Markov Chain Realization of Multiple Detection Joint Integrated Probabilistic Data Association


1
Department of Electronic Systems Engineering, Hanyang University, Ansan 15588, Korea
2
LIG System, Seoul 03130, Korea
*
Author to whom correspondence should be addressed.
Sensors 2019, 19(1), 112; https://doi.org/10.3390/s19010112
Submission received: 14 November 2018
/
Revised: 22 December 2018
/
Accepted: 26 December 2018
/
Published: 30 December 2018
(This article belongs to the Special Issue Multiple Object Tracking: Making Sense of the Sensors)
Abstract
:In multiple detection target tracking environments, PDA-based algorithms such as multiple detection joint integrated probabilistic data association (MD-JIPDA) utilize the measurement partition method to generate measurement cells. Thus, one-to-many track-to-measurements associations can be realized. However, in this structure, the number of joint data association events grows exponentially with the number of measurement cells and the number of tracks. MD-JIPDA is plagued by large increases in computational complexity when targets are closely spaced or move cross each other, especially in multiple detection scenarios. Here, the multiple detection Markov chain joint integrated probabilistic data association (MD-MC-JIPDA) is proposed, in which a Markov chain is used to generate random data association sequences. These sequences are substitutes for the association events. The Markov chain process significantly reduces the computational cost since only a few association sequences are generated while keeping preferable tracking performance. Finally, MD-MC-JIPDA is experimentally validated to demonstrate its effectiveness compared with some of the existing multiple detection data association algorithms.
1. Introduction
Target tracking and information fusion techniques have achieved more attention in recent years due to their wide applications in both military and civilian domains [1,2,3,4,5,6]. In multitarget tracking environments, the data association process decides which selected measurement comes from which target and evaluates the corresponding association probability [7,8,9]. Usually, a target can be detected once with a less-than-unity detection probability, and false alarms (clutter) are also present in the surveillance area, which leads to more challenges for the data association process.
Tracks, which are formed to estimate the trajectories of the targets, are initialized using measurements; however, they are initialized without prior information of the measurement origins. This means that true tracks that are following targets and false tracks that are following clutter are both initialized and that they propagate during the surveillance period. The problem of true and false track discrimination is introduced, known as the false track discrimination (FTD) problem in [7,10].
Among the various tracking approaches, multiple hypothesis tracking (MHT) is an algorithm that utilizes multiple-scan track-to-measurement association by evaluating the likelihoods of the association hypotheses as specified in [11] and Chapter 6.3 of [12]. In MHT, hypotheses, which can be viewed as the measurement resource declarations at each scan, are generated and updated, and then the hypothesis with the highest a posteriori probability is the resulting output for track acceptance and rejection at each scan. As we know, MHT has issues with its computational complexity, in which the number of hypotheses grows exponentially. Some heuristics have been proposed to relax the complexity [11,13,14], but there is nevertheless a sacrifice in optimality.
The joint integrated probabilistic data association (JIPDA) algorithm [8] is a pseudo-Bayesian estimator that enumerates all track-to-measurement associations and calculates the corresponding weights. JIPDA is a single-scan algorithm that implements associations between the current scan tracks and the selected measurements. Instead of trying to find one “best” measurement for a track, all measurements selected by the track are evaluated and a track state is generated by the summation of the state corresponding to each data association event over all the weighted association events. In order to obtain the association weights, the summation of the data association probabilities over all association events is needed, which is an NP-hard problem [15,16]. It has been proved that JIPDA is much more efficient compared to MHT for closely spaced targets and dense clutter environments, resulting in the extensive applicability of JIPDA.
Since JIPDA suffers from a heavy computational load, a suboptimal method is proposed in [17], called linear multitarget integrated probabilistic data association (LM-IPDA). In this algorithm, after track t selects various measurements, the measurement generated by the target being tracked by another track is treated as additional clutter for track t. This additional clutter is used to modulate the origin clutter measurement density, which allows LM-IPDA to totally bypass the joint data association step. This clutter modification process is the core of the LM approach, which upgrades the single target tracking algorithm to a multitarget tracking algorithm. This algorithm reduces the complexity of heavy multiple target tracking to that of single target tracking, but sacrifices optimality in the process.
In MHT, the hypothesis with the highest probability is utilized to accept and reject tracks, and PDA-based algorithms calculate the consecutive detection probability of each track in order to terminate unstable tracks [2,11,12,18]. In [7,19], the probability of target existence (PTE) is introduced as a track score, which is continuously updated (along with the track state) and used to confirm the track (i.e., the target tracked by the corresponding track exists). The PTE of each track is updated considering the ratios of measurement likelihood to clutter measurement density for all of the measurements selected by that track. Compared to MHT, which uses a global hypothesis, each track has a PTE, allowing JIPDA to perform track judgment for each track separately. Compared to the consecutive detection probability used by JPDA, PTE has a more stable performance.
JIPDA enumerates all possible association events in order to approximate the optimal Bayesian filter, which suffers from a large computational complexity, especially when targets are closely spaced. The Markov chain JIPDA (MC-JIPDA) generates the association events via a Markov chain process [20]. In each event generation step for a track, the current track-to-measurement assignment is only correlated with the last assignment and independent of the other tracks. The main benefit of this approach is that the number of association sequences can be controlled and only a small number of association sequences are needed. One drawback is that, repeat association sequences can be generated in the MC-JIPDA algorithm, as all association events are generated randomly.
Due to the applications of high resolution sensors and some special kinds of radars such as over-the-horizon-radar (OTHR), multiple detection target tracking generally attracts more attention from the research community [9,21,22,23,24,25,26]. For such multiple detection situations, the widely used point target assumption is relaxed and the data association process needs to assign multiple measurements to one track, which leads to the association complexity exponentially increasing compared to the single detection case.
The measurement partition method [21] is used to generate the measurement cells for each track, where each cell is a combination of selected measurements that are assumed to be target detections. This method is a mathematical technique that can be smoothly incorporated into any existing tracking algorithms. However, the number of measurement cells quickly increases with an increasing number of selected measurements, which results in an extremely high computational complexity at the track-to-measurement cell association step. Since multiple detection JIPDA (MD-JIPDA) enumerates all possible association events, it is not feasible in many multiple detection applications due to the computational resources that are required [27]. Multiple detection LM-IPDA (MD-LM-IPDA) is efficient in these multiple detection scenarios, but afflicts the deteriorating tracking performance [28].
The contributions: The multiple detection Markov chain joint integrated probabilistic data association (MD-MC-JIPDA) algorithm is proposed to solve the multiple detection target tracking problem based on a much more efficient data association sequence generation process. Instead of enumerating all feasible joint events (FJEs) for data associations among measurement cells and tracks, MD-MC-JIPDA generates a certain number of FJEs based on the Markov chain sequence of each track. Then, the corresponding event probabilities are evaluated using the measurement cells and track states under consideration. The track state and probability of target existence are updated based on these FJEs. The main benefit of this algorithm is that it needs only a small number of FJEs and this number is decided in advance and can be adjusted according to the complexity of the tracking scenario. The novel FJEs generation mechanism makes MD-MC-JIPDA algorithm much more efficient and tractable in multiple detection multitarget tracking environments.
