T.; Nishio, S. A Mobile Agents Control Method for Sensor Data Gathering Based on Geographical Granularity in Dense Mobile Sensor Networks. J. Inf. Process. 2012, 53, 741–753. [Google Scholar]
- Wang, L.; Zhang, D.; Pathak, A.; Chen, C.; Xiong, H.; Yang, D.; Wang, Y. CCS-TA: Quality-Guaranteed Online Task Allocation in Compressive Crowdsensing. In Proceedings of the 2015 ACM International Joint Conference on Pervasive and Ubiquitous Computing, (Ubicomp), Osaka, Japan, 7–11 September 2015. [Google Scholar]
- Restuccia, F.; Ghosh, N.; Bhattacharjee, S.; Das, S.; Melodia, T. Quality of Information in Mobile Crowdsensing: Survey and Research Challenges. ACM Trans. Sens. Netw. 2017, 13, 34. [Google Scholar] [CrossRef]
- Hu, T.; Xiao, M.; Hu, C.; Gao, G.; Wang, B. A QoS-sensitive task assignment algorithm for mobile crowdsensing. Pervasive Mob. Comput. 2017, 41, 333–342. [Google Scholar] [CrossRef]
- Wang, H.; Yao, K.; Pottie, G.; Estrin, D. Entropy-based Sensor Selection Heuristic for Target Localization. In Proceedings of the 3rd International Symposium on Information Processing in Sensor Networks, Berkeley, CA, USA, 26–27 April 2004. [Google Scholar]
- Zilan, R.; Erten, Y. Use of entropy to control coverage and energy dissipation in wireless sensor networks. In Proceedings of the 22nd International Symposium on Computer and Information Sciences, Ankara, Turkey, 7–9 November 2007. [Google Scholar]
- Sviridenko, M. A note on maximizing a submodular set function subject to a knapsack constraint. Oper. Res. Lett. 2004, 32, 41–43. [Google Scholar] [CrossRef]
- Andrade, D.; Resende, M.; Werneck, R. Fastlocal search for the maximum independent set problem. J. Heuristics 2012, 18, 525–547. [Google Scholar] [CrossRef]
- Wan, P.; Jia, X.; Dai, G.; Du, H.; Frieder, O. Fast and simple approximation algorithms for maximum weighted independent set of links. In Proceedings of the IEEE INFOCOM 2014—IEEE Conference on Computer Communications Infocom, Toronto, ON, Canada, 27 April–2 May 2014; pp. 1653–1661. [Google Scholar]
- Xiao, M.; Nagamochi, H. Exact algorithms for maximum independent set. Inf. Comput. 2017, 225, 126–146. [Google Scholar] [CrossRef]
- Liu, Y.; Lu, J.; Yang, H.; Xiao, X.; Wei, Z. Towards Maximum Independent Sets on Massive Graphs. Proc. VLDB Endow. 2015, 8, 2122–2133. [Google Scholar] [CrossRef]
- Sangwan, A.; Singh, R.P. Survey on Coverage Problems in Wireless Sensor Networks. Wirel. Pers. Commun. 2015, 80, 1475–1500. [Google Scholar] [CrossRef]
- Xiong, H.; Zhang, D.; Chen, G.; Wang, L.; Gauthier, V. CrowdTasker: Maximizing Coverage Quality in Piggyback Crowdsensing under Budget Constraint. In Proceedings of the 2015 IEEE International Conference on Pervasive Computing and Communications (PerCom), Louis, MO, USA, 23–27 March 2015. [Google Scholar]
- Obinikpo, A.; Zhang, Y.; Song, H.; Luan, T.; Kantarci, B. Queuing Algorithm for Effective Target Coverage in Mobile Crowd Sensing. IEEE Internet Things J. 2017, 4, 1046–1055. [Google Scholar] [CrossRef]
- Girolami, M.; Chessa, S.; Dragone, M.; Bouroche, M.; Cahill, V. Using spatial interpolation in the design of a coverage metric for Mobile CrowdSensing systems. In Proceedings of the IEEE Symposium on Computers and Communication (ISCC), Messina, Italy, 27–30 June 2016; pp. 147–152. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Description | Value or Range | ||
|---|---|---|---|---|
| Case 1 | Case 2 | Case 3 | ||
| the number of initial users | 40∼200 (step = 40) | 80 | 80 | |
| B | the budget | 100 | 40∼200 (step = 40) | 100 |
| the upper bound for user cost | 6 | 6 | 2∼10 (step = 2) | |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Sun, G.; Ding, X. Coverage-Balancing User Selection in Mobile Crowd Sensing with Budget Constraint. Sensors 2019, 19, 2371. https://doi.org/10.3390/s19102371
Wang Y, Sun G, Ding X. Coverage-Balancing User Selection in Mobile Crowd Sensing with Budget Constraint. Sensors. 2019; 19(10):2371. https://doi.org/10.3390/s19102371
Chicago/Turabian StyleWang, Yanan, Guodong Sun, and Xingjian Ding. 2019. "Coverage-Balancing User Selection in Mobile Crowd Sensing with Budget Constraint" Sensors 19, no. 10: 2371. https://doi.org/10.3390/s19102371
APA StyleWang, Y., Sun, G., & Ding, X. (2019). Coverage-Balancing User Selection in Mobile Crowd Sensing with Budget Constraint. Sensors, 19(10), 2371. https://doi.org/10.3390/s19102371