2. Assumptions and Models
This section provides the details of the assumptions and models used in this paper. Targets usually occur and disappear at random times and can be detected with a less-than-unity probability [18]. Targets become even harder to detect if they maneuver in certain ways [29]. In the bearing only case, in order to track targets, the sensor needs to navigate with more complex maneuvers compared to the targets in order to satisfy the observability condition [30].
2.1. Target Motion
The most widely used nearly constant velocity (NCV) model, in Chapter 4.2 of [31], is considered here, where the target state evolves according to
where is the state of target t at scan k, A is the state propagation matrix, and represents the zero-mean white Gaussian process noise with covariance Q.
2.2. Measurements
The standard multiple detection situation, which is caused by a high resolution sensor that can resolve multiple scattering feature points of a target, is considered. A target can be detected times with the corresponding given detection probability . Target measurements are generated by
where the parameters and are given by
in which is the measurement generation matrix for a single detection and the sign ⊕ represents the vertical vectorial concatenation operation. is the Gaussian measurement noise that in which R is the sensor error covariance. used here represents the number of target detections such that and correspond to the case that there are detections from target t at scan k.
False alarms (clutter measurements) also arise in the surveillance area. This kind of measurement is assumed to follow the Poisson/uniform distribution in this paper.
The set of measurements selected at scan k is represented by , which contains both target measurements and clutter measurements, given by
where represents the jth measurement and is the total number of selected measurements at scan k.
The set of sets of measurements collected from the initial to current scan is , which satisfies
At each scan, the measurements selected by a track are used to estimate the target state and to evaluate the target existence probability under the multiple detection paradigm.
3. Multiple Detection Markov Chain Joint Integrated Probabilistic Data Association
This section demonstrates the detailed derivations of MD-MC-JIPDA. We first introduce the track state and the measurement partition method and then focus on the structure for jointly assigning measurement cells to tracks. The contribution of MD-MC-JIPDA algorithm lies in the efficient joint assignment mechanism.
When the targets are closely spaced or move across each other, the computational burden of the joint association events increases sharply, hampering the implementation of the traditional tracking algorithms such as MHT and JIPDA. Furthermore, the multiple detection situation significantly aggravates this burden since the number of measurement cells of each track is usually much larger compared to the number of measurements selected by that track. Therefore, in an attempt to realize a real-time algorithm, the multiple detection version of the Markov chain process is proposed as an approximation of the Bayes estimator.
3.1. Track State
For a detector, there is no a priori information on the measurement origins, resulting in that a track may track a target or clutter. Thus, the existence of the target being tracked by a track is a random event. The probability of this random event is termed the probability of target existence . In MD-MC-JIPDA the track state pdf is represented by
which consists of the trajectory state and the target existence event. On the RHS of (7), we can see that the kinematic state is conditional on the target existence . Both and are propagated according to a standard predict-update mechanism [7,8].
3.2. Measurement Utilization
At each scan, each track uses the gating method, which can be found in Chapter 2.3.2 of [2], to select measurements. Since the multiple detection problem is considered, the measurements selected by a track are first used to generate measurement cells. Then, the measurement cells are used for the data association in order to update the PTE and the state of the corresponding track. Assume that track t selects three measurements and the maximum number of target originated measurements is 3. Then, the measurement cells are generated as follows:
where , and . In this case , and .
where , and . In this case , and .
where . In this case , and .
Then, these measurement cells are used in the joint data association process instead of using the single measurements , and .
3.3. Feasible Joint Event
In this part, we give a brief review of the feasible joint events of MD-JIPDA and introduce a new perspective on the probability of a feasible joint event, preparing for the derivation of MD-MC-JIPDA.
Under the multiple detection condition, measurement cells, which are composed of one or more selected measurements, are assigned to tracks in a feasible joint event [2]. In the following derivations, we assume that the cluster tracks can select all the measurements in the cluster to form feasible joint events [2].
In MD-JIPDA, the feasible joint events are used to generate the track-to-measurement cell assignments. In each feasible joint event, the assignments for all the cluster tracks and all the measurement cells are considered. The probability of a feasible joint event in MD-JIPDA is calculated by
where each track is assigned one measurement cell or is unassigned, and any two measurement cells assigned to different tracks do not share common measurements [27].
The truncated measurement cell likelihood in (8) for is calculated by
where is the concatenated measurement based on measurement cell , is
the predicted measurement and represents the corresponding innovation covariance. The details
for obtaining these parameters can be referred to [28].
In (8), is the probability that at least one target measurement is detected and is located in the selection gate of track t, given as
where is the probability that measurements are detected and are located in the selection gate of track t, given by
and is the clutter measurement density.
The predicted probability of target existence is given by
where is the transition probability that a target exists at the previous scan and keeps its existence state at the current scan, which is usually set as 0.98 [7].
The normalization constant used in (8) can be obtained based on the fact that the total probability of all data association events is
where M is the number of joint events.
In all the derivations, is used as an abbreviation of the measurement cell likelihood and this value is calculated by a modulated Kalman filter which will be given later.
Let us have another look at each joint event in terms of the tracks. Define as the event that measurement cell is assigned to track t under joint event , and as the event that there is no measurement assigned to track t under joint event . The corresponding probabilities can be found in (8) as
and
The probability of a feasible joint event , from the point of view of tracks , can be rewritten as
where N is the total number of tracks.
Therefore, a feasible joint event consists of the measurement cell-to-track assignments for all the cluster tracks, in which each track is assigned with a measurement cell ( or ).
3.4. Markov Chain Sequence
In MD-JIPDA, the number of feasible joint events grows exponentially with the number of measurement cells and the number of tracks involved. When MD-JIPDA is used for closely spaced multitarget tracking considering clutter measurements, the computational load for the feasible joint event probability calculation becomes intractable. This is the fatal weakness for applying MD-JIPDA or any other algorithms which use feasible joint events for data association to real-time multiple detection environments. Therefore, the algorithm with a limited number feasible joint events should be executed for real-time applications. In addition, the limited size feasible joint events need to represent the significant joint events and neglect insignificant joint events to obtain a reasonable data association performance.
Let us consider the Markov process which can be used to sequentially assign measurement cell to a track. The Markov process satisfies
which indicates that the state at current time depends only on the last state and has nothing to do with the previous states. Utilizing the property of (17), one can generate the state transition much more efficiently since not the entire past state but only the last state is necessary for the current state generation.
Utilizing the Markov property in (17), we can sequentially generate Markov chain. For the measurement cell-to-track assignment process, a Markov chain can be represented by the corresponding matrix of which each element is the transition probability from selecting to selecting . The transition probabilities for each track are defined as
which represents that is assigned to track t under joint event and is assigned to track t under , where . These transition probabilities satisfy
The transition probabilities that satisfy the condition that the current selection is the same as the last one are
and
where these values are generated according to (14) and (15).
Assume that the number of measurement cells of track t at scan k is . The transition probabilities that satisfy the condition that the current selection is different from the last one are given by
and
The normalization constant of these transition probabilities is given as
In each feasible joint event, any two measurement cells assigned to different tracks should not contain the same measurements.
The transition probability matrix for each track is given as (25). This matrix considers all possible transitions among the measurement cells (including ) of a track.
Suppose two tracks, t and , have selected the same measurements and . After measurement cell generation process, three measurement cells are generated, which are , and , for both track t and . The Markov chain state set is . The state transition for a track, such as t, from to is accepted with probability .
3.4.1. Data Association Sequences for a Track
An example of the transition relation among measurement cells of track t is shown in Figure 1, in which , , and are considered. From this figure, each measurement cell can transform to the other measurement cells with corresponding transition probabilities. Suppose that track t selects in the data association sequence , which means
then the third row of (25) should be used to determine which measurement cell should be selected for track t in the next data association sequence . Assume the corresponding transition probabilities are
and
Then generate a random probability to select a measurement cell for based on (29). Suppose that , which indicates that should be chosen for track t in the data association sequence .
The measurement cell selection for track t in is only related to the selection of track t in based on the transition matrix, which is the core of the proposed Markov chain sequences. Based on this process, track t generates the Markov chain sequence of length K which is , and then track also generates its Markov chain sequence of length K following the same procedure.
3.4.2. Joint Data Association Events for Multiple Tracks
If and , and and contain the same measurement, then regenerate until it selects the measurement cell which has no common measurement with to satisfy the condition of the multiple detection feasible joint event. Using the transform relation given in Figure 1 and the length of Markov chain sequence K is set to be 5, i.e., the number of FJEs in MD-MD-JIPDA is 5. The possible Markov chain sequence for track t and can be and . Then, we need to check whether the track-to-measurement cell association sequences denoted by satisfy the multiple detection feasible joint event condition.
Figure 2 demonstrates the feasible joint events generation process using the Markov chain association sequences of track t and .
In this example, , , , and . Among them violates the multiple detection feasible event condition since and contain the same measurement . So, of track should be regenerated until the multiple detection feasible joint event condition is satisfied.
Then, the probability for the feasible joint event is obtained by (16). The length of total feasible joint events K in MD-MC-JIPDA can be predetermined based on the complexities of different scenarios.
3.5. Track Update
The association probabilities of a measurement cell to a track are generated based on the corresponding feasible joint events. For simplicity, the time index k in and is omitted. Denote by the set of feasible joint events that allocate cell to track t. Notice that if there is no feasible joint event that allocates measurement cell to track t, the association probability for this measurement cell is 0.
The event that no measurement in the cluster is target t detection is the union of the data association sequences that allocate to track t, given by
The probability that no measurement in the cluster comes from target t and that target t exists is expressed as
The probability that measurement cell originates from target t and that target t exists is
Events are mutually exclusive and the union of these events is the target existence event . Therefore, the a posteriori probability of target existence is calculated by
The association probabilities are expressed by
and
For each association event, there is an update state generated by the modulated Kalman filter using the corresponding measurement cell. The detailed process of track state update can be found in [28].
After obtaining the data association probabilities and corresponding update states, the state of track t is generated according to a Gaussian mixture that considers all the association events. The final output for each track contains a track state and the probability of target existence.
3.6. Computational Complexity Analysis
In this section, we analyze the complexity of MD-JIPDA and MD-MC-JIPDA.
Suppose that there are N cluster tracks and M measurement cells which do not contain the same measurement in the cluster, then the number of feasible joint events is obtained as [17] which has the complexity of if , or similarly the feasible joint event generation shows the complexity of if . From this, the number of feasible joint events increases exponentially with M and N.
Compared to MD-JIPDA, MD-MC-JIPDA is much more efficient when many tracks share measurements since MD-MC-JIPDA requires only a certain number of FJEs. The complexity of the joint measurement cell-to-track assignment of MD-MC-JIPDA is since the number of the joint assignments required by MD-MC-JIPDA is a predetermined constant K which can be adjusted according to the complexity of the tracking scenario.
4. Simulation
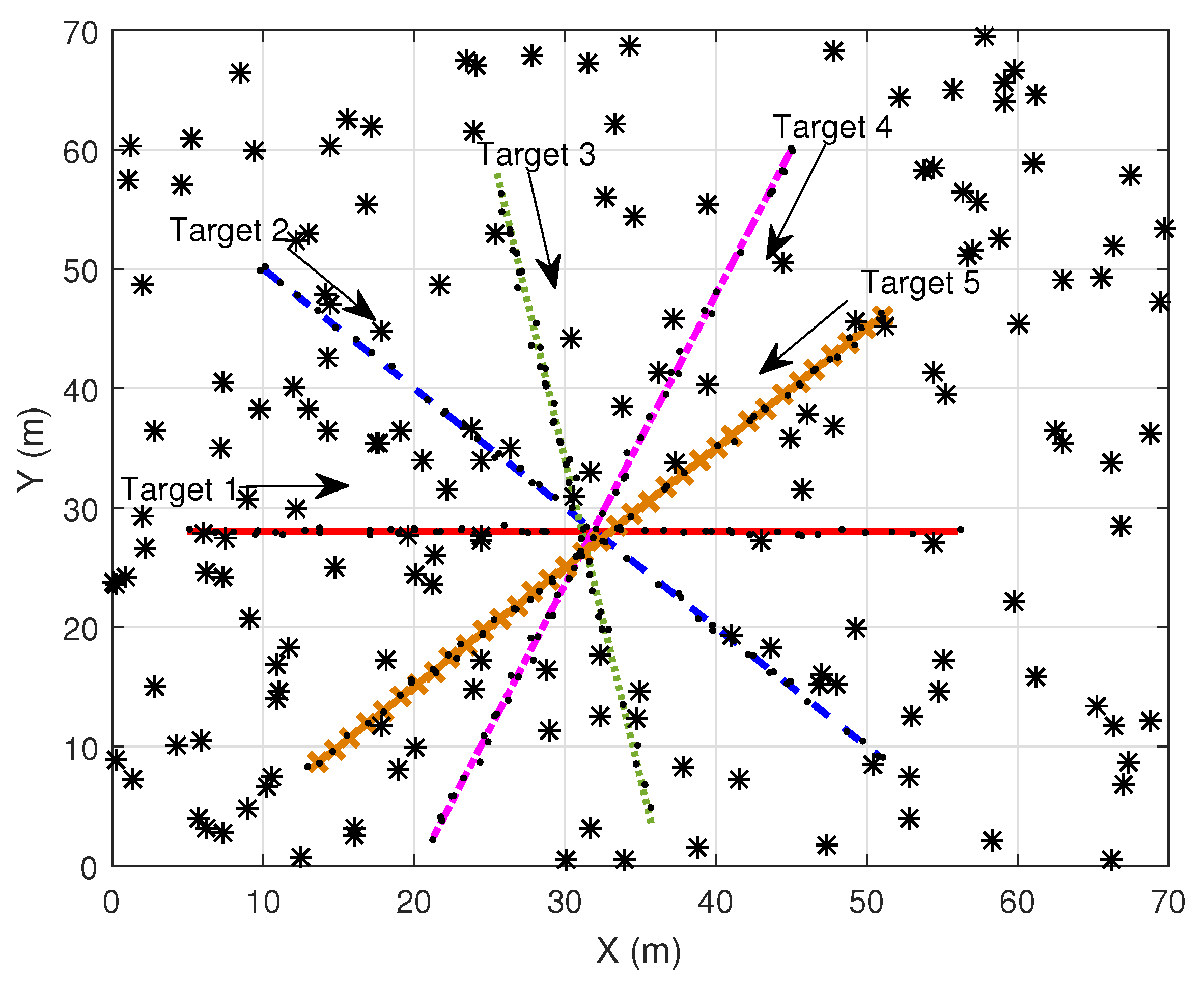
This section demonstrates the simulation performances of MD-LM-IPDA, MD-LM-ITS [32], MD-JIPDA and MD-MC-JIPDA in terms of target existence estimation, target state estimation accuracy, computational efficiency and OSPA distance [33,34]. As shown in Figure 3, five targets move in a Cartesian coordinate using a NCV model. The target state is a four dimensional vector given by , where x and y are the positions and and represent the velocities in the X and Y direction, respectively. The surveillance duration T is set to be 1 s. The state propagation and measurement generation equations are introduced in Section 2, in (1) and (2)
There are many metrics that can influence the multitarget tracking performance such as (1). the clutter measurement density; (2). the target detection probability; and (3). the spacing of the targets. Tracking becomes more difficult when the targets are closely spaced and move across each other, which could result in ambiguity of the data association among tracks and measurements. Hence, these five targets move across each other around scan 19 to test the performance.
The two-point differencing, Chapter 3.2 in [2], is used to initialize tracks. At each scan, each track uses the gating method to select measurements. Once the measurement is selected, it is marked and will not be used for track initialization. The PTE is used to cover the false track discrimination problem and once the PTE of a track exceeds the confirmation threshold, it becomes a confirmed track and stays confirmed. Then, the following method is used to determine whether this confirmed track is a confirmed true track or a confirmed false track.
Once track becomes a confirmed track, the normalized distance squared is calculated. If this normalized distance squared is within the confirmed true track test threshold (≤20), the track becomes a confirmed true track for the corresponding target; if this normalized distance squared is out of the confirmed true track test threshold (>20), the track is a confirmed false track for the corresponding target. If the normalized distance squared of a confirmed true track exceeds the confirmed false track test threshold, which is set as 40 in this manuscript, this confirmed true track is counted as a confirmed false track for the corresponding target. Otherwise, it keeps the confirmed true track status for the corresponding target. At each scan, this normalized distance squared is calculated between each of the confirmed tracks and each of the targets. If there are many confirmed true tracks for one target or there are targets sharing the same confirmed true tracks, the auction algorithm [2] is used for the assignments between confirmed true tracks and targets. If a track is counted as the confirmed false track for all the targets, it is a confirmed false track, otherwise it is the confirmed true track. In (40), is the state estimate at scan k, is the true target state at scan k, and represents the initial track covariance given by
When the track is initialized, it is assigned an initial PTE. The initial PTEs of MD-LM-IPDA, MD-LM-ITS, MD-JIPDA and MD-MC-JIPDA are different; this is so that these algorithms can be compared under the condition that all of them have the same number of confirmed false tracks. The values for the simulation parameters are shown in Table 1, where CFTs stands for the number of confirmed false tracks.
In order to obtain stable performances, data from 200 Monte Carlo simulation runs was used, where the surveillance period lasts 35 s. Only one sensor is located at the origin of the Cartesian coordinates which detects each target with probabilities (the probability that there is a single target detection is 0.5) and (the probability that there are two target detections is 0.4) at each scan. The amount of clutter at each scan follows a Poisson distribution with an average value of 5. The number of FJEs in MD-MC-JIPDA is set to be 300.
Here we introduce some parameters for track retention statistics and these parameters are counted before and after the target crossing:
- nCases: the number of tracks that are following a target at scan 13.
- nOK: the percentage of “nCases” tracks that are still following the original target at scan 33.
- nSwitched: the percentage of “nCases” tracks that end up following a different target at scan 33.
- nMerged: the percentage of “nCases” tracks that disappeared due to tracks merging between scan 13 and 33.
- nLost: the percentage of “nCases” tracks that are not following any target at scan 33.
- nResult: the number of tracks that are following a target at scan 35.
- CPU time [s]: the average computation time for one recursion cycle on a 3.10 GHz Intel PC platform and run with the Matlab Program.
These statistics are used to indicate the tracking performances before and after the target crossing. nCases is used to record the number of the confirmed true tracks at a certain time before the target crossing. nOK indicates the number of the confirmed true tracks that continuously track the same target before and after the target crossing. nSwitch indicates the number of tracks which swap the target after the target crossing. This happens from the influence of target measurement that is shared among cluster tracks and results in the tracking object changes without track termination. nMerged shows that after the target crossing, several tracks pursue the same target and thus they are merged due to similar target state estimates. nLost track is generated due to track errors, which results in the PTE drop below a certain threshold and the track is terminated. This kind of track loss usually results from the fact that the data association is invalid to some extent due to the target crossing. If nOK is bigger, it indicates that the tracking performance is better. The number of nOK tracks plus the number of nSwitch tracks comprise the number of the survived tracks in nCases tracks after the target crossing. The sum of the number of nMerged tracks and the number of nLost tracks becomes the number of terminated tracks. Finally, nResult shows the number of the confirmed true tracks at the end of the whole tracking period after the target crossing. These parameters together constitute the performance description of target tracks before and after the target crossing, which are important indices to verify the algorithm. The similar tracking performance analysis using these statistic parameters can be found in [5,28,35].
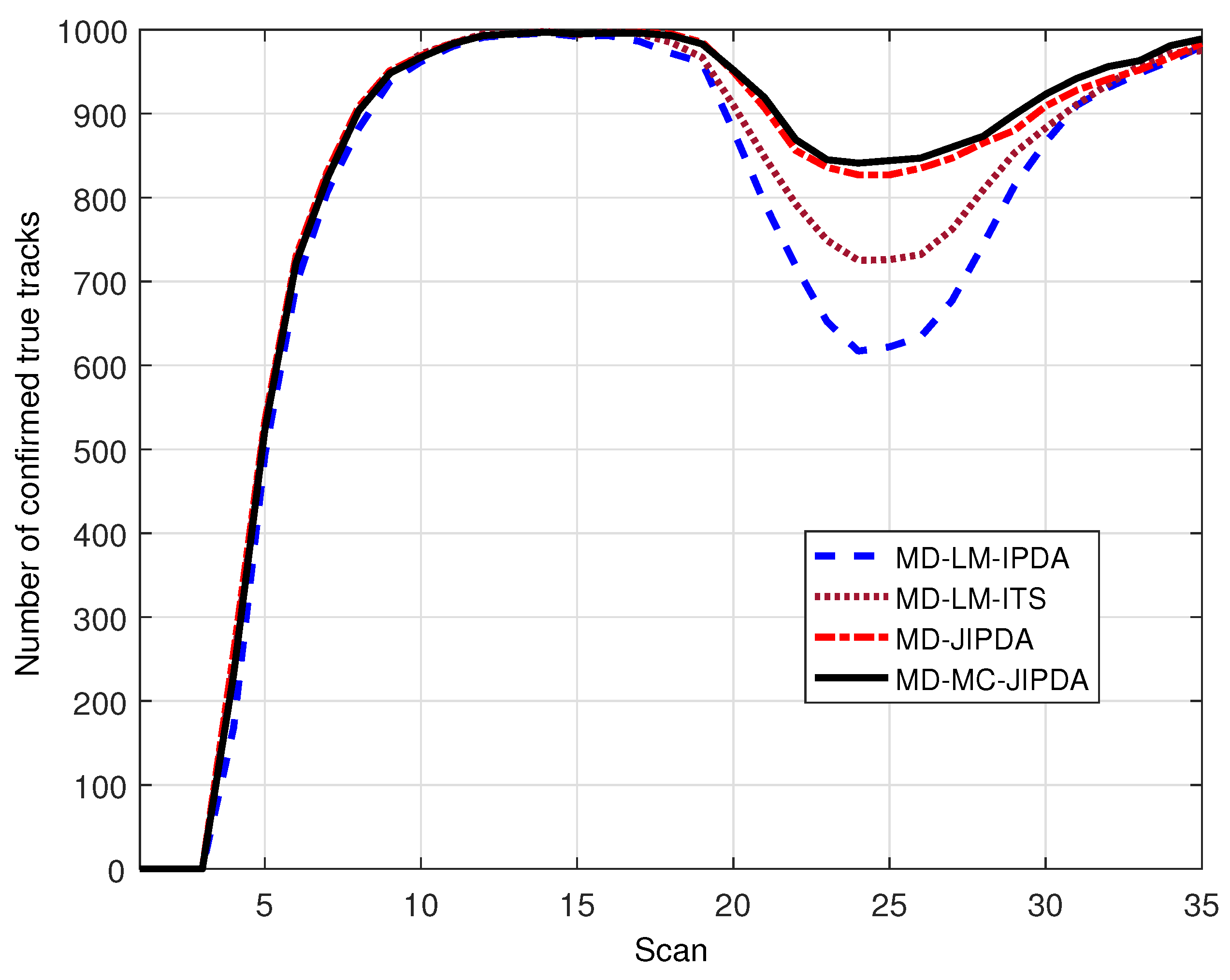
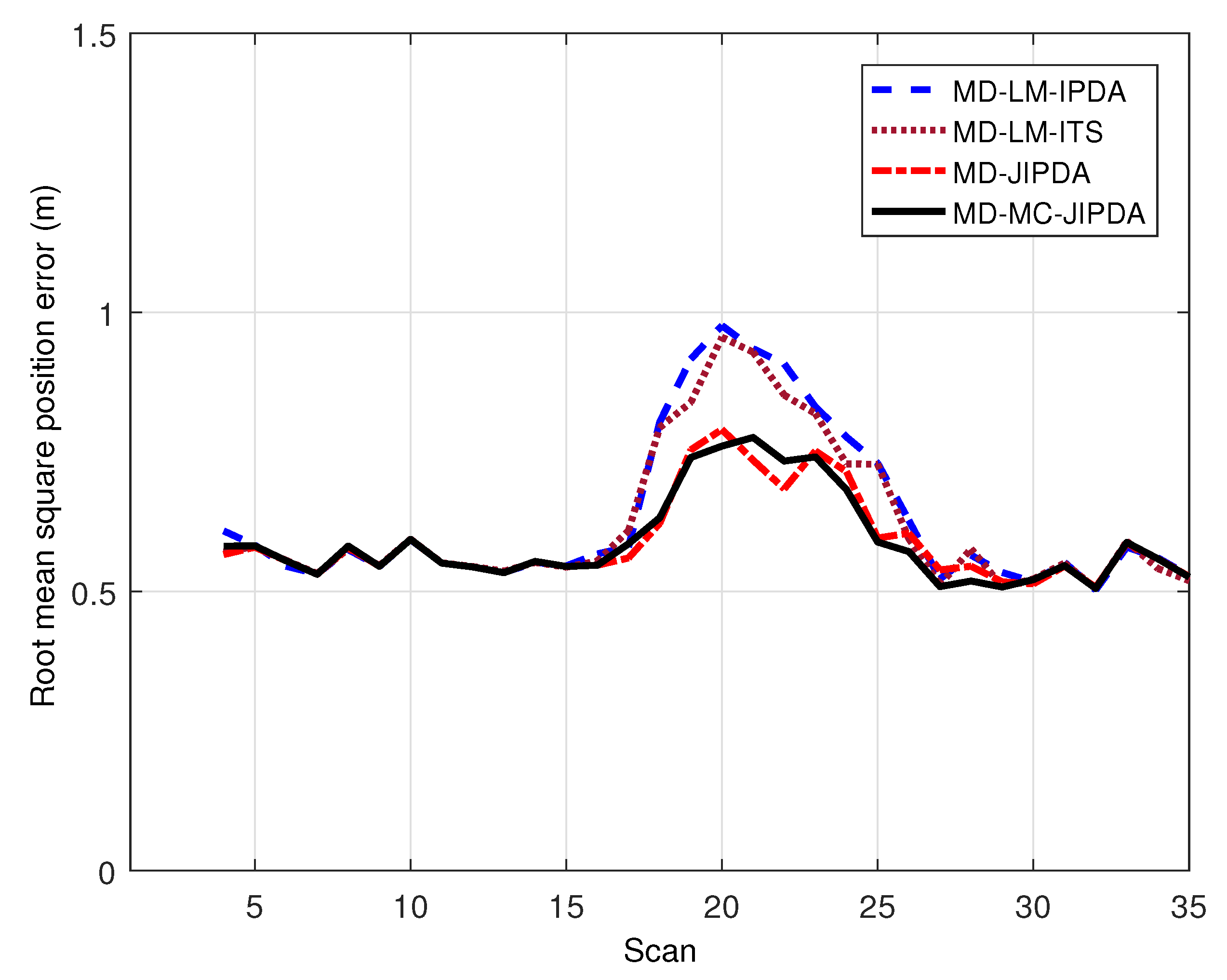
The number of confirmed true tracks for all five targets and the root mean square position error of target 5 are shown in Figure 4 and Figure 5, respectively. In Figure 4, the perfect number of confirmed true tracks (i.e., ) is 1000. There is a severe drop in the number of confirmed true track near the target crossing time, which indicates that all the algorithms in comparison experience data association difficulty when targets are located closely. However, when the targets intersect each other, there are obvious differences among the four algorithms, which indicates that MD-MC-JIPDA maintains many more tracks compared to LM-based algorithms and slightly more tracks compared to MD-JIPDA.
As for the root mean square position error, the performances of these four algorithms have the same trend of increases in the error when the targets cross. However, MD-JIPDA and MD-MC-JIPDA have obviously smaller position estimation errors compared to LM-based algorithms, which indicates MD-JIPDA and MD-MC-JIPDA are less affected by multitarget crossing. The increasing error near the target crossing leads to more shared measurements among tracks. From these results, one can see that MD-MC-JIPDA has the highest track retention rate with the satisfactory target state estimation accuracy compared with the other algorithms.
Table 2 demonstrates the track retention performances of MD-LM-IPDA, MD-LM-ITS, MD-JIPDA and MD-MC-JIPDA. From this table, MD-JIPDA and MD-MC-JIPDA are shown to have much higher percentages of nOK compared to the LM-based algorithms. MD-LM-ITS has better nOK performance compared to MD-LM-IPDA since the tracks in MD-LM-ITS maintain several track components, each component has a multi-scan data association history, for propagation, which makes MD-LM-ITS tracks more stable in the target crossing. Detailed analyzing for MD-LM-ITS is referred to [32]. MD-MC-JIPDA has a higher summation of nOK and nSwitched, which indicates more survived target tracks, and this is the reason that the CTT performance of MC-MC-JIPDA is much better compared to LM-based algorithms and slightly better compared to MD-JIPDA. Comparing the summation of nMerged and nLost, MD-MC-JIPDA has the lowest percentage of the terminated tracks. All these four algorithms have similar numbers of nResult, which suggests that the tracks are recovered after a certain time period by the track initialization.
By comparing the simulation times in Table 2, in which CPU time is the average execution time per each run, in seconds, one can see that MD-LM-IPDA, MD-LM-ITS and MD-MC-JIPDA require only a fraction of the CPU time needed for MD-JIPDA. MD-MC-JIPDA is an effective algorithm that can be processed in real-time for this scenario.
OSPA was used recently for multi-target tracking performance evaluation [33,34]. Here, we add the OSPA performance of these four algorithms for comparison. At each scan, the algorithm output the tracks with PTE higher than the threshold (given as 0.5) to generate the OSPA distance and cardinality. The other parameters used for these four algorithms are given in Table 1.
In Figure 6, OSPA distances (for p = 1 and c = 10) versus scan for 200 Monte Carlo simulation runs are shown. It can be seen that all these four algorithms show the same trend that OSPA distance is increased after the target crossing. The result suggests that both MD-JIPDA and MD-MC-JIPDA outperform MD-LM-ITS which in turn outperforms MD-LM-IPDA. Combined with the performance and the analysis given before, this result is due to the fact that MD-JIPDA and MD-MC-JIPDA have better data association performances when the cluster tracks share the cluster measurements.
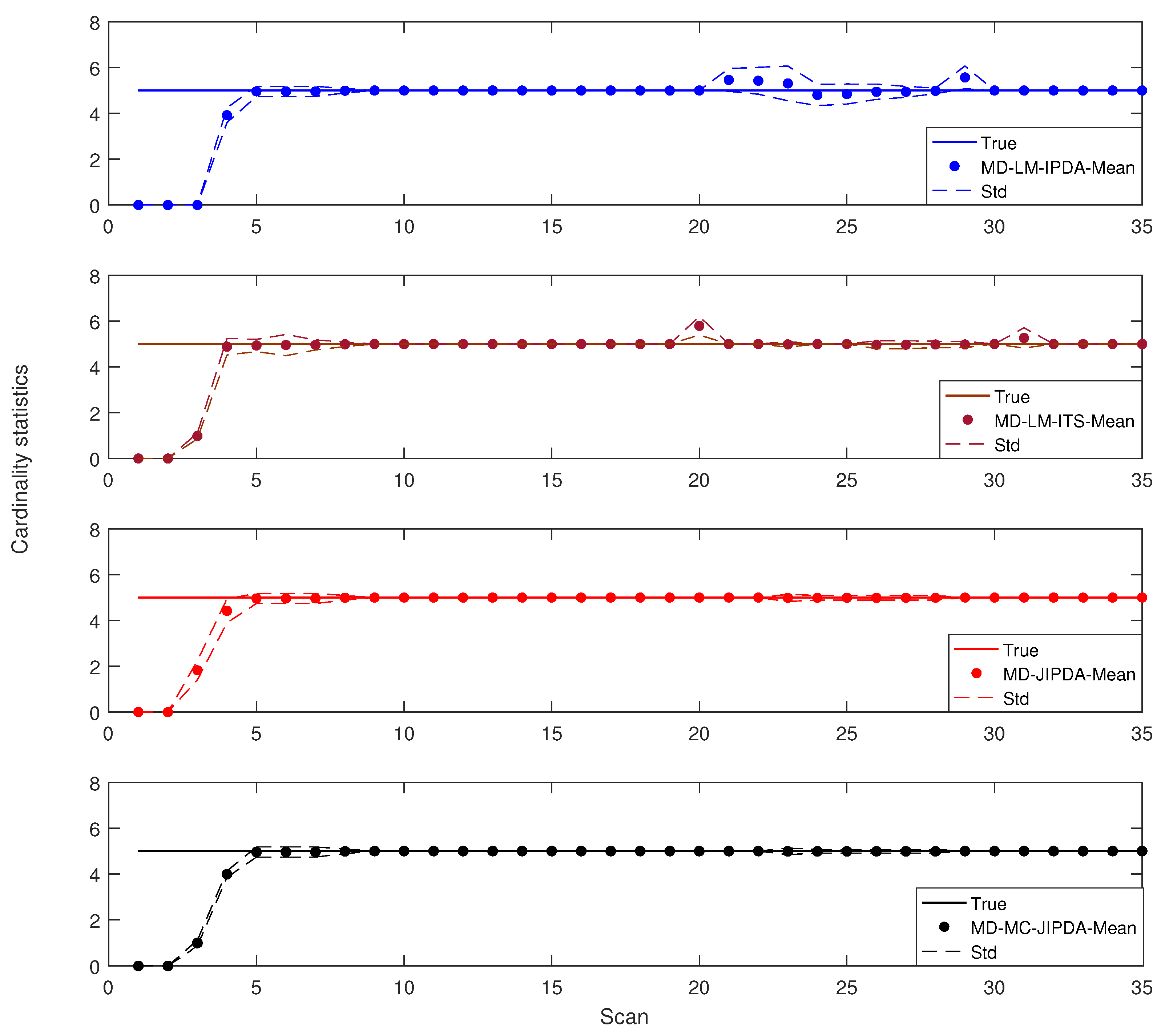
The cardinality statistics of these four algorithms are shown in Figure 7. From this figure one can see that MD-LM-IPDA has the worst tracking performance for the target crossing. The difference in cardinality statistics between MD-JIPDA and MD-MC-JIPDA is marginal. However, it can also be seen that MD-JIPDA and MD-MC-JIPDA have more reliable target number estimation performances.
5. Conclusions
The MD-MC-JIPDA algorithm is proposed for multiple detection multitarget tracking. Instead of enumerating all possible data association events, MD-MC-JIPDA generates a small number of feasible joint events according to the Markov chain sequences implemented by each of the cluster tracks. This joint data association mechanism significantly simplifies data association complexity.
In the scenario with a fixed number of targets crossing each other, MD-MC-JIPDA outperforms MD-LM-IPDA and MD-LM-ITS in the sense of the true track maintenance and the target trajectory estimation accuracy. MD-MC-JIPDA needs only a fraction of the simulation time required by MD-JIPDA but has a similar tracking performance compared with MD-JIPDA. From the tracking performance and the required simulation time, it can be seen that MD-MC-JIPDA is a real-time algorithm suitable for the multiple detection multitarget tracking.
The potential future works for the proposed algorithm are: (1) find the method to adaptively select the number of FJEs for MD-MC-JIPDA instead of predetermination; (2) in some scenarios, the switch of the tracks may cause the problem for the tracking consistency which encourages us to find a way to reduce the percentage of the track switch; (3) apply this tracking algorithm to the OTHR application. (3) ’fit’ the discrete estimates obtained by MD-MC-JIPDA to a continuous-time tracking function, which can be used to refine the estimates for any time in the effective fitting period [36].
Author Contributions
Conceptualization, Y.H. and T.L.S.; methodology, Y.H. and T.L.S.; software, Y.H.; validation, Y.H., T.L.S. and D.H.C.; formal analysis, Y.H.; investigation, Y.H. and D.H.C.; resources, Y.H. and T.L.S.; data curation, Y.H.; writing—original draft preparation, Y.H.; writing—review and editing, T.L.S.; visualization, Y.H., T.L.S. and D.H.C.; supervision, Y.H. and T.L.S.; project administration, T.L.S. and D.H.C.; funding acquisition, T.L.S.
Funding
This research was funded by LIG System Co., Ltd.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| PDA | Probabilistic data association. |
| MD-JPDA | Multiple detection joint probabilistic data association. |
| MD-MC-JIPDA | Multiple detection Markov chain joint integrated probabilistic data association. |
| FTD | False track discrimination. |
| MHT | Multiple hypothesis tracker. |
| MAP | Maximum a posteriori. |
| JIPDA | Joint integrated probabilistic data association. |
| LM-IPDA | Linear multitarget integrated probabilistic data association. |
| PTE | Probability of target existence. |
| MC-JIPDA | Markov chain JIPDA. |
| OTHR | Over-the-horizon-radar. |
| MD-JIPDA | Multiple detection JIPDA. |
| MD-LM-IPDA | Multiple detection LM-IPDA. |
| MD-LM-ITS | Multiple detection linear multitarget integrated track splitting. |
| FJEs | Feasible joint events. |
| NCV | Nearly constant velocity. |
| CFT | Confirmed false track. |
| RMSE | Root mean square error. |
Nomenclature
| t | A track as well as the potential target being tracked by this track. |
| The number of selected measurements at scan k. | |
| L | The maximum number of scattering feature points of the target. |
| The maximum number of target-originated measurements, which satisfies . | |
| The number of target originated measurements . | |
| A variable that enumerates the measurement cells under the condition that there are measurements generated by target t, and . | |
| A measurement cell specified by and at scan k. | |
| The event that target t exists at scan k. | |
| The jth feasible joint event (FJE) which assigns measurement cells to tracks. | |
| The data association event for that no measurement cell is associated to track t. | |
| The data association event for that measurement cell is associated to track t |
References
- Bar-Shalom, Y.; Li, X.R.; Kirubarajan, T. Estimation with Application to Tracking and Navigation; Wiley: New York, NY, USA, 2001. [Google Scholar]
- Bar-Shalom, Y.; Willett, P.; Tian, X. Tracking and Data Fusion; YBS: Storrs, CT, USA, 2011. [Google Scholar]
- Challa, S.; Evans, R.; Morelande, M.; Musicki, D. Fundamentals of Object Tracking; Cambridge University: Cambridge, UK, 2011. [Google Scholar]
- Papa, G.; Braca, P.; Horn, S.; Marano, S.; Matta, V.; Willett, P. Multisensor adaptive bayesian tracking under time-varying target detection probability. IEEE Trans. Aerosp. Electron. Syst. 2016, 52, 2193–2209. [Google Scholar] [CrossRef]
- Song, T.L.; Kim, H.W.; Musicki, D. Iterative joint integrated probabilistic data association for multitarget tracking. IEEE Trans. Aerosp. Electron. Syst. 2015, 51, 642–653. [Google Scholar] [CrossRef]
- Papi, F.; Vo, B.N.; Vo, B.T.; Fantacci, C.; Beard, M. Generalized labeled multi-Bernoulli approximation of multi-object densities. IEEE Trans. Signal Process. 2015, 63, 5487–5497. [Google Scholar] [CrossRef]
- Musicki, D.; Evans, R.; Stankovic, S. Integrated probabilistic data association. IEEE Trans. Autom. Control 1994, 39, 1237–1241. [Google Scholar] [CrossRef]
- Musicki, D.; Evans, R. Joint integrated probabilistic data association: JIPDA. IEEE Trans. Aerosp. Electron. Syst. 2004, 40, 1093–1099. [Google Scholar] [CrossRef]
- Habtemariam, B.; Tharmarasa, R.; Thayaparan, T.; Mallick, M.; Kirubarajan, T. A multiple-detection joint probabilistic data association filter. IEEE J. Sel. Top. Signal Process. 2013, 7, 461–471. [Google Scholar] [CrossRef]
- Musicki, D.; Evans, R. Multiscan multitarget tracking in clutter with integrated track splitting filter. IEEE Trans. Aerosp. Electron. Syst. 2009, 45, 1432–1447. [Google Scholar] [CrossRef]
- Reid, D.B.; Thomas, H. An algorithm for tracking multiple targets. IEEE Trans. Autom. Control 1979, 24, 843–854. [Google Scholar] [CrossRef]
- Bar-Shalom, Y.; Li, X.R. Multitarget-Multisensor Tracking: Principles and Techniques; YBS: Storrs, CT, USA, 1995. [Google Scholar]
- Cox, I.; Hingorani, S. An efficient implementation of Reid’s multiple hypothesis tracking algorithm and its evaluation for the purpose of visual tracking. IEEE Trans. Pattern Anal. Mach. Intell. 1996, 18, 138–150. [Google Scholar] [CrossRef]
- Salmond, D.J. Mixture reduction algorithms for target tracking in clutter. Signal Data Process. Small Targets 1990, 1305, 434–445. [Google Scholar]
- Collins, J.; Uhlmann, J. Efficient gating in data association with multivariate distributed states. IEEE Trans. Aerosp. Electron. Syst. 1992, 28, 909–916. [Google Scholar] [CrossRef]
- Valiant, L.G. The complexity of computing the permanent. Theor. Comput. Sci. 1979, 8, 189–201. [Google Scholar] [CrossRef]
- Musicki, D.; Scala, B.L. Multi-target tracking in clutter without measurement assignment. IEEE Trans. Autom. Control 2008, 44, 877–896. [Google Scholar] [CrossRef]
- Kirubarajan, T.; Bar-Shalom, Y. Probabilistic data association techniques for target tracking in clutter. Proc. IEEE 2004, 92, 536–557. [Google Scholar] [CrossRef]
- Musicki, D.; Scala, B.L.; Evans, R. Integrated track splitting filter—Efficient multi-scan single target tracking in clutter. IEEE Trans. Aerosp. Electron. Syst. 2007, 43, 1409–1425. [Google Scholar]
- Lee, E.H.; Zhang, Q.; Song, T.L. Markov chain realization of joint integrated probabilistic data association. Sensors 2017, 17, 2865. [Google Scholar] [CrossRef] [PubMed]
- Mahler, R. PHD filters for nonstandard targets, I: Extended targets. In Proceedings of the 12th International Conference on Information Fusion, Seattle, WA, USA, 6–9 July 2009; pp. 915–921. [Google Scholar]
- Habtemariam, B.K.; Tharmarasa, R.; Kirubarajan, T.; Grimmett, D.; Wakayama, C. Multiple detection probabilistic data association filter for multistatic target tracking. In Proceedings of the 14th International Conference on Information Fusion, Chicago, IL, USA, 5–8 July 2011; pp. 1–6. [Google Scholar]
- Ristic, B.; Sherrah, J. Bernoulli filter for joint detection and tracking of an extended object in clutter. IET Radar Sonar Navig. 2013, 7, 26–35. [Google Scholar] [CrossRef]
- Tang, X.; Chen, X.; McDonald, M.; Mahler, R.; Tharmarasa, R.; Kirubarajan, T. A multiple-detection probability hypothesis density filter. IEEE Trans. Signal Process. 2015, 63, 2007–2019. [Google Scholar] [CrossRef]
- Sathyan, T.; Chin, T.-J.; Arulampalam, S.; Suter, D. A multiple hypothesis tracker for multitarget tracking with multiple simultaneous measurements. IEEE J. Sel. Top. Signal Process. 2013, 7, 448–460. [Google Scholar] [CrossRef]
- Huang, Y.; Song, T.L.; Lee, J.H. Joint integrated track splitting for multi-path multi-target tracking using OTHR detections. EURASIP J. Adv. Sig. Process. 2018, 2018, 60–76. [Google Scholar] [CrossRef]
- Huang, Y.; Song, T.L.; Lee, C.M. The multiple detection joint integrated track splitting filter. In Proceedings of the CIE International Conference on Radar, Guangzhou, China, 10–13 October 2016; pp. 1–4. [Google Scholar]
- Huang, Y.; Song, T.L. Linear multitarget integrated probabilistic data association for multiple detection target tracking. IET Radar Sonar Navig. 2018, 12, 945–953. [Google Scholar] [CrossRef]
- Xu, L.F.; Li, X.R.; Duan, Z.S. Hybrid grid multiple-model estimation with application to maneuvering target tracking. IEEE Trans. Aerosp. Electron. Syst. 2016, 52, 122–136. [Google Scholar] [CrossRef]
- Musicki, D. Bearings only single-sensor target tracking using Gaussian mixtures. Automatica 2009, 45, 2088–2092. [Google Scholar] [CrossRef]
- Blackman, S.; Popoli, R. Design and Analysis of Modern Tracking Systems; Artech House: Boston, MA, USA, 1999. [Google Scholar]
- Huang, Y.; Song, T.L. Linear multitarget integrated track splitting for multiple detection target tracking. In Proceedings of the International Conference on Control, Automation and Information Sciences (ICCAIS 2017), Chiang Mai, Thailand, 31 October–1 November 2017; pp. 79–85. [Google Scholar]
- Schuhmacher, D.; Vo, B.T.; Vo, B.N. On performance evaluation of multi-object filters. In Proceedings of the 11th International Conference on Information Fusion, Cologne, Germany, 30 June–3 July 2008; pp. 1–8. [Google Scholar]
- Ristic, B.; Vo, B.N.; Clark, D. Performance evaluation of multi-target tracking using the OSPA metric. In Proceedings of the 13th International Conference on Information Fusion, Edinburgh, UK, 26–29 July 2010; pp. 1–7. [Google Scholar]
- Radosavljevic, Z.; Musicki, D.; Kovacevic, B.; Kim, W.C.; Song, T.L. Integrated particle filter for target tracking in clutter. IET Radar Sonar Navig. 2015, 9, 1063–1069. [Google Scholar] [CrossRef]
- Li, T.C.; Prieto, J.; Corchado, J.M. Fitting for smoothing: A methodology for continuous-time target track estimation. In Proceedings of the International Conference on Indoor Positioning and Indoor Navigation (IPIN), Alcala de Henares, Spain, 4–7 October 2016; pp. 1–8. [Google Scholar]
Figure 1.
Transition relationship among the measurement cells of a track.

Figure 2.
Feasible joint event generation in multiple detection Markov chain joint integrated probabilistic data association (MD-MC-JIPDA).
Figure 2.
Feasible joint event generation in multiple detection Markov chain joint integrated probabilistic data association (MD-MC-JIPDA).

Figure 3.
Simulation scenario (dots are target-originated measurements and asterisks are clutter measurements).
Figure 3.
Simulation scenario (dots are target-originated measurements and asterisks are clutter measurements).

Figure 4.
Number of confirmed true tracks for all targets.

Figure 5.
Root mean square error for target 5.

Figure 6.
OSPA distance.

Figure 7.
Cardinality statistics.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Simulation parameters for different algorithms.
| MD-LM-IPDA | MD-LM-ITS | MD-JIPDA | MD-MC-JIPDA | |
|---|---|---|---|---|
| Initial PTE | 0.000025 | 0.000065 | 0.0001 | 0.000075 |
| Confirmation PTE | 0.95 | 0.95 | 0.95 | 0.95 |
| Termination PTE | 0.000025/2 | 0.000065/2 | 0.0001/2 | 0.000075/2 |
| Number of CFTs | 2 | 2 | 2 | 2 |
Table 2.
Statistic parameters.
| MD-LM-IPDA | MD-LM-ITS | MD-JIPDA | MD-MC-JIPDA | |
|---|---|---|---|---|
| nCases | 994 | 995 | 995 | 995 |
| nOK | 43.13% | 54.25% | 68.84% | 63.50% |
| nSwitched | 18.14% | 17.81% | 13.97% | 21.03% |
| nMerged | 38.43% | 27.84% | 16.88% | 14.57% |
| nLost | 0.30 % | 0.10% | 0.31% | 0.90% |
| nResult | 980 | 975 | 984 | 989 |
| CPU time [s] | 0.42 | 2.49 | 202.97 | 1.69 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Huang, Y.; Song, T.L.; Cheagal, D.H. Markov Chain Realization of Multiple Detection Joint Integrated Probabilistic Data Association. Sensors 2019, 19, 112. https://doi.org/10.3390/s19010112
AMA Style
Huang Y, Song TL, Cheagal DH. Markov Chain Realization of Multiple Detection Joint Integrated Probabilistic Data Association. Sensors. 2019; 19(1):112. https://doi.org/10.3390/s19010112
Chicago/Turabian StyleHuang, Yuan, Taek Lyul Song, and Dae Hoon Cheagal. 2019. "Markov Chain Realization of Multiple Detection Joint Integrated Probabilistic Data Association" Sensors 19, no. 1: 112. https://doi.org/10.3390/s19010112
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.